

PHP 4 на практике
Бесплатное распространение
Стратегия Open Source наделала немало шуму в программной отрасли. Распространение исходных текстов программ в массах оказало несомненно благотворное влияние на многие проекты, в первую очередь — Linux, хотя и успех проекта Apache сильно подкрепил позиции сторонников Open Source. Сказанное относится и к истории создания РНР, поскольку поддержка пользователей со всего мира оказалась очень важным фактором в развитии проекта РНР.Принятие стратегии Open Source и бесплатное распространение исходных текстов РНР оказало неоценимую услугу пользователям. Вдобавок, отзывчивое сообщество пользователей РНР является своего рода «коллективной службой поддержки», и в популярных электронных конференциях можно найти ответы даже на самые сложные вопросы.
В следующем разделе «Рекомендации пользователей» приведены свидетельства трех видных профессионалов в области web-разработок. Из них становится ясно, почему они считают РНР такой замечательной технологией.
Безопасность
РНР предоставляет в распоряжение разработчиков и администраторов гибкие и эффективные средства безопасности, которые условно делятся на две категории: средства системного уровня и средства уровня приложения.Средства безопасности системного уровня
В РНР реализованы механизмы безопасности, находящиеся под управлением администраторов; при правильной настройке РНР это обеспечивает максимальную свободу действий и безопасность. РНР может работать в так называемом безопасном
режиме (safe mode), который ограничивает возможности применения РНР пользователями по ряду важных показателей. Например, можно ограничить максимальное время выполнения и использование памяти (неконтролируемый расход памяти отрицательно влияет на быстродействие сервера). По аналогии с cgi-bin администратор также может устанавливать ограничения на каталоги, в которых пользователь может просматривать и исполнять сценарии РНР, а также использовать сценарии РНР для просмотра конфиденциальной информации на сервере (например, файла passwd).
Средства безопасности уровня приложения
В стандартный набор функций РНР входит ряд надежных механизмов шифрования. РНР также совместим с многими приложениями независимых фирм, что позволяет легко интегрировать его с защищенными технологиями электронной коммерции (e-commerce). Другое преимущество заключается в том, что исходный текст сценариев РНР нельзя просмотреть в браузере, поскольку сценарий компилируется до его отправки по запросу пользователя. Реализация РНР на стороне сервера предотвращает похищение нетривиальных сценариев пользователями, знаний которых хватает хотя бы для выполнения команды View Source.
Тема безопасности настолько важна, что ей посвящена целая глава. За подробной информацией о средствах безопасности РНР обращайтесь к главе 16.
Гибкость
Поскольку РНР является встраиваемым (embedded) языком, он отличается исключительной гибкостью по отношению к потребностям разработчика. Хотя РНР обычно рекомендуется использовать в сочетании с HTML, он с таким же успехом интегрируется и в JavaScript, WML, XML и другие языки. Кроме того, хорошо структурированные приложения РНР легко расширяются по мере необходимости (впрочем, это относится ко всем основным языкам программирования).Нет проблем и с зависимостью от браузеров, поскольку перед отправкой клиенту сценарии РНР полностью компилируются на стороне сервера. В сущности, сценарии РНР могут передаваться любым устройствам с браузерами, включая сотовые телефоны, электронные записные книжки, пейджеры и портативные компьютеры, не говоря уже о традиционных PC. Программисты, занимающиеся вспомога-тельными утилитами, могут запускать РНР в режиме командной строки.
Поскольку РНР не содержит кода, ориентированного на конкретный web-сервер, пользователи не ограничиваются определенными серверами (возможно, незнакомыми для них). Apache, Microsoft IIS, Netscape Enterprise Server, Stronghold и Zeus — РНР работает на всех перечисленных серверах. Поскольку эти серверы работают на разных платформах, РНР в целом является платформенно-незави-симым языком и существует на таких платформах, как UNIX, Solaris, FreeBSD и Windows 95/98/NT.
Наконец, средства РНР позволяют программисту работать с внешними компонентами, такими как Enterprise Java Beans или СОМ-объекты Win32. Благодаря
этим новым возможностям РНР занимает достойное место среди современных технологий и обеспечивает масштабирование проектов до необходимых пределов.
Характеристики РНР
Как вы, вероятно, уже поняли, главным фактором при проектировании языка РНР является практичность. РНР должен предоставить программисту средства для быстрого и эффективного решения поставленных задач. Практический характер РНР обусловлен пятью важными характеристиками:традиционностью;
простотой;
эффективностью;
безопасностью;
гибкостью.
Существует еще одна «характеристика», которая делает РНР особенно привлекательным: он распространяется бесплатно!
В этой главе мы рассмотрели
В этой главе мы рассмотрели некоторые ключевые аспекты РНР:историю и особенности РНР;
установку и конфигурацию;
«переход» в РНР;
комментирование кода РНР.
Эти вопросы закладывают основу для материала следующих глав, в которых будут более подробно описаны проблемы программирования на языке РНР. В конце следующей главы вы будете знать о РНР достаточно, чтобы писать собственные программы. Новые знания будут применены на практике — мы создадим календарь, который можно будет легко вставить в существующую web-страницу. Этот проект подготовит вас к работе над web-приложением РНР Recipes.
Эффективность
Эффективность является исключительно важным фактором при программировании для многопользовательских сред, к числу которых относится и WWW. В РНР 4.0 был реализован механизм выделения ресурсов и обеспечена улучшенная поддержка объектно-ориентированного программирования, а также средства управления сеансом. В последней версии появился и механизм подсчета ссылок (reference counting), предотвращающий выделение лишней памяти.Комментарии в коде РНР
Комментарии следует использовать даже в относительно простых и незамысловатых сценариях. В РНР существуют два формата комментариев:Оба способа в конечном счете приводят к одинаковому результату и совершенно не влияют на общее быстродействие сценария. Выбор варианта остается за вами.
Однострочные комментарии
При оформлении однострочных комментариев используется два стиля комментирования. Оба стиля работают абсолютно одинаково, но в них используются разные служебные символы. В одном случае комментарий начинается с двойного символа «косая черта» (//), а в другом — с символа фунта (#). Ниже приведены примеры обоих стилей:
// Выбрать цвет роз $rose_color = "red";
# Выбрать цвет фиалок $violet_color = "blue";
print "Roses are $rose_color, violets are $violet_color"
?>
Конечно, оба стиля однострочных комментариев могут применяться для построения искусственных многострочных комментариев, как показано в следующем листинге:
// файл: example. php
// автор: У.Дж.Гилмор
// дата: 24 августа 2000 г.
print "An example with comments";
?>
Многострочные комментарии
В РНР существует возможность построения подробных комментариев, занимающих несколько строк. Такие комментарии оформляются в стиле языка С — их начало и конец обозначаются символами /* и */.
/*
Сценарий: multi_coramment_example.php
Назначение : пример использования многострочных комментариев
Автор: У.Дж.Гилмор
Дата: 14 июня 2000 г.
*/
print "A multiline comment can be found at the top of this script!";
?>
Как видите, многострочные комментарии особенно удобны для вывода относительно длинной сводной информации обо всем сценарии или его части.
Конфигурация РНР
РНР будет правильно работать и при конфигурации, выбранной по умолчанию, однако вы можете внести некоторые изменения, чтобы работа пакета лучше соответствовала вашим целям. Все параметры конфигурации находятся в файле php.ini, который по умолчанию копируется в каталог /usr/local/lib/ в процессе установки.Независимо от платформы и web-сервера, используемого в сочетании с РНР, файл php.ini содержит одинаковый набор стандартных параметров, позволяющих управлять важными аспектами работы РНР. Этот файл содержит все параметры, определяющие поведение пакета при выполнении сценария РНР. Содержимое файла php.ini читается при запуске РНР.

В версии 3.0 файл конфигурации назывался php3.ini, но в версии 4.0 ему было присвоено имя php.ini.
Краткая история
История РНР начинается с 1995 года, когда независимый программист-контрактник по имени Расмус Лердорф (Rasmus Lerdorf) написал сценарий Perl/CGI для подсчета количества посетителей сайта, прочитавших его онлайновое резюме. Его сценарий решал две задачи: регистрацию данных посетителя и вывод количества посетителей на web-странице. Развитие WWW еще только начиналось, никаких специальных средств для решения этих задач не было, и к автору хлынул поток сообщений с вопросами. Лердорф начал бесплатно раздавать свой инструментарий, названный Personal Home Page (РНР) или Hypertext Processor (гипертекстовый процессор).Шумный успех инструментария РНР заставил Лердорфа приступить к разработке расширений РНР. Одно из расширений преобразовывало данные, введенные на форме HTML, в символические переменные, что позволяло экспортировать их в другие системы. Чтобы добиться поставленной цели, Лердорф решил в дальнейших разработках перейти с Perl на С. Расширение существующего инструментария РНР привело к появлению РНР 2.0, или PHP-FI (Personal Home Page — Form Interpretator). В усовершенствовании версии 2.0 принимали участие программисты со всего мира.
Новая версия РНР пользовалась исключительной популярностью, и вскоре образовалась основная команда разработчиков. Они сохранили исходную концепцию внедрения программного кода прямо в HTML и переписали заново механизм лексического анализа, что привело к появлению РНР 3.0. К моменту выхода версии 3.0 в 1997 году свыше 50 000 пользователей применяли РНР для улучшения своих web-страниц.
В 1997 году было решено, что сокращение РНР должно означать не «Personal Home page», а «РНР Hypertext Processor» В течение следующих двух лет стремительное развитие РНР продолжалось. В язык добавлялись сотни новых функций, а количество пользователей стремительно росло. В начале 1999 года служба Netcraft (http://www.netcraft.com) сообщила о том, что, по минимальным оценкам, число пользователей РНР превысило 1 000 000, в результате чего РНР стал одним из самых популярных сценарных языков в мире.
В начале 1999 года было объявлено о предстоящем выходе РНР 4.0. Хотя одной из сильнейших сторон РНР была эффективность выполнения сценариев, при первоначальных разработках не предполагалось, что на базе РНР будут строиться крупномасштабные приложения. По этой причине была начата работа над более устойчивым механизмом лексического анализа, больше известным под названием Zend (http://www.zend.com). Работа шла быстро и завершилась 22 мая 2000 года выпуском РНР версии 4.0.
Кроме лексического анализатора Zend, компания Zend Technologies (Израиль) распространяет оптимизатор Zend, который повышает выигрыш в быстродействии от применения лексического анализатора Zend. Тесты показывают, что ускорение работы программы в результате использования оптимизатора составляет от 40 до 100 %. За дополнительной информацией обращайтесь на сайт Zend.
На момент написания этой книги, по данным Netcraft (http://www.netcraft.com), программное обеспечение РНР было установлено более чем в 3,6 миллиона доменов. Будущее РНР выглядит светлым, поскольку продукт продолжает активно использоваться как на крупных web-сайтах, так и на компьютерах отдельных пользователей.
РНР лучше всего охарактеризовать как работающий на стороне сервера встроенный язык сценариев Web, позволяющий разработчикам быстро и эффективно
строить динамические web-приложения. С позиций грамматики и синтаксиса РНР напоминает язык программирования С, хотя разработчики не постеснялись включить в него средства из других языков, в том числе из Perl, Java и C++. Среди ценных заимствованных возможностей — поддержка регулярных выражений, мощные средства работы с массивами, объектно-ориентированная методология и обширная поддержка работы с базами данных.
При написании приложений, выходящих за рамки традиционной, статической методологии разработки web-страниц (то есть HTML), РНР также может послужить ценным инструментом для создания и управления динамическим содержанием, который используется наряду с JavaScript, стилями, WML (Wireless Markup Language) и другими полезными языками. Благодаря наличию сотен стандартных функций РНР в состоянии решить практически любую задачу, которая может придти в голову разработчику. В нем имеется обширная поддержка создания графики и операций с ней, математических вычислений, средств электронной коммерции и таких популярных технологий, как XML (Extensible Markup Language), ODBC (Open Database Connectivity) и Macromedia Shockwave. Широкий выбор возможностей избавляет от необходимости рутинной и непростой работы по подключению сторонних модулей, поэтому многие разработчики со всего мира останавливают свой выбор на РНР.
Одним из главных достоинств РНР является тот факт, что он внедряется прямо в HTML-код, поэтому программисту не приходится писать программу с множеством команд для простого вывода HTML. Код HTML и РНР можно чередовать по мере необходимости. РНР позволяет написать фрагмент следующего вида:
Сообщение "Hello world!" выводится в заголовке web-страницы. Интересно то, что команда print внутри конструкции, которая обычно называется экранирующими последовательностями РНР (), представляет собой законченную программу. Ни длинного кода инициализации, ни включения библиотек — программа состоит лишь из того кода, который непосредственно решает поставленную задачу!
Конечно, для выполнения сценариев РНР необходимо предварительно установить и настроить программное обеспечение РНР на сервере. Этот процесс описан в разделе «Загрузка и установка РНР/Apache» настоящей главы. Разделу предшествуют фрагменты из отзывов нескольких пользователей, выступающих в пользу РНР, с кратким обзором языка и его истории. Но прежде чем браться за процесс установки, мы познакомимся с некоторыми характеристиками РНР. Этой теме посвящен следующий раздел.
Общие параметры конфигурации
Подробное описание всех конфигурационных параметров выходит за рамки этой книги, но некоторые директивы используются особенно часто и заслуживают отдельного упоминания. Другие параметры упоминаются в соответствующих местах следующих глав.short_open_tag [on | off]
Параметр short_open_tab [on | off] определяет возможность использования коротких тегов наряду со стандартными тегами.
asp_tags [on | off]
Параметр asp_tags [on | off] определяет возможность использования тегов в стиле ASP наряду со стандартными тегами. При использовании тегов в стиле ASP фрагменты кода РНР оформляются следующим образом:
<%
print "This is РНР code.";
%>
precision [integer]
Параметр precision [integer] задает количество значащих цифр, отображаемых в вещественных числах.
safe_mode [on | off]
Безопасный режим особенно удобен в случае, если в вашей системе работают несколько пользователей. Включение безопасного режима гарантирует, что пользователь не сможет применить сценарий РНР для получения доступа к другому файлу в системе — например, файлу passwd на компьютере Linux. Параметр safe_mode работает только в CGI-версии РНР. За дополнительной информацией по этой теме обращайтесь к главе 16.
max_execution_time [integer]
Параметр max_execution_time [integer] определяет максимальную продолжительность выполнения сценариев РНР в секундах. Такое ограничение предотвращает поглощение ценных системных ресурсов сценариями, содержащими ошибки.
error_reporting [1-8]
Параметр error_reporting [1-8] определяет уровень выдачи сообщений об ошибках в РНР. Чем выше значение, тем «чувствительнее» РНР реагирует на ошибки.
| Значение | Чувствительность | ||
| 1 | Обычные ошибки | ||
| 2 | Обычные предупреждения | ||
| 4 | Ошибки лексического анализатора | ||
| 8 | Замечания | display_errors [on | off]
 Хотя при успешном завершении действий, описанных выше, вы сможете использовать web-сервер и РНР для тестирования, это еще не значит, что ваш web-сервер будет доступен из World Wide Web. За информацией по этому вопросу обращайтесь на официальный сайт Apache (http://www.apache.org). Более того, хотя описанная процедура позволяет работать с пакетом РНР, вероятно, вы захотите изменить конфигурацию РНР так, чтобы она лучше соответствовала вашим потребностям. Эта тема рассматривается в следующем разделе «Конфигурация РНР».
Хотя при успешном завершении действий, описанных выше, вы сможете использовать web-сервер и РНР для тестирования, это еще не значит, что ваш web-сервер будет доступен из World Wide Web. За информацией по этому вопросу обращайтесь на официальный сайт Apache (http://www.apache.org). Более того, хотя описанная процедура позволяет работать с пакетом РНР, вероятно, вы захотите изменить конфигурацию РНР так, чтобы она лучше соответствовала вашим потребностям. Эта тема рассматривается в следующем разделе «Конфигурация РНР».
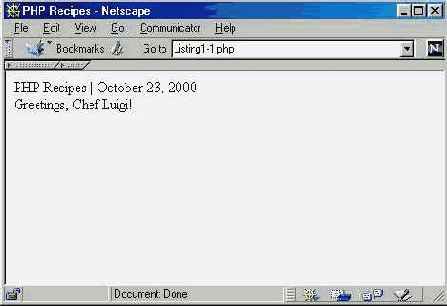
 На момент издания книги последней устойчиво работающей версией был РНР 4.0.3. Конечно, пакет РНР постоянно развивается, и номер версии непременно изменится. Я рекомендую загрузить самую свежую надежную версию продукта.
На момент издания книги последней устойчиво работающей версией был РНР 4.0.3. Конечно, пакет РНР постоянно развивается, и номер версии непременно изменится. Я рекомендую загрузить самую свежую надежную версию продукта.| Допустимые идентификаторы | Недопустимые идентификаторы | ||
| my_function | This&that | ||
| Size | !counter | ||
| _someword | 4ward | В идентификаторах учитывается регистр символов. Следовательно, переменная с именем $recipe отличается от переменных с именами $Recipe, $rEciPe и $recipE.
| Оператор преобразования типа | Новый тип | ||
| (int) или (integer) | Целое число | ||
| (real), (double) или (float) | Вещественное число | ||
| (string) | Строка | ||
| (array) | Массив | ||
| (object) | Объект | Простой пример преобразования типов:
 Для работы с массивами стандартных переменных необходимо включить директиву track_vars в файл php.ini. В РНР версии 4.0.3 директива track_vars включена постоянно.
Для работы с массивами стандартных переменных необходимо включить директиву track_vars в файл php.ini. В РНР версии 4.0.3 директива track_vars включена постоянно.| Последовательность | Смысл | ||
| \n | Новая строка | ||
| \r | Возврат курсора | ||
| \t | Горизонтальная табуляция | ||
| \\ | Обратная косая черта | ||
| \$ | Знак доллара | ||
| \" | Кавычка | ||
| \[0-7]{1,3} | Восьмеричная запись числа (в виде регулярного выражения) | ||
| \x[0-9A-Fa-f]{l,2} | Шестнадцатиричная запись числа (в виде регулярного выражения) | Второе принципиальное различие заключается в том, что в строках, заключенных в кавычки, распознаются все существующие служебные символы, а в строках, заключенных в апострофы, — только служебные символы «\\» и «\». Следующий пример наглядно демонстрирует различия между присваиванием строк, заключенных в кавычки и апострофы:
| Оператор | Ассоциативность | Цель | |
| ( ) | - | Изменение приоритета | |
| new | - | Создание экземпляров объектов | |
| ! ~ | П | Логическое отрицание, поразрядное отрицание | |
| ++ -- | П | Инкремент, декремент | |
| @ | П | Маскировка ошибок | |
| / * % | Л | Деление, умножение, остаток | |
| + - . | Л | Сложение, вычитание, конкатенация | |
| << >> | Л | Сдвиг влево, сдвиг вправо (поразрядный) | |
| < <= > >= | - | Меньше, меньше или равно, больше, больше или равно | |
| == != === <> | - | Равно, не равно, идентично, не равно | |
| & ^ | | Л | Поразрядные операции AND, XOR и OR | |
| && || | Л | Логические операции AND и OR | |
| ?: | П | Тернарный оператор | |
| = += *= /= .= | П | Операторы присваивания | |
| %= &= |= ^= | |||
| <<= >>= | |||
| AND XOR OR | Л | Логические операции AND, XOR и OR | После знакомства с концепциями операторов и операндов следующие примеры выражений выглядят значительно понятнее:
| Пример | Название | Результат | |
| Пример | Название | Результат | |
| $а = 5; | Присваивание | Переменная $а равна 5 | |
| $а += 5; | Сложение с присваиванием | Переменная $а равна сумме $а и 5 | |
| $а *= 5; | Умножение с присваиванием | Переменная $а равна произведению $а и 5 | |
| $а/=5; | Деление с присваиванием | Переменная $а равна частному отделения $а на 5 | |
| $а .= 5; | Конкатенация с присваиванием | Переменная $а равна конкатенации $а и 5 |
| Пример | Название | Результат | |
| $a = "abc"."def" | Конкатенация | Переменной $а присваивается результат конкатенации $а и $b | |
| $а - "ghijkl" | Конкатенация с присваиванием | Переменной $а присваивается результат конкатенации ее текущего значения со строкой "ghijkl" |
| Пример | Название | Результат | |
| ++$а, $а++ | Инкремент | Переменная $а увеличивается на 1 | |
| --$а, $а-- | Декремент | Переменная $а уменьшается на 1 | Интересный факт: эти операторы могут располагаться как слева, так и справа от операнда. Действия, выполняемые оператором, зависят от того, с какой стороны от операнда он находится. Рассмотрим следующий пример:
| Пример | Название | Результат | |
| $а && $b | Конъюнкция | Истина, если истинны оба операнда , | |
| $aAND$b | Конъюнкция |
| Пример | Название | Результат | |
| $a==$b | Проверка равенства | Истина, если $а и $b равны | |
| $а != $b | Проверка неравенства | Истина, если $а и $b не равны | |
| $а === $b | Проверка идентичности | Истина, если $а и $b равны и имеют одинаковый тип |
| Пример | Название | Результат | |
| $a<$b | Меньше | Истина, если переменная $а меньше $b | |
| $a>$b | Больше | Истина, если переменная $а больше $b | |
| $a <= $b | Меньше или равно | Истина, если переменная $а меньше или равна $b | |
| $a >= $b | Больше или равно | Истина, если переменная $а больше или равна $b | |
| ($a-12)?5: -1 | Тернарный оператор | Если переменная $а равна 12, возвращается значение 5, а если не равна — возвращается 1 |
| Десятичное целое | Двоичное представление | ||
| 2 | 10 | ||
| 5 | 101 | ||
| 10 | 1010 | ||
| 12 | 1100 | ||
| 145 | 10010001 | ||
| 1 452 012 | 1011000100111111101100 | Поразрядные операторы, перечисленные в табл. 3.10, представляют собой особый случай логических операторов, однако они приводят к совершенно иным результатам.
| Пример | Название | Результат | |
| $а&$b | Конъюнкция | С битами, находящимися в одинаковых разрядах $а и $b, выполняется | |
| $а|$Ь | Дизъюнкция | С битами, находящимися в одинаковых разрядах $а и $b, выполняется операция дизъюнкции | |
| $а^$b | Исключающая | С битами, находящимися в одинаковых разрядах $а и $b, выполняется операция исключающей дизъюнкции | |
| ~$b | Отрицание | Все разряды переменной $b инвертируются | |
| $а << $b | Сдвиг влево | Переменной $а присваивается значение $b, сдвинутое влево на два бита | |
| $а >> $b | Сдвиг вправо | Переменной $а присваивается значение $b, сдвинутое вправо на два бита |
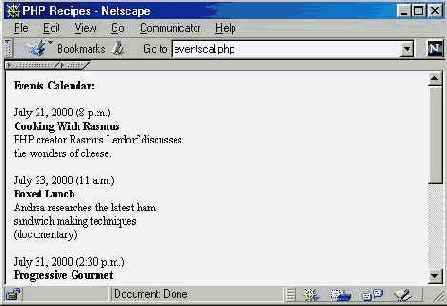
print "Events Calendar:";// Читать, пока не будет найден конец файла while (! feof(Sevents)) : // Прочитать следующую строку файла events.txt $event = fgets($events. 4096); // Разделить компоненты текущей строки на элементы массива $event_info = explode("|". Jevent); // Отформатировать и вывести информацию о событии print "$event_info[0] ( $event_info[1] ) "; print "$event_info[2] "; print "$event_info[3] "; endwhile; // Завершить таблицу print " |
fclose ($events);
?>
Этот короткий пример убедительно доказывает, что РНР позволяет даже неопытным программистам создавать реальные приложения с минимальными усилиями и затратами времени. Если какие-нибудь из представленных концепций покажутся непонятными, не огорчайтесь — на самом деле они очень просты и будут подробно описаны в следующих главах. А если вам не терпится узнать побольше об этих вопросах, обратитесь к главе 7 «Файловый ввод/вывод и файловая система» и главе 8 «Строки и регулярные выражения» поскольку большая часть незнакомого синтаксиса описана именно там.
Проверка условий
Управляющие конструкции обычно проверяют условия на истинность или ложность, и в зависимости от результата проверки выполняется то или иное действие. Рассмотрим выражение $а == $b. Это выражение истинно, если $а равно $b, и ложно в противном случае. Результат истинного выражения считается равным 1, а результат ложного выражения равен 0. Рассмотрим следующий фрагмент:$а = 5;
$b = 5;
print $а == $b;
В результате выводится значение 1. Если изменить $а или $Ь и присвоить переменной значение, отличное от 5, выводится 0.
if
Команда if представляет собой разновидность команды выбора, которая вычисляет значение выражения и в зависимости от того, будет ли полученный результат истинным или ложным, выполняет (или не выполняет) блок программного кода. Существует две общих формы команды i f:
if (выражение) {
блок
}
и
if (выражение) {
блок
}
else {
блок
}
Как упоминалось в предыдущем разделе, проверка условий дает либо истинный, либо ложный результат. Выполнение блоков зависит от результата проверки, причем блок может состоять как из одной, так и из нескольких команд. В следующем примере после проверки условия выбирается и выводится одно из двух утверждений:
if ($cooking_weight < 200) {
print "This is enough pasta (< 200g) for 1-2 people";
}
else {
print "That's a lot of pasta. Having a party perhaps?";
}
Если в результате проверки условия выполняется всего одна команда, фигурные скобки не обязательны:
if ($cooking_weight < 100) print "Are you sure this is enough?";
elseif
Команда elseif добавляет в управляющую конструкцию if дополнительный уровень проверки и увеличивает количество условий, на основании которых принимается решение:
if (выражение) {
блок
}
elseif (выражение) {
блок
}
 В РНР существует альтернативное представление команды elself — в виде двух отдельных слов else if. Оба варианта приводят к одинаковым результатам, а альтернативное представление поддерживается исключительно для удобства. Команда elself особенно полезна в тех случаях, когда происходит последовательное уточнение проверяемых условий. Обратите внимание: условие elself вычисляется лишь в том случае, если все предшествующие условия if и elself оказались ложными.
В РНР существует альтернативное представление команды elself — в виде двух отдельных слов else if. Оба варианта приводят к одинаковым результатам, а альтернативное представление поддерживается исключительно для удобства. Команда elself особенно полезна в тех случаях, когда происходит последовательное уточнение проверяемых условий. Обратите внимание: условие elself вычисляется лишь в том случае, если все предшествующие условия if и elself оказались ложными.if ($cooking_weight < 200) {
print "This is enough pasta (< 200g) for 1-2 people";
}
elseif ($cooking_weight < 500) {
print "That's a lot of pasta. Having a party perhaps?"; }
}
else {
print "Whoa! Who are you cooking for, a football team?";
}
Вложенные команды if
Вложение команд i f обеспечивает максимальный контроль над проверкой условий. Давайте исследуем эту возможность, усовершенствовав пример из предыдущих разделов. Предположим, вес продукта должен проверяться лишь в том случае, если речь идет о пасте (макаронных изделиях):
// Проверить значение $pasta
if ($food == "pasta") {
// Проверить значение $cooking_weight
if ($cooking_weight < 200) {
print "This is enough pasta (< 200g) for 1-2 people";
}
elseif ($cooking_weight < 500) {
print "That's a lot of pasta. Having a party perhaps?";
}
else {
print "Whoa! Who are you cooking for. a football team?";
}
}
Как видно из приведенного кода, вложенные команды if позволяют лучше управлять логикой работы программы. Вскоре, с увеличением объемов и сложности ваших программ, вы убедитесь, что вложение управляющих конструкций является неоценимым приемом в арсенале программиста.
