
Теоретические основы защиты информации
В настоящее время и у нас в стране, и за рубежом достаточно много публикаций по современным стандартам защиты, средствам и методам защиты. Однако работы, которая являлась бы творческим обобщением существующих формальных моделей, нормативных документов, зарубежных стандартов в области защиты информации на нашем книжном рынке пока еще не было. Авторам удалось "оживить" разрозненные, порой противоречивые фрагменты, придав им новое качество, в виде целостных теоретических основ защиты информации.Показаны пути использования формальных математических методов для защиты информации. Изложены основы теории защиты информационных систем. Приведены примеры доказательства защищенности автоматизированных информационных систем.
Для специалистов, работающих в области искусственного интеллекта, программирования для ЭВМ, защиты информационных и банковских систем.
Книга доктора физико-математических наук, член-корреспондента Академии Криптографии Российской Федерации, действительного члена Международной Академии Информации, профессора Александра Александровича Грушо и член-корреспондента Международной Академии Информатизации, кандидата физико-математических наук Елены Евгеньевны Тимониной посвящена введению в формальную теорию защиты информации. Выполненная в академическом стиле, работа наряду со строгими определениями и доказательствами содержит большое количество примеров из практической жизни, доходчиво иллюстрирующих основные теоретические положения.
Особо хотелось бы выделить разделы, посвященные гарантированно защищенным распределенным системам, доказательному подходу к построению систем защиты и определению политики безопасности. Что или кто является гарантом защищенности информации в автоматизированных системах в условиях, когда в общем виде проблема обеспечения безопасности в АИС относится к алгоритмически неразрешимым проблемам? Авторы дают ответ на этот вопрос, сведя его к вопросу о том, поддерживает или нет система защиты сформулированную политику безопасности.
На сегодняшний день и у нас в стране, и за рубежом достаточно много публикаций по современным стандартам защиты, средствам и методам защиты. Однако работы, которая являлась бы по своей сути творческим обобщением существующих формальных моделей, нормативных документов, зарубежных стандартов в области защиты информации на нашем книжном рынке не было. А.А. Грушо и Е.Е. Тимониной удалось "оживить" разрозненные, порой противоречивые фрагменты, придав им новое качество, в виде целостных теоретических основ защиты информации.
Хотелось бы отметить ориентацию данной книги на ведение учебной работы, что позволяет ее рекомендовать в качестве учебника для студентов и специалистов, работающих в области обеспечения безопасности самого широкого плана - от разработки политики безопасности для всей организации, до разработки конкретных систем защиты информации в АИС.
Доктор технических наук С. П. Расторгуев
Введение
Предлагаемая работа написана в стиле Lecture Notes и представляет введение в формальную теорию защиты информации в электронных системах обработки данных. В отличие от других руководств и пособий по защите информации здесь не ставилась задача перечислить как можно полнее все угрозы, механизмы защиты и другие детали проблемы защиты информации. Основная цель работы - доступно изложить методы анализа систем защиты информации в электронных системах обработки данных. Как большинство современных методов изучения сложных систем, анализ систем защиты предполагает иерархическую декомпозицию. Верхний уровень иерархии составляет политика безопасности со своими специфическими методами ее анализа. Следующий уровень - основные системы поддержки политики безопасности (мандатный контроль, аудит и т.д.). Затем следует уровень механизмов защиты (криптографические протоколы, криптографические алгоритмы, системы создания защищенной среды, системы обновления ресурсов и т.д.), которые позволяют реализовать системы поддержки политики безопасности. Наконец самый низкий уровень - реализация механизмов защиты (виртуальная память, теговая архитектура, защищенные режимы процессора и т.д.).
В работе рассматриваются только верхние уровни этой иерархии, так как механизмы защиты достаточно полно описаны в литературе. Ограничения изложения рамками верхних уровней иерархии позволило с высокой степенью формализации ввести основные понятия и модели защиты информации, определения, что такое "хорошая" или "плохая" системы защиты, описать доказательный подход в построении систем защиты, позволяющий говорить о гарантированно защищенных системах обработки информации. Описанный подход лежит в основе многих стандартов для систем защиты и позволяет проводить анализ и аттестование защищенных систем.
Следует обратить внимание на то, что в большинстве руководств по защите верхние уровни иерархии не отражены, или не объяснено их значение. В результате создается иллюзия, что качественная защита определяется только надежностью и количеством механизмов защиты. Наводят на определенные размышления неточные переводы требований стандартов по защите, которые привозят к нам иностранные специалисты. В связи с этим, базисом для работы явился анализ исходных текстов американских стандартов по защите и статей, в которых излагались результаты анализа моделей, лежащих в основе этих стандартов. Поэтому работу можно рассматривать как изложение определенной "платформы" для разработки систем защиты информации, которая взята за основу в США, Канаде и Западной Европе.
Глава 1 ВСПОМОГАТЕЛЬНЫЕ СТРУКТУРЫ (МОДЕЛИ), ИСПОЛЬЗУЕМЫЕ В ЗАЩИТЕ ИНФОРМАЦИИ
Для того, чтобы провести исследование и получить практический результат часто применяют следующий прием. В объект исследования вносят некоторую структуру, которая имеет искусственный характер, но облегчает исследование. Например, для анализа взаимодействия тел физики внесли в описание окружающего мира структуры силовых взаимодействий, электрических взаимодействий. Математики для анализа реальных процессов вносят структуры вероятностного пространства и вероятностей событий. Иногда говорят, что строится модель объекта. Оба названия приемлемы, однако мы предпочитаем первое, так как в ходе анализа потребуется вносить в информацию несколько структур и анализировать их взаимодействие.
В терминах моделей такие нагромождения представляются более трудными для объяснения. Далее мы рассмотрим следующие структуры, которые вносятся в неопределяемый объект под названием информация, теории защиты которого будет посвящена вся работа:
· структура языка, позволяющая говорить об информации как о дискретной системе объектов;
· иерархическая модель вычислительных систем и модель OSI/ISO, позволяющие аппаратную, программную, прикладную компоненты вычислительных систем и сетей связи представлять в виде объектов некоторых языков, а также представляют примеры неиерархической декомпозиции и анализа сложных систем;
· структура информационного потока, позволяющая описывать и анализировать угрозы информации;
· структура ценности информации, позволяющая понять, что надо и что не надо защищать;
· структуры реляционных баз данных, которые рассматриваются как примеры организации информации в вычислительных системах, и используются для пояснения наиболее трудных проблем защиты.
В заключение главы в качестве примера проблемы согласования различных структур между собой рассматривается задача совмещения одной из структур ценности информации и структуры реляционной базы данных.
1.1. ЯЗЫК, ОБЪЕКТЫ, СУБЪЕКТЫ.
Используем некоторые понятия математической логики. Пусть А конечный алфавит, А - множество слов конечной длины в алфавите А.
Из А при помощи некоторых правил выделено подмножество Я правильных слов, которое называется языком. Если Я1 - язык описания одной информации, Я2 - другой, то можно говорить о языке Я, объединяющем Я1 и Я2
описывающем ту и другую информацию. Тогда Я1 и Я2
подъязыки Я.
Будем считать, что любая информация представлена в виде слова в некотором языке Я. Кроме того, можно полагать, что состояние любого устройства в вычислительной системе достаточно полно описано словом в некотором языке.
Тогда можно отождествлять слова и состояния устройств и механизмов вычислительной системы или произвольной электронной системы обработки данных (ЭСОД). Эти предположения позволяют весь анализ вести в терминах некоторого языка.
Определение Объектом относительно языка Я (или просто объектом, когда из контекста однозначно определен язык) называется произвольное конечное множество языка Я.
Пример 1.
Произвольный файл в компьютере есть объект. В любой момент в файл может быть записано одно из конечного множества слов языка Я, в некотором алфавите А, которое отражает содержимое информации, хранящейся в файле. Значит, файл можно рассматривать как конечное множество слов, которые в нем могут быть записаны (возможные содержания файла). То, что в данный момент в файле содержится только одно слово, не исключает потенциально существования других записей в данном файле, а в понятие файла как объекта входят все допустимое множество таких записей. Естественно выделяется слово, записанное в файле в данный момент, - это состояние объекта в данный момент.
Пример 2. Пусть текст в файле разбит на параграфы так, что любой параграф также является словом языка Я и, следовательно, тоже является объектом. Таким образом, один объект может являться частью другого.
Пример 3. Принтер компьютера - объект. Существует некоторый (достаточно сложный) язык, описывающий принтер и его состояния в произвольный момент времени. Множество допустимых описаний состояний принтера является конечным подмножеством слов в этом языке. Именно это конечное множество и определяет принтер как объект.
В информации выделим особо описания преобразований данных.
Преобразование информации отображает слово, описывающее исходные данные, в другое слово. Описание преобразования данных также является словом. Примерами объектов, описывающих преобразования данных, являются программы для ЭВМ
Каждое преобразование информации может:
а) храниться;
б) действовать.
В случае а) речь идет о хранении описания преобразования в некотором объекте (файле).
В этом случае преобразование ничем не отличается от других данных. В случае б) описание программы взаимодействует с другими ресурсами вычислительной системы - памятью, процессором, коммуникациями и др.
Определение. Ресурсы системы, выделяемые для действия преобразования, называются доменом.
Однако для осуществления преобразования одних данных в другие кроме домена необходимо передать этому преобразованию особый статус в системе, при котором ресурсы системы осуществляют преобразование. Этот статус будем называть "управление".
Определение. Преобразование, которому передано управление, называется процессом.
При этом подразумевается, что преобразование осуществляется в некоторой системе, в которой ясно, что значит передать управление.
Определение. Объект, описывающий преобразование, которому выделен домен и передано управление, называется субъектом.
То есть субъект - это пара (домен, процесс). Субъект для реализации преобразования использует информацию, содержащуюся в объекте О, то есть осуществляет доступ к объекту О.
Рассмотрим некоторые основные примеры доступов.
1. Доступ субъекта S к объекту О на чтение (r) данных в объекте О.
При этом доступе данные считываются в объекте О и используются в качестве параметра в субъекте S.
2. Доступ субъекта S к объекту О на запись (w) данных в объекте О.
При этом доступе некоторые данные процесса S записываются в объект О. Здесь возможно стирание предыдущей информации.
3. Доступ субъекта S к объекту О на активизацию процесса, записанного в О как данные (ехе). При этом доступе формируется некоторый домен для преобразования, описанного в О, и передается управление соответствующей программе.
Существует множество других доступов, некоторые из них будут определены далее. Множество возможных доступов в системе будем обозначать R.
Будем обозначать множество объектов в системе обработки данных через О, а множество субъектов в этой системе S. Ясно, что каждый субъект является объектом относительно некоторого языка (который может в активной фазе сам менять свое состояние).
Поэтому S Í O. Иногда, чтобы не было различных обозначений, связанных с одним преобразованием, описание преобразования, хранящееся в памяти, тоже называют субъектом, но не активизированным. Тогда активизация такого субъекта означает пару (домен, процесс).
В различных ситуациях мы будем уточнять описание вычислительной системы. Однако мы всегда будем подразумевать нечто общее во всех системах. Это общее состоит в том, что состояние системы характеризуется некоторым множеством объектов, которое будем предполагать конечным.
В любой момент времени на множестве субъектов введем бинарное отношение a активизации. S1aS2, если субъект S1, обладая управлением и ресурсами, может передать S2 часть ресурсов и управление (активизация). Тогда в графах, которые определяются введенным бинарным отношением на множестве объектов, для которых определено понятие активизации, возможны вершины, в которые никогда не входит ни одной дуги. Таких субъектов будем называть пользователями. Субъекты, в которые никогда не входят дуги и из которых никогда не выходят дуги, исключаются.
В рассмотрении вопросов защиты информации мы примем аксиому, которая положена в основу американского стандарта по защите ("Оранжевая книга") и будет обсуждаться далее. Здесь мы сформулируем ее в следующей форме.
Аксиома. Все вопросы безопасности информации описываются доступами субъектов к объектам.
Если включить в рассмотрение гипотетически такие процессы как пожар, наводнение, физическое уничтожение и изъятие, то эта аксиома охватывает практически все известные способы нарушения безопасности в самых различных вариантах понимания безопасности. Тогда для дальнейшего рассмотрения вопросов безопасности и защиты информации достаточно рассматривать множество объектов и последовательности доступов.
Пусть время дискретно, Оt - множество объектов момент t, St - множество субъектов в момент t. На множестве объектов Оt как на вершинах определим ориентированный граф доступов Gt
следующим образом: дуга

