

Электронный учебник справочник по SPSS
Агрегирование данных (команда AGGREGATE)
Агрегирование данных (команда AGGREGATE)Нередко на основе собранных данных необходимо получить статистические сведения об укрупненных объектах. Для этого на базе исходной матрицы создается и обрабатывается статистическим пакетом новая матрица данных.
Пример. На Рисунок 2.3 приведены данные анкетного обследовании рабочих нескольких заводов. Объекты - информация о рабочих. В данных содержится в виде переменной номер завода и номер цеха, в котором трудится респондент. На основе собранных данных вычисляется новый массив информации, в котором объектами являются цеха, признаками - статистические сведения по цехам, например, доля мужчин в цехе (в %), средний возраст и т.д. Соотношение двух массивов информации приведено на Рисунок 2.3.
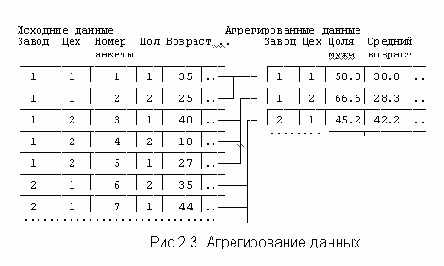
Новую матрицу агрегированных данных, организованную по тому же принципу "объект-признак", что и исходная матрица, можно получить с помощью команды AGGREGATE.
AGGREGATE /OUTFILE = 'ZECH.SPS'/BREAK ZAVOD ZECH
/PERCM = PLT(POL,2) /SRWOZR=MEAN(WOZR).
Основной способ употребления команды: подкомандой /OUTFILE указывается имя выходного файла; подкомандой /BREAK назначаются переменные "разрыва" файла данных, которыми определяются агрегируемые группы объектов. Далее записываются разделенные слэша ми "/" имена новых переменных и функции (статистики) которыми агрегируются исходные переменные, например:
Z9 "средний возраст"= MEAN(V9)/PM=PLT(V8,2).
Перед именем функции агрегирования знак равенства "=" ОБЯЗАТЕЛЕН. В списке допускается указание нескольких переменных для одной функции, в списках переменных можно использовать ключевое слово TO ( Z9 Z14= MEAN(V9 V14)/d1 to d6 = pgt(d1 to d6,0)). Число переменных в аргументе функции должно совпадать с числом новых переменных.
Анализ связи между неколичественными переменными. CROSSTABS - таблицы сопряженности
3.2 Анализ связи между неколичественными переменными. CROSSTABS - таблицы сопряженностиCROSSTABS получает таблицы сопряженности многомерных распределений и связей двух и более переменных. Рекомендуется использовать CROSSTABS для переменных с небольшим числом значений (обычно для неколичественных переменных), так как каждая комбинация значений соответствует новой клетке в таблице.
CROSSTABS /TABLES= v1 v2 BY v10 BY pol.
Таблицы сопряженности для пары переменных X и Y содержат частоты Nij, с которыми встретилось сочетание i-го значения X и j-го значения Y. Кроме того, в таблице обязательно присутствуют маргинальные частоты Ni.- равные сумме чисел Nij по строке; N.j - сумме по столбцу (частоты i-го значения X и j-го значения Y, подсчитанные независимо) и N - общее число объектов.
Таблица, заполненная одними частотами Nij, обычно не имеет смысла, так как не проясняет должным образом взаимосвязи между переменными. Для исследования взаимосвязи необходимы статистики взаимосвязи переменных и статистики связи значений.
Основные подкоманды CROSSTABS:
/TABLES - задание таблиц;
/CELLS - статистики клеток таблицы;
/STATISTICS - статистики взаимосвязи переменных.
/METHOD - метод проверки значимости связи переменных.
/BARCHART - столбиковая диаграмма.
Анкетные данные
1.1. Анкетные данныеВ большинстве социологических исследований анализируется анкетная информация. Условно эти данные можно представить в виде матрицы, строкам которой соответствуют объекты (анкеты), а столбцам - признаки (отдельные вопросы и подвопросы анкеты). Синонимом слова "признак" является слово "переменная", в дальнейшем мы будем употреблять эти термины равноправно.
В современных статистических пакетах такую информацию принято представлять в виде таблицы. Обычно обрабатывается один файл данных, визуально это напоминает таблицу Excel (один лист).
При кодировании информации удобно пользоваться определенными правилами заполнения матрицы в соответствии со структурой обрабатываемой анкеты.
CELLS статистики смещения частот
CELLS статистики смещения частотРеализованные в параметре CELLS статистики позволяют провести более сложный анализ связи переменных. Например, в таблице 3.4 можно увидеть, что среди считающих, что иностранная помощь не нужна, 12% готовы отдать острова Японии, а среди считающих, что помощь нужна - их 37%. В то же время, в целом по совокупности 15% готовы передать острова. Существенны ли отличия от долей в целом по совокупности на 3% и 22%? Может ли в следующем обследовании связь оказаться противоположной? Основой для исследования смещения выборки от истинного распределения служат значения, ожидаемые в случае независимости выборки. Подпараметр EXPECTED параметра CELLS позволяет вывести в клетках абсолютные значения частот (Nij), ожидаемых в случае независимости соответствующих клетке значений переменных. Отклонение (Nij-Eij) наблюдаемой частоты от ожидаемой - более удобная величина для анализа: она достаточно наглядна, но неясно, насколько она статистически значима.
Более полезна статистика Zij=(Nij-Eij)/?ij - стандартизованное смещение частоты; Zij выдается в клетке при указании подпараметра ASRESID (Adjusted residuals). Иными словами, Zij представляет собой отклонение наблюдаемой частоты от ожидаемой, измеренное в числе стандартных отклонений. При этом стандартное отклонение вычисляется исходя из предположения, что Nij это случайная величина, имеющая гипергеометрическое распределение:
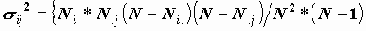
Если переменные независимы, то, при больших N, случайная величина Zij имеет нормальное распределение с параметрами (0,1). Для нее практически невероятно отклонение, большее трех стандартных отклонений, т.к. вероятность такого значения составляет менее 0.0027 (правило "трех сигм"). Поэтому, если мы получаем значение Zij, превышающее 3, то можем считать, что i-ое значение и j-ое значения X и Y связаны. На практике нередко, когда анализируетсся единственная клетка таблицы, выставляются более слабые требования. Существенными считаются односторонние отклонения, которые превышают 1,65?ij - вероятность их получения составляет 5%.
Таким образом, начиная с отклонения 1,65?ij и большего, можно уже высказывать гипотезу о существовании связи между значениями (см. таблицу нормального распределения в любом статистическоим справочнике). Эмпирическим критерием, когда распределение Zij близким к нормальному, следует считать является соотношение для дисперсии
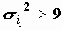 . Хотя последнее ограничение достаточно жестко.
. Хотя последнее ограничение достаточно жестко.Следует заметить, что в действительности мы имеем дело с множеством статистик значимости и, при переборе их, велика вероятность случайно получить их значения, превышающие указанные пороги. Если бы клетки были независимы, при критическом значении статистики Zij, равном 1.96 (5% уровень значимости) мы в среднем в условиях независимости данных находили бы 5 "значимых" из 100 клеток таблицы, а хотя бы одну статистику, Zij>1.96 мы можем получить с вероятностью (1-0.95100)=0.! Поэтому сложившаяся практика руководствоваться отклонением 1.65?ij оберегает нас только от грубейших ошибок.
CELLS
CELLSПараметр CELLS задает вывод некоторых статистик (см. ключевые слова параметра CELLS) для клеток таблицы сопряженности. "CELLS" переводится как "клетка". Если этот параметр не указан, то в клетках таблицы выводятся только абсолютные частоты.
CROSSTABS V1 BY V4 /CELLS = COUNT ROW COLUMN.
Параметры подкоманды /CELLS
COUNT - абсолютное число объектов (Nij);
ROW - проценты по строке;
COLUMN - проценты по столбцу;
TOTAL - проценты по отношению ко всей выборке;
EXPECTED - частоты (Eij=Ni.*N.j/N), ожидаемые в случае независимости переменных (N – общая сумма частот в таблице);
RESID - изменение частоты по сравнению с ожидаемым (Nij-Eij);
SRESID - стандартизованное изменение частоты по сравнению с ожидаемым (Nij-Eij)/
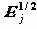 (корень из слагаемого статистики Хи-квадрат, вычисляемой для проверки гипотезы независимости);
(корень из слагаемого статистики Хи-квадрат, вычисляемой для проверки гипотезы независимости);ASRESID - стандартизованное к нормальному распределению N(0,1) изменение частоты Zij=(Nij-Eij)/?ij;
ALL - вывод для клетки всех статистик;
Частные корреляции.
Частные корреляции.Пусть имеются переменные X, Y, Z. Что, если взаимосвязь между переменными X и Y обусловлена некоторой другой переменной Z. Mожет быть она проявляется при условии этой переменной?
Для исследования этого вопроса применяется коэффициент частной корреляции. Вообще говоря, коэффициент корреляции X и Y должен зависеть от значений Z, однако известно, что в многомерной нормальной совокупности такой зависмости нет. Поэтому статистическая теория здесь разработана именно для такого случая. На практике весьма сложно доказать многомерную нормальность и часто эту технику используют для анализа данных, не имеющих слишком большие перекосы.
Не вдаваясь в подробности вычисления, коэффициент ранговой корреляции можно представить как коэффициент корреляции регрессионных остатков e x и e y уравнений
X=ax+bx*Z+e x
Y=ay+by*Z+e y
Таким образом, снимается часть зависимости, обусловленная третьей переменной, проявляется "чистая" взаимосвязь X и Y. Уравнению регрессии мы посвятим в дальнейшем специальный раздел. Здесь мы прведем пример задания частной корреляции.
Время, затраченное на покупки, и время на мытье посуды, оказывается, связаны положительно - чем больше человек тратит его на покупки, тем больше на посуду (таблица 4.16, RLMS, 7 волна). Может быть, это определяется тем, что человек вообще занимается домашней работой? Для проверки этого возьмем в качестве управляющей переменной время на уборку квартиры … и получим таблицу 4.17. Оказалось, что эта связь между временными затратами на покупку продуктов и мытье посуды имеет самостоятельный смысл, так как частная корреляция по-прежнему значима, хотя уменьшилась с 0.320 до 0.256.
Compare Means - простые параметрические методы сравнения средних.
4.3. Compare Means - простые параметрические методы сравнения средних.Параметрические методы при формулировании нулевых гипотез о равенстве средних предполагают нормальность распределения анализируемых переменных или остатков в моделях дисперсионного анализа, сравнения групп и т.д. Это условие при анализе анкетной информации выполняется весьма редко. Вероятно, наиболее удобны для такого анализа переменные, полученные усреднением множества независимых случайных величин: по центральной предельной теореме такие переменные должны иметь близкое к нормальному распределение.
 На практике нередко для больших совокупностей эти методы все-же используются и для другого рода распределений, если распределение "не слишком сильно" отклоняется от нормального. "Не слишком сильно" - неопределенное понятие, обычно это определяется визуально при рассмотрении гистограммы распределения.
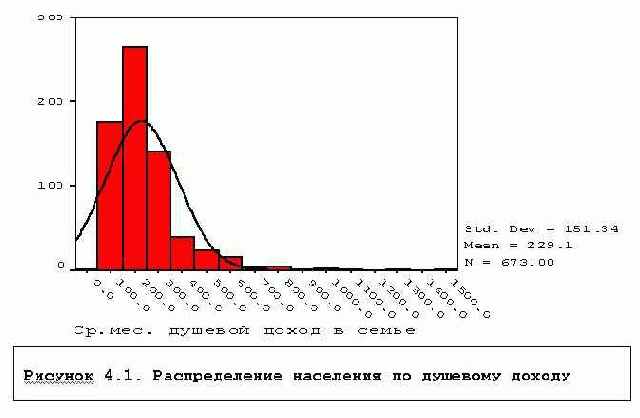
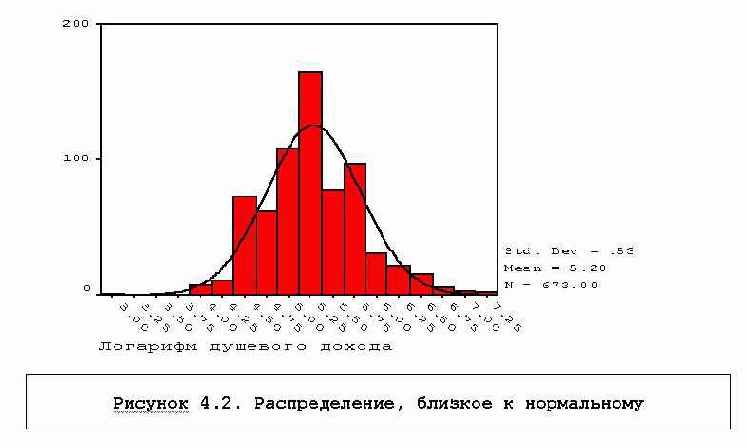
На практике нередко для больших совокупностей эти методы все-же используются и для другого рода распределений, если распределение "не слишком сильно" отклоняется от нормального. "Не слишком сильно" - неопределенное понятие, обычно это определяется визуально при рассмотрении гистограммы распределения.Взгляните, например, на распределение населения по душевому доходу - Рисунок 4.1. Распределение имеет длинный хвост в направлении больших доходов, нормальная кривая недостаточно хорошо огибает гистограмму. Если использовать вместо этой переменной логарифм доходов:
compute lnv14=ln(v14).
получаем более приемлемое распределение (см.Рисунок 4.2).
Основные формулы и идеи параметрических методов анализа средних и дисперсий рассматриваются в курсе математической статистики; и здесь, по ходу изложения материала, мы коротко напомним отдельные моменты этой теории.
DESCRIPTIVES - описательные статистики
DESCRIPTIVES - описательные статистикиЕсли команда Frequencies получает описательные статистики "попутно", то DESCRIPTIVES специально для этого предназначена.
DESCRIPTIVES VAR = V9 V14/ SAVE /STATISTICS=MEAN MIN MAX.
Синтаксис: указывается список переменных, список необходимых статистик, подкоманда сохранения в данных стандартизованных переменных (/save).
Список выдаваемых статистик здесь значительно меньше, чем в командем Frequencies: MEAN MIN SKEWNESS STDDEV SEMEAN MAX KURTOSIS VARIANCE SUM RANGE.
Стандартизованные переменные. Иногда возникает необходимость рассматривать нормированную переменную:
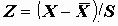 , где S - cтандартное отклонение
, где S - cтандартное отклонение 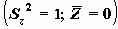 .
.Например: мы имеем данные по заработной плате за два последних года. На основании этих данных необходимо определить, в каком социальном слое находятся респонденты. Это затруднительно сделать, поскольку существенно изменился масштаб цен. Для сравнения преобразуем к стандартному виду данные по каждому году, что позволит нам проводить сравнительный анализ для определенных социальных слоев. Такой подход не учитывает всех факторов, но это реальный шаг в исследовании.
Стандартизованные переменные можно получить, указав в скобках за переменной имя новой, стандартизованной, переменной:
DESCRIPTIVES VAR V14(Z14) V9(Z9).
Или используя подкоманду SAVE. В этом случае имена новых переменных образуются следующим образом: к имени переменной добавляется слева Z.
Например,
DESCRIPTIVES VAR= V9 V14/SAVE.
Новым переменным пакет присвоит имена ZV9 и ZV14.
Напомним, что более разнообразные нормирования переменных можно получить командой RANK.
С помощью этой команды можно ранжировать значения переменной, перекодировать переменную с целью получения нормального распределения, получать процентили и др.
Душевой доход любителей сладкого и жилье. Одновременное сравнение средних по строкам таблицы.
Душевой доход любителей сладкого и жилье. Одновременное сравнение средних по строкам таблицы.Насколько отличаются доходы потребителей сладкого внутри групп по-разному обеспеченных жильем - имеющих квартиру, свой дом, часть квартиры и др.?
Для выяснения этого изучим средние логарифмы доходов (вспомним, что для получения устойчивых результатов в таких исследованиях лучше использовать логарифм дохода).
Из таблицы 3.15. видно, что обладатели отдельных квартир - самые богатые, отдельного дома - чуть победнее (скорее всего это обитатели городских окраин), а те, кто имеет часть дома или квартиры - самые бедные. У них разные условия существования и полезно изучить эти группы по отдельности. Это значит, что смещение средних в клетках таблицы нужно рассмотреть не по отношению к общему среднему (5.6), а по отношению к итогам по строкам (например, существенно ли выделяются по доходам среди обитателей домов (средний логарифм дохода равен 5.5) любители мороженого (средний логарифм дохода равен 5.9)).
Двухвыборочный критерий знаков (Sign)
5.4.1. Двухвыборочный критерий знаков (Sign)Для исследования связи пары измерений Х и Y рассматриваются знаки разностей di=Yi-Xi. В случае независимости измерений и отсутствии повторов значений di (связей) число знаков "+" (положительных di) должно подчиняться биномиальному распределению с параметром p=0.5. Именно эта гипотеза и проверяется с помощью статистики критерия - стандартизованной частоты положительных разностей.
В качестве примера по данным RLMS проверим, какой характер имели изменения веса (кг) мужчин старше 30 лет в 1994-95 гг.
COMPUTE filter_$=(a_age < 30 & ah5_1 = 1).
FILTER BY filter_$.
NPAR TEST / SIGN= am1 WITH bm1 (PAIRED).
Двухвыборочный t-тест для связанных выборок (Paired sample T-TEST)
двухвыборочный t-тест для связанных выборок (Paired sample T-TEST)Если на одних и тех же объектах дважды измеряется некоторое свойство, то проверка значимости различия средних по измеренным переменным - для этого теста. Пример задания команды:
T-TEST PAIRS= x WITH y (PAIRED) /CRITERIA=CIN(.95).
Переменные X и Y могут быть характеристиками мужа и жены при исследовании семей; по данным RLMS - измерениями, связанными с потреблением напитков в 1996 и 1998 году и т.п. Поэтому данная процедура полезна для анализа панельных данных.
Почему же здесь нельзя воспользоваться таким же анализом, как и для двух несвязанных выборок, считая, что имеются две выборки одинакового объема?
Проверка значимости различия матожиданий X и Y эквивалентна проверке гипотезы о равенстве нулю математического ожидания разности X-Y. Дисперсия разности X-Y равна D(X-Y)=D(X)+D(Y)-2cov(X,Y). Отсюда точность оценки матожидани Х-Y связана с ковариацией X и Y.
Поэтому наряду с соответствующей статистикой в выдачу по этому тесту входит и коэффициент корреляции этих переменных и наблюдаемая значимость.
Для примера взгляните на выдачу, в которой сравниваются вес 1995 и 1996 г. женщин от 30 до 40 лет (в 1995), таблицы 4.5-7, данные RLMS.
Двухвыборочный t-тест (independent sample T-TEST)
двухвыборочный t-тест (independent sample T-TEST)Вариант команды для выполнения процедуры T-TEST для сравнения средних в двух выборках имеет следующий вид:
T-TEST/GROUPS V4(1,3)/VARIABLES = V9 lnV14m.
Подкоманда GROUPS указывает переменную группирования; в скобках задаются два значения этой переменной, определяющие группы. Например, приведенная команда будет выполняться только для групп объектов, у которых V4 принимает указанные значения 1 и 3. VARIABLES задает сравниваемые (зависимые) переменные для выделенных групп объектов. Объекты можно также разбить на две группы, указав в параметре GROUPS одно значение:
T-TEST /GRO v9(30)/VAR V9 lnV14m.
В этом случае вся совокупность будет разделена на те объекты, на которых указанная переменная не больше заданного значения (v9? 30), и те, у которых она больше (v9>30).
Процедурой T-TEST проверяется гипотеза равенства средних, при этом предполагается нормальность распределения генеральной совокупности. Процедура подсчитывает средние для пары групп, стандартные ошибки, статистики и их значимость. При сравнении двух выборок нас интересует, насколько случайный характер носит различие средних - отличаются ли они значимо?
В зависимости от предположения о равенстве дисперсий испльзуются разные варианты t-статистик.
Если не предполагается равенство дисперсий в группах, то для сравнения средних принято использовать статистику
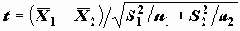 , которая в условиях гипотезы равенства матожиданий и нормальности X имеет распределение Стьюдента, число степеней которого оценивается на основе оценок дисперсий.
, которая в условиях гипотезы равенства матожиданий и нормальности X имеет распределение Стьюдента, число степеней которого оценивается на основе оценок дисперсий.Если заранее известно о равенстве дисперсий в группах, то предпочтительнее статистика
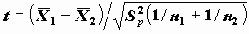 .
.При определении ее величины предварительно вычисляется объединенная дисперсия
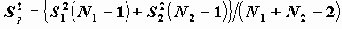 .
.Из теории известно, что при условии равенства дисперсий вычисляемая величина Sp есть несмещенная оценка дисперсии, и статистика t также имеет распределение Стьюдента.
Для проверки равенства дисперсий используется статистики Ливиня, имеющая распределение Фишера.
Двусторонней наблюдаемой значимостью, вычисляемой процедурой T-TEST, является вероятность случайно получить различия средних, такие, что ¦t-теоретическое¦>¦t-выборочного¦. Если значимость близка к 0, делаем вывод о неслучайном характере различий.
Результат выдается в двух таблицах. В первой размещены средние и характеристики разброса в группах, во второй - результаты их сравнения.
Двухвыборочный тест Колмогорова-Смирнова
5.2.1. Двухвыборочный тест Колмогорова-СмирноваДвухвыборочный тест Колмогорова-Смирнова предназначен для проверки гипотезы о совпадении распределений в паре выборок:
NPAR TESTS K-S=V14 BY V4(1,3).
В команде за ключевым словом K-S следует тестируемая переменная (в нашем примере - V14), за ней после слова BY указываются сравниваемые группы - переменная, определяющая эти группы, и соответствующие этим группам значения: V4(1,3).
Статистика критерия - абсолютная величина разности эмпирических функций распределения в указанных выборках:
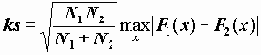 , где N1 и N2 - объемы выборок.
, где N1 и N2 - объемы выборок.В листинге выдается статистика критерия Z=ks двусторонняя значимость - вероятность случайно в условиях гипотезы превзойти выборочное значение статистики.
Пример: сравнение распределений доходов групп готовых отдать острова или их часть и придерживающихся твердой позиции:
recode v4(1,2=1)(3=2) into W4.
Var lab W4 "отношение к передаче островов".
Val lab 1 "Отдать" 2 "нет".
npar test k-s=v14 by w4(1,2).
Двухвыборочный тест Манна-Уитни (Mann-Witney)-
5.3.1. Двухвыборочный тест Манна-Уитни (Mann-Witney)-Критерий предназначен для сравнения распределений переменных в двух группах на основе сравнения рангов.
NPAR TESTS M-W = V14 BY Tp(1,4).
Задание теста аналогично заданию критерия Колмогорова-Смирнова (вместо ключевого слова K-S используется слово M-W).
Статистикой критерия, является сумма рангов объектов в меньшей группе, хотя существует пара эквивалентных формул, обозначаемых U и W. Можно также считать, что критерием является средний ранг в указанной группе. Если он значительно отклоняется от ожидаемой величины (N+1)/2 (или средние ранги в группах существенно различны) - обнаруживается отличие распределений.
Если гипотеза о совпадении распределений не отвергается, то это означает близость средних рангов в группах, не гарантируется совпадение распределений не гарантируется.
Авторам теста удалось показать асимптотическую нормальность статистики в условиях выборки групп из одной совокупности, на основе чего отыскивается наблюдаемая значимость критерия - вероятность случайно отклониться от среднего (ожидаемого) значения ранга больше, чем отклонилось выборочное значение статистики.
В выдаче распечатывается значения статистик U и W, а также двусторонняя значимость критерия.
Пример. Используя ранговый критерий, требуется сравнить по возрасту группу считающих, что острова нужно отдать по юридическим причинам, и группу имеющих иное мнение.
count d2 = v6s1 to v6s8 (2).
if (d2>0) wd2=1.
If (v4=1 or v4=2) wd2 = 2.
npar test m-w=v9 by wd2(1,3).
По величине двусторонней значимости можем сделать вывод, что тест Манна-Уитни в указанных группах не обнаружил существенных различий между распределениями по возрасту (таблицы 5.10-11).
Двухвыборочный знаково-ранговый критерий Вилкоксона (Wilcoxon)
5.4.2. Двухвыборочный знаково-ранговый критерий Вилкоксона (Wilcoxon)Ранжируются абсолютные величины разностей di=Yi-Xi. Затем рассматривается сумма рангов положительных и сумма рангов отрицательных разностей. Если связь между X и Y отсутствует и распределение одинаково, то эти две суммы должны быть примерно равны. Статистика критерия - стандартизованная разность этих сумм.
По сути, это проверка, не произошло ли между измерениями событие, существенно изменившее иерархию объектов?
Обратимся к предыдущему примеру, но проверим, будет ли преобладать отрицательный ранг изменения веса мужчин старше 30 лет?
NPAR TEST /WILCOXON=am1 WITH bm1 (PAIRED).
Факторный анализ
7.1. Факторный анализИдея метода состоит в сжатии матрицы признаков в матрицу с меньшим числом переменных, сохраняющую почти ту же самую информацию, что и исходная матрица. В основе моделей факторного анализа лежит гипотеза, что наблюдаемые переменные являются косвенными проявлениями небольшого числа скрытых (латентных) факторов. Хотя такую идею можно приписать многим методам анализа данных, обычно под моделью факторного анализа понимают представление исходных переменных в виде линейной комбинации факторов.
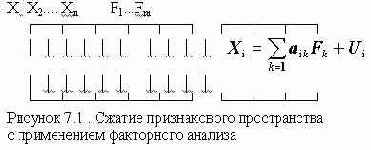 Факторы F построены так, чтобы наилучшим способом (с минимальной погрешностью) представить Х. В этой модели "скрытые" переменные Fk называются общими факторами, а переменные Ui специфическими факторами ("специфический" -это лишь один из переводов применяемого в англоязычной литературе слова Unique, в отечественной литературе в качестве определения Ui встречаются также слова "характерный", "уникальный"). Значения aik называются факторными нагрузками.
Факторы F построены так, чтобы наилучшим способом (с минимальной погрешностью) представить Х. В этой модели "скрытые" переменные Fk называются общими факторами, а переменные Ui специфическими факторами ("специфический" -это лишь один из переводов применяемого в англоязычной литературе слова Unique, в отечественной литературе в качестве определения Ui встречаются также слова "характерный", "уникальный"). Значения aik называются факторными нагрузками.Обычно (хотя и не всегда) предполагается, что Xi стандартизованы (
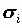 =1, Xi=0), а факторы F1,F2,…,Fm независимы и не связаны со специфическими факторами Ui (хотя существуют модели, выполненные в других предположениях). Предполагается также, что факторы Fi стандартизованы.
