

Delphi 3 и создание приложений баз данных
Понятие баз данных. Степень детализации информации в базе данных
Под базой данных (БД) понимают хранилище структурированных данных, при этом данные должны быть непротиворечивы, минимально избыточны и целостны. Что понимается под непротиворечивостью, минимальной избыточностью и целостностью информации в БД, мы рассмотрим ниже.
Обычно БД создается для хранения и доступа к данным, содержащим сведения о некоторой предметной области, то есть некоторой области человеческой деятельности или области реального мира. Всякая БД должна представлять собой систему данных о предметной области. БД, относящиеся к одной и той же предметной области, в различных случаях содержат более или менее детализированную информацию о ней. Степень детализации определяется рядом факторов, прежде всего целью использования информации из базы данных и сложностью производственных (деловых) процессов, существующих в пределах предметной области в конкретных условиях.
Приведем пример. Рассмотрим в качестве предметной области отпуск товаров со склада. Пусть существуют две изолированные друг от друга организации, испытывающие потребность в автоматизации своих производственных (деловых) процессов.
Организация А
характеризуется невысоким ассортиментом хранимых и отпускаемых товаров. Ассортимент отличается стабильностью. Состав реальных покупателей товаров исчисляется несколькими лицами (только юридическими). Предоплаты за еще не отпущенный товар не допускаются, отпуск товара в кредит не практикуется, система скидок отсутствует. Оплата производится в рублях. Отпуск товаров осуществляется с одного склада. Потребности в автоматизации учета отпуска товаров определяются двумя целями: • быстрой выдачей информации о текущих остатках товара на складе;
• ежемесячной выдачей отчета об общих суммарных отпусках товара.
Организация
Охарактеризуется множеством территориально распределенных складов, в том числе в различных государствах ближнего зарубежья. Ассортимент отпускаемых товаров высок и быстроизменчив в силу изменчивости спроса. Состав покупателей крайне разнообразен, в число покупателей входят как физические, так и юридические лица. Практикуется система скидок постоянным покупателям и покупателям, приобретающим товар свыше определенного количества и (или) суммы. Развита система предоплат, отпуска товаров в кредит. Оплата производится в местной валюте по текущему курсу доллара, реже - рубля. Потребности в автоматизации учета отпуска товаров определяются широким диапазоном целей:
• прогнозированием с определенным уровнем вероятности будущего спроса (по покупателю, товару, региону) и т.д. Ввиду различия целей внедрения БД и содержания деловых процессов в Организациях А и Б, созданные в этих организациях базы данных будут существенно отличаться друг от друга - прежде всего детализацией хранимой информации и, следовательно, структурой данных. Если для организации А в БД достаточно хранить сведения о приходе и расходе товаров и о ценах на них, то в БД организации Б необходимо хранить десятки таблиц и в процессе работы тратить дополнительные усилия (реализуемые как вручную, так и автоматически) для того, чтобы поддерживать их в согласованном состоянии.
Понятие транзакций
Под транзакцией понимается воздействие на БД, переводящее ее из одного целостного состояния в другое. Воздействие выражается в изменении данных в таблицах базы.
Если одно из изменений, вносимых в БД в рамках транзакции, завершается неуспешно, должен быть произведен откат к состоянию базы данных, имевшему место до начала транзакции. Следовательно, все изменения, внесенные в БД в рамках транзакции, либо одновременно подтверждаются, либо не подтверждается ни одно из них.
Разберем пример. Рассмотренную выше нормализованную БД, содержащую сведения об отпуске товаров со склада, дополним двумя таблицами (рис. 1.27):
•
"Статистика по товару" - содержит сведения о суммарном отпуске каждого товара со склада, начиная с начала года; • "Статистика по покупателю" - содержит сведения о суммарном отпуске
товаров каждому покупателю, начиная с начала года. Тогда транзакция по добавлению в БД сведений о расходе товара со склада будет состоять из следующих операций:
• добавление записи в таблицу "Отпуск товаров";
• отыскание записи по данному товару в таблице "Статистика по товару" и увеличение значения поля "Всего отпущено товара" на значение "Отпущено ед."; если запись по такому товару в таблице "Статистика по товару" отсутствует, она должна быть добавлена;
• отыскание записи по данному покупателю в таблице "Статистика по покупателю"; вычисление стоимости отпущенного товара и увеличение на это значение поля "Всего отпущено"; если запись по такому товару в таблице "Статистика по покупателю" отсутствует, она должна быть добавлена.
Рассмотрим случай отгрузки товара "Макароны" в количестве 100 кг по цене 3000 за кг покупателю "Продбаза № 4". Если в рамках транзакции произошел сбой по одной из операций, необходимо отменить результаты выполнения всех других операций, иначе информация в БД будет недостоверной.
Если произошел сбой на добавлении записи в таблицу "Отпуск товаров", выполнение других операций приведет к увеличению статистики в соответствующих таблицах по товару "Макароны" на 3000 кг и по покупателю "Продбаза № 4" на 300 000 руб, хотя в действительности сведения о такой отгрузке в таблице "Отпуск товаров" будут отсутствовать.
Если произошел сбой при увеличении поля "Всего отпущено товара" в таблице "Статистика по товару", а другие операции завершились успешно, значения в таблице "Статистика по товару" окажутся недостоверны, поскольку в ней не будет отражен один из фактов расхода товара "Макароны".
Если произошел сбой при записи в таблицу "Статистика по покупателю", а другие операции завершились успешно, данная таблица будет содержать недостоверные сведения о сумме отпуска товаров покупателю "Продбаза № 4"
Поэтому в случае сбоя при выполнении любой из названных операций, результаты других операций должны быть отменены. В этом случае говорят, что произошел "откат" транзакции.
Выше мы рассмотрели ссылочную целостность таблиц БД и такие механизмы ее осуществления, как правильные каскадные воздействия на записи в дочерних таблицах при изменении или удалении записи в родительской таблице. Приведенный пример показывает нам другой вид целостности - смысловую (семантическую) целостность БД. Требование смысловой целостности определяет, что данные в БД должны изменяться таким образом, чтобы не нарушались сложившиеся между ними смысловые связи. Действительно, если в случае отпуска товаров информация о расходе товара не будет учтена в соответствующей записи таблицы "Статистика по товару", но при этом будет учтена в соответствующей записи таблицы "Статистика по покупателю", произойдет нарушение достоверности данных, хотя ссылочная целостность базы данных не будет нарушена Нарушение достоверности данных в этом случае может
быть легко проверено: сумма количеств расхода всех товаров из таблицы "Статистика по товару", умноженных на соответствующие цены за единицу товара, должна сойтись с суммой отпуска по всем покупателям из таблицы "Статистика по покупателю."
Типы таблиц БД по виду их изменения -справочные, операционные и транзакционные
Разные таблицы БД различаются по способу формирования в них информации и по типу их изменения в процессе работы с приложениями, обеспечивающими доступ к этой БД. Можно выделить три типа основных таблиц по способу формирования в них значений и их дальнейшего использования.
Справочные таблицы -
содержат информацию справочного характера, обладающих невысокой степенью изменчивости по сравнению с таблицами БД других видов; как правило, находятся с операционными и транзакционными ТБД в отношении "один-ко-многим", являясь при этом родительскими таблицами. В рассматриваемой нами БД, содержащей информацию об отпуске товаров со склада, справочными таблицами являются "Товары" и "Покупатели". Приложение для операций с БД должно быть спроектировано таким образом, чтобы всякий раз, когда в другие таблицы необходимо внести название товара или покупателя, выбор производился из текущего содержимого указанных справочных таблиц. Это необходимо для того, чтобы значения полей связи и в родительских (т.е. справочных), и в дочерних таблицах (например, "Накладные", "Отпуск товаров со склада") были идентичны.
Другим назначением справочных таблиц является хранение справочных сведений о характеристиках конкретного товара (единица измерения, цена за единицу измерения) и покупателя (город, адрес). В силу принципа нормализации, хранение такой справочной информации в других таблицах БД привело бы к избыточности данных. Поэтому всякий раз, когда для каких-либо целей (для вычисления общей цены отпущенного товара по накладной и т.п.) необходимо, например, получить цену за единицу конкретного товара, она отыскивается в справочнике.
Справочники могут иметь различную степень изменчивости. В некоторых справочниках информация не меняется никогда или меняется достаточно редко. В качестве примера справочников такого рода можно привести план балансовых счетов бухгалтерского учета, коды городов, а в нашем примере -реквизиты покупателя.
В других справочниках информация меняется значительно чаще. Это более характерно для справочников, содержащих значения цен на какие либо товары, услуги - как, например, в нашем случае для таблицы "Товары". Правда, если существуют требования, согласно которым в таблице "Товары" должна отражаться история цен на конкретный товар, в эту таблицу следовало бы добавить два поля "Срок действия цены" (начало периода, конец периода действия цены), или хотя бы одно поле (начало периода действия цены). В нашем примере мы для простоты в таблицу "Товары" механизма истории цен не вводили.
Под операционными таблицами понимаются таблицы БД, в которых происходит устойчивое во времени непрерывное или периодическое обновление или добавление информации. Операционные таблицы находятся, как правило, в подчиненном отношении со справочными таблицами. Данные в операционных таблицах служат источником для формирования данных в транзакционных таблицах. На основании данных в операционных таблицах обычно формируются итоговые отчеты.
В рассматриваемом нами примере в качестве операционных выступают таблицы "Накладные" и "Отпуск товаров со склада". В них ежедневно добавляется информация о отпуске товаров со склада. Занесение данных в эти таблицы вызывает одновременные или периодические изменения в транзакционных таблицах "Статистика по товару" и "Статистика по покупателю".
Транзакционные таблицы
обычно служат для накапливания данных, основанных на значениях данных в других таблицах. Механизмы обновления транзакционных таблиц зависят от конкретной реализации системы и могу! выполняться приложением или СУБД по заданным правилам (бизнес-правила, триггеры и т.д.).
В нашем примере в качестве транзакционных выступают таблицы "Статистика по товару'.' и "Статистика по покупателю". Информация в них формируется на основании данных в операционных таблицах "Накладные" и "Отпуск товаров со склада".
Типы информационных систем
В ходе эксплуатации информационных систем, работающих с БД, приходится иметь дело с исходной и результирующей информацией. Исходная информация в производственных и финансовых системах поступает на вход информационной системы, трансформируется должным образом и до срока хранится в БД. Позднее хранимая в БД информация объединяется по различным показателям, часто с применением достаточно сложных алгоритмов, и на выходе системы появляется итоговая, или результирующая информация.
Например, в рассматриваемой нами системе обработки сведений о отпуске товаров со склада в таблицы "Накладные" и "Отпуск товаров со склада" ежедневно поступает итоговая информация. На выходе могут выдаваться сведения о суммарных оборотах по всему складу, по конкретному товару, покупателю, городу, обобщенные данные о приросте расхода того или иного товара, о динамике роста или уменьшения сроков хранения товара на складе и т.д.
Можно выделить два различных принципа формирования итоговой информации в информационных системах.
Первый принцип состоит в постепенном накапливании итоговых или промежуточных данных по мере поступления в систему исходной информации. Этот принцип требует, как правило, введения в систему транзакционных алгоритмов, реализующих немедленное изменение итоговых или промежуточных данных при подаче на вход системы исходных данных.
Главным преимуществом такого подхода является возможность практически немедленной выдачи итоговых данных по любому интересующему нас периоду, поскольку большинство расчетов для этого уже произведено при добавлении в БД исходной информации. К недостаткам можно отнести, как правило, трудоемкую реализацию таких алгоритмов, необходимость расходования ресурсов на накапливание промежуточных данных в момент добавления информации, необходимость обеспечения отказоустойчивости в работе и восстановления (то есть повторных расчетов) при сбоях.
Второй принцип состоит в формировании итоговых данных в тот момент, когда они необходимы. При добавлении в систему исходной информации не происходит никаких дополнительных расчетов, что улучшает быстродействие системы при добавлении исходных данных. Отсутствие алгоритмов немедленных расчетов итоговых данных обусловливает отсутствие необходимости их реализации в системе, что делает проектирование и физическую реализацию системы значительно более быстрой, менее трудоемкой, а логику работы системы
- более понимаемой. Однако эти достоинства влекут за собой главный недостаток
- для формирования итоговых данных часто требуются значительные вычислительные и временные ресурсы.
В приводимой нами системе элементы первого подхода можно проследить в структуре БД, в которой присутствуют таблицы "Статистика по товару" и "Статистика по покупателю". Без данных таблиц можно обойтись, однако в этом случае получение итоговых сведений придется приводить по второму
варианту.
Трудно дать рекомендации о предпочтительности того или иного метода, кроме общих. Известно, что непрерывный расчет итоговых данных эффективен для случаев, когда итоговая информация требуется непрерывно и должна поставляться по требованию в кратчайшие сроки, а также когда итоговые результаты предыдущего периода входят в состав исходных данных для последующего периода. Периодический расчет итоговых данных на основе только исходных, наоборот, лучше производить в тех случаях, когда между осознанием необходимости выдачи итоговых данных и фактом такой выдачи может лежать достаточный временной отрезок и когда есть возможность задействовать значительные вычислительные ресурсы.
Навигационный и SQL-ориентированный подходы к операциям над данными
Существует два основных подхода к операциям над данными в ТБД.
Навигационный подход
ориентирован на обработку каждой записи таблицы в отдельности. Этот подход используется в так называемых локальных (персональных, настольных) базах данных типа Paradox и dBase. При SQL-ориентированном подходе происходит обработка групп записей (этот подход часто называют ориентированным на множества записей или на наборы данных). При этом могут обрабатываться записи нескольких таблиц БД. Такой подход используют так называемые "серверные" (промышленные, удаленные) базы данных - такие как Oracle, Sybase, Informix, InterBase и др. О различиях локальных и удаленных БД будет рассказано в следующих разделах.
Реляционные базы данных
Реляционные БД представляют связанную между собой совокупность таблиц баз данных (ТБД). Связь между таблицами может находить свое отражение в структуре данных, а может только подразумеваться, то есть присутствовать на неформализованном уровне.
Каждая таблица БД представляется как совокупность строк и столбцов, где строки соответствуют экземпляру объекта, конкретному событию или явлению, а столбцы - атрибутам (признакам, характеристикам, параметрам) объекта, События, явления.
На рис. 1.1. приведен пример таблицы БД, в которой содержатся сведения об отпуске товара со склада. Столбцы представляют собой такие параметры, как дата отпуска товара, наименование отпущенного товара, наименование покупателя, количество единиц отпущенного товара. Каждая строка содержит введения о конкретном событии отпуска товара покупателю. в терминологии теории реляционных БД таблицам соответствуют отношения, столбцам - атрибуты, строкам - кортежи.
При практической разработке БД таблицы так и зовутся таблицами, строки -записями, столбцы - полями или столбцами ТБД.
Дата
Рис 1 1 Таблица базы данных "Отпуск товаров со склада "
Предшественниками реляционных БД были иерархические и сетевые базы данных. В иерархических БД информация хранилась в виде иерархий. На рис. 1.2 приведен пример такой иерархии; из ее рассмотрения становится ясно, для того, чтобы получить элемент данных А 12, нужно сначала отыскать в БД узел А, спуститься к узлу А1 и затем - к узлу А 12.
Сетевая БД характерна внутренними ссылками между структурами данных. Если от элемента В имеется ссылка на элемент А, возможен выбор элемента данных А (рис. 1.3).
Реляционные БД в 70-х годах практически вытеснили БД других видов. В качестве основной причины этого называют сложность представления данных в иерархической и сетевой моделях и необходимость определения связей между данными на этапе проектирования БД, в то время как в реляционных БД связи между таблицами могут устанавливаться непосредственно в момент выполнения запросов. Кроме того, разработчикам и пользователям значительно проще отображать сущности предметной области в табличных структурах данных.
Однако иерархический и сетевой подходы продолжают жить, они находят свое воплощение в отдельных специализированных БД и являются
одним из "кирпичиков", на которых строятся архитектуры так называемых "пост-реляционных" баз данных. Быстрыми темпами развиваются объектно-ориентированные БД, оперирующие категориями объектов, и так называемые полнотекстовые БД, позволяющие производить быстрые выборки из неструктурированной информации (например, текстов, изображений и т.д.). Однако и в настоящее время реляционные БД остаются наиболее используемыми.
Реляционные БД имеют мощный теоретический фундамент, основанный на математической теории отношений. Он был разработан доктором Эдгаром Коддом. Для построения запросов к реляционным БД был также разработан язык SQL (Structured Query Language, язык структуризированных запросов). Он приобрел характер промышленного стандарта в реляционных системах управления базами данных (СУБД). Поэтому, переходя с одной реляционной базы на другую, пользователь и разработчик имеют дело с одним и тем же языком. Другим важным плюсом SQL является то, что этот язык ориентирован на высокоуровневые операции с данными. Выдавая запрос, можно не беспокоиться о низкоуровневых проблемах доступа к данным, специфичных для каждой БД, поскольку интерпретация запросов в команды низкого уровня лежит в ведении конкретной СУБД.
Большинство разработчиков БД, не будучи знакомы с теорией реляционных БД, тем не менее эффективно выполняют свою работу, поскольку табличная форма организации данных является интуитивно понятной и подчиняется здравому смыслу. Поэтому, при наличии минимальной практики и следуя нескольким правилам, разработчик может проектировать структуры данных, не противоречащие реляционной модели.
При разработке структур реляционных БД необходимо учитывать ряд существенных моментов. Далее в этой главе мы познакомимся с особенностями организации структур данных в виде связанных таблиц БД. Для этого необходимо рассмотреть нормализацию данных, понятие нормальной формы, понятие первичных и внешних ключей и ограничения целостности.
Понятие первичного ключа
В каждой таблице БД может существовать первичный ключ. Под первичным ключом понимают поле или набор полей, однозначно идентифицирующий запись. Значение первичного ключа в таблице БД должно быть уникальным, то есть в таблице не должно существовать двух или более записей с одинаковым значением первичного ключа. Первичный ключ должен быть минимально достаточным: в нем не должно быть полей, удаление которых из первичного ключа не отразится на его уникальности.
На рис. 1.4 показана таблица "Сотрудники". В качестве первичного ключа не могут использоваться поля:
• ФИО - поскольку практически известно, что даже в одном отделе могут работать однофамильцы с одинаковыми инициалами или даже полные тезки;
• должность - поскольку хотя для данного примера названия должностей и уникальны, в любом отделе наверняка найдутся сотрудники, занимающие одну и ту же должность;
• номер отдела и год рождения - поскольку здравый смысл подсказывает, что может найтись достаточное число сотрудников, работающих в одном отделе или родившихся в одном году.
№ пропуска
Рис. 1.4. Таблица "Сотрудники"
В качестве первичного ключа может выступать номер пропуска, но при этом нужно сделать оговорку. Если номер пропуска недавно уволившегося сотрудника не может быть назначен сотруднику, впоследствии принятому на работу (т.е. является уникальным во времени), нет никаких ограничений на использование этого поля в качестве первичного ключа. Если же номер пропуска уволившегося сотрудника может быть назначен вновь поступившему сотруднику, следует изучить вопрос - удаляется ли информация об уволившемся сотруднике из базы данных? Если да, то поле может быть первичным ключом; если нет - не может быть первичным ключом, поскольку в базе данных могут присутствовать два сотрудника с одинаковым номером пропуска. В этом случае следует добавить в таблицу семантически незначащее поле (то есть не имеющего иного смысла, кроме обеспечения уникальности записи), например числовое поле NN (рис. 1.5.).
№
Рис. 1.5. Таблица "Сотрудники" после введения уникального поля
Уникальность подобного поля обычно отслеживается или программно, или автоматически. В первом случае при добавлении нового сотрудника приложение, работающее с базой данных, отыскивает максимальный номер сотрудника, увеличивает на 1 и назначает вновь добавляемой записи. Во втором случае первичный ключ реализуется через автоинкрементное поле. Для него сказанные действия выполняются автоматически системой управления базой данных. Существуют и иные способы обеспечения уникальности значений ключевого числового поля, они зависят от особенностей конкретной СУБД.
В приводившейся выше таблице "Отпуск товаров со склада" также необходимо генерировать семантически незначащий первичный ключ, поскольку, как несложно заметить, один и тот же покупатель может в течение одного и того же дня многократно закупать один и тот же товар в одинаковом количестве. Однако, если предметная область допускает использование семантически значащего уникального поля, следует использовать его. например, для расхода товаров это может быть номер накладной или номер
счета, при условии, что в организации существуют деловые правила, согласно которым один и тот же номер не может быть назначен двум счетам или накладным.
Приведем другие примеры первичных ключей:
• номер и серия паспорта;
• номер двигателя;
• фамилия и инициалы автора, название книги, год издания, издательство. В случае, если принять во внимание, что в течение одного года книга может издаваться тем же издательством повторно, в первичный ключ следует добавить номер издания (2-е, 3-е и т.д.);
• название факультета, кафедры, года приема - для именования учебных групп в вузах;
• номер лицевого счета в бухгалтерском балансе;
• дата - если событие может случиться в течение даты только единожды, например, поставка продуктов в заводскую столовую;
• дата и время отказа сетевого оборудования, а при наличии нескольких потенциально сбойных узлов - адрес (номер) узла (если сбой узла характеризуется несколькими типами ошибок - еще и номер ошибки);
• почтовый адрес организации - с указанием номеров комнат, в случае, если в одном здании располагается несколько организаций (например, офисное здание);
• банковские реквизиты;
• регистрационный номер банка, организации;
• дата, номер страхового полиса, специализация и (или) фамилия и инициалы врача-специалиста - при обращении в поликлинику и т.д.
Замечание.
Может показаться, что банковские реквизиты не могут однозначно характеризовать организацию, поскольку одна организация может иметь несколько счетов в различных банках. Но реквизиты конкретного счета являются уникальными и, следовательно, могут однозначно характеризовать организацию; наименование же организации не может однозначно характеризовать реквизиты ее банковских счетов, которых может быть несколько. На практике, реквизиты счета вряд ли будут использованы в качестве первичного ключа, поскольку эти реквизиты громоздки; тем не менее, с теоретической точки зрения, такое возможно. При детальном рассмотрении природы первичных ключей рано или поздно возникает вопрос: если в рамках данной предметной области мы можем обойтись без первичного ключа, стоит ли вводить искусственный первичный ключ? Например, пусть приведенная выше на рис. 1.1 таблица "Отпуск товаров со склада" используется только для подсчета суммарного отпуска товаров за временной период. Тогда однозначно характеризовать запись вроде бы ни к чему - записи используются только в группировках по датам. Однако в процессе отладки приложений, работающих с базами данных, при возникновении сбоев, потерь данных, нарушении смысловой целостности всегда нужно знать, с какой именно записью мы имеем дело. Роль уникального идентификатора записи в этом случае трудно переоценить. Поэтому не только правила хорошего тона при разработке структур баз данных, но и чисто практические соображения должны побудить разработчика всегда определять первичный ключ для таблицы базы данных.
Отношение "один-ко-многим"
Отношение "один-ко-многим" имеет место, когда одной записи родительской таблицы может соответствовать несколько записей в дочерней таблице.
Как видно из рис. 1.6, одной записи из родительской таблицы "Товары" может соответствовать несколько записей в дочерней таблице "Отпуск товаров". Обратите внимание на глагол может: он означает, что такая возможность - потенциальная и что в родительской таблице могут найтись записи, для которых в данный момент нет записей в дочерней таблице (например, товар "Куры").
Поэтому различают две разновидности связи "один-ко-многим" - в первом случае выдвигается жесткое требование, согласно которому всякой записи в родительской таблице должны соответствовать записи в дочерней таблице. Во втором случае подобное требование не носит жесткого характера и подразумевается (как в описанном выше случае), что некоторые записи в родительской таблице могут не иметь связанных с ними записей в дочерней таблице.
Связь "один-ко-многим" иногда называют связью "многие-к-одному". В этом случае подразумевается, что мы смотрим со стороны дочерней таблицы
на родительскую. Когда упоминают название "один-ко-многим", имеется в виду, что следует смотреть со стороны родительской таблицы на дочернюю. И в том и в другом случае сущность связи между таблицами остается неизменной.
Связь "один-ко-многим" является самой распространенной для реляционных баз данных. Как можно заметить, она позволяет моделировать иерархии данных.
В широко распространенной нотации структуры баз данных IDEFIX отношение "один-ко-многим" изображается путем соединения таблиц линией, которая на стороне дочерней таблицы оканчивается кружком или иным символом. Поля, входящие в первичный ключ для данной ТБД, всегда расположены вверху и отчеркнуты от прочих полей линией (рис. 1.7).
Отношение "один-к-одному"
Отношение "один-к-одному" имеет место, когда одной записи в родительской таблице соответствует одна запись в дочерней таблице (рис. 1.8.).
Данное отношение встречается много реже, чем отношение "один-ко-многим". Его используют, если не хотят, чтобы таблица БД "распухала" от второстепенной информации. Использование связи "один-к-одному" приводит к тому, что для чтения связанной информации в нескольких таблицах приходится производить несколько операций чтения вместо одной, когда данные хранятся в одной таблице. Кроме того, базы данных, в состав которых входят таблицы со связью "один-к-одному", не могут считаться до конца нормализованными (о нормализации см. ниже).
Связь "один-к-одному" может быть жесткой и нежесткой. В первом случае для каждой записи в родительской таблице должна существовать запись в дочерней таблице. Во втором случае - запись в дочерней таблице может как существовать, так и отсутствовать.
Отношение "многие-ко-многим"
Отношение "многие-ко-многим" имеет место, когда:
а) записи в родительской таблице может соответствовать больше одной записи в дочерней таблице;
б) записи в дочерней таблице может соответствовать больше одной записи в родительской таблице.
На рис. 1.9 показаны таблицы, состоящие в отношении "многие-к-одному". Каждой учебной группе соответствует несколько преподавателей. Каждый преподаватель может вести, во-первых, несколько разных предметов, и, во-вторых, преподавать в разных группах.
Таблица "Учебные группы и Таблица "Преподаватели" дисциплины"
Группа
Многие СУБД не поддерживают связи "многие-ко-многим" на уровне индексов и ссылочной целостности (см. следующий подраздел), хотя и позволяют реализовывать ее в таблицах неявным образом. Аналогично, мнногие CASE-средства (программы для разработки структуры базы данных в виде диаграмм и генерации на их основе физической базы данных) также нe позволяют определять эту связь между таблицами проектируемой базы даннь1Х. Считается, что всякая связь "многие-ко-многим" может быть заменена на одну или более связь "один-ко-многим". Хотя это так, по мнению автора, целесообразность применения такой связи должна рассматриваться прежде всего в контексте разрабатываемой базы данных и приложения для работы с ней, и там, где это удобно, такая связь должна реализовываться.
Связь между записями одной таблицы
Между записями одной таблицы также может существовать связь, то есть одни записи могут ссылаться на другие.
Рассмотрим пример. Пусть необходимо в реляционной БД хранить древовидную структуру произвольного уровня, например, структуру организации (рис. 1.10.) В этом случае минимально достаточно таблицы реляционной БД (рис. 1.11), в которой каждому подразделению организации соответствует одна запись. Эта запись ссылается на запись, соответствующую подразделению более высокого уровня, в которое входит данное подразделение. И только в записи о подразделении самого высокого уровня нет подобной ссылки.
Нужно заметить, что автоматическое обеспечение связен записей внутри одной таблицы реляционными СУБД не поддерживается и эти связи нужно реализовывать программно. Несложно заметить, что удаление записи, на которую имеются ссылки (у нас это записи со значением поля "№ подразделения", кроме 4,5,6,8,9,11), должно блокироваться, поскольку в противном случае в таблице будут иметь место ссылки на несуществующие номера подразделений. Также нельзя изменять номера подразделений, на которые имеются ссылки - это разрушит достоверность данных. Такие действия необходимо реализовывать программно. Рассмотренный пример является частным случаем более общей проблемы - обеспечение ссылочной целостности между таблицами базы данных. Речь об этой проблеме пойдет вследующем разделе.
Реляционные отношения (связи) между таблицами базы данных
Между двумя или более таблицами базы данных могут существовать отношения подчиненности. Отношения подчиненности определяют, что для каждой записи главной таблицы (master, называемой еще родительской) может существовать одна или несколько записей в подчиненной таблице (detail, называемой еще дочерней).
Существует три разновидности связей между таблицами базы данных: "один-ко-многим", "один-к-одному", "многие-ко-многим".
Ссылочная целостность и каскадные воздействия
Рассмотрим наиболее часто встречающуюся в базах данных связь "один-ко-многим" (рис. 1.12). Как можно заметить, дочерняя и родительская таблицы связаны между собой по общему полю "Товар". Назовем это поле полем связи.
Таблица "Товары" Таблица "Отпуск товаров"
Товар
Рис. 1.12. Связанные таблицы базы данных
Возможны два вида изменений, которые приведут к утере связей между записями в родительской и дочерней таблицах:
• изменение значения поля связи в записи родительской таблицы без изменения значений полей связи в соответствующих записях дочерней таблицы;
• изменение значения поля связи в одной из записей дочерней таблицы без соответствующего изменения значения полей связи в родительской и дочерней таблицах.
Разберем первый случай. На рис. 1.13 показано изменение значения поля "Товар" с "Сахар" на "Рафинад" в таблице "Товары". В таблице "Отпуск товаров" значение поля связи "Сахар" осталось прежним. В результате:
в дочерней таблице "Отпуск товаров" для товара "Рафинад" (таблица "Товары") нет сведений о его отпуске со склада;
• некоторые записи таблицы "Отпуск товаров" содержат сведения об отпуске товара ("Сахар"), о котором нет информации в таблице "Товары".
| Товар | Ед.изм. | Цена eд | Товар | Дата | Кол-во, ед. | |
| Рафинад | кг | 5000 --- | -|-> | Сахар | 10.01.97 | 100 |
| Макароны | кг | 7000 | |-> | Сахар | 12.01.97 | 200 |
| Куры | кг | 10000 | |-> | Сахар | 14.01.97 | 50 |
| Фанта | бут.1 л | 6000 | Макароны | 10.01.97 | 1000 | |
| Макароны | 11.01.97 | 500 | ||||
| Фанта | 10.01.97 | 2000 | ||||
| Фанта | 12.01.97 | 3000 |
Рис. 1.13. Нарушение целостности базы данных - записи с товаром "Сахар" (таблица "Отпуск товаров") не имеют родительской записи
Разберем второй случай. Пусть в одной из записей таблицы "Отпуск товаров" значение поля связи "Сахар" изменилось на "Рафинад" (рис. 1.14). В результате:
• в дочерней таблице "Отпуск товаров" недостоверны сведения об отпуске со склада товара "Сахар" (таблица "Товары");
• одна из записей таблицы "Отпуск товаров" содержит данные об отпуске товара ("Рафинад"), сведения о котором (такие, как единица измерения и цена за единицу) отсутствуют в таблице "Товары". И в первом, и втором случаях мы наблюдаем нарушение целостности базы данных, поскольку информация в ней становится недостоверной. Следовательно, нужно блокировать действия, которые нарушают целостность связей между таблицами, которую называют ссылочной целостностью. Когда говорят о ссылочной целостности, имеют в виду совокупность связей между отдельными таблицами во всей БД. Нарушение хотя бы одной такой связи делает информацию в БД недостоверной.
Таблица "Товары" Таблица "Отпуск товаров"
Товар
Рис. 1.14. Нарушение целостности базы данных - запись с товаром "Рафинад" (таблица "Отпуск товаров ") не имеет родительской записи
Чтобы предотвратить потерю ссылочной целостности, используется механизм каскадных изменений. Он состоит в обеспечении следующих требовании:
• необходимо запретить изменение поля связи в записи дочерней таблицы без синхронного изменения полей связи в родительской и дочерней таблицах; обычно инициатива изменения поля связи реализуется в записи родительской таблицы;
• при изменении поля связи в записи родительской таблице, следует синхронно изменить значения полей связи в соответствующих записях дочерней таблицы;
• при удалении записи в родительской таблице, следует удалить соответствующие записи в дочерней таблице.
Данные изменения или удаления в записях дочерней таблицы при изменении (удалении) записи родительской таблицы называются каскадными изменениями и каскадными удалениями.
Замечание 1. Существует другая разновидность каскадного удаления: при удалении родительской записи в записях дочерних таблиц значения полей связи обнуляются. Эта разновидность применяется редко.
Замечание
2. Обычно занесение записей в дочернюю таблицу осуществляется так: выбирается значение родительской записи (например, из выпадающего списка), значение поля связи фиксируется и затем автоматически заносится в поля связи дочерних записей. Метод, когда пользователь вручную заносит значения полей связи в дочерние записи, непопулярен: пользователь может внести одинаковое по смыслу, но разное по написанию значение ("Сахар", "сахар"). Много реже практикуется способ ввода дочерних записей без указания значения поля связи. Затем записи родительской и дочерних таблиц "связываются". Каскадные изменения могут блокироваться: или одновременно изменения и удаления, или изменения или удаления по отдельности. Необходимость разрешения или запрещения каскадных изменений обычно реализуется в СУБД при определении связей между таблицами. Собственно, таким образом и происходит создание ссылочной целостности. Обычно в СУБД для реализации ссылочной целостности в дочерней таблице создают внешний ключ (см. ниже), ссылающийся на родительскую таблицу, и указывают вид каскадных
воздействий. В последующем СУБД сама при необходимости реализует каскадные воздействия данного вида для указанных таблиц.
Понятие внешнего ключа
Для обеспечения ссылочной целостности в дочерней таблице создается внешний ключ. Во внешний ключ входят поля связи дочерней таблицы. Для связей типа "один-ко-многим" внешний ключ по составу полей должен совпадать с первичным ключом родительской таблицы или - реже - с частью первичного ключа (в этом случае следует признать, что нормализация таблиц БД произведена не полностью). По определениям первичного и вторичного ключей СУБД автоматически строит индексы (см. ниже). Индекс, соответствующий вторичному ключу, используется для реализации связи родительской и дочерних таблиц. Механизм индексов основан на понятии методов доступа, поэтому рассмотрим их подробнее.
Индексы и методы доступа
Порядковый № записи
Рис. 1.15. Физическая структура таблицы
Индексы представляют собой механизмы быстрого доступа к данным в таблицах БД.
Сущность индексов состоит в том, что они хранят значения индексных полей (т.е. полей, по которым построен индекс) и указатель на запись в таблице. Например, если имеется таблица (рис. 1.15.), то с логической точки зрения индексы выглядят так (рис. 1.16):
По дате прихода товара
Рис. 1 16 Логическая структура индексов
Следовательно, если нужно выбрать все записи с наименованием товара "Свекла", нет нужды просматривать всю таблицу. Достаточно найти в индексе, построенном по столбцу "Наименование товара", первый указатель на запись, содержащую товар "Свекла", и считать из таблицы эту запись, а затем повторить то же для всех иных указателей в индексе на записи с товаром "Свекла". Если нужно считать все записи из таблицы, отвечающие условию "Количество > 16", достаточно найти в индексе, построенном по столбцу "Количество", первую строку с количеством больше 16, считать запись из таблицы по указателю на нее, записанному в индексе, и в дальнейшем повторить эти действия для всех записей, у которых значение "Количество" в индексе больше 16.
В действительности индексы имеют более сложную организацию, но думается, что с логической точки зрения при проектировании баз данных полезнее представлять их структуру и их принцип использования так, как это сделано выше.
В описанном выше нехитром примере использования индексов мы сталкиваемся с двумя методами доступа к записям в таблице - последовательным и индексно-последовательным. При этом индексно-последовательный доступ неявно использует прямой и последовательный доступ.
При последовательном методе доступа для выполнения запроса к таблице БД просматриваются все записи таблицы, от первой к последней. Нет смысла говорить, что этот метод совершенно неэффективен (зачем просматривать 100 000 записей, если удовлетворяют условию запроса всего 2?). Неэффективность выражается прежде всего в потери быстродействия и напрасной трате вычислительных ресурсов. Время выполнения запроса прямо пропорционально числу записей в таблице.
При индексно-последовательном методе доступа
для выполнения запроса к таблице БД указатель в индексе устанавливается на первую строку, удовлетворяющую условию запроса (или его части), и считывается запись из таблицы по хранящемуся на нее в индексе указателю. Затем указатель в индексе перемещается на следующую строку, удовлетворяющую условию запроса (или его части), и из таблицы считывается запись. То же происходит для всех строк в индексе, удовлетворяющих условию запроса (или его части). Процесс выборки прекращается, когда текущая строка в индексе перестанет удовлетворять условию запроса. Заметим, что оговорка "удовлетворяющих условию запроса (или его части)" сделана специально, поскольку запросы, состоящие из более чем одного критерия поиска записей, приходится удовлетворять за несколько обращений с индексу. Например, для запроса, "выдать все приходы свеклы или картофеля" может потребоваться сначала отыскать все записи по приходу свеклы, а затем по приходу картофеля.
При индексно-последовательном доступе просматривается только часть индекса, а из таблицы читаются только записи, удовлетворяющие условию поиска. Метод назван индексно-последовательным потому, что:
• поиск ведется по индексу, а не по самой таблице;
• поиск в индексе начинается только с первой строки, удовлетворяющей условию запроса или его части (так называемый прямой доступ);
• строки в индексе, начиная с такой записи, просматриваются все-таки последовательно.
В том случае, если в условия запроса входят поля, по которым не построено индексов, ищется иной пригодный индекс; если такого индекса нет, производится последовательный перебор записей таблицы БД.
При прямом методе доступа запись из таблицы выбирается непосредственно, по значению одного поля или группы полей, минуя переборы других записей.
Таким образом, индексно-последовательный метод доступа использует прямой доступ при установке в индексе на первую строку, удовлетворяющую запросу или его части. После этого используется последовательный метод доступа для перемещения по строкам индекса.
Для "локальных" ("персональных") СУБД типа Paradox, dBase индексы хранятся отдельно от основной таблицы БД - в виде отдельного файла. В случае их определения в "промышленных" ("серверных") СУБД - таких как Oracle, Sybase, InterBase, SQL Server - индексы хранятся вместе с БД.
Как уже сказано выше, определения первичных и внешних ключей таблиц БД приводят к созданию индексов по полям, объявленным в составе первичных или внешних ключей. Дополнительные индексы создаются вручную или программно, если индексов, построенных по определениям первичных и внешних ключей, недостаточно для:
• обеспечения нужного порядка сортировки данных;
• оптимизации доступа к базе данных.
Нормализация таблиц при проектировании базы данных
При проектировании структуры новой БД определяют сущности (объекты, явления) предметной области, которые должны найти свое отражение в базе данных. Анализ предметной области обычно осуществляется:
• на основании существующих сведений о предметной области в широком или в узком смысле, то есть в масштабах, в которых она должна быть представлена в создаваемой БД и работающих с ней приложениях;
• исходя из целей проектирования программной системы;
• на основании представления о том, какое место БД и работающие с ней приложения займут в структуре эксплуатирующей ее организации;
• на основании представлений о том, какие изменения деловых потоков организации последуют после внедрения программной системы в эксплуатацию.
В конечном итоге анализ предметной области должен привести к созданию эскиза БД. Сначала желательно изобразить сущности и связи между ними. Как правило, каждой сущности в БД соответствует таблица. Затем - в эскизе второго порядка - для каждой таблицы БД приводится список полей записи.
Замечание.
Несмотря на существование методик анализа предметных областей, построения эскизов БД (весьма полезных при больших объемах обрабатываемых данных и деловых правил в предметной области, нередко выходящих за рамки одновременного восприятия), необходимо отметить следующее: • процесс определения окончательной структуры БД является циклическим, то есть на разных этапах проектирования - начиная от эскиза структуры БД и заканчивая опытной или даже промышленной эксплуатацией готовых программных систем - приходится возвращаться к структуре БД и вносить в нее изменения;
• в процессе моделирования предметной области участвуют такие субъективные факторы, как здравый смысл разработчика, его интуиция, привычки, личностное восприятие проблемы, стереотипы мышления и т.д. Поэтому различные разработчики наверняка предложат различные проекты структуры одной и той же БД, хотя в узловых моментах, например, в определении большей части сущностей и связей между ними, эти проекты должны быть похожи. Следовательно, с одной стороны, процесс проектирования структур БД является процессом творческим, неоднозначным, с другой стороны, узловые его моменты могут быть формализованы.
Одной из таких формализации является требование, согласно которому реляционная база данных должна быть нормализована (то есть подвергнута процедуре нормализации). Рассмотрим, что это такое.
Процесс нормализации имеет своей целью устранение избыточности данных и заключается в приведении к третьей нормальной форме (ЗНФ).
Существует несколько нормальных форм - 1НФ, 2НФ, ЗНФ, 4НФ, ЗНФ, нормальная форма Бойса-Кодда (БКНФ). При практической разработке баз данных важны первые три - 1НФ, 2 НФ, ЗНФ.
Первая нормальная форма (1НФ)
требует, чтобы каждое поле таблицы БД: • было неделимым;
• не содержало повторяющихся групп.
Неделимость
поля означает, что значение поля не должно делиться на более мелкие значения. Например, если в поле "Подразделение" содержится название факультета и название кафедры, требование неделимости не соблюдается и необходимо из данного поля выделить или название факультета, или кафедры в отдельное поле.
| Накладная №123 | ||||
| Дата |
Покупатель | Адрес | ||
| 10.01.97 |
ТОО "Геракл" | г. Москва , ул. Стромынка , 20 | ||
| Отпущен товар | Количество | ед.изм. | Цена ед.изм. | Общая стоимость |
| Тушенка | 10000 | банки | 7000 | 70 000 000 |
| Сахар | 200 | кг | 5000 | 1 000 000 |
| Макароны | 1000 | кг | 3000 | 3 000 000 |
| Итого 74 000 000 |
являются поля, содержащие одинаковые по смыслу значения. Например, если требуется получить статистику продаж четырех товаров по месяцам, можно создать поля для хранения данных о продаже по каждому товару. Однако в этом случае мы имеем дело с повторяющимися группами (рис. 1.17): Замечание.
Дефис в заголовке таблицы не является обязательным требованием именования таблиц БД; просто таблицы именуются именно такимобразом в использованной автором программе формирования IDEF1X-диаграмм базы данных (Design/IDEF). Однако, что делать, если товаров не 4, а 104? Конечно, можно определить столько полей, сколько товаров. Но как быть, если число товаров заранее не известно и по одной накладной может быть отпущено 2, а по другой- 772 товара? Реализовать запись с переменным числом полей в реляционных базах данных невозможно, поскольку запись таблицы реляционной БД должна иметь четкую структуру. Исходя из вышесказанного, повторяющиеся группы следует устранить. В результате получим запись, содержащую информацию о статистике продаж по одному товару (рис. 1.18). Для 4 товаров будем иметь 4 записи, для 104 товаров - 104 записи и для n товаров - n записей для каждого месяца.
Пример.
Пусть необходимо автоматизировать процесс отпуска товаров со склада. Товары отпускаются по накладной, примерный вид которой приводится В начале проектирования, приводя данные к первой нормальной форме, сведем имеющиеся данные в одну таблицу. Известно, что впоследствии будет необходимо производить анализ продаж по городам. Поэтому из поля "Адрес" (допускающего толкование как делимого поля) выделим в отдельное поле "Город". Известно, что каждый покупатель может закупить в один день различное количество товаров. Поэтому переборем искушение назначить каждому товару отдельное поле и выделим факт отпуска товара в отдельную запись (рис. 1.19). Для того, чтобы продолжить нормализацию данных, приведем данные ко второй нормальной форме (2НФ).
Вторая нормальная форма (2НФ)
требует, чтобы все поля таблицы зависели от первичного ключа, то есть чтобы первичный ключ однозначно определял запись и не был избыточен. Те поля, которые зависят только от части первичного ключа, должны быть выделены в составе отдельных таблиц. Продолжим рассмотрение описанного выше примера. Для приведения к 2НФ выделим поля, которые входят в первичный ключ. Дата накладной и номер накладной по отдельности не могут уникально определять запись, поскольку они будут одинаковы для всех записей, относящихся к одной и той же накладной. Поэтому введем в первичный ключ поле "Товар". При этом исходим из имеющегося правила, что по одной накладной может быть отпущено одно наименование конкретного товара, то есть не может иметь место ситуация, когда отпуск одного и того же товара оформляется в накладной двумя строками (что влечет за собой две одинаковые записи в таблице "Отпуск товаров со склада"):
| Дата | Покупатель | Адрес |
|
| 10.01.97 |
ТОО "Геракл" г. Москва , ул. Стромынка, 20 | ||
| Отпущен товар | Количество ед. изм. | Цена ед.изм | . Общая стоимость |
| Тушенка | 6000 банки | 7000 | 42 000 000 |
| Тушенка | 4000 банки | 7000 | 28 000 000 |
| Сахар | 200 кг | 5000 | 1 000 000 |
| Макароны | 1000 кг | 3000 | 3 000 000 |
| Итого 74 000 000 |
Проведя смысловой анализ зависимостей между полями таблицы, нетрудно увидеть, что созданный нами первичный ключ является избыточным: поле "Номер накладной" однозначно определяет дату и покупателя. Для данной накладной не может быть никакой иной даты и никакого иного покупателя.
Поле "Товар", будучи взято в комбинации с номером накладной, напротив, однозначно идентифицирует запись, поскольку для каждой записи ясно, о каком, собственно, товаре из множества товаров, отпущенных по данной накладной, идет речь. После уточнения состава полей в первичном ключе получим таблицу со структурой, показанной на рис. 1.21.
Первое требование 2НФ выполнено. Чего не скажешь о втором требовании, гласящем, что значения всех полей записи должны однозначно зависеть от совокупного значения первичного ключа и не должна иметь место ситуация, когда некоторые поля зависят от части первичного ключа. Действительно, при дальнейшем анализе можно увидеть, что поля "Единица измерения", "Цена за единицу измерения" зависят только от значения поля "Товар". В самом деле, стоимость единицы измерения товара и название самой единицы измерения не зависят от конкретной накладной и будут одинаковыми для всех накладных, в которые входит данный товар. Поэтому выделяем данные поля в отдельную таблицу "Товары" и определяем связь: поскольку один товар может присутствовать во многих накладных, таблицы "Товары" и "Отпуск товаров со склада" находятся в связи "один-ко-многим" (рис. 1.22.).
После анализа структуры таблицы "Отпуск товаров со склада" можно заметить, что значение поля "Покупатель" никоим образом не зависит от пары значении "Номер накладной", "Товар", а зависит только от значения поля "Номер накладной". Поэтому данное поле и зависящие от его значения поля "Город", "Адрес" выделяются в отдельную таблицу "Покупатели" (рис. 1 23.)
Анализируя далее структуру таблицы "Отпуск товаров со склада", можно заметить, что одно из оставшихся полей - "Дата" зависит только от значения поля "Номер накладной". Поэтому выделяем дату и номер накладной в отдельную таблицу "Накладные" (рис. 1.24).
Установим связи между таблицами Один покупатель может встречаться во многих накладных. Поэтому между таблицами "Покупатели" и "Накладные" имеется связь "один-ко-многим" по полю "Покупатель". Одной накладной может соответствовать несколько товаров Поэтому между таблицами "Накладные" и "Отпуск товаров со склада" имеется связь "один-ко-многим" по полю "Номер накладной" (рис 1 25).
Для того чтобы уяснить, до конца нормализованы таблицы в составе разрабатываемой нами БД или нет, проанализируем ее структуру с позиций третьей нормальной формы (ЗНФ)
Третья нормальная форма
(ЗНФ) требует, чтобы в таблице не имелось Транзитивных зависимостей между неключевыми полями, то есть чтобы значение любого поля таблицы, не входящего в первичный ключ, не зависело от значения другого поля, не входящего в первичный ключ. Продолжим рассмотрение примера. Можно увидеть, что в таблице "Отпуск товаров со склада" имеется зависимость значения поля "Общая стоимость" от значения поля "Количество". Значение поля "Общая стоимость" может вычисляться как значение поля "Количество", умноженное на значение поля "Цена за единицу измерения" из таблицы "Товары" (из записи с таким же значением поля "Товар"). Поэтому поле "Общая стоимость" из таблицы "Отпуск товаров со склада" удаляем В результате получаем нормализованную базу данных, структура которой приводится на рис. 1 26.
Замечание.
В таблице "Покупатели" значение поля "Адрес" зависит от значения поля "Город", поскольку в разных городах могут оказаться улицы с одинаковыми названиями и, соответственно, дома с одинаковыми номерами (вспомним известный кинофильм "Ирония судьбы, или с легким паром"). Думается, что такой зависимостью можно пренебречь, поскольку поле "Адрес" в нашем случае носит чисто информационный характер и не должно входить в условия запросов самостоятельно. Вообще говоря, на практике не всегда возможно получить идеально нормализованную БД. Часто к этому и не стремятся - по причинам, изложенным в следующем разделе.
Нормализация - за и против
Нормализация таблиц БД призвана устранить из них избыточную информацию. Как видно из приведенных выше примеров, таблицы нормализованной БД содержат только один элемент избыточных данных - это поля связи, присутствующие одновременно у родительской и дочерних таблиц. Поскольку избыточные данные в таблицах не хранятся, экономится дисковое пространство.
Однако у нормализованной БД есть и недостатки, прежде всего практического характера.
Чем шире число сущностей, охватываемых предметной областью, тем из большего числа таблиц будет состоять нормализованная БД. Базы данных в составе больших систем, управляющих жизнедеятельностью крупных организаций и предприятий, могут содержать сотни связанных между собою таблиц. Поскольку порог человеческого восприятия не позволяет одновременно воспринимать большое число объектов с учетом их взаимосвязей, можно утверждать, что с увеличением числа нормализованных таблиц уменьшается целостное восприятие базы данных как системы взаимосвязанных данных. Поэтому при разработке и эксплуатации крупных систем нередки ситуации, когда каждый сотрудник представляет себе процессы, протекающие только в части системы. Известны случаи эволюционного создания таких систем, принципы функционирования которых впоследствии признавались вышедшими за границы понимания.
Другим недостатком нормализованной БД является необходимость считывать из таблиц связанные данные при выполнении запросов к нескольким таблицам БД. Так, например, пусть для рассмотренной выше БД, содержащей сведения о расходе товара со склада, требуется выдать отчет, в котором для каждой накладной указан покупатель и его реквизиты (город и адрес). Для этого необходимо каждую запись в таблице "Накладные" объединить по названию покупателя (поле связи) с соответствующей записью из таблицы "Покупатели". Операции такого объединения подразумевают поиск и позиционирование в таблице "Покупатели" и могут выполняться достаточно медленно, особенно когда одна из таблиц имеет большой объем, данные в базе данных и на диске фрагментированы, и т.д. Замечено, что ненормализованные (скажем так: "не вполне нормализованные") данные отыскиваются быстрее, если они хранятся в одной таблице, по сравнению со случаем поиска данных в одной или более связанных таблиц. Подобное ускорение тем заметнее, чем больше число записей в связанных таблицах. На скорость поиска в подчиненной таблице могут оказывать негативное влияние такие факторы, как слишком
большое число вложенных полей в индексе; индекс, структура которого не совсем корректно определена, и другие факторы.
Приведенные выше соображения не следует воспринимать как призыв вовсе не нормализовывать данные. Эти соображения лишь призваны показать, что при работе с данными большого объема приходится искать компромисс между требованиями нормализации (то есть "логичности" данных и экономии места на носителях информации) и необходимостью улучшения быстродействия системы.
Фаза
Запускается транзакция БД;
Кэшированные изменения записываются в БД.
Понятие столбцов TDBGrid
Компонент TDBGrid используется для показа содержимого записей НД в табличном формате, когда строки соответствуют записям НД, а столбцы -полям записи (рис. 10 1.):
Свойство DataSource компонента TDBGrid содержит имя компонента TDataSource, который ссылается на соответствующий НД (компоненты TTable или TQuery). Изменяя значение свойства DataSource во время выполнения, можно использовать один компонент TDBGrid для показа содержимого различных наборов данных. При продуманном сценарии диалога с пользователем и интерфейса приложения это может существенно минимизировать объем и конструктивную сложность создаваемых приложений.
Для определения состава столбцов в TDBGrid можно использовать редактор столбцов (Columns Editor). В этом случае используются только те столбцы, которые созданы редакторе столбцов компонента TDBGrid, и принимаются во внимание только их характеристики. Порядок следования столбцов в сетке TDBGrid определяется порядком следования определений столбцов редакторе столбцов.
Если редактор столбцов не использовался, берутся поля (компоненты TField), объявленные при помощи редактора полей НД. При этом вид столбцов определяется соответствующими характеристиками компонентов TField, a порядок следования столбцов - порядком их определении
В случае когда для НД компоненты TField не создавались порядок следования полей и их характеристики соответствуют тем что были заданы при определении структуры записи данной ТБД в момент создания таблицы Заметим что умалчиваемыи порядок следования столбцов в TDBGrid можно изменить лишь при помощи редактора полем или редактора столбцов
Пример
В ТБД teachers db находятся сведения о сотрудниках кафедры С данной таблицей в приложении ассоциирован набор данных Table1 Для определения полей в этом НД редактор полей не использовался следовательно по умолчанию для НД Table1 используются все поля объявленные в структуре записи таблицы БД teachers db Пусть порядок следования столбцов в компоненте TDBGrid связанным с НД Table1 взят по умолчанию и совпадает с порядком следования полей в записи таблицы teachers db (рис 10 2 ) Для того чтобы изменить местоположение столбца Doljnost с 3-го на 2-е необходимо
1 Вызвать редактора полей для набора данных Table1
2 Явно добавить все поля в редакторе полеи
3 В инспекторе объектов выбрать поле Doljnost и изменить значение свойства Index с 2 на 1 или перетащить поле мышью на нужное место в окне редактора полей
Чтобы изменить заголовки столбцов в TDBGrid, следует в инспекторе объектов нужным образом изменить значения свойств Display'Label для каждого поля(рис 10 3)
Работа с компонентом TDBCtrlGrid
TDBGrid является универсальным средством для отображения групповых данных (записей из одной таблицы реляционной БД, или записей из различных связанных таблиц). Однако известно, что универсальность никогда не является полной. В некоторых случаях применение компонента TDBGrid бывает затруднено:
• большим количеством полей, в этом случае приходится или помещать все поля в TDBGrid, что обычно приводит к необходимости их горизонтальной прокрутки, или помещать в TDBGrid лишь часть полей, а прочие либо выводить в отдельной форме, активизирующейся по нажатию экранной кнопки, или располагать ниже TDBGrid как компоненты TDBText, TDBEdit, TDBRadioGroup и т.д.;
• длинными заголовками столбцов; в этом случае приходится их сокращать, что ведет к потере смысла и удобочитаемости;
• невозможностью отображать в TDBGrid значения полей в виде, предоставляемом компонентом TDBCheckBox, и т.п.
Этот список при желании можно продолжить. Для преодоления подобных трудностей создан компонент типа TDBCtrlGrid, введенный в версию Delphi 3.0. Обладая основной функциональностью обычного компонента TDBGrid, он позволяет отображать информацию из одной записи НД в прямоугольной панели и размещать эту информацию на ней произвольным образом (рис. 10.22.):
Для работы с компонентом TDBCtrlGrid необходимо поместить его в форму, связать с компонентом TDataSource, который, в свою очередь, связать с каким-либо набором данных (TTable или TQuery) и затем разместить необходимые компоненты для работы с полями базы данных (TDBText, TDBEdit, TDBCheckBox) в верхней строке TDBCtrlGrid (рис. 10.23.):
Во время выполнения приложения расположение компонентов в верхней строке TDBCtrlGridvi их состав будет реплицирован на все оставшиеся строки, как это видно из рис. 10.22.
Порядок редактирования, добавления и удаления записей непосредственно из TDBCtrlGrid аналогичен порядку редактирования, добавления и удаления записей из TDBGrid. Для вставки новой записи необходимо нажать на клавиатуре клавишу Insert или попытаться перейти с последней записи в НД вниз на одну строку (рис. 10.24).
Для изменения записи достаточно ввести новое значение в какое-либо поле. Для удаления записи необходимо нажать комбинацию клавиш Ctrl+Delete. При этом на возможности редактирования, добавления и удаления записей в TDBCtrlGrid влияет ряд свойств как других компонентов (Table. Readonly, TField.ReadOnly, TDBEdit.Readonly), размещенных на панелях TDBCtrlGrid, так и самого компонента TDBCtrlGrid (AllowDelete, Allowlnsert).
Произведем выборочный обзор свойств, методов и событий TDBCtrlGrid:
Свойства
Разрешение корректировки
property AllowDelete: Boolean; -
определяет возможность удаления записей из TDBCtrlGrid {True, по умолчанию) или невозможность удаления (False); property Allowlnsert: Boolean; -
определяет возможность вставки записей в TDBCtrlGrid (True, по умолчанию) или невозможность вставки (False); Параметры показа:
property PanelHeight: Integer; -
высота в пикселах; property PanelWidth: Integer; -
ширина в пикселах; property Orientation: DBCtrlGridOrientation; -
определяет ориентацию TDBCtrlGrid- вертикальную (по умолчанию) или горизонтальную; DBCtrlGridOrientation = (go Vertical, goHorizontal); property Pane/Border: DBCtrlGridBorder; -
определяет тип края панели -выступающий (по умолчанию) или отсутствующий; DBCtrlGridBorder = (gbNone, gbRaised); Число панелей, текущая панель, число колонок: property Pane/Count: Integer; -
число панелей, видимых в TDBCtrlGrid. property Panellndex: Integer;
- показывает, какая панель (в диапазоне 0.-PanelCount - 1) отображает текущую запись. property RowCount: Integer; -
содержит число панелей в TDBCtrlGrid, начиная с 1. Изменение этого свойства ведет, к увеличению/уменьшению числа панелей в TDBCtrlGrid без изменения их высоты (PanelHeight). Отличие этого свойства от PanelCount состоит в том, что число RowCount можно изменять, например: WITH DBCtrlGridl do RowCount := StrToInt(Edit1.Text) ;
property ColCount: Integer; -
определяет число колонок в TDBCtrlGrid. По умолчанию равно 1. Метод procedure DoKey(Key: DBCtrlGridKey);
Выполняет определенное действие над TDBCtrlGrid. Действие определяется параметром А'еу. Некоторые из возможных значений:
gkNull
Действия нет gkEditMode
Переводит компонент в режим редактирования gkLeft Moves
Перемещает компонент на 1 колонку влево, при необходимости делает прокрутку окна компонента gkRight
Перемещает на 1 колонку вправо gkUp
Перемещает на 1 запись вверх gkDown
Перемещает на 1 запись вниз gkScrolIUp
Делает запись в предыдущей строке текущей без изменения ее местоположения gkScrollDown
Делает запись в следующей строке текущей без изменения ее местоположения gkPageUp
Перемещает к предыдущей странице TDBCtrlGrid gkPageDown
Перемещает к следующей странице TDBCtrlGrid gkHome
Перемещает на первую запись gkEnd Moves
Перемещает на последнюю запись Пример. Разместим в форме 4 кнопки для перемещения к первой, последней, следующей и предыдущей записи в TDBCtrlGrid (рис. 10.25).
и напишем такие обработчики событий нажатия соответствующих клавиш:
// нажата клавиша "1-я запись"
procedure TForm1. FirstButtonCiick (Sender : T0bj]ect);
begin
DBCtrlGridl.DoKey(gkHome) ;
end;
// нажата клавиша "Последняя запись"
procedure TForm!.LastButtonClick(Sender: TObject) ;
begin
DBCtrlGridl.DoKey(gkEnd) ;
end;
// нажата клавиша "Запись вверх"
procedure TForm!.UpButtonClick(Sender: TObject) ;
begin
DBCtrlGridl.DoKey(gkScrolIUp) ;
end;
// нажата клавиша "Запись вниз"
procedure TForm! . DownButtonClick (Sender : TObjiect);
begin
DBCtrlGridl.DoKey(gkDown) ;
end;
Тогда нажатие соответствующей экранной клавиши приведет к соответствующим перемещениям компонента TDBCtrlGrid.
Можно также поставить в соответствие отдельным клавишам на клавиатуре определенные действия с TDBCtrlGrid. Например, пусть мы хотим, чтобы при нажатии клавиш происходили следующие действия:
u (up) переход на одну запись вверх
d (down) переход на одну запись вниз
f (first) переход на первую запись
I (list) переход на последнюю запись
Тогда в обработчике события OnKeyDown для TDBCtrlGrid следует записать такой код:
procedure TFormI.DBCtrlGridlKeyDown (Sender: TObject; var Key: Word; Shift: TShiftState) ;
var S : TDBCtrlGridKey;
begin
CASE Key OF
68 : S := gkScrollDown; // нажата "d"
70 : S := gkHome; // нажата "f"
76 : S := gkEnd; // нажата "1"
85 : S := gkDown; // нажата "и"
END; {case}
DBCtrlGridl.DoKey(S) ;
end;
События
Для TDBCtrlGrid определены следующие события, аналогичные одноименным событиям TDBGrid: OnClick, OnDblClick, OnDragDrop, OnDragOver, OnEndDrag, OnEnter, OnExit, OnKeyDown, OnKeyPress, OnKeyUp, OnStartDrag.
Дополнительно введены события property OnPaintPanel: TPaintPanelEvent;
TPaintPanelEvent = procedure(DBCtrlGrid: TDBCtrlGrid; Index: Integer) of object;
Наступает для каждой панели TDBCtrlGrid перед ее показом. Обработчик этого события может управлять рисованием панели. Параметр TDBCtrlGrid показывает, какой именно компонент TDBCtrlGrid отображается в данный момент; параметр Index' определяет индекс отображаемой панели. /
property OnMouseDown: TMouseEvent;
наступает, когда пользователь нажимает левую кнопку мыши, находясь при этом на TBCtrlGrid. property OnMouseUp: TMouseEvent;
наступает, когда пользователь отпускает нажатую ранее кнопку мыши, находясь при этом на TBCtrlGrid.
Работа с абзацем
Текущим в тексте форматированного комментария считается абзац, на котором находится курсор.
Свойство property Paragraph: TParaAttributes; определяет характеристики параграфа. Рассмотрим свойства компонента TParaAttributes:
• property Alignment: TAlignment;
определяет выравнивание параграфа. Значения: taLeftJustify - влево;
laCenier -
по центру; taRightJustify -
вправо. • property Firstlndent: Longint;
определяет в пикселах абзацный отступ (первой строки параграфа) относительно левого края. • property Leftlndent: Longint;
определяет в пикселах отступ всех строк параграфа от левого края. • property Numbering: TNumberingStyle;
определяет отметку параграфов. Значения: nsNone -
отметка не производится. nsBullet -
отметка производится символом '•'. • property Rightlndent: Longint;
указывает в пикселах отступ от правого края. Пример.
Определим кнопку, реализующую выравнивание текущего абзаца и напишем обработчик события нажатия этой кнопки: procedure TFormI.SpeedButton3Click(Sender: TObject) ;
begin
DBRichEdit1.Paragraph.Alignment := taCenter;
end;
TDBGrid и динамические свойства столбцов
В том случае когда столбцы таблицы (т е поля записи) определены с использованием редактора полей как компоненты типа TField столбцы показываются в сетке TDBGrid в том состоянии которое определяется их текущими свойствами Если то или иное свойство столбца можно менять в процессе выполнения приложения эти изменения немедленно отобразятся в TDBGrid Например в ходе выполнения можно менять ширину столбца (свойство компонента TField Display Width) его видимость (Visible) возможность редактирования значения столбца (ReadOnlv) порядковый номер (Index) заголовок столбца (Display Label)
Пример
Воспользуемся формой из предыдущего примера и добавим в нее компонент CheckBoxl Установим свойство Visible компонента Table lUchStepen (поте Ученая степень"), равным свойству CheckBoxl Checked Тогда отметка CheckBoxl приведет к визуализации столбца 'Ученая степень в таблице TDBGrid (рис 10 4 а), а снятие отметки- к его исчезновению' (рис 1046) procedure TFormX.CheckBox1Click(Sender: TObject);
begin
Table1UchStepen.Visible := CheckBox1.Checked;
end;
Здесь мы имеем дело с настраиваемым компонентом TDBGnd Многие свойства TDBGnd могут быть переустановлены во время выполнения приложения Это может придать самому приложению значительную гибкостьассический пример - возможность выбора пользователем порядка сортировки записей НД и порядка их расположения в TDBGnd
Пример.
Пусть таблица teachers db ассоциирована с НД Table 1, записи которого показываются в компоненте DBGndl Пусть у таблицы teachers db имеются индексы по полям 'TabNum' (уникальный, установлен в таблице по умолчанию) 'Doljnosf, 'ПО', 'UchStepen,FIO' Разместив в форме компонент TRadioGroup, сделаем выбранной по умолчанию радиокнопку с индексом 0 (соответствующую индексу по полю 'TabNum') и опишем обработчик события выбора одной из радиокнопок procedure TForm!.RadioGrouplClick(Sender: TObject);
begin
WITH Table1 do begin
CASE RadioGroupl.ItemIndex OF
0 : begin
IndexFieldNames := 'TabNum';
Table1TabNum.Index := 0;
Table1Doljnost.Index := 2;
Table1FIO.Index := 1;
Table1UchStepen.Index := 3;
end;
1 : begin
IndexFieldNames := 'Doljnosf;
Table1Doljnost.Index := 0;
TabielFIO.Index := 1;
Table1UchStepen.Index := 2,Table1TabNum Index := 3;
end;
2 : begin
IndexFieldNames := 'FIO';
Table1FIO.Index := 0;
Table1UchStepen.Index := 1;
Table1Doljnost.Index := 2;
Table1TabNum.Index := 3;
end;
3 : begin
IndexFieldNames := 'UchStepen';
Table1UchStepen.Index := 0;
Table1FIO.Index := 1;
Table1Doljnost.Index := 2;
Table1TabNum.Index := 3;
end;
END; {case}
END; {with}
end;
Тогда при выборе любой из радиокнопок произойдет переключение текущего индекса и порядка следования столбцов в TDBGnd (рис 105, 106)
Заметим, что можно было бы написать обработчик и так:
procedure TForm!.RadioGrouplClick(Sender: TObject) ;
begin
WITH Table1 do begin
CASE RadioGroupl.Itemlndex OF
0 : begin
IndexFieldNames := 'TabNum';
Table1TabNum.Index := 0;
end;
1 : begin
IndexFieldNames := 'Doljnost;
Table1Doljnost.Index := 0;
end;
2 : begin
IndexFieldNames := 'FIO';
Table1FIO.Index := 0;
end;
3 : begin
IndexFieldNames := 'UchStepen';
Table1UchStepen.Index := 0;
end;
END; {case}
END; {with}
end;
Однако в этом случае индексное поле будет первым (левым), а остальные поля будут расположены произвольным образом.
Постоянные и динамические столбцы
Когда свойства столбцов компонента TDBGrid определяются с помощью свойств компонентов TField, созданных в редакторе полей связанного с TDBGrid НД, всякое изменение свойства в TField ведет к изменению соответствующего свойства столбца. Например, изменение свойства Display Label у компонента Table1FIO для рассмотренного выше примера приведет к соответствующему изменению заголовка столбца в TDBGrid.
Связка "Компонент TField - Столбец DBGrid" хороша до тех пор, пока не возникнет необходимость а) не привязывать столбец к определенному полю ТБД; б)установить характеристики столбца в TDBGrid таким образом, чтобы они не изменялись при изменении свойств TField, даже если столбец и отображает некоторое поле из связанного с TDBGrid НД.
В этом случае в редакторе столбцов, определяются так называемые постоянные столбцы. Их можно определить, выбрав элемент меню Columns Editor во всплывающем по нажатию правой кнопки мыши меню или нажав кнопку в строке свойства TDBGrid Columns в инспекторе объектов. И тот, и другой путь приводит к активизацииредвктора столбцов компонента TDBGrid.
Заметим, что столбцы TDBGrid, основанные на использовании компонентов TField, называются динамическими столбцами.
Работа с редактором столбцов
Вызвать редактор столбцов можно, проделав следующие действия:
1. Выбрать в форме компонент TDBGrid при помощи мыши;
2. Нажать правую кнопку мыши;
3. В появившемся всплывающем меню выбрать элемент Columns Editor.
В появившемся диалоговом окне Т DBGrid Columns Editor устанавливаются свойства постоянных столбцов. Вначале список столбцов пуст. Для того чтобы добавить столбец, нужно нажать кнопку Add. Тогда будет создан столбец, не связанный ни с каким полем набора данных (рис. 10.7.а)
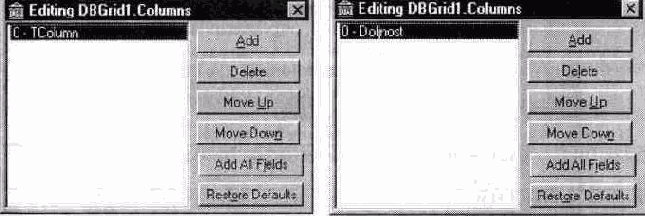
а) б)
Рис 10.7 а) столбец не связан с конкретным полем набора данных, б) столбец связан с полем Doljnost
Чтобы поставить такому столбцу в соответствие какое-либо поле НД, следует в инспекторе объектов раскрыть список в свойстве Field Name и выбрать нужное поле В этом случае столбец будет назван так же, как поле (рис. 10.7.6).
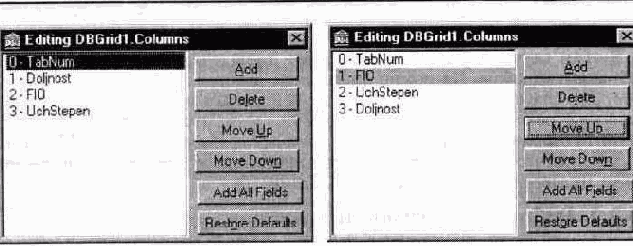
Когда нужно показывать в TDBGrid столбцы, соответствующие всем или большинству полей набора данных, лучше нажать кнопку AddAllFieldes. Тогда в список полей TDBGrid будут включены столбцы, соответствующие всем полям НД. После этого при помощи кнопки Delete следует удалить определения столбцов, которые не должны показываться в TDBGrid. Используя кнопки Move Up и Move Down, можно изменить порядок следования текущего столбца (рис. 10.8.а, б).
Свойства столбца устанавливаются в инспекторе объектов. Они определяют особенности отображения столбца в TDBGrid.
а) б)
Рис. 10.8. а) до изменения и б) после изменения порядки следования столбцов
| Aligment | Определяет выравнивание значений в столбце. По умолчанию TField. Aligment. |
| BultonStyle | Определяет тип кнопки, появляющейся в столбце в режиме редактирования: cbsAuto (по умолчанию) - автоматическая установка (показывает кнопку раскрытия выпадающего списка возможных значений, если столбец может принимать лишь одно из значений, определенных связью с иным НД, или списком свойства PickList); cbsEllipse - показывает кнопку (...) в столбце справа; обработчик нажатия кнопки соответствует обработчику события OnEditButtonCUck; cbsNone - никакой кнопки в столбце нет. |
| Color | Определяет цвет фона столбца. По умолчанию TDBGrid.Color. |
| DropDownRows | Если столбцу назначен выпадающий список возможных значений (посредством связи с другим НД или в свойстве PickList}, определяет число строк в нем. По умолчанию равно 7. |
| FieldName | Определяет поле ТБД, ассоциированное с данным постоянным столбцом. Может быть пустым (см. "Пустые постоянные столбцы"). |
| Readonly | Определяет возможность редактирования столбца из TDBGrid [True) или невозможность этого {False, по умолчанию). |
| Width | Определяет ширину столбца в пикселах. По умолчанию значение извлекается из TField. DisplayWidth, где, заметим, ширина дается в символах. |
| Font | Определяет тип, размер и цвет шрифта для вывода значений в столбце. По умолчанию TDBGrid.Font |
| PickList | В случае, если для занесения значений в столбец используется раскрывающийся список возможных значений (кроме случая связи с иным НД), определяет этот список |
| Подсвойство | Назначение |
| Aligment | Определяет выравнивание заголовка. По умолчанию -влево. |
| Caption | Определяет текст заголовка. По умолчанию TField. DisplayLabel или имя поля ТБД. |
| Color | Определяет цвет фона заголовка. По умолчанию TDBGrid.FixedColor. |
| Font | Определяет тип, размер и цвет шрифта. По умолчанию TDBGrid.TitleFont. |
Этот пример показывает, что характеристики столбцов в TDBGrid не должны совпадать друг с другом и каждый столбец может иметь свои собственные, уникальные характеристики.
Изменение свойств постоянных столбцов во время выполнения. TDBGridColumns как набор столбцов
Обратиться к конкретному постоянному столбцу компонента TDBGrid через его свойства можно как к TDBGndl .Columns.Itemsp] или как к TDBGrid l .Columns[i], где i принадлежит диапазону [0.. DBGridl.Columns.Count-1].
Свойство property Columns: TDBGridColumns; является набором столбцов TDBGrid. Методы TDBGrid. Columns мы рассмотрим ниже. В данный момент нас интересует возможность обращения к столбцам. Эту возможность обеспечивает массив property Items[Index: Integer]: TColumn; который доступен только во время выполнения программы.
Каждый i-ый столбец массива Items, в свою очередь, имеет свои собственные свойства и методы. Кратко перечислим их:
property Alignment: TAlignment; -
определяет выравнивание; property ButtonStyle: TColumnButtonStyle; -
определяет тип кнопки, назначенной столбцу (см. выше п.10.3.2); TColumnButtonStyle = (cbsAuto, cbsEllipsis, cbsNone); property Color: TColor;
- определяет цвет фона; property DropDownRows: Integer; -
определяет число строк в выпадающем списке возможных значений столбца; property Field: TField;
- ссылается на компонент TField, связанный со столбцом; property FieldName: String; -
определяет имя поля, связанного со столбцом; property Font: TFont; -
определяет шрифт для отображения содержимого столбца, его размер и цвет; property PickList: TStrings; -
определяет список возможных значений столбца; property ReadOnly: Boolean;
- разрешает (False) или запрещает (True) редактирование значений в столбце; property Title: TColumnTitle; -
определяет свойства и методы для работы с заголовком столбца: property Alignment: TAlignment; -
определяет выравнивание; property Caption : String; -
содержит текст заголовка столбца; property Color: TColor; -
определяет цвет фона заголовка столбца; property Font: TFont; -
определяет шрифт заголовка столбца, его размер и цвет; function DefaultFont: TFont; -
восстанавливает умалчиваемый шрифт; function DefaultCaption: String; -
восстанавливает умалчиваемый текст заголовка; function DefaultColor: TColor; -
восстанавливает умалчиваемый цвет заголовка; procedure RestoreDefaults; -
восстанавливает все умалчиваемые свойства заголовка столбца; property Width: Integer; -
определяет ширину столбца в пикселах; function DefaultWidth: Integer; -
восстанавливает умалчиваемую ширину столбца; function DefaultReadOnly: Boolean; -
восстанавливает умалчиваемое значение ReadOnly столбца; function DefaultColor: TColor; -
восстанавливает умалчиваемый цвет столбца; function DefaultFont: TFont;
- восстанавливает умалчиваемый шрифт столбца; procedure RestoreDefaults; -
восстанавливает все умалчиваемые свойства столбца. Пример.
Введем в приложение, рассмотренное выше, возможность динамического изменения свойств постоянных столбцов TDBGrid. Для этого разместим в форме компоненты обеспечивающие диалоги выбора шрифта и цвета - FontDialog! и ColorDialog соответственно, а также экранные кнопки, нажатие которых инициирует изменения свойств постоянных столбцов (рис. 10.10).

Рис 10.10. Форма с кнопками, нажатие которых реализует изменение шрифта, фона у столбца и т заголовка столбца
Опишем следующие обработчики событий нажатия экранных кнопок:
// Обработчик нажатия кнопки "Шрифт столбцов" Вызывает диалог выбора шрифта и устанавливает выбранный шрифт для всех столбцов
procedure TForm1.AssigningColumnsFontButtonClick(Sender: TObject) ;
var i : Integer;
begin
// в диалоге выбора шрифта текущим будет шрифт 0-го столбца
FontDialog1.Font := DBGrid1.Columns.Items [0].Font;
IF FontDialog1.Execute THEN
FOR i := 0 TO DBGrid1.Columns.Count - 1 do
DBGrid1.Columns.Items[i].Font := FontDialog1.Font;
end;
// Обработчик нажатия кнопки "Шрифт заголовков" Вызывает диалог выбора шрифта и устанавливает выбранный шрифт для заголовков всех столбцов
procedure TForml.AssignFontToColumnsCaptionsButtonClick(Sender: TObject) ;
var i : Integer;
begin
// в диалоге выбора шрифта текущим будет шрифт заголовка 0-го столбца
FontDialog1.Font := DBGrid1.Columns.Items[0].Title.Font;
IF FontDialog1.Execute THEN
FOR 1 := 0 TO DBGrid1.Columns.Count - 1 do
DBGrid1.Columns.Items[i].Title.Font := FontDialog1.Font;
end;
// Обработчик нажатия кнопки "Шрифт столбца" Вызывает диалог выбора шрифта и устанавливает выбранный шрифт для текущего столбца, индекс которого определяется как DBGrid1.Selectedlndex
procedure TForm1.AssignFontToSelectedColumnButtonClick(Sender: TObject) ;
begin
// в диалоге выбора шрифта текущим будет шрифт текущего столбца
FontDialog1.Font := DBGrid1.Columns.Items[DBGrid1.Selectedlndex].Font;
IF FontDialog1.Execute THEN
DBGrid1.Columns.Items[DBGrid1.Selectedlndex].Font :=FontDialog1.Font;
end;
// Обработчик нажатия кнопки "Фон столбца" Вызывает диалог выбора цвета и устанавливает выбранный цвет для фона текущего столбца, индекс которого определяется как DBGrid1.Selectedlndex
procedure TForm1.AssignColorToSelectedColumnButtonClick(Sender: TObject) ;
begin
// в диалоге выбора шрифта текущим будет шрифт текущего столбца
ColorDialog1. Color := DBGrid1. Columns. Items [DBGrid1. Selectedlndex] .Color;
IF ColorDialog1.Execute THEN
DBGrid1.Columns.Items[DBGrid1.Selectedlndex].Color := ColorDialog1.Color;
end;
// Обработчик нажатия кнопки "Фон заголовка столбца" Вызывает диалог выбора цвета и устанавливает выбранный цвет для фона заголовка текущего столбца, индекс которого определяется как DBGrid1.Selectedlndex
procedure TForm1.AssignColorToSelectedColumnsTitleButtonClick ( Sender: TObject) ;
begin
// в диалоге выбора шрифта текущим будет шрифт заголовка текущего столбца
ColorDialog1.Color :=
DBGrid1.Columns.Items[DBGrid1.Selectedlndex].Title.Color,
IF ColorDialog1.Execute THEN
DBGrid1.Columns.Items[DBGrid1.Selectedlndex].Title.Color := ColorDialog1.Color;
end;
Пример динамического изменения характеристик столбцов показан на рис 10.11.
Другие свойства набора столбцов TDBGridColumns
Кроме рассмотренных выше, свойство TDBGrid. Columns обладает иными полезными свойствами и методами:
property State: TDBGridColumnsState;
где TDBGridColumnsState = (csDefault, csCustomized);
Это свойство дает возможность определить во время выполнения, имеются ли в данном TDBGrid постоянные столбцы Возможные значения:
csDefault -
столбцы TDBGrid формируются на основе свойств полей ТБД; csCustomized -
в TDBGrid присутствуют постоянные столбцы. function Add: TColumn:
Этот метод создает и возвращает новый постоянный столбец (объект типа TColumn). Используется для создания нового столбца во время выполнения, поскольку для аналогичных целей во время разработки приложения используется редактор столбцов. Свойства вновь созданного столбца должны устанавливаться, как это указано в предыдущем параграфе.
procedure RebuildColumns;
Удаляет все существующие столбцы, затем, пользуясь взятой из ТБД информацией о полях, создает столбцы заново с умалчиваемыми свойствами. Если TDBGrid не ассоциирован ни с одним компонентом-источником данных TDataSource, или последний не ассоциирован ни с каким НД, выполнение данного метода приведет к уничтожению столбцов в TDBGrid.
procedure RestoreDefaults;
Возвращает всем постоянным столбцам их свойства, принятые по умолчанию.
От описанного выше метода RebuildColumns метод RestoreDefaults отличается тем, что если в TDBGrid есть постоянные столбцы, не ассоциированные ни с каким полем, эти столбцы не уничтожаются.
Пустые" постоянные столбцы
Постоянный столбец в TDBGrid не обязательно должен быть ассоциирован с каким-либо полем набора данных. В этом случае свойство столбца FiledName остается незаполненным. Такие столбцы называются пустыми. В них можно выводить какую-либо информацию, основываясь на информации из действительно существующих полей набора данных. Например, из поля набора данных, содержащего фамилию, имя и отчество, можно вывести информацию в 3 "пустых" столбца, содержащих соответственно фамилию, имя и отчество в отдельности.
Другим предназначением пустого столбца является вывод информации по требованию. Например, графические поля, если их выводить для каждой записи в отдельном столбце TDBGrid или даже для текущей записи с помощью отдельного компонента TDBImage, требуют существенных временных затрат для вывода. Поэтому поступают так: устанавливают свойство пустого столбца ButtonSty/e в значение cbsEllips и кодируют обработчик события OnEditButtonClick, которое наступает, когда нажата кнопка (...) в конкретной строке пустого столбца. Заметим, что кнопка становится видна только в режиме редактирования столбца. В обработчике события OnEditButtonClick предусматривают вызов формы, показывающей содержимое графического поля текущей записи, или активизацию компонента TDBImage, расположенного на той же форме, что и TDBGrid. Аналогичным образом можно поступать с мемо-полями набора данных.
Используя механизм кнопки (...), можно также выводить форму, показывающую записи дочерних НД. Также можно вызывать формы для расшифровки того или иного значения. Например, при показе рассчитанного значения "на руки" для приложения расчета заработной платы с помощью кнопки можно вызвать форму, в которой расшифровывается, какая сумма начислена данному работнику, какова сумма премий, как производились вычеты, налогообложение и пр.
Для рассмотренного выше примера приложения введем пустой столбец "Столбец без поля", назначим ему кнопку и напишем обработчик, констатирующий, что данный сотрудник работает в конкретной должности (рис. 10.12).
procedure TForm!.DBGrid1EditButtonClick(Sender: TObject);
begin
WITH Table1 do
ShowMessage(FieldByName('FIO').Value + ' - ' + FieldByName('Doljnosf).Value) ;
end;
Формирование списка возможных значений столбца
Если значения постоянного столбца должны выбираться из некоторого фиксированного множества и Вы хотите получать список значений при редактировании столбца непосредственно в TDBGrid, этот список должен содержаться в свойстве PickList данного постоянного столбца.
При этом возможны 2 варианта - список возможных значений столбца является фиксированным и переменным.
Вариант 1. Список возможных значений столбца является фиксированным, т.е. не изменяется во времени. Тогда достаточно на этапе конструирования программы заполнить список свойства PickList (этот список имеет тип TStrings) постоянного столбца. В свойство ButtonSty/e необходимо установить значение cbsAuto. Тогда Delphi, обнаружив, что список PickList заполнен, автоматически будет помещать в столбце при редактировании его ячейки кнопку типа ComboBox (стрелка вниз).
Например, пусть для рассматриваемого примера сотрудники кафедры могут обладать учеными степенями доктора физико-математических наук (д.ф.-м.н.), доктора технических наук (д.т.н.), кандидата физико-математических наук (к.ф.-м.н.) и кандидата технических наук (к.т.н.). Предположим, что на работу не принимаются обладатели иных ученых степеней (например, доктора и кандидаты химических или социологических наук). Таким образом, список возможных значений столбца "Уч. степень" состоит из 4 значений (рис. 10.13).
При работе приложения, если мы корректируем ячейку столбца "Уч. степени", на экране появляется кнопка типа "Стрелка вниз" (рис.10.14).
Нажатие данной кнопки приведет к появлению выпадающего списка с фиксированными значениями (рис. 10.15).
При этом выбор значения в списке приведет к копированию его в текущую ячейку столбца, и, если данный столбец связан с полем ТБД, к последующему запоминанию в качестве значения поля ТБД в текущей записи.
Заметим, что наличие выпадающего списка не препятствует пользователю занести в столбец и иную информацию (рис. 10.16).
Рассмотрим второй вариант, когда список возможных значении столбца не является фиксированным, т.е. может изменяться во времени. Почти всегда в
таком случае источником значений служит другая, справочная ТБД В процессе работы справочная ТБД может меняться, записи в ней могут корректироваться, добавляться или удаляться Все внесенные изменения должны отображаться в списке PickList для рассматриваемого столбца TDBGnd
Пусть для рассматриваемого примера список возможных должностей находится в ТБД "UCHSTEP DB" (в поле UchStepen) Тогда проблема решается, если при всякой активизации формы, на которой расположен TDBGnd с постоянным столбцом, произвести следующие действия
1 Очистить список PickList для постоянного столбца "Уч степени",
2 Поместить все значения из поля UchStepen таблицы БД "UCHSTEP DB" в список PickList для постоянного столбца "Уч степени"
procedure TForm1.FormActivate(Sender: TObject);
begin
DBGrid1.Columns.Items[3].PickList.Clear;
WITH Table2 do begin
First;
WHILE not EOF do begin
DBGrid1.Columns.Items[3].PickList.Add (FieldByName('UchStepen').Value) ;
Next;
END; {while}
END; {with}
end;
Результат работы показан на рис 1017
ЗАМЕЧАНИЕ 1. Поле UchStepen в ТБД "UCHSTEP DB" должно быть уникальным, иначе в списке PickList появятся дублирующие друг друга значения Если поле, по которому строится PickList, неуникально, нужно программно предусмотреть дополнительный анализ дублирования в списке PickList
ЗАМЕЧАНИЕ
2. Аналогичного или сходного результата можно добиться путем использования поля, возвращающего значение (lookup-поля) Более подробно см раздел "Использование компонента TField" ЗАМЕЧАНИЕ
3. Если таблица-справочник содержит больше 10-15 записей, в список PickList ее заносить нерационально, поскольку пользователю весьма трудно будет искать нужное значение К другим недостаткам описываемого подхода можно отнести то, что список PickList не позволяет редактировать таблицу-источник (представим, что в процессе работы с кадровым составом кафедры нам понадобилось внести в справочник ученых степеней степень "кандидата философских наук") Два этих обстоятельства делают работу с выпадающим списком не очень удобной Поэтому, на взгляд автора, более рационально не формировать список PickList вручную или программно, а установить в свойство ButtonStyle постоянного поля значение cbsElhps и написать в обработчике нажатия кнопки (. .) OmtButtonChck вызов модальной формы, содержащей НД справочника После этого следует определить код занесения выбранного в справочнике значения в текущую ячейку постоянного столбца. Пример Для рассмотренной выше формы
1 Добавим в приложение форму Form2 (рис. 10.18), содержащую компонент TDBGnd, в котором показываются значения из ТБД "UCHSTEP DB" с возможностью их корректировки, а также 2 экранные кнопки - "Выбрать" (со свойством Moda/Result = mrOk) и "Отменить" (со свойством ModalResult = mrCancel);
2 Установим у постоянного столбца "Уч степень" в свойство ButtonStyle значение cbsElhps,
3. Напишем такой обработчик нажатия кнопки:
procedure TForm1.DBGridlEditButtonClick(Sender: TObject);
begin
// модальный вызов справочной ТБД "Ученые степени"
Form2.ShowModal;
// Если выбрана клавиша с модальным результатом mrOk // (т.е. клавиша "Выбрать" в Form2)
IF Form2.ModalResult = mrOK THEN
begin
// если НД сотрудников кафедры не находится в режиме dsEdit или dslnsert, переводим НД в режим dsEdit,
// поскольку иначе мы не сможем изменить значения поля UchStepen
IF Tablel.State = dsBrowse THEN TableI.Edit;
// производим присваивание значения поля
Formi.Tablel.FieldByName('UchStepen').Value := Form2.Tablel.FieldByName('UchStepen').Value;
end;
end;
Результат работы показан на рис. 10.19.
Заметим, что при выходе из обработчика мы не выполняем метод Tablel. Post, т.е. оставляем НД сотрудников кафедры в одном из режимов корректировки с тем, чтобы пользователь затем смог сам либо отменить внесение изменений в TDBGrid (клавишей Esc) или подтвердить внесение изменений (перейдя на другую запись в TDBGrid).
В вызываемой форме (Form2) можно добавлять, изменять и удалять записи, прежде чем осуществить выбор.
Заметим также, что в Form2 нужно предусмотреть ситуацию, когда нажата кнопка "Выбрать" или "Отменить", а НД, связанный с ТБД "UCHSTEP.DB", остался в одном из режимов редактирования. Например, в этом случае можно не производить выбора по нажатию кнопки "Выбрать" в обработчике события OnEditButtonClick формы Formi и принудительно переводить НД Form2.Table2 в режим dsBrowse с потерей последних неподтвержденных изменений (выполняя метод Cancel):
procedure TFormI.DBGridlEditButtonClick(Sender: TObject);
begin
Form2.ShowModal;
IF Form2.Tablel.State о dsBrowse THEN
begin
Form2.Tablel.Cancel ;
ShowMessage('Изменения в справочнике не запомнены');
Exit;
end;
IF Form2.ModalResult = mrOK THEN
begin
IF Tablel.State = dsBrowse THEN TableI.Edit;
Form1.Tablel.FieldByName('UchStepen').Value :=Form2.Tablel.FieldByName('UchStepen').Value;
end;
end;
Управление видом и поведением TDBGrid
Свойство Options управляет видом и поведением TDBGrid во время выполнения. Это свойство состоит из группы логических опций, поэтому в инспекторе объектов оно помечено знаком (+). Чтобы получить доступ ко всем опциям, следует щелкнуть мышью на знаке (+). Тогда он преобразуется в знак (-) и будет раскрыт следующий список:
| dgEditing | True (по умолчанию) разрешает редактирование, вставку и удаление записей непосредственно из TDBGrid. False запрещает указанные действия. |
| DgA IwaysShowEditor | True выбор поля означает его перевод в состояние редактирования. False (по умолчанию).- поле при его выборе не переводится автоматически в режим редактирования. |
| dgTitles | True (по умолчанию), показывает заголовки столбцов в TDBGrid. False: заголовки столбцов не показываются. |
| Dglndicator | True (по умолчанию)- показывается индикатор текущей записи как самый левый серый столбец. Указатель в режиме dsBrowse - стрелка влево, в режиме dsEdit - символ I-Beam, в режиме dslnsert -звездочка.False: указатель текущей записи не показывается. |
| DgColumnsResize | True (по умолчанию).- возможно изменение ширины столбцов путем сдвига границы столбца в области заголовка. False: изменение ширины столбцов не допускается. |
| DgColLines | True (по умолчанию); показываются вертикальные линии-разделители между столбцами. Falsе: вертикальные разделители столбцов не показываются. |
| DgRowLines | True (по умолчанию).- показываются горизонтальные линии-разделители строк. False: разделители строк не показываются. |
| dgTabs | True (по умолчанию): клавиша TAB используется для передвижения между столбцами текущей записи. False: клавиша TAB используется для выхода из TDBGrid. |
| DgRowSelect | True; инверсная полоса, показывающая текущую строку TDBGrid, отмечает всю строку.False (по умолчанию).' инверсная полоса отмечает только ячейку текущего столбца. |
| DgAIwaysShowSelection | True." Инверсная полоса для отметки текущей строки показывается в TDBGrid независимо от того, обладает он фокусом управления, или нет. False (по умолчанию); инверсная полоса видна только в то время, когда TDBGrid обладает фокусом упр-ния. |
| DgConfirmDelete | True (по умолчанию).' при удалении записи из TDBGrid (комбинация клавиш Ctrl+Del) запрашивается подтверждение удаления. False: подтверждение удаления не запрашивается, запись удаляется немедленно. |
// Включение-выключение показа заголовка столбцов TDBGrid
IF CheckBoxl.Checked THEN DBGrid1.Options := DBGridI.Options + [dgTitles]
ELSE DBGrid1.Options := DBGrid1.Options - [dgTitles];
// Включение-выключение показа вертикальных и горизонтальных разделительных линий DBGrid
IF CheckBox2.Checked THEN
DBGrid1.Options := DBGrid1.Options + [dgColLines, dgRowLines]
ELSE DBGrid1.Options := DBGrid1.Options - [dgColLines, dgRowLines];
Добавление записей
НД переводится в режим добавления dslnsert, если:
• пользователь нажал на клавиатуре клавишу Insert; в этом случае в TDBGrid вставляется пустая запись между текущей записью и предшествующей ей;
• пользователь нажал на клавиатуре кнопку "стрелка вниз", находясь на последней записи НД; в этом случае в конец НД добавляется новая запись.
После этого пользователь тем или иным способом должен заполнить поля новой записи. Запоминание добавленной записи в ТБД (с автоматической выдачей метода Post) производится при переходе курсора НД на другую запись в компоненте TDBGrid. Отмена добавления новой записи (с автоматической выдачей метода Саncel) производится, если пользователь нажмет на клавиатуре клавишу Esc.
Корректировка
НД переводится в режим добавления dsEdit, если пользователь, находясь в ячейке TDBGrid, осуществил ввод любого символа.
Если ввод символа не осуществлен, то НД остается в режиме dsBrowse. При использовании в постоянном столбце TDBGrid списка возможных значений
НД остается в режиме dsBrowse и после показа в корректируемой ячейке кнопки (...) или кнопки раскрытия комбинированного списка, и в момент перемещения по списку, заданному свойством PickList или содержащемуся в иной форме. НД переходит в режим dsEdit только после ввода значения, выбранного из списка, в ячейку TDBGrid.
Возникновение исключений при добавлении и корректировке записей в TDBGrid
Возникновение исключений при добавлении или корректировки записей в компоненте TDBGrid чаще всего связано с нарушением уникальности первичного индекса или незаполнения значением поля, для которого установлено требование обязательного ввода значения. В этом случае возбуждается исключение класса EDBEngineError с сообщением 'Key Violation ' или подобным. Возникновение такого исключения не приводит к фатальным последствиям для приложения, но при этом происходит отказ от запоминания записи в ТБД. Запись остается в том режиме, в котором она была на момент попытки автоматической выдачи метода Post - в режимах dslnsert или dsEnter. Пользователю остается либо исправить значение в ключевом поле (или ввести значение в поле, помеченное как обязательное к заполнению, и т.д.), либо отказаться от запоминания записи.
Редактирование наборов данных непосредственно из TDBGrid
Записи НД, отображаемые в компоненте TDBGrid, можно добавлять, изменять или удалять, если одновременно выполняются следующие условия:
• свойство CanModify набора данных установлено в True;
• свойство Readonly компонента TDBGrid установлено в False.
Изменение записей внутри TDBGrid удобно в том случае, если НД состоит из небольшого числа полей или, если число полей в нем велико, требуется вводить или корректировать лишь некоторые из них. Преимущества такого подхода состоят и в том, что в этом случае нет необходимости вставки в приложение новой формы для изменения или добавления записи. Удобству работа с записями непосредственно из TDBGrid служит и наличие таких механизмов, как формирование выпадающего списка возможных значений в столбце -фиксированного или вновь формируемого из иного НД, а также наличие кнопки (...), по нажатию которой в обработчике события OnEditButtonClick можно, вообще говоря, делать что угодно, в том числе и вызывать форму для ввода или корректировки дополнительных полей.
Определение текущего столбца во время выполнения программы и проверка правильности индекса
Компонент TDBGrid обладает рядом методов и свойств, которые позволяют:
а) обращаться к полю TField, ассоциированному с текущим столбцом TDBGrid;
б) проверять правильность обращения к тому или иному столбцу TDBGrid.
Свойство property SelectedField: TField; позволяет обратиться к полю, ассоциированному с текущим столбцом в TDBGrid. Поскольку свойство имеет тип TField, можно использовать все свойства и методы компонента TField.
Пример.
Пусть произведен двойной щелчок мышью по некоторой ячейке TDBGrid. Если текущее поле - Doljnost, его значение записывается в компонентEdit1 с помощью такого обработчика события OnDblClick: procedure TForm!.DBGrid1DbiClick(Sender: TObject);
begin
IF DBGrid1.SelectedField.FieldName = 'Doljnost' THEN Editl.Text := DBGrid1.SelectedField.Text ELSE Editl.Text :=";
end;
Свойство property Selectedlndex: Integer; возвращает номер поля, ассоциированного с текущим столбцом в TDBGrid. Нумерация полей идет от 0. Если возвращено значение -1, никакое поле с данным столбцом не ассоциировано.
Пример,
приведенный выше для свойства SelectedField с использованием Selectedlndex, можно переписать так: procedure TForm1.DBGrid1DbiClick(Sender: TObject);
begin
IF DBGrid1.Fields[DBGrid1.Selectedlndex].FieldName = 'Doljnost' THEN
Editl.Text := DBGrid1.SelectedField.Text ELSE Editl.Text := ";
end;
Метод function ValidFieldIndex(FieldIndex: Integer): Boolean; возвращает True, если значение Fieldlndex является правильным индексом столбца TDBGrid, и False - в противном случае. Индекс признается правильным, если в TDBGrid показывается информация из поля с индексом Fieldlndex и обращение TDBGrid.Fields[FieldIndex] не вызовет ошибки. Заметим, что в НД, ассоциированном с TDBGrid, поле с индексом Fieldlndex может существовать, а в самом компоненте TDBGrid - нет. В этом случае выдается False. Такая ситуация возможна, если для формирования столбцов TDBGrid использовался редактор столбцов.
Пример.
var IndexOfSomeField : Integer;
IF DBGrid1.ValidFieldIndex(IndexOfSomeField) THEN
Labell.Caption := DBGrid1.Fields[IndexOfSomeField].Text ELSE Labell.Caption := 'Неверный индекс поля';
Изменение порядка следования столбцов во время разработки приложения
Порядок следования столбцов в TDBGrid на этапе разработки можно изменить так:
• при наличии постоянных столбцов в TDBGrid - путем изменения порядка их следования редакторе столбцов или путем перетаскивания столбцов в TDBGrid (что приводит к автоматическому изменению порядка следования столбцов и в редакторе столбцов );
при формировании колонок TDBGrid на основании списка компонентов TField - путем изменения порядка следования компонентов TField в редакторе полей или путем перетаскивания столбцов в TDBGrid;
• при формировании столбцов TDBGrid, исходя из физической структуры ТБД (что имеет место, если не применялись редактор полей илиредактор столбцов) - изменение порядка следования невозможно
Изменение порядка следования столбцов во время выполнения приложения
Изменение порядка следования столбцов во время выполнения может производиться путем перетаскивания мышью заголовка столбца на новую позицию. Это возможно только если в свойство DragMode установлено значение dmManual; если свойство имеет значение dmAutomatic, перетаскивание столбцов запрещено После перетаскивания возникает событие OnColumnMoved.
При наличии постоянных столбцов возвращение к состоянию столбцов по умолчанию
DBGndl. Columns . State
csDefault;
приведет, помимо прочего, к восстановлению исходного их порядка следования в TDBGrid.
Если в TDBGrid не используются постоянные столбцы, а источником для формирования столбцов служат компоненты TField, добавленные посредством редактора полей, изменять местоположение столбца можно:
а) путем перетаскивания столбца (что ведет к автоматическому изменению свойства TField Index};
б) программно изменяя значение свойства TFiexd Index
Если для формирования состава столбцов в TDBGrid использована физическая структура ТБД, изменить местоположение столбцов в TDBGrid нельзя.
Управление отображением данных в TDBGrid
Ниже рассмотрены средства для выделения (цветом, шрифтом и т.д.) какого-либо столбца в TDBGrid.
На характеристики представления значений в ячейках TDBGrid также могут оказывать влияние такие свойства компонентов TField, как DisplayFormat и EditFormat, которые позволяют задавать формат поля соответственно при его показе и при редактировании, причем эти свойства актуальны для всех компонентов, визуализирующих значение поля (полей), а не только для столбцов TDBGrid.
Перечисленные средства носят безусловный характер, то есть позволяют изменять характеристики показа всех значений в конкретном столбце. Однако может потребоваться выделять тем или иным образом не целый столбец, а определенные ячейки столбца, отвечающие какому-либо условию. Например, для бухгалтерских и складских программ часто принято выделять красным цветом отрицательные остатки или остатки, находящиеся ниже установленного лимита.
То, как осуществляется прорисовка данных в TDBGrid - стандартным способом или по особому сценарию - определяется свойством property DefaultDrawing: Boolean;
В случае, если имеет место управление прорисовкой со стороны самого приложения, алгоритм прорисовки должен содержаться в обработчиках событий OnDrawColumnCell или OnDrawDataCell. Заметим, что обработчик события OnDrawDataCell введен для совместимости с ранними версиями Delphi.
При автоматической прорисовке (DefaultDrawing = True) метод Paint использует цвет и шрифт свойства Canvas для прорисовки ячейки. Событие
property OnDrawColumnCell: TDrawColumnCellEvent;
TDrawColumnCellEvent = procedure (Sender: TObject; const Rect:
TRect; DataCol: Integer; Column: TColumn; State: TGridDrawState) of object;
где параметры имеют следующий смысл:
Rect - определяет область ячейки, в которой, собственно, происходит прорисовка,
Тип
TRect = record CASE Integer of
0: (Left, Top, Right, Bottom: Integer);
1: (TopLeft, BottomRight: TPoint);
END;
END;
определяет прямоугольник, в котором прорисовывается ячейка TDBGrid, координаты прямоугольника указываются или как 4 целых числа, содержащие границы прямоугольника в пиксельном исчислении, или как 2 значения типа TPoint, определяющих левый верхний и правый нижний углы прямоугольника:
TPoint = record
X: Longint;
Y: Longint;
end;
DataCol -
определяет порядковый номер текущего столбца, начиная с 0-го; • Column. TColumn - определяет текущий столбец.
• State TGridDrawState - определяет состояние ячейки.
Тип TGridDrawState = set of (gdSelected, gdFocused, gdFixed) ;
определяет множество возможных состояний ячейки TDBGrid.
Если ячейка находится в состоянии gdFocused (т.е. является текущей), в обработчике события OnDrawColumnCell происходит прорисовка инверсной полосы.
Для вывода ячеек стандартным образом используется метод
procedure DefaultDrawColumnCell(const Rect: TRect; DataCol: Integer; Column:
TColumn; State: TGridDrawState);
Используя информацию, содержащуюся в передаваемых в обработчик OnDrawColumnCell параметрах, можно изменять отображение как целых строк, так и отдельных ячеек.
Пример.
Пусть необходимо выводить белым шрифтом на красном фоне те строки НД, у которых поле'Doljnost' содержит значение 'профессор'(рис. 10.20). procedure TForm1.DBGrid1DrawColumnCell(Sender: TObject; const Rect: TRect;
DataCol: Integer; Column: TColumn; State: TGridDrawState);
begin
WITH DBGrid!.Canvas do begin
// поле "Должность" содержит значение "профессор"?
IF (Table1Doljnost.AsString = 'профессор') AND not (gdFocused in State) THEN
// - да. Выводить все ячейки строки бельм шрифтом на красном фоне
begin
Brush.Color := cIRed;
Font.Color := clWhite;
FillRect(Rect) ;
TextOut(Rect.Left, Rect.Top,Column.Field.Text) ;
end
ELSE
// - нет, текущее значение "Должности" - не "профессор". Выводим все ячейки строки стандартным образом
DBGrid1.DsfaultDrahColumnCellfRect, DataOol, Column, State);
END; {with}
end;
В отличие от предыдущего примера, в следующем выделяются не строки, а ячейки:
procedure TForm!.DBGrid1DrawColumnCell(Sender: TObject; const Rect: TRect;
DataCol: Integer; Column: TColumn; State: TGridDrawState);
begin
WITH DBGrid!.Canvas do begin
// текущий столбец - "Должность"?
IF (Column.Field.FieldName = 'Doljnost') AND not(gdFocused in State) THEN
// Текущая ячейка содержит значение "профессор"?
IF Column.Field.Text = 'профессор' THEN
// - да. Тогда вывести ячейку белым шрифтом на красном фоне
begin
Brush.Color := cIRed;
Font.Color := clWhite;
FillRect(Rect) ;
TextOut(Rect.Left, Rect.Top, Column.Field.Text);
Exit;
end;
// сюда попадаем, только если текущий столбец - не "Должность" или "Должность", но значение ячейки столбца - не "профессор"
DBGrid!.DefaultDrawColumnCell(Rect, DataCol, Column, State);
END; {with}
end;
ЗАМЕЧАНИЕ.
В показанном выше примере значение поля "Должность" имеет строковый тип. Строковые значения в ячейках TDBGrid принято выводить выровненными влево. Поэтому в процедуре TextOut(Rect.Left, Rect.Top,Column.Field.Text) ;
используется горизонтальная координата Rect.Left.
В случае, когда показываемое в ячейке значение должно быть выровнено вправо (как часто имеет место для цифровых значений), необходимо заменить координату Rect.Left на правую координату ячейки, уменьшенную на ширину выводимого в ячейке текста. Ширина текста возвращается методом TextWidth компонента TDBGrid. Canvas:
function (const Text: string): Integer;
В этом случае содержимое ячейки выводится следующим образом:
TextOutfRect.Right - 3 - TextWidth(Column.Field.Text), Rect.Top,Column.Field.Text) ;
Заметим, что дополнительный сдвиг на 3 пиксела нужен, чтобы оставить справа от текста небольшой пробел.
Заметим также, что сдвиг на 3 пиксела хорош для шрифта MS Sans Serif размером 12 пунктов, который использовался в данном примере; для других шрифтов и размеров эта величина нуждается в изменении. В общем случае, содержание алгоритма, реализующего выравнивание текста, состоит в определении длины и высоты ячейки TDBGrid, а также в определении длины и высоты выводимого в ячейку текста и в их последующем сопоставлении.
Перемещение между ячейками TDBGrid
Для перехода от текущего столбца к другому можно воспользоваться клавишей TAB - для перехода к столбцу справа от текущего;
• комбинацией клавиш SHIFT+TAB - для перехода к столбцу слева от текущего;
мышью - независимо от того, к какому столбцу нужно перейти.
При смене столбца возникают 2 события в такой очередности:
• OnColExit - наступает в момент, когда мы покидаем текущий столбец;
• OnColEnter - наступает в момент, когда новый столбец становится текущим.
В следующем примере на экран выводятся имена полей, ассоциированных с покидаемым и новым столбцами:
procedure TForm1.DBGrid1ColEnter(Sender: TObject);
begin
ShowMessage('Мы вошли в ' + DBGrid1.SelectedField.FieldName );
end;
procedure TForm1.DBGrid1ColExit(Sender: TObject);
begin
ShowMessage ('Мы покинули ' + DBGrid1.SelectedField.FieldName );
end;
Действия с мышью и клавиатурой в момент, когда TDBGrid обладает фокусом управления
Для компонента TDBGrid предусмотрены следующие события:
OnDblChck -
наступает после двойного щелчка мышью. Пример.
Пусть требуется изменить на желтый цвет фон столбца, на котором произведен двойной щелчок мышью: procedure TFormI.DBGrid1DblClick(Sender: TObject);
begin
DBGrid1.Columns.Items[DBGrid1.SelectedIndex].Color := clYellow;
end;
• OnKeyDown - наступает, когда пользователь нажимает любую клавишу или комбинацию клавиш на клавиатуре (но еще не отпустил).
• OnKey Up - наступает, когда пользователь отпускает любую клавишу или комбинацию клавиш.
• OnKeyPress - возникает, когда пользователь нажимает отдельную клавишу (цифрового или алфавитного символа) на клавиатуре, а также комбинацию клавиш, что приводит к формированию кода цифрового или алфавитного символа (например, клавишу 'и' или SHIFT + "и, что в результате дает 'U').
Пример
вызова различных форм в зависимости от нажатия той или иной клавиши: procedure TFormI.DBGrid1KeyPress(Sender: TObject; var Key: Char);
begin
ShowMessage(key);
CASE Key OF
'u' : Form2.ShowModal;
's' :
Form3.ShowModal ; END;
Компонент TDBText
Компонент TDBText применяется для показа значения текстового поля текущей записи НД. Изменять значение, показываемое при помощи TDBText, нельзя. Компонент является аналогом компонента TLabel, за исключением того, что значение для отображения берется из текущей записи НД.
Для использования компонента TDBText нужно:
• указать в свойстве property DataSource: TDataSource; имя соответствующего компонента TDataSource, связанного с НД;
• указать в параметре property DataField: String; имя поля. При заполненном свойстве DataSource в инспекторе объектов, когда мы устанавливаем значение свойства DataField, появляется список:
- имен полей, определенных в редакторе полей;
- имен всех полей НД, на который ссылается соответствующий компонент TDataSource, ест редактор полей не применялся.
Пример.
Пусть имеем ТБД "TOV.DB", в состав записи которой входят поля GrNum (номер группы товаров) и Tovar (наименование товара). Требуется в компоненте TDBGrid показывать только наименования товаров, а внизу, под TDBGrid - номер группы для текущей записи в НД. Расположим в форме компоненты DataSourcel, Table1 (указывающий на ТБД "TOV.DB") и DBGridI, связанные между собой стандартным образом. Расположим также в форме компоненты Label 1 (свойство Caption = 'Номер группы текущей записи - ') и DBTextl (рис. 11.1).
Назначим в инспекторе объектов свойства DBTexlt.DalaSource = DataSourcel и DBTextl. DataField = GrNum. Тогда во время выполнения приложения DBTextl будет показывать содержимое поля GrNum текущей записи.
Назначение компонента
Компонент TDBRichEdit позволяет просматривать и корректировать информацию в поле форматированного комментария (рис. 11.10).
Форматированный комментарий располагается в поле комментария. Текст в нем может содержать фрагменты, набранные различным шрифтом, размером,
стилем, цветом и т.д. В отличие от компонента TDBMemo, который позволяет работать только с однородным (неформатированным) текстом, компонент TDBRichEdit умеет интерпретировать специальные символы разметки текста в формате RTF (Rich Text Format).
Свойства
property AutoDisplay: Boolean;
property DataField: string;
property DataSource: TDataSource;
ro property Field: TField;
property Lines: TStrings;
procedure LoadMemo; property ReadOnly: Boolean;
аналогичны по назначению одноименным свойствам компонента TDBMemo. Длина текста форматированного комментария в символах возвращается методом function GetTextLen: Integer;
Метод procedure Clear; полностью удаляет текст из компонента.
Метод procedure Print(const Caption: string); выводит текст комментария на печать. Параметр Caption определяет заголовок в очереди печати.
Свойство property HideScrollBars; определяет, следует автоматически убирать (True) или нет (False) полосы скроллинга из окна TDBRichEdit, если в их присутствии нет необходимости.
Свойство property HideSelection: Boolean; определяет, следует (True) или не следует (False) скрывать выделение текста в окне TDBRichEdit, если фокус управления перешел к другому компоненту.
При изменении размера шрифта наступает событие property OnResizeRequest: TRichEditResizeEvent; TRichEditResizeEvent = procedure (Sender: TObject; Rect: TRect) of object ; Параметр Rect содержит сведения о новых границах изменяемого текста (в экранных координатах).
При изменениии текста наступает событие property OnChange: TNotifyEvent; TNotifyEvent = procedure(Sender: TObject) of object;
Сохранение комментария в файле и считывание комментария из файла
Форматированный комментарий может быть записан в файл и считан из него. Для этой цели применяются методы свойства Lines, procedure SaveToFUe(const FileName: string); procedure LoadFromFile(const FileName: string);
Свойство property PlainText: Boolean; указывает (True), что нужно игнорировать разметку текста (шрифт, цвет и т.д.) при записи из файла в компонент или из компонента в файл. В этом случае текст представляется в виде обычного текстового файла. Значение False (по умолчанию) указывает на необходимость принимать во внимание разметку текста. Например,
RichEdit1.PlainText := True;
RichEdit1.Lines.LoadFromFile(Path);
RichEdit2.PlainText := False;
Работа с выделенным текстом
Фрагмент текста форматированного комментария выделяется так же, как и в популярном текстовом процессоре WinWord; для выделения необходимо установить указатель мыши на начало выделяемого фрагмента, нажать левую кнопку мыши и, не отпуская кнопки, установить указатель мыши на конец фрагмента, после чего кнопку отпустить. Есть и другой способ (при помощи клавиатуры): следует переместить курсор на начало выделяемого фрагмента, нажать кнопку с изображением стрелки влево (вправо) и одновременно - кнопку Shift; движение курсора следует остановить на конце выделяемого фрагмента.
Следующие свойства позволяют определить параметры выделенного фрагмента в тексте комментария:
property SelLength: Integer;
возвращает число выделенных символов. property SelStart: Integer; возвращает номер первого выделенного символа в тексте. property SelText: string; возвращает выделенный текст. Программное изменение одного из указанных свойств изменяет границы выделенного фрагмента.
Весь текст комментария может быть выделен вручную - нажатием на клавиатуре комбинации Ctrl+A, и программно - путем выполнения метода procedure SelectAll;
Свойство property SelAttributes: TTextAttributes; позволяет установить характеристики выделенного текста. Свойства компонента TTextAttributes: . -
• property Color: TColor;
определяет цвет выделенного текста; • property Height: Integer;
определяет высоту в пикселах выделенного текста; • property Pitch: TFontPitch;
определяет, имеют ли литеры выделенного текста одинаковую ширину. Значения:
fpDefault-
определяется используемым шрифтом; fpFixed -
одинаковая ширина; fp Variable -
переменная ширина. • property Protected: Boolean;
определяет (True), что текст защищен от изменения пользователем. В случае, если пользователь пытается изменить защищенный текст, вызывается обработчик события OnProtectChange. В этом обработчике можно снять защиту. Если обработчик указанного события не определен, защищенный текст доступен только на чтение.
• property Size: Integer;
определяет высоту в пикселах выделенного текста. * property Style: TFontStyles;
определяет стиль выделенного шрифта. Множество Style может состоять из одного или нескольких значений: fsBold - жирный;
fsltalic -
наклонный; fs Underline -
подчеркнутый; fsStrikeout -
зачеркнутый. Пример.
Установить шрифт, цвет, размер и стиль выделенного текста аналогичными параметрам шрифта, выбранного посредством компонента TFontDialog: IF FontDialog1.Execute THEN begin
WITH DBRichEditl.SelAttributes do begin
Color := FontDialogl.Font.Color;
Size := FontDialogl.Font.Size;
Name := FontDialogl.Font.Name;
Style := FontDialogl.Font.Style;
END;//with
END;//if
Пример.
Сделать выделенный фрагмент текста защищенным: DBRichEditI.SelAttributes.Protected := True;
Событие
property OnProtectChange: TRichEditProtectChange;
TRichEditProtectChange = procedure(Sender: TObject; StartPos, EndPos: Integer; var AllowChange: Boolean) of object;
наступает, если пользователь пытается изменить защищенный текст. Параметры StartPos и EndPos содержат границы защищенного текста. Установка в True изменяемого параметра AllowChange разрешает изменять защищенный текст.
Пример.
В случае, если пользователь пытается изменить символ, ранее помеченный как защищенный, запрашивается подтверждение; если пользователь подтверждает изменение защищенного символа, тот изменяется; если не подтверждает, изменение символа отвергается. procedure TForm1.DBRichEdit1ProtectChange(Sender: TObject;
StartPos,
EndPos: Integer; var AllowChange: Boolean);
begin
IF MessageDIg('Изменяемый текст являются защищенным. ' + 'Желаете все-таки его изменить?',mtConfirmation,
[mbYes,mbNo],0) = mrYes THEN AllowChange := True;
end;
Выделенный фрагмент текста может быть удален методом procedure ClearSelection;
Метод procedure CopyToClipboard; копирует выделенный текст в буфер обмена Windows.
Метод procedure CutToClipboard; вырезает выделенный текст и вставляет его в буфер обмена Windows.
Метод procedure PasteFromCUpboard; вставляет содержимое буфера обмена Windows в текст комментария, начиная с текущей позиции курсора.
Пример.
Определим кнопки "Копировать в буфер обмена", "Вырезать в буфер обмена", "Вставить из буфера обмена" и напишем обработчики события нажатия этих кнопок: // кнопка "Копировать в буфер обмена"
procedure TForm1.SpeedButton6Click(Sender: TObject);
begin
DBRichEditI.CopyToClipboard;
end;
// кнопка "Вырезать в буфер обмена"
procedure TFormI.SpeedButton7Click(Sender: TObject);
begin
DBRichEditI.CutToClipboard;
end;
// кнопка "Вставить из буфера обмена"
procedure TForm1.SpeedButtonSClick(Sender: TObject);
begin
DBRichEdit1. PasteFromCUpboard;
end;
Поиск фрагмента текста
Метод function FindText(const SearchStr: string; StartPos, Length: Integer; Options: TSearchTypes): Integer; ищет в тексте комментария строку SearchStr. Поиск производится во фрагменте текста начиная с позиции StartPos и заканчивая StartPos + Length -1. Первый символ текста комментария имеет номер 0.
Если поиск успешен, возвращается номер символа, начиная с которого SearchStr входит в текст комментария. В противном случае возвращается -1.
Параметр Options представляет собой множество, в который могут входить такие элементы:
stWholeWord-
поиск ведется целыми; stMatchCase -
игнорируется разница в высоте букв. Пример.
Произвести поиск во всем тексте DBRichEdit1. Поисковая строка находится в Edit1.Text. Если фрагмент найден, выделить его. procedure TForm1.FindButtonClick(Sender: TObject) ;
begin
WITH DBRichEditl do begin
SelStart := FindText(Editl.Text,0,GetTextLen,[]) ;
SelLength := Length(Edit1.Text) ;
END;//with
end;
Компонент TDBEdit
Компонент TDBEdit позволяет редактировать значение строкового поля текущей записи НД. Он повторяет функциональность компонента TEdit (позволяющего корректировать значение переменной), но источником данных и их приемником в этом случае служит поле НД. Поэтому для TDBEdit необходимо указывать свойства
property DataSource: TDataSource; -
имя компонента DataSource, определяющего НД; * property DataField: string; -
имя редактируемого поля; property ReadOnly: Boolean; -
если содержит True, значение поля доступно только для чтения, если False - значение поля можно изменять. Пример.
Пусть необходимо корректировать, изменять, удалять текущую запись в НД, связанном с ТБД "TOV.DB" (товары), в состав записи которой входят поля GrNum (номер группы товаров) и Tovar (наименование товара). Поместим в форму компоненты Table1 (связанный с ТБД "TOV.DB") и DataSource 1, указывающий на Table I. Пусть группа кнопок реализует перевод НД в режимы dslnsert, dsEdit, а также обращение к методам Delete, Post, Cancel. Поместим в форму компоненты DBEdit1 (указывает на поле GrNum) и DBEdit2 (указывает на поле GrNazv). При добавлении новой записи или при изменении существующей необходимо вводить и корректировать значения полей в компонентах DBEdit1 и DBEdit2 (рис. 11.2).
При вводе значения в TDBEdit приложение автоматически отслеживает, чтобы введенное значение было совместимо по формату с полем набора данных, с которым связан данный компонент TDBEdit. Ввод неверных значений блокируется. Например, если в компонент TDBEdit, связанный с полем типа даты и времени, попытаться поместить строковое значение, будет возбуждено исключение.
Свойство property Text: string; хранит текущее содержимое поля НД в текстовом виде.
Событие property OnChange: TNotifyEvent; наступает при изменении значения поля.
События property OnEnter: TNotifyEvent; property OnExit: TNotifyEvent; наступают при получении и утрате фокуса управления компонентом TDBEdit.
Компонент TDBCheckBox
Компонент TDBCheckBox позволяет "отметить" и "снять отметку" с логического поля в составе текущей записи НД.
Он обладает функциональностью компонента TCheckBox, но источником данных и их приемником в этом случае служит поле НД.
Свойства property DataSource: TdataSource; property DataField: string;. property ReadOnly: Boolean; имеют такое же назначение, как и аналогичные свойства компонента TDBEdit.
Пример.
Расширим пример, приведенный выше для компонента TDBEdit. Пусть в ТБД "TOV.DB" имеется поле Uzenka (тип Boolean). Значение True в этом поле означает, что товары данной группы подлежат уценке, значение False - не подлежат. Добавим в форму компонент DBCheckBox1 (свойство DataSource = DataSource1, свойство DataField = Uzenka). Тогда в процессе работы можно устанавливать в данное поле значения True или False, делая или не делая отметки DBCheckBox1 (рис. 11.3).
ЗАМЕЧАНИЕ.
При показе содержимого НД Table1 в TDBGrid в столбце Uzenka для тех записей, у которых поле Uzenka содержит True, выводится символ '+', а для тех записей, у которых поле Uzenka содержит False - ничего не выводится. Такая функциональность реализуется в следующем обработчике события OnGetText для поля Uzenka (компонент Table1 Uzenka). procedure TForm1.Table1UzenkaGetText(Sender: TField;
var Text: string;
DisplayText: Boolean);
begin
IF DisplayText and Table1Uzenka.Value THEN Text := '+' ;
end;
Напомним, что событие OnGetText наступает перед показом содержимого поля каждой записи в визуальных компонентах.
Свойство
property Checked : Boolean;
позволяет определить, отмечено поле, на которое ссылается TDBCheckBox (значение True) или не отмечено (False).
Свойство
property State: TCheckBoxState;
возвращает состояние поля. Возможные значения:
cbUnchecked-
поле не отмечено; cbChecked -
поле отмечено; cbGrayed -
промежуточное состояние, когда поле не отмечено, но в нем показывается серый символ отметки. Он означает, что поле не содержит ни True, ни False, а содержит пустое значение. Именно это состояние присуще компоненту DBCheckBoxl при добавлении записей в приводившемся выше примере. Добиться того, чтобы во вновь добавляемых записях поле Uzenka по умолчанию содержало значение False можно в обработчике события OnNew Record компонента Table1 (событие наступает всякий раз при добавлении новой записи): procedure TForm1.Table1NewRecord(DataSet: TDataSet) ;
begin
Table1Uzenka.AsBoolean := False;
end;
Компонент TDBChechBox можно связывать и не с логическим, а с символьным полем. В этом случае необходимо установить значения приводимых ниже свойств.
Свойство
property ValueChecked: string;
устанавливает значения поля, при которых TDBCheckBox переходит в состояние cbChecked. При наличии нескольких значений они разделяются точкой с запятой:
DBCheckBox1.ValueChecked := 'True;Yes;On;Дa;Д';
Свойство
property ValueUnchecked: string;
устанавливает значения поля, при которых TDBCheckBox переходит в состояние cbUnchecked. При наличии нескольких значений они разделяются точкой с запятой:
DBCheckBoxl.ValueUnchecked := 'False;No;Off; Нет;Н';
События
property OnEnter: TNotifyEvent;
property OnExit: TNotifyEvent;
наступают при получении и утрате фокуса управления компонентом.
Событие
property OnClick: TNotifyEvent;
наступает, если на компоненте TDBCheckBox щелкнуть мышью. Поскольку именно таким образом происходит снятие отметки или отметка компонента, данное событие может использоваться для оценки изменения значения свойства Checked.
Компонент TDBRadioGroup
Компонент TDBRadioGroup служит для предоставления фиксированного набора возможных значений поля при помощи группы зависимых переключателей. Этот компонент обладает функциональностью компонента TRadioGroup, но источником данных и их приемником в этом случае служит поле НД.