тогда и только тогда, когда в момент t субъект S имеет множество доступов р к объекту О.
Согласно аксиоме, с точки зрения защиты информации, в процессе функционирования системы нас интересует только множество графов доступов {Gt}t=1T. Обозначим через Y={G} множество возможных графов доступов. Тогда Y можно рассматривать как фазовое пространство системы, а траектория в фазовом пространстве Y соответствует функционированию вычислительной системы. В этих терминах удобно представлять себе задачу защиты информации в следующем общем виде. В фазовом пространстве Y
определены возможные траектории Ф, в F выделено некоторое подмножество N неблагоприятных траекторий или участков таких траекторий, которых мы хотели бы избежать. Задача защиты информации состоит в том, чтобы любая реальная траектория вычислительного процесса в фазовом пространстве Y не попала во множество N. Как правило, в любой конкретной вычислительной системе можно наделить реальным смыслом компоненты модели Y,F и N. Например, неблагоприятными могут быть траектории, проходящие через данное множество состояний Y‘ÍY.
Чем может управлять служба защиты информации, чтобы траектории вычислительного процесса не вышли в N? Практически такое управление возможно только ограничением на доступ в каждый момент времени. Разумеется, эти ограничения могут зависеть от всей предыстории процесса. Однако, в любом случае, службе защиты доступно только локальное воздействие. Основная сложность защиты информации состоит в том, что имея возможность использовать набор локальных ограничений на доступ в каждый момент времени, мы должны решить глобальную проблему недопущения выхода любой возможной траектории в неблагоприятное множество N. При этом траектории множества N не обязательно определяются ограничениями на доступы конкретных субъектов к конкретным объектам. Возможно, что если в различные моменты вычислительного процесса субъект S получил доступ к объектам О1 и О2, то запрещенный доступ к объекту О3
реально произошел, так как из знания содержания объектов О1 и O2
можно вывести запрещенную информацию, содержащуюся в объекте O3.
Пример 4. Пусть в системе имеются два пользователя U1, и U2, один процесс S чтения на экран файла и набор файлов O1...Om. В каждый момент работает один пользователь, потом система выключается и другой пользователь включает ее заново. Возможны следующие графы доступов
R r
Uj------->S-------------Oi , i=l ,..., m, j=l , 2. (1)
Множество таких графов - y. Траектории - последовательности графов вида (1). Неблагоприятными считаются траектории, содержащие для некоторого i= 1...m состояния
R r
U1------------>S------->Oi
R r
U2------------>S------->Oi
То есть неблагоприятная ситуация, когда оба пользователя могут прочитать один объект. Ясно, что механизм защиты должен строить ограничения на очередной доступ, исходя из множества объектов, с которыми уже ознакомился другой пользователь. В этом случае, очевидно, можно доказать, что обеспечивается безопасность информации в указанном смысле.
Пример 5. В системе, описанной в примере 4, пусть неблагоприятной является любая траектория, содержащая граф вида
R r
U1------------>S------->O1
В этом случае очевидно доказывается, что система будет защищена ограничением доступа на чтение пользователя U1 к объекту О1
1.2. ИЕРАРХИЧЕСКИЕ МОДЕЛИ И МОДЕЛЬ ВЗАИМОДЕЙСТВИЯ ОТКРЫТЫХСИСТЕМ (OSI/ISO).
Ясно, что реализация автоматизированных информационных систем требует большого программно-аппаратного комплекса, который надо спроектировать, создать, поддерживать в работоспособном состоянии. Сложность этих систем такова, что требуется разработка специальной технологии проектирования и создания таких систем. В настоящее время основным инструментом решения задач анализа, проектирования, создания и поддержки в рабочем состоянии сложных систем является иерархический метод.
В основе метода лежит разбиение системы на ряд уровней, которые связаны однонаправленной функциональной зависимостью.
В литературе предлагалось несколько вариантов формального и полуформального описания такой зависимости. Например, Парнас (D.L.Parnas, 1974) описывал такую зависимость следующим образом. Уровень А зависит в правильности своего функционирования от уровня В, или уровень А обращается к уровню В, или уровень А использует уровень В, или А требует присутствия правильной версии В. Однако это неформальные описания, а формализация здесь не удается из-за широкой общности понятия "сложная система" и неоднозначности разбиения на уровни. В целях понимания одного и того же в декомпозициях различной природы сложных систем можно договориться об универсальных принципах описания иерархического метода. Предположим, что интересующая нас сложная система А адекватно описана на языке Я. Предположим, что мы провели декомпозицию (разложение) языка Я на семейство языков D1,D2,...,Dn. Если язык Di, i=2,.., n, синтаксически зависит только от словоформ языка Di-1, то будем говорить, что они образуют два соседних уровня. Тогда система А может быть описана наборами слов B1,...,Bn
в языках D1,D2,...,Dn
причем так, что описание Вi
синтаксически может зависеть только от набора Вi-1. В этом случае будем говорить об иерархической декомпозиции системы A и уровнях декомпозиции B1,...,Bn , где уровень Вi непосредственно зависит от Bi-1. Рассмотрим ряд простейших примеров иерархического построения сложных систем.
Пример 1. Пусть вся информация в системе разбита на два класса Secret и Тор Secret, которые в цифровой форме будем обозначать 0 и 1. Пусть все пользователи разбиты в своих возможностях допуска к информации на два класса, которые также будем обозначать 0 и 1. Правило допуска к информации X при запросе пользователя Y определяется условием, если класс х
запрашиваемой информации X, а класс у пользователя Y, то допуск к информации разрешен тогда и только тогда, когда x=y. Это условие можно описать формально формулой некоторого языка D2
if x=y then "Допуск Y к X"
Для вычисления этого выражения необходимо осуществить следующие операции, которые описываются в терминах языка D1:
x:=U1(X),
y:=U2(Y),
z=xÅ y
U(X,Y,z),
где U1(X) - оператор определения по имени объекта X номера класса доступа х; U2(Y) - оператор определения по имени пользователя Y номера класса допуска у; Å - сложение по mod 2; U(X, Y, z) - оператор, реализующий доступ Y к X, если z=0 , и блокирующий систему, если z=l.
По построению уровень B2 зависит от B1, а вся система представлена иерархической двухуровневой декомпозицией с языками D1 и D2. Причем Я=(D1, D2).
Пример 2. Гораздо чаще используется неформальное иерархическое описание систем. Например, часто используется иерархическая декомпозиция вычислительной системы в виде трех уровней.
Аппаратная часть - Операционная система -Пользовательские программы.
МОДЕЛЬ OSI/ISO.
1. Одним из распространенных примеров иерархической структуры языков для описания сложных систем является разработанная организацией международных стандартов (ISO) Эталонная модель взаимодействия открытых систем (OSI), которая принята ISO в 1983 г.
ISO создана, чтобы решить две задачи:
· своевременно и правильно передать данные через сеть связи (т.е. пользователями должны быть оговорены виды сигналов, правила приема и перезапуска, маршруты и т.д.);
· доставить данные пользователю в приемлемой для него распознаваемой форме.
2. Модель состоит из семи уровней. Выбор числа уровней и их функций определяется инженерными соображениями. Сначала опишем модель.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Физическая среда
Верхние уровни решают задачу представления данных пользователю в такой форме, которую он может распознать и использовать. Нижние уровни служат для организации передачи данных. Иерархия состоит в следующем. Всю информацию в процессе передачи сообщений от одного пользователя к другому можно разбить на уровни; каждый уровень является выражением некоторого языка, который описывает информацию своего уровня. В терминах языка данного уровня выражается преобразование информации и "услуги", которые на этом уровне предоставляются следующему уровню. При этом сам язык опирается на основные элементы, которые являются "услугами" языка более низкого уровня. В модели OSI язык каждого уровня вместе с порядком его использования называется протоколом этого уровня.
Каково предназначение каждого уровня, что из себя представляет язык каждого уровня?
Прикладной уровень (ПУ). ПУ имеет отношение к семантике обмениваемой информации (т.е. смыслу). Язык ПУ обеспечивает взаимопонимание двух прикладных процессов в разных точках, способствующих осуществлению желанной обработки информации. Язык ПУ описывает два вида ситуаций:
· общие элементы для всех прикладных процессов, взаимодействующих на прикладном уровне;
· специфические, нестандартизируемые элементы приложений.
Язык ПУ состоит и постоянно расширяется за счет функциональных подъязыков. Например, разработаны протоколы (языки ПУ):
· виртуальный терминал (предоставление доступа к терминалу процесса пользователя в удаленной системе);
·файл (дистанционный доступ, управление и передачу информации, накопленной в форме файла);
· протоколы передачи заданий и манипуляции (распределенная обработка информации);
·
менеджерские протоколы;
·одним из важных протоколов прикладного уровня является "электронная почта" (протокол Х.400), т.е. транспортировка сообщений между независимыми системами с различными технологиями передачи и доставки сообщений.
Уровень представления (УП). УП - решает те проблемы взаимодействия прикладных процессов, которые связаны с разнообразием представлений этих процессов. УП предоставляет услуги для двух пользователей, желающих связаться на прикладном уровне, обеспечивая обмен информацией относительно синтаксиса данных, передаваемых между ними. Это можно сделать либо в форме имен, если обеим связывающимся системам известен синтаксис, который будет использоваться, либо в форме описания синтаксиса, который будет использоваться, если он не известен. Когда синтаксис передаваемой информации отличается от синтаксиса, используемого принимающей системой, то УП должен обеспечить соответствующее преобразование.
Кроме того, УП обеспечивает открытие и закрытие связи, управление состояниями УП и контролем ошибок.
Уровень сеанса (УС). УС обеспечивает управление диалогом между обслуживаемыми процессами на уровне представления. Сеансовое соединение сначала должно быть установлено, а параметры соединения оговорены путем обмена управляющей информацией. УС предоставляет услугу синхронизации для преодоления любых обнаруженных ошибок. Это делается следующим образом: метки синхронизации вставляются в поток данных пользователями услуги сеанса. Если обнаружена ошибка, сеансовое соединение должно быть возвращено в определенное состояние, пользователи услуги должны вернуться в установленную точку диалогового потока информации, сбросить часть переданных данных и затем восстановить передачу, начиная с этой точки.
Транспортный уровень (ТУ). ТУ представляет сеансовому уровню услугу в виде надежного и прозрачного механизма передачи данных (вне зависимости от вида реальной сети) между вершинами сети.
Сетевой уровень (СУ). СУ представляет ТУ услуги связи. СУ определяет маршрут в сети. Организует сетевой обмен (протокол IP). Управляет потоками в сети.
Канальный уровень. Представляет СУ услуги канала. Эта услуга состоит в безошибочности последовательной передачи блоков данных по каналу в сети. На этом уровне реализуется синхронизация, порядок блоков, обнаружение и исправление ошибок, линейное шифрование.
Физический уровень. Физический уровень обеспечивает то, что символы, поступающие в физическую среду передачи на одном конце, достигали другого конца.
Каким образом реализуются функции обмена информацией на каждом уровне? Для этого на каждом уровне к исходному блоку данных добавляется информация в виде выражения языка соответствующего уровня (как правило в виде дополнительного заголовка).
Уровни функционально взаимодействуют, во-первых, как одинаковые уровни у различных абонентов, во-вторых, как смежные уровни в одной иерархии.
Блок данных
ПУ Блок прикладных данных ДДДДДДДДД
УП Заголовок услуги представления ППППДДДДДДДДД
УС Заголовок услуги сеанса СССССППППДДДДДДДДД
ТУ Заголовок транспортной услуги ТТТТСССССППППДДДДДДДДД
СУ Заголовок сетевой услуги ссссссссТТТТСССССППППДДДДДДДДД
КУ Заголовок канала передачи ккккккссссссссТТТТСССССППППДДДДДДДДД
ФУ
Связь любых одинаковых уровней у различных абонентов при передаче, использующей соединение, состоит из трех фаз:
а) - установление соединения;
б) - передача данных;
в) - разъединение.
В фазе а) происходит переговор о наборе параметров передачи. В фазе б) - выявление и исправление ошибок, поддержание соединения.
На каждом уровне свои способы выявления и исправления ошибок:
канал - исправление битов;
сеть - разъединение и потеря пакетов; соответственно исправление этих ошибок;
сеанс, транспортирование - исправление адресации.
Важные информационные элементы каждого уровня будем называть объектами, таким образом, связь (N-1)-го, N-го и (N+l)-го уровней выглядит следующим образом; каждый уровень содержит набор объектов, которые взаимодействуют между собой в разных системах на одном уровне.
На разных уровнях объекты взаимодействуют через ключи доступа услуг.
В модели OSI стандартизированы виды взаимодействия поставщика услуги на уровне N и потребителя на уровне (N+l). Эти виды называются примитивами услуг. Их четыре:
· запрос;
· признак;
· ответ;
· подтверждение.
Запрос подается пользователем услуги на (N+l)-м уровне системы А для того, чтобы обратиться к услуге протокола-поставщика услуги на N-уровне. Это приводит к посылке сообщения N-го уровня в систему В. В системе В запрос на уровне N вызывает появление примитива "признак", выпускаемого поставщиком услуги на уровне N в В на (N+l)-ый уровень.
Примитив "ответ" выпускается пользователем услуги на уровне N+l в В в ответ на признак, явившийся в точке доступа к услуге между уровнями N и N+l системы В. Примитив "ответ" является директивой протоколу уровня N завершить процедуру обращения примитива "признак". Протокол на уровне N в системе В генерирует сообщение, которое передается в сети и повторяется на уровне N системы А. Это вызывает посылку примитива "подтверждение", который выпускается поставщиком услуги в системе А на уровне N в точку доступа к услуге между уровнями N и N+l. На этом процедура, начатая запросом в точке доступа к услуге между уровнями N и N+l в системе А завершается.
1.3. ИНФОРМАЦИОННЫЙ ПОТОК.
Структуры информационных потоков являются основой анализа каналов утечки и обеспечения секретности информации. Эти структуры опираются на теорию информации и математическую теорию связи. Рассмотрим простейшие потоки.
1. Пусть субъект S осуществляет доступ на чтение (r) к объекту О. В этом случае говорят об информационном потоке от О к S. Здесь объект О является источником, а S - получателем информации.
2. Пусть субъект S осуществляет доступ на запись (w) к объекту О. В этом случае говорят об информационном потоке от S к О.
Здесь объект О является получателем, а S - источником информации.
Из простейших потоков можно построить сложные. Например, информационный поток от субъекта S2 к субъекту S1 по следующей схеме:
r w
S1 ----------à O ß---------- S2 (1)
Субъект S2 записывает данные в объект О, а затем S1 считывает их. Здесь S2 - источник, а S1
- получатель информации. Можно говорить о передаче информации, позволяющей реализовать поток. Каналы типа (1), которые используют общие ресурсы памяти, называются каналами по памяти.
С точки зрения защиты информации, каналы и информационные потоки бывают законными или незаконными. Незаконные информационные потоки создают утечку информации и, тем самым, могут нарушать секретность данных.
Рассматривая каналы передачи информационных потоков, можно привлечь теорию информации для вычисления количества информации в потоке и пропускной способности канала. Если незаконный канал нельзя полностью перекрыть, то доля количества информации в объекте, утекающая по этому каналу, служит мерой опасности этого канала. В оценках качества защиты информации американцы используют пороговое значение для допустимой пропускной способности незаконных каналов.
С помощью теоретико-информационных понятий информационные потоки определяются следующим образом.
Будем считать, что всю информацию о вычислительной системе можно описать конечным множеством объектов (каждый объект - это конечное множество слов в некотором языке Я). В каждом объекте выделено состояние, а совокупность состояний объектов назовем состоянием системы. Функция системы - это последовательное преобразование информации в системе под действием команд. В результате, из состояния s мы под действием команды a
перейдем в состояние s', обозначается: s|-- s'(a). Если a
последовательность команд, то композиция преобразований информации обозначается также, т.е. s|---s'(a) означает переход из состояния s в s' под действием последовательности команд a
(автоматная модель вычислительной системы).
В общем виде для объектов X в s и Y в s' определим информационный поток, позволяющий по наблюдению Y узнать содержание X.
Предположим, что состояние X и состояние Y - случайные величины с совместным распределением Р(х, у)=Р(Х=х, Y=y), где под {Х=х} понимается событие, что состояние объекта X равно значению х (аналогично в других случаях). Тогда можно определить: P(x), Р(у/х), Р(х/у), энтропию Н(Х), условную энтропию H(X/Y) и среднюю взаимную информацию
I(Х, Y) = Н(X) - H(X/Y).
Определение. Выполнение команды a в состоянии s, переводящей состояние s в s', вызывает информационный поток от X к Y (обозначение Х-->aY ),если I(Х, Y)>0. Величина I(Х, Y) называется величиной потока информации от X к Y.
Определение. Для объектов X и Y существует информационный поток величины С (бит), если существуют состояния s и s' и последовательность команд a такие, что s|-- s'(a), X-->aY.
Оценка максимального информационного потока определяется пропускной способностью канала связиХ--->a Y и равна по величине
C(a, X, Y)=max I(X, Y).
P(x)
Рассмотрим дальнейшие примеры информационных потоков в вычислительных системах.
1. Рассмотрим операцию присвоения значения переменных
Y:=X.
Пусть X - целочисленная случайная величина со значениями [0,15] и Р(x) - равновероятная мера на значениях X. Тогда Н(Х)=4 бит. После выполнения операции присвоения по полученной в состоянии s‘ величине Y однозначно восстанавливается X, следовательно H(X/Y)=0 ÞI(X, Y)=4ÞC(a, X, Y)=4, т.к. рассмотренный канал - симметричный.
2. Y:=X
Z:=Y.
Выполнение этих команд вызывает непрямой (косвенный) поток информации Х-->Z, такой же величины как прямой поток Х-->Y.
3. Z:=X + Y.
Предполагаем, что X, Y Î[0,15] и равновероятны. Тогда Н(Х)=4, H(Y)=4.
0 < H(X/Z) =å Р(х, z) logP(x/z)< 4,
(xz)
следовательно, 0 < I(Х, Z) < 4 бит.
4. Пусть X1, X2,..., Хn - независимые одинаково распределенные равновероятные случайные величины со значениями 0 и 1.
n
Z=åXi , Н(Х1) = 1,
i=1
n-1 n
H(X1/Z)= -å Р(Х1=0, Z=k) logP(X=0/Z=k)- åР(Х1=1, Z=k) logP(X=l /Z=k)
k=o k=1
Если n->¥, то H(X1/Z) = Н(Х1)(1 + O(1)), откуда следует, что I(X1/Z)=O(l).
Отсюда возникает возможность прятать конфиденциальные данные в статистические данные.
5. Z:=XÅY, X и Y - равновероятные булевы случайные величины,Å - сложение по mod 2, тогда Z не несет информации о X или Y.
6. If X=l then Y=l. ХÎ{0,1}, где величина X принимает свои значения с вероятностями Р(Х=0)=Р(Х==1)=1/2, начальное значение Y=0, Н(Х)=1.
H(X/Y)= å Р(х, у) logP(x/y)=0.
(x,y)
Следовательно, I(Х, Y) = 1. Поток называется неявным, в отличие от явного при операции присвоения.
7. If(Х=1) и (Y=l) then Z:=l.
H(X)=H(Y)=l, Z=l => X=l=Y
X=0 c P=2/3 }
Z = 0 => } апостериорные вероятности
X=1 c P=1/3 }
Отсюда Hz(X)×»O,7. Поэтому количество информации о X в Z равно
I(Z, Х) » 0,3.
Если X1, Х2,...,Хn - исходные (ценные) переменные системы (программы), а Y=(Y1,...,Ym) - выходные, то I(Xi,Y) - количество информации о Хi, в потоке, который индуцируется системой. Тогда отношение I(Xi,Y)/Н(Х1) - показатель "утечки" информации о X1. Если установить порог l> О для "утечки", то из условия при каждом i=l.....n,
I(Xi,Y)/Н(Хi)
следуют требования к защите Y.
1.4. ЦЕННОСТЬ ИНФОРМАЦИИ.
Чтобы защитить информацию, надо затратить силы и средства, а для этого надо знать какие потери мы могли бы понести.
Ясно, что в денежном выражении затраты на защиту не должны превышать возможные потери. Для решения этих задач в информацию вводятся вспомогательные структуры - ценность информации. Рассмотрим примеры.
1 . Аддитивная модель. Пусть информация представлена в виде конечного множества элементов и необходимо оценить суммарную стоимость в денежных единицах из оценок компонент. Оценка строится на основе экспертных оценок компонент, и, если денежные оценки объективны, то сумма дает искомую величину. Однако, количественная оценка компонент невсегда объективна даже при квалифицированной экспертизе. Это связано с неоднородностью компонентв целом. Поэтому делают единую иерархическую относительную шкалу (линейный порядок, который позволяет сравнивать отдельные компоненты по ценности относительно друг друга). Единая шкала означает равенство цены всех компонент, имеющих одну и туже порядковую оценку.
Пример 1 01,...,0n - объекты, шкала 1<...<5. Эксперты оценили (2, 1, 3,...., 4) - вектор относительных
ценностей объектов. Если есть цена хотя бы одного объекта, например, C1=100 руб., то вычисляется оценка одного балла С1/l. = 50 руб.,
где l - число баллов оценки первого объекта, и вычисляется цена каждого следующего объекта: C2=50руб., C3=150 руб. и т.д. Сумма дает стоимость всей информации. Если априорно известна цена информации, то относительные оценки в порядковой шкале позволяют вычислить цены компонент.
2. Анализ риска. Пусть в рамках аддитивной модели проведен учет стоимости информации в системе. Оценка возможных потерь строится на основе полученных стоимостей компонент, исходя из прогноза возможных угроз этим компонентам. Возможности угроз оцениваются вероятностями соответствующих событий, а потери подсчитываются как сумма математических ожиданий потерь для компонент по распределению возможных угроз.
Пример 2. Пусть О1,...,Оn - объекты, ценности которых С1,...,Сn. Предположим, что ущерб одному объекту не снижает цены других, и пусть вероятность нанесения ущерба объекту Оi равна рi, функция потерь ущерба для объекта Оi равна
{ Ci, если объету i нанесен ущерб,
Wi= {
{ 0, в противном случае.
Оценка потерь от реализации угроз объекту i равна EWi = piСi.
Исходя из сделанных предположений, потери в системе равны W=W1+...+Wn . Тогда ожидаемые потери(средний риск) равны:
n
EW=åpiCi
i=1
Существуют ППП, позволяющие автоматизировать оценку риска, например, RASYS.
3. Порядковая шкала ценностей. Далеко не всегда возможно и нужно давать денежную оценку информации. Например, оценка личной информации, политической информации или военной информации не всегда разумна в денежном исчислении. Однако подход, связанный со сравнением ценности отдельных информационных элементов между собой, по-прежнему имеет смысл.
Пример 3. При оценке информации в государственных структурах используется порядковая шкала ценностей. Все объекты (документы) государственного учреждения разбиваются по грифам секретности. Сами грифы секретности образуют порядковую шкалу: несекретно < для служебного пользования <секретно < совершенно секретно (НС<ДСП<С<СС) или у американцев : unclassified
4. Модель решетки ценностей. Обобщением порядковой шкалы является модель решетки. Пусть дано SC - конечное частично упорядоченное множество относительно бинарного отношения <, т.е. для каждых А, В, С выполняется
1) рефлексивность: А<А,
2) транзитивность: А<В, В<С==>А<С,
3) антисимметричность: А<В, В<А => А=В.
Определение. Для А, BÎSC элемент C=AÅBÎSCназывается наименьшей верхней границей (верхней гранью), если
1) А<С, В<С;
2) A
Элемент AÅB, вообще говоря, может не существовать. Если наименьшая верхняя граница существует, то из антисимметричности следует единственность.
Упражнение. Доказать это.
Определение. Для А, BÎC элемент E=AÄBÎSCназывается наибольшей нижней границей (нижней гранью), если
1) Е<А, Е<В;
2) D
Эта граница также может не существовать. Если она существует, то из антисимметричности следует единственность.
Упражнение. Доказать этот факт.
Определение. (SC, <) называется решеткой, если для любых А, BÎSC существует AÅBÎSC и AÄBÎSC.
Лемма. Для любого набора S={А1,...,Аn } элементов из решетки SC существуют единственные элементы,:
ÅS=A1Å...ÅAn - наименьшая верхняя граница S;
ÄS=A1Ä...ÄAn - наибольшая нижняя граница S.
Доказательство. Докажем ассоциативность операции Å.
C1=(A1ÅA2) ÅA3=A1Å(A2ÅA3)=C2.
По определению C1>A3, C1>A1ÅA2. Отсюда следует С1>Аз, С1>A2, С1>А1. Тогда C1>A2ÅA3, С1>А1, cледовательно, С1>С2. Аналогично С2>С1. Из антисимметричности С1=С2.
Отсюда следует существование и единственность ÅS. Такими же рассуждениями доказываем, что существует ÄS и она единственна. Лемма доказана.
Для всех элементов SC в конечных решетках существует верхний элемент High = ÅSC, аналогично существует нижний элемент Low = ÄSC.
Определение. Конечная линейная решетка - это линейно упорядоченное множество, можно всегда считать {0, 1 ,..., n}=SC .
Для большинства встречающихся в теории защиты информации решеток существует представление решетки в виде графа. Рассмотрим корневое дерево на вершинах из конечного множества Х={Х1, Х2...Хn }с корнем в Xi. Пусть на единственном пути, соединяющем вершину X1 с корнем, есть вершина Xj. Положим по определению, что Хi<Хj. Очевидно, что таким образом на дереве определен частичный порядок. Кроме того, для любой пары вершин Xi и Xj существует элемент ХiÅХj, который определяется точкой слияния путей из Xi и Xj в корень. Однако такая структура не является решеткой, т.к. здесь нет нижней грани. Оказывается, что от условия единственности пути в корень можно отказаться, сохраняя при этом свойства частичного порядка и существование верхней грани.
Например, добавим к построенному дереву вершину L, соединив с ней все концевые вершины. Положим i=l,...,n, L
Упражнение
Доказать этот факт.
Приведенный пример не исчерпывает множество решеток, представимых в виде графов, однако поясняет как связаны графы и решетки.
Упражнение.
Покажите, что следующие графы определяют решетки.
Не всякий граф определяет решетку. Например,
Упражнение. Доказать, что это так.
РЕШЕТКА ПОДМНОЖЕСТВ X.
Для "A, ВÎХ. Определим А<ВÞАÍВ. Все условия частичного порядка 1), 2), 3) выполняются. Кроме того, AÅB - это АÈВ, АÄВ=АÇВ. Следовательно, это решетка.
Пример 4. Х={1, 2, 3}.
( 1 2 3 )
1 2 2 3 1 3
1 2 3
Æ
Пусть программа имеет Х={Х1,...,Хm} - входные,Y1...Yn - выходные элементы. Каждый выходной элемент зависит от некоторых входных элементов. Отношение вход-выход описывается решеткой рассматриваемого типа. Решетка подмножеств строится по подмножествам X следующим образом. Для каждой ХiXi={Хi}. Для каждой YjYj={Xi|XjàYj}.
Пример 5. X1, Х2, X3, Y1, Y2. Y1 зависит только от X1,Х2; Y2 зависит от X1 и Х3.
Y1={X1,X2} Y2={X1,X3}
H
Y1 Y2
X1
X2 X3
L
MLS РЕШЕТКА
Название происходит от аббревиатуры Multilevel Security и лежит в основе государственных стандартов оценки информации. Решетка строится какпрямое произведение линейной решетки L и решетки SC подмножеств множества X, т.е. (a,b), (a’,b’) -элементы произведения, b,b’ÎL - линейная решетка, a,a’ÎSC - решетка подмножеств некоторого множества X. Тогда
(a,b)<(a’,b’)ÛaÍa’,b
Верхняя и нижняя границы определяются следующим образом:
(a,b)Å(a¢,b¢)Û(aÈa¢,max{b,b’}),
(a,b)Ä(a¢,b¢)Û(aÇa¢,min{b,b’}).
Вся информация {объекты системы} отображается в точки решетки {(а,b)}.
Линейный порядок, как правило, указывает гриф секретности. Точки множества X обычно называются категориями.
Свойства решетки в оценке информации существенно используются при классификации новых объектов, полученных в результате вычислений. Пусть дана решетка ценностей SC, множество текущих объектов О, отображение С: 0àS, программа использует информацию объектов 01,..,0n , которые классифицированы точками решетки С(01),...,С(0n). В результате работы программы появился объект О, который необходимо классифицировать. Это можно сделать, положив С(0)= C(01)Å...ÅC(0n). Такой подход к классификации наиболее распространен в государственных структурах. Например, если в сборник включаются две статьи с грифом секретно и совершенно секретно соответственно, и по тематикам: первая - кадры, вторая - криптография, то сборник приобретает гриф совершенно секретно, а его тематика определяется совокупностью тематик статей (кадры,криптография).
1.5. РЕЛЯЦИОННЫЕ БАЗЫ ДАННЫХ
Предположим, что мы хотим внести решетку ценностей (например, MLS) в конкретную информацию,которая хранится и обрабатывается на ЭВМ. Рассмотрим примеры механизмов такого внесения и проблемы, которые здесь возникают. Для определенности рассмотрим информацию, структурированную и обрабатываемую при помощи реляционной базы данных.Такая модель информации называется реляционноймоделью данных (РМ). Материалы следующих параграфов 1.5 и 1.6 базируются на работах D.Denning, T.Lunt и их коллег.
РМ состоит из отношений, которые представляют собой таблицы со многими входами, и алгебры отношений, которая позволяет строить новые отношения в терминах других отношений (в РМ входят также правила целостности хранимой информации и производной информации).
Каждое отношение R определяется схемой R (А1,...,Аn), которая характеризуется множеством атрибутовА1,..., Аn, т.е. переменных, описывающих входы таблицы.Отношение состоит из множества записей (векторов или строк), которые представляют собой значения данных в области определения атрибутов (то есть элементы таблицы - значения атрибутов).
Реляционная алгебра состоит из операторов для выбора всех или части записей, имеющих определенные значения из отношения (таблицы), и для добавления данных в различные отношения.
Для иллюстрации рассмотрим базу данных "Flight"("Полеты''). Эта база определена следующими схемами. Отношение ITEM с атрибутами: номера мест, имена, веса. Отношение Flight с атрибутами: номер рейса, дата вылета, назначение, общий вес груза. ОтношениеPAYLOAD, дающее количество использованных местна борту во время полета.
ITEM (ITEM #, ITEMNAME, Weight)
Flight (Flight #, Date, Dest, Weight)
PAYLOAD (Flight #, ITEM #, QTY, Weight)
Множество схем, определяющих отношения в базе данных, само представляется как отношение
Relation (Relname, Attmame),
которое содержит атрибуты всех отношений (иногда используется два отношения: одно для названий отношений, другое - для названий атрибутов).Например, в этой таблице запись
< Flight, Weight >
определяет, что отношение Flight содержит атрибутWeight.
ФУНКЦИОНАЛЬНАЯ ЗАВИСИМОСТЬ (FD)
Пусть X и Y два множества атрибутов в схеме R.
Определение. X функционально определяет Y(обозначается Х->Y) тогда и только тогда, когда не
существует двух различных строк (векторов) в R с одноименными значениями из X и различными из Y.
Например, в классном журнале с атрибутами имя, присутствие и отметка за данное число. Атрибут имя функционально определяет все остальные атрибуты.
Функциональная зависимость позволяет определить базовое для РМ понятие первичного ключа отношения.
Определение. Множество атрибутов называется кандидатом в ключи для отношения, если оно функционально определяет все другие атрибуты и является минимальным множеством (т.е. ни один атрибут из множества не может быть исключен так, чтобы оно по-прежнему функционально определяло остальные).
Определение. Для любого отношения один из кандидатов в ключи отношения выделяется и называется первичным ключом.
Замечание. Первичный ключ не обновляется. Первичный ключ может быть использован для выбора спецификации строк в отношении и для того,чтобы связать отношение в нечто целое.
Определение. Первичный ключ для R1, помещенныйв R2, называется вторичным ключом в R2.
Одно из основных правил целостности данных связано с первичным ключом. Целостность для элементов информации реляционной базы данных: ни одна строка таблицы не может принимать нулевое значение в каком-либо атрибуте из первичного ключа.Это свойство означает, что любые строки однозначно идентифицируемы.
Понятие функциональной зависимости позволяет определить и исследовать некоторые каналы утечки в базах данных, которые появляются из возможности вывода из одних объектов других (или еще один случай потока информации). Пусть множество F - это класс пар Х-->Y, X, YÍU=Attr(R) - множество атрибутов R.
Теорема 1. 1. Если YÍXÍU, то X->Y.
2. Если X->Y, Y->Z, X,Y,ZÍU, то X->Z.
3. Если X->Y, X->Z, X,Y ZÍU, то X->YÇZ.
4.Если X->Y, X->Z, X,Y,ZÍU, то X->YÈZ.
Доказательство.
1. Пусть есть два набора значений атрибутов Y, что у¹у'. Y соответствует компонентам вектора X, для которых значения атрибутов в X не совпадают на у и у'.
2. Для строк с различными значениями атрибутовY значения векторов для атрибутов X различны. Для строк с различными значениями Z значения Y различны. Тогда значения X различны. Следовательно,X->Z.
3. Очевидно.
4. а¹a' из YÈZ, тогда отличаются значения атрибутов хотя бы Y или Z, например, Z. Тогда есть отличия на X. Теорема доказана.
Определение. Множество пар функциональных зависимостей F+ называется замыканием множества пар функциональных зависимостей F, если F+ -множество всех функциональных зависимостей, которые порождаются множеством F при помощи пп.1, 2, 3, 4 теоремы 1, то есть конструктивно построены, исходя из F, используя правила теоремы.
Определение. Два множества функциональных зависимостей (FD) F и G называются эквивалентными,если F+=G+.
Доказанная ниже теорема позволяет значительно сократить класс множеств FD, которые необходимо изучать для одного и того же F+.
B частности, достаточно ограничиться редуцированными FD, эквивалентными F.
Определение. Множество F функциональныхзависимостей называется редуцированным, если:
1) в F нет двух пар Х->Y и X'->Y' таких, чтоX=X' и Y¹Y';
2) для всех X->Y в F XÇY=0.
Теорема 2. Для произвольного F существует редуцированный G такой, что F+=G+.
Доказательство. Для каждого Х->Y из F построим эквивалентные функциональные зависимости в G, удовлетворяющие условиям редуцированного класса. Пусть X->Y, X'->Y' из F такие, чтоХ=Х', Y¹Y'.Если Y¹Y', то возьмем в G X->YÈY' по п. 4.
Наоборот: если в G есть X->YÈY', то в G+ по п.1есть YÈY'->Y и YÈY'->Y'.
Тогда по п. 2 теоремы 1 в G+ есть Х->Y, Х->Y'.Пункт 1 доказан.
Пусть Х->Y, XÇY¹Æ.
Отсюда по п.1 и п.2 теоремы 1: Y->Y\(YÇX)=>Y->X->Y\(YÇX).
Обратно. Если X->Y\(YÇX) есть в G, то Х->Y есть в G+, т.к. по п.1 теоремы 1: X->XÇY и Х->(Y\ (YÇX))È(XÇY)=Y по п.4. Теорема доказана.
Использование функциональной зависимости для компрометации базы данных иллюстрируется следующим простым примером.
Пример 1. Пусть R - отношение в реляционной базе данных некоторой компании, содержащее атрибуты имя - ранг - зарплата. Предположим, что зарплата - совершенно секретные сведения, а имя и ранг - секретные. Предположим также, что в R выполняется следующая функциональная зависимость РАНГ -> зарплата, что означает, что все служащие одного ранга получают одинаковую зарплату. Тогда пользователь, имеющий допуск к данным не выше секретно, может получить допуск к совершенно секретной информацию о конкретном лице, если он знает соответствие ранг-зарплата хотя бы для некоторых лиц.
Для того, чтобы проанализировать возможность возникновения подобных зависимостей, надо изучить все множество F+ для набора исходных зависимостей F. Это удобнее сделать, если F - редуцированное множество, что не ограничивает общности, благодаря доказанной теореме.
ЦЕЛОСТНОСТЬ В РМ.
Если описывать условия целостности данных в РМ формально, это можно сделать, определив конъюнкцию одного или нескольких условий, которым должны удовлетворять набор атрибутов, выраженных формулами какого-либо языка.
Пример 2.
Ограничения целостности данных могут иметь следующий вид:
I=( R.1A>O)Ù(R1.A=R2.A)Ù(0
Если даны I1,...Im, то область состояний D базы данных определяется формулой