=1, Xi=0), а факторы F1,F2,…,Fm независимы и не связаны со специфическими факторами Ui (хотя существуют модели, выполненные в других предположениях). Предполагается также, что факторы Fi стандартизованы.В этих условиях факторные нагрузки aik совпадают с коэффициентами корреляции между общими факторами и переменными Xi. Дисперсия Xi раскладывается на сумму квадратов факторных нагрузок и дисперсию специфического фактора:
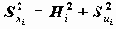 , где
, где 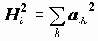
Величина
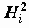 называется общностью,
называется общностью, 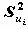 - специфичностью. Другими словами, общность представляет собой часть дисперсии переменных, объясненную факторами, специфичность - часть не объясненной факторами дисперсии.
- специфичностью. Другими словами, общность представляет собой часть дисперсии переменных, объясненную факторами, специфичность - часть не объясненной факторами дисперсии.В соответствии с постановкой задачи, необходимо искать такие факторы, при которых суммарная общность максимальна, а специфичность - минимальна.
FREQUENCIES BARCHART, PIECHART и HISTOGRAM - диаграммы распределения
FREQUENCIES BARCHART, PIECHART и HISTOGRAM - диаграммы распределения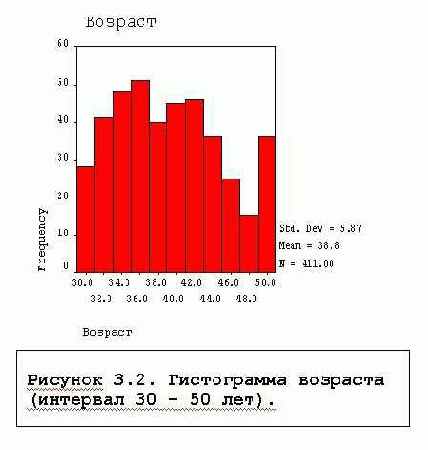 Столбиковая и круговая диаграммы полезны для неколичественных переменных. Гистограмма необходима для графического представления количественных данных. Для ее построения SPSS подбирает интервалы группирования значений переменной и представляет графически частоты или доли числа объектов, попавших в соответствующие интервалы. К сожалению, принцип определения числа интервалов в документации SPSS не описан. В синтаксисе можно задавать интервал значений, для которых выдается гистограмма, см. Рисунок 3.2, на котором представлен график, полученный командой:
Столбиковая и круговая диаграммы полезны для неколичественных переменных. Гистограмма необходима для графического представления количественных данных. Для ее построения SPSS подбирает интервалы группирования значений переменной и представляет графически частоты или доли числа объектов, попавших в соответствующие интервалы. К сожалению, принцип определения числа интервалов в документации SPSS не описан. В синтаксисе можно задавать интервал значений, для которых выдается гистограмма, см. Рисунок 3.2, на котором представлен график, полученный командой:FREQUENCIES VARIABLES = V9/ HISTOGRAM min(30), max(50).
FREQUENCIES NTILES, percentiles - процентили
FREQUENCIES NTILES, percentiles - процентилиПодкоманда NTILES задает печать n-тилей - значений переменной, делящих распределение на заданное число групп с равным числом объектов. Следующая команда выдает квинтили по доходу:
FREQUENCIES /VARIABLES=V14 /NTILES=5.
Подкоманда PERCENTILES печатает процентили (процентиль - это квантиль, рассчитанная по доле, указанной в процентах). Процентили являются значениями переменной, отделяющими указанную в процентах долю совокупности объектов. Процентили удобно использовать, если нам нужно разбить значения переменной на интервалы, которые содержали бы определенного размера группы объектов (анкет). Пример: найдем значения дохода, отделяющие 10% выборки, 50% (медиану) и 90%.
FREQUENCIES /VARIABLES= V14 /PERCENTILES 10 50 90.
FREQUENCIES - получение распределений
FREQUENCIES - получение распределенийЭта процедура предназначена для получения одномерных распределений переменных.
Процедура FREQUENCIES позволяет получить самые основные статистические характеристики случайной переменной: перечень значений, принимаемых переменной, и частотное распределение (в числовом виде и в виде процентов), т.е. сколько раз переменная принимала каждое из этих значений. Частотное распределение в зависимости от желания пользователя представляется в виде таблицы и(или) графика(по умолчанию выдается таблица). В процедуре FREQUENCIES также предусмотрен расчет описательных статистик. Пример задания команды:
FREQUENCIES VAR V2 V3S1 TO V3S4 / HISTOGRAM /STATISTICS = MEANS.
Синтаксис: указываются через пробел переменные для табулирования. Допустимы числовые и строковые переменные. Параметры процедуры необязательны и задаются ключевыми словами; ключевые слова разделяются косыми чертами "/". В параметрах могут быть подпараметры.
FREQUENCIES STATISTICS - описанельные статистики
FREQUENCIES STATISTICS - описанельные статистикиПодкоманда позволяет получить одномерные описательные статистики.
FREQUENCIES V1 V2 V4 /STATISTICS DEFAULT.
Ключевые слова:
MEAN - среднее;
SEMEAN - стандартная ошибка среднего;
MEDIAN - медиана(процентиль с 50%)
MODE - мода(наиболее частое значение)
STDDEV - стандартное отклонение;
VARIANCE - дисперсия;
KURTOSIS - эксцесс (пикообразность);
SEKURT - стандартная ошибка эксцесса
SKEWNESS - коэффициент асимметрии (скошенность);
SESKEW - стандартная ошибка коэффициента асимметрии;
RANGE - разброс = (MAX - MIN);
MINIMUM - минимум;
MAXIMUM - максимум;
SUM - сумма всех значений переменной;
ALL - все статистики.
DEFAULTS - по умолчанию МEAN, STDDEV, MIN, MAX.
Для расчета параметра SEMEAN (стандартной ошибки среднего для выборки x1, x2,…, xn) вычисляются следующие статистики:
MEAN
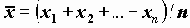
VARIANCE:
 - оценка дисперсии;
- оценка дисперсии;SEMEAN
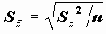 - оценка стандартной ошибки среднего.
- оценка стандартной ошибки среднего.Стандартную ошибку можно использовать для оценки доверительного интервала среднего. Напомним, что доверительным интервалом параметра называется интервал со случайными границами, накрывающий значение параметра с заданной (доверительной) вероятностью. В частности, приближенными оценками границ 95% двустороннего доверительного интервала являются значения
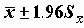 (истинное значение среднего с вероятностью 0.95 находится в этих пределах).
(истинное значение среднего с вероятностью 0.95 находится в этих пределах).Если распределение нормально, то в пределах
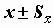 должно находиться примерно 68% наблюдений совокупности.
должно находиться примерно 68% наблюдений совокупности.Скошенность определяется расчетом третьего момента по следующей формуле:
SKEWNESS:
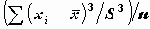 - коэффициент асимметрии.
- коэффициент асимметрии.Если полученная величина < 0, то распределение растянуто влево, если > 0, то вправо.
Пикообразность определяется значением четвертого момента:
KURTOSIS:
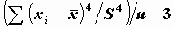 - эксцесс.
- эксцесс.Функции агрегирования
Функции агрегированияВ приведенном ниже списке функций VARS означает список переменных или переменную.
N (VARS) - число объектов, для которых VARS определены;
N - без указания переменных - число объектов в агрегируемой группе;
MIN (VARS) - минимум;
MAX (VARS) - максимум;
SD (VARS) - стандартное отклонение;
PGT (VARS,значение) - процент объектов, у которых переменная имеет значение большее, чем указанное в команде;
PLT (VARS, значение) - процент объектов, у которых переменная имеет значение меньшее, чем указанное в команде;
PIN(VARS, значение1, значение2)- доля объектов, которые находятся в интервале [значение1, значение2];
POUT(VARS, значение1, значение2)- доля объектов, которые находятся вне интервала [значение1, значение2];
| FGT (VARS, значение) FLT (VARS, значение) FIN (VARS, значение1,значение2) FOUT (VARS, значение1,значение2) |
| | | | |
Это доли, но не в процентах; |
LAST(VARS) - последнее значение переменной.
ЗАДАЧА. Получить на базе исходного агрегированный файл данных по городам (переменная G в файле OCT.SPS). Файл должен содержать переменные:
NG - число опрошенных в городе;
W1 - доля рассчитывающих на свои силы;
W2 - доля отрицательно относящихся к свободным зонам;
W3D1 TO W3D6 - доли по подсказкам на вопрос 3 о причинах не подписания договора;
W4 - доля считающих, что острова нужно отдать;
W8 - доля женщин; W9 - средний возраст;
W10 - доля лиц с высшим образованием;
WR - регион.
Все переменные, кроме W3D1 TO W3D6, могут быть непосредственно получены с использованием функций агрегирования; для формирования переменных W3D1 TO W3D6 придется специально подготовиться, пользуясь командой COUNT.
get file "D:oct.sav".
count d1 = v3s1 to v3s8(1)/ d2 = v3s1 to v3s8(2) / d3 = v3s1 to v3s8(3)
/d4 = v3s1 to v3s8(4) / d5 = v3s1 to v3s8(5) / d6 = v3s1 to v3s8(6).
Aggregate/out="D: aggr.sps"/break g/NG "число опрошенных в городе"=N/
W1 'рассч на св силы'=pin(v1,1,1)/
w2 '% отриц.относящ'=pin(v2,3,4)/w3d1 to w3d6=pgt(d1 to d6,0)/
w4 'мнен: острова отдать'=pin(v4,1,1)/
w8 'доля мужчин'=pin(v8,2,2)/
w9 'средний возраст'=mean(v9)/
w10 'доля с высшим образованием'=pin(v10,1,1)/
wr = first(r).
В новом файле будут созданы переменные W1 W2 W3D1 W3D2 W3D3 W3D4 W3D5 W3D6 W4 W8 W9 W10 WR. Так как после выполнения агрегирования остается активным исходный файл, чтобы начать работу с вновь созданным файлом необходимо вызвать его командой GET.
По данным нового файла можно, например, командой MEANS вычислить средние по регионам:
MEAN W3D1 TO W3D6 BY R.,
рассчитать корреляции долей по городам:
CORR W1 W2 WITH W3D1 TO W3D6/OPTIONS 5.
и т.д. Напомним, что объектами агрегированного файла данных являются города, и нужно серьезно подумать над интерпретацией получаемых статистик. В частности, среднее значение переменной W9 будет не средним возрастом, а средним средних возрастов по городам.
Функции для неопределенных значений
Функции для неопределенных значенийVALUE - функция игнорирования назначения пользовательского неопределенного значения;
MISSING - логическая функция для обнаружения пользовательского или системного отсутствующего значения; ее значения - истина (единица), если значение аргумента не определено, ложь (нуль) - в противном случае;
SYSMIS - то же, но только для системных неопределенных значений;
NMISS - число неопределенных значений в списке аргументов;
NVALID - число определенных значений в списке аргументов
Непараметрические тесты. Команда Nonparametric tests.
Глава 5. Непараметрические тесты. Команда Nonparametric tests.Непараметрические тесты предназначены преимущественно для проверки статистических гипотез методами, не связанными с видом распределения совокупности. В частности, применение этих методов не требует предположения о нормальности распределения, которое необходимо для правомерного использования одномерного дисперсионного анализа, процедуры T-TEST, при определении значимости корреляций и т.д. К средствам непараметрического анализа относятся в числе прочих методов тест хи-квадрат, служащий для проверки взаимосвязи между номинальными переменными и коэффициенты ранговой корреляции, которым мы уже уделили некоторое внимание.
Непараметрические тесты не ограничиваются таким исследованием связи пар переменных; они включают множество других методов, реализованных командой синтаксиса NPAR TESTS. В меню SPSS непараметрические тесты реализует команда Nonparametric tests c множеством подкоманд.
Процедура NPAR TESTS включает большую группу критериев для проверки:
Процедуры получения описательных статистик и таблиц сопряженности
Глава 3. Процедуры получения описательных статистик и таблиц сопряженностиПроцедуры статистического анализа и описания распределений снабжены обычно таким множеством подкоманд, задающих разнообразные режимы работы и параметры, что текст подсказки по соответствующим командам напоминает новогодние елки, обвешанные игрушками. Поэтому команды для выполнения этих процедур удобнее формировать в диалоговых окнах, которые позволяют успешно их формировать практическт без знания синтаксиса команд. Ниже приведены образцы применения команд преимущественно с указанием лишь основных параметров. Как мы уже отметили, потребность в пакетном режиме использования статистических процедур возникает, когда приходится многократно повторять расчет, корректируя лишь параметры.
Для первичного анализа данных обычно достаточно процедур реализучемых следующими командами:
FREQUNCIES - получение распределений;
DESCRIPTIVES - одномерные описательные статистики;
EXPLORE (EXAMINE) - одномерные описательные статистики в группах объектов;
CROSSTABS - таблицы сопряженности;
MEANS - средние;
MULTIPLE RESPONSE, GENERAL TABLE - таблицы для неальтернативных признаков.
Эти команды используются преимущестевенно для описания данных. FREQUNCIES, DESCRIPTIVES, EXPLORE (EXAMINE), CROSSTABS, находятся в разделе меню DESCRIPTIVE STATISTICS. MEANS находится в разделе COMPARE MEANS, MULTIPLE RESPONSE и GENERAL TABLE - в Custom Tables.
Характерно, что команда меню EXPLORE в синтаксисе имеет имя EXAMINE.
Статистический пакет для социологических исследований. Общее описпние и поодготовка данных
Глава 2. Статистический пакет для социологических исследований. Общее описпние и поодготовка данныхИмена переменных и метки, коды неопределенных значений
1.3. Имена переменных и метки, коды неопределенных значенийКаждый столбец данных должен быть поименован, при этом имеются короткие имена для удобства задания команд и длинные имена, удобные для выдачи результатов расчетов. В приведенной анкете можем обозначить признаки следующим образом:
v1, v2, v3s1, v3s2, v3s3, v4d1, v4d2, v4d3, v4d4, v4d5
или: sex, age, problem1,…,problem3, compl1,… compl5.
Меткой переменной может быть и непосредственная формулировка вопроса и переработанный текст вопроса , например, "Назовите, пожалуйста, ваш пол" или "Пол".
Метки значений - это текстовая расшифровка кодов значений переменных (для пола: 1 - "мужской", 2 "женский").
Коды неопределенных значений. Нередко необходимо исключить из анализа коды переменных, соответствующих неопределенным значениям. Эти коды должны быть заданы заранее.
Ниже мы увидим, каким образом указанная информация о метках и неопределенных значениях заносится в данные.
Интерпретация факторов.
Интерпретация факторов.Как же можно понять, что скрыто в найденных факторах? Основной информацией, которую использует исследователь, являются факторные нагрузки. Для интерпретации необходимо приписать фактору термин. Этот термин появляется на основе анализа корреляций фактора с исходными переменными. Например, при анализе успеваемости школьников фактор имеет высокую положительную корреляцию с оценкой по алгебре, геометрии и большую отрицательную корреляцию с оценками по рисованию - он характеризует точное мышление.
Не всегда такая интерпретация возможна. Для повышения интерпретируемости факторов добиваются большей контрастности матрицы факторных нагрузок. Метод такого улучшения результата называется методом ВРАЩЕНИЯ ФАКТOРОВ. Его суть состоит в следующем. Если мы будем вращать координатные оси, образуемые факторами, мы не потеряем в точности представления данных через новые оси, и не беда, что при этом факторы не будут упорядочены по величине объясненной ими дисперсии, зато у нас появляется возможность получить более контрастные факторные нагрузки. Вращение состоит в получении новых факторов - в виде специального вида линейной комбинации имеющихся факторов:
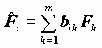
Чтобы не вводить новые обозначения, факторы и факторные нагрузки, полученные вращением, будем обозначать теми же символами, что и до вращения. Для достижения цели интерпретируемости существует достаточно много методов, которые состоят в оптимизации подходящей функции от факторных нагрузок. Мы рассмотрим реализуемый пакетом метод VARIMAX. Этот метод состоит в максимизации "дисперсии" квадратов факторных нагрузок для переменных:
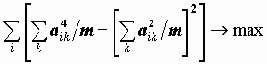
Чем сильнее разойдутся квадраты факторных нагрузок к концам отрезка [0,1], тем больше будет значение целевой функции вращения, тем четче интерпретация факторов.
Исследование структуры данных
7. Исследование структуры данныхКонечно, собирая данные, исследователь руководствуется определенными гипотезами, информация относятся к избранным предмету и теме исследования, но нередко она представляет собой сырой материал, в котором нужно изучить структуру показателей, характеризующих объекты, а также выявить однородные группы объектов. Полезно представить эту информацию в геометрическом пространстве, лаконично отразить ее особенности в классификации объектов и переменных. Такая работа создает предпосылки к созданию типологий объектов и формулированию "социального пространства", в котором обозначены расстояния между объектами наблюдения, позволяет наглядно представить свойства объектов.
Измерение силы связи между номинальными переменными
Измерение силы связи между номинальными переменнымиВ условиях, когда связь значима и величина значимости (Significance) близка к нулю, появляется необходимость оценить силу этой связи и выявить наиболее связанные переменные. Непосредственное использование коэффициента Xи-квадрат неудобно - он зависит от числа объектов, из-за чего одинаковые по пропорциям распределений таблицы на выборках разного объема будут оценены по-разному.
Коэффициент Пирсона PHI=
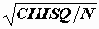 - лишен этого недостатка, но дипазн его изменения зависит от размерности таблиц:
- лишен этого недостатка, но дипазн его изменения зависит от размерности таблиц: .
.Более устойчив к размерности выборки коэффициент контингенции:
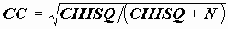 , 0
, 0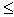 CC<1;
CC<1;еще лучше в этом отношении коэффициент Крамера
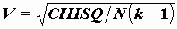 , где к=min[r,c],
, где к=min[r,c], 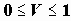 .
.Все эти коэффициенты можно использовать для оценки силы связи и, сравнивая их по величине, делать вывод о более тесной или менее тесной связи. Эти коэффициенты не носят точного характера - поэтому их использование - дело вкуса каждого исследователя.
Заметим, что коэффициенты анализа связи переменных "хи-квадрат" (CHISQ), "фи" (PHI) и обычный коэффициент корреляции изобретены Пирсоном.
Качество подгонки логистической регрессии
Качество подгонки логистической регрессииДалее в выдаче появляется описательная информация о качестве подгонки модели:
-2 Log Likelihood 3289.971
Goodness of Fit 2830.214
Cox & Snell - R^2 .072
Nagelkerke - R^2 .102
которые означают:
Как выяснить надежность результата?
Как выяснить надежность результата?В соответствии с общепринятым использованием 5%-го уровня значимости, мы можем заявить, что величина стандартизованного смещения Z, превышающая 1.96, свидетельствует о существенности связи (вероятность в условиях независимости получить большее смещение равна 5%, см. выделенные клетки со значимыми смещениями в табл.2). Однако это утверждение о значимости верно только для отдельно взятой клетки таблицы, как мы ранее показали, вероятность того, что в этой таблице из 100 независимых клеток имеется хотя бы одна "значимая" статистика, равна . Это - результат множественных сравнений статистик.
Чтобы снизить вероятность принятия случайных отклонений за закономерные, нужно использовать более жесткий критерий, хотя, конечно, и обычное применение Z-статистик позволяет избежать очевидных глупостей.
К сожалению, таблицу с Z-статистиками, подобную таблице 2, обычными средствами статистических пакетов получить сложно - в них нет средств анализа значимости по неальтернативным вопросам.
Классическая линейная модель регрессионного анализа
6.1. Классическая линейная модель регрессионного анализаЛинейная модель связывает значения зависимой переменной Y со значениями независимых показателей Xk (факторов) формулой:
Y=B0+B1X1+…+BpXp+e
где e - случайная ошибка. Здесь Xk означает не "икс в степени k", а переменная X с индексом k.
Традиционные названия "зависимая" для Y и "независимые" для Xk отражают не столько статистический смысл зависимости, сколько их содержательную интерпретацию.
Величина e называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами N(0,?2), ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные X как неслучайные значения, Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения X (например, назначили зарплату работнику), а затем измеряют Y (оценили, какой стала производительность труда). За это иногда зависимую переменную называют откликом. Теория регрессионных уравнений со случайными независимыми переменными сложнее, но известно, что, при большом числе наблюдений, использование метода разработанного для неслучайных X корректно.
Для получения оценок
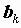 коэффициентов
коэффициентов 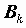 регрессии минимизируется сумма квадратов ошибок регрессии:
регрессии минимизируется сумма квадратов ошибок регрессии: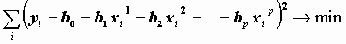
Решение задачи сводится к решению системы линейных уравнений относительно
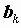 .
.На основании оценок регрессионных коэффициентов рассчитываются значения Y:
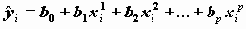
О качестве полученного уравнения регрессии можно судить, исследовав
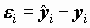 - оценки случайных ошибок уравнения. Оценка дисперсии случайной ошибки получается по формуле
- оценки случайных ошибок уравнения. Оценка дисперсии случайной ошибки получается по формуле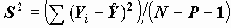 .
.Величина S называется стандартной ошибкой регрессии. Чем меньше величина S, тем лучше уравнение регрессии описывает независимую переменную Y.
Так как мы ищем оценки
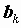 , используя случайные данные, то они, в свою очередь, будут представлять случайные величины. В связи с этим возникают вопросы:
, используя случайные данные, то они, в свою очередь, будут представлять случайные величины. В связи с этим возникают вопросы: Коэффициенты детерминации и множественной корреляции
Коэффициенты детерминации и множественной корреляцииПри сравнении качества регрессии, оцененной по различным зависимым переменным, полезно исследовать доли объясненной и необъясненной дисперсии. Отношение SSreg/SSt представляет собой оценку доли необъясненной дисперсии. Доля дисперсии зависимой переменной
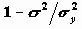 , объясненной уравнением регрессии, называется коэффициентом детерминации. В двумерном случае коэффициент детерминации совпадает с квадратом коэффициента корреляции.
, объясненной уравнением регрессии, называется коэффициентом детерминации. В двумерном случае коэффициент детерминации совпадает с квадратом коэффициента корреляции.Корень из коэффициента детерминации называется КОЭФФИЦИЕНТОМ МНОЖЕСТВЕННОЙ КОРРЕЛЯЦИИ (он является коэффициентом корреляции между y и
 ). Оценкой коэффициента детерминации (
). Оценкой коэффициента детерминации (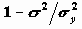 ) является
) является 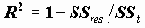 . Соответственно, величина R является оценкой коэффициента множественной корреляции. Следует иметь в виду, что
. Соответственно, величина R является оценкой коэффициента множественной корреляции. Следует иметь в виду, что 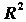 является смещенной оценкой. Корректированная оценка коэффициента детерминации получается по формуле:
является смещенной оценкой. Корректированная оценка коэффициента детерминации получается по формуле: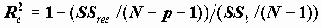
В этой формуле используются несмещенные оценки дисперсий регрессионного остатка и зависимой переменной.
Коэффициенты регрессии
Коэффициенты регрессииОсновная информация содержится в таблице коэффициентов регрессии (рисунок 6.4). Прежде всего, следует обратить внимание на значимость коэффициентов. Наблюдаемая значимость вычисляется на основе статистики Вальда. Эта статистика связана с методом максимального правдоподобия и может быть использована при оценках разнообразных параметров.
Универсальность статистики Вальда позволяет оценить значимость не только отдельных переменных, но и в целом значимость категориальных переменных, несмотря на то, что они дезагрегированы на индексные переменные. Статистика Вальда имеет распределение хи-квадрат. Число степеней свободы, равно единице, если проверяется гипотеза о равенстве нулю коэффициента при обычной или индексной переменной и, для категориальной переменной, равно числу значений без единицы (числу соответствующих индексных переменных). Квадратный корень из статистики Вальда приближенно равен отношению величины коэффициента к его стандартной ошибке - так же выражается t-статистика в обычной линейной модели регрессии.
В нашей таблице коэффициентов почти все переменные значимы на уровне значимости 5%. Закрыв глаза на возможное взаимодействие между независимыми переменными (коллинеарность), можно считать, что вероятность употребления алкоголя повышена при высокой зарплате, а также, у руководителей различного ранга. Из-за незначимости статистики Вальда нет, правда, полной уверенности относительно повышенной вероятности для начальников, имеющих более 10 подчиненных. Курение и принадлежность к мужскому полу также повышают эту вероятность, однако, взаимодействие "мужчина-зарплата" имеет обратное действие.
В этой же таблице присутствует аналог коэффициента корреляции (R), также построенный на основе статистики Вальда. Для обычных и индексных переменных положительные значения коэффициента свидетельствуют о положительной связи переменной с вероятностью события, отрицательные - об отрицательной связи.
Кроме того, мы выдали таблицу экспонент коэффициентов eB и их доверительные границы (см. рисунок 6.5). Эта таблица выдана подкомандой /PRINT=CI(95) в команде задания логистической регрессии.
Согласно модели и полученным значениям коэффициентов, при фиксированных прочих переменных, принадлежность к мужскому полу увеличивает отношение шансов "пития" и "не пития" в 2.4 раза (точнее в 1.84-3.15 раза), курения - в 1.9 раза (1.54 - 2.35), а прибавка к зарплате 100 рублей - на 4.4% (2.8%-6%), правда такая прибавка мужчине одновременно уменьшает это отношение на 3.8% (5.7%-1.9%). Быть мелким начальником - значит увеличить отношение шансов в 1.43 (1.06 - 1.9) раза, чем в среднем, а средним начальником - в 1.7 (1.07-2.67) раза.
Коэффициенты связи между ранговыми переменными
Коэффициенты связи между ранговыми переменнымиКоэффициенты BTAU (Кендалла) и CTAU (Стюарта) служат для оценки взаимосвязи ранговых переменных.
Напомним, что ранговыми переменными называются переменные, в которых можно установить порядок между значениями, например, ответы на вопрос, требующий ответа "плохо", "средне" или "хорошо"% количественные переменные, такие, как возраст, доход, также можно использовать в качестве ранговых.
Рассмотрим пары всех объектов (строк матрицы данных). Для пары объектов (i,j) рассматривается, одинаково ли упорядочиваются объекты и по переменной X и по переменной Y. (если Xi
С помощью этих коэффициентов можно проверить гипотезу независимости переменных "степень противостояния СССР и Японии" и "степень альтруизма" против гипотезы их зависимости: одинаковой или противоположной упорядоченности, предварительно построив эти переменные на основе данных по нашей учебной анкете.
Пример: рассчитаем коэффициенты BTAU и CTAU для наших переменных v1 "Точка зрения на иностранную помощь" и V4 "Возможность удовлетворить территориальные требований Японии". Следует заметить, что код значения "не знаю" этих переменных максимален - 4 (см. анкету в приложении). Это нарушает порядок градаций и неясно, каким образом повлияет на результаты. Скорее всего, эта градация занимает какое-то промежуточное место, но неясно, между какими градациями. Поэтому самым простым выходом будет пожертвовать данными и провести расчеты, объявив этот код кодом неопределенности:
missing values v1 v4(4).