Свойства
property DataSource : TDataSource;
property DataField: string;
property ReadOnly: Boolean;
аналогичны по назначению одноименным полям компонента TDBEdit.
Напомним, что число и названия вариантов возможных значений поля, содержащихся в TDBRadioGroup, определяются в его свойстве Items: TStrings.
Пример.
Расширим пример, приведенный выше для компонента TDBCheckBox. Пусть в ТБД "TOV.DB" имеется поле Hranenie типа String, которое может принимать только 2 значения ("до 5 дней", "свыше 5 дней"). Для выбора одного из этих значений добавим в форму компонент DBRadioGroup1, связав его с DataSource 1 и указав в свойстве DataField на поле Hranenie (рис. 11.4): Заметим, что индекс текущего выбора можно определить, используя свойство TDBRadioGroup.ItemIndex : Integer, которое возвращает номер выбранного значения в порядке, в котором они определены в TDBRadioGroup.Items; при этом отсчет ведется с 0. Например, для приведенного выше примера (товар "Колбаса краковская") DBRadioGroupl. ItemIndex = 0.
Свойство property Value: string; возвращает значение поля, связанного с компонентом TDBRadioGroup, в текстовом виде.
Свойство property Columns: Integer указывает, сколько назначено столбцов для вывода переключателей (в примере на рис. 11.4. Columns = 2
Событие property OnChange: TnotifyEvent наступает при изменении значения поля, связанного с компонентом TDBRadioGroup.
События property OnEnter: TNotifyEvent; property OnExit: TNotifyEvent; наступают при получении и утрате фокуса управления компонентом.
Компонент TDBListBox
Компонент TDBListBox применяется, когда нужно выбрать значение поля из предустановленного списка значений. Возможные значения содержатся в качестве строк компонента TDBListBox.
Свойства property DataSource : TDataSource; property DataField: string; property ReadOnly: Boolean; аналогичны по назначению одноименным свойствам компонента TDBEdit.
Свойство property Items: TStrings; содержит список возможных значений поля.
Пример.
Пусть в ТБД "TOV.DB" имеется поле Hranenie типа String, которое может принимать только 2 значения ("до 5 дней", "свыше 5 дней"). Для выбора одного из этих значений добавим в форму компонент DBListBox1, связав его с DataSource1 и указав в свойстве DataField на поле Hranenie (рис. 11.5). События property OnEnter: TNotifyEvent; property OnExit: TNotifyEvent; наступают при получении и утрате фокуса управления компонентом TDBEdit.
События property OnClick: TNotifyEvent; property OnDblClick: TNotifyEvent; наступают при одиночном и двойном щелчке мышью на компоненте TDBListBox
Компонент TDBComboBox
Этот компонент аналогичен компоненту TDBListBox, за исключением того, что в режиме dsBrowse текущее значение поля показывается аналогично TDBEdit, а в режимах добавления (dslnsert) и редактирования (dsEdit) при занесении значения в поле появляется "выпадающий список" (рис. 11.6.). Длина списка в строках определяется свойством property DropDownCount: Integer;
Компонент TDBLookupComboBox
Компонент TDBLookupComboBox применяется для выбора значений в поле одного набора данных (назовем его НД-1) из списка значений, источником которого выступают значения какого-либо поля из другого набора данных (НД-2). Наборы данных НД-1 и НД-2 связываются по полю связи. Это поле присутствует и в НД-1, и в НД-2 и имеет идентичный тип. Таким образом, НД-1 и НД-2 состоят в связи, как правило, "многие (НД-1) к одному (НД-2)". При этом реляционная связь может быть не оформлена при помощи первичного (НД-1) и внешнего (НД-2) индексов. Поэтому вхождения поля связи ни в текущий, ни в какой-либо иной индекс не требуется.
Разберем ключевые свойства и методы компонента TDBLookupListBox.
property DataSource: TDataSource; -
указывает на компонент TDataSource, связанный с набором данных-1. property DataField: string; -
устанавливает поле НД-1, в которое будет помещаться значение из НД-2. property ListSource: TDataSource; -
указывает на компонент TDataSource НД-2. property ListField: String; -
устанавливает поле, значения которого будут показываться в списке выбора. Если значение не заполнено, берется значение свойства Key Field. Можно указать несколько полей. Тогда все они будут показываться в списке выбора. Имена полей разделяются точкой с запятой.
property RowCount: Integer; -
указывает, сколько строк показывается в выпадающем списке. При изменении размеров списка, например путем занесения нового значения в свойство Height, RowCount изменятся автоматически. property KeyField: string; -
устанавливает поле связи между наборами данных 1 и 2. property KeyValue: Variant; -
содержит текущее значение поля связи. Если во время выполнения программы его значение изменится, будет осуществлена попытка отыскать в НД-2 запись со значением, содержащимся в этом свойстве. Пример.
Пусть в ТБД "Сотрудники" (поле Doljnost) нужно вводить значения из списка, определяемого полем Doljnost ТБД "Должности, оклады". Для иллюстрации будем в списке показывать также значения поля Oklad ТБД "Должности, оклады". С ТБД "Сотрудники" связан НД TeachersTable (TTable), с ТБД "Должности, оклады" - НД OkladyTable (TTable). С ними соответственно связаны компоненты TDataSource DS_Teachers и DS_Oklady.
Для ввода в поле Doljnost (НД TeachersTable) разместим в форме компонент DBLookupComboBox1 и установим такие значения его свойств:
DataSource DS_Teachers
DataField
Doljnost ListSource
DS_Oklady ListField
OklaD;Doljnost KeyField
Doljnost Тогда при занесении значения в поле Doljnost НД TeachersTable получим комбинированный список значений оклада и должности из НД OkladyTable (рис. 11.7).
В компоненте определены свойства property DropDownAlign : TAlign; property DropDownRows: Integer; property DropDownWidth: Integer; определяющие соответственно выравнивание, число строк в списке и его ширину, а также методы procedure DropDown; - раскрывает ("распахивает") список выбора;
procedure CloseUp; -
сворачивает распахнутый список выбора.
Компонент TDBLookupListBox
Повторяет функциональность компонента TDBLookupComboBox, за исключением того, что выбор производится не из постоянно присутствующего на экране, а "раскрывающегося" (или "выпадающего") списка. Отсутствуют следующие свойства и методы компонента TDBLookupComboBox: DropDownAlign, DropDownRows, DropDown Width, DropDown и CloseUp.
Компонент TDBMemo
Компонент TDBMemo предназначен для показа мемо-полей (полей комментариев). Поля комментариев могут хранить многострочные тексты. Компонент TDBMemo является аналогом компонента TMemo с той лишь разницей, что источником данных в этом случае служит поле комментария набора данных.
При корректировке текста комментария в компоненте TDBMemo набор данных, к которому принадлежит поле комментария, автоматически переводится в состояние dsEdit.
Пример.
Пусть в ТБД "TOV.DB" имеется поле комментария Komment. Расположим в форме компонент DBMemo1 и укажем в его свойстве DataSource имя компонента TDataSource, связанного с НД, к которому принадлежит поле комментария После этого в свойстве DataField из выпадающего списка выберем имя поля Komment. Если нужно представлять текст комментария только для просмотра, установим в свойство ReadOnly компонента DBMemo1 значение True, а если текст может изменяться - значение False (рис. 11.8).
Свойство AutoDisplay : Boolean; в состоянии True указывает на необходимость того, чтобы любые изменения в поле НД автоматически отображались и в TDBMemo. В состоянии False подобные действия не производятся и обновление информации в TDBMemo необходимо производить программно.
Свойство Alignment; TAlignment; определяет выравнивание текста в TDBMemo - влево (taLeftJustify), вправо (taRightJustify), по центру (taCenter).
Свойство WordWrap : Boolean; в состоянии Тгие разрешает показывать с новой строки те слова, которые не умещаются в области показа (при этом свойство ScrollBars не должно определять линию горизонтальной прокрутки). В состоянии False этого не происходит(рис.11.9.а и б).
Свойство ScrollBars : TScrollStyle; определяет полосы прокрутки в окне TDBMemo. отсутствие полос прокрутки (ssNone), горизонтальную (ssHorizonlal), вертикальную (ssVertical) и обе (ssBoth).
Свойство Lines: TStrings; содержит строки поля комментария. Для работы с Lines допустимо (и рекомендуется) использовать свойства и методы класса TStrings. Приведем наиболее важные из них:
• Count: Integer;
Возвращает общее число строк в Lines. • Memol.Lines|i| : String;
Позволяет обратиться к i-й строке. При этом i принадлежит к интервалу 0..Lines.Count -1. Пример.
Требуется строчные буквы всех строк в DBMemol заменить на заглавные. Для преобразования используем стандартную функцию AnsiUpperCase: procedure TForm1 .ButtonlClick (Sender: T0bj]ect) ;
var i : Integer;
begin
TableI.Edit; //набор данных - в режим редактирования
WITH DBMemol do begin
FOR i := 0 TO Lines.Count - 1 do
Lines [i] := AnsiUpperCase(Lines[i]);
END; {with}Table1.Post;
end;
Нужно отметить, что того же эффекта можно добиться, обращаясь к содержимому поля комментария как к длинному текстовому полю с использованием его свойства property Text: String; Например:
procedure TForm1.Button2Click(Sender: TObject);
begin
Table1.Edit; //набор данных - в режим редактирования
DBMemol.Text := AnsiUpperCase(DBMemol.Text);
Table1.Post;
end;
Заметим, что изменение значения свойства Text или значения одного или нескольких строк Lines не переводит НД в режим редактирования и изменения внесенные в текст комментария в TDBMemo, в поле НД, с которым этот компонент связан, не переносятся Поэтому перед внесением изменений в значения свойств Lines или Te\f следует переводить набор данных в режим dsEdif, а затем запоминать изменения методом Post
Аналогичным по последствиям будет обращение к тексту комментария через свойство Value компонента TField, назначенного полю комментария
Table1.Edit; //набор данных - в режим редактирования
Table1.Komment.Value := AnsiUpperCase(Table1Komment.Value);
Table1.Post;
В некоторых случаях бывает полезным формировать содержимое комментария во временном компоненте TMemo и затем присваивать свойство Lines компоненту TDBMemo
Table1.Edit; //набор данных - в режим редактирования
DBMemol.Lines.Assign(TmpMemo1.Lines) ;
Table1.Post;
Такой же подход нужно применять и тогда, когда содержимое поля комментария изменяется построчно
Table1.Edit; //набор данных - в режим редактирования
DBMemol.Lines [i].Add('какое-то значение') ;
Table1.Post;
Часто производимый перевод НД из состояния dsBrowse в dsEdif и обратно способен существенно замедлить работу приложения Наоборот, работая со
свойством Lines компонента TMemo, мы всегда работаем только с оперативной памятью Впоследствии накопленные изменения запоминаются в поле комментария за один раз
function Index0f(const S: string): Integer;
Возвращает индекс (начиная с 0) строки, совпадающей с S (если таковая есть), и -1, если такой строки нет procedure Clear;
Очищает Lines Значение свойства Count становится равным 0 function Add(const S: string): Integer;
Добавляет строку в конец Lines и возвращает номер добавленной строки procedure Insert (Index: Integer; const S: string);
Вставляет строку S после строки с индексом Index procedure Delete (Index: Integer);
Удаляет строку с индексом Indev Метод procedure LoadFromFile(const FileName: string); загружает в TDBMemo содержимое файла, имя которого определяется параметром FileName
Метод procedure SaveToFile(const FileName: string); записывает содержимое TDBMemo в файл FileName
Часто необходимо обеспечить поиск в тексте комментария вхождений какого-либо поискового контекста В этом случае с содержимым поля комментария работают не построчно (через свойство Lines), а как с единым целым (текстовой переменной) через свойство Text Для поиска используется символьная функция Роs, которая возвращает значение, отличное от 0, если поиск был удачен Свойства SelStart и SelLength используются для последующего выделения найденного вхождения Приведем пример простейшего контекстного поиска в поле комментария (реализован в обработчике события Find компонента FmdDialog)
procedure TForm1.FindDialog1Find(Sender: TObject);
var
ToFind: string; // строка, вхождение которой ищем
FindIn: string; // строка (Мемо), где ищем
Found: integer; // результат поиска
Index: integer; // начальная позиция (№ символа) найденного вхождения
FoundLen: integer; //длина найденного текста
begin
ToFind := FindDialog1.FindText; {Поисковая строка - из FmdDialog}
FoundLen := Length(FindDialog1.FindText); {Длина искомого фрагмента текста}
FindIn := MemoSee.DBMemol.Text; {Текст, где будем искать}
Found := Pos(ToFind, Findin) ;
IF Found > 0 then
begin {Отметим найденный фрагмент)
DBMemol.SelStart:= Found -1;
DBMemol.SelLength := FoundLen;
end
ElSE
MessageDIg('Такого вхождения нет!', mtlnformation, [mbOK], 0) ;
end;
Назначение компонента TSession
Для каждого приложения в Delphi автоматически создается компонент типа TSession с именем Session. Он управляет всеми соединениями с базами данных. Его методы и свойства носят глобальный характер для всего приложения.
Обычно в приложении имеется один поток (Thread) работы с БД. В некоторых случаях можно создать два и более потока. При этом, если в каждом из этих потоков реализовать запросы к БД, они будут выполняться независимо друг от друга. В случае нескольких потоков, компонент типа TSession создается для каждого из них.
Работа с установками BDE
Метод procedure GetAliasNames(List: TStrings); очищает список List и затем заносит в него список псевдонимов БД , определенных в BDE.
Пример:
Session.GetAliasNames(ListBoxl.Items) ; Метод procedure GetAliasParams(const AliasName: string; List: TStrings); очищает список List и затем помещает в него параметры псевдонима AliasName.
Пример:
var TekAllias : String;
Session.GetAliasParams(TekAllias, ListBox2.Items);
Примеры возвращаемых результатов:
SERVER NAME=C:\Program
Files\Borland\IntrBase\EXAMPLES\EMPLOYEE.GDB
USER NAME=SYSDBA
OPEN MODE=READ/WRITE
SCHEMA CACHE SIZE=8
LANGDRIVER=
SQLQRYMODE=
SQLPASSTHRU MODE=SHARED AUTOCOMMIT
SCHEMA CACHE TIME=-1
PATH=d:\book\data
DEFAULT DRIVER=PARADOX
ENABLE BCD=FALSE
Чтение имен таблиц базы данных
procedure GetTableNames(const DatabaseName, Pattern: string; Extensions, SystemTables: Boolean; List: TStrings); очищает список List и добавляет в него имена всех таблиц, определяемых параметром DatabaseName. Если необходимо добавить имена только некоторых таблиц, шаблон их имени указывается параметром Pattern. Значение параметра SystemTables, равное True, включит в состав таблиц, чьи имена занесены в List, имена системных таблиц (для удаленных баз данных). Установка в True параметра Extensions приведет к включению в имена таблиц расширений имени файла.
Пример:
var TekAllias : String;
Session.GetTableNames(TekAllias, '*.*', False, False, ListBox5.Items);
Метод procedure GetDriverNames(List: TStrings); очищает список List и затем заносит в него информацию об установленных на текущий момент драйверах BDE. Заметим, что драйверов 'PARADOX' и 'DBASE' не существует, поскольку эти СУБД управляются драйвером 'STANDARD'.
Пример:
Session.GetDriverNames(ListBox3.Items); Метод procedure GetDriverParams(const DriverName: string; List: TStrings); очищает список List и затем заносит в него параметы по умолчанию для драйвера, названного в параметре DriverName. В случае использования Paradox или dBASE (DriverName = 'STANDARD') , имеет место только один параметр, 'РАТН='. Драйверы SQL-СУБД могут иметь переменное число параметров.
Пример:
var TekDriver : String;
Session.GetDriverParams(TekDriver,ListBox4.Items);
Пример результата для драйвера 'INTRBASE':
SERVER NAME=IB_SERVER:/PATH/DATABASE.GDB
USER NAME=MYNAME
OPEN MODE=READ/WRITE
SCHEMA CACHE SIZE=8
LANGDRIVER=
SQLQRYMODE=
SQLPASSTHRU MODE=SHARED AUTOCOMMIT
SCHEMA CACHE TIME=-1
MAX ROWS=-1
BATCH COUNT=200
ENABLE SCHEMA CACHE=FALSE
SCHEMA CACHE DIR=
ENABLE BCD=FALSE
Пример результата для драйвера 'STANDARD:'
РАТН=
DEFAULT DRIVER=PARADOX
Список объявленных БД
Метод procedure GetAliasNames(List: TStrings); возвращает список псевдонимов БД, объявленных для BDE на данном компьютере.
Количество активных в данном приложении БД возвращает свойство property DatabaseCount: Integer; При этом отсчет активных БД ведется начиная с 0.
Свойство property Databases[Index: Integer]: TDatabase; обеспечивает доступ к активной БД с индексом Index; при этом каждой БД из списка Databases соответствует компонент типа TDatabase. Таким образом, при работе с каждой активной БД из списка Databases можно пользоваться свойствами, методами и событиями, присущими компоненту TDatabase.
Например,
поместить в ListBox2 список активных БД приложения: var i : Integer;
ListBox2.Clear;
WITH Session do begin
FOR i := 0 TO DatabaseCount - 1 do
ListBox2.Items.Add(Databases[i].DatabaseName) ;
END;//with
Хранение соединения с неактивной БД
Пусть некоторая БД имела наборы данных, открытые в определенный период времени, но затем эти НД были закрыты. Свойство property KeepConnections: Boolean; определяет, следует ли приложению хранить соединение с неактивными БД. False означает "не хранить"; при значении True соединение с неактивными БД будет ликвидировано либо при окончании работы приложения, либо после выполнения метода procedure DropConnections; К преимуществам постоянного соединения с неактивной БД можно отнести отсутствие необходимости выполнять повторное соединение с БД при открытии набора данных, использующего таблицы этой БД. А соединение, как известно, требует времени.
К недостаткам можно отнести расход ресурсов компьютера на поддержание постоянного соединения.
Работа с активными БД
Метод function OpenDatabase(const DatabaseName: string): TDatabase; пытается отыскать компонент TDatabase, у которого свойство DatabaseName совпадает с параметром DatabaseName метода FindDatabase. В случае успеха возвращается указатель на найденный и открытый компонент TDatabase; если такой компонент не существует, он создается, открывается и указатель на него возвращается в качестве результата работы метода. Метод OpenDatabase следует использовать в паре с методом CloseDatabase в блоке try...finally для обработки исключений, которые могут возникнуть при выполнении данных методов.
Метод procedure CIoseDatabase(Database: TDatabase); закрывает открытую БД, определяемую параметром Database, который содержит ссылку на экземпляр типа TDatabase. Принудительное закрытие БД практикуется достаточно редко, поскольку закрытие всех открытых БД производится при окончании работы приложения.
Метод function FindDatabase(const DatabaseName: string): TDatabase; пытается отыскать БД (компонент TDatabase} в коллекции TSession. Databases (коллекция открытых БД). Имя искомой БД определяется строковым параметром DatabaseName. Если в коллекции открытых БД сессии имеется такая БД, у которой значение DatabaseName совпадает с параметром DatabaseName метода FindDatabase, в качестве результата возвращается указатель на найденный компонент TDatabase. В противном случае возвращается nil.
Работа с паролями для Paradox-таблиц
Базой данных в Paradox, как известно, считается набор ТБД, хранящихся в одном месте. Каждая из таких таблиц физически занимает один файл и может иметь один или несколько паролей. При этом каждый из паролей может обеспечивать свои права доступа к таблице - доступ для чтения и записи, только для чтения и т.д. Более подробно с установкой паролей ТБД можно ознакомиться в среде Database Desktop, в разделе Table Properties \ Password Security. Окно Auxiliary Passwords (дополнительные пароли) позволяет определить для Paradox-ТБД несколько паролей с разными правами доступа (рис. 12.1.а и б).
Можно установить следующие права доступа:
• All - с
данными в ТБД можно делать все, плюс изменять структуру самой ТБД и физически удалять ее из БД; • Insert & Delete -
можно добавлять, удалять, очищать данные, но нельзя реструктурировать таблицу и удалять ее из БД; Data Entry - можно добавлять и изменять записи, но нельзя удалять записи, изменять структуру ТБД и удалять ее из БД;
Update -
можно просматривать записи ТБД и изменять в записях значения неиндексных полей. Остальное нельзя; Read Only -
можно просматривать данные в таблице, но изменять их нельзя. Кроме того, можно установить права доступа и к отдельным полям. Для этого необходимо сделать текущим нужное поле и нажимать кнопку Field Rights до тех пор, пока не будут выбраны нужные права по отношению к данному полю для данного пароля. Права доступа следующие:
All
(по умолчанию) - любое изменение данных в поле, с учетом накладываемых на поле ограничений, если такие определены в DataBase Desktop; Read Only -
данные можно просматривать, но не изменять; None -
данные нельзя ни просматривать, ни изменять, Database Desktop прячет значения поля после открытия ТБД. Таким образом, при попытке открытия ТБД, для которой определены пароли, выдается запрос на ввод паролей в виде следующего окна (рис. 12.2).
Add
позволяет добавить один или несколько паролей в список паролей; Remove
удаляет текущий пароль; RemoveAll удаляет все введенные пароли и список паролей очищается; Ok закрывает окно, после чего все пароли в списке анализируются на соответствие действительным паролям данной ТБД, и, если хотя бы один из них отвечает требованиям, ТБД может быть открыта; Close отменяет попытку ввести пароль, ТБД не открывается.
Средства TSession для работы с паролями
Три метода TSession позволяют вводить пароли в список, удалить текущий пароль или удалить все пароли: procedure AddPassword(const Password: string); procedure RemoveAllPasswords; procedure ReniovePassword(const Password: string);
Можно не прибегать к помощи стандартного окна ввода паролей, а вводить их, например, из компонента TEdit и затем добавлять в список паролей: Session.AddPassword(Edit1.Text) ; После этого можно применить метод Table1.Open; для попытки открытия ТБД. В том случае, если с использованием AddPassword был введен хотя бы один пароль, дающий права доступа к таблице, ТБД будет открыта В противном случае будет вызвано стандартное окно запроса паролей.
Заметим, что используя методы AddPassword. RemoveAllPaswords. RemovePassword, можно написать собственное окно ввода паролей, если Вас не устраивает стандартное окно. Принудительный вызов стандартного диалога ввода паролей реализуется методом function GetPassword: Boolean;
Он вызывает обработчик события OnPassword (если определен). В противном случае выдает стандартный диалог ввода пароля. Если пользователь нажал кнопку ОК., метод возвращает True; в случае нажатия кнопки Cancel возвращает False.
Метод может использоваться для ввода пароля с отложенным открытием БД. Если введен правильный пароль, открытие БД или ТБД (для персональных СУБД) не приведет к повторному запросу на ввод пароля.
Управление парольной защитой
Ниже описывается работа с паролями Paradox. При работе с иными СУБД обеспечение парольной защиты может отличаться.
Определение служебных каталогов сессии
Свойство property NetFileDir: string; указывает каталог, в котором содержится управляющий сетевой файл BDE PDOXUSRS.NET. Это свойство обеспечивает одновременную работу нескольких пользователей в сети. Значение свойства NetFileDir замещает значение сетевого каталога, определяемого в параметрах Paradox-драйвера в утилите настройки параметров BDE (BDE Administrator).
property PrivateDir: string;
Значение свойства PrivateDir определяет каталог, который используется для хранения временных файлов сессии БД.
Событие активизации сессии
Событие property OnStartup: TNotifyEvent; наступает при активизации сессии в тот момент, когда сессия еще не стала активной. Используя обработчик данного события, во время выполнения причожения можно устанавливать значения свойств NetFileDir и PrivateDir .
Создание графика
Для того чтобы создать график, поместите в форму компонент TDBChart в форме будет создана заготовка (рис 131) Затем щелкните мышью по этой заготовке два раза. Будет произведен переход в редактор графика В среде этого редактора можно установить свойства графика и его серий. Содержимое редактора графика представляет собой табулированный блокнот Для нового графика первой всегда показывается закладка Chart и для страницы Chart - закладка Series (рис 13 2).
Каждая из закладок на странице Chart предназначена для установки параметров того или иного компонента графика
Series -
содержит серии графика Серией называется набор точек графика На графике серии соответствует отдельная линия или ряд столбцов Если в графике несколько серий, будет визуализировано несколько линий или рядов столбцов Например, на рис 13 3 показан график, состоящий из двух серий. Первая показывает общую сумму продаж за 1 -и, 2-й, 3-й квартал, вторая - сумму продаж по конкретному покупателю General -
устанавливает общие параметры графика, такие как объемность графика, отступы от краев, возможность увеличения (Zoom) и др. Axis -
устанавливает свойства осей (рис. 13.4). В области ShowAxis определяется, для какой оси устанавливаются параметры - левой, правой, верхней или нижней. На странице, определяемой закладкой Scales, устанавливаются свойства масштаба значений по оси. Automatic устанавливает автоматическое масштабирование данных по оси - минимум и максимум вычисляются динамически, исходя из текущих значений серии. При отмене автоматического масштабирования можно установить автоматическое масштабирование минимального {Minimum} или максимального (Maximum} значения (отметка Auto). Для установки значения максимума и (или) минимума вручную следует нажать соответствующую кнопку Change. Шаг масштаба по оси выбирается автоматически, если в Desired Increment установлено значение 0. Установить фиксированное значение шага можно, нажав кнопку Change. Закладка Title позволяет установить текст заголовка по оси, угол расположения заголовка и шрифт, которым заголовок выводится. Закладка Labels задает параметры меток для оси. Закладка Tiks устанавливает параметры самой линии оси.
Titles - определяет заголовок графика, шрифт, выравнивание и др. Legend - задает параметры легенды. Легенда - область графика, где приводится информация о графике. Например, на рис. 13.5 показана легенда, которая расположена под графиком на рис. 13.3, и служит для пояснения графика.
Panel -
определяет параметры панели, на которой располагается график. Paging -
устанавливает параметры многостраничного графика. Walls
- задает "стенку" графика. Например, на рис.13.3 "стенка" расположена по левой вертикальной оси.
Добавление серии в график
На графике одновременно может располагаться несколько серий. В большинстве случаев их значения строятся по одинаковому закону и две и более серий одновременно показываются в графике для сравнения.
 Чтобы добавить в график серию, следует на странице Chart, (закладка Series) нажать кнопку Add. После этого появится окно выбора типа серии (рис 13.6).
Чтобы добавить в график серию, следует на странице Chart, (закладка Series) нажать кнопку Add. После этого появится окно выбора типа серии (рис 13.6).Рис 13.6 Редактор графика - окно выбора типа серии Рис 13.7 Редактор графика - список серий графика
После выбора типа серии в график добавляется компонент, дочерний от базового типа TChartSeries - TLineSeries, TBarSeries, TPieSeries и т.д. Выберем серию типа Line и нажмем Ok. В окне страницы Chart (закладка Series) будет показана серия (рис. 13.7).
Кнопка Add может использоваться для добавления других серий, кнопка Delete - для удаления текущей серии. После нажатия кнопки Title можно определить заголовок серии, кнопки Clone - создать новый экземпляр такой же серии в этом же графике, кнопки Change - изменить тип текущей серии.
Перейдем с закладки Chart на закладку Series. На этой странице представлен блокнот с закладками Format, General, Marks, DataSource. Рассмотрим свойства серии, которые можно установить на страницах, соответствующих этим закладкам.
Выбор источника данных
Несомненно, главные свойства серии можно определить на странице DataSource. На ней определяется источник данных для серии. Выпадающий список ниже закладки позволяет определить тип источника данных для серии:
No Data -
серии не назначается источник данных. Далее мы собираемся сделать это программно. Кроме того, заготовленный шаблон серии может в разное время использоваться для показа данных из разных источников, которые мы также собираемся переключать программно во время выполнения. Random Values -
набор случайных чисел. Бывает полезен при формировании заготовки серии, источник данных которой мы собираемся установить позднее. Function
- функция (Сору, Average, Low, High, Divide, Multiply, Subtract, Add) - служит для построения графиков на основании данных в двух или более сериях. DataSet -
позволяет указать НД, значения полей (столбцов) которого будут использоваться для формирования точек серии. В качестве НД могут выступать компоненты TTable, TQuery, TClientDataSet. Выберем DataSet и из выпадающего списка выберем компонент Table 1, ранее расположенный на нашей форме. Table1 (тип TTable) - набор данных, связанный с таблицей Kap_pryb.DB, где хранятся данные о зависимости между размером капитала некоторой фирмы (поле Kapital) и приростом дохода для каждого факта увеличения капитала (поле ProcKPred). Укажем, что поле Kapital содержит значения по оси X, а поле ProcKPred - значения по оси Y (рис. 13.8.)
ЗАМЕЧАНИЕ Не все типы серии требуют значений по осям Y или Х Для серий типа Pie, Bar можно указывать значения по одной из осей и значения меток Labels В качестве меток могут использоваться символьные поля и поля типа даты и времени Для примера приведем графики отпуска товара конкретному покупателю (рис 13 9), где в качестве данных по оси Y или Х берется сумма отпуска конкретного товара, а в качестве меток Labels - названия товаров Показаны три графика - серии типа Pie, Vertical Bar (или просто Bar) и Horizontal Bar
Серия типа Bar может содержать точки, сформированные как по осям X, Y, так и по оси Y (Bar) и меткам Labels
После того, как мы указали источник данных и поля для формирования значений по осям Х и Y, нажмем кнопку Close и выйдем изредактора графика На ранее пустой панели будет построен график (рис 13 10)
Если вернуться в редактор графика, на странице Series можно, помимо DataSource, увидеть закладки Format, General, Marks Их назначение-
Format -
определяет свойства палитры, линий графика и т д Gene/a/ - задает форматы данных
Marks -
устанавливает марки - значения в рамке над точками серии На графике, приведенном на рис 13.10, марки показывают значения узловых точек по оси Y 175, 160, 140 и 120 Марки показываются на графике, если отмечено свойство Visible, свойство Style определяет вид марок (рис 13.11)
Определение функций
На странице Series (закладка Data Source) в качестве источника данных можно определить функцию. Функция обычно используется для показа отношений между другими сериями.
Пусть для графика определены две серии, показывающие общую сумму продаж товаров по месяцам и сумму продаж для конкретного покупателя. Источниками данных этих серий выступают два компонента TQuery. Определим третью серию, которая показывала бы разницу между первыми двумя. Для этого добавим в график новую серию и на странице Series в закладке Data Source выберем Function. В диалоговом окне определения функций выберем тип функции - Subtract (вычитание). В области Source Series \ Available показаны серии, присутствующие в графике. Используя кнопку ”, переместим две упомянутые выше серии (источником которых служат TQuery) в область Selected (рис. 13.12).
Тогда на графике получим три серии, причем белым цветом показана серия, источником которой служит функция разности значений первых двух серий (рис. 13.13).
Добавление серии во время выполнения
Число серий, присутствующих в текущий момент в графике, во время выполнения можно определить при помощи метода компонента TDBChart function SeriesCount: Longint;
Список серий графика содержится в его свойстве property Series[Index:Longint]:TChartSeries; где Index лежит в диапазоне 0.. SeriesCount-1, поскольку отсчет серий идет с нуля.
Метод procedure RefreshData; обновляет данные в серии из наборов данных, которые служат их источником. Например, пусть график показывает отпуск товара конкретному покупателю. Источником данных для серии графика служит Query 1, которому в качестве параметра передается имя покупателя. При всякой смене имени покупателя происходит обновление Query 1, сопровождающееся изменением данных. Эти изменения отражаются в графике так:
Queryl.Open;
DBChartl. RefreshData;
Покажем, как можно добавить серию в график во время выполнения:
var
MySeries : TBarSeries;
MySeries := TBarSeries.Create(Self);
MySeries.ParentChart := DBChartl;
MySeries.SeriesColor := cIGreen;
MySeries.DataSource := Queryl;
MySeries.XLabelsSource := 'MES';
MySeries.YValues.ValueSource:='S';
MySeries.Active := True;
MySeries.Title := Table1POKUP.Value;
В приведенном примере создается серия типа Bar (вертикальная столбчатая диаграмма), в качестве родительского графика ей назначается DBChartl. В качестве источника данных назначается Queryl. Для формирования значений серии используются поля компонента Queryl: S (по оси Y) и MES (в качестве Labels). Затем серия активизируется (после этого она становится видна в графике) и ее заголовку присваивается наименование покупателя.
Свойства компонента TChartSeries
property Active : Boolean; - активизирует (показывает) серию в графике (значение True) и дезактивизирует (скрывает) серию (False). Например: DBChartl.Series[0].Active :=True;
property DataSource : TComponent; -
ссылается на компонент типа НД (TTable, TQuery, TClientDataSet) или на другую серию, откуда берутся данные для показа в серии. Например: DBChartl.Series[0].DataSource := Query2; property HorizAxis: THorizAxis; -
указывает, какая горизонтальная ось будет использована для серии. Значения: aTopAxis • верхняя горизонтальная ось; aBottomAxis - нижняя горизонтальная ось. property Marks : TSeriesMarks; -
описывает свойства марок серии, т.е. значений в прямоугольниках, рисуемых для каждого значения серии. Свойства объекта Marks: property Arrow : TChartPen; -
задает свойства пера, рисующего марку. Свойства объекта Arrow: property Color: TColor; -
цвет линий; property Mode: TPenMode; -
способ рисования линий; property Style: TPenStyle; -
стиль линий; property Visible: Boolean; -
видимость линий; property Width: Integer; -
задает ширину линий; property ArrowLength : Integer; -
длина в пикселях линии, соединяющей марку с соответствующим изображением элемента серии. По умолчанию 16; property BackColor: TColor; -
определяет цвет фона марки. По умолчанию $80FFFF (желтый); property Clip: Boolean; -
если содержит True, марки не могут накладываться на другие элементы графика (на легенду, метки осей и т.д.); property Font : TFont; -
определяет шрифт, которым выводится информация внутри марки; property ParentSeries : TChartSeries; -
содержит указатель на серию, к которой принадлежат марки; property Style : TSeriesMarksStyle; -
определяет содержимое марки. По умолчанию smsLabel. В обработчике события TChartSeries. OnGetMarkText можно переопределить значения, принятые по умолчанию. Например: DBChartl.Series[0].Style := smsLabelValue; Возможные значения свойства Style:
• smsValue -
значения по осиУ (YValue), за исключением THorizBarSeries (XValue). Например, "9087"; • smsPercent - процентное значение, например "44%"; для форматирования процентного значения также используется свойство TChartSeries. PercentFormat;
• smsLabel -
показывает метку, ассоциированную с точкой графика, например "Сахарный песок" (при построении графика продаж по товарам); в том случае, если метки со значениями не ассоциированы, в марках выводятся сами значения; • smsLabelPercent -
показывает метку и процентное значение, например "Сахарный песок 44%"; • smsLabelValue -
показывает метку и значение, например "Сахарный песок 9087"; • smsLegend -
показывает один из элементов легенды графика, список возможных значений доступен через свойство TChartLegend. TextStyle; • smsPercentTotal -
показывает процентное значение и общую сумму, от которой оно взято, например "44% от 20563". • smsLabelPercent Total -
показывает метку, процентное число и общую сумму, например "Сахарный песок 44% от 20563"; • smsXValue •
показывает значение по оси Х (XValue), например "01.02.1997"; • property Transparent: Boolean; -
значение True определяет, что цвет фона марки не используется (в качестве фона используется "прозрачный цвет"); по умолчанию False; property Visible : Boolean;
-определяет, видимы ли (True) или нет (False) марки на графике. property ParentChart : TCustomChart; -
указывает компонент TDBChart, к которому принадлежит серия. Изменение этого свойства позволяет во время выполнения добавлять в график новые серии, показывать серии в других графиках. Например: var
MySeries : TBarSeries;
MySeries := TBarSeries.Create(Self);
MySeries.ParentChart := DBChartI;
property PercentFormat : String; -
определяет формат показа процентных значений; property RecalcOptions: TSeriesRecalcOptions; -
указывает перечень событий, приводящих к пересчету значений серии ( учитывается только для серий, свойство DataSource которых указывает на другую серию) по умолчанию [rOnDelete, rOnModify, rOnInsert, rOnClear], property SeriesColor: TColor; -
определяет цвет, которым выводятся значения серии в графике. Например: DBChartI.Series[0].SeriesColor := clBlue;
property ShowInLegend: Boolean; -
определяет, показывать ли (True) легенду или нет (False). по умолчанию True; property Title: String; -
определяет заголовок серии; по умолчанию заголовок отсутствует, но он может быть назначен в редакторе графика (кнопка Title в окне Series). Например: DBChart1.Series[0].Title := Edit1.Text; property ValueColor[Index:LongInt]:TColor;
- массив, определяет цвет элемента серии с номером Index, например, DBChart1.Series[0].ValueColor[2] := clAqua; property ValueFormat: String; -
определяет формат показа значений серии; при прорисовке осей используется для форматирования меток, при прорисовке серии используется для форматирования значений, показываемых в марках; property ValueMarkTextlIndex:Longint]:String; -
массив значений, выводимых в марках серии; property VertAxis : TVertAxis; -
определяет местоположение вертикальной оси - слева на графике (aLeftAxis) или справа (aRightAxis); property XLabel[Index:LongInt]: String; -
массив, хранящий метки серии по оси X; Index должен находиться в диапазоне 0. Count -1; DBChartI.Series[0].XLabel[2] := Edit2.Text; property XLabelsSource: String; - имя поля НД (или иного источника значений для серии), определяемого в свойстве DataSource. Содержимое этого поля служит для отображения значений по оси X. Поле должно быть типа, к которому применяется метод AsString. Если значение свойства опущено, значения по оси Х не выводятся. Например: DBChartI.Series [0].XLabelsSource := 'MES';
property XValue[Index:LongInt] : Double;
- возвращает значение в списке XValues (см. ниже) с индексом Index (значение в диапазоне 0. Count -1). property XValues:TChartValueList; -
хранит значения серии по оси X. Значения из этого списка НЕЛЬЗЯ удалять, добавлять и т.д. напрямую. Для этого следует воспользоваться соответствующими методами компонента TChartSeries. Могут быть полезны следующие свойства TCliart ValueList: • property Valuel Index:LongInt |: Double; -
обеспечивает доступ к элементу серии с индексом Index (значение в диапазоне 0. Count -1). Например: DBChart1.Series[0].YValues.Value[2] := StrToFloat(Edit3.Text) ;
DBChart1.Series[0].Repaint;
• property ValueSource : String; -
указывает источник данных для формирования значений по оси X. В зависимости от того, каков источник данных для серии (свойство DataSource компонента TChartSeries), может содержать: 1) имя поля - числового типа, типа даты, времени, даты и времени; в этом случае свойство серии DataSource должно ссылаться на НД (TTable, TQuery, TClientDataSet), например:
DBChart1.Series[0].DataSource := Query2;
DBChart1.Series[0].XValues.ValueSource := 'Pole1';
при этом необходимо помнить, что данные будут взяты в серию только из открытого НД; если НД закрыт, то получение данных будет отложено до открытия НД;
2) имя существующего TChart ValueList из другой серии; в этом случае свойство DataSource серии должно ссылаться на другую серию, например:
DBChart1.Series[0].DataSource := DBChart2.Series [4] ;
DBChart1.Series[0].XValues.ValueSource := 'X';
Свойства property YValuetIndex:LongInt]: Double; property YValues: TChartValueList; аналогичны свойствам XValue и XValues и используются для вертикальной оси.
Методы компонента TChartSeries
function AddXY(Const AXValue, AYValue: Double; Const AXLabel: String; ACoIor: TColor): Longint;
Добавляет новую точку в серию. Параметры AXValue и AYValue содержат соответственно значения по осям Х и Y. Параметр AXLabel содержит метку для добавляемой точки серии. Параметр ACoIor определяет цвет. Функция возвращает позицию новой точки в серии. Например:
DbChartl.Series[0].AddXY(TmpX,TmpY,TmpLabel,clAqua) ;
function AddY(Const AYValue: Double; Const AXLabel: String; AColor: TColor): Longint;
добавляет в серию новое значение по оси X. Применяется для тех серий, в которых график строится по Х и меткам значений по Х (например, Pie, Bar). Назначение параметров такое же, как у метода AddXY. procedure Assign Values(Source: TChartSeries); -
копирует все точки из серии Source в текущую серию. procedure CheckDataSource; -
обновляет точки в серии, независимо от того, какой компонент является источником данных - набор данных или другая серия. Обновление производится по текущим данным источника. Метод рекомендуется вызывать в случае изменений данных в источнике. procedure Clear; -
удаляет все значения из серии; если вслед за этим не занести новых точек, будет показываться пустой график. procedure ColorRange(AValueList: TChartValueList ;Const From Value, To Value: Double; AColor: TColor);
Изменяет цвет указанного диапазона точек серии. AValueList - либо XValues, либо YValues. From Value указывает начальное, а То Value конечное значение в списке AValueList. AColor - новый цвет. Например:
WITH DbChartl.Series[0] do begin
ColorRange(XValues,XValues.Value[2], XValues.Value[2],clAqua) ;
END;//with
function Count : Longint; -
возвращает число точек в серии. Например, поместить все значения по Х и Y точек серии в ListBoxl: ListBoxl. Items . Clear;
WtTH DbChartl.Series [0] do begin for i := 0 TO Count - 1 do
ListBoxl.Items.Add(
FloatToStr(XValues.Value[i]) + ' ' + FloatToStr(YValues.Value[i])) ;
END;//with
procedure Delete(ValueIndex : Longint); -
удаляет из серии точку с номером ValueIndex. График, к которому принадлежит серия, автоматически перерисовывается. Например: DBChartl.Series[0].Delete(4) ; procedure DoSeriesClick(ValueIndex:LongInt; Button:TMouseButton; Shift:
TShiftState; X, Y: Integer); virtual; -
инициирует наступление события OnClick. function GetCursorValueIndex : Longint; -
возвращает индекс точки серии в TChart ValueList, ближе всего к которой расположен курсор мыши. Если такую точку определить не удается, возвращается - 1. Например, в следующем фрагменте Label7.Caption будет содержать индекс ближайшей точки к курсору мыши или '???', если такая точка не определена: procedure TForm1.DBChartlDblClick(Sender: TObject);
var Tmp : Integer;
begin
Tmp := DBChartl.Series[0].GetCursorValueIndex;
IF Tmp >= 0 THEN Label7.Caption := IntToStr(Tmp)
ELSE Label7.Caption := '???';
end;
procedure GetCursorValues( Var x, у: Double
); - возвращает значения по X и Y точки графика (а не только серии), ближе всего к которой расположен курсор мыши. Например, Label lO.Caption и Labell2.Caption в следующем фрагменте содержат соответственно значения координат Х и Y графика, соответствующие точке, на которой находится курсор мыши: var TmpX, TmpY : Double;
DBChartl.Series[0].GetCursorVaiues(TmpX,TmpY);
LabellO.Caption := Format('%10.2f,[TmpX]);
Labell2.Caption := Format('%10.2f,[TmpY]);
function GetHorizAxis: TChartAxis; -
возвращает указатель на назначенную серии горизонтальную ось. Используя данный указатель, можно вызывать методы оси, обращаться к ее свойствам. function GetVertAxis:TChartAxis; -
возвращает указатель на вертикальную ось. function MaxXValue: Double; virtual; -
возвращает максимальное значение по X. function MinXValue: Double; virtual; -
возвращает минимальное значение по X. function MaxYValue: Double; virtual; -
возвращает максимальное значение по Y. function MinYValue: Double; virtual; -
возвращает минимальное значение по Y. procedure RefreshSeries; -
обновляет значения серии из источника данных, указанного в свойстве DataSource. procedure Repaint; -
приводит к полной перерисовке всего графика. Рекомендуется вызывать этот метод в случае изменения хотя бы одного из основополагающих свойств серии (например, при изменении значения в DataSource и др.). function ValuesListCount:LongInt; -
возвращает число списков значений точки, используемых в серии. Обычно это 2 (XValues и YValues), но некоторые серии используют 3 (BubbleSeries - XValues, YValues, Radius; GanttSeries -Y, Start,End). function VisibleCount: Longint; -
возвращает число точек серии, видимых на графике.
События компонента TChartSeries
property OnBeforeAdd: TSeriesOnBeforeAdd;
TSeriesOnBeforeAdd = Function(Sender: TChartSeries): Boolean of object;
Наступает перед добавлением точки в серию. В обработчике данного события может производиться анализ корректности добавляемых в серию точек. Наступает также при соединении серии с источником данных (TTable или TQuery).
property OnAfterAdd: TSeriesOnAfterAdd;
TSeriesOnAfterAdd = procedure(Sender:TChartSeries; ValueIndex:Longint) of object;
Происходит после добавления точки в серию.
property OnClear Values: TSeriesOnClear;
TSeriesOnClear = procedure(Sender: TChartSeries) of object;
Происходит при очистке серии от точек.
property OnClick: TSeriesClick;
TSeriesClick = procedure(Sender:TChartSeries; ValueIndex: Longint; Button:
TMouseButton; Shift: TShiftState; X, Y: Integer);
Происходит при щелчке мышью на серии.
property OnGetMarkText: TSeriesOnGetMarkText;
TSeriesOnGetMarkText = procedure ( Sender : TChartSeries ; ValueIndex :
Longint; Var MarkText: String)
Происходит при формировании марки для точки в серии. Обработчик может использоваться для изменения содержимого марки.
Работа с сериями. Компонент TChartSeries
Компонент TChartSeries является родительским типом для серий графика (для TLineSeries, TAreaSeries, TPointSeries, TBarSeries, THorizBarSeries, TPieSeries, TChartShape, TFastLineSeries, TArrowSeries, TGanttSeries, TBubbleSeries).
Построение графиков. Компонент TDBChart
Для построения графиков используется компонент TDBChart, расположенный на странице Data Controls палитры компонентов Delphi
Компоненты для построения отчетов
В Delphi 3 на странице палитры компонентов QReport расположено около двух десятков компонентов, применяемых для построения отчетов. "Главным" компонентом, несомненно, является TQuickRep, определяющий поведение отчета в целом. Другие компоненты определяют составные части отчета:
TQRBand -
заготовка для расположения данных, заголовков, титула отчета и др.; отчет, в основном, строится из компонентов TQRBand, которые реализуют: • область заголовка отчета; • область заголовка страницы; • область заголовка группы; • область названий столбцов отчета; • область детальных данных, предназначенную для отображения данных самого нижнего уровня детализации; • область подвала группы; • область подвала страницы; • область подвала отчета.
• TQRSubDetail -
определяет область, в которой располагаются данные подчиненной таблицы при реализации в отчете связи Master-Detail на основе существующей связи между ТБД; • TQRGroup -
применяется для группировок данных в отчете; • TQRLabel -
позволяет разместить в отчете статический текст; • TQRDBText -
позволяет разместить в отчете содержимое поля набора данных; • TQRExpr -
применяется для вывода значений, являющихся результатом вычисления выражений; алгоритм вычисления выражений строится при помощи редактора формул данного компонента; • TQRSysDate -
служит для вывода в отчете даты, времени, номера страницы, счетчика повторений какого-либо значения и т.д.; • TQRMemo -
служит для вывода в отчете содержимого полей комментариев; • TQRRich Text -
служит для вывода в отчете содержимого полей форматированных комментариев; • TQRDBRich Text -
служит для вывода в отчете содержимого полей форматированных комментариев, источником которых является поле набора данных; TQRShape -
служит для вывода в отчете графических фигур, например, прямоугольников; • TQRImage -
служит для вывода в отчете графической информации, источником которой является поле набора данных; • TQRChwt -
служит для встраивания в отчет графиков.
Множественная группировка данных в отчете
Часто внутри группы должны содержаться другие группы, например, по названию товара и внутри каждой группы - по покупателям В этом случае внутри одной группы определяют другую группу посредством дополнительных компонентов TQRGroup
Пример Пусть требуется представить в отчете сведения о расходе товаров со склада, группируя данные по товарам, а внутри группы - по покупателям
Установим текущий индекс в НД Table1 по полям Tovar, Pokup Общий вид отчета приводится на рис 14.16
Вид отчета в окне предварительного просмотра представлен на рис 14.17
Построение отчета на основе
Если необходимо выдавать отчет на основе более чем одной ТБД, можно поступить двумя способами
1 В рамках компонента TQuery произвести соединение данных из нескольких таблиц БД в один НД, после чего определить в отчете нужные группировки;
2 Создать в приложении по одному НД на каждую таблицу БД, соединить эти наборы между собой связью Master-Detail (используя свойства MasterSource, MasterFields набора данных) и применить в отчете компонент (или несколько компонентов) TQRSubDetail для вывода информации из подчиненного (Detail) НД (или группы подчиненных НД), для вывода информации из основного (Master) НД, как и в обычных отчетах, применяется компонент TQRBand, у которого в свойстве BandType установлено значение rbDetail Построение отчета для первого случая осуществляется аналогично тому, как это описано выше Построение отчета для второго случая имеет некоторые отличительные особенности
Рассмотрим второй способ
Компонент TQRSubDetail предназначен для показа информации в отчете из подчиненного НД Его свойство property DataSet: TDataSet; указывает имя подчиненного НД, информация из которого будет выводиться в пространстве компонента TQRSubDetail. В остальном использование данного компонента аналогично использованию компонента TQRBand, у которого значение в свойство BandType установлено значение rbDetail
Пример
Пусть имеется таблица БД Tovary DB, содержащая помимо прочих поле Tovar (название товара) Пусть также имеется таблица БД Rashod DB, содержащая сведения об отпуске материалов со склада В состав ТБД входят поля
• N_RASH - уникальный номер события отпуска товара,
• DEN-номер дня,
• MES - номер месяца,
• GOD - номер года,
• TOVAR - наименование отпущенного товара,
• POKUP - наименование покупателя,
• KOLVO - количество единиц отпущенного товара
Таблицы Tovary DB и Rashod DB находятся в отношении "один-комногим", то есть одному товару может соответствовать более одного факта отпуска товара со склада
Разместим в форме компонент TTable (имя TovaryTable), ассоциированный с ТБД Tovary DB Разместим в форме компонент TDataSource (имя DS_TovaryTable) и свяжем его с TovaryTable. Разместим в форме компонент TTable (имя RashodTable), ассоциированный с ТБД Rashod DB
Установим связь Master-Detail в приложении между НД TovaryTable и RashodTable Для этого при помощи редактора связей установим в свойство RashodTable MasterSource значение DS_TovaryTable, и в свойство RashodTable MasterFields значение 'TOVAR' (рис 14.18)
Заметим что после установления связей между НД в НД RashodTable текущим индексом должен быть индекс по полю Tovar (свойство RashodTable IndexFieldNames = Tovar)
Приступим к разработке отчета Пусть отчет имеет имя QuickRepI Определим заголовок отчета компонент TQRBand с именем QRBand2 в свойство BandType которого установлено значение rb Title
Установим в качестве основного НД отчета TovaryTable указав QuickRepI DataSet = TovaryTable
Разместим в отчете компонент типа TQRBand с именем QRBand1 и установим в его свойство BandType значение ibDelail Этот компонент будет использоваться для выдачи детальной информации из НД TovaryTable Разместим в области компонента QRBandl компонент TQRDBText (имя QRDBText1) и свяжем его с полем Tovar НД TovaryTable
Разместим в отчете компонент TQRSubDetail (имя QRSubDetaill) Установим в его свойство DataSet значение RashodTable связав таким образом данный компонент с подчиненным НД Разместим в области компонента QRSubDetail1 три компонента TQRDBText (имена QRDBTextl QRDBText4) и свяжем их с полями НД RashodTable соответственно Pokup Kolvo D Поле D опредечено в НД RashodTable как вычисляемое по значениям полей DEN MES GOD
Разместим в области компонента QRBandl заголовки столбцов Вид формы отчета показан на рис 14.19
Войдем в режим предварительного просмотра результатов В результирующем отчете для каждой записи НД TovaryTable выводятся по (чиненные ей записи в НД RashodTable (рис 14 20)
ЗАМЕЧАНИЕ
Если необходимо определить заголовок и подвал для информации группируемой в компоненте TQRSubDetail следует воспользоваться свойством этого компонента property Bands : TQRSubDetailGroupBands,
Данное свойство обладает двумя подсвоиствами указывающими на наличие или отсутствие заголовка и подвала Это property HasHeader . Boolean;
property HasFooter. Boolean;
Построение композитного отчета
Композитный (составной сложный) отчет объединяет в себе несколько простых отчетов При выдаче композитного отчета входящие в его состав простые отчеты выводятся друг за другом
Композитный отчет реализуется при помощи компонента TQR CompositeReport В обработчике события OnAdd'Report ранее определенные простые отчеты добавляются в списковое свойство Report
procedure TCompozitnyjOtchet.QRCompositeReportlAddReports(Sender:TObject) ;
begin
WITH QRCompositeReportI do begin
Reports.Add(ManyGroup.QuickRep1) ;
Reports.Add(Prostoj) .QuickRep1) ;
END;//with
end;
В приведенном выше обработчике композитный отчет составляется из двух отчетов: QuickRep1 (определенный в форме ManyGroup) и QuickRep1 (определенный в форме Prostoj). Печать композитного отчета или его предварительный просмотр осуществляется так же, как для простых отчетов, например
QRCompositeReportI.Previewж Ha рис. 14.21. показан композитный отчет, построенный из двух ранее разработанных нами отчетов - отчета без группировок и отчета с множественными группировками по товару и покупателю.
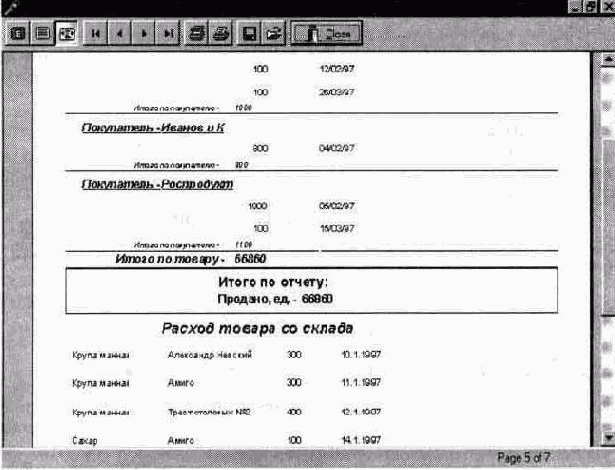
Рис 14.21. Композитный отчет, составленный из двух простых отчетов
Компонент TQuickRep

 Компонент TQuickRep определяет поведение и характеристики отчета в целом. При размещении этого компонента в форме в ней появляется сетка отчета (рис. 14.1). В дальнейшем в этой сетке располагаются составные части отчета, например, группы TQRBand (рис. 14.2).
Компонент TQuickRep определяет поведение и характеристики отчета в целом. При размещении этого компонента в форме в ней появляется сетка отчета (рис. 14.1). В дальнейшем в этой сетке располагаются составные части отчета, например, группы TQRBand (рис. 14.2).Рис 141 Пустая сетка отчета Образуется послеразмещения в форме компонента TQuickRep
Рис 14 2 Сетка отчета с размещенными в ней компонентами отчета
Перечислим важнейшие свойства, методы и события компонента TQuickRep.
Свойство property Bands: TQuickRepBands; состоит из множества логических значений (False/True), которые определяют включение в отчет отдельных видов составляющих:
• HasColumnHeader - заголовка столбцов отчета;
• HasDetail - детальной информации;
• HasPageFooter - подвала страницы;
• HasPageHeader - заголовка страницы;
• HasSummary - подвала отчета;
• Has Title - заголовка отчета.
property DataSet: TDataSet;
указывает на набор данных, на основе которого и создается отчет. Обычно для выдачи отчета используется один НД. Если нужно вывести связанную информацию из нескольких таблиц БД, ее объединяют в одном НД при помощи оператора SELECT. В этом случае в качестве НД для отчета может использоваться компонент TQuery. Информацию из нескольких связанных НД можно включать в отчет, если эти наборы данных связаны в приложении отношением Master-Detail. В этом случае в качестве НД отчета указывается Master-набор, а ссылка на соответствующие Detail-наборы осуществляется в компонентах TQRSubDetail.
Если в отчет нужно включить информацию из несвязанных наборов данных, применяют композитный отчет, то есть отчет, составленный из группы других отчетов.
property Frame: TQRFrame;
определяет параметры рамки отчета: • Color - цвет линии рамки;
DrawBottom -
определяет, следует ли выводить линию снизу; DrawLeft-
определяет, следует ли выводить линию слева; DrawRight-
определяет, следует ли выводить линию справа; Draw Top- определяет, следует ли выводить линию сверху;
Style - определяет стиль линии;
Width -
определяет ширину линии в пикселях. property Page: TQRPage;
определяет параметры страницы. property PrinterSettings: TQuickRepPrinterSettings;
определяет параметры принтера. property PrintIfEmpty: Boolean;
указывает (True), что следует печатать отчет даже в том случае, если он не содержит данных. Методы
procedure NewPage; Выполняет переход на новую страницу. Может использоваться в обработчиках событий компонентов отчета BeforePrini или AfterPrint и не может - в обработчиках событий OnPrint, OnStartPage и OnEndPage.
procedure Preview;
выводит отчет в окно предварительного просмотра (рис. 14.3). Чтобы во время разработки отчета просмотреть в окне предварительного просмотра содержимое отчета в том виде, как он будет выводиться на печать, необходимо:
выбрать отчет при помощи мыши;
• нажать правую кнопку мыши;
• во всплывающем меню выбрать элемент Preview.
Следует заметить, что при этом не будут видны некоторые данные, например, значения вычисляемых полей наборов данных. Они будут выводиться только во время выполнения.
procedure Print;
печатает отчет на принтере. procedure PrinterSetup;
обеспечивает установки параметров принтера. События
property AfterPreview : TQRAfterPreviewEvent;
наступает после закрытия окна предварительного просмотра отчета. property AfterPrint: TQRAfterPrintEvent;
наступает после вывода отчета на печать. property BeforePrint: TQRBeforePrintEvent;
наступает в момент генерации отчета, до выдачи окна предварительного просмотра отчета и до вывода отчета на печать. property OnEndPage : procedure(Sender : TObject);
наступает в момент подготовки к генерации последней страницы отчета. property OnStartPage : procedure(Sender : TObject);
наступает в момент подготовки к генерации первой страницы отчета.
Компонент TQRBand
Компоненты TQRBand являются основными составными частями отчета и используются для размещения в них статического текста и данных. Месторасположение компонента в отчете и его поведение определяются свойством property BandType : TQRBandType;
Ниже перечислены возможные значения этого свойства.
• rb Title - определяет компонент заголовка отчета. Информация, размещенная в компоненте TQRBand, располагается перед всеми другими частями отчета. Этот вид компонента TQRBand используется для вывода заголовочной информации отчета.
• rbPageHeader - определяет компонент заголовка страницы. Информация, размещенная в компоненте с этим значением свойства BandType, выводится всякий раз при печати новой страницы отчета прежде всех иных частей отчета (но после информации, размещенной в компоненте заголовка отчета - для первой страницы).
• rbDetail - компонент детальной информации. Выводится всякий раз при переходе на новую запись в НД отчета. Отчет печатается для всех записей НД, определяемого свойством отчета DataSet, начиная с первой записи и заканчивая последней. Позиционирование на первую запись и последовательный перебор записей в НД осуществляется компонентом TQuickRep автоматически.
• rbPageFooter - компонент подвала страницы. Выводится для каждой страницы отчета после всех иных данных на странице. rbSummary - компонент подвала отчета. Выводится на последней странице отчета после всей иной информации, но перед подвалом последней страницы отчета.
•
rbGroupHeader - компонент заголовка группы Применяется при группировках информации в отчете Выводится всякий раз при выводе новой группы • rbGroupFooter- компонент подвала группы Применяется при группировках информации в отчете Выводится всякий раз при окончании вывода группы, после всех данных группы
• rbSubDetail - компонент для выдачи детальной информации из подчиненного набора данных, при выводе в отчете информации из двух или более наборов данных, связанных в приложении при помощи механизма Master-Detail. Это значение присваивается компоненту автоматически, когда генерируется компонент TQRBand при размещении в форме компонента TQRSubDetail Программа не должна устанавливать это значение в свойство BandType
• rbColumnHeader - компонент для размещения заголовков столбцов Размещается в отчете на каждой странице после заголовка страницы
• rbOverlay - используется для совместимости с более ранними версиями отчетов
Свойство property Enabled : Boolean; указывает, печатается в отчете (True) или нет (False) информация, содержащаяся в компоненте TQRBand
Свойство property ForceNewPage : Boolean; указывает, должна ли информация в составе TQRBand всегда печататься с новой страницы (True) или нет (False)
Событие property BeforePrint: TQRBeforePrintEvent; наступает перед печатью информации, размещенной в области компонента TQRBand.
Создание простейшего отчета
Компоненты TQuickRep и TQRBand являются минимально достаточными для создания простого отчета, не содержащего внутри себя группировок информации.
Пусть имеется таблица БД Rashod DB, содержащая сведения об отпуске материалов со склада. В состав ТБД входят поля
• N_RASH - уникальный номер события отпуска товара;
• DEN - номер дня;
• MES - номер месяца;
•
GOD - номер года; • TOVAR - наименование отпущенного товара;
• POKUP - наименование покупателя,
• KOLVO - количество единиц отпущенного товара
Заметим, что дата отпуска товара хранится в разбивке на день, год и месяц Сделано так специально, с целью показать, как в отчетах используются выражения и вычисляемые поля
Создадим простейший отчет, состоящий из заголовка и сведений об отпуске товара В отчет включаются все факты отпуска товара Сортировка производится по номеру события отпуска товара

 Разместим в форме компонент TTable (имя Table1), свяжем с таблицей БД Rashod DB и откроем его (Active = True) Разместим в форме компонент TQuickRep (имя QuickRep!) Установим в свойство DataSef отчета значениеTable1, назначив таким образом отчету НД, записи из которого будут выводиться в отчет Добавим в отчет компонент TQRBand (имя QRBandl) Свойство BandTvpe компонента QRBandl по умолчанию установлено в значение rb Title, то есть компонент QRBandl определяет заголовок отчета Разместим в пространстве отчета, занимаемом компонентом QRBandl, компонент TQRLabel (статический текст) с именем QRLabell Установим в свойство Caption этого компонента значение 'Отпуск товаров со склада' и установим в свойстве Font жирный наклонный шрифт высотой 16 пунктов Вид отчета показан на рис 14 4
Разместим в форме компонент TTable (имя Table1), свяжем с таблицей БД Rashod DB и откроем его (Active = True) Разместим в форме компонент TQuickRep (имя QuickRep!) Установим в свойство DataSef отчета значениеTable1, назначив таким образом отчету НД, записи из которого будут выводиться в отчет Добавим в отчет компонент TQRBand (имя QRBandl) Свойство BandTvpe компонента QRBandl по умолчанию установлено в значение rb Title, то есть компонент QRBandl определяет заголовок отчета Разместим в пространстве отчета, занимаемом компонентом QRBandl, компонент TQRLabel (статический текст) с именем QRLabell Установим в свойство Caption этого компонента значение 'Отпуск товаров со склада' и установим в свойстве Font жирный наклонный шрифт высотой 16 пунктов Вид отчета показан на рис 14 4Рис 14.4 В отчете определен только его заголовок Рис 14.5 Отчет с заготовкой и группой детальной информации
Теперь разместим в отчете данные, соответствующие текущей записи таблицы Rashod Для этого поместим в отчет новый компонент TQRBand (имя QRBandl) и установим в его свойство BandType значение rbDetail Затем разместим в группе шесть компонентов TQRDBText с именами QRDBText1. QRDBText6. Свяжем данные компоненты соответственно с полями НД -N_RASH, TOVAR, KOLVO, DEN, MES, GOD Для этого в свойство DataSet каждого компонента QRDBText установим значение Table1, а в свойство DataField- значение имени соответствующего поля Вид отчета показан на рис 14.5
Для просмотра получившегося отчета щелкнем по нему правой кнопкой мыши и из всплывающего меню выберем элемент Рreview. Получим окно предварительного просмотра отчета (рис 14.6)
Чтобы окно предварительного просмотра выдавалось при активизации формы, введем в обработчик события OnActivate формы такой код
procedure TForm1.FormActivate(Sender: TObject)
begin
QuickRep!.Preview; end;
Чтобы после выхода из окна предварительного просмотра отчета закрывалась и форма, в которой расположен отчет, введем в обработчик события AfterPreviCK отчета такой код
procedure TForm1.QuickReplAfterPreview (Sender : T0bject);
begin
Form1.Close;
end;
Использование компонента TQRExpr для определения выражений
Из рис 14.6 видно что в простейшем отчете выводится дата, составленная из трех полей - DEN, MES GOD Объединим значения из этих трех полей в одно значение являющееся результатом вычисчения выражения Выражение в отчетах формируется при помощи компонента TQRExpr Удалим из компонента QRBandl компоненты QRDBText4 QRDBText6, связанные с полями DEN, MES, GOD Вместо них разместим в отчете компонент TQRExpr (имя QRExprI)
Для того чтобы войти в редактор формул данного компонента, выберем в инспекторе объектов свойство Expression и нажмем кнопку в поле данных этого свойства
Появится окно редактора формул - Expression builder, (построителя выражений) (рис 14.7)
Группа Constant позволяет включить в выражение константы, при этом комбинированный список предназначен для выбора типа константы - числовая (Numeric) или строковая (String). Группа Function позволяет включить в выражение функцию, при этом выпадающий список Category определяет категорию функции (по умолчанию показываются все функции, значение All). Группа DataField позволяет включить в выражение поля набора данных, причем список DataSet определяет НД, а в списке Fields перечисляются поля текущего НД.
В каждой из указанных групп присутствует кнопка Add. Она позволяет добавить константу, функцию или поле непосредственно в текст выражения (самая нижняя группа без названия).
Выберем в списке функций STR - функцию, преобразующую числовое значение в строковое и нажмем кнопку Add в группе функций. Поскольку функция имеет параметр, редактор формул перейдет в режим ввода параметра. Выберем в группе Data Field's окне DataSet набор данных Table1 и в списке полей - DEN, после чего нажмем кнопку Add и затем Ok. В поле формулы будет сформирована часть формула STR(Table1.DEN). На панели Operators нажмем кнопку '+'. В группе констант установим тип строковой константы (String) и введем точку, после чего нажмем кнопку Add (рис. 14.8).
Аналогичным образом введем другие части формулы, чтобы она в конечном виде была такой:
STR(Table1.DEN) + '.' + STR(Table1.MES) + '.' + STR(Table1.GOD)
Затем-нажмем кнопку Ok и выйдем в инспектор объектов. Установим в свойство AutoSize компонента QRExpr! значениеРа^е и изменим размеры компонента QRExprI так, чтобы он занимал примерно 10 символов, затем установим выравнивание вправо (свойство Alignment = taRightJustify). Запустим режим предварительного просмотра содержимого отчета (рис. 14.9). Как видим, дата отпуска товара приобрела более привычный вид.
ЗАМЕЧАНИЕ.
Другим способом составление значения даты из трех полей могло бы быть создание для НД Table1 вычисляемого поля (например, SymData) и определение алгоритма вычисления его значения в таком обработчике события OnCalcFields: procedure TForm1.Table1CalcFields(DataSet: TDataSet) ;
begin
Table1SymData.Value := Table1DEN.AsString + '.' + Table1MES.AsString + '.' + Table1GOD.AsString;
end;
Использование TQRBand для представления заголовков столбцов
Компонент TQRBand, у которого в свойство BandType установлено значение rbColumnHeader, используется для представления заголовков столбцов. Заголовки столбцов определяются при помощи компонентов TQRLabel.

 В отчете, рассмотренном в предыдущих разделах, разместим компонент TQRBand (имя QRBand3) и установим в его свойство BandTypc значение rbColumnHeader. Разместим в пространстве отчета, определяемом QRBand3, четыре компонента TQRLabel (имена QRLabel2 ... QRLabel5) и установим в свойства Caption этих компонентов соответственно значения '№№', 'Товар', 'Количество', 'Дата'. В свойстве Font данных компонентов установим режим подчеркивания шрифта, а сам шрифт определим как наклонный. Вид отчета представлен на рис. 14.10.
В отчете, рассмотренном в предыдущих разделах, разместим компонент TQRBand (имя QRBand3) и установим в его свойство BandTypc значение rbColumnHeader. Разместим в пространстве отчета, определяемом QRBand3, четыре компонента TQRLabel (имена QRLabel2 ... QRLabel5) и установим в свойства Caption этих компонентов соответственно значения '№№', 'Товар', 'Количество', 'Дата'. В свойстве Font данных компонентов установим режим подчеркивания шрифта, а сам шрифт определим как наклонный. Вид отчета представлен на рис. 14.10.Рис. 14.10. Определение заголовков столбцов Рис 14.11 В отчете появились заголоаки столбцов
Выйдем в окно предварительного просмотра отчета. Для каждой страницы отчета вверху страницы будут выводиться названия столбцов (рис. 14.11).
Использование TQRBand для показа заголовка и подвала страницы
Компонент TQRBand, у которого в свойство BandType установлено значение rbPageHeader, используется для показа заголовка страницы. Он выводится для каждой новой страницы перед выводом другой информации. Компонент TQRBand, у которого в свойство BandType установлено значение rbPageFooter, используется для показа подвала страницы. Он выводится для каждой страницы после вывода любой иной информации.
Информация в заголовке и подвале страницы может формироваться на основе статического текста (компоненты TQRLabel), значений полей (компоненты TQRDBText) и результатов вычисления выражений (компоненты TQRExpr).
В отчете, рассмотренном в предыдущих разделах, разместим компонент TQRBand (имя QRBand4) и установим в его свойство BandType значение rbPageHeader. Не будем размещать в заголовке страницы никакого текста, просто отчеркнем линию вверху страницы. Для этого установим в свойство компонента заголовка страницы Frame. DrawTop значение True, что обеспечивает вывод линии по верхнему краю области, занимаемой компонентом.
Аналогичным образом определим в отчете компонент подвала страницы (имя QRBand5) и установим в его свойство Frame.DrawBottom значение True, что обеспечивает вывод линии по нижнему краю области, занимаемой компонентом.
Войдя в режим предварительного просмотра отчета, увидим, что вверху и внизу каждой страницы отчета выводятся линии.
Использование компонента TQRSysData для показа вспомогательной и системной информации
Компонент TQRSysData используется для показа вспомогательной и системной информации. Вид показываемой информации определяется свойством property Data : TQRSysDataType;
Ниже указаны возможные значения этого свойства.
qrsColumnNo -
номер текущей колонки отчета (для одноколоночного отчета всегда 1). qrsDate -
текущая дата. arsDate Time-текущие дата и время.
qrsDetailCount -
число записей в НД; при использовании нескольких НД - число записей в master-наборе. Для случая, когда НД представлен компонентом TQuery, эта возможность может быть недоступной, что связано с характером работы компонента TQuery, который возвращает столько записей, сколько необходимо для использования в текущий момент, а остальные предоставляет по мере надобности; qrsDetaiINo -
номер текущей записи в НД. При наличии нескольких наборов - номер текущей записи в master-наборе. qrsPageNumber -
номер текущей страницы отчета. qrsPageCount -
общее число страниц отчета. qrs ReportTitle -
заголовок отчета. ars Time - текущее время.
Разместим в компоненте подвала отчета QRBand5 два компонента TQRSysData (имена QRSysDatal... QRSysData2). В свойство Data первого из них установим значение arsDate (текущая дата), второго - значение qrsPageNumber (номер текущей страницы отчета). Войдем в режим предварительного просмотра результатов отчета. Теперь в подвале каждой страницы отчета выводятся номер страницы и текущая дата (рис. 14.12).
Группировки данных в отчете
Выше мы рассмотрели отчет, в котором информация об отпуске товаров из ТБД Rashod.DB со склада выводилась "как есть". Такое представление информации в отчете не всегда информативно. Пусть, например, в нашем случае требуется сгруппировать информацию по товарам.
Для группировки информации используется компонент TQRGroup. Его свойство Expression указывает выражение. В группу входят записи НД, удовлетворяющие условию выражения. При смене значения выражения происходит смена группы. Для каждой группы, если определены, выводятся заголовок группы и подвал группы. В качестве заголовка группы служит компонент TQRBand со значением свойства BandType, равным rbColumnHeader. В качестве подвала группы служит компонент TQRBand со значением свойства BandType, равным rbGroupFooter.
Свойство FooterBand компонента TQRGroup содержит ссылку на компонент подвала группы.
В заголовке группы, как правило, выводится выражение, по которому происходит группировка, и различные заголовки, если они нужны. В подвале группы обычно выводится агрегированная информация - суммарные, средние и т.п. значения по группе.
Пример.
Построим отчет о расходе товара со склада, в котором информация группируется по наименованию товара. Для этого определим набор данных отчета (компонент TTable, имя Table1). Установим у НД текущим индекс по полю Tovar (в свойстве Fieldlndex Names или IndexNawe). Разместим в отчете: заголовок отчета - компонент TQRBand с именем QRBandl, свойство BandType = rb Title;
• заголовок столбцов - компонент TQRBand с именем QRBandS, свойство BandType = rbColumnHeader,
• группу - компонент TQRGroup с именем QRGroupl.
• область детальной информации - компонент TQRBand с именем QRBand2, свойство BandType = rbDetail;
подвал группы - компонент TQRBand с именем QRBand4, свойство BandType = rbGroupFooter.
В компоненте QRGroupl установим:
в свойство FooterBand значение QRBand4;
• в свойство Expression значение Table1.TOVAR, которое является формулой и строится в редакторе формул.
Поскольку свойство Expression не визуализирует значения выражения, необходимо разместить в группе компонент TQRExr (имя QRExrl) и определить значение его свойства Expression так, чтобы оно содержалоTable1.TOVAR.
В компоненте подвала группы QRBand4 будем подсчитывать сумму по полю Kolvo (сумму отпущенного конкретного товара). Для этого разместим в подвале группы компонент TQRExr (имя QRExr2) и определим значение его свойства Expression так, чтобы оно содержало формулу SUM(Table1.KOLVO).
В группе детальной информации разместим компоненты TQRDBText, связанные с полями Pokup и Kolvo НД. Заполним другие области отчета статическим текстом, как это показано на рис.14.13.
На рис 14.14 показан отчет в режиме предварительного просмотра На рис 14.15 показан подвал одной из групп - там выводится информация о суммарном расходе товара
Понятие многомерных данных
В процессе принятия решений во многих сферах приходится анализировать многофакторную информацию о предметной области. Пусть, к примеру, организация занимается продажами товаров. При закупках товаров эта организация должна представлять, насколько устойчив спрос на товары, каковы темпы роста спроса - по товару, по региону, по конкретным организациям, каковы расходы, прибыль и многое другое.
Ситуация, когда аналитику приходится иметь дело с многофакторными данными, осложняется двумя обстоятельствами:
• во-первых, средний человек может одновременно оперировать тремя-четырьмя сущностями, учитывая при этом связи между ними;, с увеличением числа сущностей эффективность обработки информации человеком падает;
во-вторых, чисто психологически человеку, живущему в трехмерном мире, трудно представить пространство размерностью больше 3.
Математики давно оперируют с многомерными пространствами, но это абстрактный подход. В области практических применений наша способность оперировать многомерными данными, к сожалению, является ограниченной.
При возникновении необходимости обработки многофакторной информации применяют или многомерные базы данных (они остаются за рамками нашего рассмотрения), или в реляционных СУБД реализуют такие механизмы организации данных и доступа к ним, которые резко повышают эффективность анализа многофакторных данных.
Создание сетки многомерных данных
Компонент TDecisionGrid служит для представления многомерных данных в виде таблицы, в которой измерениям соответствуют строки и столбцы. Ячейки TDecisionGrid заполняются данными, полученными на основе расчета агрегатных функций.
Разместим в форме компонент TDecisionGrid с именем DecisionGrid1. Установим в его свойство DecisionSource имя компонента DecisionSource1 После этого произойдет визуализация многомерных данных (рис. 15.8).
Вспомним оператор SELECT, в котором определены измерения и агрегация данных в многомерном кубе:
SELECT P.GOROD, R.POKUP,Т.TYP_TOVARA, R.TOVAR, R.MES,
SUM( R.KOLVO * T.ZENA) , AVG ( R.KOLVO * T.ZENA)
FROM "Rashod.DB" R, "Pokup.DB" P, "Tovary.DB" T
WHERE R.POKUP= P.POKUP AND
T.TOVAR = R.TOVAR
GROUP BY P.GOROD, R.POKUP, TYP_TOVARA, R.TOVAR, R.MES
Согласно данному оператору, в кубе имеются измерения по полям
1. GOROD (город покупателя);
2. POKUP (название покупателя);
3. TYP_TOVARA (тип товара);
4. TOVAR (название товара);
5. MES (месяц года, в который произошел отпуск товара).
В качестве данных по измерениям будет выводиться (по выбору) результат одной из следующих агрегаций:
1. суммарная стоимость отпущенного товара (KOLVO * ZENA);
2. средняя стоимость отпущенного товара (KOLVO * ZENA).
Как видно из рис 15.8, одни измерения показываются по горизонтали, построчно ("Покупатель", "Тип товара", "Товар"), другие - вертикально, как столбцы ("Город"). По умолчанию в ячейках показываются данные той агрегатной функции, которая в списке агрегатных функций в операторе SELECT указана первой. В нашем случае - это суммарная стоимость отпущенного товара SUM( R KOLVO * T.ZENA).
Раскрытие и закрытие данных по измерениям средствами компонента TDecisionGrid
Каждому измерению в сетке данных соответствует знак "+" или "-" Он указывается в ячейке, в которой содержится название предыдущего измерения Например, знак для измерения "Тип товара" находится в ячейке, в которой показывается название предыдущего измерения - "Покупатель".
Знак "+" сообщает, что информация по измерению в сетке данных не показывается. Знак "-", наоборот, свидетельствует о том, что данные по измерению показываются Если щелкнуть на значке мышью, значок переходит в противоположное состояние (с "+" на "-" и наоборот). При этом данные по измерению также переходят в противоположное состояние визуализации - если они показывались в сетке, то прячутся, и наоборот.
Важно помнить, что сокрытие данных по какому-либо измерению ведет к сокрытию данных по измерениям, расположенным правее от него. На рис 15 9 показан результат сокрытия данных по измерению "Тип товара" Как видно из рисунка, скрыты не только данные по измерению "Тип товара", но и по измерению"Товар".
Показ промежуточных сумм
Как видно из рис. 15 8, для каждого значения данных по измерению показываются промежуточные суммы. Их показ можно устранить. Для этого нужно щелкнуть по компоненту TDecisionGrid правой кнопкой мыши и во всплывающем меню выбрать Subtotals on/off. Повторный выбор данного элемента меню приведет к включению промежуточных сумм в сетку
Подобного же эффекта, но для конкретного измерения, можно добиться, если выбрать мышью ячейку заголовка конкретного измерения и нажать правую кнопку Выбор элемента Display Data and Subtotals приводит к показу промежуточных сумм Выбор элемента Display Data Only устраняет показ промежуточных сумм для измерения.
Те же действия осуществимы и для конкретного значения по измерению. Если щелкнуть правой кнопкой мыши по ячейке данных, соответствующих нужному измерению, то появится меню, в котором к элементам Display Data and Subtotals и Display Data Only добавится элемент Display Subtotals Only. Выбор этого элемента приводит к показу только промежуточных сумм. Установка одного из названных режимов показа относится не к измерению в целом, а к данным, касающимся того значения измерения, которое показывается в ячейке.
Все возможности, о которых идет речь в данном подразделе, доступны как во время разработки приложения, так и во время его выполнения
Исключение и включение измерения в состав показываемых в сетке данных
То или иное измерение может быть исключено из сетки данных или вновь добавлено в нее - как во время разработки, так и во время выполнения приложения.
Выше нами рассмотрено использование значков "+" и "-" Однако сворачивание и раскрытие данных в случае использования этих значков затрагивает и соседние измерения, расположенные справа. Механизм, о котором пойдет речь в этом подразделе, позволяет исключать или вновь включать в сетку данные, соответствующие конкретному измерению, не затрагивая при этом данных по другим измерениям
Для того чтобы скрыть данные по измерению, можно воспользоваться двумя способами.
Первый способ - щелкнуть правой кнопкой мыши по ячейке данных измерения, которое показывается построчно, и во всплывающем меню выбрать элемент Drill in to this value
Второй способ - нажать правую кнопку мыши:
• над заголовком измерения,
над пустой ячейкой в ряду ячеек сетки, расположенным над рядом, в котором показываются названия измерений;
над крайним левым (пустым) столбцом сетки, в списке измерений снять отметку с необходимого измерения.
Чтобы включить измерение в состав показываемых, нужно воспользоваться вторым способом и установить отметку у необходимого измерения.
Установка свойств показа данных по отдельному измерению
Свойство property Dimensions: TDisplayDims; представляет собой коллекцию компонентов TDisplayDim, каждый из которых позволяет управлять представлением данных, соответствующих конкретному измерению.
Рассмотрим свойства компонента TDisplayDims:
• property Count: Integer; возвращает число измерений в TDecisionGrid, то есть число компонентов TDisplayDim в коллекции TDisplayDims.
• property Items[Index: Integer]: TDisplayDim; возвращает компонент TDisplayDim с индексом Index. TDisplayDim соответствует серии данных по одному измерению. Значение Index лежит в диапазоне 0..Count-1.
Рассмотрим свойства компонента TDisplayDim, то есть серии данных по конкретному измерению в TDecisionGrid:
•• property Alignment: TAlignment;
определяет выравнивание. •• property Color: TColor;
определяет цвет фона в ячейках. •• property DisplayName: String;
определяет текст заголовка. •• property FieldName: String;
определяет имя поля, по которому строится измерение. •• property Format: String;
определяет формат представления значений в ячейках. •• property Subtotals: Boolean;
определяет, следует ли (True) или нет (False) показывать значения промежуточных сумм по измерению. На этапе конструирования программы значения приведенных выше свойств можно установить, выбрав в инспекторе объектов свойство Dimensions. После этого на экране появится список измерений и агрегированных значений (рис. 15.10). Сделав текущим нужное измерение или агрегированное значение, в инспекторе объектов можно переопределить принятые по умолчанию значения его свойств.
Свойства и события, управляющие поведением TDecisionGrid в целом
Свойства
property CaptionColor: TColor;
определяет цвет фона для заголовков столбцов и строк. property CaptionFont: TFont;
определяет шрифт для заголовков столбцов и строк. property CelIs[ACol, ARow: Integer]: String;
возвращает в строковом виде содержимое ячейки на пересечении столбца АСоl и строки ARow. ro property ColCount: Integer;
возвращает текущее число столбцов. property DataCoIor: TColor;
определяет цвет фона во всех ячейках. property DataFont: TFont;
определяет шрифт во всех ячейках. property DataSumColor: TColor;
определяет цвет фона - только в ячейках, где показываются суммы. property DecisionSource: TDecisionSource;
содержит имя компонента TDecisionSource. property DefauItColWidth: Integer;
определяет умалчиваемую ширину (в пикселях) всех ячеек TDecisionGrid. Установка нового значения этого свойства приводит к изменению ширины сразу всех ячеек компонента. property DefaultRowHeight: Integer;
определяет высоту (в пикселях) всех ячеек TDecisionGrid Установка нового значения свойства приводит к изменению высоты сразу всех ячеек компонента. property FixedCols:Integer;
возвращает число столбцов, используемых для показа заголовков измерений и меток данных, то есть для показа служебной информации. rо property FixedRows:Integer;
возвращает число строк, используемых для показа служебной информации. property GridLineColor: TColor;
определяет цвет линий, отделяющих ячейки друг от друга. property GridLineWidth: Integer;
определяет в пикселях ширину линий, отделяющих ячейки друг от друга. property LabelColor: TColor;
определяет цвет фона ячеек, в которых показываются заголовки столбцов и строк. property LabelFont: TFont;
определяет шрифт ячеек, в которых показываются заголовки столбцов и строк. property LabelSumColor: TColor;
определяет цвет фона ячеек, в которых показываются заголовки сумм. property Options: TDecisionGridOptions;
TDecisionGridOptions = set of TDecisionGridOption; представляет собой множество, которое определяет параметры показа в TDecisionGrid. В множество могут входить значения: cgGridLines -
выводятся вертикальные и горизонтальные линии, отделяющие ячейки друг от друга. cgOutliner -
заголовки измерений куба содержат знаки "+" и "-", которые позволяют открывать или закрывать измерения без помощи компонента TDecisionPivot. cgPivotable -
разрешается перетаскивать измерения способом darg and drop. ro property RowCount:Integer;
возвращает число строк в TDecisionGrid. property Totals: Boolean;
определяет, показываются (True) или нет (False) значения подсумм по измерениям. События
TDecisionDrawCeIlEvent = procedure (Sender: TObject; Col, Row: Longint;
var Value: string; var AFont: TFont; var AColor: TColor; AState: TGridDrawState;
ADrawState: TDecisionDrawState) of Object;
наступает при прорисовке ячейки в TDecisionGrid. Параметры:
Соl - номер столбца;
Row - номер строки;
Value - символьное представление значения, показываемого в ячейке;
AFont -
шрифт, которым показывается значение в ячейке; A Color - цвет фона в ячейке;
AState -
состояние ячейки. TGridDrawState = set of (gdSelected, gdFocused, gdFixed); A DrawState - множество, определяющее вид показываемых в ячейке данных. Может включать в себя значения:
• dsGroupStart - ячейка - первая строка или первый столбец для измерения. В этом случае в множество ADrawState входят также значения dsRow Value или dsCol Value.
• dsRowCaption - в ячейке показывается заголовок строки, то есть имя измерения, значения которого показываются горизонтально.
• dsColCaption - в ячейке показывается заголовок столбца, то есть имя измерения, значения которого показываются вертикально.
• dsSum - в ячейке показывается метка или значение промежуточной суммы. В этом случае в множество ADrawState входят также значения dsRow Value, dsCol Value и dsData.
• dsRow Value - в ячейке показывается одно из значений измерения (метка), а не собственно данные. Название измерения в этом случае расположено в ячейке слева.
• dsColValue - в ячейке показывается одно из значений измерения (метка), а не собственно данные. Название измерения в этом случае расположено в ячейке сверху.
• dsData - в ячейке показываются только данные.
• dsOpenAfter - ячейка имеет знак "+" в правой части, использующийся для раскрытия данных по следующему измерению. В этом случае в множество ADrawState входят также значения dsRowCaption, dsColCaption, dsRow Plus и dsColPlus.
• dsCloseAfter - ячейка имеет знак "-" в правой части, использующийся для сокрытия данных по следующему измерению. В этом случае в множество ADrawState входят также значения dsRowCaption, dsColCaption, dsRowPlus и dsColPlus.
• dsRowIndicator - ячейка используется только для показа знаков "+" или "-" и располагается в самом левом столбце TDecisionGrid. dsColIndicalor - ячейка используется только для показа знаков "+" или "-" и располагается в самой верхней строке TDecisionGrid.
• dsRowPlus - ячейка, определяемая dsRowIndicator, содержит значение "+". Появляется только совместно с dsRowIndicator.
• dsColPlus - ячейка, определяемая dsColIndicator, содержит значение "+". Появляется только совместно с dsColIndicator.
• dsNone - у ячейки нет никакого предназначения.
Пример.
Показать на красном фоне те значения в области данных (но не значений измерений!), где значение больше 2000. Сделать это для всех ячеек, кроме текущей (пусть в ней используется стандартный фон выбора - по умолчанию это синий). Для тех полей области данных, которые содержат пустые значения, выводить 0. procedure TForm1.DecisionGrid1DecisionDrawCell (Sender: TObject; Col, Row: Integer; var Value: String; var aFont: TFont; var aColor:
TColor;
AState: TGridDrawState; aDrawState: TDecisionDrawState) ;
begin
IF dsData in aDrawState THEN begin
IF Value = " THEN Value := '0';
IF not(gdFocused in AState)AND (StrToInt(Value) > 2000) THEN
AColor := cIRed;
END;//if
end;
property OnDecisionExamineCell: TDecisionExamineCellEvent;
TDecisionExamineCellEvent = procedure (Sender: TObject; ICol, IRow: Longint; ISum: Integer; const ValueArray: TSmallIntArray) of Object;
наступает, когда пользователь, находясь в ячейке данных, нажимает правую кнопку мыши. Параметры:
ICol - номер столбца ячейки;
IRon - номер строки ячейки;
ISum - номер текущей суммы;
ValueArray -
массив координат в координатной сетке TDecisionSource (а не TDecisionGrid). Для получения имени измерения, соответствующего конкретному элементу массива, следует использовать метод GetDimensionName. property OnTopLeftChanged: TNotifyEvent;
наступает при скроллинге данных в сетке TDecisionGrid. TNotifyEvent = procedure(Sender: TObject) of object;
Создание переключателя активных измерений
Компонент TDecisionPivot позволяет динамически определять текущие измерения куба, а также выбирать содержимое ячеек данных Каждому измерению куба в компоненте TDecisionPivot соответствует кнопка. Когда кнопка нажата, измерение в составе куба является открытым, то есть данные, соответствующие измерению, показываются в кубе Когда кнопка, соответствующая измерению, не нажата (отжата), данные, соответствующие измерению, в кубе не показываются Агрегатным функциям соответствует отдельная кнопка. С ее помощью в ячейках могут быть показаны данные, соответствующие конкретной агрегатной функции
Разместим в форме компонент TDecisionPivot (имя DecosionPivot1) Установим в его свойство DecisionSource имя компонента DecisionSource1.
Общий вид окна приложения показан на рис.15 11
Изменение способа показа данных по измерению
Из рисунка 15.11 видно, что кнопки в компоненте TDecisionPivot размещены в трех областях
В левой области размещена кнопка "Стоимость (сумма)". Это кнопка предназначена для выбора агрегатных функции По умолчанию в качестве текущей агрегатной функции берется первая из функций, определенных в операторе SELECT (компонент TDecisionQuery). Чтобы сменить агрегатную функцию, нужно нажать кнопку и из появившегося списка выбрать нужную функцию
Средняя область компонента TDecisionPivot содержит кнопки измерений, данные по которым показываются построчно. В нашем случае это кнопки, соответствующие измерениям "Тип товара", "Покупатель", "Товар", "Месяц".
Правая часть компонента TDecisionPivot содержит кнопки измерений, данные по которым показываются в виде столбцов. В нашем случае это кнопка, соответствующая измерению "Город".
Для того чтобы перевести кнопку из одной области в другую, следует щелкнуть по ней правой кнопкой мыши и в всплывающем меню выбрать элемент Move to roh Area (при переводе измерения в построчный показ) или Move to Column Area (при переводе измерения в показ по столбцу).
Фиксация значения в измерении
По умолчанию по измерению показываются все его данные. Например, по измерению "Покупатель" показываются все покупатели. Однако часто бывает необходимо показывать данные не по всем, а по конкретному покупателю. Для этого следует переместить указатель мыши на кнопку соответствующего измерения и нажать правую кнопку мыши, а затем выбрать элемент всплывающего меню Drilled in.
Кнопка "Покупатель" изменит свой заголовок на "Покупатель. All Values". Теперь, чтобы зафиксировать конкретного покупателя, следует нажать правую кнопку мыши и в появившемся списке выбрать название конкретного покупателя. При этом его имя будет показываться в кнопке, соответствующей измерению "Покупатель", а данные в кубе будут сечением по координате измерения "Покупатель", соответствующей конкретному покупателю (рис.15.12).
Для того чтобы вновь показывать все значения по измерению (например, всех покупателей по измерению "Покупатель"), следует установить указатель мыши на кнопку, соответствующую измерению, нажать правую кнопку мыши и во всплывающем меню снять отметку с режима Drilled in.
Свойства, управляющие представлением в форме компонента TDecisionPivot
property ButtonAutoSize: Boolean;
указывает, следует ли автоматически согласовывать размеры кнопок, соответствующих измерениям куба в компоненте TDecisionPivot, с размером самого компонента TDecisionPivot (значение True) или, независимо от размеров компонента, всегда поддерживать одни и те же размеры кнопок (значение False).
property ButtonHeight: Integer;
определяет высоту (в пикселях) кнопок в компоненте TDecisionPivot (только для случая, когда свойство ButtonAutoSize = False). property ButtonSpacing: Integer;
определяет расстояние (в пикселах) между кнопками. property ButtonWidth: Integer; определяет ширину (в пикселях) кнопок в компоненте TDecisionPivot (только для случая, когда свойство ButtonAutoSize = False).
property DecisionSource: TDecisionSource;
содержит имя компонента TDecisionSource. property GroupLayout: TDecisionButtonPosition;
TDecisionButtonPosition = (xtHorizontal, xtVertical, xtLeftTop); определяет способ расположения кнопок измерений в компоненте TDecisionPivot: xtHorizontal -
горизонтальное; xtVertical - вертикальное;
xtLeftTop -
кнопки, соответствующие измерениям, которые выводятся в виде строк, помещаются слева внизу; кнопки, соответствующие измерениям-столбцам - вверху и кнопки, соответствующие суммам - вверху слева. property Groups: TDecisionPivotOptions;
TDecisionPivotOptions = set of TDecisionPivotOption;
TDecisionPivotOption = (xtRows, xtColumns, xtSummaries);
множество, которое определяет, какие кнопки входят в TDecisionPivot. В состав множества могут входить значения:
xtRows - кнопки измерений куба, которые выводятся как строки;
xtColumns -
кнопки измерений куба, которые выводятся как столбцы; xtSummaries -
кнопки, соответствующие суммам. property GroupSpacing: Integer; определяет расстояние (в пикселах) между группами кнопок, соответствующих измерениям по строкам, по столбцам и суммам.
Метакуб (многомерный куб)
Сущность подхода, при помощи которого Delphi позволяет оперировать с многомерными данными, состоит в следующем. Данные представляются в виде так называемого метакуба (или многомерного куба), где одному фактору соответствует свое измерение.
На рис. 15.1 приведен куб. В нем представлена информация по продажам. Одно измерение соответствует городам, в которых осуществлялись продажи;
второе измерение - фирмам, которым продавался товар; третье - временным периодам.
В конкретной ячейке, как правило, представляются агрегированные данные - сумма, среднее, максимальное значение - или вновь многомерные данные (кубы). Пример такого куба, содержащего информацию об отпусках товара по конкретной фирме из конкретного города для конкретного временного отрезка, представлен на рис. 15.2.
Динамическая фиксация числа измерений
При помощи компонентов Delphi, которые будут обсуждаться ниже, в источнике данных фиксируются:
• поля - измерения метакуба;
• поля, по которым должно производиться агрегирование данных (суммирование, подсчет среднего и т.д.).
Затем определяется, какие измерения показываются как столбцы, какие -как строки. После этого пользователю предоставляется таблица многомерных данных. В форме приложения может быть расположен план метакуба, то есть список измерений, где каждому измерению соответствует кнопка. Нажимая кнопку, пользователь активизирует или деактивизирует показ данных по тому или иному измерению куба.
На рис. 15.3. показана информация из пятимерного куба. Пользователь зафиксировал текущие измерения - "Покупатель", "Месяц", "Тип товара". В ячейках показывается суммарный отпуск товара.
На рис. 15.4. показан тот же куб, в котором зафиксированы три другие измерения - "Город", "Товар", "Месяц". В ячейках показывается суммарный отпуск товара.
На рис. 15.5 показан тот же куб, в котором выбраны 4 измерения - "Город". "Покупатель", "Товар", "Месяц". В ячейках показывается суммарный отпуск товара
Обзор компонентов Delphi для разработки систем принятия решений
Компоненты для разработки систем принятия решений расположены в Delphi на странице Decision Cube.
Компонент TDecisionQuery служит для определения НД, на основании которого затем будет создаваться многомерный куб. Компонент TDecisionQuery разработан специально для указанных целей, и поэтому его использование при разработке систем принятия решений является более предпочтительным, чем использование "обычных" компонентов НД - TTable и TQuery Однако и эти компоненты могут применяться для хранения данных, на которых строится метакуб.
Компонент TDecisionCube, собственно, и реализует многомерный куб данных. Он соединяется с НД (как правило, это компонент TDecisionQuery) при помощи свойства DataSet.
Компонент TDecisionSource является аналогом "источника данных", компонента TDataSource, но адаптирован для целей работы с многомерными данными. Многомерный "источник данных" соединяется с компонентом TDecisionCube при помощи свойства DecisionCube.
Компонент TDecisionPivot позволяет открывать и закрывать измерения метакуба. Для этого пользователю следует нажать (или отжать нажатую) кнопку, соответствующую конкретному измерению. Данный компонент связан с компонентом TDecisionSource при помощи свойства DecisionSource. Применение этого компонента необязательно, поскольку компонент TDecisionGrid также содержит средства для открытия и закрытия данных по измерениям куба. Это - значки "+" и "-" в заголовках столбцов и строк, соответствующих измерениям куба.
Компонент TDecisionGrid имеет в системах многомерных данных то же функциональное предназначение, что и компонент TDBGrid при работе с обычными НД. В TDecisionGrid показываются непосредственно данные из многомерного куба. Данные по одним измерениям куба выводятся построчно (горизонтально), по другим - вертикально, в виде столбцов. Компонент связан с компонентом TDecisionSource через свойство DecisionSource.
Компонент TDecisionGraph предназначен для показа графиков, источником которых служат многомерные данные. Он связан с компонентом TDecisionSource через свойство DecisionSource.
Ниже на примере будут показаны особенности использования названных компонентов.
Пример многомерных данных
Пусть имеем три таблицы БД.
Первая таблица Tovary.DB содержит сведения о товарах. В состав таблицы входят поля:
• Tovar-наименование товара; • Typ_Tovara - тип товара; • Ed_Izm - единица измерения товара;
• Zena - цена за единицу измерения товара.
Первичный ключ построен по полю Tovar.
Вторая таблица Pokup.DB содержит сведения о покупателях товара. В состав таблицы входят поля:
• Pokup - наименование покупателя; • Gorod - город, в котором расположена организация-покупатель.
Первичный ключ построен по полю Pokup.
Третья таблица Rashod.DB содержит сведения о расходе товара со склада. В состав таблицы входят поля:
• N_Rash - уникальный номер расхода; • Den - день; • Mes - месяц; • God - год даты расхода; • Tovar - наименование товара; • Pokup - наименование покупателя; • Kolvo - количество единиц отпущенного товара.
Первичный ключ построен по полю N_Rash. Таблица находится в отношении "многие-к-одному" с таблицами Tovary.DB и Pokup.DB. Для реализации целостности построены внешние индексы по полям Tovary и Pokup.
Необходимо построить многомерный куб для представления:
• общей суммы расхода; • средней суммы расхода;
по измерениям:
• товар; • город; • покупатель; • тип товара; • месяц из даты отпуска товара.
В процессе построения многомерных данных рассмотрим особенности компонентов, перечисленных в предыдущем разделе.
Использование компонента TDecisionQuery
Разместим в форме компонент TDecisionQuery с именем DecisionQuery1. Установим в свойство Database компонента имя базы данных (в нашем случае это loc_skld). В свойстве SQL определим оператор SELECT, в котором произведем внутреннее соединение таблиц Rashod, Tovary и Pokup:
SELECT P.GOROD, R.РОКUР,Т.TYP_TOVARA, R.TOVAR, R.MES,
SUM( R.KOLVO * T.ZENA) , AVG( R.KOLVO * T.ZENA)
FROM "Rashod.DB" R, "Pokup.DB" P, "Tovary.DB" T
WHERE R.POKUP= P.POKUP AND
T.TOVAR = R.TOVAR
GROUP BY P.GOROD, R.POKUP, TYP_TOVARA, R.TOVAR, R.MES
GROUP BY P.GOROD, R.POKUP, TYP_TOVARA, R.TOVAR, R.MES
Существуют следующие правила объявления измерений в многомерном кубе:
1. поля, по которым должны строиться измерения многомерного куба, перечисляются после ключевого слова SELECT;
2. поля, по которым измерений строить не нужно, в операторе SELECT в качестве возвращаемых полей результирующего набора данных не перечисляются;
3. только после полей-источников для измерений куба перечисляются агрегатные выражения - сумма, среднее, и число повторений;
агрегированные данные затем будут выводиться по указанным ранее измерениям;
4. обязательно использование раздела ORDER BY, где необходимо перечислить все поля, по которым строятся измерения куба, причем в том же порядке, в котором они следуют после ключевого слова SELECT.
Рассмотрим приведенный выше оператор SELECT. Измерения будут построены по полям:
1.GOROD;
2. POKUP;
3. TYP_TOVARA;
4.TOVAR;
5. MES.
В качестве данных по измерениям будет выводиться (по выбору) результат одной из следующих агрегаций:
1. суммарная стоимость отпущенного товара (KOLVO * ZENA);
2. средняя стоимость отпущенного товара (KOLVO * ZENA).
Компонент TDecisionQuery настолько "похож" на компонент TQuery, что не имеет отличных от него, уникальных свойств, методов и событий. Установим значение True в свойство компонента Active. Теперь набор многомерных данных активен в нашем приложении.
Редактор многомерного запроса
Отвлечемся на некоторое время от нашего примера и рассмотрим, как использовать еще одно средство компонента TDecisionQuery - редактор многомерного запроса - для построения SQL-оператора выборки многомерных данных. Отметим при помощи мыши компонент TDecisionQuery и нажмем правую кнопку мыши, а затем во всплывающем меню выберем элемент Decision Query Editor. Появится окно редактора многомерного запроса (рис. 15.6).
В списке List of Available Fields перечислены поля таблицы БД, чье имя выбрано в выпадающем списке Table. Используя кнопки с изображением стрелок, поля, по которым должны строиться измерения в многомерном кубе, перемещают в список Dimensions. Тем же способом в список Summaries перемещаются поля, по которым необходимо производить агрегацию. Тип агрегации запрашивается тут же. Это SUM (сумма), COUNT (счетчик повторений) и AVERAGE (среднее значение).
Закладка SQL позволяет просмотреть и, если необходимо, изменить текст SQL-оператора, построенного на основе наших действий. Кнопка Query Builder позволяет перейти в режим запроса по образцу (Query By Example) для построения оператора SELECT.
Использование компонента TDecisionCube
Вернемся к примеру. Разместим в форме компонент TDecisionCube с именем DecisionCube1. Занесем в свойство DataSet имя набора данных DecisionQuery1. Определим свойства куба. Для этого отыщем в инспекторе объектов свойство DimensionMap и в поле данных этого свойства нажмем кнопку (...). Появится окно редактора многомерного куба {Decision Cube Editor). Оно показано на рис. 15.7.
В списке Available Fields перечислены поля, по которым строятся измерения куба, и формулы для расчета агрегированных значений. Для текущего поля или формулы слева показываются параметры:
Display Name -
метка, которая будет показываться для измерения в компонентах TDecisionGrid, TDecisionPivot, TDecisionGraph; • Type - тип (Dimension, Sum, Average, Count);
• Active Type - определяет показываемую информацию - As Needed (показывается, когда необходимо); Active (показывается всегда); Inactive (не показывается никогда);
•Formal - формат представления значений;
•Grouping - группировка по году, кварталу, месяцу и отдельному значению;
•Initial Value - начальное значение.
Закладка Memory Control позволяет определить установки памяти:
•максимальное число измерений, сумм, ячеек (группа Cube Maximums);
•показывать только заголовки данных во время разработки приложения для экономии времени и ресурсов компьютера (группа Designer Data Options).
Определим названия измерений и агрегированных данных (поле Display Name).
Кратко рассмотрим свойства, методы и события компонента TDecisionCube.:
Свойства
property Capacity: Integer;
определяет максимальный размер кэша в байтах для хранения многомерного массива данных куба. В случае нехватки памяти возбуждается исключение ELowCapacity Error. property DataSet: TDataSet;
содержит имя НД, который указывает данные для представления в кубе. Рекомендуется в качестве НД использовать созданный специально для указанных целей компонент TDecisionQuery. property DimensionCount: Integer;
содержит текущее число измерений в кубе. property DimensionMap: TCubeDims;
определяет параметры компонента TDecisionCube, такие как число и состав измерений куба; формат представления значений по конкретному измерению; метки, которые будут соответствовать каждому измерению в компонентах TDecisionGrid и TDecisionPivot; максимальное число измерений; состав показываемых значений. Установка указанных параметров осуществляется в редакторе куба (Decision Cube Editor), который активизируется при двойном щелчке мышью на компоненте TDecisionCube в форме приложения или при нажатии кнопки в поле данных свойства DimensionMap в инспекторе объектов. property DimensionMapCount: Integer;
содержит число полей НД, которые участвуют в формировании многомерного куба. property MaxDimensions: Integer;
содержит максимальное число измерений куба. property MaxSummaries: Integer;
содержит максимальное число сумм для куба. property ShowProgressDialog: Boolean;
определяет, нужно (True) или не нужно (False) показывать прогресс-индикатор во время формирования куба. property SummaryCount: Integer;
возвращает число полей, использованных для формирования сумм. Метод procedure ShowCubeDialog; во время выполнения осуществляет вызов редактора куба, в котором могут быть изменены или переопределены свойства куба, установленные во время разработки. Более подробно см. свойство DimensionMap.
События
property OnLowCapacity: TCapacityErrorEvent;
TCapacityErrorEvent = procedure (var Action: TErrorAction) of object;
TErrorAction = ( eaFail, eaContinue ) ;
наступает в случае, когда не хватает памяти в кэше для хранения многомерных данных. Максимальный размер кэша устанавливается в свойстве Capacity.
property OnRefresh: TCubeRefreshEvent;
TCubeRefreshEvent = procedure(DataCube: TCustomDataStore; DimMap:
TCubeDims) of object;
наступает перед изменением плана куба. Это происходит после изменения параметров куба во время выполнения (см. метод ShowCubeDialog).
Использование компонента TDecisionSource
Компонент TDecisionSource выполняет в системах представления многомерных данных те же функции, что и компонент TDataSource в системах представления обычных данных, то есть служит "источником данных" для визуальных компонентов (TDecisionGrid, TDecisionGraph). Иными словами, TDecisionSource служит в качестве связующего звена между невизуальными компонентами многомерных данных (TDecosionCube) и визуальными компонентами.
Разместим в форме компонент TDecisionSource с именем DecisionSourcel. Установим в свойство DataSet значение имени компонента TDecisionCube, то есть DecisionCubel.
Свойства и события компонента TDecisionSource описаны ниже. Некоторые из них связаны с компонентами TDecisionPivot и TDecisionGrid, которые будет рассмотрены в следующих разделах.
Свойства
property DecisionCube: TDecisionCube;
содержит имя компонента TDecisionCube. property SparseCols: boolean;
определяет, показывать или нет столбцы с пустыми значениями. property SparseRows: boolean;
определяет, показывать или нет строки с пустыми значениями. События
property OnBeginPivot: TNotifyEvent;
наступает перед изменением данных в кубе при нажатии (отжатии) кнопки, соответствующей измерению куба в компоненте TDecisionPivot, или при раскрытии/свертке данных по измерению в TdecisionGrid TNotifyEvent = procedure(Sender: TObject) of object; property OnEndPivot: TNotifyEvent;
событие вызывается той же причиной, что и событие OnBeginPivot, однако наступает после изменения данных в кубе, но до отображения этих изменений в связанных с TDecisionSource компонентах. TNotifyEvent = procedure(Sender: TObject) of object; property OnLayoutChange: TNotifyEvent;
наступает после изменения схемы данных в кубе. Событие наступает после события OnBeginPivot, но перед событием OnEndPivot и только в том случае, когда данные в кубе остаются теми же. При изменении состава измерений, которое сопровождается изменением данных в кубе, наступает событие OnNewDimensions. TNotifyEvent = procedure(Sender: TObject) of object; property OnNewDimensions: TNotifyEvent;
наступает после изменения данных в кубе. TNotifyEvent = procedure(Sender: TObject) of object;
property OnStateChange: TNotifyEvent;
наступает после изменения свойств куба (компонент TDecisionCube). TNotifyEvent = procedure(Sender: TObject) of object;
Архитектуры "файл-сервер" и "клиент-сервер"
Базы данных на персональных компьютерах развивались по направлению от настольных (desktop), или локальных приложений, когда реально с БД могло работать одно приложение, до систем коллективного доступа к БД.
Локальное приложение устанавливалось на единичном персональном компьютере; там же располагалась и БД, с которой работало данное приложение. Однако необходимость коллективной работы с одной и той же БД повлекла за собой перенос БД на сетевой сервер. Приложение, работающее с БД, располагалось также на сервере. Менее характерным был другой способ, заключавшийся в хранении приложения, обращавшегося к БД, на конкретном компьютере пользователей ("клиентов"). Были выпущены новые версии локальных СУБД, которые позволяли создавать приложения, одновременно работающие с одной БД на файловом сервере. Основной проблемой была явная или неявная обработка транзакций и неизбежно встающая при коллективном доступе проблема обеспечения смысловой и ссылочной целостности БД при одновременном изменении одних и тех же данных.
В ходе эксплуатации таких систем были выявлены общие недостатки файл-серверного подхода при обеспечении многопользовательского доступа к БД. Они состоят в следующем:
• вся тяжесть вычислительной нагрузки при доступе к БД ложится на приложение клиента, что является следствием принципа обработки информации в системах "файл-сервер": при выдаче запроса на выборку информации из таблицы вся таблица БД копируется на клиентское место, и выборка осуществляется на клиентском месте;
• локальные СУБД используют так называемый "навигационный подход", ориентированный на работу с отдельными записями; не оптимально расходуются ресурсы клиентского компьютера и сети;
например, если в результате запроса мы должны получить 2 записи из таблицы объемом 10 000 записей, все 10 000 записей будут скопированы с файл-сервера на клиентский компьютер; в результате возрастает сетевой трафик и увеличиваются требования к аппаратным мощностям пользовательского компьютера. Заметим, что потребности в постоянном увеличении вычислительных мощностей клиентского компьютера обусловливаются не только развитием программного обеспечения как такового, но и возрастанием обрабатываемых объемов информации;
• в БД на файл-сервере гораздо проще вносить изменения в отдельные таблицы, минуя приложения, непосредственно из инструментальных средств (например, из утилиты Database Desktop фирмы Borland для файлов Paradox или dBase); подобная возможность облегчается тем обстоятельством, что, фактически, у локальных СУБД база данных понятие более логическое, чем физическое, поскольку под БД понимается набор отдельных таблиц, сосуществующих в едином каталоге на диске. Все это позволяет говорить о низком уровне безопасности - как с точки зрения хищения и нанесения вреда, так и с точки зрения внесения ошибочных изменений;
• бизнес-правила в системах "файл-сервер" реализуются в приложении, что позволяет в разных приложениях, работающих с одной БД, проектировать взаимоисключающие бизнес-правила; смысловая целостность информации при этом может нарушаться;
• недостаточно развитый аппарат транзакций для локальных СУБД служит потенциальным источником ошибок как с точки зрения одновременного внесения изменений в одну и ту же запись, так и с точки зрения отката результатов серии объединенных по смыслу в единое целое операций над БД, когда некоторые из них завершились успешно, а некоторые - нет; это может нарушать ссылочную и смысловую целостность БД.
Приведенные недостатки решаются при переводе приложений из архитектуры "файл-сервер " в архитектуру "клиент-сервер ", которая знаменует собой следующий этап в развитии СУБД. Характерной особенностью архитектуры "клиент-сервер" является перенос вычислительной нагрузки на сервер БД (SQL-сервер) и максимальная разгрузка приложения клиента от вычислительной работы, а также существенное укрепление безопасности данных - как от злонамеренных, так и просто ошибочных изменений.
БД в этом случае помещается на сетевом сервере, как и в архитектуре "файл-сервер", однако прямого доступа к БД из приложений не происходит. Функции прямого обращения к БД осуществляет специальная управляющая программа - сервер БД (SQL-сервер), поставляемая разработчиком СУБД.
Взаимодействие сервера БД и приложения-клиента происходит следующим образом: клиент формирует SQL-запрос и отсылает его серверу. Сервер, приняв запрос, выполняет его и результат возвращает клиенту. В клиентском приложении в основном осуществляется интерпретация полученных от сервера данных, реализация интерфейса с пользователем и ввод данных, а также реализация части бизнес-правил.
Преимущества архитектуры "клиент-сервер":
• большинство вычислительных процессов происходит на сервере; таким образом снижаются требования к вычислительным мощностям компьютера клиента;
• снижается сетевой график за счет посылки сервером клиенту только тех данных, которые он запрашивал; например, если необходимо сделать из таблицы объемом 10 000 записей выборку, результатом которой будут всего 2 записи, сервер выполнит запрос и перешлет клиенту НД из 2 записей;
• упрощается наращивание вычислительных мощностей в условиях развития программного обеспечения и возрастания объемов обрабатываемых данных: проще и чаще дешевле усилить мощности на сетевом сервере или полностью заменить сервер на более мощный, нежели наращивать мощности или полностью заменять 100-500 клиентских компьютеров;
• БД на сервере представляет собой, как правило, единый файл, в котором содержатся таблицы БД, ограничения целостности и другие компоненты БД. Взломать такую БД, даже при наличии умысла, тяжело; значительно увеличивается защищенность БД от ввода неправильных значений, поскольку сервер БД проводит автоматическую проверку соответствия вводимых значений наложенным ограничениям и автоматически выполняет необходимые бизнес-правила; кроме того, сервер отслеживает уровни доступа для каждого пользователя и блокирует осуществление попыток выполнения неразрешенных для пользователя действий, например, изменения или просмотр таблиц; все это позволяет говорить о значительно более высоком уровне обеспечения безопасности БД и ссылочной и смысловой целостности информации;
• сервер реализует управление транзакциями и предотвращает попытки одновременного изменения одних и тех же данных; различные уровни изоляции транзакций позволяют определить поведение сервера при возникновении ситуаций одновременного изменения данных;
• безопасность системы возрастает за счет переноса большей части бизнес-правил на сервер; падает удельный вес противоречащих друг другу бизнес-правил в клиентских приложениях, выполняющих разные действия над БД; определить такие противоречивые бизнес-правила в приложениях клиента все еще можно, однако намного труднее их выполнить ввиду автоматического отслеживания сервером БД правильности данных.
Для реализации архитектуры применяют так называемые "промышленные" ("удаленные") СУБД, такие как Borland InterBase, Oracle, Informix, Sybase, DB2, MS SQL Server.
В дальнейшем реализация архитектуры "клиент-сервер" будет рассматриваться для сервера Borland InterBase. Объяснить такой выбор нетрудно. Во-первых, InterBase - "родной" сервер для Delphi (поэтому для доступа к нему не нужно устанавливать дополнительных драйверов SQL Links, что необходимо при работе из приложений, написанных на Delphi, с Oracle, Sybase и другими СУБД). Во-вторых, в поставку Delphi входит локальный (однопользовательский, на 2 одновременных подключения) сервер Local Borland InterBase. Доступен также и InterBase для Windows 95 на 4 пользователя.
Локальный InterBase может использоваться для отладочных целей. После того, как приложение отлажено на локальной версии SQL-сервера, происходит масштабирование приложения (upsizing}. БД переносится на сетевой сервер, а изменения в клиентских приложениях при этом минимальны - необходимо изменить псевдоним БД и, может быть, скорректировать некоторые параметры соединения приложения с сервером.
При переносе приложений, ранее разработанных для применения в архитектуре "файл-сервер", требуется не только частично или полностью переписывать приложения клиентов, но и преобразовывать локальную БД в серверную. Для этого под управлением серверной СУБД (например, InterBase) создают БД на сервере, куда затем "перекачивают" данные из локальных СУБД, реализованных, например, с помощью Paradox. Основная проблема, встающая в этом случае - несовместимость некоторых форматов данных или их отсутствие. Например, InterBase не поддерживает поля типа Boolean (Logical), и их необходимо реализовывать при помощи столбцов типа CHAR(l); InterBase не поддерживает автоинкрементные поля Paradox - для обеспечения уникальности значений в числовых полях в БД InterBase используют генераторы и т.д. При возникновении подобных проблем следует изучить вопросы совместимости типов данных локальной СУБД и выбранной серверной СУБД.
SQL-сервер Borland InterBase и его основные компоненты
SQL-сервер Borland InterBase является "промышленной" СУБД, предназначенной для хранения и выдачи больших объемов данных при использовании архитектуры "клиент-сервер" в условиях одновременной работы с БД множества клиентских приложений. Масштаб информационной системы при этом произволен - от системы уровня рабочей группы (под управлением Novell Netware или Windows NT на базе IBM PC) до системы уровня большого предприятия (на базе серверов IBM, Hewlett-Packard, SUN),
Рассмотрим ряд компонентов InterBase, использование которых обеспечивает максимальную вычислительную разгрузку клиентского приложения и гарантирует высокую безопасность и целостность информации.
Для задания ссылочной и смысловой целостности в БД определяются:
• отношения подчиненности между таблицами БД путем определения первичных (PRIMARY) ключей у родительских и внешних (FOREIGN) ключей у дочерних таблиц;
• ограничения на значения отдельных столбцов путем определения ограничений (CONSTRAINT) на значение домена или столбца; при этом условия ограничений могут быть весьма разнообразны - от требования попадания значения в определенный диапазон или соответствия маске до определенного отношения с одной или несколькими записями из другой таблицы (или многих таблиц) БД,
• бизнес-правила при помощи триггеров (TRIGGER) - подпрограмм, автоматически выполняемых сервером до или (и) после события изменения записи в таблице БД;
• уникальные значения нужных полей путем создания и использования генераторов (GENERATOR).
Для ускорения работы клиентских приложений с удаленной БД могут быть определены хранимые процедуры (STORED PROCEDURE), которые представляют собой подпрограммы, принимающие и возвращающие параметры и могущие выполнять запросы к БД, условные ветвления и циклическую обработку. Хранимые процедуры пишутся на специальном алгоритмическом языке. В хранимых процедурах программируются часто повторяемые последовательности запросов к БД. Текст процедур хранится на сервере в откомпилированном виде. Преимущества в использовании хранимых процедур очевидны:
• отпадает необходимость синтаксической проверки каждого запроса и его компиляции перед выполнением, что убыстряет выполнение запросов;
• отпадает необходимость реализации в приложении запросов, определенных в теле хранимых процедур;
• увеличивается скорость обработки транзакций, т.к. вместо подчас длинного SQL-запроса по сети передается относительно короткое обращение к хранимой процедуре.
В составе записи БД могут определяться blob-поля (Binary Large Object, большой двоичный объект), предназначенные для хранения больших объемов данных в виде последовательности байтов. Таким образом могут храниться текстовые и графические документы, файлы мультимедиа, звуковые файлы и т.д. Интерпретация BLOB-поля выполняется в приложении, однако разработчик может определить так называемые BLOB-фильтры для автоматического преобразования содержимого BLOB-поля к другому виду.
InterBase дает возможность использовать определяемые пользователем функции (User Defined Function, UDF), в которых могут реализовываться функциональности, отсутствующие в стандартных встроенных функциях InterBase (вычисление максимума, минимума, среднего значения, преобразование типов и приведение букв к заглавным). Например, в UDF можно реализовать извлечение из значения даты номера дня, года; определение длины символьного значения; усечение пробелов;
разные математические алгоритмы и другое. Функция пишется на любом алгоритмическом языке, позволяющем разрабатывать DLL (библиотеки динамического вызова), например на Object Pascal.
InterBase может посылать уведомления клиентским приложениям о наступлении какого-либо события (EVENT). Одновременно работающие приложения могут обмениваться сообщениями через сервер БД, вызывая хранимые процедуры, в которых реализована инициация нужного события.
Для обеспечения быстроты выполнения запросов и снятия с клиентского приложения необходимости такие запросы выдавать в БД можно определить виртуальные таблицы (или просмотры, VIEW), в которых объединяются записи из одной или более таблиц, соответствующих некоторому условию. Работа с просмотром из клиентского приложения ничем не отличается от работы с обычной таблицей. Поддерживает просмотр сервер, реагируя на изменение данных в БД. Просмотры могут быть изменяемыми и не допускающими внесения в них изменений.
Для доступа к БД используется утилита Windows Interactive SQL (WISQL). Она работает с БД напрямую через InterBase API, минуя BDE. В WISQL можно выдавать любые запросы, будь то создание БД, таблиц, изменение структуры данных, извлечение данных из БД или их изменение, а также назначение прав доступа к информации для отдельных пользователей.
Для управления SQL-сервером в целом и отдельными БД в частности используется утилита InterBase Server Manager. Здесь можно определять параметры SQL-сервера, производить сохранение, восстановление БД, сборку "мусора", определять новых пользователей, их пароли и т д.
Для просмотра БД, работы с таблицами, индексами, доменами, ограничениями и др. могут использоваться утилиты Database Desktop (весьма ограниченно) и SQL Explorer.
Для просмотра и анализа реальных процессов, происходящих на сервере при реализации пользовательского запроса, используется утилита SQL Monitor.
InterBase: некоторые технические характеристики
Приведем некоторые технические характеристики сервера (К -1024 байта)
| Характеристика | Значение |
| Максимальный размер одной БД | Рекомендуется не выше 10 Гбайт. Однако известны случаи объема одной БД в 10-20 Гбайт |
| Максимальное число таблиц в одной БД | 65,536 |
| Максимальное число полей (столбцов) в одной таблице | 1000 |
| Максимальное число записей в одной таблице | Не ограничено |
| Максимальная длина записи | 64 К (не считая полей BLOB) |
| Максимальная длина поля | 32 К (кроме полей BLOB) |
| Максимальная длина поля BLOB | Не ограничена |
| Максимальное число индексов в БД | 65,536 |
| Максимальное число полей в индексе | 16 |
| Максимальное число вложенностей SQL-запроса | 16 |
| Максимальный размер хранимой процедуры или триггера | 48 К |
| Максимальное количество UDF в базе данных | Длина имени UDF - не более 31 символов. Каждый UDF должен иметь уникальное имя. Максимальное число UDF ограничивается только требованием уникальности имени |
InterBase активно используется в США в государственном и военном секторах, что, видимо, и стало преградой для движения InterBase в Россию. В России InterBase используется с 1993 г., но интерес к этому SQL-серверу возрос только в последнее время, в связи с включением его локальной (или 4-х пользовательской версии) в состав Delphi Client/Server Suite. Внимание разработчиков БД и приложений InterBase привлек, во-первых, потому, что это "родной" продукт Borland (а средства разработки приложений этой компании давно зарекомендовали себя с положительной стороны), во-вторых, потому, что InterBase весьма прост в установке, настройке и - главное - в администрировании по сравнению с другими SQL-серверами, и в-третьих, потому, что он обладает прекрасными функциональными возможностями.
Физическая организация базы данных InterBase
База данных InterBase состоит из последовательно начиная с 0 пронумерованных страниц. Нулевая страница является служебной и содержит информацию, необходимую для соединения с БД
Размер страницы - 1 (по умолчанию), 2, 4 или 8 Кбайт. Размер страницы устанавливается при создании БД, но может быть изменен при сохранении и восстановлении БД. Одна страница читается сервером за один логический доступ к БД. Поэтому размер страницы рекомендуется делать равным размеру кластера диска, однако в зависимости от того, какие операции чаще выполняются для БД - операции чтения или записи, - рекомендуется соответствующим образом изменять размер страницы, учитывая также длину записи и наличие BLOB.