где под Ik также подразумевается множество значений, которые могут принимать атрибуты базы данных, удовлетворяющие логической формуле Ik. Будем предполагать D¹Æ.
РЕЛЯЦИОННЫЕ ОПЕРАТОРЫ (РО).
В реляционной модели выделяют реальные (или базовые) отношения, которые соответствуют хранящимся данным, и производные отношения, которые образуются с помощью реляционных операторов.
РО строит новые отношения из одного или нескольких существующих. Можно определить пять основных операторов.
1 . Select (R, F).
Строит новое отношение, состоящее из всех векторов (строк) R, удовлетворяющих F, где F -формула вида "AiQV'' или "АiqАj" где q - отношение сравнения (=, < и т.д.) и V - значение из области Di атрибута Аi. (Этот оператор также называют "q -выбор" ).
2. Project (R (Ai1,...,Aik)).
Строит новое отношение следующим образом: берутся по очереди все строки R и из каждой из них выбрасываются все элементы в координатах, не являющиеся атрибутами Ai1,...,Aik, затем удаляются дубликаты в множестве получившихся строк нового отношения.
3. Union (R1, R2).
Строит новое отношение, состоящее из строк, которые есть хотя бы в одном отношении R1 или R2.Схемы для R1 и R2 должны быть совместимы, то есть иметь одинаковое число атрибутов, согласование по области определения атрибутов.
4. Diff (R1, R2).
Строит новое отношение, состоящее из тех и только тех строк R1, которые не входят в R2. Схемы R1 и R2 должны быть совместимы.
5. Product (R1, R2).
Образует новое отношение из прямого произведения таблиц R1 и R2, т.е. каждая строка R1 приписывается каждой строке R2.
Кроме перечисленных основных РО полезно определить следующие два производных оператора.
6. Natural-join (R1, R2, (Ai1,...,Aik)).
Этот оператор выбирает и оставляет в новой таблице вектора из прямого произведения R1 и R2 такие, в которых атрибуты Ai1,...,Aik принимают одинаковое значение и затем выбрасываются лишние атрибуты (встречающиеся дважды).
7. Outer-join (R1, R2, (Ai1,...,Aik)).
Строит Natural-join из R1 и R2 и к нему добавляет каждую строку в R1, которая не имеет подходящей строки в R2, а также добавляет каждую строку в R2, которая не имеет подходящей строки в R1.
1.6. МНОГОУРОВНЕВЫЕРЕЛЯЦИОННЫЕБАЗЫ ДАННЫХ.
Следующий шаг - внести решетку ценностей в информацию, наделенную структурой реляционной базы данных. Такое внесение возможно не всегда. Функционирование базы данных может привести к противоречию с размещением информации в том или ином классе решетки и затем, к компрометации этой информации.Чтобы этого не случилось надо согласовывать все элементы БД (т.е. отношения и реляционную алгебру) и решетку ценностей. А именно, при внесении решетки в БД (короче, при классификации информации) необходимо решить следующие задачи:
1. Уметь классифицировать отдельные (неделимые) факты и объекты. В реляционных БД требуется поддерживать MLS на уровне элементов потому, что каждая строка отношения может содержать много различных фактов, имеющих разные классификации (например, время вылета - секретно, время прибытия - секретно, назначение - совершенно секретно). Хотя в литературе использовались и другие подходы.
2. Уметь создавать для просмотра пользователями виртуальные отношения. Будем называть их обзорами, в которых не все данные имеют одну классификацию. Поскольку обзоры это производные данные, то создание обзора требует проведения классификации производных данных.
3. Уметь вносить новые данные и обновлять старые, причем элементы вносимых данных могут иметь разную классификацию.
4. Необходима состоятельность классов информации, т.е. для каждого факта не должны при различных видах обработки получаться различные классы ценности. При этом пользователь может не иметь доступа к некоторым классам, но не должен из-за этого терять возможность работать с БД.
5. Уметь определять ограничения целостности на данных, имеющих различную классификацию. В частности, это надо делать автоматически, чтобы не заставлять пользователя запоминать все правила классификации информации.
6. Уметь восстанавливать данные с учетом их классификации.
Основная идея внесения MLS в БД (D. Denning, Т.Lunt и др.) состоит в создании нового отношения, где классы MLS входят как атрибуты отношения. То есть, любая данная схема расширяется включениями классификационного атрибута Сi для каждого атрибута данных Аi. Область значений Сi определяется парой классов (Li, Нi), которые определяют подрешетку отнизшего класса Li до высшего для данного атрибута класса Нi. Класс элемента аi в данном векторе определяется С(аi)=Сi в этой подрешетке (функцияC(a)=class(a) - обозначает отображение элементовРМ в решетку).
Определение. Многоуровневое базовое отношение (MLS R) определяется как произвольное отношение, у которого существуют классификационные атрибуты Сi для всех атрибутов данных Аi. Такое отношениепредставляется схемой:
R(A1, C1, ..., An, Cn)
Пример I. Решетка {S, TS}; A 1 - первичный ключ.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Определение. Атрибут Ai и соответственно атрибут Ci в MLS R называется одноуровневым, если область, определяемая Ci, - одна точка в решетке, иначе Ai
называется многоуровневым.
Определение. MLS R называется одноуровневым, если все атрибуты одноуровневые и соответствуют одному классу.
Схема для MLS R также классифицируется. Этот класс обозначается class(R) и этот класс относится к имени отношения, имени всего набора атрибутов R и схеме.
Class(R) должен доминироваться нижней гранью L1,...,Ln классификационных атрибутов С1,...,Сn в схеме. Это свойство позволяет доминировать class(R) всеми элементами таблицы.
В стандартной реляционной базе любой отсутствующий элемент представляется каким-нибудь аналогом нулевого значения. Положим, что это выполняется и для многоуровневой реляционной модели. Кроме того, нулевое значение атрибута Аi будет определять наименьшее значение Li атрибута Сi.
Тогда, если новое отношение V, например, обзор, не должен содержать TS данных, то должна осуществляться фильтрация данных, помещаемых в V. Тогда S - отфильтрованный обзор предыдущего примера,примет вид.
Пример 2.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
КЛАССИФИКАЦИОННЫЕ ОГРАНИЧЕНИЯ.
Классификация информации в ходе функционирования системы происходит автоматически на основе классификационных ограничений (КО).
Определение. КО S - это правило, которое определяет значения для одного или более классификационных атрибутов Ci. Формально S - это четверка вида:
С=(R, А, Е, L),
где R - имя отношения; А - набор из одного или нескольких атрибутов в R; Е - опциональное выражение (например, формула логики предикатов); L - класс (точка в решетке ценностей).
Правило S интерпретируется следующим образом:
if Е then class (R.A)=L,
где R.A - означают атрибуты А в отношении R. Без ограничения общности, далее полагаем, что Ai определены на множестве действительных чисел (целые числа - частный случай, а значения не целочисленных атрибутов могут быть перенумерованы).
Замечание. Класс L - это выражение, которое может быть или константой, например, Secret, Тор Secret, или содержать одну или несколько переменных. Например, "Classt(B)" или "Class(B) , Class(C)".
Определение. Два класса L1 и L2 называются равными, если они представлены символьно идентичными записями.
Замечание. Это позволяет конструктивно проверятьсостоятельность.
Выражение Е есть конъюнкция одного или более условий, которым удовлетворяют наборы атрибутов в БД (дизъюнкции сводятся к конъюнкциям).
Пример 3.
E=(R1.A>0)Ù((R1.A)=(R2.A))Ù(0
Существует 4 типа классификационных ограничений.
1. Зависящие от типа. Выражение Е отсутствует и класс L - постоянный, так что все элементы, связанные с атрибутом, имеют один класс. Этот тип ограничений определяет одноуровневый атрибут. Например,
(R, А, , secret)
(R, (А, В), , secret)
2. Зависящие от значения. Здесь или Е присутствует, или L описывается выражением от переменной (или оба случая), так что класс элемента зависит от значения элемента, или от значения или класса других данныхБД. Например,
(R, A, A=1, conf)
(R, A, A=2, secret)
(R, A, , class(R.B))
(R, A, A=1, class(R.B))
3. Зависящие от уровня источника. Класс L есть выражение "класс пользователя". Например,
( R, А, , class (user))
(R, В, В > О, class (user))
4. Зависящие от грифа источника. Класс L есть выражение *, которое означает, что субъект, вводящий элемент, определяет также и класс элемента. Например,
(R.A, , *)
(R, В, В > О, *)
СОСТОЯТЕЛЬНОСТЬ.
Напомним :
Определение. Множество классификационных ограничений называется состоятельным, если для каждой возможной строки реляционной БД из D, никакие два ограничения не определяют конфликтные классы для одного и того же элемента.
Пример 4. Рассмотрим БД Flight и классификационные ограничения на атрибуты Flight #, Dest, Date в отношении Flight.
(Flight, (Flight #, Dest, Date), ( Date < 500), Secret)
(Flight, (Flight #, Dest, Date), (1< Dest< 2), T.S)
(Flight , (Flight #, Dest, Date), (Dest>2)v(Date > 500),class(user)).
Предположим, что ограничения целостности разрешают строку со следующими значениями:
(Flight #=1750, Dest=l, Date=450).
Тогда ограничения несостоятельны, так как строка удовлетворяет обоим первым двум ограничениям, но эти ограничения не определяют одинаковые классы.
Однако классификационные ограничения не будут несостоятельными, если выполняются еще следующие ограничения целостности:
(1 500),
так как тогда нижние два из классификационных ограничений не выполняются одновременно.
Для того, чтобы определить, является ли множество классификационных ограничений состоятельным при данных ограничениях целостности, достаточно определить, является ли каждая пара ограничений Si иSj состоятельной. (По определению проверить состоятельность требуется для каждой пары. Так как надо каждый элемент покрыть хотя бы одним ограничением, если покрывают 3 и более, и они конфликтны, то, следовательно, существуют два конфликтные.)
Для проверки пары используется следующая теорема.
Теорема. 1. Данная пара Si и Sj классификационных ограничений состоятельная, если выполняется хотя бы одно из следующих условий'.
1. Li=Lj - оба ограничения определяют один класс (напоминаем, равенство символьное);
2. .A(i)ÇA(j)=Æ - Si и Sj накладывают ограничения на непересекающиеся множества атрибутов;
3. EiÇEj=Æ - оба ограничения не могут выполняться одновременно;
0
1
2
3
4
5
6
7
8
4. EiÇEjÇD=Æ - оба ограничения не совместимы с условиями целостности.
Доказательство.
1. Очевидно, так как требуется символьное равенство выражений, откуда следует, что конфликтное присвоение классов невозможно.
2. Происходит присвоение классов разным атрибутам.
3. Невозможно присвоить хоть один класс.
4. Невозможно присвоить хоть один класс. Теорема доказана.
Простые достаточные условия теоремы позволяют реализовать алгоритм, их проверяющий, и эффективно проверить состоятельность классификационных ограничений на практике.
ПОЛНОТА КЛАССИФИКАЦИОННЫХ ОГРАНИЧЕНИЙ.
Пусть доказано, что система состоятельна. Теперь надо проверить, что она полна.
Определение. Множество классификационных ограничений называется полным, если для любого набора значений атрибутов из области определения базы данных каждому элементу приписывается класс хотя бы одним классификационным ограничением.
Рассмотрим процедуру проверки полноты.
1. Для каждого атрибута А рассмотрим {Si} ивыберем все ограничения, содержащие А; если это множество пусто, то система неполная.
2. Если классификационные ограничения не покрывают область возможных значений какого-либо атрибута, то система неполная. В противном случае система ограничений полная.
Пример 5. Пусть есть два атрибута А и В
D(A) = {(АВ), 10<А<20},
D(B) = {(АВ), -10<В<30},
S1= (R, (А, В), А + 2В<30, Sec),
S2= (R, (А, В), 5А - 2В<60, Sec),
S3= (R, (А, В), ЗВ - 2А<30, Sec).
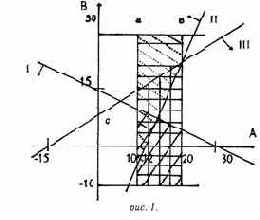
Таким образом, все точки покрыты, отсюда следует полнота. Из того, что классы одинаковы, следует состоятельность.
ПРОБЛЕМА ПОЛИИНСТАНТИНАЦИИ.
Суть проблемы поясним на простом примере.
Пример 6. Пусть пользователь получил обзор, как это было сделано в примере 2 и решил дополнить его имеющимся в его распоряжении данными. Это нельзя запрещать, т.к. легко строится канал утечки. Предположим, что он достроил отношение примера 2.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ДЕКОМПОЗИЦИЯ MLS R В СТАНДАРТНЫЕ БАЗОВЫЕ ОТНОШЕНИЯ РЕЛЯЦИОННОЙМОДЕЛИ.
Мы построим декомпозицию произвольной MLS R в семейство стандартных базовых отношений БД. Тогда реальные отношения получаются как обзор этих базовых.
При этом, стандартные базовые отношения будут одноуровневыми. Отсюда следует, что механизм хранения их идентичен механизму хранения в обычной БД (не MLS), т.е. имеется ввиду отображение при помощи программного обеспечения в файлы, сегменты и т.д. Механизм защиты здесь - внешний и не связан с конкретными элементами информации. Этот механизм определяет защиту и доступ к информации любого заданного класса.Сначала несколько замечаний.
Определение. Пусть множество атрибутов А одинаково классифицируются на всех строках отношения, тогда говорят, что они равномерно классифицированы.
Теорема 3. При выполнении основных ограничений целостности множество атрибутов первичного ключа равномерно классифицировано и этот класс доминируется классами всех остальных элементов строки.
Доказательство. Если первичный ключ не равномерно классифицирован, то возможно существует пользователь, который не имеет права на высший класс, но имеет право на низший. В этом случае, в обзоре этого отношения в атрибуте высшего класса первичного ключа должны стоять null, что противоречит требованиям целостности хранимой информации (в первичном ключе нельзя иметь null). Аналогично, если какой-то элемент имеет класс меньший, чем элементы первичного ключа, то в обзоре эта строка появится, а первичный ключ будет null. Теорема доказана.
Пусть дано R(A1,С1,..., Аn,Сn), где А1 - первичный ключ. Первый шаг декомпозиции - создать базовоеотношение R1,X для каждого значения х атрибута С1 первичного ключа А1, т.е. для каждого xÍ(L1, Н1)создаем R1.X(A1) с классом х. Назовем их "отношениями, связанными с первичным ключом". Если первичный ключ состоит из нескольких атрибутов, то, в силу равномерности классификации, можно считатьего одним атрибутом А1 с одним классификационным атрибутом С1 и для него создать R1.X(A1).
Второй шаг. Для произвольного А.(которое может также быть множеством атрибутов, но равномерно классифицированным с атрибутом Сi) образуем базовые отношения (называемые "отношения, связанные с атрибутом Аi").
Для i = 2,...,n каждой паре х,у, xÎ(L1, Н1), yÎ(Li, Нi), у>х (из теоремы 3) строим Ri,X,Y(A1, Аi) с классом у.
В этих отношениях, очевидно, А1 - первичный ключ. Однако таким отношениям присваивается класс у (поднимая, возможно, уровень значения первичного ключа, что при восстановлении исправляется исходя из информации в R1,X), таким образом, эти отношения одноуровневые по построению. Алгоритм декомпозиции следующий (заменим R на {R1,X(A1), Ri,X,Y(A1, Аi)}): для каждой строки (а1,с1,..., an,сn) в R поместим а1 в R1,C1 и для i=l,..., n поместим (а1, аn) в Ri.C1.Ci. Любая новая строка при коррекции БД разлагается также.
Пример 7.
Рассмотрим отношение из примера 1.
Очевидно, что, если исходное отношение - одноуровневое, то процедура декомпозиции тривиальна.
Рассмотрим процедуру восстановления MLS из базовых одноуровневых отношений. Определим оператор "ml", который преобразует строку стандартных отношений R1,X или Ri,X,Y , в строку MLS отношения.
а) m1(Ri,X) - многоуровневое отношение R' со схемой R'(A1,C1). Для каждой строки а1 в R1,X строка (а1, х) строится в R'.
б) m1(Ri,X,Y) - многоуровневое отношение R' со схемой R'(A1, С1, Аi, Сi). Для каждой строки а1, аi в Ri,X,Y строка (а1, х, аi, у) строится в R'.
Обозначим через УAB оператор Outer-join относительно атрибутов АВ и через U оператор Union. Тогда формула для восстановления R имеет вид:
Recover(R) = È (R’1,XУA1C1R’2,X УA1C1 ... УA1C1R’n,X),
xÎ{L1,H1}
где R'i,X= U R'i,X,Y, i = 2,..., n,
ye{max(Li,x),H,)
R’1,X = m1(R1,X),
R'i,X,Y =m1(R'i,X,Y ).
Можно доказать следующую теорему.
Теорема 4. Recover (Decompose R) = R.
Вместо доказательства восстановим пример 1.
Пример 8. m1(Ri,X) = R’i,X
m1(Ri,X,Y) = R’i,X,Y
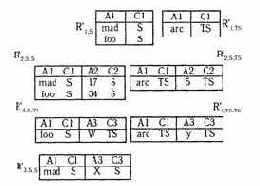
Recover(R)=((R'1SУA1C1R’2SS)УA1C1 (R'3SSUR'3STS))U
U(R'1TSУA1C1R’2TSTSУA1C1R'3TSTS).
Отсюда получаем отношение примера 1.
Глава 2
Угрозы информации
Если информация представляет ценность, то необходимо понять, в каком смысле эту ценность необходимо оберегать. Если ценность информации теряется при ее раскрытии, то говорят, что имеется опасность нарушения секретности информации. Если ценность информации теряется при изменении или уничтожении информации, то говорят, что имеется опасность для целостности информации. Если ценность информации в ее оперативном использовании, то говорят,что имеется опасность нарушения доступности информации. Если ценность информации теряется при сбоях в системе, то говорят, что есть опасность потери устойчивости к ошибкам. Как правило, рассматривают три опасности, которые надо предотвратить путем защиты: секретность, целостность, доступность. Хотя, как показывают примеры действий в боевых условиях, развитие сложных систем Hewlett-Packard, Tandem, практически добавляется четвертое направление: устойчивость к ошибкам.
Под угрозами подразумеваются пути реализации воздействий, которые считаются опасными. Например, угроза съема информации и перехвата излучения с дисплея ведет к потере секретности, угроза пожара ведет к нарушению целостности информации, угроза разрыва канала может реализовать опасность потерять доступность. Угроза сбоя электроэнергии может реализовать опасность неправильной оценки ситуации в системе управления и т.д.
В главе рассматриваются вопросы анализа опасностей, выявления угроз. Далее рассматриваются основные угрозы нарушения секретности в ЭСОД и механизмы их предотвращения, угрозы нарушения целостности и механизмы защиты от них. Связь между видом опасности и возможной угрозой состоит в месте, времени и типе атаки, реализующей угрозу. Анализ опасности должен показать, где и когда появляется ценная информация, в каком месте системы эта информация может потерять ценность. Угроза характеризует способ нападения в. определенном месте и в определенный момент. Угроза реализуется через атаку в определенном месте и в определенное время.
2.1. УГРОЗЫ СЕКРЕТНОСТИ
В руководстве по использованию стандарта защиты информации американцы говорят, что существуеттолько два пути нарушения секретности:
· утрата контроля над системой защиты;
· каналы утечки информации.
Если система обеспечения защиты перестает адекватно функционировать, то, естественно, траектории вычислительного процесса могут пройти через состояние, когда осуществляется запрещенный доступ. Каналы утечки характеризуют ту ситуацию, когда либо проектировщики не смогли предупредить, либо система не в состоянии рассматривать такой доступ как запрещенный. Утрата управления системой защиты может быть реализована оперативными мерами и здесь играют существенную роль административные и кадровые методы защиты. Утрата контроля за защитой может возникнуть в критической ситуации, которая может быть создана стихийно или искусственно. Поэтому одной из главных опасностей для системы защиты является отсутствие устойчивости к ошибкам.
Утрата контроля может возникнуть за счет взламывания защиты самой системы защиты. Противопоставить этому можно только создание защищенного домена для системы защиты.
Разумеется, в реальной жизни используются комбинации этих атак.
Большой спектр возможностей дают каналы утечки. Основной класс каналов утечки в ЭСОД - каналы по памяти (т.е. каналы, которые образуются за счет использования доступа к общим объектам системы). Графически канал по памяти можно изобразить следующим образом:

Пользователь U1 активизирует процесс, который может получить доступ на чтение к общему с пользователем U2 ресурсу О, при этом U2 может писать в О, а U1 может читать от S. Приведем примеры таких каналов.
Пример 1. В директорию О внесены имена файлов. Хотя доступ к самим файлам для субъекта S1 закрыт, доступ к директории возможен. Если субъект S2 создал закрытые файлы, то информация о файловой структуре стала доступной S1. Произошла утечка части информации. В частности, существование или нет одного конкретного файла - 1 бит.
Значит, в этом случае создан канал утечки одного бита из той информации, которая принадлежит S2.
Пример 2. Вирус-архиватор, созданный пользователем U1, заражает командные файлы пользователя U2 за счет использования совместных ресурсов объекта в виде компьютерной игры.
Съем информации осуществляется при помощи записи архива сделанных U2 файлов на каждую принесенную дискету. Это гарантирует анонимность истинного получателя информации в случае выявления вируса.
Защитные механизмы основаны на правильном выборе политики безопасности.
Пример 3. Очень важным примером канала утечки по памяти является возможность статистического вывода в базах данных. Обычно в базах данных с ограниченным доступом функции вычисления статистик по закрытым данным являются общедоступными. Это создает ситуацию совместного использования закрытых ресурсов допущенными и незаконными пользователями. Как было показано в разделе "информационные потоки", канал связи от закрытой информации к незаконному пользователю может быть сильно зашумлен. Однако использование различных статистик и модификация запросов могут позволить отфильтровать информацию.
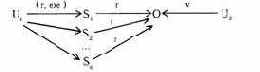
где U1 - незаконный пользователь; U2 - закон-ный пользователь ценной информации в объекте О; S1, S2,...,Sn - процессы вычисления ответов на различные запросы пользователя U1. Доступ Si к О разрешен, так как в каждом случае по О вычисляетсястатистическая характеристика, не дающая достаточно полной информации об объекте О. Защитные механизмы основаны на контроле возможностей вывода и контроле информационных потоков.
Следующий основной класс каналов утечки американцы называют каналами по времени. Канал по времени является каналом, передающим противнику информацию о процессе, промодулированном ценной закрытой информацией. Графически канал по времени можно изобразить следующей схемой