Вычисление нескольких условий
При выборе логики работы программы в управляющей структуре можно проверять комбинацию сразу нескольких условий:
if ($cooking_weight < 0) {
print "Invalid cooking weight!";
}
if ( ($cooking_weight > 0) && ($cooking_weight < 200) ) {
print "This is enough pasta (< 200g) for 1-2 people";
}
elseif ( ($cooking_weight > 200) && ($cooking_weight < 500) ) {
print "That's a lot of pasta. Having a party perhaps?";
}
else {
print "Whoa! Who are you cooking for, a football team?";
}
Проверка сложных условий позволяет устанавливать интервальные ограничения, обеспечивающие более четкий контроль над логикой выполнения программы и уменьшающие количество лишних управляющих конструкций, в результате чего программа становится более понятной.
Switch
Принцип работы конструкции switch отчасти напоминает if — результат, полученный при вычислении выражения, проверяется по списку потенциальных совпадений.Это особенно удобно при проверке нескольких значений, поскольку применение switch делает программу более наглядной и компактной. Общий формат команды switch:
switch (выражение) {
case (условие):
блок
case (условие):
блок
...
default:
блок
}
Проверяемое условие указывается в круглых скобках после ключевого слова switch. Результат его вычисления последовательно сравнивается с условиями в секциях case. При обнаружении совпадения выполняется блок соответствующей секции. Если совпадение не будет обнаружено, выполняется блок необязательной секции default.
Как будет показано в следующих главах, одной из сильнейших сторон РНР является обработка пользовательского ввода. Допустим, программа отображает раскрывающийся список с несколькими вариантами и каждая строка списка соответствует некоторой команде, выполняемой в отдельной конструкции case. Реализацию очень удобно построить на использовании команды switch:
$user_input = "recipes"; // Команда,выбранная пользователем
switch ($user_input) :
case("search") :
print "Let's perform a search!";
break;
case("dictionary") :
print "What word would you like to look up?";
break;
case("recipes") :
print "Here is a list of recipes...";
break;
default :
print "Here is the menu...";
break;
endswitch;
Как видно из приведенного фрагмента, команда switch обеспечивает четкую и наглядную организацию кода. Переменная, указанная в условии switch (в данном примере — $user_input), сравнивается с условиями всех последующих секций case. Если значение, указанное в секции case, совпадает Со значением сравниваемой переменной, выполняется блок этой секции. Команда break предотвращает проверку дальнейших секций case и завершает выполнение конструкции switch. Если ни одно из проверенных условий не выполняется, активизируется необязательная секция default. Если секция default отсутствует и ни одно из условий не выполняется, команда switch просто завершается и выполнение программы продолжается со следующей команды.
Вы должны помнить, что при отсутствии в секции case команды break (см. следующий раздел) выполнение switch продолжается со следующей команды до тех пор,
пока не встретится команда break или не будет достигнут конец конструкции switch. Следующий пример демонстрирует последствия отсутствия забытой команды break: $value = 0.4;
switch($value) :
case (0.4) :
print "value is 0.4
";
case (0.6) :
print "value is 0.6
";
break;
case (0.3) :
print "value is 0.3
";
break;
default :
print "You didn't choose a value!";
break;
endswitch;
Результат выглядит так:
value is 0.4
value is 0.6
Отсутствие команды break привело к тому, что была выполнена не только команда print в той секции, где было найдено совпадение, но и команда print в следующей секции. Затем выполнение команд конструкции switch прервалось из-за команды switch, следующей за второй командой print.
Выбор между командами switch и if практически не влияет на быстродействие про-граммы. Решение об использовании той или иной конструкции является скорее личным делом программиста.Управляющие конструкции
Управляющие конструкциипредоставляют в распоряжение программиста средства для построения сложных программ, способных проверять условия и реагировать на изменения значений входных данных во время работы. Короче говоря, эти структуры управляют выполнением программы.
Выражения
Выражениеописывает некоторое действие, выполняемое в программе. Каждое выражение состоит по крайней мере из одного операнда и одного или нескольких операторов. Прежде чем переходить к примерам, демонстрирующим использование выражений, необходимо поближе познакомиться с операторами и операндами.
While
Конструкция while предназначена для многократного (циклического) выполнения блока команд. Блок команды while выполняется до тех пор, пока условие цикла остается истинным. Общая форма цикла while выглядит так:while (выражение) :
блок
endwhile;
Рассмотрим использование цикла while на примере вычисления факториала (n!), где n = 5:
$n = 5;
$nсору = $n;
$factorial = 1; // Установить начальное значение факториала
while ($n > 0) :
$factorial - $n * $factorial;
$n--; // Уменьшить $n на 1
endwhile;
print "The factorial of $ncopy is $factorial.";
Программа выводит следующий результат:
The factorial of 5 is 120.
В этом примере $n уменьшается в конце каждой итерации. Условие цикла не должно быть истинным в тот момент, когда переменная $n станет равна 0, поскольку величина $factorial умножится на 0 — конечно, этого быть не должно.
В приведенном примере условие цикла следовало бы оптимизировать и привести его к виду $n > 1, поскольку умножать $factorial на 1 бессмысленно — число от этого не изменится. Хотя ускорение работы программы будет ничтожно малым, такие факторы всегда принимаются во внимание с ростом объема и сложности программ.PHP 4 на практике
Что такое функция?
Функциейназывается фрагмент программного кода, обладающий уникальным именем и предназначенный для решения конкретной задачи. Функция вызывается по имени в разных точках программы, что позволяет многократно выполнять фрагмент с указанным именем. Преимущество такого решения заключается в том, что блок кода пишется всего один раз, а затем легко модифицируется по мере необходимости.
Функции-переменные
Одной из интересных возможностей РНР являются функции-переменные (variable functions), то есть динамические вызовы функций, имена которых определяются во время выполнения программы. Хотя в большинстве web-приложений можно обойтись и без функций-переменных, они значительно сокращают объем и сложность программного кода, а также часто снимают необходимость в условных командах if.Вызов функции-переменной представляет собой имя переменной, за которым следует пара круглых скобок. В круглых скобках могут перечисляться параметры (однако присутствие параметров не обязательно). Обобщенный синтаксис функции-переменной:
$имя_функции( );
Следующая программа (листинг 4.6) демонстрирует эту непривычную, но полезную возможность. Допустим, программа выводит разную информацию в зависимости от языка, выбранного пользователем. В нашем примере для простоты используются приветственные сообщения для англо- и италоязычных пользователей. Алгоритм на псевдокоде:
Создать сообщение для итальянского языка в функции с именем italian.
Создать сообщение для английского языка в функции с именем english.
Передать информацию о выбранном языке в сценарий, присвоив значение переменной $language.
Переменная $language используется для выполнения функции-переменной (в приведенном примере — italian()).
Листинг 4.6. Выбор функции в зависимости от пользовательского ввода
// Приветствие на итальянском языке, function italian( ) {
" print "Benvenuti al PHP Recipes.";
}
// Приветствие на английском языке
function english( ) {
print "Welcome to PHP Recipes.";
}
// Выбрать итальянский язык
$language = "italian":
// Выполнить функцию-переменную
$language( );
Листинг 4.6 демонстрирует интересную концепцию функций-переменных и наглядно показывает, что функции-переменные способствуют уменьшению объема программного кода. Если бы не эта возможность, функцию пришлось бы выбирать командой if или switch; это привело бы к заметному увеличению объема программного кода и риску появления дополнительных ошибок при кодировании.
Определение и вызов функций
Определить новую функцию в РНР несложно. Функции могут создаваться в любой точке программ РНР, однако по соображениям структурной организации кода удобнее разместить все функции, используемые сценарием, в самом начале сценарногофайла. Существует и другой способ, заметно повышающий эффективность программирования и способствующий многократному использованию кода, — выделение функций в отдельный файл (называемый библиотекой). Библиотеки удобны тем, что их функции можно использовать в разных приложениях, не создавая лишних копий и не рискуя допустить ошибки в процессе копирования. Эта тема подробно рассматривается в разделе «Построение библиотек функций» ближе к концу главы.
Определение функции обычно состоит из трех частей:
Обобщенный синтаксис функций РНР выглядит так:
function имя_функции ([$параметр1. $параметр2, .... $параметрn]) {
тело функции
}
Имя функции должно подчиняться условиям, приведенным для идентификаторов в главе 2. После имени функции следуют обязательные круглые скобки, в которые заключается необязательный список входных параметров ($параметр1, $параметр2, .... $параметрn). Вследствие относительно либеральных принципов определения переменных в РНР указывать тип входных параметров не нужно. Хотя такой подход имеет свои преимущества, следует помнить, что механизм РНР не проверяет аргументы на соответствие тем типам, которые должны обрабатываться функцией. Случайные ошибки в использовании входных параметров могут привести к неожиданным последствиям (чтобы убедиться в том, что параметр относится к нужному типу, можно проверить его стандартной функцией gettype( )). После закрывающей круглой скобки следуют фигурные скобки, в которые заключается программный код, ассоциируемый с именем функции.
Рассмотрим простой пример использования функции. Предположим, вы хотите создать функцию для вывода лицензионной информации на web-странице:
function display_copyright() {
print "Copyright © 2001 PHP-Powered Recipes. All Rights Reserved.";
}
Если ваш web- сайт состоит из нескольких страниц, достаточно вызвать эту функцию в конце каждой страницы — и вам не придется заново переписывать один и тот же текст. А когда наступит 2002 год, одно простое изменение текста, выводимого этой функцией, приведет к автоматическому обновлению всех страниц. Если бы не преимущества функционального программирования, вам пришлось бы вручную редактировать все страницы, на которых выводится лицензионная информация.
Рассмотрим разновидность функции display_copyright(), которой при вызове передается параметр. Предположим, вы отвечаете за администрирование нескольких web-сайтов, каждому из которых присвоено отдельное имя. На каждом сайте имеется собственный административный сценарий с несколькими переменными, относящимися к этому сайту; к их числу принадлежит переменная $site_name с именем
сайта. В этом случае функцию display_copyright() можно записать следующим образом:
function display_copyright($site_name) {
print "Copyright © 2001 $site_name. All Rights Reserved.";
}
Переменная $site_name, значение которой присваивается за пределами display_copy-right(), передается функции в качестве параметра. Переданное значение можно использовать и модифицировать в любом месте функции, однако любые изменения будут действовать лишь внутри этой функции. Впрочем, специальные ключевые слова позволяют сделать так, чтобы изменения параметров распространялись и за пределы display_copyright(). Эти ключевые слова были представлены в главе 2, в общем обзоре области видимости переменных и ее отношения к функциям.
Построение библиотек функций
Библиотеки функций — одно из самых эффективных средств экономии времени при построении приложений. Предположим, вы написали серию функций для сортировки массива. Вероятно, эти функции будут неоднократно использоваться в разных приложениях. Вместо того чтобы постоянно переписывать эти функции в новый сценарий или копировать их через текстовый буфер, гораздо удобнее разместить все функции сортировки в отдельном файле и присвоить ему легко узнаваемое имя (например, array_sorting.inc). Пример такого файла приведен в листинге 4.7.Листинг 4.7.
Пример библиотеки функций (array_sorting.inc)
// Файл: array_sorting.inc
// Назначение: библиотека функций для сортировки массивов.
// Дата: 17 июля 2000 г.
function merge_sort($array. $tmparray, $right, $left) {
...
function bubble_sort($array. $n) {
...
}
function quicksort ($array. $right. $left) {
...
}
?>
Библиотека array_sorting.inc служит накопителем для всех функций сортировки. Это удобно, поскольку функции фактически группируются по своему назначению и при необходимости можно легко найти нужную функцию. Как видно из листинга 4.7, в начало библиотеки обычно включается заголовок из нескольких строк комментария, чтобы при открытии файла библиотеки можно было сразу получить краткую сводку его содержимого. После собственной библиотеки функций можно включить ее в сценарий при помощи команд РНР include( ) и require( ), в результате чего все функции библиотеки становятся доступными. В общем виде синтаксис этих команд выглядит так:
include(путь/имя_файла);
require(путь/имя_файла);
Также существует альтернативный вариант:
include "путь/имя_файла";
require "путь/имя_файла";
где путь определяет относительный или абсолютный путь к файлу. Конструкции include( ) и requirе( ) подробно описаны в главе 9. А пока достаточно запомнить, что эти конструкции используются для включения файла непосредственно в сценарий.
Предположим, вы хотите воспользоваться функциями библиотеки array_sorting.inc в сценарии. Пример включения библиотеки показан в листинге 4.8.
Листинг 4.8.
Включение библиотечного файла (array_sorting.inc) в сценарий
// Предполагается, что библиотека array_sorting.inc
// находится в одном каталоге со сценарием.
include("array_sorting.inc");
// Теперь вы можете использовать любые функции из array_sorting.inc
$some_array = array (50, 42. 35, 46);
// Использовать функцию bubble_sort()
$sorted_array = bubble_sort($some_array, 1);
Рекурсивные функции
Ситуация, при которой функция многократно вызывает сама себя, пока не будет выполнено некоторое условие, открывает замечательные возможности. При правильном использовании рекурсивные функции уменьшают объем программы и делают ее более выразительной. Рекурсивные функции особенно часто используются при выполнении повторяющихся действий — например, при поиске в файлах/массивах и построении графических изображений (например, фракталов). Классическим примером рекурсивных функций, встречающимся во многих курсах программирования, является суммирование чисел от 1 до N. Программа, приведенная в листинге 4.5, суммирует все целые числа от 1 до 10.Листинг 4.5.
Использование рекурсивной функции для суммирования последовательных целых чисел
function summation ($count) {
if ($count != 0) :
return $count + summation($count-1);
endif;
}
$sum = summation(10);
print "Summation = $sum";
В результате выполнения листинга 4.5 будет выведен следующий результат:
Summation = 55
Если функция вызывается достаточно часто, рекурсия делает программу более эффективной. Тем не менее, при использовании рекурсии необходима осторожность, поскольку ошибки могут привести к зацикливанию программы.
Вложенные функции
Функции можно вызывать внутри других функций — по аналогии с тем, как одна управляющая конструкция (if, while, for и т. д.) может находиться внутри другой. Такая возможность удобна в любых программах, и в больших, и в малых, поскольку она увеличивает степень модульности приложения и упрощает сопровождение программы.В примере, описанном выше, можно полностью избавиться от необходимости модификации даты. Для этого достаточно включить в d1splay_copyright() вызов стандартной функции РНР date( ):
function display_copyright($site_name) {
print "Copyright ©". date("Y"). "$site_name. All Rights Reserved.";
}
Параметр Y функции date( ) указывает, что возвращаемое значение представляет собой текущий год, отформатированный в виде четырех цифр. Если системная дата установлена правильно, РНР при каждом выполнении сценария будет выводить год. Функция РНР date( ) отличается исключительной гибкостью и поддерживает 25 разных флагов форматирования даты и времени.
Также допускается объявление функций внутри других функций. Тем не менее, вложенное объявление еще не делает функцию «защищенной», то есть не ограничивает возможность ее вызова той функцией, в которой она была объявлена. Более того, вложенная функция не наследует параметров родительской функции; параметры должны передаваться ей точно так же, как и любой другой функции. Впрочем, вложенные объявления функций все равно могут использоваться из соображений удобства сопровождения и наглядности. Пример вложенного объявления приведен в листинге 4.1.
Листинг 4.1.
Эффективное использование вложенных функций
function display_footer($site_name) {
function display_copyright($site_name) {
print "Copyright &сору". date("Y").
$site_name. All Rights Reserved.";
print "
home | recipes | events
tutorials | about I contact us
";
display_copyright($site_name);
print "
}
$site_name = "PHP Recipes":
display_footer($site_name);
display_copyhght($site_name);
Сценарий выводит следующий результат:
home | recipes | events
tutorials | about | contact us
Copyright © 2001 PHP Recipes. All Rights Reserved
 Обратите внимание: функцию display_copyright( ) можно вызвать и за пределами display_footer( ) по аналогии стем, как функция display_footer( ) использовалась в предыдущем примере. Концепция защищенных функций в РНР не поддерживается.
Обратите внимание: функцию display_copyright( ) можно вызвать и за пределами display_footer( ) по аналогии стем, как функция display_footer( ) использовалась в предыдущем примере. Концепция защищенных функций в РНР не поддерживается.Хотя вложенные функции не защищены от вызова из других точек сценария, они не могут вызываться до вызова своей родительской функции. При попытке вызвать вложенную функцию раньше вызова родительской функции выводится сообщение об ошибке.
Возврат значений из функции
По завершении работы функции часто бывает полезно вернуть некоторое значение, для чего результат вызова функции обычно присваивается некоторой переменной. Функции могут возвращать значения любых типов, в том числе массивы и списки. Пример приведен в листинге 4.2, где функция calculate_cost( ) вычисляет налог с заданной суммы и возвращает общую сумму вместе с налогом. Прежде чем переходить к рассмотрению листинга, просмотрите краткое описание алгоритма на псевдокоде:Перед вызовом функции задать значения переменных: $price (цена товара) и $tax (налоговая ставка).
Объявить функцию calculate_cost( ). При вызове функция получает два параметра: налоговую ставку и цену товара.
Вычислить цену с учетом налога и вернуть ее командой return.
Вызвать calculate_cost() и присвоить значение, возвращенное функцией, переменной $total_cost.
Вывести соответствующее сообщение.
Листинг 4.2.
Создание функции для вычисления налога
$price = 24.99; $tax = .06;
function calculate_cost($tax, $price) {
$sales_tax = $tax;
return $price + ($price * $sales_tax);
}
// Обратите внимание на возврат значения функцией calculate_cost(). $total_cost = calculate_cost ($tax. $price);
// Округлить цену до двух десятичных цифр.
$total_cost = round($total_cost. 2);
print "Total cost: $".$total_cost;
// $total cost = 26.49
Функции, не возвращающие значений, также называются процедурами.Существует и другой способ использования возвращаемых значений, при котором вызов функции включается прямо в условную/циклическую команду. В следующей программе (листинг 4.3) сумма счета пользователя сравнивается с предельным размером кредита. Алгоритм на псевдокоде выглядит так:
Объявить функцию check_limit( ), которая при вызове получает два параметра. Первый параметр, $total_cost, определяет общую сумму счета, накопленную пользователем до настоящего момента. Второй параметр, $credit_limit, определяет максимальную сумму, которую может потратить пользователь.
Если накопленная сумма счета превышает предельный размер кредита, функция возвращает ложное значение (0).
Если условие команды i f оказывается ложным, работа функции еще не завершена. В этом случае общая сумма не превышает предельного размера кредита, поэтому функция должна вернуть логическую истину.
Вызвать функцию check_limit( ) в условии команды if. Проверить, какое значение было возвращено при вызове — истинное или ложное. В зависимости от результата проверки выполняется то или иное действие.
Если при вызове check_limit( ) было получено значение TRUE, мы предлагаем пользователю продолжить закупку. В противном случае пользователь информируется о превышении кредита.
Листинг 4.3.
Сравнение текущей суммы счета пользователя с предельным размером кредита
$cost = 1456.22;
$limit = 1000.00;
function check_limit($total_cost. $credit_limit)
if ($total_cost > $credit_limit) :
return 0;
endif;
return 1;
}
if (check_limit($cost. $limit)) :
// Продолжить закупки
print "Keep shopping!";
else :
print "Please lower your total bill to less than $".$limit."!";
endif;
При выполнении листинга 4.3 будет выведено сообщение об ошибке, поскольку значение $cost превышает $limit.
Функция также может возвращать сразу несколько значений при помощи списка. Продолжая кулинарную тему, давайте напишем функцию, которая бы возвращала три лучших года для указанного сорта вина. Функция приведена в листинге 4.4, но сначала прочитайте алгоритм на псевдокоде:
Объявить функцию best_years( ), вызываемую с одним параметром. Параметр $label определяет сорт вина, для которого пользователь хотел бы узнать три рекомендуемых года.
Объявить два массива, $merlot и $zinfandel. В каждом массиве хранится три рекомендуемых года для соответствующего сорта вина.
Написать команду return, которая бы использовала особые возможности переменных. Выражение $$label сначала интерпретирует переменную $label, а затем интерпретирует полученное значение как имя другой переменной. В настоящем примере массив merlot возвращается в виде списка, и каждый возвращаемый год занимает свою позицию в списке, для которого вызывалась функция.
Вывести сообщение с информацией о рекомендуемых годах.
Листинг 4.4. Возвращение функцией нескольких величин
// Сорт вина, для которого выводятся лучшие годы
$label = "merlot";
// Функция использует массивы и "переменную в переменной"
// для возвращения нескольких значений.
function best_years($label) {
$merlot = array("1987", "1983", "1977");
$zinfandel = array("1992", "1990", "1989");
return $$label;
}
// Функция list( ) используется получения возвращаемых значений.
list ($yr_one, $yr_two. $yr_three) = best_years($label);
print "$label had three particularly remarkable years: $yr_one. $yr_two, and $yr_three.";
Программа выводит следующий результат:
merlot has three particularly remarkable years: 1987, 1983 and 1977.
PHP 4 на практике
Добавление и удаление элементов
К счастью, в РНР при создании массива не нужно указывать максимальное количество элементов. Это увеличивает свободу действий при операциях с массивами, поскольку вам не приходится беспокоиться о случайном выходе за границы массива, если количество элементов превысит ожидаемый порог. В РНР существует несколько функций для увеличения размеров массива. Некоторые из них были созданы для удобства программистов, привыкших работать с различными типами очередей и стеков (FIFO, FILO и т. д.), что отражается в названиях функций (push, pop, shift и unshift). Но даже если вы не знаете, что такое «очередь» или «стек», не огорчайтесь — в этих функциях нет ничего сложного. Очередью (queue) называется структура данных, из которой элементы извлекаются в порядке поступления. Стеком (stack) называется структура данных, из которой элементы извлекаются в порядке, обратном порядку их поступления.
Очередью (queue) называется структура данных, из которой элементы извлекаются в порядке поступления. Стеком (stack) называется структура данных, из которой элементы извлекаются в порядке, обратном порядку их поступления.array_push( )
Функция array_push( ) присоединяет (то есть дописывает в конец массива) один или несколько новых элементов. Синтаксис функции array_push( ):
int array_push(array массив, mixed элемент [, ...])
Длина массива возрастает прямо пропорционально количеству его элементов. Это продемонстрировано в следующем примере:
$languages = array("Spanish", "English", "French");
array_push($languages, "Russian", "German", "Gaelic");
// $languages = array("Spanish", "English", "French",
// "Russian", "German", "Gaelic")
У функции array_push( ), как и у многих стандартных функций РНР, существует «двойник» — функция аrrау_рор( ), предназначенная для извлечения элементов из массива. Главное различие между этими функциями заключается в том, что array_push( ) может добавлять несколько элементов одновременно, а аrrау_рор( ) удаляет элементы только по одному.
аrrау_рор( )
Результат работы функции аrrау_рор( ) прямо противоположен array_push( ) — эта функция извлекает (то есть удаляет) последний элемент из массива. Извлеченный элемент возвращается функцией. Синтаксис функции аrrау_рор( ):
аrrау_рор(аrrау массив)
При каждом выполнении аrrау_рор( ) размер массива уменьшается на 1. Рассмотрим пример:
$languages = array("Spanish", "English", "French",
"Russian", "German", "Gaelic");
$a_language = array_pop($languages):
// $a_language = "Gaelic"
$a_language = array_pop($languages):
// $a_language = "German"
// $languages = array ("Spanish", "English", "French", "Russian");
Функции array_push( ), и array_pop( ) удобны тем, что с их помощью можно выполнять операции с элементами и управлять размером массива, не беспокоясь о неинициализированных или пустых элементах. Такое решение работает намного эффективнее, чем любые попытки управления этими факторами со стороны программиста.
array_shift( )
Функция array_shift( ) аналогична аrrау_рор( ) с одним отличием: элемент удаляется из начала (левого края) массива. Все остальные элементы массива сдвигаются на одну позицию к началу массива. У функции array_shift( ) такой же синтаксис, как и у аггау_рор( ):
array_shift(array массив)
При работе с функцией array_shift( ) необходимо помнить, что элементы удаляются из начала массива, как показывает следующий пример:
$languages = array("Spanish", "English", "French", "Russian");
$a_language = array_shift($languages); // $a_language = "Spanish";
// $languages = array("English", "French", "Russian");
array_unshift( )
Функция array_unshift( ) дополняет array_shift( ) — новый элемент вставляется в начало массива, а остальные элементы сдвигаются на одну позицию вправо. Синтаксис команды array_unshift( ):
1nt array_unshift(array массив, mixed переменная1 [....переменная2])
При одном вызове функции можно добавить как один, так и несколько элементов, при этом размер массива возрастает пропорционально количеству добавленных элементов. Пример добавления нескольких элементов:
$languages = array("French", "Italian", "Spanish");
array_unshift($languages, "Russian", "Swahili", "Chinese");
// $languages = array("Russian", "Swahili", "Chinese",
// "French", "Italian", "Spanish");
array_pad( )
Функция array_pad( ) позволяет быстро увеличить массив до желаемого размера посредством его дополнения стандартными элементами. Синтаксис функции array_pad( ):
array arrap_pad(array массив, int размер, mixed значение):
Параметр размер определяет новую длину массива. Параметр значение задает стандартное значение, присваиваемое элементам во всех новых позициях массива. При использовании array_pad( ) необходимо учитывать некоторые обстоятельства:
Если размер положителен, массив дополняется справа, а если отрицателен — слева.
Если абсолютное значение параметра размер меньше либо равно длине массива, никаких действий не выполняется.
Абсолютным значением (модулем) целого числа называется его значение без знака. Например, абсолютное значение чисел 5 и -5 равно 5.Пример дополнения массива с конца:
$weights = array(1, 3, 5, 10, 15, 25, 50);
$weights = array_pad($weights. 10, 100);
// Результат: $weights = array(1, 3, 5, 10, 15, 25, 50, 100, 100, 100);
Пример дополнения массива с начала:
$weights = array(1, 3, 5, 10, 15, 25, 50);
$weights = array_pad($weights, -10, 100);
// Результат: $weights = array(100, 100, 100, 1, 3, 5, 10, 15, 25, 50);
Неправильная попытка дополнения массива:
$weights = array(1, 3, 5, 10, 15, 25, 50);
$weights = array_pad($weigtits, 3, 100);
// Массив $weights не изменяется:
// $weights = array(1, 3, 5, 10, 15, 25, 50);
Другие полезные функции
В этом разделе описаны некоторые функции, которые не принадлежат ни к какому конкретному разделу, но приносят несомненную пользу.array_merge( )
Функция arrayjnerge( ) сливает от 1 до N массивов, объединяя их в соответствии с порядком перечисления в параметрах. Синтаксис функции array_merge( ):
array array_merge(array массив1, array массив2, ..., array массивN]
Рассмотрим пример простого объединения массивов функцией arrayjnerge( );
$arr_1 = array("strawberry", "grape", "lemon");
$arr_2 = array("banana", "cocoa", "lime");
$arr_3 = array("peach", "orange");
$arr_4 = array_merge ($arr2, $arr_1, $arr_3):
// $arr_4 = array("banana", "cocoa", "lime", "strawberry", "grape", "lemon", "peach", "orange");
array_slice( )
Функция array_slice( ) возвращает часть массива, начальная и конечная позиция которой определяется смещением от начала и необязательным параметром длины. Синтаксис функции array_slice( ):
array array_slice(array массив, int смещение [, int длина])
Значения параметров задаются по определенным правилам:
array_splice( )
Функция array_spl ice( ) отдаленно напоминает array_slice( ) — она заменяет часть массива, определяемую начальной позицией и необязательной длиной, элементами необязательного параметра-массива. Синтаксис функции array_splice( ):
array_splice(array входной_массив, int смещение, [int длина], [array заменяющий_массив]);
Значения параметров задаются по определенным правилам:
Рассмотрим несколько примеров, наглядно демонстрирующих возможности этой функции. В этих примерах будет использоваться массив $pasta (см. выше), с которым будут выполняться различные операции.
