

Введение в SAX
Characters()
Теперь, когда вы получили элемент, пойдем дальше и выберем его данные при помощи characters(). Взглянем на сигнатуру этого метода:public void characters(char[] ch, int start, int length)
Заметьте, что нигде в методе нет информации о том, частью какого элемента являются эти символы. Если вам нужна такая информация, вы должны сохранять ее. В этом примере добавлены переменные для сохранения информации о текущем элементе и вопросе. (Тут также удалено много лишней информации, которая отображалась.)
Заметьте две важные вещи:
Это всегда учитывается проверяющим парсером.
... public void printIndent(int indentSize) { for (int s = 0; s < indentSize; s++) { System.out.print(" "); } } String thisQuestion = ""; String thisElement = "";
public void startElement(String namespaceURI, String localName, String qName, Attributes atts) throws SAXException { if (qName == "response") { System.out.println("User: " + atts.getValue("username")); } else if (qName == "question") { thisQuestion = atts.getValue("subject"); } thisElement = qName;
} public void endElement(String namespaceURI, String localName, String qName) throws SAXException { thisQuestion = ""; thisElement = "";
} public void characters(char[] ch, int start, int length) throws SAXException { if (thisElement == "question") { printIndent(4); System.out.print(thisQuestion + ": "); System.out.println(new String(ch, start, length)); } }
...
Что такое SAX?
Стандартным средством для чтения и манипулирования XML-файлами является Объектная Модель Документа, Document Object Model (DOM). К сожалению, этот метод, который включает в себя чтение всего файла и сохранение его в структуре дерева, может быть малоэффективным, медленным и требовать много ресурсов.Одной из альтернатив ему является Simple API for XML или SAX. SAX позволяет вам обрабатывать документ по мере его чтения, что устраняет необходимость ожидать с выполнением каких-то действий, пока весь документ не будет сохранен.
SAX был разработан членами почтовой рассылки XML-DEV, а его Java-версия является сейчас проектом SourceForge (см. ). Целью проекта было обеспечение более естественного средства для работы с XML - другими словами, такого, которое не включает в себя таких расходов и концептуальных сложностей, каких требует DOM.
Результатом был API, который является событийно-базированным. Парсер посылает события, такие, как начало и окончание элемента, в обработчик событий, который обрабатывает информацию. Затем с данными имеет дело само приложение. Исходный документ остается без изменений, но SAX обеспечивает средства для манипулирования данными, которые затем могут быть направлены в другой процесс или документ.
SAX не имеет держателя стандарта, он не поддерживается консорциумом World Wide Web (W3C) или каким-то другим официальным держателем, но де-факто является стандартом в сообществе XML.
DOM и обработка на базе дерева
DOM является традиционным способом обработки XML-данных. При применении DOM данные загружаются в память в древовидную структуру.Например, тот же документ, который использовался как пример в , может быть представлен в виде узлов, показанных ниже:
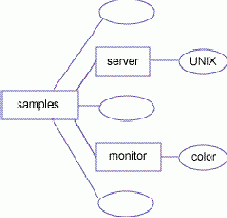
Прямоугольники представляют элементные узлы, а овалы - текстовые узлы.
DOM использует отношения предок-потомок. Например, в данном случае samples является корнем с пятью потомками: тремя текстовыми узлами (пропуски) и двумя элементными узлами, server и monitor.
Важно представлять себе, что узлы server и monitor на самом деле имеют значения null. Вместо этого они содержат текстовые узлы (UNIX и color) в качестве потомков.
EndDocument()
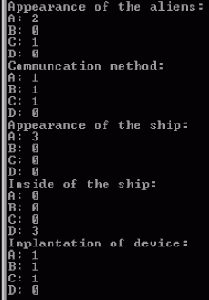
И, конечно, когда документ полностью разобран, вы захотите напечатать результат окончательного подсчета, как показано ниже.Это также хорошее место для того, чтобы завершить все незавершенные концы, которые могли накопиться за время обработки.
... if (thisQuestion.equals("implant")) { implant = implant + new String(ch, start, length); } } } public int getInstances (String all, String choice) { ... return total; } public void endDocument() { System.out.println("Appearance of the aliens:"); System.out.println("A: " + getInstances(appearance, "A")); System.out.println("B: " + getInstances(appearance, "B")); ... }
public static void main (String args[]) { ...
