Базы данных - разработка Основы баз данных Проектирование базы данных Базы данных - Разработка Управление базой данных Базы данных - СУБД Управление базой данных Базы данных - виды Базы данных - софт для разработки Базы данных - софт Язык SQL Access FoxPro Oracle Informix Линтер Postgres СУБД DB2 InterBase |

|
SQL - статьи
Изучение влияния числа пользователей
Для изучения влияния числа пользователей на изменение производительности СУБД рассмотрим результаты тестирования на сервере PROSERVER, обладающим наиболее мощными техническими характеристиками.Таблица 12
Анализ производительности СУБД и количество пользователей.
| Тест | U=1 | U=2 | U=3 | ||||||||||||||||
| D | P av | P max | D | P av | P max | D | P av | P max | |||||||||||
| Запрос №1 | |||||||||||||||||||
| MySQL 4.0.20 | 6290,2 ( ± 88,1) | 8,4 | 22,8 | 6217,0 ( ± 83,9) | 9,4 | 23,1 | 6831,3 ( ± 64,7) | 9,8 | 23,5 | ||||||||||
| MS SQL Server 7.0 SP4 | 19,8 ( ± 2,9) | 20,9 | 32 ,8 | 17,8 ( ± 1,9) | 3,4 | 16,4 | 18,2 ( ± 2,0) | 5,2 | 29,2 | ||||||||||
| MS SQL Server 2000 | 16,2 ( ± 0,9) | 6,4 | 15,3 | 16,2 ( ± 0,9) | 5,6 | 24,3 | 19,4 ( ± 2,8) | 13,3 | 27,7 | ||||||||||
| Запрос №2 | |||||||||||||||||||
| MySQL 4.0.20 | 196,4 ( ± 6,9) | 8,4 | 22,8 | 176,0 ( ± 7,9) | 9,4 | 23,1 | 164,7 ( ± 4,9) | 9,8 | 23,5 | ||||||||||
| MS SQL Server 7.0 SP4 | 17,0 ( ± 2,9) | 20,9 | 32,8 | 9,9 ( ± 2,6) | 3,4 | 16,4 | 24,5 ( ± 9,1) | 5,2 | 29,2 | ||||||||||
| MS SQL Server 2000 | 18,8 ( ± 3,3) | 6,4 | 15,3 | 26,0 ( ± 3,6) | 5,6 | 24,3 | 25,5 ( ± 2,8) | 13,3 | 27,7 | ||||||||||
| Запрос №3 | |||||||||||||||||||
| MySQL 4.0.20 | 116,2 ( ± 4,9) | 8,4 | 22,8 | 93,3 ( ± 4,9) | 9,4 | 23,1 | 85,8 ( ± 2,8) | 9,8 | 23,5 | ||||||||||
| MS SQL Server 7.0 SP4 | 5,3 ( ± 2,7) | 20,9 | 32,8 | 2,0 ( ± 1,9) | 3,4 | 16,4 | 6,3 ( ± 3,0) | 5,2 | 29,2 | ||||||||||
| MS SQL Server 2000 | 4,7 ( ± 2,6) | 6,4 | 15,3 | 5,2 ( ± 2,6) | 5,6 | 24,3 | 7,3 ( ± 2,8) | 13,3 | 27,7 |
Как видно из таблицы, достоверного снижения или увеличения производительности работы СУБД в зависимости от числа пользователей не отмечено. Вероятно, это объясняется искусственной природой запросов, а также высокой плотностью однотипного потока запросов к СУБД при многопользовательском режиме работы программы тестирования. Скорее всего, указанные особенности тестирования приводили к сильному влиянию кеширования результатов выполнения последних запросов, поэтому в ряде тестов отмечено даже снижение среднего времени выполнения запроса при увеличении числа пользователей. В условиях реальной работы пользователей с МИС вероятность появления одинакового запроса сразу от нескольких пользователей снижается практически до нуля. В связи с этим следует ожидать снижение эффекта влияние кеширования запросов совместно с увеличением числа пользователей. Достоверно (p=0,04 с U=1 до U=2, p=0,009 с U=2 до U=3) отмечено увеличение показателя средней загрузки процессора при увеличении числа пользователей. Менее достоверно (p=0,27) увеличивается показатель максимальной загрузки процессора при увеличении пользователей от 1 до 2. Однако уже при увеличении числа пользователей от 2 до 3 практически абсолютно достоверно (р=0,009) этот показатель увеличился.
В целом в ходе анализа результатов тестов следует отметить более экономный расход процессорных ресурсов СУБД MySQL по сравнению с СУБД MS SQL Server .
Microsoft SQL Server против MySQL в медицинских информационных системах
, к.т.н, ст. инженер-программист ОАО "Кондопога", инженер-программист ОАО "Кондопога"
Проектирование и разработка комплексной медицинской информационной системы (КМИС) – сложный, трудоемкий и дорогостоящий процесс. Известно, что в настоящее время в России себестоимость создания КМИС зачастую выше, чем реальная цена, по которой ее можно распространять. Поэтому поиск решений, снижающих сложность и трудоемкость процесса проектирования и практической разработки КМИС, является в настоящее время одной их приоритетных задач разработчиков, занятых в такой специфичной области, как медицина. Существует множество различных подходов для решения этой задачи, но пока говорить о безусловной приоритетности какого-то одного из них еще рано, т.к. комплексные информационные решения в медицинских учреждениях все еще являются скорее исключением, чем правилом. Остановимся на отдельном аспекте в проектировании КМИС, который, по нашему мнению, является основополагающим – это выбор системы управления базами данных (СУБД). Отметим, что, по нашим данным, с использованием СУБД на архитектуре «Клиент-Сервер» построено 71% всех известных нам медицинских информационных системы, эта доля продолжает увеличиваться.
На сегодня можно выделить 3 основных подхода в вопросе выбора СУБД:
1. КМИС разрабатывается на базе реляционной СУБД. Этот подход используется в подавляющем большинстве решений («Амулет», «Медкор-2000», « Medwork », «Дока+» и др.)
2. КМИС разрабатывается на базе пост-реляционной СУБД или объектно-ориентированной СУБД. Этот подход чаще всего используется при выборе СУБД Cache или Lotus Notes / Domino в качестве основы системы («Гиппократ», «MedTrak», «LabTrak»)
3. Объектно-реляционный подход. По нашему мнению [], это наиболее перспективное решение, учитывающее специфику предметной области и, вместе с тем, интегрирующее в себе все преимущества первых двух решений («Интерин», «ИС Кондопога»).
Выбор конкретной СУБД представляет собой сложную многопараметрическую задачу и является одним из важнейших этапов в разработке медицинской информационной системы. Выбранный программный продукт должен удовлетворять как текущим, так и будущим потребностям лечебно-профилактического учреждения (ЛПУ), при этом следует учитывать финансовые затраты на приобретение необходимого оборудования, самой системы, разработку необходимого программного обеспечения на ее основе, а также обучение персонала. [].
Очевидно, наиболее простой подход при выборе СУБД основан на оценке того, в какой мере существующие системы удовлетворяют основным требованиям создаваемого проекта информационной системы. Более сложным и дорогостоящим вариантом является создание испытательного проекта на основе нескольких СУБД и последующий выбор наиболее подходящего из кандидатов. Но, и в этом случае необходимо ограничивать круг возможных систем, опираясь на некие критерии отбора.
При разработке отечественных КМИС в основном применяются следующие СУБД: Oracle, IBM DB 2 и Informix, Borland Interbase Server, MS SQL Server, Cache, Lotus Notes / Domino, MySQL и некоторые другие. Преимущественно используется СУБД Microsoft SQL Server, чья доля составляет 62% (Рис. 1).
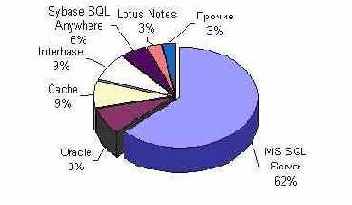
Рис. 1 . Соотношение СУБД на архитектуре «Клиент-сервер» в отечественных медицинских информационных системах
IBM и Oracle заслуженно считаются лидерами в области систем управления БД. Специалисты IBM первыми ввели понятие реляционных БД и разработали SQL. К достижениям Oracle (вне рынка мэйнфреймов) можно отнести выпуск первой коммерческой СУБД, поддерживающей SQL (1979), первой клиент-серверной версии (1987), первой 32-разрядной (1983) и 64-разрядной (1995) версий, а также первой коммерческой СУБД, перенесенной на Linux (1999) []. Вместе с тем, в медицинской предметной области все чаще предпочтение отдается Microsoft SQL Server, возможно в силу хорошей маркетинговой политике Microsoft и более простой процедуре установки и меньшей стоимости владения.
Практически все из перечисленных коммерческих СУБД являются достаточно дорогими программными продуктами. Их использование в процессе проектирования и разработки само по себе имеет значительную долю в себестоимости КМИС. Кроме того, наметившаяся в последнее время тенденция к повышению престижности и потребности в лицензионном программном обеспечении повышает общую стоимость внедрения КМИС. Это обусловлено тем, что еще пару лет назад главный врач ЛПУ, решившийся на внедрение КМИС у себя в клинике и обладающий определенной (при этом весьма ограниченной) суммой, решал главным образом два вопроса: какую КМИС выбрать и сколько необходимо компьютерной техники. Сейчас все чаще мы видим ситуацию, когда к этим двум вопросам добавляется третий: сколько необходимо лицензионного программного обеспечения?
Все вышесказанное является естественным стимулом для поиска более доступных по цене СУБД и обладающих, вместе с тем, достаточным запасом функциональности и производительности. И такое решение имеется – это использование в качестве платформы разработки КМИС продуктов Open Source, главным образом – СУБД MySQL (или ряда других, менее известных, но не менее доступных решений).
В связи с этим мы поставили себе целью на практике изучить двух наиболее ярких представителей СУБД и выяснить, какие преимущества и недостатки имеют коммерческие и свободно-распространяемые СУБД в медицинской предметной области. При этом в качестве образца коммерческой СУБД мы выбрали программное обеспечение Microsoft SQL Server версий 7.0 и 2000, а в качестве свободно-распространяемой СУБД мы выбрали MySQL версии 4.0.21.
Данное исследование выполнялось нами в течение 2004 г. на базе разработанной на основе объектно-реляционного подхода комплексной медицинской информационной системы "Кондопога". Основу системы составляет документно-ориентированное ядро, созданное на СУБД Lotus Domino . При этом небольшую часть системы, предназначенную для функционирования некоторых задач статистики и бухгалтерии, составляет реляционная база данных. Используется специально разработанная технология "вариабельного ядра" (http://iskondopoga.narod.ru/ sience/ files/ 2004/ auto_gus.pdf), в задачи которой входит автоматическое связывание и масштабирование интегрированной объектно-реляционной БД []. В качестве СУБД мы апробировали вначале MySQL, а затем Microsoft SQL Server. При этом для нас очень важным был обоснованный выбор какой-то конкретной СУБД, с необходимым обоснованием и анализом результатов практической эксплуатации обоих СУБД и оценкой результатов этих эксплуатаций. Для этого мы выполнили ряд специальных тестов, изучали удобство в развертывании, администрировании и эксплуатации, оценивали устойчивость и другие параметры.
В качестве сценария для оценки этих СУБД мы использовали статью А. Аносова «» []. В ней предлагается анализировать СУБД по ряду признаков, объединенных в общие разделы. На основе анализа этих признаков предлагается решать вопрос о приоритетности каждой конкретной СУБД для выбранной предметной области. Даже если просто отмечать, насколько хороши или плохи выделенные параметры в случае каждой конкретной СУБД, то сравнение уже двух различных систем является трудоемкой задачей. Тем не менее, четкий и глубокий сравнительный анализ на основании вышеперечисленных критериев в любом случае поможет рационально выбрать подходящую систему для конкретного проекта, и затраченные усилия не будут напрасными. Перечень критериев поможет осознать масштабность задачи и выполнить ее адекватную постановку
Рассмотрим результаты исследования. Для этого процитируем важнейшие из предложенных А.Аносовым показателей и прокомментируем их особенности для КМИС.
1. Триггеры и хранимые процедуры. Триггер – программа базы данных, вызываемая всякий раз при вставке, изменении или удалении строки таблицы. Триггеры обеспечивают проверку любых изменений на корректность, прежде чем эти изменения будут приняты. Хранимая процедура – программа, которая хранится на сервере и может вызываться клиентом. Поскольку хранимые процедуры выполняются непосредственно на сервере базы данных, обеспечивается более высокое быстродействие, нежели при выполнении тех же операций средствами клиента БД. В различных программных продуктах для реализации триггеров и хранимых процедур используются различные инструменты.
MySQL версии 4.0.21, в отличии от Microsoft SQL Server, не поддерживает ни триггеры, ни хранимые процедуры, что значительно усложняет ее использование, т.к. в приложениях системы большую часть необходимых проверок введенных данных и всевозможных блокировок, а также обеспечение целостности базы данных приходится выполнять на уровне клиентского приложения, что очень усложняет процесс создания и эксплуатации КМИС.
2. Особенности разработки приложений. Многие производители СУБД выпускают средства разработки приложений для своих систем. Как правило, эти средства позволяют наилучшим образом реализовать все возможности сервера, поэтому при анализе СУБД стоит рассмотреть также возможности средств разработки приложений.
Таблица 1
Особенности разработки приложений
| Показатель | MS SQL Server | MySQL |
| Визуальные средства проектирования | + | + |
| Многоязыковая поддержка | + | + |
| Возможности разработки web -приложений | + | + |
| Поддержка JAVA | + | |
| Встроенный язык программирования | + | |
| Data Mining | + |
3. Перечень операционных систем, под управлением которых способна работать СУБД. В этом разделе, безусловно, лидирует MySQL, которая способна работать на большинстве из имеющихся на настоящее время операционных систем. Некоторые из них имеют значительно более низкую стоимость, чем продукты фирмы Microsoft, что, конечно, ведет к снижению затрат при внедрении КМИС.
Таблица 2
Поддерживаемые операционные системы.
| Показатель | ОС |
| MS SQL Server | Windows NT,2000 (Intel и Alpha) |
| MySQL | Linux (x86, libc6,S/390,IA64, Alpha, Sparc), Windows 95/98/NT/2000/XP, Solaris 2.9 (Sparc, 64-bit, 32-bit), FreeBSD 4.x ELF (x86), Mac OS X v10.2, HP-UX 10.20 (RISC 1.0), HP-UX 11.11 (PA-RISC 1.1 или 2.0), AIX 5.1 (RS6000), QNX 6.2.0 (x86), Novell NetWare 6 (x86), SCO OpenUnix 8.0 (x86), м SGI Irix 6.5, Dec OSF 5.1 (Alpha) |
Как видно из таблицы ниже, а также по нашему опыту, требования к технической характеристике сервера у MySQL значительно ниже, чем у Microsoft SQL Server. За счет этого стоимость внедрения КМИС может быть в некоторой степени снижена.
Таблица 3
Минимальные требования к серверу.
| Показатель | ОС |
| MS SQL Server | Pentium II 350 MHz , ОЗУ – 128 Мбайт, HDD - 250 Мбайт |
| MySQL | Pentium 100 MHz , ОЗУ - 64 Мбайт (минимум), 100 Мбайт свободного места на диске |
Таблица 4
Примерная стоимость СУБД для 30 подключений
| Название СУБД | Цена, $ | Кол-во | Стоимость, $ |
| SQL Server 2000 Enterprise Edition English OpenLicensePack B * | 6643,97 | 1 | 6643,97 |
| SQL Server 2000 ClientAccessLicense English OpenLicensePack B* | 151,94 | 30 | 4558,2 |
| Всего на использование SQL Server 2000 | 11202,17 | ||
| MySQL Pro 10..49 licenses** | 315 | 1 | 315 |
** - по данным сайта http :// www . mysql . com на апрель 2003 г .
5. Производительность. Рассмотрим подробнее результаты исследования производительности различных СУБД, т.к. этот показатель является одним из основных факторов, влияющих на качество работы КМИС. При этом изучались 2 версии Microsoft SQL Server: версия 7.0 с установленным пакетом исправлений и дополнений Service Pack 4, а также версия 2000. После установки каждой СУБД на ней встроенными средствами администрирования создавалась база данных R _ TEST _ DB, в которую помещалась одна таблица с именем LVN, содержащая 65 столбцов и 20 098 строк записей. Объем таблицы 74,06 Мбайт (в формате MyISAM). В этой таблице находилась реальная информация о выданных больничных листах в одном из медицинских учреждений Карелии в период с 2-го полугодия 2002 по первое полугодие 2004 г. (24 месяца). Таблица помещалась в указанную БД во всех тестах при помощи средства DataPump, входящего в состав пакета программ Borland Delphi 6 Professional. В исследовании участвовали 3 сервера, технические характеристики которых представлены в таблице ниже.
Таблица 5
Технические характеристики серверов, участвовавших в тестировании:
| № | NetBios -имя сервера | Техническая характеристика |
| 1 | POLIKSERVER | Asus P4800Delux / P4 3,06 GHz / RAM 2 x 512 Mb DDR400 / HDD 120 Gb 7200 prn |
| 2 | SRV2 | 2 x 500 MHz Pentium III Xeon / RAM 1 Gb / RAID 5 24 Gb SCSI-160 |
| 3 | PROSERVER | 2 x 3,06 GHz Pentium 4 Xeon HT / RAM 2 Gb / RAID 5 102 Gb SCSI-320 |
Таблица 6
Технические характеристики рабочих станций,
участвовавших в тестировании:
№ |
NetBios -имя ПК |
Техническая характеристика |
1 |
Admin |
Asus P4533 / P4 1,5 MHz / RAM 512 Mb DDR333 / HDD 40 Gb 7200 prn |
2 |
Admin2 |
Asus P4800Delux / P4 3,06 GHz / RAM 2 x 512 Mb DDR400 / HDD 120 Gb 7200 prn |
3 |
Admin7 |
Asus P4533 / P4 1,5 MHz / RAM 512 Mb DDR333 / HDD 40 Gb 7200 prn |
В данном исследовании было выбрано 3 наиболее показательных вида SQL -запроса, тексты которых представлены в таблице ниже.
Таблица 7
SQL -запросы, выполнявшиеся в ходе тестирования
№ |
Название запроса |
SQL запрос |
1 |
Простой Select |
S ELECT * FROM lvn |
2 |
Вывод отчета по строкам статистики |
SELECT UNWORKSTATLINE1, COUNT(UNWORKSTATLINE1), SUM(CNUMKOIKOD) FROM lvn GROUP BY UNWORKSTATLINE1 |
3 |
Среднее количество суток по группам возрастов |
SELECT CNUMVOZRAST, AVG(VOZRAST) FROM lvn GROUP BY CNUMVOZRAST |
В таблицах с результатами исследований используются следующие переменные:
U – количество пользователей;
P av – средняя загрузка процессора(ов);
P max – максимальная загрузка процессора(ов);
D – длительность выполнения запроса, мсек.
В таблицах ниже представлены результаты выполнения запросов №1, 2 и 3. В приложении приведена исходная таблица с результатами выполнения тестов.
Таблица 8
Результаты выполнения запроса №1
| Тест | U=1 | U=2 | U=3 | ||||||
| D | P av | P max | D | P av | P max | D | P av | P max | |
|
POLIKSERVER + MySQL 4.020 |
5450,8 ( ± 66,5) |
14,3 | 46,88 |
5608,2 ( ± 71,8) |
28,8 | 64,3 |
6011,4 ( ± 68,0) |
41,3 | 62,2 |
|
POLIKSERVER + MS SQL Server 7.0 SP4 |
15,7 ( ± 0,2) |
30 ,1 | 92 |
14,1 ( ± 1,7) |
73,5 | 100 |
13,6 ( ± 1,9) |
97 | 100 |
|
POLIKSERVER + MS SQL Server 2000 |
16,2 ( ± 1,0) |
7,5 | 32,8 |
17,7 ( ± 2,4) |
21,2 | 43,7 |
19,3 ( ± 2,7) |
18,9 | 67,1 |
|
SRV2 + MySQL 4.0.20 |
6304,3 ( ± 38,3) |
28 | 51 |
6273,4 ( ± 23,2) |
63 | 98 |
6222,9 ( ± 50,9) |
86 | 100 |
|
SRV2 + MS SQL Server 7.0 SP4 |
19,2 ( ± 2,7) |
10,3 | 30,4 |
18,2 ( ± 2,1) |
19,2 | 55,5 |
32,4 ( ± 5,8) |
14 | 77,3 |
|
SRV2 + MS SQL Server 2000 |
19,4 ( ± 2,3) |
22,9 | 42,9 |
19,8 ( ± 2,8) |
41 ,4 | 84,3 |
28,7 ( ± 14,1) |
26,8 | 74,9 |
|
PROSERVER + MySQL 4.0.20 |
6290,2 ( ± 88,1) |
8,4 | 22,8 |
6217,0 ( ± 83,9) |
9,4 | 23,1 |
6831,3 ( ± 64,7) |
9,8 | 23,5 |
|
PROSERVER + MS SQL Server 7.0 SP4 |
19,8 ( ± 2,9) |
20,9 | 32,8 |
17,8 ( ± 1,9) |
3,4 | 16,4 |
18,2 ( ± 2,0) |
5,2 | 29,2 |
|
PROSERVER + MS SQL Server 2000 |
16,2 ( ± 0,9) |
6,4 | 15,3 |
16,2 ( ± 0,9) |
5,6 | 24,3 |
19,4 ( ± 2,8) |
13,3 | 27,7 |
Результаты выполнения запроса №2
| Тест | U=1 | U=2 | U=3 | ||||||
| D | P av | P max | D | P av | P max | D | P av | P max | |
|
POLIKSERVER + MySQL 4.020 |
163,0 ( ± 3,2) |
14,3 | 46,88 |
155,3 ( ± 4,0) |
28,8 | 64,3 |
153,7 ( ± 14,5) |
41,3 | 62,2 |
|
POLIKSERVER + MS SQL Server 7.0 SP4 |
153 ,3 ( ± 10,9) |
30,1 | 92 |
233,9 ( ± 21,7) |
73,5 | 100 |
340,8 ( ± 20,3) |
97 | 100 |
|
POLIKSERVER + MS SQL Server 2000 |
17,1 ( ± 1,6) |
7,5 | 32,8 |
27,0 ( ± 13,9) |
21,2 | 43,7 |
18,2 ( ± 2,1) |
18,9 | 67,1 |
|
SRV2 + MySQL 4.0.20 |
928,8 ( ± 5,4) |
28 | 51 |
961,8 ( ± 11,0) |
63 | 98 |
1276,1 ( ± 75,9) |
86 | 100 |
|
SRV2 + MS SQL Server 7.0 SP4 |
26,1 ( ± 7,1) |
10,3 | 30,4 |
31,8 ( ± 1,0) |
19,2 | 55,5 |
33,8 ( ± 3,6) |
14 | 77,3 |
|
SRV2 + MS SQL Server 2000 |
93,4 ( ± 6,7) |
22,9 | 42,9 |
92,4 ( ± 2,2) |
41,4 | 84,3 |
97,9 ( ± 8,0) |
26,8 | 74 ,9 |
|
PROSERVER + MySQL 4.0.20 |
196,4 ( ± 6,9) |
8,4 | 22,8 |
176,0 ( ± 7,9) |
9,4 | 23,1 |
164,7 ( ± 4,9) |
9,8 | 23,5 |
|
PROSERVER + MS SQL Server 7.0 SP4 |
17,0 ( ± 2,9) |
20,9 | 32,8 |
9,9 ( ± 2,6) |
3,4 | 16,4 |
24,5 ( ± 9,1) |
5,2 | 29,2 |
|
PROSERVER + MS SQL Server 2000 |
18,8 ( ± 3,3) |
6,4 | 15,3 |
26,0 ( ± 3,6) |
5,6 | 24,3 |
25,5 ( ± 2,8) |
13,3 | 27,7 |
Таблица 10
Результаты выполнения запроса №3
| Тест | U=1 | U=2 | U=3 | ||||||
| D | P av | P max | D | P av | P max | D | P av | P max | |
|
POLIKSERVER + MySQL 4.020 |
89,0 ( ± 2,9) |
14,3 | 46,88 |
85,3 ( ± 9,4) |
28,8 | 64,3 |
68,3 ( ± 2,7) |
41,3 | 62,2 |
|
POLIKSERVER + MS SQL Server 7.0 SP4 |
58,9 ( ± 3,4) |
30,1 | 92 |
85,5 ( ± 7,6) |
73,5 | 100 |
172,3 ( ± 19,9) |
97 | 100 |
|
POLIKSERVER + MS SQL Server 2000 |
3,2 ( ± 2,3) |
7,5 | 32,8 |
5,7 ( ± 2,7) |
21,2 | 43,7 |
9,9 ( ± 2,7) |
18,9 | 67,1 |
|
SRV2 + MySQL 4.0.20 |
630,9 ( ± 5,8) |
28 | 51 |
640,6 ( ± 24,2) |
63 | 98 |
933,9 ( ± 78,4) |
86 | 100 |
|
SRV2 + MS SQL Server 7.0 SP4 |
8,2 ( ± 3,1) |
10,3 | 30,4 |
10,3 ( ± 2,6) |
19,2 | 55,5 |
11,0 ( ± 4,4) |
14 | 77,3 |
|
SRV2 + MS SQL Server 2000 |
17,7 ( ± 1,9) |
22,9 | 42,9 |
16,1 ( ± 1,0) |
41,4 | 84,3 |
22,3 ( ± 6,4) |
26,8 | 74,9 |
|
PROSERVER + MySQL 4.0.20 |
116,2 ( ± 4,9) |
8,4 | 22,8 |
93,3 ( ± 4,9) |
9,4 | 23,1 |
85,8 ( ± 2,8) |
9,8 | 23,5 |
|
PROSERVER + MS SQL Server 7.0 SP4 |
5,3 ( ± 2,7) |
20,9 | 32,8 |
2,0 ( ± 1,9) |
3,4 | 16,4 |
6,3 ( ± 3,0) |
5,2 | 29,2 |
|
PROSERVER + MS SQL Server 2000 |
4,7 ( ± 2,6) |
6,4 | 15,3 |
5,2 ( ± 2,6) |
5,6 | 24,3 |
7,3 ( ± 2,8) |
13,3 | 27,7 |
Общее сравнение производительности СУБД
Таблица 11Анализ производительности СУБД по различным видам запросов (для U=1)
| СУБД | POLIKSERVER | SRV2 | PROSERVER | ||||||||||||||||
| D | P av | P max | D | P av | P max | D | P av | P max | |||||||||||
| Запрос №1 | |||||||||||||||||||
| MySQL 4.020 | 5450,8 ( ± 66,5) | 14,3 | 46,88 | 6304,3 ( ± 38,3) | 28 | 51 | 6290,2 ( ± 88,1) | 8,4 | 22,8 | ||||||||||
| MS SQL Server 7.0 SP4 | 15,7 ( ± 0,2) | 30 ,1 | 92 | 19,2 ( ± 2,7) | 10,3 | 30,4 | 19,8 ( ± 2,9) | 20,9 | 32 ,8 | ||||||||||
| MS SQL Server 2000 | 16,2 ( ± 1,0) | 7,5 | 32,8 | 19,4 ( ± 2,3) | 22,9 | 42,9 | 16,2 ( ± 0,9) | 6,4 | 15,3 | ||||||||||
| Запрос №2 | |||||||||||||||||||
| MySQL 4.020 | 163,0 ( ± 3,2) | 14,3 | 46,88 | 928,8 ( ± 5,4) | 28 | 51 | 196,4 ( ± 6,9) | 8,4 | 22,8 | ||||||||||
| MS SQL Server 7.0 SP4 | 153 ,3 ( ± 10,9) | 30,1 | 92 | 26,1 ( ± 7,1) | 10,3 | 30,4 | 17,0 ( ± 2,9) | 20,9 | 32,8 | ||||||||||
| MS SQL Server 2000 | 17,1 ( ± 1,6) | 7,5 | 32,8 | 93,4 ( ± 6,7) | 22,9 | 42,9 | 18,8 ( ± 3,3) | 6,4 | 15,3 | ||||||||||
| Запрос №3 | |||||||||||||||||||
| MySQL 4.020 | 89,0 ( ± 2,9) | 14,3 | 46,88 | 630,9 ( ± 5,8) | 28 | 51 | 116,2 ( ± 4,9) | 8,4 | 22,8 | ||||||||||
| MS SQL Server 7.0 SP4 | 58,9 ( ± 3,4) | 30,1 | 92 | 8,2 ( ± 3,1) | 10,3 | 30,4 | 5,3 ( ± 2,7) | 20,9 | 32,8 | ||||||||||
| MS SQL Server 2000 | 3,2 ( ± 2,3) | 7,5 | 32,8 | 17,7 ( ± 1,9) | 22,9 | 42,9 | 4,7 ( ± 2,6) | 6,4 | 15,3 |
Как видно из таблицы, очень сильное влияние на результаты тестов оказывает используемый сервер. Наиболее сильно расходятся результаты в случае использования 2-х процессорных серверов (SRV 2 и PROSERVER). В случае использования обычной рабочей станции POLIKSERVER в качестве сервера для реляционной СУБД результаты менее отличаются. Так, выполнение запроса №3 осуществляется MySQL на 51,1% медленнее, чем MS SQL Server 7.0 на сервере POLIKSERVER. Применение сервера SRV 2 демонстрирует снижение производительности MySQL в 76,9 раза. Исходя из этого, можно сделать вывод о том, что СУБД MS SQL Server более эффективно использует серверную платформу, причем независимо от версии. В наиболее благоприятных технических условиях СУБД MySQL выполняет запрос №1 в 347,2 раза медленнее, чем СУБД MS SQL Server 7.0. Запрос №2 выполняется MySQL лишь на 6,3% медленнее. Запрос №3 выполняется на 51,1% медленнее. В случае использования последних версий серверов ( PROSERVER ) MySQL выполняет запрос №1 в 317,7 раза медленнее, чем СУБД MS SQL Server 7.0. Запрос №2 выполняется MySQL в 11,6 раза медленнее. Запрос №3 выполняется в 21,9 раза медленнее. Таким образом, необходимо сделать вывод о том, что практически по всем видам запросов СУБД MS SQL Server выполняет их значительно быстрее, причем эта разница возрастает в случае применения настоящих серверных платформ, особенно – последних версий.