где U1 - злоумышленник; U2 - пользователь, оперирующий ценной информацией; Sц
- субъект, информация о котором представляет интерес; Sm -субъект, процесс которого модулируется информацией процесса Sц; S - процесс от имени пользователя U1, позволяющий наблюдать процесс Sm.
Функционирование канала утечки определяется той долей ценной информации о процессе Sц, которая передается путем модуляции процессу Sm.
Пример 4. Пусть процесс Sц использует принтер для печатания результатов очередного цикла обработки информации.
Процесс Sм
определяется работой принтера, который является общим ресурсом U1
и U2 с приоритетом у U2. Тогда процесс S регулярно с заданной частотой посылает запрос на использование принтера и получает отказ, когда Sц распечатывает очередную порцию информации. Тогда в единицах частоты запроса пользователь U1 получает информацию о периодах обработки процессом Sц ценной информации, то есть получаем канал утечки. Защитные механизмы от таких каналов основаны на контроле информационных потоков в системе.
Пример 5
Перехват информации в канале связи является примером канала утечки по времени. Здесь реализуется непосредственный доступ к процессу обработки (передачи) ценной информации. Съем информации об этом процессе и накопление ее во времени восстанавливают переданную ценную информацию. Защита от этих каналов основана на криптографии.
Пример 6.
Побочные каналы утечки по излучению, питанию или акустике являются типичными каналами утечки по времени. Защитные механизмы основаны на экранировании, фильтрах и зашумлении.
2.2. УГРОЗЫ ЦЕЛОСТНОСТИ
Нарушения целостности информации - это незаконные уничтожение или модификация информации.
Традиционно защита целостности относится к категории организационных мер. Основным источником угроз целостности являются пожары и стихийные бедствия. К уничтожению и модификации могут привести также случайные и преднамеренные критические ситуации в системе, вирусы, "троянские кони" и т.д.
Язык описания угроз целостности в целом аналогичен языку угроз секретности. Однако в данном случаев место каналов утечки удобнее говорить о каналах воздействия на целостность (или о каналах разрушающего воздействия). По сути они аналогичны каналам утечки, если заменить доступ (r) доступом (w).
Пример 1. Канал несанкционированной модификации, использующий "троянского коня", изображен на следующей схеме:
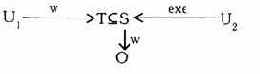
где U1 - злоумышленник; U2 - пользователь; О -объект с ценной информацией; S - процесс (про-
грамма), являющаяся общим ресурсом U1
и U2.
Пользователь U1, пользуясь правом w, модифицировал общий ресурс S, встроив в него скрытую программу Т, модифицирующую информацию в О при запуске ее пользователем U2.
Исследованием схем примера 1 занимается теория распространения вирусов.
Основой защиты целостности является своевременное регулярное копирование ценной информации.
Другой класс механизмов защиты целостности основан на идее помехозащищенного кодирования информации (введение избыточности в информацию) и составляет основу контроля целостности. Он основан на аутентификации, т.е. подтверждении подлинности, целостности информации. Подтверждение подлинности охраняет целостность интерфейса, а использование кодов аутентификации позволяют контролировать целостность файлов и сообщений. Введение избыточности в языки и формальное задание спецификации позволяет контролировать целостность программ.
Наконец, к механизмам контроля и защиты целостности информации следует отнести создание системной избыточности. В военной практике такие меры называются: повышение "живучести" системы. Использование таких механизмов позволяет также решать задачи устойчивости к ошибкам и задачи защиты от нарушений доступности.
Глава 3
Политика безопасности
Иногда удается достичь общепринятого понимания оптимальности принимаемого решения и доказать его существование. Например, в математической статистике для проверки простой гипотезы против простой альтернативы всеми признано понятие оптимального решения, которое минимизирует ошибку второго рода, а также доказано существование такого критерия (лемма Неймана-Пирсона). Однако, когда решение многоальтернативное, то общепринятого понимания оптимальности не получается, а в тех случаях, когда рассматривается вопрос об оптимальном в каком-то смысле решении, то его существование, чаще всего, удается доказать лишь в частных задачах.
Подобная ситуация существует в задачах защиты информации, поскольку неоднозначно решение о том, что информация защищена. Кроме того, система защиты - не самоцель и должна нести подчиненную функцию по сравнению с главной целью вычислительного процесса.
Приведем примеры, поясняющие эти утверждения.
Пример 1. Пусть два инженера ведут разработки двух приборов, которые требуют решения задач x1, ..., xn1 - первым и задач x’1, ..., x’n2 - вторым инженером. Предположим, что информация о решении каждой задачи собирается в отдельном файле О1,...,Оn1 и О'1,...,0'n2 соответственно. Предположим, что среди множеств задач первого и второго инженеров есть одинаковые. К сожалению, обычный офицер службы безопасности, разрешающий или запрещающий доступ к файлам, не в состоянии решить, что в двух файлах накапливается информация по решению одной задачи. Рассмотрим различные решения офицера по обеспечению безопасности информации.
1. Если он разрешит доступ инженеров к файлам друг друга, то один из них, взяв информацию другого или свою, анонимно и поэтому безнаказанно, продаст эту информацию, так как нет персональной ответственности (невозможно установить, кто продал информацию из данного файла). При этом безнаказанность может стимулировать преступление.
2. Если он не разрешит доступ инженеров к файлам друг друга, то возникает опасность ущерба из-за недоступности информации (один нашел, а второй не нашел решение одной задачи; тогда вся задача второго инженера оказалась нерешенной, из-за чего возможен большой ущерб для фирмы, т.к. соответствующий прибор сделали конкуренты).
Очевидно, что в обоих случаях достигается снижение одной опасности за счет возрастания другой.
Пример 2. Пример посвящен проблеме компромисса задачи защиты и других задач вычислительной системы. Пусть в базе данных собирается информация о здоровье частных лиц, которая в большинстве стран считается конфиденциальной. База данных нужна, т.к.эта информация позволяет эффективно производить диагностику. Если доступ к этой базе из соображений защиты информации сильно ограничен, то в такой базе не будет пользы для врачей, ставящих диагнозы, и не будет пользы от самой базы. Если доступ открыть, то возможна утечка конфиденциальной информации, за которую по суду может быть предъявлен большой иск.
Каким должно быть оптимальное решение?
Результатом решения в приведенных примерах и других аналогичных задачах является выбор правил распределения и хранения информации, а также обращения с информацией, что и называется политикой безопасности. Соблюдение политики безопасности должно обеспечить выполнение того компромисса между альтернативами, который выбрали владельцы ценной информации для ее защиты. Ясно, что, являясь результатом компромисса, политика безопасности никогда не удовлетворит все стороны, участвующие во взаимодействии с защищаемой информацией. В тоже время выбор политики безопасности - это окончательное решение проблемы: что - хорошо и что -плохо в обращении с ценной информацией. После принятия такого решения можно строить защиту, то есть систему поддержки выполнения правил политики безопасности. Таким образом, построенная система защиты информации хорошая, если она надежно поддерживает выполнение правил политики безопасности. Наоборот, система защиты информации - плохая, если она ненадежно поддерживает политику безопасности.
Такое решение проблемы защищенности информации и проблемы построения системы защиты позволяет привлечь в теорию защиты точные математические методы. То есть доказывать, что данная система в заданных условиях поддерживает политику безопасности. В этом суть доказательного подхода к защите информации, позволяющего говорить о "гарантированно защищенной системе". Смысл "гарантированной защиты" в том, что при соблюдении исходных условий заведомо выполняются все правила политики безопасности. Термин "гарантированная защита" впервые встречается в стандарте министерства обороны США на требования к защищенным системам ("Оранжевая книга").
В данной главе приводятся определения и примеры политик безопасности, показаны последствия плохо выбранных политик. Определены такие политики как дискреционная политика, политика MLS, политика защиты целостности Biba и проведен их анализ. На примере РМ рассмотрены математические проблемы корректного определения политики в данной вычислительной системе.
3.1. ОПРЕДЕЛЕНИЕ ПОЛИТИКИ БЕЗОПАСНОСТИ
Будем следовать общепринятому определению политики безопасности (ПБ), приведенному в стандарте "Оранжевая книга" (1985 г.).
Определение. Политика безопасности это набор норм, правил и практических приемов, которые регулируют управление, защиту и распределение ценной информации .
Полное описание ПБ достаточно объемно даже в простых случаях, поэтому далее будем пользоваться сокращенными описаниями.
Если вспомнить модель защиты, построенную в параграфе 1.1, то смысл политики безопасности очень прост - это набор правил управления доступом. Заметим отличие ПБ от употребляемого понятия несанкционированный доступ (НСД). Первое отличие состоит в том, что политика определяет как разрешенные, так и неразрешенные доступы. Второе отличие - ПБ по своему определению конструктивна, может быть основой определения некоторого автомата или аппарата для своей реализации.
Пример 1.
Сформулируем простую политику безопасности в некотором учреждении. Цель, стоящая перед защитой, - обеспечение секретности информации. ПБ состоит в следующем: каждый пользователь пользуется своими и только своими данными, не обмениваясь с другими пользователями. Легко построить систему, поддерживающую эту политику. Каждый пользователь имеет свой персональный компьютер в персональной охраняемой комнате, куда не допускаются кроме него посторонние лица. Легко видеть, что сформулированная выше политика реализуется в этой системе. Будем называть эту политику тривиальной разграничительной (дискреционной) политикой.
ПБ определяется неоднозначно и, естественно, всегда связана с практической реализацией системы и механизмов защиты. Например, ПБ в примере 1 может полностью измениться, если в организации нет достаточного числа компьютеров и помещений для поддержки этой политики.
Выбор ПБ определяется фазовым пространством, допустимыми природой вычислительных процессов, траекториями в нем и заданием неблагоприятного множества N. Корректность ПБ в данных конкретных условиях должна быть, вообще говоря, доказана.
Построение политики безопасности обычно соответствует следующим шагам:
1 шаг. В информацию вносится структура ценностей и проводится анализ риска.
2 шаг. Определяются правила для любого процесса пользования данным видом доступа к элементам информации, имеющим данную оценку ценностей.
Однако реализация этих шагов является сложной задачей. Результатом ошибочного или бездумного определения правил политики безопасности, как правило, является разрушение ценности информации без нарушения политики. Таким образом, даже хорошая система защиты может быть "прозрачной" для злоумышленника при плохой ПБ.
Рассмотрим следующие примеры.
Пример 2. Пусть банковские счета хранятся в зашифрованном виде в файлах ЭВМ. Для зашифрования, естественно, используется блочная система шифра, которая для надежности реализована вне компьютера и оперируется с помощью доверенного лица. Прочитав в книгах о хороших механизмах защиты, служба безопасности банка убеждена, что если шифр стойкий, то указанным способом информация хорошо защищена. Действительно, прочитать ее при хорошем шифре невозможно, но служащий банка, знающий стандарты заполнения счетов и имеющий доступ к компьютеру, может заменить часть шифртекста в своем счете на шифртекст в счете богатого клиента. Если форматы совпали, то счет такого служащего с большой вероятностью возрастет. В этом примере игра идет на том, что в данной задаче опасность для целостности информации значительно выше опасности для нарушения секретности, а выбранная политика безопасности хорошо защищает от нарушений секретности, но не ориентирована на опасность для целостности.
Пример 3. Как было описано в примере в конце параграфа 1.4 для государственных структур традиционно принято определять гриф результирующего документа как верхнюю грань грифов и категорий составляющих этот документ частей. Формальное перенесение этого правила традиционной ПБ в ПБ для электронных документов может привести к возникновению канала утечки информации. В самом деле, рассмотрим многоуровневую реляционную базу данных как в параграфе 1.7 с решеткой ценностей {несекретно(Н), секретно (C)}.
Пусть R - отношение, А1,..., Аm - атрибуты, причем А1- первичный ключ. По запросу строится "обзор" R', который состоит из элементов различной классификации. ПБ может включать одно из двух правил формализованного грифа отношения R':
1. (Привычный для госструктур) R' имеет гриф, равный наибольшему значению из грифов элементов, которые принимают входящие в него атрибуты.
2. (Как это было сделано в параграфе 1.7) R' имеет гриф, равный наименьшему значению из грифов элементов, которые принимают входящие в него атрибуты.
Покажем, что в случае 1 возможна утечка информации с грифом С пользователю, которому разрешен доступ только к информации с грифом Н. Для этого достаточно построить пример базы данных, где такая утечка очевидна.
Пусть реляционная база данных реализует геоинформационную систему. Например, она содержит географическую карту некоторого района пустыни. Базовое отношение РМ имеет три атрибута:
А1 - ключевой атрибут, содержащий координаты и размеры прямоугольного сектора в некоторой сетке координат;
А2 - изображение (карта) местности в секторе с координатами, задаваемыми атрибутом А1;
Аз - координаты колодцев с водой в рассматриваемом секторе.
Для простоты будем считать, что на запрос в базу данных мы получаем на экране изображение карты сектора, определяемого значением атрибута А1. Пустьзначения атрибутов А1 и A2 имеют гриф Н, а значения атрибута А3 - С.
Если выбрать политику безопасности пункта 1, то мы покажем, как пользователь, не имеющий доступа к секретной информации, реализует канал утечки секретных данных о том, где в пустыне находится колодец с водой (пусть, для простоты, в рассматриваемой местности есть только один колодец). Для получения секретной информации пользователь делает последовательность запросов в базу данных, причем каждый следующий запрос (можно говорить о шагах алгоритма пользователя) определяется ответом на предыдущий.
1 шаг. Разбиваем район (для удобства - квадрат) на полосы и делаем запрос на эти участки в базу данных.
Ответ возможен в двух формах:
· отказ от показа карты, если она секретная, таккак пользователю, не имеющему допуска к секретнойинформации, база данных, естественно, не должна еепоказывать;
· представление карты на экране, если она имеетгриф Н.
________________________
I I -------à отказ
________________________
I I -------à доступ разрешен
________________________
Если есть отказ в доступе, то в этом случае в прямоугольнике есть колодец.
2 шаг. Разбиваем полосу, где есть колодец (т.е. где есть отказ в доступе) пополам на две полосы и делаем два запроса в базу данных. Отказ означает, что в данной полосе есть колодец.
И так далее.
В результате вычисляется первая координата колодца с любой заданной точностью. Затем, в оставшейся полосе аналогично вычисляем вторую координату.
Таким образом, ПБ соблюдена, однако, произошла утечка секретной информации.
Если использовать ПБ пункта 2, то любой пользователь получает карту, но пользователь с допуском к секретной информации получает карту с нанесенным колодцем, а пользователь без такого доступа - без колодца. В этом случае канал, построенный выше, не работает и ПБ надежно защищает информацию.
3.2. ДИСКРЕЦИОННАЯ ПОЛИТИКА.
Заглавие параграфа является дословным переводом Discretionary policy, еще одним вариантом перевода является следующий - разграничительная политика. Рассматриваемая политика - одна из самых распространенных в мире, в системах по умолчанию имеется ввиду именно эта политика.
Пусть О - множество объектов, S - множество субъектов, SÍO. Пусть U={U1,...,Um} - множество пользователей. Определим отображение: own: 0àU.
В соответствии с этим отображением каждый объект объявляется собственностью соответствующего пользователя. Пользователь, являющийся собственником объекта, имеет все права доступа к нему, а иногда и право передавать часть или все права другим пользователям. Кроме того, собственник объекта определяет права доступа других субъектов к этому объекту, то есть политику безопасности в отношении этого объекта.
Указанные права доступа записываются в виде матрицы доступа, элементы которой - суть подмножества множества R, определяющие доступы субъекта S, к объекту 0i(i = 1, 2,...,; j = 1, 2,... ).
Существует несколько вариантов задания матрицы доступа.
1. Листы возможностей: Для каждого субъекта Si
создается лист (файл) всех объектов, к которому имеет доступ данный объект.
2. Листы контроля доступа: для каждого объекта создается список всех субъектов, имеющих право доступа к этому объекту.
Дискреционная политика связана с исходной моделью таким образом, что траектории процессов в вычислительной системе ограничиваются в каждом доступе. Причем вершины каждого графа разбиваются на классы и доступ в каждом классе определяется своими правилами каждым собственником. Множество неблагоприятных траекторий N для рассматриваемого класса политик определяется наличием неблагоприятных состояний, которые в свою очередь определяются запретами на некоторые дуги. Дискреционная политика, как самая распространенная, большe всего подвергалась исследованиям. Существует множество разновидностей этой политики. Однако многих проблем защиты эта политика решить не может. Одна из самых существенных слабостей этого jкласса политик - то, что они не выдерживают атак при помощи "Троянского коня". Это означает, в частности, что система защиты, реализующая дискреционную политику, плохо защищает от проникновения вирусов в систему и других средств скрытого разрушающего воздействия. Покажем на примере принцип атаки "Троянским конем" в случае дискреционной политики.
Пример 1. Пусть U1
- некоторый пользователь, а U2 - пользователь-злоумышленник, О1
- объект, содержащий ценную информацию, O2 - программа с "Троянским конем" Т, и М - матрица доступа, которая имеет вид:
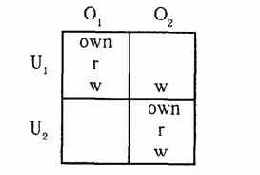
Проникновение программы происходит следующим образом. Злоумышленник U2 создает программу О2 и, являясь ее собственником, дает U1 запускать ее и писать в объект О2
информацию. После этого он инициирует каким-то образом, чтобы U1
запустил эту программу (например, О2 - представляет интересную компьютерную игру, которую он предлагает U1 для развлечения). U1
запускает О2 и тем самым запускает скрытую программу Т, которая обладая правами U1 (т.к.была запущена пользователем U1), списывает в себя информацию, содержащуюся в О1. После этого хозяин U2 объекта О2, пользуясь всеми правами, имеет возможность считать из O2 ценную информацию объекта О1.
Следующая проблема дискреционной политики -это автоматическое определение прав. Так как объектов много, то задать заранее вручную перечень прав каждого субъекта на доступ к объекту невозможно. Поэтому матрица доступа различными способами агрегируется, например, оставляются в качестве субъектов только пользователи, а в соответствующую ячейку матрицы вставляются формулы функций, вычисление которых определяет права доступа субъекта, порожденного пользователем, к объекту О. Разумеется, эти функции могут изменяться во времени. В частности, возможно изъятие прав после выполнения некоторого события. Возможны модификации, зависящие от других параметров.
Одна из важнейших проблем при использовании дискреционной политики - это проблема контроля распространения прав доступа. Чаще всего бывает,что владелец файла передает содержание файла другому пользователю и тот, тем самым, приобретает права собственника на информацию. Таким образом, права могут распространяться, и даже, если исходный владелец не хотел передавать доступ некоторому субъекту S к своей информации в О, то после нескольких шагов передача прав может состояться независимо от его воли. Возникает задача об условиях, при которых в такой системе некоторый субъект рано или поздно получит требуемый ему доступ. Эта задача иследовалась в модели "take-grant", когда форма передачи или взятия прав определяются в виде специального права доступа (вместо own). Некоторые результаты этих исследований будут приведены в главе "Математические методы анализа политики безопасности".
3.3. ПОЛИТИКА MLS.
Многоуровневая политика безопасности (политикаMLS) принята всеми развитыми государствами мира. В повседневном секретном делопроизводстве госсектор России также придерживается этой политики.
Решетка ценностей SC, введенная в параграфе 1.3 является основой политики MLS. Другой основой этой политики является понятие информационного потока (см. 1.4). Для произвольных объектов X и Y пусть имеется информационный поток Х->aY, где X -источник, Y - получатель информации. Отображениес: O->SC считается заданным. Если c(Y)>c(X), то Y -более ценный объект, чем X.
Определение. Политика MLS считает информационный поток Х->Y разрешенным тогда и только тогда, когда c(Y)>c(X) в решетке SС.
Таким образом, политика MLS имеет дело с множеством информационных потоков в системе и делит их на разрешенные и неразрешенные очень простым условием. Однако эта простота касается информационных потоков, которых в системе огромное количество. Поэтому приведенное выше определение неконструктивно. Хотелось бы иметь конструктивноеопределение на языке доступов. Рассмотрим класс систем с двумя видами доступов r и w (хотя могут быть и другие доступы, но они либо не определяют информационных потоков, либо выражаются через w и r). Пусть процесс S в ходе решения своей задачипоследовательно обращается к объектам О1,О2,...,Оn (некоторые из них могут возникнуть в ходе решения задачи). Пусть

Тогда из параграфа 1.3 следует, что при выполнении условий c(S)>c(Oit), t=l,....k, соответствующие потоки информации будут идти в разрешенном политикой MLS направлении, а при c(S)
Причем разрешенность цепочки (1) вовсе не означает, что субъект S не можетсоздать объект О такой, что c(S)>c(0). Однако он не может писать туда информацию. При передаче управления поток информации от процесса S или к нему прерывается (хотя в него другие процессы могут записывать или считывать информацию как в объект). При этом, если правила направления потока при r и w выполняются, то MLS соблюдается, если нет, то соответствующий процесс не получает доступ. Таким образом, мы приходим к управлению потоками через контроль доступов. В результате для определенного класса систем получим конструктивное описание политики MLS.
Определение. В системе с двумя доступами r и w политика MLS определяется следующими правилами доступа

Структура решетки очень помогает организации поддержки политики MLS. В самом деле, пусть имеется последовательная цепочка информационных потоков

Если каждый из потоков разрешен, то свойства решетки позволяют утверждать, что разрешен сквозной поток



MLS политика в современных системах защиты реализуется через мандатный контроль (или, также говорят, через мандатную политику). Мандатный контроль реализуется подсистемой защиты на самом низком аппаратно-программном уровне, что позволяет эффективно строить защищенную среду для механизма мандатного контроля. Устройство мандатного контроля, удовлетворяющее некоторым дополнительным, кроме перечисленных, требованиям, называется монитором обращений. Мандатный контроль еще называют обязательным, так как его проходит каждое обращение субъекта к объекту, если субъект и объект находятся под защитой системы безопасности. Организуется мандатный контроль следующим образом. Каждый объект О имеет метку с информацией о классе c(O). Каждый субъект также имеет метку, содержащую информацию о том, какой класс доступа c(S) он имеет. Мандатный контроль сравнивает метки и удовлетворяет запрос субъекта S к объекту О на чтение, если c(S)>c(0) и удовлетворяет запрос на запись, если c(S)
Тогда согласно изложенному выше мандатный контроль реализует политику MLS.
Политика MLS устойчива к атакам "Троянским конем". На чем строится защита от таких атак поясним на примере, являющимся продолжением примера1 из параграфа 3.2.
Пример 1. Пусть пользователи U1 и U2 находятся на разных уровнях, то есть c(U1)>c(U2). Тогда, если U1 может поместить в объект О1 ценную информацию, то он может писать туда и c(U2)
 .
.
Тогда c(O2)>c(U2) и пользователь U2 не имеет право прочитать в O2, что делает съем в О1 и запись в O2 бессмысленным.
Несколько слов о реализации политики безопасности MLS в рамках других структур, внесенных в информацию. Опять обратимся к примеру реляционной базы данных. Пусть структура РМ и структура решетки ценностей MLS согласованы, как это было сделано в параграфе 1.6. Пусть в системе реализован мандатный контроль, который при обращении пользователя U к базе данных на чтение позволяет извлекать и формировать "обзор" только такой информации, класс которой
Политика MLS создана, в основном, для сохранения секретности информации. Вопросы целостности при помощи этой политики не решаются или решаются как побочный результат защиты секретности. Вместе с тем, пример 2 параграфа 3.1 показывает, что они могут быть противоречивы.
Пример 2.
(Политика целостности Biba). Предположим, что опасности для нарушения секретности не существует, а единственная цель политики безопасности - защита от нарушений целостности информации.
Пусть, по-прежнему, в информацию внесена решетка ценностей SC. В этой связи любой информационный поток X -> Y может воздействовать на целостность объекта Y и совершенно не воздействовать на целостность источника X. Если в Y более ценная информация, чем в X, то такой поток при нарушении целостности Y принесет более ощутимый ущерб, чем поток в обратном направлении от более ценного объекта Y к менее ценному X. Biba предложил в качестве политики безопасности для защиты целостности следующее.
Определение. В политике Biba информационныйпоток X -->aY разрешен тогда и только тогда, когда

Можно показать, что в широком классе систем эта политика эквивалентна следующей.
Определение. Для систем с доступами w и r политика Biba разрешает доступ в следующих случаях:

Очевидно, что для реализации этой политики также подходит мандатный контроль.
Глава 4
Классификация систем защиты
В главе IV мы рассмотрим вопросы, связанные с оценкой возможностей системы защиты поддерживать политику безопасности. В параграфе 4.1 в общих чертах изложен метод анализа систем поддержки политики. В параграфе 4.2 построен пример гарантированно защищенной системы. В параграфе 4.3 изложены требования к системам защиты, поддерживающим дискреционную и MLS политики, сформулированные в американском стандарте защиты "Оранжевая книга". В этом же параграфе кратко излагается классификация систем защиты так, как она принята в указанном стандарте. В параграфе 4.4 кратко изложены принципы выбора класса защиты согласно классификации "Оранжевой книги".
4.1. ДОКАЗАТЕЛЬНЫЙ ПОДХОД К СИСТЕМАМ ЗАЩИТЫ .
СИСТЕМЫ ГАРАНТИРОВАННОЙ ЗАЩИТЫ.
Пусть задана политика безопасности Р. Тогда система защиты - хорошая, если она надежно поддерживает Р, и - плохая, если она ненадежно поддерживает Р. Однако надежность поддержки тоже надо точно определить. Здесь снова обратимся к иерархической схеме. Пусть политика Р выражена на языке Я1, формулы которого определяются через услуги U1,..., Uk.
Пример 1. Все субъекты S
системы разбиты на два множества S1 и S2, S1ÈS2=S, S1ÇS2=Æ. Все объекты, к которым может быть осуществлен доступ, разделены на два класса О1 и О2 O1ÈO2= О, O1ÇO2=Æ. Политика безопасности Р -тривиальная: субъект S может иметь доступ aÎR к объекту О тогда и только тогда, когда SÎSi, ОÎOi, i = 1, 2. Для каждого обращения субъекта S на доступ к объекту О система защиты вычисляет функции принадлежности