Удаление всех элементов с пятой позиции до конца массива:
$pasta = array_splice($pasta, 5);
Удаление пятого и шестого элементов:
$pasta = array_splice($pasta. 5, 2);
Замена пятого и шестого элементов новыми значениями:
$pasta = array_splice($pasta, 5, 2, array("element1", "element2"));
Удаление всех элементов, начиная с пятого, до третьего элемента с конца массива:
$pasta = array_splice($pasta, 5, -3);
Как видно из приведенных примеров, функция array_splice( ) обеспечивает гибкие возможности удаления элементов из массива при минимальном объеме кода.
shuffle( )
Функция shuffle( ) сортирует элементы массива в случайном порядке. Синтаксис функции shuffle( ):
void shuffle(array массив);
Многомерные массивы
Со временем ваши программы станут более сложными, и возможностей простых одномерных массивов окажется недостаточно для хранения необходимой информации. Многомерный массив (массив массивов) предоставляет в распоряжение программиста более эффективные средства для хранения информации, требующей дополнительного структурирования. Создать многомерный массив несложно — просто добавьте дополнительную пару квадратных скобок, чтобы вывести массив в новое измерение:$chessboard [1] [4] = "King"; // Двухмерный массив
$capitals["USA"] ["Ohio"] = "Columbus": // Двухмерный массив
$streets["USA"]["Ohio"]["Columbus"] = "Harrison"; // Трехмерный массив
В качестве примера рассмотрим массив, в котором хранится информация о десертах и особенностях их приготовления. Обойтись одномерным массивом было бы довольно трудно, но двухмерный массив подходит как нельзя лучше:
$desserts = аrrау(
"Fruit Cup" => array (
"calories" => "low",
"served" -> "cold",
"preparation" => "10 minutes"
),
"Brownies" => array (
"calories" -> "high",
"served" => "piping hot",
"preparation" => "45 minutes"
)
);
После создания массива к его элементам можно обращаться по соответствующим ключам:
$desserts["Fruit Cup"]["preparation"] // возвращает "10 minutes"
$desserts["Brownies"]["calories"] // возвращает "high"
Присваивание значений элементам многомерных массивов выполняется так же, как и в одномерных массивах:
$desserts["Cake"]["calories"] = "too many";
// Присваивает свойству "calories" объекта "Cake" значение "too many"
Хотя в многомерных массивах появляются новые уровни логической организации данных, многомерные массивы создаются практически так же, как и одномерные. Впрочем, ссылки на многомерные массивы в строках требуют особого внимания; этой теме посвящен следующий раздел.
Перебор элементов
В РНР существует несколько стандартных функций, предназначенных для перебора элементов массива. В совокупности эти функции обеспечивают гибкие и удобные средства для быстрой обработки и вывода содержимого массивов. Вероятно, вы будете часто использовать эти функции, поскольку они лежат в основе практически всех алгоритмов работы с массивами.reset( )
Функция reset( ) переводит внутренний указатель текущей позиции в массиве к первому элементу. Кроме того, она возвращает значение первого элемента. Синтаксис функции reset( ):
mixed reset (array массив)
Рассмотрим следующий массив:
$fruits = array("apple", "orange", "banana");
Допустим, указатель текущей позиции в этом массиве установлен на элемент "orange". Команда:
$a_fruit = reset($fruits);
вернет указатель в начало массива, то есть на элемент "apple", и вернет это значение, если результат вызова reset( ) используется в программе. Возможен и упрощенный вариант вызова:
reset($fruits);
В этом случае указатель переходит к первому элементу массива, а возвращаемое значение не используется.
each ( )
Функция each( ) при каждом вызове выполняет две операции: она возвращает пару «ключ/значение», на которую ссылается указатель текущей позиции, и перемещает указатель к следующему элементу. Синтаксис функции each( ):
array each (array массив)
Для удобства each ( ) возвращает ключ и значение в виде массива из четырех элементов; ключами этого массива являются 0, 1, value и key. Возвращаемый ключ ассоциируется с ключами 0 и key, а возвращаемое значение — с ключами 1 и value.
В следующем примере функция each ( ) возвращает элемент, находящийся в текущей позиции:
// Объявить массив из пяти элементов
$spices = array("parsley", "sage", "rosemary", "thyme", "pepper");
// Установить указатель на первый элемент массива
reset($spices);
// Создать массив $a_sp1ce. состоящий из четырех элементов
$a_spice = each($spices);
В результате выполнения приведенного фрагмента массив $a_spice будет содержать следующие пары «ключ/значение»:
После этого строку "parsley" можно вывести любой из следующих команд:
print $a_spice[1]: print $a_spice["value"];
Функция each() обычно используется в сочетании с list( ) в циклических конструкциях для перебора всех или некоторых элементов массива. При каждой итерации each( ) возвращает либо следующую пару «ключ/значение», либо логическую ложь при достижении последнего элемента массива. Вернемся к массиву $spices; чтобы вывести все элементы на экран, можно воспользоваться следующим сценарием:
// Сбросить указатель текущей позиции
reset($spices);
// Перебрать пары "ключ/значение", ограничиваясь выводом значения
while (list ($key, $val) = each ($spices) ) :
print "$val
"
endwhile;
Ниже приведен более интересный пример использования each( ) в сочетании с другими функциями, описанными в этой главе. Листинг 5.1 показывает, как при помощи этих функций вывести отформатированную таблицу стран и языков.
Листинг 5.1.
Построение таблицы HTML по содержимому массива
// Объявить ассоциативный массив стран и языков $languages = array ("Country" => "Language",
"Spain" => "Spanish",
"USA" => "English",
"France" => "French",
"Russia" => "Russian");
// Начать новую таблицу
print "
| $hd1 | $hd2 |
|---|---|
| Sctry | $lang |
?>
В результате выполнения этого кода будет построена следующая таблица HTML.
| Country | Language | ||
| Spain | Spanish | ||
| USA | English | ||
| France | French | ||
| Russia | Russian |
| Функция | Сортировка | Обратный порядок | Сохранение пар «ключ/значение» |
| sort | Значение | Нет | Нет |
| rsort | Значение | Да | Нет |
| asort | Значение | Нет | Да |
| arsort | Значение | Да | Да |
| ksort | Ключ | Нет | Да |
| krsort | Ключ | Да | Да |
| usort | Значение | ? | Нет |
| uasort | Значение | ? | Да |
| uksort | Ключ | ? | Да |
 По общепринятым правилам имена классов ООП начинаются с прописной буквы, а все слова в именах методов, кроме первого, начинаются с прописных букв (первое слово начинается со строчной буквы). Разумеется, вы можете использовать любые обозначения, которые сочтете удобными; главное — выберите стандарт и придерживайтесь его.
По общепринятым правилам имена классов ООП начинаются с прописной буквы, а все слова в именах методов, кроме первого, начинаются с прописных букв (первое слово начинается со строчной буквы). Разумеется, вы можете использовать любые обозначения, которые сочтете удобными; главное — выберите стандарт и придерживайтесь его.
 Внутренний параметр ping -с 5 (-п 5 в системе Windows) задает количество опросов сервера.
Внутренний параметр ping -с 5 (-п 5 в системе Windows) задает количество опросов сервера.| Режим | Описание | ||
| r | Только чтение. Указатель текущей позиции устанавливается в начало файла | ||
| r+ | Чтение и запись. Указатель текущей позиции устанавливается в начало файла | ||
| w | Только запись. Указатель текущей позиции устанавливается в начало файла, а все содержимое файла уничтожается. Если файл не существует, функция пытается создать его | ||
| w+ | Чтение и запись. Указатель текущей позиции устанавливается в начало файла, а все содержимое файла уничтожается. Если файл не существует, функция пытается создать его | ||
| a | Только запись. Указатель текущей позиции устанавливается в конец файла. Если файл | не существует, функция пытается создать его||
| a+ | Чтение и запись. Указатель текущей позиции устанавливается в конец файла. Если файл не существует, функция пытается создать его | <
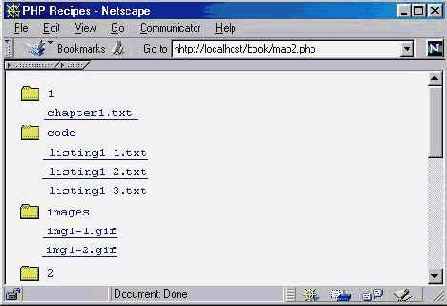
| Модификатор | Описание | ||
| m | Фрагмент текста интерпретируется как состоящий из нескольких «логических строк». По умолчанию специальные символы ^ и $ совпадают только в начале и в конце всего фрагмента. При включении «многострочного режима» при помощи модификатора m^ и $ будут совпадать в начале и в конце каждой логической строки внутри фрагмента | ||
| s | По смыслу противоположен модификатору m — при поиске фрагмент интерпретируется как одна строка, а все внутренние символы новой строки игнорируются | ||
| i | Поиск выполняется без учета регистра символов | Вводный курс получился очень кратким, поскольку полноценное описание по регулярным выражениям выходит за рамки этой книги и требует нескольких глав вместо нескольких страниц. За дополнительной информацией о синтаксисе регулярных выражений обращайтесь к следующим ресурсам Интернета:
 Работа с формами HTML в РНР описана в главе 10.
Работа с формами HTML в РНР описана в главе 10. Функция substr_replace( ), описанная ниже в этом разделе, позволяет провести заме ну лишь в определенной части строки. Ниже показано, как функция str_replace( ) используется для проведения глобальной замены в строке.
Функция substr_replace( ), описанная ниже в этом разделе, позволяет провести заме ну лишь в определенной части строки. Ниже показано, как функция str_replace( ) используется для проведения глобальной замены в строке.Copyright © 2000 PHPRecipes. All rights reserved. contact | your privacy |
Обратите внимание на использование глобальной переменной $site_email в файле колонтитула. Значение этой переменной действует в масштабах всей страницы, а мы предполагаем, что файлы header.tpl и footer.tpl будут включены в одну итоговую страницу. Также обратите внимание на присутствие пути $site_path в ссылке Privacy (Конфиденциальность). Я всегда включаю в шаблоны полные пути ко всем ссылкам — если бы URL ссылки состоял из одного имени privacy.php, то файл колонтитула был бы жестко привязан к конкретному каталогу.
Оптимизация шаблонов
Во втором (на мой взгляд, более предпочтительном) варианте шаблоны оформляются в виде функций, находящихся в отдельном файле. Тем самым обеспечивается дополнительное структурирование ваших шаблонов. Я называю этот файл инициализационным файлом и храню в нем другую полезную информацию. Поскольку мы уже рассмотрели относительно длинные примеры заголовка и колонтитула, содержимое листингов 9.10 и 9.11 было слегка сокращено для наглядной демонстрации новой идеи.Листинг 9.10.
Оптимизированный шаблон сайта (site_init.tpl)
// Файл: site_init.tpl
// Назначение: инициализационный файл PhpRecipes
// Дата: 22 августа 2000 г.
$site_name = "PHPRecipes";
$site_email = "wjgilmore@hotmail.com";
$site_path = "http://localhost/phprecipes/";
function show_header($site_name) {
This is the header
function show footer ()
?>
This Is the footer
}
?>
Листинг 9.11.
Применение инициализационного файла
// Включить инициализационный файл
include("site_init.tpl");
// Вывести заголовок
show header ($site_name);
?>
// Содержимое основной части This is some body information
// Вывести колонтитул Show_footer( );
?>
Основная часть
В основной части страницы подключается содержимое заголовка и колонтитула. В сущности, именно основная часть содержит информацию, интересующую посетителей сайта. Заголовок эффектно выглядит, колонтитул содержит полезные сведения, но именно ради основной части страницы пользователи снова и снова возвращаются на сайт. Хотя я не смогу предоставить каких-либо рекомендаций по поводу конкретной структуры страниц, шаблоны, подобные приведенному в листинге 9.7, основательно упрощают администрирование страниц.Листинг 9.7.
Пример основной части страницы (index_body.tpl)
| /tutorials.php">tutorials articles scripts contact | Welcome to PHPRecipes. the starting place for PHP scripts, tutorials, and information about gourmet cooking! |
Построение компонентов
При определении структуры типичной web-страницы я обычно разбиваю ее на три части: заголовок, основную часть и колонтитул. Как правило, в большинстве правильно организованных web-сайтов присутствует заголовок, который практически не изменяется; в основной части выводится запрашиваемое содержание сайта, поэтому она часто изменяется; наконец, колонтитул содержит информацию об авторских правах и навигационные ссылки. Колонтитул, как и заголовок, обычно остается неизменным. Не поймите меня превратно — я вовсе не пытаюсь подавлять ваши творческие устремления. Мне встречалось немало великолепных сайтов, не следовавших этим принципам. Я всего лишь пытаюсь выработать общую структуру, которая может послужить отправной точкой для дальнейшей работы.Проект: генератор страниц
Хотя в большинстве созданных мною web-сайтов основное содержимое страниц формировалось на основании информации, прочитанной из базы данных, всегда найдется несколько страниц, которые практически не изменяются. В частности, на них могут выводиться сведения о команде разработчиков, контактные данные, реклама и т. д. Я обычно храню эту «статическую» информацию в отдельной папке и использую сценарий РНР для ее загрузки при поступлении запроса. Конечно, у вас возникает вопрос — если это статическая информация, для чего нужен сценарий РНР? Почему бы не загружать обычные страницы HTML? Преимущество РНР заключается в том, что вы можете использовать шаблоны и вставлять статические фрагменты по мере необходимости.Ссылки для загрузки различных статических файлов строятся динамически. В обобщенной форме ссылка выглядит так:
<а href = "/static.php?content=$content">Static Page Name
Начнем с создания статических страниц. Для простоты я ограничусь тремя страницами, содержащими информацию о сайте (листинг 9.12), рекламу (листинг 9.13) и контактные данные (листинг 9.14).
Листинг 9.12.
Информация о сайте (about.html)
About PHPRecipes
What programmer doesn't mix all night programming with gourmet cookies. Here at PHPRecipes. hardly a night goes by without one of our coders mixing a little bit of HTML with a tasty plate of Portobello Mushrooms or even Fondue. So we decided to bring you the best of what we love most: PHP and food!
That's right, readers. Tutorials, scripts, souffles and more. 0nly at PHPRecipes.
Листинг 9.13.
Рекламная информация (advert_info.html)
Advertising Information
Regardless of whether they come to learn the latest PHP techniques or for brushing up on how
to bake chicken, you can bet our readers are decision makers. They are the Industry
professionals who make decisions about what their company purchases.
For advertising information, contact
">ads@phprecipes.com.
Листинг 9.14.
Контактные данные (contact.html)
Contact Us
Have a coding tip?
Know the perfect topping for candied yams?
Let us know! Contact the team at team@phprecipes.com.
Переходим к построению страницы static.php, которая выводит запрашиваемую статическую информацию. В этот файл (см. листинг 9.15) включаются компоненты страниц нашего сайта и инициализационный файл site_init.tpl.
Листинг 9.15.
Общий вывод статических страниц (static.php)
// Файл: static.php
// Назначение: отображение запрашиваемых статических страниц.
// ВНИМАНИЕ: предполагается, что файл "site_init.tpl" и все
// статические файлы находятся в том же каталоге.
// Загрузить функции и переменные include("site_init.tpl"):
// Вывести заголовок show_header($site_name);
// Вывести запрашиваемое содержание include("$content.html"):
// Вывести колонтитул show footer( );
?>
Теперь все готово к построению основного сценария. Просто включите в страницу
следующие ссылки:
<а href = "static.php?content=about">Static Page Name
Advertising Information
Contact Us
Если щелкнуть на любой из этих ссылок, в браузере загружается соответствующая статическая страница, внедренная в static.php!
Простые ссылки
По ссылкам пользователь может переходить как на обычные страницы HTML, так и на страницы, содержащие код РНР:<а href = "date.php">
Если щелкнуть на ссылке, в браузере будет загружена страница с именем date.php. Просто, не правда ли? Развивая приведенный пример, можно воспользоваться переменной для построения динамической ссылки:
$link = "date.php";
print "<а href = \"$link\">View today's date
\n"
?>
Вероятно, у вас возник вопрос — почему в коде ссылки перед кавычками (") ставится обратная косая черта (\)? Дело в том, что кавычки в РНР являются специальными символами и используются в качестве ограничителей строк. Следовательно, кавычки-литералы в строках должны экранироваться.
 Если необходимость экранировать кавычки вас раздражает, просто включите режим magic_quotes_gpc в файле php.ini. В результате все апострофы, кавычки, обратные косые черты и нуль-символы. в тексте автоматически экранируются!
Если необходимость экранировать кавычки вас раздражает, просто включите режим magic_quotes_gpc в файле php.ini. В результате все апострофы, кавычки, обратные косые черты и нуль-символы. в тексте автоматически экранируются!Разовьем приведенный пример. Для быстрого вывода списка ссылок в браузере можно воспользоваться массивом:
// Создать массив разделов
$contents - array("tutorials", "articles", "scripts", "contact");
// Перебрать и последовательно вывести каждый элемент массива
for ($i = 0; $i < sizeof($contents; $i++)
print " • ".$contents[$i]."
\n";
// • - специальное обозначение точки-маркера endfor;
?>
Заголовок
Заголовочный файл (вроде приведенного в листинге 9.5) присутствует практически в каждом из моих web-сайтов с поддержкой РНР. В этом файле содержитсяинформация, действующая на уровне всего сайта, — например, заголовок, контактные данные и некоторые компоненты кода HTML-страницы.
Листинг 9.5.
Пример файла заголовка
// Файл: header.tpl
// Назначение: заголовочный файл для сайта PhpRecipes .
// Дата: 22 августа 2000 г.
$site_name = "PHPRecipes";
$site_email= "wjgnmore@hotrnail.com";
$site_path = "http://localhost/phprecipes";
?>
PHPRecipes | // Вывести текущую дату и время print date ("F d, h:i a"); ?> |
Довольно часто доступ к включаемым файлам со стороны посетителей ограничивается, особенно если эти файлы содержат конфиденциальную информацию (например, пароли). В Apache можно запретить просмотр некоторых файлов редактированием файлов http.conf или htaccess. Следующий пример показывает, как запретить просмотр всех файлов с расширением .tpl:
Order allow,deny
Allow from 127.0.0.1
Deny from all
 РНР и проблемы безопасности сайтов подробно описаны в главе 16.
РНР и проблемы безопасности сайтов подробно описаны в главе 16.PHP 4 на практике
Динамическое конструирование форм
До настоящего момента я программировал все формы вручную. Любому программисту известно, что ручное кодирование — это плохо, поскольку оно увеличивает вероятность ошибок, не говоря уже о лишних затратах времени.В следующем разделе я представлю сценарий, в котором раскрывающийся список строится динамически по содержимому массива. Этот прием несложен, однако
он экономит немало времени как при исходном программировании, так и при последующем сопровождении программы.
Пример 7: построение раскрывающегося списка
Предположим, у вас имеется список сайтов, которые вы хотите порекомендовать посетителю из-за классного дизайна. Вместо того чтобы жестко кодировать каждую строку списка, можно создать массив и воспользоваться его содержимым для заполнения списка.
В листинге 10.9, как и в предыдущих примерах, реализован вариант с одним сценарием. Сначала мы проверяем, было ли присвоено значение переменной $site. Если проверка дает положительный результат, вызывается функция header( ) с параметром, в котором значение $site присоединяется к строке «Location:http://». При передаче этой команды функция header О перенаправляет браузер на указанный URL. Если значение переменной $site не задано, форма выводится в браузере. Раскрывающийся список строится в цикле, количество итераций зависит от размера массива Sfavsites. В листинге 10.9 я включил в этот массив пять своих любимых сайтов. Конечно, вы можете добавить в него сколько угодно своих сайтов.
 Запомните одно важное обстоятельство — функция header( ) должна вызываться до вывода данных в браузере. Ее нельзя просто вызвать в любой точке сценария РНР. Несвоевременные вызовы header( ) порождают столько проблем у неопытных программистов РНР, что я рекомендую повторить это правило раз пять, чтобы лучше запомнить его.
Запомните одно важное обстоятельство — функция header( ) должна вызываться до вывода данных в браузере. Ее нельзя просто вызвать в любой точке сценария РНР. Несвоевременные вызовы header( ) порождают столько проблем у неопытных программистов РНР, что я рекомендую повторить это правило раз пять, чтобы лучше запомнить его.Листинг 10.9.
Динамическое построение раскрывающегося списка
if ($site != "") :
header("Location: http://Ssite");
exit;
else :
?>
View the guestbook!
Sign the guestbook!
Файл view_guest.php (листинг 10.12) выводит всю информацию гостевой книги, хранящуюся в файле данных.
Листинг 10.12.
Файл view_guest.php
INCLUDE("init.inc");
?>
vi ew_guest ( $guest_file );
?>
Файл add_guest.php (листинг 10.13) запрашивает у пользователя новые данные для внесения в гостевую книгу. Введенная информация записывается в файл данных.
Листинг 10.13.
Файл add_guest.php
INCLUDE("init.inc");
?>
?<
// Если форма еще не отображалась - запросить данные у пользователя
if (! $seenform) :
?>
// Форма уже отображалась - добавить данные в текстовый файл.
else :
add_guest($name, $email, $comment);
print "
Your comments have been added to the guestbook.
Click here to return to the index.
";endif;
?>
К числу основных преимуществ модульной разработки приложений относится простота адаптации для других систем. Допустим, вы решили перейти от хранения данных в текстовом файле к использованию базы данных. Стоит изменить содержимое add_guest( ) и view_guest( ), и ваша гостевая книга перейдет на работу с базой данных.
На рис. 10.8 показано, как выглядит гостевая книга после сохранения пары записей.
Рис. 10.8. Просмотр гостевой книги (view_guest.php)
Информация, показанная на рис. 10.8, хранится в файле данных в следующем виде:
Oct 29 00|Michele|michelle@latorre.com|I love cheese!
Oct 29 00|Nino|nino@latorre.com|Great site!
Проверка ошибок
Обработка пользовательских данных дает осмысленный результат лишь в том случае, если данные имеют правильную структуру. Проверить достоверность введенных данных невозможно, однако вы можете проверить их целостность (например, убедиться в том, что адрес электронной почты соответствует стандартному шаблону). Хотя для проверки данных часто применяется технология JavaScript, могут возникнуть проблемы с несовместимостью браузеров. Поскольку код РНР выполняется на стороне сервера, вы всегда можете быть уверены в том, что проверка данных формы даст нужный результат (конечно, при условии правильности вашей программы).При обнаружении ошибки в данных необходимо сообщить об этом пользователю и предложить внести исправления. Существует несколько возможных решений, в том числе простой вывод сообщения об ошибке и предложение альтернативных вариантов (например, если пользователь выбирает имя, которое уже было выбрано другим пользователем). В этом разделе рассматривается процедура проверки и вывода сообщений,
Пример 6: вывод информации о пустых или ошибочно заполненных полях формы
Ни один разработчик сайта не захочет раздражать пользователя невразумительными сообщениями об ошибках в данных — особенно если пользователь запрашивает дополнительную информацию о товаре или оформляет покупку! Чтобы пользователь понял, какие поля формы остались пустыми или были заполнены неверно, сообщения должны быть четкими и конкретными.
Мы последовательно проверяем все поля формы и убеждаемся в том, что они не остались пустыми. Там, где это возможно, проверяется правильность структуры введенных данных. Если проверка прошла успешно, мы переходим к следующему полю; в противном случае программа выводит сообщение об ошибке, устанавливает флаг, который позднее используется для повторного отображения формы, и переходит к следующему полю. Процедура повторяется до тех пор, пока не будут проверены все поля формы (листинг 10.8).
Листинг 10.8.
Проверка данных формы и вывод сообщений об ошибках
// Создать форму
$form = "
":
// Заполнялась ли форма ранее?
if ($seenform != "у"):
print "$form";
// Пользователь заполнил форму. Проверить введенные данные, else :
$error_flag = "n";
// Убедиться в том. что поле имени содержит информацию
if ($name == "") :
print "* You forgot to enter your name!
":
$error_flag = "y";
endif:
// Убедиться в том. что поле адреса содержит информацию
if ($email == "") :
else :
print "* You forgot to enter your email !
"
$error_flag = "y";
// Преобразовать все алфавитные символы в адресе
// электронной почты к нижнему регистру
$email = strtolower(trim($email)):
// Убедиться в правильности синтаксиса
// адреса электронной почты
if (! @eregi('^[0-9a-z]+'.
'([0-9a-z-]+\.)+'.
'([0-9a-z]){2.4}$'. $email)) :
print "* You entered an invalid email address!
" :
$error_flag = "y";
endif;
endif;
// Если флаг ошибки $error_flag установлен.
// заново отобразить форму
if ($error_flag == "у") : print "$form";
else :
// Обработать данные пользователя
print "You entered valid form information!";
endif;
endif;
?>
Программа в листинге 10.8 убеждается в том, что поля имени и адреса электронной почты не остались пустыми, а также проверяет правильность синтаксиса вве-, денного адреса. Если в результате каких-либо проверок в форме обнаруживаются ошибки, программа выводит соответствующие сообщения и отображает форму заново — при этом вся введенная ранее информация остается в форме, благодаря чему пользователю будет проще внести исправления. Если вывести пустую форму и предложить пользователю заполнить ее заново, он может отправиться
за необходимым товаром или услугой в другое место.
Все вместе: пример формы
От описания базовых компонентов форм мы переходим к практическому примеру — построению формы для обработки данных, введенных пользователем. Допустим, вы хотите создать форму, в которой пользователь может высказать мнение о вашем Сайте. Пример такой формы приведен в листинге 10.1.Листинг 10.1.
Пример формы для сбора данных
Внешний вид формы в браузере изображен на рис. 10.7.
Рис. 10.7. Пример формы для ввода данных
Вроде бы все понятно. Возникает вопрос — как получить данные, введенные пользователем, и сделать с ними что-нибудь полезное? Этой теме посвящен следующий раздел, «Формы и РНР».
Не забывайте: все сказанное ранее — не более чем вводный курс. Приведенная информация ни в коем случае не исчерпывает всех возможностей, предоставляемых различными компонентами форм. За дополнительной информацией обращайтесь к многочисленным учебникам по работе с формами, опубликованным в Web, а также книгам по HTML.
От предварительного знакомства с формами HTML мы переходим к самому интересному — применению РНР для обработки данных, введенных пользователем в форме.
Вводные примеры
Следующие практические примеры помогут вам быстрее освоить различные аспекты обработки форм в РНР. В этих примерах продемонстрированы разные подходы к реализации интерактивных возможностей на сайте.Пример 1: передача данных формы из одного сценария в другой
В первом примере представлена характерная ситуация — когда пользовательские данные вводятся на одной странице и отображаются на другой. В листинге 10.2 приведен код формы для ввода имени пользователя и адреса электронной почты. Когда пользователь щелкает на кнопке отправки данных (кнопка Go!), форма обращается к странице, приведенной в листинге 10.3. В свою очередь, листинг 10.3 выводит переменные $name и $mail, переданные с запросом.
Листинг 10.2.
Простая форма
Листинг 10.3.
Отображение данных, введенных в листинге 10.1
// Вывести имя и адрес электронной почты.
print "Hi. $name!. Your email address is $email";
?>
В общих чертах происходит следующее: пользователь заполняет поля формы и нажимает кнопку отправки данных. Управление передается странице, приведенной в листинге 10.3, где происходит форматирование и последующее отображение данных. Как видите, все просто.
Существует и другой способ обработки данных форм, при котором используется всего один сценарий. К недостаткам этого способа относятся увеличение сценария и как следствие — затруднения с редактированием и сопровождением. Впрочем, есть и достоинства — уменьшение количества файлов, с которыми вам приходится работать. Более того, в этом варианте сокращается избыточный код при проверке ошибок (эта тема рассматривается ниже в данной главе). Конечно, в некоторых ситуациях работать с одним сценарием неудобно, но, по крайней мере, вы должны знать об этой возможности. В примере 2 воспроизводится пример 1, но с использованием лишь одного сценария.