CROSSTABS /TABLES=v4 BY v1
/STATISTIC=CHISQ BTAU CTAU CMH(1)
/CELLS= COUNT ROW COL.
Количественные шкалы:
Количественные шкалы:ИНТЕРВАЛЬНАЯ шкала предполагает, что можно определить не только порядок значений, но и расстояние между значениями. Эта шкала, однако, такова, что не имеет смысла рассматривать, во сколько раз одно значение больше другого. Пример: шкала измерения температуры по Цельсию.
ШКАЛА ОТНОШЕНИЙ в дополнение к свойствам интервальной шкалы позволяет измерять пропорции значений. Например, мы можем смело заявить, что зарплата в 1000$ вдвое выше зарплаты в 500$.
Техника анализа переменных, измеренных в количественных шкалах (интервальной и шкале отношений) обычно одинакова. В соответствии с типом шкалы измерения переменные относят к номинальным, ординальным (ранговым) и количественным типам переменных.
К особому типу относят переменные, имеющие два ответа - "да" и "нет" (например, "Имеете ли Вы телевизор?"). Эти переменные называют дихотомическими. Их удобно кодировать цифрами 1 ("да") и 0 ("нет"). Эти переменные представляют простейший вид номинальных переменных, они выражают количество (0 или 1) и поэтому часто используются в количественном анализе.
Такая классификация переменных несколько упрощает действительность. Например, переменная "время суток" при исследовании бюджета времени имеет "кольцевую" структуру, поскольку 0 часов эквивалентно 24 часам.
Еще пример: ответ на вопрос о доходах от личного подсобного хозяйства может представлять определенную сумму, быть ответом "не имею подсобного хозяйства" или ответом "не знаю" - здесь значения только частично являются количественными и упорядоченными. При кодировании значений таких значений используются специального вида коды, которые в принципе не могут встретиться в данных, например в RLMS "затрудняюсь ответить", "отказ от ответа" и "нет ответа" в вопросе о весе респондента кодируются кодами 997, 998 и 999 соответственно. Не забудьте использовать специальные команды SPSS (см. ниже команду Missing values), чтобы объявить эти числовые значения кодами неопределенности, чтобы по ошибке не получить средний вес респотдента в больше 300 килограммов!
Команда COUNT
Команда COUNTКоманда СOUNT подсчитывает число появлений указанных в ней кодов в заданном списке переменных и размещает результат в новую переменную или заменяет содержимое существующей.
Пусть нам необходимо вычислить число разумных вариантов решения проблемы островов (неальтернативный вопрос 7 анкеты о Курильских островах), а затем подсчитать число ответов на все неальтернативные вопросы анкеты.
COUNT nofvari= v7s1 to v7s7 (1 thru 11)/
nofans = v3s1 to v3s8 (1 thru 8) v5s1 to v6s8 (1 thru 8).
Еще пример, по результатам сессии (объекты - студенты, переменные - результаты экзаменов по информатике (I), математике (M), микроэкономике (E), и социологии (S)) необходимо создать переменную M45, в которой будет число пятерок и четверок, встречающихся в перечисленных переменных.
COUNT M45 = I M E S (4,5).
В команде указывается имя переменной, куда будет заноситься результат подсчета, затем, после обязательного знака "=", приводится список переменных, для которых нужно вести подсчет, и далее в круглых скобках приводится список значений переменных, число которых следует пересчитать. Значения строковых переменных должны быть заключены в апострофы. Ключевое слово SYSMIS используется для подсчета системных отсутствующих значений; MISSING позволяет подсчитать все отсутствующие значения - и пользовательские и системные. Команда допускает также ключевые слова LOWEST, HIGHEST и THRU.
Команда Explore исследование распределений и сравнение групп объектов
Команда Explore исследование распределений и сравнение групп объектовКоманда меню Explore в синтаксисе имеет имя Examine. Она является удобным инструментом исследования распределения данных в подвыборках объектов. Мы не будем подробно описывать эту процедуру, она хорошо описана в Руководстве по применению [].
Команда отличается развитыми графическими возможностями - гистограммы, диаграммы типа "ствол с листьями", ящичковые диаграммы, графики сравнения эмпирического распределения с нормальным. В число статистик включены статистики для проверки нормальности распределения, однородности дисперсий в группах. Весьма удобна для описательного анализа ящичковая диаграмма
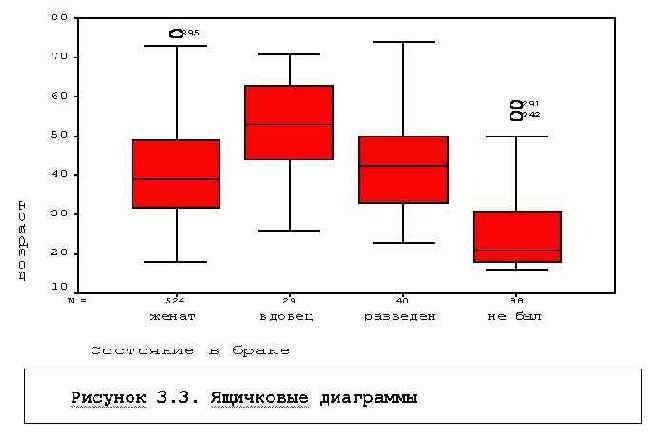 Рассмотрим, например, диаграмму распределения по возрасту в группах по семейному положению, полученную в выдаче командой:
Рассмотрим, например, диаграмму распределения по возрасту в группах по семейному положению, полученную в выдаче командой:EXAMINE VARIABLES=V9 BY v11
/PLOT BOXPLOT HISTOGRAM NPPLOT SPREADLEVEL(1)
/COMPARE GROUP /STATISTICS DESCRIPTIVES
/CINTERVAL 95 /MISSING LISTWISE /NOTOTAL.
Нижние и верхние границы "ящичков" показывают 25% и 75% процентили распределений, черта посередине - медиана, "усы" показывают максимальные и минимальные значения в группах, если они не отстоят от верхнего (нижнего) края ящичка более, чем на 1.5 его длины, иначе они показывают эту границу, а вышедшие за эти пределы значения - отмечаются отдельными точками или кружками (Рисунок 3.3).
На диаграмме ясно видно, как отличаются группы по медианному возрасту, виден перекос распределения возраста для не состоявших в браке.
Команда MEANS - сравнение характеристик числовой переменной по группам.
Команда MEANS - сравнение характеристик числовой переменной по группам.Процедура вычисляет одномерные статистики в группах - все описательные статистики, которые вычислялись командами Descriptives и Frequencies, а также гармоническое среднее, среднее геометрическое, проценты сумм значений переменных в группах и др. - всего 20 характеристик. Поэтому имя команды Means (Средние) сохранилось лишь исторически, пришло из ранних версий SPSS, где действительно ее назначением было сравнение средних. В диалоговом окне для назначения статистик используется кнопка "Options". Проводится также одномерный дисперсионный анализ.
MEANS TABLES=v14 BY v11 BY v8 /CELLS MEAN STDDEV MEDIAN COUNT /STATISTICS ANOVA.
В команде указывается список зависимых переменных, BY и список переменных, определяющих группы. Каждое дополнительное слово BY порождает следующий нижний уровень группирования, в диалоговом режиме слову BY соответствует кнопка NEXT.
Команда построения линейной модели регрессии
Команда построения линейной модели регрессииВ меню - это команда Linear Regression. В диалоговом окне команды:
Команда RANK
Команда RANKАнализируя доходы населения, мы можем работать непосредственно с доходами, вычисляя средние, корреляции и др., можем изучать иерархию семей или индивидуумов по этой переменной. Для этого нужно перейти к порядковым номерам объектов, упорядоченным по доходам. Такие порядковые номера называются рангами. Иерархию семей можно изучать, определив для каждой семьи долю (процент) семей, которые беднее ее. Наконец при этом анализе, можно разбить семьи по уровню доходов на равные 5 частей (квентили) или на 10 частей (децили). Ранги, процентили, n-тили суть преобразованные в соответствии с ранжированием объектов переменные.
Команда RANK весьма полезна, когда нужно перейти от исходных значений любых количественных переменных к рангам объектов, процентилям, децилям и квентилям и др., а может быть перекодировать переменную в соответствии с нормальным распределением.
Пусть нам необходимо получить переменные "ранг по доходам", "процентили по доходам" и "квинтильные группы по доходам".("Курильские" данные) Команда RANK создаст нам нужные переменные:
RANK VARIABLES=v14 (A) /RANK into rangv14/NTILES (5)into v14_5 /PERCENT percv14/PRINT=YES /TIES=MEAN .
VARIABLE LABELS rangv14 "ранг по доходам"/
v14_5 "квинтильные группы по доходам"/
percv14 "процентили по доходам".
Подробнее см. в "Руководстве пользователя SPSS6.1"
Команда RECODE
Команда RECODEНазначение команды: перекодирование существующей переменной. Формат команды:
RECODE V9 (0 THRU 25 = 1) (26 THRU 45 = 2) (ELSE =3).
или
RECODE V9 (0 THRU 25 = 1) (26 THRU 45 = 2) (ELSE =3) INTO W9.
Указывается переменная или список переменных со спецификациями в круглых скобках. Перекодируемые переменные в списке разделяются слэшами (/). По этой команде значения перечисленных переменных в указанных пределах будут заменены числами, следующими за знаком равенства.
Ключевое слово INTO указывает, в какую переменную (список переменных) переслать результат перекодирования, при этом соответствие между исходным списком переменных и переменными результата устанавливаются естественным образом.
Список переменных можно задать через ключевое слово TO, но всегда следует указывать переменные в том порядке, в каком они вводились либо вычислялись в программе.
Ключевые слова для задания входных значений команды RECODE:
LOWEST или LO - наименьшее значение переменной;
THRU или THR - значения переменной из указанного диапазона;
HIGHEST или HI - наибольшее значение переменной;
MISSING - отсутствующее значение, определяемое пользователем;
SYSMIS - отсутствующее значение, определяемое системой;
ELSE -все не специфицированные значения (не включаемые в SYSMIS).
Результат перекодирования - обычно код или системный код неопределенности SYSMIS, если вместе с ключевым словом ELSE употребляется слово COPY, то результатом становятся значения не включенные в списки перекодирования. Слово COPY имеет смысл употреблять, когда результат перекодирования записывается в другую переменную:
Recode educat (1=2)(2=1)(else=copy) into educat1.
Без (else=copy) в переменную educat1 будут внесены лишь перекодированные значения.
Заметим, что если переменная назначения за ключевым словом INTO ранее существовала, то она не изменит своих значений, если команда Recode не заносит в нее никаких кодов.
Среди списка значений для переменной, имеющей неопределенные значения, могут стоять слова MISSING и SYSMIS.
RECODE K9 ТO K12 (0 THRU 25 = 1)(MISSING = 10)(SYSMIS = 5).
Команда RECODE позволяет также интервалировать, группировать значения.
RECODE V11 V13 ( 8, 9, 2, 4, 7 = 1) (else=2).
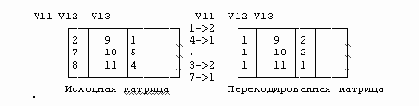 Рисунок 2.2. Перекодирование данных
Рисунок 2.2. Перекодирование данныхЧто происходит при этом с матрицей данных? Как видно из приведенной выше схемы, происходит замена значений в соответствии с приведенными в команде списками значений.
Рассмотрим примеры перекодирования кодов неопределенности. При ответах на вопросы анкеты "Курильские острова" (приложение 1) кто-то не ответил на первый вопрос, кто-то сказал "Затрудняюсь". Объединим этих респондентов. Это можно осуществить командой
RECODE V1 (SYSMIS = 4).
и, таким образом, перекодировать системный код неопределенности в код 4. Можно провести обратную операцию:
RECODE V1 (4 = SYSMIS).
Этой командой код 4 перекодируется в системный код неопределенности. При обработке данных по этому признаку объекты, для которых значение V1 было когда-то равно 4, будут исключены из статистической обработки.
Тот же эффект можно получить, воспользовавшись командой
MISSING VALUES V1(4).
При этом таблица данных не изменится; но во внутренней для SPSS информации сохранятся сведения о том, что указанный в данной команде код является пользовательским кодом неопределенности для V1.
В SPSS запрещено писать MISSING справа от знака равенства, т.е. команда
RECODE V1(4=MISSING). недопустима!
Имеется еще вариант выполнения команды RECODE с созданием новой переменной. Для этого используется уключевое слово INTO:
RECODE V11 ( 8, 9, 2, 4, 7 = 1) (else=2) INTO W11.
При таком использовании команды в большинстве случаев необходимо перечислять все коды исходной переменной, поскольку не указанные значения переходят в системные неопределенные.
Команда SPLIT FILE
Команда SPLIT FILEНередко возникает необходимость получить однотипные таблицы для различных групп наблюдений, а, возможно и сравнить их. С этой целью предусмотрена команда SPLIT FILE. Ее удобно запускать из меню редактора данных. Команда SPLIT FILE требует предварительной сортировки данных по переменным разбиения. В ней указываются переменные разбиения выборки, а также цель расщепления - получение независимых выдач для различных групп объектов (ключевое слово SEPARATE), или сравнение данных по группам (LAYERED). В последнем случае для большинства статистических программ выдачи по группам объединяются в единую таблицу.
Например, расщепление наших учебных данных выборки по полу с целью сравнения групп можно сделать программой.
SORT CASES BY v8 .
SPLIT FILE LAYERED BY v8 .
Descriptives Variables= v9 v14.
Команда Descriptives получает описательные статистики переменных. В таблице 2.2 благодаря команде SPLIT результаты работы команды Descriptives на разных группах по полу объединены в одну таблицу.
Команды COMPUTE и IF
Команды COMPUTE и IFКоманда COMPUTE вычисляет новую переменную или заменяет существующую.
Пусть, например, для приведенной в приложении 1 анкеты требуется рассчитать, сколько лет респондент проживал за Уралом (см. анкету в приложении 1).
СOMPUTE Y=V15+V16+V17.
В матрице данных создается новая переменная Y.
В команде указывается имя создаваемой переменной, за которым после обязательного знака "=" следует арифметическое выражение. Создаваемая переменная может быть функцией от других переменных.
После выполнения команды в матрицу данных в активный файл будет дописан столбец с новым именем. Если какой-либо член арифметического выражения не определен, то результатом будет системный код отсутствующего значения (SYSMIS). Например, если в команде COMPUTE Y=X-5/Z. значение переменной X не определено в соответствии с командой MISSING VALUES или имеет системный код неопределенности или, если Z=0, переменной Y присваивается системный код неопределенности SYSMIS.
Команда IF при выполнении указанного в команде условия создает новые переменные или заменяет существующие переменные арифметическими выражениями
IF (R>D OR (R>=E AND B>0))STATUS=1.
IF (STATE = 'IL') COST=COST +0.07*COST.
В ней указывается логическое выражение, за которым следует арифметическое присвоение. Логическое выражение должно быть заключено в круглые скобки. Логическое выражение в команде IF может быть ложно не только в результате выводов с позиций формальной математической логики, но в случае, если в выражении встретилось неопределенное значение. Для оператора присваивания в случае неопределенных значений переменных действуют те же правила, что и в команде COMPUTE.
В качестве логического выражения может быть и обычная числовая переменная или числовая константа. Считается, что она принимает значение "истина", если она равна 1, в противном случае ее значение - "ложь".
Область действия IF - один оператор присваивания, приведенный в тексте команды.
Пусть, например, требуется вычислить переменную D, характеризующую отклонение веса (W) от нормального (для мужчин (код значения переменной P "пол" равен 1) нормальный вес должен быть равен величине роста минус 100, для женщин (p=2) - величине роста минус 105).
IF (P = 1) d = W - (R-100).
IF (P = 2) d = W - (R-105).
В результате выполнения этих команд появляется переменная D, которая вычисляется в зависимости от значений переменной P.
В диалоговом окне содержится подробный список функций и операторов. Чтобы читатель имел представление о возможностях команд IF и COMPUTE, ниже мы представим их основные типы.
Команды Вызова Get и сохранения данных save.
команды Вызова Get и сохранения данных save.Хотя для вызова файла данных удобнее непосредственно использовать меню, команда полезна при многократном использовании данных, или использовании части данных. Примеры:
GET FILE='D:\mydir\city' /KEEP=x1 to x10, x15.
GET FILE='D:\mydir\city' /DROP=Z1, z5, z10.
Ключевое слово KEEP в первом примере говорит о том, что будут использованы лишь переменные с x1 до x10 и x15
Ключевое слово подкоманды DROP во втором примере исключает из анализа Z1, z5, z10.
Сохранение данных производится командой SAVE
SAVE FILE='D:\mydir\city' /KEEP=x1 to x10, x15 /compressed.
Подкоманда /compressed необходима для сжатия информации. Подкоманды KEEP и DROP применяются для сохранения и отбрасывания части переменных.
Корреляции (CORRELATIONS)
4.4. Корреляции (CORRELATIONS)Раздел CORRELATIONS содержит команды для получения парных (Bivariate…) и частных (Partial…) корреляций.
Критерий Фридмана (Friedman)
5.4.3. Критерий Фридмана (Friedman)Имеется k переменных. На каждом объекте независимо производится их ранжировка (по строке матрицы данных), затем вычисляется средний ранг по каждой переменной (по столбцу). Если все измерения независимы и равноценны (одинаково распределены) то все эти средние должны быть приближенно равны (k+1)/2 - среднему рангу в строке. Статистикой критерия является нормированная сумма квадратов отклонений средних рангов по переменным от общего среднего (k+1)/2, которая имеет теоретическое распределение хи-квадрат.
Как ни странно, тест Фридмана, запущенный командой
NPAR TESTS /FRIEDMAN = am1 bm1 cm1.
не показал значимых различий в измерениях веса по трем годам (см. предыдущие два примера), так как наблюдаемая значимость статистики хи-квадрат равна 0.755.
Критические значения Z-статистики при множественных сравнениях.
Критические значения Z-статистики при множественных сравнениях.Для выяснения значимости вычисляется критическое значение максимальной по модулю Z-статистики таблицы (max|Zij|) и значимыми считаем Zij, превышающие это значение. Как обычно, критическое значение выбирается так, чтобы вероятность случайно его превзойти была равна заданному значению (обычно - 5%).
Логистическая регрессия
6.2. Логистическая регрессияПредсказания событий, исследования связи событий с теми или иными факторами с нетерпением ждут от социологов. Будем считать, что событие в данных фиксируется дихотомической переменной (0 не произошло событие, 1 - произошло). Для построения модели предсказания можно было бы построить, к примеру, линейное регрессионное уравнение с зависимой дихотомической переменной Y, но оно будет не адекватно поставленной задаче, так как в классическом уравнении регрессии предполагается, что Y - непрерывная переменная. С этой целью рассматривается логистическая регрессия. Ее целью является построение модели прогноза вероятности события {Y=1} в зависимости от независимых переменных X1,…,Xp. Иначе эта связь может быть выражена в виде зависимости P{Y=1|X}=f(X)
Логистическая регрессия выражает эту связь в виде формулы
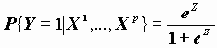 , где Z=B0+B1X1+…+BpXp (1).
, где Z=B0+B1X1+…+BpXp (1).Название "логистическая регрессия" происходит от названия логистического распределения, имеющего функцию распределения
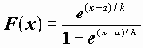 . Таким образом, модель, представленная этим видом регрессии, по сути, является функцией распределения этого закона, в которой в качестве аргумента используется линейная комбинация независимых переменных.
. Таким образом, модель, представленная этим видом регрессии, по сути, является функцией распределения этого закона, в которой в качестве аргумента используется линейная комбинация независимых переменных. Метод главных компанент
метод главных компанентОдин из наиболее распространенных методов поиска факторов, метод главных компонент, состоит в последовательном поиске факторов. Вначале ищется первый фактор, который объясняет наибольшую часть дисперсии, затем независимый от него второй фактор, объясняющий наибольшую часть оставшейся дисперсии, и т.д. Описание всей математики построения факторов слишком сложно, поэтому для пояснения сути мы прибегнем к зрительным образам (рисунок 7.2).
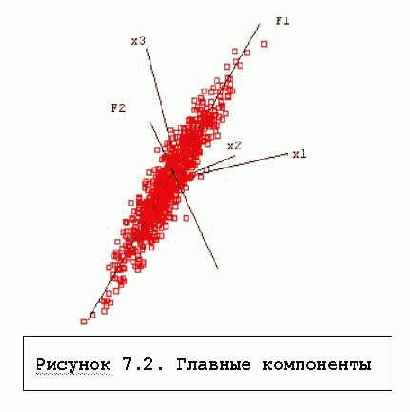 Геометрически это выглядит следующим образом. Для построения первого фактора берется прямая, проходящая через центр координат и облако рассеяния данных. Объектам можно сопоставить расстояния их проекций на эту прямую до центра координат, причем для одной из половин прямой (по отношению к нулевой точке) можно взять эти расстояния с отрицательным знаком. Такое построение представляют собой новую переменную, которую мы просто назовем осью. При построении фактора отыскивается такая ось, чтобы ее дисперсия была максимальна. Это означает, что этой осью объясняется максимум дисперсии переменных. Найденная ось после нормировки используется в качестве первого фактора. Если облако данных вытянуто в виде эллипсоида (имеет форму "огурца"), фактор совпадет с направлением, в котором вытянуты объекты, и по нему (по проекциям) с наибольшей точностью можно предсказать значения исходных переменных.
Геометрически это выглядит следующим образом. Для построения первого фактора берется прямая, проходящая через центр координат и облако рассеяния данных. Объектам можно сопоставить расстояния их проекций на эту прямую до центра координат, причем для одной из половин прямой (по отношению к нулевой точке) можно взять эти расстояния с отрицательным знаком. Такое построение представляют собой новую переменную, которую мы просто назовем осью. При построении фактора отыскивается такая ось, чтобы ее дисперсия была максимальна. Это означает, что этой осью объясняется максимум дисперсии переменных. Найденная ось после нормировки используется в качестве первого фактора. Если облако данных вытянуто в виде эллипсоида (имеет форму "огурца"), фактор совпадет с направлением, в котором вытянуты объекты, и по нему (по проекциям) с наибольшей точностью можно предсказать значения исходных переменных.Для поиска второго фактора ищется ось, перпендикулярная первому фактору, также объясняющая наибольшую часть дисперсии, не объясненной первой осью. После нормировки эта ось становится вторым фактором. Если данные представляют собой плоский элипсоид ("блин") в трехмерном пространстве, два первых фактора позволяют в точности описать эти данные.
Максимально возможное число главных компонент равно количеству переменных. Сколько главных компонент необходимо построить для оптимального представления рассматриваемых исходных факторов?
Обозначим l k объясненную главной компонентой Fk часть суммарной дисперсии совокупности исходных факторов. По умолчанию, в пакете предусмотрено продолжать строить факторы, пока l к>1. Напомним, что переменные стандартизованы, и поэтому нет смысла строить очередной фактор, если он объясняет часть дисперсии, меньшую, чем приходящуюся непосредственно на одну переменную. При этом следует учесть, что l 1>l 2>l 3,….
К сведению читателя заметим, что значения l k являются также собственными значениями корреляционной матрицы Xi, поэтому в выдаче они будут помечены текстом "EIGEN VALUE", что в переводе означает "собственные значения".
Заметим, что техника построения главных компонент расходится с теоретическими предположениями о факторах: имеется m+n независимых факторов, полученных методом главных компонент в n-мерном пространстве, что невозможно.
Множественные сравнения в таблицах для неальтернативных вопросов. Программа Typology Tables
3.4. Множественные сравнения в таблицах для неальтернативных вопросов. Программа Typology TablesКак уже было отмечено, в сложных табличных отчетах SPSS отсутствуют статистики значимости. Это касается также таблиц для неальтернативных вопросов. Этот пробел восполнила программа Typology Tables, разработанная в Институте экономики и ОПП СО РАН, г.Новосибирск.
В программе рассматриваются двумерные таблицы частотных распределений и таблицы средних по количественным переменным в группах по сочетаниям ответов на неальтернативные вопросы. Исследуется значимость отклонений частот от ожидаемых в условиях независимости ответов и отклонений средних от средних в итоговых ячейках. Эта программа может быть вставлена пунктом командой меню в SPSS версий 8, 9, 10.
МНОЖЕСТВЕННЫЕ СРАВНЕНИЯ
МНОЖЕСТВЕННЫЕ СРАВНЕНИЯМножественные сравнения являются одной из труднейших проблем в математической статистике. В действительности при анализе данных исследователи сталкиваются с ними на каждом шагу.
Пусть, например, мы рассматриваем 100 независимых таблиц сопряженности пар переменных, отбирая среди них "интересные" для анализа с использованием критических значений хи-квадрат 5%-го уровня значимости. Тогда при отсутствии связи переменных мы будем в среднем в таких испытаниях получать 5 "интересных" (значимых) таблиц, даже если связь между всеми переменными отсутствует. Таким образом, какие бы ни были плохие данные, мы что-либо будем интерпретировать. Но при повторном сборе данных - мы можем получить противоположные результаты. Вот что значит множественные сравнения!
Сравнение групповых средних это одна из немногих задач, где удалось справиться с этой проблемой.
Суть задачи состоит в отборе значимых различий множества пар групп, определяемых переменной группирования. Сравнение пары средних мы научились делать с помощью процедуры T-TEST и, казалось бы, можно, задавшись уровнем значимости, пропустить через этот тест все пары групп и отобрать различающиеся по за данному уровню. Однако, перебирая группы, мы перебираем множество случайных чисел, и, благодаря этому, можем наткнуться на значимое отличие с гораздо большей вероятностью, чем при рассмотрении одной пары групп. В частности, если группы независимы и не связаны с тестируемой переменной, при 10 сравнениях по уровню значимости 0.05 мы с вероятностью 1-(1-0.05)10=0.4 случайно получим хотя бы одно "значимое" различие.
Для пояснения механизма работы тестов множественных сравнений остановимся на 3-х из 20 тестах, реализованных в SPSS.
Согласно методу Бонферрони, в случае множественных сравнений назначается более строгий уровень значимости для попарных сравнений. Он определяется так: задается уровень значимости для множественных сравнений a m и в качестве попарного уровня значимости берется a =(1/k)a m., где k - число сравнений.
Пусть Ai - событие, состоящее в том, что мы в i- том сравнении выявили существенное отличие средних, когда средние совпадают, тогда, в соответствии с заданным уровнем значимости, P{Ai}
Метод Шеффе построен на контрастах. С его помощью проверяется гипотеза равенства нулю сразу всех контрастов, не только тех, что сравнивают пары групп. В результате он часто оказывается еще строже, чем критерий Бонферрони.
Можно ли в регрессии использовать неколичественные переменные?
Можно ли в регрессии использовать неколичественные переменные?Однозначно можно сказать, что они не могут быть использованы в качестве зависимой переменной Y. Это будет грубейшей ошибкой; в этом случае уравнением регрессии может быть предсказан, к примеру, пол имеющий код 1.5 или 0.5 при общепринятой кодировке пола 1-мужчины, 2-женщины. Может быть, это как-то интерпретируется с медицинской точки зрения, но в практике социальных исследований это будет едва ли возможно.