Исходные результаты выполнения тестов СУБД
Исходные данные тестирования СУБДТаблица 13
Исходные результаты выполнения тестов СУБД и серверов
| Код | Код теста | Код SQL -запроса | U | P max | P av | D | Ст.откл. | Дисперс. |
| 1 | 1 | 1 | 1 | 46,88 | 14,3 | 5450,8 | 185,70952 | 66,4553 |
| 1 | 1 | 2 | 1 | 46,88 | 14,3 | 163,03333 | 8,86748 | 3,17319 |
| 1 | 1 | 3 | 1 | 46,88 | 14,3 | 89,03333 | 8,14241 | 2,91373 |
| 2 | 1 | 1 | 2 | 64,28 | 28,8 | 5608,23333 | 200,64125 | 71,79855 |
| 2 | 1 | 2 | 2 | 64,28 | 28,8 | 155,3 | 11,35826 | 4,0645 |
| 2 | 1 | 3 | 2 | 64,28 | 28,8 | 85,3 | 26,547 | 9,49972 |
| 3 | 1 | 1 | 3 | 62,2 | 41,3 | 6011,43333 | 190,11815 | 68,03291 |
| 3 | 1 | 2 | 3 | 62,2 | 41,3 | 153,66667 | 40,49307 | 14,49026 |
| 3 | 1 | 3 | 3 | 62,2 | 41,3 | 68,33333 | 7,57775 | 2,71166 |
| 4 | 2 | 1 | 1 | 92 | 30,1 | 15,67742 | 0,46746 | 0,16456 |
| 4 | 2 | 2 | 1 | 92 | 30,1 | 153,53333 | 30,39488 | 10,87667 |
| 4 | 2 | 3 | 1 | 92 | 30,1 | 58,96667 | 9,63495 | 3,44782 |
| 5 | 2 | 1 | 2 | 100 | 73,5 | 14,13333 | 4,73099 | 1,69296 |
| 5 | 2 | 2 | 2 | 100 | 73,5 | 233,86667 | 60,74742 | 21,73818 |
| 5 | 2 | 3 | 2 | 100 | 73,5 | 85,46667 | 21,17189 | 7,57626 |
| 6 | 2 | 1 | 3 | 100 | 97 | 13,63333 | 5,36335 | 1,91925 |
| 6 | 2 | 2 | 3 | 100 | 97 | 340,8 | 56,78814 | 20,32138 |
| 6 | 2 | 3 | 3 | 100 | 97 | 172,33333 | 55,49134 | 19,85732 |
| 7 | 3 | 1 | 1 | 51 | 28 | 6304,33333 | 107,14798 | 38,34241 |
| 7 | 3 | 2 | 1 | 51 | 28 | 928,76667 | 15,14966 | 5,42124 |
| 7 | 3 | 3 | 1 | 51 | 28 | 630,96667 | 16,11931 | 5,76822 |
| 8 | 3 | 1 | 2 | 98 | 63 | 6273,36667 | 64,86164 | 23,21044 |
| 8 | 3 | 2 | 2 | 98 | 63 | 961,8 | 30,92615 | 11,06678 |
| 8 | 3 | 3 | 2 | 98 | 63 | 640,63333 | 67,54578 | 24,17095 |
| 9 | 3 | 1 | 3 | 100 | 86 | 6622,86667 | 142,33429 | 50,93367 |
| 9 | 3 | 2 | 3 | 100 | 86 | 1276,13333 | 212,0303 | 75,87407 |
| 9 | 3 | 3 | 3 | 100 | 86 | 933,96667 | 219,14736 | 78,42088 |
| 10 | 4 | 1 | 1 | 22,8 | 8,4 | 6290,2 | 246,26184 | 88,12367 |
| 10 | 4 | 2 | 1 | 22,8 | 8,4 | 196,4 | 19,33667 | 6,91954 |
| 10 | 4 | 3 | 1 | 22,8 | 8,4 | 116,16667 | 13,70908 | 4,90573 |
| 11 | 4 | 1 | 2 | 23,1 | 9,4 | 6217,03333 | 234,53578 | 83,92755 |
| 11 | 4 | 2 | 2 | 23,1 | 9,4 | 176,03333 | 21,99012 | 7,86906 |
| 11 | 4 | 3 | 2 | 23,1 | 9,4 | 93,3 | 13,76989 | 4,92749 |
| 12 | 4 | 1 | 3 | 23,5 | 9,8 | 6831,26667 | 180,6955 | 64,66105 |
| 12 | 4 | 2 | 3 | 23,5 | 9,8 | 164,66667 | 13,81143 | 4,94236 |
| 12 | 4 | 3 | 3 | 23,5 | 9,8 | 85,83333 | 7,71182 | 2,75964 |
| 13 | 5 | 1 | 1 | 32,8 | 20,9 | 19,76667 | 8,07747 | 2,89049 |
| 13 | 5 | 2 | 1 | 32,8 | 20,9 | 17,06667 | 8,35836 | 2,991 |
| 13 | 5 | 3 | 1 | 32,8 | 20,9 | 5,26667 | 7,45177 | 2,66658 |
| 14 | 5 | 1 | 2 | 16,4 | 3,4 | 17,76667 | 5,50565 | 1,97017 |
| 14 | 5 | 2 | 2 | 16,4 | 3,4 | 9,9 | 7,54255 | 2,69907 |
| 14 | 5 | 3 | 2 | 16,4 | 3,4 | 2,03333 | 5,18641 | 1,85593 |
| 15 | 5 | 1 | 3 | 29,2 | 5,2 | 18,23333 | 5,72529 | 2,04877 |
| 15 | 5 | 2 | 3 | 29,2 | 5,2 | 24,5 | 25,4673 | 9,11336 |
| 15 | 5 | 3 | 3 | 29,2 | 5,2 | 6,26667 | 8,66 | 3,09894 |
| 16 | 6 | 1 | 1 | 30,4 | 10,3 | 19,23333 | 7,70577 | 2,75747 |
| 16 | 6 | 2 | 1 | 30,4 | 10,3 | 26,13333 | 19,90433 | 7,12267 |
| 16 | 6 | 3 | 1 | 30,4 | 10,3 | 8,23333 | 8,68594 | 3,10822 |
| 17 | 6 | 1 | 2 | 55,5 | 19,2 | 18,23333 | 5,90866 | 2,11439 |
| 17 | 6 | 2 | 2 | 55,5 | 19,2 | 31,83333 | 2,85287 | 1,02089 |
| 17 | 6 | 3 | 2 | 55,5 | 19,2 | 10,33333 | 7,31817 | 2,61877 |
| 18 | 6 | 1 | 3 | 77,3 | 14 | 32,4 | 16,08436 | 5,75571 |
| 18 | 6 | 2 | 3 | 77,3 | 14 | 33,76667 | 9,96221 | 3,56493 |
| 18 | 6 | 3 | 3 | 77,3 | 14 | 11 | 12,29634 | 4,40019 |
| 19 | 7 | 1 | 1 | 32,8 | 7,5 | 16,16667 | 2,97863 | 1,06589 |
| 19 | 7 | 2 | 1 | 32,8 | 7,5 | 17,13333 | 4,64567 | 1,66243 |
| 19 | 7 | 3 | 1 | 32,8 | 7,5 | 3,2 | 6,4 | 2,29021 |
| 20 | 7 | 1 | 2 | 43,7 | 21,2 | 17,73333 | 6,5774 | 2,35369 |
| 20 | 7 | 2 | 2 | 43,7 | 21,2 | 27,03333 | 38,80248 | 13,88529 |
| 20 | 7 | 3 | 2 | 43,7 | 21,2 | 5,73333 | 7,5407 | 2,69841 |
| 21 | 7 | 1 | 3 | 67,1 | 18,9 | 19,26667 | 7,62423 | 2,7283 |
| 21 | 7 | 2 | 3 | 67,1 | 18,9 | 18,2 | 5,83324 | 2,0874 |
| 21 | 7 | 3 | 3 | 67,1 | 18,9 | 9,93333 | 7,56718 | 2,70788 |
| 22 | 8 | 1 | 1 | 15,3 | 6,4 | 16,2 | 2,78568 | 0,99684 |
| 22 | 8 | 2 | 1 | 15,3 | 6,4 | 18,76667 | 9,31194 | 3,33223 |
| 22 | 8 | 3 | 1 | 15,3 | 6,4 | 4,7 | 7,18401 | 2,57076 |
| 23 | 8 | 1 | 2 | 24,3 | 5,6 | 16,2 | 2,78568 | 0,99684 |
| 23 | 8 | 2 | 2 | 24,3 | 5,6 | 26,03333 | 10,13076 | 3,62524 |
| 23 | 8 | 3 | 2 | 24,3 | 5,6 | 5,2 | 7,35935 | 2,63351 |
| 25 | 8 | 1 | 3 | 27,7 | 13,3 | 19,36667 | 7,7781 | 2,78336 |
| 25 | 8 | 2 | 3 | 27,7 | 13,3 | 25,5 | 7,79637 | 2,78989 |
| 25 | 8 | 3 | 3 | 27,7 | 13,3 | 7,33333 | 7,84573 | 2,80756 |
| 26 | 9 | 1 | 1 | 42,9 | 22,9 | 19,4 | 6,48896 | 2,32205 |
| 26 | 9 | 2 | 1 | 42,9 | 22,9 | 93,36667 | 18,75897 | 6,71281 |
| 26 | 9 | 3 | 1 | 42,9 | 22,9 | 17,73333 | 5,32249 | 1,90463 |
| 27 | 9 | 1 | 2 | 84,3 | 41,4 | 19,8 | 7,99333 | 2,86038 |
| 27 | 9 | 2 | 2 | 84,3 | 41,4 | 92,36667 | 6,07993 | 2,17568 |
| 27 | 9 | 3 | 2 | 84,3 | 41,4 | 16,1 | 2,80891 | 1,00516 |
| 28 | 9 | 1 | 3 | 74,9 | 26,8 | 28,73333 | 39,54823 | 14,15215 |
| 28 | 9 | 2 | 3 | 74,9 | 26,8 | 97,86667 | 22,45103 | 8,034 |
| 28 | 9 | 3 | 3 | 74,9 | 26,8 | 22,3 | 17,93349 | 6,41742 |
Выводы по выбору СУБД с учетом анализа производительности
По результатам этого исследования, разумеется, нельзя однозначно судить о приоритете СУБД MS SQL Server над MySQL. В ходе эксплуатации различных подсистем в составе нашей медицинской информационной системы, использующих реляционную базу данных на основе СУБД MySQL мы отмечали достаточно высокую производительность на гораздо больших объемах данных. Для ее достижения применялись стандартные методы проектирования реляционной БД, целочисленные поля в качестве ключей для связанных таблиц и т.д. Однако изучение результатов, полученных в данном тестировании, позволяет сделать вывод о значительно более высокой скорости работы СУБД MS SQL Server, как наиболее распространенного представителя коммерческих СУБД. Кроме того, следует отметить выдающиеся возможности администрирования и обслуживания СУБД MS SQL Server. Аналогичные по функциональном назначению средства, имеющиеся для СУБД MySQL, значительно уступают в своих возможностях средствам MS SQL Server. Кроме этого, имеющиеся на сайте MySQL на лето 2004 программы для управления СУБД имели низкую устойчивость в работе, а в ряде случаев – вообще не выполняли тех функций, которые декларировали. Однако не следует забывать, что СУБД MySQL – полностью бесплатный продукт, готовый к использованию на абсолютно законных основаниях (если Вы только не собираетесь распространять решения, основные на этом продукте на коммерческой основе). Анализируя все вышесказанное, можно сделать вывод о том, что в настоящее время решающую роль в медицинской предметной области может играть не какие-то конкретные параметры СУБД, такие как устойчивость или производительность, а совсем другие, относящиеся скорее к сфере субъектных моментов. Основные из них – это доступность технической поддержки, регулярность появления новых версий и выпуска т.н. пакетов исправлений, наличие (в том числе в сети Internet) русскоязычной и подробной документации, профессионализм разработчиков.В качестве рекомендаций мы сформировали следующее правило: если коллектив разработчиков обладает достаточными финансовыми возможностями и если Ваши потенциальные заказчики также способны приобрести необходимое количество лицензий, следует отдавать безусловное предпочтение коммерческим СУБД, таким как Microsoft SQL Server. Если финансовые возможности как разработчика, так и потребителя информационной системы ограничены, следует выбрать СУБД MySQL, которая обладает достаточным уровнем устойчивости работы и приемлемой за свою стоимость производительностью.
Следует отметить, что по существующей практике решение об использовании той или иной СУБД принимает чаще один человек – обычно, руководитель проекта, а он может опираться отнюдь не на технические критерии. Здесь свою роль могут сыграть такие, с технической точки зрения, незначительные факторы, как рекламная раскрутка компании-производителя СУБД, использование конкретных систем на других предприятиях, стоимость. При этом последний фактор может трактоваться в двух противоположных смыслах в зависимости от финансового состояния и политики ЛПУ. С одной стороны это может быть принцип «если дороже, то значит - лучше». С другой стороны – культивирование почти бесплатного использования продукта, вплоть до «взлома» его лицензионной защиты. Очевидно, последний подход чреват коллизиями и не может привести к успеху в долгосрочной работе.
Концепция сериализуемости
Концепции транзакции и механизма блокировок хорошо документированы в литературе [BHG, PAP, PON, GR]. В следующих нескольких абзацах делается обзор терминологии, используемой в этой области.Транзакцией называют упорядоченное множество операций, переводящих базу данных из одного согласованного состояния в другое. История моделирует перекрывающееся выполнение множества транзакций в виде линейно упорядоченной последовательности их операций чтения и записи (вставки, модификации, удаления) определенных элементов данных. Говорят, что две операции в истории конфликтуют, если они выполняются различными транзакциями над одним и тем же элементом данных, и хотя бы одна из них выполняет операцию записи этого элемента данных. Согласно [EGLT], это определение можно широко интерпретировать в зависимости от того, что понимать под "элементом данных". Это может быть строка таблицы, область страницы, целая таблица или коммуникационный объект, такой, например, как сообщение в очереди. Конфликтующие операции могут возникать не только на отдельных элементах данных, но и на множествах элементов данных, покрываемых предикатными блокировками.
Отдельная история приводит к образованию графа зависимостей (dependency graph), определяющего временные потоки данных между транзакциями. Операции зафиксированных транзакций представляются вершинами графа. Если в истории операция op1
транзакции T1 конфликтует с операцией op2 транзакции T2 предшествует этой операции, то пара
Анализ уровней изолированности ANSI SQL
Сначала сделаем позитивное замечание с том, что блокировочные уровни изолированности соответствуют требованиям ANSI SQL.Замечание 2. Блокировочные протоколы во определяют блокировочные уровни изолированности, которые, как минимум, сильны настолько же, как и соответствующие основанные на феноменах уровни изолированности в . Доказательство этого утверждения приводится в [OOBBGH].
Поэтому блокировочные уровни изолированности обеспечивают, по крайней мере, не меньшую изоляцию, чем одноименные ANSI-уровни. Могут ли они обеспечивать большую изоляцию? Ответ – да, даже на самом нижнем уровне. Чтобы избежать феномена, который мы называем "грязной записью" (Dirty Write), на Locking READ UNCOMMITTED обеспечивается долговременная блокировка по записи, тогда как в определениях ANSI SQL, основанных на аномалиях, такое аномальное поведение не исключается на всех уровнях, кроме ANSI SERIALIZABLE. "Грязное чтение" определяется следующим образом.
P0 (Грязная Запись): Транзакция T1 модифицирует некоторый элемент данных. После этого другая транзакция T2 тоже модифицирует этот элемент данных перед тем, как T1 выполнит COMMITT или ROLLBACK. Если T1 или T2 после этого выполнит ROLLBACK, то становится непонятным, каким должно быть корректное значение данных. Свободной интерпретацией этого является следующая история:
P0: w1[x]...w2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
Одной из причин, по которым феномена грязной записи следует избегать, является то, что он может нарушить согласованность базы данных. Предположим, что существует ограничение на значения элементов данных x и y (например x = y). Обе транзакции, и T1, и T2, поддерживают согласованность, если выполняются порознь. Однако ограничение легко может быть нарушено, если транзакции параллельно производят операции записи в x и y в разном порядке. Это может произойти, если не допускаются грязные записи. Например, если возможна история w1[x]...w2[x]...w2[y]...c2...w1[y]...c1
то "выживут" изменения, сделанные T1 в y, и изменения, сделанные T2 в x. Если T1 записывает в оба элемента x и y 1, а T2 – 2, то результатом будет x = 2, y = 1, что нарушает ограничение x=y.
В [GLPT, BHG] и других работах рассматривается необходимость защиты от феномена P0 для возможности автоматического отката транзакций. Без защиты от P0 система не может аннулировать изменения, просто восстановив предыдущие значения. Рассмотрим историю: w1[x]w2[x]a1
Аннулирование w1[x] и восстановление предыдущего значения x не являются удовлетворительными, потому что в результате такого восстановления уничтожится и изменение x w2[x], сделанное второй транзакцией. На если не аннулировать w1[x] путем восстанавления предыдущего значения x, и вторая транзакция тоже выполнит откат, то нельзя будет аннулировать изменение w2[x] путем восстановления его предыдущего значения x! Именно поэтому даже самые слабые блокировочные системы удерживают долговременную блокировку по записи. В противном случае не смогли бы работать их механизмы восстановления.
Замечание 3. Изолированность в ANSI SQL должна быть изменена таким образом, чтобы исключить P0 на всех уровнях изолированности.
Теперь мы приведем доводы в пользу того, почему требуются именно свободные интерпретации всех трех ANSI-феноменов. Напомним, что строгие интерпретации выглядят следующим образом:
A1: w1[x]...r2[x]... ((a1 и c2) в любом порядке) (грязное чтение)
A2: r1[x]...w2[x]...c2...r1[x]...c1 (размытое или неповторимое чтение)
A3: r1[P]...w2[y in P] ...c2...r1[P]...c1 (фантом)
Согласно , на уровне изолированности READ COMMITTED запрещаются аномалии A1, на уровне REPEATABLE READ – аномалии A1 и A2, и на уровне SERIALIZABLE – аномалии A1, и A2, и A3. Рассмотрим историю H1, в которой две транзакции производят перевод 40 долларов между строками x и y в банковском балансе:
H1: r1[x=50] w1[x=10] r2[x=10] r2[y=50] c2 r1[y=50] w1[y=90] c1
История H1 демонстрирует несериализуемую, классическую проблему анализа несогласованности
(inconsistent analysis), когда транзакция T1 переводит 40 долларов с x на y, сохраняя размер общей суммы баланса, равный 100, но транзакция T2
производит чтение в тот момент, когда баланс находится в несогласованном состоянии при общей сумме равной 60. История H1 не подходит ни под одну из аномалий A1, A2 и A3. В случае A1 одна из транзакций должна была бы завершиться аварийно; для A2 элемент данных должен был бы быть прочитан одной из транзакцией повторно; в случае A3 должна была бы измениться область истинности соответствующего предиката. Ни что из этого не происходит в H1. Рассмотрим свободную интерпретацию A1, феномен P1:
P1: w1[x]...r2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
H1 действительно нарушает P1. Поэтому для того, что подразумевалось в стандарте ANSI SQL, следует выбирать интерпретацию P1, а не A1. Именно свободная интерпретация является корректной.
Аналогичные доводы показывают, что для интерпретации второго ANSI-феномена следует выбирать интерпретацию P2, а не A2. Различия между A2 и P2 видны на примере следующей истории:
H2: r1[x=50] r2[x=50] w2[x=10] r2[y=50] w2[y=90] c2 r1[y=90] c1
H2 является несериализуемой – это еще одна проблема анализа несогласованности, где T2 видит общий баланс, равный 140. В этой истории ни одна транзакция не читает грязные (т.е. незафиксированные) данные. Таким образом, история не противоречит P1. Кроме того ни один элемент данных не читается дважды и нет изменяющейся области истинности соответствующего предиката. Проблема с H2 состоит в том, что T1 читает значение y, когда значение x уже устарело. Если бы T1 прочитала значение x снова, то оно бы обновилось, но она этого не делает, и A2 к этому случаю не подходит. Заменяя A2 на P2, т.е. свободную интерпретацию, мы решаем эту проблему:
P2: r1[x]...w2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
H2 будет отвегнута при попытке второй транзакции (w2[x=10]) перезаписать значение переменной, прочитанной до этого первой транзакцией r1[x=50]. И наконец, рассмотрим A3 и историю H3:
A3: r1[P]...w2[y in P] ...c2...r1[P]...c1 (фантом)
H3: r1[P] w2[insert y to P] r2[z] w2[z] c2 r1[z] c1
T1 осуществляет поиск по условию P=<> для получения списка служащих. После этого T2 производит вставку нового служащего и потом обновляет z – счетчик служащих в компании. Затем T1 читает значение счетчика служащих, проверяет и находит рассогласование. Ясно, что эта история несериализуема, но она допустима, поскольку не подходит под A3: никакой предикат не применяется дважды. Снова только свободная интерпретация решает проблему:
P3: r1[P]...w2[y in P]... ((c1 или a1) и (c2 или a2) в любом порядке)
Если запретить P3, то история H3 станет недопустимой. Ясно, что именно это подразумевалось в стандарте ANSI SQL. Дальнейшее обсуждение направлена на то, чтобы продемонстрировать полученные результаты.
Замечание 4. Строгие интерпретации A1, A2 и A3 имеют непредусмотренные недостатки. Правильными являются свободные интерпретации. Определяя P1, P2 и P3, мы полагаем, что в ANSI имелось в виду именно это.
Замечание 5. Множество феноменов ANSI SQL неполно. Может возникнуть ряд других аномалий. Чтобы сделать определение блокировок, необходимо определить новые феномены. Кроме того, необходимо переформулировать определение P3. В следующих определениях мы опускаем (c2 или a2), что не ограничивает возможные истории.
P0: w1[x]...w2[x]... (c1 или a1) (Dirty Write, грязная запись)
P1: w1[x]...r2[x]... (c1 или a1) (Dirty Read, грязное чтение)
P2: r1[x]...w2[x]... (c1 или a1) (Fuzzy or Non-Repeatable Read, размытое или неповторимое чтение)
P3: r1[P]...w2[y in P]... (c1 или a1) (Phantom, фантом)
Заметим, что определение P3, приведенное выше, отличается от определения P3 в ANSI SQL. Определение P3 в ANSI SQL запрещает только операции вставки (и модификации в соответствии с некоторыми интерпретациями), попадающие под область действия предиката, когда определение P3, приведенное выше, запрещает любую операцию записи (вставки, модификации, удаления), попадающую под предикат, по которому была произведена операция чтения.
Определения предложенных ANSI уровней изолированности в терминах этих феноменов приведены в таблице 3.