Пример 2: альтернативная обработка формы (с одним сценарием)
Обработка данных формы в одном сценарии реализуется относительно просто. Вы проверяете, были ли присвоены значения переменным формы. Если значения присвоены, сценарий обрабатывает их (в нашем примере — просто выводит), а если нет — отображает форму. Решение о том, было ли задано значение переменной или нет, принимается при помощи функции strcmp( ), описанной в главе 8. Пример реализации формы с одним сценарием приведен в листинге 10.4. Обратите внимание: атрибут action формы ссылается на ту же страницу, в которой определяется сама форма. Условная команда i f проверяет состояние переменной скрытого поля с именем $seenform. Если значение $seenform не задано, форма отображается в браузере, а если задано — значит, форма была заполнена пользователем и введенные данные обрабатываются сценарием (в данном примере — просто выводятся в браузере).
Листинг 10.4.
Ввод данных на форме в одном сценарии
// Все кавычки внутри $form должны экранироваться,
// в противном случае произойдет ошибка.
$form = "
";
// Если форма ранее не отображалась, отобразить ее.
// Для проверки используется значение скрытой переменной $seenform.
if ($seenform != "у"):
print "$form";
else :
print "Hi. $name!. Your email address is $email";
endif;
?>
Учтите, что этот вариант создает определенные неудобства, поскольку при повторной загрузке страницы пользователь ничего не узнает о том, правильно ли были заполнены поля формы. Процедура проверки ошибок рассматривается далее в этой главе, а пока достаточно запомнить, что ввод данных можно осуществить при помощи одного сценария.
Теперь, когда вы представляете, как просто выполняются операции с формами, мы переходим к интересному примеру — автоматической отправке данных пользователя по заданному адресу электронной почты. Эта возможность реализована в примере 3.
Пример 3: автоматическая отправка данных по электронной почте
Вывести пользовательские данные в браузере несложно, но вряд ли это можно назвать содержательной обработкой пользовательского ввода. Один из способов обработки информации заключается в ее отправке по электронной почте — например, администратору сайта. Хотя при помощи гиперссылки mailto: можно отправить сообщение прямо из браузера, следует учитывать, что внешние приложения электронной почты настроены не на каждом компьютере. Следовательно, отправка сообщений с web-формы более надежно гарантирует, что сообщение будет доставлено адресату.
В следующем разделе, mail( ), создается небольшая форма, в которой пользователь вводит информацию и комментарии по поводу сайта. Затем данные форматируются соответствующим образом и передаются стандартной функции РНР mail( ). Но прежде чем переходить к построению формы, необходимо предварительно рассмотреть синтаксис функции mail( ).
mail ( )
Функция mail( ) отправляет сообщение заданному адресату по электронной почте. Синтаксис функции mail( ):
boolean mail (string получатель, string тема, string сообщение [, string доп_заголовки])
В параметре тема, как нетрудно предположить, передается тема сообщения. Параметр сообщение содержит текст сообщения, а необязательный параметр доп_за головки предназначен для включения дополнительной информации (например, атрибутов форматирования HTML), пересылаемой с сообщением.
 В системе UNIX функция mail( ) использует утилиту sendmail. В Windows эта функция работает лишь при наличии установленного почтового сервера или если функция mail( ) связана с работающим сервером SMTP. Эта задача решается модификацией переменной SMTP в файле php.ini.
В системе UNIX функция mail( ) использует утилиту sendmail. В Windows эта функция работает лишь при наличии установленного почтового сервера или если функция mail( ) связана с работающим сервером SMTP. Эта задача решается модификацией переменной SMTP в файле php.ini.Если вы сделали все необходимое и функция mail( ) работает в вашей системе, попробуйте выполнить следующий фрагмент (конечно, адрес youraddress@yourserver.com заменяется вашим настоящим адресом электронной почты):
$email = "youraddress@yourserver.com";
$subject = "This is the subject";
$message = "This is the message";
$headers = "From: somebody@somesite.com";
mail ($email, $subject, $message, $headers);
Хотя при обширной переписке, конечно, следует использовать специализированные почтовые программы вроде majordomo (http://www.greatcircle.com/majordomo), в простых случаях функции РНР mail( ) оказывается вполне достаточно.
Итак, после знакомства с функцией mail( ) можно применить ее на практике. В листинге 10.5 показано, как получить информацию от пользователя и отправить ее по адресу, заданному администратором сценария.
Листинг 10.5.
Пересылка пользовательских данных функцией mail( )
// Все кавычки внутри $form должны экранироваться.
// в противном случае произойдет ошибка.
$form = "
// Если форма ранее не отображалась, отобразить ее.
//
Для проверки используется значение скрытой переменной $seenform.
if ($seenform != "у") :
print "$form"; else :
// Переменная $recipient определяет получателя данных формы
$recipient = "yourname@youremail.com";
// Тема сообщения
$subject = "User Comments ($name)";
// Дополнительные заголовки $headers = "From: $email";
// Отправить сообщение или выдать сообщение об ошибке
mail($recipient, $subject, $comments, $headers) or die("Could not send email!");
// Вывести сообщение для пользователя
print "Thank you $name for taking a moment to send us your comments!";
endif;
?>
Неплохо, правда? Листинг 10.5 работает так же, как листинг 10.4; сначала мы проверяем, отображалась ли форма ранее. Если это происходило, программа вызывает функцию mail( ) и пользовательские данные отправляются по адресу, определяемому переменной $recipient. Затем в браузере выводится благодарственное сообщение для пользователя.
Простейшим расширением этого примера будет отправка благодарственного сообщения по электронной почте (вторым вызовом mail( )). Следующий пример развивает эту идею — пользователю предлагается на выбор несколько бюллетеней. Выбранные бюллетени отправляются по электронной почте.
Пример 4: отправка запрашиваемой информации по электронной почте
В этом примере в форме создается несколько флажков, каждый из которых соответствует отдельному документу с информацией о сайте. Пользователь устанавливает один, два или три флажка, вводит свой адрес, и запрашиваемые брошюры отправляются ему по электронной почте. Обратите внимание на применение массива при работе с флажками — это упрощает проверку выбранных флажков, а также улучшает структуру программы.
Информационные сообщения хранятся в отдельных файлах. В нашем примере используются три текстовых файла:
Исходный текст примера приведен в листинге 10.6.
Листинг 10.6.
Отправка информации, запрашиваемой пользователем
$form = "
":
if ($seenform != "y") :
print "$form"; else :
$headers = "From: devteam@yoursite.com";
// Перебрать все пары "ключ/значение"
while ( list($key, Sval) = each ($information) ) :
// Сравнить текущее значение с "у" if ($val == "у") :
// Построить имя файла, соответствующее текущему ключу
$filename = "$key.txt":
$subject = "Requested $key information";
// Открыть файл
$fd = fopen ($filename, "r");
// Прочитать содержимое всего файла в переменную $contents = fread ($fd. filesize ($filename));
// Отправить сообщение
mail($email, $subject, $contents, $headers) or die("Can't send email!");; fclose($fd);
endif;
endwhile;
// Известить пользователя об успешной отправке
print sizeof($information)." informational newsletters
have been sent to $email!";
endif;
?>
В листинге 10.6 мы перебираем пары «ключ/значение» в цикле while и отправляем только те бюллетени, у которых значение равно у. Следует помнить, что имена текстовых файлов должны соответствовать ключам массива
(site.txt, team.txt и events.txt). Имя файла строится динамически по ключу, после чего файл открывается по имени и его содержимое загружается в переменную ($contents). Затем переменная $contents передается функции mail( ) в качестве параметра.
В следующем примере пользовательские данные сохраняются в текстовом файле.
Пример 5: сохранение пользовательских данных в текстовом файле
Пользовательские данные сохраняются в текстовом файле для последующего статистического анализа, поиска и т. д. — короче, любой обработки по вашему усмотрению. В листинге 10.7, как и в предыдущих примерах, данные формы обрабатываются в одном сценарии. Пользователю предлагается ввести четыре объекта данных: имя, адрес электронной почты, язык и профессию. Введенная информация сохраняется в текстовом файле user_information.txt. Элементы данных разделяются символами «вертикальная черта» (|).
Листинг 10.7.
Сохранение пользовательской информации в текстовом файле
// Создать форму
$form = "
";
// Заполнялась ли форма ранее? if ($seenform != "у") :
print "$form"; else :
$fd = fopen("useMnformation.txt", "a");
// Убедиться, что во введенных данных не встречается
// вертикальная черта.
$name = str_replace("|", "", $name);
$email = str_replace("|", "", $email);
// Построить строку с пользовательскими данными
$user_row = $name." ".$email."|".$language." ".$job."\n";
fwrite($fd, $user_row) or die("Could not write to file!");
fclose($fd);
print "Thank you for taking a moment to fill out our brief questionnaire!":
endif;
?>
Обратите внимание на фрагмент, в котором мы проверяем, что пользователь не включил в имя или адрес электронной почты символы «вертикальная черта» (|). Функция str_replace( ) удаляет эти символы, заменяя их пустой строкой. Если бы это не было сделано, пользовательские символы | нарушили бы структуру файла данных и существенно затруднили (а то и сделали невозможным) его правильную обработку.
При работе с относительно малыми объемами информации вполне можно обойтись текстовыми файлами. Однако при большом количестве пользователей или объеме сохраняемой информации для хранения и обработки данных, введенных в форме, лучше воспользоваться базой данных. Эта тема подробно рассматривается в главе 11.
До настоящего момента предполагалось, что пользователь всегда вводит правильные данные и не действует злонамеренно. В высшей степени оптимистичное предположение! В следующем разделе мы усовершенствуем рассмотренные примеры и организуем проверку целостности данных форм. Проверка ошибок не только обеспечивает удаление неполной и неправильной информации, но и обеспечивает более эффективный и удобный интерфейс.
PHP 4 на практике
Что такое SQL?
SQL обычно описывается как стандартный язык, используемый для взаимодействия с реляционными базами данных (см. ниже). Однако SQL не является языком программирования, как С, C++ или РНР. Скорее, это интерфейсное средство для выполнения различных операций с базами данных, предоставляющее в распоряжение пользователя стандартный набор команд. Возможности SQL не ограничиваются выборкой данных из базы. В SQL поддерживаются разнообразные возможности для взаимодействия с базой данных, в том числе:— определение конструкций, используемых при хранении данных;
— загрузка данных из базы и их представление в формате, удобном для вывода;
— вставка, обновление и удаление информации;
— возможность разрешения/запрета выборки, вставки, обновления и удаления данных на уровне отдельных пользователей;
— сохранение структуры данных при возникновении таких проблем, как параллельные обновления или системные сбои.
Обратите внимание: в определении SQL было сказано, что этот язык предназначен для работы с реляционными базами данных. В реляционных СУБД данные организуются в виде набора взаимосвязанных таблиц. Связи между таблицами реализуются в виде ссылок на данные других таблиц. Таблицу можно представить себе как двухмерный массив, в котором расположение каждого элемента характеризуется определенными значениями строки и столбца. Пример реляционной базы данных изображен на рис. 11.1.
Рис. 11.1.
Пример реляционной базы данных
Как видно из рис. 11.1, каждая таблица состоит из строк (записей) и столбцов (полей). Каждому полю присваивается уникальное (в рамках данной таблицы) имя. Обратите внимание на связь между таблицами customer и orders, обозначенную стрелкой. В информацию о заказе включается короткий идентификатор клиента, что позволяет избежать избыточного хранения имени и прочих реквизитов клиента. В изображенной базе данных существует еще одна связь — между таблицами orders и products. Эта связь устанавливается по полю prod_id, в котором хранится идентификатор товара, заказанного данным клиентом (определяемого полем custjd). Наличие этих связей позволяет легко ссылаться на полные данные клиента и товара по простым идентификаторам. Правильно организованная база данных превращается в мощное средство организации и эффективного хранения данных с минимальной избыточностью. Запомните эту базу данных, я буду часто ссылаться на нее в дальнейших примерах.
Итак, как же выполняются операции с реляционными базами данных? Для этого в SQL существует специальный набор общих команд — таких, как SELECT, INSERT, UPDATE и DELETE. Например, если вам потребуется получить адрес электронной почты клиента с идентификатором 2001cu (см. рис. 11.1), достаточно выполнить следующую команду SQL:
SELECT cust_email FROM customers WHERE custjd = '2001cu'
Все вполне логично, не правда ли? В обобщенном виде команда выглядит так:
SELECT имя_поля FROM имя_таблицы [ WHERE условие ]
Квадратные скобки означают, что завершающая часть команды является необязательной. Например, для получения адресов электронной почты всех клиентов из таблицы customers достаточно выполнить следующий запрос:
SELECT cust_email FROM customers
Предположим, вы хотите включить в таблицу products новую запись. Простейшая команда вставки выглядит так:
INSERT into products VALUES ('1009pr', 'Red Tomatoes', '1.43');
Если позднее эти данные потребуется удалить, воспользуйтесь следующей командой:
DELETE FROM products WHERE prod_id = 1009r';
Существует много разновидностей команд SQL, и полное их описание выходит за рамки этой книги. На эту тему вполне можно написать отдельную книгу! Я постарался сделать так, чтобы команды SQL, используемые в примерах, были относительно простыми, но достаточно реальными. В Web существует много учебной информации и ресурсов, посвященных SQL. Некоторые ссылки приведены в конце этого раздела.
 Записывать команды SQL символами верхнего регистра необязательно. Впрочем, я предпочитаю именно такую запись, поскольку она помогает различать компоненты запроса.
Записывать команды SQL символами верхнего регистра необязательно. Впрочем, я предпочитаю именно такую запись, поскольку она помогает различать компоненты запроса.Раз вы читаете эту книгу, вероятно, вас интересует вопрос, как же организуется работа с базами данных в среде Web? Как правило, сначала при помощи какого-
либо интерфейсного языка (РНР, Java или Perl) создается соединение с базой данных, после чего программа обращается к базе с запросами, используя стандартный набор средств. Интерфейсный язык можно рассматривать как своего рода «клей», связывающий базу данных с Web. Я перехожу к своему любимому интерфейсному языку — РНР.
Дополнительные ресурсы
Ниже перечислены некоторые ресурсы Интернета, посвященные SQL. Они пригодятся как новичкам, так и опытным программистам.
PHP 4 на практике
Базы данныхСредства эффективного хранения и выборки больших объемов информации внесли огромный вклад в успешное развитие Интернета. Обычно для хранения информации используются базы данных. Работа таких известных сайтов, как Yahoo, Amazon и Ebay, в значительной степени зависит от надежности баз данных, хранящих громадные объемы информации. Конечно, поддержка баз данных ориентирована не только на интересы гигантских корпораций — в распоряжении web-программистов имеется несколько мощных реализаций баз данных, распространяемых по относительно низкой цене (а то и бесплатно).
Правильная организация базы данных обеспечивает более быстрые и гибкие возможности выборки данных. Она существенно упрощает реализацию средств поиска и сортировки, а проблемы прав доступа к информации решаются при помощи средств контроля за привилегиями, присутствующими во многих системах управления базами данных (СУБД). Кроме того, упрощаются процессы репликации и архивации данных.
Глава начинается с подробного описания выборки и обновления данных в MySQL — вероятно, самой популярной СУБД, используемой в PHP (http://www.mysql.com). На примере MySQL будет показано, как в РНР происходят загрузка и обновление данных в базе; мы рассмотрим базовые средства поиска и сортировки, используемые во многих web-приложениях. Затем мы перейдем к реализованной в РНР поддержке ODBC (Open Data Base Connectivity) — обобщенного интерфейса, который может использоваться для одновременного соединения с разными СУБД. Поддержка ODBC в РНР будет продемонстрирована на примере соединения и выборки данных из базы данных Microsoft Access. Глава завершается проектом, в котором РНР и СУБД MySQL используются для создания иерархического каталога с информацией об избранных сайтах. При включении в каталог новых сайтов пользователь относит их к одной из стандартных категорий, определяемых администратором сайта.
Прежде чем переходить к обсуждению MySQL, я хочу сказать несколько слов об SQL — самом распространенном языке для работы с базами данных. Язык SQL заложен в основу практически всех существующих СУБД. Чтобы перейти к рассмотрению примеров работы с базами данных, необходимо хотя бы в общих чертах представлять, как работает SQL.
Microsoft Access и РНР
Популярность СУБД Microsoft Access (http://www.microsoft.com/office/access) отчасти объясняется ее удобным графическим интерфейсом. Помимо использования Access в качестве самостоятельной СУБД, вы можете использовать ее графический интерфейс для организации работы с другими базами данных — например, MySQL или Microsoft SQL Server.Чтобы продемонстрировать поддержку ODBC в РНР, я опишу процесс подключения к базам данных Microsoft Access на РНР. Делается это на удивление просто, но благодаря популярности Microsoft Access это станет полезным дополнением в вашем творческом арсенале. Я опишу этот процесс шаг за шагом:
Все, что вам остается сделать — создать сценарий, в котором вы будете работать с базой данных через ODBC. В приведенном ниже сценарии общие функции ODBC (см. выше) будут использоваться для вывода всей информации из таблицы контактов, созданной при помощи мастера Access. Однако перед рассмотрением сценария желательно знать, как таблица Contacts выглядит в Access (рис. 11.3).
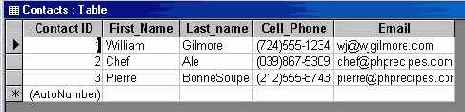
Рис. 11.3.
Таблица Contacts в MS Access
Теперь вы знаете, какая информация будет извлекаться из базы данных, и мы можем перейти к сценарию. Если вы забыли, что делает та или иная функция, обращайтесь к описанию в начале этой главы. Результаты работы листинга 11.7 представлены на рис. 11.4.
Листинг 11.7.
Применение функций ODBC для работы с MS Access
// Подключиться к источнику данных ODBC 'ContactDB' ;connect = odbc_connect("ContactDB", "","")
or die("Couldn't connect to datasource.");
// Создать текст запроса
$query = "SELECT First_Name, Last_Name, Cell_Phone, Email FROM Contacts";
// Подготовить запрос
$result = odbc_prepare($connect,$query);
// Выполнить запрос и вывести результаты
odbc_execute($result);
odbc_result_all($result, "BGCOLOR='#c0c0c0' border=1");
// Обработка результатов закончена, освободить память odbc_free_result($result);
// Закрыть соединение odbc_close($connect);
?>
Не правда ли, все просто? А самое замечательное — то, что этот сценарий полностью совместим с любой другой СУБД с поддержкой ODBC. Для тренировки попробуйте повторить все описанные действия для другой СУБД, запустите сценарий — и вы получите те же результаты, которые изображены на рис. 11.4.

Рис. 11.4.
Содержимое таблицы Contacts в web-браузере
MySQL
MySQL (http://www.mysql.com) — надежная СУБД на базе SQL, разработанная и сопровождаемая фирмой Т.с.Х DataKonsultAB (Стокгольм, Швеция). Начиная с 1995 года, MySQL стала одной из самых распространенных СУБД в мире, что отчасти обусловлено ее скоростью, надежностью и гибкой лицензионной политикой (см. ниже).Благодаря хорошим характеристикам и обширному набору стандартных интерфейсных функций, очень простых в использовании, MySQL стала самым популярным средством для работы с базами данных в РНР.
MySQL распространяется на условиях общей лицензии GNU (GPL, GNU Public License). Полное описание текущей лицензионной политики MySQL приведено на сайте MySQL (http://www.mysql.com).Настройка MySQL
После успешной установки сервер MySQL необходимо настроить. Процесс настройки в основном состоит из создания новых баз данных и редактирования таблицпривилегий MySQL. Таблицы привилегий управляют доступом к базам данных MySQL. Правильная настройка таблиц играет чрезвычайно важную роль в безопасности ваших баз данных, поэтому перед запуском сайта в рабочем режиме необходимо полностью освоить систему привилегий.
На первый взгляд, таблицы привилегий MySQL выглядят устрашающе, но если в них как следует разобраться, дальнейшее сопровождение становится очень простой задачей. Полное описание таблиц привилегий выходит за рамки этой книги. Впрочем, в Web существует немало ресурсов, предназначенных для помощи начинающим пользователям MySQL. За дополнительной информацией обращайтесь на сайт MySQL (http://www.mysql.com).
После успешной установки и настройки пакета MySQL можно начинать эксперименты с базами данных в среде Web! Именно этой теме и посвящен следующий раздел. Начнем с изучения поддержки MySQL в РНР.
ODBC
Специализированные функции хорошо подходят для работы с одним конкретным типом СУБД. Но что делать, если вам приходится подключаться к MySQL, Microsoft SQL Server и IBM DB2, притом в одном приложении? Аналогичная проблема возникает при разработке приложений, которые не должны зависеть от СУБД; такие приложения работают «над» существующей инфраструктурой клиентской базы данных. ODBC (сокращение от «Open Database Connectivity», то есть «открытая архитектура баз данных») представляет собой интерфейс прикладных программ (API), позволяющий использовать общий набор абстрактных функций для работы с разными типами баз данных. Преимущества подобного подхода очевидны — вам не придется многократно переписывать один и тот же фрагмент кода только для того, чтобы выполнять одинаковые операции с разнотипными базами данных.Работа с сервером баз данных через ODBC возможна лишь в том случае, если этот сервер является ODBC-совместимым. Другими словами, для него должны существовать драйверы ODBC. За дополнительной информацией о драйверах ODBC обращайтесь к документации СУБД. Возможно, вам придется дополнительно загрузить их из Интернета и установить на своем компьютере. Хотя стандарт ODBC, разработанный компанией Microsoft, стал открытым стандартом, он в основном используется для работы с СУБД на платформе Windows; впрочем, драйверы ODBC также существуют и на платформе Linux. Ниже приведены ссылки на драйверы для некоторых популярных СУБД.
Драйверы ODBC различаются по целям, платформе и назначению. За информацией о различных аспектах работы с этими драйверами обращайтесь к документации по конкретным пакетам. Впрочем, невзирая на все различия, использование этих драйверов в РНР обходится без проблем.
Когда вы определите, какой комплект драйверов ODBC лучше подходит для ваших целей, загрузите его и выполните все инструкции по установке и настройке. После этого можно переходить к следующему разделу — «Поддержка ODBC в РНР».
Поддержка баз данных в РНР
Если бы мне предложили назвать самый важный аспект РНР, вероятно, я бы остановился на поддержке баз данных. В РНР реализована обширная поддержка практически всех существующих серверов баз данных, в том числе:| Adabas D | Informix | PostgreSQL | |
| Dbase | Ingres | Solid | |
| Direct MS-SQL | InterBase | Sybase | |
| Empress | mSQL | UNIX dbm | |
| File-Pro (read-only) | MySQL | Velods | |
| FrontBase | ODBC | ||
| IBM DB2 | Oracle (OCI7 и OC18) | Как показывает этот список, поддержка баз данных в РНР простирается от совместимости с базами данных, известных всем (например, Oracle), до тех, о которых многие даже не слышали. Мораль — если вы собираетесь использовать серьезную СУБД для хранения информации, распространяемой через Web, скорее всего, эта база данных поддерживается в РНР. Поддержка базы данных в РНР представлена набором стандартных функций для соединения с базой, обработки запросов и разрыва связи. |
 Функция используется для открытия восстанавливаемых (persistent) соединений с базами данных. Она экономит системные ресурсы, поскольку odbc_pconnect( ) проверяет, не было ли данное соединение открыто ранее, и если было, использует предыдущее соединение.
Функция используется для открытия восстанавливаемых (persistent) соединений с базами данных. Она экономит системные ресурсы, поскольку odbc_pconnect( ) проверяет, не было ли данное соединение открыто ранее, и если было, использует предыдущее соединение.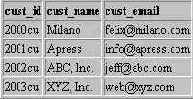
| Category: $categories[$category] |
| "; print "".$row["site_name"]." print " |
| "; print "http://". $row["url"]." "; print " |
| "; print $row["description"]." "; print " |
| There are currently no bookmarks falling under this category. Why don't you add one? |
print "Add a bookmark
// view bookmark
?>
Следующая страница, add_bookmark.php (листинг 11.9), предназначена для ввода информации о новой ссылке, включаемой в базу данных. Для обработки пользовательских данных вызывается функция add_bookmark( ).
Листинг 11.9.
Программа add_bookmark.php
INCLUDE("init.inc");
?>
if (! $seenform) :
else :
add_bookmark($category, $site_name, $url, $description);
print "
Your bookmark has been added to the repository.
Click here to return to the index.
";endif;
?>
При исходной загрузке страницы в браузере отображается форма (рис. 11.5).
После сохранения ссылки в базе программа выдает соответствующее сообщение и создает ссылку для перехода к домашней странице приложения index.php (листинг 11.11).
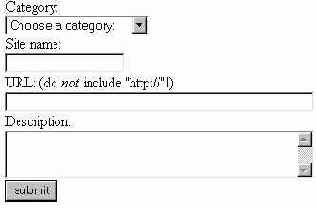
Рис. 11.5.
Форма, отображаемая страницей add_bookmark.php
Следующая страница, view_bookmark.php, просто вызывает функцию view_bookmark( ). Код этой страницы приведен в листинге 11.10.
Листинг 11.10.
Программа view_bookmark.php
INCLUDE("Listing11-8.php"); ?>
view_bookmark($category) :
?>
Если занести в категорию dining информацию о нескольких сайтах, страница view_bookmark. php будет выглядеть примерно так, как показано на рис. 11.6.
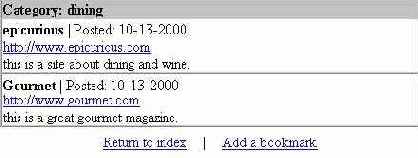
Рис. 11.6.
Выполнение страницы view_bookmark.php для категории dining
Остается лишь создать страницу, на которой пользователь выбирает ссылки из списка. Я назвал этот файл index.php (листинг 11.11).
Листинг 11.11.
Программа index.php
INCLUDE("init.inc");
?>
alink="#808040">
Choose bookmark category to view:
// Перебрать категории и создать соответствующие ссылки
while (list($key, Svalue) = each(Scategories)) :
print "$value
";
endwhile;
?>
Add a new bookmark
Если оставить в массиве $categories значения, сохраненные в файле init.inc, в результате выполнения листинга 11.11 в браузер будет отправлен код HTML, приведенный в листинге 11.12.
Листинг 11.12.
Выходные данные, сгенерированные при выполнении index.php
Choose bookmark category to view:
computers
entertainment
dining
lifestyle
government
travel
Add a new bookmark
Если щелкнуть на любой ссылке из приведенного выше,фрагмента HTML, в браузере загружается файл view_bookmark.php, который вызывает функцию view_bookmark( ) и передает ей значение переменной $category.
Простейшая поисковая система
Всем нам неоднократно приходилось пользоваться поисковыми системами в Web, но как устроены такие системы? Простейшая поисковая система принимает по крайней мере одно ключевое слово. Это слово включается в запрос SQL, который затем используется для выборки информации из базы данных. Результат поиска форматируется поисковой системой по тому или иному критерию (скажем, по категории или степени соответствия).Поисковая система, приведенная в листинге 11.5, предназначена для поиска информации о клиентах. В форме пользователь вводит ключевое слово и выбирает категорию (имя, идентификатор или адрес электронной почты клиента), в которой будет производиться поиск. Если введенное пользователем имя, идентификатор или адрес существует, поисковая система извлекает из базы данных остальные атрибуты. Затем по идентификатору покупателя из таблицы orders выбирается
история заказов. Все заказы, оформленные этим клиентом, отображаются по убыванию объема. Если заданное ключевое слово не встречается в категории, указанной пользователем, поиск прекращается, программа выводит соответствующее сообщение и снова отображает форму.
Листинг 11.5.