для субъекта и объекта: Is( S1), Is( S2), I0( O1), I0( O2). Затем вычисляется логическое выражение:
(Is( S1)Ù I0( O1))Ú (Is( S2)Ù I0( O2)).
Если полученное значение - 1 (истинно), то доступ разрешен. Если - 0 (ложно), то - неразрешен. Ясно, что язык Я1, на котором мы выразили политику безопасности Р, опирается на услуги:
·
вычисление функций принадлежности Ix(А);
· вычисление логического выражения;
· вычисление оператора "если x=l, то S ->0, если x=0, то S -+>О".
Для поддержки услуг языку Я1, требуется свой язык Я2, на котором мы определим основные выражения для предоставления услуг языку верхнего уровня. Возможно, что функции Я2 необходимо реализоватьопираясь на язык Я3 более низкого уровня и т.д.
Пусть услуги, описанные на языке Я2 мы умеем гарантировать. Тогда надежность выполнения политики Р
определяется полнотой ее описания в терминах услуг U1,...,Uk. Если модель Р - формальная, то есть язык Я1, формально определяет правила политики Р, то можно доказать или опровергнуть утверждение, что множество предоставленных услуг полностью и однозначно определяет политику Р. Гарантии выполнения этих услуг равносильны гарантиям соблюдения политики. Тогда более сложная задача сводится к более простым и к доказательству того факта, что этих услуг достаточно для выполнения политики. Все это обеспечивает доказанность защиты с точки зрения математики, или гарантированность с точки зрения уверенности в поддержке политики со стороны более простых функций.
Одновременно, изложенный подход представляет метод анализа систем защиты, позволяющий выявлять слабости в проектируемых или уже существующих системах. При этом иерархия языков может быть неоднозначной, главное - удобство представления и анализа.
Однако проводить подобный анализ в каждой системе дорого. Кроме того, методика проведения анализа государственных систем - конфиденциальная информация. Выход был найден в том, что условия теорем, доказывающих поддержку политики безопасности (включая соответствующую политику), формулировать без доказательства в виде стандарта. Такой подход американцы впервые применили в 1983 году, опубликовав открыто проект стандарта по защите информации в ЭСОД ("Оранжевая книга"), где сформулированы требования гарантированной поддержки двух классов политик - дискреционной и политики MLS. Затем этот метод они применили в 1987 г. для описания гарантированно защищенных распределенных сетей, поддерживающих те же политики, и в 1991 г.для описания требований гарантированно защищенных баз данных. Этот же путь использовали канадцы и европейские государства, создав свои стандарты защиты.
4.2. ПРИМЕР ГАРАНТИРОВАННО ЗАЩИЩЕННОЙ СИСТЕМЫ ОБРАБОТКИ ИНФОРМАЦИИ.
Построим пример гарантированно защищенной системы обработки информации. Сначала определим модель å системы, которая оперирует с ценной информацией. Считаем, что время дискретно и принимает значения из множества N={l, 2,... }, информация в системе å, включая описание самой системы, представима в форме слов некоторого гипотетического языка Я над некоторым конечным алфавитом А. Напомним, что объект в å - это конечное множество слов из Я, состояние объекта - выделенное слово из множества, определяющего этот объект. С понятием объекта связано агрегирование информации в å и о å. Например, объектом является принтер, который можно рассматривать как автомат с конечным множеством состояний, а эти состояния - суть слова языка Я. Другой пример объекта - файл.
Множество слов, которые могут быть записаны в файле, является конечным и определяет объект, а состояния объекта -это текущая запись в файле, которая тоже является словом в языке Я.
Принято считать, что вся информация о å в данный момент может быть представлена в виде состояний конечного множества объектов. Поэтому будем считать, что состояние системы å - это набор состояний ее объектов. Объекты могут создаваться и уничтожаться, поэтому можно говорить о множестве объектов системы å в момент t, которое мы будем обозначать Оt, |Ot|<¥.
Для каждого tÎN выделим в Оt подмножество St субъектов. Любой субъект SÎSt есть описание некоторого преобразования информации в системе å. Для реализации этого преобразования в å
необходимо выделить определенные ресурсы (домен) и организовать определенное взаимодействие ресурсов, приводящее к преобразованию информации, которое назовем процессом. Тогда каждый субъект может находиться в двух состояниях: в форме описания, в котором субъект называется неактивизированным, и в форме (домен, процесс), в которой субъект называется активизированным.
Активизировать субъект может только другой активизированный субъект. Для каждого tÎN на множестве St можно определить орграф Гt, где S1 и S2 из St соединены дугой S1->S2 тогда и только тогда, когда в случае активизации S1 возможна активизация S2. Если субъект S - такой, что для каждого Гt в вершину S не входит дуг, то такой субъект будем называть пользователем. Для простоты положим, что в системе S всего два пользователя: U1 и U2. Пользователи считаются активизированными по определению и могут активизировать другие субъекты.
Если в любой момент t в графе Гt в вершину S не входят дуги и не выходят дуги, то такие субъекты исключаем из рассмотрения.
Обозначим


Предположение 1. Если субъект S активизирован в момент t, то существует единственный активизированный субъект S' в St, который активизировал S.
В момент t=0 активизированы только пользователи.
Лемма. 1. Если в данный момент t активизирован субъект S, то существует единственный пользователь U, от имени которого активизирован субъект S, то есть существует цепочка

Доказательство. Согласно предположению 1 существует единственный субъект Sk, активизирующий S. Если Sk=U1, или Sk=U2, то лемма доказана. Если

Предположение 1 требует единственности идентификации субъектов. Далее будем предполагать, что каждый объект в системе имеет уникальное имя.
Кроме активизации в системе å
существуют и другие виды доступа активизированных субъектов к объектам. Будем обозначать множество всех видов доступов через R и считать |R|<¥. Если рÍR, то будем обозначать множество доступов р активизированного субъекта S к объекту О через


то будем считать, что произошел доступ

Предположение 2. Функционирование системы å описывается последовательностью доступов множеств субъектов к множествам объектов в каждый момент времени tÎN.
Обобщим введенный орграф Гt добавив дуги S ->O, обозначающие возможность любого доступа субъекта S к объекту О в момент t, в случае активизации S. Обозначим Dt(S) = {O | S -->*0 в момент t}, гдеS->*O означает возможность осуществления цепочки доступов S ->S1->S2->...Sk->O (возможность доступа к О от имени S). Тогда для любого tÎN в системе определены Dt(U1) и Dt(U2) . Будем считать, что D= Dt(U1)ÇDt(U2)
фиксировано для всех t, Ot= Dt(U1)ÈDt(U2), в начальный момент t = 0: O0={U1,U2}ÈD
Определение. Множество объектов О называется общими ресурсами системы.
В частности, средствами из D
пользователь может создавать объекты и уничтожать объекты, не принадлежащие D. Создание и уничтожение каких-либо объектов является доступом в R к некоторым объектам из O (и к уничтожаемым объектам).
Мы считаем, что из объектов системы å построена некоторая подсистема, которая реализует доступы. Будем полагать, что любое обращение субъекта S за доступом р к объекту О в эту подсистему начинается с запроса, который мы будем обозначать

При порождении объекта субъект S обращается к соответствующей процедуре, в результате которой создается объект с уникальным именем. Тогда в силу леммы 1, существует единственный пользователь, от имени которого активизирован субъект, создавший этот объект. Будем говорить, что соответствующий пользователь породил данный объект. Обозначим через Оt(U) множество объектов из Оt, которые породил пользователь U. Естественно, будем считать, чтоUÎOt(U).
Лемма 2. Для каждого tÎN, для каждого OÎOt, ОÏD, существует единственный пользователь U такой, что OÎOt(U) .
Доказательство. Поскольку O0={U1, U2}ÈD, то объект ОÏD, OÎOt, порожден в некоторый момент s, 0
Обратимся теперь к вопросам безопасности информации в системе. Если в R есть доступы read и write, то ограничимся опасностью утечки информации через каналы по памяти, которые могут возникнуть при доступах к объектам. Таким каналом может бытьследующая последовательность доступов при s



При определенных условиях может оказаться опасным доступ от имени пользователя:


С некоторой избыточностью мы исчерпаем возможные каналы по памяти, если будем считать неблагоприятными какие-либо доступы p1,p2ÍR вида


которые мы и считаем каналами утечки.
Предположение 3. Если OÎD, то доступы в (1) при любых р1 и р2 не могут создать канал утечки.
Это значит, что мы предположили невозможным отразить какую-либо ценную информацию в объектах общего доступа. Это очень сильное предположение и оно противоречит, по крайней мере, возможности присваивать уникальные имена объектам. В самом деле, если объектам присвоены уникальные имена, то в D
необходимо иметь информацию о уже присвоенных именах, что противоречит предположению 3 о том, что доступы от имени пользователей не отражаются в информации объектов общего пользования. В случае имен можно выйти из положения, используя случайные векторы, вероятности совпадения которых за обозримый период работы системы можно сделать как угодно малыми. Все построения и выводы возможны при стохастическом способе присвоения имен, но должны содержать элементы вероятностной конструкции. Чтобы не усложнять систему стохастическими элементами мы будем следовать сделанным выше предположениям.
Тогда в (1) достаточно ограничиться объектами О, не лежащими в D. Это значит, что в одном из доступов в (1) имеется

 ,
,
 , OÎOt(Uj), . (2)
, OÎOt(Uj), . (2)
то есть доступы от имени какого-либо пользователя к объекту, созданному другим пользователем. Такие доступы будем далее называть утечкой информации.
Предположение 4. Если некоторый субъект S, SÎD, активизирован от имени пользователя Ui (т.e.

Если

Теорема 1. Пусть в построенной системе выполняются предположения 1-4. Если все доступы осуществляются в соответствии с ПБ, то утечка информации (2) невозможна.
Доказательство. Предположим противное, то есть

Пусть S1,..., Sm - все активизированные субъекты, имеющие доступы bÊр, i=l,...,m, в момент t к объекту О. Тогда согласно лемме 2 множество этих субъектов разбивается на три непересекающиеся множества:
A = {S1|S1ÎD},
B = {S1|S1ÎOt(Ui)},
C = {S1|S1ÎOt(Uj),i¹j}.
Согласно лемме 1 для любого Sl, l=l.....m, существует единственный пользователь, от имени которого активизирован субъект Sl. Если S1ÎA, то согласно предположению 4 и условию теоремы 1, что доступ

разрешен, получаем, что S, активизирован от имени Uj. Это противоречит предположению.
Если S1ÎВ, то

 ,
,
и субъект

 .
.
Повторяя эти рассуждения, через k шагов получим, что
 .
.
Последний доступ невозможен, если выполняется ПБ. Поэтому предположение неверно и теорема 1 доказана.
Теперь построим удобное для реализации множество "услуг" более низкого уровня, поддерживающих ПБ. То есть мы хотим определить множество условий, реализованных в системе 2, таких, что можно доказать теорему о достаточности выполнения этих условий для выполнения правил ПБ.
Условие 1. (Идентификация и аутентификация). Если для любых tÎN, pÍR, S, ОÎОt,
Условие 2. (Разрешительная подсистема). Если SÎОt(Ui), OÎОt(Uj) и
Условие 3. (Отсутствие обходных путей политики безопасности). Для любых tÎN, рÍR, если субъект S, активизированный к моменту t, получил в момент t доступ
Теорема 2. Если в построенной системе å выполняются предположения 1-4 и условия 1-3, то выполняется политика безопасности.
Доказательство. Утверждение теоремы следует из двух утверждений:
а) Если для произвольного рÍR
б) Если SÎOt(Ui), OÎOt(Uj), i¹j, то какой-либо доступ в момент t субъекта S к объекту О невозможен.
Докажем а). Если


Докажем теперь б). Если
Если доступ
Теорема означает, что гарантировав выполнение условий 1-3, мы гарантируем выполнение политики безопасности.
Рассмотрим вопрос о создании системы, в которой можно с достаточной степенью уверенности поддерживать функции 1-3. Для этого рассмотрим следующую архитектуру:
1. В каждый момент только один пользователь может работать с системой. Физическое присутствие другого исключено.
2. При смене пользователей системы друг другом уходящий :
· записывает во внешнюю память все объекты, которые он хочет сохранить для дальнейших сеансов;
· выключает питание системы, после чего все содержимое оперативной памяти стирается, остаются записи на внешней памяти и ПЗУ, где хранятся объекты общего доступа.
3. Новый пользователь организует свою работу с включения системы и вызывает свои объекты из внешней памяти, опираясь на объекты общего пользования.
4. На шлюзе внешней памяти стоит шифратор К, который зашифровывает на текущем ключе k всю информацию, записываемую на внешнюю память, включая названия файлов. Наоборот, вся информация, поступающая из внешней памяти, расшифровывается на текущем ключе k. Внешняя память не имеет опции "просмотр директории", а любой запрос на выдачу файла функционирует так, что название запрашиваемого файла шифруется на текущем ключе k.
При смене пользователей текущий ключ k автоматически стирается (вместе с содержимым оперативной памяти), а новый пользователь в качестве текущего устанавливает свой ключ.
Покажем, что функционирование системы данной архитектуры позволяет реализовать все описанные выше свойства и, в частности, выполнить условия теорем 1 и 2.
Предположение 1 и другие допущения в описании системы вполне приемлемы для рассматриваемой архитектуры. Так как неблагоприятные состояния системы и политики безопасности выражены в терминах доступов, то для приемлемости предположения 2 достаточно, чтобы возможные вычислительные процессы однозначно отражались в терминах последовательностей доступов и значений функций принадлежности объектов к множествам Оt(U1), Оt(U2),D. Если объект только создан и находится в оперативной памяти, то доступ к нему со стороны процессов от имени создавшего пользователя автоматически разрешен и можно считать, что функция принадлежности вычислена. Если объект вызван из внешней памяти, то сам вызов и доступ к информации в объекте возможны, если установлен правильный ключ, что эквивалентно вычислению функции принадлежности к Оt(U). Предположения 3 и 4 выполняются, так как вновь подключенный пользователь работает один и вызывает из ПЗУ функции и объекты D. В системе нет субъекта, реализующего разрешительную систему, она естественно реализована за счет того, что расшифрованная информация читается тогда и только тогда, когда в шифраторе К установлен нужный ключ. Если пользователь или процесс от его имени обращается за доступом к объекту на внешней памяти, то любой доступ разрешен, если ключ зашифрования объекта (ключ создателя объекта) совпадает с ключом текущего пользователя. Наоборот, при несовпадении ключей допуск автоматически не разрешается, так как имя объекта и его содержание не расшифровываются правильно.
Таким образом, автоматически вычисляются функции принадлежности процесса и объекта при обращении через внешнюю память, что обеспечивает выполнение условия 1.
Также автоматически выполняется условие 2 о работе разрешительной системы. Условия 1 и 2 не касаются обращений процессов из D и к D. Поэтому вопросы идентификации здесь решаются за счет разделения сеансов пользователей и указанные условия выполняются.
Доступ к объекту возможен лишь при обращении к внешней памяти через шифратор, или в случае, когда объект создан в течение текущего сеанса, или вызван из ПЗУ. Если считать, что доступ к объектам в оперативной памяти автоматически опирается на данное пользователю разрешение на доступ к ним, а активизированными могут быть субъекты от его же имени, то можно считать, что любой доступ в этом случае выполняется в соответствии с условиями 1 и 2.
Что касается условия 3, то невозможность получить доступ минуя разрешительную систему определяется разнесенностью работы пользователей, отсутствием подслушивания, необходимостью расшифровывать информацию для получения доступа к ней. Это не касается объектов из D, или только созданных, где нет проблем из-за разнесенности сеансов. Также мы считаем, что отсутствует физическое проникновениеи модификация системы.
В результате получим, что данная архитектура реализует условия теорем 1 и 2 и поддерживает политику безопасности.
Суммируем то, что обеспечивает гарантии в построенной системе (то есть, что поддерживает условия теорем 1 и 2):
· обеспечение работы только одного пользователя (охрана);
· отключение питания при смене пользователей;
· стойкость шифратора К и сохранность в тайне ключей каждого пользователя;
· недопустимость физического проникновения в аппаратную часть или подслушивание (охрана).
Известно, как обеспечивать эти требования, а гарантии их обеспечения являются гарантией защищенности системы в смысле выбранной политики безопасности.
Отметим некоторые стороны построенной модели, которые будут встречаться далее.
1) Гарантии построены при четкой политике безопасности.
2) Для поддержки политики потребовалась идентификация объектов (+ вычисление добавочной идентификационной функции).
3) Для поддержки политики потребовалась аутентификация субъекта, обращающегося за допуском.
4) Значительная часть условий определяет функциональную защищенность самой системы защиты.
Далее в обзоре "Оранжевой книги" мы встретим такие же условия.
4.3. "ОРАНЖЕВАЯ КНИГА"(ОК).
OK принята стандартом в 1985 г. Министерством обороны США (DOD). Полное название документа "Department of Defense Trusted Computer System Evaluation Criteria".
OK предназначается для следующих целей:
1. Предоставить производителям стандарт, устанавливающий, какими средствами безопасности следует оснащать свои новые и планируемые продукты, чтобы поставлять на рынок доступные системы, удовлетворяющие требованиям гарантированной защищенности (имея в виду, прежде всего, защиту от раскрытия данных) для использования при обработке ценной информации.
2. Предоставить DOD метрику для военной приемкии оценки защищенности ЭСОД, предназначенных для обработки служебной и другой ценной информации.
3. Обеспечить базу для исследования требований к выбору защищенных систем.
Рассматривают два типа оценки:
· без учета среды, в которой работает техника,
· в конкретной среде (эта процедура называется аттестованием).
В 1992 году Гостехкомиссия России издала от своего имени документы, аналогичные по задачам и содержанию ОК.
Во всех документах DOD, связанных с ОК, принято одно понимание фразы обеспечение безопасности информации. Это понимание принимается как аксиома и формулируется следующим образом: безопасность= контроль за доступом.
Аксиома. ЭСОД называется безопасной, если она обеспечивает, контроль за доступом информации так, что только надлежащим образом уполномоченные лица или процессы, которые функционируют от их имени, имеют право читать, писать, создавать или уничтожать информацию.
Из этой аксиомы вытекает шесть фундаментальных требований к защищенным ЭСОД. Прежде, чем их формулировать, напомним и введем некоторые определения.
Определение. Политика безопасности - это набор норм, правил и практических приемов, которые регулируют управление, защиту и распределение ценной информации в данной организации.
Определение. Идентификация - это распознавание имени объекта. Идентифицируемый объект есть однозначно распознаваемый.
Определение. Аутентификация это подтверждение того, что предъявленное имя соответствует объекту.
Определение. ТСВ (Trusted Computing Base) - совокупность механизмов защиты в вычислительной системе (включая аппаратную и программную составляющие), которые отвечают за поддержку политики безопасности.
Определение. Аудит или отслеживание, подотчетность - это регистрация событий, позволяющая восстановить и доказать факт происшествия этих событий.
Теперь сформулируем 6 основных требований.
ПОЛИТИКА.
Требование 1 - Политика обеспечения безопасности - Необходимо иметь явную и хорошо определенную политику обеспечения безопасности. При задании идентифицированных субъектов и объектов необходимо иметь набор правил, используемых системой, для того, чтобы определить, можно ли разрешить указанному субъекту доступ к конкретному объекту. Представленные на аттестацию для использования в DOD вычислительные системы должны предусматривать реализацию мандатного контроля обеспечения безопасности, в рамках которого допускается эффективная реализация правил доступа, ориентированных на обработку конфиденциальной (например, секретной) информации. Эти правила включают такие требования: ни одно лицо, не обладающее надлежащим для допущенного персонала диапазоном полномочий, не получит доступа к секретной информации. Кроме того, также необходимы дискреционные (т.е. допускаемые по собственному усмотрению) средства управления безопасностью, которые гарантируют, что только выбранные пользователи или группы пользователей могут получить доступ к данным (реализация принципа "только те, которым необходимо знать").
Требование 2 - Маркировка - Метки, управляющие доступом, должны быть установлены и связаны с объектами. Для того, чтобы управлять доступом к информации в соответствии с правилами мандатной политики, должна быть предусмотрена возможность маркировать каждый объект меткой, которая надежно идентифицирует степень ценности объекта (например, секретности) и/или режимы допуска, предоставленные тем субъектам, которые потенциально могут запросить доступ к объекту.
ПОДОТЧЕТНОСТЬ.
Требование 3 - Идентификация - Субъекты индивидуально должны быть идентифицированы. Каждый доступ к информации должен быть рассмотрен на предмет того, кто запрашивает доступ к информации и на какие классы информации он имеет право получить доступ. Такого типа идентифицирующая и санкционирующая информация должна присутствовать и надежно защищаться вычислительной системой, а также быть связана с каждым активным элементом, выполняющим действия, имеющие отношениек безопасности системы.
Требование 4 - Подотчетность - Аудиторская информация должна селективно храниться и защищаться так, чтобы со стороны ответственной за это группы имелась возможность отслеживать действия, влияющие на безопасность. Гарантированно защищенная система должна быть в состоянии регистрировать в аудиторском файле появление событий, имеющих отношение к безопасности системы. Возможность отбирать подлежащие регистрации отслеживаемые события необходима для того, чтобы сократить издержки на аудит и обеспечить эффективный анализ. Аудиторская информация должна быть защищена от модификации, несанкционированного уничтожения, чтобы позволять выявлять и "постфактум" исследовать нарушения правил безопасности.
ГАРАНТИИ.
Требование 5 - Гарантии - Вычислительная система в своем составе обязана иметь аппаратно-программные механизмы, допускающие независимую оценку для получения достаточного уровня гарантий того, что система обеспечивает выполнение изложенных выше требований с первого по четвертое. Для того, чтобы гарантировать, что указанные четыре требования по безопасности - политика, маркировка, идентификация и аудит - реализуются вычислительной системой, необходимо предусмотреть корректно определенный и объединенный в единое целое набор программных и аппаратных средств управления, реализующий указанные функции. Указанные механизмы стандартным образом встраиваются в операционную систему и проектируются так, чтобы выполнить порученные задачи безопасным образом. Основа гарантированности таких системных механизмов при задании исходных рабочих условий должна быть явно задокументирована так, что становится возможным независимый анализ доказательства достаточности проведенных оценок.
Требование 6 - Постоянная защита - Гарантированно защищенные механизмы, реализующие указанные базовые требования, должны быть постоянно защищены от "взламывания" и/или несанкционированного внесения изменений. Никакая вычислительная система не может считаться действительно безопасной, если базовые аппаратные и программные механизмы, реализующие принятую политику, сами могут быть подвергнуты несанкционированному внесению изменений или исправлений. Выполнение требований по непрерывной защите подразумевается в течение всего жизненного цикла вычислительной системы.
ИТОГОВАЯ ИНФОРМАЦИЯ ПО КЛАССАМ КРИТЕРИЕВ ОЦЕНКИ.
Классы систем, распознаваемые при помощи критериев оценки гарантированно защищенных вычислительных систем, определяются следующим образом. Они представлены в порядке нарастания требований с точки зрения обеспечения безопасности ЭВМ.
Класс (D): Минимальная защита. Этот класс зарезервирован для тех систем, которые были подвергнуты оцениванию, но в которых не удалось достигнуть выполнения требований более высоких классов оценок.
Класс (C1): Защита, основанная на разграничении доступа (DAC).
Гарантированно защищающая вычислительная база (ТСВ) систем класса (С1) обеспечивает разделение пользователей и данных. Она включает средства управления, способные реализовать ограничения по доступу, чтобы защитить проект или частную информацию и не дать другим пользователям случайно считывать или разрушать их данные. Предполагается, что среда класса (С1) является такой средой, в которой могут кооперироваться пользователи, обрабатывающие данные, принадлежащие одному и тому же уровню секретности.
ПОЛИТИКА ОБЕСПЕЧЕНИЯ БЕЗОПАСНОСТИ.
ТСВ должна определять и управлять доступом между поименованными пользователями и поименованными объектами (например, файлами и программами) в системах автоматической обработки данных. Реализующий политику механизм (например, матрица доступа) должен позволять пользователям определять порядок и управлять использованием объектов поименованными лицами или определенными группами, а также теми и другими совместно.
ИДЕНТИФИКАЦИЯ И АУТЕНТИФИКАЦИЯ.
ТСВ должна требовать от пользователей, чтобы те идентифицировали себя перед тем, как начинать выполнять какие-либо действия, в которых ТСВ предполагается быть посредником. Более того, ТСВ обязательно должна использовать один из механизмов защиты (например, пароли) для того, чтобы проверять подлинность идентификации пользователей (аутентификация). ТСВ должна защищать аутентификационные данные таким образом, чтобы доступ к ним со стороны пользователя, не имеющего на это полномочий, был невозможен.
ГАРАНТИИ НА ПРАВИЛЬНУЮ РАБОТУ СИСТЕМЫ.
АРХИТЕКТУРА СИСТЕМЫ.
ТСВ должна содержать домен, который должен обеспечивать ее собственную работу и защищать ее от внешнего воздействия или от внесения в нее несанкционированных изменений (например, от модификаций ее кодов или структур данных). Ресурсы, контролируемые ТСВ, могут составлять подмножество объектов ЭСОД.
ЦЕЛОСТНОСТЬ СИСТЕМЫ.
Должны быть предусмотрены аппаратные и/или программные средства, предназначенные для периодической проверки на правильность и корректность функционирования аппаратных и микропрограммных элементов ТСВ.
ГАРАНТИИ НА ЖИЗНЕННЫЙ ЦИКЛ.
ТЕСТИРОВАНИЕ ФУНКЦИЙ БЕЗОПАСНОСТИ.
Механизм защиты должен соответствовать тем нормам, которые отражены в документации.
ДОКУМЕНТАЦИЯ
1. Руководство пользователя по использованию средств обеспечения безопасности.
2. Руководство администратору системы на гарантированные средства защиты.
В руководстве, ориентированном на администратора системы автоматической обработки данных, должно содержаться описание мер предосторожности и полномочий, которые необходимо контролировать в процессе функционирования средства, имеющего отношение к обеспечению режима секретности.
3. Документация по тестам.
Разработчик системы должен предусмотреть для лиц, занятых оцениванием безопасности системы, документ, в котором дается описание плана тестирования, процедур тестирования, излагающих каким способом проверяются механизмы обеспечения безопасности, и где представлены итоговые результаты функционального тестирования механизмов обеспечения безопасности.
4. Документация по проекту. В наличии должна быть документация, в которой имеется описание основополагающих принципов защиты, выбранных изготовителем данного средства или системы, а также объяснение того, как эти принципы транслируются в гарантированно защищающую вычислительную базу. Если ТСВ составлена непосредственно из модулей, то должно быть дано описание интерфейсов между этими модулями.
Класс (С2): Защита, основанная на управляемом контроле доступом.
Все требования к классу (С1) переносятся на класс(С2). Кроме того, системы этого класса реализуют структурно более "тонкое" управление доступом, в сравнении с системами класса (С1), за счет дополнительных средств управления разграничением доступа и распространением прав, а также за счет системы регистрации событий (аудит), имеющих отношение к безопасности системы и разделению ресурсов. Специально вводится требование по "очищению" ресурсов системы при повторном использовании другими процессами.
Класс(BI): Мандатная защита, основанная на присваивании меток объектам и субъектам, находящимся под контролем ТСВ.
Требования для систем класса (В1) предполагают выполнение всех требований, какие были необходимы в классе (С2). Помимо этого, необходимо представить неформальное определение модели, на которой строится политика безопасности, присваивание меток данным и мандатное управление доступом поименованных субъектов к объектам. В системе необходимо иметь средство, которое позволяет точно и надежно присваивать метки экспортируемой информации.
Класс (B2): Структурированная защита. Все требования класса (В1) должны выполняться для системы класса (В2). В системах класса (В2) ТСВ основана на четко определенной и формально задокументированной модели, в которой управление доступом, распространяется теперь на все субъекты и объекты данной системы автоматической обработки данных. Помимо этого, должен быть проведен анализ,связанный с наличием побочных каналов утечек. Необходимо провести разбиение структуры ТСВ по элементам, критическим с точки зрения защиты, и некритическим, соответственно.
Интерфейс ТСВ хорошо определен, а проект и реализация гарантированно защищающей вычислительной базы (ТСВ) выполнены так, что они позволяют проводить тщательное тестирование и полный анализ. Механизмы аутентификации усилены, управление защитой предусматривается в виде средств, предназначенных для администратора системы и для оператора, а на управление конфигурацией накладываются жесткие ограничения. Система относительно устойчива к попыткам проникновения в нее.
Класс (ВЗ): Домены безопасности.
Все требования для систем класса (B2) включены в требования к системам класса (ВЗ). ТСВ класса (ВЗ) должна реализовывать концепцию монитора обращений (RM):
· RM гарантированно защищен от несанкционированных изменений, порчи и подделки;
· RM обрабатывает все обращения;
· RM прост для анализа и тестирования на предмет правильности выполнения обработки обращений (должна быть полная система тестов, причем полнота должна быть доказана).
С этой точки зрения структура ТСВ выбирается такой, чтобы исключить коды, не существенные для реализации принятой политики обеспечения безопасности, одновременно с проработкой в процессе проектирования и реализации ТСВ системных инженерно-технических аспектов, направленных на минимизацию ее сложности. Предусматривается введение администратора безопасности системы, механизмы контроля (аудит) расширены так, чтобы обеспечить обязательную сигнализацию о всех событиях, связанных с возможным нарушением установленных в системе правил безопасности. Обязательным также является наличие процедур, обеспечивающих восстановление работоспособности системы. Система данного класса в высшей степени устойчива относительно попыток проникновения в нее.
Класс (AI): Верифицированный проект.
Системы этого класса (А1) функционально эквивалентны системам класса (ВЗ) в том отношении,
что в них не появляются какие-либо новые требования к политике обеспечения безопасности. Отличительной чертой систем данного класса является анализ ТСВ, основанный на формальной спецификации проекта и верификации ТСВ, а, в итоге, высокая степень уверенности в том, что гарантированно защищающая вычислительная база реализована правильно.
Такого рода гарантия, по своей природе технологическая, начинается уже с формальной модели политики обеспечения безопасности и формальной спецификации проекта высокого уровня. Наряду с широким и глубоким анализом процесса проектирования и разработки ТСВ, который необходимо проводить для систем класса (А1), необходимо также выполнение более строгих мер по управлению конфигурацией и специальных процедур по безопасному размещению систем в местах их дислокации. Предусматривается введение администратора безопасности системы.
4.4. 0 ВЫБОРЕ КЛАССА ЗАЩИТЫ.
Продолжим изучение вопросов, связанных с американским стандартом защиты информации "Оранжевая книга". В предыдущем параграфе были определены семь классов систем защиты информации, причем требования в классах от С к А монотонно возрастали. Американцы не опубликовали детальный анализ риска, который определяет эти требования. Однако, одновременно со стандартом, был опубликован документ "Computer Security Requirements-Guidance for Applying the DoD Trusted Computer System Evaluation Criteria in Specific Environment" (далее будем называть его "Требования"), в котором изложен порядок выбора класса систем в различных условиях. Этот документ частично отражает результаты анализа риска, основания для выбора политики безопасности в связи с этими рисками и меры обеспечения гарантий соблюдения политики безопасности. Всюду далее предполагаем, что в информацию внесена MLS решетка ценностей. Выбор требуемого класса безопасности систем определяется следующими основными факторами, характеризующими условия работы системы.
1. Безопасность режима функционирования системы. Американцы различают 5 таких режимов:
а. Режим, в котором система постоянно обрабатывает ценную информацию одного класса в окружении, которое обеспечивает безопасность для работы с этим классом.
в. Режим особой секретности самой системы. Все пользователи и элементы системы имеют один класс и могут получить доступ к любой информации.
Этот режим отличается от предыдущего тем, что здесь обрабатывается информация высших грифов секретности.
с. Многоуровневый режим, который позволяет системе обработку информации двух или более уровней секретности. Причем не все пользователи имеют допуск ко всем уровням обрабатываемой информации.
d. Контролирующий режим. Это многоуровневый режим обработки информации, при котором нет полной гарантии защищенности ТСВ. Это накладывает ограничения на допустимые классы ценной информации, подлежащей обработке.
е. Режим изолированной безопасности. Этот режим позволяет изолированно обрабатывать информацию различных классов или классифицированную и неклассифицированную информацию. Причем возможно, например, что безопасно обрабатывается только информация класса TS, а остальная информация не защищена вовсе.
2. Основой для выбора класса защиты является индекс риска. Он определяет минимальный требуемый класс.
Отобразим классы секретности в числа согласно таблице: U-0, С-1, S-2, TS-3. Эта таблица не совсем точно отражает соответствие из "Требований". Но здесь мы просто объясняем идею подхода. Определим Rmin - минимальный уровень допуска пользователя в системе, и Rmax - максимальный класс ценности информации, присутствующий в системе. В большинстве случаев индекс риска определяется по формуле:
Risk Index=Rmax-Rmin
Исключения касаются случая, когда