Таблица 3. Уровни изолированности ANSI, определенные в терминах четырех феноменов
|
Уровень изолированности |
Р0 грязная запись (Dirty Write) |
Р1 грязное чтение (Dirty Read) |
Р2 размытое чтение (Fuzzy Read) |
Р3 фантом (Phantom) |
|
ЧТЕНИЕ НЕЗАФИКСИРОВАННЫХ ДАННЫХ (READ UNCOMMITTED) |
невозможен |
возможен |
возможен |
возможен |
|
ЧТЕНИЕ ЗАФИКСИРОВАННЫХ ДАННЫХ (READ COMMITTED) |
невозможен |
невозможен |
возможен |
возможен |
|
ПОВТОРИМОЕ ЧТЕНИЕ (REPEATABLE READ) |
невозможен |
невозможен |
невозможен |
возможен |
|
СЕРИАЛИЗУЕМОСТЬ (SERIALIZABLE) |
невозможен |
невозможен |
невозможен |
невозможен |
Замечание 6. Определения блокировочных уровней изолированности в эквивалентны феноменологическим определениям в . Другими словами, P0, P1, P2 и P3 являются замаскированнымии определениями блокировочного поведения.
В дальнейшем мы будем ссылаться на уровни изолированности, перечисленные в , по их именам из этой таблицы, подразумевая их эквивалентность блокировочным уровням изолированности из . Когда мы будем употребляем термины ANSI READ UNCOMMITTED, ANSI READ COMMITTED, ANSI REPEATABLE READ и ANOMALY SERIALIZABLE, будут иметься в виду определения ANSI из (недостаточной, т.к. она не включает P0)
В следующем разделе показывается, что в ряде коммерческих реализаций изолированности обеспечиваются уровни изолированности, которые попадают между уровнями READ COMMITTED и REPEATABLE READ. Для получения осмысленных уровней изолированности, которые позволили бы четко различить эти реализации, мы примем P0 и P1 в качестве базиса, а затем добавим новые зарактерные феномены.
Благодарности
Мы выражаем благодарность Крису Ларсону (Chris Larson) из Microsoft, Алану Рейтеру (Alan Reiter), которые нашли несколько новых аномалий в ИЗОЛИРОВАННОСТИ ОБРАЗА, Франко Путзолу (Franco Putzolu) и Анил Нори (Anil Nori) из Oracle, Майку Убеллу (Mike Ubell) из компании Illustra и всем анонимным рефери из SIGMOD за ценные предложения, которые улучшили эту статью. Сашил Джодиа (Sushil Jajodia), V.Atluri и E.Bertino, которые прислали нам черновой вариант своей работы [ABJ], касающейся уровней ограниченной изолированности для многоверсионных историй.Другие многоверсионные системы
Существуют другие модели многоверсионности. В некоторых коммерческих продуктах поддерживаются версии объектов, но ограничивают область применения метода Snapshot Isolation только читающими транзакциями. (Например, SQL-92, Rdb и SET TRANSACTION READ ONLY в некоторых других базах данных [MS, HOB, DRA]; в Postgres и Illustra [STO, ILL] такие версии поддерживаются долговременно (long-term), и обеспечивается возможность темпоральных запросов.) В других реализациях допускаются изменяющие транзакции, но не поддерживается защита "Выигрывает первая зафиксированная транзакция" (например, уровень изолированности READ CONSISTENCY в Oracle [ORA]).На уровне READ CONSISTENCY в Oracle каждому SQL-оператору перед началом его выполнения дается самое свежее зафиксированное состояние базы данных. Это похоже на то, как если бы стартовая временная метка транзакции снималасьдля каждого SQL-оператора. Множество строк курсора формируется во время выполнения операции открытия курсора. Базовый механизм заново вычисляет подходящую версию строки на основе временной метки оператора. Операции вставки, модификации и удаления строк защищаются блокировками по записи, что приводит к политике "Выигрывает первая записавшая транзакция", а не к "Выигрывает первая зафиксированная транзакция". Уровень READ CONSISTENCY сильнее, чем READ COMMITTED (на нем исключается потеря изменений по курсору (P4C)), но допускает неповторимое чтение (P3), потерю изменений в общем случае (P4) и искажение чтения (A5A). Snapshot Isolation не допускает P4 и A5A.
Если пристально посмотреть на стандарт SQL, то можно сказать, что он трактует каждый оператор как атомарный. В начале каждого оператора имеется сериализуемая подтранзакция (или временная метка). Можно представить иерархию уровней изолированности, определяемых различными вариантами комбинации оператора и присоединенной к нему временной меткой. (Например, в Oracle, операция чтения по курсору имеет временнуя метку, снятую в момент открытия курсора.)
Изолированность на основе моментальных снимков
Транзакция, выполняемая на уровне изолированности на основе моментальных снимков (Snapshot Isolation), всегда читает данные из моментального снимка (зафиксированных) данных, произведенного в момент начала транзакции, который называется стартовой временной меткой (Start-Timestamp). В качестве этого момента может быть выбран любой момент до выполнения этой транзакцией первого чтения. Транзакции, выполняемая на уровне Snapshot Isolation, никогда не блокируется при попытке произвести чтение до тех пор, пока можно поддерживать данные моментального снимка, соответствующего стартовой временной метке. В этом моментальном снимке также отражаются результаты всех операций записи (модификация, вставка и удаление) данной транзакции, используемые при повторном обращении этой транзакции (по чтению или записи) к тем же элементам данных. Изменения, производимые другими транзакциями после момента стартовой временной метки, для данной транзакции являются невидимыми.Snapshot Isolation является разновидностью многоверсионных механизмов управления параллельными транзакциями (multiversion concurrency control). Он расширяет многоверсионный смешанный метод (Multiversion Mixed Method), описанный в [BHG], в котором допускается чтение данных из моментального снимка для только читающих транзакций.
Когда транзакция T1 становится готовой к фиксации, она получает временную метку фиксации (Commit-Timestamp), которая должна быть больше любой существующей Start-Timestamp и Commit-Timestamp. Транзакции T1 успешно фиксируется только в том случае, если ни одна другая транзакция T2 c Commit-Timestamp, попадающей в интервал [Start-Timestamp, Commit-Timestamp] транзакции T1, не записала в те же элементы данных, что и T1. В противном случае T1 завершается аварийно. Этот метод, называемый "Выигрывает первая зафиксированная транзакция" (First-committer-wins), устраняет потерянные изменения (феномен P4). Когда транзакция T1 фиксируется, ее изменения становятся видны всем транзакциям, у которых Start-Timestamp больше, чем Commit-Timestamp транзакции T1.
Нарушение ограничения (constrant violation) является типичным и важным типом аномалий, возникающих при параллельном выполнении транзакций. Индивидуальные базы данных удовлетворяют ограничениям, задаваемым на множествах элементов данных (например уникальность ключей, целостность ссылок, репликация строк в двух таблицах и т.д.). Все вместе они образуют неизменяемый ограничительный предикат базы данных C(DB). Предикат принимает значение True, если состояние базы данных DB согласуется с ограничениями False в противном случае. Для поддержки согласованности базы данных транзакции должны сохранять истинность ограничительного предиката: если база данных является согласованным до начала транзакции, то она останется согласованной и после ее фиксации. Если транзакция читает содержимое базы данных, нарушающее ограничительный предикат, то она испытывает аномалию нарушения ограничения из-за наличия параллельно выполняемой транзакции. Подобные нарушения ограничений называются анализом несогласованности (inconsistent analysis) [DAT].
A5 (Нарушение ограничения на элементах данных). Предположим, что C()
– ограничение между двумя элементами данных x и y из базы данных. Ниже приводятся две аномалии, возникающие при нарушении ограничения.
A5A (Искажение чтения, Read Skew). Предположим, что транзакция T1 читает x, а затем другая транзакция T2 изменяет значения x и y и фиксируется. Если теперь T1 прочитает значение y, она может обнаружить несогласованное состояние, и поэтому она произведет тоже несогласованное состояние. В терминах историй мы имеем аномалию:
A5A: r1[x]...w2[x]...w2[y]... c2...r1[y]...(c1 или a1) (искажение чтения, Read Skew)
A5B (Искажение записи, Write Skew). Предположим, что транзакция T1 читает x и y, которые согласованы в соответствии с предикатом C(), а затем другая транзакция T2 читает значения x и y, записывает x и фиксируется. После этого T1
записывает y. Если на x и y было какое-нибудь ограничение, то оно может нарушиться. В терминах историй:
A5B: r1[x]...r2[y]...w1[y]... w2[x]...(c1 или c2) (искажение записи, Write Skew)
Феномен размытого чтения (P2) является частным случаем искажения чтения, где x=y. Более часто в транзакции читаются два разных, но взаимозависимых элемента (например, поддерживается целостность ссылок). Искажение записи (Write Skew) (A5B) может возникнуть при наличии ограничения в банке, когда балансам счетов разрешается быть отрицательными, пока сумма совместно поддерживаемых балансов остается положительной. Это приводит к такой аномалии, как в истории H5.
Понятно, что ни аномалия A5A, ни A5B не могла бы возникнуть в историях с исключенным феноменом P2, поскольку в обоих случаях транзакция T2записывает элемент данных, предварительно прочитанный незафиксированной транзакцией T1. Поэтому феномены A5A и A5B полезны только для классификации уровней изолированности, более слабых, чем REPEATABLE READ.
В ANSI SQL определение уровня REPEATABLE READ в строгой интерпретации позволяет поддерживать частные случаи ограничений на строках, но в нем отсутствует общая концепция. Более конкретно, Locking REPEATABLE READ из обеспечивает защиту от нарушения ограничений на строках (row constraint violations), а определение ANSI SQL из , запрещая аномалии A1 и A2, – нет.
Возвращаясь к обсуждению уровня изолированности Snapshot Isolation, следует заметить, что он поразительно силен, даже сильнее, чем READ COMMITTED.
Замечание 8. READ COMMITTED << Snapshot Isolation
Доказательство. На уровне Snapshot Isolation механизм "выигрывает первая зафиксированная транзакция" устраняет феномен P0 (грязная запись), а механизм временных меток не допускает возникновение феномена P1 (грязное чтение). Отсюда следует, что Snapshot Isolation не слабее, чем READ COMMITTED. Кроме того, на уровне READ COMMITTED возможен феномен A5A, но он невозможен при использовании механизма временных меток на уровне Snapshot Isolation. Следовательно, READ COMMITTED << Snapshot Isolation.
Заметим, что в одноверсионной интерпретации сложно описать, как в историях на уровне Snapshot Isolation можно избежать феномена P2. Аномалия A2 произойти не может, так как транзакция на уровне Snapshot Isolation будут читать одно и то же значение элемента данных даже в том случае, когда в промежутках между чтениями этот элемент изменяется другой транзакцией. Очевидно, что в истории на уровне Snapshot Isolation может произойти аномалия искажение записи (A5B) (например, в истории H5), а в одноверсионной интерпретации историй запрещет феномена P2 устраняет A5B. Поэтому на уровне Snapshot Isolation допускаются истории с аномалиями, которые не допустимы на уровне REPEATABLE READ.
На уровне Snapshot Isolation невозможна аномалия A3. При повторном чтении транзакции по предикату после изменения данных другой транзакцией будет всегда выдаваться тот же самый старый набор данных. Но на уровне REPEATABLE READ аномалии вида A3 возможны. Snapshot Isolation не допускает историй с аномалией A3, но допускает истории с аномалией A5B, а у REPEATABLE READ все наоборот. Следовательно:
Замечание 9. REPEATABLE READ >><< Snapshot Isolation
Однако Snapshot Isolation не устраняет P3. Рассмотрим следующее ограничение: для множества рабочих заданий, определяемых предикатом, общая продолжительность этих заданий не должна превышать 8 часов. T1 читает по этому предикату, определяет, что общая продолжительность равна 7 часам и добавляет новое задание продолжительностью 1 час. Конкурирующая транзакция T2 делает то же самое. Поскольку обе транзакции вставляют разные элементы данных (а также разные значения ключей индексов, если таковые имеются), такой сценарий не устраняется механизмом "выигрывает первая зафиксированная транзакция" и может иметь место на уровне Snapshot Isolation. Но в любой эквивалентной последовательной истории такой сценарий привел бы к возникновению феномена P3.
Возможно, наиболее замечательно то, что на уровне Snapshot Isolation отсутствуют фантомы (в строгой интерпретации A3 определения ANSI). Каждая транзакция никогда не видит изменений, производимых параллельно выполняемыми транзакциями. Таким образом, без дополнительных ограничений в подразделе 4.28 в [ANSI] можно сформулировать следующий поразительный результат: (напомним, что в ANOMALY SERIALIZABLE соответствует определению ANSI SQL SERIALIZABLE)).
Замечание 10. В историях на уровне Snapshot Isolation устраняются аномалии A1, A2 и A3. Следовательно, в аномальной интерпретации ANOMALY SERIALIZABLE из ANOMALY SERIALIZABLE << Snapshot Isolation.
На уровне Snapshot Isolation разрешается выполняться транзакциям с очень старыми временными метками, что позволяет им совершать путешествия во времени, вопринимая исторические аспекты базы данных, не блокируя транзакции, изменяющие базу данных, и не блокируясь такими транзакциями. Конечно, если транзакции с очень старыми временными метками, попытались бы изменять данные, уже измененные более молодыми транзакциями транзакциями, они были бы завершены аварийным образом.
Достаточно простая реализация механизма Snapshot Isolation была предложена Ридом (Reed) в [REE]. Существует несколько коммерческих реализаций таких многоверсионных баз данных. В InterBase 4 фирмы Borland [THA] и сервере, лежащем в основе Exchange System компании Microsoft, обеспечивается Snapshot Isolation с механизмом "Выигрывает первая зафиксированная транзакция". Этот механизм заставляет систему помнить все изменения (блокировки по записи), принадлежащие каждой транзакции, которая фиксируется после снятия стартовой временной метки каждой активной транзакции. Транзакция завершается аварийным образом, если ее изменения конфликтуют с запомненными изменениями других транзакций.
"Оптимистический" подход Snapshot Isolation к управлению параллельным выполнением транзакций имеет очевидное преимущество для только читающих транзакций, но его преимущества для изменяющих транзакций до сих пор обсуждаются. Возможно, этот метод не подходит для долговременных изменяющих данные транзакций, конкурирующих с высоко состязательными кратковременными транзакциями. Кратковременные транзакции будут фиксировать свои модификации быстрее и, следовательно, поскольку "выигрывает первая зафиксировавшаяся транзакция", долговременные транзакции, вероятнее всего, будут постоянно откатываться. (Заметим, что такой сценарий привел бы к реальной пролеме и в блокировочных реализациях, а если принять решение не использовать долговременные изменяющие транзакции, то будет применим и подход Snapshot Isolation.) Конечно, в случае, когда кратковременные транзакции конфликтуют минимально, а долговременные ndash; только читают данные, подход Snapshot Isolation должен дать хорошие результаты. В случае сильной конкуренции между транзакциями сопоставимой длины Snapshot Isolation представляет собой классический оптимистический подход. Мнения относительно его полезности расходятся.
Критика уровней изолированности в стандарте ANSI SQL
Х. Беренсон, Ф. Бернштейн, Д. Грэй, Д. Мелтон, Э. О'Нил, П. О'НилИсточник: журнал Системы Управления Базами Данных # 2/1996, издательский дом «Открытые системы»
Новая редакция: Сергей Кузнецов, 2009 г.
Оригинал: Hal Berenson, Phil Bernstein, Jim Gray, Jim Melton, Elizabeth O’Neil, Patrick O'Neil. Critique of ANSI SQL Isolation Levels. Proceeding of the ACM SIGMOD International Conference, May, 1995. Текст доступен здесь.
В ANSI SQL-92 [MS, ANSI] уровни изолированности (Isolation Levels) определяются в терминах феноменов (phenomena): грязное чтение (Dirty Read), неповторимое чтение (Non-repeatable Read) и фантомы (Phantom). В статье показывается недостаточность феноменов и определений ANSI SQL для надлежащего описания нескольких популярных уровней изолированности, включая стандартные блокировочные реализации рассматриваемых уровней. Исследуется неоднозначность определений феноменов и дается более точное формальное определение феномена. Вводятся новые феномены, которые лучше характеризуют предлагаемые типы изолированности. Определяется новый тип многоверсионной изолированности называемый изолированностью на основе моментальных снимков (Snapshot Isolation).
Механизм блокировок
В большинстве SQL-продуктов изолированность реализована на основе механизма блокировок. Поэтому полезно описать уровни изолированности ANSI SQL в терминах блокировок, хотя при этом возникают некоторые проблемы.Выполнение транзакций происходит под управлением планировщика блокировок. Перед выполнением операции чтения или записи над отдельными элементами данных или множеством элементов данных транзакция делает запрос планировщику блокировок на установление соответствующей блокировки по чтению (Share) или записи (Exclusive). Две блокировки, запрошенные различными транзакциями на одном и том же элементе данных, конфликтуют, если хотя бы одна из них является блокировкой по записи.
Предикатная блокировка по чтению (записи) множества элементов данных, определяемого задаваемым условием
Транзакция обладает правильно построенными (well-formed writes) записями (чтениями), если она запрашивает блокировку по записи (чтению) каждого элемента данных или предиката перед выполнением операции записи (чтения) этого элемента данных или множества элементов данных, определяемого предикатов. Транзакция называется правильно построенной (well-formed), если правильно построены все ее операции записи и чтения. Транзакция обладает двухфазными (two-phase writes) записями (чтениями), если она не устанавливает новую блокировку по записи (чтению) на элемент данных после снятия с него блокировки по записи (чтению). Транзакция осуществляет двухфазное блокирование (two-phase locking), если она не запрашивает новeю блокировку (по записи или чтению) после снятия какой-либо блокировки.
Блокировка, запрашиваемая транзакцией, называется долговременной (long duration), если она не снимается до конца транзакции (фиксации или аварийного завершения). В противном случае блокировка называется кратковременной (short duration). На практике кратковременные блокировки обычно снимаются сразу же после завершения операции.
Если одна транзакция удерживает блокировку, а другая транзакция запрашивает установку конфликтующей блокировки, то этот запрос не удовлетворяется до тех пор, пока конфликтующая блокировка первой транзакции не будет освобождена.
Фундаментальная теорема сериализуемости гласит, что правильно построенное двухфазное блокирование гарантирует сериализуемость – каждая история, порождаемая двухфазным блокированием, эквивалентна некоторой последовательной истории. Наоборот, если транзакция не является правильно построенной или не осуществляет двухфазное блокирование, то возможны несериализуемые истории выполнения [EGLT]. Исключения составляют только вырожденные случаи.
В стремлении показать эквивалентность блокировок, зависимостей и формализмов, основанных на аномалиях, в статье [GLPT] определялись четыре степени согласованности (degrees of consistency). Определения аномалий (см. определение 1) были слишком расплывчатыми. Авторов этой статьи продолжают критиковать за этот аспект определений (см. также [GR]). Испытание временем смогли выдержать только более строгие математические определения в терминах историй, графов зависимостей и блокировок.
|
Уровень согласованности = Блокировочный уровень изолированности |
Блокировки по чтению на элементах данных и предикатах (одинаковы, если нет замечаний) |
Блокировки по записи на элементах данных и предикатах (везде одинаковы) |
|
Степень 0 |
Ничего не требуется |
Правильно построенные записи |
|
Степень 1 = блокировочное чтение незафиксированных данных (Locking READ UNCOMMllTED) |
Ничего не требуется |
Правильно построенные записи Долговременные блокировки по записи |
|
Степень 2 = Блокировочное чтение зафиксированных данных (Locking READ COMMITTED) |
Правильно построенные чтения Кратковременные блокировки по чтению (в обоих случаях) |
Правильно построенные записи Долговременные блокировки по записи |
|
Устойчивость курсора (см. разд. 4.1) (Cursor Stability) |
Правильно построенные чтения Блокировка по чтению удерживается на текущем элементе курсора Кратковременные предикатные блокировки по чтению |
Правильно построенные записи Долговременные блокировки по записи |
|
Блокировочное повторимое чтение (Locking REPEATABLE READ) |
Правильно построенные чтения Долговременные блокировки по чтению на элементах данных Кратковременные предикатные блокировки по чтению |
Правильно построенные записи Долговременные блокировки по записи |
|
Степень 3 = Блокировочная сериализуемость (Locking SERIALIZABLE) |
Правильно построенные чтения Долговременные блокировки по чтению (в обоих случаях) |
Правильно построенные записи Долговременные блокировки по записи |
Во таблице 2 определяется несколько типов изолированности в следующих терминах: области действия блокировок (элементы или предикаты), режимы (по чтению или по записи) и продолжительность (кратковременные или долговременные). Мы полагаем, что блокировочные уровни изолированности, называемые блокировочным чтением незафиксированных данных (Locking READ UNCOMMITTED), блокировочным чтением зафиксированных данных (Locking READ COMMITTED), блокировочным повторимым чтением (Locking REPEATABLE READ) и блокировочной сериализуемостью (Locking SERIALIZABLE), подразумевались в определениях уровней изолированности ANSI SQL, но, как демонстрируется позже в этой статье, они существенно отличаются от тех, которые перечислены в . Следовательно, необходимо различать уровни изолированности, определяемые в терминах блокировок, и уровни изолированности ANSI SQL, определяемые с помощью феноменов. Поэтому названия уровней изолированности в имеют префикс "Блокировочные", а в – "ANSI".
В [GLPT] определяется согласованность Степени 0, на которой разрешаются грязное чтение и запись (Dirty Reads and Writes). Требуется только атомарность операций. Степени 1, 2 и 3 аналогичны Locking READ UNCOMMITTED, Locking READ COMMITTED и Locking SERIALIZABLE соответственно. Ни одна степень согласованности не соответствует уровню изолированности Locking REPEATABLE READ.
Дейт и IBM [DAT, DB2] поначалу использовали термин "повторимые чтения" (Repeatable Reads) для обозначения сериализуемости или блокировочной сериализуемости. Этот термин кажется более понятным, чем термин "третья степень изолированности" [GLPT], хотя по значению они идентичны. Значение термина ANSI SQL REPEATABLE READ отличается от значения оригинального определения, данного Дэйтом, и мы полагаем, что принятая в ANSI SQL терминология является неудачной. Поскольку аномалия P3 специальным образом не исключается на уровне изолированности ANSI SQL REPEATABLE READ, из определения P3 ясно, что чтения НЕ являются повторимыми! В мы продолжаем неправильно использовать этот термин в Locking REPEATABLE READ, чтобы соответствовать определению ANSI. Аналогично, Дейт ввел термин "устойчивость курсора" (Cursor Stability) как более понятное название для второй степени изолированности с дополнительной защитой от потерянных изменений через курсор, как объясняется ниже в подразделе 4.1 ниже.
Определение. Уровень изолированности L1 слабее (weaker) уровня изолированности L2 (или L2 сильнее (stronger), чем L1; обозначим это как L1 << L2), если все несериализуемые истории, удовлетворяющие критериям уровня L2, также удовлетворяют критериям уровня L1, и существует хотя бы одна несериализуемая история, возможная на уровне L1 и невозможная на уровне L2. Два уровня изолированности L1 и L2 эквивалентны (equivalent), что обозначается как L1 == L2, если множества допустимых несериализуемых историй на уровнях L1 и L2 идентичны. L1 не сильнее (no stronger), L2, что обозначается как L1 << L2, если L1 << L2 или L1 == L2. Два уровня изолированности несравнимы (incomparable), что обозначается как L1 >><< L2, когда каждый уровень изолированности допускает несериализуемую историю, недопустимую на другом уровне.
Сравнивая уровни изолированности, мы различаем их только по несериализуемым историям, которые могут произойти на одном уровне и невозможны на другом. Два уровня изолированности могут также различаться по тем сериализуемым историям, которые они допускают, но мы считаем, что Locking SERIALIZABLE == Serializable, хотя хорошо известно, что блокировочный планировщик не допускает все возможные сериализуемые истории. Возможно, такие уровни изолированности несколько непрактичны, поскольку не допускают слишком много сериализуемых историй, но мы здесь этот вопрос не рассматриваем.
Эти определения приводят к слудующему замечанию.
Замечание 1.
Locking READ UNCOMMITTED << Locking READ COMMITTED << Locking REPEATABLE READ << Locking SERIALIZABLE
В следующем разделе мы сравним определения ANSI с блокировочными определениями.
Резюме и Выводы
Подводя итоги, можно сказать, что оригинальные определения уровней изолированности в ANSI SQL имеют серьезные недостатки (как пояснялось в разд. 3). Словесные определения противоречивы и неполны. Не исключается феномен грязной записи (P0). В Замечании 5 мы даем рекомендации по тому, как модифицировать определения уровней изолированности ANSI SQL, чтобы сделать их эквивалентными блокировочным уровням изолированности в [GLPT].В ANSI SQL уровень изолированности REPEATABLE READ мыслился как уровень, на котором исключаются все аномалии, кроме фантомов. Определение, данное в терминах аномалий в , не достигает этой цели, в отличие от блокировочного определения из . Выбор ANSI-термина REPEATABLE READ является вдвойне неудачным: (1) повторяемые чтения не дают повторяемых результатов; (2) в индустрии этот термин уже занят, и в некоторых продуктах повторимое чтение означает сериализуемость. Мы рекомендуем найти для этого уровня новое название.
Некоторые коммерчески популярные уровни изолированности, по степени изолированности попадающие в интервал между уровнями REPEATABLE READ и SERIALIZABLE из , в разд. 4 охарактеризованы новыми феноменами и аномалиями. Все уровни изолированности, о которых упоминается в этой статье, можно классифицировать, как показано на рис. 1 и в . Чем выше на рисунке расположен уровень, тем он сильнее (см. определение в начале подраздела 4.1). Уровни соединены линиями, помеченными феноменами или аномалиями, которые отличают один уровень от другого.
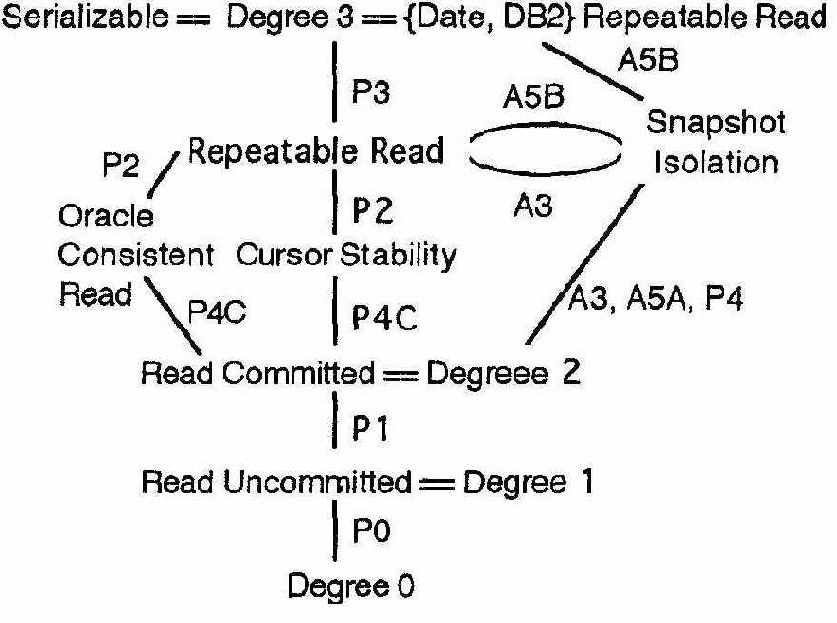
Рисунок 1. Диаграмма уровней изолированности и их взаимосвязей. Предполагается, что уровни изолированности ANSI SQL усилены в соответствии с замечанием 5 и таблицей 3. Дуги аннотированы названиями феноменов, отличающих уровни изолированности. Не показана потенциальная многоверсионная иерархия, расширяющая Snapshot Isolation на более слабые степени изолированности путем установки временных меток на пооператорной основе. Также не показаны исходные уровни изолированности ANSI SQL, основанные на строгой интерпретации феноменов P1, P2 и P3.