Простейшая поисковая система (searchengine.php)
$form =
"
// Если форма еще не отображалась - отобразить ее
if (Sseenform != "у") :
print $form; else :
// Подключиться к серверу MySQL и выбрать базу данных
@mysql_connect("localhost", "web", "ffttss")
or die(" Could not connect to MySQL server!");
@mysql_select_db("company")
or die("Could not select company database!");
// Построить и выполнить запрос
$query = "SELECT cust_id. cust_name, cust_email
FROM customers WHERE $category = '$keyword'";
$result = mysql_query($query);
// Если совпадения не найдены, вывести сообщение
// и заново отобразить форму
if (mysql_num_rows($result) == 0) :
print "Sorry, but no matches were found. Please try your search again:";
print $form;
// Найдены совпадения. Отформатировать и вывести результаты, else :
// Отформатировать и вывести значения полей.
list($id, $name, $email) = mysql_fetch_row($result);
print "
Customer Information:
";print "Name: $name
";
print "Identification #: $id
";
print "Email: $email
";
print "
Order History:
";// Построить и выполнить запрос к таблице 'orders'
$query = "SELECT order_id, prod_id, quantity
FROM orders WHERE cust_id = '$id'
ORDER BY quantity DESC";
$result = mysql_query($query):
print "
| 0rder ID | Product ID | Quantity |
|---|---|---|
| $order_id | $prod_id | $quantity | ";
endif;
endif;
?>
Если ввести ключевое слово Mi 1 апо и выбрать в раскрывающемся списке категорию Customer Name (Имя клиента), программа выводит следующую информацию:
Customer information:
Name:Milano
Identification#:2000cu
Email:felix@milano.com
Order History:
| Order Id | Product Id | Quantity | |
| 100003 | 1000pr | 12 | |
| 100005 | 1002pr | 11 | Конечно, мы рассмотрели простейшую реализацию поисковой системы. Существует немало дополнительных возможностей — поиск по нескольким ключевым словам, поиск по неполным ключевым словам или автоматическая выборка записей с похожими ключевыми словами. Попробуйте применить свою творческую фантазию и реализовать их самостоятельно.
| Order ID | Customer ID | Product ID | Quantity |
|---|---|---|---|
| $order_id | $cust_id | $prod_id | $quantity | ";
Для базы данных company, изображенной на рис. 11.1, стандартные выходные данные листинга 11.6 выглядят следующим образом:
| Order ID | Customer ID | Product ID | Quantity |
| 100003 | 2000cu | 1000pr | 12 |
| 100005 | 2000cu | 1002pr | 11 |
| 100004 | 2000cu | 1000pr | 9 |
| 100002 | 2000cu | 1001pr | 5 |
| 100001 | 2000cu | 1002pr | 3 | Обратите внимание: заголовки таблицы представляют собой гиперссылки. Поскольку по умолчанию сортировка осуществляется по полю quantity, записи отсортированы по убыванию последнего столбца. Если щелкнуть на ссылке Order_ID, страница загружается заново, но на этот раз записи сортируются по убыванию идентификатора заказа. Таблица будет выглядеть так:
| Order ID | Customer ID | Product ID | Quantity |
| 100005 | 2000cu | 1002pr | 11 |
| 100004 | 2000cu | 1000pr | 9 |
| 100003 | 2000cu | 1000pr | 12 |
| 100002 | 2000cu | 1001pr | 5 |
| 100001 | 2000cu | 1002pr | 3 | Сортировка выходных данных приносит огромную пользу при форматировании баз данных. Простая модификация запроса SELECT позволяет упорядочить данные по любому критерию — по возрастанию, по убыванию или с группировкой записей.
 В одной специфической ситуации функция mysql_affected_rows( ) работает с ошибкой. При выполнении команды DELETE без секции WHEREmysql_affected_rows( ) всегда возвращает 0.
В одной специфической ситуации функция mysql_affected_rows( ) работает с ошибкой. При выполнении команды DELETE без секции WHEREmysql_affected_rows( ) всегда возвращает 0.| Product ID | Product Name | Product Price | \n
|---|---|---|
| $id | \n$name | \n$price | \n";
mysql_close();
?>
В результате выполнения этого примера с данными, изображенными на рис. 11.1, будет получен следующий результат:
Листинг 11.2.
Результат выполнения листинга 11.1
| Product ID | Product Name | Product Price |
|---|---|---|
| 1000pr | apples | 1.23 |
| 1001pr | oranges | 2.34 |
| 1002pr | bananas | 3.45 |
| 1003pr | pears | 4.45 |
Функция mysql_result( ) удобна для работы с относительно небольшими наборами данных, однако существуют и другие функции, работающие намного эффективнее, — а именно, функции mysql_fetch_row( ) и mysql_fetch_array( ). Эти функции описаны в следующих разделах.
mysql_fetch_row()
Обычно гораздо удобнее сразу присвоить значения всех полей записи элементам индексируемого массива (начиная с индекса 0), нежели многократно вызывать mysql_result( ) для получения отдельных полей. Задача решается функцией mysql_fetch_row( ), имеющей следующий синтаксис:
array mysql_fetch_row (int результат)
Использование функции list( ) в сочетании с mysql_fetch_row( ) позволяет сэкономить несколько команд, необходимых при использовании mysql_result( ). В листинге 11.3 приведен код листинга 11.1, переписанный с использованием list( ) и mysql_fetch_row( ).
Листинг 11.3.
Выборка данных функцией mysql_fetch_row( )
@mysql_connect( "localhost", "web", "ffttss") or die("Could not connect to MySQL server!");
@mysql_select_db("company") or die("Could not select products database!");
$query = "SELECT * FROM products";
$result = mysql_query($query);
print "
| Product ID | Product Name | Product Price | \n
|---|---|---|
| ".$row["prod_id"]." | \n".$row["prod_name"]." | \n" .$row["prod_price"]. " | \n";
mysql_close();
?>
Листинг 11. 3 выдает тот же результат, что и листинг 11.1, но использует при этом меньшее количество команд.
my sq l_f etch_array ( )
Функция mysql_fetch_array( ) аналогична mysql_fetch_row( ), однако по умолчанию значения полей записи сохраняются в ассоциативном массиве. Впрочем, вы можете выбрать тип индексации (ассоциативная, числовая или комбинированная). Синтаксис функции mysql_fetch_array( ):
array mysql_fetch_array (int идентификатор результата [, тип_индексации])
В параметре идентификатор_результата передается значение, возвращенное функцией mysql_query( ). Необязательный параметр тип_индексации принимает одно из следующих значений:
Листинг 11.4 содержит очередной вариант кода листингов 11.1 и 11.3. На этот раз используется функция mysql_fetch_array( ), возвращающая ассоциативный массив полей.
Листинг 11.4.
Выборка данных функцией mysql_fetch_array( )
@mysql_connect( "local host", "web", "ffttss")
or die("Could not connect to MySQL server!");
@mysql_select_db( "company" )
or die("Could not select products database!");
$query = "SELECT * FROM products";
$result = mysql_query($query);
"
| Product ID | Product Name | Product Price | \n
|---|---|---|
| ".$row["prod_id"]." | \n".$row["prod_name"]." | \n" . $row["prod_price"] . " | \n" ;
mysql_close();
?>
Листинг 11.4 выдает тот же результат, что и листинги 11.1 и 11.3.
Того, что сейчас вы знаете о функциональных возможностях MySQL в РНР, вполне достаточно, чтобы заняться созданием довольно интересных приложений. Первое приложение, которое мы рассмотрим, представляет собой простейшую поисковую систему. Этот пример демонстрирует применение форм HTML (см. предыдущую главу) для получения данных, которые в дальнейшем используются для выборки информации из базы.
Установка
Одна из причин популярности MySQL среди пользователей РНР заключается в том, что поддержка этого сервера автоматически включается в поставку РНР. Таким образом, вам остается лишь проследить за правильной установкой пакета MySQL СУБД MySQL совместима практически с любой серьезной операционной системой, включая FreeBSD, Solaris, UNIX, Linux и различные верии Windows. Хотя лицензионная политика MySQL отличается большей гибкостью в сравнении с другими серверами баз данных, я настоятельно рекомендую ознакомиться с лицензионной информацией, размещенной на сайте MySQL (http://www.mysql.com).Последнюю версию MySQL можно принять с любого зеркального сайта. Полный список зеркальных сайтов приведен по адресу http://www.mysql.com/downloads/ mirrors.html. На момент написания книги последняя стабильная версия MySQL имела номер 3.22.32, а версия 3.32 находилась на стадии бета-тестирования. Конечно, всегда следует устанавливать последнюю стабильную версию, это в ваших интересах. Посетите ближайший «зеркальный» сайт и загрузите версию, соответствующую вашей операционной системе. В верхней части страницы расположены ссылки на новые версии для различных платформ. Обязательно прочитайте всю страницу, поскольку она завершается ссылками для некоторых специфических ОС.
Группа разработчиков MySQL подготовила подробную документацию с описанием процесса установки. Я советую внимательно изучить все общие аспекты установки, не ограничиваясь информацией, относящейся непосредственно к вашей операционной системе.
PHP 4 на практике
Недостатки системы шаблонов
Хотя рассмотренная система шаблонов справляется со своей главной задачей — полным разделением дизайна и программирования, она не лишена недостатков. Некоторые из этих недостатков перечислены ниже.Необоснованные надежды на «идеальное решение»
Шаблоны помогают четко выделить в проекте аспекты программирования и дизайна, но они не заменяют нормального взаимодействия между этими аспектами. Более того, правильность их работы зависит от предварительного согласования списка переменных, заменяемых в процессе обработки шаблона. Как и в любом успешном проекте, переходить к написанию кода РНР следует лишь после тщательной проработки спецификации всего приложения. Это значительно уменьшает вероятность ошибок при последующей обработке, приводящих к непредвиденным последствиям при использовании шаблонов.Нетривиальная система шаблонов
Как говорилось ранее, главной целью при разработке подобных систем шаблонов является фактическое отделение дизайна от функциональных возможностей. Собственно, эта система и создается для того, чтобы программисты и дизайнеры могли независимо трудиться над своими аспектами приложения, не мешая работе другой группы.К счастью, сделать это проще, чем кажется на первый взгляд, — при условии, что до
начала разработки было проведено некоторое предварительное планирование. В листинге 12.1 представлен некий базовый шаблон, созданный на основе материала этой главы.
Листинг 12.1.
Пример шаблона
Welcome to your default home page. {user_name}!
You have 5 MB and 3 email addresses at your disposal.
Have fun!
Обратите внимание на три строки (page_title, bg_color и userjiame), заключенные в фигурные скобки ({ }). Фигурные скобки имеют особый смысл при обработке шаблонов — заключенная в них строка интерпретируется как имя переменной, вместо которого подставляется ее значение. Дизайнер строит страницу по своему усмотрению; все, что от него потребуется, — включать в соответствующие места документа эти ключевые строки. Конечно, программисты и дизайнеры должны заранее согласовать имена всех переменных!
Итак, как же работает эта схема? Прежде всего, возможно, нам придется одновременно работать с несколькими шаблонами, обладающими одними и теми же общими атрибутами. В таких ситуациях применение технологии объектно-ориентированного программирования (ООП) оказывается особенно эффективным. По этой причине все функции построения и выполнения операций с шаблонами будут оформлены в виде методов класса. Определение класса начинается так:
class template {
VAR $files = array( );
VAR $variables = array( );
VAR $openi ng_escape = '{';
VAR $closing_escape = '}';
В массиве $files хранятся идентификаторы файлов и содержимое каждого файла. Атрибут $variables представляет собой двухмерный массив для хранения файлового идентификатора (ключа) и всех соответствующих переменных, обрабатываемых в схеме шаблонов. Наконец, атрибуты $opening_escape и $closing_escape задают ограничители для частей шаблона, которые должны заменяться системой. Как было показано в листинге 12.1, в наших примерах в качестве ограничителей будут использоваться фигурные скобки ({ }). Впрочем, вы можете изменить два последних атрибута и выбрать ограничители по своему усмотрению. Главное — проследите за тем, чтобы эти символы не использовались для других целей.
Каждый метод класса решает конкретную задачу, соответствующую той или иной операции в процессе обработки шаблона. На простейшем уровне этот процесс можно разделить на четыре стадии.
 Применение концепций ООП в РНР рассматривалось в главе 6. Если вы не знакомы с ООП, я рекомендую бегло просмотреть главу 6 перед тем, как читать дальше.
Применение концепций ООП в РНР рассматривалось в главе 6. Если вы не знакомы с ООП, я рекомендую бегло просмотреть главу 6 перед тем, как читать дальше.О чем говорилось выше
До настоящего момента я упоминал о двух разных подходах к созданию шаблонов РНР:Хотя первая схема более понятна и проще реализуется, она также в большей степени ограничивает вашу свободу действий. Главная проблема заключается в том, что код РНР смешивается с компонентами HTML, образующими макет страницы. Возникающие при этом проблемы связаны не только с необходимостью потенциальной поддержки одновременного доступа к странице и ее модификации, но и с повышенной вероятностью ошибок при непосредственном просмотре и редактировании страниц.
Вторая схема во многих ситуациях оказывается гораздо удобнее первой. Тем не менее, хотя структура «заголовок — основная часть — колонтитул» (см. главу 9)
хорошо подходит для структурирования относительно малых сайтов с четко определенным форматом, с увеличением объемов и сложности проекта эти ограничения проявляются все заметнее. Попытки решения этих проблем привели к разработке новой схемы применения шаблонов, более сложной по сравнению с двумя первыми, но и обладающей существенно большей гибкостью. В этой схеме разделяются два главных компонента web-приложения: дизайн и программирование. Подобное деление обеспечивает возможность параллельной разработки (web-дизайн и программирование) без необходимости постоянной координации на протяжении всего рабочего цикла. Более того, оно позволяет в будущем модифицировать один компонент, не влияя на работу другого. В следующем разделе я покажу, как устроена одна из таких схем «нетривиальных шаблонов». Следует помнить, что эта схема существует не только в РНР. Более того, она появилась задолго до РНР и в настоящее время используется в нескольких языках, включая РНР, Perl и Java Server Pages. To, что описано в этой главе, — не более чем адаптация этой схемы применительно к РНР.
Обработка файла
После того как файлы и переменные будут зарегистрированы в системе шаблонов, можно переходить к обработке зарегистрированных файлов и замене всех ссылок на переменные с соответствующими значениями. Метод file_parser( ) приведен в листинге 12.4.Листинг 12.4.
Метод обработки файла
function file_parser($file_id) {
// Сколько переменных зарегистрировано для данного файла?
$varcount = count($this->variables[$file_id]);
// Сколько файлов зарегистрировано?
$keys = array_keys($this->files):
// Если файл $file_id существует в массиве
$this->files
// и с ним связаны зарегистрированные переменные
If ( (in_array($file_id. $keys)) && ($varcount > 0) ) :
// Сбросить $x $x = 0:
// Пока остаются переменные для обработки...
while ($x < sizeof($this->variables[$file_id])) :
// Получить имя очередной переменной $string = $this->variables[$file_id][$x];
// Получить значение переменной. Обратите внимание:
// для получения значения используется конструкция $$.
// Полученное значение подставляется в файл вместо
// указанного имени переменной.GLOBAL $$string:
// Построить точный текст замены вместе с ограничителями
$needle = $this->opening_escape.$string.$this->closing_escape;
// Выполнить замену.
$this->files[$file_id] = str_replace( $needle.
$$string.
$this->files[$file_id]);
// Увеличить $х $x++;
endwhile;
endif;
}
Сначала мы проверяем, присутствует ли указанное имя файла в массиве $this->files. Если файл был зарегистрирован, мы также проверяем, были ли для него зарегистрированы переменные, и если были — значения этих переменных подставляются в содержимое $file_id. Пример:
// Включить класс шаблона include("template. class") ;
$page_title = "Welcome to your homepage!";
$bg_color = "white"; $user_name = "Chef Jacques";
// Создать новый экземпляр класса
$template = new template;
// Зарегистрировать файл "homepage.html",
II
присвоив ему псевдоним "home"
$template->register_file( "home", "homepage.html");
// Зарегистрировать несолько переменных
$template->register_variables("home", "page_titie, bg_color, user_name");
$template->file_parser("home");
Поскольку переменные page_title, bg_color и user_name были зарегистрированы, значения каждой переменной (присвоенные в начале сценария) подставляются в страницу homepage.html, хранящуюся в массиве files (атрибуте объекта-шаблона). На этом предварительная подготовка завершается, остается лишь вывести полученный шаблон в браузере. Эта операция рассматривается в следующем разделе.
Ориентация дизайна на РНР
Одна из главных целей создания шаблонов заключается в том, чтобы по возможности изолировать дизайнера от программного кода при редактировании внешнего вида и поведения страницы. В идеальном случае дизайнер должен обладать некоторыми навыками программирования или, по крайней мере, быть знакомым с общими концепциями — переменными, циклами и условными командами. Дизайнеру, абсолютно не разбирающемуся в них, применение шаблонов практически ничего не даст, кроме относительно бесполезных сведений из области синтаксиса. В общем, независимо от того, захотите вы пользоваться этим типом шаблонов или нет, я настоятельно рекомендую потратить немного времени и обучить дизайнера азам языка РНР... а еще лучше — купить ему эту книгу! От этого выиграют обе стороны, поскольку дизайнер приобретет дополнительные навыки и станет более ценным членом рабочей группы, а у программиста появится новый источник идей. Может, дизайнер и не изобретет ничего выдающегося, но зато он взглянет на ситуацию под новым углом зрения, обычно недоступным для программиста.Проект: адресная книга
Хотя системы шаблонов хорошо подходят для многих типов web-приложений, они приносят особенную пользу в приложениях, ориентированных на выборку и вывод данных, в которых особенно важно обеспечить правильное форматирование.Примером такого приложения является адресная книга. Представьте себе обычную (бумажную) адресную книгу: все страницы выглядят практически одинаково, различаются разве что буквы, с которых начинаются имена на конкретной странице. Аналогичный подход можно применить и к адресной книге на базе Web. Форматирование в данном случае играет еще более важную роль, поскольку не исключено, что данные придется экспортировать в другое приложение в каком-нибудь специфическом формате. Подобные приложения прекрасно работают на базе шаблонов, поскольку дизайнеру остается лишь создать единый формат страницы, который будет использоваться для всех 26 букв алфавита.
Прежде всего, необходимо решить, какие данные и в каком формате будут храниться в адресной книге. Конечно, оптимальным носителем информации в данном случае является база данных, поскольку это упростит такие полезные операции, как поиск и сортировка данных. В своем примере я воспользуюсь СУБД MySQL. Определение таблицы выглядит следующим образом:
mysql>CREATE table addressbook (
last_name char(35) NOT NULL,
first_name char(20) MOT NULL,
tel char(20) NOT NULL,
email char(55) NOT NULL );
Разумеется, вы можете самостоятельно добавить поля для хранения адреса, города и т. д. Для наглядности я буду использовать сокращенную таблицу, приведенную ранее.
Теперь я возьму на себя роль дизайнера и займусь созданием шаблонов. Для этого проекта нужны два шаблона. Код первого, «родительского» шаблона book.html приведен в листинге 12.8.
Листинг 12.8.
Основной шаблон адресной книги book.html
A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
Как видите, файл в основном состоит из ссылок с разными буквами алфавита. Если щелкнуть на букве, в браузере отображается информация обо всех контактах в адресной книге, фамилии которых начинаются с указанной буквы.
В странице встречаются три имени переменных, заключенных в ограничители: page_title, letter и rows_addresses. Смысл первых двух переменных очевиден: текст в заголовке страницы и буква адресной книги, использованная для выборки текущих адресных данных. Третья переменная относится к дополнительному шаблону (листинг 12.9) и определяет файл конфигурации таблицы, включаемый в основной шаблон. Файлы конфигурации таблиц используются в связи с тем, что в сложных страницах может быть одновременно задействовано несколько шаблонов, в каждом из которых данные форматируются в виде таблиц HTML. Шаблон rows.addresses (листинг 12.9) выполняет вспомогательные функции и вставляется в основной шаблон book.html. Вскоре вы поймете, почему это необходимо.
Листинг 12.9.
Вспомогательный шаблон rows.addresses
{last_name},{first_name}
{telephone}
{email}
В листинге 12.9 встречаются четыре переменных, заключенных в ограничители: last_name, first_name, telephone и emal. Смысл этих переменных очевиден (см. определение таблицы addressbook). Следует заметить, что этот файл состоит только из табличных тегов строк (
Листинг 12.10.
Исходный текст страницы, изображенной на рис. 12.1
A | B | C | D | E | F | G | H | I | J | K | L | M | N | 0 | P | Q | R | S | T | U | V | W | X | Y | Z |
(212) 563-5678 |
| " bobby@fries.com |
Frenchy.Pierre |
002-(30)-09-7654321 |
frenchy@frenchtv.com |
Как видно из приведенного листинга, в адресной книге хранятся записи двух лиц, фамилии которых начинаются с буквы F: Bobby Fries и Pierre Frenchy. Соответственно в таблицу вставляются данные двух записей.
Дизайнерская часть проекта адресной книги завершена, и я перехожу к роли программиста. Возможно, вас удивит тот факт, что класс tempiate. class (см. листинг 12.7) практически не изменился, если не считать появления одного нового метода — address_sql( ). Код этого метода приведен в листинге 12.11.
Листинг 12.11.
Обработка данных, полученных в результате запроса
class template {
VAR $files = array( );
VAR $variab!es = array( ):
VAR $sql = array();
VAR $opening_escape - '{';
VAR $closing_escape = '}';
VAR $host = "localhost";
VAR $user = "root";
VAR $pswd = "";
VAR $db = "book";
VAR $address table = "addressbook";
function address_sql($file_id, $vanable_name, $letter) {
// Подключиться к серверу MySQL и выбрать базу данных
mysql_connect($this->host, $this->user, $this->pswd)
or die("Couldn't connect to MySQL server!");
mysql_select_db($this->db) or die('Couldn't select MySQL database!");
// Обратиться с запросом к базе данных
$query = "SELECT last_name, first_name, tel, email
FROM $this->address_table WHERE lastjiame LIKE '$letter%' ";
$result = mysql_query($query);
// Открыть файл "rows.addresses"
// и прочитать его содержимое в переменную
$fh - fopen("$variable_name", "r");
$file_contents = fread($fh, filesize("rows.addresses") ):
// Заменить имена переменных в ограничителях
// данными из базы.
while ($row = mysql_fetch_array($result)) :
$new_row = $file_contents;
$new_row=str_replace($this->opening_escape.
"last_name".$this->closing_escape.
$row["last_name"]. $new_row);
$new_row=
str_replace($th1s->opening_escape.
"first_name".$this->closing_escape.
$row["first_name"], $new_row);
$new_row=str_replace($this->opening_escape.
"telephone".$this->closing_escape.
$row["tel"], $new_row);
$new_row = str_replace($this->opening_escape.
"email".$this->closing_escape,
$row["email"],
$new_row);
// Присоединить запись к итоговой строке замены
$complete_table .= $new_row;
endwhile;
$sql_array_key = $variable_name;
$this->sql[$sql_array_key] = $complete_table;
// Включить ключ в массив variables для последующего поиска
$this->variables[$file_id][ ] = $variable_name;
// Закрыть файловый манипулятор fclose(lfh);
Комментариев, приведенных в листинге 12.11, вполне достаточно для того, чтобы вы разобрались в происходящем, однако я должен сделать несколько важных замечаний. Во-первых, обратите внимание на то, что файл rows.addresses открывается только один раз. Возможен и другой вариант — многократно открывать и закрывать файл rows.addresses, каждый раз производя замену и присоединяя его содержимое к переменной $complete_table. Впрочем, такое решение будет крайне неэффективным. Потратьте немного времени и разберитесь в том, как новые данные таблицы в цикле присоединяются к переменной $complete_table.
Второе, на что следует обратить внимание при просмотре листинга 12.11, — появление пяти новых атрибутов класса: $host, $user, $pswd, $db и $address_table. В этих атрибутах хранится информация, необходимая для сервера SQL. Полагаю, смысл каждого атрибута понятен без объяснений, а если нет — вернитесь и повторите материал главы 11.
Рис. 12.1.
Страница адресной книги
Все, что осталось сделать — написать файл index.php, инициирующий обработку шаблонов, Код этого файла приведен в листинге 12.12. Если щелкнуть на одной из ссылок (index.php?letter=буква) на странице book.html (см. листинг 12.8), загружается страница index.php, которая, в свою очередь, заново строит book.html с включением новой информации.
Листинг 12.12.
Обработчик шаблонов index.php
include("Listing12-11.php"); $page_title = "Address Book";
// По умолчанию загружается страница с фамилиями,
// начинающимися с буквы 'а' if (! isset($letter) ) :
$letter = "а";
endif ;
$tpl = new template;
$tpl->register_file("book", "book.html");
$tpl->register_variables("book", "page_title.letter");
$tpl ->address_sql("book", "rows.addresses", "$letter");
$tpl ->file_parser("book");
$tpl->phnt_fil("book");
Перед вами практический пример, показывающий, как при помощи шаблонов организовать эффективное разделение труда между программистом и дизайнером. Подумайте, как бы вы использовали шаблоны для организации своих разработок. Готов поспорить, что вы найдете им полезное применение.
Расширения класса template
Конечно, класс tempi ate обладает весьма ограниченными возможностями, хотя для проектов, создаваемых на скорую руку, он вполне подходит. Объектно-ориентированные схемы хороши тем, что они позволяют легко наращивать функциональность, не беспокоясь о возможных нарушениях работы существующего кода. Допустим, вы решили создать новый метод, который будет загружать значения для последующей замены из базы данных. Хотя такой метод устроен чуть сложнее, чем метод file_parser( ), производящий простую замену глобальных переменных, его реализация на базе SQL состоит из нескольких строк и легко инкапсулируется в отдельном методе. Более того, мы создадим нечто подобное в проекте адресной книги, завершающем эту главу.В класс tempi ate можно внести несколько очевидных усовершенствований. Первое — объединение функций register_file( ) и register_variables( ), обеспечивающее автоматическую регистрацию переменных для каждого регистрируемого файла. Конечно, при этом также необходимо реализовать проверку ошибок, чтобы предотвратить регистрацию неверных файлов и переменных.
Однако на этом возможности усовершенствования далеко не исчерпаны. Подумайте, как бы вы реализовали методы, работающие с целыми массивами? На самом деле это проще, чем кажется на первый взгляд. Проанализируйте решение, использованное в проекте адресной книги в конце главы. Общие принципы легко трансформируются под любую конкретную реализацию.
Общие схемы работы с шаблонами были реализованы на нескольких языках и ни в коем случае не являются чем-то принципиально новым. В Web можно найти немало информации о реализации шаблонов. Рекомендую два особенно интересных ресурса — сборники статей, написанных с ориентацией на JavaScript:
В следующей статье затронута тема использования шаблонов применительно к Java Server Pages:
Кроме того, описанная схема построения шаблонов используется в нескольких библиотеках РНР, среди которых наибольший интерес представляют следующие:
На сайте ресурсов РНР, PHPBuilder (http://www.phpbuilder.com), также имеется несколько интересных учебников, посвященных обработке шаблонов. Кроме того, загляните на сайт РНР Classes Repository (http://phpclasses.UpperDesign.com), здесь также можно найти несколько реализаций.
Регистрация файлов
В процессе регистрации содержимое файла сохраняется в массиве с ключом, однозначно идентифицирующим этот файл. Метод register_file( ) открывает и читает содержимое файла, имя которого передается в качестве параметра. Код этого метода приведен в листинге 12.2.Листинг 12.2.
Метод регистрации файла
function register_file($file_id, $file_name) {
// Открыть $file_name для чтения или завершить программу
// с выдачей сообщения об ошибке.
$fh = fopen($file_name, "r") or die("Couldn't open $file_name!");
// Прочитать все содержимое файла $file_name в переменную.