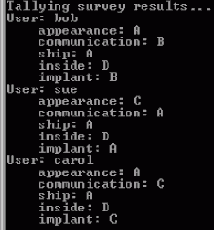
EndElement()
Может оказаться полезным замечать конец элемента. Например, это может быть сигналом к обработке содержимого элемента. Здесь вы будете использовать его для красивой печати документа с некоторыми отступами, показывающими уровень каждого элемента. Идея состоит в увеличении отступа, когда начинается новый элемент, и в уменьшении его, когда элемент заканчивается:... int indent = 0;
public void startDocument() throws SAXException { System.out.println("Tallying survey results..."); indent = -4;
} public void printIndent(int indentSize) { for (int s = 0; s < indentSize; s++) { System.out.print(" "); } }
public void startElement(String namespaceURI, String localName, String qName, Attributes atts) throws SAXException { indent = indent + 4; printIndent(indent);
System.out.print("Start element: "); System.out.println(qName); for (int att = 0; att < atts.getLength(); att++) { printIndent(indent + 4);
String attName = atts.getLocalName(att); System.out.println(" " + attName + ": " + atts.getValue(attName)); } } public void endElement(String namespaceURI, String localName, String qName) throws SAXException { printIndent(indent); System.out.println("End Element: "+localName); indent = indent - 4; }
...

Файл примера
Этот учебник демонстрирует конструирование приложения, которое использует SAX для обработки ответов группы пользователей, которых попросили заполнить анкету о случившимся с ними похищении их Пришельцами.Вот форма этой анкеты:

Ответы записаны в XML-файл:
IgnorableWhitespace()
XML-документы, выработанные людьми (в отличие от выработанных программами) часто содержат пропуски, добавляемые для того, чтобы сделать документ более легким для чтения. Под пропусками подразумеваются переводы строк, символы табуляции и пробелы. В большинстве случаев пропуски являются лишними и должны игнорироваться при обработке данных.Все проверяющие парсеры н некоторые непроверяющие передают символы пропусков в обработчик содержимого не в событии characters(), а в событии ignorableWhitespace(). Это удобно, поскольку вы можете сосредоточиться только на реальных данных.
Но что, если вам действительно нужны пропуски? В таком случает вы устанавливаете в элементе атрибут, который сигнализирует процессору о том, что не нужно игнорировать символы пропусков. Этот атрибут - xml:space, и он обычно предполагается default. (Это значит, что поведение процессора по умолчанию состоит в игнорировании пропусков.)
Чтобы сообщить процессору, что не нужно игнорировать пропуски, установите его значение в preserve так:
Инструменты
Примеры в этом учебнике, если вы решите их выполнить, требуют, чтобы у вас были установлены и корректно работали следующие инструменты. (Выполнение примеров не является обязательным для понимания.)Использование XMLFilter для преобразования данных
XMLFilters может также использоваться для быстрого и легкого преобразования данных при помощи XSLT.Само преобразование лежит вне сферы рассмотрения нашего учебника, но вот краткий взгляд на то, как вы можете применить его:
import javax.xml.transform.stream.StreamSource; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerFactory; import javax.xml.transform.sax.SAXTransformerFactory; import org.xml.sax.XMLFilter;
... public static void main (String args[]) { XMLReader xmlReader = null; try { SAXParserFactory spfactory = SAXParserFactory.newInstance(); spfactory.setValidating(false); SAXParser saxParser = spfactory.newSAXParser(); xmlReader = saxParser.getXMLReader(); TransformerFactory tFactory = TransformerFactory.newInstance(); SAXTransformerFactory saxTFactory = ((SAXTransformerFactory) tFactory); XMLFilter xmlFilter = saxTFactory.newXMLFilter(new StreamSource("surveys.xsl"));
xmlFilter.setParent(xmlReader); Serializer serializer = SerializerFactory.getSerializer( OutputProperties.getDefaultMethodProperties("xml")); serializer.setOutputStream(System.out);
xmlFilter.setContentHandler( serializer.asContentHandler() );
InputSource source = new InputSource("surveys.xml"); xmlFilter.parse(source); } catch (Exception e) { System.err.println(e); System.exit(1); } } ...
Сначала вам нужно создать фильтр - но вместо создания его с нуля, создайте фильтр, который специально предназначен для преобразования на основе таблицы стилей.
Затем, так же, как вы делали, когда выводили непосредственно в файл, создайте Serializer для вывода результата преобразования.
В основном фильтр выполняет преобразование, затем обрабатывает события на XMLReader. Однако, в конечном счете приемником являетсяSerializer.