Таблица 4. Типы изолированности, характеризуемые возможными допустимыми аномалиями
|
Уровень изолированности |
Р0 Dirty Write |
Р1 Dirty Read |
Р4С Cursor Lost Update |
P4 Lost Update |
Р2 Fuzzy Read |
Р3 Phantom |
A5A Read Skew |
A5B Write Skew |
|
READ UNCOMMITTED == Степень 1 |
невозможен |
возможен |
возможен |
возможен |
возможен |
возможен |
возможен |
возможен |
|
READ COMMITTED == Степень 2 |
невозможен |
невозможен |
возможен |
возможен |
возможен |
возможен |
возможен |
возможен |
|
CURSOR STABILITY |
невозможен |
невозможен |
невозможен |
иногда возможен |
иногда возможен |
возможен |
возможен |
иногда возможен |
|
REPEATABLE READ |
невозможен |
невозможен |
невозможен |
невозможен |
невозможен |
возможен |
невозможен |
невозможен |
|
SNAPSHOT ISOLATION |
невозможен |
невозможен |
невозможен |
невозможен |
невозможен |
иногда возможен |
невозможен |
возможен |
|
ANSI SQL SERIALIZABLE == Степень 3 == Repeatable Read Дейт, IBM, Tandem,... |
невозможен |
невозможен |
невозможен |
невозможен |
невозможен |
невозможен |
невозможен |
невозможен |
Заметим, что уровни ограниченной изолированности для многоверсионных систем никогда раньше не классифицировались, хотя реализованы в нескольких продуктах. Во многих приложениях состязания за блокировки избегаются путем использования уровней изолированности типа Cursor Stability или Read Consistency в Oracle. Snapshot Isolation имеет лучшие характеристики, чем любой из таких уровней: исключаются аномалия потерянных изменений, некоторые фантомные аномалии (например описанная в ANSI SQL), никогда не блокируются только читающие транзакции, и они не блокируют изменяющие транзакции.
Уровни изолированности в ANSI SQL
Разработчики ANSI SQL дали такое определение изолированности, которое допускает широкий спектр механизмов реализации, не только механизм блокировки. Они определили изолированность с помощью следующих трех феноменов (phenomena):P1 (грязное чтение, Dirty Read): Транзакция T1 модифицирует некоторый элемент данных. После этого другая транзакция T2 читает содержимое этого элемента данных до того, как транзакция T1 выполняет операцию COMMIT (фиксируется) или ROLLBACK
(откатывается). Если T1 затем завершается операцией ROLLBACK, то получается, что транзакция T2 прочитала элемент данных, который никогда не фиксировался и, значит, никогда реально не существовал.
P2 (неповторимое, или размытое чтение, Non-repeatable or Fuzzy Read): Транзакция T1 читает некоторый элемент данных. После этого другая транзакция T2 модифицирует или удаляет этот элемент данных и фиксируется. Если T1 после этого попытается прочитать этот элемент данных снова, то она получит другое значение или обнаружит, что элемент данных больше не существует.
P3 (фантомы, Phantom): Транзакция T1 читает набор элементов данных, удовлетворяющих некоторому условию
создает элемент данных, удовлетворяющий этому условию, и фиксируется. Если транзакция T1 повторит чтение с тем же условием
Ни один из этих феноменов не может произойти в последовательной истории. Поэтому, по теореме о сериализуемости, они не могут произойти и в сериализуемой истории [EGLT, BHG Теорема 3.6, GR Раздел 7.5.8.2, PON Теорема 9.4.2].
Истории, состоящие из операций чтения, записи, фиксации и отката, могут быть записаны в сокращенной нотации: "w1[x]" обозначает операцию записи транзакции 1 в элемент данных x (таким образом данные "модифицируются"), а "r2[x]" представляет операцию чтения x в транзакции 2. Операции чтения и записи в транзакции 1 множества записей, удовлетворяющих предикату P, обозначаются r1[P] и w1[P] соответственно. Фиксация (COMMIT) и откат (ROLLBACK) транзакции 1 обозначаются "c1" и "a1" соответственно.
Феномен P1 может быть переформулирован как запрет на следующего сценария:
(2.1) w1[x]...r2[x]... (a1 и c2 в любом порядке)
Словесное определение феномена P1 неоднозначно. Оно в действительности не настаивает на том, чтобы T1 заканчивалась аварийным образом, а только утверждает, что если это произойдет, то может случиться что-то плохое. Некоторые люди интерпретируют P1 как:
(2.2) w1[x]...r2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
Если запретить P1 в варианте (2.2), то не будет допускаться любая история, в которой T1 модифицирует элемент данных x, а затем T2 читает элемент данных x до того как T1 зафиксируется или откатится. Не требуется, чтобы T1 завершалась аварийно, или чтобы T2 фиксировалась.
Определение (2.2) является намного более свободной интерпретацией P1, чем (2.1), поскольку оно запрещает все четыре возможных варианта пар фиксация-откат транзакций T1 и T2, когда в (2.1) запрещаются только две пары из четырех. Интерпретация (2.2) феномена P1 запрещает все варианты последовательности выполнения, в которых что-то аномальное могло бы произойти в будущем. Мы называем интерпретацию (2.2) свободной интерпретацией P1, а (2.1) – строгой интерпретацией
P1. Интерпретация (2.2) определяет феномен, который может привести к аномалии, а (2.1) определяет реальную аномалию. Обозначим их P1 и A1 соответственно. Тогда:
P1: w1[x]...r2[x]... ((c1 или a1) и (c2 или a2) в любом порядке) A1: w1[x]...r2[x]... ((a1 и c2) в любом порядке)
Аналогично, словесные определения феноменов P2 и P3 тоже имеют свободную и строгую интерпретации. Обозначим свободные интерпретации через P2 и P3, а строгие через A2 и A3:
P2: r1[x]...w2[x]... ((c1 или a1) и (c2 или a2) в любом порядке) A2: r1[x]...w2[x]...c2...r1[x]...c1 P3: r1[P]...w2[y in P]... ((c1 или a1) и (c2 или a2) в любом порядке) A3: r1[P]...w2[y in P] ...c2...r1[P]...c1
В третьем разделе все варианты интерпретаций феноменов рассматриваются более подробно. Аргументируется необходимость выбора свободных интерпретаций. Заметим, что в словесном ANSI SQL определении феномена P3 после чтения множества элементов данных, удовлетворяющих предикату P, запрещается только вставлять данные, которые попадают в область действия этого предиката, а в определении P3, которое было приведено выше, запрещается производить любую операцию записи (вставку, обновление, удаление), влияющую на кортеж, который удовлетворяет предикату.
Далее в статье рассматривается концепция многозначной истории (multi-valued history, MV-история, см. [BHG], Глава 5). Если не вдаваться в детали, в многоверсионной системе может одновременно существовать несколько версий одного элемента данных. При каждом чтения должно быть совершенно ясно, какую версию данных следует читать. Известны попытки связать определения изолированности ANSI с многоверсионными системами, а также с более распространенными одноверсионными системами (single-version) (SV-истории) стандартного блокировочного планировщика. Тем не менее, словесные определения феноменов P1, P2 и P3 подразумевают одноверсионные истории. В следующем разделе показано, как мы их интерпретируем.
В таблице 1 приводятся четыре уровня изолированности, определенные в ANSI SQL. Каждый уровень изолированности характеризуется соответствующим феноменом, который не должен быть свойственен поведению транзакций на данном уровне (в строгой или свободной интерпретации). Однако сериализуемый уровень изолированности в ANSI SQL не определяется только в терминах феноменов. В подразделе 4.28 "SQL-транзакции" [ANSI] отмечается, что на уровне изолированности SERIALIZABLE должно обеспечиваться поведение, которое "общеизвестно как полностью сериализуемое выполнение". Анализируя верхнюю часть таблицы и принимая во внимание эту оговорку, обычно приходят к распространенному заблуждению, что запрет всех трех феноменов приведет к сериализуемости. Истории, исключающие три указанных феномена, в таблице 1 называются аномально сериализуемыми (ANOMALY SERIALIZABLE).
Таблица 1. Уровни изоляции ANSI SQL в терминах трех исходных феноменов
|
Уровень изолированности |
Р1 (или А1) грязное чтение (Dirty Read) |
Р2 (или А2) размытое чтение (Fuzzy Read) |
Р3 (или А3) фантом (Phantom) |
|
ANSI НЕЗАФИКСИРОВАННОЕ ЧТЕНИЕ (ANSI READ UNCOMMITTED) |
возможно |
возможно |
возможен |
|
ANSI НЕЗАФИКСИРОВАННОЕ ЧТЕНИЕ (ANSI READ UNCOMMITTED) |
невозможно |
возможно |
возможно |
|
ANSI ПОВТОРИМОЕ ЧТЕНИЕ (ANSI REPEATABLE READ) |
невозможно |
невозможно |
возможен |
|
АНОМАЛЬНАЯ СЕРИАЛИЗУЕМОСТЬ (ANOMALY SERIALIZABLE) |
невозможно |
невозможно |
невозможен |
уровни изолированности (в которые не допускается большее количество историй). В третьем разделе показано, что даже если мы берем свободные интерпретации P1, P2 и P3 и запрещаем эти феномены, то мы все равно не получим истинной сериализуемости.
Было бы проще оотказаться в [ANSI] от P3 и использовать для определения ANSI0-сериализуемости подраздел 4.28. В представлен только промежуточный результат, окончательный результат будет представлен в .
Устойчивость курсора
Тип изолированности "устойчивость курсора" (Cursor Stability) вводится для того, чтобы предотвратить феномен потерянных изменений (Lost Update).P4 (потерянные изменения, Lost Update): Аномалия потерянных изменений происходит в том случае, когда транзакция T1 читает элемент данных, после чего T2 изменяет этот элемент (на основе его предыдущего чтения), а затем T1 (основываясь на ранее прочитанном ею значении) модифицирует тот же элемент данных и фиксируется. В терминах историй это будет выглядеть следующим образом:
P4: r1[x]...w2[x]...w1[x]...c1 (Lost Update)
Как иллюстрируется в истории H4, проблема заключается в том, что даже если транзакция T2 зафиксируется, ее изменения будут потеряны.
H4: r1[x=100] r2[x=100] w2[x=120] c2 w1[x=130] c1
В конечном значении элемента x отражается только приращение 30, добавленное транзакцией T1. Феномен P4 возможен на уровне изолированности READ COMMITTED, поскольку история H4 допустима, если запрещены феномен P0 (фиксация транзакции, осуществляющей первую запись, происходит до второй записи) и P1 (в котором требуется чтение после записи). Однако запрет феномена P2 устранит и P4, поскольку w2[x] происходит после r1[x] и перед фиксацией или откатом T1. Поэтому аномалия P4 полезна для различия промежуточных уровней изолированности между уровнями READ COMMITED и REPEATABLE READ.
Уровень изолированности Cursor Stability расширяет блокировочное поведение уровня READ COMMITED для SQL-курсоров, добавляя новую операцию чтения (Fetch) по курсору rc (означает read cursor, т.е. чтение по курсору) и требуя, чтобы блокировка устанавливалась на текущем элементе курсора. Блокировка удерживается до тех пор, пока курсор не будет перемещен (пока не изменитьтся его текущий элемент) или закрыт, возможно, операцией фиксации. Естественно, транзакция, читающая по курсору, может изменить текущую строку (wc – запись по курсору), и в этом случае блокировка по записи этой строки будет сохраняться до тех пор, пока транзакция не зафиксируется, даже после передвижения курсора с последующей выборкой следующей строки. Между rc1[x] и последующей wc1[x] не может вклиниться w2[x]. Следовательно, в этом случае предотвращается феномен P4, переименованный ниже в P4C
P4C: rc1[x]...w2[x]...wc1[x]...c1 (Lost Update) (потерянные изменения)
Замечание 7.
READ COMMITTED << Cursor Stability << REPEATABLE READ
Режим Cursor Stability широко применяется в SQL-ориентированных системах для предотвращения потери изменений строк, читаемых через курсор. В некоторых системах режим READ COMMITTED в действительности является более сильным, чем Cursor Stability. Стандарт ANSI это допускает.
Техника установки курсора на элемент данных для сохранения его значения неизменным может использоваться для нескольких элементов за счет применения нескольких курсоров. Таким образом, программисты могут использовать режим Cursor Stability для обеспечения изоляции Locking REPEATABLE READ для любых транзакций, оперирующих с небольшим, фиксированным числом элементов данных. Однако этот метод неудобен и совсем не универсален. Поэтому всегда существуют истории, соответствующие феномену P4 (и, конечно, более общему P2) и не устранимые на уровне Cursor Stability.
Литеральные типы
Литеральные типы данных в модели ODMG соответствуют традиционному пониманию типа данных как множества значений, над которыми определен набор операций и механизм внешнего представления (литералов в традиционном смысле этого термина). В модели поддерживается ряд литеральных типов – базовые скалярные числовые типы, символьные и булевские типы (атомарные литералы), конструируемые типы литеральных записей (структур) и коллекций. Конструируемые литеральные типы могут основываться на любом литеральном или объектном типе, но считаются неизменными. Даты и время строятся как литеральные структуры.Можно определить четыре разновидности литеральных типов коллекций. Типы категории set – это обычные типы множеств. Типы категории bag – эти типы мультимножеств (в значениях которых допускается наличие элементов-дубликатов). Значениями типов категории list являются упорядоченные списки значений (среди них допускаются дубликаты). Наконец, значениями типа dictionary являются множества пар , причем все ключи в этих парах должны быть различными. Все определения конструируемых литеральных типов имеют рекурсивную природу. Например, можно определить тип множества структур, элементами которых будут являться списки мультимножеств и т.д.
Заметим, что конструкторы литеральных типов позволяют определять типы с произвольно сложной внутренней структурой. Но очень важно то, что в модели ODMG отсутствует возможность определения пользовательских структурных литеральных типов с собственным набором операций. По непонятным причинам авторы модели ODMG допустили эту возможность только для объектных типов.
тогда эта аббревиатура раскрывалась как
Консорциум ODMG () был образован в 1991 г. ( тогда эта аббревиатура раскрывалась как Object Database Management Group, но впоследствии приобрела более широкую трактовку – Object Data Management Group). Консорциум ODMG был тесно связан с гораздо более многочисленным консорциумом OMG (Object Management Group, ), который был образован двумя годами раньше. Основной исходной целью ODMG была выработка промышленного стандарта объектно-ориентированных баз данных (общей модели). За основу была принята базовая объектная модель OMG COM (Core Object Model). В течение десятилетнего существования ODMG опубликовала три базовых версии стандарта, последняя из которых называется ODMG 3.0 [].Модель ODMG является объектной моделью данных, включающей возможность описания как объектов, так и литеральных значений. На разработку модели повлиял тот факт, что она предназначена для поддержки работы с базами данных, так что особо важной является эффективность доступа к данным. Модель ODMG подстраивается под специфику систем баз данных следующим образом:
в модели связи между объектами отличаются от атрибутов объектов.
"Объектная" модель SQL
Как и в предыдущем разделе, начнем с общего обзора системы типов данных языка SQL, а потом сосредоточимся на средствах, которые в [] расцениваются как "объектные расширения". В основном будем основываться на стандарте SQL:1999, отмечая некоторые важные дополнения, появившиеся в стандарте SQL:2003 [].Объектные типы
Объектный тип в модели ODMG похож, скорее, на класс в языках объектно-ориентированного программирования. В отличие от литерального типа с предопределенным множеством значений, объекты объектного типа создаются динамически при явном обращении к соответствующей операции типа. По сути дела, объект является контейнером, который может содержать литеральные значения (или ссылки на объекты) в соответствии со структурой данных, специфицированной при определении объектного типа. У каждого объекта имеется уникальный OID, который обеспечивает доступ к свойствам объекта через операции, определенные для соответствующего объектного типа.Точно так же, как имеются атомарные и конструируемые литеральные типы, существуют атомарные и конструируемые объектные типы. В стандарте ODMG 3.0 говорится, что атомарными объектными типами являются только типы, определяемые пользователями (UDT). Конструируемые объектные типы включают структурные типы (в действительности, только типы даты-времени, которые в этой статье не представляют интереса) и набор типов коллекций.
Наряду с набором конструкторов литеральных типов коллекций set , bag , list , array и dictionary поддерживается аналогичный набор конструкторов объектных типов коллекций – Set , Bag , List , Array и Dictionary . В отличие от литералов-коллекций объекты-коллекции обладают объектными идентификаторами и свойством изменчивости. Во всех случаях требуется, чтобы все элементы коллекции были одного типа, литерального или объектного. И для литеральных, и для объектных коллекций поддерживается возможность итерации коллекции с перебором элементов коллекции либо в порядке, определяемом системой (для множеств и мультимножеств), либо в порядке, предполагаемом видом коллекции (для списков, массивов и словарей). Немного позже мы обсудим, для чего нужны объектные типы коллекций.
В модели ODMG UDT можно определить с помощью двух разных синтаксических конструкций языка ODL – interface и class. В обоих случаях в интерфейсной части определения UDT присутствуют следующие компоненты (некоторые из них не являются обязательными):
Определение класса отличается от определения интерфейса наличием двух необязательных разделов: extends и списка дополнительных свойств. В действительности, наиболее важным отличием класса от интерфейса является возможность наличия второго из этих разделов. В списке свойств могут присутствовать элементы extent и key. В спецификации модели данных ODMG 3.0 говорится, что для каждого класса может быть определен только один экстент, являющийся объектом-множеством всех объектов этого класса, которые после создания должны сохраняться в базе данных.
Другими словами, включение в определение UDT элемента extent приводит (а) к неявному определению объектного типа множества, элементами которого являются объекты (на самом деле, OID объектов) определяемого UDT; (б) к неявному созданию объекта этого типа множества, причем к этому объекту возможен доступ по имени UDT; (в) автоматическому обновлению состояния экстента при каждом создании/уничтожении объекта UDT. Заметим, что, во-первых, у UDT может отсутствовать экстент, и, во-вторых, объект (его OID) может входить в несколько объектных коллекций, любую из которых, наряду с экстентом UDT, можно использовать в OQL-запросах. Если объект можно трактовать как аналог стабильно хранимой переменной, а OID – как указатель на эту переменную, то объект-коллекцию можно воспринимать как контейнер коллекций OID объектов одного UDT, т.е. как контейнер коллекций указателей на переменные.
Ключ – это набор свойств объектного класса, однозначно идентифицирующий состояние каждого объекта, который входит в экстент класса (это аналог возможного ключа реляционной модели данных). Для класса может быть объявлено несколько ключей, а может не быть объявлено ни одного ключа даже при наличии определения экстента. В последнем случае в экстенте класса могут существовать разные объекты с одним и тем же состоянием.
Далее, хотя и интерфейсы, и классы являются средствами определения объектных типов, между ними проводится жесткое различие. Допускается создание объектов только тех объектных типов, которые определены как классы. Объектные типы, определенные как интерфейсы, могут использоваться только для порождения новых объектных типов (интерфейсов и классов) на основании множественного наследования. Классы могут определяться на основе множественного наследования интерфейсов и одиночного наследования классов.
Механизм наследования от интерфейсов называется в ODMG наследованием IS-A, а механизм наследования от классов – extends. Прежде чем попытаться пояснить этот подход, приведем пример графа наследования интерфейсов и классов, в котором также показывается место существующих экстентов и объектов (рис. 2).
На рис. 2 "жирными" стрелками показаны связи объектных типов по наследованию IS-A. Обычные стрелки показывают связи по наследованию extends. Пунктирные стрелки соответствуют связям экстентов и соответствующих классов. Обратите внимание, что на этом рисунке у каждого из классов, входящих в иерархию, определен свой собственный экстент. Как демонстрирует рисунок, в модели ODMG поддерживается семантика включения, означающая, что экстент любого подкласса является подмножеством экстента любого своего суперкласса (прямого или косвенного). Кроме того, независимо от наличия или отсутствия поддержки экстентов, работает полиморфизм по включению: любой объект любого подтипа является объектом любого его супертипа.
Если у некоторого подкласса свой собственный экстент не определен, то с объектами этого подкласса можно работать только через экстент какого-либо суперкласса. Стандарт не требует обязательного определения экстента. В этом случае ответственность за поддержку работы с множествами объектов ложится на прикладного программиста (для этого можно использовать типы коллекций).
Рис. 2. Пример иерархии объектных типов и их экстентов
Итак, при порождении подкласса путем наследования extends от некоторого суперкласса подкласс наследует экстент и набор ключей суперкласса. Как уже отмечалось, для подкласса можно определить свой собственный экстент. Что же касается переопределения ключей, то в стандарте отсутствуют явные указания о возможности или невозможности этого действия. Однако очевидно, что если бы было разрешено полное переопределение набора ключей для экстента подкласса, то это противоречило бы семантике включения. По нашему мнению, по этому поводу можно трактовать ODL одним из двух способов.
Объекты и литералы
Одним из важнейших отличий объектов от значений является наличие у объекта уникального идентификатора (объекты обладают свойством индивидуальности, или идентифицируемости – identity). Накладные расходы, требуемые для обращения к объекту по его идентификатору с целью получения доступа к базовым значениям данных, могут весьма сильно замедлить работу приложений. Поэтому в модели ODMG допускается описание всех данных в терминах объектов и использование традиционного вида значений, которые в модели называются литеральными значениями. Таким образом, возраст человека может задаваться целочисленным литералом, а не объектом, имеющим свойство возраст. В этом случае значение возраста будет сохраняться как часть структуры данных объекта человек, а не в отдельном объекте. Это, в частности, означает, что объект может входить в состав нескольких других объектов, а литерал – нет. Схема базы данных в модели ODMG главным образом состоит из набора объектных типов, но компонентами этих типов могут быть типы литеральных значений.Другими словами, объект идентифицируется своим объектным идентификатором (OID – Object Identifier), который полностью отделен от значений компонентов объекта, а литерал полностью идентифицируется значениями своих компонентов.
"Сближение" SQL и ODMG
Появление в стандарте SQL:1999 [] новых возможностей – определяемых пользователями типов данных (User Defined Type, UDT) и типизированных таблиц, которые получили название объектных расширений языка SQL, многими было воспринято как сближение "реляционной" и объектной моделей данных. Этому способствуют особенности терминологии стандартов SQL:1999 и SQL:2003 [], в которых значения UDT временами называют "экземплярами" (instance), различают "инстанциируемые" и "неинстанциируемые" UDT, а строки типизированных таблиц и вовсе иногда называют "объектами".На "сближение" моделей SQL и ODMG, казалось бы, указывает и возрастающая синтаксическая близость языков запросов SQL и OQL []. Пусть, например, имеется простая концептуальная схема базы данных, представленная в виде диаграммы классов UML (рис. 1).
Рис. 1. Диаграмма классов "отделы-служащие"
На этой диаграмме классы Emp ("служащие") и Dept ("отделы") связаны двумя ассоциациями, одна из которых (верхняя) устанавливает двунаправленное соответствие "n-к-одному" между служащими и отделами, в которых они работают, а вторая – взаимнооднозначное соответствие между отделами и их руководителями, которые должны являться служащими.
Понятно, что в соответствии с диаграммой с рис. 1 можно определить как схему объектной базы данных в модели ODMG, так и схему "объектно-реляционной" базы данных в модели SQL. В первом случае могут быть определены атомарные объектные типы Emp и Dept с одноименными экстентами; во втором – структурные UDT Emp_T и Dept_T, а также типизированные таблицы Emp и Dept. Предположим, что требуется найти имена всех руководителей отделов, в которых работает хотя бы один служащий, получающий заработную плату свыше 20000 руб. Тогда мы могли бы получить следующие формулировки запроса на языках OQL и SQL соответственно:
OQL: SELECT DISTINCT Emp.works_for.managed_by.empName FROM Emp WHERE Emp.empSalary > 20000.00 SQL: SELECT DISTINCT Emp>works_for>managed_by>empName FROM Emp WHERE Emp.empSalary > 20000.00
В обоих случаях результатом запроса будет множество символьных строк, представляющих имена руководителей отделов. "Точечная" нотация в OQL-запросе и "стрелочная" нотация в SQL-запросе изображают переходы по ассоциациями исходной диаграммы классов. Условие в OQL-запросе ограничивает множество объектов-служащих в экстенте Emp. Условие в SQL-запросе ограничивает множество строк-служащих в типизированной таблице Emp.
Как кажется, этот пример заставляет придти к выводу, что строка типизированной таблицы SQL является прямым аналогом объекта ODMG, а типизированная таблица SQL – это прямой аналог экстента ODMG. Цель данной статьи состоит в том, чтобы показать, что это сходство является только внешним, чисто синтаксическим. На самом деле, между моделями ODMG и SQL имеются фундаментальные различия, которые невозможно преодолеть путем синтаксических расширений языка.
В основе обеих моделей лежит соответствующая система типов данных. Для обоснования основного утверждения данной статьи необходимо произвести краткий экскурс в системы типов ODMG и SQL.
Система типов SQL
Все допустимые в SQL типы данных, которые можно использовать при определении столбцов (а также переменных языка SQL/PSM и параметров процедур, функций и методов) разбиваются на следующие категории:К теме данной статьи не относятся особенности "встроенных" типов категорий (1)-(7). Обсудим четыре последние категории. Начиная с SQL:1999, в языке поддерживается возможность использования типов данных, значения которых являются коллекциями значений некоторых других типов. В SQL:1999 были специфицированы только типы массивов. В новом стандарте SQL:2003 появилась спецификация типа мультимножества.
Типы массивов
Любой возможный тип массива получается путем применения конструктора типов ARRAY. При определении столбца, значения которого должны принадлежать некоторому типу массива, используется конструкция dt ARRAY [mc], где dt специфицирует некоторый допустимый в SQL тип данных, а mc является литералом некоторого точного числового типа с нулевой длиной шкалы и определяет максимальное число элементов в значении типа массива (в терминологии SQL:1999 это значение называется максимальной кардинальностью массива). В стандарте SQL:1999 не поддерживались многомерные массивы и массивы массивов. Однако в стандарте SQL:2003 это ограничение было снято, и теперь типом элементов любого типа коллекций может быть любой допустимый в SQL тип данных, кроме самого конструируемого типа коллекции.