Объем буфера ввода-вывода для операций чтения-записи определяется в количестве страниц (по умолчанию - 75). Если БД будет чаще читаться, объем буфера следует увеличить. Если в нее будет чаще осуществляться запись, размер буфера следует уменьшить.
В InterBase поддерживается многоверсионная структура записей. При изменении записи какой-либо транзакцией создается новая версия записи, куда помимо данных записывается номер транзакции и указатель на предыдущую версию записи. Старая версия записи помечается как измененная; ее указатель на следующую версию записи указывает на вновь созданную версию данной записи. Каждая стартующая транзакция работает с последней версией записи, изменения для которой подтверждены. Таким образом, параллельно работающие с БД транзакции всегда используют разные версии записей, что позволяет снимать блокировки для клиентских приложений, одновременно работающих с одними и теми же данными в БД. Более подробно об этом рассказано в разделе, посвященном управлению транзакциями. При удалении записи она также физически не удаляется с диска, а помечается как удаленная до тех пор, пока не завершена хотя бы одна активная транзакция, использующая эту запись.
InterBase располагает на одной странице БД версии одной записи таблицы БД. После удаления записей на странице образуются "дырки". При добавлении новой записи анализируется размер максимальной дырки и, если он меньше длины добавляемой записи, происходит компрессия страницы, в процессе которой "дырки" объединяются. Если суммарной "дырки" не хватает для размещения новой записи, та записывается с новой страницы. Загрузка страницы считается нормальной в случае, если "дырки" занимают не более 20% объема страницы.
Выделение страниц никак не оптимизировано. На отдельной служебной странице БД хранятся номера всех свободных страниц. При выделении страниц не предпринимается никаких действий по выделению непрерывных страниц для хранения записей одной таблицы БД, а выделяется первая страница в списке свободных. Если свободной страницы нет, добавляется новая в конец БД. Только в этом случае размер БД возрастает.
Многоверсионная структура записей и неоптимальное выделение страниц ведет к высокой фрагментации БД и как следствие - к замедлению работы с БД. Поэтому необходимо периодически производить дефрагментацию.
Дефрагментированная БД характеризуется расположением записей таблиц БД на непрерывных страницах и отсутствием "мусора". Под мусором понимаются версии записей, с которыми не работает никакая активная транзакция. Известно, что если транзакции, использующие не последнюю версию записи, завершились, никакая другая транзакция из вновь стартующих не будет работать с данной версией записи, поскольку имеются более поздние версии (как минимум одна).
Существует несколько способов проведения дефрагментации.
Первый состоит в сохранении БД на дисковом носителе и последующем ее восстановлении из сделанной резервной копии. Данные действия реализуются в утилите InterBase Server Manager. Этот способ является предпочтительным, поскольку гарантирует сбор всего мусора (в момент сохранения и восстановления БД не должно быть активных подключений к БД со стороны иных пользователей и потому не может быть активных транзакций).
Второй способ состоит в автоматическом сборе мусора. Интервал (sweep interval), через который происходит сборка мусора, измеряется в транзакциях. По умолчанию автоматический сбор мусора производится через каждые 20 000 транзакций. Этот показатель может быть изменен в утилите InterBase Server Manager. Там же может быть предпринята принудительная сборка мусора. Данный способ дефрагментации БД менее предпочтителен, поскольку удаляются только те старые версии записей, для которых нет активных транзакций. В результате могут быть удалены не все старые версии. При большом числе активных транзакций процесс сборки мусора может существенно замедлить их выполнение.
Если на Вашей машине установлен InterBase (локальный или многопользовательский), его старт происходит автоматически при загрузке операционной системы. Об этом сигнализирует значок
справа на нижней панели Windows 95/NT. Щелкнув на этом значке правой кнопкой мыши, можно вызвать
 вспомогательное меню. Опция Startup Configuration этого меню позволяет просмотреть и переопределить стартовые установки InterBase. Опция Shutdown завершает работу SQL-сервера. Опция Properties позволяет просматривать свойства InterBase и текущей сессии, например число активных подключений и число используемых БД.
вспомогательное меню. Опция Startup Configuration этого меню позволяет просмотреть и переопределить стартовые установки InterBase. Опция Shutdown завершает работу SQL-сервера. Опция Properties позволяет просматривать свойства InterBase и текущей сессии, например число активных подключений и число используемых БД.Delphi и InterBase
Delphi Client/Server Suite предназначена для написания приложений, работающих как с локальными, так и с удаленными данными. В последнем случае с помощью Delphi создаются клиентские приложения (забегая вперед, заметим, что в многозвенной архитектуре с помощью Delphi создаются также и серверы приложений - промежуточное звено между приложением "тонкого" клиента и SQL-сервером).
Написание приложений, работающих с локальными СУБД в однопользовательском и многопользовательском (в архитектуре "файл-сервер") режимах, несколько отлично от написания клиентских приложений, работающих с удаленными БД в архитектуре "клиент-сервер". Выделим сначала общие черты:
• для доступа как к локальным, так и к удаленным данным могут использоваться компоненты TTable, TQuery;
• в качестве промежуточного компонента между НД и визуальными компонентами для работы с данными, используется компонент TDataSource;
• состав визуальных компонентов для работы с данными одинаков при доступе как к локальным, так и удаленным данным.
Однако необходимо помнить о следующих отличиях:
• компонент TTable для доступа к удаленным данным использовать не рекомендуется, поскольку он требует передачи всех данных результата выполнения запроса к серверу, а не только той их части, которая должна быть визуализирована (что имеет место для компонента TQuery);
изменение записей БД следует производить не методами Insert, Edit, Delete, Post, Cancel, а при помощи SQL-операторов INSERT, UPDATE, DELETE (выполняемых при посредстве компонента TQuery, метод ExecSQL);
подобная рекомендация является следствием того факта, что в отличие от доступа к локальным СУБД, где главенствует навигационный (по одной записи) доступ к данным, при обращении к удаленным БД используется язык SQL, оперирующий сразу множеством записей;
• следует уделять особое внимание управлению транзакциями и в первую очередь - выбору, адекватного потребностям приложения уровня изоляции транзакций;
• для соединения с удаленной БД всех компонентов, работающих с этой БД, следует использовать как можно меньше компонентов TDatabase (в идеале - один), определяемых в приложении явно (поскольку в этом случае можно управлять параметрами соединения с удаленной БД);
• бизнес-правила, где это возможно, следует переносить на сервер, разгружая от них клиентское приложение;
• для обращения к хранимым процедурам на сервере можно использовать компонент TStoredProc;
• следует стремиться как можно меньше загружать сетевой трафик путем явного старта и подтверждения транзакций (методы TDatabase Start Transaction, TDatabase Commit), поскольку изменения БД в рамках одной транзакции выполняются одним пакетом; когда подтверждение единичных изменений БД производится неявно стартуемыми и завершаемыми (в режиме SQLPASSTHRU = SHARED AUTOCOMMIT) транзакциями, это ведет к возрастанию графика и, как следствие, к замедлению работы, часто весьма существенному;
• следует уделять существенное внимание оптимизации запросов к БД, особенно при чтении данных (SELECT), поскольку оптимально построенный запрос может выполняться в несколько раз быстрее, чем неоптимальный, и требовать меньшего количества ресурсов для своего выполнения;
• компонент TIBEventAlerter, служащий для получения от сервера уведомления о наступлении событий, может применяться только при доступе к удаленным данным.
Приведенные выше особенности разработки клиентского приложения, так же как и особенности организации серверных БД и доступа к информации в них, будут рассмотрены в следующих разделах.
Вопросы соединения с удаленным сервером
При работе с локальным сервером достаточно установить псевдоним БД (утилита BDE Administrator) и затем использовать данный псевдоним в приложении Delphi, в компонентах TDatabase и, может быть, TTable и TQuery (когда соединение с БД производится, минуя компонент TDatabase). При доступе к локальному серверу напрямую из InterBase (например, из утилиты WISQL) указывается путь к БД (InterBase работает с БД, используя собственный API и ничего не "зная" о BDE).
При работе с удаленным сервером необходимо "прописать" его на компьютере, с которого происходит обращение к серверу. При этом не важно, будем мы работать с БД на сервере при помощи BDE (т.е. с использованием псевдонимов БД) или напрямую из InterBase, указывая путь к БД непосредственно.
Для удаленного сервера (при использовании протокола TCP/IP):
1) его IP-адрес и имя должны быть описаны в файле HOSTS, например: 10.12.0.41 spv
2) протокол доступа к InterBase должен быть описан в файле SERV ICE:
gds_db 3050/tcp Оба указанных файла находятся в каталоге WINDOWS.
Создание БД "Учет товаров на складе"
Создадим простую БД для учета товаров на складе. Рассмотрим все шаги, необходимые для этого.
На рис. 17.1 приведена модель БД, которая будет далее использоваться в примерах второй части книги.
Структура процессов, подлежащих учету в нашей БД, проста. Каждый день на склад поступают товары. Допустим, процесс прихода товаров и проблема учета такого прихода нас не интересуют. Например, сведения о приходе и количестве товара аккумулируются в другой БД. Нам необходимо лишь вести учет отпуска товаров со склада. При этом подразумевается, что если товар отпускается, он на складе есть и как минимум в том количестве, которое нужно отпустить Пусть контроль за соответствием остатков товара запросам на его продажу ведет кто-нибудь другой - неважно, программа или человек.
Таким образом, предлагаемая в качестве примера простейшая БД предназначена для механического учета отпуска товара со склада.
Каждый товар имеет уникальное название (по нему построен первичный ключ) и обладает двумя атрибутами - единицей измерения и стоимостью за единицу измерения Если один и тот же товар присутствует на складе в разных единицах измерения (например, сахар в мешках, фасованный в пакетах, фасованный в коробках и т.д.; огурцы в банках и огурцы развесные и пр.), для каждого такого случая один и тот же товар должен иметь семантически одинаковое, но синтаксически разное название, например "Огурцы баночные", "Огурцы развесные" Так сделано нами для простоты Несомненно, многие разработчики БД определят в таблице "Товары" составной первичный ключ по столбцам НАЗВАНИЕ ТОВАРА и ЕД ИЗМЕРЕНИЯ, чтобы иметь возможность указывать синтаксически одно название товара для разных случаев единиц измерения Отметим, что практическая предпочтительность того или иного подхода зависит от особенностей конкретной предметной области.
Сразу оговоримся, что цена товара не имеет тенденции изменяться во времени Товар всегда отпускается по фиксированной цене, указанной в столбце ЦЕНА ЕД. ИЗМЕРЕНИЯ для данного товара Такое условие взято нами для простоты БД, иначе мы можем погрязнуть в вопросах организации складской деятельности, вместо того, чтобы акцентировать внимание на технических аспектах разработки БД. Для тех, кто не согласен с данной оговоркой, можно предложить мысленно вернуться во времена развитого социализма, когда покупка и отпуск товаров осуществлялся по установленной свыше цене, или допустить, что цены установлены в условных единицах, не подверженных воздействию инфляции.
Договоримся, что в течение одного и того же дня один и тот же покупатель может многократно получать со склада один и тот же товар. Поэтому в таблице "Расход товара" в качестве первичного ключа не годится последовательность столбцов ДАТА РАСХОДА, НАЗВАНИЕ ТОВАРА, НАЗВАНИЕ ПОКУПАТЕЛЯ. Такие значения могут дублироваться. Поэтому введем столбец НОМЕР РАСХОДА, который должен содержать некоторый уникальный номер, и примем его в качестве первичного ключа. Вопрос, каким образом попадают в данный столбец уникальные значения, оставим открытым (необходимо использование генератора, речь о котором пойдет в этой главе ниже).
Информация собственно о покупателе не требует никаких оговорок, за исключением того, что столбец ГОРОД выделен нами из АДРЕСА для дальнейших упражнений по составлению запросов и использованию оператора SELECT. Первичным ключом в данном случае служит столбец НАЗВАНИЕ ПОКУПАТЕЛЯ.
Как видим, таблица "Расход товара" является дочерней таблицей для таблиц "Товары" и "Покупатели" и находится с ними в связи "многие-к-
одному". Поэтому между дочерней таблицей и каждой из ее родительских таблиц должна быть установлена ссылочная целостность. Для этого в таблице "Товары" определим внешний ключ по столбцу "НАЗВАНИЕ ТОВАРА", ссылающийся на первичный ключ таблицы "Товары", и внешний ключ по столбцу "НАЗВАНИЕ ПОКУПАТЕЛЯ", ссылающийся на первичный ключ таблицы "Покупатели".
Создание псевдонима удаленной БД
Пусть БД будет находиться в каталоге D:\BOOK\IB_SKLAD Заметим, что на этапе создания БД и отладки приложения мы будем использовать локальный вариант InterBase, поставляемый с Delphi Client/Server Suite Пусть создаваемая БД будет иметь имя IB_SKLAD GDB. Назначим ей псевдоним ib_skl, используя утилиту BDE Administrator (рис. 17.2). Данный псевдоним будет нам нужен для написания клиентской части приложения по учету расхода товаров со склада.
Обратим внимание на то, что для БД, которые будут содержать русскоязычную текстовую информацию в строковых столбцах с использованием набора символов WIN 1251 и порядка сортировки PXW_CYRL, необходимо сразу установить для псевдонима драйвер Pdox ANSI Cyrillic в строке LANGDRIVER.
Создание БД
Используя утилиту InterBase Windows ISQL (interactive SQL), далее называемый WISQL, создадим БД. Для этого запустим утилиту WISQL и в главном меню выберем режим File \ Create Database. Далее, в окне диалога укажем имя БД, имя пользователя SYSDBA, пароль masterkey (имя и пароль системного администратора для локального сервера InterBase), а также в окне DataBase Options - параметры БД. В нашем случае в качестве единственного параметра будет введена установка по умолчанию набора символов WIN1251 (рис. 17.3).
Соединение с БД
Перед соединением с БД необходимо установить текущий набор символов в режиме Session | Advanced Settings (рис. 17.4).
Соединение с БД производится в режиме File \ Connect to DataBase. Для соединения необходимо указать имя БД, имя пользователя и пароль, (рис. 17.5)
В случае отсутствия сообщений об ошибках, соединение с БД установлено.
Создание таблиц БД
Перед созданием таблиц должны быть реализованы SQL-операторы CREATE TABLE для каждой создаваемой таблицы. Существует два способа выполнения SQL-операторов в WISQL. Первый заключается в наборе текста оператора в окне SQL Statement. В дальнейшем набранный оператор выполняется после нажатия кнопки Run. Второй способ состоит в формировании текстового файла, который содержит от одного до нескольких SQL-операторов. Такой файл выполняется в режиме File \ Run an SQL script.
Для описываемого примера воспользуемся первым способом. Поэтапно введем и выполним в окне SQL Statement (рис. 17.6) следующие операторы:
CREATE TABLE POKUPATELI(
POKUP VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
GOROD VARCHAR(12) COLLATE PXW_CYRL,
ADRES VARCHAR(20) COLLATE PXW_CYRL,
PRIMARY KEY(POKUP)
) ;
CREATE TABLE TOVARY(
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
ED_IZM VARCHAR(lO) NOT NULL COLLATE PXW_CYRL,
ZENA INTEGER NOT NULL,
PRIMARY KEY(TOVAR)
) ;
CREATE TABLE RASHOD(
N_RASH INTEGER NOT NULL,
DAT_RASH DATE NOT NULL,
KOLVO INTEGER NOT NULL,
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
POKUP VARCHAR(20) COLLATE PXW_CYRL,
PRIMARY KEY(N_RASH),
FOREIGN KEY(POKUP) REFERENCES POKUPATELI,
FOREIGN KEY(TOVAR) REFERENCES TOVARY
Для подтверждения выполненных действий выберите в главном меню режим File | Commit Work или введите в окне SQL Statement и выполните оператор COMMIT Если Вы по каким-либо причинам решили не запоминать изменений, выберите режим File | Rollback Work или выполните оператор ROLLBACK.
Выполните разъединение с БД, выбрав в главном меню опцию File | Disconnect from DataBase и затем выберите Еxit для выхода из W1SQL.
Соединение с БД из приложения
Соединение с БД, расположенной на сервере, осуществляется при помощи компонента TDataBase
Разместим в форме такой компонент с именем DataBase 1 и установим в его свойство AliasName значение ранее созданного псевдонима 'ib_skl' В свойство DaiaBaseName поместим значение 'm_sklad' Это имя будет в дальнейшем служить именем нашей БД в компонентах, реализующих запросы к базе данных
Для установки параметров соединения с БД вызовем в редактор свойств БД Для этого щелкнем по компоненту DataBasel правой кнопкой мыши и выберем в появившемся меню опцию Datable Editor Нажмем кнопку Defaults для получения параметров БД, принятых по умолчанию Введем пароль
PASSWORD=masterkey
затем укажем имя пользователя
USER NAME=SYSDBA
после чего снимем отметку с флажка Login Prompt, указывающего на необходимость выдачи окна ввода имени пользователя и пароля (рис. 17.7)
Нажмем кнопку Ok. Теперь, поскольку в параметрах БД указаны имя пользователя и пароль, приложение будет соединяться с БД автоматически. Для соединения с БД установим свойство Connected в True
Создание формы ввода в ТБД
Для каждой из таблиц создадим НД Для этого разместим в форме три компонента TTable с именами Tovary Table, Роkир Table и RashodTable. В свойство DalabaseName каждого из них занесем 'm_sklad', выбрав его из выпадающего списка псевдонимов БД. Как можно заметить, имя 'm_sklad' установлено в свойстве DataBaseName компонента Databasel, в то время как имя зарегистрированного в BDE Configuration Utility псевдонима на самом деле есть 'ib_skl'.
Для каждого TTable выберем имя соответствующей ТБД в выпадающем списке свойства TableName Затем откроем НД, установив True в свойство Active каждого TTable .
После этого разместим в форме три компонента TDataSource и три компонента TDBGrid и соединим каждый компонент TDataSource с одним из компонентов TTable (свойство DataSet) Затем соединим каждый из компонентов TDBGrid с одним из компонентов TDataSource (свойство DataSource). Затем настроим заголовки столбцов каждого компонента TDBGrid, используя редактор столбцов TDBGrid Для этого нужно сделать компонент TDBGrid текущим элементом разрабатываемой формы, нажать правую кнопку мыши, во всплывающем меню выбрать Columns Editor, в появившемся списке перемещаться по полям и для каждого поля в инспекторе объектов установить заголовок столбца TDBGrid в свойстве TitleCaption.
Занесем в таблицы информацию, подобранную таким образом, чтобы в дальнейшем рассмотреть широкий спектр возможностей, предоставляемый оператором SELECT (рис 17 8). Самая объемная глава второй части книги, посвященная часто используемому SQL-оператору SELECT, будет построена на использовании запросов к созданной нами учебной БД.
Создание триггеров для поддержания каскадных воздействий
В рассматриваемом варианте БД соединения дочерних и родительских таблиц (соответственно RASHOD и TOVARY, POKUPATELI) являются "жесткими". Напомним, что при реализации ссылочной целостности на уровне PRIMARY KEY - FOREIGN KEY нельзя изменять значение поля связи как в дочерней таблице, так и в родительской таблице, если для данного значения первичного ключа существуют дочерние записи.
Дпя избранной структуры данных
CREATE TABLE POKUPATELI(
POKUP VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
GOROD VARCHAR(12) COLLATE PXW_CYRL,
ADRES VARCHAR(20) COLLATE PXW_CYRL,
PRIMARY KEY(POKUP)
) ;
CREATE TABLE TOVARY(
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
ED_IZM VARCHAR(IO) NOT NULL COLLATE PXW_CYRL,
ZENA INTEGER NOT NULL,
PRIMARY KEY(TOVAR)
) ;
CREATE TABLE RASHOD(
N_RASH INTEGER NOT NULL,
DAT_RASH DATE NOT NULL,
KOLVO INTEGER NOT NULL,
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
POKUP VARCHAR(20) COLLATE PXW_CYRL,
PRIMARY KEY(N_RASH),
FOREIGN KEY(POKUP) REFERENCES POKUPATELI,
FOREIGN KEY(TOVAR) REFERENCES TOVARY
) ;
жирным отмечены ограничения по внешнему ключу. Таким образом, если в таблице TOVARY для какого-либо товара существует расход в таблице RASHOD, изменение названия товара в таблице TOVARY будет блокировано. При попытке изменить в таблице TOVAR значение наименования товара с "Сахар" на "Сахар кусковой" (рис. 17 9) будет возбуждено исключение из-за нарушения жестких ограничений целостности (рис. 17.10)
Можно увидеть, что жесткие ограничения целостности будут нам мешать в дальнейшем, когда возникнет необходимость изменять название товара или покупателя Если мы не будем менять названия товаров и покупателей, жесткие ограничения целостности можно оставить, однако будем считать, что потребность в подобных изменениях все-таки может возникнуть
Поэтому вместо жестких ограничений целостности нам необходимо реализовать возможность каскадных воздействий - таких, что:
• при изменении значения столбца TOVAR в таблице TOVARY эти изменения должны быть отражены в дочерних записях в таблице RASHOD (если такие есть для изменяемой записи в таблице TOVARY),
• при удалении записи в таблице TOVARY должны быть удалены дочерние записи в таблице RASHOD, если они есть
Для достижения этой цели нужно удалить не устраивающие нас ограничения целостности между таблицами TOVARY и RASHOD и затем определить в БД триггеры, реализующие каскадные воздействия
Для удаления внешнего ключа FOREIGN KEY(TOVAR) REFERENCES TOVARY необходимо удалить ограничение ссылочной целостности, определяемое этим ключом Однако в явном виде ограничение не было определено, например
CONSTRAINTS TOV_RASH FOREIGN KEY(TOVAR) REFERENCES TOVARY
где TOV_RASH есть имя ограничения Поэтому необходимо установить системное имя, присвоенное InterBase данному ограничению внешнего ключа Это системное имя, INTEG_32, можно увидеть в сообщении, выдаваемом при возбуждении исключения по нарушению жесткой ссылочной целостности (см выше) Следует убедиться, что INTEG_32 действительно есть ограничение целостности, которое следует удалить Для этой цели необходимо воспользоваться утилитой SQL Ex plorer, найдя для таблицы RASHOD узел Refrential Constraint's (рис 17.11)
Искомое нами ограничение имеет имя INTEG.32 Удалим его Для этого запустим WISQL, соединимся с БД и выполним оператор
ALTER TABLE RASHOD
DROP CONSTRAINT INTEG_32;
Затем создадим триггеры, реализующие каскадное изменение в таблице RASHOD при изменении названия товара в таблице TOVARY
CREATE TRIGGER BU_TOVARY FOR TOVARY
ACTIVE
BEFORE UPDATE
AS
BEGIN
IF (OLD.TOVAR 0 NEW.TOVAR) THEN
UPDATE RASHOD
SET TOVAR = NEW.TOVAR
WHERE TOVAR = OLD.TOVAR;
END
и каскадное удаление дочерних записей в таблице RASHOD при удалении родительской записи в таблице TOVARY:
CREATE TRIGGER AD_TOVARY FOR TOVARY
ACTIVE
AFTER DELETE
AS
BEGIN
DELETE FROM RASHOD
WHERE RASHOD.TOVAR =TOVARY.TOVAR;
END
Теперь, при изменении наименования товара в таблице TOVARY произойдут каскадные изменения наименования товара в дочерних записях таблицы RASHOD (рис 17 12 и 17 13)
Использование генератора
В таблице RASHOD первичный индекс построен по столбцу N_RASH (номер события расхода товара со склада) По этому столбцу построен первичный ключ, поскольку никакие другие столбцы или их комбинации не могут уникально идентифицировать запись, т к в принципе допускается, что один и тот же покупатель может в течение одной даты не только произвести несколько закупок одного и того же товара, но в двух или более таких закупках приобрести одинаковое количество одного и того же товара
Поэтому в столбце N_RASH должны содержаться уникальные значения Известно, что у таблиц InterBase нет столбца типа "автоинкремент", чье значение автоматически увеличивается при добавлении новой записи (как, например, у таблиц Paradox). Однако в InterBase есть генераторы, всякий раз возвращающие уникальные значения при обращении к ним при помощи функции GEN_ID Для начала определим сам генератор и установим его стартовое значение в 1, выполнив в WISQL операторы
CREATE GENERATOR RASHOD_N_RASH;
SET GENERATOR RASHOD_N_RASH TO 1;
Затем определим для БД хранимую процедуру
CREATE PROCEDURE GET_N_RASH
RETURNS (NR INTEGER)
AS
BEGIN
NR = GEN_ID(RASHOD_N_RASH,1) ;
END
В приложении, используемом для ввода информации в таблицы TOVAR, POKUPATELI, RASHOD, определим компонент StoredProc1 для вызова хранимой процедуры GET_N_RASH Определим свойства этого компонента свойству DatabaseName присвоим значение 'in_skl' (значение свойства DatabaseName компонента Database 1), свойству StoredProcName присвоим значение 'GET_N_RASH' (имя хранимой процедуры)
Далее, вызвав редактор параметров компонента StoredProcI (щелкнув по нему правой кнопкой мыши и выбрав из всплывающего меню опцию Define Parameters), убедимся, что имя и тип выходного параметра процедуры установлены правильно (рис 17.14)
Для компонента RashodTable (тип TTable), ассоциированного с таблицей RASHOD, определим обработчик события AfterInsert, наступающего немедленно после перевода RashodTable в состояние dslnsert:
procedure TForm!.RashodTableAfterInsert(DataSet: TDataSet) ;
begin
StoredProc!.ExecProc;
RashodTable.FieldByName('N_RASH').Value := StoredProcI.ParamByName('NR').Valued-end;
ЗАМЕЧАНИЕ.
Тот же код вместо обработчика события AfterInsert можно поместить в обработчик события OnNewRecord, наступающего также после перевода RashodTable в состояние dslnsert; обработчик этого события обычно используется для занесения умалчиваемого значения в столбцы добавляемой записи, что имеет место до того, как значения столбцов вновь добавляемой записи будут визуализированы и доступны для изменения пользователем. Теперь при переводе RashodTable в состояние dslnsert будет открываться компонент StoredProcI, который будет вызывать процедуру GET_N_RASH. С помощью этой процедуры определяется уникальное значение, которое затем помещается в столбец N_RASH вновь добавляемой записи. Это будет происходить до того, как вновь добавляемая запись будет показана пользователю для корректировки.
Создание приложения для занесения данных
Создадим приложение Inp dpr для занесения данных в БД "Расход товаров со склада". Для этого создадим приложение.
Установка набора символов текущей сессии
Как известно, в БД могут храниться символьные данные, использующие различные наборы символов для указания той или иной национальной кодировки. Для того, чтобы не возникало никаких проблем для обработки русскоязычных данных, перед соединением с БД (созданной с указанием DEFAULT CHARACTER SET WIN1251) необходимо выбрать элемент меню Session | Advanced Settings и установить в поле Character Set On кодировку WIN1251 (рис. 18.1), после чего нажать кнопку Ok.
Создание БД
Для создания БД необходимо выбрать элемент меню Ei/el Create Database и затем в появившемся окне ввести необходимую информацию (рис. 18.2).
Location Info - информация о расположении создаваемой БД. Local Server -данный компьютер; Remote Server - удаленный компьютер. В последнем случае необходимо указать имя сервера (поле Server) и сетевой протокол (поле Net Work Protocol). В случае использования удаленного сервера:
1) его IP-адрес и имя должны быть описаны в файле HOSTS, например: 10.12.0.41 spv
2) протокол доступа к InterBase должен быть описан в файле SERVICE: gds_db 3050/tcp
Оба указанных файла находятся в каталоге WINDOWS.
Database Name -
определяет имя создаваемой БД и полный путь к ней (поле Database). Далее необходимо ввести имя пользователя (поле User Name) и пароль (поле Password). Default Option -
параметры создаваемой БД. Именно в данном поле вводятся принимаемый по умолчанию набор символов (DEFAULT CHARACTER SET) и другие параметры, которые указываются в SQL-операторе CREATE DATABASE.
Соединение с БД
Для соединения с БД необходимо выбрать элемент меню File \ Connect to Database и указать реквизиты базы данных (рис. 18.3).
Location Info -
информация о расположении создаваемой БД. Local Server -данный компьютер; Remote Server - удаленный компьютер. В последнем случае необходимо указать имя сервера (поле Server) и сетевой протокол (поле Net Work Protocol). Database Name -
определяет имя создаваемой БД и полный путь к ней (поле Database). Далее необходимо ввести имя пользователя (поле User Name} и пароль (поле Password).
Выполнение SQL-операторов
После соединения с БД к ней можно адресовать запросы с помощью операторов SQL. В верхнем окне WISQL вводится SQL-оператор и для выполнения нажимается кнопка Run. Листать введенные SQL-операторы можно при помощи кнопок Previous и Next. В нижнем окне после выполнения оператора дублируется текст самого оператора и, в случае его правильности, показываются результаты выполнения запроса (рис. 18.4). Операторы могут завершаться точкой с запятой (при вводе операторов из WISQL это требование не является обязательным).
Могут выполняться все разрешенные SQL-операторы - от операторов определения метаданных (CREATE TABLE, CREATE PROCEDURE, DROP VIEW, DECLARE FUNCTION и т.д.) до непосредственно запросов к таблицам БД для чтения (SELECT) и изменения данных (INSERT, UPDATE, DELETE).
Подтверждение и откат изменений
При старте WISQL стартует неявная транзакция. Поэтому все запросы к БД в рамках сессии WISQL не актуализируются до выдачи подтверждения.
Подтверждение может выдаваться путем выполнения оператора COMMIT при выборе элемента меню File \ Commit Work. В последнем случае запрашивается подтверждение (рис. 18.5).
Подтверждение запрашивается также при разрыве соединения с БД (режим меню File \ Disconnect from Database) и при выходе из WISQL (режим меню File \ Exit).
При разрыве соединения с БД или при выходе из WISQL отказаться от изменений, произведенных в рамках текущей транзакции, можно при помощи оператора ROLLBACK путем выбора элемента меню File \ Rollback Work.
После подтверждения или отката транзакции неявно стартует новая транзакция. Явно запустить транзакцию можно, выполнив оператор SET TRANSACTION.
Просмотр структуры компонентов БД
Просмотр структуры компонентов БД (метаданных) осуществляется с помощью элемента меню View. Выбрав в выпадающем меню единственный элемент Metadata Information, можно затем указать компонент БД, информацию о котором необходимо получить(рис. 18.6).
Например, получим информацию о всех хранимых процедурах, объявленных в БД. Для этого в выпадающем списке выберем Procedure (поле View Information On), а поле Object Name оставим пустым (рис. 18.7) и нажмем кнопку Ok. В результате получим список хранимых процедур, объявленных в БД (рис. 18.8)
Ввод в поле Object Name имени конкретного компонента БД (в данном случае процедуры RASHOD_TOVARA) приведет к выводу тела процедуры и списка параметров (рис. 18.9).
Просмотр структуры БД
Полную структуру базы данных (все метаданные БД) можно получить, выбрав элемент меню Extract.
Выбор в выпадающем меню режима SQL Metadata for Database приведет к выдаче всех метаданных БД (в том виде, в котором их интерпретировал InterBase (рис. 18.10). Например, можно заметить, что внешние ключи, объявленные внутри оператора CREATE TABLE, преобразуются к ALTER TABLE...ADD FOREIGN KEY. Для получения данных за пределами окна воспользуйтесь полосой прокрутки. Перед выдачей метаданных поступит предложение сохранить их в файле на диске.
Выбор в выпадающем меню режима SQL Metadata for Table и выбор имени соответствующей таблицы приведут к выдаче метаданных по конкретной таблице. Перед выдачей метаданных поступит предложение сохранить их в файле на диске.
Установка режимов работы WISQL
Режимы работы текущей сессии WISQL можно определить, выбрав элемент меню Settings \ Basic Settings (рис. 18.11).
Auto Commit DDL
определяет, следует ли автоматически завершать транзакцию для операторов языка определения данных (Data Definition Language), например, CREATE TABLE, DROP PROCEDURE и т.д. По умолчанию установлено автоматическое подтверждение операторов DDL. Display Query Plan
определяет, показывать или нет план выполнения запроса на чтение данных из БД, т.е. какие реальные индексы использует InterBase для выполнения операторов SELECT (рис. 18.12). Display Statistics
определяет, выводить или нет после каждого запроса системную информацию, например: SELECT R.DAT_RASH,R.TOVAR, (R.KOLVO * Т.ZENA) AS STOIM FROM RASHOD R, TOVARY T
WHERE R.TOVAR = T.TOVAR
DAT_RASH TOVAR STOIM
10-JAN-1997 Сахар 80
10-JAN-1997 Сахар 2036
10-JAN-1997 Ставрида консерв. 15000
10-JAN-1997 Кока-кола 12000
20-JAN-1997 Сахар 120
20-JAN-1997 Кока-кола 60
20-JAN-1997 Кока-кола 3000
10-JAN-1997 Кока-кола 300
Current memory = 346112
Delta memory = -1024
Max memory = 352256
Elapsed time= 0.06 sec
Buffers = 256
Reads = 0
Writes 0
Fetches = 53
Display
in List Formal определяет, включен ли показ данных в режиме списка, то есть показ записей не по горизонтали, а по вертикали: SELECT R.DAT_RASH,R.TOVAR, (R.KOLVO * T.ZENA) AS STOIM
FROM RASHOD R, TOVARY T
WHERE R.TOVAR = T.TOVAR AND
R.KOLVO > 1000
DAT_RASH 10-JAN-1997
TOVAR Ставрида консерв.
STOIM 15000
DAT_RASH 10-JAN-1997
TOVAR Кока-кола
STOIM 12000
По умолчанию данный режим отключен.
Display Row Count
включает и отключает показ счетчика строк при выдача результата запроса: SELECT R.DAT_RASH,R.TOVAR, (R.KOLVO * T.ZENA) AS STOIM
FROM RASHOD R, TOVARY T
WHERE R.TOVAR = T.TOVAR AND
R.KOLVO > 1000
DAT_RASH TOVAR STOIM
10-JAN-1997 Ставрида консерв. 15000
10-JAN-1997 Кока-кола 12000
Records affected: 2
По умолчанию данный режим отключен.
Display Time Datatype
включает и выключает режим показа времени в значениях типа DATE, где, как известно, хранятся дата и время одновременно: SELECT R.DAT_RASH,R.TOVAR, (R.KOLVO * T.ZENA) AS STOIM
FROM RASHOD R, TOVARY T
WHERE R.TOVAR = T.TOVAR AND
R.KOLVO > 1000
DAT_RASH TOVAR STOIM
10-JAN-1997 00:00:00 Ставрида консерв. 15000
10-JAN-1997 00:00:00 Кока-кола 12000
По умолчанию данный режим отключен.
Выполнение Script-файлов
Текст SQL-запросов может быть оформлен в виде файла и затем выполнен (элемент меню File [ Run an ISQL Script}. Преимущество такого подхода очевидно в тех случаях, когда необходимо периодически выполнять повторяющиеся последовательности операторов. Операторы создания БД, таблиц, процедур, триггеров и т.д. также могут выполняться из отдельного Script-файла.
Для случая создания в Script-файле хранимых процедур и триггеров необходимо применять оператор
SET TERM НовыйРазделитель;
Необходимость его применения связана с тем, что стандартным разделителем SQL-операторов является точка с запятой ';'. В WISQL этот разделитель можно опускать, а вот в SQL-скрипте разделитель обязателен. Как известно, в теле хранимых процедур и триггеров операторы разделяются таким же разделителем:
CREATE PROCEDURE FIND_MAX_KOLVO (IN_TOVAR VARCHAR(20))
RETURNS(MAX_KOLVO INTEGER) AS
BEGIN
SELECT MAX(KOLVO)
FROM RASHOD
WHERE TOVAR = : IN_TOVAR
INTO : MAX_KOLVO;
SUSPEND;
END;
Поэтому перед выполнением оператора CREATE PROCEDURE или CREATE TRIGGER устанавливают новый разделитель, завершают им одно или несколько идущих подряд определений процедур и триггеров, а затем восстанавливают старый разделитель. Например,
SET TERM ### ;
CREATE PROCEDURE FIND_MAX_KOLVO (IN_TOVAR VARCHAR(20))
RETURNS(MAX_KOLVO INTEGER) AS
BEGIN
SELECT MAX(KOLVO)
FROM RASHOD
WHERE TOVAR = : IN_TOVAR
INTO : MAX_KOLVO;
SUSPEND;
END ###
SET TERM ; ###
При вводе и выполнении SQL-операторов непосредственно в окне WISQL, автоматически формируется последовательность операторов
SET TERM ^;
SET TERM ;^
Пример.
Рассмотрим Script-файл 'CR_DB.SQL', осуществляющий создание БД и в ней нескольких таблиц, процедур и триггеров. Перед созданием БД ее старая версия уничтожается и выполняется оператор формата SET NAMES
НаборСимволов; а именно SET NAMES WIN1251; Он аналогичен по действию установке набора символов WIN1251 в Session | Advanced Settings WISQL.
Содержимое Script-файла:
set names WIN1251;
connect "d:\book\ib_sklad\ib_sklad.gdb" USER "SYSDBA"
PASSWORD "masterkey";
drop database;
create database "d:\book\ib_sklad\ib_sklad.gdb" USER "SYSDBA"
PASSWORD "masterkey"
default character set WIN1251;
connect "d:\book\ib_sklad\ib_sklad.gdb" USER "SYSDBA"
PASSWORD "masterkey";
CREATE TABLE POKUPATELI(
POKUP VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
GOROD VARCHAR(12) COLLATE PXW_CYRL,
ADRES VARCHAR(20) COLLATE PXW_CYRL,
PRIMARY KEY(POKUP)
);
CREATE TABLE TOVARY(
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
ED_IZM VARCHAR(lO) NOT NULL COLLATE PXW_CYRL,
ZENA INTEGER NOT NULL,
PRIMARY KEY(TOVAR)
) ;
CREATE TABLE RASHOD(
N_RASH INTEGER NOT NULL,
DAT_RASH DATE NOT NULL,
KOLVO INTEGER NOT NULL,
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
POKUP VARCHAR(20) COLLATE PXW_CYRL,
PRIMARY KEY(N_RASH),
FOREIGN KEY(POKUP) REFERENCES POKUPATELI,
FOREIGN KEY(TOVAR) REFERENCES TOVARY
);
SET TERM ###;
CREATE PROCEDURE FIND_MAX_KOLVO (IN_TOVAR VARCHAR(20))
RETURNS(MAX_KOLVO INTEGER) AS
BEGIN
SELECT MAX(KOLVO)
FROM RASHOD
WHERE TOVAR = : IN_TOVAR
INTO : MAX_KOLVO;
SUSPEND;
END ###
CREATE PROCEDURE POK_LIST (IN_TOVAR VARCHAR(20))
RETURNS(РОК VARCHAR(20)) AS
DECLARE VARIABLE AVG_KOLVO INTEGER;
BEGIN
SELECT AVG(KOLVO)
FROM RASHOD
WHERE TOVAR = :IN_TOVAR
INTO : AVG_KOLVO;
FOR SELECT POKUP
FROM RASHOD
WHERE KOLVO > : AVG_KOLVO
INTO : РОК
DO
BEGIN
IF (:POK IS NULL) THEN
РОК = "Покупатель не указан";
SUSPEND;
END
END ###
CREATE TABLE TOVARY_LOG(
DAT_IZM DATE,
DEISTV CHAR(3),
OLD_TOVAR VARCHAR(20),
NEW_TOVAR VARCHAR(20)
) ###
CREATE TRIGGER TOVARY_ADD_LOG FOR TOVARY
ACTIVE
AFTER INSERT
AS
BEGIN
INSERT INTO TOVARY_LOG(DAT_IZM, DEISTV, OLD_TOVAR,
NEW_TOVAR)
VALUES ("NOW","ADD","",NEW.TOVAR) ;
END ###
CREATE TRIGGER TOVARY_UPD_LOG FOR TOVARY
ACTIVE
AFTER UPDATE
AS
BEGIN
INSERT INTO TOVARY_LOG(DAT_IZM, DEISTV, OLD_TOVAR, NEW_TOVAR)
VALUES ("NOW","UPD",OLD.TOVAR,NEW.TOVAR) ;
END ###
CREATE TRIGGER TOVARY_DEL_LOG FOR TOVARY
ACTIVE
AFTER UPDATE
AS
BEGIN
INSERT INTO TOVARY_LOG(DAT_IZM, DEISTV, OLD_TOVAR, NEW_TOVAR)
VALUES ("NOW","DEL",OLD.TOVAR,"") ;
END ###
SET TERM ; ###
COMMIT;
Работа с утилитой Windows Interactive SQL (WISQL)
Утилита WISQL позволяет:
• соединяться с БД на локальном или удаленном сервере;
• выполнять любые запросы к БД и просматривать результаты их выполнения;
• получать информацию о структуре БД.
Постановка задачи
Требуется создать в среде Delphi приложение, предназначенное для учета поступающих на склад товаров. База данных состоит из двух таблиц: справочника "Товары" и операционной таблицы "Приход товаров". Таблицы необходимо создать и хранить в формате Paradox. Отношение между таблицами "один-ко-многим", то есть одному товару в таблице "Товары" может соответствовать более одной записи в таблице "Приход товаров". Рабочая структура таблиц приведена на рис. 2.1
Для таблицы "Товары" первичный ключ построен по полю Tovar. Для таблицы "Приход товаров" первичный ключ построен по полю N_Prih Для реализации ссылочной целостности (с таблицей "Товары") необходимо построить внешний ключ по полю Tovar. Для сортировки записей при их выводе в приложении необходимо создать индекс по полям "Дата прихода", "Товар".
Создание псевдонима базы данных
При работе с таблицами локальных баз данных (в число которых входят таблицы СУБД Paradox и dBase) базой данных считается каталог на диске, в котором хранятся файлы таблиц БД, индексов, примечаний (мемо-полей) и т.д. Для хранения одной таблицы создается отдельный файл. Такие же отдельные файлы создаются для хранения индексов таблицы и мемо-полей.
Обращение к БД из утилит и программы осуществляется по псевдониму (алиасу, alias) базы данных. Такой псевдоним должен быть зарегистрирован в файле конфигурации конкретного компьютера при помощи утилиты BDE Administrator.
Пусть наша база данных будет находиться в каталоге "D:\PROBA". Присвоим псевдоним создаваемой БД. Пусть имя этого псевдонима будет "PROBA". Запустим утилиту BDE Administrator. Выберем в главном меню Элемент Object \ New. В появившемся окне (рис. 2.2) оставим тип создаваемой БД без изменений (STANDARD) и нажмем Ok.
В левом окне появившегося окна администратора БД мы увидим строку с именем STANDARDl. Изменим это имя на "PROBA". Для этого щелкнем мышью на названии БД и введем новый текст.
В правом окне приведены параметры БД. Оставим их без изменения, изменив лишь PATH. Этот параметр указывает путь к каталогу, в котором будет расположена БД. Можно ввести путь вручную, но лучше воспользоваться средствами администратора: для этого нужно щелкнуть по полю PATH и нажать на появившуюся в правом углу поля кнопку. Затем следует выбрать каталог D:\PROBA и нажать кнопку Ok (рис. 2.3.).
Теперь необходимо запомнить определение псевдонима. Для этого в левом окне администратора БД необходимо щелкнуть по имени псевдонима правой кнопкой мыши и во всплывающем меню выбрать элемент Apply. В появившемся диалоговом окне, в котором спрашивается, собираемся ли мы запоминать изменения для псевдонима, необходимо нажать кнопку Ok. Затем следует выйти из утилиты BDE Administrator. Теперь создание псевдонима завершено и к нему можно обращаться из других утилит и приложений. Однако каталог, на который ссылается псевдоним БД, еще пуст. Необходимо создать таблицы базы данных.
Объявление полей
Для создания таблиц базы данных необходимо запустить утилиту Database Desktop (DBD). После запуска утилиты установим рабочий псевдоним утилиты. Это псевдоним, с которым утилита работает по умолчанию. Если рабочий псевдоним не установлен, придется при работе с DBD всякий раз указывать псевдоним, что отнимает время.
Для установки рабочего псевдонима нужно выбрать элемент главного меню File | Working Directory и в выпадающем списке A liases выбрать имя псевдоним PROBA, после чего нажать кнопку Ok.
Для создания таблицы БД нужно выбрать элемент главного меню File \ New | Table. В появившемся окне Create Table оставляем без изменения тип создаваемой таблицы (Paradox 7) и нажимаем кнопку Ok. После этого появится окно определения структуры таблицы БД (рис. 2.4).
Каждая строка таблицы соответствует полю. Назначения столбцов:
• Fields Name - имя поля;
• Type - тип поля;
• Si:e - размер поля (для строковых полей, поскольку иные поля подразумевают размер, определяемый типом поля);
• Key - содержит звездочку '*', если поле входит в состав первичного ключа. Если в первичный ключ входит несколько полей, они должны определяться в той последовательности, в которой они присутствуют в первичном ключе. Кроме того, все поля, входящие в состав первичного индекса, должны определяться перед иными полями, то есть быть в списка полей наверху.
Определим поля, входящие в таблицу "Товары". Введем Tovary в столбец Field Name. Для того, чтобы определить тип поля, щелкните по столбцу Type и нажмите клавишу пробела. В ответ на это будет выдан список типов полей, из которых необходимо произвести выбор нужного типа (рис. 2.5).
Рис. 2.5. Выбор типа поля
Рассмотрим возможные типы полей СУБД Paradox:
| Тип поля | Обозначение | Хранимые значения |
| Alpha | A | Символьные значения длиной до 255 символов. |
| Number | N | Числовые значения с плавающей точкой в диапазоне -10307...+10308. Точность до 15 значащих цифр. |
| Money | $ | Аналогичен типу Number, но предназначен для хранения денежных сумм. Число знаков после запятой по умолчанию - 2. При показе значения выводится знак денежной единицы. |
| Short | S | Целочисленные значения в диапазоне -32 767..32 767. |
| LongInteger | I | Целочисленные значения в диапазоне -2 147 483 648 ..2 147 483 647. |
| BCD | # | Числовые значения, в том числе и дробные, в двоично-десятичном формате. Обеспечивает исключительную точность при работе с большим числом знаков в дробной части. Применяется в вычислениях, где важна точность (финансовые, научные приложения). Для проведения вычислений требует больше времени, чем для числовых полей иных типов. |
| Date | D | Значения даты (в диапазоне от 01.01.9999 до н.э. до 31.12.9999). |
| Time | T | Значения времени. |
| Timestamp | @ | Значения даты и времени. |
| Memo | M | Строковые значения длиной более 255 символов. Максимальная длина не ограничена. От 1 до 240 символов могут храниться вместе с таблицей БД; остальные хранятся в виде Memo-файла (расширение .MB) |
| Formatted Memo | F | Аналогично мемо-полю, но, может хранить форматированные тексты, в которых фрагменты текста представлены разным шрифтом, цветом и стилями. |
| Graphic Fields | G | Графические изображения в формате файлов -BMP, .PCX, -TIF, .GIF, .EPS, которые при хранении преобразуются к формату .BMP. Хранятся отдельно от основной таблицы БД. |
| OLE | 0 | Информация в форматах, поддерживаемых технологией OLE (Object Linking and Embedding) фирмы Microsoft |
| Logical | L | Логические значения ("True", "False"). Высота букв не имеет значения. |
| Autoincrement | ± | Автоинкрементное поле. Значения доступны только для чтения. Обычно - ключевое поле в составе первичного ключа. При добавлении новой записи значение поля вычисляется автоматически таким образом, чтобы в одной и той же таблице не было одинаковых значений. Значения поля из удаленных записей повторно не используются |
| Binary | В | Произвольные двоичные значения. Должны интерпретироваться приложениями пользователя. DBD не интерпретирует значения этих полей. Хранятся в отдельных от основной таблицы .МВ-файлах. Длина не определена |
| Bytes | Y | Произвольные двоичные значения, интерпретируемые приложениями пользователя, длиной от 1 до 240 байт. Хранятся вместе с таблицей БД. |
Введем определения и других столбцов таблицы Tovary (рис. 2.6). Для каждого поля определим требование обязательного заполнения поля значением. Для этого, переходя от поля к полю, включим переключатели Required Field. Другие поля служат для наложения ограничений на значение поля:
• Minimum value - определяет минимальное значение поля, Maximum value - определяет максимальное значение поля;
Default value -
определяет значение поля по умолчанию; • Picture - определяет шаблон изображения поля. Для формирования шаблона следует нажать кнопку Assist.
Отсутствие значения в одном из полей означает отсутствие ограничений на значение поля.
Запоминание таблицы
Чтобы запомнить сохраненную таблицу на диске, следует нажать кнопку Save As. Затем в появившемся окне следует указать имя таблицы (рис. 2.7). При желании можно указать каталог или псевдоним, отличные от принятых по умолчанию. Напомним, что по умолчанию принимается рабочий каталог или каталог, определяемый рабочим псевдонимом.
После того, как мы определим имя создаваемой таблицы (Tovary), в каталоге С \PROBA (он назначен псевдониму PROBA, используемому нами в качестве рабочего псевдонима) будет создан файл Tovary.DB и файлы индексов с соответствующими расширениями.
Изменение структуры существующей таблицы
Если в структуру существующей таблицы БД необходимо внести изменения, следует выбрать элемент меню File | Open | Table, в появившемся диалоговом окне выбрать имя таблицы и нажать кнопку Ok. Будет показано содержимое таблицы (на рис. 2.8: в таблице Tovary отсутствуют записи, что не удивительно, поскольку мы их еще не вводили).
В том случае, когда мы хотим ввести новые записи в таблицу прямо в DBD (а также изменить значения в некоторых записях или произвести удаление), следует нажать кнопку F9. После этого таблица будет переведена в режим внесения изменений.
Чтобы изменить структуру таблицы, выберите элемент меню Table | Restructure. Вслед за этим будет показано диалоговое окно для определения структуры таблицы.
Определение индексов
Определим структуру таблицы "Приход товаров" (рис. 2.9).
Всем полям назначим атрибут Required (требование обязательного существования значения у поля на момент его запоминания в БД), кроме поля N_Prih:, поскольку это поле автоинкрементное, заполнение его значением производится автоматически при запоминании новой записи.
Создадим индекс по полям "Дата прихода", "Товар". Для этого в комбинированном списке Table Properties (в правом верхнем углу окна) выберем элемент Secondary Indexes. После этого диалоговое окно приобретет вид, показанный на рис. 2.10.
Чтобы определить новый индекс, нажмем кнопку Define. В появившемся диалоговом окне в поле Fields содержится список полей определяемой нами таблицы. Поле Index Fields предназначено для хранения полей, входящих в создаваемый индекс. Чтобы скопировать конкретное поле из списка Fields в список Index Fields, нужно нажать кнопку с изображением правой стрелки. Последовательность добавления полей в список важна, она определяет порядок чередования полей в списке. После того, как мы поместили нужные поля в список Index Fields (рис. 2.11), нажмем кнопку Ok.
В появившемся окне запрашивается имя индекса (рис. 2.12) Следует ввести имя и нажать Ok.
Не рекомендуется составлять название индекса только из имен полей, поскольку такой способ именования индексов используется автоматически при создании ссылочной целостности между таблицами (см следующий раздел).
Как видно на рис.2.13, после добавления нового индекса его имя появилось в списке индексов.
Впоследствии, щелкнув по имени индекса, мы можем его удалить (кнопка Erase) или изменить (кнопка Modify).
Сохраним созданную нами таблицу под именем Pnhod.
Определение ссылочной целостности между таблицами
Как известно из постановки задачи, таблицы "Товары" и "Приход товаров" находятся в отношении "один-ко-многим", то есть с одной записью в таблице Tovary может быть связано несколько записей по приходу того же товара в таблице Prihod. В качестве поля связи выступает поле Tovar, присутствующее в обеих таблицах.
Определим ссылочную целостность между данными таблицами. Ссылочная целостность в Paradox определяет, во-первых, связь между таблицами, а во-вторых, вид каскадных воздействий.
Откроем таблицу Prihod (элемент меню File \ Table \ Open) и затем войдем в режим изменения структуры таблицы (Table \ Restructure). В выпадающем списке Table Properties выберем элемент Refrential Integrity и нажмем кнопку Define. В появившемся диалоговом окне (рис. 2.14) в списке Fields показаны поля таблицы Prihod, а в списке Tables - таблицы базы данных PROBA.
Выберем в списке Fields поле Tovar и нажмем кнопку с изображением стрелки вправо. Название Tovar будет записано в поле Child Fields (поле внешнего ключа дочерней таблицы).
Выберем в списке Tables таблицу Prihod и нажмем кнопку с изображением стрелки влево. В поле Parents Key (ключ родительской таблицы) будут показаны поля из первичного ключа таблицы Tovary В данном случае это поле Tovar.
Переключатели Update rules определяют вид каскадных воздействий на таблицу Prihod при изменении значения поля связи в таблице Tovary или при удалении записи в таблице Tovary:
• Cascade - каскадные изменения и удаления подчиненных записей в таблице Prihod;
• Prohibit - запрет на изменение поля связи или удаление записи в таблице
Tovary, если для данной записи есть связанные записи в таблице Prihod. Выберем Cascade (рис. 2.15) и нажмем кнопку Ok.
Будет запрошено имя - в Paradox ссылочные целостности именуются. Введем имя, например Tovary_Prihod_Integnty, и нажмем кнопку Ok. Теперь имя созданной ссылочной целостности будет помещено в список.
Запомним изменения в таблице Prihod (кнопка Save) и заново войдем в режим реструктуризации таблицы Prihod (Table | Restructure). В выпадающем списке Table properties выберем элемент Secondary Indexes (индексы таблицы, кроме индекса, построенного по определению первичного ключа). В списке индексов увидим, что появился новый индекс с именем Tovar (по полю Tovar). Этот индекс построен автоматически по неявному определению внешнего ключа при создании ссылочной целостности (рис. 2.16).
Выйдем из режима реструктуризации и покинем DBD. После этого перейдем к разработке простейшего приложения для работы с созданными таблицами.
Создание простейшего приложения
Создадим в каталоге CAPROBA подкаталог АРР. В нем мы будем хранить разработанные приложения.
Запустим Delphi. По умолчанию Delphi при своем запуске создает форму для нового приложения. Воспользуемся ею. В палитре компонентов Delphi на странице Data Access выберем мышью невизуальный компонент TTable (рис. 2.17), щелкнем на нем мышью и затем щелкнем мышью в форме. После этого, изображение компонента останется в форме.
Невизуальным компонент TTable (как и другие компоненты, например, TQuery, TDataSource) называется потому, что он применяется для хранения и доступа к данным, а не для их визуализации - для этой цели применяются визуальные компоненты (TDBGrid, TEdit и другие).
После того, как мы разместили в форме компонент TTable, установим его свойства. Для этой цели воспользуемся инспектором объектов (Object Inspector), который обычно помещается слева от формы. Если он не видим, его можно вызвать, нажав кнопку F11. Инспектор объектов позволяет устанавливать свойства того компонента в форме, который выделен при помощи мыши. Выделим мышью компонент TTable.
Установим значение свойства DatabaseName (псевдоним БД) в PROBA при помощи выпадающего списка или введя его вручную. Установим значение свойства TableName (имя таблицы БД) в Tovary.DB при помощи выпадающего списка. После этого установим значение свойства Active в True. После этого произойдет реальное связывание компонента TTable (он по умолчанию имеет имя Tablel) с реально существующей таблицей Tovary.DB.
Компонент TTable и компонент TQuery (его мы рассмотрим позже) служат для хранения наборов данных. Понятие набора данных несколько шире, чем понятие таблицы БД, поскольку набор данных может содержать:
• подмножество записей или полей таблицы БД (компоненты TTable, TQuery);
• записи, сформированные из нескольких таблиц БД (компонент TQuery). Расположим в форме компонент TDataSource. Он служит в качестве связующего звена между невизуальными компонентами (в данном случае Tablel) и визуальными компонентами, которые мы добавим в форму позднее. Поэтому компоненты TDataSource часто называют источниками данных. Установим свойство DataSef (имя набора данных) компонента TDataSource в значение Tablel путем выбора из выпадающего списка.
Расположим в форме компонент TDBGrid, взяв его из палитры компонентов (страница Data Controls). Установим свойство DataSource компонента TDBGrid в значение DataSource1 (это имя, присвоенное Delphi по умолчанию созданному нами перед этим компоненту TDataSource). Компонент TDBGrid служит для отображения записей набора данных в табличной форме.
Вид разрабатываемой формы представлен на рис. 2.18.
Выберем элемент меню File \ Save Project As и сохраним проект. Сначала запрашивается имя формы проекта (у нас форма одна, с именем Form1). Сохраним форму под именем 'appll.pas'. Затем запрашивается имя проекта. Сохраним проект под именем 'appl.dpr'.
После этого выполним приложение. (Чтобы выполнить приложение, не выходя из среды Delphi, достаточно нажать кнопку F9. Чтобы создать приложение и запустить его вне среды Delphi, следует нажать комбинацию кнопок Ctrl+F9 и затем запустить созданный файл с расширением .ехе и именем, совпадающим с именем проекта. В нашем случае следует запускать файл 'appl.exe').
Добавлять записи в набор данных (и, следовательно, в таблицу Tovary.DB) можно прямо из компонента TDBGrid.
Для добавления записи нужно нажать на клавиатуре кнопку Insert или, находясь на последней записи набора данных, кнопку "стрелка вниз". Набор данных автоматически перейдет в режим добавления новой записи. После ввода значений в поля записи запомнить запись в наборе данных можно, перейдя на другую запись при помощи клавиш управления курсором. Отказаться от запоминания записи можно, нажав кнопку Esc.
Для изменения записи следует переместить указатель текущей записи в нужное место и изменить значения там, где это необходимо. Набор данных автоматически перейдет в режим редактирования.
Для удаления записи следует установить на нее указатель текущей записи и нажать комбинацию кнопок Ctrl+Del.
На рис.2.19 показан вид приложения в момент добавления в таблицу Tovary новой записи.
Создание приложения для работы с двумя таблицами
Покажем, как в одной форме можно связать два набора данных (родительский и подчиненный) так, чтобы в подчиненном наборе данных всегда показывались записи, соответствующие текущей записи в родительском НД
Сохраним форму приложения в файле 'app21.pas', а проект приложения - в файле 'арр2 drp' Добавим в приложение компонент TTable (с именем Table2) для работы с таблицей Prihod базы данных PROBA (значения свойств такие же, как у компонента Tablel, но свойство TableName ссылается на имя таблицы Prihod DB) Установим свойство Table2 Avtive в True Добавим в форму компонент TDataSource (имя по умолчанию DataSource2). Установим свойство DataSet этого компонента в значение Table2. Разместим в форме компонент TDBGnd (имя по умолчанию DBGrid2) и установим его свойство DataSource в значение DataSource2 (рис 2 20).
Запустим приложение на выполнение. Ввод и изменение данных в таблицу Prihod будем производить также из компонента TDBGnd (рис 2 21)
Обратите внимание, значение поля N_Prih формируется автоматически
Уточнение списка полей и настройка параметров столбцов в TDBGnd. Смена активного индекса
Как можно заметить, значение поля N_Prih необходимо для обеспечения уникальности в таблице Prihod и не несет никакой иной нагрузки. Поэтому данное поле лучше не показывать в составе столбцов DBGrid2. Для этой цели сформируем список полей таблицы Prihod В Delphi имеются две возможности указать, какие из полей таблицы БД следует использовать в приложении для набора данных (в нашем случае для компонента Table2)
Первый способ состоит в использовании по умолчанию всех полей из таблицы БД, с которой ассоциирован этот набор данных Этот способ всегда используется по умолчанию и, следовательно, был неявно использован и нами при создании наборов данных Tablel и Table2
Второй способ состоит в использовании подмножества полей таблицы БД, с которой ассоциирован набор данных Для этой цели используется редактор полей набора данных, который позволяет включить в состав обрабатываемых для набора данных полей все поля или подмножество полей таблицы БД
Сохраним форму приложения как 'арр31.pas', а проект приложения как 'аррЗ.drp'. Выберем при помощи мыши компонент Table2 и нажмем правую кнопку мыши В появившемся на экране всплывающем меню выберем элемент Fields Editor В появившемся списке редактора полей (пока он пуст, рис 2 22 а) нажмем правую кнопку мыши и во всплывающем меню выберем элемент меню Add Fields Будет показан список всех полей таблицы БД Prihod.DB Отметим (при помощи мыши и кнопки Shift) все поля, кроме N_Prih (рис 2 22 б) и нажмем кнопку Add Теперь список редактора полей будет включать все отмеченные поля (рис 2 22 в)
Как можно заметить, в составе столбцов в компоненте DBGrid2 теперь присутствуют только те поля, которые добавлены для набора данных Table2 в редакторе полей (рис 2.23)
Определение для набора данных списка полей в редакторе полей приводит к тому, что для каждого добавленного таким образом поля в приложении Delphi автоматически создает компонент TField (поле набора данных) Каждый такой компонент по умолчанию именуется уникальным именем - в качестве первой составляющей имени поля берется имя набора данных (Table2), а в качестве второй составляющей - имя поля в таблице БД Так, компонент TField, соответствующий полю Tovar, будет поименован как Table2Tovar Если в редакторе полей щелкнуть по имени соответствующего поля, в инспекторе объектов можно установить или изменить свойства поля, а также определить обработчики события для конкретного поля Более подробно об этом сказано ниже в разделе, посвященном работе с полями.
Изменим параметры компонента DBGrid2 так, чтобы названия его столбцов содержали русские наименования Для этого щелкнем правой кнопкой мыши на компоненте DBGrid2, и во всплывающем меню выберем элемент Columns Editor На экране появится окно редактора столбцов компонента (рис 2 24 а) Для того, чтобы изменить характеристики столбцов в TDBGrid, нужно перейти от неявно определяемых столбцов к явно определяемым Для этого нужно щелкнуть по кнопке Add All Fields, в результате чего будут добавлены столбцы, каждый из которых соответствует полю, определенному в редакторе полей компонента Table2 (рис 2 24 б) Чтобы изменить заголовок каждого столбца, следует выбрать при помощи мыши имя столбца в редакторе столбцов, и в инспекторе объектов раскрыть список свойства Title (для чего следует щелкнуть мышью по крестику рядом с именем свойства) В элементе Caption этого списка содержится заголовок столбца, изменим соответствующим образом заголовки и затем выйдем из редактора столбцов DBGrid2 То же проделаем для набора данных Tablel (рис 2.25)
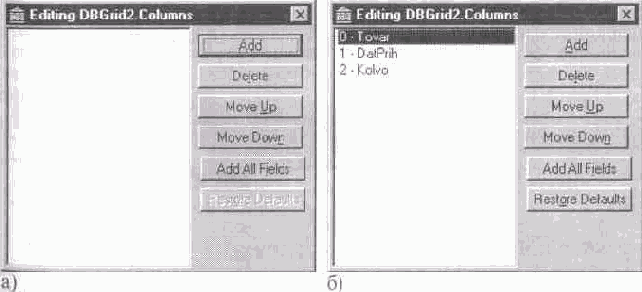
Рис 2.24 а) пустой список столбцов DBGrid2 6) заполненный список столбцов
Изменим также порядок сортировки записей в наборе данных Tdble2. Для этого в инспекторе объектов установим свойство Table2 Index FieldNames в значение 'DatPnh,Tovar' путем выбора из выпадающего списка, содержащего названия индексных полей, определенных для каждого существующего индекса таблицы Prihod DB. После этого войдем еще раз в редактор колонок DBGnd2 и при помощи мыши "перетащим" столбец DatPrih так, чтобы он предшествовал столбцу Tovar. Откомпилируем приложение и запустим его на выполнение. Как видно из рис. 2.26, набор данных Table2, ассоциированный с таблицей БД Prihod.DB, в приложении отсортирован по дате прихода, а внутри каждой даты прихода - по наименованию товара.
Определение визуальных компонентов для работы с полями записи набора данных
Сохраним форму приложения как 'арр41.pas', а приложение как 'app4.drp'. Теперь сделаем так, чтобы к полям записи в наборе данных Table2 можно было обращаться не только из сетки компонента DBGnd2, а из отдельных визуальных компонентов, позволяющих осуществлять доступ к отдельным полям записи набора данных.
Добавим в форму два компонента TDBEdit (палитра компонентов Data Controls). Разместим компонент DBEdit1 под столбцом "Дата прихода", а компонент DBEdit2 под столбцом "Количество" Определим поле, к которому можно иметь доступ через компонент DBEditl. Для этого установим значение его свойств - DataSource в DataSource2 и DataField в DatPrih. Определим поле, к которому можно иметь доступ через компонент DBEdit2 Для этого установим значение его свойств - DataSource в DataSource2 и DataField в Kolvo.
Для доступа к полю Tovar нам нужен более сложный компонент, который позволял бы вводить в поле Tovar таблицы Prihod.DB значения полей Tovar из таблицы Tovary.DB, и никакие другие значения. Для этой цели под столбцом "Товар" компонента DBGnd2 разместим компонент TDBLookupComboBox с именем по умолчанию DBLookupComboBox1. Установим свойства этого компонента.
• DataSource - в значение DataSource2,
• DataFiled - в значение Tovar,
• List Source - в значение DataSource 1
• LislField - в значение Tovar;
• Key Field - в значение Tovar
Добавим в приложение 5 компонентов кнопок TButton (страница Standard палитры компонентов). Изменим имена этих компонентов (свойство Name), используя инспектор объектов, соответственно на InsertButton, EditButton, DeleteButton, PostButton, EditButton. Изменим заголовки этих кнопок (свойство Caption), используя инспектор объектов, соответственно на "Добавить", "Изменить", "Удалить", "Запомнить", "Отменить" (рис. 2.27).
Выберем при помощи мыши кнопку InsertButton и два раза щелкнем на ней После этого мы перейдем в редактор кода и определим для кнопки InsertButton обработчик события нажатия кнопки, OnClick
procedure TForm1.InsertButtonClick(Sender: TObject);
begin
IF Table2.State = dsBrowse THEN
Table2.Insert; end;
Метод Insert переводит набор данных Table2 в состояние добавления записи dslnsert. Ввод значений полей осуществляется в компонентах DBEditl, DBLookupComboBoxl, DBEdit2 Для этого необходимо, чтобы набор данных находился в режиме просмотра dsBrowse.
Определим обработчик нажатия кнопки EditButton
procedure TFormI.EditButtonClick(Sender: TObject);
begin
IF Table2.State = dsBrowse THEN Table2.Edit;
end;
Метод Edit переводит набор данных Table2 в состояние добавления записи dsEdit. Редактирование значений полей осуществляется в компонентах DBEditl, DBLookupComboBoxl, DBEdit2 Для этого необходимо, чтобы набор данных находился в режиме просмотра dsBrowse
Определим обработчик нажатия кнопки DeleteButton
procedure TForm1.DeleteButtonClick(Sender: TObject);
begin
IF Table2.State = dsBrowse THEN
IF MessageDIg('Подтвердите удаление записи', mtConfirmation,[mbYes, mbNo],0) = mrYes THEN Table2.Delete/-
end;
Если набор данных Table2 находится в режиме просмотра записей dsBrowse, вызывается окно диалога (при выполнении функции MessageDIg), если пользователь нажимает кнопку Yes, происходит удаление текущей записи в наборе данных Table2
Определим обработчик нажатия кнопки PostButton
procedure TFormI.PostButtonClick(Sender: TObject);
begin
IF Table2.State in [dsInsert,dsEdit] THEN Table2.Post;
end;
Если набор данных находится в режиме добавления новой записи или редактирования, происходит выполнение метода набора данных Post, который запоминает текущее состояние записи в таблице БД После запоминания набор данных переводится в режим просмотра dsBrowse
Определим обработчик нажатия кнопки CancelButton
procedure TFormI.CancelButtonClick(Sender: TObject);
begin
IF Table2.State in [dslnsert,dsEdit] THEN Table2.Cancel;
end;
Если набор данных находится в режиме добавления новой записи или редактирования, происходит выполнение метода набора данных Cancel, который отменяет запоминание записи в таблице БД и переводит набор данных в режим просмотра dsBrowse
Для того чтобы набор данных нельзя было переводить в состояние добавления и изменения данных, а также удалять записи непосредственно из компонента DBGrid2, установим свойство DBGrid2 ReadOnly в значение True
После этого запустим приложение на выполнение. При добавлении новой записи или при корректировке существующей в поля можно заносить значения, используя ввод в компоненты DBEdit1, DBEdit2 и путем выбора из списка значений в компоненте DBLookupComboBoxl (рис 2.28). То же происходит при изменении записи. При удалении записи выдается окно диалога (рис 2.29)
Реализация связи Master-Detail между наборами данных
Нам известно, что таблицы базы данных Tovary.DB и Prihod.DB находятся в отношении "один-ко-многим". Поскольку мы определили ссылочную целостность между этими таблицами, можно сделать так, чтобы при установке указателя на запись в наборе данных Table1 (ассоциированном с Tovary. DB) в наборе данных Table2 (ассоциированном с Prihod.DB) показывались только записи прихода текущего товара в Table1. Это реализуется через механизм связи наборов данных Master-Detail.
Для этого откроем проект 'аррЗ.' В редакторе столбцов DBGrid2 сделаем столбец, соответствующий полю Tovary, первым по счету в DBGrid2.
В инспекторе объектов для компонента Table2 установим значение свойства MasterSource в DataSourcel. Переместимся на значение свойства MasterFields и нажмем кнопку эллипса. В появившемся окне Field Link Designer установим параметры связи. В -поле Available Indexes выберем в качестве текущего индекса по полю 'Tovar'. В списке Detail Fields выберем поле Tovar, в списке Master Fields выберем поле Tovar и нажмем кнопку Add. В поле Joined Fields будет сформировано выражение 'Tovar -> Tovar' (рис. 2.30). Нажмем кнопку Ok.
Как можно заметить, в компоненте Table2 текущий индекс (свойство Fieldlndex Names) заменен на индекс, построенный по полю 'Tovar'.
Выполним приложение. Теперь в наборе данных Table2 показываются только записи по приходу товара, текущего в наборе данных Table 1 (рис. 2.31). Мало того, при добавлении записи в набор данных Table2 значение поля Tovar по умолчанию берется равным значению поля Tovar из текущей записи в наборе данных Table1 (рис. 2.32).
Использование компонента TQuery для формирования набора данных из нескольких таблиц
Создадим новое приложение, выбрав в меню Delphi элемент File | New Application. Сохраним форму нового приложения как 'app51.pas', а само приложение как 'app5.dpr'.
Расположим в форме компонент TQuery (страница Data Access палитра компонентов). По умолчанию его имя Query1. Установим его свойство DatabaseName в PROBA. Расположим в форме компонент TDataSource (имя DataSource1). Установим его свойство DataSet в значение Queryl. Расположим в форме компонент TDBGrid. Установим его свойство DataSource в значение DataSourcel.
В инспекторе объектов для компонента Queryl найдем свойство SQL и нажмем кнопку эллипса. Затем в появившемся окне редактора наберем текст SQL-запроса
SELECT P.DatPrih, P.Tovar, P.Kolvo,Т.Zena, (P.Kolvo * Т.Zena) As Stoim
FROM Tovary T, Prihod P WHERE T.Tovar = P.Tovar ORDER BY P.DatPrih, P.Tovar
и нажмем кнопку Ok.
После этого установим свойство Queryl.Active в значение True. Набор данных Queryl содержит сведения о приходе товара со склада. В составе записи этого набора присутствуют поля DatPrih (дата прихода), Tovar (название товара), Kolvo (количество прихода), Zena (цена за ед. измерения данного товара), Stoim (стоимость прихода товара). Как видно из текста запроса в свойстве SQL, набор данных "собирается" из двух таблиц БД PROBA, Tovary.DB и Prihod.DB. При этом соединяются записи из этих таблиц БД, имеющие одинаковое значение поля Tovar (рис. 2.33)
Однако, стоит нам выполнить это приложение, и мы увидим, что в набор данных Queryl нельзя добавить новые записи и нельзя изменить или удалить существующие записи в наборе данных. Это происходит потому, что тип набора данных, "собираемого" более чем из одной таблицы БД, является доступным только для чтения.
* * *
Теперь, когда Вы попрактиковались в создании приложений Delphi, работающих с базами данных, перейдем к более детализированному рассмотрению визуальных и невизуальных компонентов Delphi для работы с данными. В следующем разделе показаны средства Delphi, доступные при разработке таких приложений, а также рассматриваются различные архитектуры приложений для работы с базами данных.
Фаза
В случае успешной записи кэшированных изменений в БД:
• происходит подтверждение транзакции БД;
• подтверждаются кэшированные изменения.
В случае неуспешной записи кэшированных изменений в БД:
• происходит откат транзакции БД;
• происходит откат кэшированных изменений, с восстановлением или без восстановления первоначальных значений записей Пользователь может скорректировать ситуацию, вызвавшую ошибку, и повторить попытку запоминания кэшированных изменений в БД.
С чего начать
Давно известно, что лучше один раз увидеть, чем сто раз услышать. При изучении программных средств еще лучше один раз попробовать. Поэтому давайте попрактикуемся в создании простейшего приложения, работающего с базами данных, пройдя при этом все этапы - от создания псевдонима базы данных до запуска разработанного приложения.
Если Вы никогда не проектировали приложений для работы с базами данных в Delphi, приобретенный опыт поможет Вам понять, что построение таких приложений в Delphi максимально упрощено. Есть и еще одно последствие выполнения описываемых упражнений: читая в последующих разделах о средствах разработки приложений баз данных в Delphi, Вы будете встречать уже знакомые названия и понятия.
Обзор типов данных InterBase
ЗАМЕЧАНИЕ. То, что для "персональных" БД типа Paradox и dBase принято называть полями записи (fields), для InterBase, как и иных "промышленных" БД, работающих с SQL, принято называть столбцами (columns). Далее будем следовать этой устоявшейся традиции.
В ТБД InterBase могут использоваться столбцы следующих типов:
| Тип столбца | Размер, байт | Описание |
| SMALLINT | 2 | Целочисленные значения от -32768 до +32767. |
| INTEGER | 4 | Целочисленные значения от -2 147 483 647 до +2 147 483 647. |
| FLOAT | 4 | Значения с плавающей точкой до 7 знаков от 3.4Е-38 до 3.4Е+38. |
| DOUBLE PRECISION |
8 | Значения с плавающей точкой до 15 знаков от1,7Е-308до1,7Е+308. |
| CHAR(n) или CHARACTER |
0-32767 | Символьный столбец длиной в п символов. |
| VARCHAR(n) или CHARACTER] VARYING | 0-32767 | Символьный столбец переменной длины, содержащий до п символов. |
| DATE | 8 | Дата в пределах от 01.01.0100 до 11.12.5941. Также может хранить сведения о времени. |
| BLOB | переменный | Любой тип двоичных данных. |
• CREATE TABLE - создать таблицу БД;
• CREATE DOMAIN - создать домен;
• ALTER TABLE - изменить структуру таблицы БД.
Синтаксис определения столбцов:
<тип_данных> = {
{SMALLINT | INTEGER | FLOAT | DOUBLE PRECISION} [<размерность_массива>]
| {DECIMAL | NUMERIC) [(точность [, масштаб])] [<размерность_массива>]
| DATE [<размерность_массива>]
| {CHAR | CHARACTER | CHARACTER VARYING | VARCHAR}
[(целое)] [<размерность_массива>] [CHARACTER SET набор_символов]
| {NCHAR I NATIONAL CHARACTER | NATIONAL CHAR}
[VARYING] [(целое)] [<размерность_массива>]
| BLOB [SUB_TYPE {целое | имя_подтипа}] [SEGMENT SIZE целое]
[CHARACTER SET набор_символов] | BLOB [(длина_сегмента [, подтип])]
}
Целочисленные значения
Столбец типа SMALLINT хранит целочисленные значения в диапазоне от -32768..+32767. При определении структуры таблицы БД в Database Desktop этот тип называется SHORT.
Столбец типа INTEGER хранит целочисленные значения в диапазоне от -2 147 483 647 до +2 147 483 647. При определении структуру таблицы БД в Database Desktop этот тип называется LONG.
Формат определения целочисленных столбцов:
<тип_данных> = {SMALLINT | INTEGER} [<размерность_массива>]
Значения с плавающей запятой
Столбец типа FLOA Т хранит значения с плавающей запятой длиной до 7 знаков в диапазоне от 3,4Е-38 до 3,4Е+38.
Столбец типа DOUBLE PRECISION хранит значения с плавающей запятой длиной до 15 знаков в диапазоне от 1,7Е-308 до 1.7Е+308.
Управлять числом знаков в дробной части числа с плавающей запятой нельзя, то есть нельзя при определении столбца БД указать фиксированное число знаков после запятой. В один и тот же столбец ТБД типа FLOAT или DOUBLE PRECISION можно поместить значения и "222.3333", и "22.33". Однако в приложении на значения таких полей можно наложить маску с точным числом знаков после запятой. Например, наложение маски '#,###.00' приведет к тому, что будут показываться только два знака после запятой. Если значение столбца имеет в дробной части более знаков, чем указано в маске, они будут округляться. Значение 100.678 в этом случае будет округлено как 100.68. Если в дробной части значения столбца меньше знаков, чем указано в маске, недостающие разряды будут дополняться нулями. Так, значение 100.2 будет показано как 100.20.
Значения указанных типов следует применять в столбцах, где число знаков в дробной части при хранении значений несущественно и где может понадобиться большая точность представляемых вещественных значений, например, до 7 (FLOAT) или до 15 (DOUBLE PRICISION) знаков после запятой.
При попытке представления числа с большим числом разрядов, чем это разрешено типом данных, хранимые данные округляются до последней значащей цифры в разрешенном разряде. Например, попытка записать в столбец типа FLOAT значение " 123.456789" приведет к запоминанию значения "123.4568".
Формат определения целочисленных значений:
<тип_данных> = {FLOAT DOUBLE PRECISION} [<размерность_массива >]
Фиксированно-десятичные значения
Типы DECIMAL и NUMERIC задают значения с плавающей запятой и определяют в них фиксированное число знаков после запятой. Формат определения этих типов
<тип_данных> ={DECIMAL | NUMERIC} [(точность [, масштаб])] [<размерность массива >]
где точность определяет число знаков в хранимом числе (максимум 15), а масштаб - число знаков после десятичной точки и может быть равен нулю. Во всех случаях масштаб должен быть меньше точности.
ВНИМАНИЕ!
Специальных столбцов типа DECIMAL и NUMERIC физически не существует; вместо этого, столбцы, описанные типами DECIMAL и NUMERIC, хранятся как INTEGER или DOUBLE PRECISION. При этом действует правило: если точность (число знаков в числе) меньше 10, то реальный тип столбца INTEGER; если точность больше или равно 10, реальный тип столбца DOUBLE PRECISION. Например:
Объявление
Известно, что в столбцах типа INTEGER дробных значений хранить нельзя. Поэтому, независимо от того, указано число знаков после десятичной точки или нет, объявление DECIMAL и NUMERIC с общим числом разрядов, меньшим 10, приведет к тому, что фактически в столбце можно будет хранить только целочисленные значения.
Пример.
Определим в ТБД 4 столбца с типами DECIMAL(5,2), DECI-MAL(12,2), DECIMAL(5,0), DECIMAL(12,0) и присвоим им всем одно и то же значение 123.4567. Результат:
DECIMAL(5,2)
Как можно заметить, действительно существенным в объявлении типов DECIMAL и NUMERIC является общее число разрядов в числе (точность);
число знаков после десятичной точки (масштаб) существенного значения не имеет.
Значения типа даты
Столбцы типа DATE позволяют хранить значения даты в пределах от 01.01.0100 до 11.12.5941, а также, вместе с датой - и значения времени. Формат объявления:
<тип_данных> = DATE [<размерность_массива >]
Формат столбца типа DATE InterBase полностью совместим с типом TDateTime, объявленном в Delphi. Этот тип позволяет одновременно хранить в одной переменной дату и время.
Если ввод данных в столбец типа DATE производится из утилиты WISQL, значения даты должны указываться в формате InterBase. Согласно этому формату, значения даты состоят из номера дня (01-31), месяца (JAN-DEC) и года. Эти значения отделяются разделителями. Стандартным разделителем является символ '-', но принимаются и пробел ' ', правый слеш '/', точка '.'. Значения дат в InterBase должны лежать в диапазоне "1-JAN-100".." 11-DEC-5941".
Пример.
Запишем в столбец DATAP типа DATE результат выполнения функции Now, определенной в Delphi (Now возвращает текущие время и дату, установленные на компьютере). Затем в Label I.Caption поместим дату, а в Label2.Caption - время из столбца DATAP: WITH Table1 do begin
Insert;
FieldByName('DATAP').Value := Now; //дата прихода товара
FieldByName('TOVAR').Value : 'Брус'; // товар
FieldByName('Kolvo').Value :- 10; // количество
Post;
Labell.Caption := DateToStr(Fields[0].Value);
Label2.Caption := TimeToStr(Fields[0].Value);
END;//with
Результат выполнения кода приведен на рис. 20.1.
Интерпретация формата представления значений типа даты зависит от настроек - программных или операционной системы компьютера. Рекомендую всякий раз при старте приложения программно переустанавливать формат даты к привычному нам российскому формату:
procedure TForm1.FormCreate(Sender: TObject) ;
begin
DateSeparator := '.';
ShortDateFormat := 'dd.mrn. yyyy' ;
ShortTimeFormat := 'hh:mm:ss';
end;
Таким образом можно игнорировать неопределенность текущих установок операционной системы на конкретном компьютере.
ЗАМЕЧАНИЕ.
В InterBase значения типа даты совместимы с рассматриваемыми ниже строковыми типами. Поэтому, если в SQL-операторах InterBase необходимо интерпретировать значения типа даты в строку, нет необходимости в приведении типов, например, можно так записать в символьное поле S1 значение типа даты (NOW возвращает текущие дату и время): UPDATE SOMETABLE
SET S1 = "Дата отгрузки" || NOW) ;
Кроме того, присвоение значения полям типа дата также производится в символьном формате:
INSERT INTO SOMETABLE (DATA_PRIHODA, KOLVO)
VALUES("01-FEB-1997",100) ;
Символьные типы данных
Столбцы типа CHAR(n) и VARCHAR(n) позволяют хранить строковые значения длиной до n символов. В любом случае n не может превышать 32 Кб.
Различие типов CHAR(n) и VARCHAR(n) документация по InterBase определяет так:
• CHAR(n)
определяет строковые столбцы фиксированной длины. Определение "фиксированная длина" означает, что даже если в столбец записано меньше п символов, незаполненное пространство заполняется пробелами. При хранении хвостовые пробелы усекаются, что позволяет хранить действительно значащее содержимое столбцов типа CHAR(n) и сближает их со строками переменной длины. При чтении значения столбца хвостовые пробелы вставляются в столбец снова (см. замечание ниже). Такой механизм придуман для экономии дискового пространства, когда действительная длина значений данного столбца в различных записях варьируется достаточно широко. • VARCHAR(n)
определяет строковые столбцы переменной длины. Определение "переменная длина" означает, что в записи хранится ровно столько символов, сколько их имеется в значении столбца. Например, если для VARCHAR(lOO) значения столбцов для одной записи -"Петров", а для другой - "Барабанов", в первом случае хранится 6 символов, а во втором - 9. Столбцы VARCHAR(n) позволяют экономить дисковое пространство, давая возможность серверу располагать больше записей на странице БД. Это увеличивает число операций ввода-вывода, возможных для одной страницы. К недостаткам относится то, что VARCHAR(n) читаются медленнее, чем CHAR(n).
Попытка записать в столбец более чем п символов приведет к усечению лишних символов.
ЗАМЕЧАНИЕ.
Опытным путем нетрудно убедиться в том, что Delphi при работе с InterBase интерпретирует столбцы типа CHAR(n) и VARCHAR(n) как TStringField. При этом: • столбцы типа CHAR(n) всегда читаются без хвостовых пробелов;
• при занесении хвостовых пробелов в столбец (а часто это бывает необходимо) CHAR(n) всегда усекает их, в то время как VARCHAR(n), наоборот, всегда их хранит.
Формат определения символьных столбцов:
<тип_данных> = {CHAR CHARACTER CHARACTER VARYING I VARCHAR} [ (n)] [<размерность_массива >] [CHARACTER SET набор_символов]
где n определяет длину символьного столбца. Если n опущено, по умолчанию подразумевается 1.
CHARACTER SET позволяет установить кодировку путем указания имени используемого набора символов. Если CHARACTER SET опущен, используется кодировка, принятая по умолчанию для БД (устанавливается в предложение DEFAULT CHARACTER SET оператора CREATE DATABASE). Рекомендуется явно указывать CHARACTER SET целиком для таблицы, базы данных или, если в таблице наборы символов различны для разных столбцов, - для каждого конкретного столбца.
Если определен набор символов, то в столбец невозможно ввести символы, не входящие в данную таблицу кодировки.
Для представления столбцов, которые будут содержать русскоязычные тексты, рекомендуем использовать набор символов WIN1251, например:
SYMPOLE CHARACTER(20) CHARACTER SET WIN1251;
Если при создании БД был принят набор символов по умолчанию, для чего в оператор CREATE DATABASE добавлено предложение DEFAULT CHARACTER SET, то этот набор символов будет принят по умолчанию для всех столбцов. Например:
CREATE DATABASE BAZA ...DEFAULT CHARACTER SET WIN1251;
При определении столбца набор символов, принятый для БД по умолчанию, можно переопределить. Для этого и служит предложение CHARACTER SET в определении столбца. Если при объявлении столбца предложение CHARACTER SET опущено, используется набор символов, принятый по умолчанию для всей БД при ее создании. Если при создании БД набор символов по умолчанию не был определен, т.е. предложение DEFAULT CHARACTER SET отсутствовало в операторе CREATE DATABASE, по умолчанию принимается набор символов NONE. Он позволяет вводить в символьные столбцы символы любых кодировок. Данные хранятся так, как они вводятся. Однако для столбцов с набором символов NONE могут возникнуть проблемы при записи их значения в столбцы, которым набор символов явно назначен.
Порядок сортировки символов
Порядок сортировки символов определяет порядок перечисления символов для набора символов. Например, порядок сортировки PXW_CYRL для кириллического набора символа WIN1251 определяет порядок следования символов 'А','Б','В',Г',...'Я'. Известно, что для символьных значений сравнение производится по правилу: меньшим считается символ, определенный в наборе символов раньше. То есть, в нашем случае, 'А' < 'Б' и 'Анискин' меньше, чем 'Артюхин', а 'Артюхин' меньше, чем 'Бармалеев' и 'Якушев'.
Порядок сортировки символов определяет, таким образом, принцип, по которому символьные значения будут сравниваться и сортироваться в операторах SELECT (если в нем присутствуют разделы WHERE, GROUP BY), при обновлении индексов и т.д.
Порядок сортировки символов определяется предложением
COLLATE
Для кириллического набора символов WIN1251 рекомендуется порядок сортировки PXW_CYRL. Например:
SYMPOLE CHARACTER (20) CHARACTER SET WIN12151 COLLATE PXW_CYRL;
Значения типа BLOB
В столбцах типа BLOB хранят данные, которые невозможно хранить в столбцах других типов. BLOB (binary large object,- большой двоичный объект) имеет переменную длину и понимается как последовательность байтов, т.е. нетипизированное, с точки зрения хранения информации, поле данных В BLOB-столбцах можно хранить графические образы, тексты большой длины, звуковые файлы, видеоизображения, мультимедиа-информацию В BLOB-столбцах также можно хранить указатели на неструктурированные файлы информации, которые расположены в ином, фиксированном месте При этом интерпретация содержимого BLOB-столбца может ложиться не только на клиентскую часть, т е. на прикладное программное обеспечение, но также и на сервер В последнем случае в серверной БД могут быть определены так называемые BLOB-фильтры, определяющие способы преобразования BLOB-значений от одного вида к другому В качестве одной из задач, могущих обусловить необходимость определения пользовательского фильтра BLOB, можно назвать преобразование изображений из одного графического формата в другой
В отличие от "персональных" (или "локальных") СУБД типа Paradox, InterBase хранит значения BLOB-столбцов не в отдельных файлах, а в самой БД. Он хранит их в виде сегментов. Одна операция ввода-вывода при доступе к BLOB-информации оперирует с одним сегментом В самой таблице БД, если в ней объявлен столбец типа BLOB, хранится указатель на начальный сегмент BLOB-столбца в области хранения BLOB-информации этой БД. Указатель на BLOB представляет собой уникальное целочисленное значение и формируется автоматически
Длина сегмента BLOB не влияет на производительность InterBase Однако, исходя из некоторых соображений, ее можно определять явно при создании BLOB-столбца
BLOBPOLE BLOB SEGMENT SIZE 1024, ...
По умолчанию длина сегмента 80; максимальная длина сегмента 32 Кбайт (32 767 байт).
Для столбца типа BLOB может быть указан подтип, определяющий, какой тип данных будет записан в этот столбец Подтип есть число. Позитивные значения зарезервированы InterBase. О (по умолчанию) для указания двоичных данных и 1 для указания ASCII-текстов Отрицательные значения могут использоваться программистами для определения собственных подтипов В общем случае указание подтипа производится через опцию SUB_TYPE
<имя столбца> BLOB SUB_TYPE 1 CHARACTER SET WIN1251 ...
Однако InterBase автоматически не отслеживает правильность занесения информации в столбцы типа BLOB. Это необходимо делать в приложениях.
Совместимость типов столбцов
При выполнении операций над столбцами следует помнить, что операции могут выполняться только над столбцами совместимых типов В случае невыполнения этого требования InterBase пытается автоматически привести типы таким образом, чтобы значения, участвующие в операции, принадлежали совместимым типам. Кроме того, для ручного приведения типов можно использовать функцию CAST, которая приводит типы внутри оператора SELECT, обычно в предложении WHERE
CAST (<значение> I NULL AS ТипДанных}
CAST может преобразовать исходные типы данных в результирующие типы
Исходные типы данных Результирующие типы данных
DATE CHAR или NUMERIC
char DATE или NUMERIC
NUMERIC DATE или CHAR
Например,
привести значение Datal (тип DATE) к типу CHAR и сравнить его со значением Date2 (типа CHAR) SELECT .....
WHERE DATE2 <= CAST (DATE1 AS CHAR);
Понятие домена
Если в таблице БД или в нескольких таблицах БД присутствуют столбцы, обладающие одними и теми же характеристиками, можно предварительно описать тип такого столбца и его поведение через домен, а затем поставить в соответствие каждому из одинаковых столбцов имя домена.
Например, создать домен POL_TYPE и затем использовать его при создании таблицы SOTR как тип столбца POL:
CREATE DOMAIN POL_TYPE AS
CHAR(3) COLLATE PXW_CYRL;
CREATE TABLE SOTR(
FIO CHAR(20) NOT NULL,
POL POL_TYPE,
OTDEL CHAR(10),
DOLJ CHAR(20),
PRIMARY KEY(FIO)
) ;
Как можно заметить, домен есть описание какого-либо столбца, то есть абстрактное понятие; как такового домена физически не существует. В языке Object Pascal сходным по назначению с определением домена является определение типа в блоке type; фактически определение типа не приводит к выделению памяти под переменную, но может использоваться при объявлении переменных в блоке var. Для приведенного выше примера, домена POL_TYPE как структуры данных физически нет, поскольку им невозможно воспользоваться для хранения данных и доступа к ним. Однако физически существует и доступен для хранения и доступа к данным столбец POL в таблице SOTR, при создании которого было использовано описание домена POL_TYPE.
Домен определяется оператором CREATE DOMAIN. Его формат:
CREATE DOMAIN домен [AS] <тип_данных>
[DEFAULT {литерал| NULL | USER}]
[NOT NULL] [CHECK (<усл_поиска_домена>)]
[COLLATE collation] ;
Предложение COLLATE позволяет указать порядок сортировки символов, например:
CREATE DOMAIN POL_TYPE AS
CHAR(3) COLLATE PXW_CYRL;
Предложение DEFAULT определяет оператор, который по умолчанию заносится в колонку, ассоциированную с доменом, при создании записи таблицы. Это значение будет присутствовать в соответствующем столбце данной записи до тех пор, пока пользователь не изменит его каким-либо образом. Значения по умолчанию могут быть выражены как:
• литерал- значение (числовое, строковое или дата);
• NULL - специфицирует пустое значение;
• USER - имя текущего пользователя.
Заметим, что значения по умолчанию, присваиваемые данному столбцу и объявленные в операторах CREATE TABLE или ALTER TABLE, переопределяют значения, присваиваемые по умолчанию тому же столбцу согласно директивам, содержащимся в CREATE DOMAIN.
Предложение NOT NULL указывает, что столбцы, ассоциированные с доменом, обязательно должны содержать какое-либо значение, отличное от пустого. Нужно следить за тем, чтобы в объявлении домена не было противоречий, например, в описании значения по умолчанию как NULL и объявлении директивы NOT NULL.
Ограничения на значения столбцов, ассоциированных с доменом
Предложение CHECK определяет требования к значениям каждого столбца, ассоциированного с доменом. Столбцу не могут быть присвоены значения, не удовлетворяющие ограничениям, наложенным в предложении CHECK. Формат ограничения, накладываемого на значения полей, ассоциированных с доменом:
<огранич_домена> = {
VALUE <оператор> <значение>
| VALUE [NOT] BETWEEN <значение1> AND <значение2>
| VALUE [NOT] LIKE <значение> [ESCAPE <значение>]
| VALUE [NOT] IN (<значение1> [, <значение2> ...]) VALUE IS [NOT] NULL
| VALUE [NOT] CONTAINING <значение>
| VALUE [NOT] STARTING [WITH] <значение>
| (<огранич домена>) | NOT <огранич домена>
| <огранич_домена> ОR<огранич_домена> | <огранич домена> AND <огранич_домена>
}
где <оператор> = {= | < | > | <= | >= | !< | !> | <> | !=}
Ключевое слово VALUE далее означает все правильные значения, которые могут быть присвоены столбцу, ассоциированному с доменом.
• VALUE <оператор> <значение>
определяет, что значение домена находится с параметром значение во взаимоотношениях, определяемых параметром оператор. Например, значение, которое может быть записано в столбец, ассоциированный с доменом ID_TYPE, должно быть больше или равно 100:
CREATE DOMAIN ID_TYPE AS INTEGER CHECK(VALUE >= 100);
• BETWEEN <значение1> AND <значение2>
определяет, что значение домена должно находиться в промежутке между значение! и значение!, включая их; • LIKE <значение1> [ESCAPE <значение2>1
определяет, что значение домена должно "походить" на параметр значение!. При этом употребляется символ '%' для указания любого значения любой длины и символ '_' (подчеркивания) для указания любого единичного символа. Например, LIKE "%USD" - вводимое значение должно оканчиваться символами 'USD', независимо от того, какие символы и сколько расположены перед ними;
LIKE "_94" - вводимое значение может содержать 4 символа, из которых первые два - любые и последние два - '94'.
ESCAPE <значение2>
используется, если в операторе LIKE символы '%' или '_' должны использоваться в шаблоне подобия. В этом случае выбирается некоторый символ, например "!", после которого символы '%', '_' входят в поисковую строку как непосредственно символы. Символ Т указывается после слова ESCAPE, например: CREATE DOMAIN SUMMA AS CHAR(lO) CHECK(LIKE "%!%" ESCAPE "!");
Значения столбца SUMMA должны заканчиваться символом "%".
• IN (<значение1 > [, <значение2>...])
определяет, что значение домена должно совпадать с одним из приведенных в списке параметров значение Х,, например: CREATE DOMAIN POL_TYPE AS CHAR(3) CHECK(VALUE IN ("Муж","Жен"));
• CONTAINING <значение>
определяет, что значение домена должно содержать вхождение параметра значение, неважно в каком месте. Например, в наименовании отдела вхождение "041" может встретиться где угодно ("Отдел-041002", "003404192", и т.д.): CREATE DOMAIN OTDEL_TYPE AS VARCHAR(lO) CHECK(VALUE CONTAINING "041") COLLATE
PXW_CYRL;
STARTING [WITH] <значение>
требует, чтобы значение домена начиналось параметром значение. Например, название отдела должно начинаться с "041": CREATE DOMAIN OTDEL_TYPE AS VARCHAR(lO) CHECK(VALUE STARTING WITH "041")
COLLATE PXW_CYRL;
• Может быть задана комбинация условий, которым должно соответствовать значение домена. В этом случае отдельные условия соединяются операторами AND или OR. Например:
CREATE DOMAIN OTDEL_TYPE AS VARCHAR(lO) CHECK(VALUE STARTING WITH "041" AND
VALUE CONTAINING "-12") COLLATE PXW_CYRL;
• Для большинства условий можно указать слово NOT, которое изменит условие с точностью до наоборот. Например: CHECK(VALUE NOT BETWEEN 1 AND 100);
Изменение определения домена
Оператор
ALTER DOMAIN имя {
[SET DEFAULT {литерал] NULL | USER}]
| [DROP DEFAULT] | [ADD [CONSTRAINT] CHECK (<огранич_домена>)] | [DROP CONSTRAINT]
};
позволяет изменить параметры домена, определенного ранее оператором CREATE DOMAIN. Однако нельзя изменить тип данных и определение NOT NULL. Следует помнить, что все сделанные изменения будут учтены для всех столбцов, определенных с использованием данного домена (в том случае, если параметры домена не были переопределены при определении столбцов таблицы или впоследствии).
SET DEFAULТ устанавливает значения по умолчанию, подобно тому, как это делается в операторе CREATE DOMAIN.
• DROP DEFAULТ отменяет текущие значения по умолчанию, назначенные домену.
• [ADD [CONSTRAINT] CHECK (<огранич_домена>)] добавляет условия, которым должны соответствовать значения столбца, ассоциированного с доменом. При этом возможно определение условий, рассмотренных выше для предложения CHECK оператора CREATE DOMAIN.
• DROP CONSTRAINT удаляет условия, определенные для домена в предложении CHECK оператора CREATE DOMAIN или предыдущих операторов ALTER DOMAIN.
Например, пусть определен домен ID_TYPE
CREATE DOMAIN ID_TYPE AS INTEGER CHECK(VALUE >= 100);
и в дальнейшем он использован при создании таблицы ААА:
CREATE TABLE ААА( ID ID_TYPE NOT NULL, FIO VARCHAR(20), PRIMARY KEY(ID));
Изменить условие, определяемое CHECK так, чтобы значение было больше или равно 100 и меньше или равно 500, можно за два такта. Сначала нужно удалить старое условие:
ALTER DOMAIN ID_TYPE DROP CONSTRAINT;
после чего добавить новое (которое на самом деле есть модифицированное старое):
ALTER DOMAIN ID_TYPE CHECK (VALUE >= 100 AND VALUE <= 500);
Заметим, что изменять определение таблицы ААА нет необходимости, и отныне в столбец ID этой таблицы можно занести значения, большие или равные 100 и меньшие или равные 500.
Общий вид оператора CREATE TABLE
Перед созданием таблиц БД необходимо продумать определение всех столбцов таблицы и характеристик каждого столбца (таких, как тип, длина, обязательность для ввода, ограничения, накладываемые на значения и пр.), индексов, ограничений целостности по отношению к другим таблицам. Если при определении столбцов используются домены, эти домены должны быть предварительно созданы оператором CREATE DOMAIN.
Та БД, в которую будет добавлена создаваемая таблица, должна быть открыта, т.е. с ней должно быть установлено активное соединение.
Создание таблицы БД осуществляется оператором
CREATE TABLE ИмяТаблицы [EXTERNAL [FILE] "<имя файла>"] (<опр_столбца> [, <опр_столбца> | <ограничение> ...]);
[EXTERNAL [FILE] "< имя файла >"]
относится к внешним, т.е. расположенным отдельно от БД, таблицам БД. • <опр_столбца> -определение столбца БД. Основные сведения об определении столбцов см. выше в разделе " Типы столбцов таблиц БД". Определение столбца имеет формат:
<опр_столбца> = опр_столбца{тип_данных | COMPUTED [BY] (<выражение>) | домен}
[DEFAULT {литерал! NULL | USER}] [NOT NULL] [<огранич_столбца>] [COLLATE collation]
где опр_столбца - имя столбца; тип_данных - тип столбца, и, возможно, размерность массива, если столбец - массив; для символьных столбцов может быть указан набор символов, отличный от принятого по умолчанию, при помощи предложения CHARACTER SET; COMPUTED [BY] (<выражете>) - служит для определения столбца вычисляемых значений (подробнее см. ниже);
domain -
имя домена, т.е. ранее описанного типа столбца; • DEFAULT определяет значение, которое по умолчанию заносится в столбец, ассоциированный с доменом, при создании записи таблицы; это значение будет присутствовать в соответствующем столбце данной записи до тех пор, пока пользователь не изменит его каким-либо образом;
значения по умолчанию (см. в п.21.1);
огранич_столбца -
ограничения, накладываемые на значения столбца (подробно рассматриваются ниже); COLLAТЕ collation
определяет порядок сортировки символов (для символьных столбцов) для набора символов, принятого по умолчанию или явно определенного предложением CHARACTER SET.
Изменение атрибутов столбца
Добавление нового столбца в таблицу БД производится оператором
ALTER TABLE <имя таблицы> ADD <определения столбца>;
Добавление новых ограничений целостности производится оператором
ALTER TABLE <имя таблицы> ADD [CONSTRAINT <имя ограничения>] <определения целостности>;
Удаление столбца (столбцов) из таблицы производится оператором
ALTER TABLE <имя таблицы> DROP <имя столбца1>[,<имя столбца2>.. . ] ;
Удаление ограничений целостности (уровень таблицы) производится оператором
ALTER TABLE <имя таблицы> DROP <имя ограничения целостности>;
Пример.
Для таблицы PRIHOD CREATE TABLE PRIHOD(ID_PRIHOD INTEGER NOT NULL PRIMARY KEY,
DATAPRIH DATE NOT NULL,
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
KOLVO INTEGER NOT NULL,
CONSTRAINT PO_TOVARU
FOREIGN KEY(TOVAR) REFERENCES SPR_TOVAR
) ;
удалить целостность PO_TOVARU: ALTER TABLE PRIHOD DROP PO_TOVARU;
ЗАМЕЧАНИЕ.
В случае необходимости непоименованной целостности придется использовать ее системное имя. Его можно узнать из системной таблицы БД с именем RDB$RELATION_CONSTRAINTS.
Удаление таблицы
Удаление таблицы целиком производится оператором DROP TABLE <имя таблицы>;
Удаление может быть блокировано для родительских таблиц, для которых в дочерних таблицах (на данный момент не удаленных) имеются ссылки по внешнему ключу этих таблиц. Действительно, удаление родительской таблицы разрушило бы ссылочную целостность. Поэтому следует либо удалить ограничения ссылочной целостности во всех дочерних таблицах, либо - по необходимости - сначала удалить сами дочерние таблицы, а затем уже удалять родительскую.
Столбцы вычисляемых значений
Такие столбцы описываются как COMPUTED [BY] (<выражение>)
Значение таких столбцов не вводится пользователем, а вычисляется автоматически согласно выражению. Тип результирующего значения и будет служить типом вычисляемого столбца. Например, таблица SAL_HIST, показанная на рис. 22.1, содержит номер квартала (QUORTER), количество продаж в данном квартале, в прошлом (LAST_YEAR) и текущем году (THIS_YEAR) и прирост продаж за квартал (GROWTH). Она создана таким образом:
CREATE TABLE SAL_HIST (
QUORTER INTEGER NOT NULL,
LAST_YEAR INTEGER,
THIS_YEAR INTEGER,
GROWTH COMPUTED BY (THIS_YEAR - LAST_YEAR),
PRIMARY KEY (QUORTER)
Ограничения целостности
Ограничения целостности бывают двух уровней:
• ограничения, накладываемые на отдельный столбец;
ограничения, накладываемые на таблицу.
В случае наложения ограничений целостности на отдельный столбец, описание ограничения приводится следом за именем столбца и его типом:
TOVAR TOVAR VARCHAR(20) NOT NULL PRIMARY KEY, ...
В данном случае столбец TOVAR составляет первичный ключ, что объявлено в предложении PRIMARY KEY.
В случае наложения ограничений на таблицу, их описание указывается после объявлений отдельных столбцов, например:
CREATE TABLE . . . (TOVAR TOVAR VARCHAR(20) NOT NULL,PRIMARY KEY(TOVAR)) ;
Первичный ключ
Если по столбцу строится первичный ключ, столбцу может быть приписан атрибут PRIMARY KEY:
CREATE TABLE SAL_HIST (QUORTER INTEGER NOT NULL PRIMARY KEY,) ;
Заметим, что первичный ключ может быть построен и путем включения имени (имен) ключевого столбца (столбцов) в качестве параметров отдельного предложения PRIMARY KEY:
CREATE TABLE SAL_HIST (QUORTER INTEGER NOT NULL,PRIMARY KEY (QUORTER)) ;
Однако и в том, и в другом случае ключевой столбец (столбцы), входящий (входящие) в состав первичного ключа, должен быть помечен как NOT NULL, поскольку первичный ключ не может быть построен даже по одному пустому значению.
Первичный ключ, если он служит для обеспечения ссылочной целостности, должен корреспондировать с внешним ключом (FOREIGN KEY) другой (дочерней) таблицы. Определение ссылочной целостности между родительской и дочерней таблицами описано ниже, в подразделе " Внешний ключ и определение ссылочной целостности ".
Уникальный ключ
Атрибут UNIQUE, если он приписан столбцу, означает, что в столбце не могут содержаться два одинаковых значения. Уникальный ключ строится по столбцу (столбцам), когда столбец не входит в состав первичного ключа, но тем не менее его значение должно всегда быть уникальным. Например, для таблицы VLADLIM ("владельцы бюджетных лимитов") первичный ключ строится по коду владельца KODVLAD, введенному для сокращения объема первичного ключа и времени поиска по нему (объем ключа по столбцу типа INTEGER много меньше объема ключа по символьному полю максимальной
длиной в 50 символов). Однако и название владельца лимита NAZVVLAD должно быть уникальным, для чего ему приписан атрибут UNIQUE:
CREATE TABLE VLADLIM (
KODVLAD INTEGER NOT NULL PRIMARY KEY,
NAZVVLAD VARCHAR(50) NOT NULL UNIQUE );
Уникальность может быть приписана и на уровне таблицы:
CREATE TABLE VLADLIM (KODVLAD INTEGER NOT NULL PRIMARY KEY,
NAZVVLAD VARCHAR(SO) NOT NULL, UNIQUE (NAZVVLAD));
Столбец, объявленный с атрибутом UNIQUE, как и первичный ключ, может применяться для обеспечения ссылочной целостности между родительской и дочерней таблицами. В этом случае столбец с атрибутом UNIQUE должен принадлежать к родительской таблице и должен корреспондировать с внешним ключом (FOREIGN KEY) другой (дочерней) таблицы.
Внешний ключ и определение ссылочной целостности
Внешний ключ строится в дочерней таблице для соединения родительской и дочерних таблиц БД. Формат определения:
FOREIGN KEY (<список столбцов внешнего ключа>)
REFERENCES <имя родительской таблицы> [<список столбцов родительской таблицы>]
Список столбцов внешнего ключа
определяет столбцы дочерней таблицы, по которым строится внешний ключ. Имя родительской таблицы
определяет таблицу, в которой описан первичный ключ (или столбец с атрибутом UNIQUE). На этот ключ (столбец) должен ссылаться данный внешний ключ дочерней таблицы для обеспечения ссылочной целостности. Список столбцов родительской таблицы необязателен при ссылке на первичный ключ родительской таблицы. При ссылке в родительской таблице на столбец с атрибутом UNIQUE этот список лучше привести. Пример.
Определим две таблицы: • родительскую "Справочник товаров" SPR_TOVAR с полями TOVAR (наименование товара), ZENA_ED (цена за единицу измерения);
первичный ключ по полю TOVAR;
• дочернюю " Приход товара на склад" PRIHOD с полями ID_PRIHOD (номер прихода), DATAPRIH (дата прихода), TOVAR (товар), KOLVO
(количество прихода, ед.). Первичный ключ по полю ID_PRIHOD внешний ключ по полю TOVAR для обеспечения ссылочной целостности с таблицей SPR_TOVAR.
Тогда для определения данных таблиц в БД необходимо выполнить операторы
CREATE TABLE SPR_TOVAR(TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
ZENA_ED INTEGER NOT NULL, PRIMARY KEY(TOVAR)) ;
CREATE TABLE PRIHOD(ID_PRIHOD INTEGER NOT NULL PRIMARY KEY,
DATAPRIH DATE NOT NULL,TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
KOLVO INTEGER NOT NULL, FOREIGN KEY(TOVAR) REFERENCES SPR_TOVAR);
Теперь для таблицы SPR_TOVAR будет установлена блокировка удаления или изменения значения в столбце TOVAR записи, если в таблице PRIHOD имеются записи о приходе этого товара.
Заметим, что определение общих полей родительской и дочерней таблиц (полей связи) должно в точности совпадать. Если в родительской таблице объявить TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
а в дочерней объявить TOVAR VARCHAR(20) NOT NULL,
то из-за различий в порядке сортировки символов эти столбцы не будут фактически идентичными, из-за чего будут постоянно возникать ошибки нарушения ссылочной целостности.
ЗАМЕЧАНИЕ.
Если ссылочная целостность между таблицей Р (родительской) и С (дочерней) обеспечивается при помощи связки PRIMARY KEY - FOREIGN KEY, то InterBase запрещает: • изменять значение столбца связи в таблице Р;
• удалять запись в таблице Р,если для нее есть записи в таблице С с таким же значением поля связи.
Иными словами, связь таблиц по внешнему ключу блокирует каскадные изменения и удаления в таблицах Р и С. В том случае, если необходимо осуществлять каскадные воздействия на таблицу С при изменении (удалении) родительской записи в Р, целостность между таблицами поддерживают при помощи триггеров, а ограничение внешнего ключа удаляют. Сам внешний ключ в дочерней таблице может и не удаляться в том случае, если он используется в запросах (оператор SELECT) оптимизатором запросов InterBase. В этом случае он определяется как индекс (оператором CREATE INDEX). Об организации ссылочной целостности при помощи триггеров, а также оптимизации запросов к БД, см. ниже соответствующие разделы.
Именование ссылочной целостности
Ссылочная целостность может именоваться:
[CONSTRAINT <имя ссылочной целостности>]
FOREIGN KEY (<список столбцов внешнего ключа>)
REFERENCES <имя родительской таблицы> [<список столбцов родительской таблицы>]
Необязательное имя ссылочной целостности присутствует в системных сообщениях относительно нарушения целостности, а также может использоваться при анализе структуры БД и изменении структуры таблиц. В случае, если имя ссылочной целостности опущено, InterBase сам установит ее имя.
Например, назначим в приведенной выше таблице PRIHOD имя ссылочной целостности:
CREATE TABLE PRIHOD(
ID_PRIHOD INTEGER NOT NULL PRIMARY KEY, DATAPRIH DATE NOT NULL,
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL, KOLVO INTEGER NOT NULL,
CONSTRAINT PO_TOVARU FOREIGN KEY(TOVAR) REFERENCES SPR_TOVAR);
Имя ссылочной целостности может назначаться также и при определении первичного ключа, и уникального набора атрибутов:
CREATE TABLE VLADLIM ( KODVLAD INTEGER NOT NULL PRIMARY KEY,
NAZVVLAD VARCHAR(50) NOT NULL, CONSTRAINT PO_NAZV UNIQUE (NAZVVLAD));
Требования к значениям столбцов
Требования к значениям отдельных столбцов могут определяться как на уровне конкретного столбца, так и на уровне таблицы. Например, для таблицы PERSON_PARAMS (параметры человека) рост (HEIGHT) должен быть больше веса (WIEGHT). Тогда данное ограничение на уровне столбца определяется следующим образом:
CREATE TABLE PERSON_PARAMS( ID INTEGER NOT NULL PRIMARY KEY,
HEIGHT INTEGER NOT NULL, WIEGHT INTEGER NOT NULL CHECK(HEIGHT >WIEGHT) ) ;
а на уровне таблицы определяется - так:
CREATE TABLE PERSON_PARAMS(ID INTEGER NOT NULL, HEIGHT INTEGER NOT NULL,
WIEGHT INTEGER NOT NULL, PRIMARY KEY(ID), CHECK(HEIGHT > WEIGHT) );
Ограничения, накладываемые на столбцы таблицы, определяются при помощи предложения CHECK, общий формат которого приводится ниже.
CHECK (<условия поиска>) <условия_поиска> = {<значение> <оператор> {<значение1> | (<выбор_одного>)}
<значение> [NOT] BETWEEN <значение1> AND <значение2>
<значение> [NOT] LIKE <значение> [ESCAPE <значение>]
<значение> [NOT] IN ( <значение1> [, <значение2> ...] |
<выбор_многих>)
<значение> IS [NOT] NULL
<значение> { [NOT] {=|<|>} I >= I <=}
{ALL ] SOME | ANY} (<выбор_многих>)
EXISTS (<выражение_выбора>)
| SINGULAR (<выражение_выбора>) | <значение> [NOT] CONTAINING <значение1>
<значение> [NOT] STARTING [WITH] <значение1>
(<условия_поиска>) NOT <условия поиска>
<условия поиска> OR <условия поиска>
<условия поиска> AND <условия_поиска>}
<значение> = {столбец | <константа> I <выражение> I <функция> | NULL I USER | RDB$DB_KEY
} [COLLATE collation]
<константа> = число | "строка"
<функция> = {
COUNT (* | [ALL] <значение> | DISTINCT <значение>)
| SUM ([ALL] <значение> | DISTINCT <значение>)
AVG ([ALL] <значение> | DISTINCT <значение>)
MAX ([ALL] <значение> | DISTINCT <значение>)
MIN ([ALL] <значение> | DISTINCT <значение>)
CAST ( <значение> AS <тип_данных>)
UPPER ( <значение>)
GEN ID (генератор, <значение>)
}
<оператор>
= {= | < | > | <= | >= | !< | !> | о | !=}. Назначение операторов: = равно;
< меньше;
> больше;
<= меньше или равно (не больше);
>= больше или равно (не меньше);
!< не меньше (больше или равно);
!> не больше (меньше или равно);
<> неравно;
!= неравно;
<выбор_одного>
= оператор SELECT, возвращающий одно значение или ни одного. <выбор_многих>
= оператор SELECT, который может возвращать более одного значения (список значений) или ни одного. <выражение_выбора>
= оператор SELECT , который может возвращать более одного значения (список значений) или ни одного. • <значение> <оператор> <значение1> определяет, что значение столбца находится со значением 1 во взаимоотношениях, определяемых оператором, который может принимать одно из следующих значений:
<оператор> = {= | < | > | <= | >= | !< | !> | <> | !=} Например, значение столбца STOLBEZ не должно быть меньше 100: CREATE TABLE TBL (CHECK(STOLBEZ >= 100););
• <значение> <оператор> (<выбор_одного>) определяет, что значение столбца находится во взаимоотношениях, определяемых оператором оператор, с результатом выполнения запроса SELECT к одной или нескольким таблицам БД, причем в качестве результата выполнения запроса возвращается единичное значение {выбор_одного).
Пример.
Пусть существует таблица TOVAR (остаток товара на складе). CREATE TABLE TOVAR (TOVAR VARCHAR(20) CHARACTER SET WIN1251 NOT NULL
COLLATE PXW_CYRL,OSTATOK INTEGER NOT NULL,PRIMARY KEY (TOVAR));
Требуется создать таблицу RASHOD (расход товара со склада) и для столбца KOLVO_R (количество расхода) предусмотреть ограничение: количество расхода данного товара не может быть больше его текущего остатка (значение столбца OSTATOK для данного значения товара) в таблице TOVAR)
CREATE TABLE RASHOD (
ID_RS INTEGER NOT NULL,
TOVAR VARCHAR(20) CHARACTER SET WIN1251 NOT NULL
COLLATE PXW_CYRL,
DATE_RASH DATE NOT NULL,
KOLVO_R INTEGER NOT NULL,
PRIMARY KEY (ID_RS),
CONSTRAINT RASH_TOVAR
FOREIGN KEY (TOVAR) REFERENCES TOVAR(TOVAR),
CONSTRAINT PO_OSTATKU
CHECK(KOLVO_R <=
(SELECT TOVAR.OSTATOK FROM TOVAR WHERE TOVAR.TOVAR = RASHOD.TOVAR))
);
• <энвчение> BETWEEN <значение1> AND <эначение2>
определяет, что значение столбца должно находиться в диапазоне от значение] до эначение2. CREATE TABLE TBL (CHECK(STOLBEZ BETWEEN 100 AND 200);) ;
• LIKE <значение> [ESCAPE <значение>]
определяет, что содержимое столбца должно "походить" на значение. При этом употребляется символ '%' для указания любого значения любой длины и символ '_' (подчеркивания) для указания любого единичного символа. Например, указание ограничения CREATE TABLE TBL (CHECK (STOLBEZ LIKE "%USD"));
читается так: вводимое в столбец значение должно оканчиваться символами •USD', независимо от того, какие символы и сколько расположены перед ними;
указание же ограничения CREATE TABLE TBL(CHECK (STOLBEZ LIKE "_94");) ;
означает, что вводимое в столбец значение может содержать 4 символа, из которых первые два - любые и последние два - '94'.
ESCAPE <значение>
используется, если в операторе LIKE символы "%" или '_' должны использоваться в шаблоне подобия. В этом случае выбирается некоторый символ, например '!', после которого символы '%', '_' входят в поисковую строку как непосредственно поисковые символы. В этом случае символ '!' указывается после слова ESCAPE, например: CREATE TABLE TBL(CHECK(STOLBEZ LIKE "%!%" ESCAPE "!"););
<значение>
{= | < | >} | >= | <=} {ALL | SOME | ANY} (<выбор_иногих>) определяет, что значение столбца больше, меньше и т.д. всех (ALL) или некоторых (SOME или ANY), значений в списке выбор_многих. Список значений выбор_иногих выдается как результат выполнения оператора SELECT по отношению к од но и или нескольким таблицам БД. Пример.
Пусть определены таблицы TOVAR и PRIHOD: CREATE TABLE TOVAR ( TOVAR VARCHAR(20) CHARACTER SET WIN1251 NOT NULL
COLLATE PXW_CYRL, PRIMARY KEY (TOVAR) );
CREATE TABLE PRIHOD ( ID_PR INTEGER NOT NULL,
TOVAR VARCHAR(20) CHARACTER SET WIN1251 NOT NULL
COLLATE PXW_CYRL,
DATE_PRIH DATE NOT NULL,
KOLVO_P INTEGER NOT NULL,
PRIMARY KEY (ID_PR)
CONSTRAINT PRIHOF_TOVAR
FOREIGN KEY (TOVAR) REFERENCES TOVAR(TOVAR)
) ;
Определим таблицу RASHOD, у которой дата расхода товара DATE_RASH больше всех дат прихода данного товара DATE_PRIH в таблице PRIHOD:
CREATE TABLE RASHOD (ID_RS INTEGER NOT NULL,
TOVAR VARCHAR(20).CHARACTER SET WIN1251 NOT NULL
COLLATE PXW_CYRL,
DATE_RASH DATE NOT NULL,
KOLVO_R INTEGER NOT NULL,
PRIMARY KEY (ID_RS),
CONSTRAINT RASH_TOVAR
FOREIGN KEY (TOVAR) REFERENCES TOVAR(TOVAR),
CONSTRAINT PO_DATE_RASH
CHECK ( DATE_RASH > ALL
SELECT DATE_PRIH
FROM PRIHOD
WHERE PRIHOD.TOVAR = RASHOD.TOVAR)));
Как видно, в операторе SELECT в предложении WHERE указана только таблица PRIHOD. Таблица RASHOD в предложении WHERE не указана, но подразумевается, поскольку именно на нее наложено ограничение PO_DA ТЕ. Кроме того, в этом случае условие выборки WHERE PRIHOD.TOVAR = RASHOD.TOVAR подразумевает текущее значение RASHOD. TOVAR, т.е. значение, введенное в добавляемую запись таблицы RASHOD, - запись, значение столбца DA TE_RASH которой и проверяется на соответствие условию, заданному в CHECK в ограничении CONSTRAINT PO_DA TE_RASH. Указание в предложении WHERE обеих таблиц, FROM PRIHOD, RASHOD приведет к тому, что условие WHERE PRIHOD.TOVAR = RASHOD.TOVAR будет воспринято как внутреннее соединение таблиц PRIHOD и RASHOD по столбцу ТОVAR. В этом случае соединение будет произведено для всех значений столбца TOVAR в таблице RASHOD, а не для текущего значения той записи таблицы RASHOD, чье значение DA TE_RASH проверяется на соответствие условию.
• EXISTS (<выражение_вь1бора>) - возвращает True, если список выражение„выбора непустой, т.е. содержит хотя бы одну строку. Список выражение_выбора выдается как результат выполнения оператора SELECT по отношению к одной или нескольким таблицам БД.
В приводимом ниже примере обязательно существование хотя бы одной записи в таблице PRIHOD с таким же значением столбца TOVAR, что и в поле TOVAR записи таблицы RASHOD.
CREATE TABLE RASHOD (ID_RS INTEGER NOT NULL,
TOVAR VARCHAR(20) CHARACTER SET WIN1251 NOT NULL
COLLATE PXW_CYRL,
DATE_RASH DATE NOT NULL,
CONSTRAINT RASH_TOVAR
FOREIGN KEY (TOVAR) REFERENCES TOVAR(TOVAR),
CONSTRAINT PO_DATE_RASH
CHECK (EXISTS (SELECT TOVAR FROM PRIHOD
WHERE PRIHOD.TOVAR = RASHOD.TOVAR))
);
• SINGULAR (<выражение_вь1бора>) - возвращает True, если список выражение_выбора содержит только одну строку. Список выражение_выбора выдается как результат выполнения оператора SELECT по отношению к одной или нескольким таблицам БД.
В приводимом ниже примере обязательно существование единственной записи в таблице PRIHOD с таким же значением столбца TOVAR, что и в поле TOVAR записи таблицы RASHOD.
CREATE TABLE RASHOD (ID_RS INTEGER NOT NULL,
TOVAR VARCHAR(20) CHARACTER SET WIN1251 NOT NULL
COLLATE PXW_CYRL,
DATE_RASH DATE NOT NULL,
CONSTRAINT RASH_TOVAR
FOREIGN KEY (TOVAR) REFERENCES TOVAR(TOVAR),
CONSTRAINT PO__DATE_RASH
CHECK (SINGULAR(SELECT TOVAR FROM PRIHOD
WHERE PRIHOD.TOVAR = RASHOD.TOVAR))
);
• <значение> CONTAINING <значение1> определяет, что значение столбца должно содержать вхождение значение1, не важно в каком месте.
В приводимом ниже примере поле значение STOLBEZ должно содержать вхождение символов 'USD', независимо от того, какие символы и в каком количестве расположены перед ними или после них.
CREATE TABLE TBL(CHECK (STOLBEZ CONTAINING "USD"));
• <значение> STARTING [WITH] <значение1> определяет, что значение столбца должно начинаться с символов значение1.
В приводимом ниже примере поле значение STOLBEZ должно начинаться с символов 'USD'.
CREATE TABLE TBL (CHECK (STOLBEZ STARTING WITH "USD")) ;
• Может быть задана комбинация условий, которым должно соответствовать значение. В этом случае отдельные условия соединяются операторами AND или OR.