Для использования в качестве независимой переменной применяются индексные переменные (в англоязычной литературе dummy-variables).
Например, для семейного положения в данных Курильского обследования (женат, вдов, разведен, холост) стоит ввести три индикаторные переменные t1, t2 и t3 для выделения женатых, вдовых, и разведенных. Эти переменные будут равны, соответственно единице или нулю, в зависимости от того принадлежит или не принадлежит респондент к соответствующей группе по семейному положению.
 Почему не 4 индексные переменные? Четвертая переменная определяется однозначно через первые три, поэтому, введение ее вызвало бы коллинеарность, не позволяющую найти коэффициенты регрессии.
Почему не 4 индексные переменные? Четвертая переменная определяется однозначно через первые три, поэтому, введение ее вызвало бы коллинеарность, не позволяющую найти коэффициенты регрессии. Вот задание, которое позволяет изучить зависимость душевого дохода от возраста и семейного положения:
compute lnv14m =ln(v14/200).
compute t1=(v11=1).
compute t2=(v11=2).
compute t3=(v11=3).
Compute v9_2=v9**2.
*квадрат возраста.
REGRESSION /DEPENDENT lnv14m /METHOD=ENTER v9 v9_2 t1 t2 t3 /SAVE PRED.
График связи возраста (V9) с предсказанным уравнением логарифмом доходов (переменная pre_2) получается командой
GRAPH /SCATTERPLOT(BIVAR)=v9 WITH pre_2 /MISSING=LISTWISE
Он представляет собой 4 параболы (рисунок 6.2). В соответствии с коэффициентами перед t1, t2 и t3 (см. таблицу 6.4), эти пораболы соответствуют, сверху вниз, холостякам, разведенным, женатым и вдовцам (порабола холостяков получается при t1=t2=t3=0).
Вероятно, полученное уравнение можно улучшить, исключив из уравнения переменные с незначимыми коэффициентами. Поскольку индексные переменные должны быть в определенной степени взаимосвязаны, уровень наблюдаемой значимости может определяться здесь коллинеарностью, поэтому "ревизию" переменных нужно проводить осторожно, чтобы существенно не ухудшить полученного уравнения.
Из-за взаимосвязи переменных здесь нет возможности говорить о том, какая переменная больше влияет на зависимую переменную. Обратите внимание на довольно редкий эффект: бета-коэффициенты для возраста и его квадрата по абсолютной величине больше 1!
Надежность и значимость коэффициента регрессии
Надежность и значимость коэффициента регрессииДля изучения "механизма" действия мультиколлинеарности на регрессионные коэффициенты рассмотрим выражение для дисперсии отдельного регрессионного коэффициента
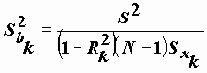
Здесь
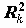 обозначен коэффициент детерминации, получаемый при построении уравнения регрессии, в котором в качестве зависимой переменной взята переменная xk. Из выражения видно, что величина коэффициента тем неустойчивее, чем сильнее переменная xk связана с остальными переменными (чем ближе к единице коэффициент детерминации
обозначен коэффициент детерминации, получаемый при построении уравнения регрессии, в котором в качестве зависимой переменной взята переменная xk. Из выражения видно, что величина коэффициента тем неустойчивее, чем сильнее переменная xk связана с остальными переменными (чем ближе к единице коэффициент детерминации 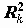 ).
).Величина 1-
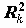 , характеризующая устойчивость регрессионного коэффициента, называется надежностью. В англоязычной литературе она обозначается словом TOLERANCE.
, характеризующая устойчивость регрессионного коэффициента, называется надежностью. В англоязычной литературе она обозначается словом TOLERANCE.Дисперсия коэффициента позволяет получить статистику для проверки его значимости
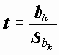 .
.Эта статистика имеет распределение Стьюдента. В выдаче пакета печатается наблюдаемая ее двусторонняя значимость - вероятность случайно при нулевом регрессионном коэффициенте Bk получить значение статистики, большее по абсолютной величине, чем выборочное.
Неальтернативные признаки
Неальтернативные признакиЕще более сложны данные по так называемым неальтернативным (многозначным) вопросам. Часто встречаются вопросы: "Какие варианты ответов, предлагаемых анкетой, Вам кажутся разумными?". В анкете на такой вопрос предлагается несколько ответов. В этих случаях признаки принято называть неальтернативными или многозначными. Неальтернативный признак можно кодировать одним из двух способов:
1. Для каждой подсказки заводится переменная, которая соответствует столбцу матрицы и кодируется с помощью 0 и 1. В частности, для ответов на четвертый вопрос анкеты примера 1 отводится 5 столбцов матрицы данных, они заполняются нулями и единицами (Рисунок 1). Нередко вместо кодов 0 и 1 используются другие коды, тогда в программах получения таблиц по неальтернативным вопросам нужно специально указывать код, соответствующей ответу "Да". Например, вопрос может быть задан следующим образом:
Согласны ли вы с тем, что
А. Нужна новая конституция?
1. Нет 2. Да 3. Не знаю
Б. Нужно переизбрать Думу?
1. Нет 2. Да 3. Не знаю
В. Нужен новый президент
1. Нет 2. Да 3. Не знаю
Г. . . . . . .
В этом случае дихотомия определяется кодом 2 и остальными кодами.
Такое представление неальтернативного признака в виде переменных, соответствующих подсказкам, называется дихотомическим. В ряде программ SPSS для обозначения этого представления данных используется текст Dichotomies counted value.
2. Кодирование порядковых номеров подсказок из текста анкеты, указанных респондентом (3 группа столбцов матрицы из примера 1.1. Рисунок 1.1). Это кодирование в виде списка. В этом случае количество столбцов матрицы, отведенных для ответов на вопрос, может быть меньше, чем количество подсказок в этом вопросе, оно зависит от числа возможных ответов. Например, для третьего вопроса анкеты из нашего примера достаточно отвести три столбца матрицы данных. Для обозначения этого способа кодирования используется ключевое слово Categories.
В приведенной выше анкете предлагается несколько вариантов ответов на третий и четвертый вопросы; ответы респондента на них кодируются в нескольких позициях строки матрицы данных.
Неколичественные данные
Неколичественные данныеЕсли в обычной линейной регрессии для работы с неколичественными переменными нам приходилось подготавливать специальные индикаторные переменные, то в реализации логистической регрессии в SPSS это делается автоматически. Для этого в диалоговом окне специально предусмотрены средства, сообщающие пакету, что ту или иную переменную следует считать категориальной. При этом, чтобы не получить линейно зависимых переменных, максимальный код ее значения (или минимальный, в зависимости от задания процедуры) не перекодируется в дихотомическую (индексную) переменную. Впрочем, средства преобразования данных позволяют не учитывать любой код значения. Имеются другие способы перекодирования категориальных (неколичественных) переменных в несколько переменных, но мы будем пользоваться только указанным, как наиболее естественным.
Неколичественные шкалы
Неколичественные шкалыНОМИНАЛЬНАЯ шкала является самым "низким" уровнем измерения. В этом случае используется только равенство или неравенство значений. Примером таких переменных являются "пол", "профессия".
ОРДИНАЛЬНАЯ или РАНГАВАЯ. Часто значения признака выражают степень проявления какого-либо свойства и могут быть упорядочены. Например, работа "интересна", "безразлична" или "не интересна". Такая шкала называется ранговой или ординальной.
О статистике Вальда
О статистике ВальдаКак отмечено в документации SPSS, недостаток статистики Вальда в том, что при малом числе наблюдений она может давать заниженные оценки наблюдаемой значимости коэффициентов. Для получения более точной информации о значимости переменных можно воспользоваться пошаговой регрессией, метод FORWARD LR (LR - likelihood ratio - отношение правдоподобия), тогда будет для каждой переменной выдана значимость включения/исключения, полученная на основе отношения функций правдоподобия модели. Поскольку основная выдача построена на основе статистики Вальда, первые выводы удобнее делать на ее основе, а потом уже уточнять результаты, если это необходимо.
Объединение файлов (merge files)
Объединение файлов (merge files)В пакете реализована возможность объединять файлы. Его предпочтительно делать с помощью меню DATA/ MERGE.
Назначение: команда позволяет объединить данные различных файлов. Рассмотрим, какие виды объединения файлов возможны.
Во-первых, это дополнение массива данных новыми ОБЪЕКТАМИ (функция ADD). На практике такая операция необходима, если
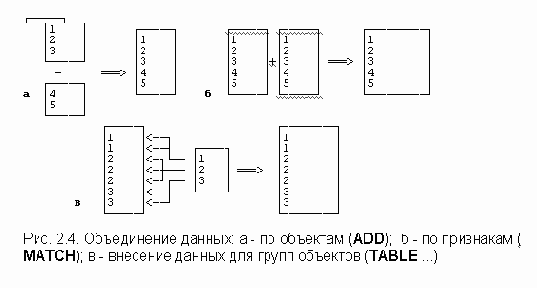 В качестве примера проведем присоединение данных агрегированного файла (см. пример из предыдущего раздела) к анкетным данным курильского обследования:
В качестве примера проведем присоединение данных агрегированного файла (см. пример из предыдущего раздела) к анкетным данным курильского обследования:get file "D:oct.sav".
SORT CASES BY g (A) .
MATCH FILES /FILE=* /TABLE='D: Aggr.sav' /BY g.
EXECUTE.
Сортировка файлов данных по ключевой переменной здесь обязательна; если данные не отсортированы, есть риск их потерять.
После объединения, в данных D:oct.sps появятся переменные d1, d2, d3, d4, d5 и d6, a также w1, w2, w4, w8, w9, w10 и wr. Теперь можно изучать, как связано "общественное мнение" с индивидуальными характеристиками респондентов.
Заметим, что "ручное" написание команды в данном случае требует особой внимательности, так как диагностика ошибок в этой команде сделана здесь не на высоком уровне.
Оценка факторов
Оценка факторовМатематический аппарат, используемый в факторном анализе, в действительности позволяет не вычислять непосредственно главные оси. И факторные нагрузки до и после вращения факторов и общности вычисляются за счет операций с корреляционной матрицей. Поэтому оценка значений факторов для объектов является одной из проблем факторного анализа.
Факторы, имеющие свойства полученных с помощью метода главных компонент, определяются на основе регрессионного уравнения. Известно, что для оценки регрессионных коэффициентов для стандартизованных переменных достаточно знать корреляционную матрицу переменных. Корреляционная матрица по переменным Xi и Fk определяется, исходя из модели и имеющейся матрицы корреляций Xi. Исходя из нее, регрессионным методом находятся факторы в виде линейных комбинаций исходных переменных:
 .
.Оценка влияния независимой переменной
Оценка влияния независимой переменнойЕсли переменные X независимы между собой, то величина коэффициента bi интерпретируется как прирост y, если Xi увеличить на единицу.
Можно ли по абсолютной величине коэффициента судить о роли соответствующего ему фактора в формировании зависимой переменной? То есть, если b1>b2, будет ли X1 важнее X2?
Абсолютные значения коэффициентов не позволяют сделать такой вывод. Однако при небольшой взаимосвязи между переменными X, если стандартизовать переменные и рассчитать уравнение регрессии для стандартизованных переменных, то оценки коэффициентов регрессии позволят по их абсолютной величине судить о том, какой аргумент в большей степени влияет на функцию.
Одномерный дисперсионный анализ Краскэла-Уоллиса (Kruskal-Wallis)
5.3.2. Одномерный дисперсионный анализ Краскэла-Уоллиса (Kruskal-Wallis)В основе сравнения средних рангов заданного числа групп лежит одномерный дисперсионный анализ, в котором вместо значений переменных используются ранги объектов исследуемой переменной.
NPAR TESTS K-W = V14 BY V4(1,3).
В условиях гипотезы равенства распределений в группах нормированный межгрупповой разброс имеет распределение, близкое к распределению хи-квадрат. В выдаче распечатывается значимость этой статистики.
Следующий пример показывает различие доходов жителей населенных пунктов разного типа.
npar test k-w=v9 by tp(1,4).
Одномерный дисперсионный анализ (ONEWAY)
Одномерный дисперсионный анализ (ONEWAY)Данная процедура позволяет проводить одномерный дисперсионный анализ, ее преимущества перед командой Means в возможности исследования равенства дисперсий в группах, исследовании полиномиальных трендов, проведения множественных сравнений:
ONEWAY lnv14m BY w10 /STATISTICS HOMOGENEITY
/POSTHOC = BTUKEY SCHEFFE BONFERRONI ALPHA(.05).
Задается тестируемая переменная, служебное слово "BY", переменная группирования, список значений в скобках. Проверка однородности дисперсий задается подкомандой /STATISTICS HOMOGENEITY, множественные сравнения - подкомандой /POSTHOC = ….
Контрасты. Контрастом называется линейная комбинация средних в группах
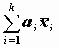 , где
, где 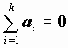 . С помощью контрастов можно проверять гипотезы об определенных соотношениях между математическими ожиданиями переменной в группах. В частности, если задать ai=-aj=1, можно проверять гипотезу о равенстве i-го и j-го среднего, можно подобрать контрасты для проверки линейного или полиномиального изменения средних (см. Руководство по применению SPSS). В условиях равенства матожиданий маловероятно существенное их отклонение от нуля.
. С помощью контрастов можно проверять гипотезы об определенных соотношениях между математическими ожиданиями переменной в группах. В частности, если задать ai=-aj=1, можно проверять гипотезу о равенстве i-го и j-го среднего, можно подобрать контрасты для проверки линейного или полиномиального изменения средних (см. Руководство по применению SPSS). В условиях равенства матожиданий маловероятно существенное их отклонение от нуля.Одновыборочные тесты
5.1. Одновыборочные тестыЭти тесты служат для проверки соответствия распределения выборки заданному.
Одновыборочный тест (One sample T-test).
Одновыборочный тест (One sample T-test).Одновыборочный тест предназначен для проверки гипотезы о равенстве математического ожидания переменной заданной величине (в общепринятых обозначениях H0: m =m 0). Напомним, что для проверки этой гипотезы используется статистика
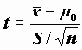 .
. Команда для проверки гипотезы выдает также двусторонний доверительный интервал.
Примеры применения одновыборочного T-теста.
Пример 1. Для устранения влияния текущего уровня цен, инфляции на выводы об уровне жизни населения уровень доходов нормируют на средние значения или медиану. Целесообразно и нам использовать промедианный доход.
Почти одновременно с моментом сбора данных на аналогичной выборке очень большего объема была получена оценка медианы душевых доходов населения (200 руб.). Если допустить, что логарифм доходов имеет нормальное распределение, то среднее промедианных доходов должно незначимо отличаться от нуля (поскольку нормальное распределение симметрично относительно математического ожидания). Проверим это:
compute lnv14m=ln(v14/200).
Variable labels lnv14m "логарифм промедианного дохода".
T-TEST /TESTVAL=0 /VARIABLES=lnv14m /CRITERIA=CIN (.95) .
Основные функции и операторы команд COMPUTE и IF:
Основные функции и операторы команд COMPUTE и IF:Арифметические операторы + , -, *, / в этих командах употребляются обычным порядком, две звездочки ** означают возведение в степень.
Результатом логической операции будет 1, если логическое выражение истинно и 0, если выражение ложно (логическое выражение (v9>30) равно 1, если v9>30, и равно 0, если v9<=30).
Допустимы операторы сравнения <, <=,<, <=, ~=, где последний оператор означает "не равно" и логические операторы ~ -отрицание (not), & - логическое "и" (and) и логическое "или" - | (or).
При вычислении логического выражения, если порядок выполнения не задан скобками, сначала выполняются арифметические операции, затем сравнения, затем логические операции. Приоритетность выполнения операций - естественна, как обычно определяется в математике и языках программирования, но следует заметить, что операции сравнения находятся на одном уровне. В частности значение выражения (5>3>2) ,будет равно 0 ("ложь"), так как в соответствии с порядком выполнения операций в этом выражении (5>3>2)=((5>3)>2)=(1>2)=0 !.
Наряду с арифметическими операторами в арифметических выражениях могут использоваться логические выражения, что позволяет достаточно компактно реализовывать преобразования данных:
Compute x=(v9>30)+v10>x+z.
Эта хитроумная команда превращает вначале выражение (v9>30) в 0 или 1 в зависимости от его истинности, затем производит вычисления левой ( (v9>30)+v10 ) и правой ( x+z )частей неравенства и в зависимости от результата сравнения присваивает переменной x значение 0 или 1.
Кроме того, имеется возможность использовать:
Арифметические функции, такие как ABS - абсолютное значение, RND - округление, TRUNC - целая часть, EXP - экспонента, LN натуральный логарифм и др. Например,
Compute LNv9=LN(V9).
Статистические функции: SUM сумма, MEAN - среднее, SD стандартное отклонение, VARIANCE - дисперсия, MIN -минимум и MAX - максимум.
Например, команда
Compute S=меаn(d1 to d10).
Вычисляет переменную, равную среднему валидных значений переменных d1,…,d10.
Функции распределения, например:
CDF.CHISQ(q,a) - распределения хи-квадрат, CDF.EXP(q,a) - экспоненциального распределения, CDF.T(q,a) - Стьюдента и др. (q - аргумент функции распределения, a - параметр соответствующего распределения). Команда
Compute y=CDF.T(x,10).
Вычисляет переменную Y, значения которой суть значения функции распределения Стьюдента с 10 степенями свободы от значений переменой x.
Если есть подозрение, что X имеет именно такое распределение, то переменная y должна иметь равномерное на отрезке (0,1) распределение. Благодаря этому можно проверить предположение о распределении X.
То же самое можно сказать о других видах распределений.
Обратные функции распределения, например,
IDF.CHISQ(p,a) - обратная функция распределения (по сути дела квантиль) хи-квадрат, IDF.F(p,a,b) - квантиль распределения Фишера, IDF.T(p,a) - квантиль распределения Стьюдента и др. (p - вероятность, a и b - параметры соответствующего распределения). Например,
Compute z= IDF.CHISQ(X,10).
Вычисляет квантиль порядка X распределения хи квадрат с 10 степенями свободы.
Такие функции полезны для вычисления значимости статистик в массовом порядке, например значимость отклонения среднего возраста по городам, в которых произведен сбор данных.
Датчики случайных чисел, например:
RV.LNORMAL(a,b) - датчик лог-нормального распределения. RV.NORMAL(a,b) - датчик нормального распределения, RV.UNIFORM(a,b) - датчик равномерного распределения (a, b - параметры соответствующего распределения).
Функция, дающая значения переменной на предыдущем объекте LAG. Пример использования (см. Рисунок 1.1, данные "Проблем и жалоб")
COMPUTE age1 = LAG(age) .
COMPUTE age2 = LAG(age,3) .
Execute.
Указанное преобразование дает сдвиг информации, показанный на Рисунок 2.1.
| N Анкеты | Пол SEX | Возраст (Age) | Возраст (Age1) | Возраст (Age2) |
| 1 | 1 | 20 | ||
| 2 | 1 | 25 | 20 | |
| 3 | 2 | 34 | 25 | |
| 4 | 1 | 18 | 34 | 20 |
| . | . | . |
Функция полезна для анализа временных рядов, при анализе анкетных данных - для поиска повторов объектов, других вспомогательных операций.
Логические функции:
RANGE(v,a1,b1,a2,b2,…) - 1, если значение V попало хотя бы в один из интервалов [a1,b1], [a2,b2],… .
ANY(v,a1,a2,…) - 1, если значение V совпало хотя бы с одним из значений a1, a2, … .
Кроме того, в пакете имеются строчные функции, функции обработки данных типа даты и времени.
Основные команды меню SPSS:
Основные команды меню SPSS:FILE
Обеспечивает доступ к файлам данных, к выходным файлам и программам преобразования данных. С файлами данных связываются окна. Если текущее окно соответствует данным наблюдений, то команда FILE обслуживает сохранение и замену данных. Если окно содержит файл синтаксиса (SYNTAX) или выдачи результатов счета (OUTPUT), то обеспечивается обработка файла синтаксиса или выдачи.
EDIT
Обеспечивает редактирование командных файлов, выходных файлов и файлов данных статистических наблюдений и др..
DATA
Обеспечивает операции над данными - сортировку, слияние различных файлов данных, агрегирование, организацию подвыборки из данных. Эта команда имеется только в меню окна редактора данных.
TRANSFORM
Обеспечивает преобразование данных. Эта команда также имеется только в меню окна редактора данных.
STATISTICS
Команда обеспечивает доступ и реализацию методов анализа данных; в 9-й версии SPSS она заменена на команду ANALISIS.
GRAPHS
Графическое представление данных.
UTILITIES
Обслуживающие программы.
WINDOOW
Обеспечивает переключение окон.
HELP
Содержит справочную информацию.
Кроме того, при работе с графиками и мобильными таблицами (PIVOT TABLES) появляются меню специального назначения.
Приведенные команды - далеко не полное описание меню, а лишь наиболее используемая его часть.
Как принято в современном интерфейсе программ, под МЕНЮ на верхней части окна в обычном режиме работы находится строка с панелью инструментов - ряд кнопок, с которыми связаны различные действия пакета. При движении курсора по этим кнопкам, на статусной строке внизу во внешней части экрана высвечивается сведения о назначении кнопки. Ниже см. дополнительную информацию о статусной строке.
Основные Команды описания данных
основные Команды описания данныхКоманда VARIABLE LABELS назначает ПЕРЕМЕННЫМ метки (расширенные текстовые наименования), которые используются при оформлении листингов.
VARIABLE LABELS V8 'ПОЛ'
V9 'Возраст'.
Синтаксис: за именем переменной указывается в апострофах ее текстовое наименование - метка. Вы должны помечать каждую переменную отдельно. Максимальная длина метки 255 символов.
Команда VALUE LABELS назначает ЗНАЧЕНИЯМ переменных метки - наименования, которые используются при оформлении листингов
VALUE LABELS V1 1 "расчет на свои силы"
2 "пределы"
3 "помощь"/
V8 1 "МУЖЧИНА"
2 "ЖЕНЩИНА"/
x1 to x10 1 "да" 2 "нет" 3 "не знаю".
Синтаксис: за именем переменной или списком переменных и кодом значения в апострофах следует метка. Максимальная длина метки не больше 60 символа. Такое назначение меток может быть определено и для списка переменных. Назначения меток должны разделяться слэшами, в качестве образца используйте приведенный пример.
Команда ADD VALUE LABELS делает то же, что и команда VALUE LABELS, но если VALUE LABELS при повторном запуске замещает все ранее назначенные метки указанных в ней переменных, команда ADD VALUE LABELS назначает метки только указанным кодам.
Команда MISSING VALUES. Как было указано выше, на практике приходится обрабатывать информацию с пропущенными данными. При кодировании неопределенных данных (таких, как ответы "не знаю", отказа ответа) необходимо выбрать символы или цифры - коды отсутствующих значений, и сообщить пакету, что они соответствует пропущенным данным. Это делается командой MISSING VALUES, которая сохраняет в справочной информации файла данных объявленные пользователем коды для неопределенных значений переменной или списка переменных. В дальнейшем, в статистических процедурах и при преобразовании данных эти коды обрабатываются специальным образом. Возможно назначение до 3-х неопределенных кодов или интервал кодов и не более одного кода.
Примеры:
MISSING VALUES X Y Z(-1)/ R(9, 99, 999)/ S1 TO S20(999 thru 100000)/ SEX (9).
MISSING VALUES v2 (Lowest thru -1)/ v10 (-1, 900 THRU Highest).
В указанном выше примере -1 назначается кодом неопределенного значения для X, Y и Z; 9, 99, 999 - для R; от 999 до 100000 - коды неопределенности переменных от S1 до S20; 9 - для SEX; от минимального кода до -1 - для v2; -1 и коды от 900 до максимального - для v10.
Ключевое слово thru определяет интервал кодов; Lowest, Highest - минимальный и максимальный коды, соответственно. Возможны сокращения этих ключевых слов до 2-х букв (th, lo, hi).
В команде указывается список переменных (разделять символом "/" необязательно), у которых может встретиться неопределенное значение, и за которым в круглых скобках указан объявленный код. Объекты с такими значениями переменных при выполнении многих пакетных процедур просто исключаются из рассмотрения.
Неопределенные значения, описанные командой MISSING VALUES, называются пользовательскими неопределенными значениями. Однако и в процессе счета могут возникнуть ситуации, когда невозможно осуществить преобразование данных: деление на 0; корень из отрицательного числа; в вычисления попал код отсутствующего значения; при чтении данных нет совпадения типа (число, символ) данных и т.д. Пакет таким неопределенным значениям присваивает специальный системный код, который в данных изображается точкой. Системный код неопределенности в процедурах и командах обозначается ключевым словом SYSMIS.
Объявление пользовательских неопределенных значений можно отменить командой MISSING VALUES с пустыми скобками.
MISSING VALUES X Y Z() R()/ S1 TO S20()/ SEX().
Основные команды преобразования данных
основные команды преобразования данныхДля преобразования данных в меню окна редактора данных имеется пункт TRANSFORMATIONS, и заготовки команд можно получать, пользуясь этим пунктом.
Преобразования в анализе данных одна из самых трудоемких частей работы. Специалист, освоивший технику преобразования данных, имеет существенный шанс для получения содержательных результатов. На практике в большинстве случаев можно обойтись следующими командами:
COMPUTE - арифметические операции над переменными;
IF - условные арифметические операции над переменными;
RECODE - перекодирование переменных;
COUNT - подсчет числа заданных кодов в списке переменных.
Основные правила написания команд на языке пакета
Основные правила написания команд на языке пакета<первая переменная TO последняя переменная>
Набрав программу, ее можно запустить полностью или частично (выделив блок), нажав кнопку
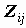 либо воспользовавшись пунктом меню RUN. Этот пункт позволяет запустить на счет SPSS-программу.
либо воспользовавшись пунктом меню RUN. Этот пункт позволяет запустить на счет SPSS-программу. Среди инструментов в окне редактирования файла SYNTAX имеется кнопка для вызова подсказки
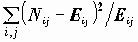 - схемы подкоманд команды. Подсказку можно получить, установив курсор на команде и щелкнув на ней левой клавишей мыши указанную кнопку.
- схемы подкоманд команды. Подсказку можно получить, установив курсор на команде и щелкнув на ней левой клавишей мыши указанную кнопку.Среди команд SPSS можно выделить три основных типа команд - команды описания данных, команды преобразования данных и статистические процедуры.
Команды описания данных устанавливают метки, неопределенные значения, типы переменных, форматы выдачи и др.
Команды преобразования данных предназначены для вычисления новых переменных и модификации имеющихся. Запуск этих команд не вызывает непосредственного преобразования данных, само преобразование происходит после запуска команды EXECUTE. Такая организация расчетов необходима для уменьшения числа обращений к данным на магнитном носителе.
Статистические процедуры предназначены для получения статистик, оценки параметров моделей, получения графиков и др.