{ 1, если есть категории, к которым кто-либо из пользователей не имеет доступа
RiskIndex = {
{ 0, в противном случае
И также некоторые исключения есть в случае обработки TS-информации.
Пример 1. Если минимальный допуск пользователя в системе - С, а максимальный гриф обрабатываемой информации - S, то Rmin =2, Rmax=3. Тогда RiskIndex = l .
В результате учета всех ценностей и определения дополнительных классов у американцев получается восемь значений индекса риска от О до 7. Для этих значений индекса риска устанавливается следующее соответствие с минимальными требуемыми классами систем в случае, когда система функционирует во враждебном окружении.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Если система функционирует в окружении, которое можно назвать "безопасным периметром", то требования к минимальным классам значительно ниже.
Глава 5
МАТЕМАТИЧЕСКИЕ МЕТОДЫ АНАЛИЗА ПОЛИТИКИ БЕЗОПАСНОСТИ
Доказательство того факта, что соблюдение политики безопасности обеспечивает то, что траектории вычислительного процесса не выйдут в неблагоприятное множество, проводится в рамках некоторой модели системы. В этой главе мы рассмотрим некоторые модели и приведем примеры результатов, которые доказываются в данной области. В параграфе 5.1 рассматривается модель распространения прав доступа в системе с дискреционной политикой безопасности. Параграф 5.2 посвящен описанию модели Белла-Лападула и доказательству теоремы BST (основной теоремы безопасности для многоуровневых систем). К сожалению, полное описание модели Белла-Лападула остается секретным и недоступным. Поэтому приведенный вариант модели и теоремы касаются случая, когда уровень объекта не меняется. В параграфе 5.3 приводится пример (модель Low WaterMark), когда уровень объекта может меняться. В параграфе 5.4 описан подход Гогена и Месгауэра в моделировании безопасных систем. Наконец, в параграфе 5.5 приводится пример модели нарушителя, который используется при анализе политики аудита в реляционных базах данных.
5.1. МОДЕЛЬ "TAKE-GRANT" .
Будем по-прежнему описывать функционирование системы при помощи графов доступов Gt и траекторий в фазовом пространстве V={G}. Единственное дополнение - правила преобразования графов.
Будем считать, что множество доступов R={r, w, c} , где r - читать, w - писать, с - вызывать. Допускается,что субъект X может иметь права aÍR на доступ к объекту Y, эти права записываются в матрице контроля доступов. Кроме этих прав мы введем еще два: право take (t) и право grant (g), которые также записываются в матрицу контроля доступов субъекта к объектам. Можно считать, что эти права определяют возможности преобразования одних графов состояний в другие. Преобразование состояний, то есть преобразование графов доступов, проводятся при помощи команд. Существует 4 вида команд, по которым один граф доступа преобразуется в другой.
1. Take. Пусть S - субъект, обладающий правом t к объекту X и aÍR некоторое право доступа объекта X к объекту Y. Тогда возможна команда "S take a forY from X". В результате выполнения этой команды в множество прав доступа субъекта S к объекту Y добавляется право a. Графически это означает, что, если в исходном графе доступов G был подграф

то в новом состоянии G', построенном по этой команде t, будет подграф
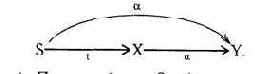
2. Grant. Пусть субъект S обладает правом g к объекту X и правом aÍR к объекту Y. Тогда возможна команда "S grant a for Y to X". В результате выполнения этой команды граф доступов G преобразуется в новый граф G', который отличается от G добавленной дугой (Х Y). Графически это означает, что если в исходном графе G был подграф
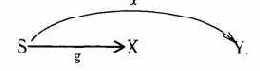
то в новом состоянии G' будет подграф
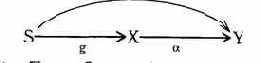
3. Create. Пусть S - субъект, bÍR. Команда "S create P for new object X" создает в графе новую вершину X и определяет Р как права доступов S к X. То есть по сравнению с графом G в новом состоянии G' добавляется подграф вида

4. Remove. Пусть S - субъект и X - объект, bÍR. Команда "S remove Р for X" исключает права доступа Р из прав субъекта S к объекту X. Графически преобразования графа доступа G в новое состояние G' в результате этой команды можно изобразить следующим образом:

в G в G’
Далее будем обозначать G|-cG', если команда с преобразует G в G', а также G |- G', если существует команда с, что G|-G'. Будем понимать под безопасностью возможность или невозможность произвольной фиксированной вершине Р получить доступ aÎR к произвольной фиксированной вершине X путем преобразования текущего графа G некоторой последовательностью команд в граф G', где указанный доступ разрешен.
Определение. В графе доступов G вершины Р и S называются tg-связными, если существует путь в G, соединяющий Р и S, безотносительно ориентации дуг, но такой, что каждое ребро этого пути имеет метку, включающую t или g.
Теорема 1. Субъект Р может получить доступа к, объекту X, если существует субъект S, имеющий доступ а, к вершине X такой, что субъекты Р и S связаны произвольно ориентированной дугой, содержащей хотя бы одно из прав t или g
Доказательство. Возможны 4 случая.
1. В G есть подграф

Тогда имеем право применить команду "Р take a for X from S" и получим в G' подграф
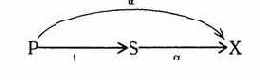
2. В G есть подграф

Тогда имеем право применить команду "S grant а for X to Р" и получим в G' подграф
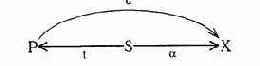
3. В графе G есть подграф

Тогда применяем следующую последовательность разрешенных команд для преобразования графа G:"Р create tg for new object Y"
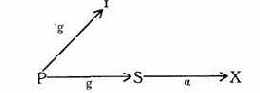
"Р grant g for Y to S"
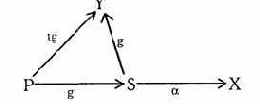
"S grant a for X to Y"
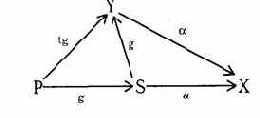
"Р takes a for X from Y"
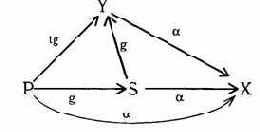
4. В графе G есть подграф

Тогда применяем следующую последовательность разрешенных команд для преобразования графа G в граф G' с дугой (Р X). "Р create tg for new object Y"
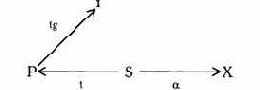
Далее будем записывать преобразования графов коротко
Теорема доказана.
Замечание. Метка с правом а на дуге в рассматриваемых графах не означает, что не может быть других прав. Это сделано для удобства.
Теорема. 2. Пусть в системе все объекты являются субъектами. Тогда субъект Р может получить доступ а к субъекту X тогда и только тогда, когда выполняются условия:
I. Существует субъект S такой, что в текущем графеG есть дуга

2. S tg-связна с Р.
Доказательство. 1. Достаточность.
Доказательство будем вести индукцией по длине n tg-пути, соединяющего S и Р. При n=l утверждение доказано в теореме 1. Пусть длина tg-пути в G, соединяющего S и Р равна n>1. Пусть также есть вершина Q на этом tg-пути, которая смежна с S. Тогда по теореме 1 можно перейти к графу G', в котором


2. Необходимость.
Пусть для пары вершин Р и X в графе G нет дуги


Пусть G' такой граф, когда впервые появляется дуга
Пусть в графе G вершины Р и S не связаны tg-путем. Тогда при любой команде с в графе G’, полученном из G командой с G|-cG’ , также нет tg-пути из Р в S. В самом деле, возьмем take
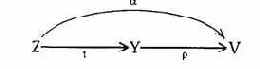
Если в р не было take или grant, то новая дуга не увеличивает количество дуг с правом take или grant в новом графе, поэтому новый tg-путь возникнуть не может. Если в р есть t или g, то между V и Z существовал tg-путь и новая дуга не увеличила числа tg-связных вершин и поэтому не могла связать Р и S.
Аналогично, если Y и Z были связаны дугой grant. Команда create также не может связать существующие вершины Р и S tg-путем.
Значит при любой последовательности команд c1,...cn, если в G нет tg-пути из Р в S, то их нет в G’ полученном из G G|-c1,...cnG’. Но это противоречит сделанному выше заключению о наличии такого пути длины 1 в графе G’. Теорема доказана.
5.2. МОДЕЛЬ БЕЛЛА-ЛАПАДУЛА (Б-Л).
Модель Б-Л построена для обоснования безопасности систем, использующих политику MLS. Материалы, в которых опубликована модель в 1976г., до сих пор недоступны. Поэтому в изложении модели Б-Л будем следовать работе J. McLean (1987), в которой классы объектов предполагаются неизменными. Для описания модели нам потребуется несколько другое описание самой вычислительной системы. Пусть определены конечные множества S, О, R, L.
S - множество субъектов системы;
О - множество объектов, не являющихся субъектами;
R - множество прав доступа; R = {read (r), write(w), execute (е), append (а)};
L - уровни секретности.
Множество V
состояний системы определяется произведением множеств:

где сомножители определяются следующим образом. В - множество текущих доступов и есть подмножество множества подмножеств произведения


М - матрица разрешенных доступов, M=|Mij|, MijÍR. F - подмножество множества


fs - уровень допуска субъектов (это некоторое отображение f: S->L);
fo - уровень секретности объектов (это некоторое отображение f: O->L);
fc - текущий уровень секретности субъектов (этотоже некоторое отображение fc: S->L).
Элементы подмножества F, которые допущены для определения состояния, должны удовлетворять соотношению:

Н - текущий уровень иерархии объектов, в работе McLean этот уровень не изменяется, совпадает с f0 и далее не рассматривается.
Элементы множества V
состояний будут обозначаться через v. Пусть определены множество Q - запросов в систему и множество D - решений по поводу этих запросов (D = {yes, nо, error}). Определим множество W действий системы как

Каждое действие системы (q, d, v2, v1) имеет следующий смысл: если система находилась в данный момент в состоянии v1, поступил запрос q, то принято решение d и система перешла в состояние v2.
Пусть Т
- множество значений времени (для удобства будем считать, что T=N
- множество натуральных чисел). Определим набор из трех функций (х, у, z)
x: T->Q,
у: T->D,
z: T->V,
и обозначим множества таких функций X, Y, Z соответственно.
Рассмотрим