• Для многих из приведенных условий (см. формат CHECK) может быть выдано отрицание при помощи слова NOT. Например:
CHECK(NOT STOLBEZ1 > STOLBEZ2);
• В качестве <значение> можно указывать имя столбца, константу, выражение, функцию.
• В качестве функций могут использоваться:
• COUNT -
счетчик повторения; • SUM -
сумма; • AVG -
среднее значение; • МАХ -
максимальное значение; • MIN -
минимальное значение; • CAST -
приведение типов; • UPPER -
приведение всех букв к заглавным; • GEN_ID -
возвращает уникальное значение генератора.
Изменение объявления таблиц
Оператор ALTER TABLE позволяет:
• добавить определение нового столбца;
• удалить столбец из таблицы;
• удалить атрибуты целостности таблицы или отдельного столбца;
добавить новые атрибуты целостности.
Перед изменением каких-либо атрибутов столбца данные, которые хранятся в нем, нужно сохранить. Для этого в таблице определяют временный столбец, в точности повторяющий все характеристики того столбца, который планируется изменить. Затем данные из изменяемого столбца копируют во временный столбец (используя, например, оператор UPDATE). После этого столбец, подлежащий изменению, попросту удаляют из таблицы, а на его месте создают новый, одноименный столбец с желаемыми атрибутами. В заключение в него копируют данные из временного столбца, а временный столбец уничтожают.
Пример.
Пусть имеется таблица CREATE TABLE SOTR(ID_SOTR INTEGER NOT NULL PRIMARY KEY,
FIO CHAR(10) COLLATE PXW_CYRL,
OTDEL VARCHAR(lO) COLLATE PXW_CYRL,
DOLJNOST CHAR(10) COLLATE PXW_CYRL
);
Пусть необходимо изменить характеристики столбца FIO, изменив тип столбца с CHAR(IO) на VARCHAR(25). Тогда:
1. Добавляем в таблицу новый временный столбец FIO_TMP, полностью повторяющий характеристики изменяемого столбца FIO:
ALTER TABLE SOTR
ADD FIO_TMP CHAR(10) CHARACTER SET WIN1251
COLLATE PXW_CYRL;
2. Копируем данные из FIO в FIO_TMP:
UPDATE SOTR
SET FIO_TMP = FIO;
3. Удаляем столбец FIO:
ALTER TABLE SOTR
DROP FIO;
4. Создаем новый столбец FIO с необходимыми характеристиками:
ALTER TABLE SOTR
ADD FIO VARCHAR(25) COLLATE PXW_CYRL;
5. Переписываем данные из временного столбца FIO_TMP в новый столбец FIO:
UPDATE SOTR
SET FIO = FIOJTMP;
6. Удаляем временный столбец FIO_TMP:
ALTER TABLE SOTR
DROP FIO_TMP;
ЗАМЕЧАНИЕ.
Следует помнить, что изменение характеристик столбца, а также удаление столбца может закончиться неудачей, если: • столбец приобретает атрибуты PRIMARY KEY или UNIQUE, но старые значения в столбце нарушают требования уникальности данных;
• удаляемый столбец входил как часть в первичный или внешний ключ, что привело к нарушению ссылочной целостности между таблицами;
• столбцу были приписаны ограничения целостности CHECK на уровне таблицы;
• столбец использовался в иных компонентах БД - в просмотрах, триггерах, в выражениях для вычисляемых столбцов.
Все вышесказанное свидетельствует о том, что в случае необходимости изменения атрибутов столбца или в случае удаления столбца, сначала необходимо тщательно проанализировать, какие последствия для таблицы и базы данных в целом может повлечь такое изменение или удаление.
Логическое разделение на ключи и индексы
В InterBase разделено понятие ключей и индексов. Это разделение, впрочем, имеет логическую окраску, то есть ценно при создании ТБД. Первичный (PRIMARY KEY) и внешний (FOREIGN KEY) ключи строятся для обеспечения ссылочной целостности реляционно связанных таблиц в БД. Первичный ключ, помимо этого, выполняет функции поддержания уникальности своих значений, что обусловлено его основным назначением - однозначно характеризовать запись в таблице БД. Для таких же целей может использоваться и просто уникальный ключ (UNIQUE).
"Обычные" индексы, создаваемые оператором CREATE INDEX, в отличие от ключей, служат для обеспечения сортировок и оптимизации доступа к данным.
С физической точки зрения, то, что логически при создании таблиц подразделялось на ключи и индексы, преобразуется в индексы. Однако, если "обычным" индексам можно назначить имя, то физические индексы, реализованные на основе определений ключей, строятся и именуются системой автоматически. Например, для таблицы SOTR будут построены два физических индекса - по первичному ключу и по "обычному" индексу DLJ:
CREATE TABLE SOTR (ID_SOTR INTEGER NOT NULL, OTDEL VARCHAR(lO) CHARACTER SET WIN1251
COLLATE PXW_CYRL, DOLJNOST CHAR(10) CHARACTER SET WIN1251
COLLATE PXW_CYRL, FIO VARCHAR(25) CHARACTER SET WIN1251
COLLATE PXW_CYRL, PRIMARY KEY (ID_SOTR)
) ;
CREATE INDEX DLJ ON SOTR (DOLJNOST) ;
но именоваться они будут следующим образом:
DLJ INDEX ON SOTR(DOLJNOST)
RDB$PRIMARY18 UNIQUE INDEX ON SOTR(ID_SOTR)
Заметим, что вывести определения всех индексов БД можно оператором SHOW INDEX;
А проделать то же для конкретной таблицы можно оператором SHOW INDEX <имя таблицы>;
Необходимость создания индексов
Индексы необходимо создавать в случае, когда по столбцу или группе столбцов:
• часто производится поиск в БД (столбец или группа столбцов часто перечисляются в предложении WHERE оператора SELECT);
• часто строятся объединения таблиц;
• часто производится сортировка в НД, возвращаемых в качестве результатов запросов к БД (то есть столбец или столбцы часто используются в предложении ORDER BY оператора SELECT).
Не рекомендуется строить индексы по столбцам или группам столбцов, которые:
• редко используются для поиска, объединения и сортировки результатов запросов;
• часто меняют значение, что приводит к необходимости часто обновлять индекс и способно существенно замедлить скорость работы с БД;
• содержат небольшое число вариантов значения.
В случае, когда при выполнении запросов используется сортировка по одним и тем же столбцам, необходимо помнить следующее: создание единого индекса по этим полям способно ускорить выполнение запросов. Однако:
• при использовании в некоторых запросах не всех столбцов из этого индекса следует использовать только непрерывную последовательность столбцов; например, если индекс построен по столбцам Р1, Р2, РЗ, Р4, то в некотором операторе SELECT допустимо указать SELECT ... ORDER BY P1,P2,P3 но никак не SELECT...ORDER BY P1,P2,P4 или SELECT...ORDER BY Р1,РЗ, Р4, поскольку в последних двух случаях индекс, построенный по столбцам Р1, Р2, РЗ, Р4, не будет использован;
• последовательность указания в предложении ORDER BY столбцов является важной; так, для индекса, построенного по столбцам Р1, Р2, РЗ, Р4, указание SELECT ... ORDER BY P2,P1,P3 не приведет к использованию указанного индекса для сортировки результирующего набора данных;
• при частом использовании в условной части WHERE оператора SELECT нескольких столбцов, связанных между собой операцией "или" (OR): SELECT . . . WHERE Р1 = значение! OR Р2 = значение2 OR РЗ = ...
вместо индекса по столбцам Р1, Р2, РЗ лучше создать несколько индексов, построенных по каждому из этих полей, поскольку в противном случае будет осуществлен последовательный просмотр всей таблицы. Это неудивительно, поскольку индексно-последовательный доступ для индекса по столбцам Р1, Р2, РЗ может быть осуществлен только для столбца Р1; значения столбцов Р2 и РЗ в этом индексе спонтанно разбросаны по индексу. Например:
Создание индекса
Индекс может быть создан оператором
CREATE [UNIQUE] |ASC[ENDING][ DESC[ENDING]]
INDEX ИмяИндекса ON ИмяТаблицы (столбец! |,столбец2 ...]);
• UNIQUE - требует создания уникального индекса, не допускающего одинаковых значений индексных полей для разных записей таблицы;
• ASC[ ENDING] - указывает на необходимость сортировки значений индексных полей по возрастанию (режим принят по умолчанию);
• DESC[ENDING] - указывает на необходимость сортировки значений индексных полей по убыванию;
• ИмяИндекса - имя создаваемого индекса;
• table - имя таблицы, для которой создается индекс;
• cтолбецN - имена столбцов, по которым создается индекс.
Например,
для таблицы PRIHOD CREATE TABLE PRIHOD(ID_PRIHOD INTEGER NOT NULL PRIMARY KEY,
DATAPRIH DATE NOT NULL,
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
KOLVO INTEGER NOT NULL
) ;
создать индекс в порядке убывания значений DATAPRIH и TOVAR:
CREATE DESC INDEX D_P ON PRIHOD (DATAPRIH,TOVAR);
Перестройка индекса
Перестройка индекса заключается в пересоздании и балансировке индекса, что наступает после деактивизации индекса оператором ALTER INDEX <имя индекса> DEACTIVATE;
и последующей его активизации оператором ALTER INDEX <имя индекса> DEACTIVATE;
Деактивизация индекса полезна также в том случае, когда имеет место вставка в таблицу БД большого числа записей. В обычном режиме добавления записей при активном индексе изменения вносятся в индекс по мере добавления записей в таблицу, что может разбалансировать индекс. Следует помнить, что:
• нельзя перестроить используемый в данный момент индекс, что может иметь место при выполнении другими пользователями запросов к БД;
• нельзя перестроить индекс, созданный в результате определения первичного и внешнего ключей, а также уникальности значений столбца или группы столбцов (PRIMARY KEY, FOREIGN KEY, UNIQUE). Для этой цели следует применять оператор ALTER TABLE;
для выполнения оператора ALTER INDEX нужно иметь соответствующие привилегии доступа к БД.
Повторное вычисление показателя "полезности" индекса
Показатель "полезности" индекса основан на сведениях о числе повторяющихся строк индекса. Он используется InterBase при доступе к таблице для выработки оптимального плана удовлетворения запроса. Пересчет показателя "полезности" производится оператором
SET STATISTICS INDEX <имя индекса:-;
Заметим что SET STATISTICS не перестраивает индекс. Для этой цели необходимо использовать оператор ALTER INDEX. Для выполнения оператора SET STATISTICS нужно иметь соответствующие привилегии
доступа к БД.
Улучшение производительности индекса
После многократного внесения изменений в таблицу БД индексы этой таблицы могут быть разбалансированы. Разбалансировка приводит к тому, что "глубина" индекса (depth) возрастает сверх критического значения (2). "Глубина" индекса - параметр, показывающий максимальное число операций, необходимых для нахождения искомого значения в таблице БД с использованием данного индекса. В случае разбалансировки индекса его ценность при выполнении запросов снижается из-за увеличения времени выполнения запроса. Поэтому время от времени необходимо производить одно из перечисленных ниже действий:
• выполнять перестройку индекса оператором ALTER INDEX;
• пересчитать показатель "выбираемости" индекса оператором SET STATISTICS;
уничтожить индекс оператором DROP INDEX и заново создать его оператором CREATE INDEX.
Удаление существующего индекса
Для удаления индекса, ранее созданного оператором CREATE INDEX, используется оператор
DROP INDEX <имя индекса>;
Нельзя удалить индекс, созданный в результате определения первичного и внешнего ключей, а также уникальности значений столбца или группы столбцов (PRIMARY KEY, FOREIGN KEY, UNIQUE). Для этой цели следует применять оператор ALTER TABLE.
Нельзя также удалить используемый индекс, что может иметь Место при выполнении другими пользователями запросов к БД. Кроме этого, для удаления индекса нужно иметь соответствующие привилегии доступа к БД.
Компонент Tdatabase
204 глава 25
25. Оператор SELECT 25.1. Простейший вид оператора SELECT *
25.2. Использование предложения WHERE *
25.2.1. Сравнение значения столбца с константой *
25.2.2. Сравнение значения столбца из одной таблицы со значением столбца из другой таблицы (внутреннее соединение) *
25.3. Использование псевдонимов таблиц *
25.4. Предложение ORDER BY - определение сортировки *
25.5. Устранение повторяющихся значений *
25.6. Расчет значений результирующих столбцов на основе арифметических выражений *
25.7. Агрегатные функции *
25.8. Использование группировок записей *
25.9. Предложение HAVING - наложение ограничений на группировку записей *
25.10. Предложение WHERE : задание сложных условий поиска *
25.10.1. Использование логических выражений *
25.10.2. Сравнение столбца с результатом вычисления выражения *
25.10.3. Использование BETWEEN *
25.10.4. Использование IN (список значений) *
25.10.5. Использование STARTING *
25.10.6. Использование CONTAINING *
25.10.7. Использование функции UPPER *
25.10.8. Использование LIKE *
25.10.9. Использование функции CAST *
25.11. Использование подзапросов *
25.12. Вложение подзапросов *
25.13. Дополнительные возможности использования подзапросов, возвр единичное значение *
25.13.1. Использование EXISTS *
25.13.2. Использование SINGULAR *
25.14. Использование подзапросов, возвращающих множество значений *
25.14.1. Использование ALL, SOME *
25.14.2. Использование HAVING и агрегатных функций для вложенных подзапросов *
25.15. Внешние соединения *
25.16. UNION - объединение результатов выполнения нескольких операторов SELECT *
25.17. Использование IS NULL *
25.18. Использование операции сцепления строк *
25.19. Работа с разными БД в одном запросе *
глава 26 26. Добавление, изменение, удаление записей 26.1. Оператор INSERT *
26.1.1. Явное указание списка значений *
26.1.2. Указание значений при помощи оператора SELECT *
26.2..0ператор UPDATE *
26.3. Оператор DELETE *
глава 27 27. Работа с просмотрами VIEW 27.1. Понятие просмотра как виртуальной таблицы *
27.2. Способы формирования просмотров *
27.3. Указание столбцов просмотра в операторе CREATE VIEW *
27.4. Обновляемые и необновляемые просмотры *
27.5. Использование CHECK OPTION *
27.6. Компоненты Delphi и использование просмотров *
глава 28
28. Работа с хранимыми процедурами 28.1. Понятие хранимой процедуры *
28.2. Создание хранимой процедуры *
28.3. Алгоритмический язык хранимых процедур *
28.3.1. Объявление локальных переменных *
28.3.2. Операторные скобки BEGIN... END *
28.3.3. Оператор присваивания *
28.3.4. Оператор IF... THEN ... ELSE *
28.3.5. Оператор SELECT *
28.3.6. Оператор FOR SELECT... DO *
28.3.7. Оператор SUSPEND *
28.3.8. Оператор WHILE... DO *
28.3.9. Оператор EXIT *
28.3.10. Оператор EXECUTE PROCEDURE *
28.3.11. Оператор POST_EVENT *
28.4. Вызов процедур выбора в приложении клиента *
28.5. Обращение к процедурам действия. *
28.6. Изменение и удаление хранимых процедур *
глава 29 29. Работа с триггерами 29.1. Создание триггеров *
29.2. Определение заголовка триггера *
29.3. Значения OLD и NEW *
29.4. Обеспечение каскадных воздействий *
29.5. Ведение журнала изменений *
29.6. Использование триггеров для реализации бизнес-правил *
29.7. Изменение и удаление триггеров *
глава 30 30. Использование генераторов * глава 31
31. Использование утилиты Database Explorer 31.1. Просмотр метаданных *
31.2. Работа с таблицами *
31.2.1. Просмотр и изменение данных *
31.2.2. Просмотр столбцов *
31.2.3. Просмотр ограничений на значения столбцов *
31.2.4. Просмотр индексов *
31.2.5. Просмотр триггеров *
глава 32 32. Транзакции 32.1. Откат изменений и целостность БД *
32.2. Понятие транзакции *
32.3. Уровни изоляции транзакций: приложение клиента *
32.3.1. Уровень изоляции транзакций Dirty Read *
32.3.2. Уровень изоляции транзакций Read Commited *
32.3.3. Уровень изоляции транзакций Repeatable Read *
32.3.4. Установка уровней изоляции транзакций в Delphi *
32.4. Свойство UpdateMode и обновление записей *
32.5. Явно и неявно стартуемые транзакции *
32.6. Управление транзакциями на SQL-сервере InterBase *
глава 33 33. Кэшированные изменения 33.1. Использование кэшированных изменений *
33.2. Активизация режима кэшированных изменений *
33.3. Отмена кэшированных изменений *
33.4. Подтверждение кэшированных изменений *
33.4.1. Подтверждение кэшированных изменений методом ApplyUpdates компонента TDatabase *
33.4.2. Подтверждение кэшированных изменений методом ApplyUpdates набора данных *
33.5. Видимость измененных записей *
33.6. Обработка ошибок. Обработчик события OnUpdateError *
33.6.1. Использование обработчика OnUpdateError *
33.6.2. Использование параметра UpdateKind *
33.6.3. Использование параметра UpdateAction *
33.6.4. Использование параметра Е *
33.7. Компонент TUpdateSQL *
33.7.1. Использование компонента TUpdateSQL *
33.7.2. Компонент TUpdateSQL: этап разработки *
33.7.3. Компонент TUpdateSQL: выполнение SQL-операторов *
глава 34 34.Работа с событиями 34.1. Понятие события *
34.2. Приложения Delphi и компонент TIBEventAlerter *
34.3. Использование компонента TIBEventAlerter для обработки событий сервера БД в клиентском приложении *
34.4. Обмен сообщениями между приложениями *
34.5. Обмен инициализирующими сообщениями между приложениями *
глава 35 35. Функции, определяемые пользователем 35.1. Понятие функции, определяемой пользователем *
35.2. Разработка DLL и UDF в Delphi *
35.2.1. Общие положения *
35.2.2. Совместимость типов параметров *
35.2.3. Особенности использования в UDF параметров типа PChar *
35.2.4. Особенности использования в UDF параметров типа даты и времени *
35.3. Объявление UDF в БД InterBase *
35.4. Пример создания DLL с несколькими UDF и объявления их в БД *
глава 36 36. Определение бизнес-правил 36.1. Размещение бизнес-правил *
36.2. Реализация бизнес-правил на сервере *
36.2.1. Ограничения значения столбца записи *
36.2.2. Запрет добавления записей в просмотре *
36.2.3. Использование триггеров для поддержания ссылочной целостности *
36.3. Реализация бизнес-правил в приложении клиента *
36.3.1. Реализация бизнес-правил в компонентах типа "набор данных" *
36.3.2. Свойство Constrained (компонент TQuery) *
36.3.3. Свойство Constraints *
36.3.4. Реализация бизнес-правил в компоненте TField *
36.3.5. Реализация бизнес-правил в иных компонентах *
36.4. Использование словаря данных для определения атрибутов полей *
глава 37
37. Оптимизация работы с БД 37.1. Оптимизация структуры БД *
37.1.1. Нормализация таблиц: теория и практика *
37.1.2. Частичная зависимость структуры данных от методов доступа к ним *
37.1.3. Физические характеристики БД *
37.2. Оптимизация запросов *
37.2.1. Оптимальная структура индексов *
37.2.2. "Полезность" индексов *
37.2.3. Просмотр плана выполнения запросов *
37.2.4. Целесообразность создания индексов *
37.2.5. Частичное использование составного индекса *
37.2.6. Многопоточность поиска по OR и IN *
37.2.7. Уменьшение общего количества индексов *
37.3. Оптимизация клиентских приложений *
37.3.1. Минимизация соединений с БД *
37.3.2. Использование TQuery *
37.3.3. Перенос тяжести вычислительной работы на сервер *
глава 38 38. Работа с утилитой InterBase Server Manager 38.1. Соединения *
38.1.1. Соединение с сервером *
38.1.2. Соединение с БД *
38.1.3. Выбор текущего сервера и БД *
38.1.4. Разрыв соединения *
38.2. Изменение конфигурации сервера *
38.3. Сбор статистики о БД *
38.3.1. Статистические данные непосредственно о БД *
38.3.2. Анализ БД *
38.4. Принудительная сборка мусора *
38.5. Создание резервной копии (сохранение) и восстановление БД *
38.5.1. Переход в однопользовательский режим соединения с БД *
38.5.2. Резервное копирование БД *
38.5.3. Восстановление БД из резервной копии *
38.6. Принудительная запись на диск *
38.7. Восстановление транзакций *
38.8. Регистрация новых пользователей *
глава 39 39. Установка привилегий доступа 39.1. Привилегии доступа по умолчанию * 39.2. Виды привилегий * 39.3. Минимальный состав параметров при предоставлении привилегий доступа к таблице БД * 39.4. Предоставление нескольких привилегий * 39.5. Предоставление привилегий нескольким пользователям * 39.6. Назначение привилегий всем пользователям * 39.7. Установка привилегий доступа к отдельным столбцам таблицы * 39.8. Предоставление пользователю права назначать привилегии другим пользователям * 39.9. Назначение привилегий вызова хранимых процедур * 39.10. Назначение процедуре прав доступа к таблице * 39.11. Ликвидация привилегий * приложение А Свойства, методы, события. Компонент TDataBase *
Компонент TDBChart *
Компонент TDBCheckBox *
Компонент TDBComboBox *
Компонент TDBCtriGrid *
Компонент TDBEdit *
Компонент TDBGrid *
Компонент TDBListBox *
Компонент TDBLookupComboBox *
Компонент TDBMemo *
Компонент TDBRadioGroup *
Компонент TDBRichEdit *
Компонент TDBText *
Компонент TDecisionCube *
Компонент TdecisionGrid *
Компонент TDecisionPivot *
Компонент TDecisionSource *
Компонент TField *
Компонент TIBEventAlerter *
Компонент TQuery *
Компонент TQRBand *
Компонент TQRExp *
Компонент TQRGroup *
Компонент TQRSubDetail *
Компонент TQRSysData *
Компонент TQuickRep *
Компонент TChartSeries *
Компонент TSession *
Компонент ТТаblе *
Компонент TUpdateSQL *
приложение B Формат SQL-операторов (СУБД InterBase)
База данных *
Создание базы данных *
Определение типа данных *
Домены *
Создание домена *
Ограничение, накладываемое на значения полей, ассоциированных с доменом *
Изменение определения домена *
Таблицы базы данных *
Определение первичного ключа *
Определение уникального ключа *
Определение ограничения внешнего ключа и ссылочной целостности с родительской таблицей *
Ограничения на значения столбца *
Добавление нового столбца в таблицу БД *
Добавление новых ограничений целостности *
Удаление столбца (столбцов) из таблицы БД *
Удаление ограничений целостности *
Удаление таблицы БД целиком *
Индексы *
Создание индекса *
Деактивизация индекса *
Активизация индекса *
Вычисление показателя "полезности" индекса *
Удаление индекса *
Выборка данных из таблиц БД *
Изменение данных *
Добавление записей *
Изменение записей *
Просмотры *
Создание просмотра *
Удаление просмотра *
Хранимые процедуры *
Создание хранимой процедуры *
Обращение к хранимой процедуре (утилита WISQL) *
Тело процедуры *
Изменение хранимой процедуры *
Удаление хранимой процедуры: *
Алгоритмический язык триггеров и хранимых процедур *
Объявление локальных переменных *
Оператор присваивания *
Условный оператор *
Оператор выбора SELECT *
Оператор циклической выборки *
Принудительная выдача выходных параметров (только хранимые процедуры) *
Оператор цикла *
Выход из процедуры, триггера *
Вложенный вызов другой хранимой процедуры *
Инициация наступления события *
Обращение к старому и новому значениям столбца (только триггеры) *
Триггеры *
Создание триггера *
Структура тела триггера *
Изменение существующего триггера *
Удаление триггера *
Генераторы *
Создание генератора *
Установка стартового значения генератора *
Транзакции *
Старт транзакции *
События *
Инициация наступления события *
UDF (Функции, определяемые пользователем) *
Объявление UDF (функций, определяемых пользователем) в базе данных *
Привилегии доступа *
Предоставление привилегий доступа к таблицам БД, просмотрам, вызовам процедур *
Отъем привилегий *
Компонент TDataBase создается для каждого факта соединения сессии с отдельной БД Если для факта конкретного соединения в приложении не предусмотрен компонент TDatabase, создается временный компонент TDatabase Таким образом, каждая открытая БД имеет свой компонент TDataBase. Список активных БД данной сессии содержится в коллекции TSession Databases, каждый элемент которой имеет тип TDatabase. Число активных БД сессии определяется через свойство TSession DatabaseCount.
Случаи явного использования в приложении компонента TDatabase чаще всего связаны с работой в архитектуре "клиент-сервер". Явно определенный в приложении компонент TDatabase позволяет управлять БД, создавая постоянные соединения с БД, настраивая сеанс соединения с сервером, управляя транзакциями и создавая локальные псевдонимы BDE в приложении.
Несомненно, каждый набор данных, работающий с таблицами одной и той же БД, может иметь с этой БД отдельное соединение. Однако это нерационально, поскольку на каждое соединение затрачиваются системные ресурсы Для минимизации их использования рекомендуется в приложении создавать единственное соединение с удаленной БД при помощи компонента TDatabase, a все наборы данных и компоненты, реализующие действия над БД, соединять с компонентом TDatabase.
Свойство property AliasName: TSymbolStr; указывает псевдоним BDE, ассоциированный с данным компонентом TDatabase. Если заполнено свойство DnverNawe, значение свойства A liasName очищается.
Свойство property DatabaseName: TFileName; определяет локальный псевдоним приложения, который может использоваться при доступе к БД вместо псевдонима BDE, пути к файлам БД или имени БД. Именно значение, определяемое данным свойством, показывается в выпадающем списке свойства DatabaseName компонентов TTab/e, TQuery и TSforedProc при разработке приложения.
Свойства соединения компонента TDatabase с удаленной БД определяются:
• параметрами псевдонима БД;
• параметрами драйвера БД (например, InterBase);
• общесистемными установками в утилите BDE Administrator.
Эти установки могут изменяться во время разработки приложения в редакторе базы данных. Для этого нужно в приложении выбрать при помощи мыши компонент TDatabase, щелкнуть по нему правой кнопкой мыши и во всплывающем меню выбрать элемент Database Editor. В диалоговом окне редактора БД (рис. 24.1) в поле Parameter overrides можно переустановить параметры псевдонима БД и драйвера.
Для того чтобы вернуться к параметрам псевдонима, принятым по умолчанию, нужно нажать кнопку Defaults (результат на рис. 24.2).
Не рекомендуется явно указывать значение параметра SERVER NAME, например
SERVER NAME=D:\BOOK\IB_SKLAD\Ib_sklad.gdb
поскольку при изменении местонахождения БД придется изменять значение пути и в параметрах компонента TDatabase (вместо того, чтобы изменить путь к БД в определении псевдонима в утилите BDE Administrator).
На панели Options имеется два поля. Снятие отметки с поля Login Prompt приводит к тому, что диалог запроса имени пользователя и пароля не выдается. В этом случае имя пользователя и пароль можно указать в параметрах соединения (в поле Parameter), например
USER NAME=SYSDBA
PASSWORD=masterkey
Отметка поля Login Prompt равносильна присваиванию значения True свойству
property LoginPrompt: Boolean;
Это свойство определяет, выдавать ли при первом соединении с БД окно ввода имени пользователя и пароля, или же они должны быть указаны в свойстве Params.
Другое поле отметки на панелях Options, Keep Inactive Connection в отмеченном состоянии означает, что соединение с БД будет храниться даже в случае, если ни один набор данных в приложении, работающий с этой БД, не открыт. Отметка поля аналогична установке в True свойства
property KeepConnection: Boolean;
указывает, следует ли хранить соединение с БД, если нет связанных с ней открытых НД. Свойство property Connected: Boolean; в значении True указывает, имеет ли компонент TDatabase активное соединение с БД.
Свойства соединения с БД могут быть переустановлены во время работы приложения. Для этого используется синтаксис доступа к конкретному параметру как к элементу компонента TStrings свойства
property Params: TStrings;
когда название параметра выступает в качестве индекса, например: Databasel.Params[' USER NAME '] := 'PASHA';
Databasel.Params['PASSWORD'] := 'ppp';
При этом следует помнить, что в момент смены параметров соединения не должно быть активного соединения с БД, то есть свойство Connected должно быть установлено в значение False.
Рассмотрим другие свойства компонента TDatabase.
Свойство property DatasetCount: Integer; определяет число активных НД, связанных с настоящей БД (компоненты TTable и TQuery).
Свойство property Datasets|Index: Integer]: TDBDataSet; представляет собой коллекцию активных НД (компоненты TDBDataSet), связанных с настоящей БД. Число компонентов определяется свойством DatasetCount. Минимальный индекс 0, максимальный DatasetCount -1.
property DriverName: TSymboIStr;
Указывает имя драйвера BDE, такого как STANDARD (dBASE и Paradox), ORACLE, SYBASE, INFORMIX или INTERBASE. Значение свойства очищается, если устанавливается значение свойства AliasName, и наоборот. property IsSQLBased: Boolean;
Указывает, ассоциирован ли данный компонент TDatabase с SQL-ориентированной БД. property SessionName: string;
Указывает компонент TSession, с которым связана БД. property Temporary: Boolean;
Указывает, создавать ли временный компонент TDatabase для БД, для которых компоненты TDatabase не определены в приложении явно. Следующие свойства используются для управления транзакциями.
property Translsolation: TTransIsolation;
Устанавливает уровень изоляции транзакций для SQL-сервера. property InTransaction: Boolean;
Возвращает True, если для компонента TDatabase (для текущего соединения с БД) существует активная транзакция, и False, если для соединения с БД активных транзакций нет. Метод procedure StartTransaction; инициирует начало транзакции. Если в этот момент активна некоторая транзакция, возбуждается исключение. Транзакционные изменения в наборах БД, имевшие место после выполнения метода Start Transaction, либо подтверждаются методом Commit, либо отменяются методом Rollback. До подтверждения или отмены изменений транзакция, начатая StartTransaction, считается активной.
Метод procedure Commit; подтверждает текущую транзакцию, т.е. подтверждает все модификации в БД, имевшие место с момента последнего вызова метода StartTransaction. Если ни одна транзакция не активна, возбуждается исключение.
Метод procedure Rollback; откатывает текущую транзакцию, т.е. отменяет все модификации в БД, имевшие место с момента последнего вызова метода Start Transaction.
Сведения об уровнях изоляции транзакций, равно как и о других вопросах, связанных со стартом, подтверждением или откатом транзакций в приложении и на сервере БД, вы можете найти в разделе книги, посвященном управлению транзакциями.
Метод procedure Apply Updates(const DataSets: array of TDataSet); применяется для подтверждения кэшированных изменений сразу в нескольких наборах данных. Список НД определяется параметром DataSets. В случае указания нескольких НД их имена разделяются запятыми.
Более подробную информацию об использовании этого метода и о кэшированных изменениях вообще Вы можете найти в разделе книги, посвященном кэшированным изменениям в БД.
Метод procedure Close; закрывает БД и все открытые НД, связанные с ней.
Метод procedure CloseDatasets; закрывает открытые НД, связанные с БД, но не закрывает саму БД.
Метод procedure Open; открывает БД, соединяя компонент TDatabase с сервером или BDE для Paradox или dBASE.
Событие TLoginEvent = procedure(Database: TDatabase; LoginParams:TStrings) of object;
property OnLogin: TLoginEvent; возникает, когда компонент TDatabase начинает сессию соединения с SQL-сервером.
204 глава 25
25. Оператор SELECT 25.1. Простейший вид оператора SELECT *
25.2. Использование предложения WHERE *
25.2.1. Сравнение значения столбца с константой *
25.2.2. Сравнение значения столбца из одной таблицы со значением столбца из другой таблицы (внутреннее соединение) *
25.3. Использование псевдонимов таблиц *
25.4. Предложение ORDER BY - определение сортировки *
25.5. Устранение повторяющихся значений *
25.6. Расчет значений результирующих столбцов на основе арифметических выражений *
25.7. Агрегатные функции *
25.8. Использование группировок записей *
25.9. Предложение HAVING - наложение ограничений на группировку записей *
25.10. Предложение WHERE : задание сложных условий поиска *
25.10.1. Использование логических выражений *
25.10.2. Сравнение столбца с результатом вычисления выражения *
25.10.3. Использование BETWEEN *
25.10.4. Использование IN (список значений) *
25.10.5. Использование STARTING *
25.10.6. Использование CONTAINING *
25.10.7. Использование функции UPPER *
25.10.8. Использование LIKE *
25.10.9. Использование функции CAST *
25.11. Использование подзапросов *
25.12. Вложение подзапросов *
25.13. Дополнительные возможности использования подзапросов, возвр единичное значение *
25.13.1. Использование EXISTS *
25.13.2. Использование SINGULAR *
25.14. Использование подзапросов, возвращающих множество значений *
25.14.1. Использование ALL, SOME *
25.14.2. Использование HAVING и агрегатных функций для вложенных подзапросов *
25.15. Внешние соединения *
25.16. UNION - объединение результатов выполнения нескольких операторов SELECT *
25.17. Использование IS NULL *
25.18. Использование операции сцепления строк *
25.19. Работа с разными БД в одном запросе *
глава 26 26. Добавление, изменение, удаление записей 26.1. Оператор INSERT *
26.1.1. Явное указание списка значений *
26.1.2. Указание значений при помощи оператора SELECT *
26.2..0ператор UPDATE *
26.3. Оператор DELETE *
глава 27 27. Работа с просмотрами VIEW 27.1. Понятие просмотра как виртуальной таблицы *
27.2. Способы формирования просмотров *
27.3. Указание столбцов просмотра в операторе CREATE VIEW *
27.4. Обновляемые и необновляемые просмотры *
27.5. Использование CHECK OPTION *
27.6. Компоненты Delphi и использование просмотров *
глава 28
28. Работа с хранимыми процедурами 28.1. Понятие хранимой процедуры *
28.2. Создание хранимой процедуры *
28.3. Алгоритмический язык хранимых процедур *
28.3.1. Объявление локальных переменных *
28.3.2. Операторные скобки BEGIN... END *
28.3.3. Оператор присваивания *
28.3.4. Оператор IF... THEN ... ELSE *
28.3.5. Оператор SELECT *
28.3.6. Оператор FOR SELECT... DO *
28.3.7. Оператор SUSPEND *
28.3.8. Оператор WHILE... DO *
28.3.9. Оператор EXIT *
28.3.10. Оператор EXECUTE PROCEDURE *
28.3.11. Оператор POST_EVENT *
28.4. Вызов процедур выбора в приложении клиента *
28.5. Обращение к процедурам действия. *
28.6. Изменение и удаление хранимых процедур *
глава 29 29. Работа с триггерами 29.1. Создание триггеров *
29.2. Определение заголовка триггера *
29.3. Значения OLD и NEW *
29.4. Обеспечение каскадных воздействий *
29.5. Ведение журнала изменений *
29.6. Использование триггеров для реализации бизнес-правил *
29.7. Изменение и удаление триггеров *
глава 30 30. Использование генераторов * глава 31
31. Использование утилиты Database Explorer 31.1. Просмотр метаданных *
31.2. Работа с таблицами *
31.2.1. Просмотр и изменение данных *
31.2.2. Просмотр столбцов *
31.2.3. Просмотр ограничений на значения столбцов *
31.2.4. Просмотр индексов *
31.2.5. Просмотр триггеров *
глава 32 32. Транзакции 32.1. Откат изменений и целостность БД *
32.2. Понятие транзакции *
32.3. Уровни изоляции транзакций: приложение клиента *
32.3.1. Уровень изоляции транзакций Dirty Read *
32.3.2. Уровень изоляции транзакций Read Commited *
32.3.3. Уровень изоляции транзакций Repeatable Read *
32.3.4. Установка уровней изоляции транзакций в Delphi *
32.4. Свойство UpdateMode и обновление записей *
32.5. Явно и неявно стартуемые транзакции *
32.6. Управление транзакциями на SQL-сервере InterBase *
глава 33 33. Кэшированные изменения 33.1. Использование кэшированных изменений *
33.2. Активизация режима кэшированных изменений *
33.3. Отмена кэшированных изменений *
33.4. Подтверждение кэшированных изменений *
33.4.1. Подтверждение кэшированных изменений методом ApplyUpdates компонента TDatabase *
33.4.2. Подтверждение кэшированных изменений методом ApplyUpdates набора данных *
33.5. Видимость измененных записей *
33.6. Обработка ошибок. Обработчик события OnUpdateError *
33.6.1. Использование обработчика OnUpdateError *
33.6.2. Использование параметра UpdateKind *
33.6.3. Использование параметра UpdateAction *
33.6.4. Использование параметра Е *
33.7. Компонент TUpdateSQL *
33.7.1. Использование компонента TUpdateSQL *
33.7.2. Компонент TUpdateSQL: этап разработки *
33.7.3. Компонент TUpdateSQL: выполнение SQL-операторов *
глава 34 34.Работа с событиями 34.1. Понятие события *
34.2. Приложения Delphi и компонент TIBEventAlerter *
34.3. Использование компонента TIBEventAlerter для обработки событий сервера БД в клиентском приложении *
34.4. Обмен сообщениями между приложениями *
34.5. Обмен инициализирующими сообщениями между приложениями *
глава 35 35. Функции, определяемые пользователем 35.1. Понятие функции, определяемой пользователем *
35.2. Разработка DLL и UDF в Delphi *
35.2.1. Общие положения *
35.2.2. Совместимость типов параметров *
35.2.3. Особенности использования в UDF параметров типа PChar *
35.2.4. Особенности использования в UDF параметров типа даты и времени *
35.3. Объявление UDF в БД InterBase *
35.4. Пример создания DLL с несколькими UDF и объявления их в БД *
глава 36 36. Определение бизнес-правил 36.1. Размещение бизнес-правил *
36.2. Реализация бизнес-правил на сервере *
36.2.1. Ограничения значения столбца записи *
36.2.2. Запрет добавления записей в просмотре *
36.2.3. Использование триггеров для поддержания ссылочной целостности *
36.3. Реализация бизнес-правил в приложении клиента *
36.3.1. Реализация бизнес-правил в компонентах типа "набор данных" *
36.3.2. Свойство Constrained (компонент TQuery) *
36.3.3. Свойство Constraints *
36.3.4. Реализация бизнес-правил в компоненте TField *
36.3.5. Реализация бизнес-правил в иных компонентах *
36.4. Использование словаря данных для определения атрибутов полей *
глава 37
37. Оптимизация работы с БД 37.1. Оптимизация структуры БД *
37.1.1. Нормализация таблиц: теория и практика *
37.1.2. Частичная зависимость структуры данных от методов доступа к ним *
37.1.3. Физические характеристики БД *
37.2. Оптимизация запросов *
37.2.1. Оптимальная структура индексов *
37.2.2. "Полезность" индексов *
37.2.3. Просмотр плана выполнения запросов *
37.2.4. Целесообразность создания индексов *
37.2.5. Частичное использование составного индекса *
37.2.6. Многопоточность поиска по OR и IN *
37.2.7. Уменьшение общего количества индексов *
37.3. Оптимизация клиентских приложений *
37.3.1. Минимизация соединений с БД *
37.3.2. Использование TQuery *
37.3.3. Перенос тяжести вычислительной работы на сервер *
глава 38 38. Работа с утилитой InterBase Server Manager 38.1. Соединения *
38.1.1. Соединение с сервером *
38.1.2. Соединение с БД *
38.1.3. Выбор текущего сервера и БД *
38.1.4. Разрыв соединения *
38.2. Изменение конфигурации сервера *
38.3. Сбор статистики о БД *
38.3.1. Статистические данные непосредственно о БД *
38.3.2. Анализ БД *
38.4. Принудительная сборка мусора *
38.5. Создание резервной копии (сохранение) и восстановление БД *
38.5.1. Переход в однопользовательский режим соединения с БД *
38.5.2. Резервное копирование БД *
38.5.3. Восстановление БД из резервной копии *
38.6. Принудительная запись на диск *
38.7. Восстановление транзакций *
38.8. Регистрация новых пользователей *
глава 39 39. Установка привилегий доступа 39.1. Привилегии доступа по умолчанию * 39.2. Виды привилегий * 39.3. Минимальный состав параметров при предоставлении привилегий доступа к таблице БД * 39.4. Предоставление нескольких привилегий * 39.5. Предоставление привилегий нескольким пользователям * 39.6. Назначение привилегий всем пользователям * 39.7. Установка привилегий доступа к отдельным столбцам таблицы * 39.8. Предоставление пользователю права назначать привилегии другим пользователям * 39.9. Назначение привилегий вызова хранимых процедур * 39.10. Назначение процедуре прав доступа к таблице * 39.11. Ликвидация привилегий * приложение А Свойства, методы, события. Компонент TDataBase *
Компонент TDBChart *
Компонент TDBCheckBox *
Компонент TDBComboBox *
Компонент TDBCtriGrid *
Компонент TDBEdit *
Компонент TDBGrid *
Компонент TDBListBox *
Компонент TDBLookupComboBox *
Компонент TDBMemo *
Компонент TDBRadioGroup *
Компонент TDBRichEdit *
Компонент TDBText *
Компонент TDecisionCube *
Компонент TdecisionGrid *
Компонент TDecisionPivot *
Компонент TDecisionSource *
Компонент TField *
Компонент TIBEventAlerter *
Компонент TQuery *
Компонент TQRBand *
Компонент TQRExp *
Компонент TQRGroup *
Компонент TQRSubDetail *
Компонент TQRSysData *
Компонент TQuickRep *
Компонент TChartSeries *
Компонент TSession *
Компонент ТТаblе *
Компонент TUpdateSQL *
приложение B Формат SQL-операторов (СУБД InterBase)
База данных *
Создание базы данных *
Определение типа данных *
Домены *
Создание домена *
Ограничение, накладываемое на значения полей, ассоциированных с доменом *
Изменение определения домена *
Таблицы базы данных *
Определение первичного ключа *
Определение уникального ключа *
Определение ограничения внешнего ключа и ссылочной целостности с родительской таблицей *
Ограничения на значения столбца *
Добавление нового столбца в таблицу БД *
Добавление новых ограничений целостности *
Удаление столбца (столбцов) из таблицы БД *
Удаление ограничений целостности *
Удаление таблицы БД целиком *
Индексы *
Создание индекса *
Деактивизация индекса *
Активизация индекса *
Вычисление показателя "полезности" индекса *
Удаление индекса *
Выборка данных из таблиц БД *
Изменение данных *
Добавление записей *
Изменение записей *
Просмотры *
Создание просмотра *
Удаление просмотра *
Хранимые процедуры *
Создание хранимой процедуры *
Обращение к хранимой процедуре (утилита WISQL) *
Тело процедуры *
Изменение хранимой процедуры *
Удаление хранимой процедуры: *
Алгоритмический язык триггеров и хранимых процедур *
Объявление локальных переменных *
Оператор присваивания *
Условный оператор *
Оператор выбора SELECT *
Оператор циклической выборки *
Принудительная выдача выходных параметров (только хранимые процедуры) *
Оператор цикла *
Выход из процедуры, триггера *
Вложенный вызов другой хранимой процедуры *
Инициация наступления события *
Обращение к старому и новому значениям столбца (только триггеры) *
Триггеры *
Создание триггера *
Структура тела триггера *
Изменение существующего триггера *
Удаление триггера *
Генераторы *
Создание генератора *
Установка стартового значения генератора *
Транзакции *
Старт транзакции *
События *
Инициация наступления события *
UDF (Функции, определяемые пользователем) *
Объявление UDF (функций, определяемых пользователем) в базе данных *
Привилегии доступа *
Предоставление привилегий доступа к таблицам БД, просмотрам, вызовам процедур *
Отъем привилегий *
Использование логических выражений
Может указываться более одного условия поиска. В этом случае они объединяются между собой при помощи логических операторов AND, OR и NOT. Их использование, а также построение из них сложных выражений подчиняется стандартным правилам, принятым для большинства алгоритмических языков (например, Object Pascal для Delphi) с одним важным исключением: операции отношения в них имеют меньший приоритет, чем логические операции, что избавляет от необходимости расстановки многочисленных скобок в сложных условиях поиска (я не работал с InterBase, но в диалекте SQL для TQuery и для MS SQL-сервер это так. Либо удалить это замечание, либо исправить примеры ниже по тексту).
Пример.
Выдать все записи из таблицы RASHOD, для каждого товара выдать его цену из таблицы TOVARY, для каждого покупателя выдать его город из таблицы POKUPATELI (результат на рис. 25.23). SELECT R.*, T.ZENA, P.ADRES FROM RASHOD R, TOVARY T, POKUPATELI P
WHERE (R.TOVAR = T.TOVAR) AND (R.POKUP = P.POKUP)
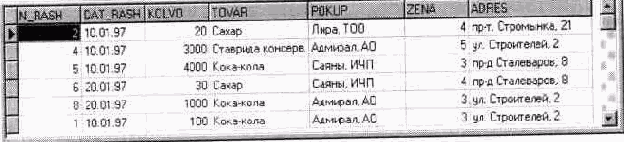
Рис.
25.23. Пример.
Выдать записи из таблицы RASHOD плюс соответствующую каждому товару цену из таблицы TOVARY. При этом количество отпуска товара должно быть не больше 30 или должно быть не меньше 3000, и название покупателя должно присутствовать (результат на рис. 25.24). SELECT R.*, T.ZENA FROM RASHOD R, TOVARY T
WHERE (R.TOVAR = T.TOVAR) AND ((R.KOLVO <=30) OR (R.KOLVO >= 3000)) AND (R.POKUP IS NOT NULL)
ORDER BY R.KOLVO

Puc. 25.24.
Сравнение столбца с результатом вычисления выражения
Условие поиска в предложении WHERE может быть сформулировано при помощи выражения:
<выражение> <оператор> <столбец>
Может использоваться и другой способ написания условия поиска, <столбец> <оператор> <выражение>
однако оно чаще всего применяется при использовании механизма вложенных подзапросов (вложенных операторов SELECT), речь о которых пойдет ниже. В этом случае результат вычисления выражения сравнивается с содержимым указанного столбца.
Пример.
Выдать из таблицы RASHOD дату, товар, стоимость отпущенного товара. При этом показывать только записи, у которых стоимость отпущенного товара больше 120 (результат на рис. 25.25). SELECT R.DAT_RASH, R.TOVAR, (R.KOLVO * T.ZENA) AS STOIM FROM RASHOD R, TOVARY T
WHERE (R.TOVAR = T.TOVAR) AND ((R.KOLVO * T.ZENA) > 120)
ORDER BY R.DAT_RASH
Использование BETWEEN
В условие поиска можно указать, что некоторое значение (столбец или вычисление значения выражения ) должно находиться в интервале между значением! и значением!'.
<значение> [NOT] BETWEEN <значение1> AND <значение2>
Зарезервированное слово NOT инвертирует условие (значение не должно находиться в интервале между значением! и значением 2).
Пример.
Выдать сведения обо всех отпусках товара, где количество отпущенного товара (в единицах) лежит в диапазоне 1000..3000 (результат на рис. 25.26). SELECT * FROM RASHOD WHERE KOLVO BETWEEN 1000 AND 3000
IN.RASH
Использование IN (список значений)
Если нужно, чтобы значение какого-либо столбца (или результат вычисления некоторого выражения) совпадало с одним из дискретных значений, в условии поиска указывается предложение
<значение> [NOT] IN (<значеиие1> 1, <значение2> ...1)
Тогда в результирующий набор данных будут включены только те записи, для которых значение, стоящее слева от слова IN, равно одному из значений, указанных в списке (<значение1> [, <значение2>...]).
Пример.
Выдать сведения обо всех отпусках товара, где количество отпущенного товара (в единицах) равно или 100, или 1000, или 3000 (результат на рис. 25.27). SELECT * FROM RASHOD WHERE KOLVO IN (100, 1000, 3000)
N_RAS'
Рис. 25.27.
ЗАМЕЧАНИЕ.
Существует вторая форма использования IN, где список возможных значений возвращается вложенным подзапросом. Этот вариант рассматривается в подразделе, посвященном подзапросам.
Использование STARTING
Если в условии поиска нужно, чтобы значение какого-либо символьного столбца или выражения начиналось с определенной подстроки, в условии поиска необходимо указать предложение
<значение> (NOT) STARTING [WITH] <подстрока>
Тогда в результирующий запрос будут включены только те строки, для которых выполняется указанное условие.
Пример.
Выдать все товары, начинающиеся с буквы "С" (результат на рис.25.28). SELECT * FROM TOVARY WHERE TOVAR STARTING WITH "C"
Использование CONTAINING
Если нужно, чтобы значение какого-либо символьного столбца или выражения включало в себя (неважно, начиная с какого символа) определенную подстроку, в условии поиска необходимо указать предложение
<значение> [NOT] CONTAINING <значение>
Тогда в результирующий запрос будут включены только те строки, для которых выполняется указанное условие.
Пример.
Выдать список всех покупателей, чей адрес содержит подстроку "Стр" (результат на рис. 25.29) SELECT * FROM POKUPATELI WHERE ADRES CONTAINING "Стр"
Использование функции UPPER
Функция UPPER(<значение>) используется для преобразования букв символьных значений (содержимого столбца, результата вычисления выражения) к заглавным. Обычно эта функция используется в условиях поиска, когда необходимо игнорировать возможную разницу в высоте букв.Функция UPPER может фигурировать как в списке столбцов результирующего набора данных (после слова SELECT), так и в условии поиска в предложении WHERE.
Пример.
Пусть нам необходимо найти всех покупателей из Москвы. Однако в таблице POKUPATELI два покупателя имеют в столбце GOROD имя города Москвы, однако в одном случае это значение 'Москва', в другом 'МОСКВА'. Если попытаться выполнить следующий запрос, то будет выдан только один покупатель (рис. 25.30). То есть результирующий НД будет неполным: SELECT * FROM POKUPATELI WHERE GOROD = 'Москва'
Проблема решается приведением обеих составляющих условия поиска к одному виду (рис. 25.31).
SELECT * FROM POKUPATELI WHERE UPPER(GOROD) = 'МОСКВА'
Использование LIKE
Предложение LIKE задает шаблоны сравнения строковых значений. Если необходимо, чтобы сравниваемое значение (значение столбца или результат вычисления строкового выражения) удовлетворяло шаблону, в условии поиска необходимо указать
<значение> [NOT] LIKE < шаблон> [ESCAPE <подшаблон>]
В шаблоне используются специальные символы - "%" и "_" . Символ "%" (процент) используется для указания любого значения любой длины и символ "_" (подчеркивание) для указания любого единичного символа. Например:
LIKE "%USD" - указывает, что сравниваемое значение должно оканчиваться символами 'USD' (Надо раз и навсегда решить, какими символами выделять строки. Обычно в тексте книги используются типографские или двойные кавычки, а в примерах - по требованию синтаксиса - апострофы. Проверить и исправить дальше по тексту), независимо от того, какие символы и сколько расположены перед ними;
LIKE "_94" - указывает, что сравниваемое значение может содержать 4 символа, из которых первые два - любые и последние два - '94'.
ESCAPE <подша6лон> используется, если в предложении LIKE символы '%' или '_' должны использоваться в шаблоне подобия как обычные символы (без учета их специальных функций). В этом случае с помощью ESCAPE указывается символ, появление которого в шаблоне отменяет специальные функции следующего за ним символа WHERE STOLBEZ LIKE "%!%" ESCAPE "!"
Пример.
Пусть нужно выдать информацию о покупателе, имя которого мы забыли, и название улицы мы помним неточно - то ли Стромынка, то ли Стормынка, то ли Сторомынка. Точно помним, что название улицы заканчивается на 'мынка'. Тогда нужно выполнить такой запрос (результат на рис. 25.32). SELECT * FROM POKUPATELI WHERE ADRES LIKE "%мынка%"
При этом шаблон "%мынка%" заканчиваем символом '%' потому, что после названия улицы в адресе идут другие реквизиты, которых, естественно, мы не помним.
Использование функции CAST
Иногда возникает потребность трактовать значение одного типа как значение другого типа. Например, использовать числовое значение как символьную строку или наоборот. В этом случае применяют функцию
CAST (<значение> AS <тип данных>)
Функция CAST делает копию значения, преобразуя его к указанному типу данных. При этом не следует забывать о множестве типов данных, в которое может быть преобразовано данное значение:
Пример.
Найти покупателя, который делал закупки то ли на 209, то ли на 309 единиц товара. На сколько именно, никто не помнит; вспомнили лишь, что последними разрядами в количестве отпускаемого товара были цифры '09'. Тогда приводим значения столбца KOLVO к типу CHARACTER и к результату применяем LIKE (рис. 25.33). ЗАМЕЧАНИЕ.
Значение типа DATE не нужно приводить к строковому типу (в примере не используется тип DATE! убрать ссылку на пример), поскольку два этих типа являются совместимыми и значение DATE в InterBase может трактоваться как строковое. Например, в приводимом ниже запросе объединяются значения типа DATE и строковое, и результат трактуется как строковое значение (результат на рис. 25.34). SELECT "Дата расхода: " I I DAT_RASH, POKUP, KOLVO FROM RASHOD WHERE KOLVO > 1000
Нигде до этого не объяснен синтаксис ||
Пример.
Выдать все покупки товара за 20 число (предположим, каждого месяца). В InterBase нет встроенных функций для разделения даты на число, месяц и год. Варианты решения: • в приложении, разработанном на Delphi, анализировать даты при помощи процедуры DecodeDate;
• написать UDF (User Defined Function, определенную пользователем функцию), которая реализует выделение номера дня из даты, и использовать имя этой функции в операторе SELECT;
• привести значение даты к типу CHAR (или, что лучше, трактовать значение даты как строковое значение) и применить к полученному значению LIKE, CONTAINING или STARTING WITH, в зависимости от потребности.
Воспользуемся последним способом (результат на рис. 25.35).
SELECT DAT_RASH, TOVAR, POKUP, KOLVO FROM RASHOD .
WHERE CAST(DAT_RASH AS CHAR(6)) STARTING WITH "20"
или, устранив ненужное, в данном случае, приведение типов,
SELECT DAT_RASH, TOVAR, POKUP, KOLVO FROM RASHOD WHERE DAT_RASH STARTING WITH "20"
Как видно из приводимого выше результата выполнения оператора SELECT, строковый формат представления значений типа DATE упрощает выделение номера дня, наименования месяца и номера года. (Ранее не был объяснен формат задания даты, поэтому не понятно, как выделять месяц)
Предложение WHERE : задание сложных условий поиска
Ранее были рассмотрены простые варианты задания условия поиска в предложении WHERE (сравнение столбца с константой и внутреннее соединение). Однако условия поиска могут быть достаточно сложными, чему способствует и сам синтаксис оператора SELECT. Рассмотрим основные конструкции для построения сложных условий поиска.
Использование подзапросов
Часто невозможно решить поставленную задачу путем использования одного запроса. Это особенно актуально в тех случаях, когда при использовании условия поиска в предложении WHERE
Сравниваемое значение> <оператор> <значение, с которым сравнивать>
значение, с которым надо сравнивать,
заранее не определено и должно быть вычислено в момент выполнения оператора SELECT. Другой причиной, которая должна побудить к использованию вложенных подзапросов, является то, что во многих случаях значение, с которым надо сравнивать, должно представлять собой не одно, а несколько значений.
Внутренний подзапрос представляет собой также оператор SELECT и кодирование его предложений подчиняется тем же правилам, что и для основного оператора SELECT.
В общем случае оператор SELECT с подзапросом имеет вид
SELECT .. .
FROM ...
WHERE Сравниваемое значение> <оператор> SELECT ...
FROM ...
WHERE ...
Пример.
Выдать все даты, на которые приходится максимальный отпуск товаров (результат на рис. 25.36). SELECT KOLVO, DAT_RASH FROM RASHOD
WHERE KOLVO = (SELECT MAX(KOLVO) FROM RASHOD
KOLVO
Puc. 25.36.
Сначала нужно найти количество максимального отпуска товаров, поскольку это значение неизвестно. Это и делает внутренний подзапрос (SELECT MAX(KOLVO) FROM RASHOD )
Далее выполняется основной запрос, как если бы он был записан так:
SELECT KOLVO, DAT_RASH FROM RASHOD WHERE KOLVO = 4000
Пример.
Усложним предыдущий пример. Определить дату, когда со склада было отгружено максимальное количество товара, и реквизиты покупателя, который этот товар купил (результат на рис. 25.37). SELECT R.KOLVO, R.DAT_RASH, P.POKUP, P.GOROD, P.ADRES
FROM RASHOD R, POKUPATELI P
WHERE (R.POKUP = P.POKUP) AND
KOLVO =(SELECT MAX(KOLVO)
FROM RASHOD
)
По сравнению с предыдущим примером в запрос включено внутреннее соединение таблиц RASHOD и POKUPATELI.
ЗАМЕЧАНИЕ.
Распространенной ошибкой является использование вложенного оператора SELECT, который вместо единичного значения способен возвращать список значений. Выше по тексту есть абзац: Другой причиной, которая должна побудить к использованию вложенных подзапросов, является то, что во многих случаях значение, с которым сравнивать, должно представлять собой не одно, а несколько значений. Поясним, почему этот абзац нельзя распространять на следующий пример.
Пример.
Найти в таблице POKUPATELI покупателя, у которого поле GOROD содержит "С-Петербург" и выдать все осуществленные им покупки товаров, из таблицы RASHOD. Может быть написан следующий потенциально ошибочный запрос (результат на рис. 25.38). SELECT R.DAT_RASH, R.TOVAR, R.KOLVO, R.POKUP FROM RASHOD R
WHERE R.POKUP = (SELECT POK.POKUP FROM POKUPATELI РОК
WHERE UPPER(РОК.GOROD) = 'С-ПЕТЕРБУРГ '
)
Хотя для значения "С-Петербург" и был выдан корректный результат, такой запрос потенциально ошибочен, поскольку способен возвращать несколько значений; например, если поменять "С-Петербург" на "Москва", получим уведомление об ошибке (рис. 25.39)
SELECT R.DAT_RASH, R.TOVAR, R.KOLVO, R.POKUP FROM RASHOD R
WHERE R.POKUP = (SELECT POK.POKUP FROM POKUPATELI РОК
WHERE UPPER(РОК.GOROD) = 'МОСКВА' )
Вложение подзапросов
Часто невозможно обойтись одним подзапросом. Тогда в подзапросе используют вложенный подзапрос.
Пример. Составить список отгрузки товаров покупателю, который в свое время купил максимальную партию какого-либо товара (результат на рис. 25.40).
SELECT RRR.* FROM RASHOD RRR
WHERE RRR.POKUP IN
(SELECT R.POKUP FROM RASHOD R
WHERE KOLVO = (SELECT MAX(RSH.KOLVO) FROM RASHOD RSH)
)
ЗАМЕЧАНИЕ.
IN использован вместо знака равенства на тот случай, если встретится два и более покупателя, имеющие одинаковое число максимальных покупок. В этом случае запрос вернет записи из RASHOD по всем таким покупателям. Использование знака равенства '=' вместо IN способно привести к ошибке при выдаче в качестве результата "среднего" запроса (SELECT R.POKUP...) множества значений вместо требуемого одного. Логический порядок выполнения запроса.
Вычисляется максимальное значение в столбце KOLVO ("самый вложенный" подзапрос SELECT MAX). Далее в "среднем" подзапросе SELECT R.POKUP выбирается покупатель, купивший какой-либо товар в количестве, равном значению, вычисленному в "самом вложенном" подзапросе. Вслед за этим "самый главный" запрос SELECT RRR выбирает записи с покупателем, наименование которого выдано "средним" подзапросом. ЗАМЕЧАНИЕ.
Поставленную задачу могут выполнить и другие запросы,например SELECT RRR.* FROM RASHOD RRR
WHERE RRR.POKUP IN
(SELECT R.POKUP FROM RASHOD R GROUP BY R.POKUP
HAVING MAX(R.KOLVO) = (SELECT MAX(RSH.KOLVO) FROM RASHOD RSH)
)
Использование EXISTS
Бывают случаи, когда в условии поиска нужно указать, что из таблицы требуется отобрать только те записи, для которых подзапрос возвращает одно или более значений. В этом случае в условии поиска указывается предложение EXISTS (<подзапрос>)
Пример. Выдать список всех покупателей, которые получали товар со склада (результат на рис. 25.41).
SELECT P.POKUP FROM POKUPATELI P
WHERE EXISTS (SELECT R.POKUP FROM RASHOD R WHERE R.POKUP = P.POKUP)
Использование SINGULAR
Если в условии поиска нужно указать, что из таблицы требуется выбрать лишь те записи, для которых подзапрос возвращает только одно значение, указывается предложение
SINGULAR (
Пример.
WHERE SINGULAR (SELECT * FROM RASHOD R WHERE R.POKUP = P.POKUP)
POKUP
Рис. 25.42
Использование ALL, SOME
Если в условиях поиска необходимо указать , что сравниваемое значение (значение столбца, результат вычисления выражения) должно находиться в определенных отношениях со всеми значениями из множества значений, возвращаемых подзапросом, применяют предложение типа
<Сравниваемое значение> {[NOT] {ALL | SOME | ANY} (<подзапрос>)
где подзапрос может возвращать более одного значения. Оператор определяет операцию сравнения (>, >=, < и т.д.). Отношение сравниваемого значения и значений, возвращаемых подзапросом, устанавливается словами ALL и SOME (ANY).
ALL
определяет, что условие поиска истинно, когда сравниваемое значение находится в отношении, определяемом оператором, со всеми значениями, возвращаемыми подзапросом. Например: WHERE STOLBEZ > ALL (SELECT POLE FROM TABLIZA)
определяет, что текущее значение столбца STOLBEZ должно быть больше всех значений в столбце POLE из таблицы TABLIZA.
SOME
(вместо него можно указать ANY) что условие поиска истинно, когда сравниваемое значение находится в отношении, определяемом оператором, хотя бы с одним значением, возвращаемым подзапросом. Например: WHERE STOLBEZ > SOME (SELECT POLE FROM TABLIZA) определяет, что текущее значение столбца STOLBEZ должно быть больше хотя бы одного значения в столбце POLE из таблицы TABLIZA.
Пример.
Перечислить все факты отгрузки товаров со склада, в которых количество единиц отгружаемого товара превышает среднее значение (результат на рис. 25.43). SELECT * FROM RASHOD R1
WHERE R1.KOLVO > ALL (SELECT AVG(R2.KOLVO) FROM RASHOD R2 GROUP BY POKUP)
Пример.
Перечислить все факты отгрузки товаров со склада, в которых количество единиц отгружаемого товара превышает среднее значение отгрузки хотя бы одного товара (результат на рис. 25.44). SELECT * FROM RASHOD R1
WHERE Rl.KOLVO > SOME (SELECT AVG(R2.KOLVO) FROM RASHOD R2 GROUP BY POKUP )
Использование HAVING и агрегатных функций для вложенных подзапросов
Если в условиях поиска для вложенного запроса нужно указать агрегатную функцию, используется HAVING..
Пример. Определить покупателя, у которого средняя покупка больше средней покупки других покупателей, и среднее число покупки этого покупателя (результат на рис. 25.45).
SELECT R1.POKUP, AVG(Rl.KOLVO) FROM RASHOD R1
GROUP BY R1.POKUP HAVING AVG(R1.KOLVO) >= ALL
(SELECT AVG(R2.KOLVO) FROM RASHOD R2 GROUP BY R2 . POKUP )
Пример. Определить адрес покупателя, который приобрел наибольшее количество товаров (результат на рис 25.46).
SELECT P.* FROM POKUPATELI P
WHERE P.POKUP =
(SELECT RR.POKUP FROM RASHOD RR
GROUP BY RR.POKUP HAVING SUM(RR.KOLVO) >= ALL
(SELECT SUM(RRR.KOLVO) FROM RASHOD RRR GROUP BY RRR.POKUP)
)
Пример. Перечислить все товары, которые приобрел покупатель, купивший наибольшее количество товаров (результат на рис. 25.47).
SELECT DISTINCT R.TOVAR FROM RASHOD R
WHERE R.POKUP =
(SELECT RR.POKUP FROM RASHOD RR
GROUP BY RR.POKUP HAVING SUM(RR.KOLVO) >= ALL
(SELECT SUM(RRR.KOLVO) FROM RASHOD RRR GROUP BY RRR.POKUP)
)
Пример.
Перечислить стоимость единиц товаров, которые приобрел покупатель, купивший наибольшее количество товаров (результат на рис 25.48) SELECT DISTINCT R.TOVAR, T.ED_IZM, T.ZENA FROM RASHOD R, TOVARY T
WHERE T.TOVAR = R.TOVAR AND R.POKUP = (SELECT RR.POKUP FROM RASHOD RR
GROUP BY RR.POKUP HAVING SUM(RR.KOLVO) >= ALL
(SELECT SUM(RRR.KOLVO) FROM RASHOD RRR GROUP BY RRR.POKUP )
Внешние соединения
Выше нами были рассмотрены внутренние соединения таблиц базы данных Напомним, что внутренние соединения имеют место, если в предложении WHERE указано условие
<имя столбца таблицы 1> <оператор> <имя столбца таблицы 2>
Например,
SELECT RASHOD.*, TOVARY.ZENA FROM RASHOD, TOVARY
WHERE RASHOD.TOVAR = TOVARY.TOVAR
В этом случае осуществляется декартово произведение таблиц 1 и 2 и из полученного НД отбираются записи, удовлетворяющие условию поиска (RASHOD TOVAR = TOVARY.TOVAR)
Существует также и другой вид соединения таблиц, внешнее соединение. Оно определяется в предложении FROM согласно спецификации SELECT {* | <значение1> [, <значение2> ...1}
FROM <таблица1> <вид соединения> JOIN < таблица2> ON <условие поиска>
Внешнее соединение похоже на внутреннее соединение, но в результирующий НД включаются также записи ведущей таблицы соединения, которые объединяются с пустым множеством записей другой таблицы. Какая из таблиц будет ведущей, определяет вид соединения
• LEFT -
(левое внешнее соединение), когда ведущей является таблица1 (расположенная слева от вида соединения); •
RIGHT - (правое внешнее соединение), когда ведущей является таблица1 (расположенная справа от вида соединения); Пример.
Пусть имеем таблицы
| A.P1 | А.Р2 | В.Р2 |
| а | х | 1 |
| B | х | 1 |
| С | у | 2 |
| d | 1 | |
| Рис 25.49 | ||
| A.P1 | А.Р2 | В.Р2 |
| а | х | 1 |
| b | х | 1 |
| с | у | 2 |
| 2 | ||
| Рис 25.50 |
Р1
SELECT A.P1, А.Р2, В.Р2 FROM A LEFT JOIN В ON А.Р2 = В.Р1
приведет к выдаче результирующего НД (рис 25.49):
Пунктиром показаны столбцы ведущей таблицы А. Как видно, для записи таблицы А, где столбец A.P1 имеет значение 'd', нет парных записей в таблице В, для которых удовлетворялось бы условие поиска А.Р2 = В.Р1. Поэтому данная запись таблицы А показана в соединении с пустой записью.
В то же время, выполнение оператора SELECT, реализующего внешнее правое соединение,
SELECT A.P1, А.Р2, В.Р2 FROM A RIGHT JOIN B ON А.Р2 = В.Р1
приведет к выдаче такого результирующего НД (рис 25.50)
Пунктиром показаны столбцы ведущей таблицы В. Как видно, для записи таблицы В, где столбец В.Р1 имеет значение 'z' и столбец В.Р2 имеет значение '2', нет парных записей в таблице А, для которых удовлетворялось бы условие поиска А.Р2= В.Р1. Поэтому данная запись таблицы В показана в соединении с пустой записью.
Пример.
Построить внешнее соединение по таблице RASHOD с таблицей POKUPATELI, т.е. показать покупателя, соответствующего каждому расходу (результат на рис.25.51). SELECT R.DAT_RASH, R.TOVAR, R.KOLVO, P.POKUP, P.GOROD
FROM RASHOD R LEFT JOIN POKUPATELI P ON R.POKUP = P.POKUP
или
SELECT R.DAT_RASH, R.TOVAR, R.KOLVO, P.POKUP, P.GOROD
FROM POKUPATELI P RIGHT JOIN RASHOD R ON R.POKUP = P.POKUP
DAT_RASH
Пример.
Построить внешнее соединение по таблице POKUPATELI с таблицей RASHOD, т.е. показать все расходы по каждому покупателю (результат на рис.25.52). SELECT P.POKUP, P.GOROD, R.DAT_RASH, R.TOVAR, R.KOLVO
FROM POKUPATELI P LEFT JOIN RASHOD R ON R.POKUP = P.POKUP
или
SELECT P.POKUP, P.GOROD, R.DAT_RASH, R.TOVAR, R.KOLVO
FROM RASHOD R RIGHT JOIN POKUPATELI P ON R.POKUP = P.POKUP
PQKUP
UNION - объединение результатов выполнения нескольких операторов SELECT
Иногда бывает полезным объединять два или более результирующих НД, возвращаемых после выполнения двух или более операторов SELECT. Такое объединение производится при помощи оператора UNION. Результирующие НД должны иметь одинаковую структуру, т.е. одинаковый состав возвращаемых столбцов. Если в результирующих НД имеется одна и та же запись, в сводном НД она не дублируется.
Пример.
Соединить результаты выполнения трех запросов: 1. (результирующий НД на рис. 25.53).
SELECT R.* FROM RASHOD R
WHERE R.TOVAR CONTAINING 'Ставрида'
2. (результирующий НД на рис. 25.54).
SELECT R.* FROM RASHOD R
WHERE R.KOLVO >= 3000
3. (результирующий НД на рис. 25.55).
SELECT R.* FROM RASHOD R
WHERE R.POKUP = 'Лира, ТОО'
Произведем объединение трех результирующих наборов данных (результат объединений на рис. 25.56).
SELECT R.* FROM RASHOD R WHERE R.TOVAR CONTAINING 'Ставрида'
UNION SELECT R.* FROM RASHOD R WHERE R.KOLVO >= 3000
UNION SELECT R.* FROM RASHOD R WHERE R.POKUP = 'Лира, ТОО'
Использование IS NULL
Если требуется выдать все записи, в которых некоторый столбец (или результат вычисления выражения) имеет значение NULL, достаточно в условии поиска указать
<значение> IS [NOT] NULL
Пример.
Показать все факты отгрузки товаров со склада, для которых не указан покупатель (результат на рис. 25.57). SELECT * FROM RASHOD WHERE POKUP IS NULL
Использование операции сцепления строк
Операция || соединяет два строковых значения, которые могут быть представлены выражениями:
<строковое выражение1> || <строковое выражение2>
Операцию || можно использовать как после слова SELECT для указания возвращаемых значений, так и в предложении WHERE.
Пример.
Выдать в виде единого столбца имена покупателей и названия их городов (результат на рис. 25.58).
Работа с разными БД в одном запросе
В одном запросе можно использовать таблицы из разных БД. В этом случае имя таблицы указывается в формате ПсевдонимБД:ИмяТаблицы
Под псевдонимом БД понимается псевдоним, определенный в утилите BDE Administrator.
Ниже приведен пример обращения в одном запросе к таблицам БД InterBase (псевдоним ' MONITOR') и Oracle (псевдоним 'DWH'):
SELECT U.* FROM ":MONITOR:NLS " N, ":DWH:OLAP_UPE" U
WHERE U.SC_CODE = N.COD_SCENARIO
ORDER BY U.SC CODE
Сравнение значения столбца с константой
При сравнении значения столбца с константой условие поиска имеет вид
<имя столбца> <оператор> константа
где в качестве оператора могут выступать операции отношения = равно
< меньше
> больше
<=
меньше или равно >= больше или равно
!< не меньше (т.е. больше или равно)
!> не больше (т.е. меньше или равно)
<> не равно
!= не равно
В качестве константы могут выступать строковые и числовые значения, указанные явно.
Пример. Показать все операции отпуска товаров объемом 20 единиц (результат на рис. 25.2)
SELECT *
FROM RASHOD R
WHERE KOLVO=20
Сравнение значения столбца
При сравнении значения столбца одной таблицы со значением столбца из другой таблицы условие поиска имеет вид
<имя столбца таблицы 1> <оператор> <имя столбца таблицы 2>
Пример.
Выдать все записи о расходе товара из таблицы RASHOD. Для каждого товара выдать его цену из таблицы ТО VARY (результат на рис. 25.3) SELECT RASHOD.*, TOVARY.ZENA
FROM RASHOD, TOVARY
WHERE RASHOD.TOVAR = TOVARY.TOVAR
При выполнении оператора SELECT для каждой записи из таблицы RASHOD ищется запись в таблице TOVARY, у которой значение в поле TOVAR совпадает со значением в поле TOVAR текущей записи таблицы RASHOD
При этом безразлично, в каком порядке перечислять таблицы в условии поиска, т.е безразлично, какая из таблиц будет упомянута слева, а какая справа. Таким образом, следующие условия поиска идентичны
RASHOD. TOVAR = TOVARY. TOVAR идентично условию
TOVARY.TOVAR = RASHOD.TOVAR
Такой способ соединения таблиц называется внутренним соединением
При внутреннем соединении двух таблиц А и В логический порядок формирования результирующего НД можно представить себе следующим образом.
1. Из столбцов, которые указаны после слова SELECT, составляется декартово произведение путем сцепления результирующих столбцов каждой записи из таблицы А и результирующих столбцов записи из таблицы В
2 Из получившегося НД отбрасываются все записи, не удовлетворяющие условию поиска в предложении WHERE
ЗАМЕЧАНИЕ
Определение "логический порядок формирования результирующего набора данных" употреблено не случайно В проектировании данных всегда различают два уровня - логический и физический. Логический уровень - это часто достаточно абстрактный уровень; физический уровень определяет действительно протекающие процессы, в большинстве случаев скрытые от взгляда, не лежащие на поверхности. Поэтому, когда мы говорим о "логическом порядке выполнения запроса", это подразумевает, что так нам легче понимать процессы, происходящие при выполнении внутреннего соединения; на самом же деле физические процессы, реально протекающие на сервере БД при выполнении запроса, могут не совпадать с нашим логическим представлением о них.
SQL-сервер при выполнении запроса всегда стремится его оптимизировать, то есть выполнить с максимальной быстротой при минимально возможных затратах ресурсов. В частности, оптимизация запросов в InterBase представляет собой "черный ящик", то есть нельзя сказать, как именно будет выполняться конкретный запрос, поскольку, помимо прочего, при оптимизации не последнюю роль играет текущее состояние БД. Подобные вопросы рассматриваются ниже в разделе, посвященном оптимизации запросов.
Пример. Пусть имеются таблицы А и В. Тогда выполнение оператора
SELECT А.P1, A.P2, В.Р2
FROM А, В
WHERE A.P2 = В.P1
с логической точки зрения приведет к формированию такого декартова произведения таблиц А (столбцы А Р1 и А Р2) и В (столбцы В.Р1 и В.Р2)
Примечание.
Столбец В.Р1, которого нет в результирующем запросе, показан для наглядности. Затем путем исключения из декартова произведения записей, не удовлетворяющих условию "A.P2 = В.Р1", будет получен такой результирующий НД:
Пример.
Выдать все записи о расходе товара из таблицы RASHOD Для каждого покупателя выдать его адрес из таблицы POKUPATELI (результат на рис 25 4) SELECT RASHOD.*, POKUPATELI.ADRES
FROM RASHOD, POKUPATELI
WHERE POKUPATELI.POKUP = RASHOD.POKUP
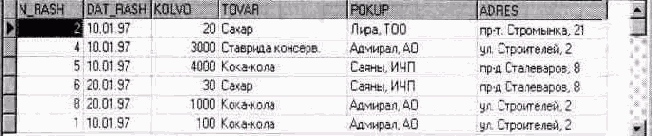
Рис 25.4 Как можно видеть, в результирующий НД не включены:
1. записи из таблицы RASHOD с пустым наименованием покупателя (записи с пустым наименованием покупателя в таблице POKUPATELI нет);
2. запись из таблицы POKUPATELI (POKUP = "Геракл"), поскольку по данному покупателю нет записей в таблице RASHOD.
Пример.
Используя оператор SELECT из предыдущего примера, выдать декартово произведение по всем столбцам таблицы RASHOD и по столбцу ADRES из таблицы POKUPATELI. Для этого нужно удалить из оператора SELECT предложение WHERE. Результат выполнения запроса не приводим из-за его величины (8 * 4 = 32 записи). SELECT RASHOD.*, POKUPATELI.ADRES
FROM RASHOD, POKUPATELI
Использование предложения WHERE
С использованием предложения WHERE оператор SELECT имеет следующий формат:
SELECT {* | <значение1> [, <значение2> ...]}
FROM <таблица1> [, < таблица2> ...]
WHERE <условия поиска>
В набор данных, который возвращается как результат выполнения оператора SELECT, будут включаться только те записи, которые удовлетворяют условию поиска. Ниже, в соответствующих подразделах, будут рассмотрены варианты формирования разнообразных условий поиска - их для оператора SELECT в SQL имеется достаточное количество, и все вместе они делают оператор исключительно мощным средством для построения запросов к БД.
Пока разберем два простейших условия поиска.
Использование псевдонимов таблиц
В приведенном выше примере оператора SELECT
SELECT RASHOD.*, POKUPATELI.ADRES
FROM RASHOD, POKUPATELI
WHERE POKUPATELI.POKUP = RASHOD.POKUP
в перечне возвращаемых столбцов после слова SELECT и в условии поиска после слова WHERE перед именем столбца через точку пишется название таблицы:
WHERE POKUPATELI.POKUP = RASHOD.POKUP
Указание имени таблицы перед именем столбца является совершенно необходимым, поскольку в разных таблицах могут оказаться одноименные столбцы (как в нашем примере), и SQL-сервер должен знать, со столбцом какой таблицы он имеет дело.
Использование общих имен таблиц для идентификации столбцов неудобно из-за своей громоздкости. Намного лучше присвоить каждой таблице какое-нибудь краткое обозначение, псевдоним. Такие псевдонимы называются псевдонимами таблиц. Они определяются после имени каждой таблицы в указании списка таблиц-источников после слова FROM:
SELECT
FROM <таблица1 псевдоним1> [, < таблица2 псевдоним2> ...]
WHERE ...
Например, приведенный выше запрос
SELECT RASHOD.*, POKUPATELI.ADRES
FROM RASHOD, POKUPATELI
WHERE POKUPATELI.POKUP = RASHOD.POKUP
после введения в него псевдонимов таблиц выглядит намного компактнее:
SELECT R.*, Р.ADRES
FROM RASHOD R, POKUPATELI P
WHERE P.POKUP = R.POKUP
Предложение ORDER BY - определение сортировки
Набор данных, выдаваемый в результате выполнения оператора SELECT, в общем случае возвращается в неотсортированном виде. Это удобно далеко не всегда. Определить, по каким полям необходимо отсортировать записи в результирующем НД, можно, указав после предложения, следующего за словом WHERE, предложение
ORDER BY <список_столбцов>
Список столбцов
должен содержать имена столбцов, по которым будет производиться сортировка. В случае указания имен нескольких столбцов, разделенных через запятую, столбец, указанный первым, будет использован для глобальной сортировки, второй столбец - для сортировки внутри группы, определяемой единым значением первого столбца, и т.д.
Пример. Выдать все записи отпуска товара "Кока-кола", отсортировав их по каждому покупателю (результат на рис. 25.5)
SELECT POKUP, DAT_RASH, TOVAR, KOLVO
FROM RASHOD
WHERE TOVAR = "Кока-кола"
ORDER BY POKUP
Пример.
Выдать все записи из таблицы RASHOD, отсортировав их по каждому покупателю (результат на рис. 25.6) SELECT POKUP, DAT_RASH, TOVAR, KOLVO
FROM RASHOD
ORDER BY POKUP
Пример.
Выдать все записи из таблицы RASHOD, отсортировав их по каждому покупателю, для каждого покупателя - по названию товара, для каждого товара - по дате (результат на рис. 25.8) SELECT POKUP, TOVAR, DAT_RASH, KOLVO
FROM RASHOD
ORDER BY POKUP, TOVAR, DAT_RASH
Устранение повторяющихся значений
Часто в результирующий НД необходимо включать не все записи с одинаковым значением какого-либо столбца (комбинации столбцов), а только одну из них. В этом случае после ключевого слова SELECT указывают ключевое слово DISTINCT
SELECT [DISTINCT | ALL] {* <значение1> [, <значение2> ...]}
FROM <таблица1> [, < таблица2> ...]
Повторяющимися считаются записи, содержащие идентичные значения во всех столбцах результирующего НД+.
Наоборот, если в результирующий запрос нужно включить все записи, после слова SELECT указывают слово ALL. В InterBase нет необходимости использовать ALL явно, поскольку это значение действует по умолчанию.
Пример.
Выдать наименования всех отпущенных со склада товаров (результат на рис. 25.9) SELECT DISTINCT TOVAR FROM RASHOD

Рис. 25.9.
ЗАМЕЧАНИЕ.
Использование в запросе DISTINCT следует ограничивать, кроме случаев, когда это действительно необходимо. Так, в рассматриваемых ниже примерах для агрегатных функций по таблице RASHOD, часто невозможно обойтись без указания DISTINCT. Причиной ограничений в применении DISTINCT является то обстоятельство, что его использование может резко замедлять выполнение запросов.
Расчет значений результирующих столбцов на основе арифметических выражений
Арифметические выраженияиспользуются для расчета значений вычисляемых столбцов результирующего НД. При их формировании следует придерживаться общих правил формирования арифметических выражений, принятых в алгоритмических языках, например Object Pascal для Delphi. При этом в списке возвращаемых столбцов после слова SELECT вместо имени вычисляемого столбца указывается выражение:
SELECT [DISTINCT ALL] {* | <столбец1> [, <выражение1> ...]} FROM <таблица1> [, < таблица2> ...]
Пример.
Выдать все записи об отпуске товаров из таблицы RASHOD, для каждого отпуска товара рассчитать общую стоимость отпущенного товара (результат на рис. 25.10) SELECT R.*, T.ZENA, R.KOLVO * T.ZENA FROM RASHOD R, TOVARY T WHERE R.TOVAR == T.TOVAR

Puc.25.10
Как видно из рисунка, результат вычисления выражения R.KOLVO * T.ZENA для каждой записи из таблицы RASHOD записан в сгенерированный столбец, которому по умолчанию присвоено имя COLUMN7. В случае, если нужно присвоить имя столбцу, содержащему результаты вычисления выражения, это имя можно указать после выражения вслед за ключевым словом AS:
SELECT ... {* | <значение1> [, <выражение1 [AS <имя столбца>]> ...]}
Пример.
Выдаваемому в предыдущем примере вычисляемому столбцу присвоить имя STOIM (рис. 25.11) SELECT R.*, T.ZENA, R.KOLVO * T.ZENA AS STOIM FROM RASHOD R, TOVARY T
WHERE R.TOVAR = T.TOVAR

Рис. 25 11.
Агрегатные функции
Агрегатные функции предназначены для выдачи итоговых значений. К агрегатным относятся функции:
COUNT (<выражение>) -
подсчитывает число вхождений значения выражения во все записи результирующего НД; • SUM(<выражение>) - суммирует значения выражения;
AVG (<выражение>) - находит среднее значение выражения;
• МАХ(<выражение>) - определяет максимальное значение выражения;
• МIN(<выражение>) - определяет минимальное значение выражения. Если из группы одинаковых записей нужно учитывать только одну, перед выражением в скобках включают слово DISTINCT
COUNT(DISTINCT POKUP)
Чаще всего в качестве выражения выступают имена столбцов. Выражение может вычисляться и по значениям нескольких таблиц. Пример. Подсчитать число покупателей, приобретавших товары на складе (рис.25.12)
SELECT COUNT(DISTINCT POKUP) AS COUNT_POKUP FROM RASHOD
Пример.
Вычислить общую стоимость отпущенных товаров за 10.01.97 (результат на рис. 25.13) SELECT SUM(R.KOLVO * T.ZENA) AS OBS_ZENA
FROM RASHOD R, TOVARY T
WHERE (R.TOVAR = T.TOVAR) AND
(R.DAT RASH = "10-JAN-1997")
Использование группировок записей
Часто нужно выдать агрегированные значения (минимум, максимум, среднее) не по всему результирующему НД, а по каждой из входящих в него групп записей, характеризующихся одинаковым значением какого-либо столбца. Например, выдать общее число отпущенного товара по каждому товару. В этом случае в оператор SELECT перед предложением WHERE вводят предложение
GROUP BY столбец [,столбец1 ...]
При этом необходимо, чтобы один из столбцов результирующего НД был представлен агрегатной функцией.
Пример.
Выдать общее количество отпуска по каждому из товаров (результат на рис. 25.14) SELECT R.TOVAR, SUM(R.KOLVO) AS OTPUSK FROM RASHOD R GROUP BY R.TOVAR
Пример.
Выдать общую сумму отпуска по каждому из товаров (результат на рис. 25.15) SELECT R.TOVAR, SUM(R.KOLVO * T.ZENA) FROM RASHOD R, TOVARY T
WHERE T.TOVAR = R.TOVAR GROUP BY R.TOVAR
Пример.
Выдать общую сумму отпуска по каждому из товаров на каждую дату (результат на рис. 25.16) SELECT R.TOVAR, R.DAT_RASH, SUM(R.KOLVO * T.ZENA)
FROM RASHOD R, TOVARY T
WHERE T.TOVAR = R.TOVAR GROUP BY R.TOVAR, R.DAT_RASH
Пример.
Выдать число покупателей на каждую дату (результат на рис. 25.17) SELECT DAT_RASH, COUNT(DISTINCT POKUP)
FROM RASHOD GROUP BY DAT RASH
Предложение HAVING - наложение ограничений на группировку записей
Если нужно в результирующем НД выдавать агрегацию не по всем группам, а только по тем из них, которые отвечают некоторому условию, после предложения GROUP BY указывают предложение
HAVING < условия_поиска >
где условия поиска указываются по тем же правилам, что и условия поиска для предложения WHERE, за важным исключением: в условии поиска предложения HAVING можно указывать агрегатные функции, чего нельзя делать в условии поиска для WHERE.
Пример.
Выдать минимальные покупки товара в единицах для всех покупателей, у которых минимальное количество покупаемого товара не меньше 100 единиц (результат на рис. 25.18). SELECT POKUP, MIN(KOLVO) FROM RASHOD
GROUP BY POKUP HAVING MIN(KOLVO) >= 100
Если не указывать
HAVING MIN(KOLVO) >= 100
будут выданы все группы (рис. 25.19).
Можно указывать различные агрегатные функции для возвращаемого столбца и условия в HAVING.
Пример.
Выдать общее количество купленного товара (в единицах) для всех покупателей, у которых минимальное количество покупаемого товара не меньше 100 единиц (результат на рис. 25.20).
Оператор SELECT
25.1. Простейший вид оператора SELECT *
25.2. Использование предложения WHERE *
25.2.1. Сравнение значения столбца с константой *
25.2.2. Сравнение значения столбца из одной таблицы со значением столбца из другой таблицы (внутреннее соединение) *
25.3. Использование псевдонимов таблиц *
25.4. Предложение ORDER BY - определение сортировки *
25.5. Устранение повторяющихся значений *
25.6. Расчет значений результирующих столбцов на основе арифметических выражений *
25.7. Агрегатные функции *
25.8. Использование группировок записей *
25.9. Предложение HAVING - наложение ограничений на группировку записей *
25.10. Предложение WHERE : задание сложных условий поиска *
25.10.1. Использование логических выражений *
25.10.2. Сравнение столбца с результатом вычисления выражения *
25.10.3. Использование BETWEEN *
25.10.4. Использование IN (список значений) *
25.10.5. Использование STARTING *
25.10.6. Использование CONTAINING *
25.10.7. Использование функции UPPER *
25.10.8. Использование LIKE *
25.10.9. Использование функции CAST *
25.11. Использование подзапросов *
25.12. Вложение подзапросов *
25.13. Дополнительные возможности использования подзапросов, возвр единичное значение *
25.13.1. Использование EXISTS *
25.13.2. Использование SINGULAR *
25.14. Использование подзапросов, возвращающих множество значений *
25.14.1. Использование ALL, SOME *
25.14.2. Использование HAVING и агрегатных функций для вложенных подзапросов *
25.15. Внешние соединения *
25.16. UNION - объединение результатов выполнения нескольких операторов SELECT *
25.17. Использование IS NULL *
25.18. Использование операции сцепления строк *
25.19. Работа с разными БД в одном запросе *
Оператор SELECT - один из наиболее важных и самый используемый оператор SQL. Он позволяет производить выборки данных из ТБД и преобразовывать к нужному виду полученные результаты. Это очень мощный оператор. При его помощи можно реализовать весьма сложные и громоздкие условия выбора данных из различных таблиц.
Для тех, кто ранее не использовал SQL для доступа к БД, примеры использования данного оператора наглядно продемонстрируют один из основополагающих принципов "больших" (промышленных) СУБД: средства хранения данных и доступа к ним отделены от средств представления данных; операции над данными производятся в масштабе наборов данных, а не отдельных записей. Разработчики, долгое время использовавшие локальные ("персональные") СУБД, в процессе перехода от Paradox, dBase, Clarion и т.п. к архитектуре "клиент-сервер" обычно при изучении оператора SELECT вынуждены менять устоявшиеся парадигмы мышления: локальные СУБД реализуют в основном навигационный подход доступа к данным (выборка по одной записи) и подразумевают достаточно прочную обратную связь между способами хранения данных, доступа к ним и их представления пользователю в приложении.
Оператор SELECT - средство, которое полностью абстрагировано от вопросов представления данных; все внимание при его применении сконцентрировано на проблемах доступа к данным.
Оператор SELECT имеет следующий формат:
SELECT [DISTINCT | ALL] {* | <значение1> [, <значение2> ...]}
FROM <таблица1> [, < таблица2> ...]
[WHERE <условия_поиска>]
[GROUP BY столбец [COLLATE collation} [,столбец! [COLLATE collation] ...]
[HAVING < условия поиска >]
[UNION <оператор select>]
[PLAN <план выполнения_запроса>]
[ORDER BY <список_столбцов>]
Этот формат с первого взгляда достаточно громоздок и кажется поэтому сложным. Такое впечатление при дальнейшем изучении оператора SELECT наверняка покажется Вам неверным. Поэтапно рассмотрим возможности, которые предоставляет оператор SELECT.
Явное указание списка значений
В этом случае оператор INSERT применяется для добавления одной записи и имеет формат
INSERT INTO <объект> [(столбец1 [, столбец2 ...])]
VALUES (<значение1> [, <значение2> ...])
Значения
назначаются столбцам по порядку следования тех и других в операторе: первому по порядку столбцу назначается первое значение, второму столбцу - второе значение и т.д. Пример.
Добавить в таблицу ТОVARY новую запись: INSERT INTO RASHOD (N_RASH, DAT_RASH,KOLVO, TOVAR, POKUP)
VALUES (45, "20-FEB-1997", 100, "Сахар", "Саяны, ИЧП")
Поскольку столбцы таблицы RASHOD указаны в полном составе и именно в том порядке, в котором они перечислены при создании таблицы RASHOD оператором CREATE TABLE, оператор можно упростить:
INSERT INTO RASHOD VALUES (45, "20-FEB-1997", 100, "Сахар", "Саяны, ИЧП")
Для установки уникального значения поля первичного ключа N_RASH можно воспользоваться генератором:
INSERT INTO RASHOD
VALUES (GEN_ID(RASHOD_N_RASH,2), "20-FEB-1997", 100,"Сахар", "Саяны, ИЧП")
Указание значений при помощи оператора SELECT
Второй формой оператора INSERT является
INSERT INTO <объект> [(столбец1 [, столбец2 ...])]
<оператор SELECT> При этом значениями, которые присваиваются столбцам, являются значения, возвращаемые оператором SELECT. Порядок их назначения столбцам аналогичен предыдущей форме оператора INSERT: значение первого по порядку столбца результирующего набора данных оператора SELECT присваивается первому столбцу оператора INSERT, второй - второму и т.д. Следует обратить внимание на важную особенность: поскольку оператор SELECT в общем случае возвращает множество записей, то и оператор INSERT в данной форме приведет к добавлению в объект аналогичного количества новых записей.
Пример.
Пусть в БД определена таблица RASHOD_DATA, по составу и порядку следования полей аналогичная таблице RASHOD: CREATE TABLE RASHOD_DATA(
N_RASH INTEGER NOT NULL,
DAT_RASH DATE NOT NULL,
KOLVO INTEGER NOT NULL,
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
POKUP VARCHAR(20) COLLATE PXW_CYRL,
PRIMARY KEY(N_RASH)
);
Пусть в эту таблицу нужно ежедневно копировать все записи о расходах товара со склада за текущую дату. Представим, что эти сведения в дальнейшем ежедневно
переправляются в территориально удаленную бухгалтерию, к офису которой не успели подвести сетевые кабели (или вообще не собираются этого делать).
Тогда ежедневная выгрузка записей из таблицы RASHOD в таблицу RASHOD_DATA будет реализовываться таким оператором:
INSERT INTO RASHOD_DATA
SELECT * FROM RASHOD WHERE DAT_RASH = "20-JAN-1997"
Пусть перед выполнением данного оператора таблица RASHOD_DATA пуста. Тогда после выполнения указанного оператора она будет иметь следующее содержимое:
N_RASH
Оператор INSERT
Оператор INSERT применяется для добавления записей в объект. В качестве объекта может выступать ТБД или просмотр (VIEW), созданный оператором CREATE VIEW. В последнем случае записи могут добавляться в несколькотаблиц.
Формат оператора INSERT:
INSERT INTO <объект> [(столбец1 [, столбец2 ...])|
{VALUES (<значение1> [, <значение2> ...]) | <оператор SELECT> }
Список столбцов указывает столбцы, которым будут присвоены значения в добавляемых записях. Список столбцов может быть опущен. В этом случае подразумеваются все столбцы объекта, причем в том порядке, в котором они определены в данном объекте.
Поставить в соответствие столбцам списки значений можно двумя способами. Первый состоит в явном указании значений после слова VALUES, второй - в формировании значений при помощи оператора SELECT.
Ператор UPDATE
Оператор UPDATE применяется для изменения значения в группе записей или - в частном случае - в одной записи объекта. В качестве объекта могут выступать ТБД или просмотр, созданный оператором CREATE VIEW. В последнем случае могут изменяться значения записей из нескольких таблиц.
Формат оператора UPDATE:
UPDATE <объект>
SET столбец1 = <значение1> (,столбец2 = <значение2>...]
[WHERE <условие поиска >]
При корректировке каждому из перечисленных столбцов присваивается соответствующее значение. Корректировка выполняется для всех записей, удовлетворяющих условию поиска. Условие поиска задается так же, как в операторе SELECT.
ВНИМАНИЕ !
Если опустить WHERE <условие поиска>, в объекте будут изменены все записи.
Пример.
В таблице RASHOD заменить дату на "24.01.97" и количество увеличить на 2 единицы для всех записей с датой "20.01.97": UPDATE RASHOD
SET DAT_RASH = "24-JAN-1997", KOLVO = KOLVO + 2
WHERE DAT_RASH = "20-JAN-1997"
Содержимое таблицы RASHOD до выполнения оператора UPDATE:
| NRASH | DATRASH | KOLVO | TOVAR | POKUP |
| 5 | 10-JAN-1997 | 4000 | Кока-кола | Саяны, ИЧП |
| 1 | 10-JAN-1997 | 100 | Кока-кола | Адмирал, АО |
| 2 | 10-JAN-1997 | 20 | Сахар | Лира, ТОО |
| 3 | 10-JAN-1997 | 509 | Сахар | |
| 4 | 10-JAN-1997 | 3000 | Ставрида консерв | Адмирал, АО |
| 8 | 20-JAN-1997 | 1000 | Кока-кола | Адмирал, АО |
| 7 | 20-JAN-1997 | 20 | Кока-кола | |
| 6 | 20-JAN-1997 | 30 | Сахар | Саяны, ИЧП |
| NRASH | DATRASH | KOLVO | TOVAR | POKUP |
| 5 | 10-JAN-1997 | 4000 | Кока-кола | Саяны, ИЧП |
| 1 | 10-JAN-1997 | 100 | Кока-кола | Адмирал, АО |
| 2 | 10-JAN-1997 | 20 | Сахар | Лира, ТОО |
| 3 | 10-JAN-1997 | 509 | Сахар . | |
| 4 | 10-JAN-1997 | 3000 | Ставрида консерв. | Адмирал, АО |
| 8 | 24-JAN-1997 | 1002 | Кока-кола | Адмирал, АО |
| 7 | 24-JAN-1997 | 22 | Кока-кола | |
| 6 | 24-JAN-1997 | 32 | Сахар | Саяны, ИЧП |
Оператор DELETE
Оператор DELETE предназначен для удаления группы записей из объекта. В качестве объекта могут выступать ТБД или просмотр, созданный оператором CREATE VIEW. В последнем случае могут удаляться записи из нескольких таблиц. В частном случае может быть удалена только одна запись.
Формат оператора DELETE:
DELETE FROM <объект> [WHERE <условие поиска>];
Удаляются все записи из объекта, удовлетворяющие условию поиска. Условие поиска задается так же, как в операторе SELECT.
ВНИМАНИЕ
! Если опустить WHERE <условие поиска>, из объекта будут удалены все записи. Пример.
Удалить из таблицы RASHOD все записи о расходе товара "Кока-кола" за дату "10.01.97". DELETE FROM RASHOD
WHERE (TOVAR = "Кока-кола") AND (DAT_RASH = "10-JAN-1997")
Добавление, изменение, удаление записей
Язык SQL ориентирован на выполнение операций над группами записей, хотя в некоторых случаях операция может проводиться и над отдельной записью. Поэтому неудивительно, что операторы добавления, изменения и удаления записей в общем случае вызывают соответствующие операции над группами записей.
ПОЯСНЕНИЕ.
Все приводимые ниже операторы выполнялись в утилите InterBase WISQL. Результаты выполнения операторов также показываются в виде, возвращаемом утилитой WISQL. Следует обратить внимание на представление дат - в WISQL они показываются в строковом виде. Не стоит беспокоиться о совместимости столбцов типа дата, когда выполняются операторы INSERT, UPDATE или DELETE при посредстве компонента TQuery из приложения, написанного на Delphi. Даты InterBase в приложениях, написанных на Delphi, без проблем представляются компонентами "поле типа даты и времени" TDateTimeField и отдельными переменными типа TDateTime.
Понятие просмотра как виртуальной таблицы
В БД может быть определен просмотр, являющий собой виртуальную таблицу, в которой представлены записи из одной или нескольких таблиц. Порядок формирования записей в просмотре определяется оператором SELECT. Для создания просмотра применяется оператор
CREATE VIEW ИмяПросмотра [(столбец_view1 [,столбец_view ...])]
AS
Для удаления просмотра используется оператор
DROP VIEW ИмяПросмотра;
Пример.
Создать просмотр, содержащий дату расхода, наименование товара, количество расхода товара из таблицы RASHOD и цену товара из таблицы TOVAR: CREATE VIEW FULL_RASHOD AS
SELECT R.DAT_RASH, R.TOVAR, R.KOLVO, T.ZENA
FROM RASHOD R, TOVARY T
WHERE R.TOVAR = T.TOVAR;
После этого к просмотру FULL_RASHOD можно обращаться как к обычной таблице БД:
SELECT * FROM FULL_RASHOD;
Преимущества создания просмотров:
• единожды определив просмотр, не нужно всякий раз формировать оператор SELECT; это важно для сложных операторов SELECT, выполняющих соединение одной или нескольких таблиц;
• просмотр может предоставлять подмножество столбцов из таблицы, что важно для обеспечения сохранности данных и, возможно, усиления безопасности.
Способы формирования просмотров
Просмотр может создаваться как:
1) вертикальный срез таблицы,
когда в просмотр включается подмножество столбцов таблицы, например: CREATE VIEW RASH_VERT AS
SELECT DAT_RASH, TOVAR, KOLVO
FROM RASHOD
2) горизонтальный срез таблицы,
когда в просмотр включаются все столбцы, но не все записи таблицы, например: CREATE VIEW RASH_HORIZ AS
SELECT * FROM RASHOD WHERE TOVAR = "Кока-кола";
3) вертикально-горизонтальный срез таблицы, когда в просмотр включается подмножество столбцов и подмножество строк, например:
CREATE VIEW RASH_VERT_HORIZ AS
SELECT DAT_RASH, TOVAR, KOLVO FROM RASHOD WHERE TOVAR = "Кока-кола";
4) подмножество строк и столбцов соединения разных таблиц, например:
CREATE VIEW FULL_RASHOD AS
SELECT R.DAT_RASH, R.TOVAR, R.KOLVO, T.ZENA
FROM RASHOD R, TOVARY T WHERE R.TOVAR = T.TOVAR;
Указание столбцов просмотра в операторе CREATE VIEW
Имена столбцов просмотра должны указываться в операторе CREATE VIEW в том случае, когда в качестве столбца просмотра определяется выражение, например:
CREATE VIEW STOIM_RASHOD (DAT_RASH, TOVAR, STOIM) AS
SELECT R.DAT_RASH, R.TOVAR, R.KOLVO * T.ZENA
FROM RASHOD R, TOVARY T WHERE R.TOVAR = T.TOVAR;
В противном случае имена столбцов просмотра указывать не обязательно. В случае, если список имен столбцов опущен, имена столбцов считаются идентичными именам полей, возвращаемых оператором SELECT.
Обновляемые и необновляемые просмотры
Чтобы просмотр можно было обновлять, то есть применять к нему операции добавления, изменения и удаления записей, необходимо одновременное выполнение трех условий:
• просмотр должен формироваться из записей только одной таблицы;
• в просмотр должен быть включен каждый столбец таблицы, имеющий атрибут NOT NULL;
• оператор SELECT просмотра не должен использовать агрегирующих функций, режима DISTINCT, предложения HAVING, соединения таблиц, хранимых процедур и функций, определенных пользователем.
Если просмотр удовлетворяет этим условиям, к нему могут применяться операторы
INSERT, UPDATE и DELETE.
Пример.
В следующем просмотре можно добавлять, корректировать и удалять записи: CREATE VIEW UPDATABLE_RASH AS
SELECT N_RASH,DAT_RASH, TOVAR, KOLVO FROM RASHOD;
Для того чтобы к просмотру можно было применить операторы UPDATE и DELETE, для него одновременно должны выполняться два условия:
• просмотр должен формироваться из записей только одной таблицы;
• оператор SELECT просмотра не использует агрегатных функций, режима DISTINCT, предложения HAVING, соединения таблиц, хранимых процедур и функций, определенных пользователем.
Пример.
В следующем просмотре можно корректировать и удалять записи, но нельзя добавлять: CREATE VIEW LESSUPDAPTABLE_RASH AS
SELECT DAT_RASH, TOVAR, KOLVO, POKUP FROM RASHOD;
Пример.
В следующем просмотре нельзя добавлять, корректировать и удалять записи: CREATE VIEW A AS
SELECT R.TOVAR, T.ZENA
FROM RASHOD R, TOVARY T WHERE R.TOVAR = T.TOVAR;
Использование CHECK OPTION
Если для обновляемого просмотра указан параметр CHECK OPTION, будут отвергаться все попытки добавления новых или изменения существующих записей таким образом, чтобы нарушалось условие WHERE оператора SELECT данного просмотра.
Пример.
В данный просмотр невозможно добавить записи со значением поля KOLVO, меньшим 1000: CREATE VIEW RASH_1000_CHECK AS
SELECT * FROM RASHOD WHERE KOLVO > 1000 WITH CHECK OPTION;
Компоненты Delphi и использование просмотров
Просмотр есть виртуальная таблица БД. "Виртуальная" означает буквально следующее: при работе с просмотром возникает впечатление, что эта таблица физически существует, хотя на самом деле это не так. Поэтому компонент TTable может содержать имя просмотра в свойстве TableName, а компонент TQuery использовать SQL-запрос, в котором наравне с "нормальными" таблицами производится обращение и к просмотру. Поведение просмотра в приложении аналогично поведению обычной таблицы БД, с учетом особенностей, определяемых параметром CHECK OPTION и возможностью полного (добавление, удаление, изменение), частичного (изменение, удаление записей) обновления просмотра или невозможностью такового. Следует помнить, что подобно НД, возвращаемому оператором SELECT, НД, возвращаемый просмотром, показывает записи в состоянии, в котором они были на момент открытия набора данных компонента TTable или TQuery. Для того чтобы внесенные после открытия НД изменения стали актуальны в просмотре, компонент, использующий просмотр, должен быть переоткрыт.
Понятие хранимой процедуры
Хранимая процедура - это модуль, написанный на процедурном языке InterBase и хранящийся в базе данных как метаданные (то есть как данные о данных). Хранимую процедуру можно вызывать из приложения.
Существует две разновидности хранимых процедур: процедуры выбора и процедуры действия.
Процедуры выбора
могут возвращать более одного значения. В приложении имя хранимой процедуры выбора подставляется в оператор SELECT вместо имени таблицы или обзора. Процедуры
действия вообще могут не возвращать данных и используются для реализации каких-либо действий. Хранимым процедурам можно передавать параметры и получать обратно значения параметров, измененные в соответствии с алгоритмами хранимых процедур.
Преимущества использования хранимых процедур:
• способность одной процедуры, расположенной на сервере, совместно использоваться многими приложениями;
• разгрузка приложений клиента путем переноса части кода на сервер и вследствие этого - упрощение клиентских приложений;
• при изменении хранимой процедуры на сервере все изменения немедленно становятся доступны для клиентских приложений; при внесении же изменений в приложение клиента требуется повторное распространение новой версии клиентского приложения между пользователями;
• улучшенные характеристики выполнения, связанные с тем, что хранимые процедуры выполняются сервером, что приводит, в частности, к уменьшению сетевого графика.
Создание хранимой процедуры
Хранимая процедура создается оператором
CREATE PROCEDURE ИмяПроцедуры
[ (входной_параметр тип_данньк [, входной_параметр тип_данных...])]
[RETURNS
(выходной_параметр тип_данньк [, выходной_параметр тип_данньк ...])] AS
<тело процедуры>;
Входные параметры
служат для передачи в процедуру значений из вызывающего приложения. Изменять значения входных параметров в теле процедуры бессмысленно: эти изменения будут забыты после окончания работы процедуры. Выходные параметры
служат для возврата результирующих значений. Значения выходных параметров устанавливаются в теле процедуры и после окончания ее работы передаются в вызывающее приложение. И входные, и выходные параметры могут быть опущены, если в них нет необходимости.
Тело процедуры имеет формат
[<объявление локальных переменных процедуры>]
BEGIN
< оператор>
[<оператор> ...]
END
Пример.
Хранимая процедура FIND_MAX_KOLVO возвращает в выходном параметре MAX_KOLVO максимальное количество отгруженного со склада товара, наименование которого передается во входном параметре IN_TOVAR: CREATE PROCEDURE FIND_MAX_KOLVO (IN_TOVAR VARCHAR(20))
RETURNS(MAX_KOLVO INTEGER) AS
BEGIN
SELECT MAX(KOLVO) FROM RASHOD WHERE TOVAR = : IN_TOVAR
INTO : MAX_KOLVO;
SUSPEND;
END
Заметим, что в приведенной процедуре за ненадобностью отсутствует определение локальных переменных.
Объявление локальных переменных
Локальные переменные, если они определены в процедуре, имеют срок жизни от начала выполнения процедуры и до ее окончания. Вне процедуры такие локальные переменные неизвестны и попытка обращения к ним вызовет ошибку. Локальные переменные используют для хранения промежуточных значений.
Формат объявления локальных переменных:
DECLARE VARIABLE <имя переменной > <тип данных>;
Пример объявления:
CREATE PROCEDURE FULL_ADR (TOVARCHIK VARCHAR(20))
RETURNS (GOROD_ADRES VARCHAR(40)) AS
DECLARE VARIABLE NAIDEN_POKUPATEL VARCHAR(20);
DECLARE VARIABLE MAX_KOLVO INTEGERS;
BEGIN
END
Оператор EXECUTE PROCEDURE
Оператор
EXECUTE PROCEDURE имя [параметр (, параметр...]];
[RETURNING_VALUES параметр [, параметр...]];
Выполняет другую хранимую процедуру из тела данной хранимой процедуры. При этом после слова PROCEDURE перечисляются входные параметры, если они есть, а после RETURNING_VALUES перечисляются выходные параметры.
Пример
Перепишем приведенную выше процедуру POK_LIST таким образом, чтобы из ее тела вызывалась другая процедура, AVG_KOLVO, возвращающая среднее число отпуска конкретного товара CREATE PROCEDURE AVG_KOLVO (TVR VARCHAR(20)
RETURNS(OUT_AVG_KOLVO INTEGER)
AS
BEGIN
SELECT AVG(KOLVO) FROM RASHOD WHERE TOVAR = :TVR INTO :OUT_AVG_KOLVO;
SUSPEND;
END
CREATE PROCEDURE POK_LIST1 (IN_TOVAR VARCHAR(20))
RETURNS(РОК VARCHAR(20)) AS
DECLARE VARIABLE AVG_KOLVO INTEGER;
BEGIN
EXECUTE PROCEDURE AVG_KOLVO(:IN_TOVAR)
RETURNING_VALUES : AVG_KOLVO;
FOR SELECT POKUP FROM RASHOD WHERE KOLVO > : AVG_KOLVO INTO : РОК
DO
BEGIN
IF (:POK IS NULL) THEN РОК = "Покупатель не указан";
SUSPEND;
END
END
Оператор POST_EVENT
Оператор POST_EVENT "Имя события";
применяется для посылки сервером клиентским приложениям сообщения о наступлении какой-либо ситуации, связанной с именем события. Приложение должно зарегистрироваться на сервере для получения уведомления о наступлении событий и указать список интересующих приложение событий. Более подробно см. раздел "Работа с событиями".
Операторные скобки BEGIN... END
Операторные скобки BEGIN ... END, во-первых, ограничивают тело процедуры, а во-вторых, могут использоваться для указания границ составного оператора.
Под простым оператором понимается единичное разрешенное действие, например:
РОК = "Покупатель не указан";
Под составным оператором понимается группа простых или составных операторов, заключенная в операторные скобки BEGIN ... END.
Оператор присваивания
Оператор присваивания служит для занесения значений в переменные. Его формат:
Имя переменной = выражение;
где в качестве выражения могут выступать переменные, арифметические и строковые выражения, в которых можно использовать встроенные функции, функции, определенные пользователем, а также генераторы. Пример:
OUT_TOVAR = UРРЕR(TOVAR);
Оператор IF... THEN ... ELSE
Условный оператор IF ... THEN ... ELSE имеет формат
IF (<условие>) THEN
< оператор 1>
[ELSE
< оператор 2>]
В случае, если условие истинно, выполняется оператор 1, если ложно -оператор 2.
Оператор SELECT
Оператор SELECT используется в хранимой процедуре для выдачи единичной сроки. По сравнению с синтаксисом обычного оператора SELECT, в процедурный оператор добавлено предложение
INTO :переменная |, переменная...]
Оно служит для указания переменных или выходных параметров, в которые должны быть записаны значения, возвращаемые оператором SELECT (те результирующие значения, которые перечисляются после ключевого слова SELECT).
Пример.
Приводимый ниже оператор SELECT возвращает среднее и сумму по столбцу KOLVO и записывает их соответственно в AVG_KOLVO и SUM_KOLVO, которые могут быть как локальными переменными, так и выходными параметрами процедуры. Расчет среднего и суммы по столбцу KOLVO производится только для записей, у которых значение столбца TOVAR совпадает с содержимым IN_TOVAR (входной параметр или локальная переменная). SELECT AVG(KOLVO), SUM(KOLVO)
FROM RASHOD WHERE TOVAR = :IN TOVAR
INTO : AVG_KOLVO, :SUM_KOLVO;
Оператор FOR SELECT... DO
Оператор FOR SELECT ... DO имеет следующий формат:
FOR
<оператор SELECT>
DO
< оператор>;
Оператор SELECT
представляется в расширенном синтаксисе оператора SELECT для алгоритмического языка хранимых процедур и триггеров, то есть в нем может присутствовать предложение INTO. Алгоритм работа оператора FOR SELECT... DO заключается в следующем. Выполняется оператор SELECT, и для каждой строки результирующего набора данных, возвращаемого данным SELECT, выполняется оператор, следующий за словом DO. Этим оператором часто бывает SUSPEND (см. ниже), который приводит к возврату выходных параметров в вызывающее приложение.
Пример.
Процедура RASHOD_TOVARA выдает все расходы товара для конкретного товара, определяемого содержимым входного параметра IN_TOVAR. Рассмотрим логику работы оператора FOR SELECT . . . DO данной процедуры. CREATE PROCEDURE RASHOD_TOVARA(IN_TOVAR VARCHAR(20))
RETURNS (OUT_DAT DATE, OUT_POKUP VARCHAR(20), OUT_KOLVO INTEGER) AS
BEGIN
FOR SELECT DAT_RASH, POKUP, KOLVO FROM RASHOD WHERE TOVAR = : IN_TOVAR
INTO :OUT DAT, :OUT_POKUP, :OUT_KOLVO
DO SUSPEND;
END
Выполняется оператор SELECT, который возвращает дату расхода, наименование покупателя и количество расхода товара для каждой записи, у которой столбец TOVAR содержит значение, идентичное значению во входном параметре IN_TOVAR. Указанные значения записываются в выходные параметры (соответственно OUT_DAT, OUT_POKUP, OUT_KOLVO). Имени параметра в этом случае предшествует двоеточие. После выдачи каждой записи результирующего НД выполняется оператор, следующий за словом DO. В данном случае это оператор SUSPEND. Он возвращает значения выходных параметров вызвавшему приложению и приостанавливает выполнение процедуры до запроса следующей порции выходных параметров от вызывающего приложения.
Такая процедура является процедурой выбора, поскольку она может возвращать множественные значения выходных параметров в вызывающее приложение. Обычно запрос к такой хранимой процедуре из вызывающего приложения осуществляется при помощи оператора SELECT, например:
SELECT MAX_KOLVO FROM FIND_MAX_KOLVO("Сахар")
Оператор SUSPEND
Оператор SUSPEND передает в вызывающее приложение значения результирующих параметров (перечисленных после слова RETURNS в описании функции), имеющие место на момент выполнения SUSPEND. После этого выполнение хранимой процедуры приостанавливается. Когда от оператора SELECT вызывающего приложения приходит запрос на следующее значение выходных параметров, выполнение хранимой процедуры возобновляется.
Пример.
Процедура POK_LIST выдает всех покупателей, у которых имеются покупки данного товара, в количестве, превосходящем средний размер покупки по данному товару. В случае, если наименование покупателя - пустое, вместо имени покупателя выводится "Покупатель не указан". CREATE PROCEDURE POK_LIST (IN_TOVAR VARCHAR(20))
RETURNS(РОК VARCHARf20)) AS
DECLARE VARIABLE AVG_KOLVO INTEGER;
BEGIN
SELECT AVG(KOLVO) FROM RASHOD WHERE TOVAR = :IN_TOVAR INTO : AVG_KOLVO;
FOR SELECT POKUP FROM RASHOD WHERE KOLVO > : AVG_KOLVO INTO : РОК
DO
BEGIN
IF (:POK IS NULL) THEN РОК = "Покупатель не указан";
SUSPEND;
END
END
Оператор WHILE... DO
Оператор имеет формат
WHILE (<условие>) DO < оператор>
Алгоритм выполнения оператора- в цикле проверяется выполнение условия, если оно истинно, выполняется оператор. Цикл продолжается до тех пор, пока условие не перестанет выполняться.
Пример.
Рассмотрим процедуру SUM_0_N, которая подсчитывает сумму всех чисел от 0 до числа, определяемого входным параметром N Вычисление суммы реализовано в цикле с использованием оператора WHILE .. DO. CREATE PROCEDURE SUM_0_N (N INTEGER)
RETURNS(S INTEGER) AS
DECLARE VARIABLE TMP INTEGER;
BEGIN
S = 0;
TMP = 1;
WHILE (TMP <= N) DO
BEGIN
S = S + TMP;
TMP = TMP + 1;
END
END
Оператор EXIT
Оператор EXIT инициирует прекращение выполнения процедуры и выход в вызывающее приложение.
Пример.
Процедура MAX_VALUE возвращает максимум из двух чисел, передаваемых как входные параметры, в случае, если одно из чисел имеет значение NULL, процедура завершается (в этом случае выходной параметр содержит значение NULL)' CREATE PROCEDURE MAX_VALUE(A INTEGER, В INTEGER)
RETURNS(M_V INTEGER) AS
BEGIN
IF ((:A IS NULL) OR (:B IS NULL )) THEN EXIT;
IF (:A > :B) THEN M_V = : A;
ELSE M_V = :B;
END
Алгоритмический язык хранимых процедур
Для написания тела хранимой процедуры применяют особый алгоритмический язык. Помимо хранимых процедур, данный язык применяется также для написания триггеров.
Рассмотрим конструкции алгоритмического языка хранимых процедур и триггеров.
Вызов процедур выбора в приложении клиента
Процедуры выбора могут возвращать несколько значений одного и того же выходного параметра или группы выходных параметров. Возврат текущего значения выходных параметров соответствует возврату строки. Таким образом, процедура выбора возвращает НД, состоящий в общем случае из нескольких строк. Для выдачи каждого значения выходных параметров в вызывающее приложение в хранимой процедуре выбора применяется оператор SUSPEND. Формирование строки результирующего НД (то есть текущих значений выходных параметров) производится операторами SELECT...INTO или FOR...SELECT.
Для обращения к хранимой процедуре выбора в приложении клиента используется компонент TQuery. Вызов хранимой процедуры производится в операторе SELECT, в предложении FROM, с указанием входных параметров процедуры. Выходные параметры процедуры (все или часть) указываются в качестве возвращаемых значений оператора SELECT.
ЗАМЕЧАНИЕ.
Для обращения к хранимой процедуре выбора может использоваться и компонент TStoredProc, открываемый при помощи метода Open. Однако в общем случае возможность обращения к процедуре выбора из компонента TStoredProc определяется особенностями SQL-сервера. К хранимым процедурам выбора, определенным в Borland InterBase, рекомендуется обращаться из оператора SELECT, который помещается в свойство SQL компонента TQuery. Пример.
Выше приводилась процедура выбора RASHOD_TOVARA, которая выдает все расходы товара для конкретного товара, определяемого содержимым входного параметра IN_TOVAR: CREATE PROCEDURE RASHOD_TOVARA(IN_TOVAR VARCHAR(20))
RETURNS (OUT_DAT DATE, OUT_POKUP VARCHAR(20), OUT_KOLVO
INTEGER) AS
BEGIN
FOR SELECT DAT_RASH, POKUP, KOLVO FROM RASHOD WHERE TOVAR = : IN_TOVAR
INTO :OUT_DAT, :OUT_POKUP, :OUT_KOLVO
DO
SUSPEND;
END
Для того чтобы обратиться к данной процедуре из клиентского приложения, разработанного на Delphi, создадим форму (рис. 28.1) разместив в ней:
1. компонент TDatabase, осуществляющий управление соединением с удаленной БД;
2. компонент TTable, ассоциированный с таблицей TOVARY, для выбора названия товара для передачи в хранимую процедуру как входного параметра;
3. компонент TQuery;
4. компонент TButton для инициации доступа к процедуре.
В свойстве SQL компонента TQuery необходимо определить SQL-запрос на обращение к процедуре:
SELECT *
FROM RASHOD_TOVARA(:PARAM1)
а в свойстве Params компонента TQuery необходимо указать тип параметра PARAM1 как String. В обработчике нажатия кнопки происходит присваивание параметру значения текущего названия товара из компонента TTable, после чего компонент TQuery активизируется:
procedure TForm1.ButtonlClick(Sender: TObject);
begin
Query1.Close;
Query1.ParamByName('param1').Value :=
Table1.FieldByName('TOVAR').Value;
Query1.Open; end;
Результаты работы приложения показаны на рисунке 28.2.
Изменение и удаление хранимых процедур
Изменение хранимой процедуры производится оператором
ALTER PROCEDURE ИмяПроцедуры
[ (входной_параметр тип_данньк [, входной_параметр тип_данных... ]) ]
[RETURNS
(входной параметр тип данных [.входной параметр тип данных ...])]
AS
<тело процедуры>;
Принципы построения оператора аналогичны изложенным выше принципам построения оператора CREATE PROCEDURE. После выполнения оператора ALTER PROCEDURE предыдущее определение процедуры заменяется на данное определение параметров, переменных и тела процедуры.
Для удаления хранимой процедуры из базы данных используется оператор
DROP PROCEDURE ИмяПроцедуры;
Создание триггеров
Триггер создается оператором
CREATE TRIGGER ИмяТриггера FOR ИмяТаблицы
[ACTIVE I INACTIVE]
{BEFORE | AFTER}
{DELETE | INSERT | UPDATE}
[POSITION номер]
AS <тело триггера>
Для определения тела триггера используется процедурный язык, рассмотренный в разделе, посвященном использованию хранимых процедур. В него добавляется возможность доступа к старому и новому значениям столбцвв изменяемой записи OLD и NEW - возможность, недоступная при определении тела хранимых процедур.
Структура отела триггера:
[<объявление локальных переменных процедуры>]
BEGIN
< оператор>
END
Определение заголовка триггера
Заголовок триггера имеет формат
... TRIGGER ИмяТриггера FOR ИмяТаблицы
[ACTIVE | INACTIVE]
{BEFORE | AFTER}
{DELETE | INSERT UPDATE}
[POSITION номер]
• ACTIVE | INACTIVE - указывает, активен триггер или нет. Можно определить триггер "про запас", установив для него INACTIVE. В дальнейшем можно переопределить триггер как активный. По умолчанию действует ACTIVE.
• BEFORE | AFTER - указывает, будет выполняться триггер до (BEFORE) или после (AFTER) запоминания изменений в БД.
• DELETE \ INSERT \ UPDATE - указывает операцию над ТБД, при выполнении которой срабатывает триггер.
• POSITION номер - указывает, каким по счету будет выполняться триггер в случае наличия группы триггеров, обладающих одинаковыми характеристиками операции и времени (до, после операции) вызова триггера. Значение номера задается числом в диапазоне 0..32 767. Триггеры с меньшими номерами выполняются раньше.
Например, если определены триггеры
CREATE TRIGGER A FOR RASHOD BEFORE INSERT POSITION 1 ...
CREATE TRIGGER С FOR RASHOD BEFORE INSERT POSITION 0...
CREATE TRIGGER D FOR RASHOD BEFORE INSERT POSITION 44 ...
CREATE TRIGGER В FOR RASHOD AFTER INSERT POSITION 1 ...
CREATE TRIGGER E FOR RASHOD AFTER INSERT POSITION 44 ...
для операции добавления новой записи в таблицу RASHOD они будут выполнены в следующей последовательности С, А, D, В, E.
Значения OLD и NEW
Значение OLD. Имя Столбца позволяет обратиться к состоянию столбца, имевшему место до внесения возможных изменений, а значение NEW. Имя Столбца - к состоянию столбца после внесения возможных изменений.
В том случае, если значение в столбце не изменилось, OLD ИмяСтолбца будет равно NEW ИмяСтолбца.
Пример.