Деление это условно. Например, статистические программы также могут вычислять новые переменные, а команды агрегирования данных, как мы увидим ниже, вычисляют статистики для групп объектов. Кроме того, имеются команды управления данными, манипуляции файлами и другие команды, не вписывающиеся в эти три группы команд.
Отбор подмножеств наблюдений
Отбор подмножеств наблюденийДля выбора подмножества наблюдений необходимо использовать команду из главного меню:
DATA
SELECT CASES
после выполнения этих команд появляется окно диалога с вариантами организации отбора данных по условию.
Невыбранные объекты могут быть исключены из сеанса работы или временно отфильтрованы. Имеется возможность организовать случайную выборку, например, выбрать 10% данных.
Если необходимость во временной выборке отпала, нужно снова обратиться к этому же пункту меню и в диалоге указать ,что необходимы все объекты (ALL CASES).
Добавление команд временного отбора данных в файл синтаксиса с использованием диалогового окна (Paste) приводит к появлению в программе целой серии команд, такой как
USE ALL.
COMPUTE filter_$=(v8 = 1).
VARIABLE LABEL filter_$ 'v8 = 1 (FILTER)'.
VALUE LABELS filter_$ 0 'Not Selected' 1 'Selected'.
FORMAT filter_$ (f1.0).
FILTER BY filter_$.
EXECUTE .
Как видно из сгенерированного SPSS текста, в случае использования условия для временной подвыборки объектов, программа выборки создает переменную фильтра (filter_$) и использует команду FILTER BY filter_$.
Можно не использовать диалога, а для временной выборки объектов сформировать программу, создающую переменную фильтра, в частности для выборки мужчин в нашем учебном массиве можно воспользоваться командой
FILTER BY V8.
Для отмены фильтра необходимо запустить команду
FILTER OFF.
Для сохранения массива данных только отобранных объектов в команде SAVE нужно использовать подкоманду /UNSELECTED DELETE:
SAVE FILE='D:\mydir\city' /KEEP=x1 to x10, x15
/UNSELECTED DELETE/COMPRESSED.
Если необходимо исключить наблюдения из массива, диалог даст последовательность команд такого типа
USE ALL.
SELECT IF(v8 = 1).
EXECUTE .
Можно обойтись и одной командой SELECT IF(v8 = 1).
Обратим еще раз внимание на то, что в результате применения команды SELECT IF не выбранные объекты теряются полностью.
Отношение шансов и логит
Отношение шансов и логитОтношение вероятности того, что событие произойдет к вероятности того, что оно не произойдет P/(1-P) называется отношением шансов.
С этим отношением связано еще одно представление логистической регрессии, получаемое за счет непосредственного задания зависимой переменной в виде Z=Ln(P/(1-P)), где P=P{Y=1|X1,…,Xp}. Переменная Z называется логитом.По сути дела, логистическая регрессия определяется уравнением регрессии Z=B0+B1X1+…+BpXp.
В связи с этим отношение шансов может быть записано в следующем виде
P/(1-P)=
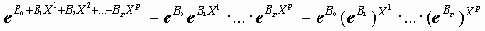 .
.Отсюда получается, что, если модель верна, при независимых X1,…,Xp изменение Xk на единицу вызывает изменение отношения шансов в
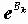 раз.
раз.Для оценки значимости коэффициента Пирсона используется критерий t=r*(N-2)/(1-r2)0.5, который в условиях нормальности и независимости переменных имеет распределение Стьюдента. Таким образом, наряду с формулировкой нулевой гипотезы здесь формулируется предположение о двумерной нормальности - довольно жесткое условие.
Для оценки значимости коэффициентов Спирмена и Кендалла используется нормальная аппроксимация этих коэфициентов. По-сути коэффициент ранговой корреляции является коэффициентом корреляции между переменными, преобразованными в ранги (или процентили), поэтому для исследования значимости с помощью этих коэффициентов не требуется делать предположения о распределении данных. Пример выдачи коэффициентов Спирмена представлен в табл.4.15. Не обнаруживается значимой связи возраста и образования (что вполне естественно), но среднемесячный душевой доход связан с образованием (это мы уже показывали).
Парные корреляции
Парные корреляцииКоманда Bivariate… меню производит вычисление таблицы коэффициентов Пирсона, характеризующего степень линейной связи, а также коэффициентов ранговой корреляции BTAU и Спирмена (Spearman). В синтаксисе эта команда имеет вид:
CORRELATIONS /VARIABLES=v9 lnv14m /PRINT=TWOTAIL NOSIG.
для обычного коэффициента корреляции и
NONPAR CORR /VARIABLES=v10 v9 v14 /PRINT=SPEARMAN.
или
NONPAR CORR /VARIABLES=v10 WITH v9 v14 /PRINT=KENDALL.
для ранговых корреляций
Подкоманда /VARIABLES в этих командах указывает список переменных или два списка переменных, разделенных словом WITH. Если указывается один список переменных, то рассчитываются коэффициенты корреляции каждой переменной с каждой переменной (квадратная таблица). Если указываются два списка, разделенные служебным словом WITH, то рассчитываются коэффициенты корреляции всех переменных, расположенных слева от WITH, с переменными, расположенными справа (прямоугольная таблица). Ключевое слово WITH можно использовать только в окне синтаксиса.
Процедура CORRELATIONS выводит: r - коэффициент корреляции Пирсона; число наблюдений (объектов) в скобках и значимость коэффициента корреляции. Коэффициент корреляции Пирсона:
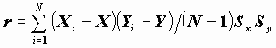 .
.Коэффициент корреляции может принимать значения от -1 до +1. При этом значимый отрицательный коэффициент корреляции позволяет принять гипотезу о наличии линейной отрицательной связи. Метод, используемый для проверки гипотезы, предполагает, также, двумерную нормальность распределения (X,Y). На практике это соответствует тому, что увеличению значения одной переменной в большинстве случаев соответствует уменьшение значения коррелируещей с ней переменной. Значимый положительный коэффициент корреляции свидетельствует о положительной связи переменных: увеличению одной переменной соответствует увеличение другой. Чем ближе абсолютное значение r к единице, тем более линейный характер носит зависимость исследуемых переменных; близость к 0 означает отсутствие линейной связи.
Насколько полученное значение коэффициента корреляции не случайно, определяется по величине значимости (Sig. (2-tailed)) - вероятности получить большее, чем выборочное значение коэффициента корреляции.
Переменные, порождаемые регрессионным уравнением
Переменные, порождаемые регрессионным уравнениемСохранение переменных, порождаемых регрессией, производится подкомандой SAVE.
Благодаря полученным оценкам коэффициентов уравнения регрессии могут быть оценены прогнозные значения зависимой переменной
 , причем они могут быть вычислены и там, где значения y определены, и там где они не определены. Прогнозные значения являются оценками средних, ожидаемых по модели значений Y, зависящих от X.
, причем они могут быть вычислены и там, где значения y определены, и там где они не определены. Прогнозные значения являются оценками средних, ожидаемых по модели значений Y, зависящих от X. Поскольку коэффициенты регрессии - случайные величины, линия регрессии также случайна. Поэтому прогнозные значения случайны и имеют некоторое стандартное отклонение
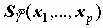 , зависящее от X. Благодаря этому можно получить и доверительные границы для прогнозных значений регрессии (средних значений y).
, зависящее от X. Благодаря этому можно получить и доверительные границы для прогнозных значений регрессии (средних значений y). Кроме того, с учетом дисперсии остатка могут быть вычислены доверительные границы значений Y (не средних, а индивидуальных!).
Для каждого объекта может быть вычислен остаток ei=
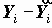 . Остаток полезен для изучения адеквантности модели данным. Это означает, что должны быть выполнены требования о независимости остатков для отдельных наблюдений, дисперсия не должна зависеть от X.
. Остаток полезен для изучения адеквантности модели данным. Это означает, что должны быть выполнены требования о независимости остатков для отдельных наблюдений, дисперсия не должна зависеть от X.Для изучения отклонений от модели удобно использовать стандартизованный остаток - деленный на стандартную ошибку регрессии.
Случайность оценки прогнозных значений Y вносит дополнительную дисперсию в регрессионный остаток, из-за этого дисперсия остатка зависит от значений независимых переменных (
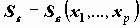 ). Стьюдентеризованный остаток - это остаток деленный на оценку дисперсии остатка:
). Стьюдентеризованный остаток - это остаток деленный на оценку дисперсии остатка: 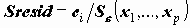 .
.Таким образом, мы можем получить: оценку (прогнозную) значений зависимой переменной Unstandardized predicted value), ее стандартное отклонение (S.E. of mean predictions), доверительные интервалы для среднего Y(X) и для Y(X) (Prediction intervals - Mean, Individual).
Это далеко не полный перечень переменных, порождаемых SPSS.
Порядок выполнения команд
Порядок выполнения командПри выполнении команд необходимо, чтобы для них были определены данные. Например, если заранее не вычислена переменная x, нельзя запустить команды
Compute y=x+1.
Descriptive var=y.
Команда compute не может вычислить переменную y, так как отсутствует переменная x, поэтому команда Descriptive не будет выполнена, так как отсутствует y.
Пошаговая процедура построения модели
Пошаговая процедура построения моделиОсновным критерием отбора аргументов должно быть качественное представление о факторах, влияющих на зависимую переменную, которую мы пытаемся смоделировать. В SPSS очень хорошо реализован процесс построения регрессионной модели: на машину переложена значительная доля трудностей в решении этой задачи. Возможно построение последовательное построение модели добавлением и удалением блоков переменных. Но мы рассмотрим только работу с отдельными переменными.
По умолчанию программа включает все заданные переменные (метод ENTER).
Метод включения и исключения переменных (STEPWISE) состоит в следующем.
Из множества факторов, рассматриваемых исследователем как возможные аргументы регрессионного уравнения, отбирается один xk, который более всего связан корреляционной зависимостью с y. Для этого рассчитываются частные коэффициенты корреляции остальных переменных с y при xk, включенном в регрессию, и выбирается следующая переменная с наибольшим частным коэффициентом корреляции. Это равносильно следующему: вычислить регрессионный остаток переменной y; вычислить регрессионный остаток независимых переменных по регрессионным уравнениям их как зависимых переменных от выбранной переменной (т.е. устранить из всех переменных влияние выбранной переменной); найти наибольший коэффициент корреляции остатков и включить соответствующую переменную x в уравнение регрессии. Далее проводится та же процедура при двух выбранных переменных, при трех и т.д.
Процедура повторяется до тех пор, пока в уравнение не будут включены все аргументы выделенные исследователем, удовлетворяющие критериям значимости включения.
Замечание: во избежание зацикливания процесса включения/исключения значимость включения устанавливается меньше значимости исключения.
использования программы Typology Tables
Пример использования программы Typology TablesВ информации RLMS сведения о покупках 3700 семей, сделанных в течение 1 недели (молочных продуктов, спиртного и табака, сладостей и другого), о размерах жилья и имеющихся в жилье удобствах, о наличии в семье дорогостоящих предметов и недвижимости.
Связаны ли ответы о покупках спиртного и табака с наличием автомобиля, дачи и других предметов крупной собственности? Этот вопрос мы проанализируем с помощью Typology Tables.
Пример логистической регрессии и статистики
Пример логистической регрессии и статистикиПроцедура логистической регрессии в SPSS в диалоговом режиме вызывается из меню командой Statistics\Regression\Binary logistic….
В качестве примера по данным RLMS изучим, как связано употребление спиртных напитков с зарплатой, полом, статусом (ранг руководителя), курит ли он.
Для этого подготовим данные: выберем в обследовании RLMS население старше 18 лет, сконструируем индикаторы курения (smoke) и пития (alcohol) (в обследовании задавался вопрос "Употребляли ли Вы в течении 30 дней алкогольные напитки")
COMPUTE filter_$=(vozr>18).
FILTER BY filter_$.
compute smoke=(dm71=1).
val lab smoke 1 "курит" 0 "не курит".
compute alcohol=(dm80=1).
val lab alcohol 1 "пьет" 0 "не пьет".
Укрупним переменную dj10 -(зарплата на основном рабочем месте). В данном случае группы по значениям этой переменной в основном достаточно наполнены, но мы с методической целью покажем один из способов укрупнения. Для этого вначале получаем переменную wage, которая содержит номера децилей по зарплате, затем среднюю зарплату по этим децилям (см. таблицу 6.5).
missing values dj6.0 (9997,9998,9999) dj10(99997,99998,99999).
RANK VARIABLES=dj10 (A) /NTILES (10) into wage /PRINT=YES /TIES=MEAN .
MEANS TABLES=dj10 BY wage /CELLS MEAN.
построения модели
Пример построения моделиОбычно демонстрацию модели начинают с простейшего примера, и такие примеры Вы можете найти в Руководстве по применению SPSS. Мы пойдем немного дальше и покажем, как получить полиномиальную регрессию.
Курильский опрос касался населения трудоспособного возраста. Как показали расчеты, в среднем меньшие доходы имеют молодые люди и люди старшего возраста. Поэтому, прогнозировать доход лучше квадратичной кривой, а не простой линейной зависимостью. В рамках линейной модели это можно сделать, введя переменную - квадрат возраста. Приведенное ниже задание SPSS предназначено для прогноза логарифма промедианного дохода (ранее сформированного).
Compute v9_2=v9**2.
*квадрат возраста.
REGRESSION /DEPENDENT lnv14m /METHOD=ENTER v9 v9_2
/SAVE PRED MCIN ICIN.
*регрессия с сохранением предсказанных значений и доверительных интервалов средних и индивидуальных прогнозных значений.
Матрица данных, собранных на основании
Пример 1.1.Анкета обследования жалоб и проблем населения (шутка)
1. Пол
3. Проблемы (укажите 3 основные проблемы):
1. Учеба
2. Свободное время
3. Любовь
4. Музыка
4. Жалобы:
1. Служба
2. Здоровье
3. Зарплата
4. Жена
5. Собака соседа
Матрица данных, собранных на основании такой анкеты, изображена на Рисунок 1.1. Пол здесь закодирован в соответствии с содержимым анкеты кодами 1 - мужчины, 2 - женщины; возраст непосредственно введен в данные; проблемы закодированы в трех переменных - указаны коды обведенных при опросе подсказок; для каждой жалобы отведена своя переменная.
| N Анкеты | 1. Пол | 2. Возраст | 3. Проблемы: | 4. Жалобы: | ||||||
| 1. Служба | 2. Здоровье | 3. Зарплата | 4. Жена | 5. Собака соседа | ||||||
| 1 | 1 | 20 | 1 | 4 | . | 1 | 0 | 0 | 0 | 1 |
| 2 | 1 | 25 | 2 | 3 | 4 | 1 | 0 | 1 | 0 | 1 |
| 3 | 2 | 34 | 1 | 2 | 4 | 1 | 0 | 0 | 0 | 1 |
| 4 | 1 | 18 | 1 | 2 | . | 0 | 0 | 0 | 0 | 1 |
| . | . | . | . | . | . | . | . | . | . | . |
На протяжении всего текста мы будем иллюстрировать работу пакета на более серьезном примере анкеты "Курильские острова", текст которой приведен в приложении 1, кроме того, иногда мы будем привлекать для анализа данные Российского мониторинга экономического положения и здоровья населения (RLMS, [13]).
Работа с функциями Missing и Sysmis.
Работа с функциями Missing и Sysmis.В РМЭЗ (российском мониторинге экономики и здоровья), волна 2, имеется переменная BO2a - ответ на вопрос "Сколько времени в течение последних 7 дней Вы потратили на работу …?", причем коды 997, 998, 999 соответствуют ответам "ЗАТРУДНЯЮСЬ ОТВЕТИТЬ", "ОТКАЗ ОТ ОТВЕТА", "НЕТ ОТВЕТА". Имеет смысл эти коды объявить пользовательскими неопределенными, а системные неопределенные коды перекодировать в 0. Делается это следующими командами.
MISSING VALUES BO2a (997, 998, 999).
If (SYSMIS(BO2a)) BO2a=0.
Execute.
Аналогичным путем в других обстоятельствах можно употребить и функцию Missing.
Работа с неопределенными значениями
Работа с неопределенными значениямиВообще говоря, если в арифметическом выражении встретится переменная с неопределенным значением, результат будет не определен, однако значения выражения
0*неопределенное значение
и
0/ неопределенное значение
приравниваются к нулю.
Работа с пользовательскими неопределенными значениями
Работа с пользовательскими неопределенными значениямиВ данных по вопросу о Курильских островах переменные V15, V16, v17 означают время проживания в Западной Сибири, Восточной Сибири и на Дальнем Востоке. Допустим, для удобства проведения текущих расчетов нулевые коды этих переменных объявлены неопределенными
Missing values V15, V16, v17 (0).
Тогда вычисление времени проживания за Уралом командой
COMPUTE Y = V15 + V16 + v17.
приведет в большинстве случаев к неопределенным значениям Y.
В этом случае функция VALUE позволит работу с пользовательскими неопределенными значениями, как с определенными:
COMPUTE Y = VAL(V15) + VAL(V16)+VAL(V17).
Работа с программой Typology Tables
Работа с программой Typology TablesКоротко статистический анализ таблиц при помощи Typology Tables можно представить последовательностью следующих естественных действий.
Регрессионный анализ
6. Регрессионный анализЗадача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии.
Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена логистической регрессии, целью которой является построение моделей, предсказывающих вероятности событий.
Решение уравнения с использованием логита.
Решение уравнения с использованием логита.Механизм решения такого уравнения можно представить следующим образом
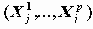 подсчитывается доля объектов, соответствующих событию {Y=1}. Эта доля является оценкой вероятности
подсчитывается доля объектов, соответствующих событию {Y=1}. Эта доля является оценкой вероятности 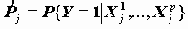 . В соответствии с этим, для каждой группы получается значение логита Zj.
. В соответствии с этим, для каждой группы получается значение логита Zj.
 оказываются равными нулю или единице. Таким образом, оценка логита для них не определена (для этих значений
оказываются равными нулю или единице. Таким образом, оценка логита для них не определена (для этих значений  ).
).В некоторых статистических пакетах такие группы объектов просто-напросто отбрасываются.
В настоящее время в статистическом пакете для оценки коэффициентов используется метод максимального правдоподобия, лишенный этого недостатка. Тем не менее, проблема, хотя и не в таком остром виде остается: если оценки вероятности для многих групп оказываются равными нулю или единице, оценки коэффициентов регрессии имеют слишком большую дисперсию. Поэтому, имея в качестве независимых переменных такие признаки, как душевой доход в сочетании с возрастом, их следует укрупнить по интервалам, приписав объектам средние значения интервалов.
Режим диалога и командный режим
2.4. Режим диалога и командный режимСамый простой способ работы в пакете - использование диалоговых окон, возникающих при вызове команд из меню.
Более сложный способ - написание программ на языке пакета. Этот способ предпочтителен при достаточно большом объеме преобразований данных. Исследователь должен иметь перед глазами программу выполненных действий для уверенности в правильности результата. Кроме того полезна возможность копирования и редактирования текста программы преобразования и анализа данных.
Впрочем, важно оптимальное сочетание диалоговых окон и языка.
Диалоговый способ удобен тем, что в диалоговом окне всегда присутствует подсказка о параметрах процедуры преобразования или анализа данных, параметры вводятся в жестко закрепленные поля, поэтому ошибки в нем практически невозможны. Этот способ оказывается полезным также для формирования команды в командном файле. Обычно в диалоговом окне присутствуют “кнопки” OK -непосредственное исполнение команды, PASTE - дописать команду в файл SYNTAX. Благодаря последнему можно писать программы не зная синтаксиса языка программирования в пакете.
Для эффективной работы в пакете необходимо знать и понимать язык программирования SPSS.
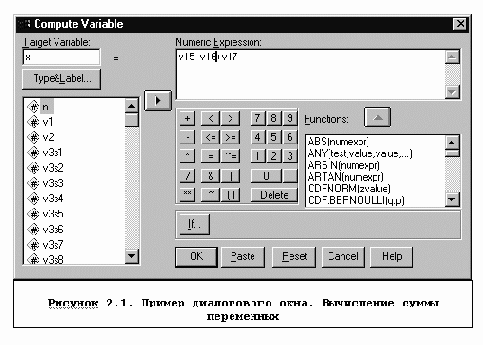
Схема организации данных, окна SPSS
2.2. Схема организации данных, окна SPSSПрежде чем приступить к описанию работы с пакетом, необходимо рассмотреть списки входных (файлов данных) и выходных файлов (создаваемых пакетом в процессе его работы).
К входным данным в системе SPSS относятся:
1. Исходные данные статистических наблюдений. Они могут быть представлены в виде системного SPSS-файла данных, в виде ASCII-файла, файла, получаемого в электронных таблицах (EXCEL, QUATTRO) в виде файлов баз данных и др.
Естественно, среди этих видов данных наиболее удобны для работы системные данные SPSS. Они содержат не только сами данные и имена переменных, но и их расширенные имена и метки значений, а также информацию о кодах неопределенных значений. Начиная с 8-й версии SPSS, хранится также информация о неальтернативных переменных.
Имена файлов эмпирических данных SPSS имеет расширение .sav. Например, D:CITY.SAV. Непосредственный ввод данных и просмотр информации в таких файлах в SPSS осуществляется через окно редактирования данных (SPSS for Windows Data Editor).
2. Данные, полученные из диалогов. Команды, запущенные из меню, вызывают диалоговые окна, которые позволяют назначить параметры и переменные для программ обработки данных.
3. Файлы синтаксиса, содержащие задание для пакета на специализированном языке пакета. Использование в анализе исключительно диалоговых окон удобно только для новичка. Опытный специалист пишет настоящие программы преобразования данных. Эти программы позволяют в любой момент воспроизвести проведенные расчеты, обнаружить ошибку преобразования данных. Они легко модифицируются для решения других задач.
Имена Файлов с программами на языке пакета имеют расширение .sps. Например, d:work1.sps. По умолчанию они будут иметь имена SYNTAX1.sps, SYNTAX2.sps,… . При необходимости эти файлы можно сохранять для дальнейшей работы.
Для создания программ на языке SPSS в SPSS предусмотрено окно синтаксиса (SYNTAX).
К выходным данным относятся:
По умолчанию файлам результатов даются имена, OUTPUT1.SPO, OUTPUT2.SPO … . Для просмотра этих файлов используется окно навигатора вывода (OUTPUT). Часть окна навигатора вывода отведена для дерева выдачи, что облегчает просмотр результатов расчетов.
Поскольку содержимое всех файлов можно просматривать и редактировать, выделение входных и выходных данных условно и определяется скорее основным их назначением.
Следует заметить, что мы не показали
Следует заметить, что мы не показали здесь часть таблицы попарных сравнений с результатами для метода Бонферрони и Шеффе; результаты аналогичны, но для указанной пары групп значимость различия по Шеффе - 0.041, по Бонферрони - 0.016. Это показывает большую чуствительность теста Тьюки.Сложные табличные отчеты. Таблицы для неальтернативных вопросов
3.3. Сложные табличные отчеты. Таблицы для неальтернативных вопросовПолучить сложные многоуровневые таблицы, содержащие описательные статистики по числовым переменным, можно используя раздел меню Custom Tables. Этот раздел соответствует команде синтаксиса TABLES. Синтаксис этой команды весьма сложен, поэтому при "ручном" наборе команды TABLES легко можно ошибиться, поэтому мы здесь не будем даже пытаться познакомить читателя с ее текстовым заданием.
Хотя раздел меню состоит из четырех команд: Basic Tables, General Tables, Multiple Responcse Tables и Tables of Frequencies. Мы не будем описывать все нюансы работы с этими командами, покажем лишь принципиально новые возможности по сравнению с Crosstabs.
Ячейки таблицы, получаемой с помощью Basic Tables, соответствуют комбинациям значений переменных. В этих ячейках
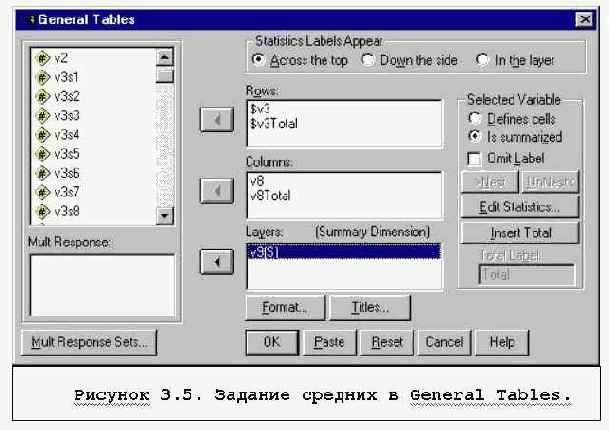 могут располагаться частоты, всевозможные проценты, средние по количественным переменным. Например, можно вычислить средние возраст и доход при различных сочетаниях пола, семейного положения и образования. Всего в диалоговом окне может быть задано около 30 статистик, но ни одной статистики, по которой можно было бы проверить значимости связи переменных и значимости различия средних в группах. Недоступны для обработки неальтернативные вопросы.
могут располагаться частоты, всевозможные проценты, средние по количественным переменным. Например, можно вычислить средние возраст и доход при различных сочетаниях пола, семейного положения и образования. Всего в диалоговом окне может быть задано около 30 статистик, но ни одной статистики, по которой можно было бы проверить значимости связи переменных и значимости различия средних в группах. Недоступны для обработки неальтернативные вопросы.Команда Tables of Frequencies по сути объединяет в одну таблицу множество одномерных распределений одних переменных в группах по комбинациям значений других переменных. Статистики - только частоты и проценты.
Не имея возможности рассматривать все возможности пакета, мы предлагаем читателю самостоятельно разобраться с командами
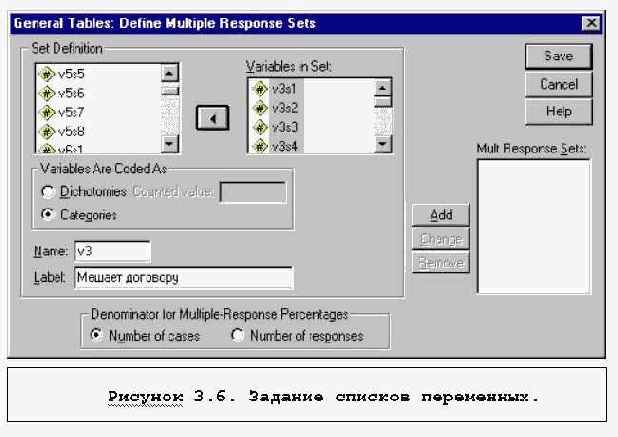 Basic Tables и Tables of Frequencies, вместо этого рассмотрим команду General Tables, имеющую принципиальное значение для анализа неальтернативных вопросов.
Basic Tables и Tables of Frequencies, вместо этого рассмотрим команду General Tables, имеющую принципиальное значение для анализа неальтернативных вопросов.Итак, команда General Tables отличается тем, что с ее помощью можно обрабатывать неальтернативные вопросы и комбинации ответов неальтернативных вопросов; в клетках таблиц для неальтернативных и обычных вопросов можно также получать средние количественных переменных.