Как работает обработка в SAX
SAX анализирует поток XML и проходит через, как по телетайпной ленте. Рассмотрим следующий XML-код:Процессор SAX, анализирующий этот код, будет генерировать, как правило, следующие события:
Начало документа Начало элемента (samples) Символы (пропуск) Начало элемента (server) Символы (UNIX) Конец элемента (server) Символы (пропуск) Начало элемента (monitor) Символы (color) Конец элемента (monitor) Символы (пропуск) Конец элемента (samples)
SAX API дает возможность разработчику выловить эти события и работать по ним.
Обработка в SAX включает в себя следующие шаги:
Как выбрать между SAX и DOM
Использовать вам DOM или SAX, зависит от нескольких факторов:Важно помнить, что SAX и DOM не являются взаимоисключающими. Вы можете использовать DOM для создания потока событий SAX, и вы можете использовать SAX для создания дерева DOM. Фактически, большинство парсеров, применяемых для создания дерева DOM, используют SAX, чтобы сделать это!
Непосредственное задание драйвера SAX
Если есть обработчик событий, то следующим шагом является создание парсера, XMLReader, при помощи драйвера SAX. Вы можете создать парсер одним из трех способов:Если вы знаете имя класса драйвера SAX, вы можете вызвать драйвер непосредственно. Например, если это класс (на самом деле не существующий) com.nc.xml.SAXDriver, вы можете применить такой код:
try { XMLReader xmlReader = new com.nc.xml.SAXDriver();
} catch (Exception e) { System.out.println("Can't create the parser: " + e.getMessage()); }
чтобы непосредственно создать XMLReader.
Вы можете также использовать системные свойства, чтобы сделать свое приложение более гибким. Например, вы можете задать имя класса как значение свойства org.xml.sax.driver из командной строки, когда вы запускаете приложение:
java -Dorg.xml.sax.driver=com.nc.xml.SAXDriver SurveyReader
(Заметьте, опция -D не допускает пробела после нее.)
Это делает информацию доступной для класса XMLReaderFactory, так что вы можете сказать:
try { XMLReader xmlReader = XMLReaderFactory.createXMLReader();
} catch (Exception e) { System.out.println("Can't create the parser: " + e.getMessage()); }
Если вы знаете имя драйвера, вы можете также передать его непосредственно как аргумент для createXMLReader().
Нужен ли мне этот учебник?
В этом учебнике исследуется Simple API for XML версии 2.0.x или SAX 2.0.x.Он предназначен для разработчиков, которые понимают XML и хотят изучить этот легкий событийно-базированный API для работы с XML-данными. Предполагается, что вы знакомы с такими концепциями, как правильное форматирование и с теговой природой XML-документа. (Вы можете получит базовые представления о самом XML из учебника .) В этом учебнике вы узнаете, как использовать SAX, чтобы выбирать, манипулировать и выводить XML-данные.
Предварительные замечания: SAX доступен во многих языках программирования, таких, как Java, Perl, C++ и Python. Этот учебник использует для демонстраций язык Java, но концепции в разных языках, по существу, одинаковы, и вы можете получить понимание SAX, даже не работая на самом деле с этими примерами.
Об авторе
Nicholas Chase, автор , участвовал в разработке Web-сайтов для таких компаний, как Lucent Technologies, Sun Microsystems, Oracle и Tampa Bay Buccaneers. Nick был преподавателем физики в высшей школе, менеджером низшего звена по использованию радиоактивных отходов, редактором онлайнового журнала научной фантастики, инженером по мультимедиа и инструктором по Oracle. В последнее время он - руководитель технического отдела фирмы Site Dynamics Interactive Communications в Clearwater, Florida, USA и автор четырех книг по Web-разработке, включая (Sams). Он любит слышать отзывы читателей, с ним можно связаться по адресу nicholas@nicholaschase.com.Обучение
Определение пространств имен
Для данных могут быть определены также и другие пространства имен. Например, созданием пространства имен revised вы можете добавить второй набор данных - скажем, о постгипнотическом состоянии, - не беспокоясь об имеющихся данных.Пространство имен вместе с алиасом создаются обычно (но не обязательно) в корневом элементе документа. Этот алиас используется как префикс для элементов и атрибутов - при необходимости, если используется более одного пространства имен, - чтобы задать правильное пространство имен.
Рассмотрим код, приведенный ниже:
Пространство имен и алиас, revised, использованы для создания дополнительного элемента question.
Помните, что revised - не пространство имен, а алиас! Настоящее пространство имен - http://www.nicholaschase.com/surveys/revised/.