Если в записи таблицы TOVARY изменилось значение столбца TOVAR, соответствующие изменения должны быть внесены в таблицу RASHOD: CREATE TRIGGER BU_TOVARY FOR TOVARY
ACTIVE
BEFORE UPDATE
AS
BEGIN
IF (OLD.TOVAR 0 NEW.TOVAR) THEN UPDATE RASHOD
SET TOVAR = NEW.TOVAR
WHERE TOVAR = OLD.TOVAR;
END
Обеспечение каскадных воздействий
Если между двумя или более ТБД установлены отношения ссылочной целостности (отношения "один-ко-многим", "один-к-одному"), при изменении столбца связи в родительской таблице должно быть изменено значение столбца связи у записей соответствующих дочерних таблиц. Такое воздействие на дочернюю таблицу носит название каскадного обновления. Если в родительской таблице удалена запись, должны быть удалены все связанные с ней записи в дочерней таблице. Такое воздействие на дочернюю таблицу носит название каскадного удаления.
Ограничение ссылочной целостности таблиц по внешнему ключу приводит к блокировке изменения и удаления записи в родительской таблице, если для нее есть дочерние записи в дочерней таблице:
CREATE TABLE TOVARY
(TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL, PRIMARY KEY(TOVAR));
CREATE TABLE RASHOD
(N_RASH INTEGER NOT NULL,
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
PRIMARY KEY(N_RASH),
FOREIGN KEY(TOVAR) REFERENCES TOVARY
);
Для реализации автоматического выполнения каскадных обновлений и изменений необходимо, во-первых, удалить ссылочные целостности, блокирующие такие изменения в определении БД и, во-вторых, определить сами триггеры для родительской таблицы.
Триггер, реализующий каскадное обновление в дочерней таблице, будет в числе прочих содержать оператор
IF (OLD.ПoлeCвязиPoдитeля <> NEW.ПoлeCвязиPoдитeля) THEN
UPDATE ДочерняяТаблица
SET ПолеСвязиДочернейТаблицы = NEW.ПолеСвязиРодителя
WHERE ПолеСвязиДочернейТаблицы = OLD.ПолеСвязиРодителя ;
Триггер, реализующий каскадное удаление в дочерней таблице, будет в числе прочих содержать оператор
DELETE FROM ДочерняяТаблица
WHERE ПолеСвязиДочернейТаблицы =ПолеСвязиРодителя ;
Пример.
Напишем триггеры, выполняющие каскадные обновления и каскадные удаления в дочерней таблице RASHOD после соответственно изменения значения столбца связи или удаления записи в родительской таблице TOVARY: CREATE TRIGGER BUJTOVARY FOR TOVARY
ACTIVE
BEFORE UPDATE
AS
BEGIN
IF (OLD.TOVAR 0 NEW.TOVAR) THEN UPDATE RASHOD
SET TOVAR = NEW.TOVAR
WHERE TOVAR = OLD.TOVAR;
END
CREATE TRIGGER AD_TOVARY FOR TOVARY
ACTIVE
AFTER DELETE
AS
BEGIN
DELETE FROM RASHOD
WHERE RASHOD.TOVAR = TOVARY.TOVAR;
END
Ведение журнала изменений
Журнал изменений в БД представляет собой таблицу БД, в которой фиксируются действия над всей базой данных или отдельными ее таблицами. В многопользовательских системах ведение такого журнала позволяет определить источник недостоверных или искаженных данных.
Пример.
Определим в базе данных таблицу TOVARY_LOG CREATE TABLE TOVARYJLOG(
DAT_IZM DATE, /* дата изменения */
DEISTV CHAR(3), /* операция */
OLD_TOVAR VARCHAR(20), /* старое значение TOVAR*/
NEW_TOVAR VARCHAR(20) /* новое значение TOVAR */
) ;
в которую будем автоматически записывать любые изменения, добавления, удаления в таблице ТО VARY. При этом будем фиксировать дату, операцию (INS, UPD, DEL) над таблицей TOVARY, а также старое и новое значение столбца TOVAR. Для операции удаления новое значение столбца TOVAR будет пустым. Для операции добавления пустым будет старое значение столбца TOVAR.
CREATE TRIGGER TOVARY_ADD_LOG FOR TOVARY
ACTIVE
AFTER INSERT
AS
BEGIN
INSERT INTO TOVARY_LOG(DAT_IZM, DEISTV, OLD_T,OVAR, NEW_TOVAR)
VALUES ("NOW","ADD","",NEW.TOVAR) ;
END
CREATE TRIGGER TOVARY_UPD_LOG FOR TOVARY
ACTIVE
AFTER UPDATE
AS
BEGIN
INSERT INTO TOVARY_LOG(DAT_IZM, DEISTV, OLD_TOVAR,
NEW_TOVAR)
VALUES ("NOW","UPD",OLD.TOVAR,NEW.TOVAR) ;
END
CREATE TRIGGER TOVARY_DEL_LOG FOR TOVARY
ACTIVE
AFTER UPDATE
AS
BEGIN
INSERT INTO TOVARY_LOG(DAT_IZM, DEISTV, OLD_TOVAR, NEW_TOVAR)
VALUES ("NOW","DEL",OLD.TOVAR,"");
END
Пусть в таблицу TOVARY внесены некоторые изменения. Тогда, выполнив оператор
SELECT * FROM TOVARY_LOG;
получим историю изменений в таблице TOVARY:
DAT_IZM DEISTV OLD_TOVAR NEW_TOVAR
30-JUN-1997 ADD оГУРЦЫ
30-JUN-1997 UPD оГУРЦЫ Огурцы
30-JUN-1997 DEL оГУРЦЫ
Использование триггеров для реализации бизнес-правил
Триггеры активно используются для реализации бизнес-правил. В частности, это может быть установка с помощью генераторов уникальных значений индексных полей, накапливание статистики в других таблицах и многое другое. К сложностям, возникающим при реализации бизнес-правил при помощи триггеров, следует отнести неразвитость средств отладки логики кода, составляющего тело триггеров.
Покажем на примерах реализацию некоторых бизнес-правил при помощи триггеров.
Пример.
Пусть столбец N_RASH в таблице RASHOD должен содержать уникальное значение. Для этой цели определим генератор RASHOD_N_RASH и установим его начальное значение 20. CREATE GENERATOR RASHOD_N_RASH;
SET GENERATOR RASHOD_N_RASH TO 20;
При добавлении новой записи будем присваивать столбцу N_RASH вновь добавляемой записи уникальное значение, полученное при помощи генератора.
CREATE TRIGGER BI_RASHOD_GEN FOR RASHOD
ACTIVE
BEFORE INSERT
BEGIN
NEW.N_RASH = GEN_ID(RASHOD_N_RASH,1);
END
Пример.
Пусть в БД имеется таблица STAT_TOVARY, в которой на каждую дату накапливается количество отпущенного товара: CREATE TABLE STAT_TOVARY(
DAT_RASH DATE NOT NULL,
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
KOLVO INTEGER NOT NULL
) ;
Тогда следующие триггеры реализуют автоматическое заполнение корректных значений в эту таблицу после добавления, изменения и удаления записи в таблице RASHOD, содержащей сведения о расходе товаров со склада:
CREATE TRIGGER AI_RASHOD FOR RASHOD
ACTIVE
AFTER INSERT
AS
DECLARE VARIABLE CNT INTEGER; DECLARE VARIABLE OLD_KOLVO_VAL INTEGER;
BEGIN
/* выбрать число записей в таблице STAT_TOVARY по данному товару за дату расхода */
SELECT COUNT(*) FROM STAT_TOVARY
WHERE (STAT_TOVARY.DAT_RASH = NEW.DAT_RASH) AND (STAT_TOVARY.TOVAR = NEW.TOVAR) INTO :CNT;
/* если число записей = 0, добавить запись в таблицу STAT_TOVARY по данному товару и дате */
IF (:CNT = 0) THEN
INSERT INTO STAT_TOVARY (DAT_RASH, TOVAR, KOLVO)
VALUES(NEW.DAT_RASH, NEW.TOVAR, NEW.KOLVO) ;
ELSE
/* иначе добавить новое количество товара в уже существующей записи для этого товара и этой даты в STAT_TOVARY */
BEGIN
SELECT KOLVO FROM STAT_TOVARY
WHERE (STAT_TOVARY.DAT_RASH = NEW.DAT_RASH) AND (STAT_TOVARY.TOVAR = NEW.TOVAR)
INTO :OLD_KOLVO_VAL;
UPDATE STAT_TOVARY
SET KOLVO = :OLD_KOLVO_VAL + NEW.KOLVO
WHERE (STAT_TOVARY.DAT_RASH = NEW.DAT_RASH) AND (STAT_TOVARY.TOVAR = NEW.TOVAR);
END
END
CREATE TRIGGER AU_RASHOD FOR RASHOD
ACTIVE
AFTER UPDATE
AS
DECLARE VARIABLE CNT INTEGER;
DECLARE VARIABLE OST_KOLVO INTEGER;
DECLARE VARIABLE OLD_KOLVO_VAL INTEGER;
BEGIN
/* в таблице статистики STAT_TOVARY найти общее количество расхода старого товара по старой дате */
/* из таблицы RASHOD */
SELECT KOLVO FROM STAT_TOVARY
WHERE (STAT_TOVARY.DAT_RASH = OLD.DAT_RASH) AND (STAT_TOVARY.TOVAR = OLD.TOVAR)
INTO :OLD_KOLVO_VAL;
/* в таблице статистики STAT_TOVARY уменьшить общее число прихода старого товара */
/* на старое значение количества расхода из таблицы RASHOD */
UPDATE STAT_TOVARY
SET KOLVO = :OLD_KOLVO_VAL - OLD.KOLVO
WHERE (STAT_TOVARY.DAT_RASH = OLD.DAT_RASH) AND (STAT_TOVARY.TOVAR = OLD.TOVAR) ;
OST_KOLVO = OLD_KOLVO_VAL - OLD.KOLVO;
/* если оставшееся количество расхода за эту дату по этому товару равно 0, удалить */
/* запись из таблицы STAT_TOVARY */
IF (:OST_KOLVO = 0) THEN
DELETE FROM STAT_TOVARY
WHERE (STAT_TOVARY.DAT_RASH = OLD.DAT_RASH) AND (STAT_TOVARY.TOVAR = OLD.TOVAR);
/* выбрать число записей в таблице STAT_TOVARY по новому товару за новую дату расхода */
SELECT COUNT (*) FROM STAT_TOVARY
WHERE (STAT_TOVARY.DAT_RASH = NEW.DAT_RASH) AND (STAT_TOVARY.TOVAR = NEW.TOVAR)
INTO :CNT;
/* если число записей = 0, добавить запись в таблицу STAT_TOVARY по новому товару и новой дате */
IF (:CNT = 0) THEN
INSERT INTO STAT_TOVARY (DAT_RASH, TOVAR, KOLVO)
VALUES(NEW.DAT_RASH, NEW.TOVAR, NEW.KOLVO) ;
ELSE
/* иначе добавить новое количество товара в уже существующей записи для данного товара*/
/* и новой даты в STAT_TOVARY*/
BEGIN
SELECT KOLVO FROM STAT_TOVARY
WHERE (STAT_TOVARY.DAT_RASH = NEW.DAT_RASH) AND (STAT_TOVARY.TOVAR = NEW.TOVAR)
INTO :OLD_KOLVO_VAL;
UPDATE STAT_TOVARY
SET KOLVO = :OLD_KOLVO_VAL + NEW.KOLVO
WHERE (STAT_TOVARY.DAT_RASH = NEW.DAT_RASH) AND (STAT_TOVARY.TOVAR = NEW.TOVAR);
END
END
CREATE TRIGGER ADL_RASHOD FOR RASHOD
ACTIVE
AFTER DELETE
AS
DECLARE VARIABLE OST_KOLVO INTEGER; DECLARE VARIABLE OLD_KOLVO_VAL INTEGER;
BEGIN
/* в таблице статистики STAT_TOVARY найти общее количество расхода товара за дату из таблицы RASHOD */
SELECT KOLVO FROM STAT_TOVARY
WHERE (STAT_TOVARY.DAT_RASH = OLD.DAT_RASH) AND (STAT_TOVARY.TOVAR = OLD.TOVAR)
INTO :OLD_KOLVO_VAL;
/* в таблице статистики STAT_TOVARY уменьшить общее число прихода товара */
/* на значение количества расхода товара из удаленной таблицы RASHOD */
UPDATE STAT_TOVARY
SET KOLVO = :OLD_KOLVO_VAL - OLD.KOLVO
WHERE (STAT_TOVARY.DAT_RASH = OLD.DAT_RASH) AND (STAT_TOVARY.TOVAR = OLD.TOVAR);
OST_KOLVO = OLD_KOLVO_VAL - OLD.KOLVO;
/* если оставшееся количество расхода по товару за эту дату равно 0, удалить запись из таблицы STAT TOVARY
IF (:OST_KOLVO = 0) THEN
DELETE FROM STAT_TOVARY
WHERE (STAT_TOVARY.DAT_RASH = OLD.DAT_RASH) AND (STAT_TOVARY.TOVAR = OLD.TOVAR);
END
Покажем состояние таблицы STAT_TOVARY после добавления в таблицу RASHOD новых записей по расходу за 12 и 14 февраля:
SELECT * FROM STAT_TOVARY ORDER BY DAT_RASH, TOVAR
DATRASH
Пусть после изменения в таблице RASHOD информации о расходе товара за 12 февраля:
• вместо 11 единиц товара "Кока-кола" в действительности пришла 21 единица товара "Ставрида консерв.";
• вместо 100 единиц товара "Сахар" пришло 98 единиц этого товара.
Покажем состояние таблицы STAT_TOVARY после внесения в таблицу RASHOD указанных изменений:
SELECT * FROM STAT_TOVARY ORDER BY DAT_RASH, TOVAR
DATRASH
Покажем состояние таблицы STAT_TOVARY после удаления расхода за 12 февраля товара "Сахар в размере 98 ед. и за 14 февраля товара "Кока-кола в размере 2 ед. из таблицы RASHOD:
SELECT * FROM STAT_TOVARY ORDER BY DAT_RASH, TOVAR
DATRASH
Изменение и удаление триггеров
Изменить существующий триггер можно при помощи оператора
ALTER TRIGGER ИмяТриггера FOR ИмяТаблицы
[ACTIVE | INACTIVE]
{BEFORE | AFTER}
{DELETE | INSERT | UPDATE}
[POSITION номер]
AS <тело триггера>
После выполнения этого оператора все старые определения триггера заменяются на определения, указанные в операторе ALTER TRIGGER
Для удаления триггера следует воспользоваться оператором
DROP TRIGGER ИмяТриггера;
Работа с триггерами
Триггер -
это процедура БД, автоматически вызываемая SQL-сервером при обновлении, удалении или добавлении новой записи в ТБД. Непосредственно из программы к триггерам обратиться нельзя. Нельзя и передавать им входные параметры и получать от них значения выходных параметров. Триггеры всегда реализуют действие. По событию изменения ТБД триггеры различаются на вызываемые при:
• добавлении новой записи;
• изменении существующей записи;
• удалении записи.
По отношению к событию, влекущему их вызов, триггеры различаются на:
• выполняемые до наступления события;
• выполняемые после наступления события. Преимущества использования триггеров:
• автоматическое обеспечение каскадных воздействий в дочерних таблицах при изменении, удалении записи в родительской таблице выполняется на сервере. Пользователю нет необходимости заботиться о программной реализации каскадных воздействий. Поскольку каскадные воздействия выполняет сервер, нет необходимости пересылать изменения в таблицах БД из приложения на сервер, что снижает загрузку сетевого трафика;
• изменения в триггерах не влекут необходимости изменения программного кода в клиентских приложениях и не требуют распространения новых версий клиентских приложений у пользователей.
ЗАМЕЧАНИЕ.
При откате транзакции откатываются также и все изменения, внесенные в БД триггерами.
Общий обзор средств для работы с базами данных
В состав Delphi Client/Server Suite входят следующие средства для разрабо1ки и эксплуатации приложений, использующих базы данных:
• BDE (Borland Database Engine), машина баз данных фирмы Borland
Представляет собой набор библиотек. Должна устанавливаться на каждом компьютере, который использует приложения для работы с БД, написанные на Delphi. Выполняет действия по доступу к данным и проверке их правильности. Является, по существу, центральным средством для работы с БД из приложений, созданных с помощью Delphi.
•SQL Links
Драйверы для работы с удаленными "промышленными" СУБД, такими как Sybase, MS SQL Server, Oracle. Для работы с "родным" SQL-сервером Borland InterBase устанавливать SQL Links нет необходимости. Доступ к таблицам локальных ("настольных", "персональных") СУБД типа Paradox, dBase также осуществляется BDE напрямую, без использования SQL Links.
• BDE Administrator
Утилита для установки псевдонимов (имен) баз данных, параметров БД и драйверов баз данных на конкретном компьютере. При работе с БД из приложения, созданного с помощью Delphi, доступ к базе данных производится по ее псевдониму (имени). Параметры БД, определяемой псевдонимом, действуют только для этой БД; параметры, установленные для драйвера БД, действуют для всех баз данных, использующих драйвер. Кроме этого, в утилите BDE Administrator можно произвести установку таких общих для всех БД параметров, как формат даты и времени, форматы представления числовых значений, используемый языковый драйвер и т.д. Поддерживает информацию о конфигурации БД на конкретном компьютере в файле IDAPI32.CFG.
• Database Desktop (DBD)
Средство для создания, изменения и просмотра БД. Эта утилита прежде всего ориентирована на работу с таблицами локальных ("персональных") СУБД, таких как Paradox и dBase. В ряде случаев может использоваться и для работы с таблицами удаленных СУБД. Например, из DBD можно с некоторыми ограничениями создавать таблицы БД, работающих под управлением InterBase, Oracle, и просматривать их содержимое.
Общая модель взаимодействия приложения, реализованного с помощью Delphi, со средствами БД приведена на рис. 3.1.
• Database Explorer (SQL Explorer)
Утилита для конфигурирования псевдонимов БД, просмотра структуры БД, таблиц БД, выдачи запросов к БД, создания словарей данных.
•SQL Monitor
Средство для трассировки выполнения SQL-запросов.
• Visual Query Builder
Средство в составе интегрированной среды Delphi для автоматического создания SQL-запросов методом QBE (Query By Example, запрос по образцу).
• Data Dictionary
Словарь данных. Средство для хранения атрибутов полей таблиц БД отдельно от самих БД и приложений. Информация о полях может использоваться различными приложениями.
• Data Module
Невизуальные компоненты типа TDataModule применяются для централизованного хранения наборов данных в приложении, работающем с БД. Одним из главных удобств является приписывание каждому набору данных правил по управлению данными. Такие правила называются бизнес-правилами. Они обычно определяют реакцию системы при добавлении, изменении, удалении данных, при вводе ошибочных значений и реализуют блокировку действий, которые могут разрушить ссылочную и смысловую целостность БД.
Такие бизнес-правила, хранящиеся централизованно на уровне приложения, при использовании одного и того же набора данных в разных формах приложения, позволяют унифицировать поведение НД на уровне всего приложения.
• Object Repository
Репозиторий объектов Delphi. Будучи единожды разработанными для какого-либо приложения, формы с визуальными и невизуальными компонентами, а также компоненты TDataModule могут сохраняться в репозитории. Тогда они могут использоваться другими, вновь создаваемыми приложениями. Таким образом устраняется необходимость повторного написания идентичного или схожего кода в приложениях.
• Data Migration Wizard
Средство для перемещения данных между БД различных типов
• Невизуальные компоненты для работы с БД
Невизуальные компоненты Delphi служат для соединения приложения с таблицами БД. Они расположены на странице компонентов Data Access палитры компонентов в интегрированной среде разработки Delphi. Невизуальный компонент "перетаскивается" из палитры компонентов в форму разрабатываемого приложения. После этого Delphi автоматически описывает в форме экземпляр компонента указанного класса. Далее разработчик определяет свойства компонента, кодирует обработчики событий, где в программном коде вызывает необходимые ему методы компонента.
• Визуальные компоненты для работы с БД
Визуальные компоненты Delphi предназначены доя визуализации записей наборов данных (например, компонент TDBGrid) или отдельных полей текущей записи набора данных (например, TDBEdit, TDBText). Эти компоненты расположены на странице компонентов Data Controls палитры компонентов в интегрированной среде разработки Delphi. Визуальный компонент "перетаскивается" из палитры компонентов в форму разрабатываемого приложения. После этого Delphi автоматически описывает в форме экземпляр компонента указанного класса. Далее разработчик определяет соединение визуального компонента с невизуальными компонентами, определяет по необходимости различные свойства компонента, кодирует обработчики событий, где в программном коде вызывает необходимые ему методы компонента.
• Компоненты для построения отчетов
В интегрированной среде разработчика Delphi на странице палитры компонентов QReport размещено около двух десятков компонентов для построения отчетов. Их добавление в приложение происходит аналогично добавлению визуальных компонентов для работы с данными.
Ранее поставлявшееся в составе Delphi автономное средство ReportSmith с Delphi версии 3 более не поставляется.
• Local InterBase Server
Локальная однопользовательская версия SQL-сервера Borland InterBase. Поддерживает 2 активных соединения клиентов с сервером. Используется в основном для создания БД, отладки клиентских приложений, которые будут работать с Удаленными БД. В дальнейшем, после отладки, БД переносятся на действительно удаленный сервер, а приложение клиентского места перенастраивается для работы с удаленной БД. Данная перенастройка обычно не требует больших трудозатрат.
• InterBase Server for Windows 95
4-х-пользовательская версия SQL-сервера Borland InterBase, которая может устанавливаться на компьютерах, работающих под управлением Windows 95. Используется для тех же цедей< что и Local InterBase Server, однако на InterBase for Windows 95 можно производить отладку в многопользовательском режиме, что важно для проверки корректности изменений, одновременно вносимых пользователями в БД при параллельной работе с ней.
На рис. 3.2. показаны основные средства в составе интегрированной среды Delphi для работы с БД
Интегрированная среда разработчика Delphi (IDE, Integrated Development Environment)
Локальные базы данных и архитектура "файл-сервер"
При работе с локальными базами данных сами БД расположены на том же компьютере, что и приложения, осуществляющие доступ к ним. Работа с БД происходит в однопользовательском режиме. BDE распложена на компьютере пользователя. Приложение ответственно за поддержание целостности БД и за выполнение запросов к БД. Общая схема однопользовательской архитектуры
показана на рис. 3.4.
При работе в архитектуре "файл-сервер" БД и приложение расположены на файловом сервере сети (например, Novell NetWare). Возможна многопользовательская работа с одной и той же БД, когда каждый пользователь со своего компьютера запускает приложение, расположенное на сетевом сервере. Тогда на компьютере пользователя запускается копия приложения. По каждому запросу к БД из приложения данные из таблиц БД перегоняются на компьютер пользователя, независимо от того, сколько реально нужно данных для выполнения запроса. После этого выполняется запрос.
Каждый пользователь имеет на своем компьютере локальную копию данных, время от времени обновляемых из реальной БД, расположенной на сетевом сервере. При этом изменения, которые каждый пользователь вносит в БД, могут быть до определенного момента неизвестны другим пользователям, что делает актуальной задачу систематического обновления данных на компьютере пользователя из реальной БД. Другой актуальной задачей является блокирование записей, которые изменяются одним из пользователей; это необходимо для того, чтобы в это время другой пользователь не внес изменений в те же данные.
В архитектуре "файл-сервер" вся тяжесть выполнения запросов к БД и управления целостностью БД ложится на приложение пользователя. БД на сервере является пассивным источником данных. Общая схема архитектуры "файл-сервер" показана на рис. 3.5.
Кардинальных различий с точки зрения архитектуры между однопользовательской архитектурой и архитектурой "файл-сервер" нет. И в том, и в ином случае в качестве СУБД применяются так называемые "персональные" (или "локальные") СУБД, такие как Paradox, dBase и пр. Сама база данных в этом случае представляет собой набор таблиц, индексных файлов, файлов полей комментариев (мемо-полей) и пр., хранящихся в одном каталоге на диске в виде отдельных файлов.
Удаленные базы данных и архитектура "клиент-сервер"
Архитектура "файл-сервер" неэффективна по крайней мере в двух отношениях:
1. При выполнении запроса к базе данных, расположенной на файловом сервере, в действительности происходит запрос к локальной копии данных на компьютере пользователя. Поэтому перед выполнением запроса данные в локальной копии обновляются из реальной БД. Данные обновляются в полном объеме. Так, если таблица БД состоит из 1000 записей, а для выполнения запроса (например, выдать сумму премий за октябрь в отделе Y) реально нужно 10 записей, все равно перегоняются все 1000 записей. Таким образом, не нужно иметь слишком много пользователей и запросов от них, чтобы серьезно "забить" сеть, что, конечно же, не может не сказаться на ее быстродействии.
2. Обеспечение целостности БД производится из приложений. Это потенциальный источник ошибок, нарушающих физическую и логическую целостность БД, поскольку различные приложения могут производить контроль целостности БД по-разному, взаимоисключающими способами, или не проводить такого контроля вовсе. Намного эффективнее управлять БД из единого места и по единым законам, нежели из разных приложений и по потенциально разным законам (все зависит от того, как написано приложение). Поэтому безопасность при работе в архитектуре "файл-сервер" невысока и всегда присутствует элемент неопределенности. Секретность и конфиденциальность при работе с БД в архитектуре "файл-сервер" обеспечить также тяжело - любой, кто имеет доступ в каталог сетевого сервера, где хранится БД, может изменять таблицы БД любым образом, копировать их, заменять и т.д.
Архитектура "клиент-сервер" разделяет функции приложения пользователя (называемого клиентом) и сервера.
Приложение-клиент формирует запрос к серверу, на котором расположена БД, на структурном языке запросов SQL (Structured Query Languague), являющемся промышленным стандартом в мире реляционных БД. Удаленный сервер принимает запрос и переадресует его SQL-серверу БД. SQL-сервер -специальная программа, управляющая удаленной базой данных. SQL-сервер обеспечивает интерпретацию запроса, его выполнение в базе данных, формирование результата выполнения запроса и выдачу его приложению-клиенту. При этом ресурсы клиентского компьютера не участвуют в физическом выполнении запроса; клиентский компьютер лишь отсылает запрос к серверной БД и получает результат, после чего интерпретирует его необходимым образом и представляет пользователю. Так как клиентскому приложению посылается результат выполнения запроса, по сети "путешествуют" только те данные, которые необходимы клиенту. В итоге снижается нагрузка на сеть. Поскольку выполнение запроса происходит там же, где хранятся данные (на сервере), нет необходимости в пересылке больших пакетов данных. Кроме того, SQL-сервер, если это возможно, оптимизирует полученный запрос таким образом, чтобы он был выполнен в минимальное время с наименьшими накладными расходами.
Все это повышает быстродействие системы и снижает время ожидания результата запроса.
При выполнении запросов сервером существенно повышается степень безопасности данных, поскольку правила целостности данных определяются в базе данных на сервере и являются едиными для всех приложений, использующих эту БД. Таким образом, исключается возможность определения противоречивых правил поддержания целостности. Мощный аппарат транзакций, поддерживаемый SQL-серверами, позволяет исключить одновременное изменение одних и тех желанных различными пользователями и предоставляет возможность откатов к первоначальным значениям при внесении в БД изменений, закончившихся аварийно.
Таким образом, функциями приложения-клиента являются:
1. посылка к серверу запросов;
2. интерпретация результатов запросов, полученных от сервера, и представление их пользователю в требуемой форме;
3. реализация интерфейса пользователя.
SQL-сервер - это программа, расположенная на компьютере сетевого сервера. SQL-сервер должен быть загружен на момент принятия запроса от клиента. Функциями сервера БД являются:
1. прием запросов от приложений-клиентов, интерпретация запросов, выполнение запросов в БД, отправка результата выполнения запроса приложению-клиенту;
2. управление целостностью БД, обеспечение системы безопасности, блокировка неверных действий приложений-клиентов;
3. хранение бизнес-правил, часто используемых запросов в уже интерпретированном виде;
4. обеспечение одновременной безопасной и отказоустойчивой многопользовательской работы с одними и теми же данными.
В архитектуре "клиент-сервер" используются так называемые "удаленные" (или "промышленные") СУБД. Промышленными они называются из-за того, что именно СУБД этого класса могут обеспечить работу информационных систем масштаба среднего и крупного предприятия, организации, банка. Локальные СУБД предназначены для однопользовательской работы или для обеспечения работы информационных систем, рассчитанных на небольшие группы пользователей.
К разрядку промышленных СУБД принадлежат Oracle, Gupta, Informix, Sybase, MS SQL Server, DB2, InterBase и ряд других.
Как правило, SQL-сервер управляется отдельным сотрудником или группой сотрудников (администраторы SQL-сервера). Они управляют физическими характеристиками баз данных, производят оптимизацию, настройку и переопределение различных компонентов БД, создают новые БД, изменяют существующие и т.д., а также выдают привилегии (разрешения на доступ определенного уровня к конкретным БД, SQL-серверу) различным пользователям.
Кроме этого, существует отдельная категория сотрудников, называемых администраторами баз данных. Как правило, это администраторы сервера, разработчики БД или пользователи, имеющие привилегии на создание, изменение, настройку оптимальных параметров отдельных серверных БД. Администраторы БД также отвечают за предоставление прав на разноуровневый доступ к сопровождаемым ими БД для других пользователей.
Использование архитектуры "клиент-сервер":
1. резко уменьшает сетевой график;
2. понижает сложность приложений-клиентов (поскольку тем уже нет 1 необходимости обеспечивать целостность и безопасность БД и следить за параметрами многопользовательской работы с БД);
3. понижает требования к аппаратным средствам, на которых эти приложения функционируют (т.е. к компьютерам пользователей- клиентов);
4. повышает надежность БД, ее целостность, безопасность и секретность.
Многозвенная архитектура "клиент-сервер"
Развитие идеи архитектуры "клиент-сервер" привело к появлению многозвенной архитектуры доступа к базам данным (в литературе ее также называют трехзвенноя архитектурой, N-tier или multi-tier архитектурой).
Архитектура "клиент-сервер" является двухзвенной. Первым звеном является приложение клиента, вторым - сервер БД и сама БД.
В трехзвенной архитектуре наборы данных, бывшие ранее "собственностью" клиентских приложений, выделяются в отдельное звено, называемое сервером приложений (рис. 3.7).
Выше говорилось о модулях данных (Data Module). По существу, это компонент Delphi контейнерного типа, подобно компоненту формы TForm, хранящий в себе другие компоненты. Такими компонентами для Data Module могут служить только невизуальные компоненты БД - компоненты типа "набор данных" (TTable, TQuery, TStoredProc) и компоненты типа TDataSource, являющиеся промежуточными компонентами, связывающими между собой компоненты типа "набор данных" и визуальные компоненты БД.
Использование контейнеров Data Module имеет то преимущество, что компоненты типа "набор данных", единожды размещенные в Data Module, могут использоваться во всех формах приложения. При этом компоненты типа "набор данных", размещенные в Data Module, обладают единым поведением для всего приложения. Это особенно важно при реализации бизнес-правил, хранящихся в приложениях клиента.
Кроме того, модули данных, экспортированные в репозиторий, могут использоваться при разработке других приложений. Это обеспечивает повторное использование единожды разработанного программного кода и гарантирует единообразное поведение наборов данных во всех приложениях, использующих один и тот же модуль данных из репозитория.
Итак, модули данных в трехзвенной архитектуре "клиент-сервер" выделяются в отдельный "сервер приложений". Совместно с ним располагается BDE. Теперь, при изменении бизнес-правил нет необходимости изменять приложения клиентов и обновлять их у всех пользователей-клиентов, как это было ранее, когда часть бизнес-правил хранилась в приложении клиента.
Сервер приложений разделяется несколькими клиентами Он формирует запрос к удаленной БД (т.е. к SQL-серверу). На нем расположены реальные наборы данных (в двухзвенной архитектуре "клиент-сервер" располагавшиеся в приложении клиента). В клиентском приложении размещается "клиентский набор данных" (компонент TClientDataSet). Он представляет собой локальную копию данных с сервера приложений. Таким образом, все изменения, вносимые пользователем в данные при помощи клиентского приложения, вносятся в локальную копию НД. При обновлении удаленного НД клиентское приложение посылает серверу приложений только изменившиеся записи. Сервер приложений, в свою очередь, отсылает эти изменения SQL-серверу, который вносит их в удаленную БД.
Взаимодействие клиентского приложения (в многозвенном приложении называемого "тонким клиентом", thin client) с сервером приложений осуществляется при помощи так называемых "брокеров данных". Это появившиеся в Delphi 3 компоненты TRemoteServer (располагающийся в приложении тонкого клиента) и TProvider (расположенный на сервере приложений).
Архитектуры баз данных
Общий состав средств, необходимых для работы готового приложения с БД, показан на рис. 3.3. Согласно этой общей схеме, мы имеем цепочку Приложение —> BDE —> базы данных
В структуре приложения имеется цепочка Невизуальные компоненты —> Визуальные компоненты
Более подробно взаимосвязи между компонентами приложения рассматриваются ниже. Местоположение BDE и самих баз данных в этой цепочке не отражены.
Между тем, местоположение BDE и баз данных зависит от используемой архитектуры. Имеется четыре разновидности архитектур баз данных:
• локальные базы данных;
• архитектура "файл-сервер";
• архитектура "клиент-сервер";
• многозвенная (трехзвенная N-tier или multi-tier) архитектура.
Использование той или иной архитектуры накладывает сильный отпечаток на общую идеологию работы приложения, на программный код в приложении, на состав компонентов для работы с БД, используемых в приложении (прежде всего это касается невизуальных компонентов).
Общая структура приложения, работающего с базами данных
На рис. 3.8 показана общая структура приложения, работающего с базами данных.
Как видно из рисунка, при рассмотрении структуры приложения работающего с БД, вполне можно абстрагироваться от расположения BDE и самой базы данных. Приложение состоит из невизуальных и визуальных компонентов работы с БД, компонентов для выдачи отчетов (которые представляют разновидность визуальных компонентов), а также модулей
данных.
Невизуальные компоненты имеют прямой выход на BDE, которая, в свою очередь, контактирует с БД.
Визуальные компоненты служат для представления данных из невизуальных компонентов, т.е. служат целям обеспечения интерфейса пользователя при работе с данными.
Модули данных служат для централизованного хранения отдельных экземпляров невизуальных компонентов с целью придания тем или иным наборам данных единообразного поведения во всем приложении.
Приложение состоит из одной или нескольких форм. Каждая форма может:
• хранить и использовать свои "собственные" невизуальные компоненты;
• использовать невизуальные компоненты, хранящиеся в одном или нескольких модулях данных;
• использовать невизуальные компоненты, хранящиеся и используемые в
других формах.
Каждая форма может воспользоваться только "собственными" визуальными компонентами, поскольку визуальные компоненты выполняют интерфейсные функции и при деактивизации формы теряют свою видимость на экране.
Просмотр метаданных
Чтобы увидеть метаданные БД, выберите нужный псевдоним в левом окне утилиты и нажмите знак '+' для раскрытия дерева метаданных. При этом для удаленных БД будут запрошены имя пользователя и пароль . В правом окне будут выведены характеристики псевдонима БД, а в левом - построено дерево метаданных (рис. 311).
Дерево метаданных включает в себя ветви:
домены;
таблицы;
виртуальные таблицы (просмотры), Procedures - хранимые процедуры;
функции, определенные пользователем,
генераторы;
- исключения;
- BLOB-фильтры. Для работы с определенным типом метаданных следует выбрать соответствующую ветвь дерева и раскрыть список, выбрав знак '+' слева от названия ветви. Если в опциях элемента меню View отмечен флаг System Data, будут показываться и системные данные, включаемые в каждую БД. На рис.31.2 показана раскрытая ветвь Tables, включающая данные о системных таблицах, а на рис. 31.3. - та же ветвь, не включающая информацию о системных таблицах.
Для каждой хранимой процедуры (ветвь Procedures} показываются входные и выходные параметры. Для каждого параметра в правом окне приводится характеризующая его информация: порядок (Order), вид - входной или выходной (Kind), имя домена (Domain), тип данных (Type), длина (Length) и число знаков в дробной части (Scale).
Для просмотра определения компонента данных (домена, таблицы, процедуры и т.д.) или его текста следует выбрать соответствующее имя в дереве в левом окне, а в правом окне выбрать закладку Definition или Text. На рис. 31.4 показан текст SQL-оператора CREATE PROCEDURE FIND_MAX_KOLVO, создавшего хранимую процедуру FIND_MAX_KOLVO.
К БД может быть выполнен SQL-запрос, при этом безразлично, на какой ветви мы будем находиться при выполнении запроса. На рис. 31.5 показано выполнение запроса, относящегося к таблицам RASHOD и ТО VARY, в то время как текущей в дереве является ветвь хранимой процедуры FIND_MAX_KOLVO.
Для выполнения SQL-оператора следует в правом окне выбрать закладку Enter SQL, набрать текст оператора и нажать кнопку с изображением молнии. Тогда, в случае корректности введенного оператора, в нижнем правом окне будет выбран результат выполнения запроса.
Таким образом, например, могут быть созданы новые таблицы, процедуры, просмотры и т.д., а также изменены и удалены существующие, то есть выполнено изменение структуры БД (аналогично тому, как это можно делать в Database Desktop или, что более характерно для удаленных БД, соответствующей утилитой интерактивного SQL, например, WISQL для InterBase). Например, введем оператор
CREATE TABLE SOMETABLE(
SOMEINT INTEGER NOT NULL,
SOMECHAR CHAR(10),
PRIMARY KEY (SOMEINT)
) ;
для создания новой таблицы БД SOMETABLE. После успешного выполнения оператора следует обновить информацию о БД в утилите Database Explorer. Для этого следует выбрать элемент меню View | Refresh. После этого имя новой таблицы появится в списке таблиц.
Просмотр и изменение данных
Чтобы просмотреть данные и, возможно, внести в них изменения, следует выбрать закладку Data и в таблице данных просмотреть и, если необходимо, изменить данные (рис. 31.6).
ЗАМЕЧАНИЕ 1.
Добавить, изменить или удалить записи также можно в окне Enter SQL с помощью операторов INSERT, UPDATE, DELETE. ЗАМЕЧАНИЕ
2 Просмотр данных в окне Data можно также осуществлять для просмотров View.
Просмотр столбцов
Ветвь Columns, исходящая из каждой таблицы, показывает названия столбцов, входящих в структуру данной ТБД. Для каждого столбца в правом окне утилиты показываются, порядковый номер, имя системного домена столбца, тип, длина, число знаков в дробной части (если есть), значение по умолчанию.
Просмотр ограничений на значения столбцов
Из узла, соответствующего имени таблицы, исходят ветви, каждая из которых определяет тот или иной вид ограничения на значения столбцов таблицы:
• Primary Key -
ограничения первичного ключа; • Referential Constraints -
ограничения ссылочной целостности; • Unique Constraints -
ограничения уникального ключа; • Check Constraints -
условные ограничения, накладываемые на значение столбца Для каждого такого ограничения показываются: имя ограничения в БД и столбцы, входящие в то или иное ограничение. Если выбрать закладку Text в правом окне, для каждого ограничения показывается соответствующий оператор ALTER TABLE ADD CONSTRAINT, приведший к созданию ограничения.
Просмотр индексов
В ветви Indices для каждой таблицы показываются индексы, построенные по ограничениям первичного и уникальных (если имеются) ключей, а также неуникальные индексы. Для каждого индекса показывается его имя и столбцы, входящие в его состав. Если выбрать закладку Text в правом окне, для каждого индекса показывается оператор CREATE INDEX, приведший к созданию индекса
Просмотр триггеров
Для каждой таблицы исходящая ветвь Triggers показывает список триггеров (если есть), определенных для таблицы. Для каждого триггера в правом окне (закладка Text) выводится текст триггера Выбрав закладку Definition, можно получить информацию о типе операции, активизирующей триггер (INSERT, UPDATE, DELETE), о времени вызова триггера относительно породившей его операции (AFTER, UPDATE) и о приоритете вызова среди других триггеров, определенных для данной операции и времени вызова (POSITION)
Использование утилиты Database Explorer
Утилита Database Explorer предназначена для:
Утилита может применяться для просмотра метаданных как удаленных (серверных), так и локальных (Paradox, dBase) БД. В последнем случае состав типов метаданных существенно меньше, поскольку для локальных БД нельзя определить как триггеры, хранимые процедуры, просмотры, функции, определенные пользователем, и т.д.
В окне утилиты две закладки - просмотр метаданных БД (Databases} и работа со словарем данных (Dictionary). Работа со словарем данных близко пересекается с понятием бизнес-правил и потому описывается в разделе "Определение бизнес-правил" (подраздел "Использование словаря данных для определения атрибутов полей").
Откат изменений и целостность БД
Существует несколько способов внесения изменений в таблицы БД.
Пусть в НД (например, TTable), ассоциированном с какой-либо ТБД, выполнено удаление, добавление или корректировка записи.
Для локальных БД (Paradox, dBase и т.д.) характерен подход немедленного отображения изменений. Когда выполняется метод Post, изменения, внесенные в запись НД, немедленно физически запоминаются в ТБД, ассоциированной с этим НД То же верно и для метода Delete - после него запись немедленно физически удаляется из ТБД, ассоциированной с этим НД.
Отказаться от изменения таблицы БД в этом случае невозможно - ведь изменения уже физически внесены в нее Правда, удаленную запись можно ввести заново вручную Или - другой вариант - удаленные записи можно сохранять в некоторой промежуточной (временной) таблице БД В случае запроса на отказ от удаления записи из этой таблицы можно перемещать в ту ТБД, из которой произошло удаление.
Необходимость отката изменений обусловливается еще и тем обстоятельством, что БД всегда должна находиться в целостном состоянии. Классическим примером перехода БД из одного целостного состояния в другое является бухгалтерская проводка, когда некоторая сумма S должна быть списана со счета К и зачислена на счет D. Только успешное выполнение этих двух операций гарантирует целостность информации в БД. Но целостность будет нарушена, если в результате сбоя сумма S будет списана со счета К, но не будет зачислена на счет D или, наоборот, зачислена на D, но не списана с К. Поэтому в случае ошибки списания/ зачисления суммы результата предыдущей операции зачисления/списания должны быть отменены.
Существуют механизмы отката изменений в БД в случае невыполнения условия успешного завершения всех операций в составе группы. Один из таких механизмов носит название обработка транзакций. Обычно обработка транзакций реализуется промышленными БД. Однако Delphi позволяет управлять транзакциями и для таблиц локальных СУБД (Paradox, dBase). Кроме того, как для промышленных, так и локальных БД Delphi предоставляет дополнительный механизм управления откатами изменений в БД - так называемые "кэшированные изменения" (cached updates, что часто переводят так же как "буферизованные изменения").
Понятие транзакции
Транзакция - это единичное или чаще групповое изменение БД, которое или выполняется полностью, или не выполняется вообще. Результаты выполнения транзакции записываются в БД только в том случае, если вся транзакция завершилась успешно.
Таким образом, транзакция переводит БД из одного целостного состояния в другое
Пример.
Пусть нужно добавить запись в таблицу "Приход", прибавить количество прихода товара (из новой записи ТБД "Приход") в запись для данного товара в ТБД "Остаток товара на складе" и прибавить стоимость поступившего товара (из новой записи ТБД "Приход") в запись для данного товара и даты прихода в ТБД "Обороты по складу" (рис 32.1) Если произошел сбой при выполнении любого метода Post, нужно отменить изменения, внесенные другими методами Post, иначе логическая целостность информации в БД будет разрушена.
Управление транзакциями на уровне приложения, разработанного на Delphi, реализуются методами компонента TDataBase.
Начало транзакции инициируется методом
procedure StartTransaction;
После выполнения этого метода все изменения, внесенные в БД, считаются принадлежащими к текущей активной транзакции. Подтвердить транзакцию, т.е. санкционировать физическое запоминание сделанных изменений в БД, можно с помощью метода
procedure Commit;
Отказаться от физического запоминания сделанных изменений в БД ("откатить" изменения), можно, выполнив метод
procedure Rollback;
Выполнение методов Commit или Rollback завершает активную транзакцию, начатую методом Start Transaction. Метод Start Transaction нельзя выполнить, если для БД в текущий момент времени имеется активная транзакция, т.е. транзакция, незавершенная методами Commit или Rollback. В этом случае возбуждается исключение.
Проверить, имеются ли на текущий момент в БД активные незавершенные транзакции, можно при помощи свойства
property In Transaction: Boolean;
Это свойство возвращает True, если для БД имеется активная транзакция, и False, если не имеется.
Предыдущий пример изменения таблиц Prihod, Ostatok и Oborot в рамках одной транзакции реализуется следующим образом (рис 32.2)
Уровень изоляции транзакций Dirty Read
При уровне изоляции транзакций Dirty Read конкурирующие транзакции видят изменения, внесенные, но неподтвержденные текущей транзакцией. Если текущая транзакция откатит сделанные изменения, другие транзакции будут видеть недостоверные данные. Этот уровень изоляции может привести к серьезным ошибкам и применяется редко.
Именно этот уровень изоляции транзакций применяется при работе с локальными БД (Paradox, dBase), если при работе с таблицами таких БД производится запуск транзакций методом Start Transaction
Уровень изоляции транзакций Read Commited
Чтение данных. Конкурирующие транзакции оперируют только подтвержденными изменениями, сделанными в текущей транзакции.
Пусть транзакции А и В запускаются приложениями, в каждом из которых открыт НД, связанный с одной и той же таблицей БД. Пусть транзакция А изменила данные, но не подтвердила изменения. Пусть конкурирующая транзакция В пытается считать эти данные. Тогда она получает их в том состоянии, в котором они находились до старта транзакции А. Иными словами, транзакция В не видит в данных, которые она читает, неподтвержденных изменений, внесенных транзакцией А. Возможен и другой вариант. Пусть транзакция А вносит изменения в данные и не подтверждает их. В это время транзакция В стартует в приложении, в котором не открыт НД, связанный с той таблицей, в которой транзакция А произвела изменения. Тогда попытка открытия транзакцией В этого НД будет отвергнута. Открытие НД станет возможным лишь после того, как А подтвердит сделанные изменения.
Изменение данных.
Пусть транзакции А и В запускаются приложениями, в каждом из которых открыт НД, связанный с одной и той же таблицей БД. Пусть транзакция А изменила данные, но не подтвердила изменения. Пусть конкурирующая транзакция В также внесла изменения в эти же данные. Тогда попытка транзакции В подтвердить внесенные ею изменения будет отвергнута.
Уровень изоляции транзакций Repeatable Read
Чтение данных. Текущая транзакция всегда видит данные в том состоянии, в котором они находились на момент старта транзакции.
Пусть транзакция А открыла НД. После этого транзакция В внесла в те же данные изменения и не подтвердила их. Тогда при повторном открытии НД транзакция А получит данные в том состоянии, в котором они находились на момент ее старта. Однако "свои" изменения А видеть будет. Пусть транзакция В подтвердила сделанные ею изменения, а транзакция А вновь открыла НД. И в этом случае транзакция А получит данные в том состоянии, в котором они находились на момент ее старта.
Изменение данных.
Пусть транзакция А внесла изменения в данные и не подтвердила их. Транзакция В после этого также внесла изменения в те же данные. Тогда попытка В подтвердить изменения будет отвергнута.
Установка уровней изоляции транзакций в Delphi
Уровень изоляции транзакций определяется свойством компонента TDatabase
property Translsolation: TTranslsolation;
возможные значения: tiDirtyRead, tiReadCommitted, tiRepeatableRead.
Разные серверы БД различным образом интерпретируют уровни изоляции транзакций, установленные в свойстве Translsolation. (Рис 32.3)
Уровни изоляции транзакций: приложение клиента
При одновременной работе нескольких клиентов с одной и той же БД возникают проблемы одновременного изменения данных.
Пусть пользователь А получил данные из таблицы RASHOD и впоследствии изменил их. В это время с той же записью в таблице RASHOD работает пользователь В. Он также изменил данные в той же записи, что и А, и пытается подтвердить их. Пользователь С работает с таблицей RASHOD в режиме только для чтения. Сразу же возникает группа вопросов - позволять или не позволять В изменять запись, если А еще не подтвердил ее изменение? Позволять ли видеть изменения, внесенные А и В? Может ли А видеть изменения, внесенные В, и наоборот?
Для разрешения указанных проблем существует несколько уровней изоляции (разграничения) транзакций.
Уровень изоляции транзакции определяет:
• могут ли другие (конкурирующие) транзакции вносить изменения в данные, измененные текущей транзакцией;
• может ли текущая транзакция видеть изменения, произведенные конкурирующими транзакциями, и наоборот.
Существуют следующие уровни изоляции транзакций - Dirty Read, Read Commited, Repeatable Read.
Свойство UpdateMode и обновление записей
Уровни изоляции транзакций определяют, что происходит, когда одна транзакция изменила данные и не подтвердила изменения, а вторая транзакция в это время читает или записывает те же данные.
Возможна также и ситуация, когда транзакция А стартовала и не вносила изменений на момент старта транзакции В. После старта транзакции В, А изменила данные и подтвердила изменения. Затем транзакция В внесла изменения и пытается их подтвердить.
Что произойдет в этом случае?
Чтобы ответить на этот вопрос, следует изучить режимы, указываемые в свойстве UpdateMode набора данных в приложении клиента - специально для разрешения подобных ситуаций.
Приложение изменяет копию записи в локальном НД на компьютере, где выполняется клиентское приложение. После выдачи подтверждения корректировки происходит отправка к серверу БД запроса на изменение значений существующей в ВД записи на новые значения, внесенные приложением в локальную копию. Для этого сервер должен найти в БД запись, которая еще сохраняет свои старые, неоткорректированные значения. По существу сервер пытается выполнить оператор UPDATE, где в предложении WHERE перечислены старые значения полей.
Если запись, которую пытается изменить сервер, уже была изменена другой транзакцией, операция UPDATE не пройдет из-за того, что записи со старыми значениями в БД физически не существует.
Свойство набора данных
property UpdateMode;
определяет, по каким полям ищется запись на сервере для обновления.
Возможные значения этого свойства:
• WhereAII (по умолчанию) - поиск записи, которая должна быть физически изменена, ведется по всем полям;
• WbereKeyOnly - поиск записи ведется только по значениям ключевых полей;
• WhereChanged - поиск ведется по ключевым полям и по тем из неключевых полей, которые были изменены при корректировке записи в приложении.
Наиболее жесткое условие поиска - WhereA II. Оно предотвращает запоминание изменений, внесенных в запись, если конкурирующая транзакция успела изменить хотя бы одно поле и подтвердить это изменение. Менее жесткое условие - WhereChanged. Оно предотвращает запоминание изменений, внесенных в запись, если конкурирующая транзакция успела изменить хотя бы одно ключевое поле или поле, которое было изменено и текущей транзакцией. Вероятность ошибок при этом выше, чем при WhereAll. Наименее жесткое и с наибольшей вероятностью ведущее к ошибке условие - WhereKeyOnly. Оно предотвращает запоминание изменений, если конкурирующая транзакция успела изменить хотя бы одно ключевое поле, которое пытается также изменить и текущая транзакция. Изменения других полей в расчет не принимаются.
Таким образом, если две или более конкурирующие транзакции пытаются осуществить корректировку одной и пой же записи, срабатывает правило:
подтверждаются изменения, внесенные транзакцией, которая раньше других успела их подтвердить; остальные изменения не запоминаются и возбуждается исключение.
| Firma | Familia | Doljnost | Oklad |
| Янтарь | Ивонов | Директор | 1000 |
Пусть в ТБД, состоящей из 4 полей (столбцов): Firma, Familia, Doljnost и Oklad, две транзакции из разных приложений пытаются изменить запись
| Firma | Familia | Doljuost | Oklad |
| Янтарь | Иванов | Директор | 2000 |
Несколько мгновений спустя пользователь В изменил должность на 'Бухгалтер' и также подтвердил транзакцию:
| Firma | Familia | Doljnost | Oklad |
| Янтарь | Ивонов | Бухгалтер | 1000 |
Явно и неявно стартуемые транзакции
Явная транзакция начинается и завершается методами - Start Transaction, Rollback/Commit компонента TDatabase. В рамках одного компонента TDatabase невозможно запустить две параллельные транзакции.
Неявная транзакция начинается методами Insert, Edit, Delete, Append и т.д. Она завершается после выполнения метода Post и откатывается в случае выполнения метода Cancel.
Неявная транзакция запускается и после посылки к серверу SQL-оператора (компонент TQuery), то есть после выполнения метода ExecSQL. Последний способ называется PassThroughSQL. Выдача автоматического подтверждения неявной транзакции определяется значением параметра SQLPASS THRU для псевдонима БД (утилита BDE Administrator). Этот параметр определяет:
• могут ли вызовы PassThroughSQL и стандартные вызовы BDE использовать одно и то же соединение с БД;
• видят ли друг друга транзакции, порожденные PassThroughSQL, и транзакции, порожденные вызовами BDE.
Значения параметра SQLPASSTHRU:
SHARED AUTOCOMMIT -
после выполнения ExecSQL, равно как и метода Post (компоненты TTable, TQuery), автоматически выдается Commit. При этом Post, Delete и PassThroughSQL могут использовать одно и то же соединение с БД (один и тот же компонент TDatabase). • SHARED NO AUTOCOMMIT - неявная транзакция, порожденная PassThroughSQL, автоматически не завершается (Commit автоматически не выдается), и подтверждение транзакции необходимо выполнять программно. При этом BDE и PassThroughSQL могут использовать одно и то же соединение с БД (один и тот же компонент TDatabase).
• NO TSHA RED - транзакции каждого типа должны использовать отдельное соединение с БД каждая. Транзакции, начатые явно при помощи TDatabase StartTransaction, игнорируются. Подтверждение транзакции должно осуществляться явно посылкой COMMIT. До этих пор изменения, внесенные PassThroughSQL, не будут видны в компонентах TTable и TQuery, работающих с БД через другое соединение .
Режим NOT SHARED следует применять только тогда, когда для управления транзакциями на сервере применяется PassThroughSQL, поскольку в этом случае игнорируются действия по управлению транзакциями компонента TDatabase. В противном случае одновременное управление транзакциями при помощи компонента TDatabase и PassThroughSQL может привести к непредсказуемым последствиям.
Режим SHARED AUTOCOMMIT не рекомендуется к применению для приложений, работающих с удаленными БД в архитектуре "клиент-сервер". В этом случае при построчных операциях с НД происходит подтверждение транзакции для каждой записи, что способно существенно увеличить сетевой график и как следствие - привести к существенному замедлению работы.
Управление транзакциями на SQL-сервере InterBase
InterBase управляет транзакциями при помощи SQL-операторов SET TRANSACTION (начать транзакцию), COMMIT (подтвердить транзакцию) и ROLLBACK, (откатить транзакцию).
Оператор SET TRANSACTION имеет формат
SET TRAXSACTION [READ WRITE |READ ONLY]
[WAIT | NO WAIT]
[[ISOLATION LEVEL] {SNAPSHOT [TABLE STABILITY]
| READ COMMITTED [[NO] RECORD_VERSION]}]
[RESERVING <список_таблиц> [FOR [SHARKD | PROTECTED][READ I WRITE]], [<список_таблиц>];
Использование кэшированных изменений
Кэширование изменений заключается в том, что создается локальная копия данных в буфере (кэше). Все последующие корректировки данных, включая изменение, удаление, добавление новых записей, происходят в этом локальном буфере. Внесенные изменения могут быть физически перенесены в БД, или может быть произведен отказ от запоминания ("откат").
К преимуществам способа кэшированных изменений перед транзакционным способом можно отнести:
• минимизацию сетевого трафика при работе с удаленным сервером;
• отсутствие блокировок на изменяемые записи
Минимизация сетевого трафика при работе с удаленным сервером.
При транзакционном способе каждая транзакция вызывает передачу на сервер пакета изменений При кэшированных изменениях все изменения передаются как один пакет. Отсутствие блокировок на изменяемые записи.
В зависимости от уровня изоляции транзакций, на измененные записи, изменение которых еще не подтверждено, может быть наложена блокировка. Например, при уровне изоляции ReadCommited блокируется возвращение результатов выполнения запросов к ТБД, если в НД попадают измененные другим пользователем записи, транзакция по которым еще не завершена. Поскольку кэшированные изменения производятся в локальном буфере клиента, блокировки на измененные записи не накладываются. Впрочем, это может создавать неудобства в том случае, когда имеется жесткое требование на блокировки измененных записей. Принятие решения о предпочтительности использования кэшированных изменений в таких случаях зависит от конкретных особенностей предметной области и приложения
Активизация режима кэшированных изменений
Кэшированные изменения могут быть включены для наборов данных (компоненты TTable, TQuery, TStoredProc) путем установки в True свойства
property CachedUpdates: Boolean;
Установка значения данного свойства может быть произведена на этапе разработки приложения и впоследствии переопределена во время работы приложения.
Отмена режима кэшированных изменений осуществляется путем установки данного свойства в False
Tovary. CachedUpdates := True;
...
Tovary. CachedUpdates := False;
Отмена кэшированных изменений
Сделанные изменения в НД (компоненты TTable, TQuery, TStoredProc) могут быть отменены методом
procedure CancelUpdates;
Подтверждение кэшированных изменений методом ApplyUpdates компонента TDatabase
Метод компонента TDatabase
procedure ApplyUpdates(const DataSets: array ofTDataSet);
применяется для подтверждения кэшированных изменений сразу в нескольких НД Список НД определяется параметром DataSets В случае указания нескольких НД их имена разделяются запятыми
Двухфазное запоминание в этом случае производится неявно' метод ApplyUpdates стартует транзакцию и пытается запомнить измененные записи в БД В случае неудачи, он откатывает транзакцию, но не изменяет статуса кэшированных изменений. Поэтому, если необходимо отменить кэшированные изменения, это необходимо сделать явно при помощи метода НД CancelUpdates. Управление ошибкой запоминания кэшированного изменения может осуществляться в обработчике события OnUpdateError. В случае успешного запоминания результатов кэшированных изменений в БД метод Apply Updates подтверждает транзакцию и подтверждает кэшированные изменения.
Пример.
Пусть требуется подтвердить кэшированные изменения НД Tovary и Rashod. В случае неудачи необходимо откатить кэшированные изменения: TRY
DataBasel.ApplyUpdates([Tovary, Rashod]);
EXCEPT
ShowMessage('Изменения сохранить нельзя: они влекут нарушение ' + 'целостности базы данных') ;
Tovary.CancelUpdates ;
Rashod.CancelUpdates;
END;//try
Подтверждение кэшированных изменений методом ApplyUpdates набора данных
Метод компонентов TTable, TQuery, TStoredProc
procedure ApplyUpdates;
применяется для подтверждения кэшированных изменений отдельного НД. Отсутствие ошибок при выполнении метода гарантирует успешность операции подтверждения.
Метод компонентов TTable, TQuery, TStoredProc
procedure CommitUpdates;
применяется для обновления в БД кэшированных изменений, успешно подтвержденных методом ApplyUpdates.
Двухфазное подтверждение в случае использования методов ApplyUpdates и CommitUpdates необходимо реализовывать явно.
Пример.
Пусть требуется подтвердить кэшированные изменения НД Tovary и Rashod. В случае неудачи необходимо откатить кэшированные изменения: Databasel.StartTransaction;
TRY
Tovary.ApplyUpdates ;
Rashod.ApplyUpdates;
Databasel.Commit;
Tovary.CommitUpdates;
Rashod.CommitUpdates ;
EXCEPT
Databasel.Rollback;
ShowMessage('Изменения могут привести к нарушению ' + 'целостности БД. Изменения отменены!' );
Tovary.CancelUpdates ;
Rashod.CancelUpdates ;
END;//try
В случае сбоя при выполнении Tovary.Apply Updates или Rashod.ApplyUpdates не произойдет подтверждения транзакции (Database]. Commit) и подтверждения кэшированных изменений для каждой из таблиц; значения измененных записей будут восстановлены в значения, имевшие место до изменений (Tovary.CancelUpdates, Tovary. CancelUpdates).
Часто важно, чтобы даже в случае неудачной попытки запомнить изменения, значения измененных записей не менялись - например, для того чтобы пользователь мог внести коррективы и попытаться снова подтвердить изменения. В этом случае из кода необходимо убрать вызов метода CancelUpdates:
Database1.StartTransaction;
TRY
Tovary.ApplyUpdates ;
Rashod.ApplyUpdates;
Databasel.Commit;
Tovary.CommitUpdates;
Rashod.CommitUpdates ;
EXCEPT
Databasel.Rollback;
ShowMessage('Изменения могут привести к нарушению ' + 'целостности БД. Изменения отменены!' );
END;//try
Подтверждение кэшированных изменений
Подтверждение кэшированных изменений реализуется в 2 фазы. Двухфазный подход имеет своей целью обеспечить восстановление БД от ошибок, особенно в случае внесения изменений в несколько ТБД. Например, при кэшированных изменениях не обнаруживаются нарушения ограничения ссылочной целостности таблиц. Они обнаруживаются только при попытке запомнить такие изменения
Видимость измененных записей
Свойство набора данных
property UpdateRecordTypes: TUpdateRecordTypes;
TUpdateRecordTypes = set of (rtModified, rtlnserted, rtDeleted, rtUnModified);
указывает, какие из записей будут "видны" в НД после проведения кэшированных изменений. Множество TUpdateRecordTypes может содержать следующие значения:
rtModified -
измененные записи rtlnserted -
добавленные записи rtDeleted -
удаленные записи rtUnmodified- неизменявшиеся записи
Пример.
Показать в НД только удаленные записи: RashodTable.UpdateRecordTypes := [rtDeleted];
Пример.
Показать в НД только неизменявшиеся, добавленные и измененные записи (удаленные не показывать): RashodTable.UpdateRecordTypes := [rtUnmodified,rtModified, rtlnserted];
ЗАМЕЧАНИЕ.
Хотя в НД могут показываться и удаленные записи, тем не менее свойство НД RecordCount возвратит количество записей за вычетом удаленных.
Использование обработчика OnUpdateError
К наиболее часто встречающимся ошибкам, происходящим при попытках подтверждения кэшированных изменений, относятся:
• нарушение значения поля связи в родительской или дочерней таблицах;
• нарушение уникальности индекса, построенного по первичному или уникальному ключу таблицы БД;
• попытка ввести в поле связи дочерней таблицы значение, отсутствующее в поле связи родительской таблицы;
• нарушение требования ввода в одно из полей обязательного значения;
• нарушение ограничений, накладываемых на значение поля.
Реагировать на ошибки, возникающие при подтверждении кэшированных изменений, можно в обработчике события OnUpdateError:
procedure TForm1.TovaryUpdateError(DataSet: TDataSet;
E: DatabaseError; UpdateKind: TUpdateKind;
var UpdateAction: TUpdateAction);
begin
...
end;
где параметры имеют следующее назначение:
набор данных, для которого при попытке подтверждения кэшированных изменений произошла ошибка;
вид изменений, при попытке подтверждения которых произошла ошибка. Возможные значения:
запись была изменена (скорректировано значение хотя бы одного поля);
запись была добавлена;
запись была удалена.
изменяемый параметр. Указывает, что нужно делать с записью, при попытке подтверждения кэшированных изменений которой произошла ошибка. Список возможных значений приводится ниже в подразделе "Использование изменяемого параметра UpdateAction".
указатель на исключительную ситуацию, возбужденную в результате невозможности подтвердить кэшированные изменений для данной записи. Может использоваться для получения сообщения об ошибке или кода ошибки. Использование данного параметра описано ниже в подразделе "Использование параметра E".
Использование параметра UpdateKind
Параметр UpdateKind позволяет в случае ошибки предпринять какие-либо действия, зависящие от способа изменения записи.
Пример.
Если произошла ошибка при попытке подтверждения кэшированного удаления записи, нужно восстановить запись: procedure TForm1.TovaryUpdateError(DataSet: TDataSet;
E: EDatabaseError; UpdateKind: TUpdateKind;
var UpdateAction: TUpdateAction);
begin
IF UpdateKind = ukDelete THEN Tovary.RevertRecord;
end;
Использование параметра UpdateAction
Изменяемый параметр UpdateAction определяет действие, которое следует произвести в отношении ошибочной записи. Действие указывается перед выходом из обработчика:
procedure TForm1.TovaryUpdateError(DataSet: TDataSet;
E: EDatabaseError; UpdateKind: TUpdateKind;
var UpdateAction: TUpdateAction);
begin
// какие-либо операторы, если нужны
UpdateAction := uaSkip;
end;
Можно указать следующие действия:
| Значение | Что влечет |
| uaFail | Отменить изменения для записи, выдать сообщение об ошибке. |
| uaAbort | Отменить изменения для записи, сообщение об ошибке не выдавать. Применяется также в случаях, когда генерируется сообщение об ошибке, отличное от выдаваемого системой. |
| uaSkip | Не отменять изменений для записи, но запись физически в таблицу БД не переносить (что, собственно, и невозможно без изменения значений записи, повлекших ошибку). |
| uaRetry | Повторить попытку подтверждения изменений для записи. Предполагается, что на момент повторения попытки значения полей данной записи скорректированы программным способом. В противном случае произойдет зацикливание. |
Такой подход противоречит транзакционному подходу, согласно котором) либо запоминаются все изменения, либо происходит их одновременный откат
Пример.
Пусть имеется таблица "Товары" и дочерняя таблица "Расход товара". Пусть эти таблицы соединены по полю связи "Товар"(рис. 33.1). Как видно из рисунка, в таблице "Товары" для товаров "Сахар" и "Сыр гудаутский" имеются дочерние записи в таблице "Расход". Изменим в таблице "Товары" наименования всех товаров и попытаемся подтвердить кэшированные изменения:
Database1.StartTransaction;
TRY
Tovary.ApplyUpdates;
Databasel.Commit;
Tovary.CommitUpdates;
EXCEPT
Databasel.Rollback;
END;//try
Тогда изменение значения в поле "Товар" для товаров "Сахар" и "Сыр гудаутский" приведет к нарушению целостности БД, поскольку в таблице "Расход" наименования товаров в поле "Товар" мы изменять не будем.
Напишем обработчик On UpdateError для НД "Товар":
procedure TForm1.TovaryUpdateError(DataSet: TDataSet;
E: EDatabaseError; UpdateKind: TUpdateKind;
var UpdateAction: TUpdateAction) ;
begin
CASE RadioGroup1.Itemlndex OF
0 : UpdateAction := uaFail;
1 : UpdateAction := uaAbort;
2 : UpdateAction := uaSkip;
3 : UpdateAction := uaRetry;
END;//case
end;
Компонент RadioGroupl содержит возможность выбора одного из значений изменяемого параметра UpdateAction.
Изменяя значение параметра UpdateAction, посмотрим, изменение каких записей будет подтверждено при возникновении ошибки при выполнении метода Tovary ApplyUpdates',
• UpdateAction = uaFail.
Как показано на рис.33.2.а) и б), в режиме uaFail результаты кэшированных изменений полностью отменены:
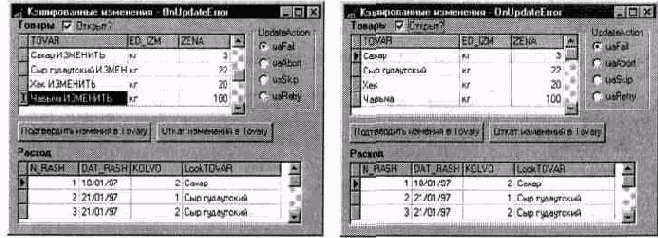
Использование параметра Е
Используя параметр Е, можно определить причину возникновения ошибки и в соответствии с этой причиной предпринять какие-либо действия.
Параметр Е содержит ссылку на исключительную ситуацию, возбужденную при диагностировании ошибки в процессе подтверждения кэшированных изменений.
Параметр Е: свойство Message
Тип исключения, на которое ссылается Е, - EDatabaseError. Код ошибки в этом типе отсутствует, но имеется свойство
property Message: string;
которое содержит текст сообщения об ошибке, выводимого на экран при возбуждении исключительной ситуации.
Пример.
Пусть известно, что при подтверждении кэшированных изменений могут возникнуть ошибки двух типов: нарушение уникальности первичного ключа и нарушение целостности БД вследствие одностороннего изменения в родительской таблице поля связи. Тогда можно предложить такой обработчик On UpdateError: procedure TForm1.TovaryUpdateError(DataSet: TDataSet;
Е: EDatabaseError; UpdateKind: TUpdateKind;
var UpdateAction: TUpdateAction);
var S : String;
PartCat, PartCode : Word;
begin
Использование компонента TUpdateSQL
Компонент TUpdateSQL используется для подтверждения кэшированных изменений в НД, связанном с компонентом TQuery. Такой НД является результатом выполнения SQL-оператора SELECT и может быть доступным для обновления или доступным только для чтения. В последнем случае свойство НД
property CanModify: Boolean;
(реальная возможность модификации НД) возвращает False, даже если свойство компонента TQuery property RequestLive: Boolean;
(разрешение модификации НД) установлено в True на этапе разработки приложения или программно во время выполнения. Компонент TUpdateSQL позволяет вносить изменения в НД, доступные только для чтения. Этот компонент как бы объединяет в себе три компонента TQuery, содержащих SQL-операторы INSERT, UPDATE, DELETE для соответственно добавления, изменения или удаления записи.
Компонент TUpdateSQL: этап разработки
1. Разместите в форме компонент TUpdateSQL.
2. Выберите компонент TQuery, кэшированные изменения в котором должен подтверждать компонент TUpdateSQL. Свойство TQuery. CachedUpdates должно быть установлено в True.
3. Укажите в свойстве TQuery. UpdateObject имя компонента TUpdateSQL.
4. Выберите мышью (сделайте текущим) компонент TUpdateSQL и дважды щелкните на нем мышью. На экране появится редактор свойств TUpdateSQL (рис. 33.7).
5. В списке Table Name выберите таблицу БД, в которой необходимо подтверждать кэшированные изменения.
6. В окне А'еу Fields выберите поля, входящие в индекс, который следует использовать при обновлении записи. Для локальных СУБД по указанным полям должен быть построен реально существующий индекс;
для удаленных СУБД существование такого индекса желательно, но не обязательно.
7. Если нужно выделить поля, входящие в первичный ключ таблицы, нажмите кнопку Primary Key Fields.
8. В окне Update Fields выделите поля, значения в которых следует обновлять;
9. Нажмите кнопку Generate SQL, чтобы сгенерировать SQL-операторы для добавления, изменения и удаления записей.
10. Перейдите на страницу SQL и просмотрите три сгенерированных оператора - INSERT, UPDATE, DELETE (рис. 33.8).
11. Измените сгенерированные операторы, если это необходимо.
Сгенерированные SQL-операторы содержатся в свойствах компонента TUpdateSQL
property InsertSQL: TStrings;
property ModifySQL: TStrings;
property DeIeteSQL: TStrings;
Компонент TUpdateSQL: выполнение SQL-операторов
Существует два способа выполнения SQL-операторов, определенных в компоненте TUpdateSQL.
Автоматическое выполнение SQL-операторов компонента TUpdateSQL
При использовании одного компонента TUpdateSQL для занесения подтвержденных изменений в ТБД следует использовать автоматический способ. Он заключается в том, что применение метода TDatabase. Apply Updates для каждой подтвержденной записи приводит к автоматическому выбору и выполнению соответствующего SQL-оператора из компонента TUpdateSQL, ассоциированного с одним из изменяемых НД.
В этом случае не нужно кодировать вызов SQL-операторов из компонента TUpdateSQL.
Использование обработчика события OnUpdateRecord для вызова SQL-операторов компонента TUpdateSQL
Если с НД связано несколько компонентов TUpdateSQL, вызов SQL-оператора из нужного компонента TUpdateSQL производят в обработчике события OnUpdateRecord. Параметры обработчика OnUpdateRecord идентичны параметрам рассмотренного выше обработчика события On UpdateError за исключением отсутствующего параметра Е:
procedure TFormI.QuerylUpdateRecord(DataSet: TDataSet;
UpdateKind: TUpdateKind; var UpdateAction: TUpdateAction);
begin
end;
Для установки значений параметров изменяемой записи используют метод SetParams компонента TUpdateSQL:
procedure SetParams(UpdateKind: TUpdateKind);
UpdateKind -
указывает тип действия: ukModify -
запись была изменена (скорректировано значение хотя бы одного поля); uklnsert -
запись была добавлена; ukDelete -
запись была удалена. Метод SetParams замещает параметры в SQL-операторе компонента TUpdateSQL значениями соответствующих полей ТБД. Какой SQL-оператор выполнять, определяет значение UpdateKind.
Для выполнения соответствующего SQL-оператора используют метод ExecSQL компонента TUpdateSQL:
procedure ExecSQL(UpdateKind: TUpdateKind);
где UpdateKind указывает тип действия.
Существует также метод Apply, который объединяет в себе функциональность методов SetParams и ExecSQL:
procedure Apply(UpdateKind: TUpdateKind);
Метод Apply в соответствии со значением параметра UpdateKind определяет требуемый SQL-оператор, изменяет параметры этого оператора и затем выполняет его.
Пример.
Обработчик события OnUpdateRecord, содержащий вызов соответствующих SQL-операторов компонента TUpdateSQL: procedure TFormI.QuerylUpdateRecord(DataSet: TDataSet;
UpdateKind: TUpdateKind; var UpdateAction: TUpdateAction);
begin
WITH DataSet.UpdateObject as TUpdateSQL do begin
SetParams(UpdateKind) ;
ExecSQL(UpdateKind) ;
END;//with
UpdateAction := uaApplied;
end;
ЗАМЕЧАНИЕ.
Значение uaApplied изменяемого параметра UpdateAction обработчика On UpdateRecord подтверждает изменения в данной записи Этот обработчик может иметь более широкое применение, однако поскольку возможности этого обработчика не всегда вписываются в транзакционный способ изменений в БД, в настоящем материале они не рассматриваются; более подробно с этими возможностями можно ознакомиться в Borland Delphi Database Application Developer's Guide
Понятие события
В SQL-языке InterBase определен оператор
POST_EVENT "Имя события";
После его выполнения наступает событие с данными именем события. Сервер БД уведомляет о наступлении события все активные приложения, зарегистрировавшие свой интерес к данному событию посредством выполнения оператора EVENT INIT. Эти операторы мы изучать не будем по той простой причине, что в клиентских приложениях, написанных на Delphi, они неявно выполняются компонентом TIBEventAlerter.
Событие представляет собой уведомление о наступлении определенной ситуации и посылается сервером БД всем клиентским приложениям, которые зарегистрировались как получатели данного события.
Обмен событиями сервера и приложения часто очень важен и может широко использоваться. Например, пусть клиентское приложение должно обновлять НД после определенного количества изменений (например, 10 или 100), внесенных в таблицу БД одновременно работающими с ней пользователями. Тогда такое обновление может производиться приложением после получения 10(100) уведомлений от сервера о наступлении события изменения БД другими приложениями.
Может иметь место и обмен уведомлениями о наступлении каких-либо событий двумя одновременно работающими с одной и той же БД клиентскими приложениями, часто выполняющими по отношению к БД различные функции. В этом случае сервер БД выступает в качестве посредника. Так, например, может быть построена и почтовая система организации, где сервер БД выполняет функции рассылки сообщений, а одна из таблиц БД (или их группа) служит в качестве системы почтовых ящиков с различными правами доступа.
Приложения Delphi и компонент TIBEventAlerter
Компонент TIBEventAlerter расположен в палитре компонентов на странице Samples. Тот факт, что он расположен не на страницах Data Contras или Data Access, можно объяснить специализацией компонента на работу с Borland InterBase.
Для клиентских приложений, работающих с Borland InterBase, этот компонент, во-первых, регистрирует на сервере приложение как приемник определенных событий, и во-вторых, позволяет эти события обрабатывать. В компоненте TIBEventAlerter определены следующие свойства, методы и события.
property Database: TDatabase; -
содержит имя компонента TDatabase, управляющего соединением с БД, работающей под управлением Borland InterBase. property Events: TStrings; -
определяет список событий, о наступлении которых сервер БД будет информировать клиентское приложение. property Registered: Boolean; -
возвращает True, если программа зарегистрирована как приемник сообщений о наступлении событий, определяемых свойством Events. procedure RegisterEvents; -
выполняет регистрацию приложения; procedure UnregisterEvents; -
отключает регистрацию приложения как приемника сообщений. Данный метод не может применяться в обработчике события OnEventAlert. Перед выполнением метода в обработчике OnEventAlert полезно установить изменяемый параметр CancelAlerts в False. procedure OnEventAlert: TEventAlert; - обработчик события TEventAlert; TEventAlert = procedure( Sender: TObject; EventName: String;
EventCount: longint; var CancelAlerts: Boolean);
Назначение параметров:
• EventName - содержит имя события, посланного сервером приложению клиента;
EventCount -
содержит количество событий (типа, определенного параметром EventName), имевших место на сервере с момента последней передачи клиентскому приложению уведомления о наступлении событий; • CancelAlerts - изменяемый параметр; значение True (по умолчанию) сообщает серверу о том, что клиентское приложение продолжает интересоваться событиями из списка, указанного в свойстве Events; False сообщает о том, что интерес приложения к уведомлению о событиях иссяк.
Использование компонента
Пусть в БД, расположенной на сервере, для таблицы БД RASHOD определены триггеры
CREATE TRIGGER AIEVENT_RASHOD FOR RASHOD
ACTIVE
AFTER INSERT
AS
BEGIN
POST_EVENT "INS_POSTED";
END
CREATE TRIGGER AUEVENT_RASHOD FOR RASHOD
ACTIVE
AFTER UPDATE
AS
BEGIN
POST_EVENT "UPD_POSTED";
END
CREATE TRIGGER ADLEVENT_RASHOD FOR RASHOD
ACTIVE
AFTER DELETE
AS
BEGIN
-POST_EVENT "DEL_POSTED";
END
Для регистрации указанных сообщений в клиентском приложении разместим компонент TIBEventAlerter с именем IBEventAlerterl. Укажем в его свойстве Database имя компонента TDatabase, управляющего соединением с удаленной БД. Установим свойство этого компонента Registered в True. В списке свойства Events определим события, при уведомлении о наступлении которых с сервера, в клиентском приложении должны предприниматься какие-либо действия (рис. 34.1).
Определим обработчик события OnEventAlert. Пусть нам необходимо, чтобы через каждые десять изменений происходило обновление набора данных RashodQuery (компонент TQuery), ассоциированного с таблицей RASHOD. Это важно, поскольку клиентское приложение "не видит" изменений в БД. сделанных другими приложениями.
procedure TFormI.IBEventAlerterlEventAlert(Sender: TObject;
EventName: string; EventCount: Longint; var CancelAlerts:
Boolean) ;
const GettingEventsCnt : Integer = 0;
STEP = 10;
Period : Integer = STEP;
begin
GettingEventsCnt := GettingEventsCnt + EventCount;
IF GettingEventsCnt > Period THEN begin
RashodQuery.Close;
RashodQuery.Open;
Period := GettingEventsCnt + STEP;
END;//if
Обмен сообщениями между приложениями
Пусть одновременно должны работать два клиентских приложения А и В, использующие одну и ту же удаленную БД. В процессе работы приложение В шлет сообщение приложению А, а то, в свою очередь, шлет приложению В подтверждение приема посланного сообщения.
Определим в удаленной БД следующие процедуры:
CREATE PROCEDURE B_SEND_INIT
AS
BEGIN
POST_EVENT "B_LOADED";
END
CREATE PROCEDURE A_SEND_INIT
AS
BEGIN
POST_EVENT "A_LOADED";
END
В форме приложения В разместим компоненты DatabaseB, IBEventAlerterB, StoredProcB (рис. 34.2).
Компонент DatabaseB управляет соединением приложения В с удаленной БД, общей для приложений А и В. Компонент StoredProcB предназначен для вызова хранимой процедуры B_SEND_INIT после нажатия кнопки "Послать сообщение к А":
procedure TFormB.SendButtonClick(Sender: TObject);
begin
DataBaseB.StartTransaction;
StoredProcB.ExecProc;
DataBaseB.Commit;
end;
ЗАМЕЧАНИЕ.
Как можно заметить, вызов хранимой процедуры на сервере должен происходить в рамках подтвержденной транзакции: сервер рассылает зарегистрировавшимся для получения сообщений клиентам сообщение о наступлении события только после завершения транзакции, внутри которой возбуждается событие.
Компонент IBEventAlerterB отслеживает получение от сервера БД сообщения о наступлении события "A_LOADED". В этом случае просто визуализируется полученное сообщение в компоненте ListBoxB:
procedure TFormB.IBEventAlerterBEventAlert(Sender: TObject;
EventName: string; EventCount: Longint; var CancelAlerts:
Boolean) ;
begin
ListBoxB.Items.Add(EventName) ;
end;
В форме приложения А (рис. 34.3) размещены компоненты DatabaseA, IBEvenlAlerterA, StoredProcA.
Компонент DatabaseA управляет соединением приложения А с удаленной БД, общей для приложений А и В. Компонент StoredProcA предназначен для вызова хранимой процедуры A_SEND_INIT. Этот вызов происходит после получения компонентом IBEventAlerter А уведомления о наступлении события "B_LOADED":
procedure TFormA.IBEventAlerterAEventAlert(Sender: TObject;
EventName: string; EventCount: Longint; var CancelAlerts:
Boolean);
begin
ListBoxA.Items.Add(EventName) ;
DataBaseA.StartTransaction;
StoredProcA.ExecProc;
DataBaseA.Commit;
end;
Обмен инициализирующими сообщениями между приложениями
Несколько усложним предыдущий пример. Пусть с удаленной БД одновременно работают приложения А и В, причем приложение А должно быть загружено в момент начала работы приложения В. Тогда приложение В должно проверить факт загрузки приложения А и, если оно не загружено, перейти в состояние ожидания. Работа приложением В может быть продолжена только после загрузки приложения А.
В этом случае приложение В должно претерпеть некоторые изменения. Отсылка сообщения к приложению А и ожидание поступления от него подтверждающего сообщения вынесена в отдельную форму WailingForm. В ней размещены компоненты DatabaseB, StoredProcB, Timer 1 и IBEventAlerterB (рис. 34.4).
Диалоговое окно "Ожидание ответа от приложения А"
Рис. 34.4. Форма WailingForm
Компонент DatabaseB управляет соединением приложения В с удаленной БД, общей для приложений А и В. Компонент StoredProcB предназначен для вызова хранимой процедуры B_SEND_INIT. Транзакция вызова хранимой процедуры осуществляется каждые 5 секунд компонентом Timer! (тип TTimer) в обработчике события On Timer:
procedure TWaitingForm.TimerlTimer(Sender: TObject);
begin
DatabaseB.StartTransaction;
StoredProcB.ExecProc;
Databases.Commit;
end;
Повторяющийся вызов хранимой процедуры необходим, чтобы приложение А, если оно загружается позднее приложения В, наверняка получило от сервера уведомление о наступлении события "B_LOADED". Как только компонент IBEvenlAlerierB получит от сервера обратное инициализирующее сообщение, посланное приложением А, компонент Timer} дезактивизируется и повторяющийся вызов хранимой процедуры B_SEND_INIT будет прекращен, программа сообщает серверу о том, что событие "A_LOADED" ее больше не интересует, а форма WailingForm закрывается:
procedure TWaitingForm.IBEventAlerterBEventAlert(Sender: TObject;
EventName: string; EventCount: Longint; var CancelAlerts: Boolean);
begin
Timer1.Enabled := False;
FormB.ListBoxB.Items.Add(EventName) ;
CancelAlerts := True;
WaitingForm.ModalResult := mrOk;
end;
Перед вызовом из главной формы приложения В форма WaitingForm динамически создается, а после окончания работы - уничтожается:
procedure TFormB.FormActivate(Sender: TObject);
begin
WaitingForm := TWaitingForm.Create(Self);
WaitingForm.ShowModal;
WaitingForm.Free;
end;
В форме WaitingForm отменены иконки выхода, минимизации и максимизации (свойство Border-Icons), чтобы предотвратить выход из формы до получения инициализирующего сообщения от приложения А.
Понятие функции, определяемой пользователем
Состав встроенных функций InterBase весьма небогат - в него входят функции вычисления агрегированных значений (MIN, MAX, SUM, A VG), функция преобразования букв UPPER и функция приведения типа CAST.
Часто разработчики нуждаются в дополнительных функциях, которые можно было бы использовать так же, как и стандартные встроенные функции InterBase. Это могут быть функции вычисления модуля от вещественного значения, определения длины строки, усечения хвостовых или ведущих пробелов в символьных значениях, извлечение из даты значения месяца, года и т.д.
Специально для таких целей в InterBase существует аппарат функции, определяемых пользователем (User Defined Functions, UDF).
Разработка UDF может осуществляться на любом алгоритмическом языке, позволяющем создавать DLL (dynamic link library, динамически загружаемые библиотеки). Каждая UDF оформляется в виде функции, входящей в состав DLL. Таким образом, одна динамически загружаемая библиотека состоит минимум из одной функции.
После того как DLL разработана, она либо перемещается в подкаталог BIN каталога размещения InterBase, либо располагается в ином каталоге, путь к которому известен в операционной системе.
Каждая функция определяется оператором DECLARE EXTERNAL FUNCTION. Этот оператор устанавливает связь между функцией из DLL и ее описанием в БД. После этого функция может использоваться в SQL-операторах наряду со стандартными функциями InterBase.
Преимущества UDF:
• динамически загружаемая библиотека и определенные в ней функции могут использоваться более чем одной БД и более чем одним приложением; таким образом осуществляется повторное использование однажды написанного кода;
• пользователь может реализовать в UDF достаточно сложные алгоритмы.
Общие положения
Чтобы создать с помощью Delphi динамически загружаемую библиотеку, необходимо в главном меню выбрать режим New и затем на странице New выбрать пиктограмму DLL для построения шаблона DLL. Текст модуля DLL должен содержать:
• заголовок Library имя, где имя - имя создаваемой DLL;
• в разделе реализации модуля нужно разместить один или несколько блоков exports, в которых через запятую перечисляются имена экспортируемых функций; каждая функция должна описываться выше блока по тексту модуля;
• каждая экспортируемая функция объявляется с использованием директив export и cdecl(последняя указывает компилятору, что функция использует соглашения для передачи параметров, принятые в C/C++).
Пример
определения функции: function SomeName(parami : Integer) : Integer; cdecl; export;
begin
end;
exports
SomeName;
Совместимость типов параметров
При описании параметров в БД (оператор DECLARE EXTERNAL FUNCTION) и параметров функций в DLL следует помнить о совместимости типов Object Pascal и InterBase:
Тип InterBase Тип Object Pascal
INTEGER Integer
DOUBLE PRECISION Double
CSTRING PChar
DATE IBDateTime = record
// нужно дополнительное преобразование значений
Days : Integer;
Msec: Cardinal;
end;
Данное соответствие типов верно для случая, когда результат функции передается в базу данных по значению. Для того чтобы результат передавался по значению, необходимо в операторе DECLARE EXTERNAL FUNCTION после слова RETURNS указать слово BY VALUE. В следующем примере объявляется функция DEN типа DATE, содержащаяся в DLL с именем UDF_DLL:
DECLARE EXTERNAL FUNCTION DEN DATE
RETURNS INTEGER BY VALUE
ENTRY_POINT "Den"
MODULE_NAME "udf_dll";
В том случае, если результат работы UDF передается в БД по ссылке, необходимо использовать указатели на соответствующие типы:
InterBase Object Pascal
INTEGER integer
DOUBLE PRECISION double
DATE IBDateTime
Тип PChar всегда передается по ссылке.
Будем использовать только параметры, передаваемые по значению, поскольку вызовы UDF предполагается осуществлять в SQL-операторах типа SELECT, INSERT, UPDATE, DELETE, а эти операторы не будут изменять содержимое параметров.
Особенности использования в UDF параметров типа PChar
Параметры типа PChar используются для совместимости с форматом представления строк C/C++, однако в Object Pascal со строками, передаваемыми как PChar, в теле функции лучше работать как с длинной строкой Pascal (String), воспользовавшись преобразованием из типа PChar в String и обратно.
Пример.
Функция принимает строку типа PChar и отсекает хвостовые и ведущие пробелы: function TrimChar(InString : PChar) : PChar; cdecl; export;
begin
Result := PChar(Trim(AnsiString(InString)));
end;
Особенности использования в UDF параметров типа даты и времени
Значения InterBase типа DATE в Object Pascal интерпретируются как запись, состоящая из двух полей - целочисленного знакового и беззнакового.
IBDateTime = record
Days : Integer;
Msec : Cardinal;
end;
Для того чтобы перевести значение из формата IBDateTime в формат даты и времени Delphi TDateTime, необходимо произвести следующее преобразование:
Объявление UDF в БД InterBase
Для объявления функции, определенной пользователем, в БД InterBase, необходимо выполнить оператор
DECLARE EXTERNAL FUNCTION ИмяФункции
[<Тип данных> | CSTRING (число) [, <Тип данных> | CSTRING (число) ...]]
RETURNS {< Тип данных > [BY VALUE] | CSTRING (число)}
ENTRY_POINT "<Имя функции в DLL>"
MODULE_NAME "< Имя DLL >";
ИмяФункции -
имя функции, под которой функция будет известна в БД. Это имя может отличаться от имени UDF в DLL. После имени функции следует список типов входных параметров функции. Это либо тип данных, разрешенный в InterBase, либо CSTRING (число для строковых значений. Число определяет размер строкового значения в символах. Если число меньше действительного размера строки, строка при передаче в UDF усекается. После слова RETURNS указывается тип возвращаемого параметра функции. Это либо тип данных, разрешенный в InterBase, либо CSTRING (число) для строковых значений. Слова BY VALUE означают, что результат функции возвращается по значению, а не по ссылке.
После ENTR Y_POINTa кавычках указывается имя функции в DLL, а после слов MODULE_NAME - имя модуля DLL (без расширения).
Удалить из БД объявление функции, определенной пользователем, можно при помощи оператора
DROP EXTERNAL FUNCTION ИмяФункции;
Пример создания DLL с несколькими UDF и объявления их в БД
Создадим DLL с именем 'UDF_DLL', в состав которой входят три функции:
library udf_dll;
uses
SysUtils,
Classes;
type
TIBDateTime = record
Days,
MSecIO : Cardinal;
end;
PInteger = ^Integer;
// функция усекает ведущие и хвостовые пробелы у строкового // значения, передаваемого как параметр function TrimChar(InString : PChar) : PChar; cdecl; export;
begin
Result := PChar(Trim(AnsiString(InString)));
end;
//функция возвращает (по значению) номер дня передаваемой в качестве параметра даты
function Den(var InDate : TIBDateTime) : Integer; cdecl; export;
var DT : TDateTime;
Gd,Ms,Dn : Word;
begin
DT := InDate.Days - 15018 + InDate.MSecIO / (MSecsPerDay * 10);
DecodeDate(DT,Gd,Ms,Dn) ;
Result := Integer(Dn);
end;
//функция возвращает (по ссылке) номер месяца передаваемой в качестве параметра даты
function Mes(var InDate : TIBDateTime) : PInteger; cdecl; export;
var DT : TDateTime;
Gd,Ms,Dn : Word;
R : Integer;
begin
DT := InDate.Days - 15018 + InDate.MSecIO / (MSecsPerDay * 10);
DecodeDate(DT,Gd,Ms,Dn);
R := Ms;
Result := @R;
end;
exports
TrimChar,
Den,
Mes;
begin
end.
После генерации модуля UDF_DLL.DLL переместим его в подкаталог BIN каталога на диске, в котором расположен сервер InterBase. Затем объявим функции в БД:
DECLARE EXTERNAL FUNCTION TRIMCHAR CSTRING(256)
RETURNS CSTRING(256)
ENTRY_POINT "TrimChar"
MODULE_NAME "udf_dll";
DECLARE EXTERNAL FUNCTION DEN DATE
RETURNS INTEGER BY VALUE
ENTRY_POINT "Den"
MODULE_NAME "udf_dll";
DECLARE EXTERNAL FUNCTION MES DATE
RETURNS INTEGER
ENTRY_POINT "Mes"
MODULE_NAME "udf_dll";
Примеры использования объявленных в БД функций пользователя в операторе SELECT:
SELECT TRIMCHAR (POKUP) || ' ' II GOROD
FROM POKUPATELI
SELECT *
FROM RASHOD
WHERE DEN(DAT_RASH) > 10;
Размещение бизнес-правил
Бизнес-правила
(БП) задают ограничения на значения данных в БД. Они также определяют механизмы, согласно которым при изменении одних данных изменяются и связанные с ними данные в той же или других таблицах БД. Таким образом, бизнес-правила определяют условия поддержания БД в целостном состоянии.
Идеология архитектуры "клиент-сервер" требует переноса максимально возможного числа БП на сервер. К преимуществам такого подхода относятся:
• гарантия целостности БД, поскольку БП сосредоточены в едином месте (в базе данных);
• автоматическое применение БП, определенных на сервере БД, для любых приложений;
• отсутствие различных реализации БП в разнотипных клиентских приложениях, работающих с БД;
• быстрое срабатывание БП, поскольку они реализуются на сервере и, следовательно, нет необходимости посылать данные клиенту, увеличивая при этом сетевой трафик;
• доступность изменений, внесенных в БП на сервере, для всех клиентских приложений, работающих с настоящей БД и отсутствие необходимости повторного распространения измененных приложений клиентов среди пользователей.
К недостаткам хранения бизнес-правил на сервере можно отнести:
• отсутствие у клиентских приложений возможности реагировать на некоторые ошибочные ситуации, возникающие на сервере при реализации БП (например, игнорирование приложениями, написанными на Delphi, ошибок при выполнении хранимых процедур на сервере);
• ограниченность возможностей SQL и языка хранимых процедур и триггеров для реализации всех возникающих потребностей определения БП.
На практике в клиентских приложениях реализуют лишь такие бизнес-правила, которые тяжело или невозможно реализовать с применением средств сервера. Все остальные БП переносятся на сервер.
Ограничения значения столбца записи
Ограничение первичного ключа
Задает требование уникальности значения поля (столбца) или группы полей (столбцов), входящих в первичный ключ, по отношению к другим записям таблицы Например,
CREATE TABLE SAL_HIST (QUORTER INTEGER NOT NULL, PRIMARY KEY (QUORTER));
Ограничение уникального ключа
Задает требование уникальности значения поля (столбца) или группы полей (столбцов), входящих в уникальный ключ, по отношению к другим записям таблицы. Например,
CREATE TABLE VLADLIM (... NAZVVLAD VARCHAR(50) NOT NULL, UNIQUE (NAZVVLAD) );
Ограничение ссылочной целостности
Задает требование, согласно которому для каждой записи в дочерней таблице должны иметься записи в родительской таблице. При этом изменение значения столбца связи в записи родителя при наличии дочерних записей блокируется, равно как и удаление родительской записи (запрет каскадных изменений и удалений). Для разрешения каскадных воздействий следует отменить ограничение ссылочной целостности и реализовать каскадные воздействия по отношению к дочерним записям (изменение поля связи, удаление) в триггерах. Например,
CREATE TABLE SPR_TOVAR(
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL, ........ PRIMARY KEY(TOVAR));
CREATE TABLE PRIHOD(
ID_PRIHOD INTEGER NOT NULL PRIMARY KEY,
.............
TOVAR VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
FOREIGN KEY(TOVAR) REFERENCES SPR_TOVAR);
Ограничение требуемого значения
Определяет, что в поле не может хранится пустое значение (NULL). Например,
CREATE TABLE TOVAR {............ OSTATOK INTEGER NOT NULL, ................. };
Значения по умолчанию
Столбцу может быть присвоено значение по умолчанию. Это значение будет актуально в том случае, если пользователь не введет в столбец никакого иного значения. Например,
CREATE TABLE SAL_HIST (QUORTER INTEGER DEFAULT 1 , .......);
Требование соответствия одному значению из списка
К столбцу может быть предъявлено ограничение, согласно которому значение столбца должно содержать одну из величин, объявленных в списке, и никакое другое. Например,
CREATE DOMAIN POL_TYPE AS CHAR(3) CHECK(VALUE IN ("Муж","Жен")) ;
Ограничение диапазона возможных значений
Такое требование определяет, что значение поля должно ограничиваться указанным диапазоном. Например,
CREATE TABLE TBL(CHECK(STOLBEZ BETWEEN 100 AND 200); ) ;
Ограничение максимума или минимума
Указывает, что поле должно превышать какое-либо значение (минимум) и/ или не превышать какое-либо значение (максимум). В приводимом ниже примере для столбца STOLBEZ в качестве минимального значения указано 100.
CREATE TABLE TBL(CHECK(STOLBEZ >= 100); );
Алгоритм вычисления значений
Для столбца, чье значение вычисляется по значениям других столбцов, может быть установлен алгоритм вычисления значения. Например,
CREATE TABLE SAL_HIST (LAST_YEAR INTEGER, THIS_YEAR INTEGER,
GROWTH COMPUTED BY ( THIS_YEAR - LAST_YEAR), ...);
Ограничение отношения между полями (столбцами) записи
Такое ограничение определяет некоторое отношение (больше, меньше, равно и т.д.) между значениями двух полей одной и той же записи. Например,
CREATE TABLE PERSON_PARAMS(
HEIGHT INTEGER NOT NULL, WIEGHT INTEGER NOT NULL CHECK(HEIGHT > WIEGHT));
Ограничение формата значения
Указывает, что в значение столбца должна входить группа символов. В приводимом ниже примере значение поля STOLBEZ должно оканчиваться символами 'USD', независимо от того, какие символы и сколько расположены перед ними.
CREATE TABLE TBL (... CHECK (STOLBEZ LIKE "%USD") ; ...);
Требование вхождения символов в значение
Устанавливает, что в значение столбца должна входить группа символов (с неопределенной позиции). В приводимом ниже примере значение поля STOLBEZ должно содержать вхождение символов 'USD', независимо от того, какие символы и сколько расположены перед ними и после них.
CREATE TABLE TBL( ... CHECK (STOLBEZ CONTAINING "USD") ; ... );
Требования присутствия ведущих символов
Устанавливает, что значение столбца должно начинаться с определенной группы символов. В приводимом ниже примере значение поля STOLBEZ должно начинаться с символов 'USD'.
CREATE TABLE TBL( ... CHECK (STOLBEZ STARTING WITH "USD") ; ... );
Требование отношения со значением в другой таблице
Устанавливает, что значение столбца находится в некотором отношении (=, >, < и т.д.) со значением, получаемым путем выполнения запроса к другой таблице. В приводимом ниже примере значение в столбце KOLVO таблицы RASHOD не должно превышать значения столбца OSTATOK из записи таблицы TOVAR, причем поле TOVAR у обеих сравниваемых записей должно иметь одинаковое значение.
CREATE TABLE RASHOD (
ID_RS INTEGER NOT NULL,
TOVAR VARCHAR(20) CHARACTER SET WIN1251 NOT NULL,
COLLATE PXW_CYRL,
KOLVO_R INTEGER NOT NULL,
...
CONSTRAINT PO_OSTATKU
CHECK(KOLVO_R <= (SELECT TOVAR.OSTATOK
FROM TOVAR WHERE TOVAR.TOVAR = RASHOD.TOVAR) )
);
Требование отношения значения столбца со всеми или некоторыми значениями в другой таблице
Устанавливает, что значение столбца находится в отношении (=, >, < и т.д.) со значением столбца всех (ALL) или некоторых (SOME) записей, получаемых путем выполнения запроса к другой таблице.
В приводимом ниже примере значение столбца DATE_RASH (таблица RASHOD) должно быть больше значений всех полей DATE_PRIH в таблице PRIHOD. При этом сравниваемые записи с PRIHOD и RASHOD должны иметь одинаковое значение столбца TOVAR.
CREATE TABLE RASHOD (ID_RS INTEGER NOT NULL,
TOVAR VARCHAR(20) CHARACTER SET WIN1251 NOT NULL,
COLLATE PXW_CYRL,
DATE_RASH DATE NOT NULL,
...
CONSTRAINT RASH_TOVAR
FOREIGN KEY (TOVAR) REFERENCES TOVAR(TOVAR),
CONSTRAINT PO_DATE_RASH
CHECK ( DATE_RASH > ALL
(SELECT DATE_PRIH FROM PRIHOD WHERE PRIHOD.TOVAR = RASHOD.TOVAR) ) ) ;
Требование существования хотя бы одной записи в другой таблице
Устанавливает, что в другой таблице должна существовать хотя бы одна запись, удовлетворяющая некоторому условию.
В приводимом ниже примере обязательно существование хотя бы одной записи в таблице PRIHOD с таким же значением столбца TOVAR, что и в поле TOVAR записи таблицы RASHOD.
CREATE TABLE RASHOD (ID_RS INTEGER NOT NULL,
TOVAR VARCHAR(20) CHARACTER SET WIN1251 NOT NULL
COLLATE PXW_CYRL,
DATE_RASH DATE NOT NULL,
...
CONSTRAINT RASH_TOVAR
FOREIGN KEY (TOVAR) REFERENCES TOVAR(TOVAR),
CONSTRAINT PO_DATE_RASH
CHECK (EXISTS (SELECT TOVAR FROM PRIHOD WHERE PRIHOD.TOVAR = RASHOD.TOVAR)));
Требование существования единственной записи в другой таблице
Устанавливает, что в другой таблице должна существовать только одна запись, удовлетворяющая некоторому условию
В приводимом ниже примере обязательно существование единственной записи в таблице PRIHOD с таким же значением столбца TOVAR, что и в столбце TOVAR записи таблицы RASHOD
CREATE TABLE RASHOD (ID_RS INTEGER NOT NULL,
TOVAR VARCHAR(20) CHARACTER SET WIN1251 NOT NULL
COLLATE PXW_CYRL,
DATE_RASH DATE NOT NULL,
Запрет добавления записей в просмотре
Для просмотра VIEW может быть включен режим WITH CHECK OPTION, предотвращающий добавление записей, не удовлетворяющих условию WHERE оператора SELECT данного просмотра Например, для приведенного ниже обзора будет отвергаться попытка добавления записи со значением поля KOLVO, меньшим 1000
CREATE VIEW RASH_1000_CHECK
AS
SELECT * FROM RASHOD WHERE KOLVO > 1000 WITH CHECK OPTION;
Использование триггеров для поддержания ссылочной целостности
Для поддержания ссылочной целостности на сервере могут использоваться триггеры. Они автоматически запускаются при выполнении любого изменения таблицы БД (добавление новой записи, корректировка или удаление существующей). Время запуска - до или после события - определяется в заголовке триггера. Большим преимуществом триггеров является возможность обращения (при изменении записи) к старому (OLD) и новому (NEW) значению столбца.
Триггеры могут использоваться для:
реализации каскадных воздействий в дочерних таблицах при изменении значения столбца связи в записи родительской таблицы или при удалении записи родительской таблицы;
• внесения уникального значения в столбец, по которому построен уникальный или первичный ключ;
внесения изменений в семантически связанные таблицы;
• ведения журнала изменений БД.
Пример.
Приводимые ниже триггеры выполняют каскадные обновления в дочерней таблице RASHOD после изменения значения столбца связи в записи в родительской таблице TOVARY: CREATE TRIGGER BU_TOVARY FOR TOVARY
ACTIVE
BEFORE UPDATE
AS
BEGIN
IF (OLD.TOVAR 0 NEW.TOVAR) THEN
UPDATE RASHOD SET TOVAR = NEW.TOVAR WHERE TOVAR = OLD.TOVAR;
END
CREATE TRIGGER AD_TOVARY FOR TOVARY
ACTIVE
AFTER DELETE
AS
BEGIN
DELETE FROM RASHOD WHERE RASHOD.TOVAR = TOVARY.TOVAR;
END
Пример.
Приводимый ниже триггер при добавлении записи в таблицу RASHOD присваивает столбцу N_RASH уникальное значение, для чего используется генератор RASHOD_N_RASH. CREATE TRIGGER BI_RASHOD_GEN FOR RASHOD ACTIVE
BEFORE INSERT
BEGIN
NEW.N_RASH = GEN_ID(RASHOD_N_RASH,1) ;
END
Пример.
Приводимый ниже триггер при добавлении новой записи в таблицу RASHOD (расход товара) прибавляет значение поля KOLVO (количество) вновь введенной записи к полю KOLVO в таблице STAT_TOVARY для записи с той же датой (DAT_RASH) и названием товара (TOVAR). Если в таблице STAT_TOVARY такая запись отсутствует, она создается. CREATE TRIGGER AI_RASHOD FOR RASHOD
ACTIVE
AFTER INSERT
AS
DECLARE VARIABLE CNT INTEGER;
DECLARE VARIABLE OLD_KOLVO_VAL INTEGER; BEGIN
/* выбрать число записей в таблице STAT_TOVARY по данному товару за дату расхода */
SELECT COUNT(*)
FROM STAT_TOVARY
WHERE (STAT_TOVARY.DAT_RASH = NEW.DAT_RASH) AND
(STAT_TOVARY.TOVAR = NEW.TOVAR)
INTO :CNT;
/* если число записей = 0, добавить запись в таблицу STAT_TOVARY по данному товару и дате */
IF (:CNT = 0) THEN INSERT INTO STAT_TOVARY (DAT_RASH, TOVAR, KOLVO)
VALUES(NEW.DAT_RASH, NEW.TOVAR, NEW.KOLVO);
ELSE
/* иначе добавить новое количество товара в уже существующей записи для нового товара */
/* и новой даты в STAT_TOVARY */
BEGIN
SELECT KOLVO FROM STAT_TOVARY
WHERE (STAT_TOVARY.DAT_RASH = NEW.DAT_RASH) AND (STAT_TOVARY.TOVAR = NEW.TOVAR)
INTO :OLD_KOLVO_VAL;
UPDATE STAT_TOVARY
SET KOLVO = :OLD_KOLVO_VAL + NEW.KOLVO
WHERE (STAT_TOVARY.DAT_RASH = NEW.DAT_RASH) AND STAT_TOVARY.TOVAR = NEW.TOVAR) ;
END
END
Пример.
Триггер реализует автоматическую фиксацию в таблице TOVARY_LOG добавлений, внесенных в таблицу ТО VARY. CREATE TRIGGER TOVARY_ADD_LOG FOR TOVARY
ACTIVE
AFTER INSERT
AS
BEGIN
INSERT INTO TOVARY_LOG(DAT_IZM, DEISTV, OLD_TOVAR,NEW_TOVAR)
VALUES ("NOW","ADD","".NEW.TOVAR) ;
END
Реализация бизнес-правил в компонентах типа "набор данных"
Компоненты типа "набор данных" позволяют реализовывать бизнес-правила в следующих обработчиках событий:
OnNewRecord -
происходит при добавлении новой записи сразу после перехода НД в состояние dslnsert из состояния dsBrowse, но перед выдачей полей новой записи пользователю для ввода значений; используется для присваивания полям значений по умолчанию; BeforeOpen, BeforeClose, BeforeCancel, BeforeEdit, Beforelnsert -
происходят до выполнения соответствующего метода; After Post, AfterDelete, AfterOpen, AfterClose, AfterCancel, AfterEdit, Afterlnsert •
происходят после выполнения соответствующего метода; не возникают, если при выполнении соответствующего метода произошел сбой; OnCalcFields -
наступает при необходимости заполнения вычисляемых полей; применяется для задания алгоритмов расчета значений вычисляемых полей; OnDeleteError -
наступает при ошибке удаления записи; OnUpdateError -
происходит при ошибке редактирования записи; OnPostError -
происходит при возникновения ошибки в ходе выполнения метода Post. Определение алгоритма вычисления значений вычисляемых полей
Обработчик события OnCalcFields применяется для определения алгоритма расчета значения вычисляемых полей. Например,
procedure SomeTableCalcFields(DataSet: TDataSet);
begin
SomeTableVychPole.Value := SomeTablePolel.Value / SomeTablePolel.Value;
end;
Присваивание значений полей по умолчанию
В обработчике события OnNewRecord можно присвоить полям вновь добавляемой записи значения по умолчанию. Эти значения останутся актуальными, если пользователь перед добавлением записи не изменит их. Например,
procedure SomeTableNewRecord(DataSet: TDataSet);
begin
WITH Some do begin
FieldByName('polel').AsInteger := ...;
FieldByName('poleN').AsInteger := ...;
END;//with
end;
Автоматическое присваивание значения полям связи
При добавлении новой записи в дочерний НД может понадобиться присвоить соответствующие значения полям связи с родительской таблицей. В дальнейшем поля связи обычно не предоставляют пользователю для редактирования.
Например,
при добавлении новой записи в таблицу ChildTable устанавливается значение поля связи, равное значению поля 'cod_parent' текущей записи родительской таблицы ParentTable: procedure ChildTableNewRecord(DataSet: TDataSet);
begin
ChildTable.FieldByName('cod_parenf).AsInteger :=
ParentTable.FieldByName('cod_parenf).AsInteger;
end;
Назначение уникального значения столбцу таблицы
Если столбцу таблицы при добавлении новой записи должно присваиваться уникальное значение, можно выполнить отдельный запрос к той же таблице, получить максимальное значение уникального поля и увеличить его на 1.
Например,
при добавлении новой записи в RashodTable выполняется формируемый запрос (компонент WorkQuery, тип TQuery), возвращающий максимальное значение поля 'cod_unique'. Будучи увеличено на 1, оно присваивается полю 'cod_unique' вновь добавляемой записи: procedure RashodTableNewRecord(DataSet: TDataSet);
var Max_cod_unique : Integer;
begin
WITH WorkQuery do begin
SQL.Clear;
SQL.ADD('SELECT MAX(COD_UNIQUE)') ;
SQL.ADD('FROM RASHOD');
Open;
Max_cod_unique := WorkQuery.Fields[0].Aslnteger + 1;
Close;
END;//with
ChildTable.FieldByName('cod_unique').Aslnteger : =Max cod unique;
end;
Назначение полю уникального значения удобнее производить в хранимой процедуре при помощи генератора. Например, если в БД определен генератор
CREATE GENERATOR X;
SET GENERATOR X TO 1;
и определена процедура
CREATE PROCEDURE GET_UNIQUE_VALUE
RETURNS(UV INTEGER) AS
BEGIN
UV = GEN_ID(X,1) ;
END
то в приложении достаточно определить компонент TStoredProc и связать его с хранимой процедурой GET_UNIQUE_VALUE. Затем в приложении, например в обработчике события OnNewRecord, нужно произвести вызов процедуры и присвоить полю уникальное значение, возвращаемое в качестве выходного параметра процедуры:
procedure RashodTableNewRecord(DataSet: TDataSet);
begin
StoredProc1.ExecProc;
ChildTable.FieldByName('cod_unique').Aslnteger := StoredProc1.ParamByName('UV).Aslnteger;
end;
Внесение изменений в связанную таблицу БД
Обычно изменения в связанные таблицы вносятся в обработчиках событий AfterPost, AfterDelete.
Например,
уменьшить значение поля 'Kolvo' таблицы StatTable на значение поля 'Kolvo' из удаленной записи таблицы RashodTable: procedure RashodTableAfterDelete(DataSet: TDataSet);
begin
WITH StatTable do begin
Edit;
FieldByName('Kolvo').Value := FieldByName('Kolvo').Value - DeletedRashodValue;
Post;
END;//with
end;
Внесение признака изменения таблицы в глобальную переменную
Для того чтобы сигнализировать клиентскому приложению об изменении записи в какой-либо таблице, устанавливают в нужное значение какую-либо глобальную переменную приложения. Анализ этой глобальной переменной может впоследствии производиться приложением со значительными временными задержками. Например,
procedure TDM.SomeTableAfterDelete(DataSet: TDataSet);
begin
IzmSomeTable := True;
end;
Свойство Constrained (компонент TQuery)
Предотвратить ввод записей, не удовлетворяющих условиям, перечисленным в предложении WHERE оператора SELECT, можно путем установки в True значения свойства
property Constrained: Boolean;
Например, для НД, возвращенного оператором
SELECT * FROM RASHOD WHERE KOLVO > 1000
при Constrained, содержащим True, будут блокироваться попытки запоминания записей со значением поля KOLVO, меньшим 1000.
Свойство Constraints
Свойство набора данных
property Constraints: TCheckConstraints;
является коллекцией ограничений на значения столбцов (полей) НД. Указание ограничения производится в SQL-подобном синтаксисе (рис. 36.1). В случае, если значение поля не удовлетворяет наложенным на него ограничениям, при попытке запоминания записи возбуждается исключение.
Реализация бизнес-правил в компоненте TField
Анализ правильности введенного в поле значения
Проверку правильности введенного в поле значения можно осуществить в обработчиках событий On Validate, OnSetText, OnChange.
Пример.
Значение поля Company не должно содержать символ '@': procedure TForm1.Table1CompanyValidate(Sender: TField);
begin
IF POS('@',Table1Company.AsString) > 0 THEN raise Exception.Create('Неверное значение');
end;
Пример.
Значение поля PUR_PRICE не должно превышать 100: procedure TForm1.Table1PUR_PRICESetText(Sender: TField;
const Text: String);
var Tmp : Real;
begin
Tmp := StrToFloat(Text) ;
IF Tmp > 100 THEN ShowMessage('Ошибочное значение')
ELSE Table1PUR_PRICE.Value := Tmp;
end;
или
procedure TForm1.Table1PUR_PRICEChange(Sender: TField);
begin
IF Table1PUR_PRICE.Value > 100 THEN raise Exception.Create('Ошибочное значение');
end;
Форматирование содержимого поля при показе и редактировании
Значения могут храниться в виде, отличном от того, в котором они показываются пользователю. Преобразование значения поля к виду, пригодному для показа пользователю, осуществляется свойствами EditMask (маска значения при редактировании записи) и DisplayFormat (маска значения при показе в визуальных компонентах), и обработчиком события OnGetText, который применяется, если возможностей DisplayFormat для преобразования значения недостаточно.
Пример.
Значение поля Company при редактировании должно показываться в кавычках, при просмотре - с заменой всех букв на заглавные: procedure TForm1.Table1CompanyGetText(Sender: TField; var Text: OpenString;
DisplayText: Boolean);
begin
IF DisplayText THEN Text := AnsiUpperCase(Table1Company.AsString)
ELSE Text := ' " ' + Table1Company.AsString + ' " ';
end;
Свойства CustomConstraint и ConstraintErrorMessage
Свойство поля
property CustomConstraint: string;
позволяет наложить ограничения на значения поля (при помощи SQL-подобного синтаксиса). Если в поле занесено значение, не отвечающее указанному ограничению, возбуждается исключение с сообщением, определяемым свойством
property ConstraintErrorMessage: string;
Реализация бизнес-правил в иных компонентах
Бизнес-правила могут реализоваться и при помощи иных компонентов приложения. Обычно при попытке выполнения некоторого действия проверяются значения каких-либо переменных, которые затем станут значениями полей (столбцов) таблицы БД, или - при вводе пользователем неверных значений -блокируется кнопка подтверждения изменений или выхода из формы.
Проверка правильности значения
Приводимый ниже пример проверяет значение в Edit 1.Text на предмет соответствия формату даты. В дальнейшем это значение, приведенное к формату даты, планируется записать в поле типа даты таблицы БД. Проверка производится в обработчике события OnButtonClick (компонент TButton):
procedure TToObrForm.GoButtonClick(Sender: TObject);
var Tmp: TDateTime;
begin
TRY
Tmp := StrToDate(Editl.Text);
EXCEPT
ShowMessage('Неверная дата') ;
Editl.SetFocus;
Exit;
END;//try
end;
Запрет подтверждения изменений в БД
В случае невыполнения какого-либо условия в форме может быть запрещена кнопка, реализующая запоминание внесенных изменения в БД:
procedure TToObrForm.GoButtonClick(Sender: TObject);
var Tmp: TDateTime;
begin
TRY
Tmp := StrToDate(Editl.Text);
EXCEPT
ShowMessage('Неверная дата');
Edit1.SetFocus;
PostButton.Enabled := False;
Exit;
END;//try
end;
Отмена выхода из формы до осуществления каких-либо действий
В случае изменения какого-либо значения и до выполнения какого-либо условия в форме может быть запрещена кнопка, реализующая выход из модальной формы:
procedure TForm1.DBEditlChange(Sender: TObject);
begin
ExitButton.Enabled := False;
end;
procedure TForm1.Table1AfterPost(DataSet: TDataSet) ;
begin
ExitButton.Enabled := True;
end;
Заметим, что из такой формы можно выйти при помощи системного меню и комбинации клавиш Alt + F4. Поэтому нужно отменить для формы системное меню и при попытке выхода в обработчике события OnCloseQuery формы такую попытку блокировать.
Выполнение действий при переходе на другую запись
Событие OnDataChange компонента TDataSource происходит при изменении текущей записи в НД (в режиме dsBrowse} или при изменении какого-либо поля записи (режим dsEdit).
В приводимом примере подразумевается, что для текущей записи в ParentTable по запросу (нажатие кнопки SelectChildRecordsButton) в НД ChildTable фильтруются дочерние записи.
При переходе на новую запись в ParentTable содержимое ChildTable до нового нажатия кнопки SelectChildRecordsButton становится неактуальным. Поэтому таблица TDBGrid, показывающая дочерние записи, окрашивается в серый цвет и визуализируется кнопка SelectChildRecordsButton:
procedure TForm1.ParentDataSourceDataChange(Sender: TObject;
Field: TField) ;
begin
IF ParentTable.State <> dsBrowse THEN Exit;
ChildDBGrid.Enadbled := True;
ChildDBGrid.Color := cISilver;
SelectChildRecordsButton.Visible := True;
end;
Те же действия можно реализовать в обработчике события AfterScroll набора данных, возникающем после перехода на новую запись в НД.
Реализация бизнес-правил в приложении клиента
Для реализации бизнес-правил в приложении клиента могут использоваться различные компоненты. В первую очередь это компоненты типа "набор данных" (TTable, TQuery, TStoredProc) и компоненты TField. Интерфейсные компоненты (например, TEdit и TButton), могут использоваться для контроля за вводом пользователя и могут блокировать закрытие формы, если он ввел неправильные значения.
Использование словаря данных для определения атрибутов полей
В том случае, когда для какого-либо поля (столбца) таблицы БД требуется определить характеристики его визуального представления, используют словарь данных.
Словарь данных позволяет:
сформировать поименованный набор атрибутов поля без привязки его к конкретному полю (столбцу) конкретной таблицы БД;
по мере необходимости ставить поименованный набор атрибутов в соответствие конкретным полям (столбцам) конкретных ТБД.
В состав атрибутов, которые можно определить в поименованном наборе атрибутов, входят: выравнивание (Alignment), заголовок поля при показе (Display Label), ширина показа (Display Width}, только для чтения (Read Only), требующее обязательного ввода значения (Required}, видимое (Visible), маска при редактировании (Edit Mask), маска при показе (Display Mask) и другие.
Пусть конкретному полю (столбцу) ставится в соответствие какой-либо набор атрибутов Тогда при добавлении этого поля в приложение в качестве компонента Tfield происходит следующее соответствующие свойства компонента принимают значение одноименных атрибутов поля
Наличие такой возможности, как назначение полям (столбцам) набора атрибутов, преследует вполне конкретную цель однажды определив в словаре данных некий абстрактный набор атрибутов, мы затем можем ставить его в соответствие полям в одной или нескольких БД и, таким образом:
• устраняем повторное определение визуальных атрибутов поля (столбца) в любом приложении, его использующем,
• придаем полю (столбцу) единообразные характеристики во всех приложениях, с ним работающих.
Рассмотрим процесс назначения атрибутов полю и затем импорт их в приложение на следующем примере.
Пусть существует таблица БД 'zpa_knig.db' (записная книжка), в состав которой входят поля NN (порядковый номер, автоинкрементное поле), FIO (фамилия, имя, отчество, символьное поле), Tel (телефон, символьное поле), Prim (примечание, символьное поле).
Пусть поле Tel должно вводится в формате (ххх) ххх-хх-хх и показываться с заголовком "Телефон" При этом известно, что поле будет использовано более чем в одном приложении и потому его визуальному представлению желательно придать определенное единообразие
Процесс назначения полю набора атрибутов в словаре данных и последующего импорта атрибутов в приложение состоит из ряда этапов.
1 Выберем в главном меню Delphi элемент Database \ Explore
2 В появившемся окне утилиты SQL Explorer выберем закладку Dictionary
3 Импортируем в словарь базу данных, содержащую таблицу 'zpa_knig db' (псевдоним БД book) Для этого в меню SQL Explorer выберем элемент Dictionary | Import from Database и затем в появившемся окне запроса выберем с помощью выпадающего меню псевдоним book, после чего нажмем кнопку Ok
4 Создадим новый набор атрибутов. Для этого установим мышь на элемент дерева AttributeSets, нажмем правую кнопку мыши и в появившемся меню выберем элемент New
5 В правом окне для вновь созданного набора атрибутов введем имя
Tel_attribute_set
В левом окне установим значения атрибутов Display Label, Edit Mask
и Display Mask (рис 36 2) 6. Подтвердим внесенные для набора атрибутов Tel_attribute_set изменения,
вызвав правой кнопкой мыши меню и выбрав элемент Apply
7 Раскроем ветвь для БД book, раскроем ветвь Tables, выберем zap_knig, раскроем ее ветвь Fields и выберем поле Те/ (правое окно) В левом окне для данного поля установим значение A ttribute set в Te/_attr;bute_scf при помощи выпадающего списка (рис 36 3)
8 Подтвердим внесение изменений в набор атрибутов для поля Tel, для чего вызовем правой кнопкой мыши всплывающее меню и выберем элемент Apply
9 В приложении Delphi разместим в форме компонент TTable, связанный с ТБД zap_kmg, а также компоненты TDataSource и TDBGrid, связанные между собой стандартным образом Как видно из рис 36 4, характеристики поля Tel пока не отражают набора атрибутов, установленных этому полю в словаре данных
10 Используя редактор полей, явно определим для Table1 компоненты TField Как видно из рис 36.5, свойства поля Tel (компонент Table1Tel, тип TStrmgField) отражают атрибуты, установленные этому полю в словаре данных.
11. В режиме выполнения приложения поле Tel использует маску ввода и маску показа, установленные в словаре данных (рис 36.6).
Рис 36.6 В режиме выполнения приложения поле Tel использует маску вводи
и меню показа, установленные в словаре данных
Нормализация таблиц: теория и практика
На быстродействие БД непосредственно влияет то, каким образом была проведена нормализация таблиц, то есть каким образом устранена в таблицах избыточность данных. Часто нормализация ухудшает быстродействие. Приведем пример. Пусть имеется таблица "Сотрудники" и таблица "Оклады":
ФИО
С точки зрения теории, нормализация таблиц приводит к наиболее ясному отображению сущностей из предметной области. Устраняя избыточность данных, она тем самым существенно экономит дисковое пространство. Например, если удалить таблицу "Оклады" и ввести поле "Оклад" в таблицу "Сотрудники", будет налицо явно нерациональное расходование дискового пространства, что всегда критично при больших объемах данных. Например, если в таблице "Сотрудники" присутствуют сведения о 1000 инженерах, одно и то же значение оклада инженера (значение 650) будет дублироваться 999 раз.