Элементам каждого значения типа массива соответствуют их порядковые номера, называемые индексами. Значение индекса всегда должно принадлежать отрезку [1, mc]. Значениями типа массива dt ARRAY [mc] являются все те массивы, состоящие из элементов типа dt, максимальное значение индекса которых cs не превосходит значения mc. При сохранении в базе данных значение типа массива занимает столько памяти, сколько требуется для сохранения cs элементов. Обеспечивается доступ к элементам массива по их индексам. В частности, можно объявить столбец типа INTEGER ARRAY [10] и при вставке строки в соответствующую таблицу задать значение только пятого элемента массива. Тогда в строку будет занесен массив из пяти элементов, причем первые четыре элемента будут содержать неопределенное значение (NULL).
Основными операциями над массивами являются выборка значения элемента массива по его индексу, изменение некоторого элемента массива или массива целиком и конкатенация (сцепление) двух массивов. Кроме того, для любого значения типа массива можно узнать значение его cs.
Типы мультимножеств
При определении столбца таблицы типа мультимножества используется конструкция dt MULTISET, где dt задает тип данных элементов конструируемого типа мультимножеств. Значениями типа мультимножеств являются мультимножества, т.е. неупорядоченные коллекции элементов одного и того же типа, среди которых допускаются дубликаты. Например, значениями типа INTEGER MULTISET являются мультимножества, элементами которых являются целые числа. Примером такого значения может быть мультимножество {12, 34, 12, 45, -64}.
В отличие от массива, мультимножество является неограниченной коллекцией; при конструировании типа мультимножеств не указывается предельная кардинальность значений этого типа. Однако это не означает, что возможность вставки элементов в мультимножество действительно не ограничена; стандарт всего лишь не требует наличия границы. Ситуация аналогична той, которая возникает при работе с таблицами, для которых в SQL не объявляется максимально допустимое число строк.
Для типов мультимножеств поддерживаются операции для преобразования типа значения-мультимножества к типу массивов или другому типу мультимножеств с совместимым типом элементов (операция CAST), для удаления дубликатов из мультимножества (функция SET), для определения числа элементов в заданном мультимножестве (функция CARDINALITY), для выборки элемента мультимножества, содержащего в точности один элемент (функция ELEMENT). Кроме того, для мультимножеств обеспечиваются операции объединения (MULTISET UNION), пересечения (MULTISET INTERSECT) и определения разности (MULTISET EXCEPT). Каждая из операций может выполняться в режиме с сохранением дубликатов (режим ALL) или с устранением дубликатов (режим DISTINCT).
Расширенные в SQL:2003 возможности работы с типами коллекций являются принципиально важными. Даже при наличии определяемых пользователями типов данных (см. ниже) и типов массивов SQL:1999 не предоставлял полных возможностей для преодоления ограничения "плоских" таблиц, исторически присущего реляционной модели данных вообще и SQL в частности. После появления конструктора типов мультимножеств и устранения ограничений на тип данных элементов коллекции, это историческое ограничение полностью ликвидировано. Мультимножество, типом элементов которого является анонимный строчный тип (см. ниже) является полным аналогом таблицы. Тем самым, в базе данных допускается произвольная вложенность таблиц. Возможности выбора структуры базы данных безгранично расширяются.
Анонимные строчные типы
Анонимный строчный тип – это конструктор типов ROW, позволяющий производить безымянные типы строк (кортежей). Любой возможный строчный тип получается путем использования конструктора ROW. При определении столбца, значения которого должны принадлежать некоторому строчному типу, используется конструкция ROW (fld1, fld2, …, fldn ), где каждый элемент fldi, определяющий поле строчного типа, задается в виде тройки fldname, fldtype, fldoptions. Подэлемент fldname задает имя соответствующего поля строчного типа. Подэлемент fldtype специфицирует тип данных этого поля. В качестве типа данных поля строчного типа можно использовать любой допустимый в SQL тип данных, включая типы коллекций, определяемые пользователями типы и другие строчные типы. Необязательный подэлемент fldoptions может задаваться для указания применяемого по умолчанию порядка сортировки, если соответствующий подэлемент fldtype указывает на тип символьных строк, а также должен задаваться, если fldtype указывает на ссылочный тип (см. ниже). Степенью строчного типа называется число его полей.
Типы, определяемые пользователем
Эта категория типов данных (вернее, подкатегория структурных UDT) наиболее тесно связана с "объектными" расширениями языка SQL. Более подробно мы обсудим структурные UDT в следующем подразделе статьи, а здесь для полноты картины приведем беглый набросок. В SQL поддерживаются две разновидности UDT.
Ссылочные типы
Эта категория типов данных имеет смысл только в контексте "объектных" расширений языка SQL, и мы снова отложим подробное обсуждение этого механизма до следующих подразделов и обсудим его здесь очень коротко. Обеспечивается механизм конструирования типов (ссылочных типов), которые используются в качестве типа специального столбца некоторого вида таблиц (типизированных таблиц), а также в качестве типов обычных столбцов таблиц, атрибутов структурных UDT, переменных и параметров. Фактически, значения ссылочного типа указывают на строки соответствующей типизированной таблицы. Более точно, каждой строке типизированной таблицы приписывается уникальное значение (нечто вроде первичного ключа, назначаемого системой или приложением), которое может использоваться в методах, определенных для табличного типа, для уникальной идентификации строк соответствующей таблицы. Эти уникальные значения называются ссылочными значениями, а их тип – ссылочным типом. Ссылочный тип может содержать только те значения, которые действительно ссылаются на экземпляры указанного типа (т.е. на строки соответствующей типизированной таблицы).
Обратим внимание читателей на то, что все категории типов SQL, кроме ссылочных типов и, частично, структурных UDT содержат совершенно традиционные типы данных, никаким образом не связанные с объектной парадигмой ODMG. Каждый тип можно использовать при спецификации столбцов таблицы, и со значениями этих столбцов можно работать через операции соответствующего типа. Однако структурные UDT и связанные с ними ссылочные типы нагружаются в стандарте SQL некоторым особым смыслом, который объявляется "объектным". Об этом мы и будем говорить далее.
Сопоставление моделей
В качестве аналога объекта в смысле модели ODMG в модели SQL выступает "экземпляр" структурного UDT, или строка типизированной таблицы, ассоциированной с этим UDT. Покажем, что эта аналогия является поверхностной и неточной. Действительно, в модели ODMG объект создается конструктором некоторого объектного типа. Объект обладает свойством индивидуальности (identity), которое выражается в том, что при создании объекта ему присваивается уникальный идентификатор (OID), отличающий его от любого другого объекта любого объектного типа. OID является внешней характеристикой объекта, значение OID не является частью состояния объекта. Объекты в модели ODMG больше всего похожи на динамические переменные в языках программирования; конструктор объектного типа похож на оператор new, создающий динамическую переменную соответствующего типа; OID, по своей сути, напоминает указатель на динамическую переменную. Операция разыменования в модели ODMG кажется аналогичной операции взятия значения элемента структуры по прямому адресу соответствующей структурной переменной.Объекты ODMG индивидуальны и в том смысле, что каждый из них существует независимо от других, представляя собой независимо идентифицируемый (адресуемый) контейнер данных. Объекты, относящиеся к общему объектному типу, могут объединяться в коллекции. Объект может входить в несколько различных коллекций, и может не входить ни в одну коллекцию; это возможно исключительно за счет наличия OID, уникально представляющего объект. В модели ODMG экстент класса введен как дополнительное и необязательное понятие. То же можно сказать и про возможность указания возможного ключа класса: это понятие не является фундаментальным и вводится по техническим соображениям. Фундаментальными основами модели ODMG является система типов (включая, конечно, типы коллекций) и OID.
Разработчики стандарта SQL утверждают, что и "объекты" SQL обладают свойством индивидуальности. Они обосновывают это тем, что строки типизированных таблиц обязательно различаются значениями самоссылающегося столбца. Другими словами, утверждается, что значение самоссылающегося столбца "экземпляра" структурного UDT (т.е. строки типизированной таблицы, ассоциированной с этим UDT) является аналогом OID. Действительно имеется некоторое сходство: ссылочные значения могут автоматически генерироваться системой при образовании нового "экземпляра" структурного UDT (вставке новой строки в типизированную таблицу), и система гарантирует уникальность каждого ссылочного значения.
Но первое важнейшее различие состоит в том, что в модели ODMG OID является внешней характеристикой объекта, не отражающейся в его состоянии, а ссылочное значение "экземпляра" структурного UDT в модели SQL является явным компонентом этого "экземпляра" (оно сохраняется в отдельном столбце типизированной таблицы). Если OID можно трактовать как абстракцию указателя, который можно использовать для прямой адресации объекта как контейнера значений (подобно тому, как производится доступ к переменной через указатель в языках программирования), то ссылочное значение в SQL можно использовать только для ассоциативной адресации (по совпадению ссылочного значения) соответствующей строки в указанной типизированной таблице (отсюда потребность в разделе SCOPE при объявлении местоположения ссылочного типа). "Экземпляры" структурного UDT в модели SQL не являются независимыми контейнерами значений; контейнером является типизированная таблица, которая представляет собой аналог именованной переменной, содержащей в каждый момент времени некоторое значение-множество с элементами-значениями соответствующего структурного UDT. Cтрока типизированной таблицы является элементом этого значения-множества. Таким образом, "экземпляр" структурного UDT в модели SQL – это совсем не объект в смысле ODMG.
Далее, в модели ODMG один объект может входить в несколько коллекций (в том числе, в экстент своего объектного типа). Нет какой-либо одной выделенной коллекции, все они образуются за счет наличия OID как полномочного внешнего представителя объекта. Запросы на языке OQL можно адресовать к любой коллекции (и к индивидуальному объекту, если известен его OID). Типизированную таблицу в модели SQL нельзя считать аналогом экстента объектного типа по двум причинам. Во-первых, можно создать несколько типизированных таблиц, ассоциированных с одним структурным UDT (этот довод не очень сильный, поскольку экстентом можно было бы считать объединение значений всех таких типизированных таблиц). Более важно то, что типизированная таблица в SQL содержит не множество объектов (т.е. OID), а множество значений структурного UDT. Конечно, в SQL можно построить коллекцию ссылочных значений строк типизированной таблицы, но к этой коллекции нельзя адресовать запросы. Другими словами, типизированная таблица в модели SQL – это совсем не экстент в смысле ODMG.
По нашему мнению, рассмотренный материал позволяет сделать вывод о том, что "объектная" модель SQL является всего лишь синтаксической надстройкой над традиционной "реляционной" моделью данных. Различия моделей SQL и ODMG гораздо более серьезны, чем синтаксическое сближение языков запросов SQL и OQL.
В заключение статьи сделаем два замечания. Во-первых, целью этой статьи не являлась критика подходов SQL и/или ODMG к организации баз данных (хотя, конечно же, такая критика возможна и, наверное, полезна). У обоих подходов имеются убежденные сторонники и противники, и эта статья написана не для них. Мы хотели лишь разъяснить реальное положение дел для людей, которые все еще надеются на возможность совершения чудес и, в частности, ожидают появления систем управления базами данных, действительно сочетающих традиционные возможности SQL с преимуществами ODMG. Похоже, что это не произойдет.
Во-вторых, еще до написания этой статьи в адрес автора звучала критика относительно завышения им роли OID в объектных моделях данных. В критических замечаниях указывалось, что на уровне модели фундаментальным абстрактным свойством является индивидуальность (identity) объектов, а OID – это техническая реализация поддержки индивидуальности. Возможно, эта критика была бы справедливой, если бы рассуждения велись в академической манере, не привязываясь к конкретной спецификации. Однако в этой статье обсуждалось соотношение модели SQL с конкретной объектной моделью ODMG 3.0. И вот цитата из [] (стр. 17):
"Поскольку у всех объектов имеются идентификаторы, любой объект можно отличить ото всех других объектов в его домене хранения. … Все идентификаторы в объектной модели ODMG являются взаимно уникальными. Представление индивидуальности объекта называется его объектным идентификатором".
Структурные UDT
В синтаксической конструкции определения структурного UDT присутствуют следующие основные компоненты (некоторые из которых являются необязательными):При определении структурного UDT можно использовать одиночное наследование. Если в определении UDT присутствует раздел подтипизации, то в нем указывается имя ранее определенного UDT, атрибуты и методы которого будут наследоваться определяемым структурным типом. Поддерживается полиморфизм по включению: любое значение любого подтипа трактуется как значение любого супертипа этого подтипа.
Структурные типы, определяемые без использования наследования, называются максимальными супертипами (поскольку у любого из таких типов супертип отсутствует). В определениях максимального структурного супертипа обязан присутствовать раздел представления, в котором специфицируются атрибуты. Имя определяемого атрибута должно отличаться от имен всех других атрибутов определяемого типа, включая имена атрибутов, наследуемых от супертипа, и имена атрибутов типа данных определяемого атрибута. Тип данных может быть любым допустимым в SQL типом данных (включая конструируемые типы ARRAY, MULTISET и ROW, а также UDT), кроме самого определяемого структурного типа и его супертипов.
Можно определить инстанциируемый (instantiable) или неинстанциируемый (not instantiable) структурный тип. Для неистанциируемого типа не определяется конструктор, и поэтому невозможно создать значение этого типа. Поэтому такие типы применимы только для определения инстанциируемых подтипов. Назначение неинстанциируемых типов состоит в моделировании абстрактных концепций, на которых основываются более конкретные концепции. Неинстанциируемые типы могут быть типами атрибутов других структурных типов, типами столбцов, переменных и т.д. Однако в соответствующем местоположении всегда должно находиться либо значение инстанциируемого подтипа данного неинстанциируемого типа, либо неопределенное значение. При отсутствии явной спецификации по умолчанию тип считается инстанциируемым.
Все, что говорилось до сих пор в этом подразделе по поводу структурных UDT, не имеет никакой "объектной" специфики. Определенный пользователем структурный тип устроен как самый обычный тип: он обладает множеством значений и набором операций, а роль литералов играет метод-конструктор. Но у структурных UDT в SQL имеется одна особенность: при определении любого UDT автоматически образуется соответствующий ссылочный тип (ref type), причем можно явно указать, каким образом устроены значения этого типа. В "объектной" модели SQL значения ссылочного типа претендуют на роль аналога OID модели ODMG. Чтобы пояснить смысл спецификации ссылочного типа, забежим немного вперед и немного поговорим о типизированных таблицах, поскольку значения ссылочного типа имеют смысл только в этом контексте.
Типизированная таблица определяется на некотором ранее определенном структурном UDT, и атрибуты этого UDT становятся столбцами таблицы. Кроме того, у типизированной таблицы создается дополнительный "самоссылающийся" (self-referensing) столбец, содержащий значения соответствующего ссылочного типа. В "объектной" модели SQL утверждается, что строки типизированных таблиц обладают всеми характеристиками объектов в объектно-ориентированных системах, включая уникальные идентификаторы (значения ссылочного типа), которые могут использоваться для ссылок из других компонентов среды.
В SQL:1999 поддерживаются три различных механизма присваивания уникальных идентификаторов экземплярам структурных типов, ассоциированных с типизированными таблицами (для всех строк таблицы, ассоциированной с данным структурным типом, используется один и тот же механизм). Уникальные идентификаторы экземпляров структурного типа (значения самоссылающегося столбца) могут представлять собой следующее:
Раздел спецификации ссылочного типа может присутствовать только в определении максимального структурного супертипа, т.е. соответствующая спецификация наследуется всеми подтипами этого супертипа. При отсутствии в определении супертипа явного раздела спецификации ссылочного типа по умолчанию предполагается автоматическая генерация ссылочных значений. Если в определении структурного типа указывается, что значения ссылочного типа будут генерироваться приложением, то в определении структурного типа должны присутствовать и спецификации преобразования ссылочных значений. Эти спецификации используются для преобразования поставленных приложением значений встроенного типа в значения, требуемые для реального выполнения ссылок на строки типизированной таблицы, и обратного преобразования.
Заметим, что хотя в SQL допускается использование ссылочного типа при определении столбца любой таблицы, атрибута структурного UDT, переменной или параметра, реальное применение ссылки (через операцию разыменования) для доступа к соответствующему "объекту" возможно только в том случае, когда при спецификации местоположения данных ссылочного типа указывается раздел SCOPE, своего рода область видимости "объектов", на которые указывают ссылки. Поскольку в качестве такой области видимости задается типизированная таблица, отложим более подробное обсуждение этого вопроса до конца следующего подраздела.
Связи
В большинстве объектных систем связи неявно моделируются как свойства, значениями которых являются объекты. Например, если служащий работает в некотором отделе, то у каждого объекта-служащего должно иметься свойство, которое можно назвать worksFor, значением которого является соответствующий объект-отдел. Возникает проблема, если у объекта-отдела имеется свойство, которое затрагивает множество служащих этого отдела (например, consists_of – множество, включающее все объекты служащих данного отдела). Эти два свойства являются несвязными, и поддержка их согласованности может вызывать значительную программистскую проблему.В модели ODMG, подобно диаграммам классов UML, различаются два вида свойств – атрибуты и связи. Атрибутами называются свойства объекта, значение которых можно получить по OID объекта, но не наоборот. Значениями атрибутов могут быть и литералы, и объекты, но только тогда, когда не требуется обратная ссылка. Связи – это инверсные свойства. В этом случае значением свойства может быть только объект, поскольку литеральные значения не обладают свойствами. Поэтому возраст служащего обычно моделируется как атрибут, а компания, в которой работает служащий, – как связь.
При определении связи должна быть определена ее инверсия. В приведенном выше примере, если worksFor определяется как связь, должно быть явно указано, что инверсией является свойство consists_of объекта-отдела, а при определении consists_of должна быть указана инверсия worksFor. После этого система баз данных должна поддерживать согласованность связанных данных, что позволяет сократить объем работы программистов приложений и повысить надежность их программ. Если в объекте-отделе свойство consists_of не требуется, то свойство объекта-служащего works_for может быть атрибутом.
Типизированные таблицы
Хотя типизированные таблицы являются важнейшим элементом "объектной" модели SQL, с точки зрения синтаксиса оператор определения типизированной таблицы представляет собой частный случай оператора создания базовой таблицы CREATE TABLE. Первой существенной особенностью оператора создания типизированной таблицы является обязательное наличие раздела, в котором указывается имя ранее определенного структурного типа. Строки типизированной таблицы называются "экземплярами" структурного типа, ассоциированного с таблицей.Далее, при определении типизированной таблицы можно объявить ее подтаблицей некоторой другой типизированной таблицы. Супертаблица должна быть ассоциирована со структурным типом, являющимся непосредственным супертипом определяемой подтаблицы. В максимальной супертаблице (типизированной таблице, не имеющей супертаблицы) образуются столбцы, соответствующие атрибутам структурного UDT, с которым ассоциирована эта таблица (а также дополнительный "самоссылающийся" столбец). Каждый столбец указанной супертаблицы наследуется подтаблицей; наследуются и характеристики столбцов супертаблицы – значения по умолчанию, ограничения целостности и т.д. Эти столбцы называются унаследованными столбцами подтаблицы, и они соответствуют атрибутам UDT подтаблицы, унаследованным от UDT супертаблицы. Кроме того, подтаблица будет содержать по одному столбцу для каждого собственного атрибута ассоциированного структурного типа. Такие столбцы подтаблицы называются заново определенными.
Как это принято в SQL, столбцы типизированной таблицы имеют порядковые номера. При этом унаследованные столбцы нумеруются до заново определенных столбцов и имеют те же номера, которые имели столбцы супертаблицы.
В определении типизированной таблицы разрешается указывать табличные ограничения целостности. Если определяется максимальная супертаблица, то в ее определении допускается спецификация первичного ключа. В определении типизированной таблицы могут также содержаться спецификации ссылочных ограничений целостности. Ссылки могут вести как на типизированную, так и на обычную таблицу.
В определении максимальной супертаблицы должна присутствовать спецификация "самоссылающегося" столбца, и самоссылающийся столбец, определенный в максимальной супертаблице, наследуется любой ее подтаблицей. Как отмечалось в предыдущем подразделе, при определении любого максимального структурного супертипа явно или неявно задается спецификация ссылочного типа, и спецификация ссылочного типа наследуется всеми подтипами этого супертипа. При определении максимальной типизированной супертаблицы необходимо дополнительно указать соответствующую спецификацию самоссылающегося столбца (в этой спецификации, по сути, повторяются правила генерации значений ссылочного типа; она логически избыточна, и, по всей вероятности, в следующих версиях стандарта SQL требование спецификации самоссылающегося столбца будет ослаблено).
Наконец, в определении типизированной таблицы могут задаваться опции столбцов. Опции столбца можно указывать только для заново определенных столбцов, для унаследованных столбцов это не допускается. Можно указывать значение столбца по умолчанию, ограничения столбца, но в контексте этой статьи наиболее важным является раздел SCOPE. Этот раздел может входить в опции только заново определяемого столбца с типом REF.
Как отмечалось в конце предыдущего подраздела, раздел SCOPE может присутствовать в спецификации любого местоположения ссылочного типа. Поэтому стоит рассмотреть эту тему в общем виде. Для объявления местоположения ссылочного типа используется следующий синтаксис:
REF (UDT_name) [SCOPE table_name]
UDT_name должно задавать имя структурного UDT, на "экземпляры" которого будут указывать значения ссылочного типа. REF-тип может использоваться к качестве типа атрибута структурного типа, и в этом случае тип с именем UDT_name может быть тем же самым, что и определяемый структурный тип. Во всех остальных случаях UDT_name должно являться именем некоторого существующего структурного типа. В необязательном разделе SCOPE задается имя типизированной таблицы table_name. Ассоциированным структурным типом этой таблицы должен быть тип с именем UDT_name.
Если местоположение объявлено с указанием раздела SCOPE, над содержащимися в нем ссылочными значениями можно выполнять операции разыменования (взятия значения указанного атрибута "объекта", на который ведет ссылка, т.е. взятия значения указанного столбца той строки типизированной таблицы, значение самоссылающегося столбца которой совпадает со значением ссылки). Кроме того, в стандартах SQL:1999/2003 определены операции вызова метода "объекта" по ссылке (т.е. вызова метода структурного UDT, ассоциированного с указанной в разделе SCOPE типизированной таблицы, для значения, находящегося в соответствующей строке этой таблицы) и разрешения ссылки (т.е. взятия всего структурного значения, находящегося в соответствующей строке типизированной таблицы).
В соответствии со спецификациями SQL:1999 при объявлении местоположения ссылочного типа с разделом SCOPE можно было дополнительно потребовать от системы поддержки целостности ссылок, т.е. гарантирования того, что в местоположении никогда не будет содержаться ссылочное значение, для которого в типизированной таблице, указанной в разделе SCOPE, не найдется строка с таким же значением самоссылающегося столбца. В стандарте SQL:2003 эта возможность исключена, поскольку спецификации SQL:1999 были неточны. Скорее всего, исправленный вариант соответствующих конструкций появится в следующей версии стандарта.
Наконец, заметим, что если раздел SCOPE включается в определение атрибута структурного UDT, то в опциях столбца типизированной таблицы, соответствующего данному атрибуту, раздел SCOPE присутствовать не может – это считается синтаксической ошибкой.
Форматирование кода и визуальное представление
Существует довольно большой набор средств форматирования SQL-кода. В их числе: Query Designer, входящий в состав SQL Server Management Studio - для форматирования достаточно скопировать запрос и активизировать панель визуального представления. Из средств сторонних разработчиков можно привести в качестве примера SQL Refactor компании Red Gate Software и QueryCommander - бесплатный инструмент с открытым кодом. Основные различия указанных средств - в разных стандартах форматирования, к которым они приводят исходные запросы и в возможности изменить это параметрами настроек.Ий признак
Невозможность визуального представления запроса. В качестве инструмента проверки на соответствие данному признаку можно предложить Query Designer из MS SQL Server. Наверное очевидно, что визуальное представление запроса помогает пониманию его структуры. Состав критичных конструкций языка SQL для этого признака можно взять из документации по SQL Server (Books Online, статья "Query Designer Considerations for SQL Server Databases"). В частности, таковой является конструкция UNION.Img2.shtml

Рис. 2. План выполнения запроса из листинга 4.
Img3.shtml
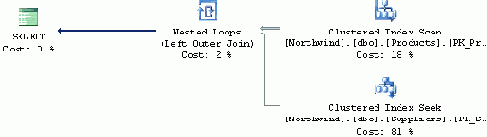
Рис. 3. План выполнения модифицированного запроса из листинга 5
Img4.shtml
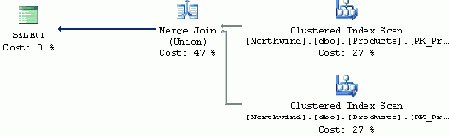
Рис. 4. План выполнения запроса с UNION (из листинга 8)
Избавление от подзапросов
Часто причиной появления в коде подзапроса связано с переносом практики работы с циклами в алгоритмических языках и неумением думать в терминах теории множеств. Простейший случай может выглядеть следующим образом:SELECT Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, (SELECT CompanyName FROM Suppliers WHERE Suppliers.SupplierID = Products.SupplierID) AS CompanyName FROM Products
Листинг 4. Простейший пример использования связанного подзапроса
Того же результата можно добиться и без использования подзапроса:
SELECT Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, Suppliers.CompanyName FROM Products LEFT OUTER JOIN Suppliers ON Suppliers.SupplierID = Products.SupplierID
Листинг 5. Вариант модификации запроса из листинга 4.
При рассмотрении планов выполнения запросов, видно, что планы выполнения обоих запросов практически одинаковые. План для исходного запроса на одно действие короче, но в процентном соотношении различие составляет менее 1%. Здесь нужно принимать во внимание, что оптимизаторы современных СУБД достаточно эффективно "разгоняют" простые запросы со связанными подзапросами. Для более сложных запросов разница может быть существеннее.
Большинство ситуаций, встречающихся в реальных запросах, сложнее, тем не менее, в модифицированном запросе должен будет появиться JOIN с таблицей (таблицами) из подзапросов. При использовании агрегатных функций в подзапросе - они перейдут в основной запрос, к которому будет добавлено предложение GROUP BY (см. листинги 6,7).
SELECT OrderDate, ShipName, (SELECT SUM(UnitPrice*Quantity) FROM OrderDetails WHERE OrderDetails.OrderID = Orders.OrderID) AS OrderSum FROM Orders
Листинг 6. Пример SELECT-команды с агрегатной функцией в подзапросе
SELECT Orders.OrderDate, Orders.ShipName, SUM(OrderDetails.UnitPrice*OrderDetails.Quantity) AS OrderSum FROM Orders LEFT OUTER JOIN OrderDetails ON OrderDetails.OrderID = Orders.OrderID GROUP BY Orders.OrderID, Orders.OrderDate, Orders.ShipName
Листинг 7. Вариант модификации запроса из листинга 6.