$file_contents = fread($fh, filesize($file_name));
// Присвоить содержимое элементу массива
// с ключом $file_id. $this->files[$file_id] = $file_contents;
// Работа с файлом завершена, закрыть его.
fclose($fh);
}
Параметр $file_id содержит идентификатор — «псевдоним» для последующих операций с файлом, упрощающий последующие вызовы метода. Идентификатор используется в качестве ключа для индексирования массива $files. Пример регистрации файла:
// Включить класс шаблона
include("tempiate.class"):
// Создать новый экземпляр класса
$template = new template:
// Зарегистрировать файл "homepage.html",
// присвоив ему псевдоним "home"
$template->register_file("home", "homepage.html");
Регистрация переменных
После регистрации файлов необходимо зарегистрировать все переменные, которые будут интерпретироваться особым образом. Метод register_variables( ) (листинг 12.3) работает по тому же принципу, что и register_file( ), — он читает имена переменных и сохраняет их в массиве $variables.Листинг 12.3.
Метод регистрации переменнных
function register_vanables($file_id, $variable_name) {
// Попытаться создать массив,
// содержащий переданные имена переменных
$input_variables - explode(".", $variable_name);
// Перебрать имена переменных
while (Iist($value) = each($input_variables)) :
// Присвоить значение очередному элементу массива
$this->variables $this->variables[$file_id][] = $value:
endwhile;
}
В параметре $file_id передается ранее присвоенный псевдоним файла. Например, в предыдущем примере файлу homepage.html был присвоен псевдоним home. Обратите внимание — при регистрации имен переменных, которые должны особым образом обрабатываться в файле homepage.html, вы должны ссылаться на файл по псевдониму! В параметре $variable_name передаются имена одной или нескольких переменных, регистрируемых для указанного псевдонима. Пример:
// Включить класс шаблона include("tempiate.class");
// Создать новый экземпляр класса $template = new template;
// Зарегистрировать файл "homepage.html",
// присвоив ему псевдоним "home" $template->register_file("home", "homepage.html");
// Зарегистрировать несколько переменных
$template->register_variablest"home", "page_title.bg_color,user_name");
Снижение быстродействия
Затраты на обработку файлов приводят к некоторому замедлению работы программы. В какой мере замедляется работа, зависит от ряда факторов, в том числе от размера страницы, размера запроса SQL (если они задействован) и аппаратной конфигурации компьютера. Как правило, эти потери настолько малы, что ими можно пренебречь, но в некоторых ситуациях они оказываются довольно значительными (например, при одновременной обработке нескольких шаблонов в условиях высокого трафика).Вывод файла
Вероятно, после обработки файла вы захотите отправить его в браузер, чтобы пользователь увидел результат обработки шаблона. В нашем примере для выводафайла создается отдельный метод, приведенный в листинге 12.5, однако в зависимости от ситуации вывод также может интегрироваться с методом f i I e_parser().
Листинг 12.5.
Метод вывода файла в браузере
function pnnt_file($file_id) {
// Вывести содержимое файла с идентификатором
$file_id print $this->files[$file id];
}
Все очень просто — при вызове print_file( ) содержимое файла, представленного ключом $file_id, передается в браузер.
В листинге 12.6 приведен пример использования класса template.
Листинг 12.6. Пример использования класса template
// Включить класс шаблона, include("tempiate.class");
// Присвоить значения переменным
$page_title = "Welcome to your homepage!";
$bg_color = "white"; $user_name = "Chef Jacques":
// Создать новый экземпляр класса $template= new template;
// Зарегистрировать файл "homepage.html" с псевдонимом "home"
$template->register_file("home", "homepage.html");
// Зарегистрировать переменные
$template->register_variables("home", "page_title, bg_color.user_name");
$template->file_parser("home");
// Передать результат в браузер
$template->print_file("home");
Если бы шаблон, приведенный в листинге 12.1, хранился в файле homepage.html в одном каталоге со сценарием из листинга 12.6, то в браузер был бы направлен следующий код HTML:
Welcome to your default home page, Chef Jacques!
You have 5 MB and 3 email addresses at your disposal.
Have fun!
Как видно из приведенного примера, все зарегистрированные переменные были заменены соответствующими значениями. При всей своей простоте класс tempi ate
обеспечивает стопроцентное разделение уровней программирования и дизайна. Полный код класса template приведен в листинге 12.7.
Листинг 12.7.
Полный код класса template
class template {
VAR $files = array( );
VAR $variables = array( );
VAR $opening_escape = '{';
VAR $closing_escape = '}' ;
// Функция: register_file( )
// Назначение: сохранение в массиве содержимого файла.
// определяемого идентификатором $file_id
function register_file($file_id. $file_name) {
// Открыть $file_name для чтения или завершить программу
// с выдачей сообщения об ошибке.
$fh = fopen($file_name, "r") or die("Couldn't open $file_name!");
// Прочитать все содержимое файла $file_name в переменную.
$file_contents = fread($fh, filesize($file_name));
// Присвоить содержимое элементу массива
// с ключом $file_id. $this->files[$file_id] = $file_contents;
// Работа с файлом завершена, закрыть его.
fclose($fh):
} // Функция: register_variables( )
// Назначение: сохранение переменных, переданных
// в параметре $variable_name. в массиве с ключом $file_id.
function register_variables($file_id, $variable_name) {
// Попытаться создать массив.
// содержащий переданные имена переменных
$input_variables = explode(".", $vahable_name);
// Перебрать имена переменных
while (list(, $value) = each($input_variables)) :
// Присвоить значение очередному элементу массива $this->variables $this->variables[$file_id][] = $value:
endwhile;
} // Функция: file_parser( )
// Назначение: замена всех зарегистрированных переменных
// в файле с идентификатором $file_id
function file_parser($file_id) {
// Сколько переменных зарегистрировано для данного файла?
$varcount = count($this->variables[$file_id]):
// Сколько файлов зарегистрировано?
$keys = array_keys($this->files):
// Если файл $file_id существует в массиве $this->files
// и с ним связаны зарегистрированные переменные
if ( (in_array($file_id. $keys)) && ($varcount > 0) ) :
// Сбросить $х $x - 0;
// Пока остаются переменные для обработки...
while ($x < sizeof($this->variables[$file_id])) :
// Получить имя очередной переменной
$string = $this->variables[$file_id][$x];
// Получить значение переменной. Обратите внимание:
// для получения значения используется конструкция $$.
// Полученное значение подставляется в файл вместо
// указанного имени переменной.
GLOBAL $$string;
// Построить точный текст замены вместе с ограничителями
$needle = $this->opemng_escape.$string.$this->closing_escape;
// Выполнить замену.
$this->files[$file_id] = str_replace( $needle, $$string,
$this->files[$file_idj);
// Увеличить $х $x++;
endwhile;
endif;
}
// Функция: print_file()
// Назначение: вывод содержимого файла,
// определяемого параметром $file_id
function print_file($file_id) {
// Вывести содержимое файла с идентификатором $file_id
print $this->files[$file_id];
}
} //END template.class
PHP 4 на практике
Что такое cookie?
Cookie представляет собой небольшой пакет информации, переданный web-сервером и хранящийся на клиентском компьютере. В cookie можно сохранить полезные данные, описывающие состояние пользовательского сеанса, чтобы в будущем загрузить их и восстановить параметры сеансовой связи между сервером и клиентом. Cookie используются на многих сайтах Интернета для расширения возможностей пользователя и повышения эффективности сайта за счет отслеживания действий и личных предпочтений пользователя. Возможность хранения этих сведений играет ключевую роль на сайтах электронной коммерции, поддерживающих персональную настройку и целевую рекламу.Вследствие того, что cookie обычно связываются с конкретным пользователем, в них часто сохраняется уникальный идентификатор пользователя (UIN). Этот идентификатор заносится в базу данных на сервере и используется в качестве ключа для выборки из базы всей информации, связанной с этим идентификатором. Конечно, сохранение UIN в cookie не является обязательным требованием; вы можете сохранить любую информацию при условии, что ее общий объем не превосходит 4 Кбайт (4096 байт).
Cookie и РНР
Хватит теории. Конечно, вам не терпится поскорее узнать, как задать значение cookie в РНР. Оказывается, очень просто — для этой цели используется стандартная функция setcookie( ).Функция setcookie( ) сохраняет cookie на компьютере пользователя. Синтаксис функции setcookie( ):
int setcookie (string имя [string значение [, int дата [, string путь [, string домен [, int безопасность]]]]])
Если вы прочитали общие сведения о cookie, то смысл параметров setcookie( ) вам уже известен. Если вы пропустили этот раздел и не знакомы с компонентами cookie, я рекомендую вернуться к началу главы и перечитать его, поскольку все параметры setcookie( ) были описаны выше.
Прежде чем следовать дальше, я попрошу вас перечитать следующую фразу не один и не два, а целых три раза. Значение cookie должно устанавливаться до передачи в браузер любой другой информации, относящейся к странице. Напишите эту фразу 500 раз в тетрадке, сделайте татуировку, научите своего попугая произносить эти слова — короче, проявите фантазию. Другими словами, значение cookie не может устанавливаться в произвольном месте web-страницы. Оно должно быть задано до отправки любых данных в браузер; в противном случае cookie не будет работать.
Есть еще одно важное ограничение, о котором также необходимо помнить, — вы не сможете создать cookie и использовать его на той же странице. Либо пользователь должен вручную обновить страницу (хотя рассчитывать на это нельзя), либо вам придется подождать следующего запроса этой страницы — и только после этого можно будет использовать cookie.
В следующем примере функция setcookie( ) используется для создания cookie с идентификатором пользователя:
$userid = "4139b31b7bab052";
$cookie_set = setcookie ("uid", $value, time()+3600, "/", ".phprecipes.com", 0);
Последствия создания cookie:
В следующем примере (листинг 13.1) cookie используется для хранения параметров форматирования страницы (в данном случае — цвета фона). Обратите внимание: значение cookie задается лишь в результате выполнения действия, установленного для формы.
Листинг 13.1.
Сохранение цвета фона, выбранного пользователем
// Если переменная $bgcolor существует
if (isset($bgcolor)) :
setcookie("bgcolor", $bgcolor, time()+3600);
?>
// Значение $bgcolor не задано, отобразить форму
else :
endif;
?>
При загрузке в браузер сценарий проверяет, было ли задано значение переменной $bgcolor. Если переменная существует, для страницы выбирается цвет фона, определяемый переменной $bgcolor. В противном случае в браузере выводится форма HTML с предложением выбрать цвет фона. После выбора цвета значение $bgcolor будет распознаваться при последующей перезагрузке той же страницы или при переходе к другой странице.
Кстати говоря, имена cookie могут выглядеть как элементы массива. Вы можете использовать имена вида uid[1], uid[2], uid[3] и т. д., а затем работать с ними, как с элементами обычного массива. Пример приведен в листинге 13.2.
Листинг 13.2.
setcookie("phprecipes[uid]", "4139b31b7bab052", time( )+3600); setcookie("phprecipes[color]", "black", time( )+3600); setcookie("phprecipes[preference]", "english", timeO+3600);
if (isset($phprecipes)) :
while (list ($name, $value) = each ($phprecipes)) :
echo "$name = $value
\n";
endwhile;
endif:
?>
В результате выполнения этого фрагмента будет выведен следующий результат (а на клиентском компьютере будут созданы три cookie):
uid = 4139b31b7bab052
color = black
preference = english
 Хотя массивы cookie очень удобны для хранения всевозможной информации, следует помнить, что некоторые браузеры ограничивают количество создаваемых cookie (например, Netscape Communicator разрешает создавать до 20 cookie на домен).
Хотя массивы cookie очень удобны для хранения всевозможной информации, следует помнить, что некоторые браузеры ограничивают количество создаваемых cookie (например, Netscape Communicator разрешает создавать до 20 cookie на домен).Cookie чаще всего применяются для хранения числовых идентификаторов (UIN), по которым в дальнейшем на сервере производится выборка информации,
относящейся к данному пользователю. Этот процесс продемонстрирован в листинге 13.3, где UIN сохраняется в базе данных MySQL. Сохраненные данные впоследствии используются для настройки параметров форматирования страницы.
Допустим, у нас имеется таблица userjnfo в базе данных с именем user. В ней хранятся следующие атрибуты пользователя: идентификатор, имя и адрес электронной почты пользователя. Определение таблицы выглядит так:
mysql>create table user_info (
->user_id char (18),
->fname char(15),
->email char(35));
По сравнению с полноценными сценариями регистрации пользователя, работа листинга 13.3 начинается «на половине пути»: предполагается, что данные пользователя (идентификатор, имя и адрес электронной почты) уже хранятся в базе данных. Чтобы пользователю не приходилось вводить всю информацию заново, идентификатор (в листинге 13.3 для простоты он равен 15) загружается из cookie на клиентском компьютере.
Листинг 13.3.
Загрузка информации пользователя из базы данных
if (! isset($userid)) :
$id = 15;
setcookie ("userid", $id, time( )+3600);
print "A cookie containing your userID has been set on your machine.
Please refresh the page to retrieve your user information";
else:
@mysql_connect("localhost", "web", "4tf9zzzf") or die("Could not connect to MySQL server!");
@mysql_select_db("user") or die("Could not select user database!");
// Объявить запрос
$query = "SELECT * FROM users13 WHERE user_id = '$userid'";
// Выполнить запрос
$result = mysql_query($query)l;
// Если совпадение будет найдено, вывести данные пользователя.
if (mysql_num_rows($result) == 1) :
$row = mysql_fetch_array($result);
print "Hi ".$row["?name"].",
";
print "Your email address is ".$row[ "email"];
else:
print "Invalid User ID!";
endif;
mysql_close();
endif;
?>
Листинг 13.3 показывает, как удобно использовать cookie для идентификации пользователей. Этот прием может использоваться в разнообразных ситуациях, от автоматической регистрации пользователя на сайте до отслеживания пользовательских параметров настройки.
В следующем разделе приведен сценарии полной регистрации пользователя и последующего сохранения UIN в базе данных.
Функции MySQL, встречающиеся в листинге 13.3, были описаны в главе 11.PHP 4 на практике
Cookie и отслеживание сеансаОтслеживание пользователей и персональная настройка сайта относятся к числу самых популярных и вместе с тем неоднозначно воспринимаемых возможностей web-сайтов. Преимущества очевидны — вы можете предлагать пользователям именно ту информацию, которая их интересует. С другой стороны, возникает немало вопросов, связанных с конфиденциальностью, поскольку появляется возможность «следить» за тем, как пользователь перемещается от страницы к странице и даже от сайта к сайту.
Если отвлечься от проблем конфиденциальности, отслеживание пользовательских данных с применением cookie или других средств приносит огромную пользу как пользователю, так и сайту, обеспечивающему эти возможности. Пользователь выигрывает от того, что содержание сайта настраивается в соответствии с его личными предпочтениями, а из сайта исключается бесполезная или не представляющая интереса информация. Для администратора сайта отслеживание пользовательских предпочтений открывает совершенно новый уровень взаимодействия с пользователем, включая возможности целевого маркетинга и анализа популярности материалов сайта. В Web, где сейчас преобладает электронная коммерция, эти возможности стали практически стандартными.
Концепция «наблюдения» за пользователем в процессе перемещения по сайту обычно называется «отслеживанием сеанса» (session tracking). Принимая во внимание огромный объем полезной информации, получаемой в результате отслеживания сеанса на сайте, можно сказать, что преимущества отслеживания сеансов и персональной настройки содержания сайта значительно превышают любые недостатки. Вряд ли эту книгу можно было бы считать полноценным учебником по РНР, если бы я не посвятил в ней целую главу средствам отслеживания сеанса в РНР. В этой главе мы рассмотрим некоторые концепции, имеющие непосредственное отношение к отслеживанию сеансов, а именно — cookie и их применение, а также уникальные идентификаторы сеансов. Глава завершается сводкой стандартных функций РНР, предназначенных для отслеживания сеансов.
Компоненты cookie
В cookie хранятся и другие компоненты, при помощи которых разработчик может ограничивать использование cookie с позиций домена, пути, срока действия и безопасности. Ниже приведены описания различных компонентов cookie:— имя cookie является обязательным параметром, по которому программа ссылается на cookie. Можно провести аналогию между именем cookie и именем переменной.
Хотя при создании cookie используются одни и те же синтаксические правила, формат хранения cookie зависит от браузера. Например, Netscape Communicator хранит cookie в формате следующего вида:
.phprecipes.com FALSE / FALSE 97728956 bgcolor blue
В Internet Explorer то же самое cookie выглядело бы иначе:
bgcolor
blue
localhost/php4/php.exe/book/13/
0
2154887040
29374385
522625408
29374377
*
Чтобы просмотреть cookie, сохраненные браузером Internet Explorer, достаточно открыть их в любом текстовом редакторе. Помните, что некоторые редакторы не обрабатывают завершающие символы новой строки и на месте этих символов в документе могут выводиться квадратики.
Internet Explorer сохраняет свои cookie в папке с именем «Cookies», a Netscape Communicator использует для этой цели один файл с именем cookies.Назначение пользовательских функций для хранения сеансовых данных
Хранить сеансовые данные в файлах удобно, но вполне возможно, вы захотите воспользоваться другими средствами — например, базами данных. А может быть, вы хотите применить один и тот же сценарий на разных сайтах для разных баз данных. Существует и другая распространенная проблема — стандартная для РНР процедура хранения сеансовых данных в файлах затрудняет совместное использование данных на разных серверах. К счастью, все эти проблемы отслеживания сеансов в РНР решаются очень просто, поскольку РНР дает пользователю возможность установить собственную процедуру сохранения при помощи стандартной функции session_set_save_handler( ).Функция session_set_save_handler( ) определяет процедуры сохранения и загрузки сеансовых данных пользовательского уровня.
Синтаксис функции session_set_save_handler():
void session_set_save_handler (string open, string close, string read, string write, string destroy, string go)
Шесть параметров session_set_save_handler( ) соответствуют шести функциям, вызываемым сеансовыми функциями РНР. Хотя имена этих функций могут быть произвольными, каждая функция должна получать жестко заданный набор параметров. Перед тем как переходить к рассмотрению примера, просмотрите таблицу 13.2 — в ней описаны назначение всех шести функций и их параметры.
Чтобы использовать функцию session_set_save_handler( ), необходимо присвоить па-раметру session.save_handler в файле php.ini значение user.Таблица 13.2.
Шесть параметров функции session_set_save_handler( )
| Параметр | Описание | ||
| sess_close( ) | Вызывается при завершении сценария, в котором реализуются сеансовые функции. Не путайте эту функцию с функцией sess_destroy( ), предназначенной для уничтожения сеансовых переменных. Функция sess_close( ) вызывается без параметров | ||
| sess_destroy($идент_ceaнca) | Удаляет все сеансовые данные. Параметр определяет удаляемый сеанс | ||
| sess_gc($срок_действия) | Удаляет все сеансы с завершенным сроком действия. Срок определяется параметром $срок_действия, значение которого задается в секундах. Параметр читается из файла php.ini и соответствует значению session.gcjifetime | ||
| sess_open($путь, $имя) | Вызывается при инициализации нового сеанса функцией session_start( ) или session_register( ). Два параметра читаются из файла php.ini и соответствуют значениям session.save_path и session.name | ||
| sess_read($ключ) | Используется для выборки значения сеансовой переменной, определяемой заданным ключом | ||
| sess_write($ключ, $значение) | Используется для сохранения сеансовых данных. Любые данные, сохраненные функцией sess_write( ), позднее могут быть прочитаны функцией sess_read( ). Параметр $ключ соответствует имени сеансовой переменной, а параметр $значение — значению, связываемому с заданным ключом | Теперь, когда вы знаете все, что необходимо знать о параметрах session_set_save_handler( ), мы рассмотрим пример реализации сеансовых функций на базе MySQL (листинг 13.8).
| Директива | Описание | ||
| session.save_handler = files | Определяет способ хранения сеансовых данных на сервере. Возможны три варианта: в файле (files), в общей памяти (mm) или с использованием функций, определяемых пользователем (User). | ||
| session.save_path =/tmp | Определяет каталог для сеансовых файлов РНР. На платформе Linux обычно используется значение по умолчанию ('/tmp'). На платформе Windows следует указать путь к какому-нибудь каталогу, в противном случае произойдет ошибка | ||
| session_use_cookies =1 | При установке этого флага для сохранения идентификатора сеанса на компьютере пользователя используются cookie | ||
| session.name =PHPRESSID. | Если флаг session.use_cookies установлен, то значение session.name |
 Функция session_start( ) возвращает TRUE независимо от результата. Следовательно, проверять ее в условиях if или в команде die( ) бессмысленно.
Функция session_start( ) возвращает TRUE независимо от результата. Следовательно, проверять ее в условиях if или в команде die( ) бессмысленно. В проекте использована методика идентификации браузера, описанная в главе 8. Если вы пропустили главу 8 или описание проекта, я настоятельно рекомендую вернуться и просмотреть код проекта.
В проекте использована методика идентификации браузера, описанная в главе 8. Если вы пропустили главу 8 или описание проекта, я настоятельно рекомендую вернуться и просмотреть код проекта.| Browser | IP | Host | TimeofVisit |
|---|---|---|---|
| $browse_type $browse_version = $op_sys | ";".$row["ip"]." | ";".$row["host"]." | ";"; print $row["TimeofVisit"]." | ";
// viewStats
?>
Фрагмент кода, приведенный в листинге 13.10, проверяет существование cookie и при необходимости вызывает функцию recordUser( ). Я привожу этот фрагмент в составе очень простого индексного файла index.php.
Листинг 13.10.
Проверка существования cookie (index.php)
include("Listing13-9.php"); if (! isset($$cookieName)) :
// Создать cookie
setcookie($cookieName, $cookieValue, time()+$timeLimit);
// Сохранить информацию о посетителе recordUser();
endif:
?>
Welcome to my site. Check out who else has recently visited.
Как организовать просмотр информации, хранящейся в базе данных MySQL, в браузере? Задача решается простым вызовом функции viewStats( ) в отдельном файле visitors.php:
include("sniffer.inc"):
include("init.inc");
?>
viewStats( );
?>
Возможно и другое решение — включить весь код HTML в функцию viewStats( ), а затем просто включить sniffer.inc, init.inc и вызов viewStats( ) в отдельный файл. Выбор зависит от того, до какой степени вы хотите интегрировать форматирование таблицы с процессом выборки данных.
На рис. 13.1 показан пример выходных данных viewStats( ) для атрибутов форматирования, заданных в файле init.inc.
Рис. 13.1.
Пример результата, сгенерированного функцией viewStats( )
Существует немало путей для расширения практических возможностей этого приложения. Например, для отслеживания посещений со страницами сайта часто связываются идентификаторы, по которым в дальнейшем можно следить за перемещением пользователей между страницами. В рассмотренном проекте для этого в таблицу MySQL следует включить дополнительное поле, в котором хранится идентификатор страницы, а затем переопределить функцию recordllser( ) с дополнительным параметром. Идентификатор страницы сохраняется в cookie. При поступлении очередного запроса сценарий проверяет существование cookie для конкретной страницы, информация о которой регистрируется в журнале.
Уникальные идентификаторы
Вероятно, у вас уже возник вопрос: как сгенерировать UIN, который действительно был бы уникальным? Отложите в сторону учебники — замысловатые алгоритмы вам не понадобятся. В РНР предусмотрено простое средство для создания уникальных UIN — встроенная функция uniqid( ).Функция uniqid( ) генерирует уникальный идентификатор.из 13 символов, значение которого основано на текущем времени. Синтаксис функции uniqid( ): int uniqid(string префикс [б boolean дополнение])
В параметре префикс передается строка, с которой должен начинаться UIN. Поскольку этот параметр является обязательным, при вызове необходимо передать хотя бы пустую строку. Если необязательный параметр дополнение равен TRUE, функция uniqid( ) генерирует UIN из 23 символов. Чтобы быстро создать уникальный идентификатор, достаточно при вызове uniqid( ) передать один параметр — пустую строку:
$uniq_id = uniqid(" ");
// Генерируется строка из 13 символов - например. '39b3209ce8ef2'
В другом варианте сгенерированное значение присоединяется к строке, определяемой параметром префикс:
$uniq_id = uniqid("php", FALSE):
// Генерируется строка из 16 символов - например. 'php39b3209ce8ef2'
Поскольку uniqid( ) генерирует UIN на основании текущего времени, существует ничтожная вероятность того, что идентификатор удастся подобрать. Чтобы значение идентификатора было действительно случайным, можно предварительно сгенерировать префикс при помощи еще одной стандартной функции РНР, rand( ). Эта возможность продемонстрирована в следующем примере:
srand((double) microtime( ) * 1000000);
$uniq_id = uniqid(rand( ));
Функция srand( ) инициализирует («раскручивает») генератор случайных чисел. Если вы хотите, чтобы функция rand( ) генерировала действительно случайные числа, необходимо предварительно вызвать srand( ). Передача rand( ) в качестве параметра uniqid( ) приводит к тому, что функция uniqid( ) вызывается с заранее сгенерированным случайным префиксом, что усложняет подбор сгенерированного UIN.
Владея методикой создания уникальных идентификаторов, мы теперь можем реализовать вполне реальную схему регистрации пользователей. При первой загрузке сценария в листинге 13.4 пользователю предлагается заполнить короткую
форму с именем и адресом электронной почты. Эта информация вместе со сгенерированным уникальным идентификатором сохраняется в таблице user_info, определение которой приведено перед листингом 13.3. Cookie с этим идентификатором сохраняется на компьютере пользователя. При всех последующих посещениях сценарий ищет в базе данных уникальный идентификатор, взятый из cookie, и выводит в браузере найденную информацию о пользователе.
Листинг 13.4.
Процесс регистрации пользователя
// Построить форму
$form = "
// Если форма еще не отображалась
// и для данного пользователя еще не существует cookie...
1f ((! isset (Sseenform)) && (! isset ($userid))) :
print $form;
// Если форма отображалась.
// но данные пользователя еще не были обработаны...
elself (isset ($seenform) && (! isset ($sserid))) :
srand ((double) microtime( ) * 1000000);
$uniq_id = uniqid(rand( ));
// Подключиться к серверу MySQL и выбрать базу данных users
@mysql_pconnect("localhost", "root", "") or die("Could not connect to MySQL server!");
@mysql_select_db("book") or die("Could not select user database!");
// Объявить и выполнить запрос
$query = "INSERT INTO users13 VALUES('$uniq_id', '$fname', '$email')";
$result = mysql_query($query) or die("Could not insert user information!");
// Создать cookie "userid" со сроком действия один месяц, setcookie ("userid", $uniq_id, tirne( )+2592000);
print "Congratulations $fname! You are now registered! Your user information will be displayed uponon each subsequent visit to this page.";
// ... иначе, если cookie существует - использовать идентификатор
// пользователя для выборки данных из базы данных users elseif (isset($userid)) :
// Подключиться к серверу MySQL и выбрать базу данных users
@mysql_pconnect("localhost", "root", "") or die("Could not connect to MySQL server!");
@mysql_select_db("book") or die("Could not select user database!");
// Объявить и выполнить запрос
$query = "SELECT * FROM users,13 WHERE user_id = '$userid' ";
$result = mysql_query($query) or die("Could not extract user information!"
$row = mysql_fetch_array($result); print "Hi ".$row["fname"].",
";
print "Your email address is ".$row["email"];
endif;
?>
Обилие команд i f позволяет организовать весь процесс регистрации и последующую идентификацию пользователя в одном сценарии. Принципиально возможны три ситуации:
Конечно, общий процесс, продемонстрированный в листинге 13.4, может применяться при работе с любыми базами данных. Листинг всего лишь на очень простом уровне показывает, как на крупных сайтах организуется сохранение пользовательских данных, благодаря которому сайт «подстраивается» под каждого посетителя.
На этом завершается наше знакомство с применением cookie в РНР. Если вы захотите побольше узнать о механизме cookie, обратитесь к ресурсам Интернета, перечисленным в следующем разделе.