С точки зрения практики, и именно на больших объемах данных, оптимизация может существенно уменьшить быстродействие. Например, при обращении к таблице "Сотрудники" часто требуется знать оклад сотрудника. Для этого необходимо обратиться к таблице "Оклады", найти нужную должность и уже затем получить оклад. Как видим, вместо одного обращения (к столбцу уже найденной записи в таблице "Сотрудники") необходимо дополнительно обратиться к таблице "Оклады", осуществить операцию поиска в ней, эффективность которого, вообще говоря, зависит от многих факторов, в первую очередь от правильного построения индексов, и уже затем считать нужное значение оклада. При обращении к одной, пусть большой, таблице БД, затрачивается меньше времени, чем при обращении к нескольким, более мелким таблицам.
Кроме того, на практике высокая степень нормализации таблиц приводит к большому количеству таблиц, в результате чего структура информации в БД не воспринимается разработчиком целостно. Невозможность целостного представления структуры данных в БД является одним из "человеческих факторов", способных внести серьезные ошибки в структуру БД уже на стадии разработки БД, что впоследствии может иметь самые серьезные - и всегда негативные - последствия. Например, БД, состоящая из 50-100 таблиц, каждая из которых имеет минимум 2-3 связи с другими ТБД, уже выходит за рамки человеческого понимания, не говоря о БД в 500 и более таблиц.
Поэтому при проектировании структуры БД следует учитывать как отрицательные, так и положительные стороны нормализации таблиц. Обычно жертвуют дополнительным расходом дисковой памяти для хранения не полностью нормализованных таблиц, стремясь обеспечить максимальное быстродействие, что актуально при возрастании числа пользователей, одновременно работающих с системой.
Частичная зависимость структуры данных от методов доступа к ним
Хотя из теории известно, что структура данных в БД должна быть независима от способов доступа к данным, на практике это обычно не так. Приведем пример.
Пусть в БД, работающей под управлением InterBase, имеется родительская таблица "Бюджетные лимиты подразделения" и подчиненные ей таблицы "Корректировки лимита", "Суммы сверх лимита", "Расходы лимитированных средств". При каждом расходовании лимитных средств (например, на покупку компьютеров) необходимо вычислить текущий остаток по такой формуле:
S1 + S2 +S3 - S4
где
S1 - начальный лимит (ТБД "Бюджетные лимиты подразделения");
S2 - сумма всех корректировок лимита по данному подразделению (таблица "Корректировки лимита");
S3 - сумма всех записей сверх лимита по данному подразделению (таблица "Суммы сверх лимита");
S4 - сумма всех предыдущих расходов подразделения по данному лимиту (таблица "Расходы лимитированных средств").
Пусть это соответственно значения 10000000 + 1000000 + 400000 - 6000000 = 5400000(рублей).
Пусть требуется записать сведения о расходе 3000000 рублей. Однако нужно быть уверенным в том, что другой пользователь в этот же самый момент не изменит ни одну из записей в указанных таблицах, результатом чего будет изменение остатка лимитных средств 5400000 (наверняка в меньшую сторону).
Чтобы блокировать текущий лимит данного подразделения, добавим в таблицу "Бюджетные лимиты подразделения" поле STATUS CHAR(l), и каждую транзакцию на изменение таблиц "Бюджетные лимиты подразделения", "Корректировки лимита", "Суммы сверх лимита", "Расходы лимитированных средств" в приложении будем начинать с изменения этого статуса:
Database1.StartTransaction;
TQuery1.Params[0] := Code;
// Code = код записи в ТБД "Бюджетные лимиты подразделения"
TRY
TQueryl.ExecSQL;
{Текст запроса вида
UPDATE ... SET STATUS = 'A' WHERE CodeZap = :Par1...}
{Вычисление текущего остатка данного бюджетного лимита по данному подразделению}
{Выполнение действий по изменению записей в дочерних таблицах}
EXCEPT
...
Тогда всякая другая транзакция, желающая изменить записи в дочерних таблицах (подчиненных текущей записи в таблице "Бюджетные лимиты подразделения") при выполнении TQuery1.ExecSQL возбудит исключение (deadlock) в связи с тем, что запись изменена другой транзакцией, пока не подтвердившей и не отменившей сделанных ею изменений. Однако эта блокировка не распространяется на другие бюджетные лимиты данного подразделения или других подразделений.
Как видим, введение дополнительного поля способно обеспечить желаемый режим разграничения доступа к данным.
Таким образом, проектируя логическую структуру данных в БД, невозможно абстрагироваться от того, каким образом эти данные будут обрабатываться на сервере и в клиентском приложении.
Заметим, что зависимость между структурой запросов к БД (в основном в операторе SELECT) и структурой и составом индексов таблиц также свидетельствует о связи между структурой данных и методами доступа к ним.
Физические характеристики БД
Для быстрого доступа к записям таблицы БД необходимо, чтобы таблица физически занимала в БД непрерывный блок страниц. Известно, что при выделении новых страниц в БД InterBase не делает никаких попыток выделять смежные страницы для хранения одной и той же таблицы БД. Поэтому данные, относящиеся к одной странице в БД, могут быть фрагментированы.
Хранение множественных поколений записей также приводит к сильному "загрязнению" БД и замедляет работу с ней. Напомним, что при всяком изменении записи фактически создается новая версия записи. Версии записей, измененные или добавленные транзакциями, которые впоследствии отменяются, из БД не удаляются. Кроме того, при удалении записей из БД не происходит перемещение оставшихся записей с тем, чтобы удалить образовавшиеся "дыры" на страницах БД.
Решением указанных проблем является периодическое создание резервной копии и восстановление из нее БД. При этом:
• собирается "мусор", т.е. версии записей, которые далее не будут востребованы;
• устраняются "дыры" на страницах БД, образовавшиеся после удаления записей;
• каждая таблица размещается в непрерывном блоке страниц.
Немаловажным является и размер самой страницы БД. Запись таблицы БД должна размещаться максимум на одной странице БД. Как известно, чтение-запись в БД InterBase осуществляются страницами. Поэтому, если размер страницы мал для хранения одной записи и она располагается на более чем одной странице, для чтения такой записи нужно выполнить несколько физических операций чтения. С другой стороны, размер страницы не должен быть слишком велик, поскольку в этом случае будут считываться ненужные записи.
Размер буфера ввода-вывода также способен оказывать влияние на быстродействие при работе с базой. Для БД, к которым чаще применяются операции чтения, рекомендуется увеличить размер буфера ввода-вывода. Для БД, в которых чаще выполняются операции записи данных, размер буфера рекомендуется уменьшить.
Оптимизация структуры БД
Для обеспечения оптимального доступа к информации в БД при проектировании физической и логической структуры БД следует учитывать ряд факторов. Перечислим некоторые из них.
Оптимальная структура индексов
От структуры индексов таблиц БД в огромной степени зависит эффективность выполнения запросов. При выполнении запросов InterBase сначала просматривает список индексов, определенных для таблиц, участвующих в запросе. Затем выбирается одна из двух схем выполнения запроса - использовать имеющиеся индексы или последовательно просмотреть таблицы. Оптимизатор InterBase стремится выполнить запрос с максимальным быстродействием и с минимальными накладными расходами. Он всегда оптимизирует запрос при его первом использовании, основываясь на текущем состоянии БД. Повторно параметрические запросы, у которых меняются только значения запросов, не оптимизируются.
Происходит лишь предварительное связывание формальных и фактических параметров, после чего запрос выполняется.
Хотя состояние БД может меняться и поэтому полностью предсказать, по какой схеме оптимизатор InterBase будет выполнять запрос, нельзя, существуют общие положения, которые следует учитывать при проектировании запросов.
Полезность" индексов
Эффективность использования индекса при поиске информации в таблице БД сильно зависит от того, построен ли индекс по уникальным значениям и, если нет, насколько отличаются данные, по которым он построен.
Пусть необходимо выбрать из таблицы RASHOD все записи о расходе товара за 10.01.1997, у которых количество расходуемого товара превышает 300 единиц:
SELECT * FROM RASHOD WHERE DAT_RASH = "10/01/1997" AND KOLVO > 300
При выполнении запроса InterBase определяет - есть ли индексы, построенные одновременно по столбцам DAT_RASH и KOLVO, столбцам KOLVO и DAT_RASH, или индексы, в которые указанные столбцы входят в качестве ведущих (например, индекс, построенный по столбцам DAT_RASH, KOLVO, TOVAR, но не индекс, построенный по столбцам DAT_RASH, TOVAR, KOLVO). При отсутствии таких индексов проверяется наличие индексов отдельно по столбцам DAT_RASH и KOLVO.
В случае отсутствия таких индексов поиск записей, удовлетворяющих запросу, осуществляется путем перебора всех записей в таблице, т.е. путем последовательного доступа, что обеспечивает наименьшую эффективность выполнения запроса. В случае нескольких индексов, по которым можно осуществить поиск (например, индекс по столбцам DATJR.ASH, KOLVO и по столбцам KOLVO, DAT_RASH), выбирается для использования тот, у которого выше показатель полезности индекса (selectivity).
Показатель полезности индекса
рассчитывается как число различающихся значений индексных полей внутри индекса, отнесенное к среднему количеству записей. Этот показатель рассчитывается при создании индекса. После внесения изменений в таблицу, по которой построен индекс, меняется степень отличия значений столбцов, по которым построен индекс. Поэтому рассчитанный показатель полезности может не отражать реального состояния индекса и значение показателя рекомендуется принудительно пересчитывать: время от времени - при внесении небольших изменений и всегда - при внесении существенных изменений. Пересчет реализуется оператором SET STATISTIC INDEX ИмяИндекса
Среднее количество записей -
показатель, который рассчитывается всякий раз при оптимизации запроса как количество страниц БД, занятых этой таблицей, деленное на максимальное число записей на странице. Уменьшение числа страниц, занятых БД, и уничтожение на них "дыр" ведут к уменьшению показателя среднего числа записей и, как следствие - к повышению показателя полезности индексов. Это еще один аргумент в пользу периодического сжатия БД путем создания резервной копии и восстановления из нее БД. Для участия в выполнении запроса выбираются индексы с максимальным показателем полезности. Такие индексы обеспечивают более быстрый поиск. Максимальным показателем полезности обладают уникальные индексы, т.е. индексы, построенные по определениям первичных и уникальных ключей.
Просмотр плана выполнения запросов
При выполнении запросов к БД в утилите WISQL установим режим показа плана выполнения запроса (выбрав элемент меню Session | Bas'ic Settings и отметив режим Display Query Plan). Тогда при выполнении запросов будет выводиться и план их выполнения. Под планом выполнения запроса понимается перечень индексов, используемых InterBase при выполнении запроса. Слово NATURAL означает последовательный перебор таблицы. Например,
SELECT RASHOD.*, TOVARY.ZENA
FROM RASHOD, TOVARY
WHERE RASHOD.TOVAR = TOVARY.TOVAR
PLAN JOIN (RASHOD NATURAL,TOVARY INDEX (RDB$PRIMARY8))
NRASH
Для принудительного выполнения запроса по тому или иному плану, следует в операторе SELECT использовать предложение
PLAN <план выполнения_запроса>
< план выполнения запроса > =
[JOIN | [SORT] MERGE] (<элемент_плана> | < план _выполнения_запроса >
[, < элемент плана > I < план выполнения запроса > . . . ] )
<элемент_плана> = {таблица | алиас}
NATURAL | INDEX ( <индекс> [, < индекс >...]) I ORDER < индекс >
Синтаксис предложения PLAN относится как к единичной таблице БД, так и к нескольким таблицам. В последнем случае выполняется соединение таблиц для увеличения скорости выполнения запроса, что определяется использованием необязательного ключевого слова JOIN. В том случае, если не существует индексов, по которым данные таблицы могли бы быть соединены, для увеличения скорости выполнения запроса указывают ключевые слова SORT MERGE.
<элемент_плана>
является именем таблицы, в которой производится поиск данных. В том случае, если одна и та же таблица несколько раз участвует в запросе, для сокращения текста плана полезно использовать ее псевдоним, то есть обозначение, указываемое в предложении FROM после имени таблицы. Следующие ключевые слова определяют способ доступа к данным. NATURAL (по умолчанию) - указывает, что для поиска записей применяется последовательный доступ. Это единственный способ поиска записей в том случае, если нет подходящих индексов.
INDEX - указывает один или несколько индексов, которые должны использоваться для поиска записей, удовлетворяющих условию запроса.
ORDER - указывает, что <элемент_плана> должен быть отсортирован по указанному индексу.
Целесообразность создания индексов
Индексы необходимо создавать в случае, когда по столбцу или группе столбцов часто
• производится поиск в БД (столбец или группа столбцов часто перечисляются в предложении WHERE оператора SELECT);
• строятся объединения таблиц;
производится сортировка НД, возвращаемых в качестве результатов запросов к БД (т.е. столбец или столбцы часто используются в предложении ORDER BY оператора SELECT).
Не рекомендуется строить индексы по столбцам или группам столбцов, которые:
• редко используются для поиска, объединения и сортировки результатов запросов;
• содержат часто меняющиеся значения, что приводит к необходимости частого обновления индекса и способно существенно замедлить скорость работы с БД;
• содержат небольшое количество вариантов значения.
Частичное использование составного индекса
Если запросы часто используют для поиска одни и те же столбцы, следует построить по этим столбцам индекс (если это возможно), так, чтобы чаще используемые столбцы выступали в качестве ведущих полей индекса. Тогда при поиске может быть использована часть индексных полей.
Пример.
Пусть часто выполняются запросы SELECT * FROM SOME TABLE WHERE A = : ParamA AND В = :ParamB
SELECT * FROM SOME TABLE
WHERE A = : ParamA AND В = :ParamB AND С = :ParamC
SELECT * FROM SOME TABLE
WHERE A = : ParamA AND В = :ParamB AND С = :ParamC AND D = :ParamD
SELECT * FROM SOMETABLE
ORDER BY А,В
Тогда, построив индекс по столбцам А, В, С, D, мы можем с большой долей уверенности утверждать, что данный индекс будет использован при оптимизации всех четырех запросов. В первом случае будут использовано подмножество индекса, т.е. значения А, В; во втором - значения А, В, С, в третьем - А, В, С, D (то есть все значения индекса); в четвертом - А, В.
Следует помнить, что при использовании в запросах не всех столбцов из индекса, можно использовать только непрерывную последовательность столбцов, что важно для указания порядка сортировки в предложении ORDER BY. Например, если индекс построен по столбцам А, В, С, D, этот индекс не может использоваться для выполнения запросов
SELECT * FROM SOMETABLE ORDER BY А,С
SELECT * FROM SOMETABLE ORDER BY B,D
Порядок следования условий по столбцам в предложении WHERE оператора SELECT не важен (если условия объединены с помощью AND). Например, для выполнения следующих запросов может использоваться один и тот же индекс:
SELECT * FROM SOMETABLE WHERE A = 100 AND В = 200
SELECT * FROM SOMETABLE WHERE В = 200 AND A = 100
Однако при указании уровней сортировки в предложении ORDER BY оператора SELECT порядок следования столбцов является существенным. Например, для выполнения следующих запросов не может использоваться один и тот же индекс:
SELECT * FROM SOMETABLE ORDER BY А, В, С
SELECT * FROM SOMETABLE ORDER BY А, С, В
Многопоточность поиска по OR и IN
При частом использовании в условной части WHERE оператора SELECT нескольких столбцов, связанных между собой операцией "или" (OR):
SELECT * WHERE A = 100 OR В = 200 OR С = 300
вместо индекса по столбцам А, В, С лучше создать несколько индексов, построенных по каждому из этих полей, поскольку в противном случае будет осуществлен последовательный просмотр всей таблицы. Это неудивительно, так как индексно-последовательный доступ для индексов А, В, С может быть осуществлен только для столбца А; значения столбцов В и С в этом случае спонтанно разбросаны по индексу. Важно помнить, что при использовании оператора OR в условной части оператора SELECT каждая часть условия влечет за собой отдельное сканирование таблиц, участвующих в запросе. Так, например, при выполнении оператора SELECT с условной частью
WHERE А = 100 OR В = 200 OR С = 300
будет осуществлено три отдельных сканирования таблицы (таблиц) для поиска значений, удовлетворяющих условиям А = 100; В = 200; С = 300.
Отдельный поток поиска порождает и каждый элемент в списке IN. Например,
WHERE A IN (100,200,300)
интерпретируется как
WHERE А = 100 OR А = 200 OR A = 300.
Однако при указании диапазона BETWEEN
WHERE A BETWEEN 100 AND 300
этого не происходит. Поэтому там, где возможно, следует заменять IN на BETWEEN.
Уменьшение общего количества индексов
Следует стремиться к уменьшению количества индексов, поскольку при большом их количестве снижается скорость добавления, изменения и удаления записей в таблицах БД. Как правило, в БД определяется два вида индексов : индексы, фактически использующиеся запросами для доступа к данным, и индексы, введенные в БД для обеспечения ссылочной целостности между родительскими и дочерними таблицами БД. Если индексы не используются при доступе к данным, их следует удалять, а ссылочную целостность обеспечивать с использованием триггеров.
Оптимизация запросов
Оптимизация запросов к БД связана с построением адекватной запросам и оптимальной структуры индексов таблиц БД и оптимизацией собственно текстов запросов.
Минимизация соединений с БД
Для соединения с удаленной БД в клиентских Delphi-приложениях используется компонент TDatabase. Он служит для:
• создания постоянного соединения с БД;
• создания локального псевдонима БД;
• изменения параметров соединения, установленных для псевдонима БД (в утилите BDE Administrator);
• управления транзакциями.
Если не использовать компонент TDatabase, то соединение с БД может, в принципе, осуществлять каждый компонент типа "набор данных" (TTable, TQuery, TStoredProc). Однако следует помнить, что каждое соединение с БД потребляет системные ресурсы и их чрезмерный расход может сказаться на эффективности доступа к БД. Кроме того, при соединении с удаленной БД "напрямую", из компонентов типа "набор данных", невозможно изменять предустановленные параметры соединения.
Поэтому рекомендуется снижать число соединений с удаленной БД к минимуму, а в идеале - иметь одно соединение с каждой БД.
Использование TQuery
Хотя при доступе к таблицам БД может использоваться два компонента типа "набор данных" -TTable и TQuery, для доступа к удаленным данным рекомендуется использовать комнонент TQuery.
ПРИМЕЧАНИЕ.
Компонент TStoredProc используется только для работы с вызываемыми процедурами и не применяется для работы с процедурами выбора, которые также могут возвращать наборы данных. Для работы с процедурами выбора также используется компонент TQuery. Предпочтительность использования TQuery при доступе к удаленным данным определяется следующими причинами:
• при доступе к табличным данным компонент TTable считывает все записи удаленной таблицы, в то время как TQuery - ровно столько, сколько нужно для текущих целей визуализации, например, для заполнения сетки TDBGrid; при доступе к таблицам большого объема использование TTable может привести к существенным временным задержкам;
• компоненты TTable и TQuery имеют разную природу: TTable ориентирован на навигационный метод доступа к данным, что более характерно для работы с локальными СУБД; TQuery ориентирован на работу с множествами записей, что характерно при доступе к удаленным БД в архитектуре "клиент-сервер"; TTable позволяет обратиться к одной таблице БД, TQuery - к результатам выполнения запроса одновременно к нескольким ТБД; соответственно, подтверждение изменений данных в TTable осуществляется для каждой записи, что существенно увеличивает сетевой трафик; изменение данных при использовании TQuery может производиться сразу над множеством записей с использованием операторов INSERT, UPDATE, DELETE;
• при помощи компонента TQuery можно выполнять разнообразные SQL-операторы, как возвращающие НД (SELECT), так и не возвращающие его (INSERT, и т.д.).
Перенос тяжести вычислительной работы на сервер
При работе с удаленными БД следует стремиться перенести всю тяжесть вычислительной работы на сервер, по возможности оставив приложению клиента лишь работу по реализации интерфейса с пользователем, отсылки запросов к серверу и интерпретации полученных от него данных.
Не надо обращаться к серверу с запросом необоснованно большого объема данных, на которые приходится накладывать фильтры в самом клиентском приложении.
Следует максимально использовать возможности сервера, памятуя о том, что он может выполнять большинство требований приложения быстрее и оптимальнее и, кроме того, серверу не нужно пересылать данные самому себе по сети.
Реализуйте ограничения на значения вводимых пользователем данных при помощи аппарата ограничений БД (CONSTRAINTS), а ссылочную целостность - при помощи триггеров.
Запросы, требующие при своем выполнении ветвящихся или циклических алгоритмов, а также всевозможные вычисления значений, основанные на текущих данных из БД, реализуйте при помощи хранимых процедур.
Бизнес-правила, связанные с транзакционными изменениями ряда таблиц, реализуйте при помощи триггеров.
Получайте уникальные значения числовых полей при помощи генераторов.
Повторяющиеся действия, которые могут разделяться различными приложениями и использоваться в SQL-операторах, реализуйте при помощи функций, определенных пользователем (UDF).
Перенос тяжести вычислительной работы на сервер, во-первых, убыстряет работу клиентского приложения, а во-вторых, минимизирует возможность возникновения ошибок.
Оптимизация клиентских приложений
От того, каким образом организуется доступ к удаленной БД, во многом зависит, насколько эффективно будет работать с ней данное приложение.
Оптимизация работы с БД
Под оптимальной работой с БД обычно понимают создание таких условий, когда обеспечивается наибольшее быстродействие БД при минимально возможных затратах ресурсов.
Оптимизация зависит от многих факторов, которые можно разбить на три группы:
• оптимизация структуры БД;
оптимизация запросов;
• оптимизация клиентского приложения.
Такой важный фактор, как производительность сервера, не часто (к сожалению) может подвергаться воздействию со стороны разработчиков БД и приложений для работы с БД. Поэтому, декларировав известный факт, что чем мощнее аппаратура сервера, тем лучше, рассмотрим такие факторы, которые поддаются воздействию со стороны разработчиков и администраторов БД.
Соединение с сервером
Для соединения с сервером выберите элемент меню File \ Server Login, затем укажите имя сервера, протокол и введите имя пользователя и пароль (рис 38 1)
Соединение с БД
Для соединения с БД следует выбрать элемент меню File | Database Connect и указать имя БД (рис. 38.2).
Выбор текущего сервера и БД
Одновременно может быть установлено соединение с несколькими серверами и базами данных. Для выбора конкретного сервера или БД установите на них инверсную полосу в окне утилиты (рис. 38.3).
Разрыв соединения
Для разрыва соединения с БД выберите элемент меню File \ Database Disconnect
Для разрыва соединения с сервером выберите элемент меню File [ Server Logout При этом будут разорваны все соединения с БД этого сервера
Изменение конфигурации сервера
Описываемые ниже изменения может производить только пользователь SYSDBA (системный администратор). Выберите элемент меню Tasks \ Server Config. В окне IB Settings можно изменить значения следующих параметров-
Database Cache -
для каждой БД, с которой установлено соединение, задает размер буфера (кэша) в страницах. В этом кэше размещаются страницы БД. Увеличение размера кэша может существенно ускорить работу с БД, поскольку реально операции чтения/записи будут относиться не к физической БД на диске, а к кэшу в оперативной памяти. Перенос страниц из памяти в физическую БД проводится в фоновом режиме. Однако слишком большой размер кэша при наличии одновременно выполняющихся запросов ко многим БД может привести к нехватке памяти и замедлению работы. Чтобы определить реально необходимый размер кэша, следует умножить число страниц БД на объем страницы в килобайтах (эти параметры задаются при создании БД). Client map size
определяет размер буфера для каждого соединения с клиентом. По умолчанию равен 4 Кбайт, может изменяться в диапазоне 1...8 Кбайт. Потребность в изменении данного параметра может возникнуть при работе с BLOB-полями. На странице OS Settings можно (только системному администратору, пользователь SYSDBA) устанавливать значения следующих параметров:
Process Working Set -
определяет дополнительную память, резервируемую InterBase для своих нужд, совместно с буфером, размер которого задается параметром Database Cache; Minimum и Maximum определяют диапазон дополнительной памяти в страницах. Process Priority Class
определяет приоритет задач сервера по отношению к другим задачам, выполняющимся на данном компьютере. Установка в этом параметре значения High обоснована в следующих случаях: при работе InterBase на выделенном для этого компьютере в условиях отсутствия других приложений;
при наличии большого числа пользователей, активно читающих и записывающих информацию в БД.
Статистические данные непосредственно о БД
Для запуска процесса сбора статистики выберите элемент меню Tasks | Database Statistics. В появившемся текстовом окне (рис. 38.4) будет выдан статистический отчет.
Секция Database header page information содержит сведения из заголовочной страницы БД.
Flags -
указывает флаг БД. Некоторые значения: 1 - БД является "зеркальной" копией основной БД;
2 - разрешен режим принудительной записи (forced writes), когда запись данньк производится в физической БД; при отмене этого режима запись производится в буфер, а потом в фоновом режиме (обычно при переполнении буфера) переносится на диск; при сбое системы данные из буфера могут быть потеряны, что чревато непредсказуемыми последствиями.
Checksum -
Контрольная сумма заголовка БД. Уникальное значение, которое вычисляется по всем данным в заголовке БД. Используется для анализа правильности данных в заголовке БД. Generation -
счетчик, который увеличивается на 1 при каждом обновлении данных в заголовке БД. Page size -
размер страницы БД в байтах. ODS version -
версия структуры БД на диске. Oldest transaction -
номер старейшей незавершенной транзакции (см. также Next transaction). Незавершенной считается транзакция, если она активна, отменена (rolled back) или зависла (in limbo, то есть во время ее действия и до применения к ней подтверждения или отката произошел сбой, и после него невозможно сказать, завершена транзакция или нет; такое возможно для транзакций, охватывающих БД, которые расположены на различных серверах). Oldest active -
старейшая активная транзакция. Next transaction -
номер, который будет присвоен следующей транзакции. При выполнении условия Next transaction - Oldest transaction > Sweep interval производится автоматическая чистка мусора в БД. Sweep interval (no умолчанию 20 000) - число транзакций, через которое происходит автоматическая чистка мусора. Sequence number -
номер первой страницы БД. Next attachment ID -
номер следующего соединения с БД. Number of cache buffers -
размер буфера в страницах БД. Next header page -
номер следующей страницы заголовка БД. Creation date -
дата создания БД. Attributes -
атрибуты БД. Секция Database file sequence описывает характеристики последовательности файлов, из которых состоит БД.
Секция Database log page information содержит информацию о страницах журнала БД (только для серверов NetWare).
Анализ БД
Выберите View | Database Analysis в окне Database Statistics. Вы получите информацию обо всех таблицах и индексах БД.
Принудительная сборка мусора
Для принудительной сборки мусора выберите элемент меню Maintenance \ Sweep. Необходимость сборки мусора обусловливается следующим. При чтении транзакцией записи, все старые версии этой записи, не использующиеся активными транзакциями, удаляются. Это касается только записей, созданных подтвержденными транзакциями. Версии, созданные транзакциями, впоследствии откатившимися (rolled back), а также старые версии записей, закрепленные за активными транзакциями, остаются в БД. Это сильно увеличивает объем БД и понижает быстродействие работы с ней. Поэтому в целях оптимизации используют сборку мусора (garbage collection).
Пример.
Извлечения из статистики БД до и после сборки мусора:
До сборки мусора:
Oldest transaction 2549
Oldest active 13438
Next transaction 13441
После сборки мусора:
Oldest transaction 13441
Oldest active 13441
Next transaction 13442
Изменение значения sweep interwal, использующегося для включения автоматической сборки мусора, может быть произведено в элементе меню Maintenance | Database Properties (рис. 38.5). Однако следует помнить о том обстоятельстве, что автоматическая сборка мусора может быть неэффективной, если в момент ее осуществления имеется много активных транзакций вследствие интенсивной работа клиентов с БД: в этом случае, во-первых, много версий записей, занятых активными транзакциями, не войдет в число "собранных" записей; во-вторых, сборка мусора существенно замедлит выполнение активных транзакций. Поэтому рекомендуется собирать мусор либо вручную при минимальном числе пользователей, либо при восстановлении БД (когда подключений к БД быть вообще не должно). Просмотреть активных пользователей можно, выбрав элемент меню Maintenance \ Database Connections (рис. 38.6).
Active Database Connections
Database с:\proiect\monitor\db\MON.gdb
User Name
SYSDBA
Переход в однопользовательский режим соединения с БД
Создание резервной копии может производиться без отключения других пользователей Однако следует помнить, что в этом случае в резервной копии будут сохранены все данные, измененные на момент создания резервной копии Поэтому резервное копирование обычно осуществляют в момент отсутствия соединений с БД со стороны пользователей Это бывает обычно в вечерние, ночные или утренние часы. Существующие соединения пользователей могут быть принудительно разорваны Для этого нужно выбрать элемент меню Maintenance \ Database Shutdown и в диалоговом окне (рис. 38 7) установить параметры принудительного разъединения.
Deny new connections while waiting -
все существующие соединения пользователей с БД должны завершить свои операции Если по истечении указанного ниже периода времени остались активные соединения с пользователями, БД не переводится в однопользовательский режим, необходимый для создания резервной копии. Deny new transactions while waiting - существующие транзакции должны завершиться (Server Manager ожидает их завершения). Старт новых транзакций блокируется Если по истечении указанного ниже периода времени остались активные транзакции, БД не переводится в однопользовательский режим.
Force shutdown after the time-out period -
активные транзакции могут выполняться в течение указанного ниже периода Если в конце данного периода остаются активные транзакции, они принудительно откатываются и затем все соединения с пользователями принудительно разрываются
Резервное копирование БД
Для создания резервной копии БД следует выбрать элемент меню Tasks | Backup и в диалоговом окне (рис 38 8) указать путь к БД, которая должна служить источником для создания резервной копии, а также путь и имя файла резервной копии В окне Options указываются необязательные параметры резервного копирования БД
Transportable Format -
создание транспортного формата резервной копии в общем формате представления данных, что делает возможным перенесение БД в другие операционные среды, для которых существуют реализации InterBase. Back Up Metadata Only -
сохранять только метаданные, игнорируя страницы данных. Полезно в том случае, когда нужно создать заготовку пустой БД (например, при дистрибутировании разработанной программной системы). Disable Garbage Collection -
не производить сборку мусора при сохранении БД. Ignore Transaction in Limbo -
игнорировать при сохранении БД транзакции in limbo (транзакции, о которых нельзя сказать, завершились они или откатились; возникают при двухфазной фиксации транзакций для БД, расположенной на разных серверах, если операция подтверждена на одном сервере, а на другом в момент подтверждения транзакции произошел аппаратный сбой). Для восстановления транзакций in limbo перед созданием резервной копии следует выбрать элемент меню Maintenance \ Transaction Recovery. Ignore Checksums -
игнорировать неверные контрольные суммы заголовочных страниц БД, где хранится информация о БД, необходимая для соединения с нею; отключение данного режима (по умолчанию) предотвращает сохранение БД с разрушенной структурой. Verbose Output -
получение расширенного отчета (в отдельном окне) о ходе создания резервной копии БД.
Восстановление БД из резервной копии
Для того чтобы восстановить БД из ранее сделанной резервной копии, необходимо выбрать в меню режим меню Tasks | Restore и затем в диалоговом окне указать путь и название резервной копии и БД, которая будет восстановлена (рис 38 9) В правой части диалогового окна параметр Page Size устанавливает размер страницы восстанавливаемой БД Там же могут быть установлены следующие параметры-
Replace Existing Database -
заменят существующую БД с тем же именем, если она расположена в том каталоге, куда должна помещаться восстанавливаемая БД Commit After Each Table -
подтверждать восстановление после каждой таблицы Это актуально в тех случаях, когда в резервной копии имеются разрушенные данные и следует восстанавливать не все из них. Restore Without Shadow -
при восстановлении БД не создавать теневой (зеркальной) копии БД, если для этой БД назначено автоматическое ведение теневой копии. Это может быть необходимо в случаях восстановления БД на сервере, который не поддерживает теневого копирования, восстанавливаемая БД сама является теневой копией БД При этом в восстановленной БД будут уничтожены определения теневой БД, если восстановление БД, для которой ранее осуществлялось теневое копирование, осуществляется с включенным режимом Restore Without Shadow
Deactivate Indexes -
отключить восстановление индексов InterBase строит индексы после того, как БД восстановлена. Если в БД, служившей источником для создания резервной копии, существуют дублированные значения столбцов, по которым построены уникальные или первичные индексы, попытка перестройки индексов для восстановленной БД вызовет ошибку В этом случае следует отключить восстановление индексов и затем, используя утилиту WISQL, устранить дублирование значений. После этого можно активизировать индексы (SQL-оператор ALTER INDEX) Do Not Restore Validity Conditions -
не восстанавливать определения ограничений ссылочной целостности. Это важно в том случае, когда резервная копия БД содержит устаревшие ограничения ссылочной целостности, которые должны быть заменены новыми Verbose Output -
получение расширенного отчета (в отдельном окне) о ходе восстановления БД из резервной копии В том случае, когда восстанавливаемая БД должна располагаться в нескольких физических файлах, следует нажать кнопку Multi-File и в окне диалога (рис 38.10) в поле File Path указать имя каждого файла БД и его размер в страницах в поле Sire Затем следует нажать кнопку Save Тогда имя файла и его размер появятся в списке File List Изменить характеристики фай па из списка можно после нажатия кнопки Modify Для удаления файла из списка используйте кнопку Delete
Создание резервной копии (сохранение) и восстановление БД
Сохранение БД может иметь своей целью
Принудительная запись на диск
Записи таблиц при добавлении или изменении их в БД могут помещаться в буфер или немедленно физически записываться на диск В первом случае записи из буфера физически записываются на диск после заполнения буфера
Режим накапливания изменений в буфере экономит время и улучшает быстродействие при работе с БД, поскольку достаточно медленное обращение к диску происходит реже Однако в случае сбоя данные из буфера теряются, не будучи записаны на диск, что способно серьезно нарушить целостность БД
Поэтому рекомендуется второй метод, метод немедленной (принудительной) записи на диск (forced writes) Этот режим установлен для сервера БД по умолчанию Отключить или повторно включить его можно в диалоговом окне установки свойств БД. Это окно вызывается при выборе элемента меню Maintenance \ Database Properties (отметка Enable Forced Writes)
Восстановление транзакций
В случае, если транзакция затрагивает БД, расположенные на разных серверах, подтверждение такой транзакции осуществляется в две фазы Все действия при этом выполняются автоматически и не требуют программирования При возникновении ошибки в ходе выполнения двухфазной фиксации транзакция считается потерянной и относительно нее сервер БД не может решить, закончилась она или откатилась
Для восстановления таких транзакций следует выбрать опцию меню Maintenance Transaction Recovery В диалоговом окне будут показаны в виде списка транзакции in limbo Они могут быть подтверждены или отменены Для каждой транзакции могут быть показаны все связанные с ней транзакции (путем выбора знака '+' слева от транзакции)
Регистрация новых пользователей
Регистрация новых пользователей может осуществляться администратором системы Для этого следует выбрать элемент меню Tas/:s | Us'er Security В появившемся окне будет указан список имен зарегистрированных на сервере пользователей (рис 38 11)
Рис 38.11 Регистрация пользователей
Добавление нового пользователя реализуется по нажатию кнопки Add User. В этом случае необходимо указать имя пользователя и пароль (рис.38.12). Они будут запрашиваться при доступе к БД.
Изменение реквизитов пользователя производится после нажатия кнопки Modify User, удаление - по нажатию кнопки Delete User.
Работа с утилитой InterBase Server Manager
Утилита InterBase Server Manager служит для .
Привилегии доступа по умолчанию
По умолчанию доступ к таблицам и хранимым процедурам имеет только тот пользователь, который их создал. Кроме того, системный администратор имеет доступ ко всем компонентам БД.
Назначение процедуре прав доступа к таблице
Если хранимая процедура выполняет какие-либо действия над таблицей SOMETABLE, а пользователь, имеющий право вызывать эту процедуру, не имеет прав доступа к этой таблице, следует указать права доступа к ней для самой процедуры:
GRANT SELECT ON SOMETABLE TO PROCEDURE SOMEPROC
Ликвидация привилегий
Ликвидация ранее выданных пользователю привилегий осуществляется при помощи оператора REVOKE. Его формат:
REVOKE [GRANT OPTION FOR]{
{ALL [PRIVILEGES] | SELECT | DELETE | INSERT
I UPDATE [(столбец [.столбец ...])]}
ON [TABLE] {ИмяТаблицы | ИмяПросмотра}
FROM {<объект> | <список пользователей>}
I EXECUTE ON PROCEDURE ИмяПроцедуры
FROM {<объект> | < список_пользователей >}
};
где все параметры идентичны по содержанию параметрам оператора GRANT, за исключением параметра
GRANT OPTION FOR -
удаляет право выдачи привилегий у пользователей из <списка_пользователей>. При этом <объект> не указывается. Привилегию может ликвидировать только тот, кто ее выдал. Если пользователь лишается привилегии определенного вида, назначенные ему привилегии всех остальных видов остаются в его собственности. Например:
GRANT ALL ON RASHOD TO DIMA
REVOKE INSERT ON RASHOD FROM DIMA
После выполнения REVOKE пользователь DIMA будет обладать правами изменения (UPDATE), удаления (DELETE) и выборки данных (SELECT) из таблицы RASHOD.
Лишение пользователя права назначать привилегии другим пользователям ведет к утрате данной привилегии всеми пользователями, которым он успел ее назначить. Привилегии, установленные для всех пользователей (PUBLIC), отнимаются также у всех пользователей (PUBLIC).
Виды привилегий
Ниже перечислены виды привилегий и ключевые слова в операторе GRANT, соответствующие этим привилегиям.
Ключевое слово
Минимальный состав параметров при предоставлении привилегий доступа к таблице БД
Для предоставления пользователю привилегии доступа к таблице в операторе GRANT необходимо указать как минимум следующие параметры:
ключевое слово, обозначающее вид привилегии доступа;
имя таблицы;
имя пользователя.
Например,
предоставить пользователю PASHA привилегию на выполнение поиска данных в таблице ТО VARY: GRANT SELECT ON TOVARY TO PASHA
Предоставление нескольких привилегий
Чтобы в одном операторе GRANT предоставить пользователю не одну, а несколько привилегий, следует привести список этих привилегий: GRANT SELECT, INSERT ON TOVARY TO DIMA
Словом ALL обозначается предоставление пользователю всех привилегий, то есть права считывания, добавления, изменения и удаления: GRANT ALL ON RASHOD TO PASHA
Предоставление привилегий нескольким пользователям
Если необходимо предоставить одну или несколько привилегий ряду пользователей, можно выполнить оператор GRANT для каждого пользователя, или указать список пользователей в одном операторе GRANT:
GRANT SELECT, INSERT, UPDATE ON RASHOD TO PASHA, DIMA
Назначение привилегий всем пользователям
В случае, если определенный вид привилегий по доступу к таблице должен быть назначен всем пользователям, в операторе GRANT указывают ключевое слово PUBLIC вместо списка имен пользователей:
GRANT SELECT, INSERT, UPDATE ON RASHOD TO PUBLIC
Установка привилегий доступа к отдельным столбцам таблицы
Привилегия на изменения определенных (не всех) столбцов таблицы также может быть указана в операторе GRANT для отдельных пользователей. В этом случае имена столбцов перечисляются в скобках после ключевого слова UPDATE: GRANT UPDATE (DAT_RASH, TOVAR, KOLVO) ON RASHOD TO DIMA
Предоставление пользователю права назначать привилегии другим пользователям
Если в операторе GRANT при предоставлении пользователю привилегии доступа к таблице указать необязательный параметр WITH GRANT OPTION, данный пользователь получит право назначать ту же привилегию другим пользователям. Например, после выполнения оператора
GRANT DELETE ON RASHOD TO PASHA WITH GRANT OPTION
пользователь PASHA получит право предоставлять привилегию удаления из таблицы RASHOD другим пользователям.
Назначение привилегий вызова хранимых процедур
При назначении привилегии вызова хранимой процедуры оператор GRANT имеет следующий формат:
GRANT EXECUTE ON PROCEDURE ИмяПроцедуры ТО <список_пользователей>
Например,
следующий оператор GRANT предоставляет право вызова процедуры MAX_VALUE: GRANT EXECUTE ON PROCEDURE MAX_VALUE TO PASHA
Установка привилегий доступа
Привилегия доступа - возможность определенного пользователя выполнять определенный вид действий над определенными таблицами базы данных. Привилегии доступа могут устанавливаться как системным администратором (пользователем с именем SYSDBA), так и пользователем, которому системный администратор предоставил такое право.
Установка привилегий производится оператором GRANT. Его формат:
GRANT{
{ALL [PRIVILEGES] I SELECT | DELETE I INSERT
I UPDATE [(столбец [.столбец ...])]}
ON [TABLE] {ИмяТаблицы I ИмяПросмотра}
TO {<объект> I <список_пользователей>}
I EXECUTE ON PROCEDURE procname
TO {<объект > < список_пользователей>}
};
<объект > = PROCEDURE ИмяПРоцедуры | TRIGGER ИмяТриггера |
VIEW ИмяПросмотра | [USER] ИмяПользователя |
PUBLIC [, <объект>]
< список пользователей > = [USER] ИмяПользователя[, [USER]
ИмяПользователя...] [WITH GRANT OPTION]
Обзор не визуальных компонентов для работы с базами данных
TSession
Обзор визуальных компонентов для работы с базами данных
TDBText
Иерархия классов важнейших невизуальных компонентов для представления данных и доступа к ним
TComponent
TSession
TDatabase
TDataSource
TDataSet
TBDEDataSet
TDBDataSet
TTable
TQuery
TStoredProc
TClientDataSet
TField
TBIobField
TGraphicField
TMemoField
TbooleanField
TBooleanField
TBmaryField
TBytesField
TVarBytesField
TDateTimeField
TDateField
TTimeField
TNumericField
TBCDField
TFloatField
TCurrencyField
TIntegerField
TAutoIncField
TSmallIntField
TWordField
TStringField
Приведенная здесь иерархия показывает, что свойства, методы и события, объявленные у компонентов-предков, по праву наследования доступны и у их компонентов-потомков.
Например, в одном из последующих разделов достаточно подробно описывается родительский компонент TField (поле набора данных), его методы, свойства и события; однако дочерние компоненты TField описываются далеко не столь подробно. Причина этому в том, что все события, методы и свойства, присущие группе компонентов, достаточно описать один раз.
Другим примером может служить TDataSet: многие его свойства, методы и события по праву наследования доступны и у его потомков - компонентов TTable и TQuery.
О наследовании компонентами-потомками свойств, методов и событий своих родителей следует помнить постоянно.
Функциональная иерархия компонентов Delphi для работы с базами данных
Если иерархия классов компонентов, приведенная в предыдущем подразделе, призвана показать, кто является чьим потомком и, следовательно, кто может использовать свойства, методы и события родителя, то приводимая на рис.4.1 функциональная иерархия не зависит от "классовой" структуры.
В функциональной иерархии показывается, какие компоненты являются свойствами других компонентов и, соответственно, к каким компонентам, связанным с текущим, мы можем получить доступ
Приведенная схема призвана показать следующее.
Используя неявно создаваемый или явно созданный компонент TSession (подробности в соответствующем разделе), можно определить, какие базы данных в текущий момент активны для приложения (свойство Databases).
Используя компонент TDatabase, можно определить, какие наборы данных используются приложением (компонент TDataSet).
Используя компонент TDataSet, можно:
• для НД, связанных с компонентом TTable:
• узнать, какие индексы определены для таблицы БД, ассоциированной с этим набором данных (компонент TIndexDef);
• для каждого индекса получить информацию об индексных полях и перейти к использованию свойств и методов отдельного индексного поля;
• получить информацию обо всех полях, определенных в структуре ТБД, ассоциированной с данным компонентом TTable (свойство FieldDefs.Items);
• для всех наборов данных (компоненты TTable, TQuery, TStoredProc ) -получить информацию обо всех активных полях набора данных и получить доступ к свойствам и методам каждого активного поля. Таким образом, информация о структурах данных различных уровней носит в приложении Delphi сквозной характер. Взяв за стартовую точку текущую сессию (сеанс) приложения по работе с БД, можно "спуститься" к отдельному полю какого-либо набора данных.
Более подробно о работе каждого компонента и о связи его с другими -визуальными и невизуальными компонентами для работы с данными - будет рассказано в соответствующих разделах.
Как связаны друг с другом компоненты для работы с базами данных
Визуальные и невизуальные компоненты связываются друг с другом при помощи свойств. Значения этих свойств обычно устанавливаются на этапе разработки приложения, но могут устанавливаться и во время выполнения приложения. На рис. 4.2 показано, через какие свойства различные компоненты связаны друг с другом.
Первым уровнем являются псевдонимы BDE, устанавливаемые при помощи ВDE Administrator. На псевдоним ссылается компонент типа "набор данных" (показанные на рисунке компоненты TTable и Tquery, не показанный компонент TStoredProc, применяемый преимущественно в архитектуре "клиент-сервер"). Имя псевдонима БД записывается как значение свойства DataBaseName этих компонентов.
При работе в архитектуре "клиент-сервер" псевдоним БД часто записывается в свойство AliasName компонента TDatabase, отвечающего за связь с удаленной БД. База данных получает новый псевдоним (свойство DataBaseName компонента TDatabase). В этом случае компоненты типа "набор данных" в свойстве DataBaseName хранят значение из свойства DataBaseName компонента TDatabase.
Компонент TTable работает с записями одной физической таблицы БД. Поэтому свойство TableName этого компонента хранит имя этой таблицы БД.
Компонент TQuery в общем случае возвращает набор данных, записи которого получены в результате выполнения запроса к одной или нескольким таблицам БД. Имена таблиц и условия выборки из них записей устанавливаются в запросе (SQL-оператор SELECT), который хранится в свойстве SQL компонента TQuery.
Имя любого компонента типа "набор данных" хранится в его свойстве Name. Свойство Active указывает, активен ли (открыт, готов для доступа к данным) соответствующий набор данных (значение True) или не активен (значение False). Открытие НД производится на этапе разработки приложения и во время выполнения установкой свойства Active в значение True, а также во время выполнения - при помощи метода Open этого набора данных.
Для связи визуальных и невизуальных компонентов для работы с данными используется компонент "промежуточного уровня", TDataSource (источник данных). Его свойство DataSet содержит имя соответствующего компонента типа "набор данных".
Визуальные компоненты разделяются на работающие с множеством записей набора данных (например, TDBGrid) и с отдельным полем (TDBEdit и другие). Соответственно, компоненты, работающие с множеством записей, ссылаются в своем свойстве DataSource только на имя компонента TDataSource;
компоненты, работающие с конкретным полем, кроме этого ссылаются на имя поля НД (свойство FieldName). Список доступных полей набора данных хранится в свойстве Fields соответствующего компонента типа "набор данных".
Назначение BDE Administrator
В Delphi для доступа к базам данных из приложения, как известно, используется цепочка "Приложение -> BDE -> База данных". Это означает, что при любом обращении к БД из приложения реально адресуется BDE (напомним, это аббревиатура Borland Database Engine, машины баз данных фирмы Borland). BDE, используя собственные функции, связывается непосредственно с базой данных. Действия, осуществляемые при этом BDE, мы здесь обсуждать не будем, поскольку эта тема отдельного рассмотрения.
Для работы с конкретной базой данных BDE, во-первых, должна знать:
• где БД физически расположена;
• параметры этой БД,
• общие параметры драйвера БД того типа, к которому принадлежит обрабатываемая БД;
• общие системные установки.
Параметры драйвера БД определяют параметры конкретной БД, значения которых не указаны.
Системные установки являются общими для всех драйверов. Замечание. Те,-кто работал с Delphi версий 1 и 2, будут поначалу неприятно удивлены, не обнаружив в 3-ей версии BDE Configuration Utility. Именно ее функции и выполняет в Delphi 3 утилита BDE Administrator Несомненно, что Вы найдете в ней много общего с BDE Configuration Utility.
Создание псевдонима БД
Параметры БД и ее местоположение определяются псевдонимом БД. Псевдоним - это некоторое имя (псевдоним БД). Именно этот псевдоним и используют при логическом обращении к БД компоненты типа "набор данных" приложения Delphi, например TTable и TQuery. BDE считывает параметры, поставленные в соответствие данному псевдониму, что во многом определяет ее дальнейшие действия по физической работе с БД.
Псевдонимы баз данных определяются в утилите BDE Administrator. Для того, чтобы определить псевдоним, необходимо:
1. Выбрать элемент меню Object \ New;
2. Выбрать в появившемся окне имя драйвера базы данных (STANDARD для Paradox и dBase, MSACCESS для Microsoft Access, ORACLE INTRBASE, SYBASE, MSSQL, INFORMIX, DB2 соответственно для баз данных Oracle, InterBase, Sybase, MS SQL Server, Informix, DB2 и, если установлен, драйвер ODBC);
4. Ввести имя псевдонима в левом окне;
5. Определить необходимые параметры псевдонима в правом окне (рис. 5.1);
6. Щелкнуть по псевдониму правой кнопкой мыши и выбрать во всплывающем меню элемент Apply для подтверждения или Cancel для отказа.
Поскольку в настоящей книге основной упор делается на использование "родных" баз данных Borland (Paradox и InterBase), опишем далее параметры драйверов этих баз данных. Для получения информации о создании псевдонимов БД иных типов обратитесь к системной документации и встроенной системе помощи.
Параметры баз данных типа STANDARD
Этот тип используется для доступа к локальным БД (Paradox, dBase). Таблицы, индексы, мемо-поля локальных БД хранятся раздельно друг от друга, каждый в своем файле. База данных в этом случае - группа таких файлов, собранных в одном каталоге на диске. Псевдоним БД указывает на такой каталог.
При определении псевдонима БД указываются следующие параметры:
DRIVER -
определяет тип СУБД (PARADOX, DBASE или ASCIIDRV для довольно редкого случая использования в качестве таблиц БД колумнированных, т.е. разбитых на колонки, текстовых файлов); ENABLE BCD -
указывает на необходимость для BDE переводить целые и десятичные значения полей в значения BCD (binary coded decimal, двоично-десятичные кодированные значения). BCD позволяет устранить ошибки округления, имеющие место, например, когда результат выражения (1/3)*3 равен 0.99998 или 1.000001, что имеет место для операций над целыми и десятичными значениями. TRUE заставляет BDE преобразовывать целые и десятичные значения в BCD-формат, PATH - указывает путь на диске к каталогу, в котором расположены файлы БД.
Установки параметров драйвера PARADOX
Параметры, присущие всем БД того или иного типа, устанавливаются для драйверов БД. Затем они применяются к псевдониму каждой БД того же типа. Некоторые параметры могут быть переопределены для конкретного псевдонима, а некоторые - нет.
Установка параметров драйверов производится после выбора закладки Configuration и раскрытия дерева до ветви Drivers \ Native \ Имя драйвера (рис.5 2). В ветви Drivers \ ODBC производятся установки драйвера ODBC.
Параметры драйвера PARADOX:
VERSION -
Внутренняя версия драйвера Paradox; TYPE -
Тип сервера - SERVER (SQL-сервер) или FILE (однопользовательские БД, файл-серверные БД). NET DIR -
Каталог, в котором расположен сетевой управляющий файл PDOXUSRS.NET. Для работы с файлами Paradox в сети необходимо установить параметр NET DIR , предварительно расположив фат PDOXUSRS.NET в указанном каталоге. LANGDRIVER -
Языковый драйвер, используемый для кодировки символьных полей и определяющий также порядок сортировки символьных значений. Для русскоязычных приложений рекомендуется Pdox ANSI Cyrillic.
Для этого драйвера без ошибок работают символьные функции для перевода строчных букв в заглавные и обратно Ansi UpperCa “ и AnsiLowerCase. LEVEL -
Тип временных таблиц Paradox (уровень версии)' 7 - 32-битные таблицы Paradox для Windows;
5 - Таблицы Paradox 5.0;
4 - Стандартный формат таблиц (Paradox 4.0);
3 - Формат таблиц, совместимый с Paradox 3.5 и более ранними версиями.
По умолчанию принят 4 уровень. Уровни 4 и 5 позволяют использовать blob-поля, вторичные индексы, строгие ограничения ссылочной целостности.
7 уровень следует использовать в случае применения поддержки улучшенной индексации таблиц
BLOCK SIZE -
Определяет размер блока на диске при хранении записей таблиц Paradox. По умолчанию 2048. Размер блока кратен 1024 байтам Возможные значения для уровней 5 и 7. 1024,2048,4096, 16384 или 32768. Для уровней 3 и 4 - 1024, 2048 или 4096. • FILL FACTOR -
Процент заполнения блока на диске, когда Paradox начнет выделение нового блока Значение в диапазоне 1 .100 По умоччанию 95. Малые размеры блока улучшают быстродействие индексов, но увеличивают их размер; большие размеры блока уменьшают размер индекса, но ухудшают их быстродействие. • STRICTINTEGRTY -
Указывает, могут ли изменяться значения в таблицах Paradox в приложениях, не поддерживающие ссылочную целостность (к примеру, Paradox 4.0). Значение TRUE запрещает изменять таблицы Paradox 4.0, связанные ссылочной целостностью; FALSE разрешает такие изменения с риском нарушения ссылочной целостности. По умолчанию TRUE.
Установки параметров драйвера INTERBASE
VERSION - неизменяемый параметр. Содержит версию драйвера InterBase.
TYPE -
значение SERVER указывает, что работа с БД происходит с использованием SQL-сервера. DLL -
неизменяемый параметр, для внутреннего использования. Содержит имя библиотеки динамического вызова (DLL, dynamic link library) для работы с 16-разрядными вызовами. DLL32 -
неизменяемый параметр, для внутреннего использования Содержит имя библиотеки динамического вызова (DLL, dynamic link library) для работы с 32-разрядными вызовами. TRACE MODE -
числовое значение, определяющее способ трассировки информации в системный журнал. BATCH COUNT -
число записей, изменяемых в рамках неявной транзакции. Перед изменением записей автоматически стартует транзакция на сервере. После изменения этого числа записей транзакция на сервере автоматически подтверждается. Более подробно о явном и неявном старте и подтверждении транзакций см. раздел книги, посвященный управлению транзакциями. Использование BATCH COUNT дает возможность изменить число записей в пакете обновлений для каждой подтвержденной транзакции, если размер подобного пакета на сервере недостаточно велик. По умолчанию - число записей, умещающихся в пакете длиной 32 К. ENABLE BCD -
Указывает на необходимость для BDE переводить целые и десятичные значения полей в значения BCD. ENABLE SCHEMA CACHE -
при значении TRUE позволяет хранить сведения о структуре, удаленной БД на клиентском компьютере в каталоге, определяемом параметром SCHEMA CACHE DIR. Хранение структуры БД хорошо тем, что в этом случае BDE не нужно всякий раз считывать данную информацию из удаленной БД, что экономит время и ресурсы. Однако хранение структуры БД возможно лишь для БД, чья структура (состав таблиц, столбцов, индексов и др.) не изменяется во времени. В противном случае выдается ошибка. SCHEMA CACHE TIME -
в случае хранения сведений о структуре БД параметр указывает, с какой периодичностью BDE обновляет сведения о структуре БД. Значения: • 0 - хранение схемы БД не используется;
• 1 (по умолчанию) - после закрытия БД в приложении (т.е. после разрыва соединения с БД);
• число в диапазоне 1..2 147 483 647 - число секунд для обновления
сведений о структуре БД.
LANGDRIVER -
Языковый драйвер, используемый для кодировки символьных полей и определяющий также порядок сортировки символьных значений. Для русскоязычных приложений рекомендуется Pdox ANSI Cyrillic. Для этого драйвера без ошибок работают символьные функции преобразования строчных/заглавных букв AnsiUpperCase и AnsiLowerCase. Pdox ANSI Cyrillic совместим с кодировкой символов InterBase WIN 1251 и порядком сортировки символов (collation order) PXW_CYRL. Эти значения указываются в БД в атрибутах: DEFAULT CHARACTER SET для баз данных, CHARACTER SET и COLLATE для доменов и столбцов. МАХ ROWS -
указывает максимальное число записей, которые драйвер пытается считать из удаленной БД при посылке каждого SQL-запроса к серверу, с учетом запросов на чтение структуры БД и проверки соответствия значений столбцов накладываемым на них ограничениям. Используется для предотвращения безграничного расхода системных ресурсов, например, при выдаче оператора "SELECT *..." для большой по объему таблицы БД. Малое значение МАХ ROWS может привести к тому, что таблица БД не сможет быть открыта, поскольку запрос чтения структуры таблицы может возвратить больше записей, чем указано в МАХ ROWS. Однако МАХ ROWS никак не воздействует на не-обновляемые запросы. По умолчанию принято (-1), что означает отсутствие лимита на количество считываемых строк. В случае, если количество возвращаемых строк больше установленного лимита, выдается ошибка DBIERR_ROWFETCHLIMIT. Поэтому следует перенастраивать такие приложения для использования DBIERR.ROWFETCHLIMIT вместо DBIERR_EOF (конец данных). OPEN MODE - устанавливает режим чтения-записи данных из (в) БД (значение READ/WRITE, по умолчанию) и режим "только для чтения" (READ ONLY).
SERVER
NAME - для удаленных БД содержит имя сетевого сервера и путь к БД на сетевом сервере. Вид указания имени сервера и пути зависит от используемого сетевого протокола. Для протокола TCP/IP при расположении БД на сервере, который работает под управлением Windows NT/95, указание пути к удаленной БД производится в формате ИмяСервера:Путь\ИмяБД.gdb, например:
mdl:c:\ptoject\bd\mon.gdb
При этом должны быть соответствующим образом настроены файлы HOSTS и SERVICES на компьютере, имеющем доступ к удаленной БД (более подробно см. раздел, посвященный введению в технологию "клиент-сервер", где, в частности, обсуждаются вопросы связи БД InterBase и клиентских приложений, созданных с помощью Delphi). SQLPASSTHRU MODE - важнейший в рамках технологии "клиент-сервер" режим, определяющий, каким образом происходит взаимодействие BDE с сервером на уровне транзакций приложения клиента.
Значение параметра определяет, может ли BDE передавать серверу собственные команды для управления запросами, или нет. В последнем случае используется Passthrough SQL - операторы SQL, выполняемые при помощи компонента TQuery клиентского приложения. Также данный параметр определяет режимы использования неявного старта и подтверждения транзакций. Более подробно с данной проблематикой можно ознакомиться в разделе книги, посвященном управлению транзакциями.
Параметр SQLPASSTHRU MODE может принимать следующие значения:
• SHARED AUTOCOMMIT - PassthroughSQL и команды BDE используют одно и то же соединение с удаленной БД, реализуемое в приложении через один компонент TDatabase. В том случае, если в приложении транзакция явно не реализуется методом TDatabase-StartTransaction, происходит неявный старт транзакции и ее автоматическое подтверждение.
• SHARED NOAUTOCOMMIT -
Passthrough SQL и команды BDE используют одно и то же соединение с удаленной БД, неявные транзакции стартуют аналогично режиму SHARED AUTOCOMMIT, однако их неявного подтверждения не происходит и это нужно делать явно. Поведение Passthrough SQL в этом случае зависит от сервера. • NOT SHARED -
Passthrough SQL и команды BDE не могут использовать одно и то же соединение с удаленной БД. Обновляемые запросы на SQL не поддерживаются псевдонимами БД, для которых установлен режим NOT SHARED. SHARED AUTOCOMMIT и SHARED NOAUTOCOMMIT не поддерживают всех операторов Passthrough SQL. В режимах SHARED AUTOCOMMIT или SHARED NOAUTOCOMMIT не следует управлять транзакциями при помощи SQL-оператора SET TRANSACTION.
SQLQRYMODE
определяет режим выполнения запросов SQL. Возможные значения:
• NULL
(по умолчанию) - для доступа как к локальным, так и серверным БД. Запросы вначале посылаются к SQL-серверу. Если тот не в состоянии выполнить запрос, он выполняется локально. • SERVER -
только серверные БД. Запрос посылается SQL-серверу. Если сервер не может выполнить запрос, локального выполнения не происходит. • LOCAL -
только локальные БД. Запрос всегда выполняется на клиентской машине, т.е. локально. Заметим, что запрос может быть отвергнут сервером БД, если: 1. имеет место гетерогенный запрос, т.е. запрос к различным БД;
2. запрос состоит более чем из одного SQL-оператора;
3. сервер БД не поддерживает синтаксис операторов, присутствующих в запросе.
• USER
NAME - определяет имя, которое выдается в качестве подсказки имени пользователя при запросе имени пользователя и пароля в момент соединения с БД.
Системные стартовые установки
Выбрав закладку Configuration, раскройте ветвь дерева System \ Init. Здесь могут быть установлены стартовые параметры запуска приложения, работающего с BDE (рис. 5.2). Кроме языкового драйвера, эти установки меняются редко и хотя бы на первых порах при работе с BDE рекомендуется не изменять установки, принятые по умолчанию.
Назначение параметров:
• AUTO ODBC -
TRUE определяет импорт установленных драйверов ODBC. По умолчанию FALSE. • DATA REPOSITORY -
определяет имя активного словаря данных. • DEFAULT DRIVER -
Имя драйвера, установленного по умолчанию для локальных БД (для псевдонимов, у которых в параметре TYPE установлено значение FILE и при указании имен файлов не указаны расширения). LANGDRIVER -
языковый драйвер по умолчанию. Для русскоязычных данных рекомендуется Pdox ANSI Cyrillic. • LOCAL SHARE -
определяет способность разделять доступ к локальным данным между активными приложениями, как использующими, так и не использующими BDE. Значение TRUE необходимо установить, если доступ к данным будет производиться в приложениях с использованием BDE и в обход BDE. По умолчанию FALSE. • MAXBUFSIZE
- Максимальный размер буфера (кэша) базы данных, в килобайтах. Значение должно быть кратным 128. По умолчанию 2048. • MINBUFSIZE - Минимальный размер буфера (кэша) базы данных, в килобайтах. Значение должно находиться в диапазоне 32... 65535. По умолчанию 128. • MAXFILEHANDLES -
максимальное число дескрипторов (handle), используемых BDE. Значение в диапазоне 5...4096. Большое значение увеличивает производительность, но требует большего числа ресурсов Windows. По умолчанию 48. MEMSIZE -
максимальный размер памяти, доступный BDE для использования. По умолчанию 16MB. • SHAREDMEMSIZE -
Максимальное количество памяти в килобайтах, которое BDE может использовать для разделения ресурсов. По умолчанию 2048 К. Разделяемыми ресурсами являются дескрипторы (handle), драйверы, табличные объекты и др.. Если их число велико, значение в SHAREDMEMSIZE следует увеличить. • SHAREDMEMLOCATION -
Содержит адрес менеджера, управляющего разделяемой памятью. Менеджер загружается в память, начиная с указанного адреса. Если этот адрес конфликтует с другими приложениями, его следует изменить. Значения по умолчанию - ЕООО (Windows 95), 7000 (Windows NT). • SQLQRYMODE
определяет режим выполнения запросов SQL (см. выше). • VERSION
- неизменяемый параметр, определяющий текущую версию BDE.
Параметры формата даты
SEPARATOR - задает символ для разделения дня, месяца, года в значениях даты, например символ "/" ("31/12/96"). По умолчанию берется символ из системных установок Windows .
• MODE -
задает порядок следования дня (D), месяца (М) и года (Y) в дате. Возможные значения: О (MDY), 1 (DMY), 2 (YMD). По умолчанию берется порядок следования из системных установок Windows. • FOURDIGITYEAR -
определяет, показывать ли в значении года две (FALSE) или четыре (TRUE) цифры. • YEARBIASED -
указывает BDE, как преобразовывать значение года, введенное в виде двух цифр (96). Значение TRUE обязывает прибавлять к двузначному году 1900 (введено 96, получено 1996). При значении FALSE этого не происходит (введено 96, получено 0096). По умолчанию TRUE. • LEADINGZEROM -
указывает (TRUE), что для одноразрядных значений месяца необходимо прибавлять ведущий ноль (например, "16/4/96" преобразовать к виду "16/04/96"). По умолчанию FALSE. • LEADINGZEROD - указывает (TRUE), что для одноразрядных значений дня необходимо прибавлять ведущий ноль (например, "6/12/96" преобразовать к виду "06/12/96"). По умолчанию FALSE.
Параметры формата времени
• TWELVEHOUR - определяет, показывается ли время в двенадцатичасовом формате (TRUE) или в двадцатичетырехчасовом (FALSE). Например, время "10:20 РМ" (12-часовой формат) в 24-часовом формате - "22:20". По умолчанию TRUE.
• AMSTRING -
устанавливает символы, определяющие время до полудня для 12-часового формата. По умолчанию "AM". • PMSTRING -
устанавливает символы, определяющие время после полудня для 12-часового формата. По умолчанию "РМ". • SECONDS -
определяет, показываются ли секунды (TRUE) или нет (FALSE). По умолчанию TRUE. MILSECONDS -
определяет, показываются ли миллисекунды (TRUE) или нет (FALSE). По умолчанию FALSE.
Параметры числового формата
Устанавливают порядок преобразования строковых значении в числовой формат.
• DECIMALSEPARATOR -
устанавливает символ, отделяющий целую часть числа от дробной. По умолчанию берется значение, установленное в Windows. •
THOUSANDSEPARATOR - устанавливает символ, служащий разделителем тысяч в целой части числа (например, 7,654,321.00). По умолчанию берется значение, установленное в Windows. •
DECIMALDIGITS - указывает число разрядов в дробной части числа. По умолчанию 2. LEADINGZERON
- указывает, имеют ли числа в диапазоне 1..-1 ноль в целой части (TRUE) или нет (FALSE). Например, 0.22 и .22. По умолчанию TRUE.
Установки форматов
Ветвь System \ Formats используется для установки форматов даты (Date}, времени (Time} и числовых значений (Number}.
Сохранение конфигурации в отдельном файле
Текущая конфигурация со значениями псевдонимов, драйверов и стартовых настроек может быть сохранена в файле. Для этого нужно выбрать раздел меню Object | Save As Configuration и указать имя, после чего нажать кнопку Ok. По умолчанию конфигурация записывается в файл Program Files\Borland\ Common Files\BDE\Idapi32.cfg. Этот файл обновляется автоматически после выполнения подтверждения для всех изменений (Object \ Apply) или для каждого изменения (Apply в контекстном меню, вызываемой правой кнопкой мыши).
Файл конфигурации, отличный от принятого по умолчанию, может быть загружен (Object \ Open Configuration).
Объединение файлов конфигурации
Файлы конфигурации могут быть объединены. Это важно в том случае, когда необходимо установить на компьютер приложение или группу приложений. При этом нужно добавить в файл конфигурации новые псевдонимы БД. Можно завести их вручную. Однако, если вместе с дистрибутивом приложений поставляется и конфигурационный файл, псевдонимы из него могут быть добавлены в основную (или любую другую) конфигурацию. Для этого нужно выбрать элемент меню Object | Merge Configuration и выбрать конфигурационный файл, информация из которого будет добавляться, и затем ответить Yes на грозное предупреждение о том, что результаты объединения не могут быть отменены операцией Undo. На рис. 5.3, 5.4 и 5.5 представлены исходная конфигурация, добавляемая конфигурация и результирующая конфигурация.
Применение TField
Компонент TField позволяет обращаться к полям таблиц баз данных. Каждый набор данных - неважно, ТТаЫе или TQuery - состоит из записей, а те, в свою очередь, состоят из полей. Таким образом, в составе записи имеется минимум одно поле.
В Delphi имеется возможность использовать при работе с НД или все поля, определенные в данной ТБД на текущий момент, или использовать только часть существующих полей.
Использование только части имеющихся полей дает то преимущество, что значения неиспользуемых полей не могут быть изменены ни вследствие алгоритмической ошибки, ни вследствие злонамеренного умысла, поскольку неиспользуемые поля считаются неизвестными.
Существует два способа задания состава полей для НД.
Первый
состоит в том, что после создания НД (компонент ТТаЫе или TQuery) не предпринимается никаких дополнительных действий по уточнению состава полей. Тогда: •
для компонента TTable - будет разрешен доступ ко всем полям, определенным в данный момент в ТБД, связанной с компонентом ТТаЫе; •
для компонента TQuery - будет разрешен доступ ко всем полям (в том числе и результатам выражений), указанным в списке возвращаемых полей в операторе SELECT. Хотя этот оператор в результате выполнения SQL-запроса может возвращать НД, составленный из нескольких физических ТБД, сами поля будут считаться принадлежащими к единому НД, образовавшемуся в результате выполнения SQL-запроса из свойства TQuery.SQL. К полю в этом случае можно обращаться с помощью метода FieldByName компонентов TTable и TQuery function FieldByName(const FieldName: string): TField;
или через свойство указанных компонентов Fields [Index], которое возвращает указатель на тип TField. Подробнее об этом свойстве будет сказано ниже.
Определить во время выполнения приложения, используются для набора данных все поля по умолчанию или только их часть, определенная посредством редактора полей, можно при помощи свойства набора данных
го, rt property DefaultFields: Boolean;
ЗАМЕЧАНИЕ.
Аббревиатура го (read only) означает, что свойство доступно только для чтения; rt (run time) означает, что свойство доступно только во время выполнения приложения. Полный список принятых сокращений см. в начале книги. Значение True указывает, что используются поля по умолчанию; False - что используются поля, определенные при помощи редактора полей.
Второй
способ определения состава полей заключается в том, что для данного НД поля как компоненты TField добавляются в форму с помощью редактора полей Delphi. О нем будет сказано чуть ниже. К таким полям можно обращаться через его имя, определяемое в свойстве Name компонента TField, соответствующего данному полю.
По умолчанию, при добавлении в форму компонента TField, его имя генерируется так: берется имя НД (т.е. значение свойства Name компонента TTable или TQuery, к которому принадлежит поле) и к нему добавляется имя поля, взятое из структуры ТБД (TTable) или из запроса (TQuery).
Так, поле с именем FIO, используемый в НД Students, при добавлении в форму средствами редактора полей, получит имя StudentsFIO.
ЗАМЕЧАНИЕ.
Это имя будет относиться целиком к компоненту TField, а не только к значению (например, "Иванов И.И."), которое поле FIO содержит в текущей записи ТБД. Компонент TField, как будет показано ниже, обладает рядом свойств, методов и событий, обращаться к которым следует через указание имени компонента TField и имени свойства, метода или обработчика события, например: StudentsFIO. Index := 5; // изменить порядковый номер поля StudentsFIO. Readonly := True; //запретить изменение значений поля
Таким образом, экземпляр StudentsFIO компонента TField трактуется не как конкретное значение, которое принимает поле FIO в конкретной строке ТБД, а как весь столбец набора данных, обладающий единым поведением, т.е. едиными свойствами, методами и событиями для всех записей набора данных. Значение поля для текущей записи доступно с помощью свойств Value, AsBoolean, AsString и т.д. Например:
IF StudentsFIO.AsString = 'Иванов' then ....
Итак, когда поле НД определено в форме в качестве экземпляра компонента TField, к нему можно обращаться по имени (содержащемуся в свойстве Name), а также через метод НД FieldByName и свойство Fields [Index].
Если хотя бы для одного поля НД создан компонент TField, первый принцип, т.е. принцип использования всех полей ТБД или результата SQL-запроса, отвергается. В НД будут считаться определенными только те поля, для которых созданы компоненты TField, а иные поля - отвергаться как несуществующие для данного НД (TTable или TQuery).
К "несуществующим" полям обратиться изданного НД нельзя никак. Такие попытки будут возбуждать исключительные ситуации с сообщением 'Field <имя> not found'.
Вновь вернуться к принципу использования всех полей ТБД или результата SQL-запроса можно, удалив в редакторе полей все определенные ранее TField или добавив с его помощью недостающие поля.
То, какие поля определять в данном НД, зависит от назначения разрабатываемого приложения и диктуется целесообразностью.
ЗАМЕЧАНИЕ.
Если нужно иметь доступ к полю, но не показывать его значений в компонентах, визуализирующих данные (например, в компоненте TDBGrid), свойство Visible этого поля следует установить в состояние False.
Поля выбора данных
Кроме обычных полей, связанных с полями ТБД, и вычисляемых полей, в Delphi имеется возможность создавать поля выбора данных (lookup).
Поля выбора данных
одного набора данных содержат значения их другого набора данных, связанного по ключу с НД, к которому принадлежит поле выбора данных. Поле выбора данных всегда доступно только для чтения и не может быть одновременно полем выбора данных и вычисляемым полем. Реляционное отношение НД, служащего источником значений для поля выбора данных и НД, к которому оно принадлежит, есть "один-ко-многим" и реже "один-к-одному". Это означает, что на один вариант значения в наборе данных-источнике должно приходиться одно или несколько связанных значений в НД, к которому принадлежит поле выбора. Для определения поля набора данных необходимо создать новое поле в редакторе полей, сразу же установив радио-группу Field Type в значение Lookup (рис. 6.5.).
Затем устанавливаем значения свойств:
DataSet -
Имя НД-источника значений для поля выбора данных; Key Fields -
Индексные поля набора данных-владельца поля выбора данных. По этим полям НД-владелец соединяется с НД-источником значений поля выбора данных. Если в индексе имеется несколько полей, они перечисляются через точку с запятой; Lookup Fields - Индексные поля НД-источника значений для поля выбора. По значениям этих индексных полей устанавливается связь набора-источника со значениями индексных полей НД-владельца поля выбора (они указаны в параметре Key Fields). Если в индексе имеется несколько полей, они перечисляются через точку с запятой;
Result Field -
Поле набора данных-источника, возвращаемое в качестве результата. Необходимо следить, чтобы тип вновь создаваемого поля и поля результата совпадали. Указанным выше параметрам редактора полей соответствуют свойства компонента TField
property LookupDataSet: TDataSet;
property KeyFields: string;
property LookupKeyFields: string;
property LookupResultField: string;
Аналогичным по последствиям будет установка соответствующих свойств в инспекторе объектов для вновь добавляемого поля. Заметим, что свойство поля
property Lookup: Boolean;
должно быть установлено в True.
Разберем пример отношения "один-к-одному" Пусть существует ТБД 'Сотрудники", которая включает в себя поля "Табельный номер" (TabNum), "ФИО" (FIO), "Должность" (Doljnost) и "Ученая степень" (UchStepen) С ней ассоциирован НД Table 1 (рис 6 6)
и ТБД "Информация о сотрудниках", которая включает в себя ФИО сотрудника (поле FIO), год рождения (GodRojd) и семейное положение (SemPoloj). С ней ассоциирован НД DataModule1 Table1 (рис 6 7). ТБД "Сотрудники" и "Информация о сотрудниках" связаны по индексу, образованному полями FIO
Требуется при просмотре в ТБД "Сотрудники" выводить год рождения данного сотрудника ниже компонента TDBGrid, в DBTextl
Для этой цели для Tablel, связанной с НД "Сотрудники", входим в редактор почеи и создаем новое поле, сразу же установив радио-группу Field Type в значение Lookup (рис 6 8)
Затем устанавливаем значения свойств
DataSet
НД DataModule Table1, который связан с ТБД "Информация о сотрудниках"), Key Fields
поле FIO НД Tablel (ТБД "Сотрудники"), которое отображается в TDBGrid), Lookup Fields
поле FIO НД DataModulel Table (ТБД "Информация о сотрудниках"), Result Field
поле GodRojd НД DataModulel Tablel (ТБД "Информация о сотрудниках") Таким образом, нами определен новый компонент Table 1GR типа TField (а точнее, TStringField), источником данных для которого служит поле GodRojd ТБД "Информация о сотрудниках", из той ее записи, у которой значение поля FIO совпадает со значением поля FIO соответствующей записи ТБД "Сотрудники"
Далее размещаем в форме компоненты Label 1 и DBTextl (связанный с полем Table1GR) Тогда для текущей записи сотрудника в DBGndl в DBText1 отображается год рождения для данного сотрудника из ТБД "Информация о сотрудниках"(рис 6.9)
Поля выбора данных, использующиеся
Поля выбора данных могут использоваться для автоматического занесения информации в данную ТБД из другой ТБД. Часто это очень удобно. Рассмотрим пример, для чего несколько модифицируем показанные выше ТБД.
Допустим имеется ТБД "Сотрудники" состоящая из полей: уникальное TabNum (табельный номер), FIO (ФИО), KodDol (код должности), и ТБД "Оклады", состоящая из полей уникальное KodDol (код должности), ОоЦпо$1(должность), Oklad (оклад). ТБД "Сотрудники" и "Оклады" состоят в связи "многие-к-одному" или, если смотреть со стороны ТБД "Оклады", "один-ко-многим". Полем связи является Doljnost.
Как видно, в ТБД "Сотрудники" может быть несколько записей с одним и тем же значением поля KodDol (например, 144), в то время как в ТБД "Оклады" конкретный код должности может встречаться только единожды.
Присвоение кодов каким-либо атрибутам таблиц БД является весьма распространенным приемом. Если по этим атрибутам для нескольких ТБД имеют место реляционные отношения, для хранения индексов по кодам (цифровым полям) и их использования для доступа к данным требуется много меньше дискового пространства и времени, нежели для хранения индексов по оригинальным значениям. В нашем примере это обосновано: лучше строить индекс по коду (слово), нежели по символьному значению поля Doljnost (рис. 6.10). Это особенно актуально, если символьное поле имеет большую длину (например, 200 символов). Индексы по таким полям получаются очень большими.
Другой выгодой от использования кодов является то, что в справочнике (lookup-ТБД) "Оклады" коды должности KodDol представляют собой автоинкрементное поле, т.е. поле, уникальное значение которого BDE устанавливает автоматически. В дальнейшем его менять нельзя. Это снимает необходимость каскадного изменения в дочерней ТБД "Сотрудники" при изменении значения поля связи (KodDol) в родительской ТБД "Оклады". ЗАМЕЧАНИЕ. Автоинкрементные поля более свойственны локальным СУБД. Для удаленных (серверных) СУБД автоинкрементные поля заменяются другими механизмами, например, генераторами (InterBase). Если бы связь между данными ТБД была установлена по полю Doljnost, a не KodDol, то при изменении значения должности с "приват-доцент" на "доцент" в ТБД "Оклады" на значение "доцент" должны были бы измениться значения всех записей в ТБД "Сотрудники", у которых поле Doljnost содержит значение "приват-доцент" (рис. 6.11, 6.12).
Однако поскольку мы используем для связи между названными таблицами код, в ТБД "Оклады" значение поля Doljnost можно менять сколь угодно много раз - на связь между ТБД это не окажет никакого влияния. Заметим, что по полю Doljnost в ТБД "Оклады" должен быть построен уникальный индекс, чтобы предотвратить возможность ввода двух одинаковых должностей с разными окладами. В данном примере кодом будет являться поле KodDol, a семантически значимым полем поле Doljnost. Более подробно с данным вопросом можно ознакомиться в разделе "Обеспечение ссылочной целостности"
Поставим задачу. Пусть при вводе данных в ТБД "Сотрудники" нам известна должность конкретного сотрудника, но кода ее, мы, разумеется, не помним. Поэтому нужно:
• обеспечить просмотр и выбор интересующей должности из справочника (lookup-ТБД) "Оклады";
• обеспечить занесение кода этой должности из поля KodDol ТБД "Оклады" в поле KodDol ТБД "Сотрудники".
В форме НД SotrTable соответствует ТБД "Сотрудники", а НД OkladyTable соответствует ТБД "Oklady".
Добавим в набор данных SotrTable поле выбора данных Lookupchik (рис. 6.13)
Значения параметров поля выбора, показанные на рис. 6.13, можно читать так "Исходя из реляционной связи по полю KodDol со стороны НД SotrTable (свойство Key Fields) и по полю KodDol (свойство LookupKeys) со стороны набора данных-источника значений поля выбора (набора данных OkladyTable, свойство DalaSel), заполнять поле реляционной связи в SotrTable значением, взятым из записи, которая будет выбрана в ниспадающем меню В ниспадающем меню показывать только поле Doljnost (параметр ResultField) НД OkladyTable "
Буфер значений полей выбора данных
Свойство
property LookupCache: Boolean;
определяет, будут ли значения полей выбора данных храниться в кэше (буфере) - значение True -, или нет (значение False).
Свойство
ro property LookupList: TLookupList;
содержит список значений из набора данных-источника для полей выбора данных, индексированных набором значений полей, список которых содержится в свойстве KeyFields. Метод ValueOfKey компонента TLookupList возвращает результирующее поле (значение поля выбора данных)
Value := LookupList.ValueOfKey(DataSet.FieldValues[KeyFields]) ;
Список полей выбора данных формируется после открытия НД или после обновления списка методом компонента Tfield procedure RefreshLookupList;
Обзор полей TxxxField
• TStringField - хранит строковое значение длиной до 255 символов. Строки большей длины нужно хранить в blob-полях (TMemoField).
Свойство property Transliterate: Boolean; указывает, следует ли производить преобразование символов в ANSI в том случае, если символьные поля в ТБД-источнике находятся не в ANSI-кодировке или содержат расширенные ASCII-символы. Когда свойство установлено в True, для
преобразования ASCII символов в иную кодировку используется функция AnsiToNative и функция NativeToAnsi для перевода в ANSI.
• целочисленные поля -
применяются для хранения целых чисел различной длины: TIntegerField-
от -2,147,483,648 до 2,147,483,647 TSmallintField -
от -32,768 до 32,767 TWordField
- от 0 до 65,535 Свойства property MaxValue: Longint; и property MinValue: Longint; могут определять максимальное и минимальное значение поля.
• числовые поля с плавающей точкой -
применяются для хранения целых чисел различной длины: TFloatField -
числа, чьи абсолютные значения - 5.0*10-324 to 1.7*10+308 до 15-16 TCurrencyField -
аналогично TFloatField, но в денежном формате TBCDField -
вещественные десятичные числа с фиксированным числом разрядов после точки. До 18 символов. Диапазон представляемых чисел зависит от числа знаков. Применяется только для Paradox. Свойство property Precision: Integer; позволяет указать число знаков после десятичной точки (по умолчанию 15).
Свойства property MaxValue: Longint; и property MinValue: Longint; могут определять максимальное и минимальное значение поля.
• TBooleanField -
содержит значения True или False. • поля даты и времени:
TDateTimeField -
содержит значения даты и времени в формате TDateTime. TDateField -
значения даты в формате TDate TTimeField
- значения времени в формате TTime. • поля для хранения значений произвольных форматов:
TBIobField -
произвольное байтовое поле без ограничения длины. Метод procedure LoadFromFile(const FileName: string); загружает содержимое поля из файла, метод procedure LoadFromStream(Stream: TStream); - из потока.
Метод procedure SaveToFile(const FileName: string); сохраняет содержимое поля в файле, метод procedure SaveToStream(Stream: TStream); - в потоке.
Свойство property BlobSize: Integer; содержит размер в байтах blob-поля данной записи.
Свойство property Transliterate: Boolean; указывает, следует ли производить преобразование символов в ANSI в том случае, если blob-поля в ТБД-источнике находятся не в ANSI-кодировке или содержат расширенные ASCII-символы. Когда свойство установлено в True, для преобразования ASCII символов в иную кодировку используется функция AnsiToNative и функция NativeToAnsi для перевода в ANSI.
Свойство property BlobType: TBIobType; возвращает тип blob-поля. Возможные значения: ftBlob, ftMemo, ftGraphic, ftFmtMemo, ftParadoxOle, ftDBaseOle, ftTypedBinary.
TBytesField -
произвольное байтовое поле без ограничения длины. Не имеет методов LoadFromFile, LoadFromStream, SaveToFile, SaveToStream. Свойство property DataSize: Word
позволяет определить во время выполнения, сколько байт нужно для хранения поля в памяти. TVarBytesFieId -
произвольное байтовое поле длиной до 65,535 байт. Текущая длина может быть получена из первых двух байт поля. TMemoField -
строковое значение неопределенной длины (мемо-поле). Метод procedure Clear; очищает мемо-поле.
Метод procedure LoadFromFile(const FileName: string); загружает содержимое поля из файла, метод procedure LoadFromStream(Stream: TStream); - из потока.
Метод procedure SaveToFile(const FileName: string); сохраняет содержимое поля в файле, метод procedure SaveToStream(Stream: TStream); - в потоке.
Свойство property BlobSize: Integer; содержит размер в байтах blob-поля данной записи.
Свойство property Transliterate: Boolean; указывает, следует ли производить преобразование символов в ANSI в том случае, если blob-поля в ТБД-источнике находятся не в ANSI-кодировке или содержат расширенные ASCII-символы. Когда свойство установлено в True, для преобразования ASCII символов в иную кодировку используется функция AnsiToNative и функция NativeToAnsi для перевода в ANSI.
Для работы с мемо-полями в БД Delphi предоставляет компонент TDBMemo. Его описание приводится в разделе "Компоненты для работы с текущей записью набора данных ".
TGraphicField -
произвольное байтовое поле, трактуемое как графическое изображение.
Информация о типе поля
Свойство го property DataType: TFieldType;
возвращает информацию о типе данных поля.
Возможные значения:
ftUnknown неизвестный или неопределенный тип
ftString строковое или символьное поле
ftSmallint 16-битное целое
ftlnteger 32-битное целое
ftWord 16-битное беззнаковое
ftBoolean логическое поле
ftFloat числовое с плавающей точкой
ftCurrency поле в денежном формате
ftBCD двоично-десятичное поле
ftDate поле типа даты
ftTime поле типа времени
ftDateTime поле типа даты и времени
ftBytes фиксированное число байт в двоичном представлении
fiVarBytes переменное число байт в двоичном представлении
ftAutoInc автоинкрементное поле (автоматически увеличивающийся счетчик, 32-битное целое)
FtBlob большой двоичный объект
FtMemo текстовое мемо-поле
FtGraphic графическое поле
FtFmtMemo форматированное текстовое мемо-поле
FtParadoxOle поле Paradox OLE
FtDBaseOle поле dBASE OLE
FtTypedBinary типизированное двоичное поле
Информация о виде поля
Вид поля определяется свойством
property FieldKind: TFieldKind;
Возможны следующие значения:
fkData физическое поле в базе данных
fkCalculated вычисляемое поле
fkLookup поле, возвращающее значение (lookup-поле)
fkInternalCalc вычисляемое поле, значение которого можно хранить в наборе данных
ЗАМЕЧАНИЕ.
Поле awssiflcInternalCalc есть вычисляемое поле, которое может записываться в набор данных. Однако не следует путать его с просто вычисляемым (fkCalculated) полем. Последнее определяется как вычисляемое в редакторе полей и алгоритм его расчета задается в обработчике события набора данных OnCalcFields. Просто вычисляемые поля не могут храниться в качестве полей НД. Поле вида fkInternalCalc может храниться в НД, но оно не определяется как вычисляемое в редакторе полей, а вычисляется SQL-сервером или BDE и содержится в "живом" (то есть доступном для изменения) наборе данных, возвращаемом как результат выполнения SQL-запроса.
Имя поля в SQL-запросах
Пусть после выполнения запроса
SELECT TOVAR AS Т, ZENA AS Z FROM TOVARY WHERE ZENA > 100
получим набор данных, состоящий из полей Т и Z. Чтобы определить для такого поля, какое физическое поле в таблице послужило источником его формирования, используют свойство property Origin: string;
Однако, значение свойства Origin доступно в среде редактора полей и только для тех полей, для которых явно создан компонент TField в редакторе полей.
Проверка применимости символа в поле
Свойство function IsValidChar(InputChar: Char): Boolean; virtual;
возвращает True, если символ InputChar может быть записан в поле того или иного вида:
| Тип поля | Верные символы |
| FtBoolean | все |
| FtSmallInt | числа 0 ..9, плюс (+), минус (-). |
| FtWord | числа 0 ..9, плюс (+), минус (-) |
| FtAutoInc | числа 0 ..9, плюс (+), минус (-) |
| FtDate | все |
| Ftlnteger | числа 0 ..9, плюс (+), минус (-) |
| FtTime | все |
| FtCurrency | числа 0 ..9, плюс (+), минус (-), буква Е или е и разделитель дробной и целой части (определяется текущими установками Windows на конкретном компьютере) |
| FtDateTime | все |
| ftFloat | числа 0 ..9, плюс (+), минус (-), буква Е или е и разделитель дробной и целой части (определяется текущими установками Windows на конкретном компьютере) |
| ftBCD | числа 0 ..9, плюс (+), минус (-), разделитель дробной и целой части (определяется текущими установками Windows на конкретном компьютере) |
| ftString | все |
| ftVarBytes | все |
| ftBytes | все |
| ftBlob | все |
| ftDBaseOle | все |
| ftFmtMemo | все |
| ftGraphic | все |
| ftMemo | все |
| ftParadoxOle | все |
| ftTypedBinary | все |
| ftUnknown | все |
Использование редактора полей
Для того, чтобы определить один или несколько компонентов TField, нужно:
1. Выбрать необходимый НД (компонент TTable или TQuery);
2. Нажать правую кнопку мыши;
3. Во всплывающем меню выбрать режим Field Editor (запуская тем самым редактор полей};
4. Вновь нажать правую кнопку мыши и во всплывающем меню выбрать Add Fields',
5. В появившемся списке полей ТБД (TTable) или полей, участвующих в запросе (TQuery), выбрать необходимые (рис. 6.1)
и нажать кнопку Ok. Для каждого из указанных полей будет создан компонент TField:
6. Если необходимо изменить свойства конкретного поля или написать обработчик для какого-либо события, необходимо в редакторе полей выбрать нужное поле и, используя инспектор объектов, установить значение в свойство или определить обработчик события.
Типы полей
Поля в таблицах баз данных различаются по типу - символьные, целочисленные, логические, blob-поля и т.д.
Соответственно, по типу различаются и компоненты TField, и собственно, TField есть родительский тип, определяющий базовые свойства и методы для своих потомков, типизированных полей. Иерархия компонентов- полей такова:
TField
TBIobField большой двоичный объект
TGraphicField графическое поле(работает с содержимым blob-поля как с графическим изображением)
TMemoField мемо-поле (интерпретирует BLOB-поле как большой текст)
TBooleanField логическое поле
TBinaryField нетипизированное двоичное поле
TBytesFieid поле для хранения байтовых значений фиксированной длины
TVarBytesField поле для хранения байтовых значений переменной длины
TDateTimeField поле для хранения даты и времени
TDateField поле для хранения только даты
TTimeField поле для хранения только времзни
TNumericField поле для хранения числовых значений
TBCDField BCD-значений
TFloaTField значений с плавающей точкой
TCurrencyField в том числе в денежном формате
TIntegerField целочисленных значений
TAutoIncField в том числе автоинкрементных
TSmallIntField в том числе коротких целых
TWordField в том числе в формате беззнакового длинного целого
TStringField поле для хранения строковых значений
Особенности каждого типа будут рассмотрены ниже, равно как и процедуры и функции Delphi, применяемые для работы с полями определенных типов. Покажем общие для всех этих типов свойства, методы и события.
Обращение к полям и их значениям
Как было сказано в п. 6.1, следует различать обращение к полю и обращение к его значению. Рассмотрим способы обращения к полям.
К полю можно обратиться, указав имя поля несколькими способами :
1. Если полю соответствует компонент TField - через имя данного компонента, которое определяется свойством Name. Повторим, что по умолчанию имя компонента TField устанавливается как результат сцепления имени TTable или TQuery и собственно имени поля в ТБД. Например, для поля FIO, определенного в ТБД, работа с которой происходит через Table 1, по умолчанию будет выбрано имя Table I FIO. Тогда использование поля происходит подобно приведенному ниже:
Table1FIO.AsString := 'Иванов'; // или
Table1FIO.Value := 'Иванов';
2. Используя метод FieldByName ('ИмяПоля ') набора данных, function FieldByName(const FieldName: string): TField;
Например,
Table1.FieldByName('FIO).AsString := 'Иванов'; //или
Table1.FieldByName('FIO).Value:= 'Иванов';
3. Используя свойство Fields[индекс] набора данных,
property Fields[Index: Integer]: TField;
Индекс
является порядковым номером поля в определении ТБД. Отсчет идет от 0. Пусть поле Name определено в ТБД третьим по счету. Тогда его индекс равен 2 и использование поля может происходить так: Table1.Fields[2].AsString := 'Иванов'; // или
Tablel.Fields[2].Value:= 'Иванов' ;
Если поле входит в индекс данного НД, свойство IsIndexField: Boolean;
возвращает во время выполнения значение True.
4. Используя свойство набора данных
property FieldValues|const FieldName: string]: Variant;
Это свойство позволяет обращаться к полю через его имя, указываемое как содержимое параметра FieldName, например: Tablel.FieldValues['FIO'] := 'Иванов';
Поскольку свойство FieldValues принимается для набора данных по умолчанию, его имя при обращении к полю можно опускать: Tablel['Name'] := 'Иванов' ;
ЗАМЕЧАНИЕ 1.
Более предпочтительным считается обращение к полю через его имя или через метод FieldByName, поскольку в этом случае мы обращаемся к конкретному полю по его имени. Следовательно, к несуществующему полю обратиться нельзя. Пусть поле FIO удалено из структуры ТБД. Тогда обращение к нему по имени из ассоциированного с данной ТБД НД приведет к ошибке.
Менее предпочтительным является обращение к полю через свойство набора данных Fields [индекс]. Если поле FIO было объявлено в ТБД вторым по счету (обращение Fields[l]), а затем удалено из структуры ТБД, обращение Fields[l] в программном коде будет воспринято как обращение к физически второму полю в ТБД. Этим полем будет третье поле, следовавшее за FIO перед тем, как FIO было удалено из структуры ТБД. После удаления FIO третье поле станет по счету вторым.
Налицо алгоритмическая ошибка, которая может быть не распознана, если FIO и поле, ставшее после удаления FIO вторым, имеют одинаковые или совместимые типы.
Такие ошибки очень трудно локализовать. Поэтому, если это возможно, следует воздержаться от обращения к полю через Fields [индекс].
ЗАМЕЧАНИЕ 2
. Свойство Index компонента TField содержит порядковый номер поля: • в ТБД, если для компонента TTable, ассоциированного с данной ТБД, не создано ни одного компонента TField;
• в списке компонентов TField, относящихся к данному НД - для компонента TTable, если для него определен хотя бы один TField, и всегда - для компонента TQuery.
Порядок следования полей важен, когда содержимое НД визуализируется посредством компонента TDBGrid. В этом случае номер столбца в компоненте TDBGrid соответствует номеру поля в списке TField. И наоборот, если изменить порядок столбца в компоненте TDBGrid (например, "перетащив" столбец на другое место), это приведет к изменению индекса и Fields[l] до перетаскивания будет относиться к другому полю, нежели Fields[l] после перетаскивания столбцов, поскольку свойство Index перетаскиваемого и некоторых других полей изменится.
Это относится как к случаю, когда TField для НД определены, так и к случаю, когда используются все поля ТБД. В последнем случае "перетаскивание" столбца в компоненте TDBGrid на новое место, конечно, не изменит физического порядка следования полей в структуре ТБД; однако с логической точки зрения его индекс (порядковый номер) для данного НД изменится.
Последствия, которые могут принести в структуру НД изменения свойства Index, делают обращения к полю через свойство Fields [индекс] набора данных нежелательными.
Обращение к значению поля. Свойства Value и AsNNN
К значению поля можно обратиться при помощи свойств Value и AsNNN. Свойство
property Value: Variant
возвращает значения следующих типов:
property Value Variant; // Все компоненты
property Value string; //TStringField, TBIobField
property Value Longint; //TAutoIncField, TIntegerField, TSmallintField,TWordField
property Value Double; //TBCDField, TCurrencyField, TFloatField
property Value Boolean; //TBooleanField
property Value TDateTime; //TDateField, TDateTimeField, TTimeField
Это дает возможность пользоваться свойствами приведения типов полей (AsString, Aslnteger и т.д.) в гораздо меньших масштабах. Тем не менее, обойтись без них удается далеко не всегда.
Аналогичные значения возвращает рассмотренное в предыдущем разделе свойство набора данных FieldValues.
Например,
var N : Integer;
N := TablelNumber.Value; // TablelNumber типа TIngereField
Обращение к значению поля через свойство
AsNNN. Существуют следующие свойства приведения типов полей:
property AsBoolean: Boolean;
property AsCurrency: Currency;
property AsDateTime: TDateTime;
property AsFloat: Double;
property Aslnteger: Integer;
property AsString: String;
property As Variant: Variant;
Каждое из этих свойств приводит значение поля к соответствующему типу данных, означенному в названии свойства. Например, если TablelNumber -компонент TIntegerField (поле, хранящее целочисленные значения), для приведения его к типу String можно воспользоваться свойством
Editl.Text := TablelNumber.AsString;
Несомненно, тип поля должен быть совместимым с типом данных, к которому приводится значение поля. Например, если TablelSumma - компонент TFloatField (поле, хранящее вещественные значения), попытка привести его к несовместимому типу Boolean, IF TablelSumma.AsBoolean THEN ...
приведет к ошибке компиляции.
В приводимой ниже таблице показана совместимость значений полей разных типов.
Обозначение:
= типы равнозначны;
+ преобразование возможно;
+ RI преобразование возможно, округление до ближайшего целого;
? преобразование происходит, если возможно; часто зависит от формата показа (свойство DisplayFormat);
х преобразование не разрешено;
Рассмотрим свойства семейства AsNNN более подробно:
property AsBoolean: Boolean; -
числовые значения приводятся к типу Boolean, если содержат 0 (False) или 1 (True). Символьные значения - если содержат в качестве первого символа "Y", "у", "Т" или "t" (или "Yes" или "True"), и False во всех иных случаях. property AsDateTime: TDateTime; -
для приведения к типу TDateTime значений TDateField, TDateTimeField и TTimeField, хотя вместо этого лучше использовать свойство Value, а также для приведения к типу TDateTime строковых значений, находящихся в соответствующем формате. property AsFloat: Double; -
служит для приведения к типу Double значений полей TFloatField, TBCDField и TCurrencyField, AsFloat, хотя вместо этого лучше использовать свойство Value. property Aslnteger: Longint; -
служит для приведения к типу Longint полей типа TIntegerField, TSmallintField и TWordField, хотя вместо этого лучше использовать свойство Value. Для полей типа TStringField преобразование к Longint выполняется, если оно возможно.
property AsCurrency: Currency; -
служит для приведения к типу Currency. property AsString: string; - служит для приведения к типу String. property As Variant: Variant; - служит для приведения к типу Variant.
Событие OnGetText
Пусть поле ТБД хранится не в том виде, в котором должно показываться. Тогда отформатировать его перед тем, как оно будет показано в визуальных компонентах, работающих с данными - TDBGrid, TDBEdit и т.д., можно, определив алгоритм форматирования в обработчике события OnGetText для данного компонента TField.
В процедуре-обработчике присутствуют такие параметры:
Text -
отформатированное значение, показываемое в столбце компонента TDBGrid, в TDBEdit или других визуальных компонентах, связанных с БД; Display Text -
позволяет определить, произошло событие OnGetText при показе значения (значений) поля (True) или при модификации пользователем значения поля (False). Пример.
Пусть поле Company входит в состав ТБД, содержимое которой показывается в TDBGrid с использованием Table 1. Необходимо при показе содержимое данного поля заключать в кавычки (хотя оно хранится без кавычек). Если пользователь захочет изменить значение поля в какой-либо записи, нужно показывать содержимое поля, представленное заглавными буквами. procedure TForm1.Table1CompanyGetText(Sender: TField; var
Text: OpenString;
DisplayText: Boolean);
begin
IF DisplayText THEN
Text := '"' + TablelCompany.AsString + '"'
ELSE
Text := AnsiUpperCase(TablelCompany.AsString);
end;
Когда происходит показ некоторой записи из Table 1 в TDBGrid, для нее возникает событие OnGetText и вызывается приведенный выше обработчик с DisplayText = True. В результате в компоненте TDBGrid весь столбец, соответствующий полю TablelCompany, будет содержать значения в кавычках.
Затем, если пользователь захочет в какой-либо записи изменить значение данного поля, оно будет выдано ему для редактирования заглавными буквами.
ОГРАНИЧЕНИЕ.
Если для поля определен обработчик события OnGetText, игнорируются режимы форматирования, определенные в свойствах DisplayFormat и EditMask данного поля.
Свойство DisplayFormat
Свойство
property DisplayFormat: string;
применяется для форматирования при показе полей типа TDateField, TDateTimeField, TIntegerField, TSmallintField, TTimeField, TWordField.
Для форматирования полей типа TIntegerField, TSmallintField и TWordField может также применяться стандартная процедура procedure Str(X [: Width [: Decimals ]]; var S);
Для форматирования полей типа TDateField, TDateTimeField и TTimeField применяется функция function Date TimeToStr (Date Time: TDateTime): String;
Для форматирования полей типа TBCDField, TCurrencyField и TFloatField применяется функция function FloatToTextFmt(Buffer: PChar; Value: Extended:
Format: PChar): Integer;
Поддерживаются следующие спецификаторы форматов:
| Спец-р | Что влечет |
| 0 | Число. Если незначащий разряд равен 0, показывать его. |
| # | Число. Если незначащий разряд равен 0, не показывать его. |
| Десятичная точка. Разделяет целую и дробную часть числа Принимается во внимание только первая точка, остальные игнорируются. | |
| ' | Разделитель тысяч. Каждая группа чисел из 3 разрядов в целой части отделяется от иных разрядов запятой. |
| ' | Разделяет положительное, отрицательное и нулевое значение. |
| Е+ | Научный формат действительных чисел |
| "XX' или 'XX' | Символы внутри двойных или одинарных парных кавычек не форматируются и выводятся как есть. Например, число 123.45 с форматом '#.# "рублей"' выведется как '123.5 рублей' |
| Форматируемое число | 987654.321 | -987654.321 | 0.27 | -0.27 | 0 |
| не форматировано | 987654.321 | -987654.321 | 0.27 | -0.27 | 0 |
| 0 | 987654 | -987654 | 0 | 0 | 0 |
| 0.00 | 987654.32 | -987654.32 | 0.27 | 0 | 0.00 |
| # | 987654 | -987654 | |||
| #.## | 987654.32 | -987654.32 | .27 | -.27 | |
| #,##0.00 | 987,654.32 | -987,654.32 | 0.27 | -0.27 | 0.00 |
| #,##0.00; (#,##0.0) | 987,654.32 | (987,654.32) | 0.27 | (0.3) | 0.00 |
| #,##0.00;; Нолик | 987,654.32 | -987,654.32 | 0.27 | -0.27 | Нолик |
| О.ОООЕ+00 | 9.877Е+05 | -9.877Е+0 | 2.700Е-01 | -2.700E-01 | 0.000Е+00 |
| #.###Е-0 | 9.877Е5 | -9.877Е5 | 2.7Е-1 | -2.7Е-1 | 0Е0 |
ЗАМЕЧАНИЕ.
Формат показа поля может быть динамически переназначен во время выполнения. Например, для заполнения данной таблицы мы воспользовались компонентами Edit1 и Button1 и производили динамическую замену формата поля Table I Salary так: procedure TForm1.Button1Click(Sender: TObject);
begin
Table1Salary.DisplayFormat := Edit1.Text;
end;
DisplayFormat
игнорируется, если определен обработчик для события OnGetText. ЗАМЕЧАНИЕ.
В случае, если поле, требующее обязательного ввода в него значения (свойство Required = True), на момент запоминания в таблице БД (т.е. на момент начала выполнения метода Post) содержит пустое или нулевое значение, возбуждается исключение EDBEditError.
Форматирование полей во время их редактирования
Свойство property EditMask: string;
служит для контроля правильности вводимых в поле значений. Ограничения накладываются при помощи формата. Если некоторый введенный символ не удовлетворяет маске, он не воспринимается.
Для строковых полей значение данного свойства может использоваться для форматирования не только входных, но и выходных значений вместе со свойством Display Text.
Маска представляет собой символьную строку. Она состоит из 3-х частей:
1. Собственно маска;
2. Символ, определяющий, будут ли литералы (символ после указателя '\') включаться в форматируемое значение как его часть (значение 1) или не будут(значение 0);
3. Символ, используемый в маске для представления пробела.
Символы, которые могут входить в маску:
| ! | Подавляет ведущие пробелы. В отсутствие этого символа в данных подавляются хвостовые пробелы |
| > | Все следующие символы будут на верхнем регистре, пока не встретится символ < |
| < | Все следующие символы будут на нижнем регистре, пока не встретится символ > |
| <> | Регистр не проверяется. Все остается на том регистре, как ввел пользователь |
| \ | Следующий за ним символ является литералом, т.е. включается в форматируемое значение |
| L | В данной позиции должен появиться только символ алфавита |
| | | Аналогично L, но символ в данной позиции может и отсутствовать |
| А | В данной позиции должен появиться только символ алфавита или цифра |
| а | Аналогично А, но символ в данной позиции может и отсутствовать |
| С | В позиции обязателен любой символ |
| с | Аналогично С, но символ в данной позиции может отсутствовать |
| 0 | В данной позиции обязателен цифровой символ |
| 9 | В данной позиции должен появляться только цифровой символ или не появляться никакой |
| # | В данной позиции должен появляться только цифровой символ плюс или минус или не появляться никакой |
| : | Разделитель часов, минут и секунд для значения типа времени Если в данной национальной кодировке для указанных целей используется иной символ, он используется вместо символа ':' |
| / | Разделитель месяца, дня и года в датах. Если в данной национальной кодировке для указанных целей используется иной символ, он используется вместо символа ':' |
| ; | Разделитель частей маски |
| _ | Заменитель пробела в маске |
| Имя константы | Нач.значение | Смысл |
| DetaultBlank | _ | Обозначение пробела в маске |
| MaskFieldSeparator | , | Разделитель частей маски |
| MaskNoSave | 0 | Если 0, символы маски не будут включаться в значение; если 1,-будут. |
Маска '!\(999\)000\-00\-00;1;_'. Введено '0952223344'. В период ввода представлялось на экране как '(095)222-33-44', запомнилось как '(095)222-33-44'. Если бы была использована маска '!\(999\)000\-00\-00;0;_', в период ввода представлялось на экране как '(095)222-33-44', запомнилось как '0952223344'. Значение свойства Edit Mask игнорируется, если определен обработчик для события OnGelText.
Свойство го property EditMaskPtr: string;
возвращает значение маски редактирования. Поскольку свойство доступно только на чтение, его следует использовать вместо EditMask в тех случаях, когда маска должна быть только прочитана. В итоге мы защищаемся от случайных изменений маски.
Свойство property EditFormat: string;
применяется для форматирования значений полей типа TIntegerField, TSmallintField, TWordField перед их редактированием. Форматирование выполняется функцией Float To TextFmt.
Пример.
Пусть значение поля 3456.777. Тогда если EditFormat := '#.#', то при редактировании значение поля первоначально будет показано как 3456.8. Свойство property Text: string;
содержит строковое изображение значения поля в том виде, в котором оно показывается в визуальном компоненте, когда НД находится в режиме редактирования (dsEdit) . Свойство Display Text содержит строковое изображение значения поля, когда НД находится не в режиме редактирования.
Свойство IsNull и обработчики событий OnSetText, On Validate, OnChange
Свойство IsNull: Boolean; во время выполнения возвращает True, если поле содержит пустое значение.
Проверить введенное в поле значение на его соответствие некоторым ограничениям или условиям можно в обработчике события OnValidate. Это событие наступает при изменении значения поля либо вручную, либо программно. Событие наступает до выполнения метода Post, который запоминает изменения БД. Поэтому, если полю присвоено неверное значение, выполнение метода Post можно предотвратить, выполнив метод Abort или возбудив исключительную ситуацию (raise Exception.Create}. Заметим, что для новых записей данное событие выставляется также, поскольку при занесении значений в поля пустые значения заменяются на непустые (т.е. модифи-цируются). Данный подход контроля правильности значений называется ориентированным на поля.
Существует и другой подход, ориентированный на записи. Он состоит в том, что в структуре ТБД при ее определении описываются ограничения на значения, которые может принимать данное поле. В этом случае контроль правильности ведется автоматически.
Пример.
Пусть поле Table I Company не должно содержать символа '@'. procedure TForm1.Table1CompanyValidate(Sender: TField) ;
begin
IF POS('@',TablelCompany.AsString) > 0 THEN
begin
ShowMessage('Обнаружен символ @!');
Abort;
end;
end;
или
procedure TForm1.Table1CompanyValidate(Sender: TField);
begin
IF POS('@',TablelCompany.AsString) > 0 THEN
raise Exception.Create('Неверное значение');
end;
Если символ '@' содержится в значении, присвоенном полю, метод Abort или принудительно возбужденная исключительная ситуация не позволят выполниться методу Post и запись с неверным полем не будет физически записана в БД НД останется в том состоянии, в котором он находился (режиме редактирования dsEdit или добавления новой записи dslnsert}.
Для проверки введенного значения может быть использовано и другое событие, OnSetText Подобно событию OnVahdate, оно возникает при изменении значения поля Однако на момент события новое значение полю не присвоено и, если этого не сделать программно в обработчике события, сделано никогда не будет.
Например,
пусть в поле Table 1PUR_PRICE типа TFloatField было изменено значение с 10 на 200 Пусть новое значение не должно превышать 100 Тогда обработчик события будет выглядеть так procedure TFormI.TablelPUR_PRICESetText(Sender: TField; const Text: String);
var Tmp : Real;
begin
Tmp := StrToFloat(Text);
IF Tmp > 100 THEN
ShowMessage('Ошибочное значение')
ELSE
TablelPUR_PRICE.Value := Tmp;
end;
что аналогично такому обработчику события OnVahdate.
procedure TFormI.TablelPUR_PRICEValidate(Sender: TField);
begin
IF TablelPUR_PRICE.Value > 100 THEN begin
ShowMessage('Ошибочное значение');
Abort;
END;//if
end;
Как видно, особенность события OnSetText состоит в том, что в обработчик передается константа-параметр Text, содержащая в текстовом виде новое значение, назначенное полю, в то время как действительное значение поля остается без изменения
Третье событие, OnChange, может быть использовано для тех же целей, что и On Validate
procedure TFormI.TablelPUR_PRICEChange(Sender: TField);
begin
IF TablelPUR_PRICE.Value > 100 THEN
raise Exception.Create('Ошибочное значение');
end;
Порядок вызова обработчиков событий OnSetText, On Validate, OnChange
При изменении значения поля события, обработчики которых позволяют контролировать правильность занесенного в поле значения, вызываются в следующей последовательности
1 OnSetText;
2 On Validate,
3 OnChange
Это важно, когда действия по проверке правильности нового значения поля сосредоточены не в одном обработчике, а распределены в обработчиках разных событий
Относительно события OnSetText известно, что если полю присвоено ошибочное значение, то нет нужды выполнять метод Abort или возбуждать исключительную ситуацию для предотвращения занесения этой записи в ТБД (поскольку новое значение в поле в этом случае еще не занесено) Наоборот, если поле удовлетворяет критериям правильности, в него программно нужно записать введенное пользователем новое значение (передаваемое в обработчик как параметр const Text String)
В обработчиках событий OnVahdate и OnChange, наоборот, в этом случае необходимо выполнять метол Abort или возбуждать исключительную ситуацию для предотвращения занесения этой записи в ТБД (поскольку новое значение в поле в этом случае уже занесено)
Однако следует помнить, что событие OnChange возникает только после события On Validate Поэтому, обработчик события OnChange может быть и не вызван, если обработчик On Validate выполняет метод Abort или возбуждает исключительную ситуацию для того, чтобы измененная запись с некорректным значением поля не была записана в ТБД
Значение поля по умолчанию и ограничения на значения поля
Значение поля по умолчанию можно установить при помощи свойства property DefaultExpression: string;
В случае указания значений, отличных от целочисленного, они должны заключаться в кавычки
В компоненте TField могут быть определены ограничения на значения этого или иных полей. Ограничение указывается при помощи SQL-подобного синтаксиса в свойстве
property CustomConstraint: string;
например,
TablelOklad.CustomConstraint :=' Oklad >= 300 and Oklad <= 2000';
Свойство property ConstraintErrorMessage: string;
позволяет указать сообщение об ошибке, выдаваемое пользователю в случае, если введенное значение поля не удовлетворяет ограничению, указанному в свойстве CustomConstraint, например
TablelOklad. ConstraintErrorMessage := ' Оклад должен быть в диапазоне 300...2000 ';
Свойство property ImportedConstraint: string;
содержит ограничения значения поля, "навязанные" сервером. Их не нужно переопределять; дополнительные ограничения можно наложить при помощи свойства CustomConstraint.
Свойство ro property HasConstraints: Boolean;
возвращает True, если для поля определены ограничения в свойствах CustomConstraint, ImportedConstraint или DefaultExpression. В противном случае свойство возвращает False.
Создание вычисляемых полей
Если необходимо создать вычисляемое поле, значение которого вычисляется по значениям других полей, поступают так:
1. В редакторе полей необходимо создать новое поле, пометив его как Calculated. Для этого нужно сделать текущим (при помощи мыши) необходимый НД, нажать правую кнопку мыши, выбрать в меню Field Editor и снова нажать правую кнопку мыши и выбрать в меню New Field. Затем в окне диалога необходимо указать имя поля, его тип и для строковых полей - длину (рис. 6.3).
Для нового поля будет создан компонент TField, доступ к которому отныне можно осуществлять редакторе полей. 2. Для компонента НД, к которому принадлежит вычисляемое поле,
необходимо определить обработчик события OnCalcFields. Например, для НД Table 1, ассоциированному с ТБД "Сотрудники", будем заносить в вычисляемое поле TablelVychis! значение 'Да', если в поле Table1inYaz (знание иностранных языков) этой записи содержится значение True. В противном случае в поле TablelVychis! будем заносить пустое значение (форма приложения показана на рис. 6.4.):
procedure TGridForm.TablelCalcFields(DataSet: TDataSet) ;
begin
IF Table1InYaz.Value THEN TablelVychos!.AsString := 'Да' ELSE
TablelVychosl.AsString := '';
end;
Событие OnCalcFields возникает всякий раз, когда курсор (указатель записи) перемещается в НД от записи к записи (например, после выполнения методов Next, Last и т.д., или при движении по записям в TDBGrid вручную). Это событие возникает и при инициализации НД (после открытия), а также после фильтрации записей в НД, что, впрочем также связано с изменением местоположения указателя записи.
Кроме того, если свойство набора данных AutoCalcFields установлено в True, событие OnCalcFields наступает также и при модификации значений невычисляемых полей в режимах dslnsert и dsEdit данного НД или НД, реляционно с ним связанного (когда установлены ограничения целостности в самой ТБД, а не тогда, когда они подразумеваются).
Процедура-обработчик события OnCalcFields содержит реализацию алгоритма вычисления значения вычисляемого поля или группы полей. Необходимо помнить, что в этом обработчике значение может быть присвоено только вычисляемому полю и не может - полю, определенному в структуре таблицы БД.
ЗАМЕЧАНИЕ.
Иногда бывает необходимым присваивать вычисляемым полям значения, не содержащиеся в полях других таблиц. Иными словами, иногда бывает полезным записывать в вычисляемое поле значение некоторых переменных формы. Например, пусть мы добавляем записи в НД ТЫ, по некоторому алгоритму рассчитывая значения поля Summa. Пусть для расчета значения поля Summa используется переменная TekOstatok. И мы хотим значение TekOstatok для каждой записи занести в вычисляемое поле TbITO. И здесь встречается одна сложность: занесение значения в вычисляемое поле производится в обработчике события OnCalcFields и это происходит в то время, когда значения локальной переменной TekOstatok уже утрачены.
В этой ситуации в процессе выполнения алгоритма, добавляющего записи в ТЬ1, приходится запоминать значения локальной переменной в каком-либо динамическом списке, а затем извлекать из него соответствующие элементы в обработчике события OnCalcFields, присваивая значения этих элементов полю TbITO.
Набор данных TTable
TTable содержит записи, источником которых может быть только одна ТБД. Состав записей зависит от того, производится ли в TTable фильтрация по какому-либо условию. Если нет, то в TTable будут представлены все записи ТБД, ассоциированной с данной TTable; если да, то в TTable попадут только записи, удовлетворяющие условию фильтрации.
По той причине, что одна и та же TTable может в один момент времени содержать неотфильтрованные записи, в другой - отфильтрованные по одному условию и в третий момент времени - записи, отфильтрованные по третьему условию, считают, что НД TTable содержит подмножество множества записей ТБД, которая ассоциирована с данным TTable.
Псевдоним БД указывается в свойстве DatabaseName, имя ассоциированной ТБД - в свойстве TableName.
Набор данных TQuery
TQuery содержит записи, источником которых могут являться несколько ТБД, а также агрегированные значения (такие как сумма, минимум, максимум, среднее), просчитанные по полям одной или нескольких таблиц.
НД формируется так: выполняется SQL-запрос, представленный оператором SELECT (свойство SQL), и в качестве НД возвращаются записи из таблиц-источников, удовлетворяющие определенным условиям (если они имеются).
ТБД-источники перечисляются в разделе FROM оператора SELECT. Условия выборки записей указываются в разделе WHERE. Записи результирующего НД состоят из полей, перечисленных после ключевого слова SELECT (или, если указан символ * - всех полей). Например:
SELECT T.NumTeacher, S.NumStudent, T.ExamDate
FROM teachers T, students S WHERE (T.Kurs = S.Kurs)
В данном случае будет возвращен НД, состоящий из записей, источником которых служат ТБД teachers и students. Эти записи должны удовлетворять условию равенства поля Kurs обеих ТБД. В результирующем НД будет всего 3 поля - NumTeacher, ExamDate из teachers и NumStudent из students.
Более подробно об операторе SELECT и иных SQL-операторах см. соответствующие разделы во второй части книги.
Псевдоним БД указывается в свойстве DatabaseName. В случае, если псевдоним указан, все ТБД в разделе FROM оператора SELECT считаются принадлежащими данной БД; в противном случае для каждой ТБД необходимо указывать маршрут поиска, а если он не указан, ТБД должны располагаться в текущем каталоге.
Как и в случае использования TTable, НД TQuery может содержать полное множество записей какой-либо ТБД. В этом случае, являющемся, вообще говоря, частным, в качестве списка полей следует указать символ "*", выборка должна вестись из одной ТБД и должно отсутствовать условие фильтрации в операторе SELECT.
Понятие наборов данных
Под набором данных в Delphi понимается группа записей из одной или нескольких ТБД, доступная для использования через компоненты TTable или TQuery.
Как набор данных, рассматривается также компонент TStoredProc (хранимая процедура в серверной базе данных, возвращающая набор данных). Однако применение компонента TStoredProc ограничено. Во-первых, он может применяться только для серверных (удаленных) БД; во-вторых, только для тех из них, которые поддерживают механизмы хранимых процедур, возвращающих набор данных. Поэтому в дальнейшем при рассмотрении наборов данных, будем ориентироваться в основном на компоненты TTable и TQuery.
Если рассматривать иерархию компонентов Delphi, компоненты TTable и TQuery являются наследниками компонента TDBDataSet, потомка компонента TBDEDataSet, который, в свою очередь, является наследником компонента TDataSet.
Компоненты TTable и TQuery имеют общие свойства, методы и события;
это обусловливается тем, что они имеют общих "родителей". Именно эти свойства, методы и события рассматриваются в настоящем разделе. При этом TTable и TQuery называются общим термином "набор данных" (НД). В литературе по Delphi TTable и TQuery при рассмотрении их общих свойств часто называют типом DataSet, по имени типа их предка.
TTable и TQuery имеют также свойства, методы и события, присущие только TTable или только TQuery. Такие свойства, методы и события для каждого из данных компонентов рассматриваются далее в отдельных главах, посвященных каждому из указанных компонентов.
Перед рассмотрением общих возможностей для работы с НД разберем общие черты и различия TTable и TQuery.
Блокировка таблиц в многопользовательском режиме
При работе с таблицами локальных СУБД (Paradox dBase) в многопользовательском режиме может возникнуть ситуация, когда на период внесения изменений в какую-либо таблицу БД одним пользователем следует блокировать внесение изменений в таблицу со стороны других пользователей. Более жестким ограничением может служить запрет на просмотр содержимого таблицы со стороны других пользователей.
Запрет внесения изменений или просмотра другими пользователями НД, ассоциированного с данной таблицей, достигается с помощью метода procedure LockTable(LockType: TLockType); где параметр LockType определяет вид запрета:
ItReadLock -
запретить чтение; ItWriteLock -
запретить запись Можно запретить и чтение, и запись данных, но для этого нужно вызвать метод LockTable дважды.
Попытка внесения изменений в НД, ассоциированный с таблицей БД, для которой запрещена запись данных, равно как и попытка чтения из запрещенной для чтения таблицы , приводят к возбуждению исключения EDBEngmeError с сообщением 'Table is locked .'.
После того, как необходимость запрета пропадет, он должен быть отменен, что осуществляется методом procedure UnlockTable(LockType: TLockType); где параметр LockType указывает тип снимаемого запрета. Пример. Если таблица БД запрещена для записи в нее данных, в приложениях других пользователей исключение возбуждается при попытке перевести НД, ассоциированный с таблицей, в режим dsEdit (методом Edit), или удалить запись (метод Delete}. Будем анализировать успешность выполнения метода Edit в обработчике события возникновения ошибки при попытке перевести НД в режим редактирования Для этого можно написать такой обработчик события OnEditError.
procedure TForm1. Table1EditError(DataSet: TDataSet; E: EDatabaseError;
var Action: TDataAction);
begin
ShowMessage ('Таблица блокирована на запись другим пользователем') ;
Action := daAbort;
end;
ЗАМЕЧАНИЕ.
В архитектуре "клиент-сервер" не возникает потребности в реализации программных блокировок. Возможность одного пользователя вносить изменения в данные, уже корректируемые другим пользователем, определяется уровнем изоляции транзакций в приложении (свойство Translsolation компонента TDatabase) и уровнем изоляции транзакций сервера, а также механизмом блокировок сервера. Обычно блокировка накладывается на запись, измененную в рамках незавершенной транзакции. Однако, например, SQL-сервер Borland InterBase не блокирует чтение из записей, которые изменяются другим пользователем в рамках еще не завершенной транзакции В этом случае тот пользователь, чье приложение читает записи, видит записи в их последнем подтвержденном состоянии.
Синхронизация содержимого наборов данных в одном приложении
Как известно, в приложении может существовать несколько НД, ассоциированных с одной и той же таблицей БД. Например, это может быть компонент Table1, расположенный в модуле данных (Data Module) приложения, и компонент Table2, расположенный в форме и выполняющий там специфические функции, отличные от функций компонента Table 1. Тогда, если эти компоненты активны во время выполнения приложения, нужно обновлять содержимое одного набора данных в случае обновления другого.
Если, например, изменяется TDataModulel. Table 1, то для синхронизации изменения с содержимым TForm1 .Table2 следует написать такие обработчики событий:
procedure TDataModulel.TablelAfterDelete(DataSet: TDataSet);
begin
TFormI.Table2.Refresh;
end;
procedure TDataModulel.Table1AfterPost(DataSet: TDataSet);
begin
TFormI.Table2.Refresh; end;
Синхронизация содержимого наборов данных в разных приложениях
При многопользовательском режиме доступа к БД из нескольких копий одного и того же приложения бывает необходимо обеспечить такую функциональность, чтобы каждый пользователь видел подтвержденные изменения, внесенные другими пользователями.