Избавление от UNION
Наиболее простым примером использования UNION, от которого можно избавиться, является цепочка предложений UNION, основанных на одной и той же базовой таблице. Примеры исходного запроса и преобразованного приведены в листингах 8,9.SELECT ProductID, ProductName, UnitPrice FROM Products WHERE ProductName LIKE 'A%'
UNION
SELECT ProductID, ProductName, UnitPrice FROM Products WHERE UnitPrice <= 40
Листинг 8.Запрос с UNION на основе одной базовой таблице
SELECT ProductID, ProductName, UnitPrice FROM Products WHERE ProductName LIKE 'A%' OR UnitPrice <= 40
Листинг 9. Модифицированный запрос (замена UNION на OR)
Очевидно, что модифицированный запрос имеет более простой дизайн. Для наглядной иллюстрации критичности использования UNION, ниже приведены планы выполнения этих запросов.

Рис. 5. План выполнения запроса после замены UNION на OR
В некоторых ситуациях в использовании UNION нет необходимости и достаточно более производительного предложения UNION ALL (при его выполнении не происходит объединения повторяющихся строк).
Методы модификации запросов
Для минимизации риска Мартин Фаулер[] рекомендует проводить рефакторинг "маленькими шажочками", осуществляя проверку результата после каждого из них. Часть его книги составляет каталог методов рефакторинга - попытка классифицировать и описать наиболее часто встречающиеся модификации кода (предназначенные, прежде всего, для объектно-ориентированного программирования). Подобный каталог можно составить и для SQL. Ниже, в качестве примера, приведены четыре метода рефакторинга для наиболее простых ситуаций.Ой признак
Точно так же, как и для алгоритмических языков, проблемой, с точки зрения дизайна и сопровождения, является наличие дублирующего кода.Устранение этих двух недостатков (1-го и 2-го признака), скорее всего не изменит скорость выполнения запроса, но поможет лучшему пониманию его структуры и упростит внесение дальнейших изменений.
Следующие признаки "плохих" запросов будут связаны уже с их структурой. Поскольку все они определяются через наличие некоторых конструкций языка SQL, то воспринимать их нужно с оговоркой, что использование данных конструкций в запросе не является безальтернативным и от них можно избавиться.
Практически любой разработчик
Прежде чем заниматься переделкой кода, для начала надо четко определить, чем он плох, к чему надо стремиться, какими характеристиками должен обладать "совершенный запрос". Ниже предлагается ряд признаков "плохого" кода, при этом подразумевается, что по функциональности запрос уже нас устраивает и выдает в точнсти те данные, которые требуются.Программные средства рефакторинга SQL
Действия программиста, выполняемые при проведении рефакторинга, можно поделить на 3 группы: форматирование кода, непосредственное применение методов рефакторинга - преобразований кода и проверку того, что конечный запрос не отличается от исходного по набору возвращаемых данных. Частично эти действия могут быть автоматизированы, точно так же, как они автоматизируются для ряда объектно-ориентированных языков программирования. Ниже приведен краткий обзор средств, которые могут быть использованы для рефакторинга SQL-запросов. Обзор не претендует на полноту и ориентирован, в основном, на программные инструменты, входящие в состав средств разработки компании Microsoft или дополняющие их.Программы для рефакторинга запросов
Автору статьи не удалось найти средства, автоматизирующие непосредственно проведение рефакторинга SQL-кода. Единственный программный продукт, который претендует на эту роль (по крайней мере - по названию) - SQL Refactor, предлагает только возможности форматирования кода, выделение части SQL-кода в качестве хранимой процедуры и разбиение предложения CREATE TABLE на две части (с разделением уже существующих колонок между двумя таблицами). Никаких сервисов по модификации структуры запросов не предлагается.Unit-тестирование для SQL-запросов
В экстремальном программировании практика проведения рефакторинга тесно связана с практикой написания тестов модулей, или unit-тестов. Основная аргументация связи этих практик - невозможность смело переделывать работающий код, если нет механизмов быстрой проверки того, что внесенные изменения его не испортили. В принципе, вполне возможно написание unit-тестов средствами, приспособленными для тестирования программ алгоритмических языков (jUnit, csUnit, встроенными механизмами написания unit-тестов в MS Visual Studio 2005). В случаях, если запросы пишутся для серверных компонентов, обеспечивающих доступ к базам данных, эти тесты могут вполне органично вписываться в общую систему тестирования этих компонентов. При этом необходимо учитывать особенность тестирования запросов: нужны механизмы сравнения наборов данных, а не отдельных значений. Удалось найти всего три средства построения unit-тестов, связанных с тестированием SQL-запросов: SQLUnit, DbUnit и TSQLUnit. Все три средства являются узкоспециализированными: DbUnit и SQLUnit исходно ориентированы на Java-разработчиков, TSQLUnit - требует написания unit-тестов на языке Python. Из них только в DbUnit есть функция сравнения наборов данных, в двух оставшихся - такая возможность отсутствует.Выделение пользовательской функции
Мотивом для проведения такого рефакторинга является частое использование некоторых стандартных вычислений, встречающееся в рамках одного запроса или группы запросов. Пример: расчет первого числа месяца для некоторой даты на языке SQL:DATEADD(dd, 1-DAY(@date), @date)
Понятно, что запись не является особо сложной или громоздкой, но, тем не менее, ее многократное использование не способствует улучшению читаемости кода. Если поместить этот расчет в функцию, ее вызов будет выглядеть так:
FirstDayOfMonth(@date)
Такая запись уже не требует написания комментария (лучшая документация для исходного кода - это он сам).
Выделение представления
Это преобразование может быть оправдано как для повторяющегося участка кода, встречающегося в группе запросов, так и для отдельного запроса. Информативное имя представления также повысит читаемость кода. Особенностью данной модификации является то, что выделяемый участок кода не будет неразрывным в исходном запросе. В листинге 3 цветовым выделением обозначены фрагменты кода, которые необходимо перенести в представление, содержащее информацию таблиц Order и OrderDetails.SELECT Suppliers.CompanyName, Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, OrderDetails.UnitPrice, OrderDetails.Quantity, OrderDetails.Discount, Orders.OrderDate, Orders.ShipName
FROM Suppliers INNER JOIN Products ON Suppliers.SupplierID = Products.SupplierID INNER JOIN OrderDetails ON Products.ProductID = OrderDetails.ProductID INNER JOIN Orders ON OrderDetails.OrderID = Orders.OrderID
WHERE (OrderDetails.Discount = 0) AND (Orders.OrderDate > '06/11/1996')
Листинг 3.Фрагменты кода, формирующие представление.
Эта особенность требует проведения значительного количества мелких действий при осуществлении подобного преобразования вручную.
Ый признак
Код может быть "плохо оформлен", в этом случае его сложно понимать, соответственно - сложно переделывать. Для разработчика это должно означать несоответствие оформления запроса некоторым правилам, стандарту кодирования. Если не рассматривать правила именований объектов баз данных (считается, что схему данных изменить нельзя), то стандарт кодирования должен описывать, как должен быть отформатирован запрос (отступы, пробелы, длина строк…) и как должны именоваться объявляемые в его рамках переменные и алиасы (псевдонимы). Сюда же можно отнести требование использования только стандартных ключевых слов языка SQL и только в несокращенной форме.Наглядно пользу форматирования кода можно продемонстрировать на следующем примере - листинг 1.
SELECT Suppliers.CompanyName, Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, OrderDetails.UnitPrice, OrderDetails.Quantity, OrderDetails.Discount, Orders.OrderDate, Orders.ShipName FROM Suppliers INNER JOIN Products ON Suppliers.SupplierID = Products.SupplierID INNER JOIN OrderDetails ON Products.ProductID = OrderDetails.ProductID INNER JOIN Orders ON OrderDetails.OrderID = Orders.OrderID WHERE (OrderDetails.Discount = 0) AND (Orders.OrderDate > '06/11/1996')
Листинг 1.Пример неформатированного запроса.
Тот же запрос после обработки может выглядеть так:
SELECT Suppliers.CompanyName, Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, OrderDetails.UnitPrice, OrderDetails.Quantity, OrderDetails.Discount, Orders.OrderDate, Orders.ShipName FROM Suppliers INNER JOIN Products ON Suppliers.SupplierID = Products.SupplierID INNER JOIN OrderDetails ON Products.ProductID = OrderDetails.ProductID INNER JOIN Orders ON OrderDetails.OrderID = Orders.OrderID WHERE (OrderDetails.Discount = 0) AND (Orders.OrderDate > '06/11/1996')
Листинг 2. Запрос после проведения форматирования.
Наличие в запросе медленно работающих конструкций. В качестве примера можно привести использование связанных подзапросов. Избавление от подзапросов помимо увеличения скорости выполнения запроса, в большинстве случаев улучшит его читаемость. Предложения UNION также относятся к медленно работающим, т.к. в них требуется отбрасывать избыточные дубликаты [].
Невозможность построения на основе запроса индексированного представления. Если забежать вперед и предположить, что, несмотря на все ухищрения, запрос работает недостаточно быстро, то следующим способом его ускорить можно предложить получение требуемых данных на основе индексированного представления. Перечень ограничений можно опять же получить из документации SQL Server (Books Online, статья "Creating an Indexed View"). В "черный список" снова попали подзапросы и UNION, а также:
Соответствие всем этим требованиям - конечно же, очень сильное ограничение. Естественно, что далеко не все запросы можно перестроить в соответствие с ними. Важно, чтобы программист понимал критичность использования некоторых конструкций с точки зрения производительности и дизайна кода. Во многих ситуациях реально из запроса выделить часть, удовлетворяющую ограничениям индексированного представления и построить индексированный view только для этой части.
к проведению модификации существующего кода
Подход к проведению модификации существующего кода вполне оправдывает себя в применении к SQL-запросам. К сожалению, на сегодняшний день выбор средств автоматизации рефакторинга SQL весьма скуден, а имеющиеся средства недостаточно функциональны. Это скорее всего связано с тем фактом, что XP зародилось в среде разработчиков, программирующих преимущественно на объектно-ориентированных языках и специфичностью характера проведения рефакторинга для SQL-кода.SQL и MapReduce: новые возможности или латание старых дыр?
Сергей КузнецовЭта заметка возникла в связи с переводом статьи Эрика Фридмана (Eric Friedman) и др. "SQL/MapReduce: практический подход к поддержке самоописываемых, полиморфных и параллелизуемых функций, определяемых пользователями". Сначала я, как обычно, хотел написать небольшое предисловие к своему переводу статьи, но затем у меня возникло сильное желание прокомментировать один из ее подразделов, а размер этого комментария явно превышал допустимые размеры комментариев, которые уместно помещать в сносках. Поэтому я решил сделать отдельную заметку, а на нее уже сослаться из текста перевода.
Сначала я коротко расскажу о том, почему я решил перевести статью Эрика Фридмана и др., и что я в ней считаю особенно интересным. На самом деле, желание разобраться с подходом компании Asterdata к интеграции подходов SQL и MapReduce для управления аналитическими базами данных возникло у меня после знакомства с подходом компании Greenplum, переводом статьи Джеффри Коэна (Jeffrey Cohen) и др. "МОГучие способности: новые приемы анализа больших данных", нескольких выступлений на семинарах и конференциях и написания собственной статьи "Год эпохи перемен в технологии баз данных".
Напомню, что в Greenplum подход MapReduce интегрируется в среду массивно-параллельной SQL-ориентированной системы баз данных, прежде всего, для того, чтобы у аналитиков имелась возможность в процедурном стиле создавать на стороне сервера баз данных новые параллельные аналитические приложения на разных языках программирования. Насколько я понимаю, в случае Greenplum в руки разработчиков серверных аналитических приложений даются средства MapReduce в чистом виде, а сами эти средства реализуются за счет использования механизмов расширения функциональности СУБД Postgres. Следует отметить, что при этом одной из проблем своей параллельной СУБД разработчики Greenplum считают трудности распараллеливания определяемых пользователями функций (user-defined function, UDF) среды SQL.
Авторы статьи "SQL/MapReduce: практический подход к поддержке самоописываемых, полиморфных и параллелизуемых функций, определяемых пользователями", как, собственно, следует из ее названия, подходят к делу с другой стороны. На основе применения духа (а не буквы) парадигмы MapReduce они предлагают механизм реализации определяемых пользователями функций (более точно, табличных функций, т.е. функций, основным аргументом и значением которых являются таблицы), параллельность выполнения которых предполагается по умолчанию.
Не буду здесь распространяться об интересных особенностях самоописания и динамического полиморфизма SQL/MR-функций. Чтобы с этим разобраться, нужно внимательно читать основную статью. Замечу лишь, что эти особенности способствуют повторному использованию UDF, допускают динамическую оптимизацию запросов, в которых используются вызовы таких функций, и т.д.
Авторы демонстрируют ряд практических задач, решение которых средствами чистого SQL затруднительно (или вообще невозможно), а применение SQL/MR-функций упрощает решение и приводит к существенному выигрышу в производительности.
В статье все хорошо и убедительно говорится вплоть до подраздела 6.2, который убедительным мне не кажется, и по поводу которого и затеяна эта заметка. Кратко перескажу суть задачи, обсуждаемой в этом подразделе. Имеется таблица Clicks(user_id int, page_id int), каждая строка которой соответствует обращению пользователя с идентификатором user_id к Web-странице с идентификтором page_id. Задается n множеств идетификаторов страниц SET1,..., SETn (в статье они называется поисковыми наборами). Требуется найти идентификаторы всех пользователей, которые обращались ко всем страницам, идентификаторы которых содержатся хотя бы в одном из множеств SETi (1 ≤ i ≤ n).
Авторы не приводят текст своего SQL-запроса, решающего эту задачу, поскольку у них он получился слишком объемным, но приводят его основую идею (которая мне кажется ужасной!). Пусть имеется только один поисковый набор SET1, и пусть он содержит k1 идентификаторов страниц. Тогда в запросе сначала выполняется k1 соединений таблицы Clicks по user_id, а полученные кортежи сравниваются с кортежем, представляющим (в некотором порядке) все идентификаторы страниц из SET1.
Понятно, что такой запрос выдаст правильный результат, но сначала будет произведено множество лишних кортежей, а затем выполнено множество лишних сравнений. Конечно, такой запрос будет выполняться очень долго и примет совсем страшный вид, если задается несколько поисковых наборов разного размера. Поэтому сравнивать время выполнения такого запроса со временем выполнения разумно написанной SQL/MR-функции, как минимум, некорректно.
Хотя авторы считают свой запрос "наиболее оптимизированным", мне достаточно быстро пришла в голову формулировка (с небольшими вольностями), которая, совершенно очевидно, может привести к существенному убыстрению времени выполнения. Вот она:
(SELECT 'SET1', user_id FROM Clicks WHERE page_id IN SET1 GROUP BY user_id HAVING COUNT(DISTINCT page_id) = k1) UNION ... UNION (SELECT 'SETn', user_id FROM Clicks WHERE page_id IN SETn
GROUP BY user_id HAVING COUNT(DISTINCT page_id) = kn)
Это тоже не очень хороший запрос, поскольку при наличии n поисковых наборов потребуется n раз выполнять однотипные действия над таблицей Clicks. Но здесь, по крайней мере, нет соединений, и каждый подзапрос может быть выполнен достаточно эффективно. (Кстати, в качестве дополнительного преимущества приведенный запрос для каждого результирующего user_id выдает номер поискового набора, которому он удовлетворяет.)
Почему же не удается написать SQL-запрос, при выполнении которого выполнялись бы такие же естественные действия, которые выполяются при наличии определяемой авторами SQL/MR-функции? Ответ очень прост: это связано с тем, что в современном стандарте SQL нет условия, проверяющего вхождение одного множества в другое. Можно многими способами проверить вхождение в таблицу некоторой строки, а проверить вхождение одной таблицы в другую – нельзя.
Самое смешное, что на заре SQL в середине 1970-х гг. такая возможность имелась (см. например, статью Дона Чемберлина (D.D. Chamberlin) и др. "SEQUEL 2: унифицированный подход к определению, манипулированию и контролю данных". В этом варианте SQL имелся предикат CONTAINS, служащий именно для проверки вхождения одного множества кортежей в другое множество (или мультимножество). С использованием этого предиката (и операции SET, позволяющей образовать множество значений заданного столбца в группе строк таблицы) нужный нам запрос можно было бы сформулировать (немного неформально) следующим лаконочным образом:
SELECT user_id FROM Clicks GROUP BY user_id HAVING SET(page_id) CONTAINS SET1 OR SET(page_id) CONTAINS SET2 ... OR SET(page_id) CONTAINS SETn;
Легко заметить, что естественным способом обработки такого запроса в массивно-параллельной среде было бы разделение таблицы Clicks по значениям столбца user_id и выполнение за один проход всех проверок, т.е. ровно то же, что делается при выполнении SQL/MR-функции из подраздела 6.2 статьи "SQL/MapReduce: практический подход к поддержке самоописываемых, полиморфных и параллелизуемых функций, определяемых пользователями". Кроме того, развитый оптимизатор запросов оценил бы и другие возможные способы выполнения этого запроса и выбрал бы из них действительно оптимальный способ при текущем состоянии базы данных, а не тот, который почему-то нравится (или навязывается?) пользователю.
Мораль моей заметки в том, что, безусловно, сообщество баз данных должно смотреть по сторонам и заимствовать полезные подходы, возникшие в смежных областях. Однако стоит ли использовать чужие идеи для латания известных технологических дыр, с которыми можно справиться собственными силами?
Julian Hyde. Data in Flight.
Джулиан ХайдПеревод: Сергей Кузнецов
Оригинал: Julian Hyde. Data in Flight. How streaming SQL technology can help solve the Web 2.0 data crunch. ACM Queue, vol. 7, no. 11, December 2009
Другие приложения систем обработки запросов к потоковым данным
Подобно тому, что технология реляционных баз данных является горизонтальной, используемой для самых разных целей, от обслуживания Web-страниц до обработки транзакций и организации хранилищ данных, потоковые SQL-системы могут быть применены для решения различных проблем.Одна из областей приложений называется CEP (complex event processing – обработка сложных событий). Запрос к системе CEP направлен на поиск последовательностей событий в одном или нескольких потоках, сопоставление их с некоторым шаблоном и создание "сложного события", представляющего бизнес-интерес. Системы CEP применяются, в частности, в приложениях обнаружения электронного мошенничества и электронной торговли.
В индустрии под термином CEP понимаются системы обработки запросов к потоковым данным в целом. К сожалению, это приводит к религиозным войнам между поставщиками систем, опирающихся на SQL, и систем, в которых SQL не используется. Кроме того, возникает излишняя фокусировка на финансовых приложениях, что приводит к пренебрежению другими областями приложений.
Упоминавшиеся выше запросы к данным об использовании Web-страниц являются простым примером приложения мониторинга. Подобные приложения отслеживают изменения в транзакциях, представляющих работающий бизнес, и предупреждают обслуживающий персонал, если не все дела идут хорошо. В отличие от CEP-запросов, которые сопоставляют с заданными шаблонами отдельные записи, запросы мониторинга находят важную информацию путем агрегирования большого числа записей и определения тенденций. Приложения мониторинга также могут заполнять в реальном времени информационные панели (dashboard), являющиеся бизнес-эквивалентом спидометра, термометра и манометра.
У потоковых запросов имеется естественная синергия с хранилищами данных, поскольку в обоих случаях используется SQL. В хранилище данных сохраняются огромные объемы исторических данных, требуемых для анализа бизнеса через "зеркало заднего вида", в то время как система обработки запросов к потоковым данным пополняет хранилище данными и обеспечивает "передний обзор" информации, чтобы "рулить компанией".
Cистема обработки запросов к потоковым данным выполняет те же функции, что и средство ETL (extract, transform, load – извлечение, преобразование, загрузка), но она функционирует непрерывно. Традиционный процесс ETL представляет собой последовательность шагов, вызываемых в виде пакетного задания. Время цикла процесса ETL ограничивает актуальность данных в хранилище данных; трудно добиться, чтобы это время было меньше нескольких минут. Например, большая часть шагов, требующих переработки большого объема данных, выполняется на основе запросов к хранилищу данных: поиск существующих значений в таблице измерений (например, клиентов, совершивших предыдущую покупку) и заполнение сводных таблиц. Система обработки запросов к потоковым данным может кэшировать информацию, требуемую для выполнения этих шагов, снимая излишнюю нагрузку с хранилища данных, в то время как процесс ETL является слишком кратковременным, чтобы в нем было выгодно производить кэширование.
На рис. 1 показана арихитектура системы бизнес-аналитики реального времени. Кроме непрерывного выполнения ETL, система обработки запросов к потоковым данным заполняет информационную панель бизнес-показателями, генерирует предупреждения, если значения этих показателей выходят за приемлемые границы и в упреждающем режиме поддерживает кэш OLAP-сервера (online analytical processing – оперативная аналитическая обработка), основанного на хранилище данных.
Рис. 1. Непрерывный процесс ETL с использованием системы обработки запросов к потоковым данным
Сегодня большая часть "данных на лету" передается с использованием промежуточного программного обеспечения, ориентированного на обмен сообщениями. Подобно промежуточному программному обеспечению, системы обработки запросов к потоковым данным могут доставлять сообщения надежно, с высокой пропускной способностью и малыми задержками. Кроме того, они могут применять операции SQL для маршрутизации, комбинирования и преобразования сообщений "на лету". По мере достижения зрелости эти системы могут начать играть роль промежуточного программного обеспечения и стирать границы между механизмами передачи сообщений, непрерывными процессами ETL и технологиями баз данных за счет повсеместного применения ETL.
От переводчика
Статья, перевод которой предлагается вашему вниманию, очень популярна. В ней практически отсутствуют какие-либо технические детали, касающиеся организации систем обработки запросов к потоковым данным. Однако, на мой взгляд, она обеспечивает понимание сути таких систем, их отличий от систем управления базами данных, а также областей приложений, для которых такие системы могут быть полезными.Следует заметить, что пик исследовательских работ, посвященных непрерывной обработке запросов (и не только над потоковыми данными) пришелся на начало 2000-х гг., когда, в частности, выполнялись известные проекты Aurora и TelegraphCQ. В дополнение к чрезвычайно краткому списку литературы, приводимому в статье, рекомендую обратить внимание на подборку статей, опубликованных в Bulletin of the Technical Committee on Data Engineering, March 2003, Vol. 26, No. 1. Кроме того, я считаю несправедливым отсутствие ссылки на сайт компании StreamBase, основанной Майклом Стоунбрейкером (Machael Stonebraker) в 2003 г. и выпустившей первую производственную систему обработки запросов к потоковым данным.
Как показывает статья, теперь в секторе рынка таких систем имеется выбор. Насколько я понимаю, программное обеспечение, производимое компанией SQLStream, в которой работает автор статьи, можно бесплатно скачать и опробовать в реальных приложениях. Мне кажется, что пора осваивать эту технологию. Пора, друзья!
Web-приложения производят данные с колоссальной скоростью, и эта скорость возрастает с каждым годом по мере того как Web занимает все более важное место в жизни людей. Быстро расширяющейся частью нашей жизни являются и другие источники данных, например, системы мониторинга окружающей среды или службы отслеживания текущего местоположения людей. Несмотря на постоянное повышение пропускной способности Internet, пользователям и препринимателям требуется возможность наблюдения интересующих их данных со все меньшими задержками. Этому отчасти способствуют достижения в области аппаратуры компьютеров (удешевление основной и дисковой памяти, увеличение числа ядер процессоров), но этого недостаточно для удовлетворения требования повышения пропускной способности при одновоеменном снижении времени задержки.
Технологии наращивания мощности Web- приложений должны быть достаточно простыми, во-первых, поскольку должна обеспечиваться возможность их быстрого изменения и масштабного внедрения с минимальными усилиями, а во-вторых, потому что люди, создающие Web-приложения, являются специалистами широкого профиля, и они не готовы изучать сложные, трудно настаиваемые технологии, используемые системными программистами.
Выполнение запросов над потоками данных – это новая технология, обеспечивающая обработку быстро поступающих данных и производящая результаты с небольшими задержками. Эта технология появилась в сообществе исследователей баз данных, и поэтому она обладает некоторыми характеристиками, сделавшими популярными реляционные системы базы данных, но, несомненно, это не СУБД. В системах баз данных сначала данные поступают в базу данных и сохраняются на дисках, а потом уже пользователи применяют к этим сохраненным данным запросы. В систему обработки запросов над потоковыми данными запросы поступают раньше, чем данные. Данные проходят через несколько постоянно выполняемых запросов, и преобразованные данные поступают в приложения. Можно сказать, что в реляционных СУБД данные обрабатываются в состоянии покоя, а в системах обработки запросов над потоковыми данными – на лету.
В реляционных базах данных основным примитивом являются таблицы. Таблица заполняется записями, каждая из которых имеет один и тот же тип записи, задаваемый несколькими именованными строго типизированными столбцами. Внутри записей отсутствует какой-либо внутренний порядок столбцов. При выполнении запросов, обычно представляемых на языке SQL, выбираются записи из одной или нескольких таблиц, и они преобразуются с использованием небольшого набора мощных реляционных операций.
В системах обработки запросов над потоковыми данными соответствующими примитивами являются потоки. Как и у таблицы, у потока имеется некоторый тип записи, но записи не хранятся, а поступают в потоке. В потоковой системе записи естественным образом упорядочены, и у каждой записи имеется временная метка, показывающая, когда эта запись была создана. У реляционных операций, поддерживаемых в реляционных базах данных, имеются аналоги в потоковой системе, и эти аналоги достаточно похожи на реляционные операции, чтобы для формулировки потоковых запросов можно было использовать SQL.
Чтобы проиллюстрировать, как система обработки запросов над потоковыми данными может помочь решить проблемы обработки данных на лету, рассмотрим следующий пример.
Преимущества потоков
Почему система выполнения запросов над потоковыми данными оказывается более эффективной, чем реляционная СУБД, при решении проблем обработки данных "на лету"?Прежде всего, в этих системам такие проблемы выражаются очень по-разному. База данных хранит данные, а приложения выполняют над этими данными запросы (и транзакции). В системе обработки запросов над потоковыми данными сохраняются запросы, а данные для этих запросов поступают из внешнего мира. Здесь нет никаких транзакций, потому что данные "протекают" через систему.
При работе с базой данных требуется загружать и индексировать данные, запускать запросы над всем набором данных и изымать предыдущие результаты. Система обработки запросов над потоковыми данными обрабатывает только новые данные. Она удерживает только те данные, которые ей еще нужны (например, данные за последнюю минуту), и, поскольку обычно эти данные умещаются в основной памяти, не требуются обмены с дисками.
Реляционная СУБД функционирует на основе того предположения, что все данные являются одинаково важными, но в бизнес-приложениях то, что произошло минуту назад, часто важнее того, что произошло вчера, и гораздо важнее того, что произошло год назад. По мере роста базы данных приходится раскидывать данные по разным дискам и создавать индексы, чтобы обеспечить доступ ко всем данным за константное время.