Определение. Системой å(Q, D, W, z0) называетсяподмножество
(x, y, z)Îå(Q, D, W, z0)Û(xt, yt, zt, zt-1)ÎW
для каждого значения tÎT, где z0- начальное состояние системы.
Определение. Каждый набор (х, у, z)Îå(Q, D, W, z0) называется реализацией системы.
Определение. Если (х, у, z) - реализация системы, то каждая четверка (xt, yt, zt, zt-1) называется действием системы.
Нетрудно видеть, что при отсутствии ограничений на запросы таким образом определен некоторый автомат, у которого входной алфавит Q, а выходной D, а множество внутренних состояний V. Автомат задается множеством своих реализаций. Перейдем к определению понятий, связанных с безопасностью системы.
Определение. Тройка (S, О, X)ÎS´O´R удовлетворяет свойству простой секретности (ss-свойство) относительно f, если X=execute, или X=append, или, если X=read и fs(S)>fo(0), или X=write и fs(S)>f0(S).
Определение. Состояние v=(b, М, f, h) обладает ss-свойством, если для каждого элемента (S,О,Х)ÎB этот элемент обладает ss-свойством относительно f.
Определение. Состояние v=(b, М, f, h) обладает *-свойством, если для каждого (S, О, X)ÎB при X=write текущий уровень субъекта fc(S) равен уровню объекта f0(O), или при X=read fc(S)>f0(O), или при X=append fo(O)>fc(S).
Определение. Состояние обладает *-свойством относительно множества субъектов S', S'ÎS, если оно выполняется для всех троек (S, О, X) таких, что SÎS'
Определение. Субъекты из множества S\S' называются доверенными.
Лемма. Из * -свойства для состояния v=(b, М, f, h) следует ss-свойство относительно f для всех (S, О,Х)ÎB.
Доказательство. Утверждение следует из условия fs(S)>fc(S).
Определение. Состояние v=(b, М, f, h) обладает ds -свойством, если "(S, О, X)Îb=>XÎmso, где M=||mso||- матрица доступа состояния v.
Определение. Состояние v = (b, М., f, h) называется безопасным, если оно обладает одновременно ss-свойством, *- свойством относительно S' и ds-свойством.
Напомним формулировку политики MLS, связанной с решеткой ценностей SC´L, где L - линейный порядок, SC - решетка подмножеств в информации: информационный поток между двумя объектами называется разрешенным, если класс объекта источника доминируется классом объекта получателя. Из определения ss-свойства следует, что в безопасном состоянии возможно чтение вниз, что согласуется с эквивалентным определением MLS политики. Кроме того, ss-свойство определяет ограничение на возможность модификации, которое связано с write:
fs(S)>fo(0).
Объясним *-свойство. Если субъект может понизить свой текущий допуск до fc(S)=f0(O), то, согласно *-свойству, он может писать в объект. При этом он не может читать объекты на более высоких уровнях, хотя допуск fs(S) ему это может позволить. Тем самым исключается возможный канал утечки:
High O fs(S)
^
| r
|
|
Low S ----à O2 fc(S)
w
Таким образом, при записи информационный поток опять не может быть направлен вниз. Исключение возможно только для доверенных субъектов, которым разрешено строить информационный поток вниз. При этом доверенность субъекта означает безопасность такого потока вниз (поэтому эти потоки считаются разрешенными). Сказанное выше означает, что безопасное состояние модели Б-Л поддерживает политику MLS.
Значит, для того, чтобы доказать, что любой поток на траектории вычислительной системы разрешен, достаточно показать, что выходя из безопасного состояния и следуя допустимым действиям мы опять приходим в безопасное состояние, тем самым любая реализация процесса будет безопасной. Проведем строгое обоснование этого вывода.
Определение. Реализация (х, у, z) системы å(Q, D,W, z) обладает ss-свойством ( *-свойством, ds- свойством), если в последовательности (z0, z1,.....) каждое состояние zn обладает ss-свойством ( * -свойством , ds-свойством).
Определение. Система обладает ss-свойством ( соответственно, *-свойством, ds-свойством), если каждая ее реализация обладает ss-свойством (соответственно, *-свойством, ds-свойством).
Определение. Система называется безопасной, если она обладает одновременно ss-свойством, *-cвойством, и ds - свойством.
Теорема A1. å(Q, D, W, z0) обладает ss -свойством для любого начального z0, которое обладает ss-свойством тогда и только тогда, когда W удовлетворяет следующим условиям для каждого действия (q, d, (b*, М*, i*, h*), (b, М, f, h)):
(I) "(S, 0, X)Îb*| b обладает ss-свойством относительно f*.
(2) если (S, О, X)Îb и не обладает ss-свойством относительно f*, то (S, О, X)Ïb*
Доказательство. "(S, О, Х)Îb* возможно либо (S,О, Х)Îb, или (S, О, X)Îb*\b. Условие (1) означает, что состояние (b*, М*, f*, h*) пополнилось элементами (S, О, X), обладающими ss - свойством относительно f*. Условие (2) означает, что элементы b*, перешедшие из b, обладают ss - свойством относительно f*. Следовательно, "(S, О, X)Îb* обладает ss-свойством относительно f*. Пусть любое состояние обладает ss-свойством относительно своего f. Тогда (1) выполняется, т.к. ss-свойство выполняется для всех (S, О,X) из b*. И, если (S, О, X)Îb и перешло в b*, то, в силу ss-свойства (S, О, X) обладает ss - свойством относительно f*. Что и требовалось доказать.
Теорема A2. Система å(R, D, W, z0) обладает *- свойством относительно S' для любого начального состояния z0, обладающего *-свойством относительно S' тогда и только тогда, когда W удовлетворяет следующим условиям для каждого действия (q, d, (b*, М*,f*, h*), (b, М, f, h)):
(I) "SÎS’, "(S, O, X)Îb*\ b обладает *-свойством относительно f*;
(II) "SÎS’, "(S, O, X)Îb и (S, O, X) обладает *-свойством относительно f*, то (S, O, X)Ïb*.
Доказательство проводится аналогично.
Упражнение. Доказать теорему А2.
Теорема АЗ. Система å(Q, D, W, z0) обладает ds-свойством тогда и только тогда, когда для любого начального состояния, обладающего ds-свойством, W удовлетворяет следующим условиям для любого действия (q, d, (b*, М*, f*, h*), (b, М, f, h)):
(I) (S, О, X)Îb*| b то ХÎтso*,
(II) (S, 0, X)Îb*| b XÏmso*, то (S, 0, X)Ïb*
Доказательство проводится аналогично.
Упражнение. Доказать теорему АЗ.
Теорема (Basic Security Theorem). Система å(Q, D, W, z0 ) - безопасная тогда и только тогда, когда z0 - безопасное состояние и W удовлетворяет условиям теорем A1, А2, АЗ для каждого действия.
Доказательство. Теорема BST следует из теорем А1, А2, АЗ.
5.3. МОДЕЛЬ LOW-WATER-MARK (LWM).
Данная модель является конкретизацией модели Б-Л, а также дает пример того, что происходит, когда изменения уровня секретности объекта возможны. Политика безопасности прежняя: все объекты системы классифицированы по узлам решетки ценностей (MLS) и поток информации разрешен только "снизу вверх" .
В рассматриваемой системе один объект (неактивный), три операции с объектом, включающие запросы на доступ:
· read,
· write,
· reset.
Эти операции используются несколькими субъектами (процессами), имеющими фиксированные уровни секретности (для простоты - классы секретности образуют линейный порядок). Напомним формальное требование политики о том, что информация может двигаться только "снизу вверх". Поток информации возможен тогда и только тогда, когда реализуется доступ субъекта к объекту вида w или r. При помощи r поток считается разрешенным, если fs(S)>fo(0).
При команде w поток считается разрешенным, еслисубъект S не может прочитать информацию в объекте уровня fs(S)
Таким образом, условия ss в данной системе выглядят стандартно: если X=w или r, то могут быть разрешены доступы (S, 0, X) при выполнении fs(S)>f0(0).
Условие *:
если X=w, то fs(S)=f0(0),
если X=r, то fs(S)>fo(0).
Опишем функционирование системы и докажем,что выполняются условия ss и *. Уровень объекта О в LWM может меняться: при команде write может снизиться, а при команде reset подняться следующим образом. По команде reset класс объекта поднимается и становится максимальным в линейном порядке. После этого все субъекты приобретают право w, но read имеют право только субъекты, находящие на максимальном уровне решетки. При команде write гриф объекта снижается до уровня субъекта, давшего команду w. При снижении уровня секретности объекта вся прежняя информация в объекте стирается и записывается информация процессом, вызвавшем команду write. Право write имеет любой субъект, у которого fs(S)
|
|
|
|
|
Процесс S получает содержимое объекта O |
|
|
Уровень объекта становится равным уровню S. Данные от S записываются в O. |
|
|
Уровень объекта устанавливается выше всех уровней процессов. |
Доказательство. Если fs(S)>fo(0), то r доступ S к О разрешен. Если fs(S)=fo(0), то w доступ S к О разрешен. Таким образом ss и * выполнены. Что и требовалось доказать.
Однако все рассуждения останутся теми же, если отказаться от условия, что при команде write в случае снижения уровня объекта все стирается. То есть здесь также будут выполняться условия * и ss, но ясно, что в этом случае возможна утечка информации. В самом деле, любой процесс нижнего уровня, запросив объект для записи, снижает гриф объекта, а получив доступ w, получает возможность r. Возникает канал утечки (¯w, ®r), при этом в предыдущей модели свойство * выбрано для закрытия канала ( r, ®w). Данный пример показывает, что определение безопасного состояния в модели Б-Л неполное и смысл этой модели только в перекрытии каналов указанных видов. Если "доверенный" процесс снижения грифа объекта работает неправильно, то система перестает быть безопасной.
5.4. МОДЕЛИ J.GOGUEN, J.MESEGUER (G-M).
Модели G-M - автоматные модели безопасных систем. Начнем с простейшего случая системы с "фиксированной" защитой. Пусть V
- множество состояний системы (V - конечное и определяется программами, данными, сообщениями и пр.), С - множество команд, которые могут вызвать изменения состояния (также конечное множество), S - множество пользователей (конечное множество). Смена состояний определяется функцией:
do:V ´ S ´ С®V.
Некоторые действия пользователей могут не разрешаться системой. Вся информация о том, что разрешено ("возможности" пользователей) пользователям сведена в с-таблицу t. В рассматриваемом случае "возможности" в с-таблице t совпадают с матрицей доступа. Если пользователь не может осуществить некоторую команду с, то
do (v, S, c) = v.
Предположим, что для каждого пользователя S и состояния v определено, что "выдается" этому пользователю (т.е., что он видит) на выходе системы. Выход определяется функцией
out: V´ S®Out,
где Out - множество всех возможных выходов (экранов, листингов и т.д.).
Мы говорим о выходе для пользователя S, игнорируя возможности S подсмотреть другие выходы.
Таким образом получили определение некоторого класса автоматов, которые будут встречаться далее.
Определение. Автомат М состоит из множеств:
S - называемых пользователями;
V - называемых состояниями;
С - называемых командами;
Out - называемых выходами;
и функций:
· выходной функции out: V´ S ® Out, которая "говорит, что данный пользователь видит, когда автомат находится в данном состоянии ";
· функции переходов do: V´S´С®V, которая "говорит, как изменяется состояние автомата под действием команд";
и начального состояния v0.
Системы с изменяющимися "возможностями" защиты определяют следующими образами.
Пусть Capt - множество всех таблиц "возможностей", СС - множество с-команд (команд управления "возможностями"). Их эффект описывается функцией:
cdo: Capt´ S ´ CC®Capt.
При отсутствии у пользователя S права на с-команду положим cdo(t, S, c)=t. Пусть VC - множество команд, изменяющих состояние. Теперь можем определить С-автомат, который лежит в основе дальнейшего.
Определение. С-автомат М определяется множествами:
S - "пользователи";
V - "состояния";
VC - "команды состояния";
Out - "выходы";
Capt - "с-таблицы";
СС - "с-команды",
и функциями:
· выхода out: V´Capt´S®Out, которая "говорит, что данный пользователь видит, когда автомат находится в данном состоянии v, а допуски определяются с-таблицей";
· переходов do: V´Capt´S´VC®V, которая "говорит, как меняются состояния под действием команд";
· изменения с-таблиц cdo: Capt´S´СС®Capt, которая "говорит, как меняется с - таблица под действием с", и начального состояния, которое определяется с-таблицей t и состоянием v.
Будем считать
C=CCÈVC.
То, что мы определили на языке теории автоматов, называется последовательным соединением автоматов .
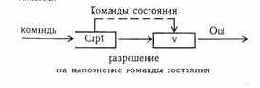
Определение. Подмножества множества команд С называются возможностями
Ab=2c.
Если дан С-автомат М, мы можем построить функцию переходов всей системы в множестве состояний V´Capt:
cvdo: V ´Capt´S´С®V´Capt,
где
cvdo(v, t, S, с) = (do(v, t, S, с), t), если cÎVC,
cvdo(v, t, S, с) = (v, cdo(t, S, c)), если cÎCC.
Стандартно доопределяется функция cvdo на конечных последовательностях входов
cvdo: V´Capt´(S´С)*®V´Capt
следующим образом:
cvdo(v, t, Nil) = (v, t),
если входная последовательность пустая;
cvdo(v, t, W(S, c))=cvdo(cvdo(v, t, W), S, c)),
где W(S, С) - входное слово, кончающееся на (S,С) и начинающееся подсловом W.
Определение. Если W входное слово, то[[W]] = (..., (vi ti),...), где последовательность состоянии вычисляется в соответствии с определенной выше функцией переходов под воздействием входной последовательности W.
Введем понятие информационного влияния одной группы на другую, смысл которого состоит в том, что используя некоторые возможности одна группа пользователей не влияет на то, что видит каждый пользователь другой группы. Для этого определим [[W]]s - выход для S при выполнении входного слова W С -автомата М:
[[W]]s=out([[W]], S),
где
out([[W]]s, S) = (... out(v, t, S)...),
[[W]] = (..., (vi, ti),...).
Пусть GÍS, AÍC, WÎ(S´C)*.
Определение. Pg(W) - подпоследовательность W, получающаяся выбрасыванием всех пар (S, с) при SÎG, Pa(W) - подпоследовательность W, получающаяся выбрасыванием из W всех пар (S, с) при cÎA, PGA(W) -подпоследовательность W, получающаяся выбрасыванием пар (S, с), SÎG и сÎА.
Пример 1. G={S, Р}, А={с1, с2}.
PGA((S', с), (S, сз), (S, с2), (Р', с))= (S', с), (S, с3), (Р', с). Определим несколько вариантов понятия независимости .
Пусть GÍS, G’ÍS.
Определение. G информационно не влияет на G' (обозначается G: | G'), если "WÎ(S´С)* и "SÎG' [[W]]s = [[PA(W)]]s
Аналогично определяется невлияние для возможностей А
(или группы G и возможностей А).
Определение. А
информационно не влияет на G (обозначается А: | G) , если "WÎ(S´С)* и "SÎG [[W]]s= [[PA(W)]]s
Определение. Пользователи G, используя возможности А, информационно не влияют на G' (обозначается A.G: | G'), если "WÎ( S´С)* и "S´G' [[W]]s=[[PA(W)]]s.
Пример 2. Если А: | {S}, то команды из А не влияют на выход, выданный S. Если A={create, write, modify, deleted} для файла F, то А: | {S} означает, что информация читаемая S в F не может измениться любой из команд в А. Если F не существовал, то для S будет всегда выдаваться информация, что F не существует.
Определение. Политика безопасности в модели G-М - это набор утверждений о невлиянии.
Пример 3. MLS политика. Пусть L - линейно упорядоченное множество уровней секретности и задано отображение
level: S->L.
Определим: "xÎL
S[-¥, x] = {SeS | level(S)
S[x,+¥] = {SeS| level(S)>x}.
Определение. MLS политика в модели G-M определяется следующим набором утверждений о невлиянии:
"xÎL, "x'ÎL, х>х',
S[x, +¥]:| S[ -¥, x'].
Говорят, что GÍS невидимо для остальных пользователей, если G:|

Используя это понятие легко обобщить определение MLS политики на случай, когда L - решетка.
Определение. MLS политика в модели G-M определяется следующим набором утверждений о невлиянии:
"xÎL S\S[-¥, х] - невидимо для остальных пользователей.
Пример 4. Одним из важнейших примеров политики безопасности, легко выражаемой в G-M модели, является режим изоляции.
Определение. Группа G называется изолированной,если G:|
Система полностью изолирована, если каждый пользователь изолирован.
Пример 5. Контроль канала. В модели G-M канал определяется как набор команд АÍС .
Пусть G, G'ÍS.
Определение. G и G' могут связываться только через канал А тогда и только тогда, когда