В клиентских приложениях, работающих в рамках архитектуры "клиент-сервер", подобная функциональность обеспечивается автоматически при уровне изоляции транзакций (Read Committed) и при условии использования компонента TTable. Компонент TQuery, выполнив запрос на чтение к удаленной БД, показывает записи НД в неизменном виде, независимо от того, изменялось ли после запроса содержимое таблицы БД. Для обновления информации в НД, реализуемом при помощи TQuery, приходится закрывать и повторно открывать компонент TQuery, т.е. повторно выполнять запрос к удаленной БД. При уровне изоляции транзакций Repeatable read пользователь в рамках транзакции видит данные только в том состоянии, в котором они находились на момент старта транзакции.
В приложениях, работающих в архитектуре "файл-сервер" (с использованием таблиц локальных СУБД Paradox, dBase), не происходит обновления в наборе данных (находящегося в режиме dsBrowse) в приложении одного пользователя, после внесения изменения в эту таблицу БД другим пользователем в своем
приложении. Отображение изменений производится лишь после выполнения данным пользователем метода Post или Delete. Если НД находится в состоянии dsBrowse, его обновление можно реализовать периодически, например, с помощью таймера:
procedure TFormI.TimerlTimer(Sender: TObject) ;
begin
IF Table1.State = dsBrowse THEN Table1.Refresh; end;
или, если нужно обновлять все НД приложения:
procedure TFormI.TimerlTimer(Sender: TObject);
var DSCnt : Integer;
i : Integer; begin
WITH Session.Databases [0] do begin
DSCnt := DataSetCount; // Получаем количество открытых НД
FOR i := О ТО DSCnt - 1 do // Обновляем каждый из них
IF DataSets[i].State = dsBrowse THEN
DataSets[i].Refresh;
END;//with
end;
Если нужно обновлять лишь некоторые из наборов данных, указатели на них можно поместить в список TStringsListl. Этот список можно создать и наполнить в момент создания формы (но не в момент ее активизации, т.к. форма может активизироваться много раз - после минимизации или после вызова другого приложения). При разрушении формы список удаляется:
var
DSList : TStringList;
procedure TFormI.FormCreate(Sender: TObject);
begin
DSList := TStringList.Create; // Создаем список
DSList.AddOb]ect(' '/Tablel); // Помешаем в него ссылку на Tablel
DSList. Add0b;ect (' \Table2); // и Table2
Timeri.Enabled := True; // Включаем таймер
end;
procedure TFormI.TimerlTimer(Sender: TObject) ;
var i : Integer;
begin
WITH DSList do begin
FOR i := 0 TO Count - 1 do
IF (Objects [i] as TDataSet).State = dsBrowse THEN (Objects[i] as TDataSet).Refresh;
END;//with
end;
procedure TFormI.FormDestroy(Sender: TObject);
begin
DSList.Free;
end;
Синхронизация содержимого наборов данных
Записи НД (компонент TTable, TQuery) размещаются в локальной копии на компьютере, на котором выполняется приложение Обновление локальной копии данных происходит в случае выполнения из данного приложения операции модификации НД (добавления, изменения или удаления записи, т е выполнения методов Post или Delete) Однако возникают случаи, когда содержимое локальной копии данных на конкретном компьютере (то есть, попросту говоря, содержимое НД) должно быть обновлено из физической таблицы БД (или синхронизировано с физической таблицей БД) Это достигается путем выполнения метода procedure Refresh;
При этом может встретиться два основных способа применения этого метода. Они рассматриваются ниже.
Обработка ошибок смены состоянии набора данных
В случае неудачи при выполнении методов Insert, Edit, Delete и Post обработку ошибки можно реализовать в соответствующих обработчиках событий OnEditError (ошибки при выполнении Insert и Edit}, OnDeleteError (ошибки при выполнении Delete} и OnPostError (ошибки при выполнении Post):
property OnEditError: TDataSetErrorEven;
property OnDeleteError: TDataSetErrorEven;
property OnPostError: TDataSetErrorEven;
где
TDataSetErrorEvent = procedure(DataSet: TDataSet; E: EDatabaseError;
var Action: TDataAction) of object;
TDataAction = (daFail, daAbort, daRetry);
назначение параметров:
DataSel -
указатель на компонент, в котором произошла ошибка; Е -
ссылка на объект-исключение; Action -
действие: daFail -
выполнение метода, вызвавшего ошибку, отменяется, выводится сообщение об ошибке; daAbort -
выполнение метода, вызвавшего ошибку, отменяется, сообщение об ошибке не выводится; daRetry -
метод, вызвавший ошибку, после выхода из обработчика выполняется заново; при этом в теле обработчика должна быть скорректирована причина ошибки, иначе произойдет зацикливание программы. Пример.
Пусть необходимо выдать программное сообщение пользователю и отменить выполнение ошибочного метода, если возникает ошибка при выполнении метода Insert или Edit (например, таблица заблокирована другим пользователем). Тогда можно использовать такой обработчик события OnEditError: procedure TFormI.TablelEditError(DataSet: TDataSet; E:
EDatabaseError;
var Action: TDataAction);
begin
ShowMessage('Таблица Сотрудников заблокирована другим ' + 'пользователем') ;
Action := daAbort;
end;
Ограничения на значения полей
Набор данных имеет свойство property Constraints: TCheckConstraints; которое представляет собой коллекцию компонентов TCheckConstraints. Каждый такой компонент определяет ограничение, накладываемое на значение одного или более полей. Число ограничений, созданных для НД, определяется свойством коллекции Constraints property Count: Integer; Доступ к отдельному ограничению с индексом Index осуществляется при помощи свойства property Items|Index: Integer): TCheckConstraint;
При этом значение Index должно находиться в диапазоне 0..Count - 1. На рис. 7.40 показан список ограничений, определенных для НД, как он выглядит при обращении к свойству Constraints набора данных в инспекторе объектов.
Каждое ограничение имеет тип TCheckConstraint. Рассмотрим свойства этого компонента.
property CustomConstraint: string;
Содержит текст ограничения на значение поля (полей) в SQL-подобном синтаксисе, например:
Table1.Constraints. .Items[i].CustomConstraint := 'Razrjad > 7 and Razr]ad < 15';
property ErrorMessage string;
Содержит текст сообщения об ошибке. Это сообщение выводится, если пользователь предпримет попытку запомнить запись, поля которой не удовлетворяют данному ограничению (рис. 7.41). property FromDictionary: Boolean;
Указывает источник формирования ограничения - словарь данных (значение True) или непосредственно приложение (False). property ImportedConstraint string;
Используется для запоминания SQL-текста ограничения, импортированного из SQL-сервера или словаря данных.
Состояния наборов данных
НД могут находиться в одном из 6 состояний:
| dslnactive | НД закрыт. |
| dsBrowse | Состояние по умолчанию для открытого НД. Показывает, что записи просматриваются, но в данный момент не изменяются. |
| dsEdit | НД находится в состоянии редактирования текущей записи (после явно или неявно вызванного метода Edit). |
| dslnsert | НД находится в состоянии добавления новой записи (после явно или неявно вызванного метода Insert или Append). |
| dsSetKey | НД находится в состоянии поиска записи по критерию, заданному методами FindKey, GotoKey, FindNearest или GotoNearest. По окончании поиска НД переходит в состояние dsBrowse. |
| dsCalcFields | Выполняется установление значений вычисляемых полей (по алгоритму, заданному в обработчике события OnCalcFields). В данном режиме изменения в НД вноситься не могут. После выхода из режима НД переходит в предыдущее состояние. |
| dsFilter | Обрабатывается фильтрация записей в НД при свойстве Filtered, установленном в True. Имеет место текущий вызов события OnFilterRecord для определения того, удовлетворяет ли текущая запись условию фильтрации, описанному в обработчике данного события. После выполнения события OnFilterRecord НД переводится в состояние dsBrowse. |
• Inactive—>dsBrowse
НД во время выполнения программы можно открыть методами Table. Open, Query. Open. Во время разработки и во время выполнения НД можно открыть, установив в True свойства Table. Active и Query. Active. •
dsBrowse—>Inactive НД во время выполнения программы можно закрыть методами Table. Close, Query. Close. Во время разработки и во время выполнения НД можно закрыть, установив в False свойства Table.Active и Query.Active. Заметим, что если какая-либо запись на момент закрытия НД находится в режиме редактирования (dsEdit) или добавления новой записи (dslnsert), применение метода Close не приводит к автоматической выдаче метода Post. Таким образом, НД закрывается, находясь в режимах dslnsert или dsEdit, а не dsBrowse. В этом случае изменения, сделанные в записи, не запоминаются. Для перевода НД из указанных режимов в режим dsBrowse, перед тем как НД закрывается, используйте обработчик события BeforeClose. Заметим, что описанная ситуация будет встречаться в первую очередь для внезапно или принудительно закрываемых НД.
• dsBrowse—>dsEdit
Перевести НД в режим редактирования можно методом Edit. После этого значения полей текущей записи можно изменять. • dsEdit—> dsBrowse
Метод Post приводит к запоминанию измененной записи в НД. Метод Cancel отменяет изменения, сделанные в полях записи. Запись не запоминается в НД. • dsBrowse—>dslnsert
Перевести НД в режим вставки можно методами Insert или Append, После этого программе становится доступна пустая запись, полям которой нужно присвоить какие-либо значения. Чтобы полям новой записи присвоить умалчиваемые значения , следует воспользоваться обработчиком события OnNewRecord. •
dslnsert—> dsBrowse Метод Post добавляет новую запись в НД. Если НД не находится в режиме dslnsert, возбуждается исключительная ситуация. Метод Cancel отменяет добавление новой записи в НД. Содержимое полей, назначенных новой записи, теряется. • dsBrowse—>dsSetKey
НД находится в данном состоянии, когда осуществляется поиск записи, удовлетворяющей условию, установленному методом SetKey (и затем, возможно, измененному методом EditKey). Именно эти методы и переводят НД в режим dsBrowse. Поиск записи производится одним из следующих методов: GoToKey, GoToNearest, FindKey, FindNearest. В случае успешного или неуспешного завершения метода поиска, НД переводится в состояние dsBrowse. • dsBrowse—>dsFilter
НД находится в данном состоянии всякий раз, когда приложение обрабатывает событие OnFilterRecord при фильтрации записей (при свойстве Filtered = True). При этом НД переводится из состояния dsBrowse в состояние dsFilter. Это предотвращает модификацию НД во время фильтрации. После завершения вызова обработчика события OnFilterRecord НД переводится в состояние dsBrowse. Вызов события OnFilterRecord производится для каждой записи НД при установке свойства Filtered в состояние True. Получить текущее состояние НД
можно, используя метод State. Он возвращает следующие константы: dslnactive, dsBrowse, dsEdit, dslnsert, dsSetKey, dsCalcFields, dsFilter. Пример
IF Tablel.State = dslnactive THEN Table1.Active := True; Реакция на изменение состояния набора данных.
Событие OnStateChange (компонент DataSource) наступает всякий раз при изменении состояния НД. Следующий пример показывает, как отобразить на экране (в компоненте Label 1) сообщение о текущем состоянии НД: procedure TForm1.DataSourcelStateChange(Sender: TObject);
var S : String;
begin
CASE Table1.State OF
dslnactive S = 'He активна' ;
dsBrowse S = 'Просмотр' ;
dsEdit S = 'Редактирование';
dslnsert S = 'Вставка';
dsSetKey S = 'Установка ключа' ;
dsCalcFields S = 'Вычисляемое поле' ;
END; {case}
Label1.Caption := S;
end;
Свойства некоторых компонентов, в первую очередь Enabled, могут зависеть от состояния НД. Например, если кнопка Button 1 должна быть доступной для нажатия только в режиме dslnsert, допустим такой код:
procedure TFormI.DataSourcelStateChange(Sender: Tobject) ;
begin
Button1.Enabled := (Tablel.State = dslnsert);
end;
Общие положения
Существует два способа работы с записями в НД.
Способ, основанный на использовании операторов SQL, предполагает оперирование группами записей. Именно так работают SQL-операторы группового обновления НД UPDATE, INSERT, DELETE и выборки групп записей SELECT. Записи, удовлетворяющие некоторому условию, выдаются группами; даже если условию удовлетворяет только одна запись, считается, что в данном случае группа состоит из одной записи.
Второй способ состоит в оперировании единичными записями. Если необходимо изменить, добавить или удалить группу записей, необходимая операция выполняется для каждой из таких записей. Для этого такие записи в НД нужно отыскать, для чего применяются навигационные методы. Они всегда работают с единичной записью и связанны с понятием курсора НД.
Понятие курсора набора данных.
Под курсором набора данных понимается указатель текущей записи в конкретном наборе данных. Текущая запись - та запись, над которой в данный момент времени можно выполнять какие-либо операции (удаление, изменение, чтение значений, содержащихся в записи полей). Существует 5 методов для изменения курсора НД:
| Procedure First; | Устанавливает курсор на первую запись в наборе данных. |
| procedure Last; | Устанавливает курсор на последнюю запись в наборе данных. |
| procedure Next; | Перемещает курсор на следующую запись в наборе данных. |
| procedure Prior; | Перемещает курсор на предыдущую запись в наборе данных. |
| function MoveBy(n:Integer): Integer; | Перемещает курсор на n записей к'концу набора данных (n > 0) или к началу набора (n < 0.) |
Определение начала и конца набора данных
Свойство property BOF: Boolean;
Возвращает True, если курсор установлен на первую запись в наборе данных.
Свойство property EOF: Boolean;
извращает True, если курсор установлен на последнюю запись в наборе данных.
Порядок следования и порядок сортировки записей
Может сложиться впечатление, что первая и последняя записи набора Данных всегда фиксированы, что это физически первая и последняя записи в наборе данных. Это неверно. Во-первых, как уже отмечалось выше, набор данных может содержать часть записей из ТБД. Поэтому набор данных -понятие логическое, а не физическое. Для TTable последовательность расположения записей в наборе данных определяется используемьш индексом, обуславливающим сортировку. Для TQuery порядок следования записей либо случаен, особенно при использовании в качестве источника более одной ТБД, либо упорядочен в порядке перечисления полей, в разделе ORDER BY.
Начиная работать с НД, имеющим одну сортировку записей, мы можем затем переопределить сортировку, и записи "перестроятся" в соответствии с новой сортировкой, т.е. логический порядок их следования изменится.
При изучении вопросов навигации по НД следует говорить прежде всего о Логическом характере следования записей, поскольку физический характер их расположения в конкретном случае неизвестен.
Пусть, например, имеется ТБД, состоящая из 2 полей: Name (Фамилия сотрудника) и Oklad (Оклад). Пусть в ТБД имеется 10 записей, которые вводились следующим образом и. следовательно, в таком порядке и хранятся:
Пусть данная ТБД проиндексирована по 2 индексам. Первый - по возрастанию поля Name, второй - по возрастанию поля Oklad.
Пусть в наборе данных, связанном с этой ТБД, установлен фильтр на поле Oklad (см. метод SetRange). Значение в этом поле должно лежать в диапазоне 500..1500. Если порядок прохождения записей определяется индексом по полю Name (Tablel.IndexfieldNames := 'Name'), получим следующий НД (рис. 7.1):
Если порядок прохождения записей определяется индексом по полю Oklad. получим следующий НД (рис. 7.2):
Как можно заметить, при сортировке по полю Name метод Last установит курсор на запись со значением поля Name, равным 'Якунин'; при сортировке по полю Oklad - на запись со значением поля Name, равным Name=' Юрьев'. Аналогично, если текущей является 3-я по счету запись от начала НД, для первого случая это будет 'Юрьев', для второго - 'Якунин'. Метод Next переместит курсор для первого случая на запись 'Иванов', для второго - на запись 'Якунин'.
Навигация по набору данных вниз
Для выполнения действий, начиная от некоторой стартовой записи и до конца набора данных, используют цикл WHILE not EOF. Стартовая запись может устанавливаться методом FindKey (см. ниже). Приведем пример для случая, когда стартовая запись - первая в наборе:
WITH Tablel do begin First;
WHILE not EOF do begin
{Какие-либо действия}
Next;
END; {while]
END; {with}
Навигация по набору данных вверх
Для выполнения каких-либо действий, начиная от некоторой стартовой записи и до начала набора данных, используют цикл WHILE not BOF. Стартовая запись может устанавливаться методом FindKey (см. ниже). Приведем пример для случая, когда стартовая запись - последняя в наборе:
WITH Tablel do begin Last;
WHILE not BOF do begin
{Какие-либо действия}
Prior;
END; {while}
END; {with}
Спонтанные перемещения по набору данных
Вообще говоря, часто необходимо в зависимости от каких-либо условий "прыгать" по НД взад-вперед. Поэтому распространен вариант одновременного использования Next, Prior и MoveBy в одном программном блоке. При этом важно помнить о том обстоятельстве, что применение метода Edit, когда изменяется значение индексного поля, по которому в настоящий момент ведется сортировка в НД, может переместить запись вниз или вверх. Например, для приводимой выше таблицы, состоящей из полей Name и Oklad, выполним следующий код, осуществляющий увеличение окладов сотрудников на 1000:
Tablel.IndexFieldnames := 'Oklad';
WITH Tablel do begin
First;
WHILE not EOF do begin
Edit;
TablelOklad.Value := TablelOklad.Value + 1000;
Post;
Next;
END;//while
END; //with
Нетрудно убедиться, что указанный фрагмент не будет правильно работать: оклад господина Яковлева (500) после увеличения на 1000 составит 1500, поэтому запись переместится в НД после записи 'Юрьев', в то же время оставаясь текущей. После запоминания измененной записи (Post) будет предпринята попытка перейти к следующей записи (Next). Однако наша запись, прежде логически первая, после изменения поля Oklad стала логически последней. Поскольку курсор НД находится на последней записи, свойство Tablel.EOF будет автоматически установлено в True. Поэтому метод Next выполнен не будет. На новом шаге цикла WHILE (2-м по счету) произойдет остановка цикла из-за выполнения условия прекращения цикла (рис. 7.3):
Поэтому следует всегда придерживаться правила: не изменять значения индексного поля при прохождении набора данных в цикле.
Можно предложить способ решения данной проблемы, который состоит в простом переборе записей при отключенной сортировке по исходному индексу или при сортировке по другому индексу. Например, для описанного выше НД следующий код будет правильным (результат работы - на рис. 7.5.):
var OldIndexFieldnames : String;
begin
// запомним старое индексное поле
OldIndexFieldnames := Tablel.IndexFieldnames;
// назначим индекс по неизменяемому полю
Tablel.IndexFieldnames := 'Name';
WITH Tablel do begin
First;
WHILE not EOF do begin
Edit;
TablelOklad.Value := TablelOklad.Value + 1000;
Post;
Next;
END;//while
END; //with
// восстановим старое индексное поле
Tablel.IndexFieldnames := OldIndexFieldnames;
IF OldIndexFieldnames = 'Oklad' THEN
TablelOklad.Index := 0;
Поскольку значение ключевого поля не изменяется, порядок следования записей остается прежним.
Рассмотрим другой способ. Он состоит в применении к набору данных временной фильтрации.
ЗАМЕЧАНИЕ.
Данный способ приводится лишь для того, чтобы показать, что могут иметь место и другие подходы к разрешению указанной проблемы. Однако лучше не привыкать к подобному "хитроумию", поскольку оно оправдано лишь когда проблему невозможно разрешить другими способами. Способ изменения текущего индекса, рассмотренный выше, проще и безопаснее. Второй способ имеет более узкое применение, поскольку в этом случае индексное поле должно иметь у всех записей одно и то же значение. Рекомендую повторно вернуться к его рассмотрению после того, как вы ознакомитесь с фильтрацией записей в НД при помощи свойства Filtered, которое описано ниже Пусть в НД для рассмотренного выше примера имеется поле Otdel. Пусть текущий индекс в НД - также построен по полю Otdel. Имеются 2 отдела: Х и Z. Пусть необходимо сменить название отдела Х на Y. Разместим в форме 2 компонента TEdit - OldOtdelEdit, для указания имени отдела, которое требуется заменить, и NewOtdelEdit, для указания нового имени отдела (рис. 7.6.):
Для набора данных Tablel определим обработчик события OnFilterRecord
procedure TFormI.Table1FilterRecord(DataSet: TDataSet;
var Accept: Boolean);
begin
Accept := TablelOtdel.AsString = OldOtdelEdit.Text;
end;
Этот обработчик будет фильтровать в НД Tablel только те записи, у которых поле Otdel содержит старое значение отдела.
Поясним, что в примере используется свойство набора данных
property RecordCount: Integer;
Оно возвращает текущее число записей в НД.
Определим обработчик события нажатия кнопки "Все записи - изменить код отдела":
procedure TFormI.Button4Click(Sender: TObject);
begin
// включим фильтрацию по старому имени отдела
Tablel.Filtered := True;
//последовательно перебираем записи
WITH Tablel do begin
First;
WHILE not (RecordCount = 0) do begin
Edit;
//изменяем название отдела
TablelOtdel.Value := NewOtdelEdit.Text;
//после запоминания изменений запись перестает
//удовлетворять условиям фильтрации и "исчезает"
//из набора данных. После выполнения каждого метода Post
//отфильтрованный набор данных уменьшается на одну запись
Post;
END;//while
END; //with
// отменим фильтрацию
Tablel.Filtered := False;
end;
Заметим, что в цикле нет перехода к новой записи с помощью метода Next. Дело в том, что перед началом изменения значения поля Otdel включается фильтрация. После того, как значение поля изменилось, запись перестает удовлетворять условию фильтрации, поскольку фильтрация ведется по старому значению поля Otdel. Такая запись, не удовлетворяющая условию фильтрации, в НД не входит. После того, как все записи изменены, фильтрация отменяется. Отметим также, что условием окончания цикла WHILE сделан факт отсутствия в НД записей (при включенной фильтрации это записи, удовлетворяющие условию фильтрации).
Результаты работы показаны на рис. 7.7. и 7.8.
Такой способ часто применим при работе со связанными НД, родительским и дочерним. Заметим, что фильтрация в данном примере обеспечивается свойством Filtered, общим для TTable и TQuery. Однако можно применять и иные средства фильтрации, например, метод SetRange компонента TTable.
Реакция на изменение курсора набора данных
Событие OnDataChange (компонент DataSource) возникает всякий раз при изменении курсора НД, т.е. при переходе к новой текущей записи. Это событие возникает, когда курсор БД уже находится на новой записи.
Событие происходит и в режимах dslnsert и dsEdit:
- при изменении какого-либо поля;
- при первом перемещении с измененного поля на другое поле. Два события компонента типа "набор данных" также происходят при переходе к новой записи:
property BeforeScroll: TDataSetNotifyEventI;
Событие наступает перед переходом на другую запись в наборе данных. property AfterScroll: TDataSetNotifyEventI;
Событие наступает после перехода на другую запись в наборе данных.
Временное отключение визуализации при работе с НД
При выполнении действий с НД, влекущих за собой частое изменение местоположения курсора БД, в визуальном компоненте, показывающем записи (например, TDBGrid) или текущую запись (TDBEdit и др.), будет возникать эффект "прокрутки" записей. Он не всем нравится. Кроме этого, при смене местоположения курсора БД (т.е. при смене текущей записи НД) необходимо время для отражения произошедших изменений в визуальном компоненте.
Для устранения данной проблемы имеются методы procedure DisableControls; procedure EnableControls;
Первый отключает связь с визуальным компонентом, а второй -восстанавливает ее. Например, при последовательном переборе записей НД, произведенном таким образом:
WITH Tablel do begin
DisableControls;
First;
WHILE not EOF do begin
{Какие-либо действия}
Next;
END; {while}
EnableControls;
END; {with}
в таблице компонента DBGridI не будет видно эффекта прокрутки записей. Наоборот, у пользователя возникнет иллюзия, что курсор БД сразу переустановился с текущей записи набора данных на его последнюю запись.
Свойства, запрещающие или разрешающие изменять записи в НД
Свойство property CanModify: Boolean;
набора данных определяет, может ли НД переводиться в состояние dslnsert и dsEdit (CanModify= True) или не может (CanModify =False). Это свойство зависит от значения свойства Readonly набора данных. Если Read0nly= True, CanModify автоматически переводится в False. Когда Read0nly= False, CanModify может принимать значения как True, так и False, устанавливая таким образом возможность изменения НД в зависимости от каких-либо условий.
Свойство AutoEdit компонента TDataSourse, связанного с данным НД, определяет, возможен ли (True) автоматический перевод НД в состояние dsEdit, или невозможен (False). В последнем случае для изменения НД программа должна вызвать метод Edit . Свойство AutoEdit не влияет на возможность перевода в состояние dslnsert. Для того, чтобы запретить НД переход в режим dslnsert, достаточно либо сделать НД открытым только для чтения (свойство НД ReadOnly = True), либо установить режим НД Readonly = True для полей, входящих в состав первичного ключа. В этом случае корректировка записи будет возможна, за исключением указанных полей.
НД автоматически может переводиться в состояние dslnsert или dsEdit, если пользователь в визуальном компоненте, связанном с НД, выполняет определенные действия. Вид этих действий зависит от визуального компонента, связанного с НД.
Например, для перехода в режим dsEdit в компоненте TDBGrid, связанном с набором данных, достаточно изменить значение любого поля; в компонентах TDBEdit или TDBMemo, связанных с отдельными полями НД, следует изменить значение поля, с которым связаны TDBEdit или TDBMemo; для компонента DBNavigator, связанного с данным НД, нужно нажать соответствующую кнопку и т.д.
Изменение текущей записи
Чтобы изменить запись в НД, этот НД нужно перевести методом Edit из состояния dsBrowse в состояние dsEdit, затем произвести изменение значения одного или нескольких полей записи и использовать метод Post для запоминания измененной записи в НД. Post в данном случае при благополучном исходе переводит НД из состояния dsEdit в состояние dsBrowse.
Для отказа от запоминания измененной записи в НД используется метод Cancel. Он также переводит НД из состояния dsEdit в состояние dsBrowse.
Метод Edit Редактирование записи должно быть разрешено (свойство property ReadOnly: Boolean; должно быть установлено в False). Помимо этого, могут быть запрещены для корректировки отдельные поля записи (когда свойство Readonly соответствующих компонентов TField установлено в True). Метод Edit может вызываться: программно, автоматически, когда пользователь в визуальном компоненте, связанном с НД, выполняет определенные действия. Вид этих действий зависит от визуального компонента.
Автоматический перевод набора данных в режим редактирования должен быть разрешен свойством AutoEdit соответствующего компонента DataSource (значение True).
Пример.
Изменение значения поля Oklad в текущей записи набора данных, запоминание изменений. Новое значение оклада вводится пользователем в поле ввода в форме (компонент TEdit с именем Editi). Введенное пользователем значение доступно через свойство Editl.Text. Это свойство строкового типа, поэтому оно должно быть преобразовано в целочисленный вид перед присваиванием его числовому полю Oklad. WITH Tablel. do begin
Edit;
FieldByName('Oklad').Value := IntToStr(Editl.Text);
Post;
END;//with
Метод SetFields
Метод
procedure SetFields(const Values: array ofconst);
объединяет функциональность методов Edit, Post и действий по присваиванию значений полям изменяемой записи. В ходе выполнения метода сначала НД переводится в режим dsEdit. Затем полям записи присваиваются значения, перечисленные в открытом массиве Values При этом первое значение в списке присваивается первому полю, второе - второму и т.д Естественно, что значения в списке должны быть совместимы с теми полями, которым они присваиваются. Например, попытка присвоить полю типа Real символьное значение приведет к возбуждению исключительной ситуации
Если в списке число значений меньше числа полей записи, те поля, которым "не хватило" значений, сохраняют свое первоначальное значение. Наоборот, если значений больше, чем нужно для заполнения полей, "лишние" значения теряются.
После успешного присваивания значения полям записи автоматически выполняется метод Post.
Метод SetFields обычно выполняется после того, как пользователь введет значения в переменные и будет произведен контроль правильности их значений
Пример.
Table1.SetFields(['Петров', 'Бухгалтер']) ;
Добавление новой записи
Чтобы добавить новую запись в НД, нужно вызвать метод Insert для перевода НД из состояния dsBrowse в состояние dsEdit Затем производится присваивание значения одному или нескольким полям записи, после чего выполняется метод Post для запоминания новой записи в НД Post при благополучном исходе переводит НД из состояния dsEdit в состояние dsBrowse
Для отказа от запоминания новой записи в НД используется метод Cancel Он также переводит НД из состояния dsEdit в состояние dsBrowse.
Метод Insert При добавлении записи изменение НД должно быть разрешено (свойство Readonly должно быть установлено в False). Помимо этого, могут быть запрещены для изменения отдельные поля записи (когда свойство Readonly соответствующих компонентов TField установлено в True). В этом случае в них нельзя ввести новые значения.
Метод Insert может вызываться: программно, автоматически, когда пользователь в визуальном компоненте, связанном с НД, предпринимает соответствующие действия. Для перехода в режим dslnsert в компоненте TDBGrid достаточно нажать на клавиатуре клавишу Insert или, находясь на последней записи НД, попытаться перейти на нижнюю, несуществующую запись. То же происходит при нажатии соответствующей кнопки связанного с данным НД компонента TDBNavigator,.
Пример.
Добавление записи Table1.Insert;
// установка значений полей добавляемой записи
Tablel.Post;
Метод Append
Метод procedure Append; аналогичен методу Insert, но он добавляет запись в конец набора данных, в то время как Insert добавляет ее после текущей записи.
Для индексированных НД применение метода Append приводит к тем же последствиям, что и применение метода Insert.
Метод InsertRecord
Метод procedure InsertRecord(const Values: array ofconst); объединяет функциональность методов Insert, Post и действий по присваиванию значений полям новой записи. В функциональном отношении он полностью аналогичен методу SetFields (см. выше).
Метод AppendRecord
Метод procedure AppendRecord(const Values: array of const); отличен от метода InsertRecord только тем, что помещает новую запись не после текущей записи, а вслед за последней записью НД.
Запоминание изменений - метод Post
Выполнение метода Post приводит к запоминанию изменений, сделанных в режиме добавления или изменения записи.
Если НД не находится в режиме dslnsert или dsEdit, применение Post приводит к возбуждению исключительной ситуации. Вызов Post зависит от способа, которым ранее был вызван метод Insert или Edit: программно; автоматически.
Post
обычно вызывается автоматически, если пользователь предпринимает соответствующие действия, направленные на запоминание измененной записи в НД. Вид этих действий зависит от визуального компонента, связанного с НД. Например, для компонента TDBGrid, связанного с набором данных, это -переход к другой записи. Для НД, управляемого компонентом TDBNavigator, это - нажатие соответствующей экранной клавиши компонента TDBNavigator. Реже изменения в наборе данных, автоматически переведенном в режим редактирования, запоминаются путем программного вызова метода Post. Метод Post, независимо от того, вызывается он программно или автоматически, может завершиться неудачно. Причиной этого могут послужить неверные значения в соответствующих полях записи. Например:
• поле обязательного заполнения (свойство Required = True у соответствующего компонента TField) содержит пустое значение;
• для ТБД, для которой определен уникальный ключ, возникла ситуация дублирования ключа (Key Violation), то есть ключевое поле (группа полей) данной записи содержит значение, которое уже хранится в этом поле (группе полей) в другой записи;
обработчики событий типа OnValidate (компонент TField) или BeforePostRecord обнаружили, что какое-либо поле содержит неверное значение, не удовлетворяющее некоторым условиям. В этом случае программно возбуждается исключительная ситуация, которая подавляет выполнение Post.
В лучшем случае при возникновении препятствий для выполнения Post запись переводится в состояние, в котором НД находился до выполнения метода (dslnsert или dsEdit).
Отмена сделанных изменений - метод Cancel
Метод Cancel отменяет все изменения, сделанные в записи. Если НД находился в режиме добавления новой записи, запись в НД не добавляется. Если НД находился в режиме изменения записи, изменявшаяся запись в НД не записывается и данные в ней остаются в том состоянии, в котором они находились до перехода в режим dsEdit. Сам НД переводится в режим dsBrowse. Вызов Cancel зависит от способа, которым ранее был вызван метод Insert или Edit: программно; автоматически.
Cancel
вызывается автоматически, если пользователь предпримет соответствующие действия, направленные на запоминание измененной записи в НД. Вид этих действий зависит от визуального компонента, связанного с НД. Например, для компонента TDBGrid, связанного с набором данных, это нажатие клавиши Esc. Для НД, управляемого компонентом TDBNavigator, это нажатие соответствующей экранной клавиши компонента TDBNavigator.
Оценка изменения записи
Часто бывает необходимо знать, вносились ли в запись изменения в режимах dslnsert или dsEdit. Это актуально в тех случаях, когда внесение изменений в поля записи зависит от каких-либо условий, которые могут наступать или не наступать в разные моменты работы приложения. Свойство НД property Modified: Boolean; автоматически устанавливается в True, если значение какого-либо поля записи НД было изменено в режимах dslnsert или dsEdit. Методы Post и Cancel переводят свойство в состояние False.
Пример.
В следующем фрагменте запись будет запомнена в НД, только если в нее вносились изменения: Table1.Edit;
IP Tablel.Modified THEN Post ELSE Cancel;
Реакция на изменение данных
Событие On UpdateData (компонент DataSource) возникает для измененной (или вновь добавляемой) записи, когда выполнен метод Post, но физическое перезаписывание измененной записи в ТБД еще не произошло.
Событие On Validate (компонент TField) возникает после любого изменения значения поля, произведенного вручную или программно (это относится и к вводу значения в поле при создании новой записи). Это событие служит для контроля правильности значений поля, если на него накладываются какие-либо ограничения. Событие возникает перед выполнением метода Post, физически записывающего измененную запись в ТБД. В случае несоответствия значения поля накладываемым ограничениям выполнение Post (и, следовательно, физическое запоминание в БД записи с неверным полем) можно предотвратить, используя метод Abort или принудительно возбудив исключительную ситуацию (raise Exception. Create). Например,
procedure TForm1.TableKodIzdeliaValidate(Sender: TField);
begin
IF TableKodIzdelia.AsInteger > 1000 THEN raise Exception.Create('Неверное значение кода изделия');
end;
Удаление записи
Удаление текущей записи в наборе данных реализуется методом Delete. Например: Table1.Delete;
Удаление записи может производиться: программно; автоматически, если это предусмотрено в том или ином компоненте. Так, в компоненте TDBGrid нажатие комбинации клавиш Ctrl + Del влечет за собой удаление записи, которое, в соответствии с опциями настройки TDBGrid, может выполняться как с запросом подтверждения, так и без него.
Необходимо помнить об одной важной особенности. Записи в различных СУБД могут удаляться 2 способами:
• пометка записи в ТБД как удаленной. Сама запись физически не удаляется из НД. В зависимости от СУБД новые записи могут записываться на место помеченных как "удаленные" или в конец ТБД. В последнем случае такие ТБД могут "разбухать" до больших размеров, поэтому время от времени для них проводят операцию сжатия, при которой помеченные как удаленные записи физически уничтожаются, а остальные записи "сдвигаются" вверх, заполняя образовавшиеся пустоты в ТБД. немедленное удаление записей из ТБД, вследствие чего последующие записи "сдвигаются" вверх, заполняя образовавшиеся в ТБД пустоты. В Delphi при работе с НД реализован второй метод. После удаления записи все оставшиеся записи "сдвигаются" наверх. При удалении одной записи это может быть несущественным, однако, если нужно удалить несколько записей, это способно внести осложнения. Например, пусть требуется удалить все записи в Tablel. Можно было бы предположить, что данную потребность можно реализовать следующим программным кодом:
WITH Tablel do begin
First;
WHILE not EOF do begin
Delete;
Next; // Ошибка!
END;//while
END;//with
Однако в действительности этот код приведет к удалению примерно половины записей в Tablel. Причина этого лежит в том, что когда мы удаляем запись (например, № 3), последующие записи автоматически перемещаются вверх, и поэтому запись, бывшая до удаления следующей (№ 4), становится текущей (№ 3). После выполнения метода Next осуществляется переход к записи № 4. Таким образом, записи удаляются через одну (см. рис. 7.9 и 7.10).
Удалив ненужный вызов Next, мы сотрем все записи:
WITH Tablel do begin
First;
WHILE not (RecordCount = 0) do
Delete;
END;//with
Чаще всего нужно удалять не все записи НД а часть записей, удовлетворяющих некоторому условию Рассмотрим два способа
ЗАМЕЧАНИЕ Я рекомендую вернуться к повторному рассмотрению этих способов после того как вы ознакомитесь
- с фильтрацией записей в НД при помощи свойства Filtered
- с поиском записей в НД при помощи метода Locate
Материал о них приведен в данномраздече ниже
Во-первых, можно воспользоваться временной фильтрацией удаляемых записей в момент группового удаления (См п 7 3 6)
Второй способ состоит в использовании метода Locate, реализующего поиск необходимой записи по точному соответствию значений некоторых полей
Метод Locate указывает поля, по которым ведется поиск, и значения этих полей, по которым нужно найти записи В нашем случае это поле Otdel и свойство OtdelEdit Text (компонент TEdit), где содержится наименование отдела, по которому нужно удалить все записи в НД Если запись с таким значением поля Otdel найдена, Locate возвращает True, в противном случае
False Как только запись найдена она удаляется, когда Locate возвратит False это значит что все записи с указанным наименованием одела удалены (см рис 7 13 и 7 14)
// Обработчик нажатия кнопки 'Удалить все записи с указанным отделом"
procedure TFormI Button4Click(Sender TObject);
begin
WITH Tablel do begin
First;
WHILE Locate('Otdel', OtdeiEdit Text,[]) do Delete;
END; //with
end;
ЗАМЕЧАНИЕ.
Для больших НД, а также если в процессе удаления в НД меняются индексы, определяющие текущую сортировку, рекомендуется перед реализацией удаления отключать связь НД с управляющими компонентами, а по окончании удаления - включать- WITH Tablel do begin
DisableControls;
EnableControls;
END; {with}
Сценарий обновления записей на одной форме с компонентом TDBGrid
Записи набора данных периодически добавляются, изменяются и удаляются Если выполнение указанных действий ложится на пользователя, в приложении должны быть реализованы удобный интерфейс добавления, изменения и удаления записей
Несомненно, действия над набором данных в этом случае тесно связаны с вопросами реализации пользовательского интерфейса в приложении Материал именно такого рода содержится в данном разделе Он будет полезен начинающим разработчикам или тем, кто только начинает изучать Delphi, поскольку показывает, что соединение пользовательского интерфейса и действий над набором данных не является чем-то исключительно сложным
Если Вас не интересует, как можно реализовать в форме интерфейс пользователя для внесения изменений в набор данных, Вы можете пропустить данный раздел
Существует несколько вариантов внесения изменений в набор данных в приложении-
• изменения реализуются при выполнении программного кода Как правило, такой способ внесения изменений в НД используется для транзакционных таблиц, т е таблиц, данные в которых формируются приложением автоматически Например, в транзакционную таблицу "Суммарный отпуск товаров" приложением автоматически вносятся изменения при вводе записей в другую, операционную таблицу БД, "Отпуск товаров"
• изменения в НД вносит пользователь. Реализовать пользовательский интерфейс в этом случае можно одним из следующих способов
• пользователь вносит изменения в НД, пользуясь компонентом TDBGrid. Например, для добавления новой записи в НД он нажимает на клавиатуре кнопку Insert, после чего в TDBGrid появляется новая, пустая строка; вводит данные в поля новой строки, запоминает новую запись (перемещая курсор на другую запись) или отказывается от запоминания, нажимая на клавиатуре кнопку Esc;
• пользователь нажимает одну из трех кнопок "Добавить", "Изменить", "Удалить", которые размещены в той же форме, что и компонент TDBGrid, в котором показываются записи набора данных По нажатию кнопки набор данных переводится в соответствующее состояние и вызывается другая форма, в которую пользователь вводит новые значения полей записи и нажимает кнопку "Запомнить изменения " , "Отменить" или "Подтвердить удаление записи". После этого реализуются необходимые действия, то есть выполняются методы Post, Cancel или Delete;
• пользователь нажимает одну из трех кнопок "Добавить", "Изменить", "Удалить", которые размещены в той же форме, что и компонент TDBGrid, в котором показываются записи набора данных. По нажатию кнопки набор данных переводится в соответствующее состояние и в этой же форме активизируется панель, на которой расположены поля текущей записи набора данных. Пользователь вводит новые значения полей записи, после чего подтверждает или отменяет добавление или изменение записи, при удалении записи ему, разумеется, ничего вводить не нужно, а нужно лишь удаление подтвердить или отменить. Рассмотрим реализацию последнего сценария. Пусть имеется ТБД Sklady, записи которой содержат наименования складов Предположим, что эта ТБД будет использоваться в приложении как справочник Запись состоит из единственного поля Sklad. По этому полю построен первичный индекс, т е. данное поле может содержать только уникальное значение.
Поместим в форму компонент DBGndl для показа записей из ТБД Sklady Первоначальную высоту TDBGrid определим равной 257 Ниже DBGndl поместим в форме панель PanelToInput Values и определим ее как "невидимую" (свойство Visible = False) В'данной панели расположим компонент DBEdit1, который ссылается на поле Sklad Соответственно, когда панель невидима, невидимы и компоненты, в ней расположенные
Поместим в форму панель InsertEditDeletePanel и установим ее свойство Visible = True. В панели разместим экранные кнопки для работы с отдельной записью "BcTaBHTb"(InsertButton), "Изменить" (EditButton), "Удалить" (DeleteButton), и кнопку для выхода "Выйти" (ExitButton) с модальным свойством ModalResult = mrOk
Поместим в форме панель PostCancelPanel и сделаем ее невидимой (свойство Visible = False) Разместим в панели экранные кнопки "Запомнить" (PostButton) и "Отменить"(Сапсе1Вийоп) для запоминания сделанных изменений в БД или отказа от запоминания (рис 7.15)
Совместим местоположение панелей PostCancelPanel и InsertEditDeletePanel, сделав их одинаковыми по размеру (рис. 7.16):
Напишем следующие обработчики нажатия экранных кнопок:
// константы для обозначения высоты TDBGrid
const
NORMAL_HEIGHT = 257; // в режиме просмотра записей
UPDATE_HEIGHT = 193; // в режимах добавления и изменения
// Обработчик нажатия кнопки "Включить"
procedure TFormI.InsertButtonClick(Sender: TObject);
begin
// визуализируем панель с кнопками "Запомнить", "Отменить'
PostCancelPanel.Visible := True;
// делаем невидимой панель с кнопками "Включить",
// "Изменить" и т.д.
InsertEditDeletePanel.Visible := False;
// уменьшаем высоту DBGrid
DBGridl.Height := UPDATE_HEIGHT;
// делаем видимой панель для ввода значения в запись
PanelToInputValues.Visible := True;
// переводим НД в режим добавления записи
Tablel.Insert;
// передаем фокус управления на ввод значения в запись
DBEditI.SetFocus;
end;
// Обработчик нажатия кнопки "Изменить"
procedure TFormI.EditButtonClick (Sender: TObject);
begin
// делаем невидимой панель с кнопками "Включить",
// "Изменить" и т.д.
InsertEditDeletePanel.Visible := False;
// уменьшаем высоту DBGrid
DBGridl.Height := UPDATE_HEIGHT;
// делаем видимой панель для ввода значения в запись
PanelToInputValues.Visible := True;
// переводим НД в режим редактирования записи
Tablel.Edit;
// передаем фокус управления на ввод значения в запись
DBEditI.SetFocus;
end;
// Обработчик нажатия кнопки "Удалить"
procedure TFormI.DeleteButtonClick(Sender: TObject);
begin
// удаляем запись, в случае подтверждения пользователем
IF MessageDIg('Подтвердите удаление записи',
mtConfirmation,[mbYes,mbNo],0) = mrYes THEN
Tablel.Delete;
// передаем управление на DBGrid
DBGridI.SetFocus ;
end;
// Обработчик нажатия кнопки "Запомнить"
procedure TFormI.PostButtonClick(Sender: TObject);
begin
// пытаемся запомнить изменения в ТБД; при возникновении //исключения полагаем, что его причиной является дублирова
//ние ключа. В этом случае сообщаем пользователю и отменяем
//внесение изменений в ТБД
TRY
Tablel.Post;
EXCEPT
on EDBEngineError do begin
MessageDIg('Такая запись уже есть',mtlnformation, [mbOk],0) ;
Tablel.Cancel;
end; {on}
END; {try}
// увеличиваем высоту DBGrid
DBGridI.Height := NORMAL_HEIGHT;
// делаем невидимой панель для ввода значения в запись
PanelToInputValues.Visible := False;
// делаем невидимой панель для ввода значения в запись
PostCancelPanel.Visible := False;
// делаем видимой панель с кнопками "Включить", "Изменить" и т.д.
InsertEditDeletePanel.Visible := True;
// передаем управление на DBGrid
DBGridI.SetFocus ;
end;
// Обработчик нажатия кнопки "Отменить"
procedure TFormI.CancelButtonClick(Sender: TObject);
begin
Tablel.Cancel;
// увеличиваем высоту DBGrid
DBGridI.Height := NORMAL_HEIGHT;
// делаем невидимой панель для ввода значения в запись
PostCancelPanel.Visible := False;
// делаем видимой панель с кнопками "Включить", "Изменить" и т.д.
InsertEditDeletePanel.Visible := True;
// делаем невидимой панель для ввода значения в запись
PanelToInputValues.Visible := False;
// передаем управление на DBGrid
DBGridI.SetFocus;
end;
// Обработчик события выхода из формы.
// Если в этот момент НД находится в состоянии,
// отличном от dsBrowse, т.е. в dslnsert, dsEdit,
// он принудительно возвращается в состояние dsBrowse.
procedure TFormI.FormDeactivate(Sender: TObject);
begin
IF Tablel.State 0 dsBrowse THEN Tablel.Cancel;
end;
В режиме просмотра записей (dsBrowse) видим окно, показанное на рис. 7.17
А в режимах добавления новой записи (dslnsert) или редактирования (dsEdit) видим окно, (рис. 7.18)
При нажатии кнопки "Удалить" выдается модальная форма подтверждения удаления (рис. 7.19). Эта форма реализуется функцией Delphi MessageDlg.
Закладки на записях НД
Подобно тому, как в книге нужную страницу можно заложить закладкой и впоследствии быстро найти эту страницу, в НД аналогичные действия можно осуществить для записи. Для этой цели НД обладает следующими методами:
function GetBookmark: Tbookmark -
создает для текущей записи объект-закладку и возвращает ссылку на него; procedure GotoBookmark(Bookmark : Tbookmark) -
перемещает курсор БД на запись, определяемую закладкой-параметром; procedure FreeBookmark(Bookmark : Tbookmark)
- освобождает системные ресурсы закладки Bookmark; function Bookmark Valid(Bookmark: TBookmark): Boolean; -
возвращает True, если закладке Bookmark назначено значение, и False - если не назначено; function CompareBookmarks(Bookmarkl, Bookmark!: TBookmark): Integer; -
сравнивает две закладки, Bookmark 1 и Bookmark!, и возвращает: 0 - если закладки идентичны; 1 - если различаются; тип TBookmark - указатель на экземпляр типа "закладка".
ЗАМЕЧАНИЕ
Метод GotoBookmark возбуждает исключительную ситуацию, если передаваемый параметр не указывает на закладку (т.е. если закладка не создана, а мы пытаемся на нее перейти). Пример var MyBookmark : TBookMark;
{ заложить закладку }
MyBookmark := Tablel.GetBookmark;
{ перейти на запись, на которой заложена закладка}
IF Tablel. BookmarkValid. (MyBookmark) THEN
Tablel.GotoBookmark(MyBookmark);
{ освободить ресурсы, выделенные для закладки}
IF Tablel. BookmarkValid(MyBookmark) THEN
Tablel.FreeBookmark(MyBookmark);
Закладки используются в первую очередь тогда, когда :
1. Нужно проделать какие-либо действия над НД, изменяющие местоположение курсора БД;
2. Вернуться к той записи, которая была текущей перед выполнением п. 1.
Метод Locate
function Locate(const KeyFields: string; const Key Values: Variant;
Options: TLocateOptions): Boolean;
Метод Locate ищет первую запись, удовлетворяющую критерию поиска, и если такая запись найдена, делает ее текущей. В этом случае в качестве результата возвращается True. Если поиск был неуспешен, возвращается False.
Параметры:
Список KeyFields указывает поле или несколько полей, по которым ведется поиск, в виде строкового выражения. В случае нескольких поисковых полей их названия разделяются точкой с запятой.
Критерии поиска задаются в вариантном массиве Key Values так, что i-e значение в Key Values ставится в соответствие i-му полю в KeyFields. В случае поиска по одному полю в Key Values указывается одно значение.
Options
позволяет указать необязательные значения режимов поиска: loCaselnsensilive -
поиск ведется без учета высоты букв, т.е. если в Key Values указано 'принтер', а в некоторой записи в данном поле встретилось 'Принтер' или 'ПРИНТЕР', запись считается удовлетворяющей условию поиска; loPartialKey -
запись считается удовлетворяющей условию поиска, если она содержит часть поискового контекста; например, удовлетворяющими контексту 'Ма' будут признаны записи с значениями в искомом поле "Машин ', 'Макаров' и т.д. Locate
отличается от методов FindKey, FindNearest, GoToKey, Go ToNearest (компонент TTable) следующим: • FindKey, FindNearest, GoToKey, Go ToNearest производят поиск только по полям, входящим в состав текущего индекса TTable; в случае, когда условию поиска удовлетворяет несколько записей, текущей станет логически самая первая из них (в порядке сортировки записей в НД, определяемом текущим индексом);
• Locate производит поиск по любому полю; поле или поля, по которым производится поиск, могут не только не входить в текущий индекс, но и не быть индексными вообще.
В случае, если поля поиска входят в какой-либо индекс, Locate использует этот индекс при поиске. Если искомые поля входят в несколько индексов, трудно сказать, какой из них будет использован. Соответственно, трудно предсказать, какая запись из множества записей, удовлетворяющих критерию поиска, будет сделана текущей - особенно в случае, если поиск ведется не по текущему индексу.
При поиске по полям, не входящим ни в один индекс, применяются фильтры BDE.
Пример.
Пусть имеется ТБД "Сотрудники кафедры" с целочисленным TabNum (табельный номер) и строковыми полями FIO (ФИО), Doljnos) (Должность), UchStepen (Ученая степень). Пусть ТБД имеет индексы по полям: 'TabNum' , 'FIO', 'Doljnost;FIO'.
Пример
А. Осуществим поиск по полям 'Doljnost; UchStepen' (индексное и неиндексное) при различных текущих индексах в НД. Поисковый контекст -['доцент', 'кхн'] при режиме частичного совпадения значений: procedure TFormX.LocateButtonClick(Sender: TObject);
begin
Tablel.Locate ( 'Doljnost;UchStepen',
VarArrayOf(['доцент','кхн']),[loPartialKey]) ;
end;
Результаты поиска показаны на рис.7.20 - 7.22. Как видно из рисунков, при различных текущих индексах в момент выполнения поиска, результаты поиска также могут быть различными.
Пример Б Осуществим поиск по полю 'FIO' ( входит в два индекса) при различных текущих индексах в НД Поисковый контекст - ['Ма'] при режиме частичного совпадения значении
procedure TFormX.LocateButtonClick(Sender: TObject);
begin
Tablel.Locate('FIO','Ma', [ioPartialKey]) ;
end;
Этому критерию соответствуют записи с FIO = 'Манишкина А А ', 'Мануйлова В А','Маслаченко В Ф ', ' Массалитин В Ф ' (см рис 7 23 - 7 25) Как видим, результат поиска при различных текущих индексах одинаков
Пример В
Пусть заранее неизвестно, по какому полю необходимо производить поиск Тогда поместим в форму компонент RadioGroup1, в котором перечислим поля поиска, и компонент Edit1 для ввода условий поиска (см рис 7.26) Напишем такой обработчик
procedure TFormX.ButtonlClick(Sender: TObject) ;
var Pole : Shortstring;
begin
CASE RadioGroupl.Itemlndex OF
0 : Pole := 'TabNum' ;
1 : Pole := 'FIO';
2 : Pole := 'Doljnost;
3 : Pole := 'UchStepen';
END;
IF not Tablel.Locate(Pole,Editl.Text,[loCaselnsensitive, loPartialKey]) THEN ShowMessage('Запись не найдена');
end;
Преимущество показанного способа в том, что мы вместо выполнения нескольких Locate (для поиска по каждому полю) выполняем один метод Locate независимо от поля, по которому производится поиск
Использование методов FindFirst, FindLast, FindNext, FindPrior
Известно, что набор данных может быть отфильтрован с использованием свойства Filtered Условие фильтрации задается свойством Filter или описывается в обработчике события OnFliter Re cord Свойство Filtered указывает, выполнять ли фильтрацию (значение True) или нет (значение False) В этом случае в НД показываются все записи, а не только удовлетворяющие условию фильтрации
Для НД, в котором определены условия фильтрации, но сама фильтрация в текущий момент не включена, Delphi предоставляет интересную возможность Она заключается в том, что в неотфильтрованном в данный момент НД можно обеспечить навигацию только между теми записями, которые удовлетворяют условию фильтрации (оно в текущий момент, когда свойство Filtered = False, не действует)
Для этой цели используются методы FindFirst, FindLast. FindNext, FindPrior
Условие фильтрации можно сделать совпадающим с условием поиска, указанным в параметре./^ Values метода Locate При этом поиск с помощью указанных методов имеет довольно большое преимущество перед поиском с помощью Locate если в Locate можно указывать только значения, то в условии фильтрации можно указывать логические условия, например
Accept := (DataSet['Doljnosf] = 'доцент') AND (DataSet['TabNum'] > 150000);
т е. включать в НД только записи о сотрудниках-доцентах, и притом не всех, а только тех из них, у которых табельный номер больше 150000
В случае, если искомая запись найдена, данные методы возвращают True, в противном случае - False. Аналогичный результат возвращает свойство Found
function FindFirst: Boolean; -
переходит на первую запись, удовлетворяющую фильтру; function FindLast: Boolean; -
переходит на последнюю запись, удовлетворяющую фильтру; function FindNext: Boolean; -
переходит на следующую запись, удовлетворяющую фильтру; function FindPrior: Boolean; -
переходит на предыдущую запись, удовлетворяющую фильтру; property Found: Boolean; -
возвращает True, если последнее обращение к одному из методов FindFirst, FindLast, FindNext, FindPrior привело к нахождению нужной записи. Пример.
Предоставить пользователю возможность перемещаться на первую, последнюю, следующую, предыдущую запись, удовлетворяющую условию "Содержимое Edit1 входит как часть ФИО сотрудника". Заметим, что свойство Table1.Filtered = False, т.е. хотя в обработчике события Table1.OnFilterRecord и указано условие фильтрации, в НД показываются все записи, и он остается в неотфильтрованном состоянии (см. рис. 7.27 и 7.28) условие
фильтрации procedure TFormX.TablelFilterRecord(DataSet: TDataSet;
var Accept: Boolean);
begin
Accept := POS(Editl.Text,DataSet['FIO']) > 0;
end;
// нажата кнопка "Первая"
procedure TFormX.FindFirstButtonClick(Sender: T0b;ect) ;
begin
Labell .Caption := ";
IF not Tablel.FindFirst THEN
Labell.Caption := 'Нет такой записи';
end;
// нажата кнопка "Последняя"
procedure TFormX . FmdLastButtonClick (Sender : TObject) ;
begin
Labell.Caption := ";
IF not Tablel.FindLast THEN
Labell.Caption := 'Нет такой записи';
end;
// нажата кнопка "Следующая"
procedure TFormX.FindNextButtonClick(Sender: TObject);
begin
Labell.Caption := ";
IF not Tablel.FindNext THEN
Labell.Caption := 'Нет такой записи';
end;
// нажата кнопка "Предыдущая"
procedure TFormX.FindPriorButtonClick(Sender: TOb^ect) ;
begin
Labell.Caption := ";
IF not Tabiel.FindPrior THEN
Labell.Caption := 'Нет такой записи';
end;
Заметим, что поскольку фильтрация записей с использованием события OnFilter Record или (и) свойства Filter может применяться только на небольших объемах записей (из-за того, что при этом используется последовательный метод доступа к записям в ТБД), аналогичные ограничения накладываются и на поиск записей с использованием методов FindFirst, FindLast, FindNext, FindPrior.
Метод Lookup
function Lookup(const KeyFields: string; const Key Values: Variant;
const ResultFields: string): Variant;
Метод Lookup находит запись, удовлетворяющую условию, но не делает ее текущей, а возвращает значения некоторых полей этой записи. Тип результата - Variant или вариантный массив. Независимо от успеха поиска записи, указатель текущей записи в НД не изменяется.
Lookup осуществляет поиск только на точное соответствие критерия поиска и значения полей записи. Такой режим, как loPartialKey метода Locate (поиск по частичному соответствию значений), отсутствует.
Параметры:
В KeyFields указывается список полей, по которым необходимо осуществить поиск. При наличии в этом списке более чем одного поля, соседние поля разделяются точкой с запятой.
Key Values
указывает поисковые значения полей, список которых содержится в KeyFields. Если имеется несколько поисковых полей каждому i-му полю в списке KeyFields ставится в соответствие i-oe значение в списке Key Values. При наличии одного поля, его поисковое значение можно указывать в качестве Key Values непосредственно; в случае нескольких полей - их необходимо приводить к типу вариантного массива при помощи Var-Array'Of. В качестве поисковых полей можно указывать поля как входящие в какой-либо индекс, так и не входящие в него; тип текущего индекса не имеет значения. Если поисковые поля входят в какие-либо индексы, их использование производится автоматически; в противном случае используются фильтры BDE.
Если запись в результате поиска не найдена, метод Lookup возвращает Null, что выявляется при помощи предложения
IF VarType(LookupResults) = varNull THEN ...
В противном случае Lookup возвращает из этой записи значения полей, список которых указан в ResultFields. При этом размерность результата зависит от того, сколько результирующих полей указано в ResultFields'.
• указано одно поле - результатом будет значение соответствующего типа или Null, если поле в найденной записи содержит пустое значение;
указано несколько полей - результатом будет вариантный массив, число элементов в котором меньше или равно числу результирующих полей;
меньше потому, что некоторые поля найденной записи могут содержать пустые значения. Рассмотрим несколько вариантов.
Пример
А. Одно результирующее поле (результат - значение типа Variant) Будем осуществлять поиск в ТБД "Сотрудники" по полю 'FIO'. Поисковое значение будем вводить в Edit I. В качестве результата будем выдавать значение поля "UchStepen' (ученая степень) найденной записи. procedure TFormX.LookuplButtonClick(Sender: TObject);
var
LookupResults : Variant; // результат
begin
// осуществить поиск
LookupResults := Tablel.Lookup('FIO', Editl.Text, 'UchStepen') ;
Label 1.Caption := ";
// содержит ли результат пустое значение или Null?
CASE VarType(LookupResults) OF
varEmpt : Labell.Caption := 'Пустой результат';
varNull : Labell.Caption := 'Запись не найдена';
ELSE
// нет, результат содержит какое-то значение
Labell.Caption := LookupResults;
END; //case
end;
Заметим,что в присваивании
Labell.Caption := LookupResults;
имеет место приведение вариантного типа к строковому. Более подробно о приведении вариантных типов см. описание вариантного типа в документации и встроенной системе помощи Delphi.
Пример Б.
Несколько результирующих полей (результат - вариантный массив) Некоторые сведения по использованию вариантного массива:
Если переменная типа Variant является вариантным массивом, функция VarIsArray(LookupResults) возвращает True.
При работе с переменным числом возвращаемых полей, в конкретном случае верхнюю и нижнюю границы массива LookupResults можно определить при помощи функций VarArrayLowBound(LookupResults, 1) и VarArrayHigh-Bound( LookupResults, 1).
Тип i-го элемента вариантного массива можно определить как VarType (LookupResults [ i]).
Будем осуществлять поиск в ТБД "Сотрудники" по полю 'FIO\ Поисковое значение будем вводить в Editi. В качестве результата будем выдавать значения полей "TabNum,DolJnost,UchStepen' найденной записи (табельный номер, должность, ученая степень).
procedure TFormX.LookupButtonClick(Sender: TObject) ;
var
LookupResults : Variant; // результат
begin
// осуществить поиск
LookupResults := Tablel.Lookup('FIO', Editl.Text, '' TabNum;Doljnost;UchStepen') ;
// будем показывать значения результирующих полей в TLabel
Labell.Caption := ";
Label2.Caption := ";
Label3.Caption := ";
// результат - вариантный массив ?
IF VarIsArray(LookupResults) THEN
begin
Labell.Caption := LookupResults[0];
IF LookupResults[1] 0 Null THEN
Label2.Caption := LookupResults [1];
IF LookupResults[2] о Null THEN
Label3.Caption := LookupResults [2];
end // then
ELSE
// результат - не вариантный массив, а единичное значение
CASE VarType(LookupResults) OF
varEmpty : Labell.Caption := 'Пустой результат';
varNull : Labell.Caption := 'Запись не найдена';
END; //case
end;
Если запись не найдена, VarType (LookupResults) возвращает значение varNull; если поиск по какой-либо причине не был произведен, VarType (LookupResults) возвращает значение varEmpty. Если какое-либо из полей, чьи значения возвращаются в результате поиска в вариантном массиве, содержит пустое значение, соответствующий элемент вариантного массива также будет содержать пустое значение (Null). В этом случае обращение к нему возбудит исключительную ситуацию, поэтому нужна предварительная проверка.
Поиск записей в наборах данных
Помимо приводимых ниже средств поиска записей в НД, можно воспользоваться методами Find, Go ToKey, FindNearest, Go ToNearest компонента TTable.
Свойство Filtered
property Filtered: Boolean;
Свойство Filtered, установленное в True, инициирует фильтрацию, условие которой записано или в обработчике события OnFilterRecord, или содержится как строковое значение в свойстве Filter. Если установлены разные условия фильтрации и в событии OnFilterRecord, и в свойстве Filter, выполняются оба.
Например, если в НД одновременно установлены фильтры
Tablel.Filter = ' [Doljnost] = 'профессор''';
procedure TFormX.TablelFilterRecord(DataSet: TDataSet;
var Accept: Boolean);
begin
Accept := DataSet['UchStepen'] = 'дтн';
end;
то установка Tablel Filtered в True приведет к двум фильтрациям; в результирующем наборе данных будут показаны только записи, у которых поле Doljnost содержит значение 'профессор' и поле UchStepen содержит значение 'дтн'.
Установка Filtered^ False приведет к отмене фильтрации, условия которой указаны в событии OnFilterRecord или (и) свойстве Filter. При этом фильтрация,
наложенная на НД методом SetRange или ApplyRange и ему сопутствующими методами, не нарушается
Пример
Пусть ТБД "Сотрудники" подвергается фильтрации procedure TFormI.Table1FilterRecord(DataSet: TDataSet;
var Accept: Boolean);
begin
Accept := DataSet['UchStepen'] = 'доцент';
end;
и по нажатию кнопки "SetRange" показываются только записи, у которых табельный номер больше 150000
procedure TFormI.SetRangeClick(Sender: TObject) ;
begin
Tablel.SetRange ( [150000],[900000]) ;
end;
Нажатие клавиши "CancelRange" снимает фильтрацию по табельному номеру (рис 7 29 - 7 31)
procedure TFormI.CancelRangeClick(Sender: TOb^ect);
begin
Tablel.CancelRange;
end;
Последовательность установки фильтров произвольна - SetRange может применяться после Filtered = True, и наоборот
Отмена одного из этих условий фильтрации не приводит к отмене другого способа фильтрации (рис 7 32, 7 33)
или
Событие OnFilterRecord
property OnFilterRecord: TFilterRecordEvent;
Событие OnFilterRecord возникает, когда свойство Filtered устанавливается в Tine Обработчик события OnFilterRecord имеет два параметра имя фильтруемого набора данных и var Accept, указывающий условия фильтрации записей в НД В отфильтрованный ИД включаются только те записи, для которых параметр Accept имеет значение True
В условие фильтрации могут входить любые поля НД, в том числе не входящие в текущий индекс, а также не входящие ни в один индекс Возможность фильтрации НД по неиндексным полям, а также полям, не входящим в текущий индекс, выгодно отличает способ фильтрации с использованием события OnFilterRecord и свойства Filteredот способов фильтрации с использованием методов Set Range, Apply Range и им сопутствующих методов (компонент TTable) Последние, как будет показано в разделе, посвященном компоненту TTable, позволяют производить фильтрацию НД только по индексным полям, входящим к тому же в состав индекса, текущего на момент фильтрации Кроме этого, второй способ часто не позволяет реализовывать сложные логические конструкции при указании условий фильтрации
Однако следует помнить о том, что при указании условий фильтрации НД в обработчике OnFilterRecord, в нем последовательно перебираются все записи ТБД при анализе их на предмет соответствия условию фильтрации, в то время как методы SetRange, ApplyRange и им сопутствующие методы используют индексно-последовательный метод доступа, т е работают с частью записей в физической ТБД Это делает использование OnFilterRecord предпочтительным для небольших объемов записей и сильно ограничивает применение данного способа фильтрации при больших объемах данных
Всякий раз, когда приложение обрабатывает событие OnFilterRecord, НД переводится из состояния dsBrowse в состояние dsFilter Это предотвращает модификацию НД во время фильтрации После завершения текущего вызова обработчика события OnFilterRecord, НД переводится в состояние dsBro\\se
Пример
Отфильтровать ТБД "Сотрудники" согласно условию "Показать всех доцентов" procedure TFormI.TablelFilterRecord(DataSet: TDataSet;
var Accept: Boolean);
begin
Accept := DataSet['Doljnost] = 'доцент';
end;
Прцмер
Отфильтровать ТБД "Сотрудники' по условию 'Показать всех сотрудников с табельным номером, вводимым в Editi, и с вхождением в ФИО символов, вводимых пользователем в Edit2" procedure TFormI.TablelFilterRecord(DataSet: TDataSet;
var Accept: Boolean);
begin
Accept :- (DataSet['TabNum'] > Editi.Text))
AND (Pos(Edit2.Text,DataSet['FIO']) > 0);
end;
Методы FindFirst, FindLast, FindNext, FindPrior (см. выше подраздел "Поиск записей в наборах данных") также используют свойство OnFilterRecord, когда выполняют навигацию по НД.
Свойство Filter
property Filter: string;
Свойство Filter позволяет указать условия фильтрации. В этом случае НД будет отфильтрован, как только его свойство Filtered станет равным True. Синтаксис похож на синтаксис предложения WHERE SQL-оператора SELECT с тем исключением, что: имена переменных программы указывать нельзя, можно указывать имена полей и литералы (явно заданные значения).
Можно применять операторы отношения:
< Меньше чем; > Больше чем; >= Больше или равно; <= Меньше или равно; = Равно; <> Не равно
а также использовать логические операторы AND, NOT и OR:
([Doljnost] = 'доцент') AND ([TabNum] > 300000)
Строку фильтрации можно ввести во время выполнения (рис. 7.34, 7.35):
//когда проставляется галка в поле компонента CheckBoxl (то есть
//когда CheckBoxl.Checked =True), пользователь включает
//фильтрацию; когда пользователь снимает отметку (то есть когда
// CheckBoxl.Checked =True), пользователь выключает фильтрацию
procedure TFormI.CheckBoxIClick(Sender: TObject);
begin
Table1.Filter := Editl.Text;
Table1.Filtered := CheckBoxl.Checked;
end;
Однако при этом нужно следить, чтобы введенная строка соответствовала требованиям, предъявляемым к синтаксису строки Filter.
Другим способом мог бы быть обработчик, считывающий значения фильтрации и преобразующий их к формату строки Filter. На рис. 7.36 и 7.37 показана форма, где значения, по которым осуществляется фильтрация, вводятся в поля компонентов TEdit1. После этого приложение автоматически формирует строку условия фильтрации и заносит ее в свойство Filter. Сформированная строка условия фильтрации для наглядности показывается в форме приложения в компоненте Label3.
Свойство FilterOptions
property FilterOptions: TFilterOptions;
TFilterOption = (foCaseInsensitive, foNoPartialCompare);
Свойство FilterOptions позволяет установить режимы фильтрации с использованием свойства Filter. По умолчанию FilterOptions = [ ];
foCaseInsensitive -
Фильтрация производится без учета разницы в высоте букв; foNoPartialCompare -
поиск производится на точное соответствие. В противном случае, при фильтре FIO = 'Ма' в отфильтрованный НД будут включены записи, у которых в поле FIO частично входит "Ма". например (если не используется опция foCaseInsensitive), 'Мануйлова' и 'Комарова'.
Навигация в неотфильтрованном НД между записями, удовлетворяющими фильтру
Методы FindFirst, FindLast, FindNext, FindPrior позволяют перемещаться в неотфильтрованном НД (у которого Filtered = False) между записями, удовлетворяющими условию фильтрации. Условие фильтрации задается событием OnFilterRecord или (и) свойством Filter. Действие данных методов таково: они кратковременно переводят НД в отфильтрованное состояние (Filtered = True) без визуализации этой фильтрации в TDBGrid или другом подобном компоненте, находят соответствующую запись и переводят НД в неотфильтрованное состояние (Filtered = False).
Если искомая запись найдена, данные методы возвращают True, в противном случае - False. Аналогичный результат возвращает свойство Found.
Более подробно указанные методы рассмотрены в подразделе "Поиск записей в наборах данных" (см. п.7.7).
Фильтрация записей в наборах данных
Помимо описываемых ниже средств, для фильтрации данных могут использоваться: методы SetRange или ApplyRange (и сопутствующие им методы) - в компоненте Table; секция WHERE оператора SELECT языка SQL - в компоненте TQuery.
Использование компонента TFieldDefs
Компонент TFieldDefs содержит информацию о полях, объявленных в составе ТБД, ассоциированной с данным НД.
Для НД типа TTable компонент TFieldDefs содержит информацию обо всех полях, объявленных в структуре ТБД, ассоциированной с данным TTable. He следует путать это свойство с свойством Fields, которое содержит информацию о всех компонентах типа TField, объявленных для данного набора данных с использованием редактора полей.
Для НД типа TQuery компонент TFieldDefs содержит информацию обо всех полях, объявленных в качестве возвращаемых полей в операторе SELECT. Подробнее см. замечание, помещенное в конце данного подраздела. Свойство набора данных
property FieldDefs: TFieldDefs;
в качестве результата возвращает указатель на объект типа TFieldDefs данного НД и, таким образом, с его помощью можно использовать свойства и методы
компонента TFieldDefs для определения числа и характеристик полей, объявленных в таблице базы данных, ассоциированной с данным НД. Рассмотрим свойства и методы компонента TFieldDefs.
Свойства компонента TFieldDefs
• property Count: Integer;
Возвращает количество компонентов типа TIndexDef, каждый из которых содержит информацию о конкретном поле в составе ТБД. • property Items[Index: Integer]: TFieldDef;
Данное свойство является набором объектов типа TFieldDef, каждый из которых содержит информацию о конкретном поле, объявленном в составе ТБД. Доступ к конкретному объекту осуществляется через указание Items[Index], где Index лежит в диапазоне Q..Count-\. Объект типа TFiezldDef обладает следующими свойствами:
• property DataType: TFieldType;
Свойство DataType возвращает тип поля как значение из перечислимого типа TFieldType: TFieldType = (ftString, ftSmallint, ftlnteger, ftWord, ftBoolean, ftFloat, ftCurrency, ftBCD, ftDate, ftTime, ftDateTime, ftBytes, ftVarBytes, ftAutoInc, ftBlob, ftMemo, ftGraphic, ftFmtMemo, ftParadoxOle, ftDBaseOle, ftTypedBinary);
• property FieldNo: Integer;
Свойство FieldNo возвращает физический номер поля, использующийся Borland Database Engine (BDE) для доступа к полю. • property Name: string;
Свойство Name возвращает физическое имя поля в ТБД. • property Required: Boolean;
Данное свойство возвращает True, если поле требует обязательного заполнения каким-либо значением, и False в противном случае. • property Size: Integer;
Данное свойство возвращает размер поля. Он важен для полей типов: ftString, ftBCD, ftBytes, ftVarBytes, ftBlob, ftMemo or ftGraphic. Для полей всех остальных типов размер поля определяется его типом. Для полей BCD возвращается число знаков после десятичной точки. Пример.
Считать сведения о полях ТБД, ассоциированной с Table 1, и поместить в ListBox1 информацию об имени каждого поля, его типе, размере и значении его свойства Required (результат работы приводимого кода на рис.7.38): var i : Integer;
TipPolja : String; // тип поля
Tmp : String; // результат форматирования
TmpReq : String[3];//рабочая переменная
begin
ListBoxl.Clear;
Tablel.FieldDefs.Update;
// считываем поля и заносим в ListBoxl сведения об
//их имени, типе, размере и свойстве Required
FOR i := О ТО Tablel.FieldDefs.Count - 1 do begin
CASE Tablel.FieldDefs.Items[i].DataType OF
ftString TipPolja = 'String';
ftSmallint TipPolja = 'Smallint' ;
ftlnteger TipPolja == 'Integer';
ftWord TipPolja = 'Word';
ftBoolean TipPolja = 'Boolean';
ftFloat TipPolja = 'Float';
ftCurrency TipPolja = 'Currency' ;
ftBCD TipPol;a = 'BCD';
ftDate TipPolja = 'Date';
ftTime TipPolja = 'Time';
ftDateTime TipPolja = 'DateTime';
ftBytes TipPolja = 'Bytes' ;
ftVarBytes TipPolja = 'VarBytes' ;
ftAutoInc TipPolja = 'AutoInc';
ftBlob TipPolja = 'Blob';
ftMemo TipPolja = 'Memo';
ftGraphic TipPolja = 'Graphic';
ftFmtMemo TipPolja = 'FmtMemo' ;
ftParadoxOle TipPolja = 'ParadoxOle';
ftDBaseOle TipPolja = 'DBaseOle';
ftTypedBinary TipPolja = 'TypedBinary';
END;
IF Tablel.FieldDefs.Items[i].Required THEN
TmpReq := 'Req'
ELSE
TmpReq := ' - ';
Tmp := Format('%-16s %-10s %-5s %4d', [Tablel.FieldDefs.Items[i].Name, TipPol]a, TmpReq, Tablel.FieldDefs.Items[i].Size]) ;
ListBoxl.Items.Add(Tmp);
END;
Методы компонента TFieldDefs
procedure Add(const Name: string; DataType: TFieldType; Size: Word; Required: Boolean);
Метод Add добавляет в список Items новый элемент- поле.
Параметр Name определяет имя нового поля.
Параметр DataType определяет тип поля как одно из значений перечислимого типа TFieldType (см. выше описание свойства TTable. TFieldDefs.Items [Index].DataType).
Параметр Si:e указывает размер поля или 0 в случае, когда размер поля явно определяется его типом (например, ftlnteger определяет целочисленное поле длиной в слово).
Параметр Required определяет, должно ли поле в обязательном порядке содержать какое-либо значение, или не должно.
procedure Clear;
Метод Clear очищает FieldDefs. Это необходимо, например, при создании новой ТБД (см. метод TTable. CreateTable. function Find(const Name: string): TFieldDef;
Метод Find ищет поле по его имени, определяемому параметром Name. В случае успеха метод возвращает указатель на объект TIndexDefs. Items. •
function Index0f(const Name: string): Integer; Метод Index Of ищет поле по его имени и возвращает индекс объекта TIndexDefs списке Items. У найденного элемента значение свойства Name совпадает с параметром Name метода. procedure Update;
Метод Update обновляет содержимое свойства TFieldDef текущей информацией о полях в составе ТБД. Он также позволяет заносить в TFieldDef информацию о полях неоткрытого НД. ЗАМЕЧАНИЕ.
Для НД типа TQuery в свойстве FieldDefs будет содержаться информация только о тех полях, которые представлены в списке после оператора SELECT: SELECT P.NN, P.DatePrih, P.Tovar
FROM prihod P
WHERE ...
Тогда свойство FieldDefs будет содержать информацию только о полях NN, DatePrih, Tovar таблицы Prihod.
Это правило действует и для случая двух и более таблиц БД, участвующих в запросе:
SELECT P.NN, P.DatePrih, P.Tovar, P.Kolvo, K.KursUSD
FROM prihod P, KursUSD К
WHERE K.Datel= P.DatePrih
В случае использования в качестве полей результирующего запроса агрегированных функций типа SUM, а также результатов выражений, имя вычисляемого или агрегированного поля берется по его псевдониму, следующему после ключевого слова as:
SELECT P.NN, P.DatePrih, P.Tovar, P.Kolvo, K.KursUSD, P.KolVo * K.KursUSD as Zena
FROM prihod P, KursUSD К
WHERE K.Datel= P.DatePrih
В данном случае вычисляемое поле P.KolVo * K.KursUSD имеет в результирующем НД имя ' Zena '.
Если псеводним вычисляемому или агрегированному полю не присвоен, его имя берется как копия арифметического выражения, по которому значение этого поля вычисляется. Например:
SELECT P.NN, P.DatePrih, P.Tovar, P.Kolvo, K.KursUSD,
P.KolVo * K.KursUSD
FROM prihod P, KursUSD К
WHERE K.Datel= P.DatePrih
Имя вычисляемого по выражению P.Kolvo * K.KursUSD поля будет P.KolVo * K.KursUSD '.
Использование свойств FieldCount и Fields
property FieldCount: Integer;
Свойство FieldCount возвращает число компонентов TField, определенных в редакторе полей для данного НД. В общем случае число TField не равно числу полей, физически объявленных в ТБД, ассоциированной с данным TTable, поскольку из объявленных полей в качестве TField могут быть добавлены не все, плюс к тому могут быть объявлены, например, вычисляемые поля.
В том случае, если с использованием редактора полей ни одно поле из физически объявленных в структуре ТБД не было добавлено в форму в качестве TField, FieldCount будет возвращать значение, совпадающее с числом физически объявленных в ТБД полей.
Для компонента TQuery всегда будет возвращаться число полей, объявленных в качестве полей возвращаемого результирующего НД в операторе SELECT:
SELECT F.polel, F.pole2, S.pole99, ...
FROM first F, second S, ...
При этом не важно, сколько имеется ТБД-источников для SQL-запроса и к какому из них принадлежат возвращаемые поля, поскольку они считаются принадлежащими набору данных, возвращаемому в результате выполнения оператора SELECT, и ни с чем иным в данном контексте не ассоциируются.
property Fields[Index: Integer]: TField;
Свойство Fields есть набор компонентов TField, определенных для НД. К отдельному полю можно обратиться, указав Fields /Index J, где Index лежит в диапазоне O..Count-1. Пример.
Пусть в редакторе полей для Table 1 определена группа полей (компонентов TField). Необходимо записать в ListBox2 имена физических полей и для каждого из них - имя компонента TField, ассоциированного с полем: ListBox2.Clear;
FOR i := 0 ТО Table1.FieldCount - 1 do
ListBox2.Items.Add(Format('%-16s %-10s', [Tablel.Fields[i].FieldName, Tablel.Fields[i].Name])) ;
Как можно видеть из рис.7.39, использование свойств FieldDefs и Fields имеет разную природу: если первое выдает информацию о физически объявленных полях в ТБД, второе выдает сведения о логических полях НД, т.е. полях, добавленных в коллекцию объектов типа TField для этого НД:
Рис 7.39 Информация о компонентах TField
Заметим, что поле VychislPole является вычисляемым и физически в структуре ТБД отсутствует.
Свойства DefaultFields, CacheBlobs, метод ClearFields
Свойство property DefaultFields Boolean; содержит True, если для НД используются динамически создаваемые поля (из структуры записи таблицы БД), и False, если для НД определены постоянные поля (компоненты TField) в редакторе полей.
procedure ClearFields;
Метод очищает содержимое полей текущей записи набора данных. Если НД не находится в режиме вставки новой записи или редактирования, возбуждается исключение. В случае успешного выполнения вызывается обработчик события OnDataChange для компонента TDataSource, связанного с НД. property CacheBlobs: Boolean;
Определяет, выделяется ли в памяти буфер для хранения содержимого blob-поля текущей записи НД. Если свойство установлено в True (значение по умолчанию), буфер выделяется, если False - нет. Буфер необходим, если содержимое blob-поля (например, мемо-поля) показывается в форме для текущей записи НД и должно быстро обновляться при переходе на новую запись.
Способы обращения к полям набора данных
function FieldByName(const FieldName: string): TField;
Позволяет обращаться к полю, объявленному в структуре таблицы (TTable), или к полю, перечисленному в числе прочих в структуре набора данных, возвращаемого оператором SELECT (компонент TQuery). Например:
Table1.FieldByName('FIO').Value := 'Иванов И.И.';
Аналогичным целям служит свойство property FieIdValues[const FieldName: string]: Variant;
Оно позволяет обращаться к полю по его имени FieldName, например:
Table1.FieldValues['FIO'] := 'Иванов И.И.';
НД данных по умолчанию, его имя при обращении к полю можно опускать
Table1['FIO'] := 'Иванов И.И.';
property Fields(Index: Integer]: TField;
Позволяет обращаться к полю НД по его индексу Например: Table1.Fields[2].Value := 'Иванов И.И.';
К компоненту TField, созданному с помощью редактора полей, можно также обращаться через его имя. По умолчанию оно формируется из имени набора данных и названия поля:
Table1FIO.Value := 'Иванов И.И.';
Получение информации об индексах ТБД
Компонент TindexDefs содержит информацию обо всех индексах таблицы базы данных, объявленных в ней в текущий момент. У TTable имеется свойство property IndexDefs: TIndexDefs; которое содержит ссылку на объект класса TIndexDefs. Поэтому для каждого компонента TTable всегда можно получить информацию об индексах данной ТБД через свойства и методы TIndexDefs. Рассмотрим эти методы и свойства.
Свойства:
property Count: Integer; -
возвращает число индексов; property Items[Index: Integer|: TIndexDef; -
коллекция объектов типа TIndexDef, каждый из которых содержит информацию о конкретном индексе. Index должен принадлежать диапазону [0..Count-1]. Экземпляр типа TIndexDef имеет следующие свойства (информацию о методах объекта данного класса можно получить в системе помощи Delphi):
property Name: string; -
возвращает имя индекса; Пример.
Записать в ListBox1 имена всех индексов ТБД, ассоциированной с Table 1: ListBoxl.Clear;
Table1.IndexDefs.Update;
FOR i := 0 TO Tablel.IndexDefs.Count - 1 do ListBoxl.Items.Add(Tablel.IndexDefs[i].Name) ;
Перед считыванием значения свойства Name необходимо выполнить метод Tablel IndexDefs.Update (см. ниже) для обновления информации обо всех имеющихся индексах.
Отметим, что для Paradox-таблиц имя первичного индекса не выдается; вместо этого выдается пустая строка, поскольку первичный индекс для Paradox-таблиц не имеет имени (рис. 8.1):
Пустую строку имени первичного индекса можно заменять, например, словом 'Primary':
var i : Integer;
Ima : String;
begin
ListBox1:Clear;
Table1.IndexDefs.Update;
FOR i := 0 TO Table1.IndexDefs.Count - 1 do begin
Ima := Table1.IndexDefs[i].Name;
IF Ima = '' THEN Ima := 'Primary';
ListBoxl.Items.Add(Ima) ;
END; //FOR
end;
property Fields: string, -
возвращает список полей, по которым построен данный индекс Поля в строке разделены точкой с запятой Именно в таком виде строку можно указывать в свойстве IndexFie!dNames (компонент TTable) property Options: TIndexOptions -
возвращает характеристики индекса в виде множества TIndexOptions = set of (ixPrimary ixUnique, ixDescending, ixNonMaintatned, ixCaselnsensitne). Таким образом, возвращаемое значение может состоять максимум из 6 элементов Пример
Показать в Edit1 Text список полей индекса, чье имя является текущим в ListBox1 (результат на рис 82) // обработчик события выбора элемента в ListBoxl:
procedure TForm1.ListBox1Click(Sender: TObject);
var Teklndex : Integer;
begin
Teklndex := ListBox1.Itemlndex; { индекс текущего элемента в ListBoxl}
Edit1.Text := Tablel.IndexDefs[Teklndex].Fields;
Label2.Caption := 'Поля индекса ' + ListBoxl.Items[Teklndex] + ':' ;
end;
Методы
procedure Add(const Name, Fields: string; Options: TIndexOptions);
Метод Add создает новый объект TIndexDef и помещает его в коллекцию TIndexDefs Items На момент создания должны быть определены такие параметры нового объекта TIndexDef, как Name, Fields, Options Их назначение совпадает с назначением аналогичных свойств компонента TindexDef . Этот метод в основном используется при создании новых таблиц
procedure Update;
обновляет элементы коллекции TIndexDefs Items текущей информацией из НД, причем обновление может производиться и без открытия набора данных procedure Clear;
очищает элементы коллекции TIndexDefs Items function Index0f(const Name: string): Integer;
возвращает из коллекции TIndexDefs Items индекс элемента, у которого свойство Name совпадает с параметром Name данного метода function FindIndexForFields(const Fields: string): TIndexDef;
Отыскивает индекс по списку его полей, которые содержатся в строке Fields Возвращает указатель на объект TIndexDefв коллекции TIndexDefs Items, в котором содержимое свойства Fields совпадает с параметром Fields индекса Метод GetIndexNames
procedure GetIndexNames(List: Tstrings) - возвращает в параметре List список имен индексов Заметим, что для Paradox-таблиц имя главного индекса не выдается
Пример.
Выдать список индексов ТБД, ассоциированной с Table1 (рис.8.3): ListBox2.Clear;
Tablel.GetIndexNames(ListBox2.Items) ;
Свойства IndexFieldCount и IndexFields
Свойство IndexFieldCount: Integer; - возвращает число полей в текущем индексе НД. Номер первого поля 0.
Свойство IndexFields[Index: Integer]: TField; содержит набор полей текущего индекса; обращение IndexFields [Index] возвращает информацию о поле, определенном в текущем индексе под номером Index (нумерация полей начинается с 0). Для n определенных полей Index лежит в диапазоне 0.. (n-1). Например, чтобы записать в ListBox1 имена всех полей текущего индекса, можно использовать такой фрагмент программы:
var i : Integer;
ListBox1.Clear;
For i:= 0 TO Tablel.IndexFieldCount - 1 do ListBoxl.Items.Add(Tablel.IndexFields[I].FieldName) ;
Поскольку при обращении к Index Fields [Index] возвращается указатель на объект типа TField, для данного поля текущего индекса можно пользоваться всеми свойствами и методами типа TField.
Установка текущего индекса ТТаЫе
То, какой индекс является текущим для данного НД (компонент TTable), в ряде случаев имеет важное значение.
Во-первых, текущий индекс определяет поля, по которым будет отсортирован данный НД. Это важно как с точки зрения доступа к данным, так и с точки зрения их визуализации: представление данных должно быть максимально информативным. Плюс к этому пользователь должен быстро находить нужную ему информацию и видеть группировки записей внутри НД.
Во-вторых, многие методы и свойства TTable работают напрямую с текущим индексом. Это, например, метод SetRange для фильтрации записей в TTable и связанные с ним; методы для поиска записи, удовлетворяющей условию - FindKey, FindNearest и другие.
Для указания индекса, по которому будет производиться сортировка в НД, связанном с данным компонентом TTable, имеются два взаимоисключающих способа.
1) Путем занесения имени индекса в свойство property IndexName: string; например:
Tablel.IndexName := 'INDEX_BY_FIO';
Пример.
Для описанного выше примера заполнения ListBox именами доступных индексов сделаем для Table текущим индекс, имя которого является текущим в ListBoxl: Tablel.IndexName := ListBoxl.Items[ListBox1.Itemlndex];
В силу того, что имя главного (первичного) индекса для Paradox-таблиц не выводится, данный фрагмент кода может сделать текущим только вторичный индекс.
2) Путем занесения списка индексных полей в свойство property IndexFieldNames: string;
В случае указания нескольких полей их имена разделяются точкой с запятой. Пример:
Table1.IndexFieldNames := 'FIO; Doljnost';
Индекс с указанными полями должен физически существовать. Попытка присвоить свойству IndexFieldNames список полей, не являющихся полями какого-либо индекса, вызовет исключительную ситуацию. Данное свойство особенно ценно для Paradox-таблиц, т.к. позволяет сделать текущим главный (первичный) индекс путем перечисления входящих в него полей.
Добавление нового индекса
Добавление нового индекса происходит в режиме исключительного доступа к ТБД (свойство Exclusive = True) и осуществляется методом procedure Addlndex(const Name, Fields: string; Options: TIndexOptions); где параметр Name определяет имя индекса, а параметр Fields - список индексных полей. В случае нескольких полей их имена должны разделяться точкой с запятой. Должны указываться только поля, объявленные в структуре ТБД. В противном случае будет возбуждена исключительная ситуация и создание индекса будет блокировано. Параметр Options является множеством, которое содержит значения, определяющие свойства индекса:
TIndexOptions = set of (ixPrimary, ixUnique, ixDescending,ixExpression, ixCaseInsensitive) ;
ixPrimary -
определяет первичный индекс; ixUnique -
определяет уникальный индекс; ixDescending -
определяет индекс, построенный по убыванию значений ключевых полей (по умолчанию строится индекс по возрастанию значений ключевых полей); ixCaseInsensitive -
определяет индекс, нечувствительный к высоте букв. Так, например, если для индекса установлен этот режим, значения "КАРТОФЕЛЬ", "Картофель" и "картофель" будут сочтены идентичными. Например,
определить новый индекс с именем WWW, построенный по полям 'NN; DatePrih', нечувствительный к высоте букв: Table1.Close;
Table1.Exclusive := True;
Table1.Open;
Table1.Addlndex('WWW, 'NN; DatePrih' , [ixCaseInsensitive]);
Table1.Close;
Table1.Exclusive := False;
Table1.Open;
Удаление существующего индекса
Удаление существующего индекса происходит в режиме исключительного доступа к ТБД (свойство Exclusive = True) и осуществляется методом procedure Deletelndex(const Name: string); где параметр Name определяет имя удаляемого индекса. При попытке удаления несуществующего индекса возбуждается исключительная ситуация и удаление блокируется.
Пример.
Удалить индекс с именем WWW: Table1.Deletelndex('WWW) ;
Установка приоритетного доступа при многопользовательском режиме
Свойство Exclusive дает пользователю исключительный доступ к НД (значение True). Это означает, что никто иной не только не может вносить изменения в НД, но вообще не имеет доступа к НД. Установить исключительный доступ можно, лишь когда ни один пользователь не имеет доступа к НД и тот не открыт.
Для SQL-таблиц исключительный доступ может означать запрет изменения НД другими пользователями. Однако последние могут просматривать содержимое НД.
ЗАМЕЧАНИЕ.
Delphi тоже считается в данном случае пользователем. Поэтому, если в программном коде делается попытка получения прав исключительного доступа к ТБД Table1.Exclusive := True; и программа запущена из Delphi, попытка получения исключительных прав будет блокирована, поскольку на Вашей машине имеется два пользователя, осуществляющих доступ к этой ТБД: выполняющееся приложение и Delphi. То же произойдет, если на момент попытки получения исключительных прав из работающего приложения в Database Desktop будет открыта данная ТБД.
Очистка записей ТБД
Метод procedure EmptyTable; уничтожает все записи в ТБД, связанной с данным НД. После этой операции ТБД будет пустой. Метод применим только к закрытым НД, и только для случая исключительного доступа (см. выше). В противном случае возбуждается исключение и очистка ТБД блокируется.
Пример.
Очистить от записей ТБД, ассоциированную с НД Tablel: Table1.Close;
Table1.Exclusive := True;
Table1.EmptyTable;
Table1.Exclusive := False;
Table1.Open;
Еще раз напомню, что таблица не будет очищена, если этот фрагмент выполняется из среды Delphi.
Уничтожение таблицы
procedure DeleteTable; физически удаляет ТБД. Метод применим только к закрытым НД.
Создание новой таблицы
procedure CreateTable; создает новую пустую таблицу. Перед созданием таблицы для данного компонента TTable нужно указать:
• имя БД - в свойстве DatabaseName;
• имя таблицы - в свойстве TableName;
• тип таблицы - в свойстве ТаblеТуре. Возможно указание следующих типов:
ttASCII
: многоколончатый текстовый файл, используемый для чтения как ТБД; ttDBase
: таблица dBASE; ttParadox
: таблица Paradox; описания полей - в свойстве FieldDefs;
описания индексов - в свойстве IndexDefs.
Для добавления описаний полей в свойство FieldDefs оно сначала очищается, а затем для каждого поля информация в FieldDefs заносится методом
procedure Add(const Name: string; DataType: TFieldType; Size: Word; Required: Boolean);
где: параметр Name определяет имя поля; параметр DataType определяет тип поля:
TFieldType = (ftUnknown, ftString, ftSmallint, ftlnteger, ftWord, ftBoolean, ftFloat, ftCurrency, ftBCD, ftDate, ftTime, ftDateTime, ftBytes, ftVarBytes, ftAutoInc, ftBlob, ftMemo, ftGraphic, ftFmtMemo, ftParadoxOle, ftDBaseOle, ftTypedBinary) ;
параметр Size определяет размер поля (если его указание необходимо) или 0 (если тип поля подразумевает его размер, например ftlnteger);
параметр Required определяет, должно ли поле в обязательном порядке содержать значение.
Для добавления описаний индексов в свойство IndexDefs оно сначала очищается, а затем для каждого поля информация в IndexDefs заносится методом procedure Add(const Name, Fields: string; Options: TIndexOptions); где параметр Name определяет название индекса; параметр Fields определяет список индексных полей. В случае нескольких полей их имена разделяются точкой с запятой. Могут быть указаны только те поля, описания которых перед этим добавлены в свойство FieldDefs; параметр Options определяет свойства индекса (см. описание метода Addlndex).
Пример.
Создать новую ТБД с именем 'NewT' в БД 'book1', состоящую из двух полей - символьного поля FIO и целочисленного Oklad, с одним первичным индексом по полю FIO: WITH Table1 do begin
// укажем БД, имя новой ТБД, тип ТБД
Active := False;
DatabaseName := 'book';
TableName := Editl.Text;
TableType := ttParadox;
// опишем поля создаваемой ТБД
WITH FieldDefs do begin
Clear;
Add('FIO', ftString, 30, False);
Add('Oklad', ftlnteger, 0, False);
END;//with FieldDefs
// опишем индексы создаваемой ТБД
WITH IndexDefs do begin
Clear;
Add('Index_FIO', 'FIO', [ixPrimary, ixUnique]) ;
END;//with IndexDefs
CreateTable; // создадим ТБД
Active := True; // откроем ее
END;//WITH Tablel
Заметим, что ТБД может быть создана также и при помощи SQL-оператора CREA ТЕ TABLE. Для "персональных" СУБД типа Paradox и dBase это альтернативный методу CreateTable способ; для "промышленных" СУБД это единственный способ динамического создания ТБД из работающего приложения, реализованного с помощью Delphi.
Обзор методов
Для поиска записей в НД в компоненте TTable применяются следующие методы:
function FindKey([список значений]): Boolean -
ищет запись, точно удовлетворяющую условиям в списке значений; существует также дублирующий его метод GoToKey; procedure FindNearest([список значений]) -
ищет запись, приблизительно Удовлетворяющую условиям в списке значений; существует также дублирующий его метод GoToNearest; Помимо этого, у TTable имеются методы, унаследованные от родительского класса TDBDataSet:
function Locate([список полей], [список значений]) : Boolean -
устанавливает указатель на запись, у которой список полей точно или неточно содержит значения из списка значении. function Lookup([список поисковых полей], [список значений], [список результирующих полей]) : Variant; -
возвращает значения полей из списка результирующих полей для записи в НД, у которой поля из списка поисковых полей точно содержат значения из списка значений. Указатель текущей записи не меняется. Эти методы рассмотрены в разделе, описывающем общие свойства и методы наборов данных.
Установка значений для поиска
Поиск может осуществляться только по индексным полям. Состав полей, используемых для идентификации нужной записи при поиске в НД, определяется текущим индексом. Поэтому, если поля, по которым необходимо осуществить поиск, не входят в индекс, являющийся текущим в данный момент, в качестве текущего индекса нужно установить индекс, построенный по полям, по значениям которых и планируется осуществить поиск. Напомним, что для установки текущего индекса используют свойства IndexFieldNames или IndexName.
Для индексов, в состав которых входит более одного поля, должны указываться значения всех полей, входящих в индекс, или значения полей старших уровней вложенности. Более подробно см. ниже, подраздел "Поиск по части текущего индекса ".
Точный поиск
Для точного поиска (поиска на точное соответствие) применяется метод function FindKey( [список значений]): Boolean;
При поиске на точное соответствие предпринимается попытка отыскать в НД запись, у которой индексные поля соответствуют значениям, указанным в списке значений. Если такая запись найдена, метод FindKey возвращает True и указатель текущей записи в НД (курсор НД) устанавливается на эту запись, т.е. она делается текущей. Если найдена группа записей, отвечающая условию, текущей становится логически первая из них. Если запись не найдена, курсор НД не перемещается и метод FindKey возвращает False.
Пример. Пусть имеется НД с полями GrNum (номер группы), NN (номенклатурный номер товара), Tovar (наименование товара):
Предположим, что поисковое значение GrNum вводится в Edit1, a NN - в Edit2 (рис.8.4). Тогда обработчик нажатия клавиши поиска FindButton может выглядеть так (для простоты в обработчике не контролируется правильность ввода в компонентах Edit1, Edit2):
procedure TForm1.FindButtonClick(Sender: T0b]ect);
var GrTmp, NNTmp : Longint;
begin
GrTmp := StrToInt(Edit1.Text);
NNTmp := StrToInt(Edit2.Text);
// поиск записи
IF not Table1.FindKey([GrTmp,NNTmp]) then ShowMessage ('Нет товара с такой группой и номером!');
end;
Пусть в Edit1 введено "12" и в Edit2 - "4". Тогда указатель переместится на запись, у которой значение GrNum равно 12 и значение поля NN равно 4 (рис. 8.5):
Пусть в Editi введено "12" и в Edit2 введено "О". Тогда указатель не переместится с текущей записи и будет выдано сообщение 'Нет товара с такой группой и номером!'.
Для неточного поиска в Delphi имеется группа методов SetKey, EditKey, GotoKey, которые должны выполняться вместе и которые по функциональности аналогичны методу FindKey. Использование их является менее удобным. Сначала нужно перевести НД в состояние dsSetKey (методом SetKey или, если он уже применялся для данного индекса, EditKey), затем присвоить поисковые значения полям и выполнить метод GoToKey. После этого НД переходит в состояние dsBrowse. Результат выполнения аналогичен результату, возвращаемому методом FindKey. Например, код
IF not Table1.FindKey([GrTmp,NNTmp]) then ShowMessage('Нет товара с такой группой и номером!');
эквивалентен более громоздкому коду с применением GotoKey.
Table1.SetKey;
Table1GrNum.Value := GrTmp;
Table1NN.Value := NNTmp;
IF not Table1.GoToKey then
ShowMessage('Нет товара с такой группой и номером! ');
Неточный поиск
Неточный поиск (поиск на неточное, приблизительное соответствие) осуществляется методом
procedure FindNearest( [список параметров]);
При поиске на неточное соответствие предпринимается попытка отыскать в НД запись, у которой индексные поля соответствуют значениям, указанным в списке значений. Если такая запись найдена, указатель текущей записи в НД перемещается на нее или на следующую за ней запись, в зависимости от значения свойства property KeyExclusive: Boolean. Если KeyExclusive = False (пo умолчанию), указатель текущей записи перемещается на нее. Если KeyExclusive = True, указатель текущей записи перемещается на следующую запись.
Если запись не найдена, указатель текущей записи всегда перемещается на ближайшую запись с большим значением индекса.
В приводимых ниже примерах подразумевается KeyExclusive = False.
Предположим, что поисковое значение GrNum вводится в Editi, а NN - в Edit2. Тогда обработчик нажатия клавиши поиска FindButton может выглядеть так:
procedure TForm1.FindButtonClick(Sender: TObject) ;
var GrTmp, NNTmp : Longint;
begin
GrTmp := StrToInt(Edit1.Text);
NNTmp := StrToInt(Edit2.Text);
//Поиск записи
Table1.FindNearest([GrTmp,NNTmp]) ;
end;
Пусть в Edit1 введено "12" и в Edit2 введено "4". Тогда указатель переместится на запись, у которой поле GrNum содержит 12 и поле NN содержит 4 (рис. 8.6):
Пусть в Edit 1 введено " 12" и в Edit2 введено "О". Тогда указатель переместится на запись с большим значением индекса. Наращение индекса ведется по внутреннему полю (если оно есть) и только затем - по полю более высокого приоритета. В нашем случае внутреннее поле в индексе - NN. В данном случае в НД имеется запись с тем же номером группы и большим номенклатурным номером (рис. 8.7):
Однако если в Editi введено "50" и в Edit2 введено "О" (или что-либо другое, для данного состояния НД это неважно), записи с той же группой (50) и большим значением номенклатурного номера нет. Поэтому указатель записи перемещается на запись с большим номером группы (рис. 8.8).
Заметим, что теоретически возможно в условиях поиска опускать значение внешнего поля индекса (в нашем случае поля GrNum). Например, можно задать в Edit1 "0" и в Edit2 - "1". Однако, вопреки ожиданиям, курсор НД не встанет на первую запись с номенклатурным номером 1 для первой попавшейся группы, а встанет на первую запись с группой, превышающей 0, т.е. на логически первую запись в НД при сортировке по полям GrNum, NN (рис. 8.9).
Существует более громоздкая альтернатива методу FindNearest -выполнение группы методов Set Key, EditKey, GoToNearest и заполнение полей поисковыми значениями (подробнее см. в конце описания метода FindKey). Например, выполнение метода
Table1.FindNearest([GrTmp,NNTmp]) ; может быть заменено эквивалентным по последствиям кодом
Table1.SetKey;
Table1GrNum.Value := GrTmp;
Table1NN.Value := NNTmp;
Table1.GotoNearest;
ЗАМЕЧАНИЕ.
Если нужно осуществить поиск по индексу, отличному от текущего, необходимо: 1. сохранить список текущих индексных полей в строковой переменной;
2. заменить список текущих индексных полей НД на необходимый;
3. осуществить поиск;
4. восстановить список текущих индексных полей НД из строковой переменной.
Пример.
Пусть текущая сортировка в НД осуществляется по имени товара (т.е. в текущий момент Tablel. IndexFieldNames = 'Tovar') и текущей является вторая логическая запись (рис. 8.10). Тогда после выполнения обработчика нажатия кнопки FindButton, если в Editi введено "100" и в Edit2 введено "О":
procedure TForm1.FindButtonClick(Sender: TObject) ;
var GrTmp, NNTmp : Longint;
OldIndexFieldNames : Strings;
begin
OldIndexFieldNames := Tablel.IndexFieldNames;
Tablel .IndexFieldNames := 'GrNunuNN';
{...}
Table1.FindNearest([GrTmp,NNTmp]) ;
Table1.IndexFieldNames := OldIndexFieldNames;
end;
указатель записи встанет на искомую запись (рис. 8.11).
Перед выполнением последней строки обработчика
Table1.IndexFieldNames := OldIndexFieldNames;
НД будет иметь вид, показанный на рис. 8.12.
Восстановление исходного индекса в последней строке приведет к изменению логического следования записей в НД, но текущая запись останется прежней. Причиной этого является правило: простое изменение сортировки в НД, если оно не сопровождалось изменением условий фильтрации записей в НД, не влечет изменения местоположения курсора НД.
Инкрементальный локатор
Под локатором будем понимать механизм поиска (точного или приблизительного) записей в НД с последующим позиционированием на них курсора компонента TTable. Для реализации локатора обычно применяется один или несколько компонентов TEdit для ввода условий поиска и кнопка TButton, обработчик события нажатия которой и реализует поиск.
Описанные выше обработчики события нажатия кнопки FindButton реализуют локаторы. Однако, вне рассмотрения остался еще один режим: по вводу каждого символа в TEdit переходить на запись, ближе всего лежащую к искомой. Чем больше введено символов, тем ближе курсор БД к искомой записи. Такой локатор называется инкрементальным.
Пусть необходимо реализовать инкрементальный локатор для уточняющего поиска записи по названию товара. Пусть описанный выше НД отсортирован по индексному полю 'Tovar'. Пусть текущая запись в нем - логически первая. Тогда он имеет вид, показанный на рис. 8.13.
Ввод значения для поиска осуществляется в компонент Edit3. Напишем обработчик для события OnChange, возникающего при любом изменении значения в Edit3:
procedure TForm1.Edit3Change(Sender: T0b;ect) ;
begin
Table1.FindNearest([Edit3.Text]) ;
end;
Пусть нам нужно сделать текущей запись с наименованием товара "Комплект отверток". При использовании описываемого механизма инкрементального локатора необязательно вводить это название полностью. Курсор НД будет приближаться к искомой записи по мере ввода символов в Edit3.
Введем в Edit3 символ "К" (Edit3.Text = 'К');
Тогда Tablel.FindNearest([Edit3.Text]) ;
есть на самом
деле Table1.FindNearest(['К']) ; в результате курсор переместится на 1-ю запись, имеющую в поле Tovar значение, большее строки 'К' (рис. 8.14).
Введем в Edit3 следующий символ, "о" (Edit3.Text = 'Ко').
В результате курсор переместится на 1-ю запись, имеющую в поле Tovar значение, большее строки 'Ко' (рис. 8.15).
Это и есть искомая запись. Заметим, что применение инкрементальных локаторов возможно не только для символьных полей, но и для числовых. Пусть для того же НД, отсортированного по номеру группы (рис.8.16).
производится поиск по этому номеру. Для этой цели используется такой обработчик изменения значения в компоненте Editi:
procedure TForm1.Edit1Change(Sender: TObject) ;
var GrTmp : Longint;
begin
GrTmp := StrToInt(Edit1.Text);
//поиск записи
Table1.FindNearest([GrTmp]) ;
end;
Будем вводить в Edit1 значение "100". Тогда после ввода "1" текущей останется запись с номером группы, равным 1 (рис. 8.17).
после ввода "100" текущей станет запись с номером группы, равным 100, т.е. удовлетворяющая условию поиска (рис. 8.19):
Поиск по части текущего индекса
Если это необходимо, можно осуществлять поиск по частичному множеству индексных полей. Тогда поиск будет производиться не по всем полям данного индекса, а по их части. Для этого необходимо с помощью свойства property KeyFieldCount: Integer; указать, сколько начальных полей индекса будут использоваться при поиске Установка значения свойства KeyFieldCount актуальна только в случае использования методов GoToKey и GoToNearest. Как осуществить поиск по частичному множеству индексных полей для методов Find и FmdNearest, см ниже.
Пример.
Пусть при текущем индексе по полям 'Doljnost; FIO' необходимо осуществить поиск по должности, и по 'должности; ФИО'. Условия поиска будем вводить в Editi (должность) и Edit2 (ФИО) Результаты работы приводимого ниже кода показаны на рис 8.20 а и 8 20 б. procedure TForm1.OneFieldFindButtonClick(Sender: T0bject);
begin
// поиск по 1 полю индекса
WITH Table1 do begin
SetKey;
KeyFieldCount := 1;
Table1Doljnost.Value := Editl.Text;
GoToNearest;
END; // with
end;
procedure TForm1. FullKeyFmfButtonClick (Sender : TObject);
begin
// поиск по 2 полям индекса
WITH Table1 do begin
SetKey;
KeyFieldCount := 2; II на всякий случай, восстановим
Table1Doljnost.Value := Edit1.Text;
Table1FIO.Value := Edit2.Text;
GoToNearest;
END; // with
end;
При этом есть ограничения- подмножество полей индекса должно быть в полном индексе непрерывным, т.е при индексе из 4 полей можно осуществить поиск по 1-му, 2-му, 3-му полям одновременно и нельзя по 1-му, 4-му, 6-му полям.
При использовании методов FindKey и FindNearest необходимости в использовании KeyFieldCount нет; для поиска по частичному соответствию достаточно указать в списке часть полей данного индекса:
// поиск по одному полю из двух
WITH Tablel do
FindNearest ( [Editl.Text] ) ;
// поиск по двум полям из двух:
WITH Tablel do
FindNearest( [Editl.Text, Edit2.Text] ) ;
Обзор методов
Помимо описываемых ниже методов, присущих только TTable, наборы данных имеют также общие свойства, методы и события для фильтрации записей - Filter, Filtered, OnFilter-Record, FindFirst, FindLast, FindNext, FmdPrior Они описаны в разделе "Общие принципы работы с наборами данных"
Для фильтрации записей ТБД, собственно TTable имеет следующие методы:
procedure SetRangeStart; -
устанавливает нижнюю границу фильтра; procedure EditRangeEnd;-
устанавливает верхнюю границу фильтра; procedure ApplyRange;
- осуществляет фильтрацию записей в TTable; условия фильтрации определяются методами SetRangeStart и SetRangeEnd, procedure SetRange(const StartValues, EndValues: array of const);-
имеет тот же эффект, что и последовательное выполнение методов SetRangeStart, SetRangeEnd и ApplyRange. В качестве параметра используются массивы констант, каждый из которых содержит значения ключевых полей. Заметим, что фильтрация методами ApplyRange/SetRange должна проводиться по ключевым полям. По умолчанию берется текущий индекс, определяемый свойством TTable.IndexNamewiH TTable.IndexFieldNames. В случае, если значения этих свойств не установлены, по умолчанию используется главный индекс ТБД. Поэтому, если нужно использовать индекс, отличный от главного, необходимо явно переустановить значение свойства TTable.IndexName (имя текущего индекса) или TTable.IndexFieldNames (список полей текущего индекса).
Ограничения возможностей фильтрации при использовании методов SetRange/SetRangeStart и др.
Заметим, что рассмотренный механизм фильтрации позволяет отфильтровывать только те записи, у которых значения ключевых полей больше или равны нижней границе и меньше или равны верхней границе фильтрации. Иными словами, затруднительно задать сложное условие типа "все записи, у которых поле А < 100 и7и поле Z содержит вхождение строкм “поиск” ".
При возникновении подобных проблем вместо компонента TTable стоит использовать компонент TQuery и запросы на SQL.
Использование SetRange
Метод procedure SetRange(const StartValues, EndValues: array ofconst); показывает в НД только те записи, индексные поля которых лежат в диапазоне [StartValues.. EndValues].
Пример.
Пусть В НД Tablel показываются все записи из ТБД "TOV.DB" (Товары). Включим в структуру записи НД Tablel 2 поля : GrNum (Номер группы, Smallint) и Tovar (Наименование товара, String). Пусть текущий индекс построен по полю 'GrNum'.
Тогда, для фильтрации записей в НД таким образом, чтобы показывались записи только с определенным номером группы, располагаем в форме компоненты Edit1 (для ввода номера группы) и CheckBox1. Если CheckBox1 отмечен (CheckBoxl.Checked = True), то производится фильтрация по номеру группы, введенному в Edit1; если CheckBoxl не отмечен или с него снята отметка (CheckBox1 -Checked = False), в НД показываются все записи из ТБД "TOV.DB" (рис.8.21).
Напишем обработчик события CheckBox1.OnClick, возникающего при отметке CheckBoxl. Заметим, что для простоты правильность ввода в Editi не проверяется.
procedure TForm1.CheckBoxIClick(Sender: TObject);
var GrNumTmp : Integer;
begin
IF CheckBoxl.Checked THEN
begin
GrNumTmp := StrToInt(Edit1.Text);
{————фильтрация записей в НД————}
WITH Tablel do begin
CancelRange;
SetRange([GrNumTmp],[GrNumTmp]) ;
END; {with}
end {then}
ELSE
{—————отмена фильтрации ——————}
Tablel.CancelRange;
end;
Неотфильтрованный НД показан на рис.8.21.
В отфильтрованном НД показываются только те записи, индексное поле текущего индекса у которых (т.е. в нашем случае поле GrNum) имеет значение, лежащее в заданном диапазоне. В данном случае диапазон определяется переменной GrNumTmp. Поэтому для GrNumTmp =3 будут показаны записи, принадлежащие к одной группе 3 (рис.8.22).
Если бы мы хотели, чтобы в НД фильтровались записи из нескольких групп, то нам следовало бы добавить в форму второй компонент Edit2, в котором вводился бы номер конечной группы, в то время как в Edit1 вводился бы номер начальной группы. Далее необходимо модифицировать обработчик события CheckBoxl.OnClick, изменив SetRange на SetRange([GrNumTmpl],[GrNumTmp2]);
procedure TForm1.CheckBoxIClick(Sender: T0b;ect) ;
var GrNumTrnpl,GrNumTmp2 : Integer;
begin
IF CheckBoxl.Checked THEN
begin
GrNumTmp1 := StrToInt(Edit1.Text);
GrNumTmp2 := StrToInt(Edit2.Text) ;
{————фильтрация записей в НД-———}
WITH Table1 do begin
CancelRange;
SetRange([GrNumTrnpl],[GrNumTmp2]) ;
END; {with}
end {then}
ELSE
{
———отмена фильтрации ——————} Table1.CancelRange;
end;
Результаты фильтрации записей с номерами группы от 2 до 4 показаны на рис.8.23.
Методы SetRangeStart, SetRangeEnd, ApplyRange
Эти методы (см. п.8.4.1) являются альтернативой методу SetRange, который объединяет в себе функциональность трех указанных методов.
В частности, рассмотренная в предыдущем примере фильтрация по начальному и конечному номеру группы может быть реализована таким образом:
procedure TForm1.CheckBoxIClick(Sender: TObject);
var GrNumTrnp1, GrNumTmp2 : Integer;
begin
IF CheckBox1.Checked THEN
begin
WITH Tablel do begin
CancelRange;
SetRangeStart ;
Table1. FieldByName ('GrNum') . Aslnteger: = GrNumTnpl ;
SetRangeEnd;
Tablel. FieldByName ('GrNum') .Aslnteger := GrMumTmp2 ;
ApplyRange;
END; {with}
end {then}
ELSE
Tablel.CancelRange;
end;
Метод CancelRange
Метод procedure CancelRange; служит для отмены предыдущих условий фильтрации. Если предыдущую фильтрацию не отменить, возможно, следующие фильтрации принесут не такой результат, которого Вы ожидаете.
Изменим пример, приводившийся выше. Сначала удалим из него вызов метода CancelRange. Пусть изначально НД сортируется по наименованию товара (поле 'Tovar'). Разместим в форме группу зависимых переключателей RadioGroup1, позволяющую переключать текущие индексы Tablel:
procedure TFormI.RadioGroup1Click(Sender: TObject);
begin
WITH RadioGroupl do begin
CASE Itemlndex OF
0 : Table1.IndexFieldNames := 'Tovar'; //текущий индекс по полю 'Tovar'
1 : Tablel.IndexFieldNames := 'GrNum'; //текущий индекс по полю 'GrNum'
END;//case
END;//with
end;
Когда пользователь хочет произвести фильтрацию по номеру группы, он нажимает кнопку "Фильтровать", для которой реализован следующий обработчик нажатия:
procedure TForm1.Button1Click(Sender: TObject);
var GrNumTrnp1,GrNumTmp2 : Integer;
begin
{проверка правильности Edit1.Text и Edit2.Text фильтрация по начальному и конечному номеру группы}
WITH Tablel do begin
//отмечаем строку текущего выбора в RadioGroupl:
RadioGroupl.Itemlndex := 1;
{смена текущего индекса}
IndexFieldNames := 'GrNum';
SetRange ( [GrNumTrnp1] , [GrNumTmp2] ) ;
END; {with}
end;
Как видно, для фильтрации по полю GrNum необходимо сменить текущий индекс таким образом, чтобы GrNum было индексным полем. Начинаем работу с неотфильтрованным НД (рис.8.24):
Фильтруем НД по номеру группы, например, только по 3 группе (рис.8.25).
Через некоторое время возвращаемся к сортировке по товару. Для этого отмечаем соответствующий переключатель в группе RadioGroup1. При этом видим, что показываются записи всех групп (рис.8.26):
Это происходит от того, что при смене текущего индекса невозможно осуществить фильтрацию по другому индексу, уже не являющемуся текущим.
Пусть через некоторое время нам вновь необходимо отфильтровать НД по третьей группе. Напомним, что обработчик нажатия кнопки "Фильтровать" снова сделает текущим индекс, построенный по полю GrNum. И с удивлением отмечаем, что хотя сортировка и меняется (по GrNum), фильтрации не происходит (рис.8.27).
Однако, если попробовать сделать фильтрацию по группе с номером 2, фильтрация будет осуществлена (рис.8.28).
Увиденное можно объяснить следующим образом. Первоначально имеет место фильтрация по индексу GrNum в диапазоне номеров групп [3..3]. После этого мы делаем текущим индекс, построенный по полю Tovar. Фильтрация по группам теперь невозможна, поскольку поле GrNum не входит в новый текущий индекс. Когда мы вновь делаем текущим индекс, построенный по полю GrNum, при этом не меняя диапазона групп [3..3], фильтрация не выполняется, поскольку она не отменена и диапазоны фильтрации не изменились. Когда же мы задаем новые условия фильтрации в диапазоне групп [2..2], НД фильтруется, т.к. изменился диапазон.
Обойти эту особенность можно, отменяя перед новой фильтрацией (по какому бы то ни было индексу) результаты предыдущей фильтрации методом НД CancelRange:
procedure TForm1.ButtonlClick(Sender: T0bject) ;
var GrNumTrnp1,GrNumTmp2 : Integer;
begin
{
проверка правильности Edit1.Text и Edit2.Text} {фильтрация по начальному и конечному номеру группы}
WITH Tablel do begin
CancelRange;
//отмечаем строку выбора текущего выбора в RadioGroupl:
RadioGroup1.Itemlndex := 1;
{смена текущего индекса}
IndexFieldNames := 'GrNum';
SetRange([GrNumTrnpl],[GrNumTmp2]) ;
END; {with}
end;
Методы EditRangeStart, EditRangeEnd
procedure EditRangeStart;
procedure EditRangeEnd;
Эти методы предназначены для смены условий фильтрации, установленных ранее с использованием методов соответственно SetRangeStart и SetRangeEnd. Напомним, что сама фильтрация в этом случае выполняется методом Apply Range. Преимущества их использования ясны не всегда. Например, можно было бы предположить, что для рассмотренной в п.8.4.4 ситуации эти методы способны заменить использование CancelRange :
procedure TFormI.ButtonlClick(Sender: TObject);
var GrNumTrnpl, GrNumTmp2 : Integer;
const Num : Integer = 0;
begin
{проверка правильности Edit.Text}
INC(Num) ;
WITH Table1 do begin
IF Num = 1 THEN
begin
SetRangeStart;
FieldByName('GrNum').As Integer:= GrNumTrnp1;
SetRangeEnd;
FieldByName('GrNum').Aslnteger := GrNumTmp2;
ApplyRange;
end
ELSE
begin
EditRangeStart;
FieldByName('GrNum').Aslnteger:= GrNumTrnp1;
EditRangeEnd;
FieldByName('GrNum').Aslnteger := GrNumTmp2;
ApplyRange;
end;
END; {with}
end;
Однако результат будет таким же ошибочным. Указанный код будет правильно работать только в случае, когда индекс по 'GrNum' является принятым по умолчанию и в процессе работы не изменяется (представим, что в показанном выше примере мы удалили переключатели RadioGroupl для выбора текущего индекса). Однако в этом случае правильно работает и код
procedure TForm1.ButtonlClick(Sender: TObject);
var GrNumTrnp1,GrNumTmp2 : Integers;
begin
{проверка правильности Edit1.Text и Edit2.Text}
{фильтрация по начальному и конечному номеру группы}
WITH Tablel do begin
SetRangeStart;
FieldByName('GrNum') .Aslnteger:= GrNumTrnp1;
SetRangeEnd;
FieldByName('GrNum').Aslnteger := GrNumTmp2;
ApplyRange;
END; {with}
end;
Свойство KeyExclusive
Свойство property KeyExclusive: Boolean; применяется для фильтрации записей в TTable с использованием методов SetRangeStart, SetRangeEnd u EditRangeStart, EditRangeEnd.
Свойство KeyExclusive влияет на включение в отфильтрованный НД записей, у которых индексные поля содержат граничные значения диапазона фильтрации. KeyExclusive включается и отключается отдельно для начального и конечного условия фильтрации.
Если свойство для данной границы диапазона фильтрации (верхней или нижней) установлено в False, записи, содержащие в индексном поле (полях) значение, указанное в качестве данной границы диапазона, включаются в отфильтрованный НД; если установлено в True, - не включаются. По умолчанию применяется значение False. Например:
WITH Tablel do begin
CancelRange;
SetRangeStart;
KeyExclusive := True;
FieldByName('GrNum').Aslnteger:= GrNumTrnp1;
SetRangeEnd;
FieldByName('GrNum').Aslnteger := GrNumTmp2;
ApplyRange;
END; {with}
Фильтрация по составному индексу
Если индекс, по которому необходимо осуществить фильтрацию, состоит более чем одного поля:
• при использовании метода Set Range значения полей должны перечисляться через запятую внутри квадратных скобок;
• при использовании SetRangeStart, SetRangeEnd и т.д. значение каждого поля должно устанавливаться явно.
Пример.
Пусть рассмотренный выше НД отсортирован по индексу, состоящему из полей 'GrNum;Tovar'. Реализуем фильтрацию записей по заданному значению поля GrNum и любому значению поля Tovar (рис.8.29). Для простоты проверку правильности ввода номера группы не производим. Обработчик выбора CheckBoxl ("Фильтровать") выглядит так:
procedure TFormI.CheckBoxIClick(Sender: TObject);
var GrNumTmp : Integer;
TovarTmp : String;
begin
IF CheckBoxl.Checked THEN
begin
GrNumTmp := StrToInt(Editi.Text);
TovarTmp := Edit2.Text;
{
——————фильтрация записей в НД————} WITH Tablel do begin
CancelRange;
SetRange([GrNumTmp,TovarTmp],[GrNumTmp,'яя']) ;
END; {with}
end {then}
ELSE
{
————————отмена фильтрации ———} Tablel.CancelRange;
end;
Реализацию выборки обеспечивает метод
SetRange([GrNumTmp,TovarTmp],[GrNumTmp,'яя']);
Интересно, что если требуется показывать в НД все записи группы, начинающиеся со значения в Edit2.Text, то в качестве значения товара в конечном условии фильтрации нужно объявить максимально возможное значение, которое может встретиться в качестве названия товара. Поскольку строчные буквы имеют бoльшие коды, чем заглавные, и название товара не может начинаться с 'яя', эти символы вполне могут использоваться как верхний ограничитель наименования товара.
Пусть введена группа и не введено наименование товара. В этом случае в отфильтрованный НД попадут все товары данной группы, т.е. записи , у которых определено наименование товара (рис.8.30):
Пусть введен номер группы и наименовании товара - 'Макароны'. В этом случае в отфильтрованный НД попадут товары данной группы, у которых наименование больше или равно "Макароны" (рис.8.31):
Фильтрация по частичному соответствию
Для случаев сортировки по символьным полям полезно делать фильтрацию по частичному соответствию индексного поля (полей) условиям фильтрации.
Пример.