В системе обработки запросов на потоковыми данными рабочие наборы имеют меньшие размеры и могут размещаться в основной памяти. Поскольку в запросах содержатся спецификации окон, и сами запросы создаются до поступления данных, системе обработки запросов над потоковыми данными не нужно угадывать, какие данные требуется сохранять. У системы обработки запросов над потоковыми данными имеется и еще одно преимущество над реляционной СУБД: сокращенные накладные расходы на управление параллелизмом и повышенная эффективность из-за асинхронности обработки данных. Поскольку СУБД изменяет структуры данных, которые могут читать и изменять другие приложения, в ней требуются механизмы управления параллелизмом. В системе обработки запросов над потоковыми данными отсутствует конкуренция за блокировки, поскольку данные, поступающие от всех приложений, ставятся в очередь и обрабатываются, когда система становится готовой к этому.
Другими словами, система обработки запросов над потоковыми данными работает с данными асинхронно. Асинхронная обработка – это характеристика высокопроизводительных серверных приложений, от приложений обработки транзакций до приложений обработки электронной почты, равно как и индексирования страниц Web. Асинхронность позволяет системе изменять свои единицы работы – от обработки отдельных записей при низкой загрузке системы до обработки пакетов из многих записей при повышении нагрузки – для получения выигрыша в эффективности за счет, например, локальности ссылок. Можно было бы подумать, что у асинхронной системы увеличивается время ответа, поскольку она обрабатывает данные, "когда захочет", но в действительности она достигает заданной пропускной способности при гораздо меньшей нагрузке системы и поэтому обеспечивает более быстрое время ответа, чем синхронная система. Реляционная СУБД не только синхронна сама по себе, но обычно вынуждает работать в режиме отдельных записей и приложения.
Теперь должно быть ясно, что обработка "под давлением" данных более эффективна для работы с данными "на лету". Однако этого можно достичь не только на основе системы обработки запросов над потоковыми данными. Streaming SQL не делает ничего такого, что было бы невозможно сделать раньше. Например, можно было бы решить многие проблемы с использованием некоторой шины сообщений, представляемых в формате XML, и некоторого процедурного языка для взятия сообщений из шины, их преобразования и помещения обратно в шину. Однако при этом пришлось столкнуться с проблемами эффективности (разбор XML обходится не дешево), масштабируемости (как расщепить проблему на подроблемы, которые можно было бы решать в отдельных потоках управления или машинах?), алгоритмистики (как эффективно объединить два потока, связать два потока по общему ключу или агрегировать поток?) и конфигурирования (как проинформировать все компоненты системы при изменении какого-либо правила?). В большинстве современных приложений используются реляционные СУБД, чтобы избежать работы с файлами данных напрямую, и основания для применения систем обработки запросов к потоковым данным являются очень схожими.
Сравнение СУБД и систем обработки запросов к потоковым данным
В СУБД и системах обработки запросов к потоковым данным поддерживается схожая семантика SQL, но при обработке данных "на лету" они ведут себя очень по-разному. Почему система обработки запросов к потоковым данным в таких ситуациях работает более эффективно? Для ответа на этот вопрос полезно взглянуть на происхождение таких систем.Иногда для обозначения подобных систем используется термин потоковая база данных, который обманчиво наводит на мысль, что такая система сохраняет данные. Системы обработки запросов к потоковым данным происходят из исследовательского сообщества, в частности, от проектов STREAMS (Stanford) [1], Aurora (MIT/Brown/Brandeis) [2] и Telegraph [3]. Системы обработки запросов к потоковым данным основываются на реляционной модели, определяющей реляционные базы данных и, как мы увидим, этот фундамент придает им мощность, гибкость и пригодность для производственного использования.
Реляционная модель, впервые описанная Э.Ф. Коддом (E. F. Codd), является простым и единообразным способом описания структур баз данных. Модель состоит из отношений (именованных коллекций записей) и набора простых операций для комбинирования этих отношений: селекция(select), проекция (project), соединение (join), агрегирование (aggregate) и объединение (union). Реляционная модель естественным образом обеспечивает независимость данных – отделение логической структуры данных от их физического представления. Поскольку создатель запроса не знает, как физически организованы данные, важным компонентом СУБД является оптимизатор запросов, производящий выбор из многих возможных алгоритмов выполнения запроса.
SQL впервые появился на рынке в конце 1970-х. Некоторые люди считают этот язык небезупречным с теоретической точки зрения (в особенности после добавления в него расширений, относящихся к таким нереляционным понятиям, как объекты и вложенные таблицы), но, тем не менее, в нем воплощаются основные принципы реляционной модели. Язык является декларативным, что дает возможность оптимизировать запросы, так что пользователь (или система) может настроить приложение без потребности в его переписывании. Поэтому можно отложить настройку новой схемы базы данных до тех пор, пока приложение не будет в основном написано, и можно безопасным образом производить рефакторинг существующей схемы базы данных. SQL прост, надежен и неприхотлив, и многие разработчики понимают этот язык.
Потоки вносят в реляционную модель новое измерение. По-прежнему можно применять базовые операции (селекция, проекция, соединение и т.д.), но можно задать системе и такой вопрос: "Если бы некоторый запрос с соединением выполнялся секунду тому назад, и снова выполнялся бы в настоящее время, то чем бы отличались его результаты?".
Это позволяет подходить к решению проблем совсем другим образом. В качестве аналогии обсудим, как можно было бы измерить скорость автомобиля, движущегося по автостраде. Можно было бы посмотреть на часы, проезжая очередной километровый знак, еще раз посмотреть на часы, достигнув следующего километрового знака, перевести прошедшее время в доли часа и поделить единицу на полученную величину. В качестве альтернативы можно использовать спидометр, устройство, в котором стрелка двигается под действием вырабатываемого тока, сила которого пропорциональна частоте вращения колес автомобиля, пропорциональной, в свою очередь, скорости автомобиля. Метод, основанный на километровых знаках, преобразует в скорость длину пути и время, в то время как спидометр измеряет скорость непосредственно, используя некоторый набор количественных показателей, пропорциональных скорости.
Длина пройденного пути и скорость – это связанные количественные показатели; в дифференциальном исчислении скорость является производной пути по времени. Аналогично, поток является производной таблицы. Ровно так же, как спидометр обеспечивает более точное решение проблемы измерения скорости машины, система обработки запросов над потоковыми данными часто оказывается намного более эффективной, чем реляционная СУБД для приложений обработки данных, работающих с быстро поступающими данными, зависящими от времени.
к потоковым данным основываются на
Системы обработки запросов к потоковым данным основываются на той же технологии, что и реляционные СУБД, но предназначены для обработки данных "на лету". Системы обработки запросов к потоковым данным могут способствовать намного более эффективному решению некоторых распространенных проблем, чем СУБД, посколькуПоскольку и системы обработки запросов к потоковым данным, и реляционные СУБД используют язык SQL, они могут применяться совместно для решения проблем мониторинга и бизнес-анализа данных в реальном времени. SQL делает их доступными для большого числа людей, обладающих опытом использования этого языка.
Ровно так же, как СУБД могут применяться для решения большого числа проблем, от обработки транзакций до организации хранилищ данных, системы обработки запросов к потоковым данным могут поддерживать приложения, связанные с корпоративной передачей сообщений, обработкой сложных событий, непрерывной интеграцией данных, а также в новых прикладных областях, которые продолжают обнаруживаться.
Запросы к данным о посещении Web-сайтов
Предположим, что нам требуется отслеживать наиболее популярные страницы некоторого Web-сайта. При каждом обращении пользователей к Web-серверу генерируется запись в журнальном файле, содержащая данные о времени, URI данной страницы и IP-адресе обращающегося пользователя. Некоторый адаптер может непрерывно анализировать журнальный файл и образовывать поток записей. Показанный ниже запрос вычисляет число запросов в минуту к каждой странице Web-сайта. Возможные результаты приведены в табл. 1.SELECT STREAM ROWTIME, uri, COUNT(*) FROM PageRequests GROUP BY FLOOR(ROWTIME TO MINUTE), uri;
Таблица 1
В этом примере, как и в других примерах данной статьи, для формулировки запроса используется язык запросов SQLstream. Этот язык является стандартным языком SQL с несколькими потоковыми расширениями [4]. Другие системы обработки запросов к потоковым данным обладают аналогичными возможностями.
Единственными расширениями SQL, используемыми в данном запросе, являются ключевое слово STREAM и системный столбец ROWTIME. Если убрать из запроса ключевое слово STREAM и преобразовать PageRequests в таблицу со столбцом ROWTIME, то полученный запрос можно было бы выполнить в традиционной СУБД, такой как Oracle или MySQL. При выполнении такого запроса анализировались бы все обращения к страницам Web-сайта, произведенные до настоящего времени. Однако если PageRequests является потоком, то ключевое слово STREAM указывает системе на необходимость подсоединиться к этому потоку и применять операцию ко всем будущим записям.
Каждую минуту этот запрос генерирует набор записей, подытоживающих трафик на каждой странице в течение этой минуты. Результирующие строки с временной меткой 10:00:00 подытоживают все обращения, произошедшие между моментами времени 10:00 и 10:01(включая 10:00 и не включая 10:01). Строки в потоке PageRequests упорядочиваются по значениям системного столбца ROWTIME, так что результирующие строки с временной меткой 10:00:00 буквально выталкиваются при поступлении первой строки с временной меткой 10:01:00 или более поздней. Система обработки запросов к потоковым данным обычно обрабатывает данные и доставляет результаты только при поступлении новых данных, так что можно сказать, что она работает "под давлением" данных. Это отличается от подхода "вытягивания" данных, применяемого в реляционных СУБД, где приложения должны постоянно опрашивать систему для получения новых результатов.
В следующем примере находятся URI, для которых число обращений больше обычного. Сначала представление PageRequestsWithCount вычисляет число обращений за последний час к каждому URI и их среднее значение за последние 24 часа. Затем запрос выбирает URI, для которых число обращений за последний час более чем в три раза превышает это усредненное число.
CREATE VIEW PageRequestsWithCount AS SELECT STREAM ROWTIME, uri, COUNT(*) OVER lastHour AS hourlyRate, COUNT(*) OVER lastDay / 24 AS hourlyRateLastDay FROM PageRequests WINDOW lastHour AS ( PARTITION BY uri RANGE INTERVAL ‘1’ HOUR PRECEDING) lastDay AS ( PARTITION BY uri RANGE INTERVAL ‘1’ DAY PRECEDING);
SELECT STREAM * FROM PageRequestsWithCount WHERE rate > hourlyRateLastDay * 3;
В отличие от предыдущего запроса, в котором использовался раздел GROUP BY для агрегации многих записей в одну сводную для каждого заданного промежутка времени, в данном запросе используется оконное (windowed) агрегатное выражение (агрегатная функция НАД окном, aggregate-function OVER window) для добавления к каждой строке аналитических значений. Поскольку в каждую строку добавляются статистические данные за последние час и день, не требуется накапливать пакет записей. Такой запрос можно использовать для постоянной поддержки списка "наиболее популярных страниц" своего сайта, а в коммерческих сайтах он может применяться для определения товаров, объемы продаж которых превышают норму.
Аргументы поиска
Простейший способ снизить объем ввода/вывода, необходимого для обработки запроса - это уменьшить количество строк, которые должен проанализировать SQL Server. Это делается с помощью задания выборочных критериев поиска в обороте WHERE, входящем в структуру запроса. Эти критерии обычно называются аргументами поиска. Они помогают оптимизатору запросов, давая подсказки относительно того, какой метод доступа к данным окажется самым быстрым. Аргументы поиска представляются в виде следующей записи:Имя Столбца оператор [Имя Столбца или константа]
где оператором может быть один из следующих знаков сравнения =, <, >, <=, <=. Аргументы поиска могут быть соединены булевским оператором AND. Фраза BETWEEN ..... AND также допустима, поскольку задаваемое ею условие может быть по-другому сформулировано с помощью операторов >= и <=. Ниже приведено несколько примеров аргументов поиска:
LastName = ..... LastName >= ..... OrderDate .....
Обратите внимание на то, что не был упомянут ни один отрицательный оператор. Для обработки запроса, содержащего оборот WHERE (ProductId <>2) SQL Server просматривает каждую строку, проверяя, не равно ли ее значение двум. Даже индекс по ProductId не так уж сильно облегчает ситуацию, если только строки, содержащие значение 2 не составляют весьма незначительную часть таблицы. Почти во всех случаях SQL Server выполнит этот запрос просмотром таблицы, а не индекса.
С точки зрения оптимизации запросов оператор LIKE почти столь же неэффективен, как и оператор NOT. Если в вашем запросе присутствует, например, такой оборот
WHERE LastName LIKE '%Мс%',
то SQL Server выполнит поиск заданного образца во всем столбце. Индекс не поможет, поэтому можно предполагать, что оптимизатор запросов выберет сканирование таблицы. Существует только один тип исключений, - когда аргумент поиска выглядят, к примеру, следующим образом:
WHERE LastName LIKE 'Le%'.
Разница заключается в том, что этот критерий поиска логически эквивалентен выражению
WHERE LastName >= 'Le' AND LastName < 'LF',
которое по определению представляет собой аргумент поиска.
Вообще говоря, аргументы поиска помогают запросам тем, что облегчают оптимизатору запросов определение степени селективности индекса при обработке данного запроса. Обороты, использующие операторы =, <, >, являются именно такими аргументами поиска, поскольку они ограничивают область поиска только строками, попадающими в результирующий набор. Оператор = ограничивает область поиска до единственной строки, а операторы < и > сужают ее до некоторого диапазона.
Селективность оборота отражает, насколько эффективно аргумент поиска сужает область просмотра. Этот показатель может быть измерен отношением числа возвращаемых строк к суммарному количеству строк в таблице. (Приведенное определение нарочно немного упрощено, для того чтобы сделать обсуждение более наглядным.) Низкий процент означает, что оборот обладает высокой селективностью; напротив, высокий процент соответствует слабой селективности. Поскольку оператор AND коммутативен (то есть, a AND b означает то же самое, что и b AND a), оптимизатор запросов может выбирать для обработки запроса наиболее селективный оборот из числа оборотов, объединенных оператором AND. Это оправдано, ведь выбор наиболее селективного оборота способен заметно снизить объем выполняемых операций ввода/вывода.
В качестве примера рассмотрим запрос
SELECT .... "213-46-8915"....
Оба оборота, составляющие оборот WHERE, являются аргументами поиска. Но столбец state (штат), скорее всего, не обеспечит получение единственного значения, а столбец au_id непременно гарантирует это, так как он является первичным ключом таблицы. Чтобы понять, что оборот au_id = "213-46- 8915" обладает очень высокой селективностью, а оборот state = "СА", наоборот, средней или даже низкой, вряд ли требуется знать что-либо еще. Конечно, если бы нашлась только одна строка, в столбце state которой было бы значение, соответствующее штату СА, то оба оборота были бы одинаково селективны.
Оптимизатор запросов решает, насколько селективен аргумент поиска, исходя из статистики соответствующего индекса. Статистика дает приблизительное представление о том, сколько записей будет удовлетворять заданному критерию. В таком случае, если оптимизатор запросов знает, сколько строк содержится в таблице, и сколько строк будет возвращено при использовании условий обеих частей оборота WHERE, то не составит труда решить, какой индекс целесообразно использовать. (Применение статистики в SQL Server 7.0 более подробно описано в статье Кэйлен Дилани "Статистика SQL Server : полезный инструмент оптимизатора запросов".) В рассматриваемом запросе, если имеются индексы и по столбцу state, и по столбцу au_id, то оптимизатор запросов выберет индекс по au_id. Если же индекс по au_id отсутствует, а по state создан, то оптимизатор запросов выберет его. Это вполне логично, поскольку в любом случае применение индекса более селективно, чем сканирование всей таблицы. При отсутствии обоих индексов единственным остающимся решением является сканирование таблицы для выявления всех строк, которые удовлетворяют условиям.
(Более подробно работа оптимизатора запросов изложена в книге "SQL Server 6.5 корпорации Microsoft " ("Microsoft SQL Server 6.5 unleashed"), выпущенной издательством в 1998 году. В ней рассмотрено несколько наиболее распространенных сценариев. Конечно, проработка каждого примера займет время, но зато вы станете гораздо лучше писать запросы, если разберетесь в том, каким образом действует оптимизатор. В книге "Внутри SQL Server 6.5" ("Inside SQL Server 6.5" ) также хорошо рассказано о работе оптимизатора запросов.)
Что оптимизировать?
SQL Server 6.5 использует стоимостной оптимизатор запросов. Для большинства запросов наибольший вклад в стоимость вносят операции ввода/вывода, связанные с использованием диска. Поскольку скорость работы жесткого диска в сотни раз ниже скорости выполнения операций в оперативной памяти, то что бы ни предпринималось для уменьшения числа обращений к диску, безусловно, окажет влияние на производительность. Поэтому на базовом уровне сначала следует попробовать оптимизировать физический ввод/вывод, - считывание страницы с жесткого диска, а уже затем логический ввод/вывод, - считывание страницы памяти.Для оптимизации сервера прежде всего следует убедиться в том, что для SQL Server выделен максимально возможный объем оперативной памяти. Логическое чтение всегда происходит во много раз быстрее, чем физическое. В идеальном случае места в кэше оперативной памяти должно быть достаточно для размещения всей базы данных. К сожалению, нельзя остановиться только на минимизации физических операций чтения. Даже логическое чтение занимает какое-то время, а тысячи и даже миллионы таких операций потребуют значительно больше времени.
В качестве примера рассмотрим простое объединение двух таблиц:
SELECT ..... ......
Один из клиентов спросил автора статьи, почему этот запрос выполняется так долго. После того, как автор статьи запустил утилиту SHOWPLAN и взглянул на план запроса, ответ стал очевиден: таблица Payroll_Checks не имела индекса по столбцу empId. В таблице Employees содержалось около 10000 записей, а таблицу Payroll_Checks составляли 750 000 строк. Поскольку индекс отсутствовал, SQL Server сканировал таблицу Payroll_Checks 10 000 раз. Когда автор прервал выполнение запроса, сервер уже выполнил 15 миллионов логических операций ввода/вывода. Создание индекса по столбцу сократило время обработки до секунд, а число логических операций ввода/вывода до приблизительно 750000.
В предлагаемой статье рассматриваются способы
, #03/2000Татьяна Крамарская
В предлагаемой статье рассматриваются способы получения информации о физической структуре базы данных, отражение этой структуры в служебных таблицах и динамика работы SQL Server 7.0 с экстентами.
Я думаю, этот материал будет интересен специалистам, которые знакомы с документацией по SQL Server 7.0, уже имеют опыт работы и хотят глубже проникнуть в механизмы, используемые сервером.
Физическая структура данных SQL Server 7.0, в курсах Microsoft Official Curriculum (MOC), к сожалению, не рассматривается. В документации общая схема, конечно, изложена, но не описана динамика роста таблиц и индексов. Предлагаю рассмотреть динамику использования сервером физической структуры данных на простых примерах.
Не буду повторять сведения из документации, напомню лишь, что страница - это 8К, а экстентом называют последовательно расположенные 8 страниц (64К). SQL Server использует два типа экстентов: однородные и смешанные. Однородные экстенты всегда принадлежат только одному объекту. Смешанный экстент может использоваться восемью объектами.
Для изучения физической структуры данных проведем простой эксперимент.
Создадим несколько маленьких таблиц, которые не имеют кластеризованного индекса, т. е. расположены на диске вперемежку.
Итак, три таблицы TA1, TA2 и ТA3 в базе данных MYDB.
USE MYDB
CREATE TABLE TA1 (COL_1 CHAR (8000) NOT NULL)
CREATE TABLE TA2 (COL_1 CHAR (8000) NOT NULL)
CREATE TABLE TA3 (COL_1 CHAR (8000) NOT NULL)
Проверим, где расположена первая страница каждой таблицы и сколько места выделено и используется в таблице TA1. Вспомним, что поле FIRST - это первая страница, ROOT - последняя, FIRSTIAM - первая страница в списке IAM-страниц, индексных карт размещения.
В SQL Server 7.0 страница всегда идентифицируется парой параметров
Ниже приведена программа, которая выполняет эту работу, см. Листинг 1.
Результат имеет вид, показанный на Рисунке 1:

РИСУНОК 1.
Итак, мы видим, что первые страницы таблиц расположены не подряд, а через одну. Потому что сразу за первой страницей данных таблицы следует ее индексная карта размещения, IAM-страница.
Добавим одну запись и посмотрим на занимаемое таблицей пространство.
INSERT INTO TA1(COL_1) VALUES ('1')
EXEC SP_SPACEUSED TA1
name rows reserved data index_size unused -------------------------------------------
TA1 116 KB 8 KB 8 KB 0 KB
Теперь добавим еще одну запись и посмотрим, как изменилось значение поля ROOT, указывающего на последнюю страницу (Листинг 2).
Один из возможных результатов выглядит так:
Root converted root -------------------------------
1:100 0x6400000000100
Повторим эту процедуру семь раз, увеличивая соответственно значение поля COL_1, пока в таблице не появится 9 записей.
Еще раз выберем информацию из таблицы sysindexes, как мы делали ранее, результат представлен на Рисунке 2:
РИСУНОК 2.
Выполним хранимую процедуру
EXEC SP_SPACEUSED TA1
name rows reserved data index_size unused -------------------------------------------
TA1 9 136 Kв 72 Kв 8 Kв 56 Kв
Как видно из результата выполнения sp_spaceused, размер зарезервированного пространства 136 Кбайт, а размер данных 72 Кбайт.
Исследуем теперь заголовок страницы данных и индексной карты размещения.
Чтобы прочитать заголовок страницы, используем команду DBCC PAGE.
В качестве номера страницы будем подставлять значение полей FIRST, ROOT и FIRSTIAM из таблицы sysindexes, предварительно преобразовав их.
Например, для первой страницы таблицы TA1:
DBCC TRACEON (3604)
DBCC page ('MYDB', 1,86,0,0)
Результат на Рисунке 3.
РИСУНОК 3.
Заметьте, что идентификатор объекта (m_objId) в заголовке страницы соответствует результату выполнения оператора SELECT OBJECT_ID ('TAl'), и страница принадлежит таблице ТA1.
Тип экстента смешанный, страница заполнена на 100%.
Аналогичным образом можно прочитать заголовок индексной карты размещения.
DBCC TRACEON (3604)
DBCC page ('MYDB', 1,87,0,0)
Результат представлен на Рисунке 4.

РИСУНОК 4.
Заметим, что в заголовке страницы указан ее тип IAM_PG, тип экстента и заполнение.
Прочитаем заголовок последней страницы таблицы ТA1.
DBCC TRACEON (3604)
DBCC page ('MYDB', 1,112,0,0)
Результат на Рисунке 5.

РИСУНОК 5.
Тип экстента в данном случае не смешанный, а однородный.
Для более эффективного управления дисковым пространством SQL Server не выделяет маленьким таблицам сразу целый экстент. Для новой таблицы или индекса, как правило, выделяется место на смешанном экстенте. Когда объем таблицы или индекса увеличивается до восьми страниц, все последующие экстенты будут однородными. Место выделяется на доступных смешанных экстентах до тех пор, пока данные не займут по объему восемь страниц, тогда следующий выделенный экстент будет полностью принадлежать таблице. Если на смешанных экстентах места нет, а объем таблицы не достиг восьми страниц, выделяется новый экстент, но он будет объявлен смешанным. Например, таблица занимает две страницы на смешанном экстенте, и в нее еще добавляется сразу шесть записей; а если свободных страниц на смешанных экстентах нет, будет выделен новый смешанный экстент, и на нем разместится 6 записей. Потом добавляется еще одна запись. Будет выделен полный новый однородный экстент, и на нем размещена новая запись. Таким образом, начало таблицы в подобных случаях располагается на смешанном экстенте. Однако возможны и другие варианты. Например, используем оператор SELECT INTO. Выберем из нашей таблицы ТА1 7 записей и поместим их во вновь созданную таблицу ТА4.
SELECT * INTO TA4 FROM TT1 WHERE COL_1 NOT IN ('8','9')
Каким образом при этом будет выделено место? Результат чтения из sysindexes может выглядеть так, как показано на Рисунке 6.

РИСУНОК 6.
Индексирование: скорее искусство, чем наука
Невозможно писать эффективные запросы, ничего не зная про индексы таблиц. Без хороших индексов даже самые простенькие запросы могут ужасающим образом замедлить работу системы. Единственный способ защиты от этого, - знать строение данных и рассматривать индексы в качестве неотъемлемой части ваших запросов.Те индексы, которые прекрасно работали во время проектирования и тестирования, могут оказаться практически неприемлемыми на этапе промышленной эксплуатации системы. Это часто вызвано тем, что представление разработчиков о структуре данных имеет мало общего с реальностью. Автор данной статьи видел системы, которые замечательно работали у одних клиентов, и показывали совершенно неудовлетворительные результаты у других. Это было связано с тем, что способ кластеризации данных в таблице не позволял оптимизатору запросов должным образом применять индексы. Если вам поступают жалобы на производительность вашей системы, то имейте в виду эту ситуацию и не полагайтесь на то, что одни и те же индексы подойдут всем вашим клиентам.
А теперь очертим основы концепции правильного выбора типа индексов и столбцов, по которым они должны строиться. Прежде всего, поскольку для каждой таблицы можно создать только один кластеризованный индекс, его надо строить так, чтобы удовлетворить максимально возможное число запросов. Кластеризованные индексы более всего полезны для запросов, использующих условия на диапазон значений. Это обусловлено тем, что уровень листьев такого индекса содержит данные, отсортированные в порядке значений индекса. Наибольший выигрыш от применения кластеризованного индекса получается в тех случаях, когда оборот WHERE запроса содержит операторы >, < или BETWEEN .... AND, а также оборот GROUP BY, в которых столбцы перечислены в том же порядке, что и в индексе. Хотя это может и не помочь в поиске строк, но кластеризованный индекс способен улучшить производительность системы при обработке оборотов ORDER BY, если и в индексе и в обороте ORDER BY использованы одни и те же столбцы, причем в совпадающем порядке.
Поскольку промежуточный уровень кластеризованного индекса крайне мал, он прекрасно работает при поиске уникальных значений. Однако некластеризованные индексы лучше работают для "точечных" запросов, которые должны найти небольшое число строк. Обороты WHERE с оператором = являются первыми кандидатами на построение некластеризованных индексов по соответствующим столбцам. Этот тип индекса также очень хорош для функций агрегирования MIN и MAX, потому что легко найти первую и последнюю записи для диапазона значений, если воспользоваться уровнем листьев индекса. Наконец, некластеризованные индексы очень существенно ускоряют выполнение функции COUNT, так как сканирование уровня листьев индекса происходит намного быстрее сканирования таблицы.