Для получения таблицы с использованием неальтернативных вопросов необходимо через диалоговое окно General Tables (см. Рисунок 3.5) выйти в окно задания списков переменных для неальтернативных вопросов (см. кнопку Mult Response Sets, Рисунок 3.6) и задать списки этих переменных. Словом Dichotomies Counted Value обозначается дихотомическое кодирование этих вопросов, словом Categories - кодирование в виде списка подсказок.
При вычислении процентов в таблицах для неальтернативных вопросов рассматриваются две возможности, в качестве знаменателя использовать сумму ответов или число наблюдений (анкет). Причем в последнем случае берутся не все объекты, а только анкеты ответивших на соответствующий вопрос.
В SPSS, начиная с 8-й версии, информация о неальтернативных вопросах сохраняется в файле данных. Поэтому, если группы переменных были уже сформированы в прошлых сеансах работы с SPSS, соответствующие имена можно использовать непосредственно.
После задания групп переменных в окне Mult Response основного окна General Tables: появятся их имена, начинающиеся со знака доллара. Эти имена могут использоваться для задания строк, столбцов, слоев таблицы.
Для того, чтобы в таблице были статистики количественной переменной, нужно эту переменную разместить в окно Layers и отметить, что она суммируема (Is summarized в сведенниях о выбранной переменной в основном диалоговом окне General Tables). По умолчанию средние выводятся в целом формате, что часто неудобно, поэтому обычно нужно его исправить (кнопка Format).
Итоговые строки и столбцы назначаются специально (кнопка Totals).
При вычислении частотных таблиц следует позаботиться о задании процентов в числе статистик. Не забудьте, что частотные таблицы без задания процентов в большинстве случаев бессмысленны.
Сохранение переменных
Сохранение переменныхПрограмма позволяется сохранить множество переменных, среди которых наиболее полезной является, вероятно, предсказанная вероятность.
Стандартизация переменных. Бета коэффициенты
Стандартизация переменных. Бета коэффициентыСтандартизация переменных, т.е. замена переменных xk на
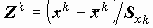 и y на
и y на 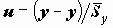 , приводит к уравнению
, приводит к уравнению 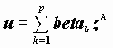 ,
, где k - порядковый номер независимой переменной.
Коэффициенты в последнем уравнении получены при одинаковых масштабах изменения всех переменных и сравнимы. Более того, если "независимые" переменные независимы между собой, beta коэффициенты суть коэффициенты корреляции между xk и y. Таким образом, в последнем случае коэффициенты beta непосредственно характеризуют связь x и y.
В случае взаимосвязи между аргументами в правой части уравнения могут происходить странные вещи. Несмотря на связь переменных xk и y, beta - коэффициент может оказаться равным нулю; мало того, его величина может оказаться больше единицы!
Взаимосвязь аргументов в правой части регрессионного уравнения называется мультиколлинеарностью. При наличии мультиколлинеарности переменных по коэффициентам регрессии нельзя судить о влиянии этих переменных на функцию.
Статистические гипотезы в факторном анализе
Статистические гипотезы в факторном анализеВ SPSS предусмотрена проверка теста Барлетта о сферичности распределения данных. В предположении многомерной нормальности распределения здесь проверяется, не диагональна ли матрица корреляций. Если гипотеза не отвергается (наблюдаемый уровень значимости велик, скажем больше 5%) - нет смысла в факторном анализе, поскольку направления главных осей случайны. Этот тест предусмотрен в диалоговом окне факторного анализа, вместе с возможностью получения описательных статистик переменных и матрицы корреляций. На практике предположение о многомерной нормальности проверить весьма трудно, поэтому факторный анализ чаще применяется без такого анализа.
Статистические эксперименты
Статистические экспериментыДля выяснения критического значения max|Zij| многократно (заданное число раз) имитируется ситуация независимости ответов, соответствующих строкам и столбцам. В ходе имитации в клетках таблицы получаются значения Z-статистик. Такая имитация осуществляется за счет случайного перемешивания данных, которое можно представить так: мы как будто рассыпали листочки с разными вопросами анкеты и случайно собираем их вместе.
По эмпирической функции распределения получается критические значения для максимума Z-статистики.
Эксперименты позволяют также оценить в каждой клетке наблюдаемую множественную значимость Z-статистики - вероятность на всей таблице случайно получить большее значение Z-статистики.
Статистический эксперимент для оценки значимости и ее прямое вычисление
Статистический эксперимент для оценки значимости и ее прямое вычислениеЧто же делать, когда количество наблюдений не позволяет воспользоваться аппроксимацией распределения статистики CHISQ распределением хи-квадрат? В действительности нормальная аппроксимация необходима лишь для того, чтобы можно было вычислить вероятность P{CHISQтеор.>CHISQвыбороч.}. То, что CHISQтеор. имеет распределение хи-квадрат - лишь техническая подробность, связанная с упрощением и ускорением вычислений. То же касается и других статистик значимости (CTAU, BTAU). Современная вычислительная техника позволяет во многих случаях обойтись без использования аппроксимации, вычислить вероятности за счет имитации сбора данных в условиях независимости (метод Монте-Карло) или воспользовавшись непосредственным вычислением вероятности.
В многих процедурах SPSS, в том числе и в Crosstabs, реализованы метод Монте-Карло и прямое вычисление вероятностей.
В методе Монте-Карло проводятся компьютерные эксперименты, в которых многократно случайно перемешиваются данные. В каждом эксперименте вычисляется значение статистики значимости и сравнивается с наблюдаемой ее величиной. Доля случаев, когда статистика превысила наблюдаемое значение, является оценкой уровня значимости. Поскольку оценка вычисляется на основе случайных экспериментов, в дополнеие к оценке уровня значимости выдается его доверительный интервал. Число экспериментов и доверительная вероятность задается заранее.
В методе прямого вычисления рассматривается обобщение гипергеометрического распределения для таблицы сопряженности. Процедура весьма трудоемка и имеет смысл для небольших данных. Заранее задается время счета и, если программа не успела справиться с вычислениями, выдается результат, полученный на основе аппроксимаций.
В диалоговом окне Crosstabs (как, впрочем, и в окнах для других непараметрических процедур) указанные методы включаются с помощью кнопки EXACT.
Пример. Решается вопрос, как связаны "Точка зрения на иностранную помощь" и "Возможность удовлетворить территориальные требований Японии" на выборке, ограниченной жителями Дальнего Востока (276 наблюдений).
Для решения используется
CROSSTABS /TABLES=v4 BY v1 /STATISTIC=CHISQ /CELLS= COUNT Row Col /METHOD=MC CIN(99) SAMPLES(10000).
Параметры последней подкоманды, "/METHOD=MC CIN(99) SAMPLES(10000)", говорят о том, что значимость оценивается методом Монте Карло (MC), будет получен 99% доверительный интервал для оценки наболюдаемой значимости (CIN(99)) с использованием 10000 экспериментов (SAMPLES(10000)).
В результате получаем таблицу 3.8, в которой размещены значимости всех исследуемых статистик. Исследуемые в статистическом эксперименте статистики включают дополнительно обобщение точного теста Фишера (Fisher's Exact Test). Статистика для этого теста имеет вид FI=-2log(g P), где g - константа, зависящая от итоговых частот таблицы, а P - вероятность получить наблюдаемую таблицу в условиях независимости переменных. Статистика FI также имеет асимптотическое распределение хи-квадрат (в условиях гипотезы независимости). Следует заметить, что значимость, вычисленная на основе аппроксимации, выглядит значительно оптимистичнее с точки зрения обнаружения связи, чем при прямых вычислениях, да это и не мудрено - доля клеток, в которых ожидаемая частота меньше 5 равна 56.3%, а минимальная ожидаемая частота равна 0.47.
Опыт показывает, что точный тест на основе прямого вычисления вероятности требует очень много времени. Нашей задаче оказалось недостаточным 25 мин. на персональном компьютере с процессором 200mhz.
STATISTICS - исследование связи неколичественных перемееных
STATISTICS - исследование связи неколичественных перемееныхВ предыдущем разделе изучалась связь значений переменных. Для получения ответа о связи переменных в целом используется подкоманда STATISTICS с параметрами, указывающими на статистику или коэффициент для исследования связи переменных. Вот некоторые из этих параметров:
CHISQ - позволяет оценить связь с помощью критерия Xи-квадрат; кроме коэффициента Xи-квадрат при задании этого ключевого слова выдается отношение правдоподобия (Likelihood Ratio). А также статистика для проверки линейной связи. Последняя статистика редко используется, в связи с чем не рассматривается в данных методических рекомендациях.
PHI - коэффициент PHI-Пирсона; вместе с этим коэффициентом выдается коэффициент V-Крамера;
CC - коэффициент контингенции;
BTAU - Тау-В Кендалла для ранговых переменных;
CTAU - Тау-С Стюарта для ранговых переменных;
ALL - указанные статистики и еще около десятка различных статистик.
Как можно охарактеризовать в целом связь НЕКОЛИЧЕСТВЕННЫХ переменных? Для характеристики связи номинальных переменных наиболее часто используется критерий Xи-квадрат (CHISQ), основанный на вычислении статистики
CHISQ=
.Эта статистка показывает расстояние эмпирически полученной таблицы сопряженности от ожидаемой теоретически: расстояние между значениями выборочной таблицы Nij и ожидаемой в условиях независимости таблицы Eij. Само по себе значение статистики ни о чем не говорит, важно знать вероятность получения расстояния CHISQ, большего, чем наблюдаемое на случайной выборке. Эта вероятность называется наблюдаемой значимостью и обозначается словом SIGNIFICANCE (возможны сокращения - Sig., P-значения).
CHISQ в условиях независимости и при достаточном числе наблюдений имеет распределение, близкое к распределению Xи-квадрат с (r-1)(c-1) степенями свободы, где r - число строк в таблице, с число столбцов (CHISQтеор.» c 2((r-1)(c-1))). Существует эмпирическое правило, по которому считается, что CHISQ достаточно точно аппроксимируется теоретическим распределением c 2((r-1)(c-1)), если среди ожидаемых частот Eij не более 20% меньше 5 и нет Eij, меньших 1.
Поэтому рекомендуется использовать критерий хи-квадрат в CROSSTABS для переменных с небольшим числом значений, что достигается перекодировкой переменных. В выдаче присутствует информация о числе клеток, где это соотношение не выполняется. Пакет выдает выборочное значение CHISQ и его значимость. Вместе с критерием Xи-квадрат выдается также логарифм отношения правдоподобия LI:
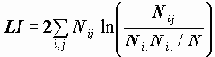 ,
,имеющее асимптотически то же распределение, но более устойчивое к объему выборки. Поэтому при оценке связи пары признаков мы рекомендуем пользоваться отношением правдоподобия. Для всех критериев выдается значимость:
SIGNIFICANCE - вероятность случайно получить большее значение, чем выборочное. Таким образом, для CHISQ наблюдаемая значимость (SIG) равна P{CHISQтеор.>CHISQвыбороч.} и, аналогично, для отношения правдоподобия LI наблюдаемая значимость (SIG) равна P{LIтеор.>LIвыбороч.}. Пример задания для исследования связи ответа на вопрос о необходимости иностранной помощи (v1) и полом (v8):
CROSSTABS v8 by v1 /cells count row col asresid /STATISTICS=CHISQ.
Статусная строка
Статусная строкаСтатусная строка показывает, текущее состояние данных и процесса счета, например:
Transformations pending - задержка преобразований (например, если за преобразованиями не следует команда EXECUTE или статистическая процедура).
Weight on - данные взвешены
Split on - данные для проведения расчетов разбиты на группы
Filter on - включена временная выборка данных
Другая информация.
Структура пакета
2.1. Структура пакетаПакет включает в себя команды определения данных, преобразования данных, команды выбора объектов. В нем реализованы следующие методы статистической обработки информации:
- суммарные статистики по отдельным переменным;
- частоты, суммарные статистики и графики для произвольно го числа переменных;
- построение N-мерных таблиц сопряженности и получение мер связи;
- средние, стандартные отклонения и суммы по группам;
- дисперсионный анализ и множественные сравнения;
- корреляционный анализ;
- дискриминантный анализ;
- однофакторный дисперсионный анализ;
- обшая линейная модель дисперсионного анализа (GLM);
- факторный анализ;
- кластерный анализ;
- иерархический кластерный анализ;
- иерархический лог-линейный анализ;
- многомерный дисперсионный анализ;
- непараметрические тесты;
- множественная регрессия;
- методы оптимального шкалирования;
- и т.д.
Кроме того, пакет позволяет получать разнообразные графики - столбиковые и круговые, ящичковые диаграммы, поля рассеяния и гистограммы и др..
Существует ли линейная регрессионная зависимость?
Существует ли линейная регрессионная зависимость?Для проверки одновременного отличия всех коэффициентов регрессии от нуля проведем анализ квадратичного разброса значений зависимой переменной относительно среднего. Его можно разложить на две суммы следующим образом:
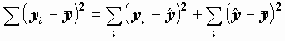
В этом разложении обычно обозначают
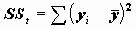 - общую сумму квадратов отклонений;
- общую сумму квадратов отклонений;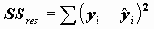 - сумму квадратов регрессионных отклонений;
- сумму квадратов регрессионных отклонений;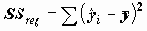 - разброс по линии регрессии.
- разброс по линии регрессии.Статистика
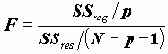 в условиях гипотезы равенства нулю регрессионных коэффициентов имеет распределение Фишера и, естественно, по этой статистике проверяют, являются ли коэффициенты B1,…,Bp одновременно нулевыми. Если наблюдаемая значимость статистики Фишера мала (например, sig F=0.003), то это означает, что данные распределены вдоль линии регрессии; если велика (например, Sign F=0.5), то, следовательно, данные не связаны такой линейной связью.
в условиях гипотезы равенства нулю регрессионных коэффициентов имеет распределение Фишера и, естественно, по этой статистике проверяют, являются ли коэффициенты B1,…,Bp одновременно нулевыми. Если наблюдаемая значимость статистики Фишера мала (например, sig F=0.003), то это означает, что данные распределены вдоль линии регрессии; если велика (например, Sign F=0.5), то, следовательно, данные не связаны такой линейной связью.TABLES задание таблиц
/TABLES задание таблицПараметр TABLES может быть опущен:
CROSSTABS v1 TO v5 BY v10.
Строки таблицы сопряженности соответствуют значениям переменной, указанной в тексте команды перед ключевым словом "BY"; столбцы матрицы соответствуют значениям переменной, расположенной после "BY".
Пример - совместное распределение по региону (R), точке зрения на иностранную помощь (v1) и полу (V8):
CROSSTABS TABLES R BY v1 BY v8/cells = COUNT ROW.
В результате выполнения этой команды рассчитывается таблица 3.3. Перед ключевым словом BY указываются переменные, по которым вычисляется двухвходовая таблица (переменная, значения которой идентифицируют строки), после ключевого слова BY указываются переменные, идентифицирующие столбцы. За следующими BY идут переменные условий, определяющие подвыборки, на которых рассчитываются таблицы. Хотя в современной версии пакета эти таблицы объединяются в одну таблицу, их статистический анализ производится по-отдельности. Ключевым словом BY могут разделяться и списки переменных. В этом случае процедурой получаются таблицы по всем парам таблиц из первого и второго списка. Например,
CROSSTABS V8 V11 V12 BY V4 V1.
Эта команда выведет таблицу сопряженности: V8 c V4, V8 c V1, V11 c V4, V11 c V1 и т.д., то есть сочетания по всем переменным, перечисленным в команде. Всего будет выдано на печать 6 таблиц. Если более двух списков переменных разделены ключевыми словами "BY", то переменные, стоящие за вторым, третьим и т.д. "BY", задают условия получения таблиц. Таблицы формируются на подвыборках, соответствующих сочетаниям значений этих переменных.
Cравнение распределения доходов в двух группах на основе критерия Колмогорова-Смирнова,.
Таблица 5.7. Cравнение распределения доходов в двух группах на основе критерия Колмогорова-Смирнова,.| V14 Душевой доход в семье | ||
| Most Extreme Differences | Absolute | 0.05 |
| Positive | 0.05 | |
| Negative | -0.028 | |
| Kolmogorov-Smirnov Z | 0.455 | |
| Asymp. Sig. (2-tailed) | 0.986 |
Дисперсия, объясненная факторным анализом
Таблица 7.1. Дисперсия, объясненная факторным анализом| Initial Eigenvalues | Extraction Sums of Squared Loadings | |||||
| Component | Total | % of Variance | Cumulative% | Total | % of Variance | Cumulative % |
| 1 | 2.402 | 40.038 | 40.038 | 2.402 | 40.038 | 40.038 |
| 2 | 1.393 | 23.210 | 63.249 | 1.393 | 23.210 | 63.249 |
| 3 | .853 | 14.220 | 77.468 | |||
| 4 | .719 | 11.977 | 89.445 | |||
| 5 | .345 | 5.752 | 95.197 | |||
| 6 | .288 | 4.803 | 100.000 |
Дисперсионный анализ уравнения
Таблица 6.2. Дисперсионный анализ уравнения| Sum of Squares | df | Mean Square | F | Sig. | |
| Regression | 8.484 | 2 | 4.242 | 15.232 | .000 |
| Residual | 181.298 | 651 | .278 | ||
| Total | 189.782 | 653 |
b Dependent Variable: LNV14M логарифм промедианного дохода
Хи-квадрат тесты, оценка значимости методом Монте-Карло.
Таблица 3.8. Хи-квадрат тесты, оценка значимости методом Монте-Карло.| Value | Df | Asymp. Sig. (2-sided) | Monte Carlo Sig. (2-sided) | ||||
| Sig. | 99% Confidence Interval | ||||||
| Lower Bound | Upper Bound | ||||||
| Pearson Chi-Square | 21.6 | 9 | 0.010 | 0.0155 | 0.012 | 0.019 | |
| Likelihood Ratio | 18.9 | 9 | 0.026 | 0.0327 | 0.028 | 0.037 | |
| Fisher's Exact Test | 19.1 | 0.0103 | 0.008 | 0.013 | |||
| Linear-by-Linear Association | 0.3 | 1 | 0.611 | 0.6492 | 0.637 | 0.661 | |
| N of Valid Cases | 276 | ||||||
Интервалы для мужчин и женщин
Таблица 2.1. Интервалы для мужчин и женщин| Интервалы возраста | 1 | 2 | 3 | 4 | 5 |
| Мужчины | до 18 | до 33 | до 45 | До 60 | >60 лет |
| Женщины | до 18 | до 33 | до 45 | До 55 | >55 лет |
Recode v9 (lo thru 18=1)(18 thru 33=2)(33 thru 45=3)(45 thru 60=4)(60 thru hi=5) into w9.
Else if (v8=2).
Recode v9 (lo thru 18=1)(18 thru 33=2)(33 thru 45=3)(45 thru 55=4)(55 thru hi=5) into w9.
END IF.
Здесь для мужчин в переменной w9 получаются одни интервалы значений, для женщин - другие. Если бы не было неопределенных значений v8, можно было бы вместо "Else if (v8=2)." использовать просто "Else".
Заметим, что команды RECODE и COUNT непосредственно не могут выполняться на подвыборках объектов, но с командами DO IF и END IF их выполнение возможно. Именно это используется при задании таких условных команд из диалоговых окон.
Напомним, что команды, запущенные без команды Execute, накапливаются в памяти, но не выполняются (Transformations pending в статусной строке). Поэтому, из-за ошибки между DO IF и END IF, в память попадает только DO IF. После исправления ошибки и запуска программы оказывается больше запущенных команд DO IF, чем END IF, и сообщение об ошибке повторяется. Это следствие того, что команды IF, COMPUTE, COUNT, RECODE преобразуют данные не сразу, а после запуска команды EXECUTE.
Для того, чтобы справиться с этой ситуацией, следует запустить отдельно команду
CLEAR TRANSFORMATIONS.
Эта команда очистит память от невыполненных команд.
Коэффициент корреляции времени приготовления пищи и закупки продуктов
Таблица 4.16. Коэффициент корреляции времени приготовления пищи и закупки продуктов| CO17A время на приготовления пищи | ||
| CO15A время на покупку продуктов | Pearson Correlation | 0.3193 |
| Sig. (2-tailed) | 0.0000 | |
| N | 3549 |
Таблица 4.17. Коэффициент корреляции времени приготовления пищи и закупки продуктов
| Controlling for.. CO19A (время на уборку квартиры ) | CO17A время на приготовления пищи | |
| CO15A время на покупку продуктов | Pearson Correlation | 0. 2558 |
| Sig. (2-tailed) | 0.0000 | |
| N | 3546 |
Коэффициенты для ранговых переменных
Таблица 3.7. Коэффициенты для ранговых переменных| Value | Asymp. Std. Error | Approx. T | Approx. Sig. | |
| Kendall's tau-b | -0.158 | 0.043 | -3.571 | 0.000 |
| Kendall's tau-c | -0.094 | 0.026 | -3.571 | 0.000 |
Можно с уверенностью утверждать, что преобладает обратная связь между рангами: чем меньше желание отдать острова, тем больше преобладает мнение, что помощь необходима.
Коэффициенты корреляции Спирмена (Spearman's rho)
Таблица 4.15. Коэффициенты корреляции Спирмена (Spearman's rho)| V9 Возраст | V14 Ср.мес. душевой доход в семье | ||
| V10 Образование | Correlation Coefficient | -.021 | -.086 |
| Sig. (2-tailed) | .574 | .026 | |
| N | 692 | 671 |
Коэффициенты регрессии с индексными переменными.
Таблица 6.4. Коэффициенты регрессии с индексными переменными.| B | Std. Error | Beta | T | Sig. | |
| (Constant) | -1.1721 | 0.1937 | -6.0500 | 0.0000 | |
| V9 Возраст | 0.0635 | 0.0105 | 1.4298 | 6.0299 | 0.0000 |
| V9_2 | -0.0007 | 0.0001 | -1.3243 | -5.7351 | 0.0000 |
| T1 Женат | -0.2030 | 0.0766 | -0.1540 | -2.6488 | 0.0083 |
| T2 Вдовец | -0.2471 | 0.1352 | -0.0850 | -1.8279 | 0.0680 |
| T3 Разведен | -0.1494 | 0.1134 | -0.0661 | -1.3176 | 0.1881 |
Коэффициенты регрессии.
Таблица 6.3. Коэффициенты регрессии.| Unstandardized Coefficients | Standardized Coefficients | T | Sig. | ||
| B | Std. Error | Beta | |||
| (Constant) | -1.0569 | 0.1888 | -5.5992 | 0.0000 | |
| V9 Возраст | 0.0505 | 0.0093 | 1.1406 | 5.4267 | 0.0000 |
| V9_2 | -0.0006 | 0.0001 | -1.0829 | -5.1521 | 0.0000 |
Лог.промед.дохода = -1.0569+0.0505*возраст-0.0006*возраст2
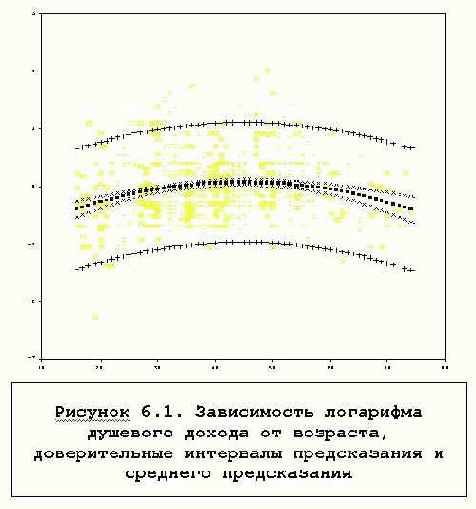 Стандартная ошибка коэффициентов регрессии значительно меньше величин самих коэффициентов, их отношения - t статистики, по абсолютной величине больше 5. Наблюдаемая значимость статистик (Sig) равна нулю, поэтому гипотеза о равенстве коэффициентов нулю отвергается для каждого коэффициента. Стоит обратить внимание на редкую ситуацию - коэффициенты бета по абсолютной величине больше единицы. Это произошло, по-видимому, из-за того, что корреляция между возрастом и его квадратом весьма велика.
Стандартная ошибка коэффициентов регрессии значительно меньше величин самих коэффициентов, их отношения - t статистики, по абсолютной величине больше 5. Наблюдаемая значимость статистик (Sig) равна нулю, поэтому гипотеза о равенстве коэффициентов нулю отвергается для каждого коэффициента. Стоит обратить внимание на редкую ситуацию - коэффициенты бета по абсолютной величине больше единицы. Это произошло, по-видимому, из-за того, что корреляция между возрастом и его квадратом весьма велика. Рисунок 6.1 показывает линию регрессии и доверительные границы для M(y) - матожидания y и для индивидуальных значений y. Он получается с помощью наложения полей рассеяния возраста с зависимой переменной, с переменной - прогнозом, с переменными - доверительными границами:
GRAPH /SCATTERPLOT(OVERLAY)=v9 v9 v9 v9 v9 v9 WITH pre_1 lmci_1 umci_1 lici_1 uici_1 lnv14m(PAIR).
Границы для M(y) значительно уже, чем для y, так как последние должны охватывать больше 95% точек графика.
На графике не прослеживается явной зависимости дисперсии остатка от значений независимой переменной - возраста. Некоторое сужение рассеяния данных для старших возрастов произошло, вероятно, за счет общего уменьшения плотности двумерного распределения.
Критерий Манна-Уитни. Суммы рангов.
Таблица 5.10. Критерий Манна-Уитни. Суммы рангов.| WD2 | N | Mean Rank | Sum of Ranks | |
| V9 Возраст | 1 | 117 | 116.7 | 13650.5 |
| 2 | 103 | 103.5 | 10659.5 | |
| Total | 220 |
Критерий Манна-Уитни. Значимость критерия.
Таблица 5.11. Критерий Манна-Уитни. Значимость критерия.| V9 Возраст | |
| Mann-Whitney U | 5303.5 |
| Wilcoxon W | 10659.5 |
| Z | -1.533 |
| Asymp. Sig. (2-tailed) | 0.125 |
Матрица факторных нагрузок после вращения факторов
Таблица 7.3. Матрица факторных нагрузок после вращения факторов| Component | ||
| 1 | 2 | |
| W3D3 незаинтересованность Японии | 0.887 | 0.049 |
| W3D4 разные политические симпатии | 0.810 | -0.208 |
| W3D2 недоверие к друг другу | -0.643 | 0.095 |
| W3D5 нежелание Японии признать границы | 0.025 | -0.834 |
| W3D6 нежелание СССР рассматривать вопрос | -0.014 | 0.773 |
| W3D1 нет необходимости, отношения нормальны | -0.416 | 0.646 |
Факторные нагрузки этой матрицы свидетельствуют, что фактор 2 существенно связан с W3D6 - долей считающих, что договор не подписан, так как СССР не желает рассматривать вопрос об островах, и отрицательно - с долей считающих, что все беды из-за непризнания границ Японией (W3D5); имеется относитеельно небольшая положительная его связь с W3D1 - "нет необходимости, отношения нормальны". Можно условно назвать этот фактор "фактором несоветской ориентации".