Пример 6. Информационный поток Пусть а, b, с, d -процессы и А1, A2, Аз - каналы такие, что а, b, с, d могут связываться только по схеме
Эта картинка описывается следующими утверждениями о невлиянии:
{b, c, d}: | {a} A1, {a}: | {b, c, d}
{c, d}: | {b} A2, {b}: | {c}
{c}: | {d} A3, {b}: | {d}
{d} : | {c}
5.5. МОДЕЛЬ ВЫЯВЛЕНИЯ НАРУШЕНИЯ БЕЗОПАСНОСТИ.
Один из путей реализации сложной политики безопасности, в которой решения о доступах принимаются с учетом предыстории функционирования системы, - анализ данных аудита. Если такой анализ возможно проводить в реальном масштабе времени, то аудиторская информация (АИ) совместно с системой принятия решений превращаются в мощное средство поддержки политики безопасности. Такой подход представляется перспективным с точки зрения использования вычислительных средств общего назначения, которые не могут гарантировано поддерживать основные защитные механизмы. Но, даже не в реальном масштабе времени, АИ и экспертная система, позволяющая вести анализ АИ, являются важным механизмом выявления нарушений или попыток нарушения политики безопасности, так как реализуют механизм ответственности пользователей за свои действия в системе.
По сути анализ АИ имеет единственную цель выявлять нарушения безопасности (даже в случаях, которые не учитываются политикой безопасности). Далее мы изложим пример организации такого анализа, который известен из литературы под названием "Модель выявления нарушения безопасности". Эта модель, опубликованная D.Denning в 1987 г., явилась базисом создания экспертной системы IDES для решения задач выявления нарушений безопасности. Модель включает 6 основных компонент:
· субъекты, которые инициируют деятельность в системе, обычно - это пользователи;
· объекты, которые составляют ресурсы системы - файлы, команды, аппаратная часть;
· АИ - записи, порожденные действиями или нарушениями доступов субъектов к объектам;
· профили - это структуры, которые характеризуют поведение субъектов в отношении объектов в терминах статистических и поведенческих моделей;
· аномальные данные, которые характеризуют выявленные случаи ненормального поведения;
· правила функционирования экспертной системы при обработке информации, управление.
Основная идея модели - определить нормальное поведение системы с тем, чтобы на его фоне выявлять ненормальные факты и тенденции. Определению субъектов и объектов мы уделили достаточное вниманиев параграфе 1.1. Остановимся подробнее на описаниии примерах остальных элементов модели.
АИ - это совокупность записей, каждая из которых в модели представляет 6-мерный вектор, компоненты которого несут следующую информацию:
<субъект; действие; объект; условия для предоставления исключения; лист использования ресурсов; время>,
где смысл компонент следующий.
Действие - операция, которую осуществляет субъект и объект.
Условия для предоставления исключения, если они присутствуют, определяют, что дополнительно надо предпринять субъекту, чтобы получить требуемый доступ.
Лист использования ресурсов может содержать, например, число строчек, напечатанных принтером, время занятости CPU (центрального процессора) и т.д.
Время - уникальная метка времени и даты, когда произошло действие.
Так как АИ связана с субъектами и объектами, то данные АИ подобны по организации матрице доступа, где указаны права доступа каждого субъекта к любому объекту. В матрице АИ в клетках описана активность субъекта по отношению к объекту.
Пример 1.
Рассмотрим команду
Copy-Game.exe to
которую использовал пользователь Smith для того, чтобы скопировать файл "Game" в библиотеку; копирование не выполнено, так как Smith не имеет праваписать в библиотеку. АИ, соответствующая этому примеру будет состоять из записей:
(Smith, execute, < Library> Сору.ехе, О,
CPU = 00002, 11.05.85.21678)
(Smith, Read,
11.05.85.21679)
(Smith, Write,
Write - violation. Records = 0, 1 1 .05.85.2 1 680).
Рассмотрим подробнее понятие "профиль". Профили описывают обычное поведение субъектов по отношению к объектам. Это поведение характеризуется набором статистических характеристик, вычисленных по наблюдениям за действиями субъекта по отношению к объекту, а также некоторой статистической моделью такого поведения. Приведем примеры таких статистических характеристик.
1. Частоты встречаемости событий. Например, частота встречаемости заданной команды в течение часа работы системы и т.д.
2. Длина временного промежутка между осуществлением некоторых событий.
3. Количество ресурсов, которые были затрачены в связи с каким-либо событием. Например, время работы CPU при запуске некоторой программы, число задействованных элементов аппаратной части и др.
Статистические модели строятся по наблюденным значениям статистических характеристик с учетом статистической обработки данных. Например, некоторый процесс характеризуется устойчивым средним числом встречаемости данной команды, которая может быть уверенно заключена в доверительный интервал в 3s, где s - стандартное отклонение частоты встречаемости этого события.
Чаще всего статистические модели являются многомерными и определяются многомерными статистическими методами. Наиболее сложные модели - это случайные процессы, характеристики моделей являются некоторыми функционалами от случайных процессов. Например, моменты остановки программы и т.д.
В нормальных условиях статистические характеристики находятся в границах своих значений. Если происходит ненормальное явление, то возможно наблюдать статистически значимое отклонение от средних параметров статистических моделей.
Пример 2.
Реализация канала утечки по времени, приведенного в примере 4 параграфа 2.1, требует повторяющегося запроса на принтер, а затем отказа от него. Ясно, что в реализации такого канала частота обращения к принтеру возрастает, что, естественно, приведет к значимому отклонению этой характеристики от модели повседневного использования принтера данным пользователем.
Описание профиля или его структура состоит из 10 компонентов, которые, кроме собственно статистической модели, определяют АИ с ней связанную. Структура профиля может быть представлена следующим вектором:
<Имя переменной; отражаемые действия; имеющиеся исключения; данные использования ресурсов; период измерений; тип статистики; порог допустимых значений; субъект; объект; значение последнего наблюдения модели>.
К сожалению, анализ на уровне субъект - объект в значительной степени затруднен. Поэтому аналогичные структуры (профили) создаются для агрегированных субъектов и объектов. Например, для некоторого фиксированного множества субъектов в отношении всех возможных объектов. Другой пример: действия всех пользователей в отношении данного объекта.
Основной сложностью при внедрении этой моделиявляется выбор и построение профилей.
Пример 3.
Рассмотрим систему с 1000 пользователями; у каждого пользователя в среднем 200 файлов, что дает 200000 файлов в системе. Тогда имеем 200 млн. возможных комбинаций: пользователь-файл. Даже, если предположить, что каждый пользователь осуществляет доступ к 300 файлам, то необходимо создать 300 000 профилей.
Пример 3 показывает, что необходимо применять специальные приемы для сокращения информации.
Если обнаружено ненормальное поведение, то немедленно делается запись в сборнике аномальных фактов. Каждая запись в этом сборнике - трехмерный вектор, имеющий следующие компоненты:
<событие; время; в отношении какого профиля получено отклонение > .
Применение рассмотренной модели дало хорошие результаты. Вместе с тем требуют исследований такие вопросы:
· насколько надежно предложенный метод выявляет нарушения безопасности;
· какова доля нарушений безопасности, для которых работает метод;
·выбор инструментов статистической обработки данных и моделей профилей требует обоснования;
· идеология самого быстрого обнаружения ещене ясна.
Глава 6 ГАРАНТИРОВАННО ЗАЩИЩЕННЫЕРАСПРЕДЕЛЕННЫЕ СИСТЕМЫ
Глава VI посвящена вопросам защиты сетей межмашинного обмена информацией.
Основной аспект нашего изучения - распространение стандарта " Оранжевая книга" на распределенные системы обработки информации. Базисом для предложенного ниже подхода является "Trusted Network Interpretation", которая была выпущена DoD в 1987 г. в составе "радужной" серии. Эта книга известна под названием "Красная книга" (КК). В главе приведены результаты, заимствованные из КК и связанные с методами анализа защищенных сетей и синтеза гарантированно защищенных распределенных систем обработки информации.
В отличии от "монолитных" вычислительных систем, имеющих заданный периметр и спецификацию, распределенные системы не имеют ограниченного периметра, а число компонент их может меняться. Между компонентами в сетях существуют каналы, которые могут проходить по незащищенной или враждебной территории. Этими чертами различия междумонолитной и распределенными вычислительнами системами исчерпываются. Следовательно, если как-то учтены перечисленные различия, то все вопросы защиты вычислительных и распределенных систем одинаковы. Таким образом, к распределенным системам можно попытаться применить критерии гарантированной защищенности вычислительных систем, например, "Оранжевой книги".
Возможны два подхода к анализу и оценке защищенности распределенной системы.
1. Каждая компонента распределенной системы есть самостоятельная защищенная система, а, в целом, сеть представляет множество взаимодействующих, защищенных порознь систем. Такая сеть не есть одно целое и вопросы ее гарантированной защиты сводятся к доказательству защищенности компонент в условиях рассматриваемого окружения и организации защищенных шлюзов для взаимодействия компонент. Однако, никто не отвечает за информацию в сети целиком.
2. Все компоненты и связи между ними составляют единое целое. В этом случае существует лицо (центр), которое берет на себя обязательство обеспечить безопасность в сети. Здесь эта безопасность относится к сети в целом, несмотря на неопределенный периметр и изменяемую конфигурацию.
Тогда должна существовать некоторая политика безопасности и средства сети, поддерживающие эту политику (NTCB). При этом средства поддержки безопасности в сети вовсе не должны составлять полный комплекс (удовлетворяющий стандарту OK) механизмов защиты в каждой отдельной компоненте. Однако они, в целом, должны составлять единый механизм защиты, который в случае использования дискреционной и мандатной политики может анализироваться на предмет соответствия стандарту ОК. В частности, для класса ВЗ и выше NTCB должна реализовывать монитор обращения во всей сети. Отсюда возникает задача синтеза из отдельных компонент NTCB, поддерживающую политику в сети, а также задача оценки защитных функций компонент, из которых NTCB возможно синтезировать. В КК все рассмотренные вопросы поставлены с точки зрения проведения оценки распределенной системы. Предложенный подход (он же применим в анализе и синтезе таких систем) состоит в том, чтобы по сети построить гипотетическую монолитную систему с ТСВ, совпадающей по функциям с NTCB, и ее оценивать. С другой стороны, при создании распределенной системы можно сначала создать гипотетический проект монолитной защищенной системы, а затем провести декомпозицию его по компонентам распределенной системы с сохранением защитных свойств. И, наконец, всем известна "слабость" ОК, состоящая в том, что слабо отработана проблема контроля защищенности при модификациях или замене подсистем. Если для монолитной вычислительной системы эта слабость была преодолима, то в распределенных системах проблема наращивания компонент без переоценки всего в целом становится принципиальной. В параграфе 6.1 на основе теоремы о синтезе монитора обращения в NTCB из мониторов обращений компонент строится главная составляющая NTCB - контроль за доступами. Отсюда следует описанная вкратце декомпозиция монолитных систем, в которых есть монитор обращения, и синтез распределенной системы в монолитную вычислительную систему с ТСВ, реализующей монитор обращения. В параграфе 6.2 описаны подходы КК к анализу компонент и примеры встраивания таких компонентв гарантированно защищенную распределенную систему, в которой функции NTCB распределены по компонентам.
6.1. СИНТЕЗ И ДЕКОМПОЗИЦИЯ ЗАЩИТЫ В РАСПРЕДЕЛЕННЫХСИСТЕМАХ.
Рассмотрим сеть, компоненты которой связаны каналами связи, а каждая из компонент несет некоторые функции защиты. Основное требование при анализе безопасности распределенной системы как одного целого - является общая политика безопасности. Тогда вопрос защищенности распределенной системы как одного целого состоит в организации согласованного действия компонент защиты по поддержке политики безопасности всей сети. Решению этой проблемы противостоят опасности нарушения защиты информации при передаче ее по каналам связи, а также опасности асинхронного функционирования компонент защиты.
В связи с этим предположим, что ТСВ компонент в каждом локальном случае поддерживают функции монитора обращения. Единая политика безопасности в сети не означает, что все ТСВ компонент поддерживают одну и ту же политику и соответствуют требованиям одного класса. Например, одна компонента может быть классифицирована по классу С2 (хотя в ней тоже мы требуем дополнительно наличие монитора обращения), а другая - по классу ВЗ. При этом обе компоненты поддерживают единые дискреционную и мандатную политики, хотя первая компонента -
одноуровневая (соответствует одному классу обрабатываемой информации), а вторая - поддерживает MLS политику в полном объеме. Кроме того, в обоих компонентах предполагается единая система категорий и единые ограничения на распространение прав в дискреционной политике (по крайней мере она должна вкладываться в единую систему категорий и прав).
Рассмотрим вопрос, когда совокупность мониторов обращения в подсистемах реализует монитор обращения во всей распределенной сети. В КК формулируются условия, позволяющие это сделать.
Теорема. Пусть выполнены следующие условия.
1. Каждый субъект сети существует только в одной компоненте на протяжении всего жизненного цикла.
2. Каждый субъект может иметь доступ только к объектам своей компоненты.
3. Каждая компонента содержит отнесенный к этой компоненте монитор обращений, который рассматривает только обращения субъектов этой компоненты к объектам этой компоненты.
4. Все каналы, связывающие компоненты, не компрометируют безопасность информации, в них проходящей.
Тогда совокупность мониторов обращения компонент является монитором обращения в сети.
Доказательство. Этот результат потребует дополнительного уточнения некоторых основных понятий. Рассмотрим сеть из компонент, связанных безопасными каналами связи. Напомним, что любой объект представляет собой конечное непустое множество слов некоторого языка. Добавим к этому, что объект существует только при условии, что возможен доступ к содержанию объекта, то есть мы предполагаем наличие хотя бы одного слова из множества, определяющего объект, к которому возможен в данный момент доступ хотя бы одного субъекта. Тогда информация, передаваемая по безопасному каналу связи, не является объектом, так как до момента окончания приема, нет ни одного слова на приемном конце, к которому хотя бы один субъект может получить доступ. В самом канале, если он не может компрометировать информацию при передаче, мы считаем невозможным доступ к информации и поэтому это не объект. На передающем конце информация передается из некоторого объекта и при передаче мы считаем, что есть некоторый субъект на передающем конце, который в течение передачи имеет доступ к объекту на передающем конце и представляет собой интерфейс с многоуровневым прибором ввода/вывода (концепция такого экспорта информации изложена в OK). После окончания передачи на приемном конце сформировался новый объект, который, вообще говоря, не имеет отношения к объекту на передающем конце и из которого шла перекачка информации.
Рассмотрим формальное объединение мониторов обращения компонент. Тогда из вышесказанного следует, что нет объектов вне локальных компонент, а дистанционный доступ происходит за счет создания нового объекта, который полностью контролируется локальной ТСВ компоненты. Покажем, что формальное объединение мониторов обращения компонент-монитор обращения сети М.
1) Каждое обращение субъекта к объекту в системе происходит через М.
В самом деле, каждый субъект существует только в одной компоненте по усл. 1 и может обращаться к объектам только своей компоненты по усл. 2. Поэтому все обращения в системе ограничены рамками компонент. А тогда каждое обращение обрабатывается монитором обращения соответствующей компоненты по определению монитора обращения.
2) Монитор обращения каждой компоненты по определению гарантированно защищен. Поэтому объединение их гарантированно защищено.
3)
Функционирование всех мониторов обращения компонент полностью тестируется (то есть существует полная система тестов). Тогда совокупность тестов компонент полностью тестирует М.
Теорема доказана.
Теперь рассмотрим вопрос о синтезе единой вычислительной системы из компонент таким образом,что анализ защищенности сети эквивалентен анализу такой вычислительной системы. Пусть вычислительная система обладает следующими свойствами. Это многоуровневая, многопрограммная система, удовлетворяющая условиям соответствующего класса OK(например, ВЗ). В системе информация ТСВ распределена среди одновременно работающих процессоров, которые соединены одной шиной. В системе функционирует одна операционная система, которая поддерживает процесс на любом процессоре. Каждый процесс может использовать внешние приборы через запрос в ТСВ, где реализован монитор обращения. Можно показать, что единая NTCB в распределенной системе, эквивалентной описанной выше вычислительной системе, реализует в компонентах мониторы обращения, объединение которых дает монитор обращения NTCB (по доказанной теореме). А ТСВ вычислительной системы эквивалентна NTCB сети после декомпозиции этой вычислительной системы.
Этот подход позволяет проводить анализ распределенной системы как единой вычислительной системы. Можно действовать наоборот. Создать проект монолитной защищенной вычислительной системы описанного типа, а затем реализовать ее представление в виде распределенной сети.
Заметим, что некоторые компоненты монитора обращений NTCB могут быть вырожденными. Кроме того, наличие монитора обращений вовсе не означает, что в компоненте есть все функции ТСВ системы защиты по какому-либо классу.
Единая распределенная система тем и хороша, что ТСВ сети можно построить из компонент, не содержащих в отдельности все функции защиты.
В заключение сформулируем требования, которым должен удовлетворять использованный в теореме безопасный канал связи:
1. Безопасность связи - устойчивость к несанкционированным раскрытию или модификации передаваемой ценной информации.
2. Надежность связи - не допускает отказ от доставки сообщения, неправильную доставку, доставку ошибочных данных.
3. Имитозащита - не допускает изменений в критичной для этого информации (метки и т.д.).
4. Не допускает скрытые каналы утечки за счет модуляции параметров канала.
6.2. АНАЛИЗ КОМПОНЕНТ РАСПРЕДЕЛЕННОЙ СИСТЕМЫ.
Анализ и оценка защиты распределенных систем, как единого целого, предполагает анализ частей, а затем построение оценки защищенности всей системы в целом. Анализ компонент и синтез единой оценки защищенности всей системы необходим также при модернизации системы, при замене старых компонент новыми, при синтезе системы из блоков или частей, для того, чтобы иметь возможность использовать разработки различных производителей, для доказательства существования NTCB, удовлетворяющей требованиям ОК.
При анализе возникают две проблемы.
1 . Как разделить сеть так, чтобы из анализа и оценки компонент можно построить оценку защищенности системы в целом.
2. Какими критериями надо пользоваться при анализе компонент и как из результатов для компонент синтезировать общую оценку.
В предыдущем параграфе мы наметили контуры ответа на первый вопрос. В случае, когда декомпозиция происходит так, что в каждой компоненте реализован монитор обращения, то, при выполнении условий теоремы предыдущего параграфа, во всей системе есть монитор обращения. Тогда гипотетическоеобъединение распределенной системы в единую вычислительную систему, как это было обозначено выше, позволяет провести анализ наличия всех остальных функций NTCB. И наоборот, декомпозиция единой гарантированно защищенной вычислительной системы из предыдущего параграфа так, что в любой компоненте реализован монитор обращений, позволяет рассредоточить функции NTCB по различным компонентам.
В " Красной книге" допускается, что ТСВ любого класса (с соответствующими оговорками) может быть синтезирована из реализации 4 функций:
· поддержки дискреционной политики (Д);
· поддержки мандатного контроля (М);
· функции идентификации/аутентификации (I);
· аудита (А).
Исходя из этого предполагается, что любая подсистема защиты, подлежащая отдельной оценке и экспертизе на предмет встраивания в распределенную систему, должна удовлетворять внутри себя условиям теоремы параграфа 6.1 и выполнять некоторый набор из перечисленных функций (всего имеется 16 вариантов таких наборов). При наличии этих свойств подсистема может быть компонентой распределенной сети и входить в NTCB. Приведем примеры включения таких подсистем.
Пример 1. Пусть дана М - компонента (то есть подсистема, единственной функцией которой является поддержка мандатного контроля доступа). Пусть также эта подсистема обладает монитором обращений, оценена как самостоятельная система по классу А1. Тогда ее можно включить как компоненту в гарантированно защищенную распределенную систему обработки информации, например, для выполнения функций многоуровневой коммутации пакетов. Покажем это на схеме, взятой из "Красной книги".
На приведенной схеме показана взаимосвязь М -компоненты с другими компонентами и, в частности, с подсистемами ТСВ. Минимальное взаимодействиенеобходимо с системой аудита.
Пример 2. Данный пример из "Красной книги" показывает использование Д-компоненты в качестве одноуровневого файлового сервера сети.
В этом примере обозначение С2+ показывает, что система может быть оценена по классу С2, но иметь дополнительные функции, которые присущи дискреционной политике и аудиту в классе ВЗ и выше. (Дополнительно требуется выполнение функции блокировки при превышении числа опасных событий выше порога, матрица запрещенных доступов и т.д.)
Пример 3. В данном примере мы покажем использование компоненты I для организации интерфейса с несекретными пользователями. Основная функция компоненты - контроль доступа терминала. Вся работа по аутентификации пользователя проводится в этой компоненте, а затем в разрешение доступа и аудиторскую информацию переписываются только идентификаторы вместе с соответствующей информацией.
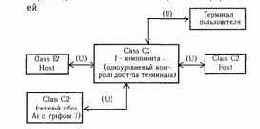
Пример 4. В рассматриваемом примере, также взятом из "Красной книги", А - компонента выполняет функцию сбора одноуровневой АИ в сети. Обозначение C2+ показывает, что в системе, классифицированной уровнем С2, выполняются дополнительные (по классу ВЗ) функции.
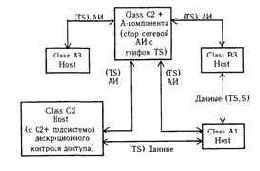
Глава 7 ПРОБЛЕМА
ПОСТРОЕНИЯ ГАРАНТИРОВАННО ЗАЩИЩЕННЫХ БАЗ ДАННЫХ
Создание гарантированно защищенных баз данных связано с некоторыми общими проблемами синтеза систем защиты. Эти проблемы отражены в "Розовой книге" (Trusted Database Management System Interpretation of the Trasted Computer System EvaluationCriteria, 1991). Промежуток в 4 года между второй, "Красной книгой", и "Розовой книгой" показывает, что за эти годы решались трудные задачи теории зашиты информации. В самом деле, если политика безопасности в базе данных не включает вопросов, связанных с взаимным выводом информации и каналов утечки, основанных на этом выводе, вопросов восстановления зашумленной информации путем повторных запросов в базу данных, то такая политика не является адекватной для безопасности информации. Однако, все эти вопросы нельзя включать в политику безопасности, поддерживаемую самой вычислительной системой, что приведет к симбиозу операционной системы и системы управления базой данных. Вместе с тем, сложилась такая практика, что производителями операционных систем и систем управления базами данных являются разные фирмы или организации, что делает такой симбиоз невозможным. Поэтому политика безопасности частично должна поддерживаться самой базой данных. Аналогичные проблемы возникают при модернизации защищенных систем и могут быть сформулированы как противоречие между единой оценкой защищенности всей системы и многопрофильностью подсистем, создаваемых различными производителями.
С аналогичной проблемой мы сталкивались в главе VI. Однако теперь существенным образом возникает зависимость частей защиты друг от друга (ТСВ вычислительной системы управляет субъектами системы защиты (ТСВ), поддерживающей политику безопасности базы данных). Такая структура не вкладывается в систему независимых защищенных компонент распределенной сети. В параграфе 7.1 приводится описание модели ТСВ-подмножеств, иерархически связанных друг с другом, которые при выполнении некоторых дополнительных условий могут удовлетворять условиям ТСВ системы. В параграфе 7.2 приведены наиболее распространенные архитектуры защищенных баз данных, в которых теория параграфа 7.1 может быть реализована.
7.1. ИЕРАРХИЧЕСКИЙ МЕТОД ПОСТРОЕНИЯ ЗАЩИТЫ .
В данном параграфе рассматривается еще один пример иерархической декомпозиции сложных систем. Если в параграфе 1.2 мы рассматривали примеры, не связанные непосредственно с задачей защиты, то сейчас основное внимание будет посвящено иерархическому построению ТСВ в электронных системах обработки данных. Как и раньше, основная задача ТСВ - поддержка монитора обращений. Однако, в отличие от теории предыдущего параграфа, где мониторы обращения были независимыми, сейчас мы покажем, что одни ТСВ-подмножества могут использовать ресурсы в других ТСВ-подмножествах. А именно, рассмотрим следующую модель.
Определение. ТСВ-подмножество М есть совокупность программно-аппаратных ресурсов системы, которые управляют доступами множества S субъектов к множеству О объектов на основе четко определенной политики Р и удовлетворяет свойствам:
1) М определяет и контролирует каждый доступ кобъектам из О со стороны субъектов из S;
2) М гарантировано защищено;
3)М достаточно просто устроено, чтобы существовала возможность проанализировать его системой тестов, полнота которых доказана.
Зависимость ТСВ-подмножеств состоит в том, что М использует ресурсы точно определенного множества более примитивных ТСВ-подмножеств (то есть предполагается заданным некоторый частичный порядок на ТСВ-подмножествах), для того, чтобы создать объекты из О, создать и поддерживать структуры данных и поддерживать политику Р.
Если более примитивных ТСВ-подмножеств нет, то такое ТСВ-подмножество опирается в решении тех же задач на аппаратную часть.
Отметим, что кроме монитора обращений необходимо существование механизма поддержки этого монитора. Рассмотрим условия, при которых из ТСВ-подмножеств удается собрать ТСВ системы (то есть доказать, что выполняются все требования к ТСВ).
Пусть даны ТСВ-подмножества M(i), которые управляют доступом субъектов S(i) к объектам 0(i) в соответствии с политикой безопасности P(i). Предположим, что нет объектов в системе, которые контролируются более, чем одним ТСВ-подмножеством. Здесь принимается та же точка зрения, как в главе VI, состоящая в том, что ТСВ-подмножества могут экспортировать объекты, подлежащие управлению другим ТСВ-подмножеством. Однако принятый и переданный объекты - это разные объекты, контролируемые разными ТСВ-подмножествами. При этом политика безопасности P(i) ТСВ-подмножества M(i) может отличаться от политики безопасности P(j) ТСВ-подмножества M(j). Однако все вместе должны составлять единую политику Р системы, причем каждое правило из Р должно поддерживаться определенной системой ТСВ-подмножеств.
Необходимо также предполагать, что каждый доверенный субъект, то есть субъект, который может нарушать правила P(i) является частью ТСВ-подмножества M(i).
Рассмотрим ограничения на зависимости ТСВ-подмножеств.
Определение. ТСВ-подмножество А прямо зависит (в своей правильности) от ТСВ-подмножества В тогда и только тогда, когда доводы о подтверждении правильности А (верификация установки А обозначается vA) частично или полностью основаны на предположении, что В установлена верно в соответствии соспецификацией В (обозначается sB).
Определение. ТСВ-подмножество А менее примитивно, чем ТСВ-подмножество В, если:
а) А прямо зависит от В;
б) существует цепочка ТСВ-подмножеств от А к В такая, что каждый элемент цепи прямо зависит от предыдущего элемента цепи.
Рассмотрим примеры, поясняющие понятие зависимости, взятые из "Розовой книги".
Пример 1. Пусть ТСВ-подмножество В предоставляет услугу в виде "файла", которым В управляет в соответствии с политикой Р(В), а ТСВ-подмножествоА использует В- файл для хранения информации. Если vA использует факт, что различные В-файлы действительно различаются и доступ к ним определяется политикой Р(В), то vA полагается на факт, что sB и В соответствуют друг другу. Тогда А прямо зависит от В.
Пример 2. Пусть А и В взаимно не доверяющие друг другу системы бронирования авиабилетов, расположенные отдельно и принадлежащие различным организациям. Предположим sA и sB дают возможность получить заказ на бронирование по сети от других систем, используя взаимно согласованный протокол. Пусть этот протокол полностью определен и соответствует sA и sB. Пусть также vA и vB с заданной степенью уверенности подтверждают, что А и В соответствуют своим спецификациям sA и sB. А не зависит в правильности своей установки от правильности установки В, так как sA - полная, то есть какая бы последовательность бит не пришла от В, sA определяет, что А должна делать, а vA демонстрирует, что именно это и делается. Аналогично, В не зависит от правильности А. Поэтому А и В не зависят одна отдругой.
Пример 3. Пусть А является сервером электронной почты, а В управляет запросами в базу данных. Спецификация sA может совсем не упоминать систему управления базой данных, она просто определяет интерфейс почтовой системы. Однако в vA мы находим, что программа обеспечения А использует таблицы, предоставляемые В, для хранения сообщений А и В на различных, связанных машинах. Ни sB, ни vB не упоминают о почтовой системе. Как и в предыдущем примере, sB полностью определяет поведение В для всех получаемых последовательностей бит. Здесь А прямо зависит от В, но В не зависит от А. Отметим, что информационные потоки в обоих направлениях являются законными и никоим образом не компрометируют целостность В. Зависимость находится в другой плоскости от потока данных.
Этот пример замечателен тем, что анализ структуры элементов не позволяет выявить существование зависимости, при этом архитектура системы внешне совпадает с приведенной в примере 2 архитектурой взаимно независимых систем.
Кроме того, этот пример показывает, что описания интерфейса не достаточно для выявления зависимостей.
Пример 4. Пусть А и В взаимно зависимые системы. А зависит от В и В зависит от А. Это значит, что правильность установки vA доказывается из предположения, что В установлена правильно в соответствии с sB. Также правильность установки vB доказывается из предположения, что А установлена правильно в соответствии с sA. Пусть vA и vB подтверждают правильность установки А и В. Однако отсюда не следует, что А и В функционируют правильно.
В самом деле, если А и В функционируют правильно относительно sA и sB, то vA и vB поддерживают правильность установки. Если А установлено неправильно по отношению к sA и В установлено неправильно по отношению к sB, то никто не мешает возникновению ситуации, когда vA подтверждает правильность исходя из того, что В не соответствует sB. Аналогично, vB подтверждает правильность установки sB, хотя А не соответствует sA. Тогда можно доказать, что vA и vB подтверждают правильность А и В, хотя А и В установлены неверно.
Для того, чтобы понять возникающую здесь коллизию, рассмотрим две системы бронирования билетов на самолеты А и В, как в примере 2. Предположим, что А содержит информацию об исходных пунктах и времени вылета всех полетов в США, а В - в Европе. Пусть sA включает утверждение, что А обеспечивает пассажирам услугу в подборе вылета по транзиту, минимизирующем время ожидания следующего полета. Пусть sB предлагает аналогичные услуги. Из утверждения А соответствует sA и В соответствует sB можно вывести истинность утверждения, что А соответствует спецификации sA в предоставлении услуги подбора транзитного рейса в Европе и Америке. Аналогичное утверждение можно вывести для В. Однако, если А хранит информацию в местном времени, а В - во времени по Гринвичу, то транзитный маршрут, составленный А и В на основе информации, полученной друг от друга, будет неправильным из-за различия во времени. То есть каждая система функционирует правильно, но результат неверен.
Это происходит из-за того, что А и В зависимы.
Гарантии защищенности ТСВ-подмножеств имеют большое значение в проблеме построения единой ТСВ системы из ТСВ-подмножеств. В случае зависимых ТСВ-подмножеств менее примитивное ТСВ-подмножество может использовать объекты и субъекты, предоставленные более примитивным ТСВ-подмножеством. Потому первая проблема состоит в доказательстве того факта, что невозможны никакие изменения данных, критических для политики безопасности, или кодов ТСВ-подмножества. То есть никакая внешняя по отношению к ТСВ-подмножеству система (кроме, может быть, более примитивных ТСВ-подмножеств) не может инициировать произвольное изменение кодов ТСВ-подмножества или его структур данных. Вторая проблема состоит в доказательстве того, что данные, хранящиеся в ТСВ-подмножестве и критичные для политики безопасности, не могут изменяться иначе, чем в соответствии с логикой ТСВ-подмножества. Разумеется, эти доказательства возможны при условии правильности той информации, которая вносится в ТСВ-подмножество более примитивным ТСВ-подмножеством.
Ясно, что в доказательстве возможности построения единой ТСВ системы из ТСВ-подмножеств присутствуют условия не только на локальные свойства ТСВ-подмножеств, но также интегральные требования.
Суммируем перечень всех условий, которые необходимо выполнить, чтобы из семейства ТСВ-подмножеств можно было бы синтезировать ТСВ системы. Если, кроме нижеприведенных требований, выполняются требования какого-либо класса в стандарте "Оранжевая книга", то построенная таким образом система может быть аттестована по соответствующему классу.
Условия:
1. ТСВ-подмножества четко определены.
2. Политика безопасности системы распределена по ТСВ-подмножествам.
3. Каждое ТСВ-подмножество M(i) включает доверенные процессы по отношению к своей политике безопасности P(i).
4. Архитектура ТСВ-подмножеств четко определена .
5. Все ТСВ-подмножества занимают различные домены.
6.Во всех случаях примитивные ТСВ-подмножества поддерживают правильное функционирование монитора обращений в менее примитивном ТСВ-подмножестве.
7.2. ГАРАНТИРОВАННО ЗАЩИЩЕННЫЕ БАЗЫ ДАННЫХ.
Будем предполагать, что гарантированно защищенная база данных может быть инсталирована только на платформе гарантированно защищенной вычислительной системы. Тогда ТСВ всей системы получается из ТСВ-подмножества вычислительной системы и ТСВ-подмножества базы данных. Причем в возникающей здесь иерархической структуре ТСВ-подмножество вычислительной системы является более примитивным,чем ТСВ-подмножество базы данных.
Рассмотрим несколько примеров архитектур баз данных, позволяющих говорить о гарантированной защищенности.
Пример 1. Одноуровневая база данных. Пусть все пользователи имеют одинаковый допуск ко всей информации, содержащейся в базе данных и в вычислительной системе. В этом случае возможно применение базы данных общего назначения на охраняемой вычислительной системе. В случае высокого класса хранящейся в базе данных информации, согласно "Требованиям" к применению "Оранжевой книги" должна использоваться система класса С2 (наличие аудита).
Пример 2. Многоуровневая база данных с ядерной архитектурой. Эта архитектура подробно рассматривалась в параграфах 1.6-1.7, 5.5 и в ряде примеров. Исследования по данной архитектуре проводились System Research Institute группой ученых под руководством D.Denning и T.Lunt. Цель исследований: построить гарантированно защищенную базу данных по классу А1. Данная архитектура может быть представлена следующей схемой.
На этой схеме ТСВ вычислительной системы разрешает формировать отношения, содержащие информацию, разрешенную для данного класса пользователя. Сама система управления базой данных является системой общего пользования. Однако в данной архитектуре серьезной проблемой является полиинстантинация. Вместе с тем, здесь на системном уровне видно, как доказывать, что база данных поддерживает MLS-политику (на уровне ядра реализована модель невлияния G - М).
Пример 3.
Модификацией архитектуры примера 2 является дублирующая архитектура. Она основана на гарантированно правильном разделении пользователей.
Фактически система представляет композицию одноуровневых баз данных примера 1. Здесь также на системном уровне видно, как доказывать защищенность системы.
Пример 4.
Исторически одной из первых была предложена архитектура "базы данных с замком целостности". Это разработка ВВС США, анонсированная в1983 г. Схематически данная архитектура может быть представлена следующим образом.
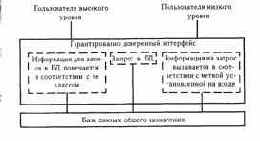
Недостатком этой архитектуры является то, что *-свойство приходится нарушать почти в каждой транзакции.
Пример 5. Базы данных, которые американцы называют архитектурой с "гарантированно защищенным субъектом". Эти системы предполагают наличие ТСВ-подмножеств в самой базе данных, причем ТСВ базы данных реализует свою составляющую политики безопасности.

К этому классу относятся системы управлениябазами данных ORACLE, INFORMIX, INGRES и т.д.
Основная сложность в том, что описания политик безопасности и доказательства их поддержки недоступны. Кроме того, большой объем программного обеспечения не позволяет провести достаточный анализ.
Пример 6. Базы данных с распределенным доменом защиты. Используется идея "Красной книги" о распределенной NTCB, как совокупность ТСВ компонент. Этот подход можно изобразить на схеме.
Каждая компонента на этой схеме гарантировано защищена.
Литература
I. Department of Defense Trusted Computer System Evaluation Criteria, DoD, 1985.
2. Computer Security Requirements. Guidence for Applying the Department of Defense Trusted Computer System Evaluation Criteria in Specific Environments, DoD, 1985.
3. Trusted Network Interpretation of the Trusted Computer System Evaluation Criteria, NCSC, 1987.
4. Trusted Database Management System Interpretation of the Trusted Computer System Evaluation Criteria, NCSC, 1991.
5. D. Denning, Cryptography and Data Security, Addison Wesley, Reading (MA), 1983.
6. Data Communications and Networks 3, Edited byR.L. Brewster, Redwood Books, Trowbridge, Wiltshire. 1994.
7. D.Russell, G.T.Gangemi Sr., Computer Security Basics, O'Reilly & Associates, Inc., 1991.
8. D. Denning, An Intrution Detection Model, IEEE Trunsactions on Software Engineering, v. SE-13,№ I, 1987, pp 222-232.
9. J.A. Goguen, J. Meseguer, Securiti Policies and Securiti Models, Proceedings of the 1982 Sympsium
on Security and Privacy, IEEE, April 20-21, 1982.Oakland, CA, IEEE Catalog №82CHI753, pp. I 1-26.
10. J. McLean, Reasoning About Security Models, Proceedings, IEEE Symposium on Privasy and Security, Oakland, CA, April 27-29, 1987, IEEE Computer Society Press, 1987, pp. 123-131.
11. J Fellows, J. Hemenway, The Architecture of a Distributed Trusted Computing Base, Proceedings, 10th National Computer Security Conference, Baltimore, MD, September 21-24, 1987, National Bureau of Standards/National Computer SecurityCenter, 1987, pp. 68-77.
12. D. Denning, et al., Views for Multilevel Database Security, IEEE Trunsactions on Software Engineering, v. SE-13, № 2, 1987, pp 129-140.
13. D. Denning, et al., Multilevel Relational DataModel, Proceedings, IEEE Symposium on Privasy and Security, Oakland, CA, April 27-29, 1987, IEEE Computer Society Press, 1987, pp. 220-242.
14. R.R Kenning, S.A Walker, Computer Architecture and Database Security, Proceedings, 9th National Computer Security Conference, Gaithersburg, MD, September 15-18, 1986, National Bureau of Standards/National Computer Security Center,1986, pp. 216-230.
15. R. Schell, D. Denning, Integrity in Trusted Database Systems, Proceedings, 9th National Computer Security Conference, Gaithersburg, MD, September 15-18, 1986, National Bureau of Standards/National Computer Security Center,1986, pp. 30-36.
16. S.G. Aki, D. Denning, Checking Classification Constraints for Consistency and Completeness, Proceedings, IEEE Symposium on Privasy and Security, Oakland, CA, April 27-29, 1987, IEEE Computer Society Press, 1987, pp. 196-201.
17. T-A. Su, G. Ozsoyoglu, Data Dependencies and Inference Control in Multilevel Relational Database Systems, Proceedings, IEEE Symposiumon Privasy and Security, Oakland, CA, April 27-29,1987, IEEE Computer Society Press, 1987, pp. 202-211.