Куда двигаться дальше?
Полезно воспользоваться окном ISQL, для того чтобы проследить за изменением реакции SQL Server на введение различных индексов для одной и той же таблицы. Enterprise Manager может показать сведения о селективности индексов таблицы, а SQL Trace позволяет получить сценарии всех запросов, направляемых на сервер. Настраивая индексы, переделывая сценарии и отмечая изменения времени обработки запросов, можно получить представление о том, какие индексы будут наилучшими при промышленной эксплуатации системы. Просто следите за количеством операций ввода/вывода, необходимых для обработки ваших запросов, и не забывайте, что любое средство снижения их числа окажет положительное влияние и на производительность системы в целом.Морис Льюис () является президентом компании Holitech, специализирующейся на консалтинге и обучении технологиям Internet и разработкам корпорации Microsoft в области баз данных.
Магический размер строки
Первый шаг в минимизации операций ввода/вывода - убедиться в том, что строка сделана настолько компактной, насколько это возможно. В SQL Server строки не могут простираться на несколько страниц. В SQL Server 6.5 заголовок страницы не может превышать 32 байтов, а данные - занимать более 2016 байтов. Каждая строка данных содержит также область переполнения строки. Максимально допустимая длина отдельной строки составляет 1962 байта, включая область переполнения. Это ограничение выбрано с таким расчетом, чтобы вставляемая или удаляемая строка базы данных смогла бы также поместиться в строку журнала транзакций. Поэтому, хотя длина одной строки и не превысит 1962 байтов, две строки могут полностью занять все 2016 байтов, отведенных под данные на странице. Следствием этого является тот факт, что определенные значения длины строки могут существенно понизить процент операций ввода/вывода. Например, если длина строки составляет 1009 байтов, то на странице уместится только одна строка. Если же уменьшить длину строки всего только на один байт, то на страницу поместятся две строки. То есть, можно наполовину снизить обращения к вводу/выводу для таблицы, убрав всего один байт! Аналогичные ситуации имеют место для следующих размеров строк: 673, 505, 404 байтов и т.д. Если вам удастся сохранить размер строки ниже указанных пределов, то тем самым вы уменьшите долю операций ввода/вывода соответственно на 33, 25 и 20 процентов.Все строки могут иметь несколько байтов переполнения, которые следует учитывать в расчетах. Отметим, что переполнение строк переменной длины больше, чем переполнение строк фиксированной длины. Чтобы выяснить, имеется ли у вас на страницах неиспользуемое место, запустите DBCC SHOWCONTIG. Это позволит вам определить среднюю плотность страницы и среднее число свободных байтов на странице. Наиболее вероятными кандидатами на звание "чемпиона по расточительству пространства" будут те таблицы, у которых среднее число свободных байтов близко к размеру строки.
Аналогичным образом, ситуации неэкономного использования памяти часто возникают у таблиц, в которых было произведено удаление большого количества строк, и отсутствуют кластеризованные индексы. В результате удалений на страницах образуются пустые места, а поскольку SQL Server не может повторно использовать пространство страницы, если у таблицы нет кластеризованного индекса, то все новые строки данной таблицы располагаются на последней странице. В результате этого страницы такой таблицы будут заполнены менее, чем на 100 процентов, что увеличит число операций ввода/вывода. Прежде чем пытаться ужать длину строки подобной таблицы, создайте для нее кластеризованный индекс. После этого запустите еще раз DBCC SHOWCONTIG, чтобы увидеть, сколько у таблицы остается свободного места.
Настройка SQL Server 6.5 на обработку запросов c высокой производительностью
Журнал , #01/2000Морис Льюис
Администраторам баз данных наверняка приходилось настраивать сервер базы данных на быструю и эффективную обработку посылаемых приложениями запросов. Независимо от того, кем было разработано приложение, - сторонними фирмами или своей командой программистов, на программу лучше смотреть, как на черный ящик, в котором ничего изменить нельзя. Выполнить настройку производительности на уровне сервера можно различными способами: улучшением организации ввода/вывода данных на диски, увеличением памяти или созданием и модификацией индексов. Но с другой стороны, производительность прикладной системы зависит от конструкции базы данных и от написанных для нее запросов. Те разработчики приложений, использующих базы данных, которые понимают, каким образом SQL Server оптимизирует и обрабатывает запросы, обычно создают программное обеспечение, обладающее наилучшей производительностью. И у них не возникает проблем и неприятных сюрпризов при расширении масштаба приложения от небольшой системы до крупного проекта. Существует несколько простых приемов для SQL Server 6.5, которые обеспечат оптимальную производительность, если применить их к базе данных и к запросам.
Непредвиденный ввод/вывод при обновлениях
Вы можете думать, будто вашей таблице не нужен кластеризованный индекс, потому что строки из нее не удаляются. В таком случае, для вас может стать неприятным сюрпризом известие о том, что оператор UPDATE тоже может создавать пустые места в таблице. На первый взгляд кажется, что такое прямолинейное обновление, как в следующем примере, не таит никаких опасностей:UPDATE .... 9102 .....
Однако это обновление может потенциально стать причиной колоссального числа записей в журнал транзакций. Проблема проистекает из способа, которым SQL Server структурирует серии операций для предотвращения нарушения ограничений целостности. Приведем простой пример:
UPDATE .....
Если au_id является первичным (или уникальным) ключом, то обновление первой строки может привести к нарушению ограничения уникальности, особенно если au_id - монотонно возрастающая величина. Но ведь оператор UPDATE корректен, так каким же образом SQL Server сможет выполнить его без нарушения ограничений? Здесь SQL Server прибегает к использованию режима отсроченного обновления, при котором операция обновления разбивается на две части: сначала удаляется старая строка, а затем вводится новая, содержащая требуемое значение.
SQL Server обрабатывает эту ситуацию, помещая в журнал транзакций не операционные записи, говорящие о том, какую операцию необходимо выполнить. Затем, после выявления всех затрагиваемых строк, и записи в журнал операций удаления и вставки, SQL Server возвращается к началу транзакции и приступает к выполнению операций удаления. Когда все удаления будут произведены, SQL Server начинает вставлять строки. Все эти удаления и вставки теперь представляют собой полноценные операции, а потому сопровождаются модификацией всех затрагиваемых индексов.
Отсроченные обновления могут существенно снизить производительность как базы данных, так и приложения, поскольку они не только приводят к большим расходам пространства под записи журнала транзакций, но и выполняются медленнее, чем обновления в прямом режиме. Чем дольше происходит обновление, тем больше времени длятся исключающие блокировки, а следовательно, другим пользователям приходится дольше ждать освобождения страницы. Это повышает вероятность возникновения тупиковой ситуации.
SQL Server 6.5 способен выполнять операции обновления четырьмя различными способами. Самым быстрым является прямое обновление замещением. При этом не происходит никаких перемещений, а в журнал транзакций помещается единственная запись, содержащая информацию о том, какие байты получили новые значения. Самым медленным способом является отсроченное обновление, которое было описано выше. Оба других способа представляют собой прямые обновления (то есть никаких лишних записей в журнал транзакций не производится), но запись новых значений происходит не на то же самое место, на котором помещались обновляемые данные. Поэтому некоторые перемещения данных все-таки имеют место. Чтобы обновление, которое вы собираетесь сделать, проводилось в режиме прямого обновления замещением, должен быть исполнен такой длинный список условий, что в данной статье просто не представляется возможным все это изложить. В "SQL Server 6.5 Books Online" (BOL) есть раздел, называемый "Прямой режим обновления" (The update mode is direct). В нем перечислены некоторые условия, которые непременно должны выполнены, чтобы SQL Server произвел обновление прямым замещением. Однако в BOL иногда путаются прямое обновление и замещение, что приводит к некорректности некоторых рассуждений. Самым полным опубликованным описанием различных типов обновлений признана книга "Внутри SQL Server 6.5" (Inside SQL Server 6.5) Рона Саукапа, выпущенная в 1997 году издательством Microsoft Press.
Два основных условия, которые непременно должны быть выполнены, чтобы обновление проводилось в прямом режиме методом замещения, заключаются в следующем. Во-первых, нельзя обновлять ключевые столбцы в кластеризованном индексе, а во-вторых, таблица не может быть помечена для репликации. Модификации кластеризованного индекса заставляют SQL Server перемещать строку на новое физическое место, отвечающее ее содержанию. А это всегда сопровождается сначала удалением, а затем вставкой строки. При репликациях происходит чтение журнала и формирование команд ODBC для подписчиков. Поэтому комбинация удаление/вставка представляется наиболее простым описанием операции обновления. Обе ситуации исключают обновление прямым замещением.
Аналогичные правила применимы к столбцам переменной длины и к столбцам, содержащим неопределенные значения. При обновлениях, затрагивающих многие строки, столбец обязан иметь фиксированную длину, чтобы допустить замещение старого значения новым. SQL Server хранит столбец с неопределенными значениями как столбец переменной длины, даже в тех случаях, когда программист объявил его в качестве столбца с фиксированной длиной. Для обновления множества строк столбца с неопределенными значениями SQL Server всегда применяет отложенное обновление.
Прекрасные результаты приносит знание этих ограничений и их учет при конфигурировании базы данных, особенно когда вы стремитесь выжать все возможное из производительности при обновлениях. Применение методов, обеспечивающих прямое замещение, позволяет сэкономить на вводе/выводе при записи в журнал, на вводе/выводе при чтении логических страниц журнала, и кроме того, сберечь время на резервировании и восстановлении журнала, а также при восстановлении базы данных. При проектировании баз данных полезно придерживаться стандарта, в соответствии с которым следует использовать только столбцы фиксированной длины, не содержащие неопределенные значения. Если вы, читатель, программируете, то помните о свойствах обновляемых столбцов и учитывайте их влияние на производительность при написании операторов UPDATE. Кроме того, тщательно выбирайте момент для запуска этих операторов.
Оптимизация запросов: вечнозеленая область
Сергей Кузнецов24.04.2003
Оптимизаторы запросов — наиболее хитроумные, наиболее сложные и наиболее интересные компоненты СУБД. Историю этого направления принято отсчитывать с середины 70-х годов, хотя наверняка исследования проводились и раньше. Пионерские работы, в которых были получены фундаментальные результаты, относящиеся к оптимизации запросов, были выполнены в рамках проектов System R корпорации IBM [1, 2] и Ingres университета Беркли [3]. В System R были заложены основы техники оптимизации запросов на основе оценок стоимости плана выполнения запроса [4]. В университетском проекте Ingres, фактически использовались методы, которые позже стали называть семантической оптимизацией запросов.
В маленькой редакторской заметке невозможно привести обзор подходов к оптимизации запросов в SQL-ориентированных СУБД. Могу порекомендовать собственный обзор [5] (достаточно старый, но остающийся актуальным) и существенно более новый обзор Чаудхари [6]. Здесь же мне бы хотелось отметить некоторые вехи в истории развития методов оптимизации, которые имеют непосредственное отношение к статье Маркла, Лохмана и Рамана.
Начнем с формулировки проблемы оптимизации SQL-запросов. (Трудно сказать, насколько тесно эта проблема и имеющиеся методы ее решения связаны со спецификой языка SQL; как показывает текущий опыт, многие аспекты оптимизации перекладываются, например, на совсем иной язык запросов Xquery.) Язык SQL декларативен. В формулировках SQL-запросов указывается, какими свойствами должны обладать данные, которые хочет получить пользователь, но ничего не говорится о том, как система должна реально выполнить запрос. Проблема в том, чтобы по декларативной формулировке запроса найти — или построить — программу (в мире SQL такую программу принято называть планом выполнения запроса), которая выполнялась бы максимально эффективно и выдавала бы результаты, соответствующие указанным в запросе свойствам. Более точно, основная трудность состоит в том, что нужно уметь (1) построить все возможные программы, результаты которых соответствуют указанным свойствам, и (2) выбрать из множества этих программ (найти в пространстве планов выполнения запроса) такую программу, выполнение которой было бы наиболее эффективным.
Заметной в этом направлении была работа [7], в которой, в частности, было показано, что всегда имеет смысл преобразовывать формулировку запроса к такому виду, чтобы ограничения индивидуальных таблиц производились до их соединения (predicate push down). Очень важную роль в истории логической оптимизации запросов сыграла серия статей, начало которой положил Вон Ким [8]. В них было показано, как можно преобразовать SQL-запросы, в разделе FROM которых присутствуют подзапросы, в запросы с соединениями. Важность этих результатов в том, что: (1) SQL стимулирует использование запросов с вложенными подзапросами; (2) в большинстве оптимизаторов запросов для реализации таких запросов используется некоторая фиксированная стратегия генерации планов (в основном, вложенные циклы); (3) альтернативные формулировки запросов с соединениями допускают порождения большего числа планов, среди которых могут находиться наиболее эффективные. Другими словами, этот подход позволяет разумным образом расширить пространство поиска оптимальных планов выполнения запросов.
Что касается второй части проблемы, то в подходе, предложенном IBM, общая оценка стоимости плана выполнения запроса базировалась на оценках селективности простых предикатов сравнения. Основной изъян работы Селинджер состоял в том, что эта работа основывалась на двух неправомерных предположениях о том, что распределение значений любого столбца любой таблицы базы данных является равномерным, а распределения значений любых двух столбцов одной или двух таблиц являются независимыми. Собственно, уже тогда было понятно, что опираясь на эти предположения, оптимизатор запросов может выбрать для исполнения далеко не самый оптимальный план запроса (а иногда и самый неэффективный план). Непреодолимая трудность заключалась в том, что было непонятно, каким образом надежно оценивать реальное распределение значений в данном столбце данной таблицы.
Абсолютно пионерская работа в этом направлении была выполнена Пятецким-Шапиро (кстати, этот господин является выпускником кафедры математической логики механико-математического факультета МГУ) [11]. Опираясь на статистику Колмогорова и используя оригинальный подход псевдогистограмм, он показал, каким образом можно достаточно строго аппроксимировать функцию распределения значений столбца таблицы на основе небольшого числа выборок из текущего содержимого базы данных. В большинстве современных СУБД оптимизаторы запросов основывают свои оценки на статистике в виде гистограмм Пятецкого-Шапиро.
Исключительно важную роль в истории оптимизации запросов сыграл экспериментальный проект IBM Starburst. Этот замечательный проект, на результатах которого основана современная DB2 Universal Database, преследовал цель создания действующего стенда СУБД, на котором можно было бы опробовать и сравнить разные методы организации систем, в том числе и методы оптимизации запросов. Проект продемонстрировал возможность построения системы и, в частности, подсистемы оптимизации запросов некоторым унифицированным образом, когда СУБД работает под управлением заданного набора правил в среде продукционной системы.
Теперь, что касается самонастраивающихся оптимизаторов запросов. Эта идея (как и большинство идей вообще) не нова. В конце 70-х — начале 80-х годов много писалось о так называемой «глобальной» оптимизации запросов, под которой, главным образом, понимался механизм автоматического поддержания набора индексов, обеспечивающих возможность оптимального выполнения запросов данной рабочей нагрузки СУБД. В то время результаты исследований не нашли практического применения. В конце 90-х к этой идее обратились исследователи корпораций Microsoft и Oracle (см., в частности, [6]).
Статья, представляемая вниманию читателей, имеет несколько иное направление. Это не столько самонастраиваемая, сколько адаптивная оптимизация, поскольку во время выполнения запроса собираются реальные (а не статистические) данные о состоянии базы данных, которые могут быть использованы как для оптимизации последующих запросов, так и для повторной оптимизации текущего запроса. Замечу, что Гай Лохман относится к старожилам лаборатории IBM Almaden Research Center; он начинал работать еще во время проекта System R. Мне было очень интересно читать и редактировать эту статью, чего и вам желаю.
SQL Server в вопросах и ответах
#01/99 | Карен Уоттерсон независимый журналист, редактор и консультант по клиент-серверным системам и хранилищам данных. Ей можно написать по адресу . Брайан Моран президент группы пользователей и директор по технологиям СУБД Spectrum Technology Group. Имеет сертификаты MCSE, MCSD и MCT. Ему можно написать по адресу . |
В: Я установил SQL Server 7.0, но когда я запускаю Enterprise Manager, я не вижу баз данных master, model и msdb. Кроме того, я не вижу системных таблиц в пользовательских базах данных. В чем причина?
О: Вы указали SQL Server не отображать системные объекты. Щелкните правой клавишей мыши на имени сервера в Enterprise Manager и выберите Edit SQL Server Registration Properties. Поставьте метку в окошке напротив надписи Show system databases and objects.
В SQL Server 7.0 предусмотрена удобная функция, позволяющая включить или отключить отображение системных объектов и таблиц. Однако на наш взгляд, она могла бы быть более гибкой. В частности, можно было бы сделать так, чтобы пользователи могли видеть определенные системные объекты, например таблицу sysobjects.
В: Из-за особенности типа datetime в SQL Server 6.5 затруднены арифметические действия над датами и их форматирование. Почему в SQL 7.0 Microsoft не устранила этот недостаток и не добавила функции вроде LAST_DAY (последний день месяца) и NEXT_DAY (следующий день недели)?
О: Мы согласны, что работать с типом datetime трудно. В частности, в SQL Server для выполнения простых арифметических действий над датами (например, для прибавления к заданной дате нескольких дней), приходится пользоваться функцией DATEPART(). Однако при внесении изменений в основные типы данных могут возникнуть серьезные проблемы с обратной совместимостью. В SQL Server 7.0 операции с датами стало осуществлять несколько легче. В качестве примера приведем следующий SQL-код: DECLARE @datevalue datetime SELECT @datevalue = "1/1/99" PRINT "Добавим 5 суток" SELECT @datevalue + 5 PRINT "Теперь добавим 5.25 суток (или 5 суток 6 часов)" SELECT @datevalue + 5.25 Его выполнение на SQL Server 7.0 приводит к следующим результатам: z Добавим 5 суток 1999-01-06 00:00:00.000 Теперь добавим 5,25 суток (или 5 суток 6 часов) 1999-01-06 06:00:00:00.000
Как видно, SQL Server 7.0 позволяет добавлять время к заданной дате (в сутках) с помощью оператора сложения (+). Кроме того, для выполнения той же операции можно воспользоваться командой T-SQL DATEADD, хотя на наш взгляд, с оператором сложения работать проще.
Кроме того, упоминания заслуживает функция GETDATE(). Ею можно пользоваться для вывода текущей даты и времени в отчетах, а также при сравнениях и для датирования результатов контрольных проверок. Кроме того, GETDATE() можно пользоваться в качестве значения по умолчанию при вводе данных.
В: Для соединения системы на базе SQL Server 6.5 с системой на основе SQL Server 7.0 (я обладаю правами системного администратора) я испробовал следующий метод. На системе с SQL Server 7.0 я выполнил команду sp_addlinkedsrvlogin. Для создания одинакового набора параметров входа на обоих серверах я последовательно присвоил @useself значения FALSE и TRUE. Затем я выполнил sp_addlinkedserver и обновил каталог хранимых процедур на системе с SQL Server 6.5. Однако при попытке выполнить распределенный гетерогенный запрос я получил следующее сообщение об ошибке: Что я сделал неправильно?
О: Лучший путь устранения этой проблемы - просмотреть каждый шаг, разобраться, что делает SQL Server, и постараться понять, где ошибка. В данном случае вы, возможно, не разобрались с новой для SQL Server функцией связанных серверов; между тем, у процессов выполнения распределенных гетерогенных запросов и запросов более привычных видов есть немало общих этапов.
Провести диагностику данной проблемы без доступа к серверам нелегко, но в подобных случаях причину нередко следует искать в конфигурации NetLib или в конфликтах пользовательских прав на уровне системы безопасности самой NT. Чтобы упростить рассмотрение проблемы, назовем сервер, осуществляющий запрос, , а связанный сервер - . Приведенное сообщение об ошибке говорит о том, что используется соединение Named Pipes, и что SQL Server 7.0 не видит системы с SQL Server 6.5 в сети.
Для успешного выполнения распределенного запроса на обоих серверах должен работать компонент Named Pipes. Кроме того, пользователь, осуществляющий запрос, должен иметь право доступа к сервису NT Server, работающему на физической машине с TargetServer. При инсталляции SQL Server компонент Named Pipes устанавливается по умолчанию, поэтому мы предполагаем, что эта важная часть NetLibs установлена на обе системы, и причина проблемы не в ней.
Если причина не в Named Pipes, то в проблема, возможно, в профиле пользователя, от имени которого осуществляется запрос к TargetServer. Запрос осуществляется от имени пользователя, по регистрации которого на SourceServer был запущен сервис MSSQLServer. Таким образом мы можем сузить круг возможных источников проблемы до двух: либо MSSQLServer работает на SourceServer в пользовательском профиле LocalSystem, который не имеет права доступа к сети; либо MSSQLServer был запущен пользователем, не располагающим правом доступа к сервису NT Server, работающему на TargetServer.
В данном случае сервис MSSQLServer запущен в пользовательском профиле LocalSystem. Чтобы решить проблему, вам необходимо при загрузке войти в систему от имени пользователя, имеющего разрешение на доступ к удаленным машинам.
В: Я воспользовался входящим в состав SQL Server 7.0 мастером создания комплектов сервисов преобразования данных (Data Transformations Services, DTS). Для соединений я сохранил имена, предложенные мне по умолчанию, но я теперь хочу изменить их, придав им более описательный характер. Как это сделать?
О: DTS и мастер создания комплектов DTS - замечательные новые функции SQL Server. Однако они обладают рядом мелких, но неприятных недостатков, таких как невозможность переименовать соединения. К счастью, это ограничение можно обойти.
Допустим, к примеру, вы создали простой комплект, который экспортирует данные из таблицы authors в базе данных pubs в двумерный файл, и вы не снабдили комплект документацией. Для простоты вы сохранили имена соединений, предложенные вам по умолчанию источником OLE DB, на котором они основаны. Другими словами, эти имена практически ничего не говорят об источнике соединения. Когда вы завершили работу над комплектом, ваш начальник потребовал от вас, чтобы названия соединений соответствовали принятым в компании правилам назначения имен.
Экран 1: Создание нового соединения
Решить задачу, казалось бы, просто - переименовать соединение. Однако мастер создания комплектов DTS этого сделать не позволяет. Самый простой выход из положения - воспользоваться следующим примером для создания нового соединения.
Вначале щелкните правой клавишей мыши на названии соединения и выберите Properties. Затем в показанном на экране 1 диалоге Connection Properties выберите New Connection. Введите в текстовом окне New Connection новое название соединения и нажмите Оk. Система спросит "хотите ли вы, чтобы заданные вами ранее преобразования при создании данного соединения были сброшены?" Нажмите No. Нажмите No еще раз в ответ на следующий вопрос и процесс переименования будет завершен.
О: SQL Server 2000 позволяет хранить дополнительные свойства многих типов объектов базы данных. Дополнительные свойства определяются пользователем и имеют тип SQL_ VARIANT. Программисты, работающие с VB, знакомы с типом данных VARIANT. Подобно типу данных в VB, SQL_VARIANT позволяет хранить различные типы данных в поле, параметре или переменной. Каждый экземпляр столбца SQL_VARIANT состоит из двух частей: собственно данные и метаданные, описывающие значение (например базовый тип данных поля, максимальный размер, точность и collation - сопоставление). Для получения мета-данных экземпляра SQL_VARIANT можно использовать функцию SQL_VARIANT_ PROPERTY.
Например, чтобы сохранить описание столбца au_id в таблице authors в базе данных pubs, нужно щелкнуть правой кнопкой мыши на имени столбца в окне Object Browser (новый интерфейс Query Analyzer), затем выбрать Extended Properties. Теперь следует добавить новое свойство WhatAmI и внести значение "I am the author id column!!!". То же самое можно сделать, используя процедуру sp_addextendedproperty:
sp_addextendedproperty 'WhatAmI2','This is a new property value','user', dbo, 'table', authors, 'column', au_id
Затем можно применить стандартный оператор SELECT с новой функцией fn_listextendedproperty, чтобы извлечь информацию:
SELECT * FROM ::fn_listextendedproperty(NULL, 'user', 'dbo','table','authors', 'column', default)
Objtype objname name value COLUMN au_id WhatAmI I am the author id column!!! COLUMN au_id WhatAmI2 This is a new property value SELECT * FROM ::fn_listextendedproperty(NULL,'user','dbo','table', 'authors', 'column',default)
В: Я имею сертификат MCSE и собираюсь получить сертификат администратора БД (MCDBA). Я знаю, что для развертывания приложений SQL Server недостаточно прочитать специальную литературу. Тем не менее могли бы Вы рекомендовать какие-то источники информации для начинающих? У меня уже есть "Microsoft SQL Server 7.0 System Administration Training Kit" (Microsoft Press, 1999) и William Robert Stanek's "Microsoft SQL Server 7.0 Administrator's Pocket Consultant" (Microsoft Press, 1999).
О: Лучше всего разработать приложение (или прототип), которое решает реальные задачи. Советую придумать приложение для себя или создать базу данных для небольшой организации.
Чтобы приобрести дополнительный опыт, импортируйте необработанные статистические данные в новую базу данных MS SQL или OLAP куб и представьте, что Вы - конечный пользователь, который хочет проанализировать данные. Изучите OLAP и приложение Food Mart. Можно поэкспериментировать с приложением "Duwamish" - его Вы найдете в Microsoft Developer Network (MSDN). Установите и исследуйте его в целом и покомпонентно, пересоберите. Более полную информацию и примеры Вы найдете на сайте Microsoft: и .
Помимо этого, стоит присоединиться к группе новостей news://msnews.microsoft.com/microsoft.public.msdn.duwamish, а также посмотреть новые примеры приложений - Fitch и Mather Stocks на сайте
В: Я писал хранимую процедуру и столкнулся с проблемой при использовании оператора TOP с локальной переменной вместо фиксированного числа. Например, когда я пишу:
DECLARE @Counter INT SELECT @Counter=5 SELECT TOP @Counter * FROM
процедура возвращает ошибку. Но строка
SELECT TOP 5 * FROM
работает. Что делать в таком случае?
О: Согласно SQL Server Books Online (BOL), можно использовать N в разделе TOP, чтобы ограничить количество строк, возвращаемых в результате исполнения SELECT запроса. Но N должно быть числом типа integer. В SQL Server 7.0 язык Transact SQL (T-SQL) не позволяет задействовать локальную переменную в разделе TOP N, даже если та имеет тип integer. Локальные и глобальные переменные можно идентифицировать с помощью префиксов: @ - для локальных и @@ - для глобальных переменных. Можно также использовать оператор SET, чтобы присвоить значение локальной переменной, или же определить локальные переменные, ссылаясь на них в списке полей оператора SELECT. Следующий пример, вероятно, поможет решить Вашу задачу:
DECLARE @counter INT DECLARE @sql VARCHAR(255) SET @Counter=5 SELECT @sql =