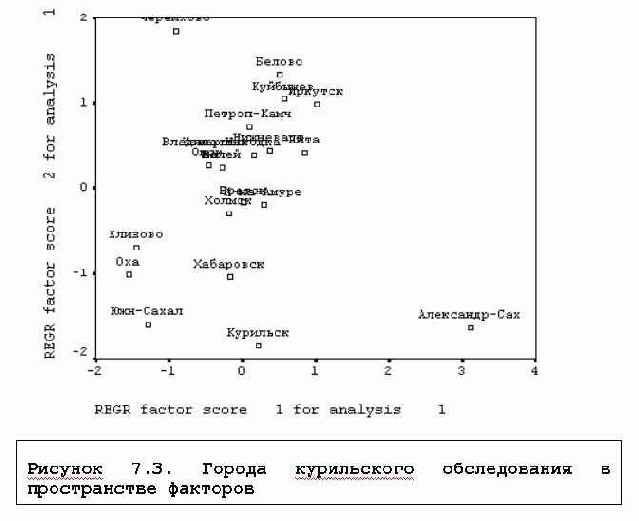 Первыйй фактор связан с переменными W3D3 - "нет заинтересованности Японии", W3D4 "разные политические симпатии", и несколько слабее, отрицательно, с W3D2 - "недоверие к друг другу". Условно его можно назвать фактором "судьбы". Конечно, в серьезных исследованиях можно было бы проверить факторы с самых различных сторон, нам же пока достаточно пояснить принцип интерпретации, который состоит в формулировке содержания фактора, ухватывающего суть явления.
Первыйй фактор связан с переменными W3D3 - "нет заинтересованности Японии", W3D4 "разные политические симпатии", и несколько слабее, отрицательно, с W3D2 - "недоверие к друг другу". Условно его можно назвать фактором "судьбы". Конечно, в серьезных исследованиях можно было бы проверить факторы с самых различных сторон, нам же пока достаточно пояснить принцип интерпретации, который состоит в формулировке содержания фактора, ухватывающего суть явления.Сохраненные в виде переменных подкомандой SAVE факторы могут быть использованы для исследования данных, конструирования типологий и т.д. В частности, с помощью команды GRAPH мы получили поле рассеяния наших объектов - городов в просранстве двух переменных-факторов. По этому графику, например, можно заключить, что жители Александровска-Сахалинского проявили в Курильском опросе наибольшую "несоветскую" ориентацию; они менее всего склонны считать, что договора нет потому, что "так сложилось" из-за "недоверия" между странами и из-за разных политических симпатий.
Матрица факторных нагрузок
Таблица 7.2. Матрица факторных нагрузок| Component | ||
| 1 | 2 | |
| W3D4 разные политические симпатии | .769 | .327 |
| W3D1 нет необходимости, отношения нормальны | -.723 | .260 |
| W3D3 незаинтересованность Японии | .674 | .578 |
| W3D2 недоверие к друг другу | -.569 | -.315 |
| W3D5 нежелание Японии признать границы | .527 | -.647 |
| W3D6 нежелание СССР рассматривать вопрос | -.481 | .605 |
Метод медиан. Разделение на две подвыборки.
Таблица 5.8. Метод медиан. Разделение на две подвыборки.| TP тип поселения | |||||
| Растущие | Стабильные | крупные | гигант | ||
| V14 Ср.мес. душевой доход в семье | > Median | 84 | 104 | 62 | 12 |
| <= Median | 90 | 126 | 139 | 56 |
Метод медиан. Значимость критерия.
Таблица 5.9. Метод медиан. Значимость критерия.| V14 Ср.мес. душевой доход в семье | |
| N | 673 |
| Median | 200 |
| Chi-Square | 28.698 |
| Df | 3 |
| Asymp. Sig. | 0 |
Наблюдаемые и ожидаемые частоты
Общие характеристики уравнения
Таблица 6.1. Общие характеристики уравнения| R | R Square | Adjusted R Square | Std. Error of the Estimate |
| .211 | .045 | .042 | .5277 |
b Dependent Variable: LNV14M логарифм промедианного дохода
Результаты дисперсионного анализа уравнения регрессии показывает, что гипотеза равенства всех коэффициентов регрессии нулю должна быть отклонена.
Одновыборочный t-тест. Средний промедианный доход незначимо отличается от нуля.
Таблица 4.1. Одновыборочный t-тест. Средний промедианный доход незначимо отличается от нуля.| T | Df | Sig. (2-tailed) | Mean Difference | 95% Confidence Interval of the Difference | ||
| Lower | Upper | |||||
| LNV14M | -0.831 | 672 | 0.406 | -0.017 | -0.058 | 0.023 |
Пример. Есть предположение, что малообразованное население имеет средний логарифм доходов, существенно меньший среднего по совокупности объектов. В нашей анкете образование закодировано следующим образом:
1 Высшее;
2 незак/высш;
3 среднее спец;
4 ПТУ,ФЗУ;
5 10-11кл;
6 7-9 кл.;
7 4-6 кл.;
8 менее 4-х классов;
9 нет образования.
Проверим предположение, воспользовавшись временной выборкой данных о респондентах, имеющих образование не выше среднего.
compute f= (v10>3).
*формирование переменной фильтра.
filter f.
T-TEST /TESTVAL=0 / VARIABLES=lnv14 /CRITERIA=CIN (.95) .
filter off.
Одновыборочный T-тест
Таблица 4.2. Одновыборочный T-тест. Средний промедианный доход в группе с относительно низким образованием отличается от нуля при уровне значимости 5%.| T | Df | Sig. (2-tailed) | Mean Difference | 95% Confidence Interval of the Difference | ||
| Lower | Upper | |||||
| LNV14 | -2.0316 | 162 | 0.0438 | -0.0956 | -0.1886 | -0.0027 |
Oneway, группы неразличимых средних
Таблица 4.13. Oneway, группы неразличимых средних| W10 образование | 1 | 2 | ||
| Tukey HSD | 2.00 н/высш | 37 | -0.248 | |
| 5.00 ниже среднего | 33 | -0.107 | -0.107 | |
| 4.00 среднее | 130 | -0.093 | -0.093 | |
| 3.00 ср спец | 220 | 0.009 | ||
| 1.00 Высшее | 251 | 0.048 | ||
| Sig. | 0.429 | 0.436 | ||
| Scheffe | 2.00 н/высш | 37 | -0.248 | |
| 5.00 ниже среднего | 33 | -0.107 | -0.107 | |
| 4.00 среднее | 130 | -0.093 | -0.093 | |
| 3.00 ср спец | 220 | 0.009 | 0.009 | |
| 1.00 Высшее | 251 | 0.048 | ||
| Sig. | 0.093 | 0.579 |
Oneway, множественные попарные сравнения
Таблица 4.14. Oneway, множественные попарные сравнения| Mean Difference (I-J) | Std. Error | Sig. | 95% Confidence Interval | ||||
| (I) W10 образование | (J) W10 образование | Lower Bound | Upper Bound | ||||
| Tukey HSD | 1.00 Высшее | 2.00 н/высш | 0.296* | 0.093 | 0.013 | 0.041 | 0.551 |
| 3.00 ср спец | 0.039 | 0.049 | 0.934 | -0.095 | 0.172 | ||
| 4.00 среднее | 0.140 | 0.057 | 0.102 | -0.016 | 0.297 | ||
| 5.00 ниже среднего | 0.154 | 0.098 | 0.516 | -0.113 | 0.422 | ||
| 2.00 н/высш | 1.00 Высшее | -0.296* | 0.093 | 0.013 | -0.551 | -0.041 | |
| 3.00 ср спец | -0.257 | 0.094 | 0.050 | -0.514 | 0.000 | ||
| 4.00 среднее | -0.155 | 0.099 | 0.515 | -0.425 | 0.114 | ||
| 5.00 ниже среднего | -0.142 | 0.127 | 0.799 | -0.488 | 0.205 | ||
| 3.00 ср спец | 1.00 Высшее | -0.039 | 0.049 | 0.934 | -0.172 | 0.095 | |
| 2.00 н/высш | 0.257 | 0.094 | 0.050 | 0.000 | 0.514 | ||
| 4.00 среднее | 0.102 | 0.059 | 0.412 | -0.058 | 0.262 | ||
| 5.00 ниже среднего | 0.116 | 0.099 | 0.769 | -0.154 | 0.386 | ||
| 4.00 среднее | 1.00 Высшее | -0.140 | 0.057 | 0.102 | -0.297 | 0.016 | |
| 2.00 н/высш | 0.155 | 0.099 | 0.515 | -0.114 | 0.425 | ||
| 3.00 ср спец | -0.102 | 0.059 | 0.412 | -0.262 | 0.058 | ||
| 5.00 ниже среднего | 0.014 | 0.103 | 1.000 | -0.268 | 0.296 | ||
| 5.00 ниже среднего | 1.00 Высшее | -0.154 | 0.098 | 0.516 | -0.422 | 0.113 | |
| 2.00 н/высш | 0.142 | 0.127 | 0.799 | -0.205 | 0.488 | ||
| 3.00 ср спец | -0.116 | 0.099 | 0.769 | -0.386 | 0.154 | ||
| 4.00 среднее | -0.014 | 0.103 | 1.000 | -0.296 | 0.268 | ||
recode v10 (4 5 =4) (6 7 8=5) (else=copy) into w10.
var lab w10 "образование".
value lab w10 1 "Высшее" 2 "н/высш" 3 "ср. спец" 4 "среднее" 5 "ниже среднего".
ONEWAY lnv14m BY w10 /STATISTICS DESCRIPTIVES HOMOGENEITY /POSTHOC = BTUKEY SCHEFFE BONFERRONI ALPHA(.05).
На основании полученной выдачи видим, что:
Oneway, обычный дисперсионный анализ
Таблица 4.12. Oneway, обычный дисперсионный анализ| Sum of Squares | df | Mean Square | F | Sig. | |
| Between Groups | 4.187 | 4 | 1.047 | 3.724 | 0.005 |
| Within Groups | 187.202 | 666 | 0.281 | ||
| Total | 191.389 | 670 |
Oneway, проверка однородности дисперсий
Таблица 4.11. Oneway, проверка однородности дисперсий| Levene Statistic | df1 | df2 | Sig. |
| 2.282 | 4 | 666 | 0.059 |
Oneway, сравнение среднего промедианного логарифма доходов.
Таблица 4.10. Oneway, сравнение среднего промедианного логарифма доходов.| N | Mean | Std. Deviation | Std. Error | 95% Confidence Interval for Mean | Minimum | Maximum | ||
| Lower Bound | Upper Bound | |||||||
| 1.00 Высшее | 251 | 0.048 | 0.511 | 0.032 | -0.016 | 0.111 | -1.050 | 2.015 |
| 2.00 н/высш | 37 | -0.248 | 0.606 | 0.100 | -0.450 | -0.046 | -1.386 | 1.099 |
| 3.00 ср спец | 220 | 0.009 | 0.479 | 0.032 | -0.055 | 0.073 | -1.386 | 1.740 |
| 4.00 среднее | 130 | -0.093 | 0.619 | 0.054 | -0.200 | 0.015 | -2.254 | 1.504 |
| 5.00 ниже сред. | 33 | -0.107 | 0.530 | 0.092 | -0.295 | 0.081 | -0.916 | 1.099 |
| Total | 671 | -0.016 | 0.534 | 0.021 | -0.057 | 0.024 | -2.254 | 2.015 |
Описательные статистики, полученные при расщеплении данных для сравнения групп
Таблица 2.2. Описательные статистики, полученные при расщеплении данных для сравнения групп| V8 Пол | N | Minimum | Maximum | Mean | Std. Deviation | |
| 1 муж. | V9 Возраст | 354 | 16.0 | 76.0 | 39.6 | 13.0 |
| V14 Ср.мес. душевой доход | 341 | 21.0 | 1254.0 | 237.9 | 168.2 | |
| Valid N (listwise) | 335 | |||||
| 2 жен. | V9 Возраст | 344 | 16.0 | 74.0 | 39.5 | 12.2 |
| V14 Ср.мес. душевой доход | 324 | 50.0 | 1500.0 | 219.8 | 132.8 | |
| Valid N (listwise) | 317 |
SORT CASES BY v8 .
SPLIT FILE SEPARATE BY v8 .
Descriptives Variables= v9 v14.
будут получены две отдельные таблицы.
Таблица показывает, что преобладает
Таблица 5.16 показывает, что преобладает уменьшение веса, что подтверждается наблюдаемой значимостью статистики критерия, равной 0.00053 (таблица 5.17).Таблица показывает, что уравнение
Таблица 5.1 показывает, что уравнение объясняет всего 4.5% дисперсии зависимой переменной (коэффициент детерминации R2=.045), скорректированная величина коэффициента равна 0.042, а коэффициент множественной корреляции равен 0.211. Много это или мало, трудно сказать, поскольку у нас нет подобных результатов на других данных, но то, что здесь есть взаимосвязь, можно понять, рассматривая таблицу 6.2.Покупка алкоголя и табачных
Таблица 3.10. Покупка алкоголя и табачных изделий и наличие крупной собственности (фрагмент таблицы сопряженности, частоты и % по строкам)
Z-статистики в таблице 3.11 показывают значимость связей некоторых ответов. Однако множественные сравнения не позволяют полностью доверять этим результатам.
Таблица получена в результате
Таблица 3.4 получена в результате преобразования данных и применения процедуры CROSSTABS с параметром CELLS:recode v4 (1,2=1)(3=2)(4=3) into W4.
var lab W4 "Возможность удовлетворить территориториальные требования Японии".
Val lab W4 1 "отдать" 2 "не надо" "не знаю".
CROSSTABS /TABLES = v1 BY W4 /CELLS= COUNT ROW col.
Верхний процент в клетке соответствует отношению абсолютного числа объектов, попавших в эту клетку, к итоговой сумме по строке. Нижний процент соответствует отношению значения клетки к итоговой сумме по столбцу. По величине процентов, приведенных в клетках, можно сравнивать группы респондентов по распределению как по "вертикальной" переменной, так и по "горизонтальной".
В частности, анализируя первую строку матрицы (она соответствует ответам тех респондентов, которые считают, что иностранная помощь не нужна), видим, что основная часть - 81.7% этой группы респондентов против передачи островов Японии. При этом их доля среди тех, кто против передачи островов, составляет всего 27.2%; а основная часть (62.0%) противников передачи островов допускает возможность получения ограниченной иностранной помощи. В последнем столбце таблицы расположены итоги по каждой строке, которые совпадают с распределением по переменной V1. Так как до выполнения команды CROSSTABS, были объявлены неопределенные значения v1 и v4, таблица рассчитывалась без их учета, поэтому объем выборки, учтенный в таблице, составил 712 анкет из 721 имеющихся. Аналогичные данные приведены в строке TOTAL для столбцов.
Проценты в Crosstabs позволяют изучать взаимосвязь переменных, а не только структуру таблицы. В частности, сравнивая строки, можно сделать заключение, что более склонны отдать острова те, кто считает, что нужна помощь восточным регионам (37%), чем те, кто считает, что помощи не нужно. Можно взять в качестве точки отсчета распределение в целом по совокупности (15% всего готовы отдать все или часть островов в среднем по массиву).
Таблица , полученная по совокупности
Таблица 3.10, полученная по совокупности городских семей (подвыборка из RLMS 2604 семей), показывает такую связь. В таблице строки соответствуют ответам по одному, столбцы - ответам по другому вопросу, отличие от обычной таблицы частот только в том, что группы объектов (семей), соответствующие разным ответам, могут пересекаться.Явно видно, что в семьях, владеющих крупной собственностью, употребляют больше алкоголя и табака (может быть, сказывается наличие в них большего числа мужчин?). Однако, насколько надежен этот вывод? Особенно для группы владельцев грузового автомобиля - уж слишком мала эта группа для надежных выводов.
Проверка лог-нормальности распределения доходов
Таблица 5.6. Проверка лог-нормальности распределения доходов| LNV14 | ||
| N | 673 | |
| Normal Parameters | Mean | 5.2812 |
| Std. Deviation | 0.5344 | |
| Most Extreme Differences | Absolute | 0.098 |
| Positive | 0.098 | |
| Negative | -0.055 | |
| Kolmogorov-Smirnov Z | 2.54 | |
| Asymp. Sig. (2-tailed) | 0 |
Иногда бывает необходимо проверить законы распределения не предусмотренные в NPAR TESTS. В этом случае вспомните, что распределение непрерывной случайной величины h =Fx (x ), где F - функция распределения x , равномерно на отрезке (0,1). Таким образом, воспользовавшись статистическими функциями преобразования данных SPSS, из тестируемой переменной можно всегда получить переменную, имеющую теоретически равномерное распределение и проверив, действительно ли ее распределение равномерно, принять или отвергнуть гипотезу о виде распределения Fx (x).
Проверка нормальности распределения доходов с использованием критерия Колмогорова-Смирнова.
Таблица 5.5. Проверка нормальности распределения доходов с использованием критерия Колмогорова-Смирнова.| V14 Душевой доход в семье | ||
| N | 673 | |
| Normal Parameters | Mean | 229.11 |
| Std. Deviation | 151.34 | |
| Most Extreme Differences | Absolute | 0.187 |
| Positive | 0.187 | |
| Negative | -0.149 | |
| Kolmogorov-Smirnov Z | 4.85 | |
| Asymp. Sig. (2-tailed) | 0 |
Например, проверим нормальности распределения доходов командой:
NPAR TESTS K-S(NORMAL) = V14.
Поскольку двусторонняя значимость в таблице 5.5 (2-tailed P) равна нулю, то можем сделать вывод, что полученная разность фиксирует существенное отличие распределения по доходам от нормального. Во многих исследованиях используется вместо дохода используется его логарифм, распределение которого считается близким к нормальному. Проверим нормальность логарифма доходов:
compute lnv14=ln(v14).
npar test k-s(normal)=w14.
Распределение переменной
Таблица 3.3. Распределение переменной "Точка зрения на иностранную помощь" в разрезе региона и пола респондентов.| V1 точка зр. на иностр. Помощь | ||||||||
| V8 Пол | Не нужна | огранич. | Нужна | не знаю | Total | |||
| Муж. | R регион | Дальн В | Count | 25 | 91 | 22 | 7 | 145 |
| % | 17.2 | 62.8 | 15.2 | 4.8 | 100 | |||
| Вост сиб | Count | 25 | 56 | 13 | 1 | 95 | ||
| % | 26.3 | 58.9 | 13.7 | 1.1 | 100 | |||
| Зап Сиб | Count | 38 | 65 | 13 | 3 | 119 | ||
| % | 31.9 | 54.6 | 10.9 | 2.5 | 100 | |||
| Total | Count | 88 | 212 | 48 | 11 | 359 | ||
| % | 24.5 | 59.1 | 13.4 | 3.1 | 100 | |||
| жен. | R регион | Дальн В | Count | 26 | 87 | 9 | 6 | 128 |
| % | 20.3 | 68.0 | 7.0 | 4.7 | 100 | |||
| Вост сиб | Count | 23 | 54 | 6 | 7 | 90 | ||
| % | 25.6 | 60.0 | 6.7 | 7.8 | 100 | |||
| Зап Сиб | Count | 40 | 75 | 9 | 7 | 131 | ||
| % | 30.5 | 57.3 | 6.9 | 5.3 | 100 | |||
| Total | Count | 89 | 216 | 24 | 20 | 349 | ||
| % | 25.5 | 61.9 | 6.9 | 5.7 | 100 | |||
Если мы хотим получить в одной команде CROSSTABS несколько независимых таблиц, то следует отделять списки переменных символом "/":.
CROSSTABS V8 V11 BY V4 V1/ V12 BY V1/cells row.
Распределение по переменной V- точка зрения на иностранную помощь
Таблица 3.1. Распределение по переменной V1 - точка зрения на иностранную помощь| Frequency | Percent | Valid Percent | Cumulative Percent | ||
| Valid | 1 не нужна | 177 | 24.5 | 24.7 | 24.7 |
| 2 огранич. | 433 | 60.1 | 60.5 | 85.2 | |
| 3 нужна | 73 | 10.1 | 10.2 | 95.4 | |
| 4 не знаю | 33 | 4.6 | 4.6 | 100 | |
| Total | 716 | 99.3 | 100 | ||
| Missing | 0 | 5 | 0.7 | ||
| Total | 721 | 100 |
MISSING VALUES V1(0).
FREQUENCIES V1 /BARCHART .
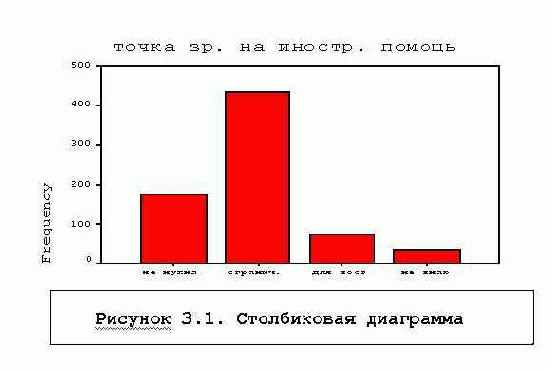 В колонке "Percent" проценты даны относительно всего объема выборки с учетом неопределенных кодов. В колонке "Valid Percent" приведены проценты в выборке без неопределенных кодов. В колонке "Cum Percent" - суммарный процент с нарастающим итогом. Суммарный процент не учитывает неопределенные коды, т.е. дается для выборки без объектов с неопределенными значениями. В данном примере была предусмотрена обработка неопределенных пользовательских значений, заданных нулевым кодом (5 респондентов из 721 не ответили на первый вопрос и были закодированы при наборе данных "0"). Наиболее распространенным (433 ответа) было мнение, что островам нужна ограниченная иностранная помощь. Кроме того, на данном примере можно наблюдать, насколько важно в практической работе использовать VAR LAB и VAL LAB - команды присвоения признакам текстовых имен.
В колонке "Percent" проценты даны относительно всего объема выборки с учетом неопределенных кодов. В колонке "Valid Percent" приведены проценты в выборке без неопределенных кодов. В колонке "Cum Percent" - суммарный процент с нарастающим итогом. Суммарный процент не учитывает неопределенные коды, т.е. дается для выборки без объектов с неопределенными значениями. В данном примере была предусмотрена обработка неопределенных пользовательских значений, заданных нулевым кодом (5 респондентов из 721 не ответили на первый вопрос и были закодированы при наборе данных "0"). Наиболее распространенным (433 ответа) было мнение, что островам нужна ограниченная иностранная помощь. Кроме того, на данном примере можно наблюдать, насколько важно в практической работе использовать VAR LAB и VAL LAB - команды присвоения признакам текстовых имен. В процедуре FREQUENCIES полезно использовать следующие необязательные параметры:
/BARCHART - столбиковая диаграмма
/PIECHART - круговая диаграмма
/HISTOGRAM - гистограмма
/NTILES - n-тили (квартили, квинтили, децили и др.)
/PERCENTILES - процентили
/STATISTICS
Результаты однофакторного дисперсионного анализа
Таблица 4.9. Результаты однофакторного дисперсионного анализа| Sum of Squares | df | Mean Square | F | Sig. | ||
| LNV14M Логарифм душевого дохода * V11 Cостояние в браке | Between Groups | 0.40 | 3 | 0.13 | 0.465 | 0.707 |
| Within Groups | 188.51 | 650 | 0.29 | |||
| Total | 188.92 | 653 |
Таблица содержит сведения об информативности
Таблица 7.1 содержит сведения об информативности полученных главных компонент. Первый фактор объясняет часть общей дисперсии, равную 2.402 (40.04%), фактор 2 - 1.393 (23.21%), третий - .853 (14.22%) и т.д. Первые два фактора объясняют 63.25% дисперсии, первые три - 77.47%. Поскольку уже третья компонента объясяет менее 1 дисперсии, рассматривается всего 2 фактора - какой смысл рассмативать факторы, объясняющие меньше дисперсии, чем переменная из исходых данных?Матрица факторных нагрузок факторов - главных компонент представлена в таблице 7.2. Мы не будем анализировать эту матрицу, а ниже подробнее проанализируем факторные нагрузки после вращения (таблица 7.3).
Среднемессячный душевой доход в семье
Таблица 4.8. Среднемессячный душевой доход в семье| V11 Cостояние в браке | V8 Пол | Mean | Std. Deviation | Median | N |
| 1 женат | 1 муж. | 228.4 | 152.9 | 200 | 271 |
| 2 жен. | 225.7 | 140.8 | 200 | 242 | |
| Total | 227.1 | 147.2 | 200 | 513 | |
| 2 вдовец | 1 муж. | 276.0 | 111.0 | 270 | 5 |
| 2 жен. | 192.8 | 112.7 | 155 | 20 | |
| Total | 209.4 | 115.1 | 168 | 25 | |
| 3 разведен | 1 муж. | 331.9 | 230.0 | 295 | 16 |
| 2 жен. | 195.9 | 86.1 | 180 | 25 | |
| Total | 249.0 | 169.7 | 200 | 41 | |
| 4 не был | 1 муж. | 263.3 | 223.0 | 200 | 41 |
| 2 жен. | 212.2 | 118.6 | 200 | 34 | |
| Total | 240.2 | 183.9 | 200 | 75 | |
| Total | 1 муж. | 238.4 | 167.8 | 200 | 333 |
| 2 жен. | 219.9 | 133.4 | 200 | 321 | |
| Total | 229.3 | 152.0 | 200 | 654 |
Мы можем сколько угодно описывать эту таблицу, но описание не будет доказательством какой-либо истины, пока оно не подтверждено статистическим выводом. Такая таблица может быть источником гипотез о взаимосвязи, которые в дальнейшем следует проверить.
Одномерноый дисперсионный анализ здесь проводится только по переменным первого уровня задания групп.
Напомним, что суть этого анализа состоит в вычислениии межгруппового квадратичныого разброса зависимой переменной SSв (Between groups) и внутригруппового разброса, обозначается SSw (Within groups). Величина SSв характеризует, насколько сильно отклонились от общего среднего средние между группами, а SSw - отклонения от центров групп. Статистика
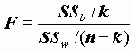 в условиях гипотезы равенства средних и дисперсий распределения при нормальном распределении X в группах имеет распределение Фишера. F представляет собой в определенном смысле расстояние наблюдаемой от таблицы, в которой нет никаких зависимостей - средние в группах совпадают.
в условиях гипотезы равенства средних и дисперсий распределения при нормальном распределении X в группах имеет распределение Фишера. F представляет собой в определенном смысле расстояние наблюдаемой от таблицы, в которой нет никаких зависимостей - средние в группах совпадают.
юЕН ВПМШЫЕ F, ФЕН УХЭЕУФЧЕООЕЕ ЪБЧЙУЙНПУФШ, ПДОБЛП УБНБ РП УЕВЕ ЧЕМЙЮЙОБ F ОЙ П ЮЕН ОЕ ЗПЧПТЙФ. пФЧЕФ ОБ ЧПРТПУ ДБЕФ, ЛБЛ ПВЩЮОП, ЧЕМЙЮЙОБ ОБВМАДБЕНПК ЪОБЮЙНПУФЙ F - ЛТЙФЕТЙС: SIGNIFICANCE - ЧЕТПСФОПУФШ УМХЮБКОП РПМХЮЙФШ ЪОБЮЕОЙЕ F, ВПМШЫЕЕ ЧЩВПТПЮОПЗП SIG=P{F>FЧЩВ}.