Пусть рассматривавшаяся выше ТБД отсортирована п( наименованию товара 'Tovar' (рис.8.32): Обработчик отметки CheckBox1 ("Фильтровать"):
procedure TForm1.CheckBoxIClick(Sender: TObject);
begin
IF CheckBoxl.Checked THEN
begin
{————фильтрация записей в НД————}
WITH Tablel do begin
CancelRange;
SetRange([Editl.Text],['яя']);
END; {with}
end {then}
ELSE
{———отмена фильтрации ——————}
Tablel.CancelRange;
end;
В этом случае в НД будут показаны все записи с названием товара, равны или большим указанного в Edit1 (рис.8.33):
Сменим вызов метода SetRange на следующий:
SetRange([Edit1.Text],[Edit1.Text + 'яя']);
Тогда в результате фильтрации в отфильтрованный НД попадут только записи, начинающиеся с введенного в Editi фрагмента названия товара, т.е. с буквы М (рис.8.34):
Фильтрация по части составного индекса
В качестве условий фильтрации могут быть заданы не все поля текущего индекса, а только ведущее поле или группа ведущих полей.
В частности, для предыдущего примера можно указать в качестве текущего индекс 'Tovar;GrNum'. Тогда применение метода
SetRange([Edit1.Text],[Edit1.Text + 'яя']);
означает, что, поскольку в квадратных скобках в качестве начального и конечного условия фильтрации указаны не два значения поля, а одно, фильтрацию) следует проводить на предмет соответствия ведущего поля индекса (в нашем случае 'Tovar') заданному поисковому значению (в нашем случае начальное значение - Edit1.Text; конечное значение - Edit1.Text + 'яя').
Совмещение курсоров двух НД
Часто, при одновременной работе с одной и той же ТБД выгодно применять два или более НД. Например, если в записи много полей, ее неудобно изменять в одном компоненте TDBGrid и для этого удобнее воспользоваться отдельной формой (см. следующий раздел). В этом случае требуется совместить курсоры двух НД, для того чтобы работа производилась с одной и той же физической записью ТБД.
Для этой цели применяется метод procedure Table1 .GoToCurrent(Table2:TTable); устанавливающий курсор НД Table 1 на ту же запись, на которой находится курсор НД Table2.
ЗАМЕЧАНИЕ.
Метод GoToCurrent переводит НД Table1 в режим dsBrowse с запоминанием изменений (метод Post). В случае невозможности перевода в режим dsBrowse возбуждается исключение и курсор НД Table2 остается неизменным (т.е. совмещение курсоров не происходит).
Создание отдельной формы
Пусть имеется ТБД "Сотрудники кафедры" и необходимо добавлять новые или корректировать существующие записи ТБД не в TDBGrid, а в отдельной форме. Назовем форму, в которой расположен TDBGrid, родительской. Назовем форму, в которой осуществляется добавление или корректировка записи, дочерней. Соответственно, TTable, расположеннье в этих формах, назовем родительским и дочерним. В этом случае порядок действий таков:
1. Заводим новую форму (дочернюю), в ней - TTable, TDataSource и группу компонентов TDBEdit (TDBComboBox, TDBLookup и т.д.), связанных между собой стандартным образом. Естественно, что компоненты TTable в родительской и дочерней формах должны указывать на одну таблицу базы данных. Желательно, чтобы и индексные файлы в них были одинаковы (свойство Table IndexName) Внешний вид этих форм показан соответственно на рис 8.35.а и 8.35 б.
И в родительской и в дочерней форме компонент TTable, связанный с ТБД "Сотрудники кафедры", имеет имя Table1. Поэтому в тех случаях, когда из дочерней формы нужно обратиться к Table1 в родительской форме, следует приписывать ей в качестве префикса название родительской формы, Prnt. Table7. В то же время, при обращении к Table1, принадлежащему дочерней форме, из самой дочерней формы можно указывать префикс {Chld.Table7), а можно и не указывать (Table1), например: Table1.GoToCurrent(PrntForm.Table1);
Здесь Table1.GoCurrent означает "выполнить метод GoToCnrrent, принадлежащий компоненту Table1 дочерней формы". Чтобы исключить разночтения, будем далее в программном коде явно указывать название формы при обращении к Table1
ChldForm.Table1.GoToCurrent(PrntForm.Table1);
2. В модуле unit, содержащем родительскую форму, разместим тестовую переменную SotrState, проинициализировав ее пустым значением:
const
SotrState : String = '';
Эта переменная пригодится нам в дальнейшем для передачи в дочернюю форму кода требуемой операции 'Insert' или 'Edit'. Можно, конечно, было переводить родительскую TTable в режимы dslnsert или dsEdit в родительской форме, однако применение такого подхода работает при совмещении указателей на компонент TDataSource (см. ниже раздел "Переназначение DataSource во время выполнения"), но не подходит при использовании в дочерней форме метода GoToCurrent: этот метод автоматически переводит родительский НД в режим dsBrowse
3. В родительской форме добавляем 2 кнопки для вызова дочерней формы одну (InsertButton) на добавление записи, другую (EditButton) - на корректировку При этом присваиваем переменной SotrState соответственно значение 'Insert' или 'Edit'.
После возврата из дочерней формы переменной SotrState присваивается пустое значение.
4 В процедуре дочерней формы, вызываемой при активизации формы, для случая добавлении записи переводим Table дочерней формы в состояние dsInsert, для случая корректировки - совмещаем курсоры Table родительской и дочерней форм.
ДочерняяТаЬ1е.GoToCurrent(PoдитeльcкaяTable) и затем переводим дочернюю форму в состояние dsEdit.
5 В дочерней форме добавляем клавиши "Запомнить" (PostButton) и "Отменить" (CancelButton) Кнопке "Отменить" приписываем модальный результат mrCancel (установив свойство ModalResult = mrCancel). Это важно, поскольку дочерняя форма будет вызываться из родительской как модальная Кнопке "Запомнить" свойство mrOk не назначаем (т е. ее свойство ModalResult = mrNone). В случае, если выполнение метода Post прошло успешно (и исключение не было возбуждено), явно устанавливаем результат работы родительской формы в mrOk: Chid.ModalResult := mrOk;
Это нужно для того, чтобы в случае неуспешности выполнения метода Post мы могли вернуть фокус управления на поля дочерней формы для того, чтобы пользователь попробовал скорректировать значения и повторить попытку выполнения метода Post для запоминания изменений, внесенных в запись НД в дочерней форме. Если бы кнопка "Отменить" автоматически выставляла модальный результат mrOk при своем нажатии, после завершения обработчика нажатия этой кнопки происходил бы выход из дочерней формы, несмотря на то, что содержащийся в обработчике текст в случае неудачи Post предписывает не выходить из дочерней формы, а передать фокус управления ее полям.
6. Как сказано выше, в обработчике нажатия клавиши "Запомнить" выполняем метод Post, а в обработчике нажатия клавиши "Отменить" - метод Cancel, по отношению к НД Table1 дочерней формы. Поскольку Table1 как дочерней, так и родительской формы, во-первых, связаны с одной и той же ТБД "Сотрудники кафедры", а во-вторых, курсоры этих НД совмещены (что актуально для режима dsEdit), выполнение Chid.Table1.Post равносильно выполнению Prnt.Table1 .Post. В случае возбуждения исключения EDBEngineError для простоты полагаем, что произошло дублирование ключевого поля (если в ТБД есть уникальные ключевые поля), хотя, впрочем, могут быть и другие причины.
Заметим, что для PrntForm.Table1 нужно вызывать метод Refresh, который обновляет содержимое НД в родительской форме.
Родительская форма:
// нажата кнопка "Вставить"
procedure TPrntForm.InsertButtonClick(Sender: TObject);
begin
SotrState := 'Insert';
ChldForm.ShowModal;
SotrState := '';
end;
// нажата кнопка "Изменить"
procedure TPrntForm.EditButtonClick (Sender: TObject) ;
begin
SotrState := 'Edit';
ChldForm.ShowModal;
SotrState := '';
end;
// нажата кнопка "Удалить"
procedure TPrntForm.DeleteButtonClick(Sender: TObject);
begin
IF MessageDIg('Подтвердите удаление записи',
mtlnformation, [mbYes, mbNo], 0) = mrYes THEN
Prnt.Table1.Delete;
end;
Дочерняя форма: при активизации дочерней формы переводим НД в режимы Insert или Edit. В последнем случае совмещаем курсоры
procedure TChldForm.FormActivate(Sender: TObject);
begin
IF SotrState = 'Edit' THEN
begin
ChldForm.Table1.GoToCurrent(PrntForm.Table1);
ChldForm.Table1.Edit;
end
ELSE
ChldForm.Table1.Insert;
end;
// обработчик нажатия клавиши "Запомнить"
procedure TChldForm.PostButtonClick(Sender: TObject);
begin
TRY
ChldForm.Table1.Post;
PrntForm.Table1.Refresh;
IF SotrState = 'Insert' THEN
PrntForm.Table1.GoToCurrent(ChldForm.Table1);
// при успешном выполнении Post выходим из модальной формы:
ChldForm.ModalResult := mrOk;
EXCEPT
on EDBEngineError do begin
ShowMessage('Дублирование ключевого поля!');
DBEditI.SetFocus; // возвращаемся на 1 поле DBEdit
end; {on}
ELSE
begin
ShowMessage('Ошибка иного типа при Post');
DBEditI.SetFocus;
end;
END; {try}
end;
// нажата кнопка "Отменить" (ModalResult = mrCancel)
Procedure TChldForm.CancelButtonClick (Sender: TObject);
begin ChldForm.Table1.Cancel;
end;
// если при выходе из дочерней формы набор данных - не в состоянии dsBrowse (что может быть при нажатии кнопки 'х') вверху слева, НД принудителъно переводится в режим dsBrowse
procedure TChldForm.FormDeactivate(Sender: TObject);
begin
IF ChldForm.Table1.State <> dsBrowse THEN
ChldForm.Table1.Cancel;
end;
КОММЕНТАРИЙ.
Может оказаться, что на момент выхода из формы методы Posг или Cancel к НД не выполнены (например, когда выход осуществляется также по нажатию иных кнопок, например "Выход"). Поэтому в родительской форме, после выхода из дочерней формы, будет нелишним проверить, находится ли НД в состоянии dsBrowse и если нет, принудительно перевести его в это состояния методом Cancel, отменяющим все сделанные изменения в записи. Естественно, что можно предусмотреть и иную реакцию на попытку выхода при НД, находящемся в режимах dslnsert или dsEdit. Представление обеих форм в момент внесения изменений в ТБД из дочерней формы показано на рис.8.36.
Переназначение TDataSource во время выполнения
Способ совмещения курсоров не является единственным для обеспечения работы с НД из разных форм. Другой способ состоит в переадресации компонента TDaгaSource во время выполнения.
Пусть имеется задача, когда из разных форм нужно работать с одним и тем же НД. Частным случаем данной задачи является форма обновления записей, рассмотренная в предыдущем разделе. В этом случае необходимо:
1. В родительской форме расположить компоненты TDataSource (назовем его DataSourcel), TTable, TDBGrid (или иные визуальные компоненты для
работы с БД) и связать указанные компоненты между собой стандартным способом.
2. Во всех дочерних таблицах расположить компоненты TDataSource (назовем его DataSource2), TDBEdit (или иные визуальные компоненты для работы с БД) и связать их с DataSource2. При этом свойство DataSource2.DataSet не должно указывать ни на какой НД, т.е. должно оставаться пустым в инспекторе объектов во время проектирования, а во время выполнения в обработчике события создания дочерней формы полезно поместить предложение DataSource2.DataSet := nil;
Часто бывает полезным для присваивания имен полей расположить в дочерней форме еще и компонент TTable, связав его стандартным образом с DataSource2 и визуальными компонентами для работы с НД. Однако после этого компонент Table нужно из дочерней формы удалить и очистить свойство DataSource2. DataSet описанным выше образом.
3. Во время выполнения в обработчик события активизации дочерней формы или при вызове дочерней формы из родительской необходимо поместить предложение
DataSource2.DataSet := ИМяРодительскойФормы.ИмяКомпонентаТаЬ1е;
Таким образом, DataSource дочерней формы будет указывать на НД из родительской формы и работать с его текущей записью.
Изменение в дочерней форме местоположения курсора НД приведет к тому, что данное изменение будет актуально и в родительской форме, равно как любые действия по изменению, добавлению и удалению записей НД, произведенные в дочерней форме. Причина простая: и родительская, и дочерняя формы работают с одним и тем же НД.
Подобные действия можно реализовать в любом количестве дочерних форм, таким образом одновременно работая с одним и тем же набором данных из разных форм.
4. При деактивизации дочерней формы необходимо разрушить связь между DataSource дочерней формы и НД из родительской формы, включив в обработчик события деактивизации дочерней формы предложение
DataSource2.DataSet := nil;
Создание отдельной формы
Этот пример аналогичен приведенному в разделе "Создание отдельной формы для изменения записи ПД. Форма добавления 1корректировки записи с использованием механизма совмещения курсоров ".
Отличия в реализации следующие. Во-первых, НД переводится в состояние Insert или Edit в родительской форме. Во-вторых, в дочерней форме доступ к НД осуществляется переадресацией DataSource во время выполнения.
Родительская форма:
// нажата кнопка "Вставить"
procedure TPrntForm.InsertButtonClick(Sender: TObject);
begin
PrntForm.Table1.Insert;
ChldForm.ShowModal;
end;
// нажата кнопка "Изменить"
procedure TPrntForm.EditButtonClick(Sender: TObject);
begin
PrntForm.Table1.Edit;
ChldForm.ShowModal;
end;
// нажата кнопка "Удалить"
procedure TPrntForm.DeleteButtonClick(Sender: TObject);
begin
IF MessageDIg('Подтвердите удаление записи', mtlnformation, [mbYes, mbNo], 0) = mrYes THEN PrntForm.Table1.Delete;
end;
Дочерняя форма:
// обработчик активизации дочерней формы
procedure TChldForm.FormActivate(Sender: TObject);
begin
// при активизации дочерней формы ее DataSource указывает на НД из родительской формы
ChldForm.DataSourcel.DataSet := PrntForm.Table1;
end;
// обработчик нажатия клавиши "Запомнить"
procedure TChldForm.PostButtonClick(Sender: TObject);
begin
TRY
PrntForm.Table1.Post;
// при успешном выполнении Post выходим из модальной формы:
ChldForm.ModalResult := mrOk;
EXCEPT
on EDBEngineError do begin
ShowMessage('Дублирование ключевого поля!');
DBEditI.SetFocus; // возвращаемся на 1 поле DBEdit
end; {on}
ELSE
begin
ShowMessage('Ошибка иного типа при Post');
DBEditI.SetFocus;
end;
END; {try}
end;
// нажата кнопка "Отменить" (ModalResulfc = mrCancel)
procedure TChldForm.CancelButtonClick(Sender: TObject);
begin
PrntForm.Table1.Cancel;
end; ,
// обработчик события деактивизации дочерней формы DataSource дочерней формы указывает в "пустоту";
// принудительный перевод НД в состояние Browse, если на момент выхода из дочерней формы НД находится
// в ином состоянии
procedure TChldForm.FormDeactivate(Sender: TObject);
begin
ChldForm.DataSourcel.DataSet := nil;
IF PrntForm.Table1.State <> dsBrowse THEN
PrntForm.Table1.Cancel;
end;
// обработчик события создания формы
procedure TChldForm.FormCreate(Sender: TObject);
begin
// DataSource дочерней формы изначально указывает в "пустоту"
ChldForm.DataSourcel.DataSet := nil;
end;
Использование контейнера TDataModule
Компонент типа TDataModule представляет собой контейнер, в который вмещаются компоненты TTable, TQuery, DataSource и т.д. Создать экземпляр dataModule можно, выбрав в среде Delphi пункт меню File|NewDataModule. Компонент TDataModule похож на форму (TForm) в том отношении, что служит контейнером для иных компонентов. Однако, в отличие от TForm, в dataModule можно помещать только невизуальные компоненты для работы базами данных. Связь компонентов TDataSource, TTable и TQuery, расположенных в DataModule, производится так же, как если бы они были расположены в одной форме.
TDataModule нужно сохранить под каким-либо именем и добавить имя модуля unit, в котором описан TDataModule, в текст модулей unit всех иных рм приложения, которые будут использовать НД и TDataSource, положенные в этом TDataModule. Это производится в главном меню среды delphi, в элементе меню File|Use Unit.
В дальнейшем визуальные компоненты, работающие с данным НД, должны в своем свойстве DataSource содержать имя соответствующего компонента
TDataSource из TDataModule. При этом имя является составным: сначала идет имя компонента TDataModule и затем через точку - имя компонента TDataSource, например, DataModulel.DataSource1.
Перепишем предыдущий пример для использования механизма TDataModule. Для этого добавим в приложение компонент DataModule1 и разместим в нем компоненты Table1 (связанный с ТБД "Сотрудники кафедры") и DataSourcel (связанный с DataModulel.Table1).
Тогда в родительской форме установим свойство DBGrid1.DataSource = DataModulel .DataSourcel; в дочерней форме установим свойства DataSource всех компонентов, работающих с отдельными полями ТБД "Сотрудники кафедры" (в данном случае это компоненты TDBEdit) равными DataModulel .DataSourcel. При этом не будем забывать о заполнении свойства DataField этиx компонентов, иначе компоненты TDBEdit не будут связаны с полями. Пример компонента TDataModule с размещенными в нем компонентами TTable и TDataSource показан на рис. 8.37.
Виды родительской и дочерней форм во время разработки приложения показаны соответственно на рис. 8.38 а) и б).
Как видно из рисунков, в формах PrntForm и ChldForm напрочь отсутствуют компоненты TTable и TDataSource, связанные с ТБД "Сотрудники кафедры".
Приведем обработчики событий для обеих форм:
Родительская форма
// нажата кнопка "Вставить"
procedure TPrntForm.InsertButtonClick(Sender: TObject);
begin
DataModulel.Table1.Insert;
ChldForm.ShowModal ;
end;
// нажата кнопка "Изменить"
procedure TPrntForm.EditButtonClick(Sender: TObject);
begin
DataModulel.Table1.Edit;
ChldForm.ShowModal ;
end;
// нажата кнопка "Удалить"
procedure TPrntForm.DeleteButtonClick(Sender: TObject);
begin
IF MessageDIg('Подтвердите удаление записи',
mtInformation, [mbYes, mbNo], 0) = mrYes THEN DataModulel.Table1.Delete;
end;
Дочерняя форма
// обработчик нажатия клавиши "Запомнить"
procedure TChldForm.PostButtonClick(Sender: TObject);
begin
TRY
DataModulel.Table1.Post;
// при успешном выполнении Post выходим из модальной формы:
ChldForm.ModalResult := mrOk;
EXCEPT
on EDBEngineError do begin
ShowMessage('Дублирование ключевого поля!');
DBEdit1.SetFocus; // возвращаемся на 1 поле DBEdit
end; {on}
ELSE
begin
ShowMessage('Ошибка иного типа при Post');
DBEdit1.SetFocus;
end;
END; {try}
end;
// нажата кнопка "Отменить" (ModalResulfc = mrCancel)
procedure TChldForm.CancelButtonClick(Sender: TObject);
begin
DataModulel.Table1.Cancels;
end;
Множественный взгляд на НД
Часто в некий момент времени требуется: обращаться к одному и тому же НД из разных форм; работать с одной и той же ТБД, используемой для получения разных НД с помощью компонентов, размещенных в одной или разных формах.
Чтобы работа с одной ТБД из разных наборов или форм происходила над одной и той же физической записью ТБД, можно применять следующие механизмы: совмещать курсоры разных НД методом GotoCurrent; переназначать свойство DataSet компонента TDataSource во время выполнения; использовать в разных формах НД и TDataSource, расположенные в одном и том же контейнере TDataModule.
Общие сведения
Компонент TQuery предназначен для: работы с НД, источником данных для которого могут служить записи как одной, так и нескольких ТБД (TQuery, возвращающий набор данных); выполнения запросов к БД, не возвращающих наборов данных (добавление, изменение, удаление записей в таблицах БД и др ) Основные отличия компонента данных TQuery, возвращающего набор данных, от выполняющего сходные функции компонента TTable:
НД, возвращаемый TQuery, может быть составлен из записей нескольких таблиц (над которыми выполнена операция объединения. Join);
• в общем случае НД, возвращаемый TQuery, даже если источником этого НД служит одна таблица БД, предполагает обращение к подмножеству записей и столбцов (полей), в то время как TTable ориентирован на работу со всеми записями и полями и для того, чтобы работать в нем с подмножеством строк и полей, необходимо предпринять дополнительные действия (фильтрацию записей, ограничение состава полей в редакторе полей).
Результирующий НД компонента TQuery формируется путем выполнения запроса к БД на языке SQL (Structured Query Languague, язык структурированных запросов). Такой запрос использует SQL-оператор SELECT. Текст любого запроса хранится в свойстве SQL компонента TQuery.
Запросы, выполняемые компонентом TQuery - независимо от того, возвращают они набор данных или просто производят какие-либо действия в БД, - могут быть статическими и динамическими
Статический запрос
характерен тем, что описывающий его SQL-оператор не изменяется в процессе выполнения приложения. SQL-оператор динамического запроса может частично изменяться в процессе выполнения приложения. В этом случае изменяемые части SQL-запроса оформляют в качестве параметров, значения которых могут многократно изменяться в процессе выполнения приложения. Таким образом можно использовать один компонент TQuery для выполнения множества разнесенных во времени запросов к БД, различающихся по значению параметров. Заметим, что состав параметров также может меняться во время выполнения. Это более характерно для формируемых запросов - разновидности динамических запросов.
Формируемые запросы -
такие запросы, текст SQL-оператора которых формируется программно в процессе выполнения приложения. Действия по формированию такого запроса состоят в очистке предыдущего содержимого свойства SQL и программного занесения в это свойство нового текста SQL-запроса (вид которого зависит от текущей ситуации и определяется рядом условий), а также в последующем его выполнении. Такая задача является тривиальной, поскольку свойство SQL имеет тип TString, то есть являет собой экземпляр динамического строкового списка Таким образом, один компонент TQuery используется для выполнения таких различных запросов, как, например, SELECT и INSERT SQL-операторы (SELECT, INSERT, UPDATE, DELETE), применяемые в компоненте TQuery, достаточно подробно описаны в части книги, посвященной использованию SQL-сервера InterBase и архитектуры "клиент-сервер".
Использование TQuery для получения агрегированных значений
Часто нужно подсчитать некоторые агрегированные значения данных (минимум, максимум, среднее, счетчик повторений). В дальнейшем полученные значения могут входить в какие-либо условные операторы или операторы выбора приложения.
Пусть, например, необходимо помещать уникальное значение в поле N_RASH (номер записи расхода со склада) в таблицу RASHOD. SQL-операторы INSERT, UPDATE не работают с автоинкрементными полями (локальные СУБД). Поэтому при занесении новой записи в таблицу RASHOD нужно определить уникальное значение поля N_RASH, для чего можно сделать запрос к таблице RASHOD:
WITH WorkQuery do begin
Close;
Clear;
SQL.Add('SELECT COUNT(*), MAX(N_RASH) AS M') ;
SQL.Add('FROM RASHOD') ;
Open;
END;//with
Пусть добавление новой записи реализуется в компоненте InsertQuery следующим динамическим оператором:
INSERT INTO RASHOD (N_RASH, DAT_RASH, KOLVO, TOVAR, POKUP)
VALUES(:N_RASH,:DAT_RASH, :KOLVO,:TOVAR, :POKUP)
Тогда в параметр :N_RASH следует поместить значение поля М набора данных компонента WorkQuery:
WITH InsertQuery do begin
ParamByName('N_RASH').AsInteger :=
WorkQuery.FieldByName('M').AsInteger + 1;
ExecSQL;
END; //with
ПОЯСНЕНИЕ.
После выполнения запроса в компоненте WorkQuery выдается результирующий НД, содержащий одну строку. Указатель текущей записи во вновь открытом НД всегда устанавливается на первую запись. Поэтому, даже если таблица RASHOD пуста, в поле М будет значение NULL, преобразуемое затем свойством AsInteger в 0. Набор данных в компоненте WorkQuery мог бы не содержать ни одной строки (если в ТБД RASHOD не было ни одной строки) тогда и только тогда, если бы подсчет максимума производился оператором
SELECT MAX(N_RASH) AS M FROM RASHOD
Однако, применяя вместо этого оператор
SELECT COUNT(*), MAX(N_RASH) AS M FROM RASHOD
мы всегда получаем хотя бы одну запись в результирующем НД, поскольку COUNT(*) всегда возвратит значение, отличное от NULL.
Использование компонента TQuery для локальных и удаленных БД
Использование компонента TQuery происходит аналогично для случая выполнения запросов к таблицам локальных СУБД (Paradox, dBase и т.д.) и для случая выполнения запросов к удаленным СУБД (InterBase, Oracle, Informix, Sybase, MS SQL Server). Имеются, правда, ограничения для случая запросов к таблицам локальных СУБД. Эти ограничения состоят в усеченных возможностях использования синтаксиса SQL-операторов.
Характеристики работы компонента TQuery для случая локальных и удаленных СУБД позволяют рекомендовать:
не использовать компонент TQuery для выполнения простых запросов к локальным таблицам там, где вполне можно обойтись компонентом TTable, поскольку TQuery работает медленнее - он всегда создает промежуточную таблицу для формирования возвращаемого набора данных;
• стараться как можно чаще использовать компонент TQuery для доступа к удаленным таблицам.
Явная предпочтительность использования компонента TQuery при доступе к удаленным таблицам определяется способом занесения записей в результирующий НД. Компонент TTable при своем открытии считывает все записи из удаленной таблицы. Если на записи в TTable наложена фильтрация (например, методом SetRange), она выполняется уже в клиентском приложении, что уже не оптимально. Применяемый для аналогичных целей компонент TQuery считывает нужное число записей (например, достаточное количество записей для визуализации в компоненте TDBGnd), а оставшиеся записи считывает по необходимости. Временные задержки при этом особенно актуальны для таблиц, состоящих из большого числа записей.
Одиночные изменения в удаленной таблице, вносимые из TTable при помощи методов Post, Delete, если они совершаются в рамках отдельной транзакции, также способны существенно замедлить работу с БД. Компонента TQuery, посылающие серверу БД запросы на удаление, добавление, корректировку записей, как правило, действуют над группами записей в рамках одной транзакции. Кроме того, даже по своей идеологии компоненты TQuery много больше соответствуют архитектуре "клиент-сервер" и идеологии серверных БД, поскольку одним из основных положений при работе с данными в SQL является оперирование множествами записей. TTable рассчитан на работу с одиночными записями и по своей сущности больше отвечает идеологии локальных (настольных, персональных) СУБД, исповедующих навигационный подход.
ЗАМЕЧАНИЕ.
В примерах, приводимых к излагаемому материалу, в частности, по созданию приложений в архитектуре "клиент-сервер", встречается доступ к удаленным таблицам при помощи компонента TTable, но в основном из-за того, что реально "удаленная" БД работает под управлением локальной версии SQL-сервера Borland InterBase, поставляемого вместе с Delphi Client/Server Suite, а также из-за того, что объем данных в учебных таблицах не превышает 10 записей. Исследовать процесс соединения с сервером и реальные процессы доступа к БД, которые порождают те или иные SQL-операторы, можно, запустив приложение на выполнение под средой Delphi и вызвав SQL Monitor (пункт главного меню Database \ SQL Monitor или запустив его как отдельное приложение). В качестве примера приведем окно SQL Monitor, показывающее (рис. 9.11 и 9.12) операции над БД из приложения для выполнения оператора SELECT, реализующего внутреннее соединение таблиц RASHOD (8 записей) и TOVARY (3 записи):
SELECT R.DAT_RASH, R.TOVAR, R.KOLVO, Т.ZENA FROM RASHOD R, TOVARY T WHERE R.TOVAR = T.TOVAR
Для некоторого убыстрения доступа к НД, который должен просматриваться последовательно только в направлении от начала до конца, можно установить в свойство UniDirectional компонента TQuery значение False:
property UniDirectional: Boolean;
Это позволит отключить для НД механизм двунаправленных курсоров в BDE, что для больших объемов записей способно привести к экономии времени и ресурсов.
Соединение компонента TQuery с базой данных
Для случаев работы с локальными и удаленными БД имеются некоторые различия в способе соединения компонента TQuery с базой данных, для которой и будет выполняться SQL-оператор из свойства SQL этого компонента Свойствос property Database: TDatabase; возвращает указатель на компонент TDatabase, выполняющий соединение данного TQuery с базой данных. Если компонент TDatabase явно в приложении не создан (что характерно при работе с локальными БД), на период сеанса автоматически создается временный компонент TDatabase.
Свойство property DatabaseName: TFileName; позволяет указать, с какой БД будет работать компонент TQuery.
При работе с локальными БД в свойстве DatabaseName указывается:
• псевдоним БД, ранее определенный при помощи утилиты BDE Administrator,
• переопределенный псевдоним из свойства DatabaseName явно определенного компонента TDatabase, если он используется;
• путь на диске к конкретному каталогу (если свойство DatabaseName хранит пустое значение, подразумевается, что указан текущий каталог). Если свойство DatabaseName хранит пустое значение (подразумевается путь • текущий каталог) или явно указан путь на диске к вполне конкретному каталогу, БД будут искаться именно там (для случая работы с локальными СУБД).
Например, при запросе "выбрать все записи из таблицы RASHOD" имя таблицы в операторе SELECT можно указать следующим образом:
• если свойство DatabaseName хранит пустое значение (подразумевается путь к текущему каталогу)
SELECT *
FROM "RASHOD.DB"
или, если в установках BDE указано, что в случае отсутствия расширения для файла локальной таблицы по умолчанию берутся таблицы Paradox, просто
SELECT *
FROM RASHOD
• если свойство DaгabaseName хранит пустое значение (подразумевается путь к конкретному каталогу), этот каталог можно указать в составе имени файла ТБД:
SELECT *
FROM "С:\BOOK\LOC_SKLD\RASHOD.DB"
где "C:\BOOK\LOC_SKLD" указывает конкретный каталог, в котором следует искать файл "RASHOD.DB";
если свойство DaгabaseName хранит псевдоним БД, переустановленный псевдоним БД или путь к конкретному каталогу
SELECT *
FROM RASHOD
При работе с удаленными БД
(архитектура "клиент-сервер") в свойстве DatabaseNawe указывается: • псевдоним БД, ранее определенный при помощи BDE Administrator;
• переопределенный псевдоним из свойства DatabaseName явно определенного компонента TDatabase, если он используется.
Соединение компонента TQuery и визуальных компонентов для работы с данными
Соединение компонента TQuery с визуальными компонентами происходит через промежуточный компонент TDataSource. Для этого в компоненте TDataSource в свойстве DataSet необходимо указать имя компонента TQuery. В визуальных компонентах (TDBGrid, TDBEdit и т.д.) в свойстве DaгaSource указывается имя компонента TDataSource и, если необходимо, в свойстве DataField выбирается имя интересующего поля.
Выполнение статических запросов
Для формирования статического запроса необходимо:
1. Выбрать для существующего компонента TQuery в инспекторе объектов свойство SQL и нажать кнопку в правой части строки;
2. В появившемся окне текстового редактора набрать текст SQL-запроса (рис. 9.1);
3. Установить свойство Active компонента TQuery в True, если НД должен быть открыт в момент начала работы приложения или оставить свойство Active в состоянии False, если открытие НД будет производиться в программе в некоторый момент работы приложения.
Условия выборки записей, единожды реализованные по статическому запросу, изменить нельзя, поскольку текст SQL-оператора данного запроса в программе не изменяется. Например, в компоненте TQuery, использующем оператор SELECT, показанный выше, закрытие и повторное открытие компонента приведет к выдаче результирующего НД, в который будут включены все записи из таблицы RASHOD, присутствующие в данной таблице на момент повторного открытия компонента TQuery.
Формирование текста SQL-оператора SELECT может осуществляться не вручную, а при помощи встроенного в Delphi средства Visual Query Builder, действующего по принципу QBE (Query By Example, запрос по образцу). Для его запуска нужно сделать компонент TQuery текущим, нажать правую кнопку мыши и выбрать режим Query Builder. Заметим, что в TQuery на момент запуска Visual Query Builder должно быть установлено значение свойства DaгabaseName.
Visual Query Builder запрашивает имена таблиц, которые будут участвовать в запросе (рис. 9.2). Выбрав нужную таблицу, нажмите кнопку Add и так до тех пор, пока не будут выбраны все нужные таблицы. После этого нажмите кнопку Cancel.
Далее в появившемся окне из верхней его части берется название соответствующего поля и "перетаскивается" в нижнюю часть; для каждого такого поля создается столбец условий . По информации в ячейках таких столбцов и строится текст SQL-запроса. Например, для того, чтобы реализовать внутреннее соединение таблиц RASHOD и ТО VARY по условию TOVARY.TOVAR = RASHOD.TOVAR, следует ввести TOVARY.TOVAR в графе Criteria для столбца, соответствующего таблице RASHOD (рис.9.3) или RASHOD.TOVAR для столбца, соответствующего таблице ТОVARY.
Сформированный запрос может быть просмотрен (кнопка с изображением очков) и выполнен (кнопка с изображением зеленого треугольника). Кнопка с изображением галочки приводит к закрытию Visual Query Builder и выходу в приложение. При этом текст сформированного запроса помещается в свойство SQL данного компонента TQuery (рис. 9.4).
Visual Query Builder обычно используется для создания черновых вариантов оператора SELECT. Впоследствии текст запроса трансформируется разработчиком к нужному виду.
Для тех, кто только начинает осваивать язык SQL, Visual Query Builder может послужить средством обучения синтаксису оператора SELECT.
Методы открытия и закрытия компонента TQuery
Компонент TQuery может возвращать НД (если компонент использует оператор SELECT, то есть осуществляет выборку из одной или более таблиц БД) и выполнять действие над одной или более таблицей БД (SQL-операторы INSERT, UPDATE, DELETE).
В случае использования оператора SELECT после открытия компонента TQuery возвращается НД, в котором указатель текущей записи всегда установлен на первую запись (если она имеется). Такой компонент TQuery следует открывать:
• установкой свойства Active в значение True, или
• выполнением метода
procedure Open;
Например,
RashodQuery.Active := True;
TovaryQuery.Open;
В случае использования операторов INSERT, UPDATE, DELETE набор данных не возвращается. Такой компонент TQuery следует открывать, выполняя метод
procedure ExecSQL;
Например,
InsertQuery.ExecSQL;
Метод ExecSQL посылает серверу для выполнения SQL-оператор из свойства SQL данного компонента TQuery.
Закрытие компонента TQuery осуществляется методом procedure Close; или установкой в False свойства Active, например:
RashodQuery.Active := False;
TovaryQuery.Open;
При этом следует помнить, что для компонента TQuery, не возвращающего набор данных, выполнение метода Close не имеет последствий, поскольку с данным компонентом не связан открытый НД. Для динамических запросов, особенно для отсылаемых к удаленной БД, полезно использовать методы, осуществляющие "связывание" параметров с их фактическими значениями (Prepare) и отменяюще такое "связывание" (UnPrepare) Более подробно о них будет рассказано далее в подразделах, посвященных выполнению динамических запросов.
Изменяемые TQuery
Записи НД, возвращаемые компонентом TQuery, могут изменяться, подобно тому, как это происходит в компоненте TTable. Записи можно редактировать в компоненте TDBGrid, связанном с TQuery (метод автоматического перевода НД в состояния dsInsert, dsEdit, автоматического выполнения методов Insert, Edit, Delete, Post и Cancel). Также может применяться метод программного формирования значения полей записи, ввода таких значений с использованием компонента TDBEdit, TDBCheckBox и других. В этом случае методы Insert, Edit, Delete, Post и Cancel вызываются в программе явно .
Возможность изменения НД, возвращаемого после выполнения оператора SELECT, определяется свойством property CanModify: Boolean; Значение этого свойства устанавливается автоматически, исходя из определенных факторов. Если в процессе выполнения свойство CanModify установлено в True, набор данных доступен для изменения. При значении False записи НД не могут быть добавлены, изменены или удалены.
Свойство CanModify всегда устанавливается в False, если в False установлено свойство RequestLive компонента TQuery: property RequestLive: Boolean; Значение данного свойства может быть установлено как во время проектирования, так и во время разработки приложения. По умолчанию всегда устанавливается False (НД доступен только для чтения). Однако установка данного свойства в значение True (НД может быть изменен) вовсе не означает, что НД действительно будет позволено изменяться и что свойство CanModify будет установлено в True. Это произойдет только в том случае, если синтаксис оператора SELECT при выполнении запроса будет признан "верным".
Синтаксис оператора SELECT будет признан "неверным", если:
• НД формируется более чем из одной ТБД;
• присутствует предложение принудительной сортировки результирующего набора данных ORDER BY;
• значения хотя бы одного столбца результирующего НД сформировано с использованием агрегатных функций (SUM, COUNT, AVG, MIN, MAX);
• при доступе к СУБД Sybase в таблице отсутствует уникальный индекс
В том случае, если свойство RequestLive установлено в True, а синтаксис оператора SELECT признан "неверным":
• возвращается НД, доступный только для чтения - при доступе к таблицам локальных СУБД (Paradox, dBase);
• выдается ошибка - при доступе к серверным СУБД (InterBase, Oracle) и т.д.
Если изменения, внесенные в НД методами Post, Delete, не отображаются в НД, его содержимое можно обновить методом procedure Refresh; Однако в этом случае оператор SELECT должен быть выполнен для таблицы локальной СУБД и эта таблица должна иметь уникальный индекс. Для НД, возвращенных в результате выполнения запроса к удаленной СУБД, выполнение метода Refresh не влечет за собой никаких последствий.
Для случая работы с удаленными БД следует избегать выполнения изменений при помощи методов Insert, Edit, Delete записей в НД, полученного при помощи TQuery. В этом случае вся нагрузка на модификацию удаленных Таблиц ложится на клиентское приложение, в то время как в соответствии с одним из краеугольных камней идеологии "клиент-сервер" - вся тяжесть операций по физическому доступу к БД должна ложиться на сервер БД.
Предотвратить ввод записей, не удовлетворяющих условиям, перечисленным в предложении WHERE оператора SELECT, можно путем установки в True значения свойства
property Constrained: Boolean;
Например, для НД, полученного по запросу
SELECT *
FROM RASHOD
WHERE KOLVO > 1000
при Constrained, установленном в True, будут блокироваться попытки запоминания записей со значением поля KOLVO, меньшим 1000.
В том случае, если НД доступен только для чтения, его записи могут быть изменены при помощи SQL-операторов INSERT, UPDATE, DELETE. При этом изменения в НД не отображаются Для отображения изменений НД следует переоткрыть, выполнив метод Close и повторно Open. Повторное открытие НД устанавливает указатель текущей записи на первую строку, что удобно далеко не всегда. В этом случае можно
1) вносить изменения в НД пакетом, визуализируя их путем его повторного открытия после равных порций изменений - например, после каждых 10 изменений, этот метод больше подходит для случаев значительного количества изменений в НД;
2) реализовать в форме локатор - механизм поиска записи, удовлетворяющей некоторому условию (значение условия можно вводить, например, в компонент TEdit или группу компонентов TEdit или автоматически помещать туда значения полей, однозначно идентифицирующих запись, для последней добавленной или измененной записи). Поиск реализуется при нажатии экранной кнопки. Для поиска используется метод Locate, например:
procedure TForm1.LocatorButtonClick(Sender: TObject);
begin
RashodQuery.Locate('N_RASH',Editl.Text, [loPartialKey]);
end;
3) перед повторным открытием НД запоминать значение поля (полей), однозначно идентифицирующего запись, и после открытия восстанавливать местоположение указателя текущей записи при помощи метода Locate.
Например,
пусть в набор данных (компонент RashodQuery) добавляются записи при помощи SQL-оператора INSERT (компонент InsertQuery). Однозначно идентифицирует запись в НД RashodQuery поле 'М'. Тогда восстановление указателя текущей записи после повторного открытия НД RashodQuery может быть реализован так: TmpN_Rash := FieldByName('М').Aslnteger;
InsertQuery.ExecSQL;
RashodQuery.Close;
RashodQuery.Open;
RashodQuery.Locate('М',TmpN_Rash, []);
Заметим, что такой подход не годится для случая удаления записей при помощи SQL-оператора DELETE, поскольку после удаления в НД не существует записи с запомненным значением уникального поля (полей).
Понятие динамического запроса
Динамическим (параметрическим) является запрос, в SQL-операторе которого в процессе выполнения приложения могут изменяться отдельные его составляющие В этом случае изменяемая часть оператора оформляется как параметры.
Например, пусть в процессе выполнения приложения может быть выдан запрос 'выдать все записи из таблицы RASHOD, относящиеся к расходу товара "Сахар" со склада 10 января 1997 г.'
SELECT *
FROM RASHOD
WHERE (TOVAR = "Сахар") AND
(DAT_RASH = "10.01.97")
и запрос выдать все записи из таблицы RASHOD, относящиеся к расходу товара "Кока-кола" со склада 20 января 1997 г.'
SELECT *
FROM RASHOD
WHERE (TOVAR = "Кока-кола") AND
(DAT_RASH = "20.01.97")
а также аналогичный запрос по расходу других товаров за другие даты. Конечно, каждый такой запрос можно реализовать в отдельном компоненте TQuery, но только теоретически - при достаточно большом числе товаров и дат расхода число компонентов TQuery должно стремиться к бесконечности. Поэтому разумнее применить только один компонент TQuery, указав в его свойстве SQL оператор, в котором изменяющиеся части заменены на параметры:
SELECT *
FROM RASHOD
WHERE (TOVAR = :TOVAR) AND
(DAT_RASH = :DAT_RASH)
Под параметром понимается имя, предваренное кавычками ':'. В динамических запросах параметры всегда заменяют значения, которые могут изменяться в процессе выполнения. Имена параметров произвольны и могут не совпадать со значениями полей таблицы, которым они обычно ставятся в соответствие:
SELECT *
FROM RASHOD
WHERE (TOVAR = :PARAMETR1) AND
(DAT_RASH = : ZNACHENIE)
Формирование динамического запроса
Для формирования динамического запроса необходимо:
1. выбрать для существующего компонента TQuery в инспекторе объектов свойство SQL и нажать кнопку текстового редактора;
2. в появившемся окне текстового редактора набрать текст SQL-запроса с параметрами;
3. выбрать в инспекторе объектов свойство Params и нажать кнопку в строке данного свойства; в появившемся окне будут показаны имена всех параметров, введенных в текст динамического SQL-оператора на шаге 2; список параметров отслеживается автоматически всякий раз при изменении содержимого свойства SQL;
4. каждому параметру из списка необходимо поставить в соответствие определенный тип и, если нужно, стартовое значение в поле Value. Переключатель Null Value позволяет указать в качестве стартового значения NULL (рис. 9.5). Стартовые значения присваивать необязательно, однако каждому параметру необходимо поставить в соответствие определенный тип данных, иначе попытка открытия компонента TQuery приведет к возбуждению исключения;
5.
компонент TQuery можно сделать активным (установить свойство Active = True) на стадии разработки приложения только в том случае, если каждому из параметров присвоено стартовое значение. Компонент TQuery, содержащий динамический запрос, если его свойство Active установлено на этапе разработки в значение True, открывается при
создании формы, содержащей данный компонент TQuery. При этом он использует значения параметров, установленные по умолчанию (стартовые значения). Если хотя бы одному из параметров не назначено стартовое значение, выдается ошибка.
Если компонент TQuery, содержащий динамический запрос, не открыт в момент создания формы, его можно открыть в некоторый момент времени, программно установив значения параметров и выполнив метод Open или установив свойство Active в True.
Впоследствии всякий раз, когда необходимо изменить значения параметров запроса (что приведет к выдаче другого НД), нужно закрыть компонент TQuery, программно присвоить значения параметрам и повторно открыть компонент.
Установка значений параметров динамического запроса во время выполнения
Самым распространенным способом указания текущих значений параметров является их ввод пользователем в поля ввода (компоненты TEdit и другие) и последующее программное назначение параметров.
Параметры компонента TQuery доступны через его свойство property Params[Index: Word]:TParams;
Это свойство является набором параметров, где каждый параметр определяется индексом в диапазоне (0...ParamCount-l, где ParamCount есть число параметров, которое можно получить с помощью свойства ParamCount компонента TQuery: property ParamCount: Word;
Обратиться к конкретному параметру можно:
1) указав индекс параметра в свойстве Params компонента TQuery, например, Params[0]. Порядок следования параметров аналогичен показываемому в окне редактора параметров (активизирующегося после нажатия кнопки в строке свойства Params инспектора объектов);
2) через метод компонента Tquery function ParamByName(const Value: string): TParam;
где Value определяет имя параметра.
Для установки значения конкретного параметра используется одно из свойств компонента TParam A \NNN (AsString, Aslnteger и т.д.) или более общее свойство property Value: Variant;
Например,
RashodQuery.Params[0].AsDate := StrToDate(Edit1.Text) ;
RashodQuery.ParamByName('DAT_RASH').Value := TmpDat_Rash;
Пример.
Для динамического запроса "выдать записи по расходу товара, определяемого параметром :TOVAR, за дату, определяемую параметром :DAT RASH": SELECT *
FROM RASHOD
WHERE (TOVAR = :TOVAR) AND
(DAT_RASH = :DAT_RASH)
будем вводить текущие значения параметров в компоненты типа TEdit с именами Dat_Rash_Edit и Tovar_Edit. Открытие НД (компонент TQuery с именем RashodQuery) будем производить после нажатия кнопки GoButton (рис. 9.6).
Обработчик события OnClick кнопки GoButton:
procedure TForm1.GoButtonClick(Sender: TObject);
var TmpDat_Rash : TDateTime;
begin
TRY
TmpDat_Rash := StrToDate(Dat_Rash_Edit.Text);
EXCEPT
ShowMessage('Неверная дата');
Dat_Rash_Edit.SetFocus ;
Exit;
END;//try
WITH RashodQuery do begin
Close;
ParamByName('DAT_RASH').Value := TmpDat_Rash;
ParamByName('TOVAR').Value := Tovar_Edit.Text; Open;
END;//with
end;
Вначале производится проверка введенного пользователем значения даты на соответствие формату даты, а затем присвоение значений параметрам и открытие НД.
ЗАМЕЧАНИЕ 1.
По разным причинам попытка открыть НД может быть неуспешной. Поэтому рекомендуется помещать программный код, реализующий открытие НД, внутрь оператора TRY, например: TRY
RashodQuery.Open;
EXCEPT
END;//try
ЗАМЕЧАНИЕ 2.
Параметры более чувствительны к значениям даты и времени, чем поля (компонент TField). Известно, что переменные типа TDateTime хранят дату и время, и, если при преобразовании AsDateTime время или дата отсутствуют, они устанавливаются в значении поля, равными нулю: SomeField.AsDateTime := StrToDate(Edit1.Text);
Подобное преобразование для параметра может стать источником ошибки на этапе выполнения. Поэтому для отдельных значений даты параметрам в инспекторе объектов может быть поставлен в соответствие тип Date или Time, а не только тип DateTime. В первом случае преобразовывать дату следует, используя свойство компонента TParam AsDate, а во втором - используя свойство AsTime компонента TParam:
SomeQuery.ParamByName('DateParam').AsDate := ...
SomeQuery.ParamByName('TimeParam').AsTime := ...
Методы Prepare и Unprepare
Синтаксис SQL-операторов проверяется только при их выполнении. Проверка синтаксиса требует времени, что особенно актуально для больших запросов при обращении к удаленным БД. Однако в динамических запросах изменяются только значения параметров, а сам синтаксис хотя бы единожды исполненного SQL-оператора является верным. Поэтому каждый раз выполнять проверку синтаксиса такого оператора не следует. Вместо этого запрос компилируется в исполняемый код и, если текст его не изменялся, а изменялись только значения параметров, проверка синтаксиса не производится и происходит немедленное выполнение уже скомпилированного запроса.
Для того чтобы "подготовить" запрос к многократному использованию, следует хотя бы один раз выполнить метод Prepare компонента TQuery: procedure Prepare; Выполнение этого метода для динамических запросов с неизменным синтаксисом лучше делать в обработчике события формы OnCreate. В дальнейшем можно многократно присваивать параметрам различные значения и выполнять запрос методами Open и ExecSQL.
Выполнение метода Prepare необязательно в том смысле, что и без этого запрос будет выполнен. Однако выполнение метода Prepare для динамических запросов строго рекомендуется. В противном случае "подготовка" будет производиться всякий раз при выполнении запроса.
Свойство компонента Tquery property Prepared: Boolean; возвращает True, если НД был "подготовлен" методом Prepare.
Метод procedure UnPrepare; позволяет освободить ресурсы, выделенные для "подготовленного" запроса. Этот метод неявно вызывается всякий раз, когда изменяется текст SQL-оператора запроса, что также ведет к немедленному закрытию НД.
Указание значения NULL для параметров
Значение NULL показывает отсутствие значения в поле или присутствие неопределенного значения. Для числовых полей значение 0 и пустая строка " для строковых полей - это вполне определенные значения, отличные от NULL (значение неопределенное).
Часто при добавлении или корректировки записей (SQL-операторы INSERT, UPDATE) необходимо указать значение NULL для какого-либо параметра. Для этого следует выполнить метод Clear компонента ТРаrат:
procedure Clear;
Например,
пусть для корректировки записи в таблице RASHOD используется компонент TQuery с именем UpdateQuery, в свойстве SQL которого указан оператор UPDATE RASHOD
SET DAT_RASH = :new_DAT_RASH,
KOLVO = :new_KOLVO,
TOVAR = :new_TOVAR,
POKUP = :new_POKUP
WHERE
(N_RASH = :old_N_RASH)
Пусть, в частности, значение параметра :new_POKUP (название покупателя) вводится пользователем в компонент TEdit с именем Pokup_Edit. Пусть на значение поля POKUP в таблице RASHOD наложено ограничение, согласно которому значение поля должно либо быть равным NULL, либо совпадать с одним из значений поля POKUP в таблице POKUPATELI.
Если пользователь ввел в поле ввода компонента Pokup_Edit пустую строку ("), присваивание
UpdateQuery.ParamByName('new_POKUP').Value := Pokup_Edit.Text;
и последующее выполнение метода UpdateQuery.ExecSQL приведет к ошибке, поскольку в таблице POKUPATELI нет записи со значением " в поле POKUP. Поэтому в случае, если в Pokup_Edit введена пустая строка, параметру :new_POKUP присваивается значение NULL:
IF Pokup_Edit.Text = '' THEN
ParamByName('new_POKUP').Clear
ELSE
ParamByName('new_POKUP').Value := Pokup_Edit.Text;
Передача параметров через свойство DataSource
Для передачи параметров может служить свойство DataSource компонента TQuery: property DataSource: TDataSource; В случае использования этого свойства явные присваивания значений параметрам динамического запроса не производятся, то есть не кодируются операторы присваивания типа
Query1.ParamByName('ИмяПараметра').Value := Значение;
Как же поступает приложение, когда нужно открыть набор данных (выполнить метод Open) и когда у динамического запроса есть параметры, а значения им не присвоены?
В этом случае приложение определяет, имеется ли ссылка на какой-либо компонент TDataSource в свойстве DataSource. Если ссылки нет, возбуждается исключительная ситуация; если есть, то в наборе данных, связанном с TDataSource, отыскиваются поля, одноименные параметрам динамического запроса. Если такие поля есть, их текущие значения берутся в качестве значений параметров; если таких полей нет, возбуждается исключительная ситуация.
Пример. Пусть в свойстве SQL компонента RashodQuery содержится динамический запрос
SELECT *
FROM RASHOD
WHERE TOVAR = :TOVAR
ORDER BY DAT_RASH, KOLVO
Компонент RashodQuery открыт при старте приложения и значение параметру :TOVAR перед этим не назначалось. Свойство RashodQuery.DataSet = DS_TovarQuery. DS_TovarQuery - компонент типа TDataSource; он связан с набором данных TovaryQuery, у которого есть поле Tovar. Поэтому в качестве значения параметра :TOVAR берется текущее значение поля Tovar из НД TovaryQuery, как если бы это было назначено при помощи оператора
RashodQuery.ParamByName('Tovar').Value :=
TovaryQuery.FieldByName('Tovar').Value;
Отметим, что при смене текущей записи в наборе данных TovaryQuery автоматически переоткрывается и в нем показываются записи, соответствующие текущему значению поля Tovar набора данных TovaryQuery.
Вид окна программы, содержащей оба названных компонента, приводится на рис.9.7.
Формируемые запросы
Часто один компонент TQuery используют для выполнения различных отстоящих друг от друга во времени запросов. Такой подход уменьшает число используемых компонентов, но может привести к возрастанию программного кода.
Свойство SQL компонента TQuery имеет тип TStrings: property SQL: TStrings; и потому содержимое свойства SQL может формироваться программно методами Add (добавить элемент). Delete (удалить элемент), Clear (очистить список) и прочими.
Пример.
Пусть компонент RashodQuery используется для выполнения динамического запроса SELECT *
FROM RASHOD
WHERE POKUP = :POKUP
то есть запрос "выдать все записи из таблицы расхода товаров RASHOD, у которых имя покупателя POKUP совпадает со значением, указанным в параметре :POKUP". Пусть значение в параметр :POKUP берется из поля POKUP текущей на данный момент записи в таблице POKUPATELI (компонент PokupQuery):
WITH RashodQuery do begin Close;
ParamByName('POKUP').Value :=PokupQuery.FieldByName('POKUP').Value;
Open;
END;//with
Тогда и динамический оператор, и использование параметров можно заменить на следующий код:
WITH RashodQuery do begin
Close; SQL.Add ('SELECT *') ;
SQL.Add('FROM RASHOD')
SQL.Add('WHERE POKUP = ' + PokupQuery.FieldByName('POKUP').AsString) ;
Open;
END;//with
Заметим, что второй вариант лучше использовать в том случае, когда вид выполняемого запроса не повторяется во времени. В противном случае целесообразнее использовать динамический запрос.
Пример.
Пусть для оператора UPDATE, выполняющего корректировку записи в таблице RASHOD, значения полей DAT_RASH, KOLVO, TOVAR, POKUP могут вводиться компонентами TEdit с именами Dat_Rash_Edit, Kolvo_Edit, Tovar_Edit, Pokup_Edit. Требуется сформировать такой SQL-оператор, чтобы в нем указывались в качестве обновляемых только поля, для которых введено значение в соответствующих компонентах. Вид формы показан на рис. 9.8. Для формирования оператора UPDATE используется такой обработчик нажатия экранной кнопки "Изменить": procedure TForm!.UpdateButtonClick(Sender: TObject) ;
var TmpN_Rash : Integer;
Cnt : Integer; //счетчик непустых TEdit
Separator : String[1]; //запятая или пустая строка
begin
{ проверку правильности соответствия значения в Dat Rash Edit.Text формату даты и значения в Koivo_Edit.Text формату целого числа для простоты не производим }
Cnt := 0;
IF Dat_Rash_Edit.Text 0 " THEN INC(Cnt);
IF Kolvo_Edit.Text 0 " THEN INC(Cnt);
IF Tovar_Edit.Text 0 " THEN INC(Cnt);
IF Pokup_Edit.Text 0 " THEN INC(Cnt);
IF Cnt = 0 THEN begin
ShowMessage('He введено ни одно новое значение');
Dat_Rash_Edit.SetFocus;
Exit;
END;//if
//формирование текста оператора UPDATE
WITH ListBoxl.Items do begin
Clear;
Add ('UPDATE RASHOD') ;
Add('SET') ;
IF Dat_Rash_Edit.Text <> " THEN begin
DEC(Cnt) ;
IF Cnt > 0 THEN
Separator := ','
ELSE Separator := " ;
Add(' DAT_RASH = \" + Dat_Rash_Edit.Text + '"' -Separator);
END;//if
IF Kolvo_Edit.Text 0 "THEN begin
DEC(Cnt) ;
IF Cnt > 0 THEN
Separator := ','
ELSE
Separator := " ;
Add(' KOLVO = ' + Kolvo_Edit.Text + Separator);
END;//if
IF Tovar_Edit.Text <> " THEN begin
DEC(Cnt);
IF Cnt > 0 THEN Separator := ','
ELSE Separator := " ;
Add(' TOVAR = "' + Tovar_Edit.Text + '"' + Separator);
END;//if
IF Pokup_Edit.Text <> " THEN
Add(' POKUP = "' + Pokup_Edit.Text + '"');
TmpN_Rash := RashodQuery.FieldByName('N_RASH').As Integer;
Add('WHERE N_RASH = ' + IntToSTr(TmpN_Rash)) ;
END;//with
//выполнение сформированного SQL-оператора
WITH UpdateQuery do begin
SQL.Clear;
SQL := ListBoxl.Items;
TRY
ExecSQL;
EXCEPT
on EDBEngineError do begin
ShowMessage('Ошибка БД. Проверьте уникальность номера ' + 'расхода!');
Exit;
end;//do
ELSE
SHowMessage('Неклассифицированная ошибка при ExecSQL') ;
END;//try
RashodQuery.Close;
RashodQuery.Open;
END;//with
Динамический редактор SQL
Разработаем приложение, в котором пользователь сам вводит текст SQL-запроса, а приложение (если текст запроса правильный) этот запрос выполняет и выдает результаты.
Пусть SQL-оператор вводится в некоторое поле ввода (лучше типа TMemo). После ввода пользователь нажимает экранную кнопку "Выполнить", и только что введенный им запрос выполняется для одной или более ТБД. Вид окна программы, реализующей динамический редактор SQL-операторов, показан на рис.9.9. Результат выполнения запроса выводится в отдельной форме после нажатия в основной форме кнопки "Выполнить SQL-запрос" (рис. 9.10).
Техника реализации такого режима работы проста: текст запроса вводится в компонент Memo1 и перед выполнением переписывается в свойство SQL компонента TQuery (Form2. Query I):
procedure TForm1.GoQueryButtonClick(Sender: TObject) ;
begin
Form2.Query1.Close;
Form2.Query1.SQL.Clear;
Form2.Query1.SQL.Add(Memol.Text) ;
Form2.Query1.Open;
Form2.Show; end;
А) б)
Рис 332 а) до подтверждения изменений (UpdateAction = uaFail). б) после подтверждения изменений, открытия и закрытия НД "Товары " (UpdateAction = uaFail)
• UpdateAction = uaAbort.
Как показано на рис.33.3.а) и б), в режиме uaAbort результаты кэшированных изменений полностью отменены:

Рис 33.3 а) до подтверждения изменений (Update Action =uaAbort), б) noc-ie подтверждения изменений, открытия и закрытия НД "Товары" (UpdateAclion = uaAbort)
UpdateAction = uaSkip.
Как показано на рис.34.а) и б), в режиме uaSkip результаты кэшированных изменений отменены частично:
Рис 33.5. а) до подтверждения изменений (UpdateAction = uaRetry), 6) после подтверждения изменений, открытия и закрытия НД "Товары" (UpdateAction = uaRetry)
Причина зависания проста: при UpdateAction = uaRetry происходит попытка заново подтвердить квитированные изменения для записи, на которой произошла ошибка; однако поскольку значение поля "Товар" не изменилось, повторная попытка вызовет ошибку, для которой назначено действие новой попытки подтверждения, и т.д.
Введем в обработчик события OnUpdateError для режима UpdateAction = uaRetry возврат к старому значению поля "Товар" для записей, на которых попытка подтверждения изменений вызывает ошибку:
procedure TForm1.TovaryUpdateError(DataSet: TDataSet;
E: EDatabaseError; UpdateKind: TUpdateKind;
var UpdateAction: TUpdateAction);
begin
CASE RadioGroup1.ItemIndex OF
0 : UpdateAction := uaFail;
1 : UpdateAction := uaAbort;
2 : UpdateAction := uaSkip;
3 : begin
Tovary.FieldByName('Tovar').NewValue :=Tovary.FieldByName('Tovar').OldValue;
UpdateAction := uaRetry;
end;
END;//case
end;
Тогда обработчик OnUpdateError будет действовать, как если бы было установлено UpdateAction = uaSkip (рис. ЗЗ.6.а) и б)).
Рис 33.6 а) до подтверждения изменений (UpdateAction = uaRetry) с откатом ошибочных записей к старому значению, б) после подтверждения изменений, открытия и закрытия НД "Товары" (UpdateAction = uaRetry) с откатом
ошибочных записей к старому значению
ДaтаDelphi =ДатаInterBase.Days -15018 +ДamaInlerBase.MSec/(MSecsPerDay * 10);
где константа MSecsPerDay определена в Delphi как число миллисекунд в сутках.
в котором будет храниться создаваемая
19. Создание базы данных
19.1. Оператор CREATE DATABASE
Для создания БД используется оператор
CREATE {DATABASE SCHEMA} "<имя_файла>" [USER "имя_пользователя" [PASSWORD "пароль"]]
[PAGE_SIZE [=] целое] [LENGTH [=] целое [PAGE[S]]] [DEFAULT CHARACTER SET набор_символов]
[<вторичный_файл>]; <вторичный_файл> = FILE "<имя_файла>" [<файлов_информ>] [<вторичный_файл>]
<файлов_информ> = LENGTH [=] целое [PAGE[S]] | STARTING [AT [PAGE]] целое [<файлов_информ>]
| Аргумент | Описание |
| "<имя_фаила > " | Указывает спецификации файла, в котором будет храниться создаваемая БД Эти спецификации зависят от платформы |
| USER "имя_пользователя" | Имя пользователя, которое вместе с паролем, определяемым PASSWORD, проверяется при соединении пользователя с сервером, на котором расположена БД |
| PASSWORD "пароль" | Пароль, который вместе с именем пользователя проверяется при соединении пользователя с сервером |
| PAGESIZE [=] целoe | Размер страницы БД в байтах Допустимые размеры" 1024 (по умолчанию), 2048, 4096 или 8192 |
|
DEFAULТ СНАRACTER SET набор_символов |
Определяет набор символов, применимый в БД Если не указан, по умолчанию берется NONE. |
| FILE "<имя_файла>" | Имя одного или нескольких файлов, в которых будет располагаться БД |
| STARTING [AT [PAGE]] | Если БД располагается в нескольких файлах, это предложение позволяет определить, с какой страницы БД располагается в указанном файле. |
| LENGTH [=] целое [PAGE[S]] | Длина файла в страницах По умолчанию 75 страниц Минимум 50 страниц Максимум ограничен фактически имеющимся дисковым пространством |
При добавлении в БД записей, она увеличивается в объеме. Если нет никаких ограничений на размер БД, с теоретической точки зрения размер файла, в котором БД хранится, ограничен лишь объемом диска. Однако бывает необходимо, чтобы физический размер файла БД был фиксирован. Подобная необходимость может возникать в условиях ограничений на доступное дисковое пространство. В этом случае БД хранится не в одном файле, а в нескольких, а сами файлы могут располагаться на физически разных носителях. Самый первый файл БД называется первичньш, остальные - вторичными. Предложение STARTING AT [PAGE] указывает, с какой страницы начинается тот или иной вторичный файл. Предложение "LENGTH = целое" указывает длину того или иного файла. Например:
CREATE DATABASE "D:\BD\SKLAD.GDB"
FILE "D:\BD\SKLAD.GD1" STARTING AT PAGE 1001
LENGTH 500
FILE "D:\BD\SKLAD.GD2"
Здесь определяется БД "D:\BD\SKLAD.GDB", состоящая из 3 файлов: первичного "D:\BD\SKLAD.GDB" (длиной 1000 страниц), "D:\BD\SKLAD.GD1" длиной 500 страниц и "D:\BD\SKLAD.GD2" неопределенной длины.Если для вторичного файла не объявлена длина,следует указывать, с какой страницы он должен начинаться.
19.3. Определение пароля
Пароль при создании БД указывается для того, чтобы сервер смог идентифицировать пользователя по паре значений "имя пользователя -пароль": CREATE DATABASE "D:\BD\SKLAD.GDB" USER "XXX" PASSWORD "YYY" Эти имя и пароль принадлежат пользователю, создающему БД, и служат именно для идентификации пользователя. Не следует путать указываемые здесь имя пользователя и пароль с правами доступа к самой БД.
19.4. Указание размера страницы БД
Размер страницы указывается в байтах и может быть 1024, 2048,4096 или 8192 байт, например:
CREATE DATABASE "BAZA.GDB" PAGE_SIZE 4096;
Увеличение размера страницы может привести к ускорению работы с БД, поскольку:
уменьшается глубина индексов (depth, число шагов, за которое при помощи индекса будут найдены требуемые записи);
уменьшается число операций чтения при считывании длинных записей, поскольку за одну операцию чтения всегда считывается одна страница, запись, расположенная на одной странице, будет считана за один раз;
при малом объеме страницы запись располагается на нескольких страницах и соответственно считывается за несколько операций чтения.
Увеличение размера страницы не оправдано в том случае, если запросы на чтение к БД в основном возвращают небольшое число записей, не занимающих всю страницу. Поскольку за операцию чтения считывается одна страница БД, будет считываться много лишних записей.
19.5. Указание национальной кодировки символов, принимаемой по умолчанию
Для символьных столбцов в составе таблиц БД используются различные национальные кодировки. При создании БД национальный набор символов устанавливается предложением
DEFAULT CHARACTER SET набор_символов
Например, CREATE DATABASE "BAZA.GDB" ... DEFAULT CHARACTER SET WIN1251;
В дальнейшем всем создаваемым символьным столбцам таблиц БД (типы CHAR, VARCHAR) ставится в соответствие указанный набор_символов, например объявление в одной из таблиц базы данных BAZA.GDB столбца FAMILIA VARCHAR(25); интерпретируется как объявление FAMILIA VARCHAR(25) CHARACTER SET WIN1251; Изменить кодировку, принятую для БД по умолчанию, можно при определении конкретных доменов и столбцов.
Для БД, в которых столбцы будут хранить русские слова, рекомендуется кодировка WIN1251. К сожалению, на уровне создания БД невозможно установить по умолчанию порядок сортировки символов (collation order). Его определяют при объявлении доменов и отдельных столбцов (см. соответствующие разделы). Для получения списка доступных кодировок обратитесь к встроенной системе помощи InterBase.
в состав первичного или уникального
30. Использование генераторов
Часто в состав первичного или уникального ключа входят цифровые поля, значения которых должны быть уникальны, то есть не повторяться ни в какой другой записи таблицы. В одних случаях такое значение является семантически значимым и формируется пользователем по определенному алгоритму -например, номер лицевого счета в банке. В других случаях лучше предоставить выработку такого значения приложению или серверу БД.
Для локальных СУБД (например, Paradox) для названной цели применяются автоинкрементные поля. При добавлении новой записи BDE автоматически устанавливает значение автоинкрементного поля так, чтобы оно было уникальным и не совпадало со значением данного автоинкрементного поля в других записях таблицы - не только существующих, но и удаленных. Иными словами, ранее использовавшееся значение автоинкрементного поля, даже если оно освободилось в результате удаления записи, никогда не назначается вновь. Изменить значение автоинкрементного поля нельзя.
В InterBase отсутствует аппарат автоинкрементных столбцов. Вместо этого для установки уникальных значений столбцов можно использовать аппарат генераторов.
Генератором называется хранимый на сервере БД механизм, возвращающий уникальные значения, никогда не совпадающие со значениями, выданными данным генератором в прошлом.
Для создания генератора используется оператор CREATE GENERATOR ИмяГенератора;
Для генератора необходимо установить стартовое значение при помощи оператора
SET GENERATOR ИмяГенератора ТО СтартовоеЗначение;
При этом СтартовоеЗначение должно быть целочисленным. Для получения уникального значения к генератору можно обратиться с помощью функции GEN_ID (ИмяГенератора, шаг);
Эта функция возвращает увеличенное на шаг предыдущее значение, выданное генератором (или увеличенное на шаг стартовое значение, если ранее обращений к генератору не было).
Значение шага должно принадлежать диапазону -231...+231 -1.
ЗАМЕЧАНИЕ.
Не рекомендуется переустанавливать стартовое значение генератора или менять шаг при разных обращениях к GEN_ID. В противном случае генератор может выдать неуникальное значение и, как следствие, будет возбуждено исключение "Дублирование первичного или уникального ключа" при попытке запоминания новой записи в ТБД. Пример.
Пусть в БД определен генератор, возвращающий уникальное значение для столбца N_RASH в таблице RASHOD: CREATE GENERATOR RASHOD_N_RASH;
SET GENERATOR RASHOD_N_RASH TO 20;
Обращение к генератору непосредственно из оператора INSERT:
INSERT INTO RASHOD (N_RASH, DAT_RASH, KOLVO, TOVAR, POKUP)
VALUES(GEN_ID(RASHOD_N_RASH,1),"10-JAN-1997",100,"Сахар", "Лира, ТОО")
Присваивание ключевому столбцу уникального значения может быть реализовано через триггер, вызываемый перед запоминанием новой записи в БД:
CREATE TRIGGER BI_RASHOD FOR RASHOD
ACTIVE
BEFORE INSERT
AS
BEGIN
NEW.N_RASH = GEN_ID(RASHOD_N_RASH,1);
END
При этом в клиентском приложении, реализующем добавление новых записей в таблицу, столбец с уникальными значениями (в нашем случае N_RASH) в программе не заполняется и оператор INSERT имеет вид
INSERT INTO RASHOD (DAT_RASH, KOLVO, TOVAR, POKUP)
VALUES(:DAT_RASH, :KOLVO, :TOVAR, :POKUP)
Как можно заметить, столбец N_RASH в операторе не упоминается: все необходимые действия по заполнению этого столбца уникальным значением выполняет триггер BI_RASHOD.
В ряде случаев для доступа к содержимому таблиц удаленных БД в клиентских приложениях, разработанных с помощью Delphi, используют компонент TTable, который применяется для добавления, удаления и корректировки данных в этих таблицах. Здесь использование триггера может натолкнуться на неожиданное препятствие: при добавлении записи (метод Post компонента TTable) BDE отслеживает адекватность введенных значений столбцов добавляемой записи наложенным на эти столбцы ограничениям. Такой анализ осуществляется при выполнении метода Post в клиентском приложении (и, стало быть, до активизации триггера на сервере БД). При этом столбец с уникальным значением не заполнен, что с точки зрения BDE есть ошибка (поскольку данный столбец описан при создании с атрибутом NOT NULL, что обязательно для всех столбцов, входящих в первичный или просто уникальный ключ).
"Обмануть" BDE можно, присваивая столбцу N_RASH любое значение, которое затем будет заменяться триггером на значение, полученное при помощи функции GEN_ID. Однако более корректным будет в данном случае использование не триггера, а процедуры:
CREATE PROCEDURE GET_N_RASH
RETURNS (NR INTEGER)
AS
BEGIN
NR = GEN_ID(RASHOD_N_RASH,1) ;
END
При добавлении новой записи в таблицу в клиентском приложении вызов этой процедуры реализуется при помощи компонента TStoredProc, непосредственно после перевода компонента TTable в состояние dslnsert:
procedure TForm1.RashodTableAfterInsert(DataSet: TDataSet) ;
begin
StoredProc1.Close;
StoredProc1.ExecProc;
RashodTable.FieldByName('N_RASH').Value := StoredProc1.ParamByName('NR').Value;
StoredProc1.Close;
end;
Заметим, что приведенные выше действия могут быть также реализованы в обработчике события OnNewRecord компонента TTable.
Добавление нового столбца в таблицу БД
ALTER TABLE <имя таблицы> ADD Определения столбца>;
Добавление новых ограничений целостности
ALTER TABLE <имя таблицы> ADD [CONSTRAINT <имя ограничения>] Определения целостности>;
Добавление записей
INSERT INTO <объект> [(столбец! [, столбец2 ...])]
{VALUES (<значение1> [, <значение2> ...]) I <оператор SELECT> }
Firma
При значении WhereAll обновления, сделанные пользователем В, будут отклонены и запись останется в том виде, в который она перешла после завершения транзакции пользователем А.
При значении WhereKeyOnly BDE будет идентифицировать в ТБД ту запись, которую нужно обновить, по значению индексного поля (полей). Пусть такое поле в данном случае Firma. Пользователь А не изменял значение этого поля -как было 'Янтарь', так и осталось. Поэтому обновление записи для пользователя В будет разрешено. В результате запись, о которой идет речь, будет в ТБД иметь вид то есть станет недостоверной.
При значении WhereChanged идентификация в ТБД записи, которая должна быть замещена, ведется на соответствие ключевого поля и поля, которое изменено. В данном случае это поля Firma и Doljnost. Поскольку пользователь А не менял этих полей, запись будет найдена и данные в ТБД вновь окажутся недостоверными.
Где
• READ WRITE \ READ ONLY устанавливает уровень доступа к данным (по умолчанию READ WRITE);
• WAIT | NO WAIT определяет поведение при возникновении конфликта по обновлению записи данной транзакции с другой транзакцией, ранее сделавшей изменение в той же записи: WAIT (по умолчанию) побуждает данную транзакцию ожидать завершения конкурирующей транзакции;
NO WAIT определяет аварийное завершение данной транзакции;
• ISOLATION LEVEL определяет уровни изоляции транзакций на сервере (по умолчанию SNAPSHOT);
• RESERVING в рамках данной транзакции запирает (lock) таблицы, приведенные в одном или нескольких списках таблиц.
В последнем случае каждому элементу списка таблиц ставятся в соответствие параметры:
PROTECTED READ -
конкурирующие транзакции могут читать данные, но не могут изменять; PROTECTED WRITE -
читать данные могут только транзакции с уровнями SNAPSHOT или READ COMMITTED и никакая конкурирующая транзакция не может их изменять.
Geneial SQL eiroi. multiple rows in singleton select.
Рис. 25.39. "Общая ошибка при выполнении SQL; возвращено множество значений, когда требуется единичное значение ".
Дело в том, что в качестве возвращаемого столбца таблицы POKUPATELI используется столбец POKUP, значения в котором могут быть неуникальны, поскольку может быть несколько покупателей из одного города.
Поэтому следует придерживаться правила оценивать, какой результат -множественный или единичный - будет в общем случае возвращать подзапрос. (И что делать после оценки? Я бы изменил оператор = на in where r.pokup in select.... и пояснил отсутствие ошибки)
Информация о таблице БД
• Primary pointer page - номер начальной страницы таблицы БД.
• Index root page -
номер начальной страницы для хранения индексов таблицы БД. • Data pages - общее число страниц для хранения данных.
• Average fill -
процент заполнения страниц для хранения данных. Fill distribution -
диаграмма заполнения страниц для хранения данных. Пример. Информация о таблице SPISKI: SPISKI (38) Primary pointer page: 272, Index root page: 273 Data pages: 6, data page slots: 6, average fill: 65% Fill distribution:
0 - 19% = 0
20 - 39% = 0
40 - 59% = 1
60 - 79% = 5
80 - 99% = 0
Информация об индексе
Index -
Имя индекса. Depth -
Число уровней в дереве индексных страниц (оптимальный показатель - не больше 3. При глубине индекса (depth) больше 3 сортировка с его использованием становится неэффективной. Leaf buckets - Число страниц нижнего уровня в дереве индексных страниц. Nodes -
Общее число страниц в дереве. Average data length -
Средняя длина каждого ключа в байтах. Total dup -
Общее число строк индекса с дублированными значениями индексных полей. Мах dup -
Число строк индекса с максимальным числом дублированных значений индексных полей. Fill distribution - Гистограмма, показывающая число индексных страниц, соответствующих определенному проценту заполнения. Пример:
Index RDB$FOREIGN11 (1)
Depth: 1, leaf buckets: 1, nodes: 39
Average data length: 5.00, total dup: 16, max dup: 6
Fill distribution:
0 - 19% = 0
20 - 39% = 0
40 - 59% = 1
60 - 79% = 0
80 - 99% = 0
Изменение хранимой процедуры
ALTER PROCEDURE ИмяПроцедуры
[ (входной_параметр тип_данных [, входной параметр тип данных...])]
[RETURNS
(входной параметр тип данных [,входной параметр тип данных ...])]
AS
<тело процедуры>;
Изменение определения домена
ALTER DOMAIN имя {
[SET DEFAULT {литерал! NULL | USER}]
I [DROP DEFAULT]
I [ADD [CONSTRAINT] CHECK (<огранич_домена>)]
I [DROP CONSTRAINT]
Изменение существующего триггера
ALTER TRIGGER ИмяТриггера FOR ИмяТаблицы
[ACTIVE I INACTIVE]
{BEFORE | AFTER}
{DELETE INSERT | UPDATE}
[POSITION номер]
AS <тело триггера>
Изменение записей
UPDATE <объект>
SET столбец! = <значение1> [,столбец2 = <значение2>...]
[WHERE <условие поиска >]
Удаление записей
DELETE FROM <объект>
[WHERE <условие поиска>];
Компонент TDBComboBox
Свойства property DataField: string; - содержит имя поля.
property DataSource: TDataSowce; -
определяет имя связанного с НД компонента DataSource. property DropDownCount: Integer; -
определяет число строк в выпадающем списке. property Items : Tstrings; -
хранит список вариантов значения поля. property ReadOnly: Boolean; -
содержит True, если значение поля доступно только для чтения.
Компонент TDBLookupComboBox
ПРИМЕЧАНИЕ. Набор данных-1 (НД-1), к которому принадлежит поле, возвращающее значение из НД-2; набор данных-2 (НД-2), из которого берется значение.
Компонент TStoredProc
Процедура действия возвращает один экземпляр значения выходного параметра или группы параметров. Этим она отличается от хранимой процедуры выбора, которая за одно выполнение способна возвратить несколько экземпляров выходных параметров.
В утилите WISQL InterBase хранимую процедуру действия можно вызвать при помощи оператора
EXECUTE PROCEDURE имя [параметр [, параметр ...|];
Например, вызов процедуры STOIM с указанием двух входных параметров приведет к выдаче значения выходного параметра в окне результатов WISQL (рис. 28.3).
При помощи WISQL удобно отлаживать хранимые процедуры действия, а также производить пробные запуски хранимых процедур выбора, которые в этом случае возвращают только первую строку результирующего для процедуры набора данных (то есть первый экземпляр выходных параметров). После отладки синтаксиса и получения правдоподобных результатов последующую отладку процедур выбора следует производить в приложении клиента.
Из приложения клиента процедуру действия вызывают при помощи компонента TStoredProc. Для этого в его свойство DatabaseName помещают псевдоним удаленной БД, в которой расположена хранимая процедура. Затем выбирают имя соответствующей хранимой процедуры из выпадающего списка в свойстве StoredProcNawe компонента TStoredProc. При этом происходит считывание имен входных и выходных параметров и их типов. Их можно увидеть, нажав кнопку (...) в свойстве Params или вызвав редактор определения параметров компонента TStoredProc. Для этого необходимо сделать компонент текущим, нажать правую кнопку мыши и в появившемся меню выбрать опцию Define Parameters. Вид представления параметров в редакторе определения параметров компонента TStoredProc показан на рисунке 28.4.
В окне Parameter Name указываются имена параметров. Поле Parameter Type устанавливает тип параметра (Input, Output). Поле Data Type определяет тип данных параметра. Поле Value устанавливает значение параметра по умолчанию.
ЗАМЕЧАНИЕ.
При считывании характеристик параметров непосредственно из хранимой процедуры Delphi блокирует кнопки Add, Delete, Clear, предназначенные для добавления, удаления, очистки характеристик параметра. Для других случаев параметры можно определять явно. При этом необходимо заботиться о соответствии типов данных параметров процедуры и компонента TStoredProc. Имена параметров и порядок их следования могут не совпадать с именами и порядком следования параметров в хранимой процедуре на сервере. В этом случае указать соответствие параметров компонента и процедуры на сервере можно, используя свойство компонента TStoredProc property ParamBindMode: TParamBindMode;
для которого допустимы значения
pbByName
- (по умолчанию) соответствие параметров ведется по именам (имена одинаковых параметров в компоненте и процедуре на сервере должны совпадать); pbByNumber
- соответствие параметров производится по их порядковым номерам: производится попытка первый по порядку параметр компонента соотнести с первым по порядку параметром процедуры на сервере, второй - со вторым и т.д. Установить значения входных параметров и получить значения выходных параметров процедуры можно, используя метод
function ParamByName(const Value: string): TParam;
Например,
// входной параметр StoredProc2.ParamByName('IN_TOVAR').Value :=
Table1.FieldByName('TOVAR').Value;
// выходной параметр
Label5.Caption := IntToStr(StoredProc2.ParamByName('MAX_KOLVO').Value) ;
Перед выполнением процедуры нужно произвести связывание параметров компонента TStoredProc и параметров хранимой процедуры при помощи метода
procedure Prepare;
Вызов хранимой процедуры действия осуществляется методом procedure ExecProc;
Пример.
Пусть на сервере определены хранимые процедуры действия FIND_MAX_KOLVO и STOIM. Осуществим их вызов из клиентского приложения, написанного на Delphi. Процедура FIND_MAX_KOLVO возвращает в выходном параметре MAX_KOLVO максимальную партию отгруженного товара, наименование которого передается во входном параметре IN_TOVAR:
CREATE PROCEDURE FIND_MAX_KOLVO (IN_TOVAR VARCHAR(20))
RETURNS(MAX_KOLVO INTEGER) AS
BEGIN
SELECT MAX(KOLVO) FROM RASHOD WHERE TOVAR = : IN_TOVAR INTO : MAX_KOLVO;
SUSPEND;
END
Процедура STOIM возвращает стоимость количества товара. Параметр IN_KOLVO определяет число единиц товара; IN_TOVAR определяет название товара.
CREATE PROCEDURE STOIM (IN_TOVAR VARCHAR (20) , IN_KOLVO INTEGER)
RETURNS(OUT_STOIM INTEGER) AS
DECLARE VARIABLE ZENA_ED INTEGER;
BEGIN
SELECT ZENA FROM TOVARY WHERE TOVAR = :IN_TOVAR INTO : ZENA_ED;
OUT_STOIM = ZENA_ED * IN_KOLVO;
END
Расположим в форме:
1. компонент TTable, ассоциированный с таблицей TOVARY, для выбора названия товара для его передачи в хранимую процедуру как входного параметра;
2. компонент TStoredProc (имя StoredProc!) для выполнения процедуры STOIM;
3. компонент TStoredProc (имя StoredProc2) для выполнения процедуры FIND_MAX_KOLVO;
4. компонент TButton для инициации выполнения хранимых процедур;
5. два компонента TLabel для визуализации результатов выполнения процедуры.
Напишем обработчик нажатия кнопки, в котором происходит присваивание значений входных параметров и получение значений выходных параметров процедур:
procedure TForm1.Button1Click(Sender: TObject);
begin
StoredProc2.UnPrepare;
StoredProc1.UnPrepare;
StoredProc1.ParamByName('IN_TOVAR').Value := Table1.FieldByName('TOVAR').Value;
StoredProc1.ParamByName('IN_KOLVO').Value := StoredProc2.ParamByName('MAX_KOLVO').Value;
StoredProc1.Prepare;
StoredProc1.ExecProc;
Label3.Caption :=IntToStr(StoredProc!.ParamByName('OUT_STOIM').Value) ;
StoredProc2.ParamByName('IN_TOVAR').Value := Table1.FieldByName('TOVAR').Value;
StoredProc2.Prepare;
StoredProc2.ExecProc;
Label5.Caption := IntToStr(StoredProc2.ParamByName('MAX_KOLVO').Value) ;
end;
Результат работы приложения приведен на рисунке 28.5.

Рис. 28.5. Значения максимального отпуска товара (количество и стоимость) возвращаются хранимой процедурой выбора как выходные параметры
Компонент ТТаblе
Приводимые ниже свойства, методы, события уникальны для компонента TTable. Помимо этого, TTable обладает также свойствами, методами, событиями, общими для наборов данных. Они описаны в разделе "Наборы данных".
Методы
procedure Apply Updates (const DataSets: array of TDataSet); -
применяется для подтверждения кэшированных изменений сразу в нескольких НД. Список НД определяется параметром DataSets. В случае указания нескольких НД их имена разделяются запятыми. procedure Close; -
закрывает БД и все связанные с ней открытые НД. procedure CloseDatasets; -
закрывает открытые НД, связанные с БД, но не закрывает саму БД. procedure Commit; -
подтверждает текущую транзакцию, т.е. подтверждает все модификации в БД, имевшие место с момента последнего вызова метода Start Transaction. Если ни одна транзакция не активна, возбуждается исключение. procedure Open; -
открывает БД, соединяя компонент TDatabase с сервером или BDE для Paradox или dBASE. procedure Rollback; -
откатывает текущую транзакцию, т.е. отменяет все модификации в БД, имевшие место с момента последнего вызова метода Start Transaction. procedure StartTransaction;
- инициирует начало транзакции. Если в этот момент активна некоторая транзакция, возбуждается исключение. Транзакционные изменения в наборах БД, имевшие место после выполнения метода StartTransaction, либо подтверждаются методом Commit, либо отменяются методом Rollback. До подтверждения или отмены изменений транзакция, начатая StartTransaction, считается активной.
procedure Append; -
переводит НД в состояние dslnsert, добавляет новую запись с пустыми полями. Применение метода Род! запоминает новую запись в БД после последней записи. Метод рассчитан на неиндексированные НД. Для индексированных НД его выполнение имеет те же последствия, что и выполнение метода Insert. procedure AppendRecordfconst Values: array of const); -
метод аналогичен последовательному выполнению цепочки "выполнить метод Append", "присвоить значения полям данных из списка", "выполнить метод Post". procedure Apply Updates; -
применяется для подтверждения кэшированных изменений для отдельного НД. procedure Cancel; -
отменяет изменения, сделанные в существующей записи (режим dsEdit), или добавление новой записи в БД (режим dslnsert). procedure CancelUpdates; -
отменяет кэшированные изменения в НД, сделанные с момента последнего выполнения метода ApplyUpdates, либо, если такой метод ни разу не выполнялся, все изменения, сделанные с момента перехода НД в режим кэшированных изменений (CachedUpdates = True). procedure ClearFields
; - очищает содержимое полей текущей записи набора данных. Если НД не находится в режиме вставки новой записи или редактирования, возбуждается исключение. В случае успешного выполнения вызывается обработчик события OnDalaChange (компонент TDataSource, связанный с НД), поскольку реальное содержимое записи при очистке полей изменяется. procedure Close; -
закрывает НД; procedure CommitUpdates; -
применяется для обновления в БД кэшированных изменений, успешно подтвержденных методом Apply Updates. Успешность подтверждения состоит в том, что при подтверждении кэшированных изменений не было выдано ни одной ошибки. procedure Delete; -
удаляет текущую запись из НД, сдвигая оставшиеся записи "вверх". procedure DisableControls;
и procedure EnableControls; - отключают и затем восстанавливают связь с визуальными компонентами, связанными с данным НД (например, TDBGrid). Это важно при выполнении действий с НД, влекущих за собой частое изменение местоположения курсора БД, чтобы в визуальном компоненте не возникал эффект "прокрутки" записей и не тратилось время на обновление изменений. procedure Edit; -
переводит НД в режим редактирования (dsEdit), после чего значения полей можно изменять. Выполнение метода Post приводит к сохранению измененной записи в НД. Выполнение метода Cancel приводит к отказу от сделанных изменений. function FindFirst: Boolean; -
ищет первую в НД запись, удовлетворяющую фильтру, условие которого определяется обработчиком события OnFi/terRecord или (и) свойством Filter. function FindLast: Boolean; -
ищет последнюю запись, удовлетворяющую фильтру, условие которого определяется обработчиком события OnFilterRecord или (и) свойством Filter. function FindNext: Boolean; -
переходит на следующую запись, удовлетворяющую фильтру, условие которого определяется обработчиком события OnFilterRecord или (и) свойством Filter. junction FindPrior: Boolean; -
переходит на предыдущую запись, удовлетворяющую фильтру, условие которого определяется обработчиком события OnFilterRecord или (и) свойством Filter. procedure First; -
устанавливает курсор на логически первую запись в наборе данных. procedure FreeBookmark( Bookmark: TBookmark); -
освобождает системные ресурсы для закладки Bookmark. function GetBookmark: TBookmark; -
создает для текущей записи закладку и возвращает ссылку на нее; procedure GotoBookmark( Bookmark: TBookmark); -
перемещает курсор БД на запись, определяемую закладкой Bookmark; procedure Insert; -
переводит НД в состояние dslnsert, добавляет новую запись с пустыми полями. Метод Post запоминает новую запись в БД после текущей записи. Выполнение метода Cancel приводит к отказу от добавления новой записи. procedure InsertRecord(const Values: array ofconst); -
аналогична последовательному выполнению цепочки "выполнить метод Insert", "назначить значения полям данных из списка", "выполнить метод Post". procedure Last; -
устанавливает курсор на логически последнюю запись в наборе данных. function Locate(const KeyFields: string; const KeyValues: Variant;
Options: TLocateOptions): Boolean; -
осуществляет поиск в НД записи, удовлетворяющей (полностью или частично) условиям KeyValues, в полях, список которых задается KeyFields. При нахождении записи делает ее текущей в НД. В качестве поисковых могут задаваться как индексные, так и неиндексные поля. Текущий индекс значения не имеет. procedure LockTable(LockType: TLockType); -
накладывает на таблицу БД (Paradox, dBase) блокировку на операции чтения или записи; в дальнейшем блокировка может быть снята методом Unlock Table. TLockType = (ItReadLock, ItWriteLock);
function Lookup(const KeyFields: string; const KeyValues: Variant;
const ResultFields: string): Variant; -
ищет в НД запись, удовлетворяющую условию KeyValues, в полях, список которых задается KeyFields, и возвращает список значений полей, заданных ResultFields. Указатель записи при этом не изменяется. В качестве поисковых могут задаваться как индексные, так и неиндексные поля. Текущий индекс значения не имеет. function MoveBy (Distance: Integer): Integer; -
перемещает курсор НД на Distance записей к концу набора данных (Distance > 0) или к его началу (Distance < 0) в логическом порядке, определенном индексом (свойство IndexFieldNames или IndexName). procedure Next; -
перемещает курсор НД на следующую запись в НД в логическом порядке, определенном индексом (свойство IndexFieldNames или IndexName). procedure Open; •
открывает НД. procedure Post; -
переводит НД из режимов dsEdit или dslnsert в режим dsBrowse. Измененная (режим dsEdit) или новая запись (режим dslnsert) записывается в НД. procedure Prior; -
перемещает курсор НД на предыдущую запись в НД в логическом порядке, определенном индексом (свойство IndexFieldNames или IndexName}. procedure Refresh; -
обновляет НД из таблицы БД; служит для синхронизации нескольких НД, работающих с одной таблицей в одном приложении, а также -в многопользовательском режиме в архитектуре "файл-сервер" - для показа в НД обновлений, внесенных в таблицу другими пользователями. procedure SelFields (const Values: array ofconst);
- аналогична последовательному выполнению цепочки "выполнить метод Edit", "присвоить значения полям данных из списка", "выполнить метод Post". procedure UnlockTable(LockType: TLockType); •
снимает с таблицы БД (Paradox, dBase) блокировку на операции чтения или записи, ранее наложенную на таблицу методом Lock Table. TLockType = (ItReadLock, ItWriteLock);
События property AfterCancel: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает немедленно после выполнения метода Cancel. В момент события изменения в записи уже потеряны. Это событие может не возникнуть в том случае, если вызов обработчика метода Cancel блокирован в силу наступления каких-либо условий в обработчике события BeforeCancel
property AfterClose: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает немедленно после выполнения метода Close или установки свойства Active в False. В момент события НД уже закрыт. Это событие может не возникнуть в том случае, если вызов обработчика метода Close блокирован в силу наступления каких-либо условий в обработчике события BeforeClose.
property AfterDelete: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает немедленно после выполнения метода Delete. В момент события запись уже удалена. Это событие может не возникнуть в том случае, если вызов обработчика метода Delete блокирован в силу наступления каких-либо условий в обработчике события BeforeDelete.
property AfterEdit: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает немедленно после выполнения метода Edit, сразу же после перехода в состояние dsEdit из состояния dsBrowse. В момент события изменения в запись еще не внесены. Это событие может не возникнуть в том случае, если вызов обработчика метода Edit блокирован в силу наступления каких-либо условий в обработчике события BeforeEdit.
property Afterlnsert: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает немедленно после выполнения метода Insert или Append, сразу же после перехода в состояние dslnsert из состояния dsBrowse. В момент события изменения в запись еще не внесены. Это событие может не возникнуть в том случае, если вызов обработчика метода Insert блокирован в силу наступления каких-либо условий в обработчике события Beforelnsert.
Назначить полям добавляемой записи значения по умолчанию можно в методе OnNewRecord.
property AfterOpen: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает немедленно после выполнения метода Open или установки свойства Active в True. В момент события НД уже открыт. Это событие может не возникнуть в том случае, если вызов обработчика метода Open блокирован в силу наступления каких-либо условий в обработчике события BeforeOpen.
property AfterPost: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает после выполнения метода Post. Курсор в момент наступления события не позиционирован на запомненную запись, если НД (в этом случае компонент TTable) ранжирован (отфильтрован) при помощи методов ApplyRange или SetRange свойства Filter или события OnFUterRecord, а запоминаемая запись имеет значения фильтруемых полей, выходящих за диапазон фильтра. В противных случаях курсор указывает на запомненную запись.
Это событие может не возникнуть в том случае, если вызов обработчика метода Post блокирован в силу наступления каких-либо условий в обработчике события BeforePost.
property AfterScroll: TDataSetNotifyEventI;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Событие наступает после перехода на другую запись в НД. property BeforeCancel: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает перед выполнением метода Cancel, но после обращения к нему. В обработчике можно воспрепятствовать выполнению метода Cancel путем принудительного возбуждения исключительной ситуации, вызова метода Abort или выполнения иных действий, которые заведомо приведут к возбуждению исключения.
property BeforeClose: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает перед выполнением метода Close, но после его вызова. В обработчике можно воспрепятствовать выполнению метода Close путем принудительного возбуждения исключительной ситуации, вызова метода Abort или выполнения иных действий, которые заведомо приведут к возбуждению исключения.
Используется для перевода НД в режим dsBrowse, если на момент закрытия НД находится в режимах dsEdit или dslnsert. В этом случае для перевода НД в режим dsBrowse нужно вызвать метод Post (с запоминанием изменений) или метод Cancel (для отмены изменений).
property BeforeDelete: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает перед выполнением метода Delete, но после его вызова. В обработчике можно воспрепятствовать выполнению метода Delete путем принудительного возбуждения исключительной ситуации, вызова метода Abort или выполнения иных действий, которые заведомо приведут к возбуждению исключения.
property BeforeEdit: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает перед выполнением метода Edit, но после его вызова. В обработчике можно воспрепятствовать выполнению метода Edit путем принудительного возбуждения исключительной ситуации, вызова метода Abort или выполнения иных действий, которые заведомо приведут к возбуждению исключения.
property Beforelnsert: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает перед физическим выполнением метода Insert, но после его вызова.
В обработчике можно воспрепятствовать выполнению метода Insert путем принудительного возбуждения исключительной ситуации, вызова метода Abort или выполнения иных действий, которые заведомо приведут к возбуждению исключения.
property BeforeOpen: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает перед физическим выполнением метода Open, но после его вызова. В обработчике можно воспрепятствовать выполнению метода Open путем принудительного возбуждения исключительной ситуации, вызова метода Abort или выполнения иных действий, которые заведомо приведут к возбуждению исключения property BeforePost: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Наступает перед физическим выполнением метода Post, но после его вызова. В обработчике можно воспрепятствовать выполнению метода Post путем принудительного возбуждения исключительной ситуации, вызова метода Abort или выполнения иных действий, которые заведомо приведут к возбуждению исключения.
property BeforeScroll: TDataSetNotifyEventI;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Событие наступает перед выполнением перехода на другую запись в НД. property OnDeleteError: TDataSet ErrorEvent;
TDataSetErrorEvent = procedure(DataSet: TDataSet; E: EDatabaseError;
var Action: TDataAction) of object;
TDataAction = (daFail, daAbort, daRetry);
Наступает при неудачном выполнении метода Delete.
property OnCalcFields: TDafaSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Используется для расчета значений вычисляемых полей. Определяет алгоритм, по которому следует рассчитывать значения таких полей. Наступает при чтении информации из ТБД. Кроме того, если свойство AutoCalcFields имеет значение True, событие OnCalcFields наступает также и при модификации значений невычисляемых полей в режимах dslnsert и dsEdit данного НД или НД, с ним связанного (когда установлены ограничения целостности в самой ТБД, а не тогда, когда они подразумеваются).
Поскольку событие OnCalcFields наступает очень часто, его обработчик должен содержать максимально возможно короткий код.
Нельзя реализовывать в обработчике данного события действия, которые ведут к изменению значений полей записи, поскольку этот метод будет вызван снова, что приведет к зацикливанию.
property OnEditError: TDataSetErrorEvent;
TDataSetErrorEvent = procedure(DataSet: TDataSet; E: EDatabaseError;
var Action: TDataAction) of object;
TDataAction = (daFail, daAbort, daRetry);
Наступает при неудачном выполнении методов Insert и Edit. property OnFilterRecord: TFilterRecordEvent;
TFilterRecordEvent = procedure(DataSet: TDataSet; var Accept: Boolean) of object;
Задает условия фильтрации; возникает, когда свойство Filtered устанавливается в True. Альтернативный способ фильтрации по любым” в том числе неиндексным, полям, для свойства Filter. Однако может использоваться совместно с ним, а также с фильтрациями, накладываемыми при помощи методов SetRange и Apply Range.
property OnNewRecord: TDataSetNotifyEvent;
TDataSetNotifyEvent = procedure(DataSet: TDataSet) of object;
Используется для присваивания значений по умолчанию полям вновь создаваемой записи НД перед тем как эта запись станет доступна пользователю для ввода значений полей. Присваивание значений по умолчанию не устанавливает в свойство Modifyed значение True. Наступает после события BeforeInserf и до события Afterlnsert.
property OnPostError: TDataSetErrorEvent;
TDataSetErrorEvent = procedure(DataSet: TDataSet; E: EDatabaseError;
var Action: TDataAction) of object;
TDataAction = (daFail, daAbort, daRetry);
Наступает при неудачном выполнении метода Post. property OnUpdate Error: TUpdateErrorEvent;
TUpdateErrorEvent = procedure(DataSet: TDataSet; E: EDatabaseError;
UpdateKind: TUpdateKind; var UpdateAction: TUpdateAction) of object;
Наступает в случае, если при попытке подтверждения кэшированных изменений для НД происходит ошибка.
property OnUpdateRecord: TUpdateRecordEvent;
TUpdateErrorEvent = procedure(DataSet: TDataSet; E: EDatabaseError;
UpdateKind: TUpdateKind; var UpdateAction: TUpdateAction) of object;
Наступает для каждого факта внесения изменений в запись НД (добавление, изменение, удаление записи), если НД находится в режиме кэшированных изменений.
function SeriesCount : Longint; -
возвращает число серий, присутствующих в текущий момент в графике. procedure RefreshData; -
обновляет данные в серии из НД, которые служат их источником.
procedure DoKey(Key: DBCtrlGridKey); -
выполняет определенное действие, задаваемое параметром Key. Некоторые из возможных значений этого параметра: gkNull
Действия нет. gkEditMode
Перевод в режим редактирования. gkLeft Moves
Перемещение на 1 колонку влево со скроллингом (если нужен). gkRight
Перемещение на 1 колонку вправо. gkUp
Перемещение на 1 запись вверх. gkDown
Перемещение на 1 запись вниз. gkScrolIUp
Делает запись в предыдущей строке текущей без изменения ее местоположения. gkScrollDown
Делает запись в следующей строке текущей, без изменения ее местоположения. gkPage Up
Перемещение к предыдущей странице TDBCtrlGrid. gkPageDown
Перемещение к следующей странице TDBCtrlGrid. gkHome
Перемещение на первую запись. gkEnd Moves
Перемещение на последнюю запись.
• procedure DefaultDrawColumnCell(const Rect: TRect; DataCol: Integer; Column:
TColumn; State: TGridDrawState); -
выводит ячейки TDBGrid стандартным способом (по умолчанию), как это было бы, если бы свойство TDBGrid Default Drawing содержало значение True. Обычно это актуально, если свойство Default Drawing равно False и для вывода содержимого ячеек используется обработчик OnDrawColumnCell или OnDrawDataCell, где некоторые ячейки (строки) могут выводиться нестандартно (иным цветом, шрифтом, фоном, с особенным форматированием значения), а некоторые ячейки должны выводиться стандартным способом. В последнем случае из OnDrawColumnCell или OnDrawDataCell и вызывается метод DefaultDrawColumnCell. • function ValidFieldIndex(FieldIndex: Integer): Boolean; -
возвращает True, если значение Fieldlndex является правильным индексом столбца TDBGrid, и False -в противном случае.
procedure CloseUp; -
сворачивает распахнутый список выбора. procedure DropDown; -
раскрывает ("распахивает") список выбора. Компонент TDBLookupListBox
LoadFromFile(const FileName: string);
загружает в TDBMemo содержимое файла, имя которого определяется константой или переменной FileName.
SaveToFUe(const FileName: string);
записывает содержимое TDBMemo в файл, имя которого определяется константой или переменной FileName.
procedure Clear; -
полностью удаляет текст из компонента. procedure ClearSelection; -
удаляет выделенный фрагмент текста. procedure CopyToClipboard; -
копирует выделенный фрагмент текста в буфер обмена Windows. procedure CutToClipboard; -
вырезает выделенный фрагмент текста и вставляет его в буфер обмена Windows. junction GetTextLen: Integer; -
возвращает длину текста. function FindText(const SearchStr: string; StartPos, Length: Integer; Options:
TSearchTypes): Integer; -
производит поиск вхождения в текст комментария строки SearchStr. Поиск производится во фрагменте текста, начиная с позиции StartPos и заканчивая StartPos + Length -1. Первый символ текста комментария имеет номер 0. Если поиск успешен, возвращается номер символа, начиная с которого SearchStr входит в текст комментария. В противном случае возвращается -1.
Параметр Options представляет собой множество, в которое могут входить элементы:
st Whole Word - строка SearchStr должна содержать целое слово (если занимает фрагмент слова, этот факт при поиске не учитывается);
stMatchCase -
величина букв SearchStr и найденного фрагмента должна совпадать. procedure LoadMemo; -
загружает содержимое поля комментария в компонент TDBRichEdit. Этот метод необходимо использовать, когда при изменении курсора набора данных не происходит обновления компонента TDBRichEdit содержимым поля комментария текущей записи, т.е. когда свойство AutoDisplay находится в значении False. procedure PasteFromClipboard; -
вставляет содержимое буфера обмена Windows в текст комментария, начиная с текущей позиции курсора. procedure Print (const Caption: string); -
выводит текст комментария на печать. Параметр Caption определяет заголовок в очереди печати. procedure SelectAll; -
выделяет весь текст.
procedure ShowCubeDialog; -
во время выполнения осуществляет вход в редактор куба, в котором могут быть изменены или переопределены свойства куба, установленные во время разработки. Более подробно см. свойство DimensionMap.
procedure RegisterEvents; -
выполняет регистрацию приложения как приемника сообщений от сервера БД о наступлении событий, определяемых свойством Events procedure UnregisterEvents; -
отключает регистрацию приложения как приемника сообщений от сервера БД о наступлении событий, определяемых свойством Events. Данный метод не может применяться в обработчике события OnEventAlert. Перед выполнением метода в обработчике OnEventAlert полезно установить изменяемый параметр CancelAlerts ъ False.
procedure ExecSQL; -
открывает НД, если в свойстве SQL содержится SQL-запрос на выполнение действия (отличный от оператора SELECT). procedure Open; -
открывает НД, если в свойстве SQL содержится SQL-запрос на выборку данных (оператор SELECT). procedure Prepare; -
подготавливает динамический запрос к выполнению. procedure UnPrepare; -
высвобождает ресурсы, занимаемые запросом, ранее подготовленным к выполнению методом Prepare.
procedure NewPage; -
выполняет переход на новую страницу. Может использоваться в обработчиках событий компонентов отчета BeforePrint или AfterPrint и не может - в обработчиках событий OnPrint, OnStartPage и OnEndPage. procedure Preview; -
выводит отчет в окно предварительного просмотра. procedure Print; - печатает отчет. procedure PrinterSetup; -
выдает диалоговое окно установки параметров принтера.
function AddXY(Const AXValue, AYValue: Double; Const AXLabel: String; A Color: TColor) : Longint; -
добавляет новую точку в серию. Параметры AXValue и AYValue содержат соответственно значения по осям Х и Y. Параметр AXLabel содержит метку для добавляемой точки серии. Параметр AColor определяет цвет. Функция возвращает позицию новой точки в серии. function AddY (Const A Y Value: Double; Const AXLabel: String; AColor: TColor):
Longint; -
добавляет в серию новое значение по оси X. Применяется для тех серий, в которых график строится по Х и меткам значений по Х (например, Pie, Bar). Назначение параметров такое же, как у метода AddXY. procedure Assign Values (Source : TChartSeries); -
копирует все точки из серии Source в текущую серию. procedure CheckDataSource; -
обновляет точки в серии, независимо от того, какой компонент является источником данных - НД или другая серия. Обновление производится по текущим данным источника. Метод рекомендуется вызывать в случае изменений данных в источнике. procedure Clear; -
удаляет все значения из серии; если вслед за этим не занести новых точек, будет показываться пустой график. procedure ColorRange(A ValueList: TChartValueList; Const From Value, To Value:
Double; AColor: TColor); -
изменяет цвет указанного диапазона точек серии. AValueList - либо XValues, либо YValues. FromValue указывает начальное, а То Value конечное значение в списке AValueList. AColor - новый цвет. function Count: Longint; -
возвращает число точек в серии. procedure Delete (Valuelndex : Longint); -
удаляет из серии точку с номером ValueIndex. График, к которому принадлежит серия, автоматически перерисовывается. procedure DoSeriesClick( Valuelndex.•Longint; Button:TMouseB utton; Shift:
TShiftState; X, Y: Integer); virtual; -
инициирует наступление события OnCUck. function GetCursor Valuelndex : Longint; -
возвращает индекс точки серии в TChart ValueList, ближе всего к которой расположен курсор мыши. Если такую точку определить не удается, возвращается -1. procedure GetCursor Values ( Var x,y : Double ); -
возвращает значения по X и Y точки графика (а не только серии), ближе всего к которой расположен курсор мыши.; function GetHorizAxis :• TChartAxis; -
возвращает указатель на назначенную серии горизонтальную ось. Используя данный указатель, можно вызывать методы оси, обращаться к ее свойствам. function GetVertAxis:TChartAxis; -
возвращает указатель на вертикальную ось. function MaxX Value: Double; virtual; -
возвращает максимальное значение по X. function MinXValue : Double; virtual; -
возвращает минимальное значение по X. function MaxY Value: Double; virtual; -
возвращает максимальное значение по Y. function MinYValue: Double; virtual; - возвращает минимальное значение по Y. procedure RefreshSeries; -
обновляет значения серии из источника данных, указанного в свойстве DataSource. procedure Repaint; -
приводит к полной перерисовке всего графика. Рекомендуется вызывать этот метод в случае изменения хотя бы одного из основополагающих свойств серии (например, при изменении значения в DataSource и др.). function ValuesListCount:Longint; -
возвращает количество используемых в серии списков значений точки. Обычно это 2 списка (XValues и YValues), но некоторые серии используют 3 (BubbleSeries - XValues, YValues, Radius; GanttSeries -Y, Start, End). function VisibleCount: Longint; -
возвращает количество видимых на графике точек серии,
procedure AddPassword(const Password: string); -
добавляет пароль. procedure CloseDatabase (Database: TDatabase); -
закрывает открытую БД, определяемую параметром Database. Принудительное закрытие БД практикуется достаточно редко, поскольку закрытие всех открытых БД производится при окончании работы приложения. procedure DropConnections; -
разрывает имеющиеся соединения с БД в рамках сессии. function FindDatabase (const DatabaseName: string): TDatabase; -
пытается отыскать БД (компонент TDatabase} в коллекции TSession. Databases (коллекция открытых БД). Имя искомой БД определяется строковым параметром DatabaseName. Если в коллекции открытых БД сессии имеется такая БД, у которой значение DatabaseName совпадает с параметром DatabaseName метода FindDatabase, в качестве результата возвращается указатель на найденный компонент TDatabase. В противном случае (поиск неудачен) возвращается nil. procedure Get AliasNamesf List: TStrings); -
очищает список List и затем заносит в него список псевдонимов БД , определенных в BDE. procedure GetAliasParams(const AliasName: string; List: TStrings); -
очищает список List и затем помещает в него параметры псевдонима, определяемого строкой AliasName. procedure GetDriverNames(List: TStrings); -
очищает список List и затем заносит в него информацию об установленных на текущий момент драйверах BDE. Заметим, что драйверов 'PARADOX' и 'DBASE' не существует, поскольку эти СУБД управляются драйвером 'STANDARD'. procedure GetDriverParams(const DriverName: string; List: TStrings); -
очищает список List и затем заносит в него умалчиваемые параметры для драйвера, указанного в параметре DriverName. В случае использования Paradox или dBASE (DriverName = 'STANDARD'), в списке указывается только один параметр - 'РАТН='. Драйверы SQL-СУБД могут иметь переменное число параметров. function GetPassword: Boolean; -
реализует принудительный вызов стандартного диалога ввода паролей. procedure GetTableNames (const DatabaseName, Pattern: string; Extensions, SystemTables: Boolean; List: TStrings); -
очищает список List и добавляет в него имена всех таблиц, определяемых параметром DatabaseName. Если необходимо добавить имена только некоторых таблиц, шаблон их имени указывается параметром Pattern. Значение параметра System Tables, равное True, включит в состав таблиц, чьи имена занесены в List, имена системных таблиц (для удаленных баз данных). Установка в True параметра Extensions приведет к включению в имена таблиц расширений имени файла. function OpenDatabase(const DatabaseName: string): TDatabase; -
пытается отыскать компонент TDatabase, у которого свойство DatabaseName совпадает с параметром DatabaseName метода FindDatabase. В случае успеха возвращается указатель на найденный и открытый компонент TDatabase; если такой компонент не существует, он создается, открывается и указатель на него возвращается в качестве результата работы метода. procedure RemoveAllPasswords; -
удаляет все пароли. procedure RemovePassword(const Password: string); -
удаляет конкретный пароль.
procedure ApplyRange; -
осуществляет фильтрацию записей в TTable. Условия фильтрации определяются SetRangeStart и SetRangeEnd. procedure CancelRange; -
отменяет режим фильтрации. НД возвращается к неотфильтрованному состоянию. procedure DeleteTable; -
физически удаляет ТБД из базы данных. Метод применим только к закрытым НД. procedure EditKey; -
используется для перевода в состояние dsSetKey, если ранее для поиска с использованием GoToKey или GoToNearest по этому же индексу использовался SetKey. procedure EditRangeEnd;
- позволяет изменить верхнюю границу фильтра, ранее установленную при помощи SetRangeEnd. procedure EditRangeStart;
- позволяет изменить нижнюю границу фильтра, ранее установленную при помощи SetRangeStart. procedure Empty Table; -
уничтожает все записи в ТБД, связанной с НД. После этой операции ТБД будет пустой. Метод применим только к закрытым НД. function FindKey (const Key Values: array ofconst): Boolean; -
осуществляет поиск в НД записи, у которой индексные поля текущего индекса НД содержат те же значения, что и Key Values. Если запись найдена, курсор НД перемещается на нее и метод возвращает True. В противном случае местоположение курсора не изменяется и метод возвращает False. procedure FindNearest(const Key Values: array ofconst); -
осуществляет поиск в НД записи, у которой индексные поля текущего индекса НД содержат те же значения, что и Key Values. Если запись найдена, курсор НД перемещается на нее. В противном случае курсор перемещается на запись с большим значением индекса. procedure GotoCurrent (Tablet: TTable); -
устанавливает курсор БД набора данных Table 1 на ту же запись, на которой находится курсор БД набора данных Table2. Это важно в тех случаях, когда при одновременной работе с одной и той же ТБД выгодно применять два или более НД. В этом случае требуется совместить курсоры БД двух НД, чтобы работа производилась с одной и той же физической записью ТБД. function GotoKey: Boolean; -
аналогичен FindKey, однако значения индексных полей должны быть установлены явно (через Fields [индекс}, FieldByName или имя поля}. procedure GotoNearest; -
аналогичен FindNearest, однако значения индексных полей должны быть установлены явно (через Fields [индекс], FieldByName или имя поля). procedure SetKey; -
переводит НД в состояние dsSetKey поиска записи. Метод используется явно для методов поиска на точное соответствие GoToKey и неточное соответствие GoToNearest, дублирующих методы FindKey и FindNearest (при их выполнении SetKey вызывается неявно). procedure SetRange (const Start Values, EndValues: array ofconst); -
имеет тот же эффект, как и применение SetRangeStart, Set Range End” Apply Range. В качестве параметра используются массивы констант, каждый из которых содержит значения ключевых полей. procedure SetRangeEnd; -
устанавливает, что определяемое ниже значение ключевого поля (полей) будет рассматриваться как верхняя граница фильтра; procedure SetRangeStart; -
устанавливает, что определяемое ниже значение ключевого поля (полей) будет рассматриваться как нижняя граница фильтра;
procedure SetParams(UpdateKind: TUpdateKind); -
используется для установки значений параметров SQL-оператора, который должен обновить кэшированные изменения записи НД. Вид соответствующего оператора выбирается из свойств InsertSQL, ModifySQL, DeleteSQL компонента TUpdateSQL и определяется параметром UpdateKind. Применяется только при способе подтверждения изменений, использующем обработчик On UpdateRecord изменяемого набора данных.
procedure ExecSQL (UpdateKind: TUpdateKind); -
выполняет SQL-оператор для записи результатов кэшированных изменений в физическую ТБД. Вид соответствующего оператора выбирается из свойств InsertSQL, ModifySQL, DeleteSQL компонента TUpdateSQL и определяется параметром UpdateKind. Применяется только при способе подтверждения изменений, использующем обработчик On UpdateRecord изменяемого набора данных.
procedure Apply (UpdateKind: TUpdateKind); -
объединяет в себе функциональность методов SetParams и ExecSQL. В соответствии со зныачением параметра UpdateKind определяет требуемый SQL-оператор, заносит действительные значения в параметры этого оператора и затем выполняет сам оператор.
Объявление локальных переменных
DECLARE VARIABLE <имя переменной > <тип данных>;
Объявление UDF (функций, определяемых пользователем) в базе данных
DECLARE EXTERNAL FUNCTION ИмяФункции
[<Тип данных> | CSTRING (число) [, <Тип данньк> | CSTRING (число) ...]]
RETURNS {< Тип данных > [BY VALUE] | CSTRING (число)}
ENTRY_POINT "<Имя функции в DLL>"
MODULE_NAME "< Имя DLL >";
Обращение к хранимой процедуре (утилита WISQL)
EXECUTE PROCEDURE имя [параметр [, параметр ...]];
Ограничение, накладываемое на значения полей, ассоциированных с доменом
<огранич_домена> = {
VALUE <оператор> <значение>
VALUE [NOT] BETWEEN <значение1> AND <значение2>
VALUE [NOT] LIKE <значение> [ESCAPE <значение>]
VALUE [NOT] IN (<значение1> [, <значение2> ...])
VALUE IS [NOT] NULL
VALUE [NOT] CONTAINING <значение>
VALUE [NOT] STARTING [WITH] <значение>
(<огранич_домена>)
NOT <огранич_домена>
<огранич_домена> OR <огранич_домена>
<огранич домена> AND <огранич домена>
}
где <оператор> = {= | < | > | <= | >= [ !< | !> | о | !=}
Ограничения на значения столбца
CHECK (<условия_поиска>)
<условия поиска> =
{<значение> <оператор> {<значение1> | (<выбор_одного>)}
I <значение> [NOT] BETWEEN <значение1> AND <значение2>
<значение> [NOT] LIKE <значение> [ESCAPE <значение>]
| <значение> [NOT] IN (<значение1> [, <значение2> ...]
I <выбор_многих>)
I <значение> IS [NOT] NULL
| <значение> {[NOT] {= I < I >} >= | <=}
{ALL | SOME | ANY} (<выбор_многих>)
EXISTS (<выражение_выбора>)
SINGULAR (<выражение_выбора>)
<значение> [NOT] CONTAINING <значение1>
| <значение> [NOT] STARTING [WITH] <значение1>
I (<условия_поиска>)
I NOT <условия_поиска>
I <условия_поиска> OR <условия_поиска>
<условия_поиска> AND <условия_поиска>}
<значение> = {столбец | <константа> | <выражение> | <функция>
I NULL | USER I RDB$DB_KEY
} [COLLATE collation]
<константа> = число | "строка"
<функция> = {
COUNT (* I [ALL] <значение> I DISTINCT <значение>)
SUM ([ALL] <значение> | DISTINCT <значение>)
AVG ([ALL] <значение> | DISTINCT <значение>)
МАХ ([ALL] <значение> | DISTINCT <значение>)
MIN ([ALL] <значение> | DISTINCT <значение>)
CAST (<значение> AS <тип_данных>)
UPPER (<значение>)
GEN_ID (генератор, <значение>)
}
<оператор> = {= | < | > | <= ( >= | !< f !> | <> | !=}
<выбор_ одного =
оператор SELECT, возвращающий одно значение или ни одного. <выбор многих>
= оператор SELECT, который может возвращать более одного значения (список значений) или ни одного. <выражение_выбора> = оператор SELECT , который может возвращать более одного значения (список значений) или ни одного.
Оператор циклической выборки
FOR
<оператор SELECT>
DO
<составной оператор>;
Оператор выбора SELECT
Стандартный оператор SELECT InterBase, расширенный за счет предложения INTO
SELECT [DISTINCT | ALL] {* | <значение1> [, <значение2> ...]}
FROM <таблица1> [, < таблица2> ...]
[WHERE <условия поиска>]
[GROUP BY столбец [COLLATE collation]
[,столбец! [COLLATE collation] ...]
[HAVING < условия_поиска >]
[UNION
[PLAN <план_ выполнения_запроса>]
[ORDER BY <список_столбцов>]
INTO :переменная [, переменная...]
Определение ограничения внешнего ключа и ссылочной целостности с родительской таблицей
[CONSTRAINT <имя ссылочной целостности>]
FOREIGN KEY (<список столбцов внешнего ключа>)
REFERENCES <имя родительской таблицы> [<список столбцов
родительской таблицы>]
Определение типа данных
<тип_данных> = {
{SMALLINT | INTEGER | FLOAT | DOUBLE PRECISION}
[<размерность_массива>]
I {DECIMAL | NUMERIC} [(точность [, масштаб])]
[<размерность_массива>]
I DATE [<размерность массива>]
I {CHAR I CHARACTER | CHARACTER VARYING I VARCHAR}
[(целое)] [<размерность_массива>] [CHARACTER SET набор_символов]
I {NCHAR | NATIONAL CHARACTER | NATIONAL CHAR}
[VARYING] [(целое)] [<размерность_массива>]
I BLOB [SUB_TYPE {целое | имя_подтипа}] [SEGMENT SIZE целое]
[CHARACTER SET набор_символов]
I BLOB [(длина_сегмента [, подтип])]}
Отъем привилегий
REVOKE [GRANT OPTION FOR]{
{ALL [PRIVILEGES] | SELECT | DELETE | INSERT
I UPDATE [(столбец [.столбец ...])]}
ON [TABLE] {ИмяТаблицы | ИмяПросмотра}
FROM {<объект> | <список пользователей>}
I EXECUTE ON PROCEDURE ИмяПроцедуры
FROM {<объект> | < список пользователей >}
};
Предоставление привилегий доступа к таблицам БД, просмотрам, вызовам процедур
GRANT{
{ALL [PRIVILEGES] | SELECT DELETE | INSERT I UPDATE [(столбец [,столбец ...])]}
ON [TABLE] {ИмяТаблицы | ИмяПросмотра}
TO {<объект> | <список_пользователей>}
I EXECUTE ON PROCEDURE procname
TO {<объект > | < список_пользователей>}
};
<объект > = PROCEDURE ИмяПроцедуры | TRIGGER ИмяТриггера |
VIEW ИмяПросмотра | [USER] ИмяПользователя | PUBLIC [, <объект>]
< список_пользователей > = [USER] ИмяПользователя[, [USER]
ИмяПользователя...] [WITH GRANT OPTION]
Свойства, методы, события
Свойства, методы, события.
Компонент TDataBase *
Свойства *
Методы *
События *
Свойства *
Методы *
Компонент TDBChart *
Свойства *
Методы *
Компонент TDBCheckBox *
Свойства *
События *
Компонент TDBComboBox *
События *
Компонент TDBCtriGrid *
Свойства *
Методы *
События *
Компонент TDBEdit *
Свойства *
События *
Компонент TDBGrid *
Свойства *
Методы *
События *
Компонент TDBListBox *
Свойства *
События *
Компонент TDBLookupComboBox *
Свойства *
Методы *
Свойства *
Компонент TDBMemo *
Свойства *
Методы *
Компонент TDBRadioGroup *
Свойства *
События *
Компонент TDBRichEdit *
Свойства *
Методы *
События *
Компонент TDBText *
Свойства *
Компонент TDecisionCube *
Свойства *
Методы *
События *
Компонент TdecisionGrid *
Свойства *
События *
Компонент TDecisionPivot *
Свойства *
Компонент TDecisionSource *
Свойства *
События *
Компонент TField *
Свойства *
События *
Компонент TIBEventAlerter *
Свойства *
Методы *
События *
Компонент TQuery *
Свойства *
Методы *
Компонент TQRBand *
Свойства *
События *
Компонент TQRExp *
Свойства *
Компонент TQRGroup *
Свойства *
Компонент TQRSubDetail *
Свойства *
Компонент TQRSysData *
Свойства *
Компонент TQuickRep *
Свойства *
Методы *
События *
Компонент TChartSeries *
Свойства *
Методы *
События *
Компонент TSession *
Свойства *
Методы *
События *
Компонент ТТаblе *
Свойства *
Методы *
Компонент TUpdateSQL *
Свойства *
Методы *
Биржа
Бытует мнение о том, что самые большие деньги обретаются на биржах. Спорить не буду, их там есть. Другое дело не всем они достаются. Здесь собраны сведения не только о валютном рынке, но и о биржах вообще. Связано это с тем, что методика и методология работы на них очень похожи. Конечно, есть нюансы связанные с особенностями конкретного рынка, но основные подходы можно назвать общими.Биржевая азбука
Аксиомы спекулянта
Биржевая аналитика
Биржевой беттинг
Биржевые брокеры
Биржевые букмекеры
Биржевой дилинг
Закон о биржах
Биржевые заявки
Знакомство с биржей
Игра на бирже
Срочный рынок и биржа
Ставки на биржи
Биржевые термины
Биржевая торговля
Биржевые индексы
Иностранные биржи
Биржевые инструменты
Биржевая информация
История биржи
Лекции о бирже
Биржевые манипуляции
Методика торгов на бирже
Мониторинг биржи
Виды биржевых сделок
Игра на повышение на бирже
Биржевой торговый автомат
Биржевой тренажер
Биржевые университеты
Условия торговли на бирже
Биржевая ставка на снижения
Мотивы поведения на бирже
Биржевой надзор
Обучение торговле на бирже
Биржевые площадки
Биржевые прогнозы
Биржи в Россия
Биржевые сделки
Биржевые системы торговли
Биржевые словари
Биржевые спекуляция
Характеристики торгов га бирже
Критерий Келли на бирже
Спор о цене на бирже
Субъекты рынка - биржа