Ссылки по теме
Дополнительную информацию о cookie и их использовании можно найти в специализированных web-pecypcax:
Как говорилось выше, в cookie очень удобно хранить параметры, специфические для данного пользователя, автоматически загружаемые при последующих посещениях сайта. Впрочем, на cookie нельзя полностью положиться, потому что пользователи могут запретить их использование на своем компьютере в настройках браузера. К счастью, в РНР для сохранения подобной информации существует и другой способ. Эта методика называется отслеживанием сеанса (session tracking) и рассматривается в следующем разделе.
PHP 4 на практике
Другие полезные функции
В РНР также существуют другие функции, упрощающие процесс обработки кода XML.utf8_decode( )
Функция преобразует данные в кодировку ISO-8859-1. Предполагается, что преобразуемые данные находятся в кодировке UTF-8. Синтаксис:
string utf8_decode(string данные)
Параметр данные содержит преобразуемые данные в кодировке UTF-8.
utf8_encode( )
Функция преобразует данные из кодировки ISO-8859-1 в кодировку UTF-8. Синтаксис:
string utf8_decode(string данные)
Параметр данные содержит преобразуемые данные в кодировке ISO-8859-1.
xml_get_error_code( )
Функция xm1_get_error_code( ) получает код ошибки, возникшей в процессе обработки XML. Код ошибки передается функции xml_error_string( ) (см. ниже) для интерпретации. Синтаксис:
int xml_error_code(int анализатор)
Параметр функции определяет анализатор XML. Пример использования приведен ниже, в описании функции xml_get_current_line_number( ).
xml_error_string( )
Ошибкам, возникающим в процессе анализа кода XML, присваиваются числовые коды. Функция xml_error_string( ) возвращает текстовое описание ошибки по ее коду. Синтаксис:
string xml_error_string(int код)
В параметре функции передается код ошибки (вероятно, полученный при вызове функции xml_get_error_code( )). Пример использования функции приведен ниже, в описании функции xml_get_current_line_number( ).
xml_get_current_line_number( )
Функция возвращает номер текущей строки, обрабатываемой анализатором XML. Синтаксис:
int xml_get_current_line_number(int анализатор)
Параметр функции определяет анализатор XML. Пример использования функции:
while ($line - fread($fh. 4096)) :
if (! xml_parse($xml_parser. $line. feof($fh)));
$err_string - xml_error_string(xml_get_error_code($xml_parser));
$line_number - xml_get_current_line_number($xml_parser);
print "Error! [Line Sline_number]: $err_string";
endif;
endwhile;
Например, если ошибка была обнаружена в шестой строке файла, определяемого манипулятором $fh, сообщение будет выглядеть примерно так:
Error! [Line 6]:mi snatched tag
xml_get_current_column_number( )
Функция xml_get_current_colunin_number( ) может использоваться в сочетании с xml_get_current_line_number( ) для определения точного местонахождения ошибки в документе XML. Синтаксис:
int xml_get_current_column_number(int анализатор)
Параметр функции определяет анализатор XML. Давайте усовершенствуем предыдущий пример:
while ($line = fread($fh. 4096)) :
if (! xml_parse($xml_parser, $line, feof($fh))):
$err_string = xml_error_string(xml_get_error_code($xml_parser));
$line_number = xml_get_current_line_number($xml_parser);
$column_number = xml_get_current_column_number($xml_parser)
print "Error! [Line $line_nuimber, Column $column_number]: $err_string";
endif;
endwhile;
Например, если ошибка была обнаружена в шестой строке файла, определяемого манипулятором $fh, сообщение будет выглядеть примерно так:
Error! [Line 6 Column 2]:mismatched tag
Функции обработки кода XML
Хотя реализация всех функций-обработчиков не обязательна (документы XML не обязаны содержать элементы всех типов), по крайней мере три функции должны присутствовать во всех сценариях, работающих с XML.xml_parser_create( )
Перед обработкой документа XML необходимо предварительно создать анализатор. Синтаксис:
int xml_parser_create([stnng кодировка])
Необязательный параметр определяет кодировку исходного текста. В настоящее время поддерживаются три варианта кодировки:
По аналогии с тем, как функция fopen( ) возвращает манипулятор открытого файла, функция xml_parser_create( ) также возвращает манипулятор, используемый для вызова различных функций в процессе обработки XML. При одновременной обработке нескольких документов можно создать сразу несколько анализаторов.
xml_parse()
Функция xml_parse( ) выполняет обработку документа XML. Синтаксис:
int xml_parse(int анализатор, string данные [int завершение])
Первый параметр определяет анализатор XML (используется значение, возвращаемое при вызове xml_parser_create( )). Если необязательный параметр завершение равен TRUE, передаваемый фрагмент данных является последним. Как правило, это происходит при достижении конца обрабатываемого файла.
xml_parser_free( )
Функция освобождает ресурсы, выделенные для работы анализатора. Синтаксис:
int xml_parser_free(int анализатор)
Параметр функции определяет анализатор XML.
PHP 4 на практике
РНР и XMLБесспорно, развитие World Wide Web оказало заметное влияние на способы обмена информацией. Вследствие огромных размеров этой электронной сети соблюдение стандартов превратилось из простого удобства в обязательное требование — конечно, если ваша организация собирается в полной мере использовать потенциал Web. Одним из таких стандартов является язык XML (extensible Markup Language) — удобное средство обмена данными между организациями и приложениями.
В начале этой главы приведены общие сведения о XML, при этом особое внимание уделяется общему синтаксису языка. Второй раздел посвящен средствам РНР для работы с XML. Мы рассмотрим стандартные функции поддержки XML, а также схему общего процесса обработки файлов в формате XML. Этот материал позволит вам лучше понять, чем же так ценен XML и как РНР может применяться для разработки полезных и интересных приложений на базе XML.
Но прежде чем переходить к непосредственному описанию XML, я расскажу о том, как же развивались концепции, в конечном счете приведшие к возникновению формата XML.
Язык SGML
SGML представляет собой международный стандарт обмена электронной информацией между различными аппаратными и программными компонентами. По названию можно предположить, что SGML — это язык. На самом деле это не совсем так, поскольку SGML в действительности определяет формализованный набор правил для создания языков. На базе SGML были созданы два самых популярных языка разметки — HTML и XML. Как вы уже знаете, HTML — плат-форменно- и аппаратно-независимый язык, предназначенный для форматирования и отображения текста. То же самое можно сказать и о XML.Появление стандарта SGML было обусловлено необходимостью совместного использования данных разными приложениями и операционными системами. Даже в далеких 60-х годах у пользователей компьютеров возникало немало проблем с совместимостью. Проанализировав недостатки многих нестандартных языков разметки, трое ученых из IBM — Чарльз Гольдфарб (Charles Goldfarb), Эд Мо-шер (Ed Mosher) и Рэй Лори (Ray Lorie) — сформулировали три общих принципа, обеспечивающих возможность совместной работы с документами в разных операционных системах:
Правила, определяющие формат документа, задают количество и маркировку языковых конструкций, используемых в документе. Применение стандартного формата гарантирует, что пользователь будет точно знать структуру содержимого документа. Обратите внимание: речь идет не о формате отображения документа, а о его структурном формате. Набор правил, описывающих этот формат, называется «определением типа документа» (document type definition, DTD).
Эти три правила были заложены в основу предшественника SGML — GML (Generalized Markup Language). Исследования и разработка GML продолжались около десяти лет, пока в результате соглашения, заключенного международной группой разработчиков, не появился стандарт SGML.
В 1980-х годах необходимость в общих средствах обмена информацией непрерывно возрастала, и SGML вскоре превратился в отраслевой стандарт (в 1986 году он был принят в качестве стандарта ISO). Даже в наши дни этот стандарт занимает достаточно сильные позиции, поскольку многие организации, работающие с огромными объемами информации, полагаются на SGML как на удобное и надежное средство хранения данных. Чтобы подкрепить сказанное, замечу, что Бюро патентов и товарных знаков США (http://www.uspto.gov), Служба внутренних сборов США (http://www.irs.gov) и Библиотека Конгресса (http://lcweb.loc.gov) используют SGML в своих основных приложениях. Только представьте, какой объем документации проходит через эти организации за год!
 Одним из лучших ресурсов Интернета, посвященных SGML, XML и другим языкам раз-метки, является сайт Robin Cover/OASIS XML Cover Pages (http://www.oasis-open.org/cover).
Одним из лучших ресурсов Интернета, посвященных SGML, XML и другим языкам раз-метки, является сайт Robin Cover/OASIS XML Cover Pages (http://www.oasis-open.org/cover).Идея передачи гипертекстовых документов через web-браузер, предложенная Тимом Бернерсом-Ли (Tim Berners-Lee), не требовала многих возможностей, поддерживаемых полной реализацией SGML. В результате появился известный язык разметки HTML.
Несколько слов о РНР и XML
В этой главе мы познакомились с XML и различными функциями РНР, предназначенными для обработки документов в формате XML. Поскольку основной темой книги является РНР, я описал лишь одну из трех спецификаций стандарта XML и не упомянул о том, как работают XSL и XLL. Конечно, полноценное отделение содержания от представления требует использования всех трех компонентов или по меньшей мере XML и XSL.К сожалению, на момент написания книги РНР еще не обладал возможностями, которые бы позволяли работать с XML исключительно средствами РНР. Конечно,
возможности РНР продолжают расширяться, и в будущем эта проблема обязательно будет решена.
Особого внимания в этой области заслуживает XSL-процессор Sablotron, разработанный компанией Ginger Alliance Lts. (http://www.gingerall.com). 12 октября 2000 года было объявлено о том, что РНР 4.03 отныне распространяется с модулем расширения Sablotron для платформ Linux и Windows. Обязательно проследите за дальнейшим развитием событий.Определение типа документа (DTD)
DTDпредставляет собой совокупность синтаксических правил, на основе которых проверяется структура документа XML. В DTD явно определяется структура документа XML, указываются элементы и их атрибуты, а также приводится другая информация, распространяющаяся на все документы XML, созданные на основе данного DTD.
Учтите, что наличие DTD не является обязательным. Если DTD существует, система XML руководствуется им при интерпретации документа XML. Если DTD отсутствует, предполагается, что система XML должна интерпретировать документ по собственным правилам. Впрочем, для документов XML все же рекомендуется создавать DTD, поскольку это упрощает их интерпретацию и проверку структуры.
DTD можно включить непосредственно в документ XML, сослаться на него по URL или использовать комбинацию этих двух способов. При непосредственном включении DTD в документ XML определение DTD располагается сразу же после пролога:
...прочие объявления...
] >
Атрибут имя_корневого_элемента соответствует имени корневого элемента в тегах, содержащих весь документ XML. В секции «прочих объявлений» находятся определения элементов, атрибутов и т. д.
Возможно, вы предпочитаете разместить DTD в отдельном файле, чтобы обеспечить модульную структуру программы. Давайте посмотрим, как выглядит ссылка на внешний DTD в документе XML. Задача решается одной простой командой:
Как и в случае с внутренним объявлением DTD, имя_корневого_элемента должно соответствовать имени корневого элемента в тегах, содержащих весь документ XML. Атрибут SYSTEM указывает на то, что some_dtd.dtd находится на локальном сервере. Впрочем, на файл some_dtd.dtd также можно сослаться по его абсолютному URL. Наконец, в кавычках указывается URL внешнего DTD, расположенного на локальном или на удаленном сервере.
Как же создать DTD для листинга 14.1? Во-первых, мы собираемся создать в документе XML ссылку на внешний DTD. Как упоминалось в предыдущем разделе, ссылка на DTD выглядит так:
Возвращаясь к листингу 14.1, мы видим, что cookbook является именем корневого элемента, a cookbook.dtd — именем DTD-файла. Содержимое DTD показано в листинге 14.2, а ниже приведены подробные описания всех строк.
Листинг 14.2.
DTD для листинга 14.1 (cookbook.dtd)
] >
Что же означает этот загадочный документ? Несмотря на внешнюю сложность, в действительности он довольно прост. Давайте переберем все содержимое листинга 14.2:
Перед нами пролог XML, о котором уже говорилось выше.
Вторая строка сообщает, что далее следует DTD с именем cookbook.
Третья строка описывает элемент XML, в данном случае — корневой элемент cookbook. После него следует слово recipe, заключенное в круглые скобки. Это означает, что в теги cookbook заключается вложенный тег с именем recipe. Знак + говорит о том, что в родительских тегах cookbook находится одна или несколько пар тегов recipe.
Четвертая строка описывает тег recipe. В ней сообщается, что в тег recipe входят четыре вложенных тега: title, description, ingredients и process. Поскольку после имен тегов не указываются признаки повторения (см. следующий раздел), внутри тегов recipe должна быть заключена ровно одна пара каждого из перечисленных тегов.
Перед нами первое определение тега, который не содержит вложенных тегов. В соответствии с определением он содержит #PCDATA, то есть произвольные символьные данные, не считающиеся частью разметки.
В соответствии с определением элемент ingredients содержит один или несколько тегов с именем ingredient. Обратитесь к листингу 14.1, и вы все поймете.
Поскольку элемент ingredient соответствует отдельному ингредиенту, вполне логично, что этот элемент содержит простые символьные данные.
Элемент process содержит один или несколько экземпляров элемента step.
Элемент step, как и элемент ingredient, соответствует отдельному пункту в списке более высокого уровня. Следовательно, он должен содержать символьные данные.
Обратите внимание: элемент recipe в листинге 14.1 содержит атрибут. Этот атрибут, category, определяет общую категорию, к которой относится рецепт — в приведенном примере это категория «итальянская кухня» (Italian). В определении ATTLIST указывается как имя элемента, так и имя атрибута. Кроме того, отнесение каждого рецепта к определенной категории упрощает классификацию, поэтому атрибут объявляется обязательным (#REQUIRED).
]>
Последняя строка просто завершает определение DTD. Определение всегда должно быть должным образом завершено, иначе произойдет ошибка.
В завершение этого раздела я приведу сводку основных компонентов типичного DTD-файла:
Некоторые из этих компонентов уже встречались нам в описании листинга 14.2. Далее каждый компонент будет описан более подробно.
Объявления элементов
Все элементы, используемые в документе XML, должны быть определены в DTD, прилагаемом к документу. Мы уже встречались с двумя распространенными разновидностями определений: для элемента, содержащего другие элементы, и элемента, содержащего символьные данные. Данное определение свидетельствует, что элемент содержит только символьные данные:
Следующее определение элемента process говорит о том, что он содержит ровно один вложенный элемент с именем step:
Впрочем, процессы (process) из одного шага (step) встречаются довольно редко — скорее всего, шагов будет несколько. Чтобы указать, что элемент содержит один или несколько экземпляров вложенного элемента step, следует воспользоваться признаком
повторения:
Количество вложенных элементов можно задать несколькими способами. Полный список операторов элементов приведен в табл. 14.1.
Таблица 14.1.
Операторы элементов
| Признак | Значение |
| ? | Ноль или ровно один экземпляр |
| * | Ноль или несколько экземпляров |
| + | Один или несколько экземпляров |
| Ровно один экземпляр |
| | | Один из элементов |
| , | Перечисление элементов | Если элемент будет содержать несколько вложенных элементов, их следует перечислить через запятую в определении родительского элемента:
| Флаг | Описание |
| #FIXED | Во всех экземплярах элемента в документе атрибуту может присваиваться только одно конкретное значение |
| #IMPLIED | Если атрибут не указан в элементе, используется значение по умолчанию |
| #REQUIRED | Атрибут является обязательным и должен присутствовать во всех экземплярах элемента в документе |
// Включить файл, имя которого определяется // переданным параметром. INCLUDE("$winID.inc"); ?> |
close window |
Остается лишь создать файлы для ссылок в листинге 15.4. Поскольку в ссылках передаются три уникальных идентификатора (1, 2 и 3), мы должны создать три файла. Первый файл, содержащий контактную информацию, сохраняется с именем Line:
Contact Us
Следующий файл (местонахождение) сохраняется с именем 2.inс.
Driving Directions |
Последний файл (сводка погоды) сохраняется с именем 3.inc. Обратите внимание на вызов функции РНР, возвращающей текущую дату, — этот пример наглядно показывает, как легко РНР интегрируется с JavaScript: ,
Weather ReportToday: Birr... Brisk, with blowing and drifting snow. Tonight: Winter Weather Advisory. 7-10 inches snow expected. |
На рис. 15.1 показано, как выглядит временное окно, открываемое по третьей ссылке.
Рис. 15.1.
Сводка погоды во временном окне
Наше короткое знакомство с интеграцией PHP/JavaScript подходит к концу. Мы рассмотрели несколько простых, но вполне реальных примеров, которые при желании легко адаптируются для более сложных целей. При объединении РНР с JavaScript или любой другой технологией, ориентированной на работу на стороне сервера, необходимо правильно определить возможности браузера, чтобы предотвратить случайные ошибки. Всегда полезно поэкспериментировать с другими технологиями, интегрируемыми с кодом РНР; только проследите за тем, чтобы не отпугнуть пользователей от сайта недоступными возможностями или содержанием, которое невозможно просмотреть.
Следующий раздел посвящен СОМ — еще одной технологии, с которой легко работать средствами РНР.
Дополнительная информация
Ниже перечислены ссылки на некоторые полезные ресурсы, посвященные СОМ и найденные мной в Интернете:PHP 4 на практике
JavaScript и COMКак неоднократно упоминалось в книге, одной из самых замечательных особенностей РНР является простота его интеграции с другими технологиями. Примеры такой интеграции уже встречались при описании работы с базами данных, ODBC и XML. В этой главе будет показано, как просто организуется работа РНР в комбинации с JavaScript и приложениями на базе СОМ. Ниже приводятся общие сведения о JavaScript и СОМ, подкрепленные примерами их использования в РНР. К концу главы вы узнаете немало полезного об этих замечательных технологиях и о том, как они применяются в РНР.
JavaScript
Сценарный язык JavaScript обладает чрезвычайно богатыми возможностями для разработки Интернет-приложений, работающих как на клиентской, так и на серверной стороне. У этого языка есть немало интересных особенностей, и одна из них — возможность обработки не только данных, но и событий. Событие определяется как некоторое действие, выполненное в контексте браузера, — например, щелчок мышью или загрузка страницы.Любой программист с опытом работы на РНР, Pascal или C++ освоит JavaScript без особого труда. Если вы не программировали на этих языках, не огорчайтесь — JavaScript изучается легко. Разработчики JavaScript (как, впрочем, и разработчики РНР) в первую очередь ориентировались на решение реальных, практических задач.
Если вы хотите воспользоваться средствами обработки,событий JavaScript, сохранив при этом многочисленные преимущества РНР, могу вас обрадовать — РНР интегрируется с JavaScript так же легко, как и с HTML. В сущности, JavaScript неплохо дополняет РНР — на нем удобно делать то, что неудобно делать в РНР, и наоборот.
Но прежде чем интегрировать РНР с JavaScript, следует учесть, что некоторые пользователи отключают поддержку JavaScript в своих браузерах или работают в браузерах, вообще не поддерживающих JavaScript (представьте, такое тоже бывает!). В РНР предусмотрены простые средства для распознавания таких ситуаций.
Поддержка СОМ в РНР
Стандартные функции РНР, предназначенные для работы с СОМ, создают объекты СОМ и используют их свойства и методы. Пожалуйста, не забывайте о том, что эта поддержка присутствует только в версии РНР для Windows. Следующие примеры были протестированы для Microsoft Word 2000. За информацией об объектах, методах и событиях, используемых в программе, обращайтесь на web-сайт MSDN (http://msdn.microsoft.com/library/officedev/off2000/ wotocobjectmodelapplication.htm).Создание экземпляров объектов СОМ
Экземпляры объектов СОМ создаются вызовом new, как при обычном объектно-ориентированном программировании. Синтаксис:
object new СОМ("обьекг.класс" [, string удаленный_адрес])
Параметр объект.класс определяет модуль СОМ, присутствующий на сервере. Необязательный параметр удаленный_адрес используется в том случае, если объект СОМ создается на удаленном компьютере. Допустим, вы хотите создать экземпляр объекта для приложения MS Word. При этом приложение Microsoft Word запускается так, словно вы запустили его вручную (разумеется, для этого MS Word должен быть установлен на компьютере). Команда имеет следующий синтаксис:
$word=new COM("word.application") or die("Couldn't start Word!");
После того как экземпляр объекта СОМ будет создан, можно приступать к работе с различными методами и свойствами этого объекта. Допустим, вы захотели активизировать окно Word. Следующая команда изменяет атрибут видимости объекта, в результате чего графический интерфейс приложения отображается на экране:
$word->visible = 1:
He огорчайтесь, если эта команда выглядит непонятной. Вызов методов объектов СОМ рассматривается в следующем разделе.
Вызов методов объекта СОМ
Методы объектов СОМ вызываются в типичном для ООП формате, с использованием ссылки из объектной переменной. Синтаксис:
объект->имя_метода([значение, ...])
Объект соответствует экземпляру объекта СОМ, созданному описанным выше способом. Параметр имя_метода определяет имя метода, определенного в классе объект. Необязательный параметр значение позволяет передавать параметры при вызове методов, допускающих (или требующих) дополнительных данных. Как и при вызове обычных функций, параметры разделяются запятыми. Если после создания экземпляра объекта СОМ, представляющего MS Word, вы захотите создать в приложении новый документ, просто вызовите соответствующий метод. Задача решается методом add( ) субкласса Documents экземпляра $word:
$word->Documents->Add( );
Обратите внимание: для вызова методов используется очень логичный синтаксис в стиле ООП. В результате выполнения этой команды в окне приложения MS Word открывается новый документ.
com_get( )
Функция com_get( ) возвращает значение свойства объектов СОМ. Синтаксис:
mixed com_get(resource объект, string свойство)
Первый параметр определяет экземпляр объекта СОМ, а второй — атрибут класса, к которому относится данный экземпляр.
// Создать экземпляр объекта для приложения MS Word
$word=new COM("word.application") or die("Couldn't start Word!");
// Режим CapsLock либо включен (свойство CapsLock = 0),
// либо выключен (свойство CapsLock = 1).
$flag = com_get(Sword->Application.CapsLock)
// Преобразовать значение Sflag (0 или 1) в логическое значение
if ($flag == 1) :
$flag = "YES";
else :
$flag = "NO";
endif;
// Вывести сообщение
print "CAPS Lock activated: $flag";
$word->Quit();
?>
Существует и другое решение — значение атрибута CapsLock можно получить при помощи стандартного для ООП синтаксиса обращения к атрибутам. В предыдущем примере для этого следует заменить строку
$flag = com_get($word->Application,CapsLock)
следующей строкой:
$flag = $word->Application->CapsLock:
Атрибуты объекта позволяют получать разнообразную информацию о характеристиках приложения. Более того, многим атрибутам можно присваивать новые значения. Это делается при помощи функции com_set( ).
com_set( )
Функция com_set( ) присваивает атрибуту объекта новое значение:
void com_set(resource объект, string свойство, mixed значение)
Первый параметр определяет экземпляр объекта СОМ, а второй — атрибут класса, к которому относится данный экземпляр. Третий параметр определяет новое значение свойства.
Следующая программа (листинг 15.6) запускает Microsoft Word и активизирует окно приложения. Затем она создает новый документ, добавляет в него строку текста и выбирает режим сохранения документа (атрибут DefaultSaveFormat) в текстовом формате. Результат виден при открытии окна Сохранить как (Save As) — в списке Тип файла (Save As Type) автоматически выбирается строка Только текст (Text Only). После сохранения документа приложение Microsoft Word закрывается.
Листинг 15.6.
Выбор типа документа по умолчанию
// Создать экземпляр объекта для приложения MS Word
$word-new COMC'word.application") or die("Couldn't start Word!");
// Активизировать окно MS Word $word->visible = 1;
// Создать новый документ $word->Documents->Add();
// Вставить в документ фрагмент текста
$word->Selection->Typetext("php's com functionality is cool\n");
// Выбрать текстовый режим сохранения
$ok = com_set($word->Application, DefaultSaveFormat, "Text");
// Запросить у пользователя имя и сохранить документ.
// Обратите внимание: по умолчанию документ сохраняется
// в текстовом формате! $word->Documents[l]->Save;
// Выйти из MS Word
$word->Quit();
?>
Существует и другое решение — новое значение атрибута DefaultSaveFormat можно присвоить непосредственно, как обычной переменной. В листинге 15.6 для этого следует заменить строку
$ok = com_set($word->Application, DefaultSaveFormat, "Text");
следующей строкой:
$word->Application->DefaultSaveFormat = "Text";
Итак, вы получили общее представление об управлении приложениями Windows через поддержку СОМ в РНР. Мы переходим к занимательному примеру, кото-
рый наглядно показывает, каких полезных и впечатляющих результатов можно добиться при помощи СОМ.
Проверка поддержки JavaScript
Правильное определение возможностей браузера избавит пользователей от неприятностей при посещении вашего сайта. Ничто так не действует на нервы, как град раздражающих сообщений «JavaScript Error» или недоступность каких-то средств сайта из-за того, что использованные вами технологии не поддерживаются браузером. К счастью, в РНР предусмотрено простое средство для проверки возможностей браузера — стандартная функция get_browser( ).get_browser( )
Функция get_browser( ) возвращает информацию о возможностях браузера в виде объекта. Синтаксис:
object get_browser([string агент])
Необязательный параметр агент используется для получения характеристик конкретного браузера. Как правило, функция get_browser( ) вызывается без параметров, поскольку по умолчанию она использует глобальную переменную РНР $HTTP_USER_AGENT.
Стандартный список возможностей браузера хранится в файле browcap, путь к которому определяется параметром browcap в файле php.ini. По умолчанию эта строка выглядит следующим образом:
;browcap = extra/browcap.ini
Файл browser.ini был разработан компанией cyScape, Inc. Последняя версия этого файла находится по адресу http://www.cyscape.com/browcap. Загрузите и распакуйте этот файл в каталог на сервере. Запомните имя каталога, оно понадобится вам для обновления параметра browcap в файле php.ini.
В принципе, после загрузки browcap.ini и редактирования файла php.ini вы можете включать в свои программы проверку возможностей браузера. Впрочем, я рекомендую сначала открыть файл browser.ini и ознакомиться с его структурой, а затем просмотреть листинги 15.1 и 15.2. В листинге 15.1 приведен очень простой пример отображения всех возможностей браузера в самом браузере. Листинг 15.2 ограничивается лишь одной возможностью — поддержкой JavaScript.
Листинг
15.1. Отображение всех атрибутов браузера
// Получить информацию о браузере
$browser = get_browser();
// Преобразовать $browser в массив
Sbrowser = (array) Sbrowser;
while (list ($key, $value) = each ($browser)) :
// Присвоить нули пустым элементам массива
if ($value == "") : $value = 0;
endif;
print "$key : $value
";
endwhile;
?>
Для браузера Microsoft Internet Explorer 5.0 листинг 15.1 выводит следующий результат:
browser_name_pattern : Mozilla/4\.0 (compatible; MSIE 5\..*)
parent IE 5.0
browser : 5.0
version : 15
majorver : #5
minorver : #5
frames : 1
tables : 1
cookies : 1
backgroundsounds : 1
vbscript : 1
javascript : 1
javaapplets : 1
activexcontrols : 1
win16 : 0
beta : 0
ak : 0
sk : 0
aol : 0
crawler : 0
cdf : 1
В листинге 15.2 приведен простой, но эффективный сценарий, который при помощи файла browcap.ini определяет, включена ли поддержка JavaScript в браузере.
Листинг 15.2.
Проверка поддержки JavaScript
$browser = get_browser( );
// Преобразовать $browser в массив $browser = (array) $browser;
if ($browser["javascript"] == 1) :
print "Javascript enabled!";
else :
print "No javascript allowed!";
endif;
?>
Листинг 15.2 проверяет, присутствует ли ключ javascript для заданного браузера. Если ключ присутствует и равен 1, в браузере выводится сообщение о поддержке JavaScript. В противном случае выводится сообщение об ошибке. Конечно, в реальной программе вместо выдачи сообщения следует выполнить какие-нибудь полезные действия.