еЭЕ ТБЪ ПВТБФЙН ЧОЙНБОЙЕ ОБ ФП, ЮФП Ч ФБЛПН БОБМЙЪЕ ЙУРПМШЪХЕФУС РТЕДРПМПЦЕОЙЕ П ОПТНБМШОПУФЙ ТБУРТЕДЕМЕОЙС ЪБЧЙУЙНПК РЕТЕНЕООПК. оЕ УМЕДХЕФ РТПЧПДЙФШ ОЕРПУТЕДУФЧЕООП ДЙУРЕТУЙПООЩК БОБМЙЪ РЕТЕНЕООЩИ У УХЭЕУФЧЕООП ПФМЙЮБАЭЙНУС ПФ ОПТНБМШОПЗП ТБУРТЕДЕМЕОЙЕН. оБРТЙНЕТ, РЕТЕНЕООХА "ДХЫЕЧПК ДПИПД"
ч ФБВМЙГЕ4.9. РТЙЧЕДЕОБ ЧЩДБЮБ ПДОПНЕТОПЗП ДЙУРЕТУЙПООПЗП БОБМЙЪБ РПУМЕ ЧЩРПМОЕОЙС ЛПНБОДЩ
MEANS TABLES=lnv14m BY v11 BY v8 /STATISTICS ANOVA .
оБВМАДБЕНЩК ХТПЧЕОШ ЪОБЮЙНПУФЙ 0.707 УЧЙДЕФЕМШУФЧХЕ П ФПН, ЮФП ОБ ОБЫЙИ ДБООЩИ ХЛБЪБООЩН НЕФПДПН УЧСЪШ ОЕ ПВОБТХЦЙЧБЕФУС.
средних. Молочные продукты
Таблица средних. Молочные продукты и жилплощадь. Душевой доход любителей сладкого и жилье. Одновременное сравнение средних по строкам таблицы.
Душевой доход любителей сладкого и жилье. Одновременное сравнение средних по строкам таблицы.Средний логарифм доходов
Таблица 3.15. Средний логарифм доходов в группах по жилищным условиям и по покупкам сладкого (среднее, стд.отклонение, численность в группах).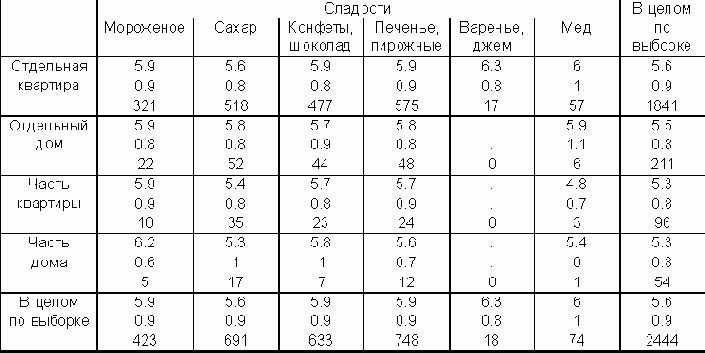
Средний возраст в группах
Таблица 3.9. Средний возраст в группах по ответам на вопрос 3 "Что мешает заключить договор" для мужчин и женщин.| Возраст | |||||||
| Пол | Total | ||||||
| 1 муж. | 2 жен. | Mean | Valid N | ||||
| Mean | Valid N | Mean | Valid N | ||||
| $V3 | 1 нет необх | 38.0 | 38 | 40.5 | 22 | 38.9 | 60 |
| 2 недоверие | 45.4 | 41 | 44.0 | 45 | 44.7 | 86 | |
| 3 незаинт Яп | 37.4 | 32 | 36.5 | 56 | 36.8 | 88 | |
| 4 разн полит | 39.8 | 41 | 36.5 | 30 | 38.4 | 71 | |
| 5 непризн гр | 39.8 | 163 | 40.8 | 151 | 40.2 | 314 | |
| 6 нежел СССР | 38.2 | 82 | 39.3 | 61 | 38.7 | 143 | |
| 7 другое | 38.6 | 5 | 44.3 | 3 | 40.8 | 8 | |
| 8 не знаю | 35.0 | 24 | 36.5 | 53 | 36.0 | 77 | |
| Total | 39.4 | 426 | 39.5 | 421 | 39.4 | 847 |
Пример. Синтаксис задания расчета среднего возраста в группах по ответам на вопрос 3 "Что мешает заключить договор" для мужчин и женщин имеет следующий вид:
* General Tables.
TABLES /OBSERVATION= v9 /MRGROUP $v3 v3s1 to v3s8
/GBASE=CASES /FTOTAL= $t000001 "Total" $t000003 "Total"
/TABLE=$v3 + $t000001 BY v8 > (STATISTICS) + $t000003 BY v9
/STATISTICS mean(v9(COMMA7.1)) validn(v9(COMMA5.0)).
Результат представлен таблицей 3.9. Самая "старая" группа - те, кто считает, что мешает взаимное недоверие, как для респондентов мужского пола, так и для женского. К сожалению, насколько это отличие статистически значимо, выяснить по полученной таблице невозможно.
Обратите внимание, что общая сумма здесь - 847 ответов, на 135 больше, чем объектов в выборке. Это произошло из-за того, что один респондент может дать несколько ответов.
Команда Multiple Response Tables, по сути, несколько облегченный вариант Gentral Tables.
Средняя зарплата по децилям.
Таблица 6.5. Средняя зарплата по децилям.| WAGE децили зарплаты | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| DJ10 зарплата за 30 дней | 101 | 211 | 307 | 416 | 542 | 703 | 853 | 1108 | 1565 | 3464 |
recode wage (1=1.01) (2=2.11) (3=3.07) (4=4.16) (5=5.42) (6=7.03) (7=8.53) (8=11.08) (9=15.65) (10 =34.64).
recode dj6.0 (sysmis=4)(1 thru 5=1)(6 thru 10=2) (10 thru hi=3) into manag.
var lab manag "статус" wage "зaработок".
val lab manag 4 "не начальник" 1 "шеф" 2 "начальничек" 3 "начальник".
exec.
Далее формируем переменную manag - " статус" из переменной dj6.0 - количество подчиненных.
Запускаем команду построения регрессии LOGISTIC REGRESSION, в которой использованы переменные wage - зарплата, manag статус, dh5 - пол (1 мужчины, 2 женщины) smoke - курение (1 курит, 0 не курит), dh5* wage - "взаимодействие" пола с зарплатой (для женщин значение - 0, для мужчин - совпадает с зарплатой).
LOGISTIC REGRESSION VAR=alcohol /METHOD=ENTER wage manag dh5 smoke dh5*wage /CONTRAST (dh5)=Indicator /CONTRAST (manag)=Indicator /CONTRAST (smoke)=Indicator /PRINT=CI(95) /CRITERIA PIN(.05) POUT(.10) ITERATE(20) CUT(.69) .
В выдаче программа, прежде всего, сообщает о перекодировании данных:
Dependent Variable Encoding:
Original Internal
Value Value
.00 0
1.00 1
Следует обратить внимание, что зависимая переменная здесь должна быть дихотомической, и ее максимальный код считается кодом события, вероятность которого прогнозируется. Например, если Вы закодировали переменную ALCOHOL 1-употреблял, 2-не употреблял, то будет прогнозироваться вероятность не употребления алкоголя.
Далее идут сведения о кодировании индексных переменных для категориальных переменных; из-за их естественности мы их здесь не приводим.
Далее следуют обозначения для переменных взаимодействия, в нашем простом случае это:
Interactions:
INT_1 DH5(1) by WAGE
Средняя жилплощадь в группах семей по покупкам молочных продуктов.
Таблица 3.13. Средняя жилплощадь в группах семей по покупкам молочных продуктов.
Узнать это, определить, какое смещение значимо, а какое - нет, помогут множественные сравнения Z-статистик отклонения средних в клетках от среднего по всей совокупности (см. таблицу 5). В ней выделена единственная значимая на 5% уровне клетка, показывающая относительно малую обеспеченность жилплощадью покупателей кисломолочных продуктов (скорее всего, эти покупатели - из молодых семей с детьми). Абсолютная величина ее значения (-2.87) случайно может быть перекрыта лишь с вероятностью 0.029 (наблюдаемая множественная значимость равна 2.9%).
Статистика хи-квадрат
Анализируя таблицу 5.1, уже по отклонениям расчетных значений от ожидаемых (см. столбец RESIDUAL), видим, что эмпирическое распределение сильно отличается от теоретического. Достаточно высокое значение критерия (Chi-Square =8.333, таблица 5.2) мало информативно. Ответ о совпадении нашего распределения с теоретическим заключен в анализе наблюдаемого уровня значимости. Его малая величина (Asymp. Sig.=0.016) показывает, что полученные отклонения значимы: вероятность получить большие значения Хи-квадрат равна 1.6%, гипотеза о соответствии выборки указанной генеральной совокупности может быть отвергнута на уровне значимости 5%.
Таким образом, для данного случая тест показал существенное различие теоретического и эмпирического распределений.
Приведем пример применения метода статистического моделирования Монте-Карло. В этом примере производится 100000 экспериментов по моделированию выборки из генеральной совокупности с заданными вероятностями (p1=0.3, p2=0.3, p3=0.4):
NPAR TEST /CHISQUARE=w9 /EXPECTED=3 3 4 /METHOD=MC CIN(99) SAMPLES(100000).
Естественно при такой большой выборке был получен тот же результат (таблица 5.3). Уровень значимости этим методом оценивается приближенно, на основе статистических экспериментов - чем больше экспериментов, тем точнее. Поскольку оценка значимости получена на основе случайных экспериментов, выдается доверительный интервал для уровня значимости (99%-й по умолчанию). Точечная оценка наблюдаемого уровня значимости (Monte Carlo Sig) совпадает с асимптотической оценкой (Asymp. Sig., табл.5.3), "оптимистическая" нижняя граница равна 0.015, "пессимистическая" верхняя - 0.017. Таким образом, со всех точек зрения отклонение распределения значимо.
Статистики по переменной V - "Душевой доход", выданные командой FREQUENCIES
Таблица 3.2. Статистики по переменной V14 - "Душевой доход", выданные командой FREQUENCIES| N | Valid | 673 |
| Missing | 48 | |
| Mean | 229.11 | |
| Std. Error of Mean | 5.83 | |
| Median | 200 | |
| Mode | 200 | |
| Std. Deviation | 151.342 | |
| Variance | 22904.531 | |
| Skewness | 3.035 | |
| Std. Error of Skewness | 0.094 | |
| Kurtosis | 15.080 | |
| Std. Error of Kurtosis | 0.188 | |
| Range | 1479 | |
| Minimum | 21 | |
| Maximum | 1500 | |
| Sum | 154190 | |
| Percentiles | 10 | 100 |
| 25 | 140 | |
| 50 | 200 | |
| 75 | 280 | |
| 90 | 400 |
Перечисленные статистики играют в анализе данных особую роль - они позволяют провести первый этап статистических исследований выборки, проверить нормальность ее распределения. Ниже приведен пример описательных статистик, полученных для переменной "Среднемесячный душевой доход в семье", построенной по ответам на 14-й вопрос анкеты "Курильские острова" командой
FREQUENCIES VARIABLES=V14 /NTILES=4 /PERCENTILES= 10 90
/STATISTICS=STDDEV VARIANCE RANGE MINIMUM MAXIMUM SEMEAN MEAN MEDIAN MODE SUM SKEWNESS SESKEW KURTOSIS SEKURT .
которая вычисляет, также, n-тили и процентили.
Анализируя полученные данные (таблица 3.2), видим, что доход в семьях меняется в диапазоне от 21 рубля до 1500 рублей (разброс равен 1479). При этом средний доход составил около 230 рублей. Приближенными границами пятипроцентного доверительного интервала для истинного среднего будут значения: 229.11± 1.96*5.83, где 1.96 - критическое значение нормального распределения для p=0.05/2=0.025. Скошенность skewness=3.035 Пикообразность kurtosis=15.080 и пикообразность kurtosis=15.080 значительно больше нуля (их стандартные ошибки, 0.094 и 0.188, свидетельствуют о статистической значимости такого отличия).
Результатом задания процентилей и n-тилей являются выданные в таблице процентили (у 10% выборки доход меньше 100 руб., у 90% - меньше 400; имеются также 25%, 50%, 75% процентили).
Связь наблюдения и предсказания в логистической регрессии
Таблица 6.6. Связь наблюдения и предсказания в логистической регрессии| Наблюдается | Предсказано | ||
| Не пьет | Пьет | Всего | |
| Не пьет | 43.8% | 21.5% | 31.3% |
| Пьет | 56.2% | 78.5% | 68.7% |
Связь "Точки зрения на
Таблица 3.4. Связь "Точки зрения на иностранную помощь" и "Возможн. удовлетворить территор. требований Японии" (частоты и проценты)| V1 точка зрения на иностранную помощь | V4 Возможность удовлетворить территориториальные требования Японии | Total | |||
| 1 отдать | 2 не надо | 3 не знаю | |||
| не нужна | Count | 21 | 143 | 11 | 175 |
| % row | 12.0 | 81.7 | 6.3 | 100.0 | |
| % col | 19.6 | 27.2 | 13.9 | 24.6 | |
| огранич. | Count | 57 | 326 | 48 | 431 |
| % row | 13.2 | 75.6 | 11.1 | 100.0 | |
| % col | 53.3 | 62.0 | 60.8 | 60.5 | |
| Нужна | Count | 27 | 32 | 14 | 73 |
| % row | 37.0 | 43.8 | 19.2 | 100.0 | |
| % col | 25.2 | 6.1 | 17.7 | 10.3 | |
| не знаю | Count | 2 | 25 | 6 | 33 |
| % row | 6.1 | 75.8 | 18.2 | 100.0 | |
| % col | 1.9 | 4.8 | 7.6 | 4.6 | |
| Total | Count | 107 | 526 | 79 | 712 |
| % row | 15.0 | 73.9 | 11.1 | 100.0 | |
| % col | 100.0 | 100.0 | 100.0 | 100.0 | |
В таблице 3.5 получен ответ на поставленный в начале раздела вопрос: смещение частоты в клетке "Отдать острова" - "Нужна помощь" (residual=16) оказалось существенным, Z=5.5, в то же время смещение частоты на 5.3 в клетке "помощь не нужна - отдать" - не значимо (Z=1.3). Кроме того, в полученной значимой связи можно еще раз убедиться, рассмотрев таблицу 6 с процентными распределениями (в среднем по совокупности 15% считают, что острова можно отдать, в то время как в этой группе таковых 37%!). В то же время, судя по статистикам, хотя видна отрицательная связь значений "нужна ограниченная помощь" - "отдать острова", она не достаточно значима.
Надеемся, что нам удалось показать, что эти статистики наиболее интересны для интерпретации. К сожалению, в SPSS расчет
реализован без учета размеров выборки, что необходимо иметь в виду, так как для малых выборок эти вероятностные рассуждения оказываются неточными.T-тест на связанных выборках, корреляции
Таблица 4.6. T-тест на связанных выборках, корреляции| N | Correlation | Sig. | |
| AM1 Вес 1995 & BM1 Вес 1996 | 793 | 0.914 | 0.0000 |
T-тест на связанных выборках, описательные статистики
Таблица 4.5. T-тест на связанных выборках, описательные статистики| Mean | N | Std. Deviation | Std. Error Mean | |
| AM1 Вес 1995 | 67.59 | 793 | 13.72 | 0.49 |
| BM1 Вес 1996 | 68.12 | 793 | 14.22 | 0.50 |
T-тест на связанных выборках, сравнение средних
Таблица 4.7. T-тест на связанных выборках, сравнение средних| Paired Differences Mean | Std. Deviation | Std. Error Mean | 95% Confidence Interval of the Difference | t | Df | Sig. (2-tailed) | ||
| Lower | Upper | |||||||
| AM1 Вес 1995 & BM1 Вес 1996 | -0.53 | 5.81 | 0.21 | -0.93 | -0.12 | -2.547 | 792 | 0.011 |
T-тест, описательные статистики по группам
Таблица 4.3. T-тест, описательные статистики по группам| V9 Возраст | N | Mean | Std. Deviation | Std. Error Mean | |
| LNV14M | >= 30 | 521 | 0.019 | 0.517 | 0.023 |
| < 30 | 133 | -0.177 | 0.593 | 0.051 |
T-тест, сравнение средних и дисперсий в группах
Таблица 4.4. T-тест, сравнение средних и дисперсий в группах| Levene's Test for Equality of Variances | T | Df | Sig. (2-tailed) | Mean Difference | Std. Error Difference | 95% Confidence Interval of the Difference | |||
| F | Sig. | ||||||||
| Lower | Upper | ||||||||
| Equal variances assumed | 2.47 | 0.1162 | 3.78 | 652 | 0.000 | 0.196 | 0.052 | 0.094 | 0.298 |
| Equal variances not assumed | 3.48 | 186.42 | 0.001 | 0.196 | 0.056 | 0.085 | 0.307 | ||
Tест Фридмана. Средние ранги.
Таблица 5.18. Tест Фридмана. Средние ранги.| Mean Rank | |
| AM1 вес в 1994г. | 2 |
| BM1 вес в 1995г. | 2.13 |
| CM1 вес в 1996г. | 1.87 |
Tест Фридмана. Значимость.
Таблица 5.19. Tест Фридмана. Значимость.| N | 15 |
| Chi-Square | 0.561 |
| Df | 2 |
| Asymp. Sig. | 0.755 |
Тест Хи-квадрат. *
Тест, основанный на биномиальном распределении *
Тест Колмогорова-Смирнова *
5.2. Тесты сравнения нескольких выборок *
Двухвыборочный тест Колмогорова-Смирнова *
Тест медиан *
5.3. Тесты для ранговых переменных *
Двухвыборочный тест Манна-Уитни (Mann-Witney)- *
Одномерный дисперсионный анализ Краскэла-Уоллиса (Kruskal-Wallis) *
5.4. Тесты для связанных выборок (related samples) *
Двухвыборочный критерий знаков (Sign) *
Двухвыборочный знаково-ранговый критерий Уилкоксона (Wilcoxon) *
Критерий Фридмана (Friedman) *
Тест Краскэла Уоллиса. Средние ранги.
Таблица 5.12. Тест Краскэла Уоллиса. Средние ранги.| TP тип поселен | N | Mean Rank | |
| V14 Ср.мес. душевой доход в семье | 1.00 растущие | 174 | 382 |
| 2.00 стабильные | 230 | 365.2 | |
| 3.00 крупные | 201 | 304.6 | |
| 4.00 гигант | 68 | 222.2 | |
| Total | 673 |
Тест Краскэла-Уоллиса. Значимость критерия.
Таблица 5.13. Тест Краскэла-Уоллиса. Значимость критерия.| V14 Ср.мес. душевой доход в семье | |
| Chi-Square | 43.702 |
| Df | 3 |
| Asymp. Sig. | 0 |
Тест знаков для парных наблюдений. Частоты
Таблица 5.14. Тест знаков для парных наблюдений. Частоты| Frequencies | ||
| N | ||
| BM1 вес в 1995г. - AM1 вес в 1994г. | Negative Differences | 877 |
| Positive Differences | 722 | |
| Ties | 350 | |
| Total | 1949 |
Таблица 5.15. Тест знаков для парных наблюдений. Значимость критерия.
| Test Statistics | |
| BM1 вес в 1995г. - AM1 вес в 1994г. | |
| Z | -3.8512 |
| Asymp. Sig. (2-tailed) | 0.000118 |
Тесты ХИ-квадрат
Таблица 3.6. Тесты ХИ-квадрат| Value | df | Asymp. Sig. (2-sided) | |
| Pearson Chi-Square | 10.517 | 3 | .015 |
| Likelihood Ratio | 10.708 | 3 | .013 |
| Linear-by-Linear Association | .156 | 1 | .693 |
| N of Valid Cases | 708 |
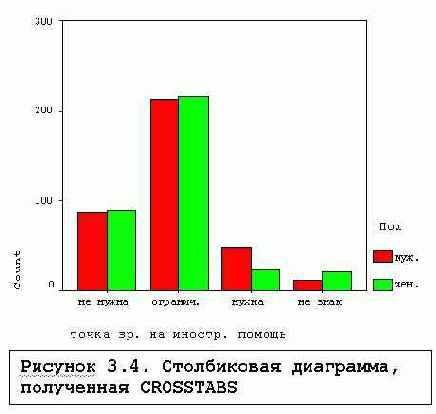 В приведенном примере наблюдаемая значимость CHISQ составила около 1.5% (см. Asymp. Sig. (2-sided)), значимость LI примерно 1.3%. С такой вероятностью случайно в условиях независимости можно получить большие значения соответствующих статистик, поэтому, в соответствии с 5% уровнем значимости, переменные v8 и v1 следует считать связанными (1.3%<5%). Таким образом, мужчины и женщины имеют разные мнения в вопросе об иностранной помощи.
В приведенном примере наблюдаемая значимость CHISQ составила около 1.5% (см. Asymp. Sig. (2-sided)), значимость LI примерно 1.3%. С такой вероятностью случайно в условиях независимости можно получить большие значения соответствующих статистик, поэтому, в соответствии с 5% уровнем значимости, переменные v8 и v1 следует считать связанными (1.3%<5%). Таким образом, мужчины и женщины имеют разные мнения в вопросе об иностранной помощи. Если теперь взглянуть на Z-статистики, можно увидеть, в клетке "мужчины" - "помощь нужна" эта статистика равна 2.9, и о помощи говорят вдвое больше мужчин, чем женщин. Мы не будем приводить здесь эту таблицу, а покажем лишь столбиковую диаграмму на Рисунок 3.4, полученную командой
ROSSTABS v8 by v4 /cells count row col asresid/BARCHART.
Z-статистики и значимость
Таблица 3.11. Z-статистики и значимость (%) связи покупки алкоголя и табачных изделий и наличие крупной собственности (фрагмент таблицы, Z-статистики)
В таблице 3.12 отмечены значимые с точки зрения множественнях сравнений Z-статистики. При этом оценка 5% критического значения Z равна 3.09, а не 1.96, как это было бы в обычном анализе.
В каждой клетке расположены также наблюдаемые множественные значимости. Например, Z статистика 6.46 в клетке "Легковой автомобиль - пиво" практически не может быть получена случайно (вероятность получить большее значение равна нулю), а связь, характеризуемая значением Z=2.84 в клетке "Другая квартира - водка" - под сомнением: такие и большие значения в одной из 28 клеток таблицы можно получить случайно с вероятностью 10.8%.
Z-статистики отклонений средних для таблицы ( множественное критическое значение равно ).
Таблица 3.14. Z-статистики отклонений средних для таблицы 4 (5% множественное критическое значение равно 2.69).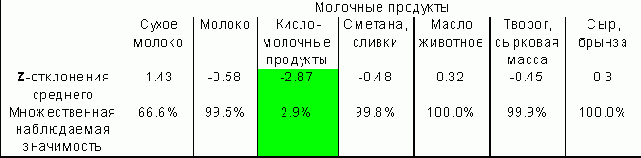
Таблица 3.16. Z-статистики отклонений средних для таблицы 6 (5% множественное критическое значение равно 3.1).
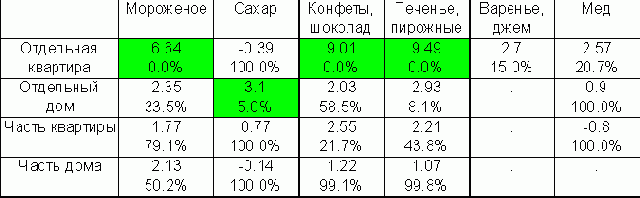
Таким образом, мы одновременно рассматриваем Z статистики для каждой группы и проводим множественные сравнения 21 смещения средних (покупателями джема и варенья оказались только жители отдельных квартир, поэтому для части клеток таблицы средние и, следовательно, Z-статистики их отклонений не определены). Способы определения значимости смещений в двумерной таблице и одномерной таблице средних идентичны, здесь также используется перемешивание данных по зависимой переменной.
На основании таблицы 3.16 можно достоверно утверждать, что среди обитателей отдельных квартир большие доходы имеют семьи любителей мороженого, конфет и печенья с пирожными; среди жильцов отдельных домов существенно выделяются по доходам семьи у покупателей сахара (только в 5% случаев в таблице случайно можно получить большие Z-статистики). В остальных клетках таблицы Z - статистики незначимы - либо отклонения несущественны, либо выборка маловата, чтобы делать надежные выводы.
Z-статистики отклонений
Таблица 3.12. Z-статистики отклонений частот и их наблюдаемая множественная значимость (в %, 5% критическое значение max|Zij|=3.09).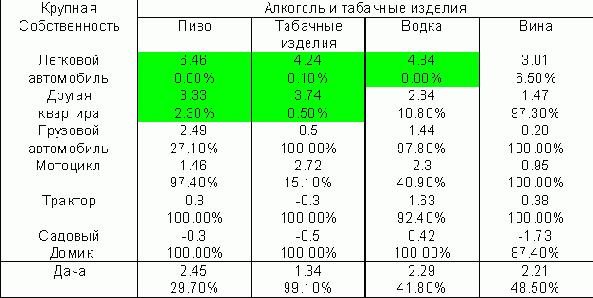
Значимость критерия хи-квадрат
Таблица 5.3. Значимость критерия хи-квадрат| W9 | |||
| Chi-Square | 8.333 | ||
| Df | 2 | ||
| Asymp. Sig. | 0.016 | ||
| Monte Carlo Sig | Sig. | 0.016 | |
| 99% Confidence Interval | Lower Bound | 0.015 | |
| Upper Bound | 0.017 |
Таблица 5.4. Значимость критерия хи-квадрат
| Category | N | Observed Prop. | Test Prop. | Asymp. Sig. (2-tailed) | Exact Sig. (2-tailed) | |
| Group 1 | 1 муж. | 362 | 0.508 | 0.5 | 0.708 | 0.708 |
| Group 2 | 2 жен. | 351 | 0.492 | |||
| Total | 713 | 1 |
Знаково-ранговый тест Вилкоксона. Средние ранги.
Таблица 5.16. Знаково-ранговый тест Вилкоксона. Средние ранги.| BM1 вес в 1995г. - AM1 вес в 1994г. | N | Mean Rank | Sum of Ranks | |
| Negative Ranks | 877 | 802.2 | 703500 | |
| Positive Ranks | 722 | 797.4 | 575700 | |
| Ties | 350 | |||
| Total | 1949 |
Таблица 5.17. Знаково-ранговый тест Вилкоксона. Средние ранги.
| BM1 вес в 1995г. - AM1 вес в 1994г. | |
| Z | -3.46504 |
| Asymp. Sig. (2-tailed) | 0.00053 |