Следующие два примера показывают, как легко РНР,интегрируется с JavaScript. Листинг 15.3 определяет параметры экрана (разрешение и цветовую глубину) средствами JavaScript и затем выводит их средствами РНР. Листинг 15.4 (см. следующий раздел) показывает, как при помощи шаблона РНР во временном (pop-up) окне, вызванном из кода JavaScript, выводится информация о ссылке, на которой щелкнул пользователь.
Листинг 15.3.
Определение цветовой глубины и разрешения экрана
echo "Browser: $type Version: $version
";
echo "Screen Resolution: $screenWidth x $screenHeight pixels.
";
if ($browserWidth != 0) :
echo "Browser resolution: $browserWidth x $browserHeight pixels.";
else :
echo " No javascript browser resolution support for Internet Explorer";
endif;
?>
СОМ
Технология СОМ (сокращение от «Component Object Model», то есть «модель составного объекта») обеспечивает взаимодействие между приложениями, работающими на разных языках и платформах. Такое взаимодействие в значительной мере способствует идее построения многократно используемых, легко сопровождаемых и адаптируемых программных компонентов (в последнее время к этим трем принципам проявляется повышенное внимание в области компьютерных технологий). Хотя СОМ обычно рассматривается как спецификация, ориентированная в первую очередь на продукты Microsoft, поддержка СОМ уже реализована во многих языках (например, в РНР, Java, C++ и Delphi) и существует на многих платформах, включая Windows, Linux и Macintosh.Что же вам даст объединение СОМ с РНР? Во-первых, средства СОМ позволяют напрямую взаимодействовать со многими приложениями Microsoft. Ниже рассмотрен интересный пример — форматирование и вывод в Microsoft Word записей базы данных, полученных из Web. В следующем разделе вы увидите, как легко решается эта задача.
 На нескольких страницах, посвященных технологии СОМ, эту огромную тему нельзя осветить даже поверхностно. Ситуация осложняется тем, что возможности использования СОМ в языке РНР почти не документируются. За дополнительной информацией о механизме работы СОМ обращайтесь к ресурсам, перечисленным в конце этой главы.
На нескольких страницах, посвященных технологии СОМ, эту огромную тему нельзя осветить даже поверхностно. Ситуация осложняется тем, что возможности использования СОМ в языке РНР почти не документируются. За дополнительной информацией о механизме работы СОМ обращайтесь к ресурсам, перечисленным в конце этой главы.РНР содержит несколько стандартных функций для работы с СОМ. Учтите, эти функции поддерживаются только в версии РНР для Windows! Прежде чем переходить к примерам, мы рассмотрим все эти функции.
Запись информации в документ Microsoft Word
Допустим, вам потребовалось отформатировать информацию, загруженную из базы данных, в документе Word для построения отчета. Весь процесс автоматизируется всего в нескольких строках кода РНР. Для демонстрационных целей я воспользуюсь таблицей addressbook из проекта адресной книги, приведенного в конце главы 12. Алгоритм работы сценария выглядит следующим образом:Программный код приведен в листинге 15.7.
Листинг 15.7.
Запись информации в документ Microsoft Word // Создать соединение с сервером MySQL
$host = "localhost";
$user = "root";
$pswd = "";
$db = "book";
$address_table = "addressbook";
mysql_connect($host. $user, $pswd)
or die("Couldn't connect to MySQL server!");
mysql_select_db($db) or die("Couldn't select database!");
// Выбрать из базы данных все записи
$query = "SELECT * FROM $address_table ORDER BY lastjiame";
Sresult = mysql_query($query):
// Создать новый объект COM для приложения MS Word
$word=new COM("word.application") or die("Couldn't start Word!");
// Активизировать окно MS Word $word->visible = 1;
// Открыть пустой документ. $word->Documents->Add( );
// Перебрать записи из таблицы адресов
while($row = mysql_fetch_array($result));
$last_name = $row["last_name"];
$first_name = $row["first_name"];
$tel = $row["tel"];
$email = $row["email"];
// Вывести данные таблицы в открытый документ Word.
$word->Selection->Typetext("$last_name. $first_name\n"); $word->Selection->Typetext("tel. $tel\n"): $word->Selection->Typetext("email. $email:\n");
endwhile;
// Запросить у пользователя имя документа.
$word->Documents[l]->Save;
// Выйти из MS Word
$word->Quit();
?>
При всей простоте рассмотренный пример наглядно показывает, как писать приложения РНР для пересылки содержимого базы данных в приложения Windows. Можно написать и более сложное приложение, обеспечивающее синхронизацию данных, полученных из Web, из Microsoft Outlook. Все, что для этого нужно — получить ссылку на объекты, свойства и методы Outlook, после чего можно переходить к экспериментам (обзор объектной модели всех приложений семейства Office приведен по адресу http://www.microsoft.com/officedev/articles/Opg/toc/PGTOC.htm).
PHP 4 на практике
Аутентификация пользователя
Правильно введенные имя и пароль открывают пользователю доступ к каталогам сервера, недоступным для анонимного доступа. Этот принцип аутентификации обычно называется схемой «запрос/ответ» (challenge/response). Запросом является приглашение к вводу имени и пароля, а ответом — введенные данные. Если введенная комбинация верна, пользователю предоставляется доступ к защищенным каталогам; в противном случае попытка получения доступа отклоняется с выводом соответствующего сообщения.Как правило, для ввода имени и пароля применяются диалоговые окна, активизируемые вызовом функции header( ) (листинг 16.2).
Листинг 16.2.
Запрос данных для аутентификации пользователя header( 'WWW-Authenticate: Basic realm="Secret Family Recipes"');
header ('HTTP/1.0 401 Unauthorized');
exit;
?>
Выполнение фрагмента из листинга 16.2 всего лишь активизирует окно для ввода данных. Примерный вид этого окна изображен на рис. 16.1.
Рис. 16.1.
Окно аутентификации пользователя
Следующим шагом после подготовки интерфейса для ввода является обработка имени пользователя и пароля. В РНР имя и пароль хранятся в двух глобальных переменных, $PHP_AUTH_USER (имя) и $PHP_AUTH_PW (пароль). В листинге 16.3 показано, как проверяются значения этих переменных. Если данные не были введены, окно аутентификации отображается заново.
 Экспериментируя со сценариями этого раздела, вы увидите, что окно аутентификации не всегда появляется после обновления страницы. Проблема кроется не в программе, а в том, как окна аутентификации реализованы в браузере. Чтобы вызвать окно, вам придется закрыть и перезапустить браузер.
Экспериментируя со сценариями этого раздела, вы увидите, что окно аутентификации не всегда появляется после обновления страницы. Проблема кроется не в программе, а в том, как окна аутентификации реализованы в браузере. Чтобы вызвать окно, вам придется закрыть и перезапустить браузер.Листинг 16.3.
Проверка глобальных переменных аутентификации в РНР
If ( (! isset ($PHP_AUTH_USER)) || (! isset ($PHP_AUTH_PW)) ):
headert 'WWW-Authenticate: Basic realm="Secret Family Recipes'");
header(''HTTP/1.0 401 Unauthorized');
print "You are attempting to enter a restricted area. Authorization is required.";
exit;
endif;
?>
В простейшей, но недостаточно гибкой схеме ограничения доступа к странице имя пользователя и пароль жестко кодируются в сценарии. В листинге 16.4 приведен вариант предыдущего примера, построенный с использованием этой схемы.
Листинг 16.4.
Жесткое кодирование имени и пароля в сценарии
if ( (! isset ($PHP_AUTH_USER)) | (! isset ($PHP_AUTH_PW)) || ($РНР AUTH USER != 'secret') | ($PHP_AUTH_PW !- 'recipes') ) :
header('WWW-Authenticate: Basic realm="Secret Family Recipes'"); header('HTTP/1.0 401 Unauthorized');
print "You are attempting to enter a restricted area. Authorization is required,
exit;
endif;
?>
Аутентификация с несколькими пользователями
Хотя вариант, приведенный в листинге 16.4, неплохо подходит для небольших статических групп пользователей, для ограничения доступа к некоторым областям web-сайта обычно выбираются более гибкие и надежные решения. Вероятно, вы предпочтете создать отдельные имя и пароль для каждого пользователя, которому предоставляется расширенный доступ. Существует несколько реализаций этой схемы, из которых чаще всего встречается чтение аутентификационных данных из текстового файла или базы данных.Хранение информации в текстовом файле
Существует очень простое, но эффективное решение — хранить аутентификацион-ные данные в текстовом файле. В каждой строке файла содержится отдельная пара «имя:пароль»; в,процессе проверки программа последовательно читает и проверяет все строки файла. Примерный вид текстового файла приведен в листинге 16.5.
Листинг 16.5.
Типичный текстовый файл с параметрами аутентификации (authenticate.txt)
brian:snaidni00
alessia:aiggaips
gary:9avaj9
chris:poghsawcd
matt:tsoptaes
Как видно из листинга, каждая строка приведенного файла состоит из имени пользователя и пароля, разделенных двоеточием (:). Таким образом, при использовании этого файла существует пять комбинаций «имя/пароль», обеспечивающих доступ к ограниченным ресурсам. Каждый раз, когда пользователь вводит имя и пароль в окне, сценарий открывает текстовый файл и последовательно ищет в нем совпадающую пару. Если совпадение находится, запрашиваемый доступ пользователю предоставляется, а если нет — запрос отклоняется. Процедура аутентификации продемонстрирована в листинге 16.6.
Листинг 16.6.
Аутентификация на основе текстового файла $file = "Listing16-5.txt":
$fp = fopen($file, "r"):
$auth_file = fread ($fp, filesize($fp)):
fclose($fp);
$authorized = 0;
// Сохранить строки файла в виде элементов массива
$elements = explode ("\n", $auth_file);
foreach ($elements as $element) {
list ($user, $pw) = split (":", $element);
if (($user == $PHP_AUTH_U$ER) && ($pw = $PHP_AUTH_PW)) :
Листинг 16.7.
Аутентификация пользователя посредством поиска в базе данных
if (!isset($PHP_AUTH_USER)) :
header( 'WWW-Authenticate: Basic realm="Secret Family Recipes'");
header('HTTP/1.0 401 Unauthorized');
exit;
else :
// Создать содинение с базой данных MySQL
mysql_connect ("host", "user", "password")
or die ("Can't connect to database!");
mysql_select_db ("useMnfo")
or die ("Can't select database!");
// Обратиться к таблице user_authenticate
// для поиска совпадающей строки
$query = "select userid from user_authenticate where
username = '$PHP_AUTH_USER' and
password = '$PHP_AUTH_PW'";
$result = mysql_query (Squery):
// Если совпадение не найдено, вывести окно аутентификации
if (mysql_numrows($result) != 1) :
header('WWW-Authenticate: Basic realm="Secret Family Recipes'");
header ('HTTP/ 1.0 401 Unauthorized');
exit;
// Если проверка пройдена, получить идентификатор пользователя
else ;
Suserid = mysql_result (user_authenticate, 0, $result);
endif;
endif;
?>
Безопасность данных
Даже после того, как вы обеспечили надежную конфигурацию сервера, необходимо постоянно помнить о потенциальной угрозе для системы безопасности, исходящей из программного кода РНР. Не подумайте, что язык РНР недостаточно надежен — теоретическую брешь в системе безопасности можно создать на любом языке программирования. Тем не менее, учитывая широкое распространение РНР для программирования в распределенных средах с большим количеством пользователей (то есть в Web), вероятность попыток «взлома» ваших программ со стороны пользователей существенно возрастает. Вы должны сами позаботиться о том, чтобы этого не произошло.Безопасный режим и работа РНР в режиме модуля Apache
Следует помнить, что при работе РНР в режиме модуля Apache безопасный режим недоступен. Это объясняется тем, что модуль РНР работает в составе сервера Apache, поэтому все сценарии РНР работают под тем же UID, что и сам сервер Apache. Поскольку ограничения вызова функций в безопасном режиме основаны на сравнении UID, этот режим полноценно работает только при использовании CGI-версии РНР в сочетании с suExec (http://www.apache.org/docs/ suexec.html). Дело в том, что CGI-версия РНР работает как отдельный процесс, что позволяет динамически изменять UID средствами suExec. Если вас интересует использование РНР в безопасном режиме, вероятно, вам следует остановить свой выбор на комбинации CGI/suExec, хотя за это приходится расплачиваться быстродействием.Другой важный аспект конфигурации — запрет на просмотр некоторых файлов в браузере. Конечно, секретные пароли или другие конфигурационные данные должны оставаться недоступными для внешних пользователей. Эта тема рассматривается в следующем разделе.
CCVS
Технология CCVS (Credit Card Verification System) была разработана RedHat (http://www.redhat.com) для независимой обработки сделок по кредитным картам. Она позволяет напрямую обращаться к агентствам кредитных карт вместо того, чтобы пользоваться услугами третьих сторон (например, Cybercash). Технология CCVS совместима со многими платформами Linux/UNIX и легко адаптируется, поскольку RedHat предоставляет исходные тексты. Для использования средств CCVS РНР необходимо откомпилировать с ключом
Для использования средств CCVS РНР необходимо откомпилировать с ключом -with-ccvs[-DIR].
За дополнительной информацией о CCVS обращайтесь по адресам:
Cybercash
Компания Cybercash, Inc. (http://www.cybercash.com) предлагает разнообразные услуги по проверке кредитных карт и проведению сделок, а также программное обеспечение для тех, кто желает использовать эти услуги в своих web-приложениях.Сценарии, написанные на Perl, могут взаимодействовать со службой проведения сделок Cybercash. Учитывая это обстоятельство, пользователи РНР обычно интегрируют Cybercash со своими сайтами одним из следующих способов:
Для использования средств Cybercash РНР необходимо откомпилировать с ключом -with-cybercash[=DIR].Как и в случае с Verisign, помните, что включение поддержки Cybercash при компиляции РНР еще не означает, что вы можете пользоваться этой службой! Услуги Cybercash не бесплатны и могут обойтись довольно дорого (подключение к службе Cybercash Commerce Cash Register в настоящее время стоит $495, ежемесячная оплата составляет $20, а каждая сделка стоит $0,20). Тем не менее, невзирая на все расходы, многие разработчики РНР считают, что Cybercash является одним из лучших решений.
Прежде чем оплачивать услуги Cybercash, вы можете протестировать свой сценарий при помощи тестового входа (эту услугу Cybercash предлагает бесплатно). Бесплатное тестирование сценариев избавит вас от лишних расходов в процессе отладки программ. Дополнительную информацию можно получить на сайте Cybercash.
Ресурсы Интернета, посвященные Cybercash:
Disable_functions
В этом параметре через запятую перечисляются имена функций, выполнение которых требуется запретить. Обратите внимание — этот параметр никак не связан с safe_mode. Например, чтобы запретить вызовы функций fopen( ), popen( ) и file( ), достаточно включить в конфигурационный файл следующую строку:disable_functions = fopen, popen.file
Doc_root
Параметру присваивается путь к корневому каталогу для файлов РНР. Если значение doc_root представляет собой пустую строку, оно игнорируется и сценарии РНР выполняются в полном соответствии с URL. Если безопасный режим включен, а параметр doc_root содержит непустое значение, то сценарии РНР за пределами этого каталога выполняться не будут.Дополнительная информация
В этом разделе описаны лишь те средства, которые в той или иной степени интегрируются в РНР. Впрочем, этим ваши возможности не ограничиваются. Помните о том, что при помощи функций рореn( ) или ехес( ) можно работать с любыми технологиями шифрования, разработанными независимыми фирмами, — например, PGP (http://www.pgpi.org) или GPG (http://www.gnupg.org).Ниже перечислены некоторые ресурсы Интернета, посвященные криптографии и информационной безопасности:
В завершение этого раздела я хочу лишний раз напомнить об осторожности. Прежде чем включать поддержку шифрования данных в критические приложения, потратьте немного времени на изучение механики шифрования. В мире безопасности данных неведение всегда приводит к печальным результатам. Если вы слабо разбираетесь в этой теме, обязательно ознакомьтесь с приведенными ссылками — они дают превосходное представление о многих аспектах шифрования и безопасности данных.
PHP 4 на практике
БезопасностьNon sum qualis eram
(Я не такой, каким был раньше).
Гораций
Когда-то, наткнувшись на эту цитату из Горация, я подумал, что она очень точно отражает суть сетевой безопасности, и сохранил ее где-то в недрах своего жесткого диска на будущее.
Конечно, читатель недоумевает — какое отношение древнеримский поэт Гораций имеет к сетевой безопасности? Безопасность — одна из тем, порождающих нескончаемый поток информации и вечно меняющихся в соответствии с новыми технологическими веяниями. Короче говоря, она в любой момент «не такая, какой была раньше». Вы никогда не можете полагаться на свои познания в этой области, поскольку в момент выхода на широкий рынок любая технология либо устаревает, либо обречена на устаревание в ближайшем будущем. Чтобы добиться относительной безопасности при построении серверных приложений, вам придется постоянно следить за последними достижениями в этой области или нанять кого-нибудь, кто это будет делать за вас.
Применительно к РНР тема безопасности выглядит многогранной, причем некоторые ее аспекты связаны с безопасностью самого сервера. Ведь безопасность сервера во многих отношениях определяет безопасность данных, обрабатываемых сценариям РНР. Я настоятельно рекомендую собрать как можно больше информации о вашем web-сервере и постоянно следить за всеми обновлениями и исправлениями. Вероятно, большинство читателей работает с сервером Apache, поэтому я советую почаще посещать сайт Apache (http://www.apache.org) и замечательный сайт Apache Week (http://www.apacheweek.org). Впрочем, безопасностью сервера дело не ограничивается — РНР также в определенной степени влияет на безопасность системы за счет правильного выбора параметров конфигурации и защищенного программирования.
Последняя глава этой книги состоит из пяти разделов:
Хотя ни один из этих разделов не содержит ответов на все вопросы, относящиеся к построению защищенных приложений на базе РНР, по крайней мере, они закладывают основу для дальнейших самостоятельных исследований.
Электронная коммерция
Появление электронной коммерции вызвало настоящий ажиотаж во всем мире. Бесспорно, она обладает многочисленными достоинствами и открывает массу новых возможностей. К счастью, читатели, занимающиеся разработкой собственных коммерческих сайтов, могут воспользоваться надежными коммерческими технологиями, легко интегрируемыми в сценарии РНР. В этом разделе кратко описаны самые популярные из этих технологий.Маскировка файлов данных и конфигурационных файлов
Этот раздел посвящен процедуре, которая играет очень важную роль независимо от используемого языка программирования. На примере сервера Apache я покажу, как легко нарушить вашу систему безопасности, если вы не предпримете необходимых шагов для «маскировки» файлов, не предназначенных для внешних пользователей.В конфигурационном файле Apache httpd.conf присутствует параметр DocumentRoot. С его помощью устанавливается путь к каталогу, который рассматривается сервером как общедоступный каталог HTML. Считается, что любой файл в этом каталоге может быть передан в пользовательский браузер, даже если расширение этого файла не опознано. Пользователи не могут просматривать файлы, находящиеся за пределами этого каталога. Следовательно, конфигурационные файлы никогда
не следует хранить в каталоге DocumentRoot!
Для примера создайте файл и введите в нем какой-нибудь «секретный» текст. Сохраните этот файл в общедоступном каталоге HTML с именем secrets и каким-нибудь экзотическим расширением типа .zkgjg. Разумеется, сервер не распознает это расширение, но все равно попытается передать запрошенные данные. Теперь запустите браузер и введите URL со ссылкой на этот файл. Интересно, правда? К счастью, у этой проблемы существует два простых решения.
Хранение файлов за пределами корневого каталога документов
В первом варианте вы просто сохраняете все файлы, которые не должны просматриваться пользователями, вне корневого каталога документов и в дальнейшем включаете их в сценарии РНР директивой include( ). Допустим, параметр DocumentRoot настроен следующим образом:
DocumentRoot C:\Program Files\Apache Group\Apache\htdocs # Windows
DocumentRoot /www/apache/home # Другие системы
Предположим, у вас имеется файл с атрибутами доступа (хост, имя пользователя, пароль) к базе данных MySQL. Конечно, этот файл не должен попадаться на глаза посторонним, поэтому вы сохраняете его вне корневого каталога документов. Например, в системе Windows можно воспользоваться каталогом C:/Program FHes/mysecretdata, а в UNIX — каталогом /usr/local/mysecretdata.
Чтобы воспользоваться атрибутами доступа в сценарии, достаточно включить эти файлы с указанием полного пути. Пример для Windows:
INCLUDE("С:/Program Files/mysecretdata/mysqlaccess.inc");
Пример для UNIX:
INCLUDE("/usr/local/mysecretdata/mysqlaccess.inc");
Конечно, при отключении безопасного режима (см. предыдущий раздел) это не помешает другим пользователям, которые могут выполнять сценарии РНР, включить этот файл в свои сценарии. Следовательно, в многопользовательской среде эту меру безопасности желательно сочетать с включением безопасного режима.
Настройка файла httpd.conf
Во втором варианте доступ к файлам с конфиденциальной информацией ограничивается по расширению файла, при этом используется параметр FILES файла httpd.conf. Допустим, вы хотите запретить пользователям доступ к файлам с расширением .inc. Для этого достаточно включить в файл httpd.conf следующий фрагмент:
Order allow, deny
Deny from all
После редактирования файла перезапустите сервер Apache, после этого все попытки запросить любой файл с расширением .inc в браузере отклоняются сервером. Впрочем, эти файлы все равно могут включаться в сценарии РНР. Кстати говоря, при просмотре файла httpd.conf вы увидите, что этот способ применяется для ограничения доступа к файлам .htaccess. Эти файлы используются для парольной защиты каталогов и рассматриваются в конце главы.
Max_execution_time
Параметр указывает максимальную продолжительность выполнения сценария (в секундах). По истечении указанного срока сценарий автоматически завершается, что помогает бороться с чрезмерными затратами процессорного времени на выполнение пользовательских сценариев. По умолчанию параметр равен 30 секундам. Если присвоить ему 0, время выполнения сценариев не ограничивается.Memory_limit
Параметр определяет максимальный объем памяти (в байтах), используемой сценарием. По умолчанию параметр равен 8 Мбайт (8 388 608 байт).Обработка пользовательского ввода
Хотя обработка данных, введенных пользователем, является важной частью практически любого нормального приложения, необходимо постоянно помнить о возможности передачи неправильных данных (злонамеренной или случайной). В web-приложениях эта опасность выражена еще сильнее, поскольку пользователи могут выполнять системные команды при помощи таких функций, как system( ) или ехес( ).Простейший способ борьбы с потенциально опасным пользовательским вводом — обработка полученных данных стандартной функцией escapeshellcmd( ).
escapeshellcmd( )
Функция escapeshellcmd( ) экранирует все сомнительные символы в строке, которые могут привести к выполнению потенциально опасной системной команды:
string escapeshellcmd(string команда)
Чтобы вы лучше представили, к каким последствиям может привести бездумное использование полученных данных, представьте, что вы предоставили пользователям возможность выполнения системных команд — например, `ls -l`. Но если пользователь введет команду `rm -rf *` и вы используете ее для эхо-вывода или вставите в вызов ехес( ) или system( ), это приведет к рекурсивному удалению файлов и каталогов на сервере! Проблемы можно решить предварительной «очисткой» команды при помощи функции escapeshel lcmd( ). В примере `rm -rf *` после предварительной обработки функцией escapeshellcmd( ) строка превращается в \ `rm -rf *\`.
Обратные апострофы (backticks) представляют собой оператор РНР, который пытается выполнить строку, заключенную между апострофами. Результаты выполнения направляются прямо на экран или присваиваются переменной.При обработке пользовательского ввода возникает и другая проблема — возможное внедрение тегов HTML. Особенно серьезные проблемы возникают при отображении введенной информации в браузере (как, например, на форуме). Присутствие тегов HTML в отображаемом сообщении может нарушить структуру страницы, исказить ее внешний вид или вообще помешать загрузке. Проблема решается обработкой пользовательского ввода функцией strip_tags( ).
strip_tags( )
Функция strip_tags( ) удаляет из строки все теги HTML. Синтаксис:
string strip_tags (string строка [, string разрешенные_теги])
Первый параметр определяет строку, из которой удаляются теги, а второй необязательный параметр определяет теги, остающиеся в строке. Например, теги курсивного начертания (<1 >...) не причинят особого вреда, но лишние табличные теги (например,
$input = "I really love РНР!";
$input = strip_tags($input);
// Результат: $input = "I really love PHP!";
На этом завершается краткое знакомство с двумя функциями, часто используемыми при обработке пользовательского ввода. Следующий раздел посвящен шифрованию данных, причем особое внимание, как обычно, уделяется стандартным функциям РНР.
Общие функции шифрования
Шифрование данных в Web имеет смысл только в том случае, если сценарии, в которых используются средства шифрования, работают на защищенном сервере. Почему? Поскольку РНР является сценарным языком, работающим на стороне сервера, перед шифрованием данные должны быть отправлены на сервер в простом текстовом формате. Если данные передаются через незащищенное соединение, существует немало способов перехвата этой информации в процессе ее пересылки от пользователя на сервер. За дополнительными сведениями о защите сервера Apache обращайтесь на сайт http://www.apache-ssl.org. Читателям, работающим с другими web-серверами, следует обращаться к документации. Скорее всего, для этих серверов существует хотя бы одно (а может, и больше) решение области безопасности.md5( )
Хэширующий алгоритм MD5 используется (в частности) для создания цифровых подписей, позволяющих однозначно идентифицировать отправителя. В РНР для этого алгоритма существует специальная функция
string md5(string строка)
MD5 является алгоритмом «одностороннего» хэширования; это означает, что данные, хэшируемые функцией md5(), восстановить уже невозможно.
Алгоритм MD5 также применяется при проверке паролей. Поскольку теоретически невозможно восстановить исходную строку, обработанную алгоритмом MD5, можно хэшировать пароль функцией md5( ) и затем сравнивать зашифрованный пароль с результатом обработки пароля, введенного пользователем при попытке получения доступа к конфиденциальной информации.
Допустим, у нас имеется некоторый секретный пароль toystore с хэш-кодом 745e2abd7c52eeldd7cl4aeOd71b9d76. Хэшированное значение сохраняется на сервере и сравнивается с хэш-эквивалентом пароля, введенного пользователем. Даже если злоумышленник получит доступ к зашифрованному паролю, это ни на что не повлияет, поскольку он (теоретически) не сможет восстановить по нему оригинал. Пример хэширования строки:
$val = "secret";
$hash_val = md5 ($val);
// $hash_val = "Clab6fb9182fl6eed935bal9aa830788";
В следующем раздеяе я представлю другой способ шифрования данных, в котором используется одна из стандартных функций РНР.
crypt( )
Функция crypt( ) является удобным средством для одностороннего шифрования данных. Под «односторонним шифрованием» я подразумеваю, что данные могут только шифроваться — алгоритмы для расшифровки данных, обработанных функцией crypt( ), пока неизвестны. Синтаксис:
string cкypt(string строке [, детерминант])
Первый параметр определяет строку, шифруемую функцией crypt( ). Необязательный второй параметр определяет алгоритм, используемый при шифровании. Точнее, тип алгоритма определяется длиной детерминанта. Различные типы алгоритмов и длины их детерминантов перечислены в табл. 16.2.
Таблица 16.2.
Алгоритмы шифрования и длины их детерминантов
| Алгоритм | Длина |
| CRYPT_STD_DES | 2 |
| CRYPT_EXT_OES | 9 |
| CRYPT_MD5 | 12 |
| CRYPT BLOWFISH | 16 | В листинге 16.1 продемонстрировано использование функции crypt( ) для создания и сравнения зашифрованных паролей.
| SHA1 | RIPEMD160 | MD5 |
| GOST | TIGER | SNEFRU |
| HAVAL | CRC32 |
| RIPEMD128 |
| CRC32B | mcrypt( ) |
| chgrp | include | require |
| chmod | link | rmdir |
| chown | passthru | symlink |
| exec | popen | system |
| fopen | readfile | unlink |
| file | rename |